
Determination of “Neutral”–“Pain”, “Neutral”–“Pleasure”, and “Pleasure”–“Pain” Affective State Distances by Using AI Image Analysis of Facial Expressions

 , , , and
, , , and
Abstract
:1. Introduction
1.1. Overall Benefits of the Insights We Present in This Manuscript
1.2. Using AI as a Novel Approach to Analyzing Facial Expressions of Pain and Pleasure
1.3. Previous Reasearch into Facial Expression of (Intense) Affective States
1.4. Novelty of the Approach Presented in This Paper
1.5. Fields of Study in Which the Results Are of Importance
2. Materials and Methods
2.1. Materials
2.2. Methods
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- Every user has his/her own folder structure. By “path” (below), we mean the path to the folders containing the video frames.
- The command line Join[…] is long because it loads a segment of the video dynamically. It is modified accordingly for other videos loaded for further frame extraction.
- The above structure is suitably modified for the other faces of Actress A.
- The five faces are aligned.
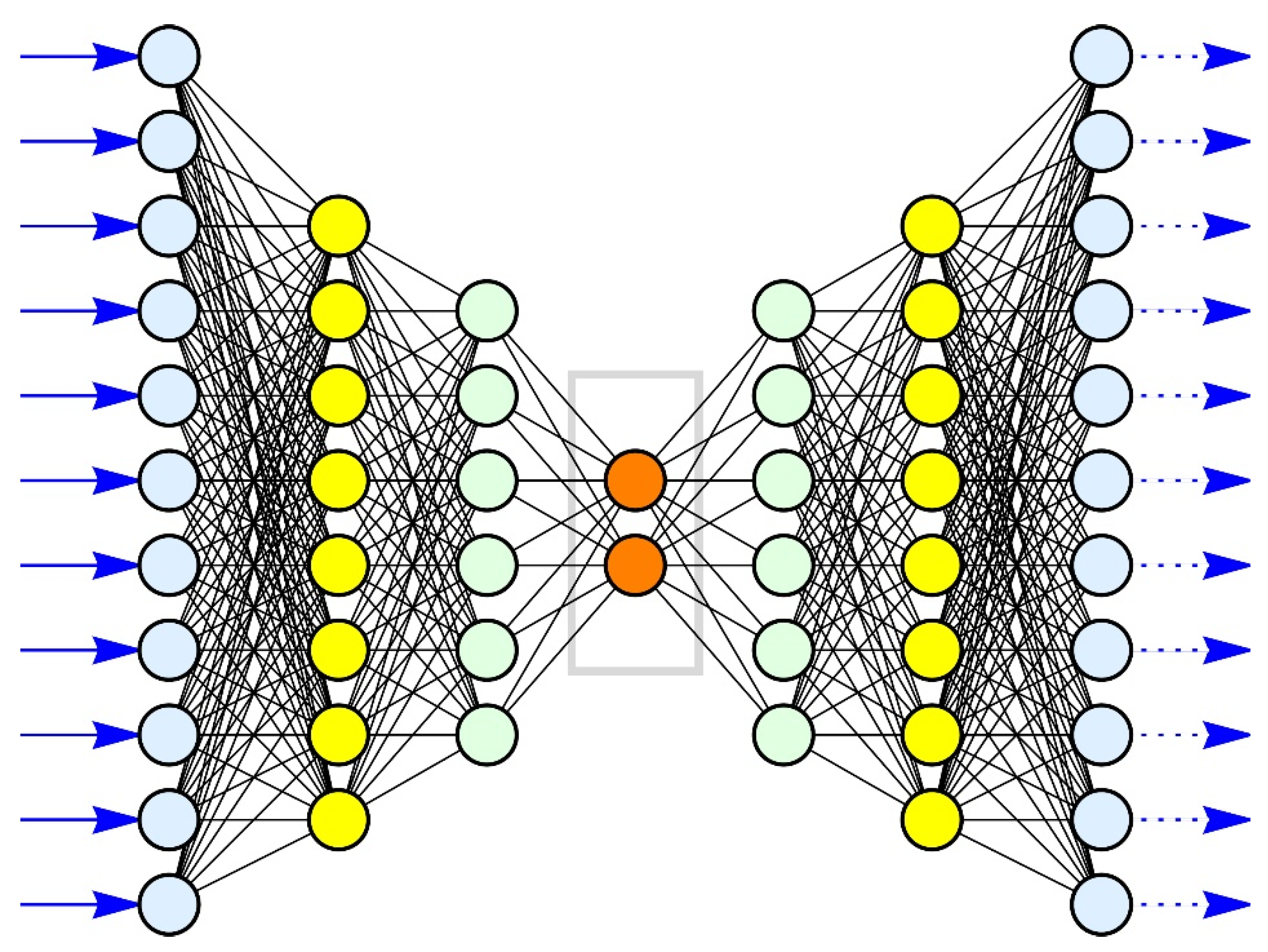
- The proprietary code from MATHEMATICA uses AI (internally trained) to extract feature vectors from the list of faces.
- The proprietary code from MATHEMATICA uses a neural network to dimension-reduce the feature vectors.
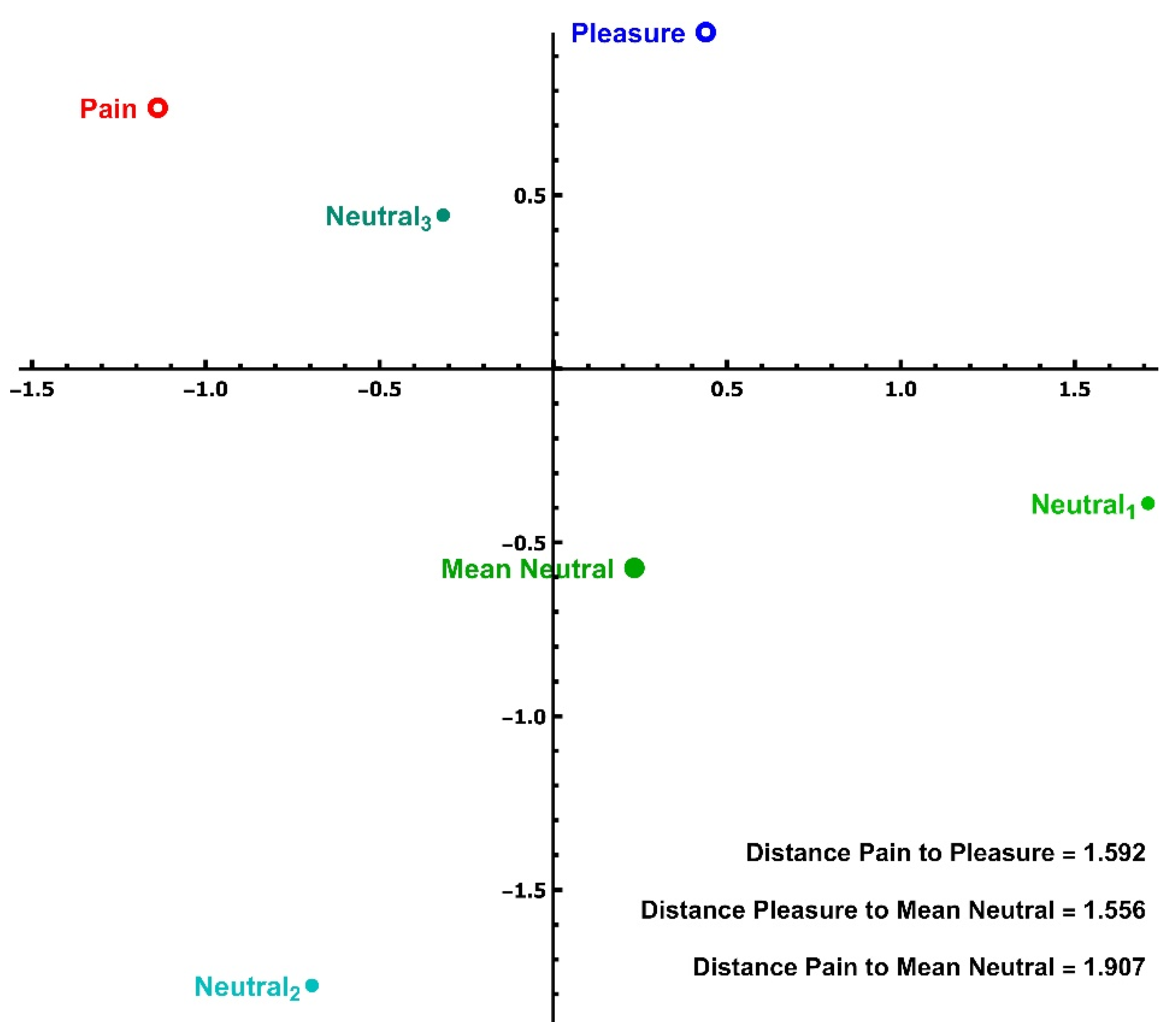
- The (Euclidean) distances are computed.
- The above steps are repeated for the other faces; A⟶B, A⟶C, … and so on up to and including A⟶T.
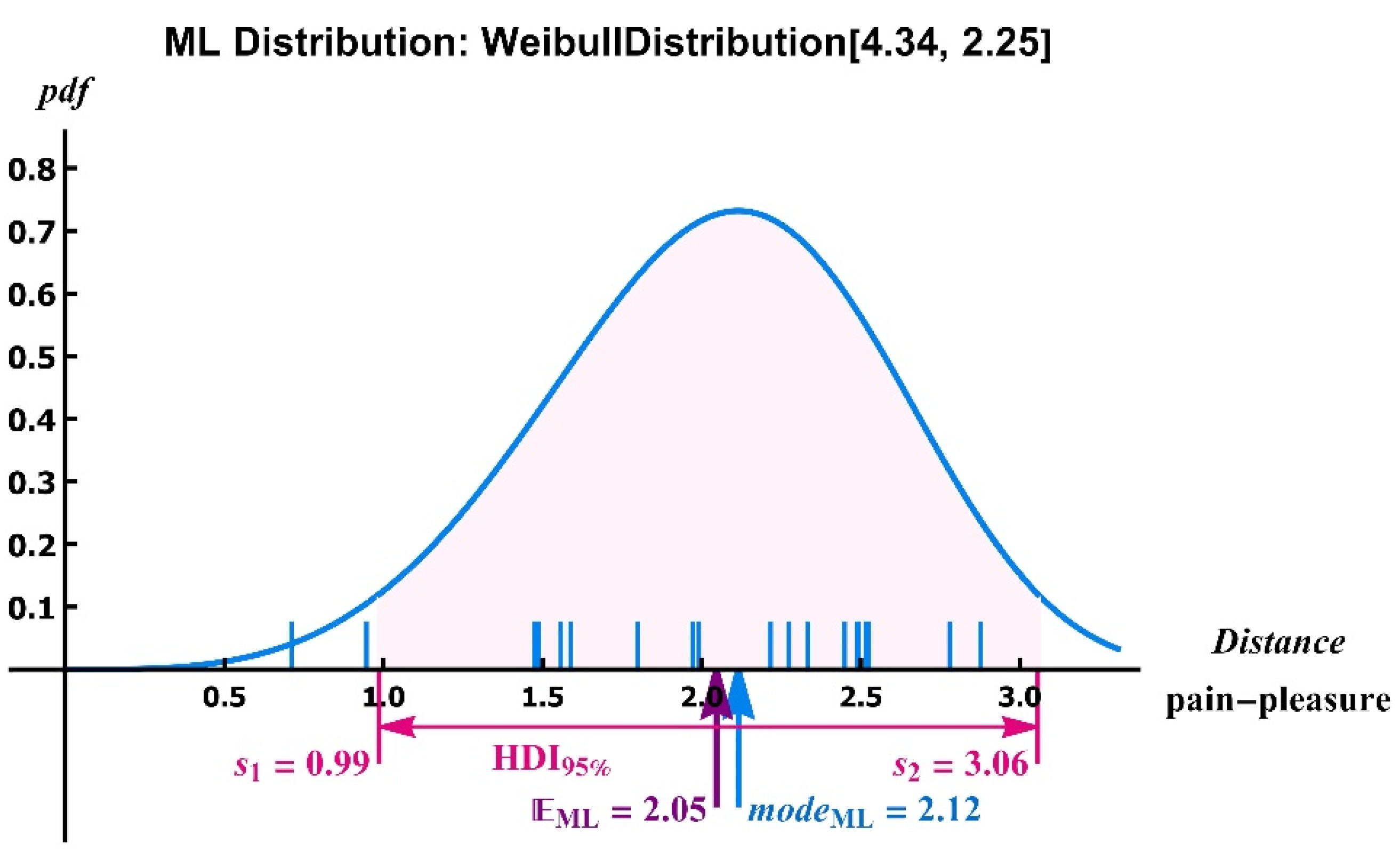
- The commands below are used to find the ML distribution of the distances.
- The code below is used to determine the HDI95% uncertainty interval. Note that the precision arithmetic requires several hundered (decimal) digits.
- The code below calculates the SVD and the approximation using only the first three singular values.
- The code below generates a list of colors needed for the graphics.
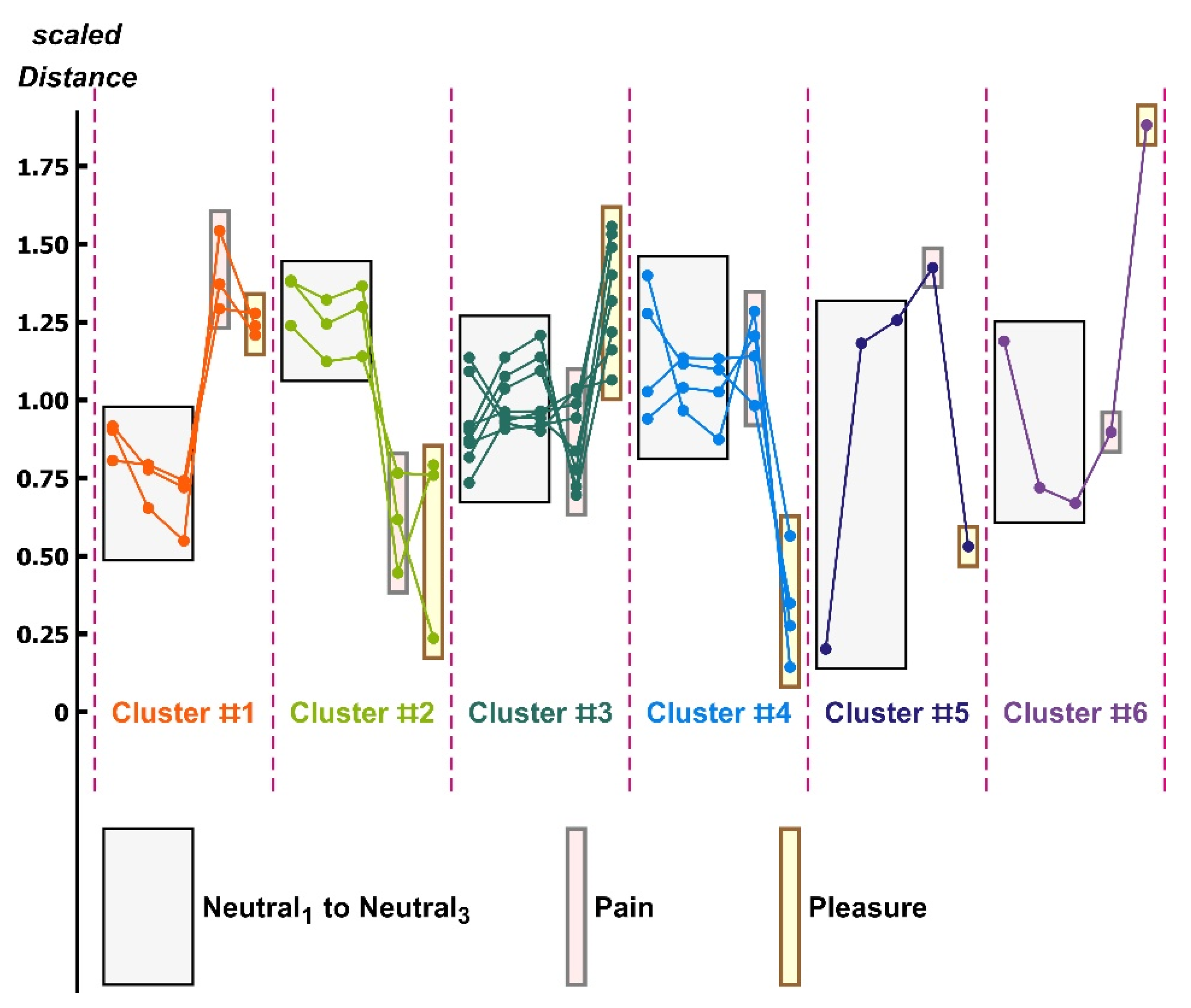
- The code below finds the clusters of the SVD-3 approximated coordinates of the affective state distances.
- A suite of graphics routines (not listed) are used to display the results for the manuscript.
References
- Prossinger, H.; Hladky, T.; Binter, J.; Boschetti, S.; Riha, D. Visual Analysis of Emotions Using AI Image-Processing Software: Possible Male/Female Differences between the Emotion Pairs “Neutral”–“Fear” and “Pleasure”–“Pain”. In Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference, Virtual Event, 29 June–2 July 2021; pp. 342–346. [Google Scholar]
- Butow, P.; Hoque, E. Using artificial intelligence to analyse and teach communication in healthcare. Breast 2020, 50, 49–55. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hassan, T.; Seuß, D.; Wollenberg, J.; Weitz, K.; Kunz, M.; Lautenbacher, S.; Schmid, U. Automatic detection of pain from facial expressions: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1815–1831. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Namba, S.; Sato, W.; Osumi, M.; Shimokawa, K. Assessing automated facial action unit detection systems for analyzing cross-domain facial expression databases. Sensors 2021, 21, 4222. [Google Scholar] [CrossRef] [PubMed]
- Weitz, K.; Hassan, T.; Schmid, U.; Garbas, J.U. Deep-learned faces of pain and emotions: Elucidating the differences of facial expressions with the help of explainable AI methods. Tm-Tech. Mess. 2019, 86, 404–412. [Google Scholar] [CrossRef]
- Dildine, T.C.; Atlas, L.Y. The need for diversity in research on facial expressions of pain. Pain 2019, 160, 1901. [Google Scholar] [PubMed]
- Barrett, L.F. AI weighs in on debate about universal facial expressions. Nature 2021, 589, 202–204. [Google Scholar] [CrossRef] [PubMed]
- Cowen, A.S.; Keltner, D.; Schroff, F.; Jou, B.; Adam, H.; Prasad, G. Sixteen facial expressions occur in similar contexts worldwide. Nature 2021, 589, 251–257. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P. Facial expression and emotion. Am. Psychol. 1993, 48, 384–392. [Google Scholar] [CrossRef]
- Valente, D.; Theurel, A.; Gentaz, E. The role of visual experience in the production of emotional facial expressions by blind people: A review. Psychon. Bull. Rev. 2018, 25, 483–497. [Google Scholar] [CrossRef] [Green Version]
- Gendron, M.; Barrett, L.F. Reconstructing the past: A century of ideas about emotion in psychology. Emot. Rev. 2009, 1, 316–339. [Google Scholar] [CrossRef] [PubMed]
- van der Struijk, S.; Huang, H.H.; Mirzaei, M.S.; Nishida, T. FACSvatar: An Open Source Modular Framework for Real-Time FACS based Facial Animation. In Proceedings of the 18th International Conference on Intelligent Virtual Agents, Sydney, Australia, 5–8 November 2018; pp. 159–164. [Google Scholar]
- Chen, C.; Crivelli, C.; Garrod, O.G.; Schyns, P.G.; Fernández-Dols, J.M.; Jack, R.E. Distinct facial expressions represent pain and pleasure across cultures. Proc. Natl. Acad. Sci. USA 2018, 115, E10013–E10021. [Google Scholar] [CrossRef] [Green Version]
- Wenzler, S.; Levine, S.; van Dick, R.; Oertel-Knöchel, V.; Aviezer, H. Beyond pleasure and pain: Facial expression ambiguity in adults and children during intense situations. Emotion 2016, 16, 807. [Google Scholar] [CrossRef]
- Aviezer, H.; Trope, Y.; Todorov, A. Body cues, not facial expressions, discriminate between intense positive and negative emotions. Science 2012, 338, 1225–1229. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fernández-Dols, J.M.; Carrera, P.; Crivelli, C. Facial behavior while experiencing sexual excitement. J. Nonverbal Behav. 2011, 35, 63–71. [Google Scholar] [CrossRef]
- Hughes, S.M.; Nicholson, S.E. Sex differences in the assessment of pain versus sexual pleasure facial expressions. J. Soc. Evol. Cult. Psychol. 2008, 2, 289. [Google Scholar] [CrossRef]
- Abramson, L.; Marom, I.; Petranker, R.; Aviezer, H. Is fear in your head? A comparison of instructed and real-life expressions of emotion in the face and body. Emotion 2017, 17, 557. [Google Scholar] [CrossRef] [PubMed]
- Elisason, S.R. Maximum Likelihood Estimation. Logic and Practice; SAGE Publications: Newbury Park, CA, USA, 1993. [Google Scholar]
- Kruschke, J.K. Doing Bayesian Data Analysis. A Tutorial with R, JAGS, and Stan, 2nd ed.; Academic Press/Elsevier: London, UK, 2015. [Google Scholar]
- Leon, S.J. Linear Algebra with Applications, 5th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 1998. [Google Scholar]
- Strang, G. Linear Algebra and Learning from Data; Wellesley-Cambridge Press: Wellesley, MI, USA, 2019. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence. A Modern Approach, 3rd ed.; Pearson: Harlow, UK, 2010. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning, 3rd ed.; MIT Press: Cambridge, MI, USA, 2016. [Google Scholar]
- Boschetti, S.; Hladký, T.; Machová, K.; Říha, D.; Binter, J. Judgement of extreme affective state expressions in approach/avoidance paradigm. Hum. Ethol. 2021, 36, 7. [Google Scholar]
- McKinney, S.M.; Sieniek, M.; Godbole, V.; Godwin, J.; Antropova, N.; Ashrafian, H.; Shetty, S. International evaluation of an AI system for breast cancer screening. Nature 2020, 577, 89–94. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | ML Numerical Values |
|---|---|
| Mode | |
| E | |
| HDI95% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prossinger, H.; Hladký, T.; Boschetti, S.; Říha, D.; Binter, J. Determination of “Neutral”–“Pain”, “Neutral”–“Pleasure”, and “Pleasure”–“Pain” Affective State Distances by Using AI Image Analysis of Facial Expressions. Technologies 2022, 10, 75. https://doi.org/10.3390/technologies10040075
Prossinger H, Hladký T, Boschetti S, Říha D, Binter J. Determination of “Neutral”–“Pain”, “Neutral”–“Pleasure”, and “Pleasure”–“Pain” Affective State Distances by Using AI Image Analysis of Facial Expressions. Technologies. 2022; 10(4):75. https://doi.org/10.3390/technologies10040075
Chicago/Turabian StyleProssinger, Hermann, Tomáš Hladký, Silvia Boschetti, Daniel Říha, and Jakub Binter. 2022. "Determination of “Neutral”–“Pain”, “Neutral”–“Pleasure”, and “Pleasure”–“Pain” Affective State Distances by Using AI Image Analysis of Facial Expressions" Technologies 10, no. 4: 75. https://doi.org/10.3390/technologies10040075
APA StyleProssinger, H., Hladký, T., Boschetti, S., Říha, D., & Binter, J. (2022). Determination of “Neutral”–“Pain”, “Neutral”–“Pleasure”, and “Pleasure”–“Pain” Affective State Distances by Using AI Image Analysis of Facial Expressions. Technologies, 10(4), 75. https://doi.org/10.3390/technologies10040075