
Utterance-Final Voice Quality in American English and Mexican Spanish Bilinguals

Abstract
1. Introduction
1.1. Phrase-Final Breath and Phrase-Final Creak
1.2. Voice Quality among English–Spanish Bilinguals
1.3. The Current Study
2. Methods
2.1. Participants
2.2. Procedure
2.3. Data Processing and Analysis
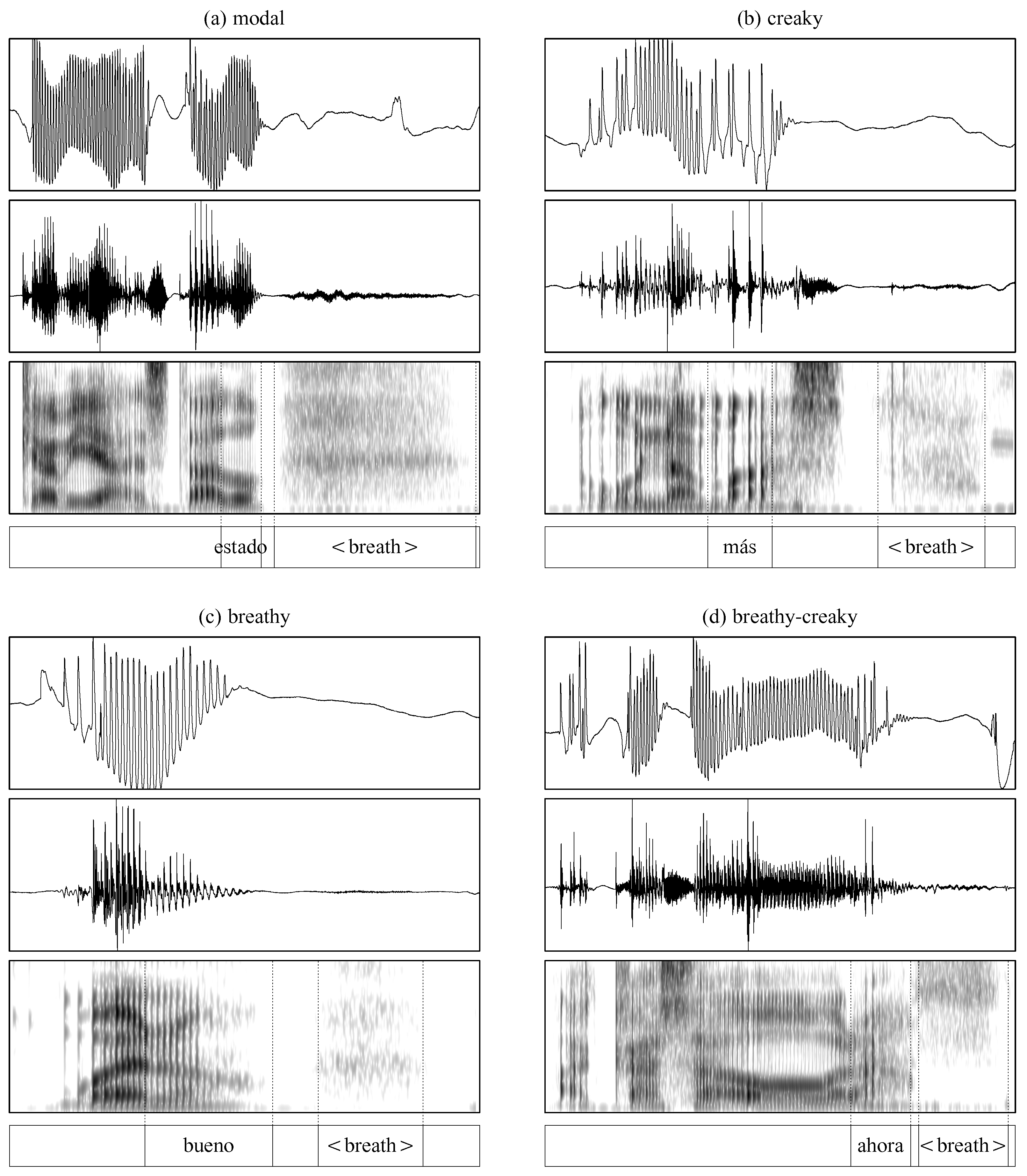
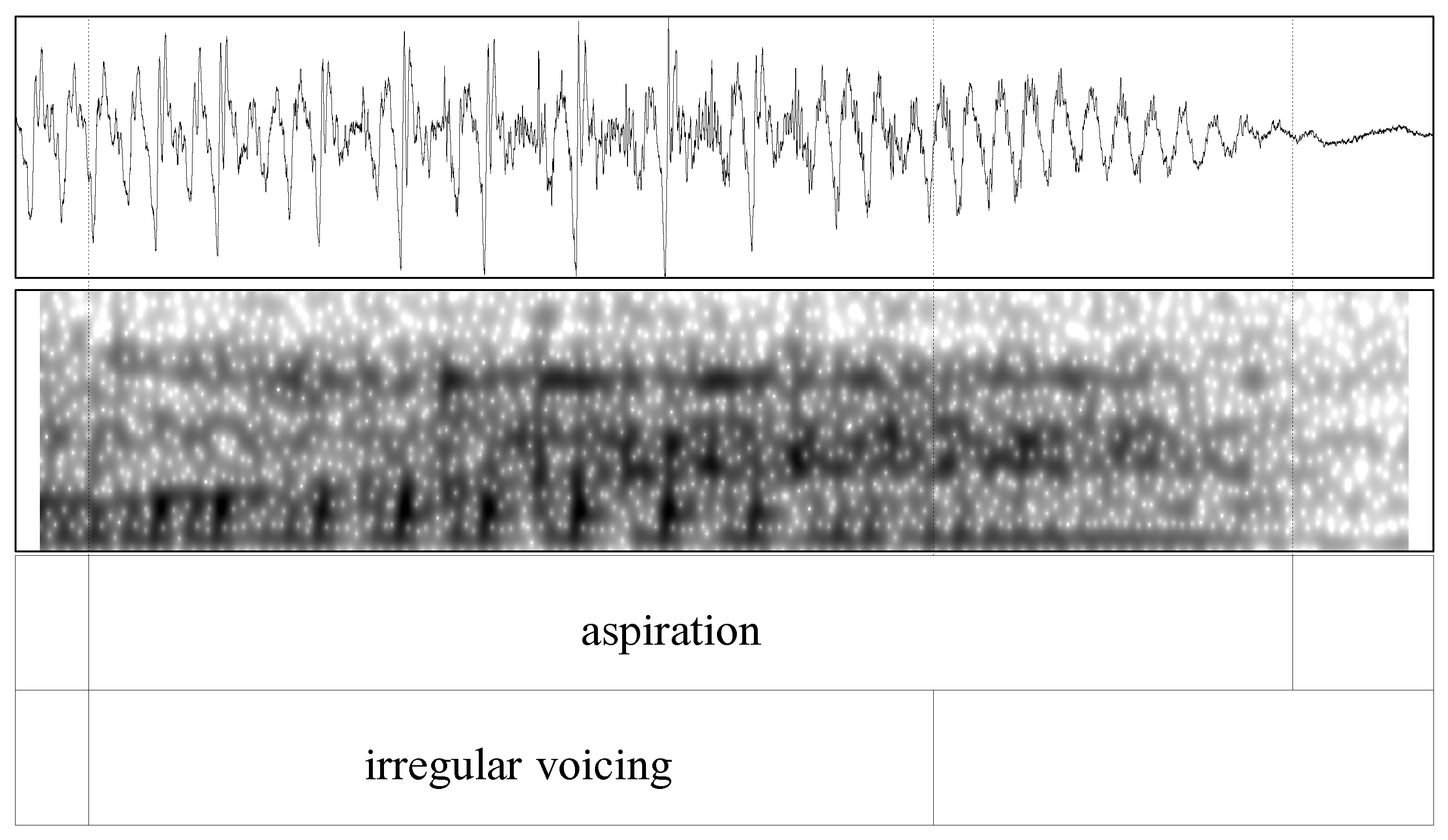
2.3.1. Coding Voice Qualities
2.3.2. Processing of the EGG and Acoustic Measures
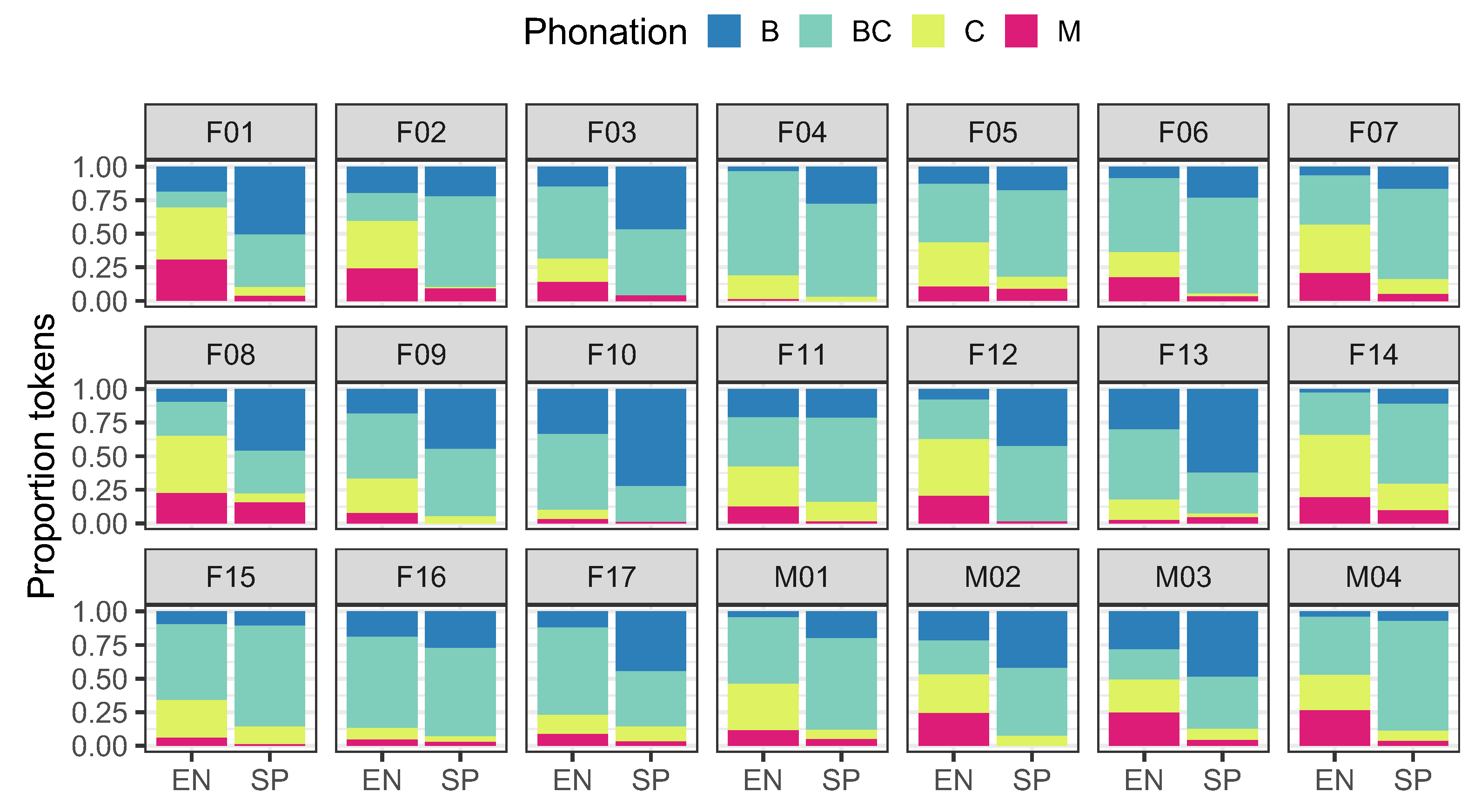
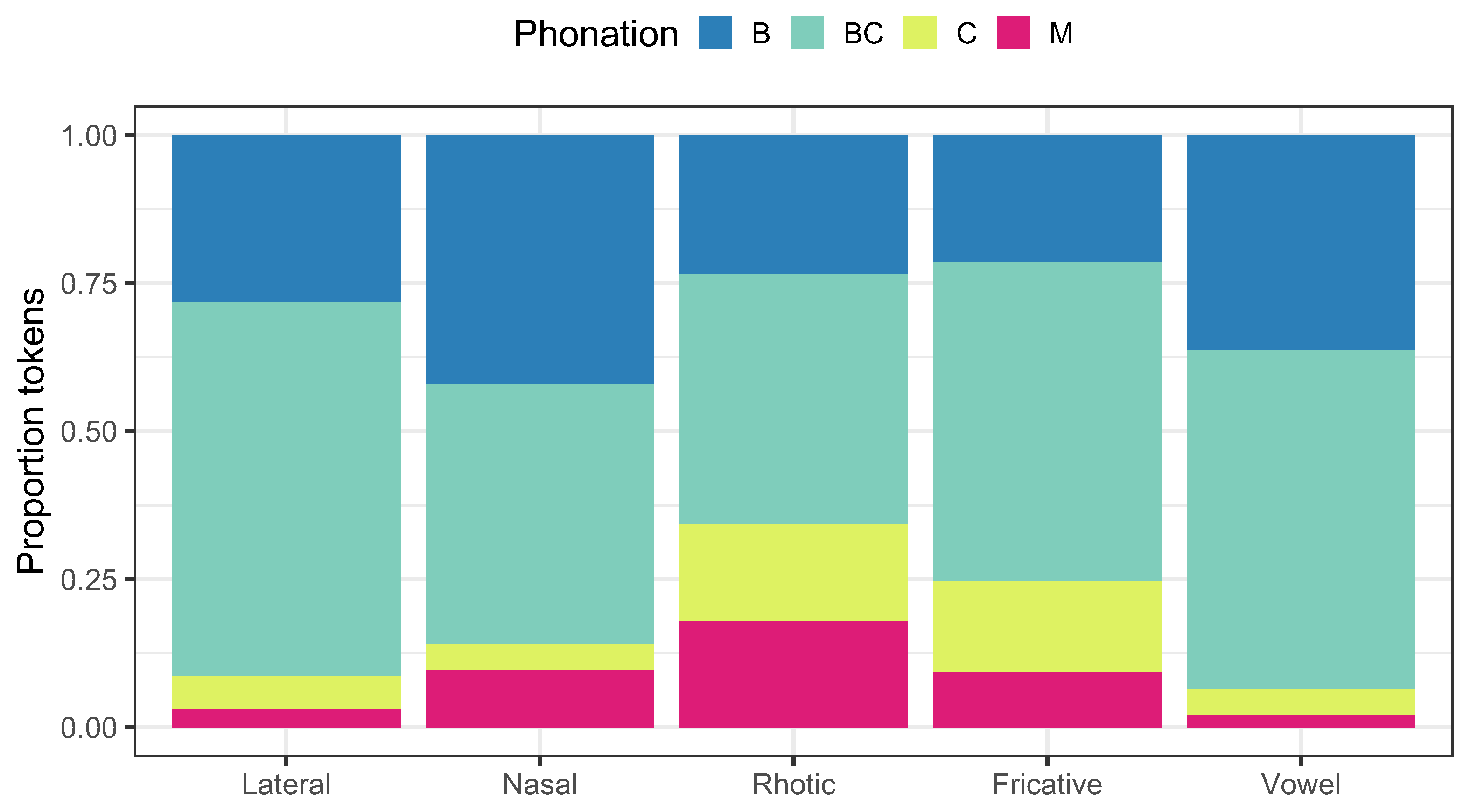
3. Results of Voice Quality Categorization
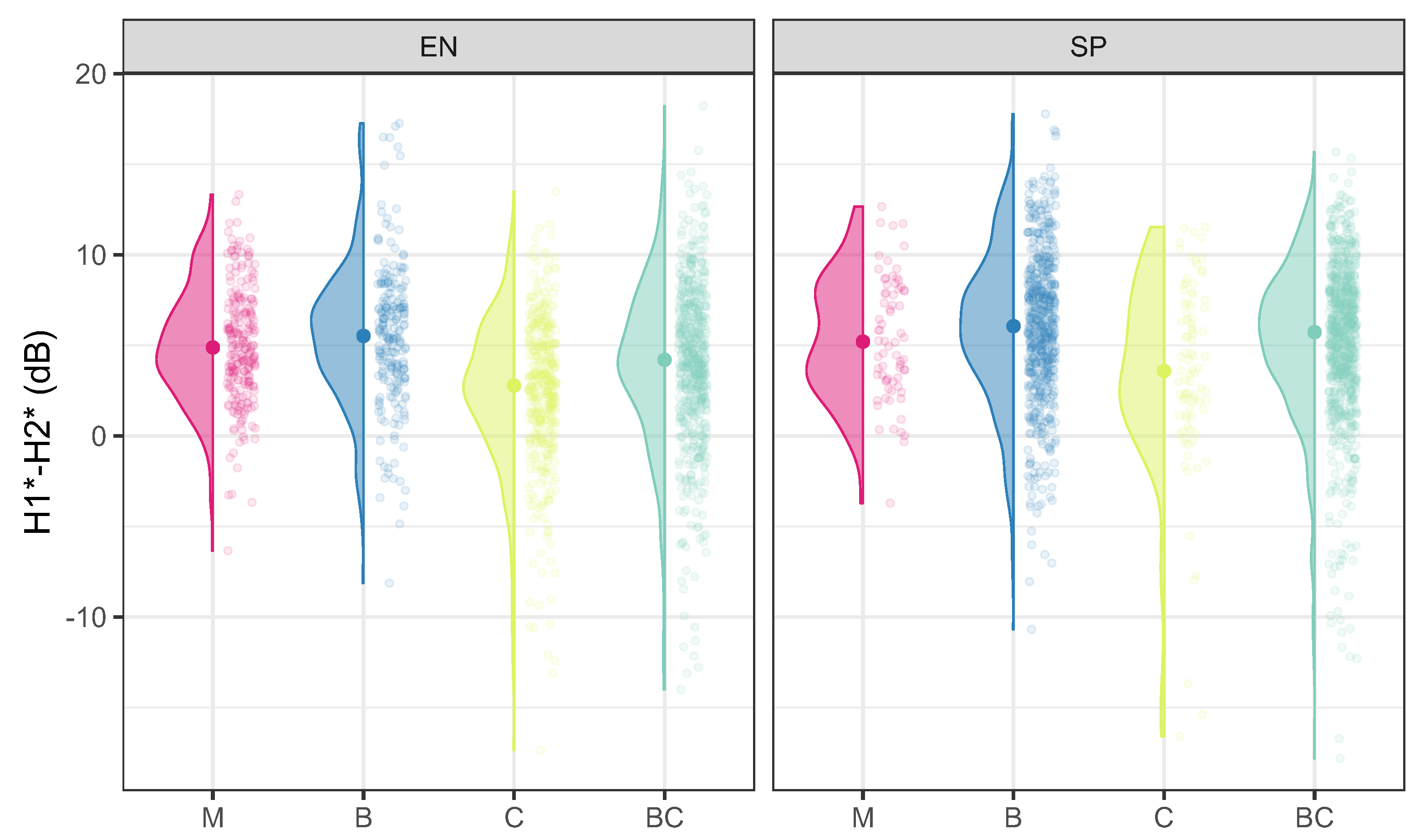
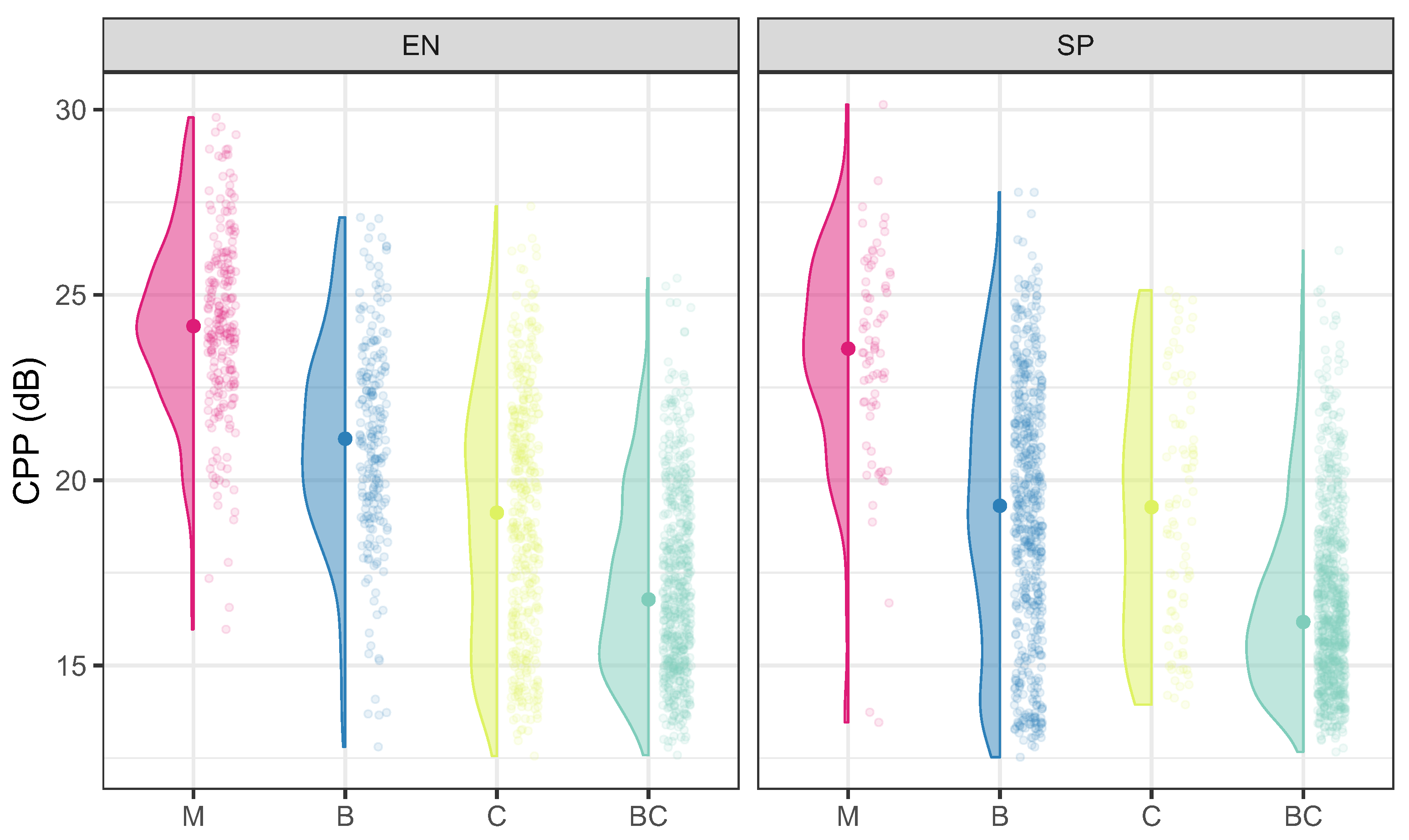
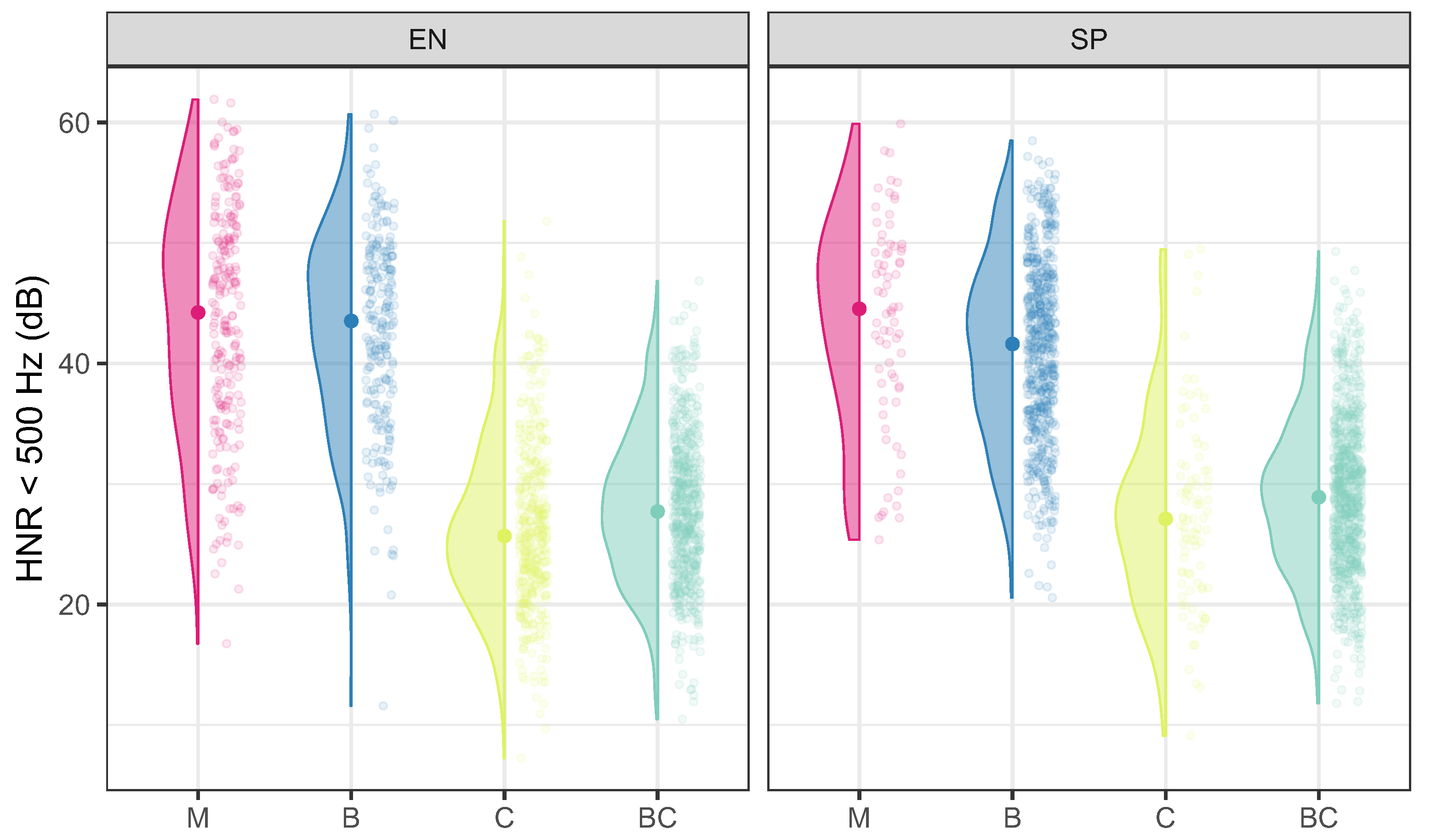
4. EGG and Acoustic Description
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | “The d in absolute final position, followed by a pause is pronounced in a particularly weak and relaxed manner [...] voicing ceases almost at the same time as the linguodental contact is made; moreover, the airflow, preparing for the following pause, is usually so faint that in fact the articulation is almost silent” (translated by Marc Garellek). |
| 2 | The English and Spanish texts both came from https://www.thespanishexperiment.com/stories/redridinghood, accessed on 5 February 2024. |
| 3 | An initial exploration of the data revealed no effect of language order, so this factor was excluded in the reported models. |
References
- Avelino, Heriberto. 2018. Mexico City Spanish. Journal of the International Phonetic Association 48: 223–30. [Google Scholar] [CrossRef]
- Becker, Kara, Sameer ud Dowla Khan, and Lal Zimman. 2022. Beyond binary gender: Creaky voice, gender, and the variationist enterprise. Language Variation and Change 34: 215–38. [Google Scholar] [CrossRef]
- Bird, Elizabeth, and Marc Garellek. 2019. Dynamics of voice quality over the course of the English utterance. In Proceedings of the 19th International Congress of Phonetic Sciences. Edited by Sasha Calhoun, Paola Escudero, Marija Tabain and Paul Warren. Canberra: Australasian Speech Science and Technology Association Inc., pp. 2406–10. [Google Scholar]
- Boersma, Paul, and David Weenink. 2024. Praat: Doing Phonetics by Computer [Computer Program]. Version 6.4.05. Available online: http://www.praat.org/ (accessed on 5 February 2024).
- Bolyanatz, Mariška. 2023. Creaky voice in Chilean Spanish: A tool for organizing discourse and invoking alignment. Languages 8: 161. [Google Scholar] [CrossRef]
- Bruyninckx, Marielle, Bernard Harmegnies, Joaquim Llisterri, and Dolors Poch-Oiivé. 1994. Language-induced voice quality variability in bilinguals. Journal of Phonetics 22: 19–31. [Google Scholar] [CrossRef]
- Cantor-Cutiva, Lady Catherine, Pasquale Bottalico, Jossemia Webster, Charles Nudelman, and Eric Hunter. 2023. The effect of bilingualism on production and perception of vocal fry. Journal of Voice 36: 970.e1–970.e10. [Google Scholar] [CrossRef] [PubMed]
- Dabkowski, Meghan Frances. 2018. Variable Vowel Reduction in Mexico City Spanish. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA. [Google Scholar]
- Dallaston, Katherine, and Gerard Docherty. 2020. The quantitative prevalence of creaky voice (vocal fry) in varieties of English: A systematic review of the literature. PLoS ONE 15: e0229960. [Google Scholar] [CrossRef] [PubMed]
- Davidson, Lisa. 2020. The versatility of creaky phonation: Segmental, prosodic, and sociolinguistic uses in the world’s languages. Wiley Interdisciplinary Reviews: Cognitive Science 12: e1547. [Google Scholar] [CrossRef]
- de Krom, Guus. 1993. A cepstrum-based technique for determining harmonics-to-noise ratio in speech signals. Journal of Speech and Hearing Research 36: 254–66. [Google Scholar] [CrossRef]
- Eckert, Penelope, and Robert J. Podesva. 2021. Non-binary approaches to gender and sexuality. In The Routledge Handbook of Language, Gender, and Sexuality. Edited by Jo Angouri and Judith Baxter. Oxford and New York: Routledge, pp. 25–36. [Google Scholar] [CrossRef]
- Esling, John H., Scott R. Moisik, Allison Benner, and Lise Crevier-Buchman. 2019. Voice Quality: The Laryngeal Articulator Model. Cambridge: Cambridge University Press. [Google Scholar] [CrossRef]
- Farnetani, Edda, and Daniel Recasens. 2010. Coarticulation and connected speech processes. In The Handbook of Phonetic Sciences, 2nd ed. Edited by William J. Hardcastle, John Laver and Fiona E. Gibbon. Oxford: Wiley-Blackwell, pp. 316–52. [Google Scholar] [CrossRef]
- Garcia, Dalia L., and Tamar H. Gollan. 2022. The MINT Sprint: Exploring a fast administration procedure with an expanded multilingual naming test. Journal of the International Neuropsychological Society 28: 845–61. [Google Scholar] [CrossRef]
- Garellek, Marc. 2019. The phonetics of voice. In Routledge Handbook of Phonetics. Edited by William Katz and Peter Assmann. Oxford: Routledge, pp. 75–106. [Google Scholar] [CrossRef]
- Garellek, Marc. 2020. Acoustic discriminability of the complex phonation system in !Xóõ. Phonetica 77: 131–60. [Google Scholar] [CrossRef]
- Garellek, Marc. 2022. Theoretical achievements of phonetics in the 21st century: Phonetics of voice quality. Journal of Phonetics 94: 101155. [Google Scholar] [CrossRef]
- Garellek, Marc. 2014. Voice quality strengthening and glottalization. Journal of Phonetics 45: 106–13. [Google Scholar] [CrossRef]
- Garellek, Marc, Yuan Chai, Yaqian Huang, and Maxine Van Doren. 2023. Voicing of glottal consonants and non-modal vowels. Journal of the International Phonetic Association 53: 305–32. [Google Scholar] [CrossRef]
- Garellek, Marc, Patricia Keating, Christina M. Esposito, and Jody Kreiman. 2013. Voice quality and tone identification in White Hmong. Journal of the Acoustical Society of America 133: 1078–89. [Google Scholar] [CrossRef] [PubMed]
- Gibson, Todd A., Connie Summers, and Sydney Walls. 2017. Vocal fry use in adult female speakers exposed to two languages. Journal of Voice 31: 510.e1–510.e5. [Google Scholar] [CrossRef]
- González, Carolina, Christine Weissglass, and Daniel Bates. 2022. Creaky voice and prosodic boundaries in Spanish: An acoustic study. Studies in Hispanic and Lusophone Linguistics 15: 33–65. [Google Scholar] [CrossRef]
- Green, David W. 1998. Mental control of the bilingual lexico-semantic system. Bilingualism: Language and Cognition 1: 67–81. [Google Scholar] [CrossRef]
- Howard, David M. 1995. Variation of electrolaryngographically derived closed quotient for trained and untrained adult female singers. Journal of Voice 9: 163–72. [Google Scholar] [CrossRef] [PubMed]
- Huang, Yaqian. 2023. Phonetics of Period Doubling. Ph.D. Thesis, UC San Diego, La Jolla, CA, USA. [Google Scholar]
- Johnson, Khia A., and Molly Babel. 2023. The structure of acoustic voice variation in bilingual speech. Journal of the Acoustical Society of America 153: 3221–38. [Google Scholar] [CrossRef]
- Jun, Sun-Ah. 2005. Prosodic typology. In Prosodic Typology. Edited by Sun-Ah Jun. Oxford: Oxford University Press, pp. 430–58. [Google Scholar] [CrossRef]
- Kawahara, Hideki, Alain de Cheveigné, and Roy D. Patterson. 1998. An instantaneous-frequency-based pitch extraction method for high-quality speech transformation: Revised TEMPO in the STRAIGHT-suite. Paper presented at the 5th International Conference on Spoken Language Processing (ICSLP 1998), Paper 0659. Sydney, Australia, November 30–December 4. [Google Scholar]
- Keating, Patricia, Marc Garellek, and Jody Kreiman. 2015. Acoustic properties of different kinds of creaky voice. Paper presented at 18th International Congress of Phonetic Sciences, Glasgow, UK, August 10–14. [Google Scholar]
- Keating, Patricia, Jianjing Kuang, Marc Garellek, Christina M. Esposito, and Sameer ud Dowla Khan. 2023. A cross-language acoustic space for phonation distinctions. Language 99: 351–89. [Google Scholar] [CrossRef]
- Keating, Patricia A., Marc Garellek, Jody Kreiman, and Yuan Chai. 2023. Acoustic properties of subtypes of creaky voice. Paper presented at the Spring 2023 Meeting of the Acoustical Society of America, Chicago, IL, USA, May 8–12. [Google Scholar]
- Kendall, Tyler, Nicolai Pharao, Jane Stuart-Smith, and Charlotte Vaughn. 2023. Advancements of phonetics in the 21st century: Theoretical issues in sociophonetics. Journal of Phonetics 98: 101226. [Google Scholar] [CrossRef]
- Kim, Ji Young. 2017. Voice quality transfer in the production of Spanish heritage speakers and English l2 learners of Spanish. In Romance Languages and Linguistic Theory 11: Selected Papers from the 44th Linguistic Symposium on Romance Languages (LSRL), London, Ontario. Edited by Silvia Perpiñán, David Heap, Itziri Moreno-Villamar and Adriana Soto-Corominas. Amsterdam and Philadelphia: John Benjamins, pp. 191–207. [Google Scholar] [CrossRef]
- Kreiman, Jody, Bruce R. Gerratt, Marc Garellek, Robin Samlan, and Zhaoyan Zhang. 2014. Toward a unified theory of voice production and perception. Loquens 1: e009. [Google Scholar] [CrossRef] [PubMed]
- Kreiman, Jody, Yen-Liang Shue, Gang Chen, Markus Iseli, Bruce R. Gerratt, Juergen Neubauer, and Abeer Alwan. 2012. Variability in the relationships among voice quality, harmonic amplitudes, open quotient, and glottal area waveform shape in sustained phonation. Journal of the Acoustical Society of America 132: 2625–32. [Google Scholar] [CrossRef] [PubMed]
- Kuang, Jianjing. 2017. Covariation between voice quality and pitch: Revisiting the case of Mandarin creaky voice. Journal of the Acoustical Society of America 142: 1693–706. [Google Scholar] [CrossRef] [PubMed]
- Kuznetsova, Alexandra, Per Bruun Brockhoff, and Rune Haubo Bojesen Christensen. 2015. lmerTest: R Package Version 2.0-20. Available online: https://cran.r-project.org/package=lmerTest (accessed on 5 February 2024).
- Ladd, D. Robert. 2001. Intonation. In Language Typology and Language Universals: An International Handbook. Edited by Martin Haspelmath, Ekkehard König, Wulf Oesterreicher and Wolfgang Raible. Berlin and New York: de Gruyter, vol. 2, pp. 1380–90. [Google Scholar] [CrossRef]
- Ladefoged, Peter, and Norris P. McKinney. 1963. Loudness, sound pressure, and subglottal pressure in speech. Journal of the Acoustical Society of America 35: 454–60. [Google Scholar] [CrossRef]
- Lang, Benjamin. 2023. Reconstructing the perception of gender identity, sexual orientation, and gender expression in American English. In Proceedings of the 20th International Congress of the Phonetic Sciences. Edited by Radek Skarnitzl and Jan Volín. Prague: Guarant International, pp. 2552–56. [Google Scholar]
- Laver, John. 1980. The Phonetic Description of Voice Quality. Cambridge: Cambridge University Press. [Google Scholar]
- Montrul, Silvina. 2015. Dominance and proficiency in early and late bilingualism. In Language Dominance in Bilinguals: Issues of Measurement and Conceptualization. Edited by Carmen Silva-Corvalán and Jeanine Treffers-Daller. Cambridge: Cambridge University Press, pp. 15–35. [Google Scholar] [CrossRef]
- Navarro Tomás, Tomás. 1918. Manual de pronunciación española. Madrid: Centro de estudios históricos. [Google Scholar]
- Olson, Daniel J. 2013. Bilingual language switching and selection at the phonetic level: Asymmetrical transfer in VOT production. Journal of Phonetics 41: 407–20. [Google Scholar] [CrossRef]
- Piccinini, Page, and Amalia Arvaniti. 2019. Dominance, mode, and individual variation in bilingual speech production and perception. Linguistic Approaches to Bilingualism 9: 628–58. [Google Scholar] [CrossRef]
- Piccinini, Page Elizabeth. 2016. Cross-Language Activation and the Phonetics of Code-Switching. Ph.D. Thesis, UC San Diego, La Jolla, CA, USA. [Google Scholar]
- Podesva, Robert J., and Patrick Callier. 2015. Voice quality and identity. Annual Review of Applied Linguistics 35: 173–94. [Google Scholar] [CrossRef]
- Redi, Laura, and Stefanie Shattuck-Hufnagel. 2001. Variation in the realization of glottalization in normal speakers. Journal of Phonetics 29: 407–29. [Google Scholar] [CrossRef]
- Salgado, Hugo. 2023. New Voices for Ancestral Sounds: The Acquisition of Nawat Phonology by Speakers of Salvadoran Spanish. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA. [Google Scholar]
- Seyfarth, Scott, and Marc Garellek. 2018. Plosive voicing acoustics and voice quality in Yerevan Armenian. Journal of Phonetics 71: 425–50. [Google Scholar] [CrossRef]
- Shue, Yen-Liang, Patricia A. Keating, Chad Vicenik, and Kristine Yu. 2011. VoiceSauce: A program for voice analysis. Paper presented at the International Congress of Phonetic Sciences, Hong Kong, China, August 17–21; pp. 1846–49. [Google Scholar]
- Simonet, Miquel. 2010. Dark and clear laterals in Catalan and Spanish: Interaction of phonetic categories in early bilinguals. Journal of Phonetics 38: 663–78. [Google Scholar] [CrossRef]
- Slifka, Janet. 2000. Respiratory Constraints on Speech Production at Prosodic Boundaries. Ph.D. Thesis, MIT, Cambridge, MA, USA. [Google Scholar]
- Slifka, Janet. 2006. Some physiological correlates to regular and irregular phonation at the end of an utterance. Journal of Voice 20: 171–86. [Google Scholar] [CrossRef] [PubMed]
- Sundara, Megha, Linda Polka, and Shari Baum. 2006. Production of coronal stops by simultaneous bilingual adults. Bilingualism: Language and Cognition 9: 97–114. [Google Scholar] [CrossRef]
- Todaka, Yuichi. 1993. A Cross-Language Study of Voice Quality: Bilingual Japanese and American English Speakers. Ph.D. thesis, UCLA, Los Angeles, CA, USA. [Google Scholar]

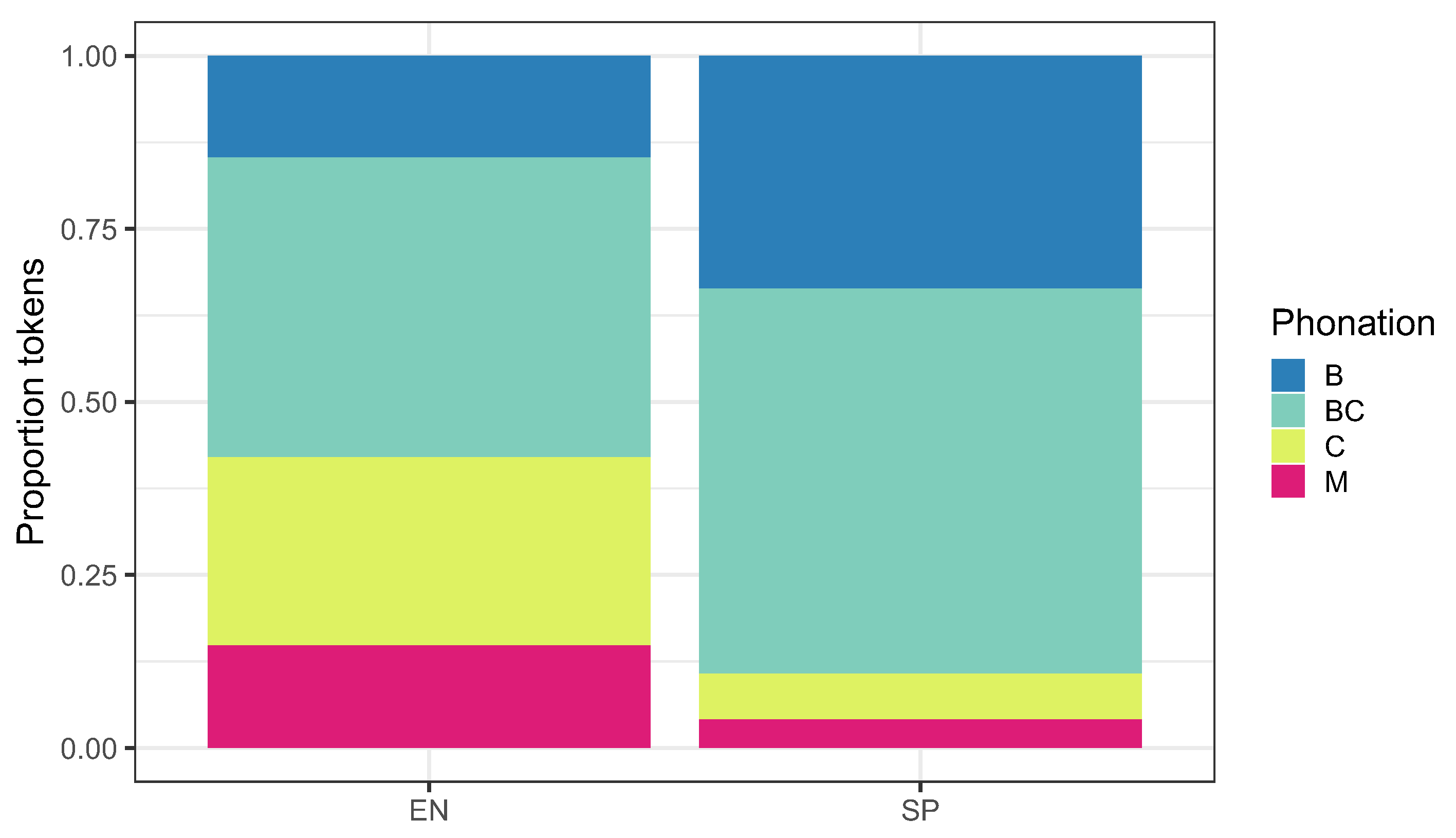



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Participant | Age | Area Raised 0–7/7–14 | MINT Score (English–Spanish) |
|---|---|---|---|
| F01 | 19 | US/US | 16 |
| F02 | 18 | US/US | –9 |
| F03 | 28 | US, MEX/US | 0 |
| F04 | 21 | MEX/MEX | –5 |
| F05 | 20 | MEX/US | 8 |
| F06 | 20 | US/US | 43 |
| F07 | 20 | US/US | 15 |
| M01 | 18 | MEX/MEX | 1 |
| F08 | 20 | US/US | 12 |
| F09 | 22 | US/US | 40 |
| M02 | 18 | US/US | 31 |
| F10 | 30 | US, MEX/US, MEX | 0 |
| F11 | 19 | US/US | 26 |
| F12 | 25 | MEX/MEX | –9 |
| M03 | 22 | MEX/US | 15 |
| F13 | 18 | US/US | 30 |
| F14 | 19 | MEX, US/US | 35 |
| F15 | 25 | US/US | 13 |
| F16 | 18 | US/US | 31 |
| F17 | 25 | US/US | 33 |
| M04 | 21 | US/US | 25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duarte-Borquez, C.; Van Doren, M.; Garellek, M. Utterance-Final Voice Quality in American English and Mexican Spanish Bilinguals. Languages 2024, 9, 70. https://doi.org/10.3390/languages9030070
Duarte-Borquez C, Van Doren M, Garellek M. Utterance-Final Voice Quality in American English and Mexican Spanish Bilinguals. Languages. 2024; 9(3):70. https://doi.org/10.3390/languages9030070
Chicago/Turabian StyleDuarte-Borquez, Claudia, Maxine Van Doren, and Marc Garellek. 2024. "Utterance-Final Voice Quality in American English and Mexican Spanish Bilinguals" Languages 9, no. 3: 70. https://doi.org/10.3390/languages9030070
APA StyleDuarte-Borquez, C., Van Doren, M., & Garellek, M. (2024). Utterance-Final Voice Quality in American English and Mexican Spanish Bilinguals. Languages, 9(3), 70. https://doi.org/10.3390/languages9030070