Abstract
This study used online and offline tasks to examine whether proficient Korean learners of Chinese can analyze the syntactic structure of separable verbs in a native-like manner during real-time processing. Separable verbs are considered a unique grammar in Chinese, involving an interface of lexicon and syntax. Despite their lexical status, separable verbs occur in the form of syntactic phrases, with constituents modified by phrase-level rules in syntax. The present study demonstrates that despite native-like offline judgments on the syntactic analysis of separable verbs, the same grammatical information was not utilized in the L2 real-time processing. The results of the experiments indicate that the structural information of separable verbs was employed less in the L2 online processing due to overreliance on the lexical representations of these compounds. In contrast, it was shown that L1 speakers could access both syntactic and lexical information associated with separable verbs during real-time processing. It is suggested that when processing a construction involving an interface of syntax and lexicon, L2 speakers rely heavily on lexicon storage and underutilize structural information.
1. Introduction
A large body of psycholinguistic research has presented mixed results on whether L2 speakers can process the morphological structure in a native-like manner. Some studies demonstrate that L2 grammar processing of morphologically complex words can be guided by structural information just like L1 grammar processing with an increased proficiency level (e.g., Feldman et al. 2010; Pliatsikas and Marinis 2013; Coughlin and Tremblay 2015; Foote 2017). However, several studies on L2 morphological processing provide evidence that L1 and L2 speakers employ qualitatively distinct processing systems and explain the L1–L2 differences in terms of the Shallow Structure Hypothesis (hereafter, SSH) (Silva and Clahsen 2008; Clahsen and Neubauer 2010; Clahsen et al. 2013, 2015; Kirkici and Clahsen 2013; Heyer and Clahsen 2015; Farhy et al. 2018; Jacob et al. 2018; Song et al. 2020). The SSH was first proposed to account for nontarget-like grammatical processing by L2 speakers during real-time sentence processing (Clahsen and Felser 2006a, 2006b). The SSH suggests that L1 grammar processing predominantly relies on structural information, whereas even highly proficient L2 speakers tend to underuse structural information relative to non-structural information. For instance, native speakers may display sensitivity to grammatical violations during real-time processing when reading sentences involving an agreement violation like “* He like to play tennis”. In contrast, even proficient L2 speakers are less likely to detect the agreement violation as they tend to depend heavily on the lexical meaning of words. Recent research indicates that SSH can also apply to the structural analysis of morphologically complex words. This is evidenced by L2 speakers showing less sensitivity to morphological structures and tending to depend heavily on information stored in the lexical storage, including surface forms in their lexical storage (Silva and Clahsen 2008; Clahsen and Neubauer 2010; Kirkici and Clahsen 2013) and semantic conditions or orthographic overlaps (Heyer and Clahsen 2015; Clahsen et al. 2013, 2015; Song et al. 2020). Therefore, it has been postulated that L2 speakers, due to their overreliance on non-structural information, are not able to construct detailed structural representations of morphologically complex words during real-time processing at the same level as native speakers. While the majority of studies on L2 morphological processing have focused on inflection and derivation, the present study aims to test the SSH based on a unique type of Chinese compound that has dual status as both a word and phrase. Separable VO compound verbs (hereafter separable verbs) are considered a gray area involving an interface of lexicon and syntax in the Chinese language (Packard 2000). Although separable verbs are recognized as words listed in the lexicon in their base form, they behave as a VP-like structure, with each constituent modified via syntactic operations as in (1). Danxin carry-heart ‘worry’ in (1) is a word with a specialized meaning whose internal meaning should not be further analyzed via phrase-level rules in accordance with the Lexical Integrity Principle (Huang 1984; Di Sciullo and Williams 1987; Bresnan and Mchombo 1995). Yet, it is syntactically reanalyzed into a VP, with each constituent behaving as a verb and an object respectively.
| (1) | a. | Compound | b. | Syntactically reanalyzed compound | ||
| Danxin | Dan-le | ta de | xin | |||
| carry heart | carry-PERF | he POSS | heart | |||
| ‘to worry’ | ‘worried about him’ | |||||
Exploring the L2 processing of separable verbs, which are linguistically ambiguous between words and phrases, can help determine whether these speakers rely more on non-structural (lexical-semantic) information than structural information during real-time grammar processing. The dual nature of separable verbs consistently proves problematic for L2 speakers from various L1 backgrounds in syntactically analyzing these forms in both written and spoken production, as they often depend on their lexical representations (Cao 2020; Zhang 2018; Wang 2015; Yang 2006). Yet, separable verbs are introduced early in Chinese language instruction, and previous studies utilizing offline tasks have demonstrated that as L2 speakers gain more exposure to Chinese language learning, their understanding of the syntactic structure associated with these words improves (Zhou and Li 2015; Shen 2019).
Although traditional offline tasks, such as acceptability judgment task (AJT) and grammaticality judgment task (GJT), have shown a positive correlation between proficiency and L2 acquisition of the syntactic structure related to separable verbs, they provide little insight into the online processing of this construction by L2 speakers. These tasks do not simulate real-time processing pressures, offer participants time to monitor responses, and often involve explicit metalinguistic knowledge, which differs from real-time processing’s reliance on implicit linguistic knowledge acquired through language exposure (Ellis 2005; Paradis 2009). Consequently, offline tasks may not capture the automatic and subconscious nature of online language processing fully (Segalowitz 2003). Against this background, this study adopts a self-paced reading task (SPRT) to capture L2 speakers’ online processing of separable verbs, providing insight into the use of grammatical information during real-time reading. By monitoring reading times for words or phrases region by region, SPRT can identify which structures are challenging and when these difficulties arise (Just et al. 1982). This granular data can uncover the mechanisms of L2 grammatical processing, offering an implicit measure less influenced by metalinguistic knowledge (Marinis et al. 2005). Hence, this study employs SPRT to investigate whether proficient L2 Chinese speakers can analyze the syntactic structure of Chinese separable verbs during real-time reading comprehension, minimizing attention to grammatical information.
The paper is organized as follows: Section 2 introduces the linguistic properties of Chinese separable verbs and discusses the previous studies on the L2 acquisition of separable verbs; Section 3 explains the methodology used in the study; Section 4 reports the results of the experiment; Section 5 discusses the findings of the research; and Section 6 concludes the paper with directions for future research.
2. Background
2.1. Chinese Separable Verbs
In Chinese, a compounding construction can be identified as a word if it fulfills the following conditions: (a) it contains at least one bound morpheme; (b) it has a specialized meaning; and (c) constituents cannot be separated via syntactic operations (e.g., Chao 1968; Li and Thompson 1981; Packard 2000). If a construction violates all the conditions in the lexicality criteria, it is recognized as a syntactic phrase. For instance, he-tang drink-soup, ‘drink soup’ is a syntactic VO phrase because its constituents are free morphemes, with its meaning compositionally computed. Additionally, there is no restriction on separating the constituents of he-tang via syntactic operations, as illustrated in (2).
| (2) | wo | he-le | wo | didi | dian | de | tang |
| I | drink-perf | I | brother | order | DE | soup | |
| ‘I drank the soup my brother ordered.’ | |||||||
On the other hand, dong-yuan move-person, ‘mobilize’ is a fully lexicalized compound whose constituents are completely inseparable. Furthermore, it has a specialized meaning that cannot be deduced compositionally. Being a transitive verb, it can also take a direct object, as in (3).
| (3) | Tamen | zhe | ci | dongyuan-le | san | bai | ge | ren |
| They | this | time | mobilize-PERF | three | hundred | CLASS | person | |
| ‘They mobilized 300 people this time.’ | ||||||||
While fully lexicalized words and syntactic phrases can be distinguished straightforwardly, the linguistic status of separable verbs like shui-jiao sleep-sleep ‘sleep’ and kai-che drive-car ‘drive’ remains up for debate due to their dual status as words and phrases. Although separable verbs are conventionally treated as single lexical units, as evidenced by their listing in modern Chinese dictionaries, they often occur in the form of syntactic phrases with constituents detached from each other by other linguistic elements. Separable verbs are often viewed as a linguistic phenomenon corresponding to noun incorporation in Chinese (Huang et al. 2009; Luo 2022; Wang 2022), in which a noun, usually the object of a verb, is incorporated into the verb to form a complex predicate (Mithun 1984). One of the typical characteristics of noun incorporation is that the incorporated noun does not refer to a specific entity but merges into the verb to create a verb-object construction denoting a generic or institutionalized activity (Badan 2013; Luo 2022; Wang 2022). For instance, in kai-che drive-car ‘drive’ the noun che ‘car’ does not refer to a specific entity of a car but is integrated into the verb to form a complex predicate meaning the generic activity of ‘driving’. Many instances of separable verbs are formed by spelling out a dummy object typical of or synonymous with the corresponding verb, as in shui-jiao v.sleep-n.sleep and pao-bu run-walk ‘run’ or using a dummy verb as in da-ge hit-hiccup ‘hiccup’ and zuo-meng do-dream ‘dream’ (Cheng and Sybesma 1998; Badan 2013). Though semantically intransitive, separable verbs are analyzed into a construction corresponding to a verb+object phrase, as in the case of pao-bu run-step ‘run’ presented in (4). However, although the nominal constituent is analyzed as a syntactic argument in (4), the original meaning of the construction remains unchanged, with the noun semantically incorporated into the verb even after being syntactically modified. The syntactically modified phrase maintains the original specialized meaning of ‘run’ instead of describing the event of ‘running a step’, where the object is semantically interpreted as an argument of the verb.
| (4) | biye | zhiqian | yao | hui | xuexiao | pao | zuihou | yi-ci | bu. |
| graduate | before | need | return | school | run | last | one-CL | step | |
| ‘(I) would like to return to school and run for the last time before graduating.’ | |||||||||
Furthermore, there are also a considerable number of separable verbs that cannot easily fit into the categories of dummy object or dummy verb constructions. Examples include separable verbs such as li-fa manage-hair, ‘get a haircut’, and xi-zao wash-bath ‘shower’, where the object constituent is not semantically redundant or synonymous with the verb constituent. The nominal constituent can be analyzed as a syntactic argument as it is given a syntactic slot as an object, as is the case with the syntactic modification of the separable word li-fa ‘get a haircut’ in (5).
| (5) | Wo | li-le | ge | shi-yuan | de | fa |
| I | manage-PERF | CL | ten-Yuan | DE | hair | |
| ‘I got a haircut that costs 10 Yuan.’ | ||||||
Though analyzed as the syntactic argument, the nominal constituent fa ‘hair’ cannot serve as a semantic argument to the verb li ‘manage’ as it does not refer to a specific entity of hair belonging to a certain individual. Instead, the meaning of the object is incorporated into the verb, and the resulting complex predicate refers to an institutionalized activity of ‘getting a haircut’. Hence, the modifier shi-yuan ’10 yuan’ in (5) does not modify the object constituent to convey the meaning of ‘a specific individual’s hair that is worth 10 yuan’. Instead, it modifies the entire VO construction and conveys the meaning of ‘receiving an activity of getting a haircut, which costs 10 yuan.’ Such a mismatch in syntax and semantics presents difficulties in establishing a clear-cut definition of separable verbs in linguistic terms. From the lexicalist viewpoint, separable verbs exhibit similarities to fully lexicalized words due to their specialized meanings and bound morpheme compounding. As such, lexicalist theories view separable verbs as words subject to grammatical operations for contextual sentence needs (Chi 1985; Packard 2000). On the contrary, syntax-oriented accounts emphasize their separability and consider them as idiomatic phrases stored in the lexicon, even when not separated (Huang 1984; Her 1997).
Although there are theoretical concerns regarding the distinction between separable verbs with and without dummy elements, they are often grouped under the same category in L2 Chinese instruction, as pedagogical grammar tends to be simplistic and incomplete instead of reflecting the entire picture of linguistic knowledge (Ionin and Montrul 2023). Frequently used dummy constructions such as chi-fan eat-rice ‘eat’ and zuo-meng do-dream ‘dream’ are not distinguished from non-dummy constructions in L2 Chinese instruction. Moreover, separable verbs are introduced as lexical items along with fully lexicalized words, with emphasis on their specialized or lexicalized meaning (Lü 2008). Despite the distinction between dummy and non-dummy constructions in terms of their syntactic nature and degree of lexicalization, the present study applied a broad definition of separable verbs by treating them under the same category, in order to reflect the current model of pedagogical instruction. However, attempts were made to minimize the number of dummy constructions by completely excluding those consisting of a dummy verb. As for the separable verbs with a dummy object, only a few of those used with high frequency were included as test items in the present study. More details on the test items are described in a later section.
In an attempt to investigate the L2 online processing of separable verbs, the present study concerns whether L2 speakers can identify the syntactic structure of separable verbs and non-lexical VPs when reading these words during reading comprehension. While non-lexical VPs should be handled mainly via syntactic computation, online processing of separable verbs may involve two independent linguistic domains, lexicon, and syntax. Non-lexical VPs are not listed in the lexicon, and hence, their structure should only be computed as phrases consisting of a verb and an object (e.g., [VP [V’ [V jia ‘add] [NP [N’ [N shui ‘water]]]]). Although separable verbs are represented as single lexical units in the mental lexicon (e.g., [V xizao ‘shower’]), they should be analyzed into a hierarchically deeper structure (e.g., [VP [V’ [V xi ‘wash’] [NP [N’ [N zao ‘bath’]]]]) than fully lexicalized compounds for further syntactic modification. Hence, the present study aims to test whether L2 speakers can process the structural information as well as the lexical representations of separable verbs during real-time reading comprehension. Table 1 summarizes the comparison of non-lexical VPs and separable verbs regarding their syntactic and lexical-semantic properties.

Table 1.
Characteristics of VO Phrases and Separable Verbs.
2.2. Prior Studies on L2 Acquisition of Separable Verbs
The previous studies on learners’ usage of separable verbs (Cao 2020; Zhang 2018; Wang 2015; Yang 2006) show that regardless of different L1 backgrounds (e.g., Korean, English, Thai, Japanese, Indonesian, etc.), learners display converging error patterns of treating separable verbs strictly as words. These studies attribute L2 learners’ difficulty with separable verbs to their overreliance on the L1 translation equivalent. Because vocabularies are commonly introduced with meaning translated into learners’ L1 in L2 instruction, strong connections are built between L2 words and their L1 translation equivalents in the bilingual lexicon (Jiang 2000, 2002). Consequently, L2 learners tend to transfer the morpho-syntactic information of L1 words and produce grammatically incorrect usages of the corresponding words in L2. This pattern is also frequently observed in L2 usages of separable words, for which learners apply the syntactic structure of their L1 translation equivalents. For instance, the separable verb bang-mang help-busy ‘to help’ is translated into a single word in Korean (top-ta ‘help’). Since bangmang behaves as a transitive VP-like structure on its own, it is unable to take a direct object. Instead, what should be realized as a direct object must occur in the form of modification on the object constituent mang, as shown in (6a). However, Korean learners of Chinese are likely to treat bangmang as fully lexicalized compounds and place a direct object after it based on the transitive argument structure of the L1 translation equivalent (e.g., ne-ka ku-lul top-ta I-NOM he-ACC help ‘I help him.’) as in (6b). Furthermore, overreliance on lexical representations of separable verbs hinders L2 learners from using aspect markers correctly on these words. Instead of attaching an aspect marker to the verb constituent morpheme (e.g., (7a)), L2 learners prefer to place an aspect marker at the end of the entire construction, as in (7b).
| (6) | L2 grammar errors on bangmang ‘help’ | ||||||
| a. | Wo | yao | bang | ta | de | mang | |
| I | will | help | he | POSS | busy | ||
| ‘I will help him.’ | |||||||
| b. | *wo | yao | bangmang | ta | |||
| I | will | help | he | ||||
| (7) | L2 aspect marking error on jie-hun tie-wedding ‘to marry’ | ||||||
| a. | Ta | hai | mei | jie-guo | hun | ||
| he | yet | not | tie-EXP | marriage | |||
| ‘he has not married yet.’ | |||||||
| b. | *Ta | hai | mei | jiehun-guo. | |||
| He | yet | not | marry-EXP | ||||
In addition to the negative L1 lexical transfer, insufficient coverage of the target grammar has been pointed out as one of the main sources of the difficulty for learners to successfully acquire the syntactic variations of separable verbs (Lü 2008; Cao 2020). Moreover, since separable verbs are far more frequently separated in spoken than formal contexts (Wang 2009; Siewierska et al. 2010), learners, who are exposed to the target language mainly through classroom instruction, receive limited input on the syntactic variations of these words.
Despite the difficulties of separable verbs in L2 acquisition, recent studies using grammaticality judgment tasks (Shen 2019; Gao et al. 2022) demonstrate that L2 learners can improve their structural awareness of separable verbs with increased experience with L2 instruction. Shen (2019) used a series of offline tasks, including a cloze task, a familiarity task, and a grammaticality judgment task, to test L2 learners of different instruction levels (1st to 3rd-year levels) on the syntactic status of separable verbs. The overall result of the study indicates that learners’ experience with formal instruction significantly impacts their knowledge of the phrasal usages of separable words. Although the accuracy rates were relatively low even at the 3rd year level, learners’ abilities to (a) identify the syntactic structure of separable words and (b) detect errors in incorrectly separated usages enhanced as their proficiency level progressed. Using a timed grammaticality judgment task (GJT), Gao et al. (2022) also found that L2 learners can improve their ability to identify the syntactic structure of separable verbs with an increase in proficiency, despite the low level of accuracy in using the syntactically analyzed forms in an oral production task. In the timed GJT, the participants were given 10 s to respond to a sentence including either a grammatical or ungrammatical usage of separable verbs in phrasal forms (e.g., xi-guo-zao wash-EXP-bath ‘to have showered’ vs. *xizao-guo shower-EXP). The results of the timed GJT showed that learners’ accuracy in grammatical judgment was positively mediated by their L2 Chinese proficiency score.
Although the previous study based on untimed and timed judgment tasks suggests that L2 learners can improve structural knowledge of separable verbs through increased experience with the target language, it is unclear whether the relevant knowledge can be utilized during real-time comprehension in L2. Previous psycholinguistic studies suggest that even after having acquired target-like knowledge of a certain structure, it may not necessarily be accessed by L2 speakers online due to overreliance on non-structural information in the L2 processing system, in line with the SSH (e.g., Felser and Cunnings 2012). Therefore, the present study employed both an offline acceptability judgment task (AJT) and an online self-paced reading task (SPRT) to investigate whether L2 speakers can use the relevant grammatical information to analyze the syntactic structure of separable verbs during real-time sentence comprehension.
2.3. Shallow Morphological Processing in L2
The Shallow Structure Hypothesis (SSH) proposes that L1 and L2 processing share the same mechanisms, but the L1/L2 difference can be attributed to learners’ inability to employ grammatical structure efficiently during online processing (Clahsen and Felser 2006a, 2006b). Although the SSH was first introduced to explain nonnative grammatical processing during real-time sentence reading, it has also been attested in a series of L2 morphological processing studies (e.g., Silva and Clahsen 2008; Clahsen and Neubauer 2010; Clahsen et al. 2013; Kirkici and Clahsen 2013; Heyer and Clahsen 2015; Song et al. 2020). Studies on morphologically complex words in English, German, and Turkish using a masked priming paradigm present that L2 learners are less likely to analyze the morphological structure of inflected or derived words due to their overreliance on non-structural information (Silva and Clahsen 2008; Heyer and Clahsen 2015; Kirkici and Clahsen 2013).
These studies explain the L1–L2 difference in morphological processing in terms of the declarative/procedural (DP) model, which posits qualitatively different processing systems for L1 and L2 (Ullman 2001, 2014). Under the D/P model, declarative memory underlies stored knowledge of words, phrases, or linguistic chunks learned as explicit facts, whereas procedural memory subserves grammatical structural building or combinatorial rules of language. The DP model assumes that procedural memory is less involved in grammar processing by late L2 learners due to its attenuation after the so-called critical period. Following the DP model, the previous masked priming studies in English and Turkish demonstrate that L2 speakers show partially or fully native-like morphological priming for derived words but not for inflected words and attribute the L1–L2 difference to overreliance on lexical storage in the L2 processing system (Silva and Clahsen 2008; Kirkici and Clahsen 2013). While both derived words are stored as lexical entries along with base forms, inflected words represent form-function mapping, which is not exhaustively listed in lexical storage. Therefore, the morphological priming of derived words in L2 processing is interpreted as L2 speakers’ sensitivity to shared lexemes between lexical entries stored in lexical storage. On the other hand, no morphological priming is obtainable from inflected words, which are assumed to involve pure combinatorial processes.
Clahsen et al. (2013) also found supporting evidence for L2 shallow morphological processing by focusing on a unique linguistic phenomenon called plurals-in-derivation in English using an offline judgment task and an online eye-movement experiment. The morphological constraint strictly prevents regular plural forms, generated via rule-governed grammar, from feeding either derivation or compounding (Kiparsky 1982). Consequently, derived or compound words with a regularly inflected plural form as non-head (e.g., *pigs-less) are considered far less acceptable than those with an uninflected singular form as non-head (e.g., pig-less) and marginally less acceptable than irregular plural non-head (e.g., ? oxen-less). On the other hand, the semantic constraint does not allow any plural forms, regardless of regularity, to occur as non-heads in compound words (Haskell et al. 2003). Under the semantic constraint, only singular base forms should occur as the non-head of derived or compound words, while both regular and irregular plural forms are not allowed to do so (e.g., pig-less, ox-less vs. *pigs-less, *oxen-less). Using offline and online tasks, Clahsen et al. (2013) show that while Dutch L2 speakers of English demonstrated native-like sensitivity to the morphological constraint in the offline judgment, their online processing of plurals-in-derivations was not guided by the same grammatical condition, showing sensitivity mainly to the semantic constraint. The study attributes the L1–L2 difference in online performance to the overreliance on lexical storage in the L2 processing system. While regular and irregular forms are distinguished in the L1 processing via the involvement of rule-governed grammar, the whole-word representations of both plural forms retrieved from lexical storage are mainly utilized in the L2 processing. Therefore, L2 speakers only make the semantic or categorical distinctions of singular and plural forms based on the lexical representations when processing the non-head of multimorphemic derived words.
A more recent study on English tri-morphemic compounds (Song et al. 2020) provides additional evidence for shallow morphological processing by demonstrating that L2 processing depends more on non-structural information than L1 processing. The study found that L1 word recognition of tri-morphemic words (e.g., unkindness [[un [kind]]-ness]) was primed by morphologically related constituents (e.g., unkind), but not by semantically and formally related non-constituents (e.g., kindness). In contrast, L2 word recognition of tri-morphemic words was primed by both morphologically related constituents and semantically and formally related non-constituents. The results of this study indicate that while L1 morphological processing is mainly guided by structural information, L2 speakers tend to depend more on non-structural information such as semantic and orthographic overlap when processing multimorphemic words in real time.
Overall, the findings from the studies supporting the SSH suggest that L2 morphological processing underuses grammatical information due to overreliance on lexical-semantic information (e.g., overreliance on surface forms of inflected words stored in lexical storage; higher sensitivity to semantic or orthographic information of morphologically complex words). Given this, it is predicted that even proficient L2 speakers may be unable to syntactically analyze separable verbs in phrases during real-time processing. It is assumed that separable verbs involve two linguistic domains: lexicon, through which corresponding word representations are retrieved (e.g., [V xizao]), and syntax, which is applied to building syntactic constructions (e.g., [VP [V’ [V xi ‘wash’] [NP [N’ [N zao ‘bath’]]]]). Due to overreliance on lexical storage, L2 speakers in the present study are predicted to process separable verbs only via lexicon.
3. Experiment
The current study examined whether proficient L2 Chinese speakers can integrate the syntactic status of separable verbs in real-time processing. An offline acceptability judgment task (AJT) and an online self-paced reading task (SPRT) were conducted to examine whether L2 speakers employ structural information or simply rely on lexical storage when processing separable verbs online. In the experiment, the target structures include separable verbs and non-lexical VPs to examine whether the detailed structural processing is operative for both constructions or less operative for the former, involving a lexicon-syntax interface.
Methodology
Each participant completed a self-paced reading and an AJT. After completing the SPRT and the AJT, only L2 participants were further asked to do a proficiency test and a language background survey.
- Participants
32 native speakers of Mandarin Chinese were recruited in Beijing as the control group. All L1 participants were 18 years of age or older. 32 advanced-level L2 learners were also recruited from universities located in Beijing as the experiment group. All L2 participants were L1 Korean speakers enrolled in an undergraduate or graduate program in China at the time of the study. The mean age of the L2 participants was 22.28 (sd = 2.46), and their mean length of residence in the country was 4.87 years (sd = 2.99).
- b.
- Proficiency Test
22 L2 participants were certified for HSK 6 (the highest level of the standardized Chinese proficiency test) and 10 participants for HSK 5 (the second highest level of the standardized Chinese proficiency test). In order to confirm L2 participants’ proficiency at the time of the experiment, the present study used a 16-item cloze test, which was used as a placement test by the Chinese language program at a US university in the Midwest. The proficiency test includes sentences with one blank in them. Each question was answered in five multiple choices. The proficiency test was administered using a survey from Qualtrics. The average score of the L2 participants was 13.6 (sd = 1.43) out of 16. 29 participants were considered to have proficiency beyond the highest level offered by the Chinese language program of the US university in the Midwest.
- c.
- Materials for the SPRT and AJT
Test materials were designed to examine whether L2 speakers can process the syntactic analysis of separable verbs online. For this purpose, separable verbs and non-lexical VPs were included as test items to confirm whether learners can syntactically analyze both constructions in online and offline conditions. The test items were designed to measure L2 speakers’ ability to analyze the syntactic structure of separable verbs and non-lexical VPs by focusing on their sensitivity to the verb modification rule on these two constructions. Separation by an aspect marker or resultative complement was selected as a means to diagnose L2 syntactic processing in the present study because it is considered the most common pattern used in the phrasal usages of separable verbs (Siewierska et al. 2010). Since an aspect marker or resultative complement targets a verb in syntax, it was included to test whether participants analyze separable verbs only as words (e.g., *xizao-guo shower-EXP ‘have showered’) or reanalyze them into syntactic constructions consisting of a verb and an object (e.g., xi-guo-zao wash-EXP-bath ‘to have showered’) during real-time processing. Given this, the L2 syntactic processing in the present study was inferred from whether a parser can demonstrate delayed reading times for incorrect verb modification on separable verbs and non-lexical VPs.
The test items were created with a 2 × 2 design (Condition: SV/VP × Grammar: Grammatical/Ungrammatical). 16 pairs of grammatical and ungrammatical separable verbs and 16 pairs of grammatical and ungrammatical VPs were included as test items. Separable verbs were selected from A Dictionary of the Usage of Common Chinese Separable Verbs (Zhou 2011). Furthermore, attempts were made to minimize the number of separable verbs consisting of dummy elements by completely excluding those with a dummy verb. As for the separable verbs with a dummy object, only four of those that are introduced as words in the early stages of L2 Chinese instruction were included in the test item. These items include pao-bu run-step ‘run’, shui-jiao sleep-sleep ‘sleep’, hua-bing slide-ice ‘skate’, and you-yong swim-swim ‘swim’.
Non-lexical VPs were created with the same length as separable verbs with two monomorphemic words, and it was ensured that they were not listed in Chinese dictionaries to confirm their non-lexicality. The separable verb items and the VP items were controlled in total constituent frequency (constituent 1 + constituent 2), lexical neighbor size (the number of words sharing the same constituents), and stroke number. The constituent frequency was counted from the BCC corpus developed by Beijing Language and Culture University. One-way ANOVA tests revealed that all three factors were controlled across the separable verb and the VP conditions. The information on the test items is presented in Table 2.
Table 2.
Test Item Information.
The location of an aspect marker or resultative complement modulated the grammaticality. The same grammatical rules are applied to both separable verbs and non-lexical VPs. While an aspect marker or resultative complement is inserted between two constituent morphemes in the grammatical condition, it is located at the end of a word/phrase in the ungrammatical condition, as in Table 3a,b.
Table 3.
(a) Sample Stimulus Item for separable verbs. (b) Sample Stimulus Item for VO phrases.
The region of interest is located in Word 4, and two spillover regions are analyzed in Words 5 and 6. Since syntactically analyzed separable verbs are considered phrases, an aspect marker should be attached to the verbal head morpheme. If attached at the end of the entire construction, this would cause ungrammaticality. The same grammaticality rule applies to the phrase condition. Since VPs are created with two free morphemes (monomorphemic verb + monomorphemic noun), verb modification must take place to the right of the verb. Otherwise, it would cause ungrammaticality. In addition, two aspect markers and two resultative complements (-hao ‘done well’. -wan ‘completely done, -guo ‘experiential aspect’, -zhe ‘progressive aspect’) were used to prevent participants from developing task strategies, and 4 pairs of grammatical and ungrammatical test items were created for each aspect marker/resultative complement across separable verb and phrase conditions. The 64 items (corresponding to 32 grammatical/ungrammatical pairs) were distributed across two lists in a Latin-square design; each list contained 32 target items: 8 grammatical separable verbs, 8 ungrammatical separable verbs, 8 grammatical phrases, and 8 ungrammatical phrases.
There were 96 filler items per list. These included 32 sentences testing negation (16 grammatical, 16 ungrammatical), 32 sentences with relative clauses (16 grammatical, 16 ungrammatical), and 32 items for a different experiment, all of which were grammatical sentences. The same materials were used for the AJT and SPRT, but the sentences were presented as a whole.
- d.
- SPRT: Procedures
Participants performed a non-cumulative, self-paced reading task administered by Paradigm Software installed on a personal laptop in a quiet room. Subjects were instructed to read sentences at their own pace on the screen by pressing the spacebar key. Each press of the spacebar key reveals one region of a sentence, and the previous region disappears as the subsequent region becomes visible. After reading each sentence, participants were asked to answer a simple yes/no comprehension question based on the sentence’s content. Before the test session, participants completed a practice session with eight sample items to become familiar with the task format.
- e.
- AJT: Procedures
After completing the self-paced reading task, participants were asked to complete an acceptability judgment. The AJT was administered using a survey form on Qualtrics. Ratings were given on a 5-point scale, with 1 indicating ‘totally unacceptable’ and 5 indicating ‘totally acceptable.’ There was no time limit for the AJT, and participants could take as much time as needed to respond. In the AJT, the participants were given the same list of items as in the SPRT.
- f.
- Predictions
Chinese native speakers are expected to show sensitivity to ungrammatical verb modification at the end of the entire construction for both separable verbs and non-lexical VPs. In contrast, L2 shallow morphological processing predicts that L2 speakers may not demonstrate native-like sensitivity to incorrect verb modification on separable verbs because it is assumed that the L2 processing system relies heavily on the lexical representations of morphologically complex words. To apply verb modification correctly, a separable verb should be analyzed into a syntactic phrase whose structure is hierarchically deeper than a single lexical item. Yet, since L2 morphological processing prioritizes lexical storage over structural information, L2 speakers are predicted to rely heavily on lexical representations of separable verbs and apply incorrect verb modification at the end of the entire compound during real-time processing.
As for the non-lexical VPs, a possible scenario is that target-like structural processing is operative in L2 for such simple syntactic constructions consisting of two morphemes. Since non-lexical VPs do not have lexical representations, there is less demand for L2 speakers to process syntactic and lexical information in parallel in this case. With sufficient resources available to process the structural information, L2 speakers may be able to build syntactic representations of non-lexical VPs in a native-like manner. Hence, L2 speakers are predicted to display native-like sensitivity to aspect marking violations on non-lexical VPs based on the correct syntactic representations.
4. Results
4.1. Acceptability Judgment Task
The descriptive results for the AJT are given in Figure 1. L1 and L2 participants rated grammatical items higher than ungrammatical items across different structure types (separable verbs and non-lexical phrases). The dependent measure was ordinal (a 5-point scale), so a cumulative link mixed model was run to analyze the ordinal data using the clmm() function in R (in the ‘ordinal’ package, Christensen 2022). Two analyses were conducted for the AJT data. The first analysis compared L1 and L2 offline performances in the AJT. Only the L2 data were analyzed in the second analysis, with proficiency scores included as a continuous variable in the model. In order to maintain consistency with the self-paced reading data, which excluded one L2 participant who failed to meet the comprehension cut-off (70%), the responses from the same participant were removed from the analysis.
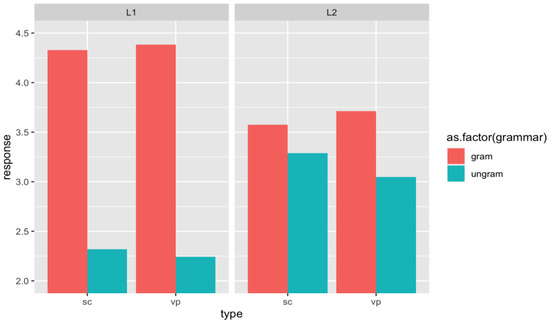
Figure 1.
L1 and L2 Means Ratings in the AJT. (SC = separable verbs; VP = non-lexical verb phrase).
4.1.1. Analysis 1: L1 and L2 Group Comparison
L1 and L2 groups were compared based on their performance in the AJT. The fixed effects were Type (2 levels: Separable Verb vs. Phrase), Grammar (2 levels: Grammatical vs. Ungrammatical), and Group (2 levels: L1 vs. L2). The model also included both by-participants and by-items random intercepts. Based on the results of the anova() function, the model containing a three-way interaction was selected for the analysis.
The model output is given in Table 4. The model yielded significant main effects of Grammar (Estimate = −3.23, SE = 0.18, z = −18.03, p < 0.001), Group (Estimate = −1.30, SE = 0.17, z = −7.75, p < 0.001), but no effect of Type. There was a significant interaction of Grammar and Group (Estimate = 2.87 SE = 0.24, z = 12.06, p < 0.001), but no other interactions were significant. The interaction was explored using the emmeans() function (Lenth 2020). The pairwise comparison revealed that the grammatical items were rated significantly higher than the ungrammatical items by both L1 (Estimate = 3.41, SE = 0.14, z = 24.68, p < 0.0001) and L2 groups (Estimate = 0.71, SE = 0.12, z = 6.04, p < 0.0001). The comparison further revealed that the ratings for ungrammatical items were significantly higher in the L2 group than the L1 group (L1 Grammatical–L2 Grammatical: Estimate = 1.17, SE = 0.12, z = 9.53, p < 0.0001), but those for the grammatical items were lower in the L2 group than in the L1 group (L1 Ungrammatical–L2 Ungrammatical: Estimate = −1.53, SE = 0.12, z = −12.50, p < 0.0001).
Table 4.
L1 and L2 AJT Analysis.
The model output shows that the L1 and L2 groups demonstrated similar patterns as they rated the correctly verb-modified items above the ungrammatical items across the separable verb and non-lexical VP conditions. However, the interaction between Grammar and Status indicates that the L2 grammatical judgment was not as decisive as the L1 judgment.
4.1.2. Analysis 2: Effects of Proficiency
The L2 AJT data were further analyzed to examine whether proficiency mediates the attainment of explicit knowledge. The model for Analysis 2 was run to analyze the L2 data only using the clmm() function in R. The model included Type (2 levels: Separable Verbs vs. Phrases); Grammar (2 levels: Grammatical vs. Ungrammatical); and Proficiency (a continuous variable) as fixed effects. The continuous variable was centered using the scale() function. The model also included by-participants and by-items random intercepts. A three-way interaction (Type*Grammar*Proficiency) was also introduced into the model. The model output is presented in Table 5.
Table 5.
L2 AJT Analysis with Proficiency.
The model yielded a main effect of Grammar (Estimate = −0.43, SE = 0.17, z = −2.58, p < 0.02), indicating that L2 speakers rated the ungrammatical items significantly lower than the grammatical items. There was also an interaction of Type and Grammar (Estimate = −0.67, SE = 0.24, z = −2.82, p < 0.005). A posthoc pairwise comparison revealed that ratings for the grammatical were higher than the ungrammatical items for separable verbs (Grammatical Separable Verb–Ungrammatical Separable Verb: Estimate = 0.43, SE = 0.17, z = 2.57, p < 0.05) and for VPs (Grammatical VP–Ungrammatical VP: Estimate = 1.09, SE = 0.17, z = 6.36, p < 0.0001). The interaction of Grammar and Type indicates that although L2 speakers could detect verb modification violations for both separable verbs and non-lexical VPs, the level of sensitivity was higher for the latter. No main effect of Proficiency was obtained from the model, and it did not interact with any other main effects.
4.2. RT Analysis
The comprehension question accuracy rate was 90% for the L1 group and 84% for the L2 group. The accuracy rates show that the participants were paying attention to the test sentences. The cut-off for comprehension accuracy was set at 70% (e.g., Foote 2011), and the data points from one L2 participant were removed from the analysis. Reading Times below 100 ms were excluded, and RTs over 3 SD away from the mean were also replaced with the cut-off value (e.g., Wei et al. 2018; Ionin et al. 2021). As a result, 1.8% of the data points were affected by data trimming. Furthermore, RTs were log-transformed to improve the normal distribution of the dependent variables. Statistical analyses were conducted on the critical region (Word 4) and the subsequent spillover region (Word 5).
The log-transformed RT in the target and spillover regions was analyzed via a linear mixed effects model using the lmer() function in R since the dependent variable was continuous (Bates et al. 2014). Because the L1 and L2 reading times are significantly different, the L1 and L2 data were analyzed separately (e.g., Marsden et al. 2018; Ionin et al. 2021; Ahn 2021). Separate analyses were conducted for the target and spillover regions. As a result, four separate analyses were conducted: L1 RT on the target region; L2 RT on the target region; L1 RT on the spillover region; and L2 RT on the spillover region.
The models included Type (2 levels: Separable Verbs vs. VP) and Grammar (Grammatical vs. Ungrammatical) as fixed effects. An interaction between Type and Grammar was also included in the model for each analysis. The model fit was tested for all four separate analyses. A full model was first considered with the maximal structure including by-participant and by-item random intercepts and a by-participant random slope for the interaction of Type and Grammar following the suggestions of Barr et al. (2013). The full model was compared with the model that contained only random intercepts using the anova() function. The full model either failed to converge or did not improve the model fit relative to the one only including random intercepts in all four analyses. Hence, the output of the model only including the random intercepts is reported for the L1 and L2 RT data in the target and spill-over regions. Figure 2 displays the mean log-transformed reading time by L1 and L2 participants for each region.
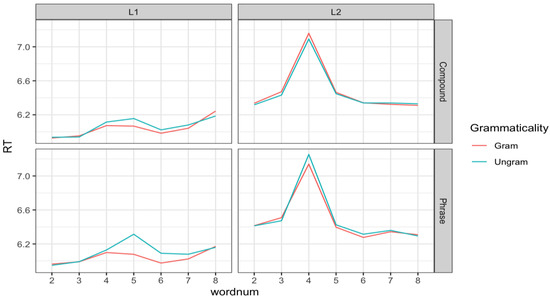
Figure 2.
Mean Log-transformed Reading Time for Each Region by L1 and L2 Participants.
4.2.1. Target Region RT (Word 4)
Two separate linear mixed random effects models were run to analyze the L1 and L2 groups’ RT on the target region. Dependent variables were log-transformed RT. The two models included Type (2 levels: Separable Verb vs. Phrase) and Grammar (Grammatical vs. Ungrammatical) as fixed effects with by-participants and by-items random intercepts. The model also included an interaction between Type and Grammar. The model output for the L1 data in Table 6 did not yield any main effects or interactions.
Table 6.
L1 Target Region RT Analysis.
The L2 RT model output in Table 7 revealed no main effect, but there was a significant interaction between Type and Grammar (Estimate = 0.11, SE = 0.05, t = 2.72, p < 0.03). The interaction was explored using the emmeans() function. The pairwise comparison shows that the L2 group slowed down significantly on the incorrectly verb-modified items relative to the grammatical items in the VP condition (Grammatical VP–Ungrammatical VP: Estimate = −0.09, SE = 0.04, t = −2.71, p < 0.05). In contrast, no difference in the RT was obtained between the grammatical and ungrammatical items in the separable verb condition. In the target region, the L1 group did not show any sensitivity to grammaticality, whereas the L2 group was sensitive to the incorrect aspect marking only for the phrase items.
Table 7.
L2 Target Region RT Analysis.
4.2.2. Spillover Region 1 (Word 5)
The model output for the L1 RT in the spillover region is given in Table 8. The model yielded a significant main effect of Grammar (Estimate = 0.09, SE = 0.03, t = 0.17, p < 0.01), suggesting that the L1 group slowed down for the ungrammatical items relative to the grammatical items in the spillover region. There was a significant interaction between Type and Grammar (Estimate = 0.12, SE = 0.04, t = 2.82, p < 0.01). The interaction of Type and Grammar was explored using the emmeans() function. The posthoc pairwise comparison revealed that the L1 speakers slowed down on the ungrammatical items relative to the grammatical items in both separable verbs (Estimate = −0.09, SE = 0.03, t = −2.82, p < 0.03) and non-lexical VPs (Estimate = −0.21, SE = 0.03, t = −6.74, p < 0.0001). The pairwise comparison also revealed no difference in RT between grammatical VP and ungrammatical separable verb items. This suggests that incorrect verb modification of separable verbs did not cause much interruption to the L1 readers to the level that it could be processed as fast as grammatically verb-modified non-lexical VPs. Despite the interaction of Type and Grammar, the main effect of grammaticality indicates that L1 speakers could still analyze the syntactic structure of separable verbs and apply the relevant grammatical rule during the online task. The L2 RT model output in Table 9 did not yield any main effects or interactions.
Table 8.
L1 Spillover Region RT Analysis.
Table 9.
L2 Spill-over Region RT Analysis.
4.2.3. Effects of Proficiency on L2 RT
It was examined whether the proficiency level modulates the L2 speakers’ sensitivity to the grammatical errors in the phrases and compounds during the online task. Since there was a significant result only in the target region for the L2 speakers, the analysis was only conducted for the L2 learners’ RT in the target region. A linear mixed effects model was run using the lmer() function in R. The model included Condition (2 levels: Separable Verbs vs. Phrases); Grammar (2 levels: Grammatical vs. Ungrammatical); and Proficiency (a continuous variable) as fixed effects. The continuous variables were centered using the scale() function. A three-way interaction of Type*Grammar*Proficiency was introduced in the model. The model also included by-participants and by-items random intercepts. The model output is given in Table 10.
Table 10.
L2 Target Region Analysis with Proficiency.
The model yielded a main effect of Proficiency, indicating faster reading with increased proficiency (Estimate = −0.13, SE = 0.04, t = −3.08, p < 0.005.). However, the effect of Proficiency did not interact with any other variables in the model. There was a significant interaction between Type and Grammar (Estimate = 0.12, SE = 0.05, t = 2.33, p < 0.03). A post hoc pairwise comparison was conducted using the emmeans() function. The pairwise comparison revealed that L2 speakers slowed down on the ungrammatical items relative to the grammatical items in the phrase condition (Grammatical Phrase–Ungrammatical Phrase: Estimate = −0.12, SE = 0.04, t = 2.96, p < 0.05). In the separable verb condition, there was no difference in the RT between the grammatical and ungrammatical items. The model output indicates that L2 speakers may not be able to enhance the ability to analyze the syntactic structure of the separable verbs during real-time processing even with an increased proficiency level.
5. Discussion
This section discusses the results of the AJT and SPRT experiments, focusing on whether L2 speakers can process the syntactic analysis of separable verbs during real-time comprehension. In the experiments, the ability to analyze the syntactic structure of separable verbs and non-lexical VPs was determined by whether L2 speakers could demonstrate native-like sensitivity to verb modification violations on these constructions. The main results are summarized as follows:
- –
- In the offline judgment task, both L1 and L2 speakers found the ungrammatical verb modification on separable verbs and non-lexical VPs less acceptable than the grammatical verb modification condition. Though not completely target-like, proficient L2 speakers in the present study have developed target-like syntactic awareness of separable verbs and non-lexical VPs.
- –
- In the online task, the main effect of grammaticality in the L1 RT data indicates that L1 speakers could analyze the syntactic structure of separable verbs and non-lexical VPs by showing sensitivity to incorrect verb modification on both constructions. Yet, the interaction of grammaticality and compound type in the L1 RT data indicates that the lexical status of separable verbs elicited reduced sensitivity to incorrect verb modification on separable verbs relative to non-lexical verb phrases. Overall, L1 RT data suggests that L1 speakers can analyze the syntactic structure of separable verbs while activating their lexical representations during real-time processing.
- –
- In the L2 RT data, no main effect was found but an interaction of grammaticality and compound type. The interaction indicates that L2 speakers could analyze the syntactic structure of non-lexical VPs but not for separable verbs, as they failed to show sensitivity to incorrect aspect marking on the latter (e.g., xizao ‘shower’, *xizao-guo shower-EXP). The results of the L2 RT data suggest that L2 speakers could not build syntactic representations of separable verbs during real-time processing due to overreliance on their lexical representations.
The findings of the present study highlight that proficient L2 speakers may have persistent difficulty constructing detailed grammatical representations of separable verbs during online processing despite having reached a relatively high level of proficiency. The previous studies on L2 acquisition of separable verbs using offline tasks demonstrated the potential for L2 speakers to develop enhanced explicit knowledge of their syntactic separability with increased proficiency (e.g., Shen 2019; Gao et al. 2022). In a similar vein, the results of the L2 offline judgment in the present study found that, though not completely native-like, proficient L2 speakers can, at least display native-like patterns in terms of explicit knowledge by demonstrating the ability to identify the syntactic structure of separable verbs in the untimed AJT. The L2 offline judgments indicate that proficient Korean L2 speakers of Chinese can to a certain degree, attain the explicit grammatical knowledge associated with the syntactic status of separable verbs despite the absence of the equivalent grammar in their L1. Considering that all the L2 participants were undergraduate or graduate students enrolled in degree programs at Chinese universities, the native-like pattern of the L2 offline judgment can be attributed to their extensive experience with language learning and immersion in the authentic L2 environment.
Nonetheless, insights from L2 online performance suggest that explicit knowledge, which is crucial for the syntactic analysis of separable verbs, might not be optimally utilized during online processing. This could potentially stem from L2 speakers’ inclination to heavily depend on non-structural information or lexical storage over structural information, as posited by the Shallow Structure Hypothesis (SSH) (Clahsen and Felser 2006a, 2006b; Clahsen and Felser 2018). Separable verbs are understood as involving an interface of lexicon and syntax. While they are stored as words in the lexicon, their internal structure is syntactically analyzed into a VP, which has a hierarchically deeper structure than a lexical constituent in syntax (e.g., [V xizao] vs. [VP [V’ [V xi] [NP [N’ [N zao]]]]). However, the lack of sensitivity to the syntactic structure of separable verbs in the L2 online processing implies that L2 speakers may overly depend on the lexical storage, thereby failing to access the relevant syntactic information during real-time reading comprehension. Moreover, given that separable verbs denote a unified semantic concept by expressing a generic or institutionalized activity due to noun incorporation (Luo 2022; Wang 2022), L2 speakers might lean towards viewing separable verbs as singular linguistic entities rather than constructions available for syntactic analysis due to their heavy dependence on lexical-semantic information during online processing. Consistent with the previous studies that have demonstrated a qualitative difference in L1 and L2 processing of morphological structure (e.g., Silva and Clahsen 2008; Clahsen and Neubauer 2010; Clahsen et al. 2013; Kirkici and Clahsen 2013), the present shows that even proficient L2 Korean speakers of Chinese have persistent difficulties building detailed hierarchical representations of separable verbs despite the native-like patterning in the corresponding explicit knowledge, possibly due to heavy reliance on their lexical representations stored in the mental lexicon or semantic information referring to a single unitary concept.
Another notable finding from the present study is that the L1–L2 similarities were found in real-time processing: (1) L2 speakers were able to process the syntactic structure of non-lexical VPs in a native-like manner; (2) both L1 and L2 online processing patterns were affected by lexical representations of separable verbs. Firstly, the native-like processing of non-lexical VPs in L2 indicates that L2 speakers can build structural representations of a simple dimorphemic VO construction, which is not stored in the lexicon. However, the same level of structural processing does not appear to be employed by L2 speakers for separable verbs, which involve an interface of lexicon and syntax. The native-like processing of non-lexical VPs indicates that detailed structural processing is not completely absent in L2 but may be less operative when there is a higher demand for integrating structural information with different types of non-structural information.
Moreover, the interaction of grammaticality and construction type in the L1 and L2 online processing indicates that both L1 and L2 speakers tend to activate lexical representations of separable verbs during real-time sentence comprehension. Although the effect of lexicality on separable verbs was not obtained for either L1 or L2 speakers in the offline judgment task, it was found to affect both L1 and L2 online processing patterns. Though different in degrees, L1 and L2 speakers demonstrated reduced sensitivity to aspect marking violation on separable verbs (e.g., *xizao-guo shower-EXP) relative to that on non-lexical VPs (e.g., *jia-shui-guo add-water-EXP) in their online performances. Unlike in the offline AJT, which focuses on grammatical well-formedness, participants read sentences to respond to comprehension questions in the SPRT. It can be speculated that the comprehension-based nature of the SPRT elicited both L1 and L2 speakers to show a higher level of sensitivity to the semantic information of a word or phrase presented in each region. As a result, the lexical representations of separable verbs might have provided some advantages in identifying the meaning for L1 and L2 speakers via direct access to the mental lexicon during real-time comprehension. However, while activating the lexical representations of separable verbs, L1 speakers could still correctly analyze their syntactic structure, as indicated by the main effect of grammaticality in the L1 RT data. The L1 processing of separable verbs indicates that L1 speakers can efficiently access syntactic and lexical-semantic information during real-time processing. In contrast, it appears that the lexical-semantic information is prioritized over the structural information in L2 processing. Hence, L2 speakers could not process the syntactic structure of separable verbs as efficiently as native speakers by failing to show sensitivity to incorrect verb modification applied to them.
6. Conclusions and Directions for Future Research
The results of the present study are in line with the SSH, which proposes that L2 speakers, even at a highly proficient level, underutilize structural information relative to non-structural information during real-time processing (Clahsen and Felser 2018). Specifically, when processing constructions involving an interface of lexicon and syntax, L2 speakers tend to rely heavily on lexical representations and fail to process structural information to the level of native-like detail. When there is a demand to process both structural and non-structural information, L2 speakers rely more on the latter and, hence, build less detailed structural representations than L1 speakers.
In future research, it is necessary to examine whether the native-like detailed structural processing of separable verbs can be mediated by the age of acquisition. Though highly proficient and immersed in the target language environment, all the L2 participants in the present study were late bilingual speakers, who started learning the language past the so-called critical period. Under the declarative/procedural (DP) model (Ullman 2001, 2014), procedural memory subserves grammatical processing, whereas declarative memory pertains to stored knowledge of words, idioms, or grammatical rules explicitly learned as facts. It is suggested that procedural memory is more likely to be affected by the maturation process than declarative memory, which continues to develop until early adulthood. Following the DP model, the L1–L2 difference in structural processing is often attributed to limited access to procedural memory and active involvement of declarative memory by adult L2 speakers, whose onset of acquisition mostly takes place later than the adolescent period. Given this, follow-up research needs to test early bilingual L2 Chinese speakers to verify whether the age of acquisition is closely associated with the development of a native-like ability to integrate structural information with non-structural information during the real-time processing of morphologically complex words.
Funding
This research received no external funding.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and approved by the Institutional Review Board of the University of Illinois, Urbana Champaign (Protocol Code: 20436, 12/9/2019).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
All datasets are available at https://doi.org/10.6084/m9.figshare.22783592.
Conflicts of Interest
The author declares no conflict of interest.
References
- Ahn, Hyunah. 2021. From Interlanguage grammar to target grammar in L2 processing of definiteness as uniqueness. Second Language Research 37: 91–119. [Google Scholar] [CrossRef]
- Badan, Linda. 2013. Verb-object constructions in Mandarin: A comparison with Ewe. Linguistic Review 30: 373–422. [Google Scholar] [CrossRef][Green Version]
- Barr, Dale, Roger Levy, Christoph Scheepers, and Harry Tily. 2013. Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language 68: 255–78. [Google Scholar] [CrossRef]
- Bates, Douglas, Martin Machler, and Benjamin Bolker. 2014. lme4: Linear mixed-effects models using Eigen and S4. Journal of Statistical Software 67: 1–48. [Google Scholar]
- Bresnan, Joan, and Sam A. Mchombo. 1995. The lexical integrity principle: Evidence from Bantu. Natural Language and Linguistic Theory 13: 181–252. [Google Scholar] [CrossRef]
- Cao, Dezhi. 2020. 日韩留学生使用离合词的偏误分析及教学对策 [Error analysis and teaching strategy for separable verb usages by Japanese and Korean learners]. 延边教育学院学报 [Journal of Yanbian Institute of Education] 34: 52–55. [Google Scholar]
- Chao, Yuen Ren. 1968. A Grammar of Spoken Chinese. Berkeley: University of California Press. [Google Scholar]
- Cheng, Lisa Lai-Shen, and Rint Sybesma. 1998. On Dummy Objects and the Transitivity of Run. Linguistics in the Netherlands 15: 81–93. [Google Scholar] [CrossRef]
- Chi, Telee. 1985. A Lexical Analysis of Verb-Noun Compounds in Mandarin Chinese. Taipei: Crane. [Google Scholar]
- Christensen, Rune Haubo Bojesen. 2022. Ordinal—Regression Models for Ordinal Data. R Package Version 2022-11-16. Available online: http://www.cran.r-project.org/package=ordinal/ (accessed on 4 December 2022).
- Clahsen, Harlad, and Claudia Felser. 2006a. Grammatical processing in language learners. Applied Psycholinguistics 27: 3–42. [Google Scholar] [CrossRef]
- Clahsen, Harald, and Claudia Felser. 2006b. How native-like is non-native language processing? Trends in Cognitive Sciences 10: 564–70. [Google Scholar] [CrossRef]
- Clahsen, Harald, and Claudia Felser. 2018. Some note on the shallow structure hypothesis. Studies in Second Language Acquisition 40: 693–706. [Google Scholar] [CrossRef]
- Clahsen, Harald, and Kathleen Neubauer. 2010. Morphology, frequency, and the processing of derived words in native and non-native speakers. Lingua 120: 2627–37. [Google Scholar] [CrossRef]
- Clahsen, Haral, Loay Balkhair, John-Sebastian Schutter, and Ian Cunnings. 2013. The time course of morphological processing in a second language. Second Language Research 29: 7–31. [Google Scholar] [CrossRef]
- Clahsen, Harald, Sabrina Gerth, Vera Heyer, and Esther Schott. 2015. Morphology constrains native and non-native word formation in different ways: Evidence from plurals inside compounds. The Mental Lexicon 10: 53–87. [Google Scholar] [CrossRef][Green Version]
- Coughlin, Caitlin E., and Annie Tremblay. 2015. Morphological decomposition in native and non-native French speakers. Bilingualism 18: 524–42. [Google Scholar] [CrossRef]
- Di Sciullo, Anna Maria, and Edwin Williams. 1987. On the Definition of Word. Cambridge: MIT Press. [Google Scholar]
- Ellis, Rod. 2005. Measuring implicit and explicit knowledge of a second language: A psychometric study. Studies in Second Language Acquisition 27: 141–72. [Google Scholar] [CrossRef]
- Farhy, Yael, Joao Veríssimo, and Harald Clahsen. 2018. Do late bilinguals access pure morphology during word recognition? A masked-priming study on Hebrew as a second language. Bilingualism 21: 945–51. [Google Scholar] [CrossRef]
- Feldman, Laurie Beth, Aleksandar Kostic, Dana M. Basnight-Brown, Dusica Filipovic Durdevic, and Matthew John Pastizzo. 2010. Morphological facilitation for regular and irregular verb formations in native and non-native speakers: Little evidence for two distinct mechanisms. Bilingualism 13: 119–35. [Google Scholar] [CrossRef] [PubMed]
- Felser, Claudia, and Ian Cunnings. 2012. Processing reflexives in a second language: The timing of structural and discourse-level constraints. Applied Psycholinguistics 33: 571–603. [Google Scholar] [CrossRef]
- Foote, Rebecca. 2011. Integrated knowledge of agreement in early and late English–Spanish bilinguals. Applied Psycholinguistics 32: 187–220. [Google Scholar] [CrossRef]
- Foote, Rebecca. 2017. The storage and processing of morphologically complex words in L2 SPANISH. Studies in Second Language Acquisition 39: 735–67. [Google Scholar] [CrossRef]
- Gao, Zhe, Seth Wiener, and Brian MacWhinney. 2022. Acquisition of Chinese Verb Separation by Adult L2 Learners. Languages 7: 225. [Google Scholar] [CrossRef]
- Haskell, Todd R., Maryellen C. MacDonald, and Mark S. Seidenberg. 2003. Language learning and innateness: Some implications of Compounds Research. Cognitive Psychology 47: 119–63. [Google Scholar] [CrossRef] [PubMed]
- Her, One-Soon. 1997. Interaction and explanation: The case of variation in Chinese VO construction. Journal of Chinese Linguistics 25: 146–65. Available online: http://www.jstor.org/stable/23753984 (accessed on 4 December 2022).
- Heyer, Vera, and Harald Clahsen. 2015. Late bilinguals see a scan in scanner and in scandal: Dissecting formal overlap from morphological priming in the processing of derived words. Bilingualism 18: 543–50. [Google Scholar] [CrossRef]
- Huang, James. 1984. Phrase Structure, lexical integrity, and Chinese compounds. Journal of the Chinese Language Teachers Association 19: 53–78. [Google Scholar]
- Huang, James, Audrey Li, and Yafei Li. 2009. The Syntax of Chinese. Cambridge: Cambridge University Press. [Google Scholar]
- Ionin, Tania, and Silvina Montrul. 2023. Second Language Acquisition: Introducing Intervention Research. Cambridge: Cambridge University Press. [Google Scholar]
- Ionin, Tania, Sea Hee Choi, and Qiufen Liu. 2021. Knowledge of indefinite articles in L2-English: Online vs. offline performance. Second Language Research 37: 121–60. [Google Scholar] [CrossRef]
- Jacob, Gunnar, Vera Heyer, and Joao Veríssimo. 2018. Aiming at the same target: A masked priming study directly comparing derivation and inflection in the second language. International Journal of Bilingualism 22: 619–37. [Google Scholar] [CrossRef]
- Jiang, Nan. 2000. Lexical representation and development in a second language. Applied Linguistics 21: 47–77. [Google Scholar] [CrossRef]
- Jiang, Nan. 2002. Form-meaning mapping in vocabulary acquisition in a second language. Studies in Second Language Acquisition 24: 617–37. [Google Scholar] [CrossRef]
- Just, Marcel Adam, Patricia A. Carpenter, and Jacqueline D. Woolley. 1982. Paradigms and processes in reading comprehension. Journal of Experimental Psychology: General 111: 228–38. [Google Scholar] [CrossRef] [PubMed]
- Kiparsky, Paul. 1982. From cyclic phonology to lexical phonology. In The Structure of Phonological Representations. Edited by Harry van der Hulst and Norval Smith. Dordrecht: Foris, pp. 131–75. [Google Scholar]
- Kirkici, Bilal, and Harald Clahsen. 2013. Inflection and derivation in native and non-native language processing: Masked priming experiments on Turkish. Bilingualism 16: 776–91. [Google Scholar] [CrossRef]
- Lenth, Russell. 2020. Emmeans: Estimated Marginal Means, Aka Least-Squares Means, Aka Least-Squares Means. R Package, version 1.4.4. Vienna: R Core Team. [Google Scholar]
- Li, Charles, and Sandra Thompson. 1981. Mandarin Chinese: A Functional Reference Grammar. Berkeley: University of California Press. [Google Scholar]
- Lü, Wenhua. 2008. Explorations of Grammar of Teaching Chinese as a Foreign Language. Beijing: Beijing Language and Culture University Press. [Google Scholar]
- Luo, Qiongpeng. 2022. Bare nouns, incorporation, and event kinds in Mandarin Chinese. Journal of East Asian Linguistics 31: 221–63. [Google Scholar] [CrossRef]
- Marinis, Theodore, Leah Roberts, Claudia Felser, and Harald Clahsen. 2005. Gaps in Second Language Sentence Processing. Studies in Second Language Acquisition 27: 53–78. [Google Scholar] [CrossRef]
- Marsden, Emma, Sophie Thompson, and Luke Plonsky. 2018. A methodological synthesis of self-paced reading in second language research. Applied Psycholinguistics 39: 861–904. [Google Scholar] [CrossRef]
- Mithun, Marianne. 1984. The evolution of noun incorporation. Language 60: 847–94. [Google Scholar] [CrossRef]
- Packard, Jerome. 2000. The Morphology of Chinese. Cambridge: Cambridge University Press. [Google Scholar]
- Paradis, Michel. 2009. Declarative and Procedural Determinants of Second Languages (Studies in Bilingualism 40). Amsterdam: John Benjamins. [Google Scholar]
- Pliatsikas, Christos, and Theodoros Marinis. 2013. Processing of regular and irregular past tense morphology in highly proficient second language learners of English: A self-paced reading study. Applied Psycholinguistics 34: 943–70. [Google Scholar] [CrossRef]
- Segalowitz, Norman. 2003. Automaticity and Second Languages. In The Handbook of Second Language Acquisition. Edited by Catherine Doughty and Michael H. Long. Oxford: Blackwell, pp. 382–408. [Google Scholar]
- Shen, Helen H. 2019. Morphological awareness of separable words among Chinese L2 learners. Chinese as a Second Language Research 8: 167–95. [Google Scholar] [CrossRef]
- Siewierska, Anna, Jiajin Xu, and Richard Xiao. 2010. Bang-le yi ge da mang (offered a big helping hand): A corpus study of the splittable compounds in spoken and written Chinese. Language Sciences 32: 464–87. [Google Scholar] [CrossRef]
- Silva, Renita, and Harald Clahsen. 2008. Morphologically complex words in L1 and L2 processing: Evidence from masked priming experiments in English. Bilingualism 11: 245–60. [Google Scholar] [CrossRef]
- Song, Yoonsang, Youngah Do, Arthur L. Thompson, Eileen R. Waegemaekers, and Jongbong Lee. 2020. Second language users exhibit shallow morphological processing. Studies in Second Language Acquisition 42: 1121–36. [Google Scholar] [CrossRef]
- Ullman, Michael T. 2001. The neural basis of lexicon and grammar in first and second language: The declarative/procedural model. Bilingualism: Language and Cognition 4: 105–22. [Google Scholar] [CrossRef]
- Ullman, Michael T. 2014. The declarative/procedural model: A neurobiologically motivated theory of first and second language. In Theories in Second Language Acquisition: An Introduction. London: Routledge, pp. 135–58. [Google Scholar] [CrossRef]
- Wang, Haifeng. 2009. A study of the characteristics of the separated forms of Chinese separable verbs in difference genres. CNKI Applied Linguistics 3: 81–89. [Google Scholar]
- Wang, Jiatian. 2015. 韩国学生习得VO式离合词的偏误分析 [Analysis of errors in Korean learners’ acquisition of VO separable words]. 汉语文教学 [Sinogram Culture] 2015: 74–78. [Google Scholar]
- Wang, Yong. 2022. From syntax to morphology. Studies in Language 46: 872–900. [Google Scholar] [CrossRef]
- Wei, Hang, Julie E. Boland, Zhengguang G. Cai, Yuan Fang, and Min Wang. 2018. Lexicalized structural priming in second language online sentence comprehension. Second Language Research 34: 395–416. [Google Scholar] [CrossRef]
- Yang, Zhenglin. 2006. An analysis into intermediate Korean students’ acquisition of Chinese separable verb-object verbs. Journal of Kunming University of Science and Technology 6: 5–8. [Google Scholar]
- Zhang, Lei. 2018. 基于HSK动态语料库的动宾式离合词习得偏误分析 [Analysis of errors in acquisition of VO separable words based on HSK Dynamic Composition Corpus]. 语言文学学术研究 [Sinogram Culture] 2018: 60–63. [Google Scholar]
- Zhou, Shangzhi. 2011. 汉语常用离合词用法词典 [A Dictionary of the Usage of Common Chinese Separable Words]. Beijing 北京: Beijing Language and Culture University Press 北京语言大学出版社. [Google Scholar]
- Zhou, Lin, and Binxin Li. 2015. An empirical study on teaching separable words to learners of Chinese as a second language. Chinese Teaching in the World 29: 423–32. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).