
The Role of Prediction Error in 4-Year-Olds’ Learning of English Direct Object Datives


Abstract
:1. Introduction
1.1. Why Are DOs Harder to Understand for Children?
1.2. This Study: Manipulating the Strength of Children’s Expectations
2. Materials and Methods
2.1. Participants
Power and Sample Size
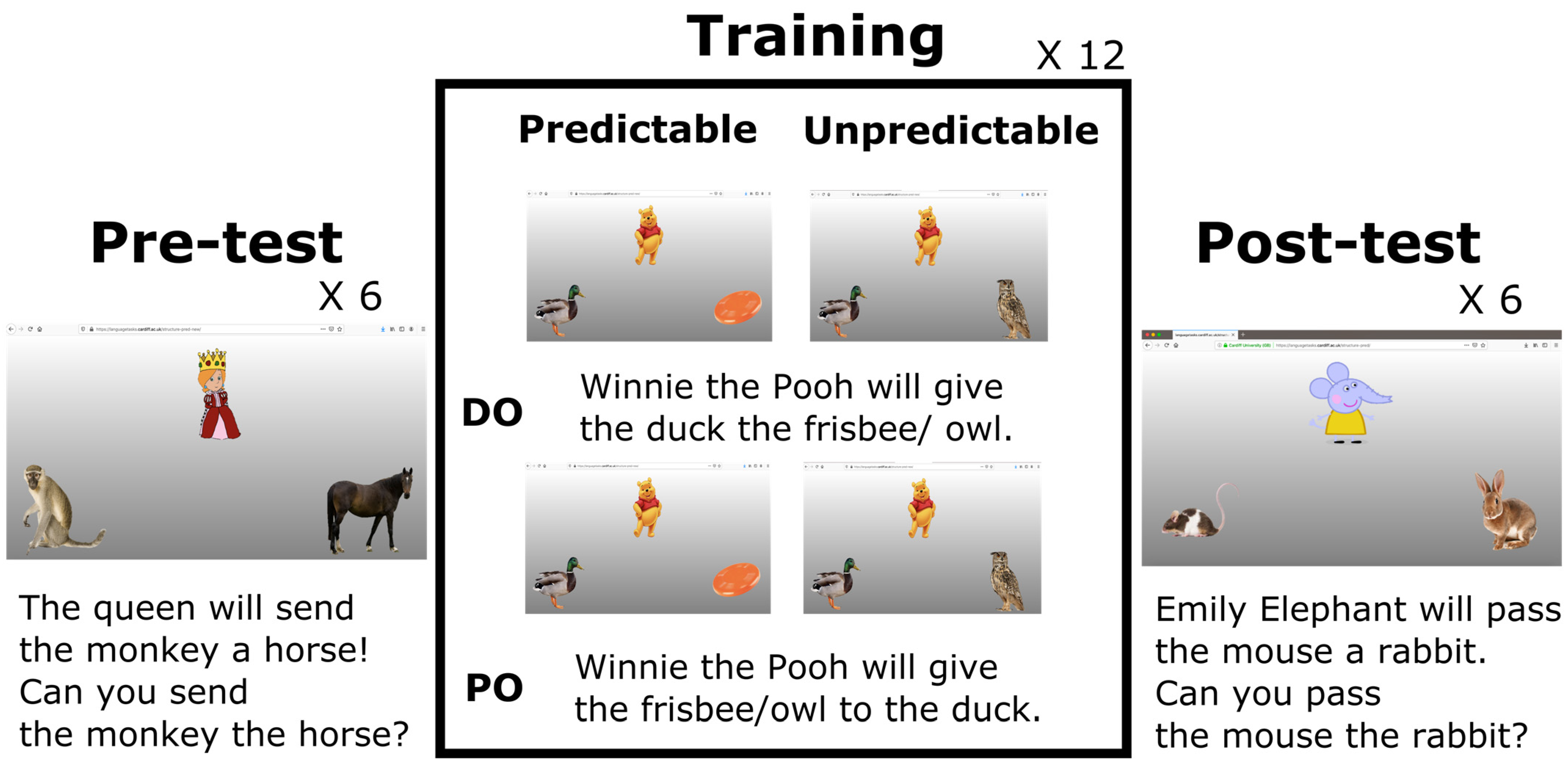
2.2. Materials and Procedure
2.2.1. Pre-Test and Post-Test
2.2.2. Training
2.3. Data Analysis
3. Results
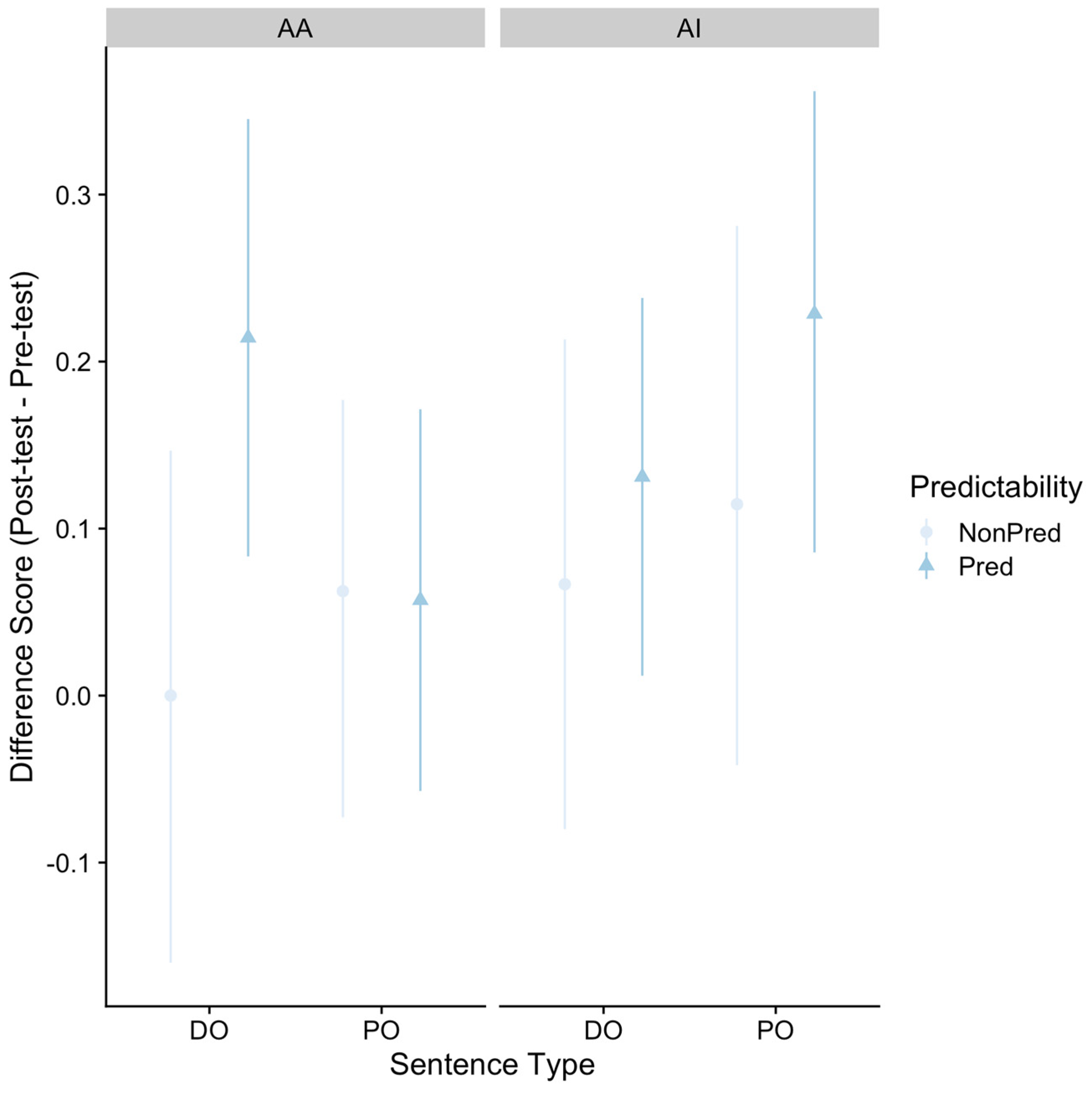
3.1. Planned Analyses
3.2. Additional Exploratory Analyses
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Albers, Casper, and Daniël Lakens. 2018. When power analyses based on pilot data are biased: Inaccurate effect size estimators and follow-up bias. Journal of Experimental Social Psychology 74: 187–95. [Google Scholar] [CrossRef]
- Arai, Manabu, and Reiko Mazuka. 2014. The development of Japanese passive syntax as indexed by structural priming in comprehension. Quarterly Journal of Experimental Psychology 67: 60–78. [Google Scholar] [CrossRef]
- Arnon, Inbal. 2015. What can frequency effects tell us about the building blocks and mechanisms of language learning? Journal of Child Language 42: 274–77. [Google Scholar] [CrossRef]
- Arunachalam, Sudha. 2016. Preschoolers’ Acquisition of Novel Verbs in the Double Object Dative. Cognitive Science 41: 831–54. [Google Scholar] [CrossRef]
- Bates, Douglas, Martin Maechler, Ben Bolker, and Steve Walker. 2023. Lme4: Linear Mixed-Effects Models Using Eigen and S4. R Package Version 1.1-33. Vienna: R Development Core Team. [Google Scholar]
- Bencini, Giulia ML, and Virginia V. Valian. 2008. Abstract sentence representations in 3-year-olds: Evidence from language production and comprehension. Journal of Memory and Language 59: 97–113. [Google Scholar] [CrossRef]
- Bishop, Dorothy. 2003. Test for Reception of Grammar, TROG-2. London: Pearson. [Google Scholar]
- Borovsky, Arielle, Jeffrey L. Elman, and Anne Fernald. 2012. Knowing a lot for one’s age: Vocabulary skill and not age is associated with anticipatory incremental sentence interpretation in children and adults. Journal of Experimental Child Psychology 112: 417–36. [Google Scholar] [CrossRef]
- Brysbaert, Marc, and Andrew Biemiller. 2017. Test-based age-of-acquisition norms for 44 thousand English word meanings. Behavior Research Methods 49: 1520–23. [Google Scholar] [CrossRef]
- Buckle, Leone, Elena Lieven, and Anna L. Theakston. 2017. The effects of animacy and syntax on priming: A developmental study. Frontiers in Psychology 8: 2246. [Google Scholar] [CrossRef]
- Chang, Franklin, Gary S. Dell, and Kathryn Bock. 2006. Becoming syntactic. Psychological Review 113: 234–72. [Google Scholar] [CrossRef]
- Conwell, Erin, and Katherine Demuth. 2007. Early syntactic productivity: Evidence from dative shift. Cognition 103: 163–79. [Google Scholar] [CrossRef]
- Dell, Gary S., and Franklin Chang. 2014. The P-chain: Relating sentence production and its disorders to comprehension and acquisition. Philosophical Transactions of the Royal Society B: Biological Sciences 369: 20120394. [Google Scholar] [CrossRef]
- Fazekas, Judit, Andrew Jessop, Julian Pine, and Caroline Rowland. 2020. Do children learn from their prediction mistakes? A registered report evaluating error-based theories of language acquisition. Royal Society Open Science 7: 180877. [Google Scholar] [CrossRef]
- Gambi, Chiara, Martin J. Pickering, and Hugh Rabagliati. 2016. Beyond Associations: Sensitivity to structure in pre-schoolers’ linguistic predictions. Cognition 157: 340–51. [Google Scholar] [CrossRef]
- Gambi, Chiara, Priya Jindal, Sophie Sharpe, Martin J. Pickering, and Hugh Rabagliati. 2021. The relation between preschoolers’ vocabulary development and their ability to predict and recognize words. Child Development 92: 1048–66. [Google Scholar] [CrossRef]
- Jaeger, T. Florian, and Neal E. Snider. 2013. Alignment as a consequence of expectation adaptation: Syntactic priming is affected by the prime’s prediction error given both prior and recent experience. Cognition 127: 57–83. [Google Scholar] [CrossRef]
- MacWhinney, Brian. 2000. The CHILDES Project: Tools for Analyzing Talk, 3rd ed. Cambridge: Lawrence Erlbaum, vol. 2. [Google Scholar]
- Mani, Nivedita, and Falk Huettig. 2012. Prediction during language processing is a piece of cake—but only for skilled producers. Journal of Experimental Psychology: Human Perception and Performance 38: 843–47. [Google Scholar] [CrossRef]
- Messenger, Katherine, ed. 2022. Syntactic Priming in Language Acquisition Representations, Mechanisms and Applications. Amsterdam: John Benjamins, p. 226. [Google Scholar]
- Osgood, Charles E., and Annette M. Zehler. 1981. Acquisition of bi-transitive sentences: Pre-linguistic determinants of language acquisition. Journal of Child Language 8: 367–83. [Google Scholar] [CrossRef]
- Peter, Michelle, Franklin Chang, Julian M. Pine, Ryan Blything, and Caroline F. Rowland. 2015. When and how do children develop knowledge of verb argument structure? Evidence from verb bias effects in a structural priming task. Journal of Memory and Language 81: 1–15. [Google Scholar] [CrossRef]
- Pickering, Martin J., and Victor S. Ferreira. 2008. Structural priming: A critical review. Psychological Bulletin 134: 427. [Google Scholar] [CrossRef]
- R Development Core Team. n.d.R Package Version 4.3.1. Available online: https://cran.r-project.org/bin/macosx/ (accessed on 1 September 2023).
- Rowland, Caroline F., and Claire L. Noble. 2010. The role of syntactic structure in children’s sentence comprehension: Evidence from the dative. Language Learning and Development 7: 55–75. [Google Scholar] [CrossRef]
- Rowland, Caroline F., Claire H. Noble, and Angel Chan. 2014. Competition all the way down: How children learn word order cues to sentence meaning. In Competing Motivations in Grammar and Usage. Edited by Brian MacWhinney, Andrej Malchukov and Edith Moravcsik. Oxford: Oxford University Press, pp. 125–43. [Google Scholar]
- Rowland, Caroline F., Franklin Chang, Ben Ambridge, Julian M. Pine, and Elena V.M. Lieven. 2012. The development of abstract syntax: Evidence from structural priming and the lexical boost. Cognition 125: 49–63. [Google Scholar] [CrossRef]
- Thothathiri, Malathi, and Jesse Snedeker. 2008. Syntactic priming during language comprehension in three-and four-year-old children. Journal of Memory and Language 58: 188–213. [Google Scholar] [CrossRef]
- Tooley, Kristen M., and Matthew J. Traxler. 2010. Syntactic priming effects in comprehension: A critical review. Language and Linguistics Compass 4: 925–37. [Google Scholar] [CrossRef]
- Tooley, Kristen M., Martin J. Pickering, and Matthew J. Traxler. 2019. Lexically-mediated syntactic priming effects in comprehension: Sources of facilitation. Quarterly Journal of Experimental Psychology 72: 2176–96. [Google Scholar] [CrossRef]
- Westfall, Jacob, David A. Kenny, and Charles M. Judd. 2014. Statistical power and optimal design in experiments in which samples of participants respond to samples of stimuli. Journal of Experimental Psychology: General 143: 2020. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Training | N | Mean Age (Months) | Age Range |
|---|---|---|---|
| DO Unpred | 25 | 52.24 | (48–63) |
| DO Pred | 28 | 51.96 | (47–63) |
| PO Unpred | 32 | 54.84 | (48–67) |
| PO Pred | 35 | 53.71 | (47–68) |
| Sentence Type | Predictability | Trial Difficulty | Mean Accuracy (SD) | |
|---|---|---|---|---|
| Pre-Test | Post-Test | |||
| DO | NonPred | AA | 41.33 (33.72) | 41.33 (37.61) |
| DO | NonPred | AI | 48 (39.77) | 54.67 (39.53) |
| DO | Pred | AA | 36.9 (34.35) | 58.33 (28.15) |
| DO | Pred | AI | 55.95 (34.01) | 69.05 (28.59) |
| PO | NonPred | AA | 34.38 (35.4) | 40.62 (34.64) |
| PO | NonPred | AI | 47.92 (40.55) | 59.38 (39.47) |
| PO | Pred | AA | 33.33 (35.24) | 39.05 (35.69) |
| PO | Pred | AI | 40.95 (37.12) | 63.81 (39.08) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gambi, C.; Messenger, K. The Role of Prediction Error in 4-Year-Olds’ Learning of English Direct Object Datives. Languages 2023, 8, 276. https://doi.org/10.3390/languages8040276
Gambi C, Messenger K. The Role of Prediction Error in 4-Year-Olds’ Learning of English Direct Object Datives. Languages. 2023; 8(4):276. https://doi.org/10.3390/languages8040276
Chicago/Turabian StyleGambi, Chiara, and Katherine Messenger. 2023. "The Role of Prediction Error in 4-Year-Olds’ Learning of English Direct Object Datives" Languages 8, no. 4: 276. https://doi.org/10.3390/languages8040276
APA StyleGambi, C., & Messenger, K. (2023). The Role of Prediction Error in 4-Year-Olds’ Learning of English Direct Object Datives. Languages, 8(4), 276. https://doi.org/10.3390/languages8040276