1. Introduction
A portfolio can be defined as a collection of assets, which can include cash, real estate, stocks, or crypto. Portfolio optimization concerns maximizing returns and minimizing risks; returns are the expected profit from the investment, whereas risks are the possible changes in values of the investment. In
Markowitz (
1952), the authors proposed the use of the means and variances of the portfolio as the return and risk measures. Good practice in portfolio optimization is very crucial in investment, because it greatly affects the outcome of the investment. In this paper, we focus on portfolios consisting of correlated stocks.
The model proposed by
Markowitz (
1952) has been studied by many researchers over the years. A possible approach for the problem is the capital asset pricing model (CAPM). CAPM has been used extensively by many financial practitioners. In
Parmikanti et al. (
2020), the authors studied portfolio optimization under CAPM with a heteroscedastic model for the return series. Since its introduction, many improvements have been made to the model. Some improvements add practical constraints, which can be discrete or continuous; hence, the resulting model becomes mixed-integer nonlinear programming (MINLP). For instance,
Jobst et al. (
2001) and
Bartholomew-Biggs and Kane (
2009) considered adding roundlot constraints, which means that shares must be bought in a multiple of some integer. In
Jobst et al. (
2001), the authors used the FortMP solver, whereas
Bartholomew-Biggs and Kane (
2009) used DIRECT hybridized with quasi-Newton methodology. In
Jobst et al. (
2001), the authors also noted that the resulting efficiency is not continuous, making CAPM inapplicable in this case. With increasing complexity, various techniques also emerged. AUGMECON2 is a state-of-the-art multi-objective MINLP solver. It was introduced by
Mavrotas and Florios (
2013) and has been shown to very effective in solving multi-objective MINLP. Recent use of AUGMECON2 in portfolio optimization can be found in
Chen et al. (
2021). The downside of this method is its computational complexity. In
Chen et al. (
2021), the authors noted that for some large-dimensional problems, AUGMECON2 did not give a converged solution after 7 days.
To circumvent the complexity of exact methods, an efficient optimizer is needed. One popular approach is to use metaheuristic algorithms. Metaheuristic algorithms are usually inspired by natural processes in biology, chemistry, physics, or society. Most of the time, it is expected that metaheuristic algorithms can produce near-optimal solutions. Furthermore, an exact method is expected to be implemented later to obtain more accuracy, such in
Bartholomew-Biggs and Kane (
2009). In
Chang et al. (
2000), the authors proposed a series of modified metaheuristic algorithms that exploit the structure of the MV model with cardinality and quantity constraints. The metaheuristic algorithms used were genetic algorithm (GA), tabu search (TS), and simulated annealing (SA). To handle the cardinality and quantity constraints, they implemented an algorithm to adjust the solutions.
Another example of a metaheuristic algorithm is biogeography-based optimization (BBO). It was developed by
Simon (
2008); its inspiration is the dynamics of the geography of habitats. It basically consists of migration and mutation. Elitism is also added to ensure faster convergence. BBO has been used to solve numerous optimization problems in the real world. Some newer applications of BBO can be found in
Reihanian et al. (
2023) and
Ren et al. (
2023). Those studies concluded that BBO is a very powerful optimizer. For MINLP,
Garg (
2015) showed the efficiency of BBO in solving reliability problems and the results demonstrated the superiority of BBO over other metaheuristics. In their approach, the integral and discrete constraints were treated as if they were continuous, but in the function evaluation, they were rounded accordingly. This is sensible, because BBO is known for its effectiveness in continuous optimization. One of the reasons why we chose BBO is that it requires minimal parameters and is easy to implement.
For applications in portfolio optimization, there are some entries in the literature that have used BBO as the main optimizer. In
Ye et al. (
2017), the authors used BBO to solve a portfolio optimization problem with second-order stochastic dominance constraints. In
Garg and Deep (
2019), the authors used a variant of BBO called Laplacian biogeogeography-based optimization (LX-BBO) to find portfolio allocation from 10 assets in an MV model. In
Panwar et al. (
2018), the authors used BBO to solve a constrained MV model and applied the results in forecasting via Monte Carlo. The number of assets used in that research was 15.
Over the time, the number of companies listed in the stock markets are increasing. There are many markets with a very large number of companies. Although this provides a good opportunity for investors to choose assets, this also creates the problem in choosing suitable assets. In
Perold (
2022), the author studied how to efficiently choose a subset of a large set to optimize a portfolio. He considered a constrained portfolio optimization with a cardinality constraint and a quantity constraint. His method was inspired by quadratic programming techniques and was later improved to work very well for solving portfolio optimization. In
Qu et al. (
2017), the authors considered a multiobjective constrained mean-variance model and used four methods to solve the problem. The methods they used were Normalized Multiobjective Evolutionary Algorithm based on Decomposition (NMOEA/D), Multiobjective Differential Evolution based on Summation Sorting (MODE-SS), and Multiobjective Differential Evolution based on Nondomination Sorting (MODE-NDS), Multiobjective Comprehensive Learning Particle Swarm Optimizer (MO-CLPSO), and Nondominated Sorting Genetic Algorithm II (NSGA-II). The constraint they added to the model was a preselection constraint. They concluded that the methods were efficient for large-scale portfolio optimization. They also suggested adding practical constraints such as the cardinality constraint and the quantity constraint for further research.
In this paper, we proposed the usage of the heuristic ideas of
Chang et al. (
2000) but implemented in a BBO framework to solve a constrained MV model. The reason we used the ideas of
Chang et al. (
2000) is that they worked very well on a large-scale portfolio in their study. The dimensions studied by that work were 31, 85, 89, 98, and 225. Their methods could solve a large-scale portfolio optimization problem with high accuracy and in short time. It is clear that standard methods do not solve this problem effectively because the computational complexity is very large.
We used data from ORLibrary, which is available online. The same data were used in
Chang et al. (
2000) and
Kabbani (
2022). We also compare our results with theirs using the same performance metric. The results show that BBO is competitive in comparison to other methods.
The organization of this paper is as follows.
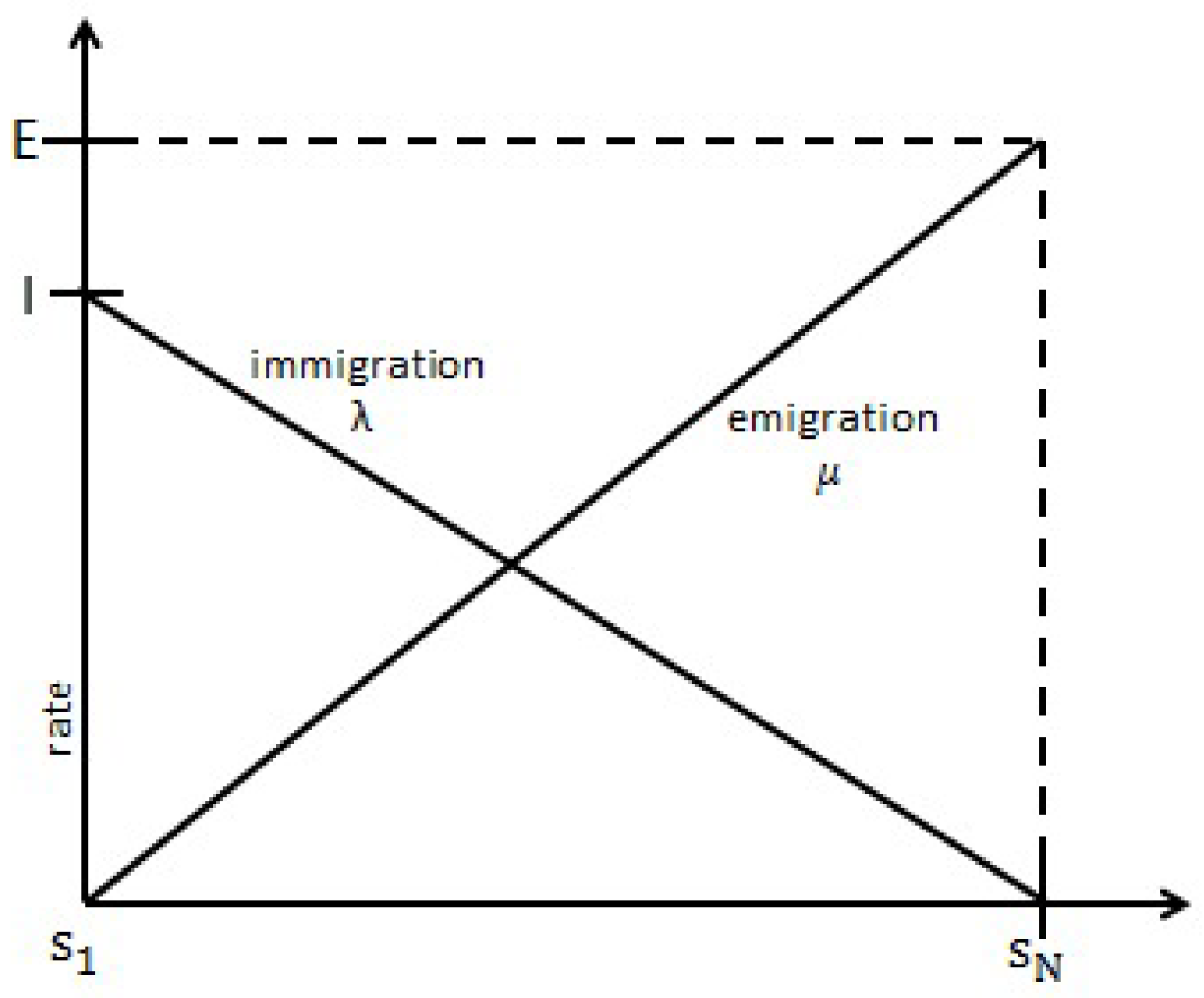
Section 2 introduces the problems that we solve in this paper and how we solve them. The problem is multiobjective constrained portfolio optimization. Then, introduce biogeography-based optimization (BBO) before detailing the method we propose.
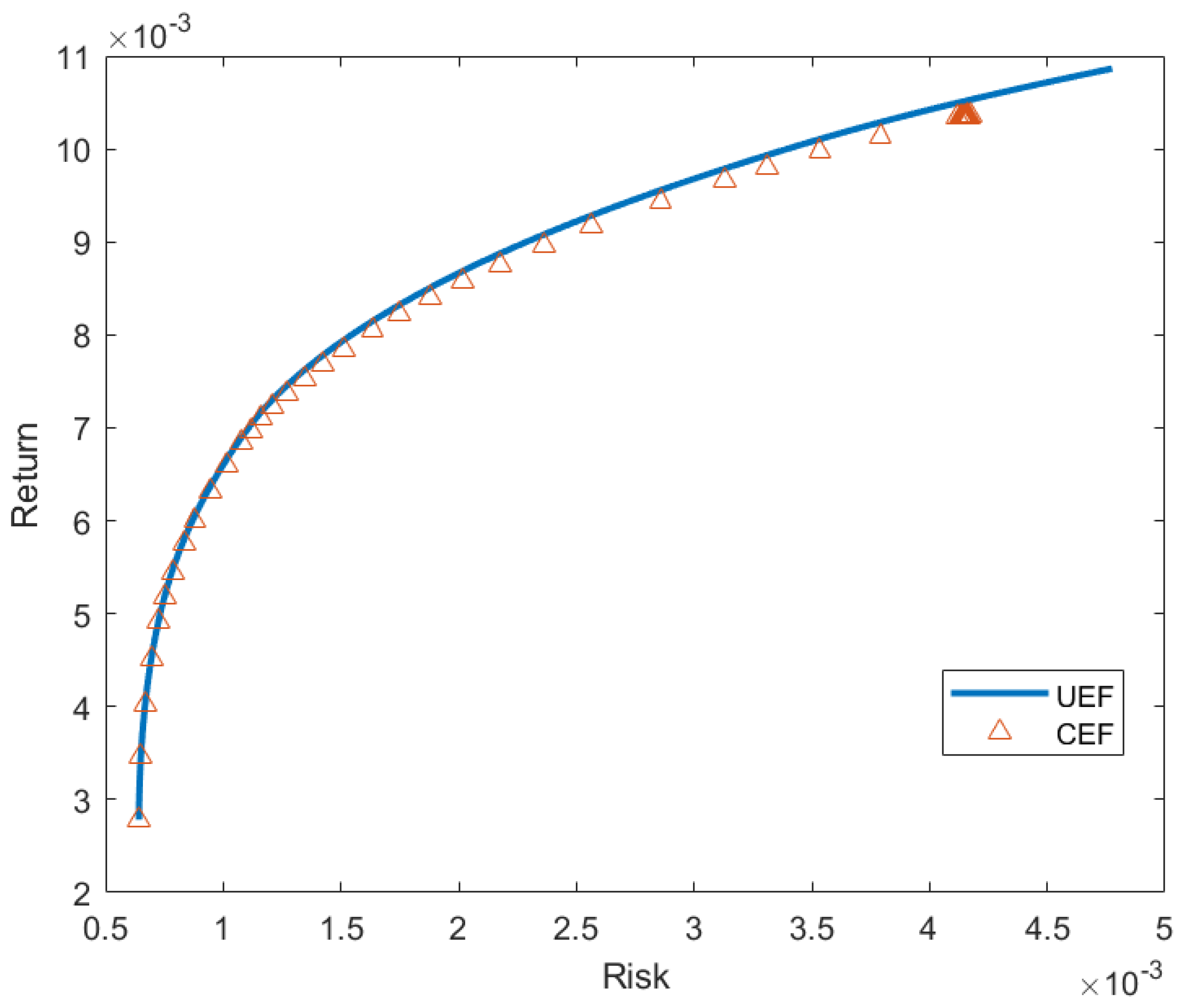
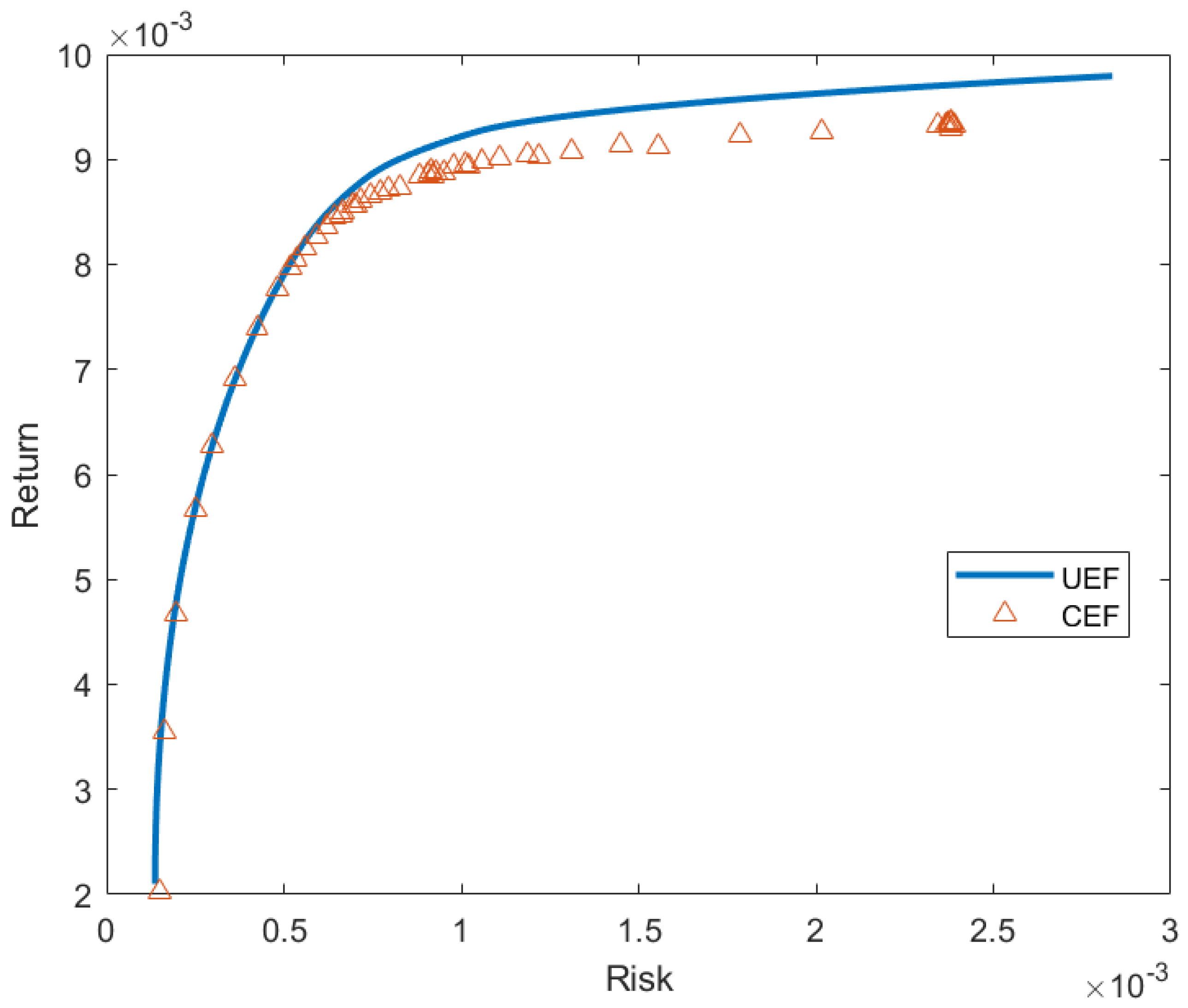
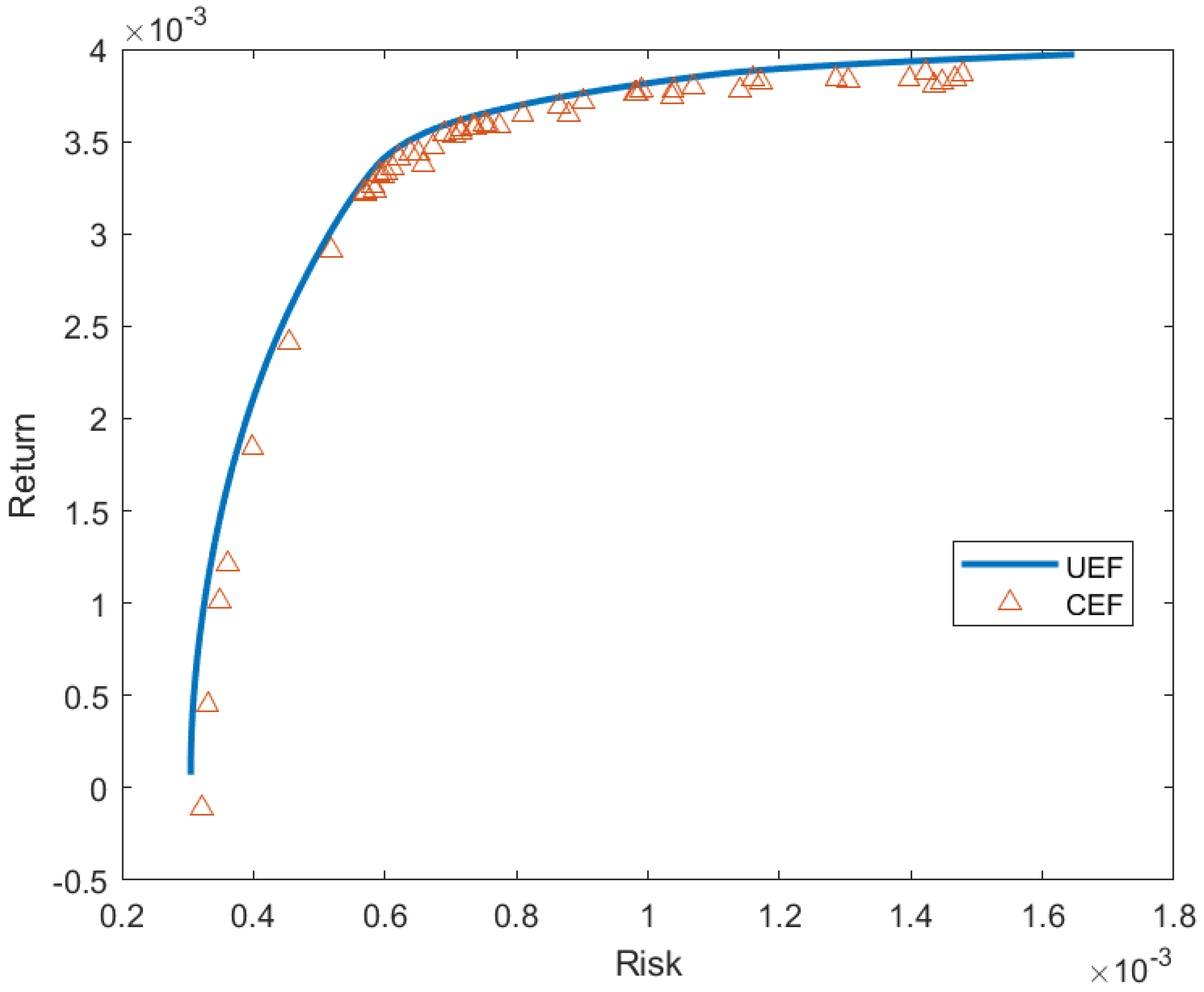
Section 3 contains the results of our proposed approach and a comparison with other studies. Conclusions and further improvements are also included in that section.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}