1. Introduction
It is well known that many syntactically full-fledged sentences in a text can be perceived as semantically incomplete in so far as they contain underspecified meanings, context-sensitive expressions, or implicit contents.
1 Think of pronouns or quantified expressions, which cannot be interpreted without the addressee retrieving from the context the antecedent of the pronoun or the quantification domain. In this paper, we are specifically interested in the implicit meaning conveyed by a text, which has been shown to play a central role in comprehension. Indeed, understanding a text is not just a matter of understanding the literal meaning of each sentence that makes it up, but of gaining access to the elements of implicit meaning that make it possible to turn this sequence of sentences into a cohesive whole (by reconstructing the identity and inclusion relationships between the referents mentioned) and a coherent whole (by reconstructing the temporal and logical links between the situations described). So even if the sentence constitutes, one way or another, a unit of thought, the question we aim to address here is: Does it constitute a “unit of understanding” for the pupils? More precisely, how relevant is the concept of a sentence when it comes to retrieving the implicit information that contributes to the global coherence of texts the pupils have to read?
By implicitness, we mean the covert pieces of information that are necessary to reach an accurate understanding of what is meant in a text. We will call “implicit” the elements of meaning that are inferred (in a broad sense) from what is said, without having been explicitly said. Implicit contents are of a very varied nature. Since
Ducrot (
1972), it is usual to distinguish the linguistic or literal implicit, associated with presuppositions, from the discursive implicit, corresponding to what
Grice (
[1967] 1975) referred to as implicatures.
Presuppositions are characterized by the presence of a trigger, a linguistic element (a word or a grammatical construction) which is part of what is literally said. It is because the speaker uses the verb
continuer ‘continue’ in (1a) that the addressee makes the inference (1b). As one can continue only what was started before,
continuer ‘continue’ presupposes having started. The source of the presupposition is lexical: the presence of the word in the statement is enough for the presupposition to emerge.
| (1) | a. | Tom continue à faire des progrès en calcul. |
| | | ‘Tom continues to make progress in arithmetic.’ |
| | b. | Tom avait déjà fait des progrès en calcul. |
| | | ‘Tom had already made some progress in arithmetic.’ |
Implicatures also convey implicit information. They are non logical inferences: “A implicature is a proposition that is implied by the utterance of a sentence in a context even though that proposition is not a part of nor an entailment of what was actually said” (
Gazdar 1979, p. 38). In this respect, implicatures differ from logical consequences.
Grice (
[1967] 1975), who introduced the term
implicature, distinguishes conventional implicatures (about which he says little and which we don’t consider here) from conversational implicatures. He shows that the content of a conversational implicature is not attached to a particular linguistic form (and in this respect implicatures differ from presuppositions) but is the result of the articulation of a content and a general principle of interpretation: the Cooperative Principle. Knowledge of this principle, mutually shared by the dialogue participants, leads them to make assumptions about Speaker intentions and enables them to derive supplementary meaning associated with an utterance. Grice considers the Cooperative Principle as the foundation of the rules that govern conversation in its ordinary use, what he calls Maxims of Conversation. Example (2) illustrates how participants in the conversation rely on the Principle of Cooperation and the Quantity Maxim to derive the implicature (2b). The addressee must engage in a reasoning process which is based both on the use of a lexical element (here the numeral
two) and on a conversational rule derived from the Quantity Maxim, which stipulate in substance that the speaker has said everything he could say, no more, no less. If (2a) generates the implicature (2b), it is because the speaker used the numeral
two rather than the immediately following numeral,
three, and that numerals form a scale. (2b) exemplifies a case of scalar implicature
2. However, the source of the implicit in (2a) cannot be reduced to a lexical element; mastery of conversational uses and the implementation of reasoning based on the comparison of the entire statement with other possible statements are also required. Furthermore, it has to be noted that implicatures are defeasible inferences, which means that they are only probable; they are drawn in situations, as long there is no indication to the contrary
| (2) | a. | Tom a réussi deux exercices. |
| | | ‘Tom successfully completed two exercises.’ |
| | b. | Tom a réussi deux exercices et pas plus. |
| | | ‘Tom successfully completed two exercises and no more.’ |
| | c. | Tom a réussi deux exercices, même trois si je me souviens bien. |
| | | ‘Tom successfully completed two exercises, even three if I remember |
| | | correctly.’ |
In addition to these two types of implicit meaning, there is a third type, which differs from the previous ones in that it is not associated with the use of a particular lexical item. This third type of implicitness is typically attached to stylistic devices, such as irony, which can lead to giving a statement an interpretation diametrically opposed to its literal meaning. This is the case with (4a) which, in context (3), loses its literal and compositional meaning and means (4b), the exact opposite, instead. Generally speaking,
3 irony is viewed as the act of meaning something by saying something quite different, while making one’s communicative intention clear enough to be recovered. In ironic statements, there is no enrichment of the literal meaning (contrary to usual implicatures), but rather the substitution of a completely different meaning in place of the literal meaning. And such a substitution is obligatory: The addressee needs to achieve it lest the whole text appear globally incoherent. To do this, they must take into account the context. Irony is by nature context-sensitive; the same sentence, depending on the context, will or will not be interpreted as ironic. To interpret a statement as ironic, the addressee has to look outside the limits of the ironic sentence.
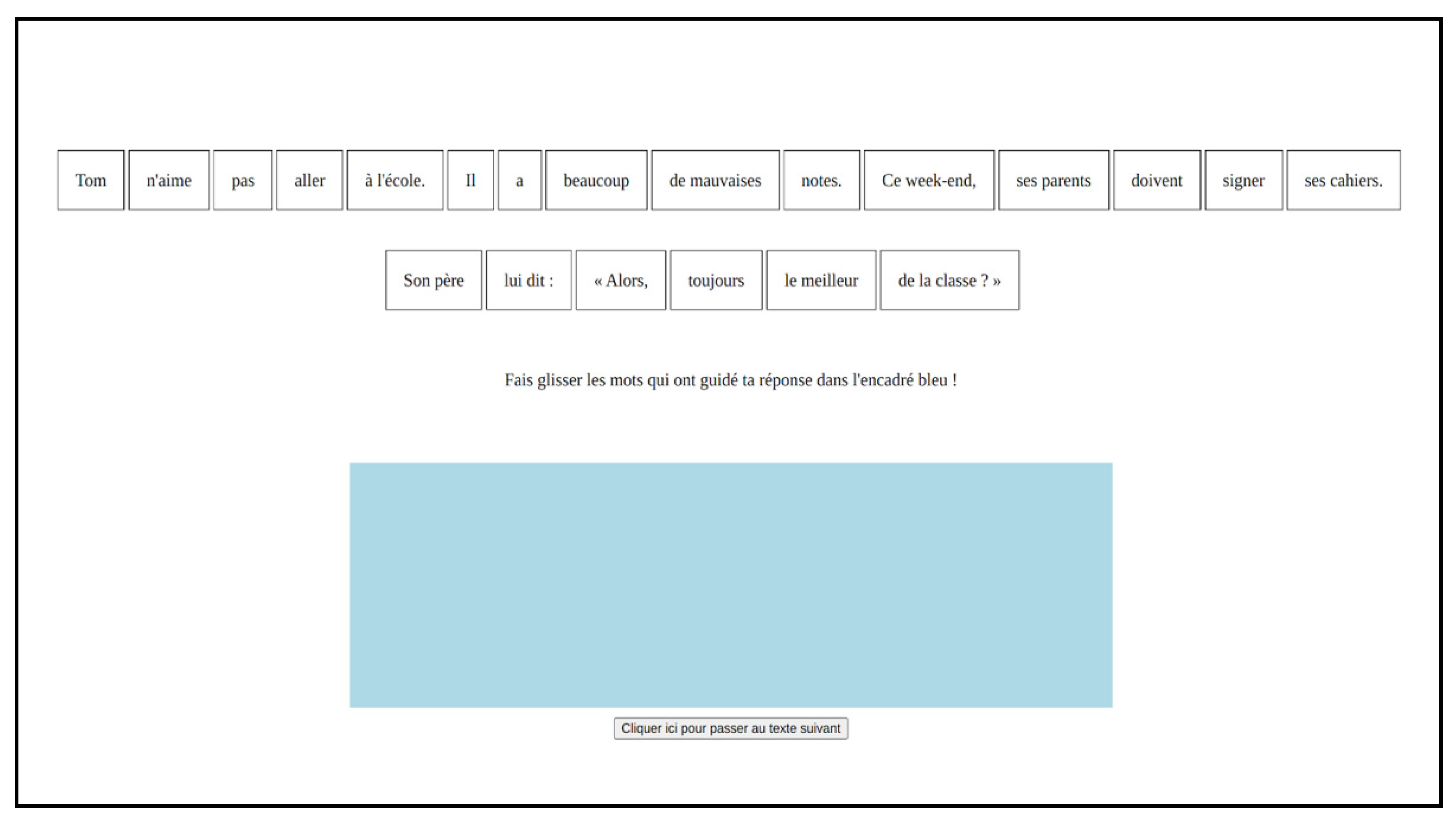
| (3) | Tom n’aime pas aller à l’école. Il a beaucoup de mauvaises notes. |
| | Ce week-end, ses parents doivent signer ses cahiers. Son père lui dit: |
| | ‘Tom doesn’t like going to school. His grades are poor. This weekend, |
| | his parents have to sign his exercise books. His father said to him:’ |
| (4) | a. | Alors, toujours le meilleur de la classe? |
| | | ‘So, still top of the class?’ |
| | b. | Tu nous rapportes encore de mauvaises notes? |
| | | ‘Have you brought bad grades home yet again?’ |
In this paper, we focus on these three types of implicitness (presuppositions, generalized conversational implicatures, and irony) because the psycholinguistic literature has shown that they are already cognitively accessible to children from the age of five in favorable contexts
4 (
Scoville and Gordon 1980;
Pouscoulous et al. 2007;
Loukusa and Leinonen 2008;
Eiteljoerge et al. 2018). We are interested in what, in the process of interpretation, really triggers the understanding of these three types of implicitness both among primary school students and among adults. We chose to approach this issue by asking ourselves to what extent the concept of sentence/sentential unit is relevant and privileged in this comprehension task. In particular, are the elements perceived as responsible for implicit meanings (the triggers) located within the sentence which conveys implicit contents? Or, on the contrary, is the processing of these implicit meanings carried out at another level than the sentence, relying on the understanding of segments that are either smaller (such as words or phrases) or larger (such as the context)?
As a starting point, we considered the following three theoretical hypotheses.
(1) Presuppositions are usually triggered by lexical items or specific syntactic constructions (such as clefts for example), so they can be detected on a very local scale and at a subsentential level. In this case, we expect a more local comprehension, with phrases being more relevant than sentences for understanding presuppositions.
(2) Conversational implicatures can also be associated with particular linguistic material, but they are defeasible inferences that are computed by reasoning on the maxims of conversation, the speaker’s presumed intentions, and the relevant surrounding information; they are more context-sensitive and should be detected on a less local scale, within larger text spans possibly of sentential dimension (in particular sentences often constitute a minimal relevant domain to check whether or not an implicature is canceled or suspended). Compared to presuppositions, we expect a less local comprehension, and segments larger than phrases should be necessary for understanding implicatures.
(3) As for irony, its understanding requires that the addressee/reader recognizes a form of discordance, dissociation, or pretense by the speaker between what is said and what is actually meant (
Garmendia 2018). In this case, the addressee needs to be much better acquainted with the context of the utterance to be able to make such speculations, and one can assume that irony will rarely be detected at the level of the single statement or sentence bearing it; a larger extent of context must be taken into account, especially in written texts. Concretely, we expect a more global comprehension of irony, with large parts of the text being important for understanding this type of implicitness.
To test these hypotheses, we designed an experiment whose goal was twofold: (i) to observe how these three kinds of implicit contents are correctly understood by pupils throughout their schooling and by adults and (ii) to identify the linguistic clues that enable them to draw these inferences. More specifically, we looked at where the words or chunks of words that participants considered relevant to justify their understanding of the implicit contents occurred in the text: within the target sentence (containing the implicit information) or in the preceding context. This enabled us to address the questions of whether the concept of sentence is intuitively perceived as a necessary “unit of understanding” with regard to implicitness and whether it is perceived as a sufficient one.
If, in order to justify their answers, participants (either children or adults) select more often segments from the context, we can infer that understanding the sentence carrying the implicit is not, in itself, sufficient to construe the implicitness. If participants select segments from the context less often, we can assume that understanding the sentence suffices to detect the implicit meaning.
With regard to the selection made by participants in the target sentence, if segments from the target sentence are less often selected, and if these are precisely the triggers of presuppositions or implicatures, then we can conjecture that a global comprehension of the sentence is not absolutely necessary for recognition of the implicit meaning. More precisely, this would indicate that correct understanding by children of certain implicit contents depends above all on their semantic mastery of specific lexical items or syntactic construes, which have been identified locally. Conversely, if segments are more often selected within the target sentence, we can infer that a global comprehension of the sentence is a necessary step for recognizing the implicit meaning and that detecting local triggers alone is not sufficient. Note that to diagnose the necessary nature of sentence comprehension, we did not expect participants to select every segment in the sentence. We left the participants free to consider that certain segments might be of secondary importance in justifying their responses. Our initial predictions, in line with the theoretical hypotheses mentioned above, were the following:
For the presuppositions, we expected that global comprehension of the target sentence would appear to be sufficient but not necessary. We expected that the sentence as a unit would not be perceived as relevant and that only segments from the target sentence would be more often selected.
For irony, we expected that global comprehension of the target sentence would be necessary but not sufficient and that the context would be heavily called upon (i.e., segments from the context would be more often selected).
For implicatures, our prediction was more complex: we expected global comprehension of the target sentence to appear more often as not sufficient (to emphasize the role of context) but also less often as necessary (to emphasize the locality of the implicature). For example, we would expect a more often selection of segments in the context sentence than for presupposition, but still less often than for irony.
The paper is organized as follows. In
Section 2, we describe the experimental method we used to answer the question we address: what role does the sentence play as a unit of understanding in the detection of implicitness? To do this, we provide details about the participants, the material and the experimental design, and the analysis method. Then, we present in
Section 3 the results concerning on the one hand the understanding of the different types of implicitness and on the other hand the parts of the text that the participants identify as having allowed them to interpret implicit meaning. In
Section 4, we discuss the results before concluding the paper.
4. Discussion
In this paper, we compared to what extent children and adults understand and interpret the three types of implicitness, i.e., presupposition, implicature, and irony.
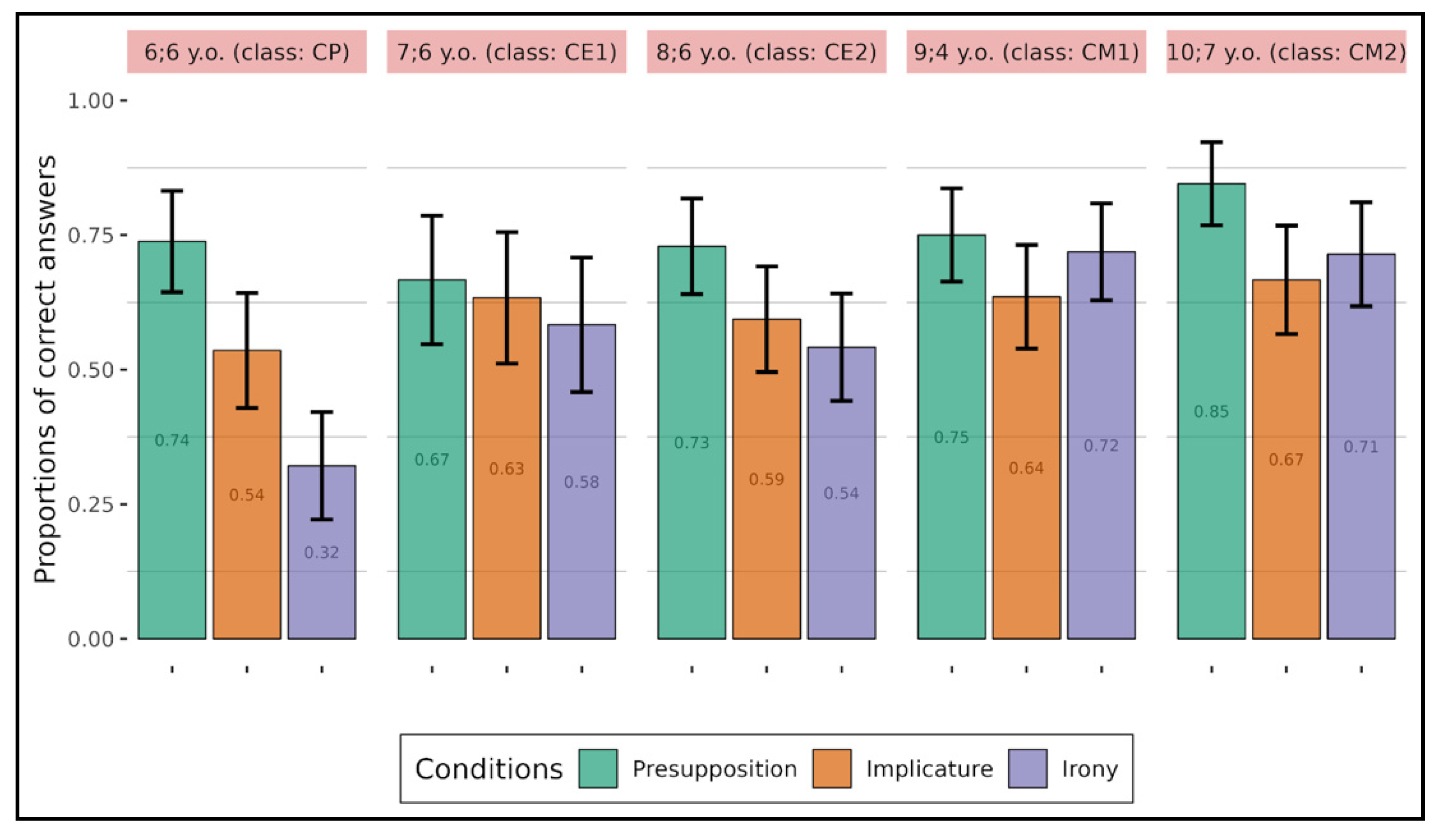
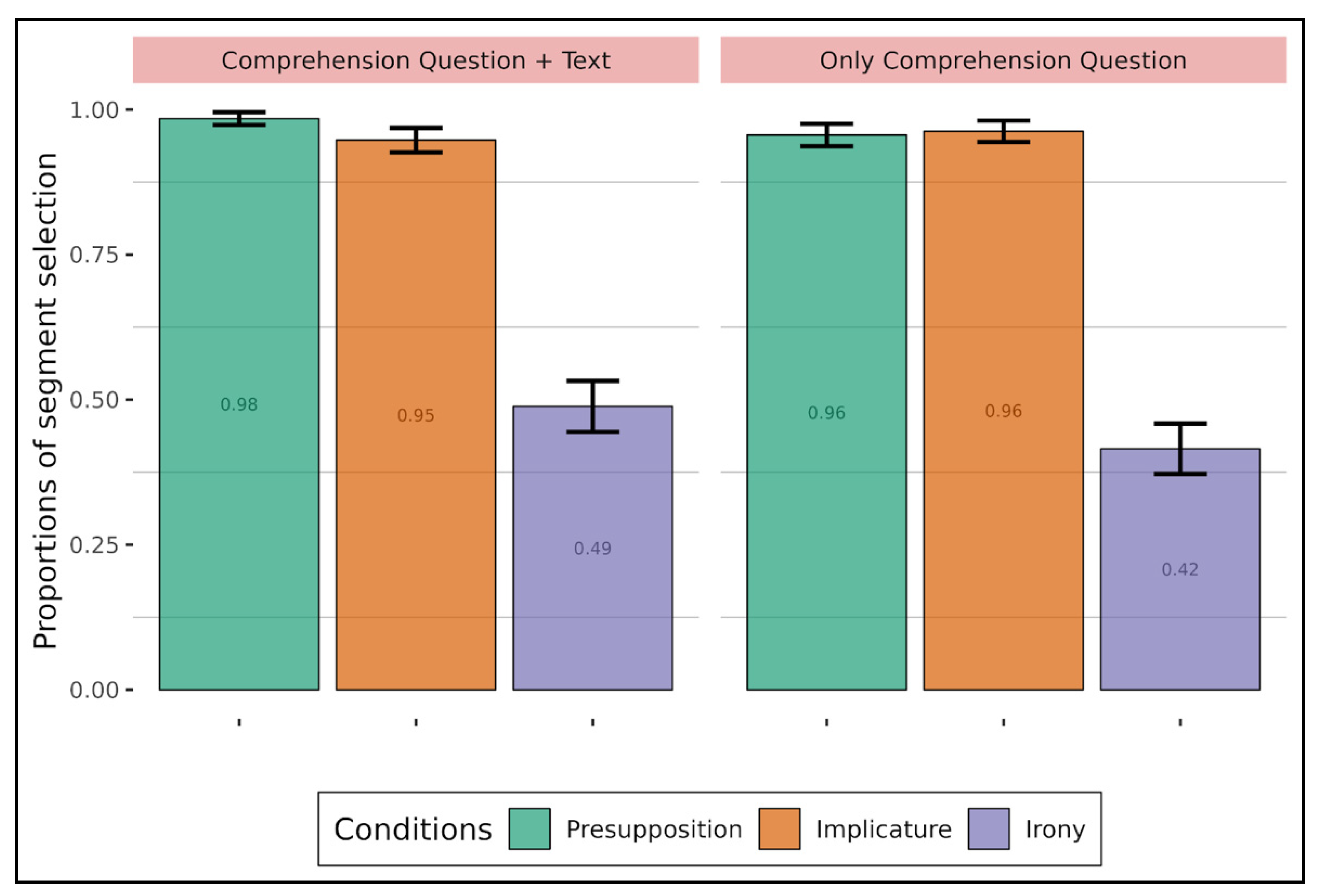
For comprehension of implicitness, we found that, even though children at an earlier age have difficulty with all types of implicitness, especially irony (
Figure 2), as they get older (e.g., at the end of primary school), they quickly understand them and the pattern that we found in children in higher classes resembled the one we found in adults (
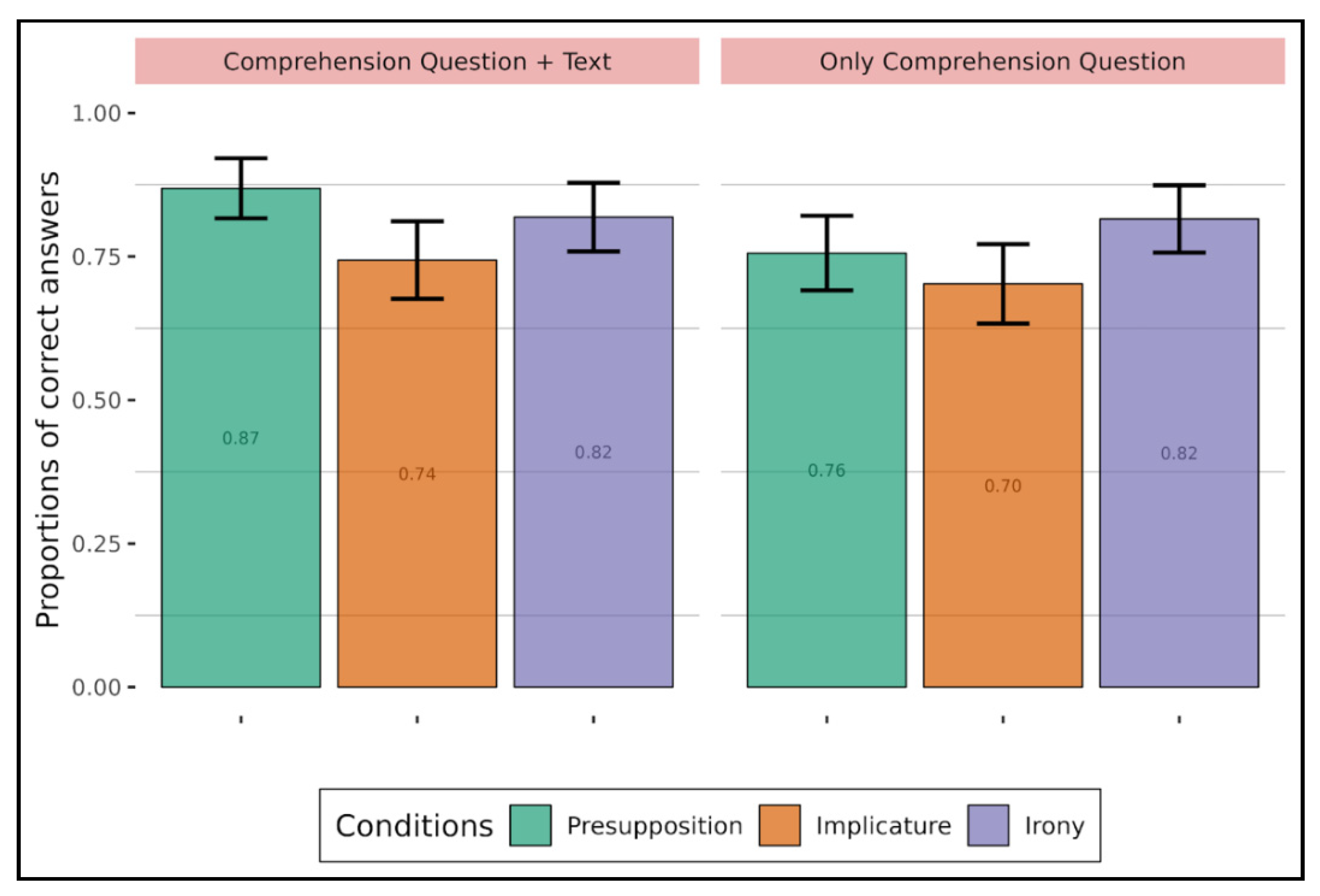
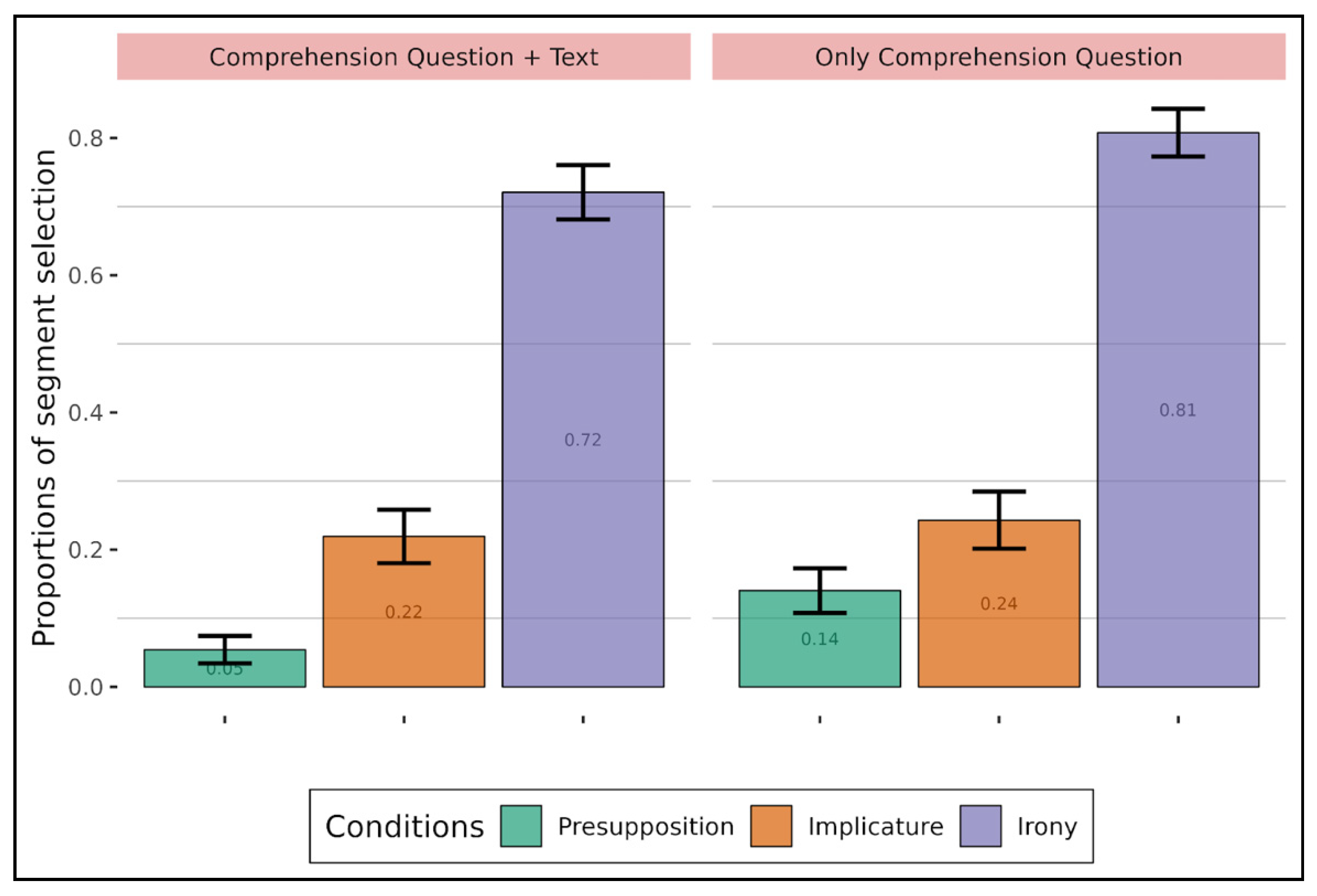
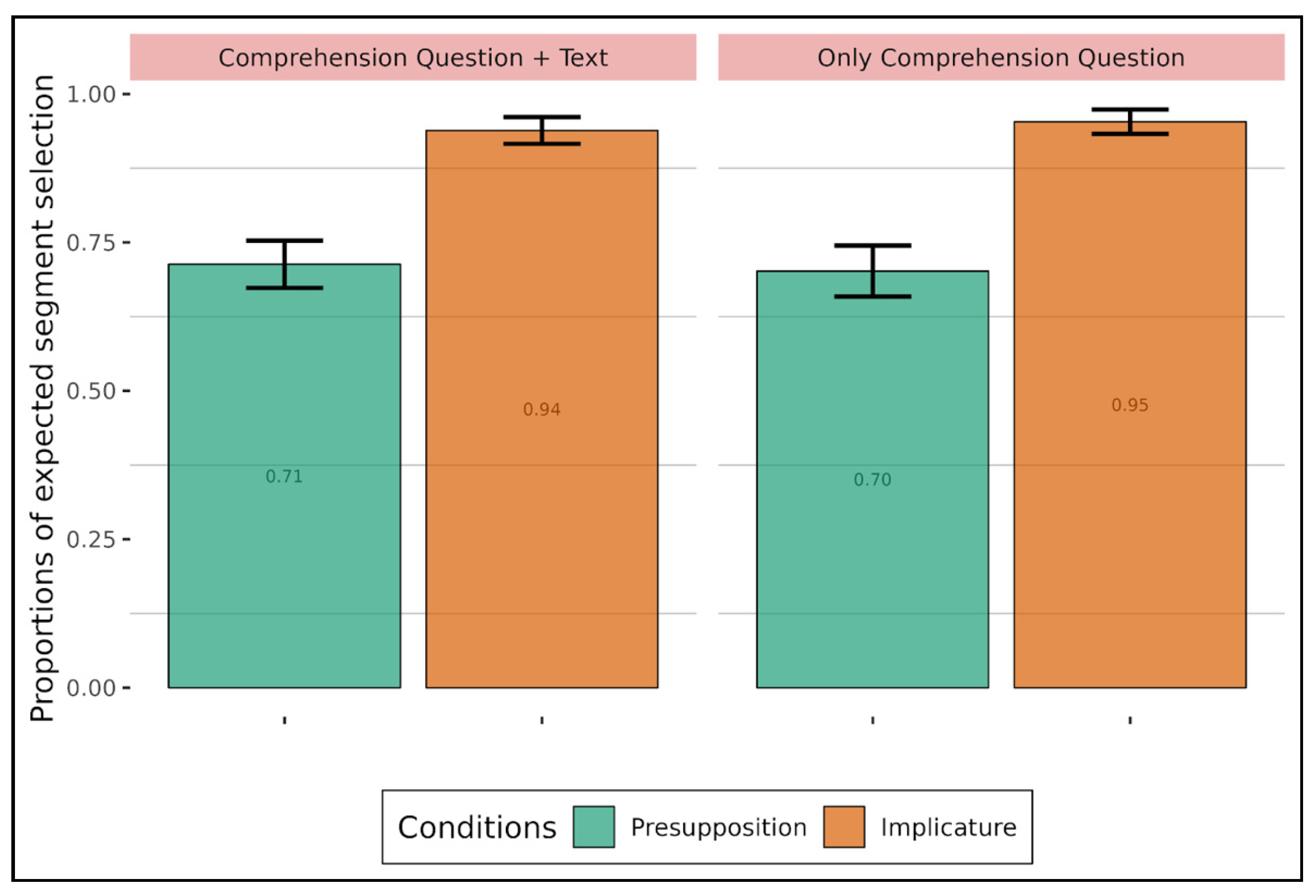
Figure 3). Interestingly, two observations emerge from
Figure 3. First, the presupposition-irony and presupposition-implicature comparisons showed a difference depending on whether the text was displayed or not, with better accuracy when the text was not displayed for implicature and irony compared to presupposition. This difference is due to the fact that adults understand presupposition better when the text is displayed (0.86) than when it is not displayed (0.76). It thus seems that the text variable mainly has an influence on presupposition. A possible explanation is that the presupposed content is background content, which does not contribute to the main point of the utterance, the at-issue content (cf.
Tonhauser et al. 2018). This is not the case for the other two types of implicitness, which are part of the main topic of the discussion. This is particularly evident with irony since not understanding the implicit content in ironic statements results in misinterpretation.
The second observation is that implicature was less well understood among adults whereas irony seemed to be quite well understood (compared to presupposition), making implicature the most difficult type of implicitness in this experiment. In this respect, it should be pointed out that having the text on screen during question answering makes the interpretation of implicature worse for adults (again compared to presupposition). A possible explanation could be that when adults have the full text in front of them, they are more likely to stick to the (visible) literal meaning and hence more likely to refrain from drawing the pragmatic and defeasible inferences. More generally, during the comprehension task, participants may tend not to over-interpret the texts. Since conversational implicatures are non-monotonic inferences (they are only probable and can be canceled), participants may prefer to dutifully avoid them in their answers.
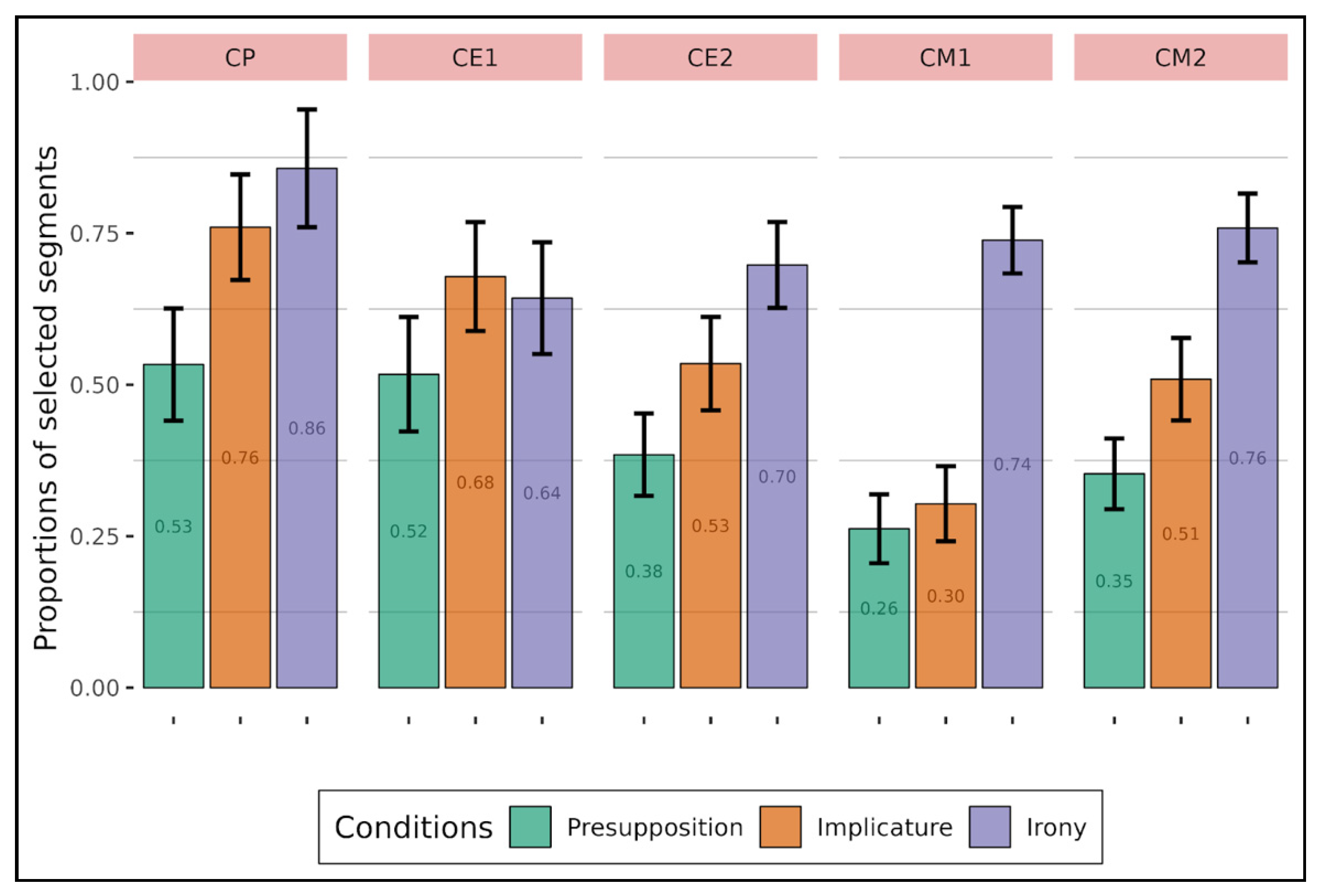
As for the selection of word segments, either in the context or in the target sentence (
Figure 4,
Figure 5,
Figure 6 and
Figure 7), we noticed that, again, children behave in a similar way to adults when they get older, in this case at the end of primary school. However, when looking at the figures qualitatively (
Figure 4 for children and
Figure 5 for adults), children selected segments more often in general than adults.
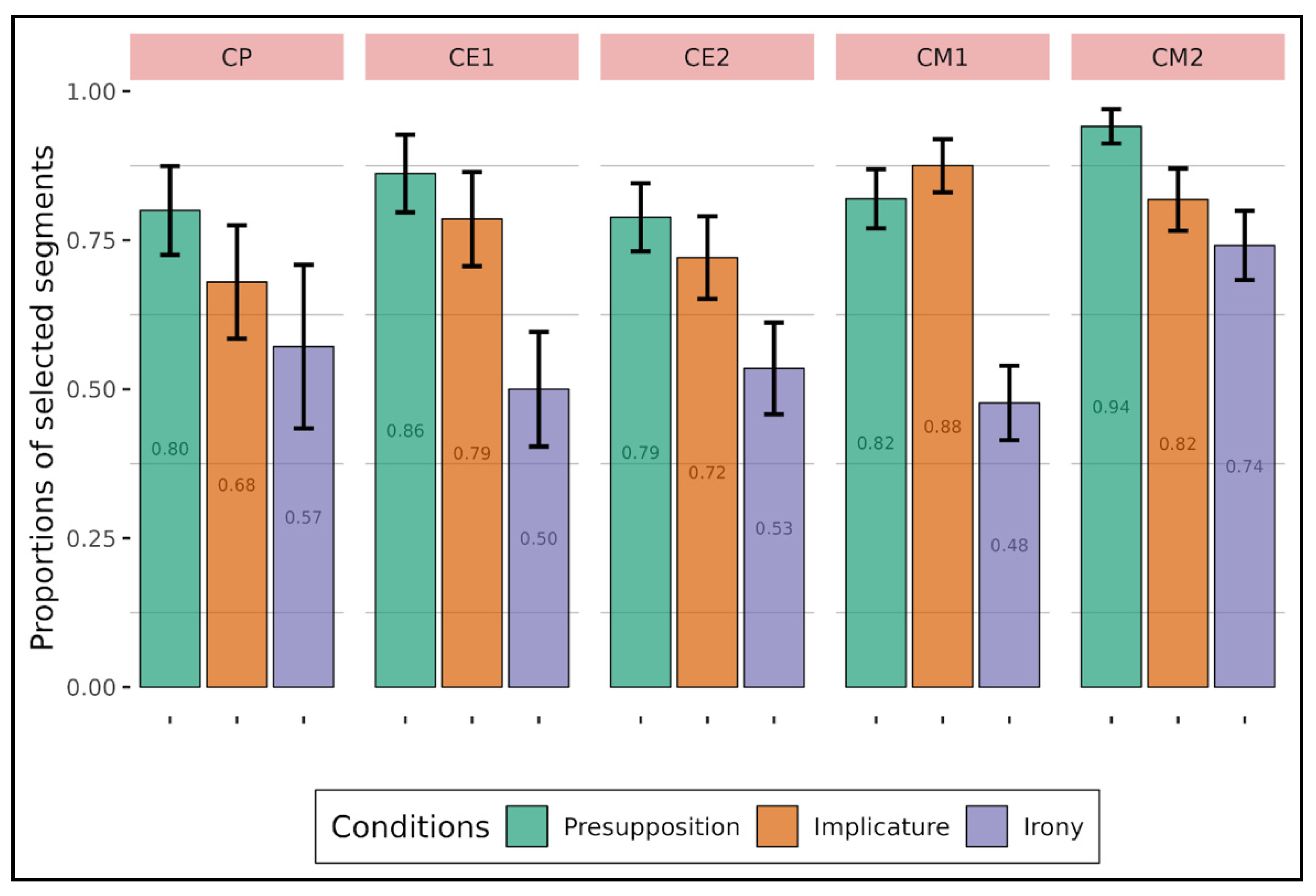
Looking back at our hypotheses, presupposition should be detected on a local scale, meaning that participants should select segments especially within the target sentence and not outside. The results confirmed this for adults (
Figure 5 and
Figure 7), and children at an older age (
Figure 4 and
Figure 6). Indeed, in the target sentence, compared to presupposition, participants selected segments less often in the irony condition and the implicature condition (for children only). However, it was the other way around for the selection in the context, with participants selecting segments more often in the irony and implicature conditions compared to presupposition, both in adults and children. Phrases seem to be sufficient to interpret and understand presupposition, and hence a full comprehension of the target sentence does not appear as a necessary condition.
Regarding irony, it should be more difficult to detect it at a very local scale since the reader needs to realize a certain discordance between what is said and what is meant. The results showed that this seems to be the case: adults as well as children selected segments less often for irony compared to the other types of implicit in the target sentence (
Figure 6 for children and
Figure 7 for adults), while they selected segments more often in the context (
Figure 4 for children and
Figure 5 for adults). This is in line with the theory that irony cannot be detected and understood within a single statement only (i.e., one single sentence).
As for conversational implicatures, the hypothesis was that they should be more context-sensitive than presupposition, which is shown by the results found in the context: adults (especially when the text is displayed) and children did select segments more often in the implicature condition than in the presupposition condition, meaning that conversational implicature may be detected and understood on a less local scale than presuppositions in general.
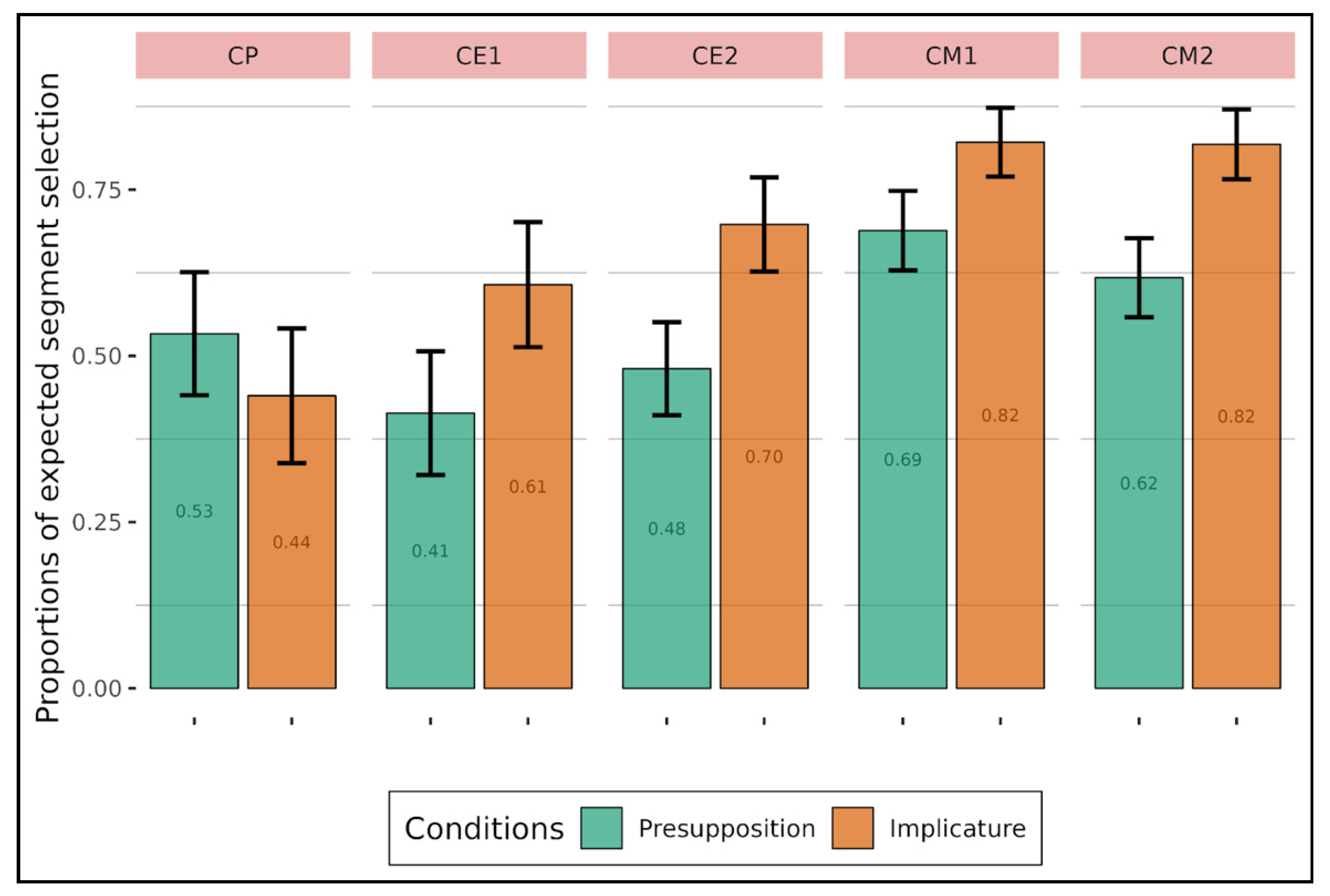
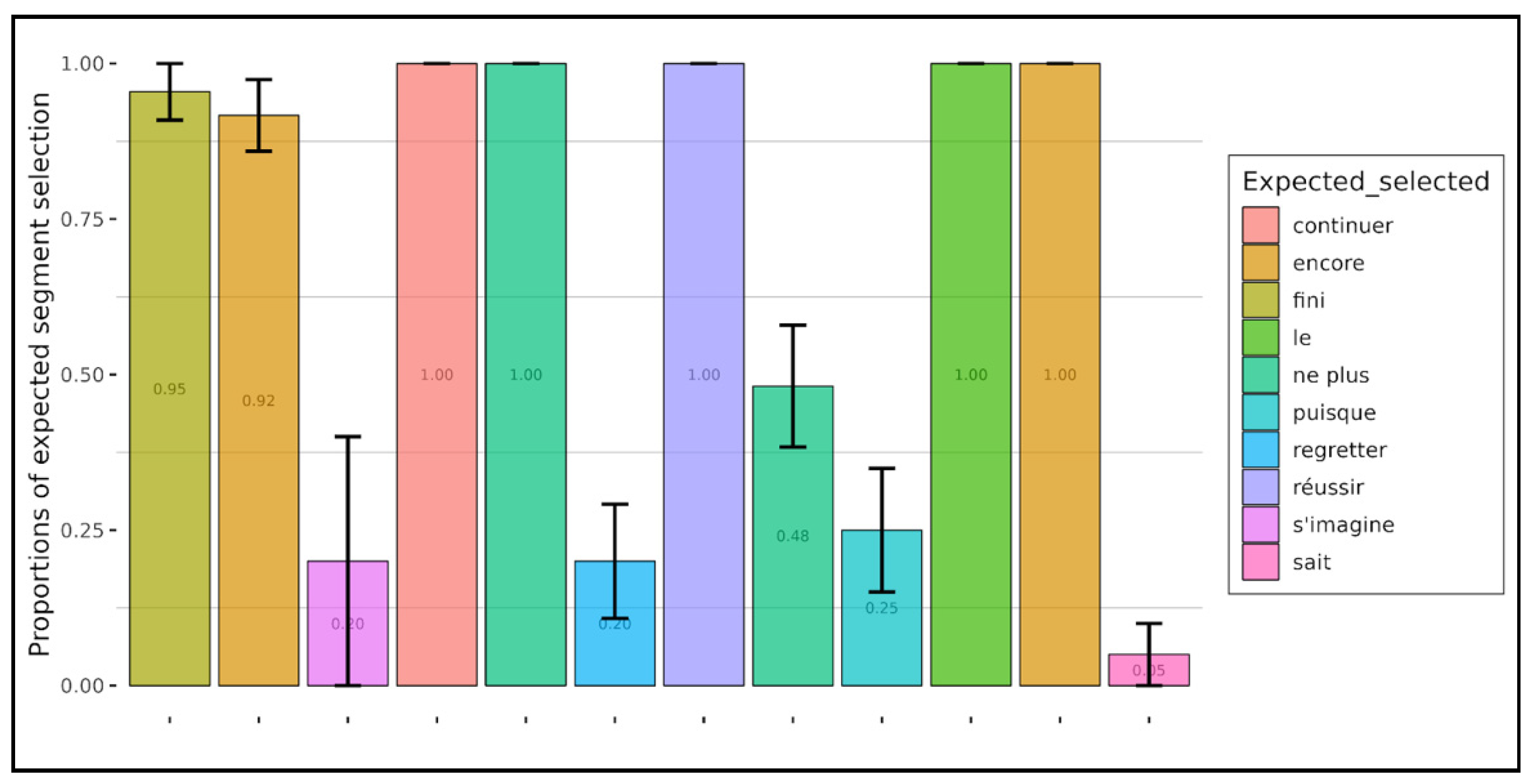
Comparing the segments selected in the context with the segments selected in the target sentence enabled us to determine whether the understanding of the target sentence was sufficient for understanding each type of implicit. The results showed a difference between presupposition and implicature on the one hand and irony on the other. But to determine whether understanding the target sentence was necessary for understanding the implicit associated with presuppositions and implicatures, we checked whether the trigger for these types of implicit, what we called “the expected word segment”, was among the segments selected by the participants. When looking descriptively at the presuppositions and implicatures used in the experiment (
Figure 8 and
Figure 9), we observed that both adults and children (except for the first grade—CP) selected the expected word segments less often for presupposition than for implicature. Generally speaking, then, it appears that both adults and children accurately detected presupposition, but they were likely to “miss” its actual linguistic trigger.
To understand these results, which our hypotheses did not allow us to anticipate, we looked at the scores item by item, for presuppositions and implicatures.
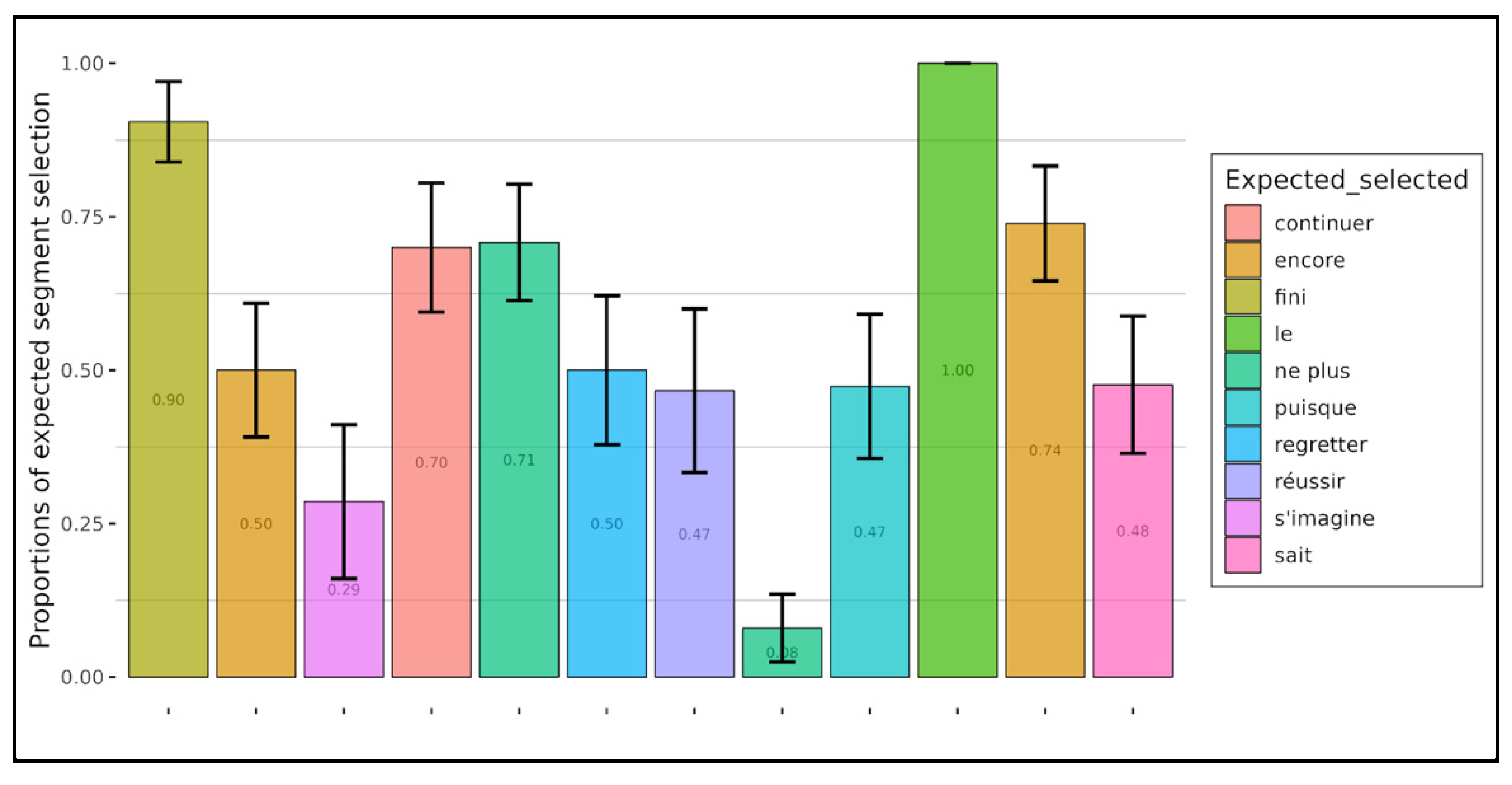
Figure 10 and
Figure 11 show the results for presuppositions, respectively for all children (independent of the class variable) and adults.
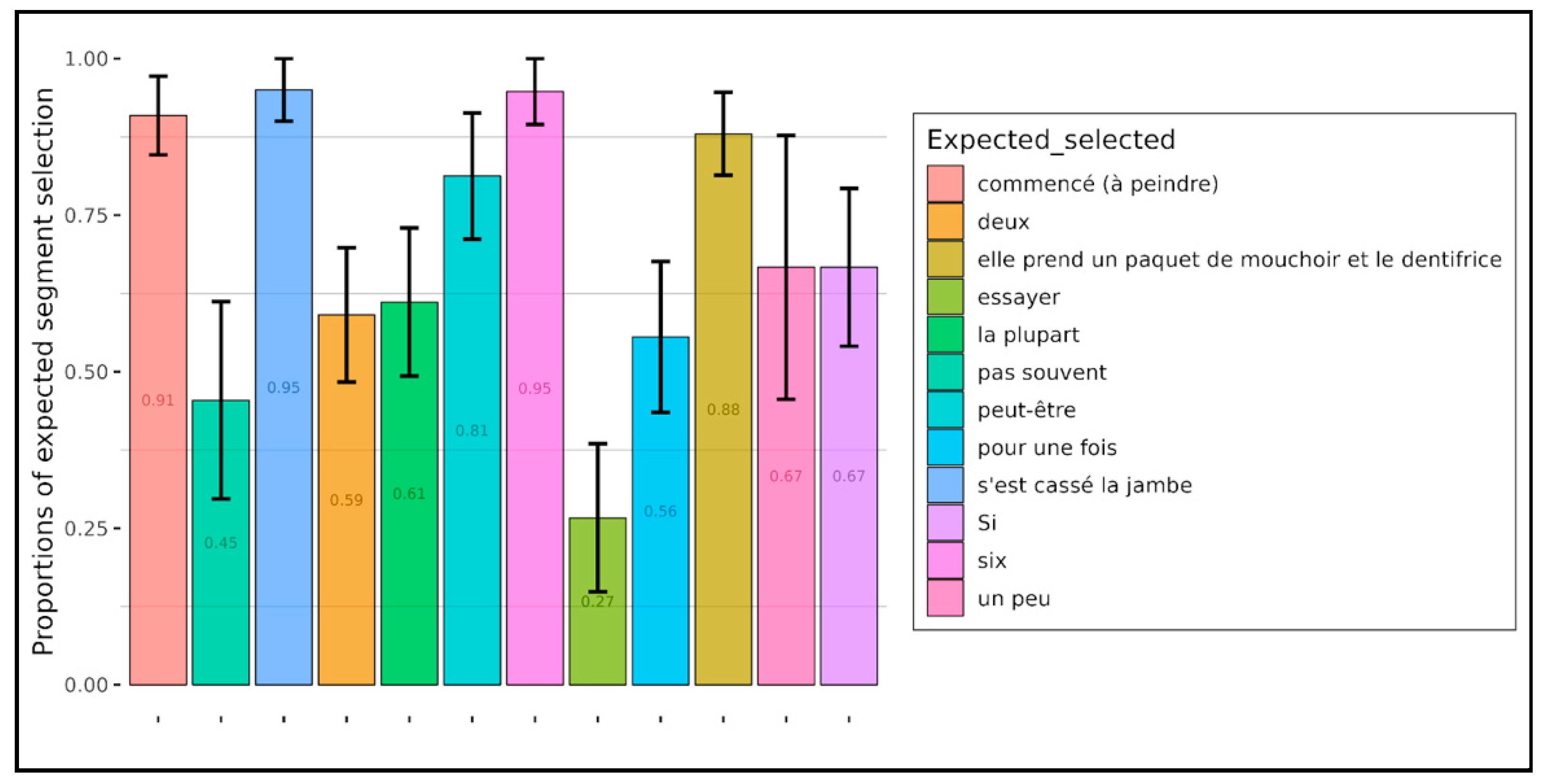
Figure 12 and
Figure 13 show the results for implicatures, respectively for all children (independent of the class variable) and adults. The color bars correspond to the types of presupposition (
Figure 10 and
Figure 11) or implicature (
Figure 12 and
Figure 13). For each figure, 1 means that participants selected at least one word expected segment, and 0 means that participants did not select the expected segment. For example, in
Figure 10, children had a mean selection of 0.90 for the expected segment
fini (finished), meaning that they more often selected the expected segment compared to the expected segments
ne plus (no more) where the mean selection of the expected segments is 0.08 (closer to 0).
For presuppositions, a wide variation was observed depending on the triggers, and interestingly, the differences identified with children widened with adults, resulting in a bipartition of items among adults: on the one hand, items recognized as presupposition triggers (proportions close to 1) and on the other hand, items not recognized as such (proportions below 0.5, which can reach 0.05). This variation can be explained if we consider the following. First, it is not surprising that the participants selected other word segments than the trigger alone in order to justify their understanding; usually, the full phrasing of the propositional content that constitutes the presupposition includes large parts of the target sentence. For instance, the sentence
Tom continue à faire des progrès en calcul (“Tom continues to progress in arithmetic”) and the associated presupposition
Tom avait déjà fait des progrès en calcul (“Tom had already made progress in arithmetic”) share the material
Tom and
faire des progrès en calcul; these elements can naturally be perceived as clues that help to determine the presupposed content. Furthermore, the situation is even more striking when the trigger is just a factive operator: in such a case the presupposition merely amounts to the truth of a proposition already overtly given in the target sentence (
elle ne sait pas que Ludo déteste la soupe ‘She doesn’t know that Ludo hates soup’ presupposes the content of the subordinate clause
Ludo déteste la soupe ‘Ludo hates soup’). Accordingly, some participants may view the real trigger as playing a less significant role in the computation of the presupposition than the subordinate clause itself. In fact, among the poorly recognized items were the factive verbs
savoir ‘to know’ and
regretter ‘to regret’, and the factive conjunction
puisque ‘since’. The counterfactual verb
s’imaginer ‘wrongly imagine’, which we chose because it has been analyzed in detail by
Ducrot (
1968), was also poorly recognized, but it is easily confused with the verb
imaginer ‘imagine’, which is not presuppositional, and its interpretation requires a very good knowledge of the French lexicon. Lastly, one of the two items including the negation
ne plus ‘not anymore’ was not well recognized, but in this item, “ne plus” was in the scope of a modal verb “he shouldn’t eat any more”, which may have contributed to making it more difficult to calculate the presupposition: “he has already eaten some”. In light of the above, it appears that the concept of presupposition, as characterized in theoretical linguistics, seems to cover two classes of triggers not equally well recognized by the participants: The first class includes factual and counterfactual triggers, often misidentified as triggers, and the other class includes, among others, aspectual triggers. On this topic, readers are referred to the literature on strong and weak presupposition triggers (see
Cummins et al. (
2013);
Romoli (
2015)).
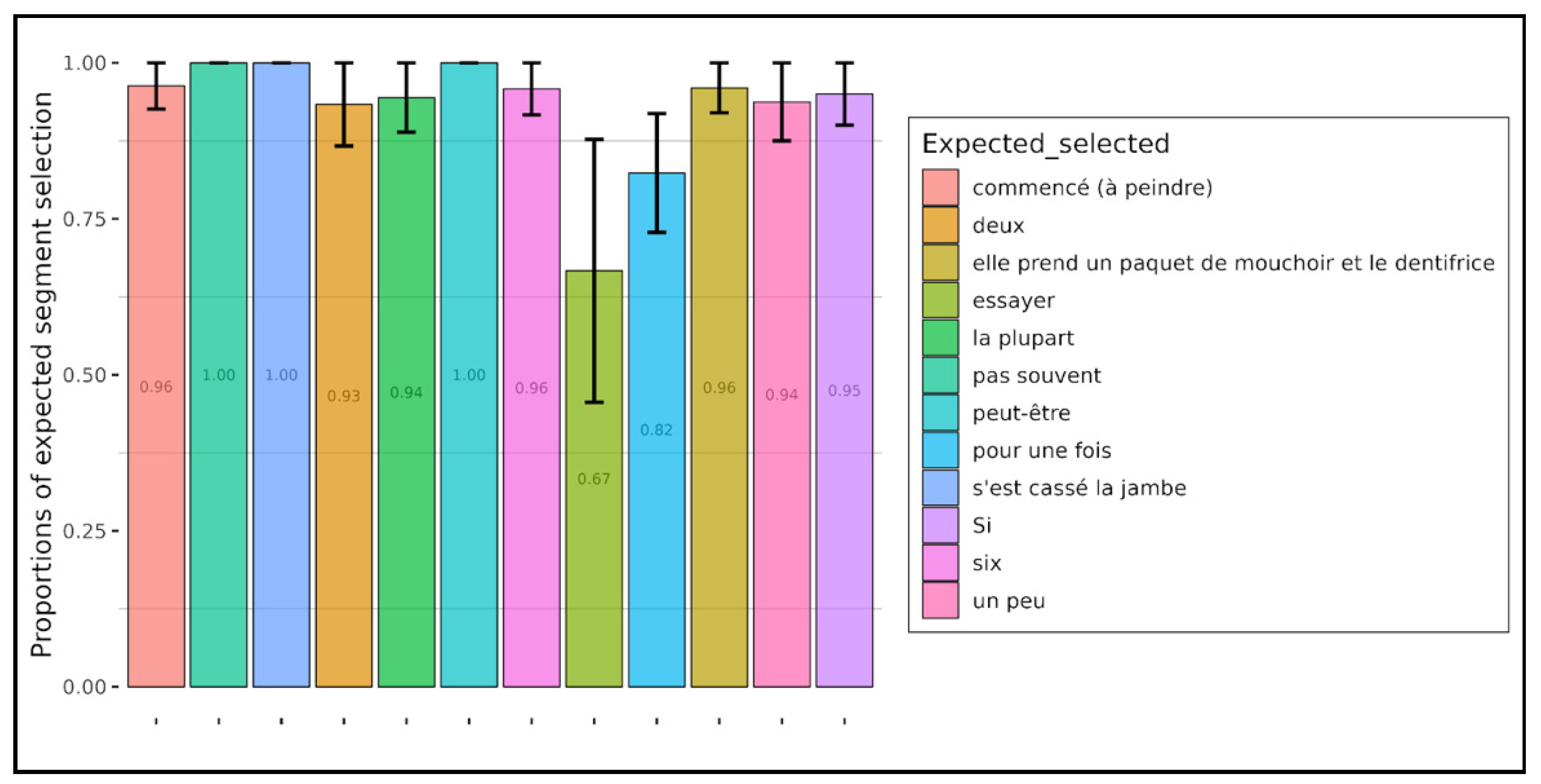
As far as implicatures are concerned, we can see that their triggers are very unevenly recognized by children, while adults recognize them well. There are just two exceptions, one of which is the verb essayer ‘to try’. But in the item, this verb was in the present tense and participants were asked whether the target sentence generated the implicature “won’t succeed”. Even if this implicature exists, it is quite easily canceled out, which is probably why it was less frequently recognized than the other implicatures in the experiment. It would have probably been different with a verb in the past tense. The other exception is for the expression pour une fois ‘for once’, and the expected implicature ‘not being used to’. This implicature was less well recognized than the others, but it was still fairly well recognized (above 0.8). This lower score is perhaps due to the fact that ‘for once’ in the target sentence and ‘not being used to’ in the comprehension question are two expressions that do not belong to the same syntactic paradigm and cannot be placed, as such, on a Horn scale. This could explain why participants had more difficulty generating an implicature with this item.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}