4. The Co-Citation Analysis
So far, we have been discussing some relatively superficial characteristics of the 2020 data. In this section, we move onto a more detailed consideration of the patterns of co-citation within the data set. This kind of analysis can be traced back to a series of influential papers published by Small (e.g.,
Small 1973), suggesting that authors who are frequently cited alongside each other can help us to identify thematic trends in a body of research. In L2 vocabulary research, for example, one important strand of research concerns the structure of a bilingual speaker’s mental lexicon, and recent research in this area will almost always cite pioneering work by de Groot, van Hell, Kroll, and Green. These four authors form the core of a cluster of researchers who tend to be co-cited in this context. The question we are interested in is what clusters can we identify in the 2020 research?
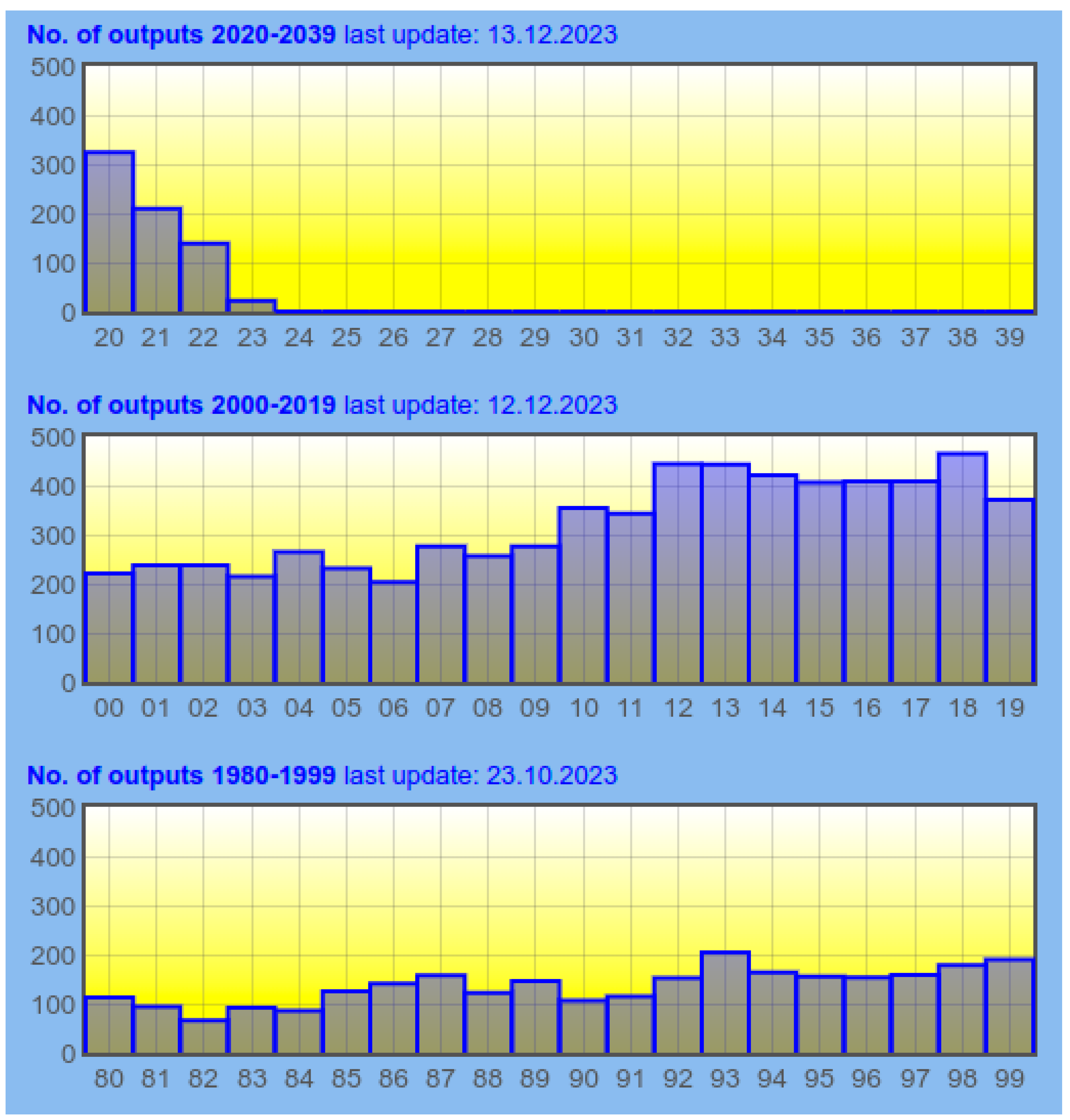
Author co-citation analysis, the main analysis tool used in this paper, traditionally makes a number of simplifying assumptions. The most straightforward assumption is that our analysis is based on two main types of research output: journal articles and chapters appearing in edited volumes. Monographs, theses, and non-standard reports are eliminated from the analysis on the grounds that the way references are used in work of this type tends to be very different from the way they are used in journal papers and similar reports. As we have seen in the previous section, the full 2020 data set contains seven books, three theses, and a computer program which are not included in the analysis that follows.
The second assumption traditionally made in author co-citation analyses is that the structure of the field is best captured by looking at a small number of sources who are most frequently cited in the data set. Conventionally, this number is set at about 100 sources—an arbitrary figure, largely driven by a need to keep the data manageable and easy to visualise.
The first step of the analysis involves identifying a set of authors who meet this inclusion criterion. With the 2020 data set, we can get close to this conventional figure by choosing to work with the 104 sources that are cited in at least 17 papers. (Note, though, that if we had adopted this criterion for the 1990 data set, only one source would have qualified—another example of the grade inflation that we noted in the previous section.)
The next step involves drawing up a large matrix which shows the number of times each of the 104 authors is co-cited with each of the other authors in the matrix. Once these data are in place, they can be submitted to a standard mapping program which converts the matrix to a two-dimensional mapping. In the analyses that follow, I used the
Gephi program to perform this conversion (
Bastian et al. 2009). Normally, this results in a mapping which looks like
Figure 1, but, as we will see, the 2020 data set has some characteristics that make it difficult to process.
Figure 3 illustrates the main problem with this data set. This figure is a spanning tree which shows the strongest co-citation links between the most frequently cited 51 sources in the data set. Each of the 51 sources is cited at least 25 times in the data set. Each node is connected to the tree by its strongest co-citation link—the weakest link in the figure is the link between Nation and Kroll, which occurs only 14 times in the data set; all the other links are stronger than this. The ten strongest links in the spanning tree are listed in
Table 4.
Gephi’s analysis of these data suggests that we can identify four clusters in this data set—the clusters focussed on Nation, Schmitt, Webb, and Paribakht, respectively. However, this spanning tree mapping is very unusual, in that we have three very small clusters and one enormous cluster focussed on Nation. This large cluster includes 37 of the 51 most-cited sources in the 2020 data set—73% of all the sources that appear in the figure.
1 The most striking feature of this main cluster is that it has very little internal structure. Of the 37 members of this cluster, 36 members are maximally co-cited with Nation: the only source who does not fit this pattern is Goldstein (most often co-cited with Laufer). It is possible to identify some sub-clusters within the largest cluster, and I have arranged the nodes in
Figure 3 to reflect a speculative interpretation of these sub-clusters. However, even where the focus of a sub-cluster is relatively clear—as with the sub-cluster whose main focus is on eye-tracking (Pellicer-Sanchez, Peters, de Smedt, and Elgort)—the sources are still more strongly co-cited with Nation than they are with each other. The smaller cluster focussed around Schmitt accounts for a further 16% of the sources, bringing the tally of sources counted in the two main clusters to 89% of the total.
Clearly, the 2020 map is structurally very different from the 1990 map shown in
Figure 1, where the clusters are smaller. Here, Nation’s influence is so dominant that it prevents the more detailed structure of the co-citations from becoming apparent. However, we can get around this problem by arguing that Nation’s influence in the 2020 data is so all-pervasive that it does not actually make a distinctive contribution to the structure of the data set. This means that we might be able to ignore Nation, and explore the co-citation patterns in the rest of the data. Essentially, this involves building a “donut map” which ignores the massive impact of dominant sources like Nation, and allows weaker relationships to emerge from his shadow, as it were.
Figure 4 shows the results of an analysis of this sort.
The donut map of the 2020 data set is fairly easy to interpret. The core of the map consists of six very significant influences. The predominant influence is Schmitt, followed closely by Laufer. Hulstijn, Webb, Cobb, and Meara make up the rest of this core, but the co-citations between all six of these influences are very strong. This core is surrounded by a group of lesser influences. Waring, Horst, Read, NC Ellis, Pellicer-Sanchez, Paribakht, Wesche, Beglar, Peters, Coxhead, and D Schmitt make up this group of less central authors. Their co-citation links are more focussed than those of the central core.
Gephi identified nine clusters in the 2020 data set, together with one isolated source (de Bot). These clusters are described below.
The largest cluster, Cluster A, is focussed on Schmitt. This cluster contains 20 members, many of whom are closely associated with Nottingham University. The cluster seems to include a number of sub-clusters. McCarthy, Carter, Biber, and Sinclair appear in my earlier analyses as a distinct cluster dealing with formal descriptions of lexis and corpus analysis. Chamot, Oxford, and Dornyei make up a sub-cluster that deals with motivation and strategies. Wray and Gyllstad represent a research strand that deals with collocations and multi-word lexical items. (Note, though, that the VARGA database does not systematically monitor research on multi-word items, so the analysis may be underestimating the importance of this research strand.)
Cluster B, with 19 members focussed on Laufer and Hulstijn, looks to be mainly concerned with implicit and explicit vocabulary acquisition in a variety of contexts.
Cluster C, with 14 members focussed on Webb, consists of a subgroup of sources working on word lists (Davies, Gardiner, Coxhead, and the historically important West), and the degree of coverage provided by these word lists. It also includes Diane Schmitt and Clapham, whose work with Norbert Schmitt provides a standard assessment tool for measuring vocabulary mastery that is based on frequency counts.
Cluster D, with 12 members focussed on Pellicer-Sánchez, seems to be a methodologically motivated cluster, whose members use eye-tracking to study L2 reading.
Cluster E, also with 12 members, is also a characterised by a distinctive methodology. This cluster seems to be mainly concerned with lexical inferencing, but it also contains a sub-cluster that uses word-association methods in an attempt to assess vocabulary depth. This cluster is particularly associated with the research group at Swansea University.
Cluster F, with 10 members focussed on Cobb, is also concerned with vocabulary uptake from reading, though Cobb’s web-site is an important methodological resource in a number of disparate areas.
Cluster G, a smaller cluster with only seven members, is another methodological cluster, this one concerned with ways of assessing change in vocabulary knowledge. Wesche and Paribakht’s Vocabulary Knowledge Scale is the standard tool here (cf.
Wesche and Paribakht 1996).
Cluster H, with only three members, is a group of L1 reading researchers whose work has seriously influenced the thinking of L2 vocabulary research.
Cluster I, again with only three members, is the remains of a psycholinguistics research tradition dealing with the structure of bilingual lexicons. This tradition played a very significant role in earlier periods of L2 vocabulary research, but by 2020 this role seems to be diminishing in this map, and the members of this cluster have become detached from the main L2 vocabulary research clusters. There are some weaker links with other nodes, but they are not strong enough to appear in
Figure 3.
De Bot appears in
Figure 3 as a detached singleton with no connections to the rest of the network. This, again, is the result of the filters applied to the data: de Bot is substantially cited in the 2020 data set (17 times), but he is most frequently co-cited with authors who do not appear in the list of most-cited sources.
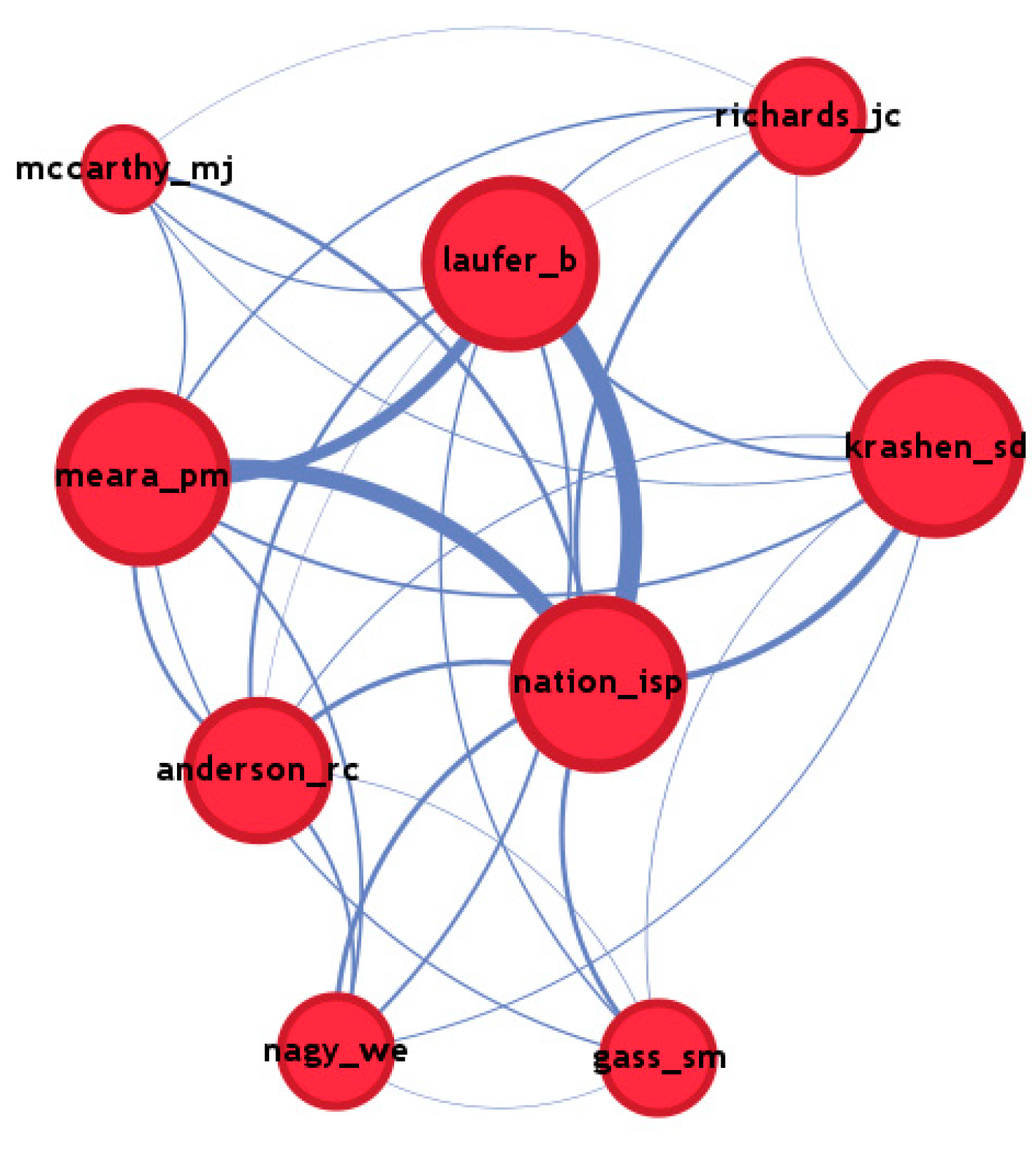
A number of points emerge from this analysis. Firstly, only nine significant influences survived from 1990 through to 2020. All nine sources were still co-cited in the 2020 data set, and some were very strongly co-cited (See
Figure 5). The core of this map is the Laufer–Meara–Nation triangle. Anderson and Nagy are part of an L1 reading theme, while Krashen is mainly cited for his claims about incidental L2 vocabulary acquisition from reading. McCarthy is the main survivor from the corpus linguistics theme that dominated L2 vocabulary research in the early 1990s. Richards is mostly cited for his classic work on what it means to know a word (
Richards 1976). Gass is mostly cited here for her recent work on subtitled input and eye-tracking.
Clearly, the majority of the significant influences who appear in the 2020 map are relatively recent new-comers (See
Table 5). I do not yet have enough data to determine exactly when these new sources rose to prominence, but it is probably safe to say that Schmitt, Hulstijn, Read, and Cobb first become important sources in the 1990s, while most of the other new sources have a much shorter bibliometric history.
The second point to emerge from the analysis is that a number of significant influences who appeared in the 1990 data set can no longer lay claim to this role in the 2020 data. Some of these authors continue to be cited in the 2020 data, but their influence is a pale shadow of what it was. Corder, Schouten-van Parreren, Palmberg, and Levenston—all very significant influences in the 1990 data set—are cited only once in 2020, for example. Kellerman and Stevick are cited only twice. An interesting case is Aitchison. She was cited five times in the 1990 data set. In the 2020 data set she is cited 14 times: far more frequently than she was cited in 1990 but slightly fewer times than the stricter threshold I have used for the 2020 map (another example of the grade inflation trend that I mentioned earlier.)
This leads us to ask what areas of interest present in the 1990 map no longer have a presence in the 2020 map. I think we can identify six main areas that were important in 1990, but seem to be less important in 2020. The most obvious loss is the disappearance of all the members of Cluster III, Cluster IV, and Cluster VI in the 1990 map (see
Figure 1). These clusters contain a number of sources whose main interest was the practical applications of vocabulary theory to teaching—Gairns and Redman, and Rudzka, Ostyn, Channell, and Putseys are particularly important in this context. Also important is the disappearance of the Scandinavian research group—Palmberg, Phillipson, Haastrup, Faerch, and Kasper—that strongly influenced the 1990s research on lexical inferencing. Transfer and lexical errors (Kellerman, Ringbom, and Corder) no longer seem to play a role in the 2020 research. L1 vocabulary development (HH Clark and R Brown) was an important influence in 1990 but not, it seems, in 2020. None of the members of the psycholinguistics cluster (Cluster II in
Figure 1) met the inclusion threshold for the 2020 map, although this strand of research is represented by three new sources (de Groot, van Hell, and Kroll) in 2020.
What replaces these historical concerns?
Figure 6 shows a spanning tree analysis of the new sources in the 2020 map, and we can begin to answer this question by identifying the clusters which emerge in this map.
This map, again, is relatively easy to interpret. The spine of the map runs from left to right, from Hulstijn through Schmitt to Webb and Cobb. Gephi found 10 clusters in this data set, but once again we have the problem that a single node dominates the map and prevents the finer structure from emerging. Schmitt and Webb seem to play the same role here as Nation did in
Figure 3. Gephi did manage to find some interpretable clusters in this tree, but these clusters are mostly formed of sources who co-author a small number of frequently cited papers (
Wesche and Paribakht 1996;
Hulstijn et al. 1996; and
Cobb and Horst 2019, for example). It is possible to disaggregate the single massive cluster dominated by Schmitt and Webb, and I have reflected this in the way I have drawn the map. However, the dominant position of Schmitt suggests that what we have here is another case where a donut map makes more sense than the straightforward spanning tree.
Figure 7 shows a donut map of the newcomers with Schmitt’s co-citations and Webb’s co-citations excluded from the analysis.
This mapping is extremely easy to interpret. The core of the map is a set of highly interconnected hubs. The most significant influence in the map is Hulstijn, followed closely by NC Ellis, Cobb, Horst, Read, Pellicer-Sanchez, and Peters. The strongest co-citation links between these central hubs are listed in
Table 6.
Gephi’s analysis suggests that there are 11 clusters in this data set, and they can be straightforwardly identified as the main research trends in the 2020 data set.
Cluster A, the largest cluster focussed on Hulstijn and NC Ellis, seems to consist of two smaller clusters, one comprised mainly of psychologists whose work has strongly influenced research on L2 word recognition, the other dealing more specifically with word recognition by bilinguals.
Cluster B, focussed on John Read, looks like a group of sources interested in depth of vocabulary knowledge. This cluster also contains a sub-cluster that focusses on word-associations.
Cluster C, focussed on Pellicer-Sanchez, contains a number of sources who use eye-tracking as their main methodology.
Cluster D, focussed on Coxhead, is largely concerned with word lists and analyses of corpora for L2 vocabulary teaching.
Cluster E, focussed on Horst and Waring, is mainly concerned with vocabulary acquisition from reading.
Cluster F is strongly influenced by the coh-metrix approach to learner output.
Cluster G is concerned with modified input for L2 learning.
Cluster H is mainly focussed on measures of vocabulary size.
Cluster I is an L2 reading cluster.
Cluster J is a set of sources that uses Wesche and Paribakht’s Vocabulary Knowledge Scale as a way of assessing the partial learning of words.
Finally, Cluster K, focussed on Oxford, is a set of sources whose main interest is learning strategies.
Most readers who are familiar with the current L2 vocabulary research would probably agree that this map does capture the main trends in the research quite well. However, we need to bear in mind that a lot of data were eliminated in order for us to reach this plausible conclusion. See
Section 5 below.
An alternative, more nuanced conclusion is that the current research can be seen to be made up of four main components: we have a core of historically important sources closely associated with Nation; a more recent core of very significant sources (Schmitt and Webb) that is very widely co-cited in the more recent research but not in the earlier research; a number of new sources that act as hubs for a cluster; a number of other, but less influential, sources. This last group can be split into two smaller groups: a group of older sources that were significant in earlier maps, whose influence appears to be waning (Corder and Krashen are good examples of this), and a small group of genuinely new sources whose importance is on the rise.
What the maps cannot tell us is what kind of temporal trajectory is being followed by these sources. Clearly the maps do not tell us anything in detail about what is going on between the two snapshots taken in 1990 and 2020. Some of the research trends identified in the maps are recent and genuinely new (eye-tracking, for example). Others are long-standing interests, but the sources that allow them to be identified have changed (de Groot, van Hell, and Kroll, for example, replacing Kirsner and colleagues investigating the way bilingual lexicons are organised). The thirty-year gap between 1990 and 2020 is very large in research terms, covering several generations of research students. Clearly, more work is needed to clarify how the field is developing between these two snapshots (
Meara 2020).
5. The Other Research
So far, I have discussed the broad patterns of author co-citations in the 2020 data set, with a particular focus on the role of Nation in shaping the overall structure of this research. I have also noted that this discussion was based on an analysis of the most frequently cited 104 authors in the 2020 data. It will be obvious, however, that restricting the analysis in this way means that we are not taking any account of the many other sources that are not cited to the same extent.
Figure 7, for example, takes no account of the sources in the 2020 data set that are cited fewer than 17 times. The data set actually contains 2601 sources that are cited more than once, so the mapping in
Figure 7 is based on only 4% of the data available for analysis. In contrast, the 1990 map shown in
Figure 1 captured nearly 23% of all the co-citations that appeared twice or more in the data set, and this makes it much easier to justify the inclusion threshold—only the very weakest of co-citation links were ignored in the 1990 map. Clearly, this problem becomes more serious as the data sets get larger, and the inclusion threshold that gives us about 100 sources excludes an ever-increasing proportion of the data set.
This difficulty seems to arise because of the grade inflation factor. A particular factor is that the average number of research outputs cited by a typical paper has exploded since 1990. In 1990, the average number of sources cited in a paper was 25—though many papers cited fewer than 10 sources. By 2020, this figure had increased to 74, with 17 papers citing more than 150 authors, and one paper (
Sulpizio et al. 2020) citing 673 authors! Partly, of course this increase comes about simply because there is more research available to be cited, a significant increase in the number of papers with multiple authors, and the increasing appearance of meta-analyses, but this is not the whole story. As the number of research outputs increases, the co-citation statistics are dominated by derivative research, papers that largely duplicate things we know already, do not use innovative methodologies, and do not push the boundaries of theory. This type of research tends to cite “the usual suspects”, sources that lend a certain amount of legitimacy to a paper, but are not necessarily engaged with. The result is that the co-citation maps become overwhelmed by a canonical list of sources that are widely cited, but are not truly reflective of the current research fronts. These features do not entirely invalidate the analysis that I have presented in this paper, but they do suggest that research fronts in L2 vocabulary research might be more elusive and harder to recognise than we had expected.
This raises the question whether the conventional practice of working with only the most frequently cited sources in a data set, producing mappings which take into account only a hundred of these sources, needs to be rethought. Perhaps we should be looking for research clusters that meet common objective criteria, rather than the arbitrary thresholds that underpin maps like
Figure 7?
I have not yet managed to find a methodology that could automatically identify and extract less frequently cited but still interesting clusters in very large data sets. However, anyone familiar with the entire 2020 oeuvre will realise that there are a number of themes running through this work which look as though they might be embryonic themes—themes that are not cited often enough for them to appear in the main mappings, yet nonetheless capture some important growing topics of interest in L2 vocabulary research. I have listed some of these themes in
Table 7, along with some papers published in 2020 which exemplify them. Several of these themes represent a substantial amount of research output: the gaming theme, for instance, appears in at least 10 papers in 2020. Gaming does not appear explicitly in
Figure 7. Had these papers appeared in 1990, however, they would easily have met the threshold for inclusion in the 1990 map, and gaming would have appeared in
Figure 1 as a very significant research cluster.
Space does not allow me to follow up this idea here, and we cannot investigate the characteristics of these sub-threshold clusters in any detail. However, I will be reporting an analysis that tries to establish objective criteria for identifying clusters of this sort in a follow-up paper. In the meantime, there is one set of research papers which can be objectively identified and analysed using the same approach that we used in the previous section. This is a subset of the 2020 data set that does not cite Nation among its sources. This work is not marginal, but its relationship to the work that does cite Nation means that it tends to get overlooked. It is instructive to examine how this work differs from the work we have discussed so far.
The 2020 data set contains a subset of 74 papers which unusually do not cite Nation among their references. These 74 papers do cite other sources, however—5214 in total, of which 4468 are cited only once. The distribution of these papers is summarised in
Table 8. The most frequently cited sources in this subset of the data are Schmitt (19 citations); Kroll (12 citations); van Hell (11 citations); and Bates, Brysbaert, Laufer, and Perfetti (10 citations each). The overall distribution of these citations is shown in
Table 9. What is striking here is the fact that only two of the very significant influences that we identified in the larger 2020 data set appear in this smaller set (Schmitt and Laufer).
Figure 8 shows this smaller data set as a spanning tree mapping. The map is made up of 61 sources that are co-cited at least five times in the reduced data set; each node is connected by an edge to the node it is most frequently co-cited with. The spine of this mapping is the set of co-citations that link van Hell, Kroll, Bates, Brysbaert, and Schmitt. The strongest links in the mapping are reported in
Table 9.
Gephi’s analysis found eight clusters in this data set.
Cluster A, dominated by van Hell, is made up of sources that are interested in bilingual lexicons, and use word recognition as their main methodological tool.
Cluster B, dominated by Kroll, shares many of the same concerns as Cluster A, but seems to be more concerned with productive vocabulary, whereas Cluster A focusses on receptive vocabulary. Cluster B also makes use of more formal models, notably the Bilingual Interactive Activation model (
Dijkstra et al. 1998).
Cluster C is a set of statistical sources that identify methodological features in Cluster A and Cluster B. Cluster D, dominated by Brysbaert, also seems to be a methodological cluster. Brysbaert has published a large set of vocabulary size tests for several different languages, and a number of norms lists which are routinely used by the sources in Cluster A and Cluster B. The other members of this cluster seem to be interested mainly in reading behaviour. This theme is also picked up in
Cluster F, a group of sources whose main interest is reading behaviour in young bilingual speakers.
Cluster E is a much reduced set of the influences who appear in
Figure 6. The striking feature here is how small this cluster is, and how few co-citation links there are between this cluster and the rest of the map.
Cluster F is a small, detached cluster of Canadian researchers who mainly work on English/French bilinguals. The detached status of this cluster starkly emphasises the dominance of English language research in all the maps we have discussed so far in this report.
Almost all of the sources identified in
Figure 8 will be unfamiliar to researchers working in the more mainstream L2 vocabulary tradition.
Figure 8 strongly suggests that the research clusters identified in
Figure 7 are only part of a much more complicated research endeavour. Yes, the main bulk of the 2020 research clusters around a small number of very significant sources, that most researchers in the Applied Linguistics tradition would immediately recognise, but there exists alongside these sources at least one other “invisible college”, a set of clusters which is numerically large, intellectually coherent, but to a large extent independent of the main research trends identified in
Figure 7. The data suggest that we have two quite separate research traditions here, one where researchers see their roots in Applied Linguistics research, the other looking more towards psychology. There is very little direct contact between these two traditions, with almost no overlap in the sources that they cite, despite a shared set of research questions, particularly an interest in L2 reading behaviour. There is clearly a case for encouraging closer collaboration between the two traditions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}