3.1. Data
We use monthly data covering the period September 1999 to September 2013, resulting in 168 observations. The start date of the sample was chosen aiming to purge data that may have been influenced by the transition period in Brazil from the pegged exchange rate regime to the floating exchange rate regime.
Regarding the assets, it was selected shares from the BOVESPA (São Paulo Stock Exchange) stock exchange that presented quote data and book value between September 1999 and September 2013 and were part of the Bovespa Index within this period. According to the Bovespa Index Methodology among the conditions for a share to be part of the index are: have a trading presence of at least 95% in a one-year period and play a role in terms of financial volume equal to or greater than 0.1%, also in a one-year period. In total, 17 shares were selected, representing nine economic sectors: food and beverages, banking, industry, oil and gas, telecommunications, energy, mining, tobacco and aircraft production.
Table 1 enumerates those shares.
It is important to highlight the difference between the proposed model here and those developed by
Flister et al. (
2011) and
Fischberg Blank et al. (
2014). In those works, portfolio returns built based on the size and the book-to-market ratio were used, while here we work with basic shares. Another innovation of this work is the inclusion of other conditioning variables, as discussed below.
Credit Spread in Brazil—Due to a lack of long-term bonds in Brazil before 2000, when were issued several government bonds series LTN, NTN-F and NTN-B, in this work the country’s credit spread used was the SWAP360 (swap rate—DI—360 days—period average -% p.y.) available in IPEADATA. The correlation of the used SWAP360 with the fixed 1-year rates for the actual LTN bonds also available in IPEADATA from May 2000 presents a correlation of 99.85%. So, this was the component of the model that represents the Brazilian credit spread.
Variables related to stock prices—Share Price over Book-Value (P/BV): ratio between the share price and its book value. This parameter is used by the market to observe how far the price of the shares is from its book value. Price over Earnings (P/E): ratio between the share price and the earnings per share in a one-year period. The parameter is used to observe if the share has good returns comparing to its price traded on the stock exchange.
Proxy for Consumption—A difference between this study and that of
Mazzeu et al. (
2013) is the inclusion of the above variables and a
proxy for consumption. In the A&F model, it was used the variable related to consumption, called CAY (Consumption; Asset Holdings and Labor Income relationship), in the state-space model together with other macroeconomic variables. However, given that in Brazil there is not an analogous variable available, it was decided to use an alternative variable: the total electricity consumption (obtained in IPEADATA). As the results show, it was significant in the models of several of the analyzed shares.
3.2. Parameters Estimation
To obtain the results, as explained in this paper, the Kalman filter algorithm was applied to the state-space system of Equations (12)–(14). The autoregressive parameter , the standard deviations of the errors and , and the conditioning variables coefficients were estimated by maximum likelihood.
There were estimated seven different models for each share, where five of them used the dynamic beta model of A&F to Brazil. From these five models, the first was estimated without conditioning variables; the second was estimated only with the variables related to the share price P/BV and P/E; the third was estimated only with the SWAP360; the fourth was estimated only with the variable electricity consumption, and the fifth was estimated with all previous variables together. The sixth model was estimated with the CAPM beta as random walk, which was also estimated by maximum likelihood. The seventh model, aiming to compare with the others, was the traditional CAPM with the fixed beta, which was estimated by ordinary least squares—OLS.
Therefore, 119 models were estimated; from them, 85 are dynamic CAPM with learning, 17 are the CAPM with a random walk beta and 17 are the comparative classical CAPM. All the estimation results, as well as their
p-values, are reported in
Table A1,
Table A2,
Table A3,
Table A4,
Table A5,
Table A6,
Table A7 and
Table A8 of
Appendix A.
From the 102 estimates of the learning CAPM performed for the 17 stocks, in only one of them the maximum likelihood estimation did not converge. This occurred for USIM5 share and the model that did not converge was the one that uses SWAP 360. The possible explanation is the existence of a singular covariance matrix, so that the coefficients are not unique. For that reason, we report “N.A.” in the corresponding row of
Table A4.
In the work of A&F, it was analyzed only the error levels given by RMSE and CPE parameters. In the present work, in addition, it was made a significance analysis of the estimated coefficients in each model.
As in some stocks, more than one model obtained significant parameters, we used the AIC-Akaike Info Criterion, Schwarz and Hannan-Quinn to select the model. The result of each selection criteria is in
Appendix B, the result with the best models according to coefficients of significance criteria can be seen in
Table 3 below.
From these results, some economic explanations can be given for the choice of models using exogenous variables. For example, the only two private banks whose shares are in the sample, the BBDC4 and ITSA4 had, as the best model, the one using SWAP360. This result confirms the theory that a variable that directly affects the return of banks is the market interest rate. On the other hand, the BBAS3 share, a Brazilian state-owned bank, does not have the model with SWAP360 as the best one. Possibly, this result is due to the composition of the loan portfolio of the bank, which differs greatly from the composition of private banks’ credit portfolios. Other stocks whose models were chosen using the SWAP360 were KLBN4 and VALE5. They represent exporting companies whose dollar-hedging contracts depend directly on the country’s interest rates.
The BRKM5 and ELET6 shares were those whose dynamic models of A&F without exogenous variables presented the best explanation levels. This result leads us to conclude that the behaviors of their betas are related not only to the beta in the previous time, but also to the long-term beta.
The CRUZ3 share was the only one that got the A&F model with the exogenous variable of Electric Power as the best model, bringing a surprising relationship between the consumption proxy given by electricity consumption and the behavior of the share, which represents a tobacco sector company.
The VIVT4 share was the one that got the A&F model with variables related to the share price as the best model. Therefore, this is a stock whose beta depends on the company’s fundamentals, which are linked to the relationship between price and profit of the share and between price and asset value of the company.
For the remaining shares, the models that obtained the greater confidence percentages were those with the random walk beta. Thus, for these shares the behavior of their betas is given only by its previous beta plus a random error with variance .
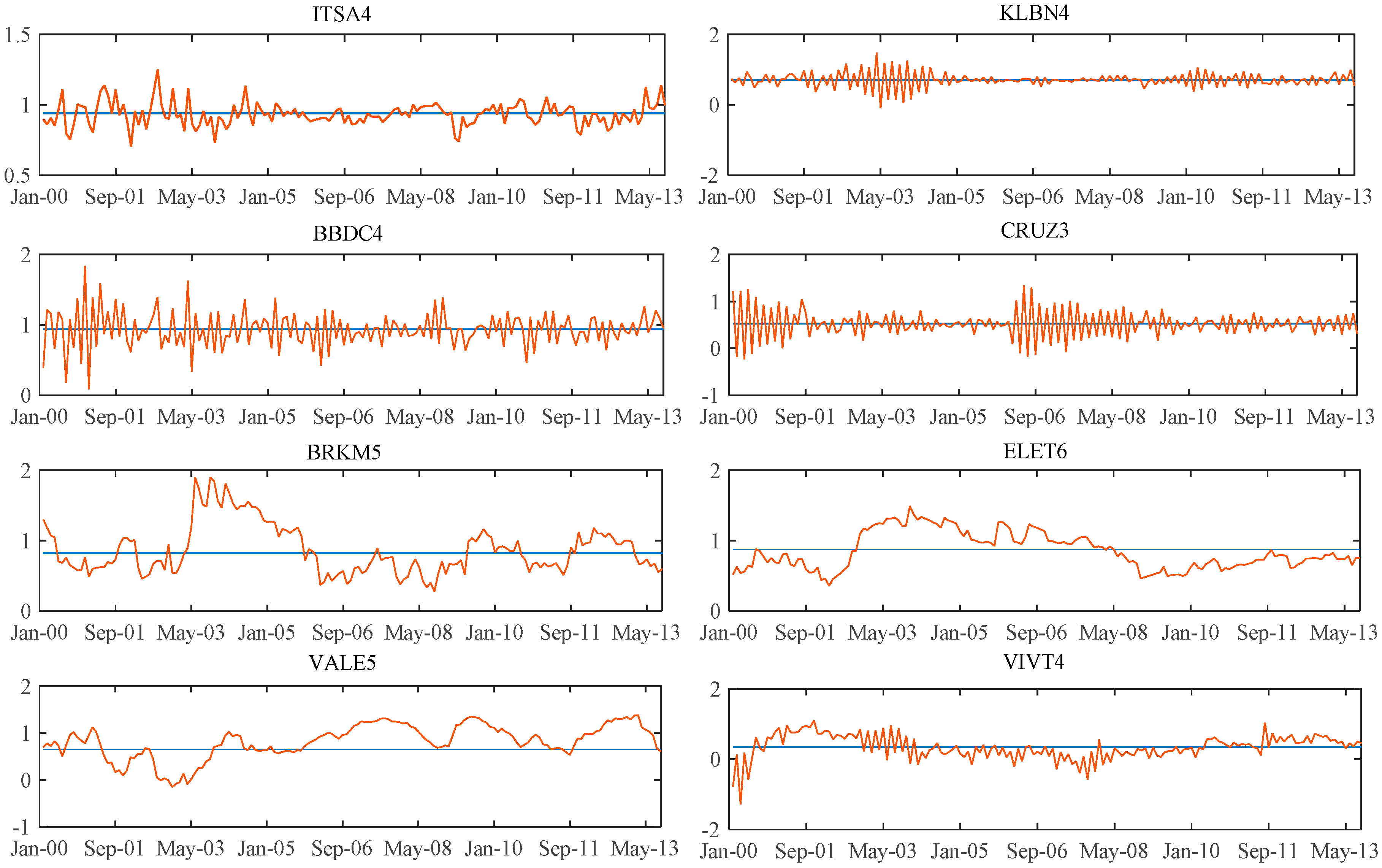
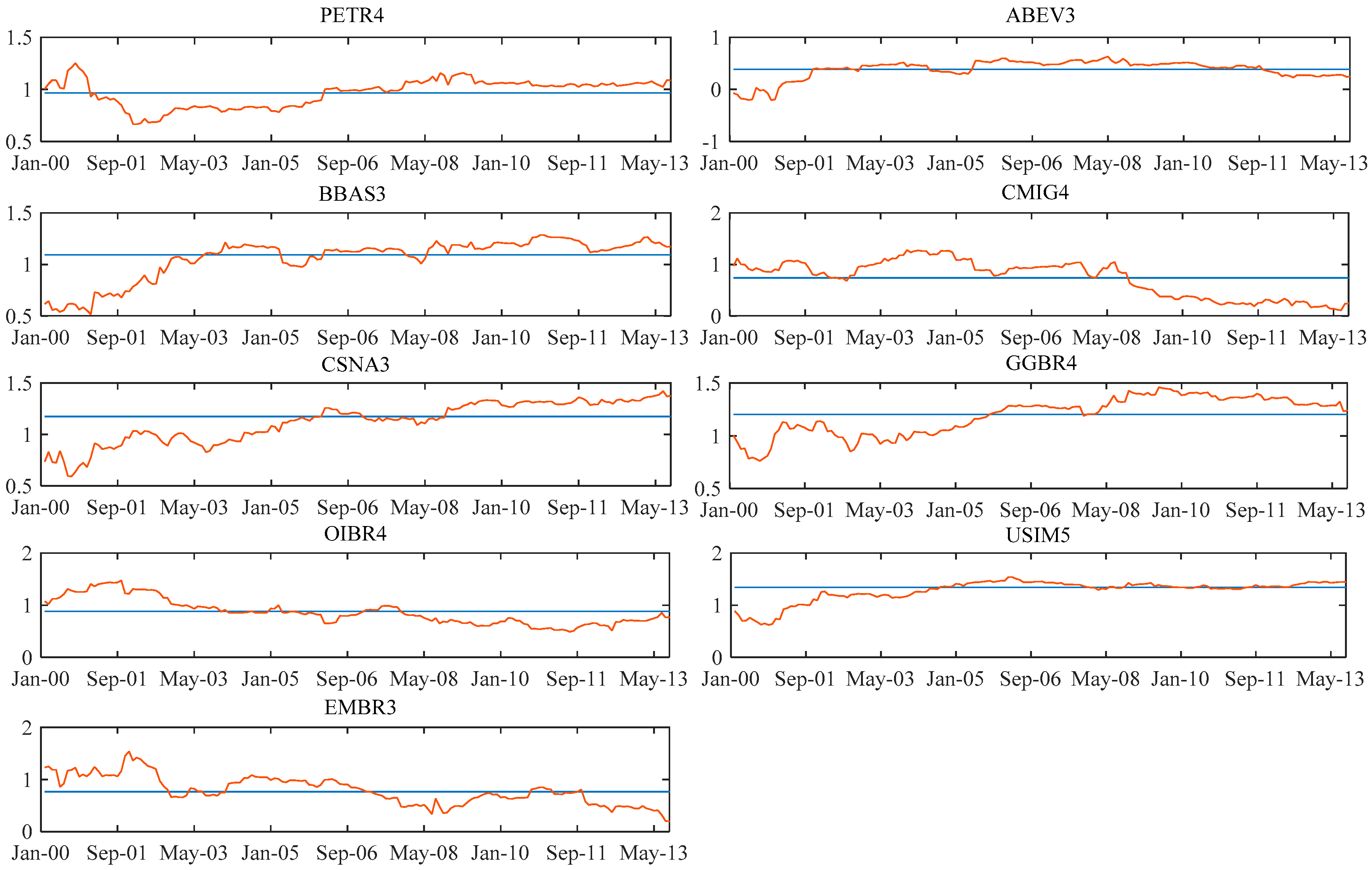
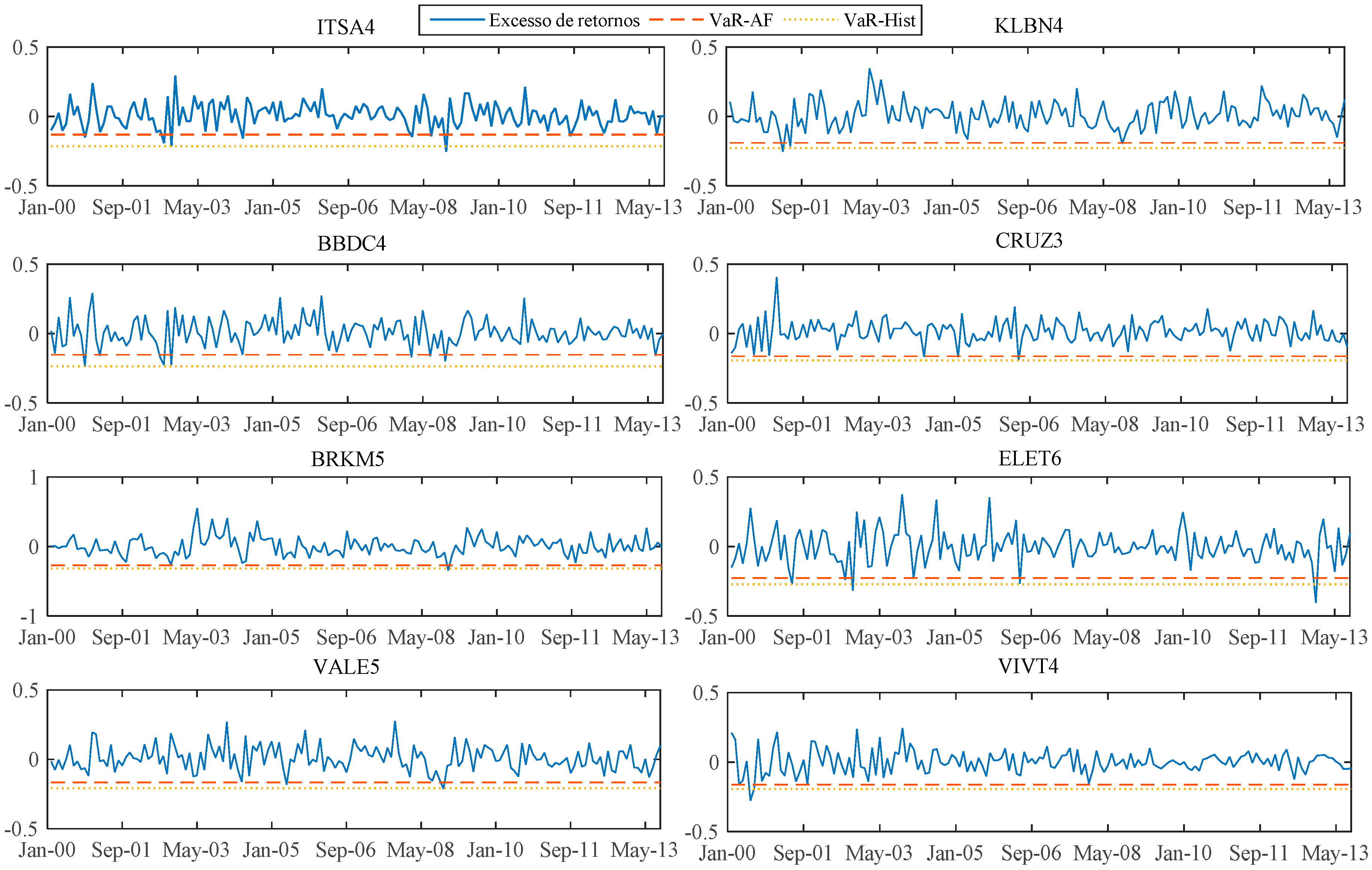
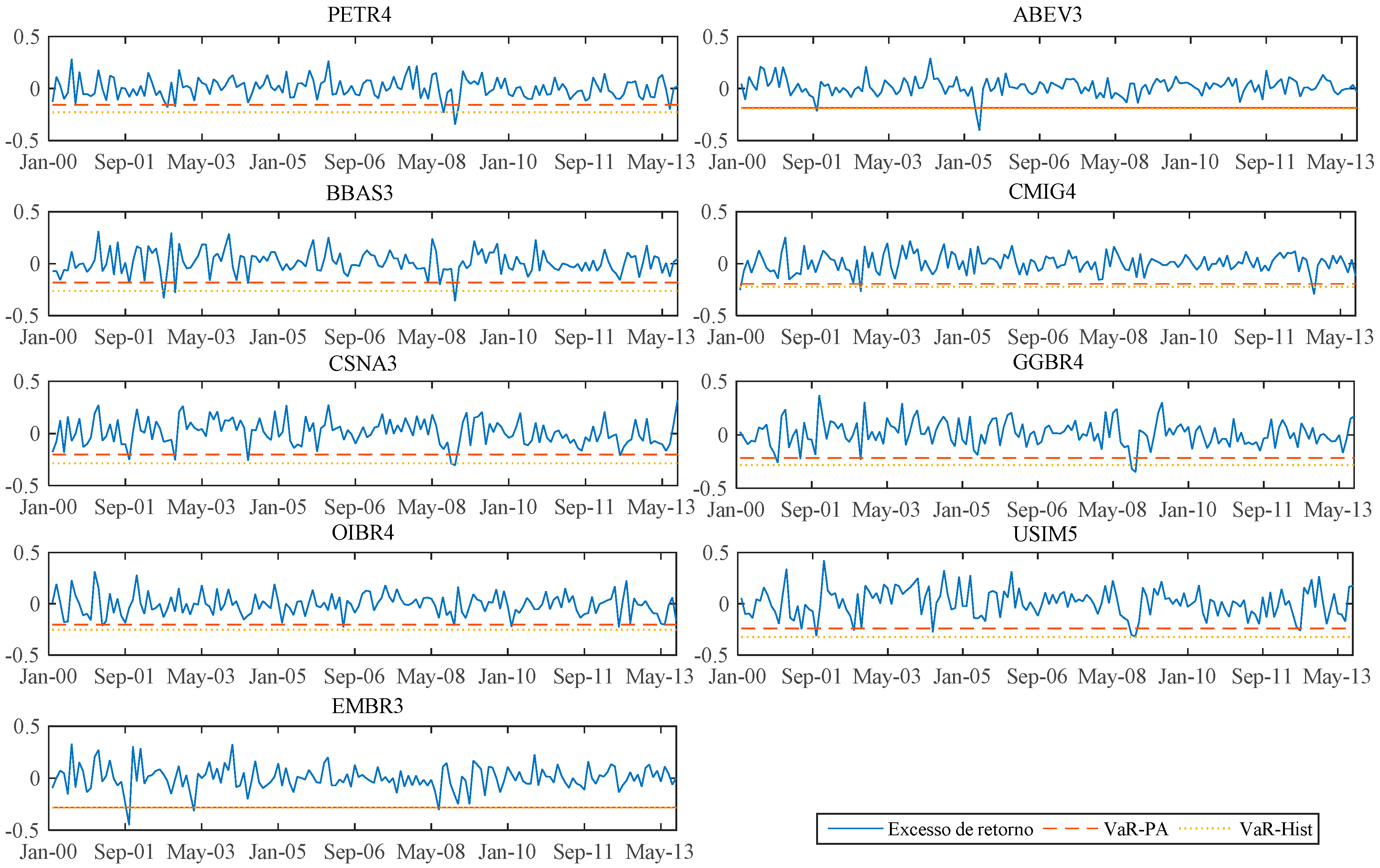
For the shares whose most significant models were the dynamic A&F, we represented in the graphs set C-1 of
Appendix C the dynamic behavior of the beta versus its
B (long-term beta) adapted by the Kalman filter. For the shares whose most significant models are the ones with beta following a random walk, we represent in the
Appendix C, graphs set C-2, the dynamic behavior of the beta versus the fixed beta estimated by OLS in the traditional CAPM.
The C-2 graphs set provides evidence of the relationship between fixed betas of the CAPM obtained by OLS and dynamic betas obtained from the Kalman filter. An important point in the analysis of the results is the evidence of the proximity between the dynamic betas and the fixed betas. This occurs because of the assumption of the mean reversion that is intrinsic in the used filter, making the current estimated value of beta affected by the level of betas from the past.
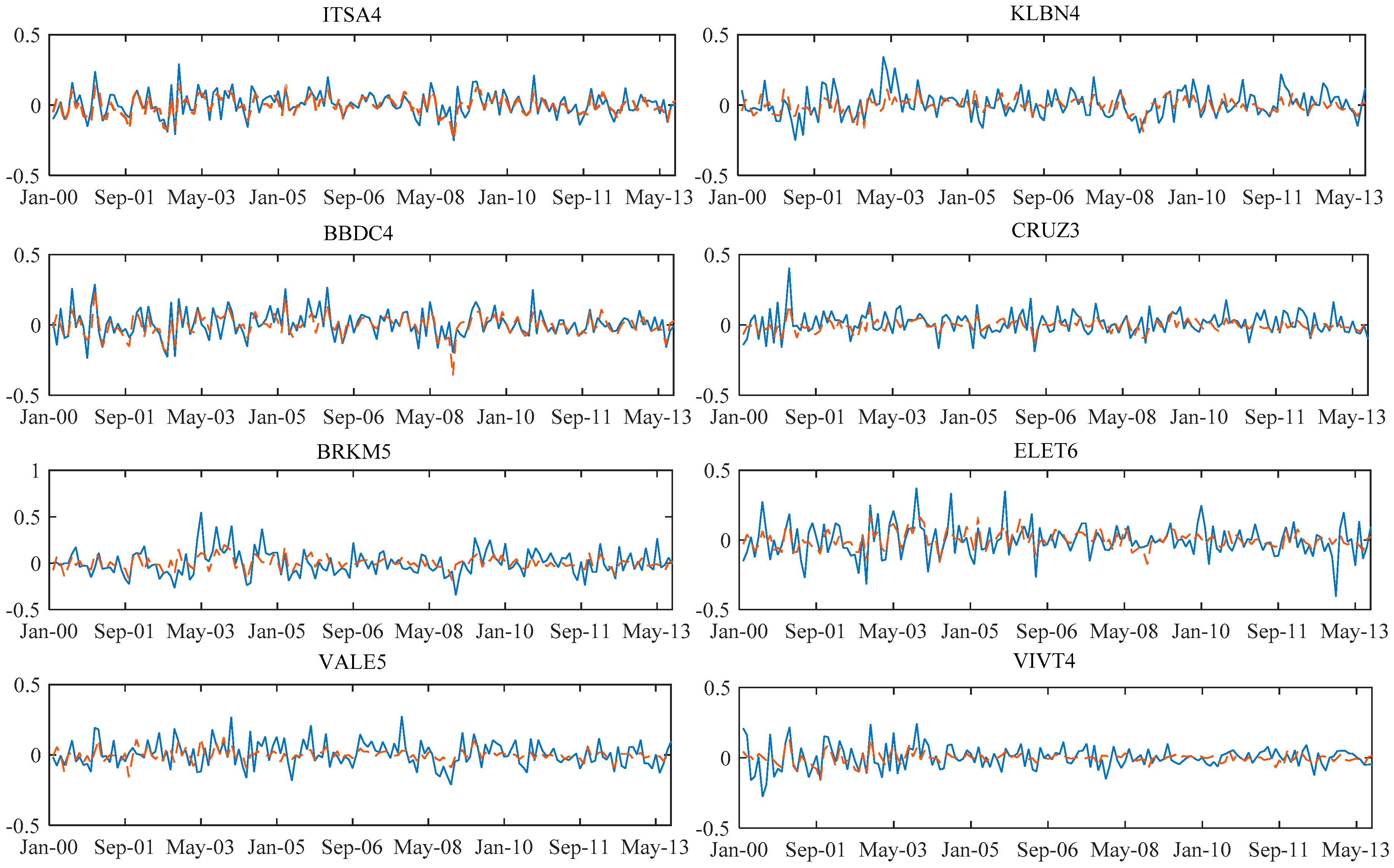
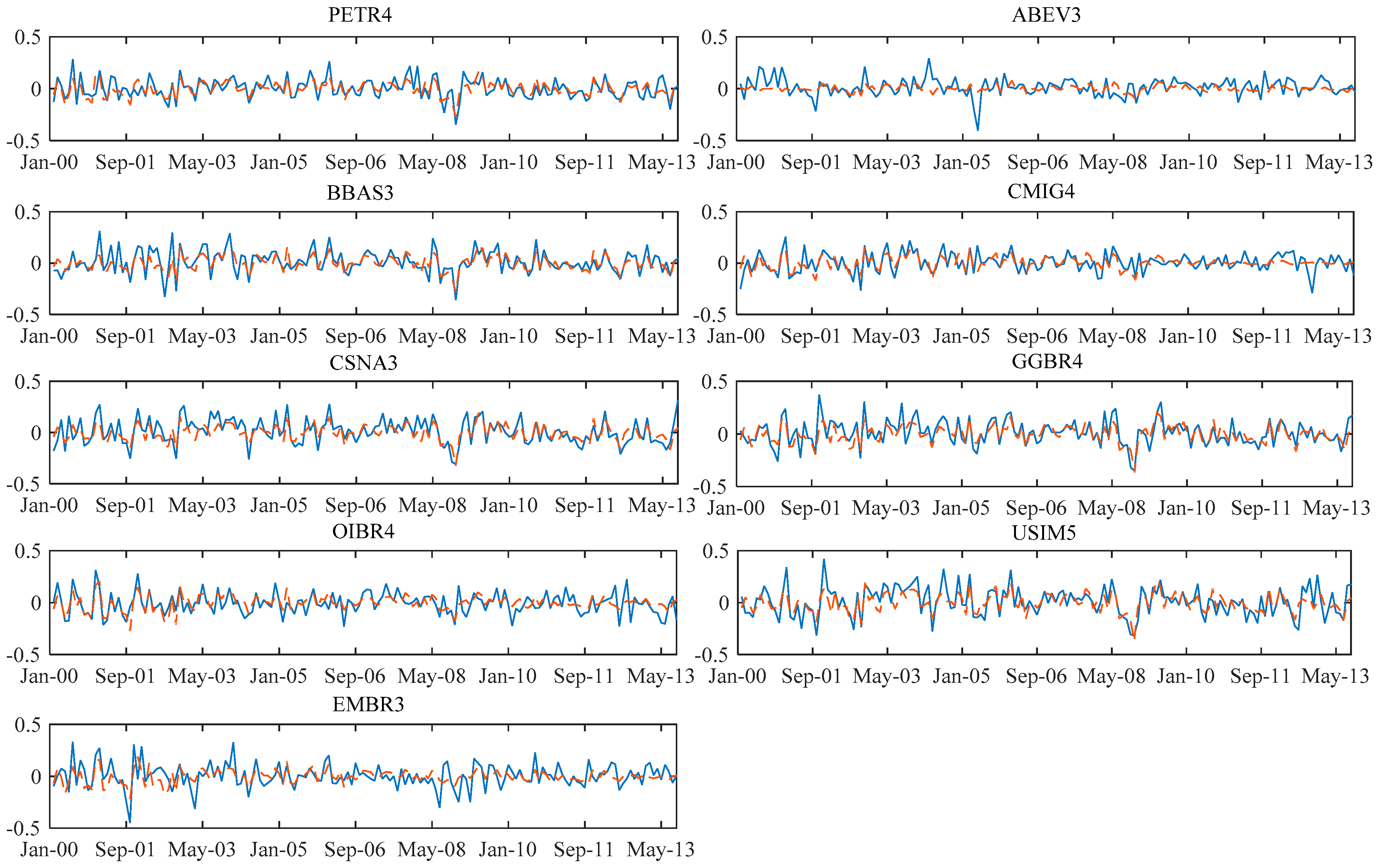
The graphs showing the result of the predicted return of the model of each share
compared to the return that actually occurred in each time “
t” are shown in
Appendix D.
3.3. Learning CAPM Estimation Errors
To analyze the goodness-of-fit of the models, two measures of the asset pricing errors were calculated, the RMSE (Root Mean Squared Error) and CPE (Composite Pricing Error). The RMSE for each model and each share is reported in
Table 4 below. We can observe that, systematically, the model with all conditioning variables has the lowest RMSE. This is in line with the findings of A&F.
In addition to the test above, we calculate the CPE that, due to its nature, gives lower weight to the alphas of the most volatile stocks. The result is reported in
Table 5.
Thus, on the whole result of RMSE and CPE parameters, the model with the best goodness-of-fit was using all the exogenous variables.
However, comparing the results of the model selection by the confidence level with the methodology of minor errors, RMSE and CPE, the conclusion is that they diverge. In the first, which uses the p-values for each estimated coefficient as indicators together with the information criteria for the selection of the best models, there was no selection of the one with all exogenous variables. However, in the methodology that uses RMSE and CPE, the model with all exogenous variables is preferred. This difference shows, therefore, that we must be careful when using the A&F methodology for simple shares, because the minor errors method could select models with low explanatory power of the betas behavior of each action.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





