

Exploring Semanticity for Content and Function Word Distinction in Catalan


Abstract
1. Introduction
The meaning of a natural-language expression is determined by the meanings of its immediate sub-expressions and the way in which they were combined.
2. Related Work
2.1. Word Connectivity, Co-Occurrence, and Compositionality
2.2. Statistical Laws on Meaning
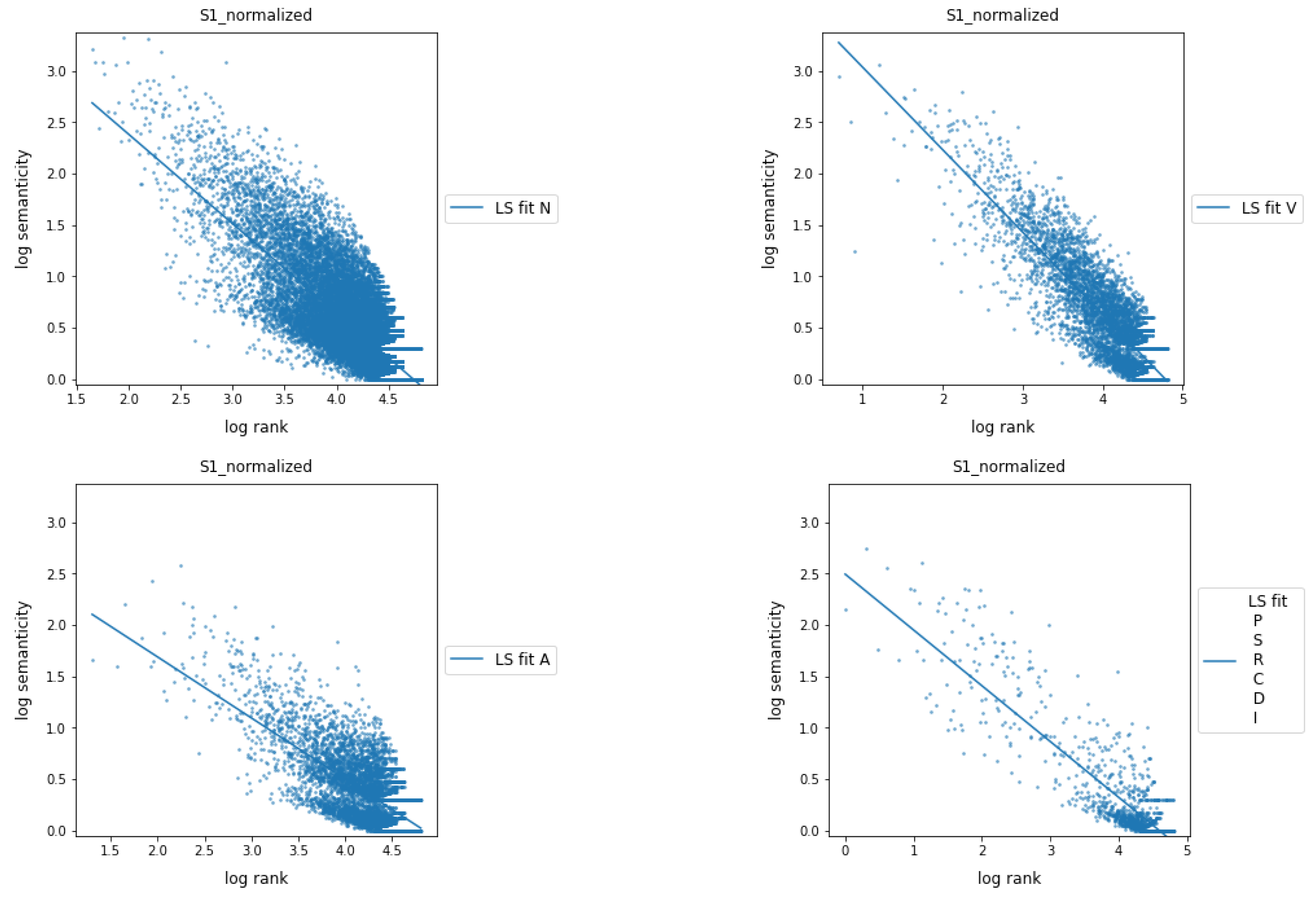
2.3. Lexical Categories
3. Semanticity
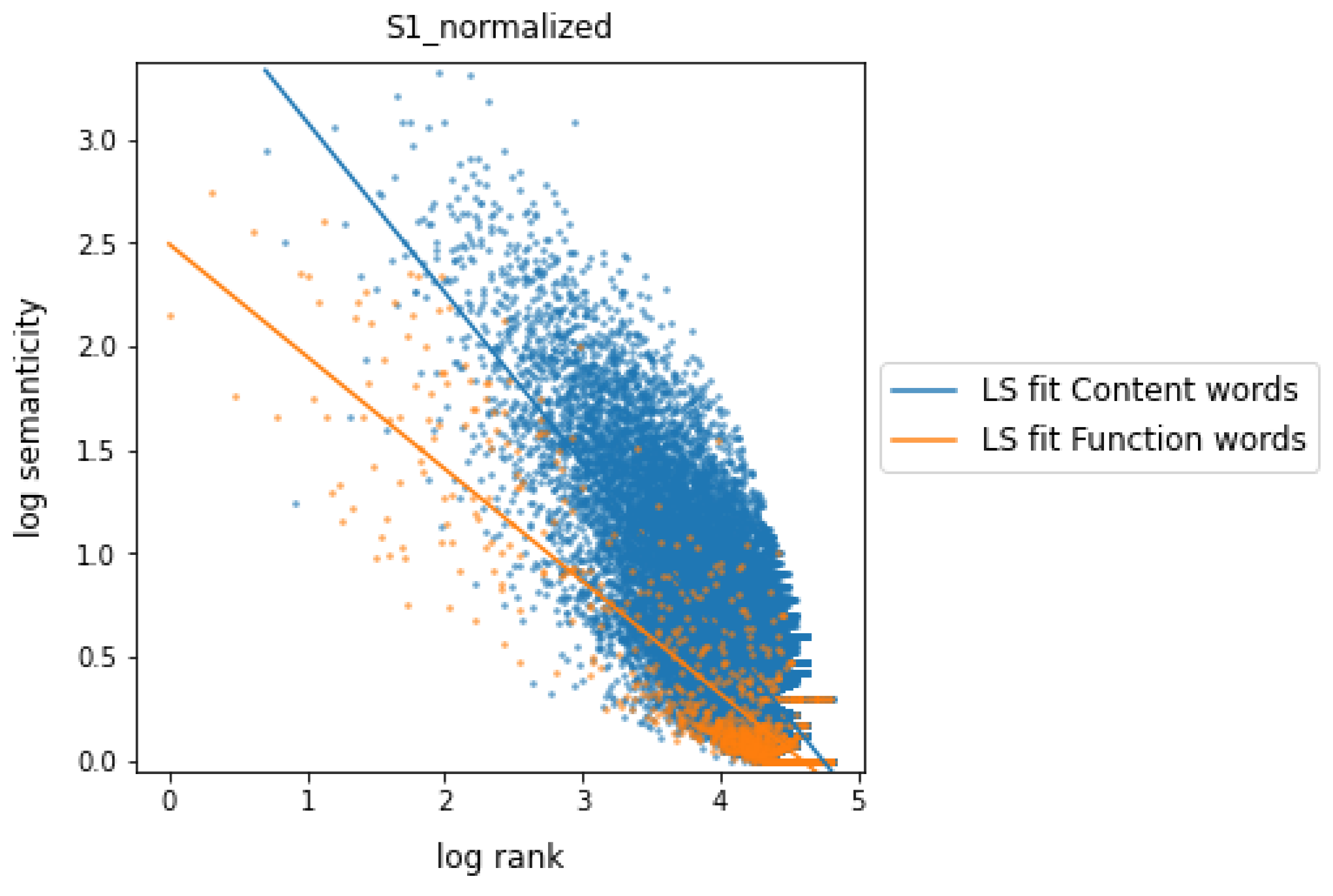
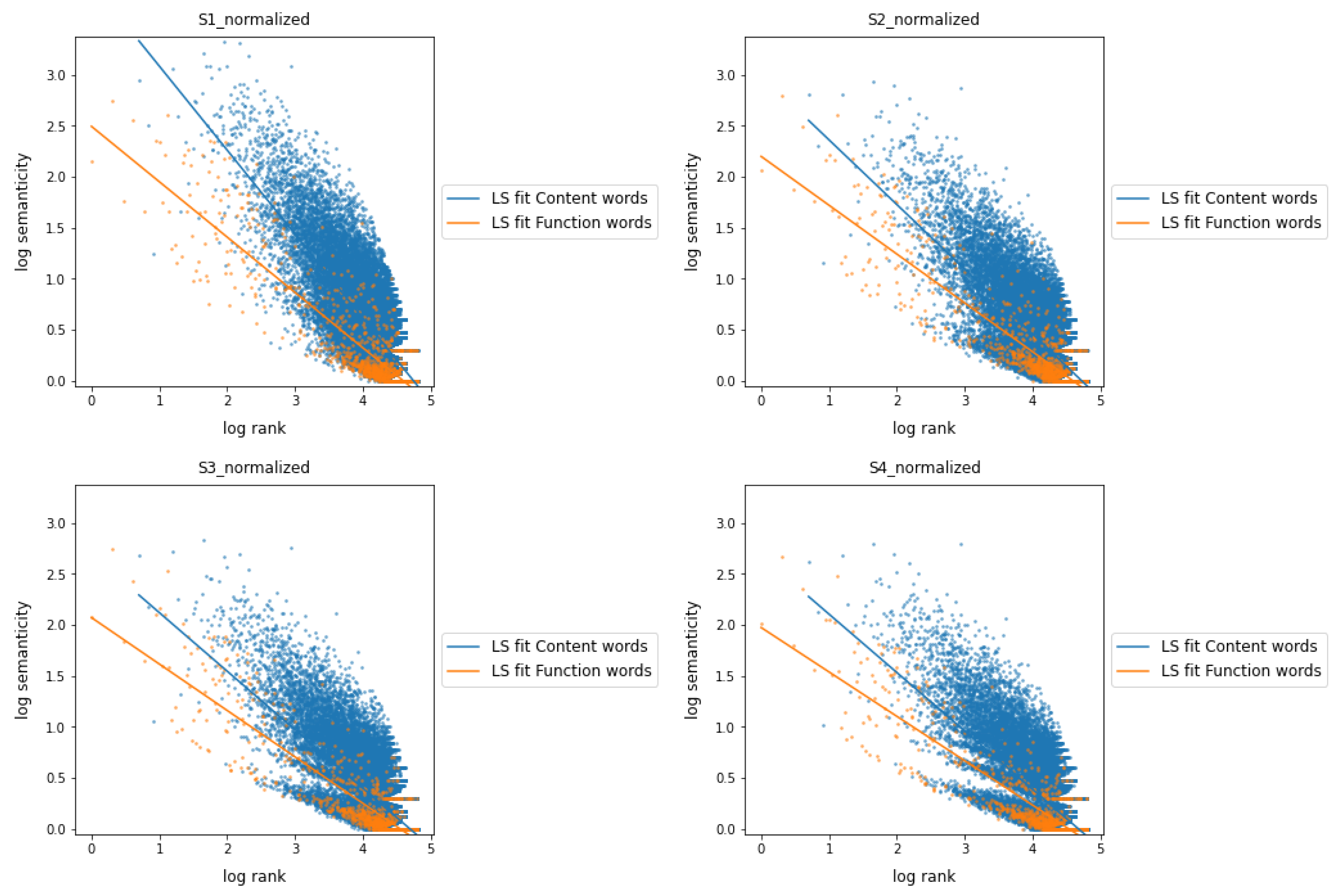
Semanticity vs. Frequency Rank
4. Data
4.1. CTILC Corpus
4.2. DIEC2 Dictionary
4.3. CTILC Corpus and DIEC2 Dictionary Intersection
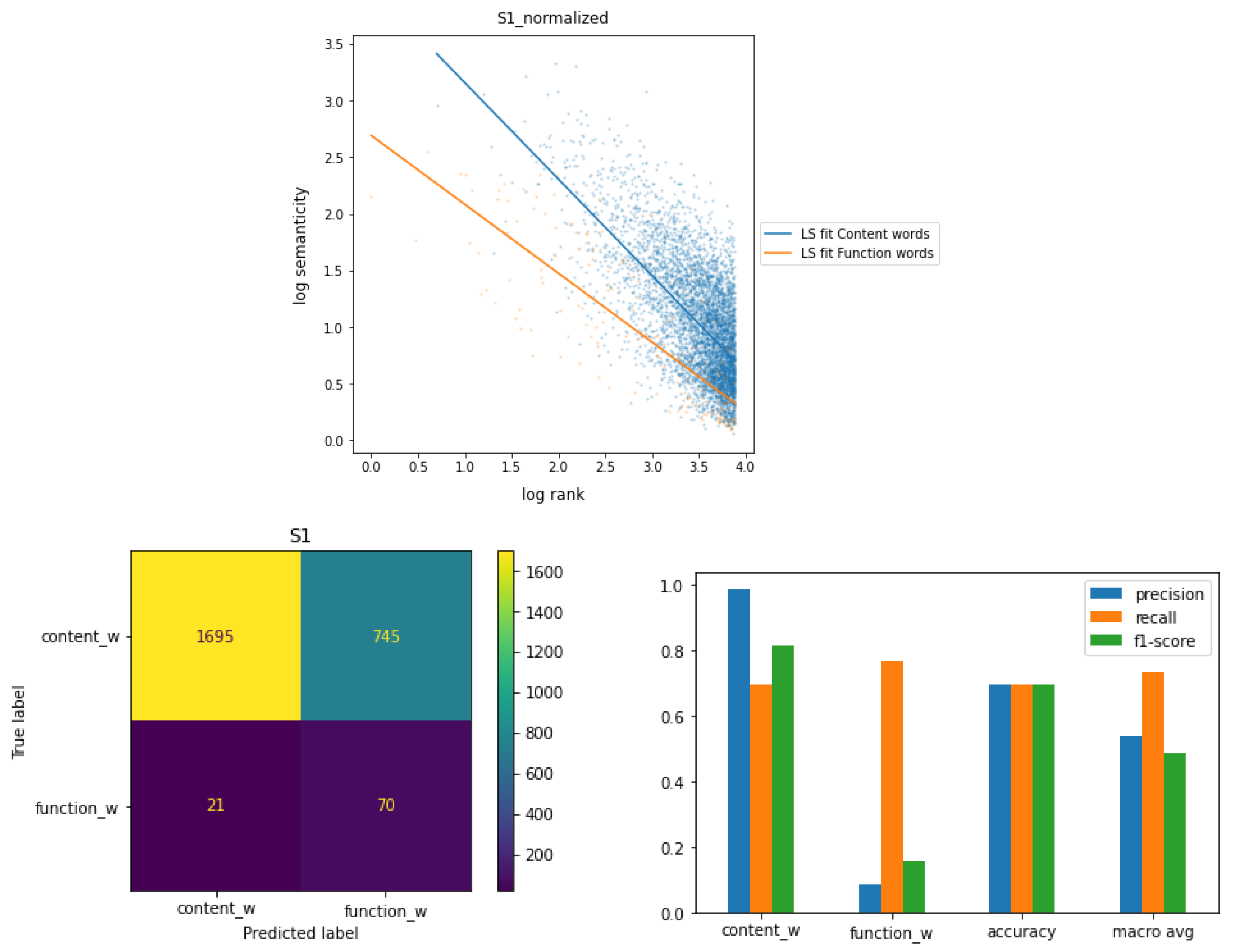
5. Results
6. Discussion
The distinction between content words and function words is a central one in studies on the syntactic categories of natural language. (...) a number of characteristic properties have been identified, which make it possible to classify some lexical item as belonging to the class of content words or that of function words. But as with all types of categorization, there are elements, which cannot be put straightforwardly under one of the two classes. Certain lexical items display ambiguous behavior: they share properties with lexical categories and at the same time they display functional characteristics.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | See (Ferrer-i-Cancho 2004) for a definition of Euclidean distance between linked words. |
| 2 | For a part-of-speech to be considered, it must have more than 20 different tokens. |
References
- Amigó, Enrique, Alejandro Ariza-Casabona, Victor Fresno, and M. Antònia Martí. 2022. Information theory–based compositional distributional semantics. Computational Linguistics 48: 907–48. [Google Scholar] [CrossRef]
- Baayen, R. Harald, and Fermín Moscoso del Prado Martín. 2005. Semantic density and past-tense formation in three germanic languages. Language 81: 666–98. [Google Scholar] [CrossRef]
- Baayen, R. Harald, Richard Piepenbrock, and Leon Gulikers. 1995. The celex lexical database (release 2). In Distributed by the Linguistic Data Consortium. Philadelphia: University of Pennsylvania. [Google Scholar]
- Baddeley, Alan D. 1997. Human Memory: Theory and Practice. London: Psychology Press. [Google Scholar]
- Barabási, Albert-László, and Eric Bonabeau. 2003. Scale-free networks. Scientific American 288: 60–69. [Google Scholar] [CrossRef] [PubMed]
- Baronchelli, Andrea, Ramon Ferrer-i-Cancho, Romualdo Pastor-Satorras, Nick Chater, and Morten H. Christiansen. 2013. Networks in cognitive science. Trends in Cognitive Sciences 17: 348–60. [Google Scholar] [CrossRef] [PubMed]
- Bell, Alan, Jason M. Brenier, Michelle Gregory, Cynthia Girand, and Dan Jurafsky. 2009. Predictability effects on durations of content and function words in conversational English. Journal of Memory and Language 60: 92–111. [Google Scholar] [CrossRef]
- Borge-Holthoefer, Javier, and Alex Arenas. 2010. Categorizing words through semantic memory navigation. The European Physical Journal B 74: 265–270. [Google Scholar] [CrossRef]
- Bosque, Ignacio. 2024. Four dialectal uses of the adverb Siempre and their grammatical properties. Languages 9: 30. [Google Scholar] [CrossRef]
- Broido, Anna D., and Aaron Clauset. 2019. Scale-free networks are rare. Nature Communications 10: 1017. [Google Scholar] [CrossRef]
- Bunge, Mario. 2013. La ciencia: Su método y su filosofía. Pamplona: Laetoli. [Google Scholar]
- Bybee, Joan. 1998. The emergent lexicon. Chicago Linguistic Society 34: 421–35. [Google Scholar]
- Català, Neus, Jaume Baixeries, Ramon Ferrer-i-Cancho, Lluís Padró, and Antoni Hernández-Fernández. 2021. Zipf’s laws of meaning in Catalan. PLoS ONE 16: e0260849. [Google Scholar] [CrossRef]
- Català, Neus, Jaume Baixeries, Lucas Lacasa, and Antoni Hernández-Fernández. 2023. Semanticity, a new concept in quantitative linguistics: An analysis of Catalan. Paper presented at the Qualico 2023, 12th International Quantitative Linguistics Conference, Lausanne, Switzerland, June 28–30. [Google Scholar]
- Chung, Cindy, and James W. Pennebaker. 2007. The psychological functions of function words. Social Communication 1: 343–59. [Google Scholar]
- Condon, Edward U. 1928. Statistics of vocabulary. Science 67: 300. [Google Scholar] [CrossRef] [PubMed]
- Corver, Norbert, and Henk van Riemsdijk. 2001. Semi-Lexical Categories: The Function of Content Words and the Content of Function Words. Berlin and New York: Walter de Gruyter. [Google Scholar]
- De Zubicaray, Greig I., and Niels O. Schiller. 2019. The Oxford Handbook of Neurolinguistics. Oxford: Oxford University Press. [Google Scholar]
- Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis: Association for Computational Linguistics, pp. 4171–86. [Google Scholar]
- Diaz, Michele T., and Gregory McCarthy. 2009. A comparison of brain activity evoked by single content and function words: An FMRI investigation of implicit word processing. Brain Research 1282: 38–49. [Google Scholar] [CrossRef] [PubMed]
- Donatelli, Lucia, and Alexander Koller. 2023. Compositionality in computational linguistics. Annual Review of Linguistics 9: 463–81. [Google Scholar] [CrossRef]
- Duplâtre, Olivier, and Pierre-Yves Modicom. 2022. Introduction–adverbs and adverbials: Categorial issues. Adverbs and adverbials: Categorial issues 371: 1–28. [Google Scholar]
- Feist, Jim. 2022. Significance in Language: A Theory of Semantics. Abingdon: Taylor & Francis. [Google Scholar]
- Ferrer-i-Cancho, Ramon. 2004. Euclidean distance between syntactically linked words. Physical Review E 70: 056135. [Google Scholar] [CrossRef] [PubMed]
- Ferrer-i-Cancho, Ramon. 2019. The sum of edge lengths in random linear arrangements. Journal of Statistical Mechanics: Theory and Experiment 2019: 053401. [Google Scholar] [CrossRef]
- Ferrer-i-Cancho, Ramon, Antoni Hernández-Fernández, David Lusseau, Govindasamy Agoramoorthy, Minna J. Hsu, and Stuart Semple. 2013. Compression as a universal principle of animal behavior. Cognitive Science 37: 1565–78. [Google Scholar] [CrossRef] [PubMed]
- Ferrer-i-Cancho, Ramon, and Ricard V. Solé. 2001. Two regimes in the frequency of words and the origins of complex lexicons: Zipf’s law revisited. Journal of Quantitative Linguistics 8: 165–73. [Google Scholar] [CrossRef]
- Ferrer-i-Cancho, Ramon, and Ricard V. Solé. 2001. The small world of human language. Proceedings of the Royal Society of London. Series B: Biological Sciences 268: 2261–65. [Google Scholar] [CrossRef]
- Ferrer-i-Cancho, Ramon, and Michael S. Vitevitch. 2018. The origins of Zipf’s meaning-frequency law. Journal of the Association for Information Science and Technology 69: 1369–79. [Google Scholar] [CrossRef]
- Gaskell, M. Gareth, Gerry Altmann, and Gerry T.M. Altmann. 2007. The Oxford Handbook of Psycholinguistics. Oxford: Oxford University Press. [Google Scholar]
- Hallonsten Halling, Pernilla. 2018. Adverbs: A Typological Study of a Disputed Category. Ph. D. thesis, Department of Linguistics, Stockholm University, Stockholm, Sweden. [Google Scholar]
- Harris, Zellig S. 1954. Distributional structure. Word 10: 146–62. [Google Scholar] [CrossRef]
- Haspelmath, Martin. 2001. Language Typology and Language Universals: An International Handbook. Berlin and New York: Walter de Gruyter, vol. 20. [Google Scholar]
- Hengeveld, Kees. 2023. Adverbs. In The Oxford Handbook of Word Classes. Oxford: Oxford University Press. [Google Scholar] [CrossRef]
- Hernández-Fernández, Antoni. 2021. Qualitative and quantitative examples of natural and artificial phenomena. Biosemiotics 14: 377–90. [Google Scholar] [CrossRef]
- Hernández-Fernández, Antoni, Iván G. Torre, Juan-María Garrido, and Lucas Lacasa. 2019. Linguistic laws in speech: The case of Catalan and Spanish. Entropy 21: 1153. [Google Scholar] [CrossRef]
- Hernández-Fernández, Antoni, Juan María Garrido, Bartolo Luque, and Iván González Torre. 2022. Linguistic laws in Catalan. Quantitative Approaches to Universality and Individuality in Language 75: 49. [Google Scholar]
- Hernández-Fernández, Antoni, and Iván G. Torre. 2022. Compression principle and Zipf’s law of brevity in infochemical communication. Biology Letters 18: 20220162. [Google Scholar] [CrossRef] [PubMed]
- Hockett, Charles F. 1960. The origin of speech. Scientific American 203: 88–97. [Google Scholar] [CrossRef]
- Hoffman, Paul, Matthew A. Lambon Ralph, and Timothy T. Rogers. 2013. Semantic diversity: A measure of semantic ambiguity based on variability in the contextual usage of words. Behavior Research Methods 45: 718–30. [Google Scholar] [CrossRef]
- Ilgen, Bahar, and Bahar Karaoglan. 2007. Investigation of Zipf’s ‘law-of-meaning’ on turkish corpora. Paper presented at the 2007 22nd International Symposium on Computer and Information Sciences, Ankara, Turkey, November 7–9; pp. 1–6. [Google Scholar] [CrossRef]
- Ipsen, Mads. 2004. Evolutionary reconstruction of networks. In Function and Regulation of Cellular Systems. Basel: Birkhäuser, pp. 241–49. [Google Scholar]
- Krauska, Alexandra, and Ellen Lau. 2022. Moving away from lexicalism in psycho-and neuro-linguistics. Frontiers in Language Sciences 2: 1125127. [Google Scholar] [CrossRef]
- Kumar, Abhilasha A. 2021. Semantic memory: A review of methods, models, and current challenges. Psychonomic Bulletin & Review 28: 40–80. [Google Scholar]
- Liang, Wei. 2017. Spectra of English evolving word co-occurrence networks. Physica A: Statistical Mechanics and its Applications 468: 802–8. [Google Scholar] [CrossRef]
- Mahowald, Kyle, Isabelle Dautriche, Mika Braginsky, and Ted Gibson. 2022. Efficient communication and the organization of the lexicon. In The Oxford Handbook of the Mental Lexicon. Oxford: Oxford University Press, pp. 200–20. [Google Scholar]
- Mahowald, Kyle, Isabelle Dautriche, Edward Gibson, and Steven T. Piantadosi. 2018. Word forms are structured for efficient use. Cognitive Science 42: 3116–34. [Google Scholar] [CrossRef] [PubMed]
- Montemurro, Marcelo A. 2001. Beyond the Zipf–Mandelbrot law in quantitative linguistics. Physica A: Statistical Mechanics and Its Applications 300: 567–78. [Google Scholar] [CrossRef]
- Motter, Adilson E., Alessandro P. S. De Moura, Ying-Cheng Lai, and Partha Dasgupta. 2002. Topology of the conceptual network of language. Physical Review E 65: 065102. [Google Scholar] [CrossRef]
- Nelson, L. Douglas, Cathy L. McEvoy, and Thomas A. Schreiber. 1999. The University of South Florida Word Association Norms. Available online: http://w3.usf.edu/FreeAssociation (accessed on 29 March 2024).
- Pulvermüller, Friedemann. 1999. Words in the brain’s language. Behavioral and Brain Sciences 22: 253–79. [Google Scholar] [CrossRef]
- Radford, Alec, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI Blog 1: 9. [Google Scholar]
- Rauh, Gisa. 2015. Adverbs as a linguistic category (?). In Adverbs: Functional and Diachronic Aspects. Edited by Karin Pittner, Daniela Elsner and Fabian Barteld. Amsterdam and Philadelphia: John Benjamins Publishing Company, pp. 19–46. [Google Scholar]
- Regier, Terry, Charles Kemp, and Paul Kay. 2015. Word meanings across languages support efficient communication. In The Handbook of Language Emergence. Hoboken: Wiley-Blackwell, pp. 237–63. [Google Scholar]
- Riezler, Stefan, and Michael Hagmann. 2021. Validity, reliability, and significance: Empirical methods for nlp and data science. Synthesis Lectures on Human Language Technologies 14: 1–165. [Google Scholar]
- Sahlgren, Magnus. 2008. The distributional hypothesis. Italian Journal of Disability Studies 20: 33–53. [Google Scholar]
- Schneider, Nathan, Vivek Srikumar, Jena D. Hwang, and Martha Palmer. 2015. A hierarchy with, of, and for preposition supersenses. Paper presented at 9th Linguistic Annotation Workshop, Denver, CO, USA, June 5; pp. 112–23. [Google Scholar]
- Segalowitz, Sidney J., and Korri C. Lane. 2000. Lexical access of function versus content words. Brain and Language 75: 376–89. [Google Scholar] [CrossRef]
- Schachter, Paul, and Timothy Shopen. 2007. Parts-of-speech systems. In Language Typology and Syntactic Description. Vol. 1: Clause Structure. Cambridge: Cambridge University Press, pp. 1–60. [Google Scholar]
- Steyvers, Mark, and Joshua B. Tenenbaum. 2005. The large-scale structure of semantic networks: Statistical analyses and a model of semantic growth. Cognitive Science 29: 41–78. [Google Scholar] [CrossRef]
- Thoppilan, Romal, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, and et al. 2022. Lamda: Language models for dialog applications. arXiv arXiv:2201.08239. [Google Scholar]
- Torre, Iván G, Bartolo Luque, Lucas Lacasa, Christopher T Kello, and Antoni Hernández-Fernández. 2019. On the physical origin of linguistic laws and lognormality in speech. Royal Society Open Science 6: 191023. [Google Scholar] [CrossRef]
- Watts, Duncan J., and Steven H. Strogatz. 1998. Collective dynamics of ‘small-world’ networks. Nature 393: 440–42. [Google Scholar] [CrossRef]
- Williams, Jake Ryland, James P. Bagrow, Christopher M. Danforth, and Peter Sheridan Dodds. 2015. Text mixing shapes the anatomy of rank-frequency distributions. Physical Review E 91: 052811. [Google Scholar] [CrossRef]
- Yarkoni, Tal, and Jacob Westfall. 2017. Choosing prediction over explanation in psychology: Lessons from machine learning. Perspectives on Psychological Science 12: 1100–22. [Google Scholar] [CrossRef]
- Zipf, George Kingsley. 1932. Selected Studies of the Principle of Relative Frequency in Language. Cambridge: Harvard University Press. [Google Scholar]
- Zipf, George Kingsley. 1945. The meaning-frequency relationship of words. The Journal of General Psychology 33: 251–56. [Google Scholar] [CrossRef]
- Zipf, George Kingsley. 1949. Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology. Cambridge: Addison-Wesley. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Part of Speech | Number |
|---|---|
| noun (N) | 17,567 |
| verb (V) | 5573 |
| adjective (A) | 7037 |
| adverb (R) | 1363 |
| pronoun (P), adposition (S), conjunction (C), determiner (D), interjection (I), | 130 |
| Total | 31,670 |
| PoS | Slope at | Slope at | Slope at | Slope at |
|---|---|---|---|---|
| N | ||||
| V | ||||
| A | ||||
| P, S, R, C, D, I |
| Word Class | Slope at | Slope at | Slope at | Slope at |
|---|---|---|---|---|
| Content words | ||||
| Function words |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Català, N.; Baixeries, J.; Hernández-Fernández, A. Exploring Semanticity for Content and Function Word Distinction in Catalan. Languages 2024, 9, 179. https://doi.org/10.3390/languages9050179
Català N, Baixeries J, Hernández-Fernández A. Exploring Semanticity for Content and Function Word Distinction in Catalan. Languages. 2024; 9(5):179. https://doi.org/10.3390/languages9050179
Chicago/Turabian StyleCatalà, Neus, Jaume Baixeries, and Antoni Hernández-Fernández. 2024. "Exploring Semanticity for Content and Function Word Distinction in Catalan" Languages 9, no. 5: 179. https://doi.org/10.3390/languages9050179
APA StyleCatalà, N., Baixeries, J., & Hernández-Fernández, A. (2024). Exploring Semanticity for Content and Function Word Distinction in Catalan. Languages, 9(5), 179. https://doi.org/10.3390/languages9050179