A framework which provides such an interface, however, is the recently proposed
Meaning First model (
Guasti et al. 2023;
Sauerland and Alexiadou 2020). In this model, the combination of primitive thought concepts (including logical operators and maximally decomposed lexical/contentful concepts/meanings) into a so-called conceptual structure precedes externalization, which is understood as a mapping of this structure to an arrangement of morphemes (so-called compression). Note that the operation that combines concepts into more complex concepts is assumed to be binary like
Chomsky (
1995)’s Merge (
Sauerland and Alexiadou 2020, p. 3;
Sauerland et al. 2023, p. 1). Therefore, the conceptual structures it generates are hierarchical structures very similar to the hierarchical structures created by Merge in standard minimalism, the difference being that the latter contain linguistic elements as leaves that are interpreted in a distinct subsequent module, while the former contains meaningful thought concepts that are compressed into linguistic representations in a distinct subsequent module. This is particularly relevant in light of the critical role that hierarchy plays in human language (for recent assessments see e.g.,
Brennan and Hale 2019;
Greco et al. 2023).
14 Importantly, the hierarchical organization allows us to make reference to constituency, thereby at least in principle allowing us to incorporate much of the insights of minimalist syntactic work into the model. Exactly how to achieve this is beyond the scope of the present paper (for some suggestions see
Sauerland et al. 2023). For the purposes of this paper, we can roughly equate the conceptual structure with a hierarchical semantic representation, where each concept corresponds to an element in the semantics. In this model, meaning directly feeds the morphological component (39).
This architecture has some notable consequences. First, as meaning is computed prior to morphological realization, it is unaffected by any morphological processes. This will become important in
Section 4.1, where the negation concept is duplicated in the morphology without a concomitant duplication of its negative meaning. Second, the model leaves no room for a syntactic component in the canonical sense. That is, there is no (hierarchy-altering) movement, only linearization, and no Agree, but rather morphological duplication or base-generation of the relevant features/concepts in different positions.
Despite those differences, we contend that the broader empirical asymmetries between different parts of linguistic structures are best represented as hierarchical relations. Therefore, we take it that the semantic concepts corresponding to a verb and its arguments must stand in essentially the same structural relation to each other as the verb and its arguments in standard minimalist structures do. For this reason and for better comprehensibility, we can and will continue to use minimalist labels such as V, VP, NP, DP, and v. These should be understood as a shorthand for whichever combinations of primitive semantic concepts turn out to be behind them.
In what follows, we will investigate NC and NIs from a morphological perspective within the Meaning First model, where semantics is visible to morphology and morphology can be sensitive to semantics. In doing so, we hope to overcome the challenges a syntactic Agree account faces, which were pointed out in the previous section. To model the cross-linguistic phenomenon of NC, our proposal makes use of a morphological reduplication rule of the Neg operator in the context of an indefinite. Since predictions about acquisition are an integral part of Meaning First, we can readily map out strategies how each solution accounts for the NC errors children make in acquisition.
4.1. Negative Concord as Reduplication
We will develop our main idea by comparing strict NC grammars to non-NC grammars. An extension of our proposal to non-strict NC languages will be discussed in
Section 4.2. In (40), we show how single negation readings are expressed in the strict NC language Hungarian and the non-NC language Dutch. As shown in (40a), the negative marker
nem in Hungarian is obligatorily present with the NCI
semmit ‘nothing’ to express a single negation reading. Compare this to Dutch in (40b) where the NCI
niemand ‘nobody’ is sufficient to signal negation.
One way to capture concord phenomena, and specifically NC, is to reduplicate the
neg concept in the morphological component, so that more than one exponent realises negation.
15 We will attempt to develop such an approach in this section, while also attending to the problems the previous approaches had. In order to pursue a morphological account, it seems reasonable to pursue a theory where the semantic components
neg and
exists which make up negated indefinites are always in a local configuration independent of position or grammar. Moreover, at least negation should take scope above the propositional level to allow the split scope readings with a modal discussed in (20). One way to achieve this underlying semantic structure is by assuming that (negated) indefinites constitute choice functions, i.e., functions
f that take a property as an argument and return an individual of that set (
Kratzer 1998;
Reinhart 1997;
Winter 1997). A choice function
f must be existentially bound, often assumed to happen at the sentence level. Since negated indefinites scope under negation, we assume with
Reinhart (
1997) and
Winter (
1997) that choice functions do not have to be existentially bound at the top-most level of semantic structure. Thus, we propose in this section that the semantic input for NCIs/NIs is the structure in (41).
16| (41) | (Negated) indefinites as choice functions: |
| |  |
The structure in (41) provides us with a way to capture the split scope data. We follow
Abels and Martí (
2010) in assuming that (i) the interpretation of an indefinite is split up, so that the quantificational determiner scopes high but the NP restriction is interpreted low, i.e., a choice function analysis, and (ii) the low scope existential reading of the indefinite is a case of pseudo-scope (
Kratzer 1998), i.e., it is derived via binding of the world index of the restrictor NP by the modal. We briefly illustrate the analysis in (42) with example (20c) repeated from the previous section. Although the compositional details in our analysis diverge to some extent from
Abels and Martí (
2010),
17 the resulting meaning of (42a) is the same and thus directly taken from their work, see (42c). The sentence in (42a) is predicted to be true if and only if there is no choice function that in all relevant worlds
picks a tie from
that you wear in
. In other words, you don’t have to wear a tie in every world, i.e., the split scope reading of (42a).
| (42) | Split scope readings | |
| | a. | Du | musst | keine | Krawatte | anziehen. | (Penka 2007, p. 270) |
| | | you | must | n-indef | tie | wear | |
| | | ‘It is not required that you wear a tie.’ |
| | b. |  | (cf. Abels and Martí 2010, p. 440) |
| | c. | 〚(42a)〛 iff CF, you wear f(tie) in |
| | | (Abels and Martí 2010, p. 441) |
There is another benefit of the choice function analysis over the existential quantifier analysis worth discussing. As was discussed in the previous section, the Agree accounts cannot explain why NC is cross-linguistically restricted to indefinites. The account proposed in this section has at least some potential to provide an explanation. If it really is the property of high existential closure of a choice function that is responsible for reduplicating neg since it puts the existential in the vicinity of the negative operator, we predict that NC should not be possible with e.g., definite determiners since they are traditionally interpreted in their base position and not at the propositional level. Whether we predict NC with other types of quantifying determiners, however, relies on what is believed to be modeled with choice functions. One reason for why choice functions have been originally reserved for indefinites is the observation that only indefinites, but not other quantifiers, can scope out of islands. Under the assumption that QR obeys islands, exceptionally wide scope indefinites have received a choice function analysis which does not require movement. The fact that NC only occurs with indefinites can potentially be seen as another piece of evidence that a choice function analysis is specifically reserved for indefinites.
Let us now turn to the morphological realisation of the semantic structure proposed in (41). As mentioned at the beginning of this section, we propose that languages which display NCIs or NIs have a morphological rule that duplicates
neg in the local context of an existential (43a). This type of rule is essentially equivalent to the
enrichment rules proposed in
Müller’s (
2007) Distributed Morphology account of extended exponence. His enrichment rules, conceptualized as the complementary version of the more widely adopted
impoverishment rules (
Bonet 1991;
Noyer 1992), introduce an (additional token of a) feature F on a head H in the context of F (⌀⟶ [F] / [F]
), that is, they act as feature duplication rules. While enrichment rules operate on morphosyntactic features, our duplication rule must operate on the input that the morphological component receives from the semantic/conceptual component, i.e., it must operate on semantic elements/concepts. One consequence of the Meaning First architecture is that the open bracket ‘[’ in the contextual restriction indicates immediate scope. Thus, (43a) triggers the creation of
neg if
neg and an existential are structurally adjacent (cf.
Merchant 2015 on the locality of allomorphy triggers) such that
neg scopes over the existential. Another consequence of the Meaning First architecture is that duplication of
neg does not alter the semantics since the meaning of the structure has been computed prior to its transfer to morphology. As the inert semantic elements/concepts serve as the input to realisation by phonological exponents (much akin to Vocabulary Insertion in Distributed Morphology) they essentially adopt the role of the morphosyntactic features in standard realisational models of morphology. Thereby, the close resemblance bordering on identity between our duplication rule and enrichment rules is further emphasized. Moreover, our approach shows parallels with accounts of reduplication as actual doubling of a morphological constituent, such as e.g.,
Inkelas (
2005);
Inkelas and Zoll (
2005). In order to derive the difference between NC and non-NC grammars, we additionally postulate that the latter have an additional morphological rule which deletes
neg in the local context of an existential and
neg (43b). In light of the discussion of enrichment rules, it is evident how this deletion rule is basically identical to
impoverishment rules (
Bonet 1991;
Noyer 1992; see also
Keine and Müller 2022 for a recent overview) or
obliteration (
Arregi and Nevins 2007,
2012) in Distributed Morphology.
18| (43) | Compressor rules / morphological rules |
| | a. | neg-duplication: ⌀⟶neg / neg [ ∃ |
| | b. | neg-deletion: neg⟶⌀ / [ neg ∃ |
The following structures show the effect of such rules for each type of grammar. We indicate duplicates with
<neg> and deleted structure with

for clarity. Vocabulary insertion is straightforward in this system,
neg receives spell-out as the negative marker and
neg+
as the NCI/NI. Since non-NC grammars have an additional impoverishment rule before vocabulary insertion, the negative marker is never realised in the context of an existential. Note that the addition of the
<neg> duplicate does not lead to double negation readings, as
neg-duplication counter-feeds semantic interpretation. This follows intrinsically from the Meaning First architecture since the morphological component is only responsible for realising the underlying semantic structure, thus no morphological rule can affect the meaning of a sentence.
| (44) | a. | NC grammar:neg-duplication |
| | |  |
| | b. | Non-NC grammar:neg-duplication ≺ neg-deletion |
| | |  |
Before we move on to detailed derivations of the NC data, we have to address the distribution of the (negated) indefinite determiner. With nothing else being said, we predict determiners analysed by choice functions to be realised at the propositional level, away from their NP restrictors, contrary to fact. This follows from our assumption that the determiner constitutes the realisation of
. Fortunately, there are ways to influence the linearization of the determiner. Given that semantic structure feeds morpho-syntax, we can formulate a rule that makes reference to semantic dependencies such as the one between
and
f(NP) and which determines for each language whether the head and tail of a dependency are pronounced together, and if so, whether they are pronounced at the head or the tail of the dependency. We call this rule
bundling. For indefinites specifically, we propose that
is always linearized adjacent to
f(NP), as a result of bundling. Thus, there is a bundling rule for indefinites which enforces bundling at the tail of the dependency, as illustrated in (45), where an underscore indicates the previous position for clarity.
19| (45) | Bundling: |
| |  |
We are now in a position to discuss the crucial distinctions concerning NC grammars and non-NC grammars. We use Hungarian and Dutch as representatives of each category and provide the relevant vocabulary items in (46) and (47), i.e., the negative markers in (46a)/(47a), the negative indefinites in (46b)/(47b), and the positive indefinites in (46c)/(47c).
| (47) | VIs for non-NC grammar, Dutch |
| | a. | /niet/ ⇔ [neg] |
| | b. | /niets/, /niemand/ ⇔ [neg,∃] |
| | c. | /iets/, /iemand/ ⇔ [∃] |
| (47) | VIs for NC grammar, Hungarian |
| | a. | /nem/ ⇔ [neg] |
| | b. | /semmit/, /senki/ ⇔ [neg,∃] |
| | c. | /valamit/, /valaki/ ⇔ [∃] |
In (48) and (49), we show how single negation readings are derived; examples are repeated for convenience. The semantic input for each grammar is the same, compare (48b) and (49b). The local configuration of
neg and
triggers
neg-duplication. Since this rule exists in both grammars, it applies to the semantic input, see (48c) and (49c). Non-NC grammars additionally have a
neg-deletion rule and (49c) provides the right locality configuration,
neg-deletion applies in (49d). Finally, both grammars have a bundling rule which enforces choice function determiners to be linearized adjacent to the choice function, shown in (48d) and (49e), which eventually provide the input for vocabulary insertion.
| (48) | Single negation reading in NC grammar (Hungarian) | |
| | a. | Balázs | nem | látott | semmit. | (Giannakidou and Zeijlstra 2017, p. 7) |
| | | Balázs | not | saw | n-thing | |
| | | ‘Balázs didn’t see anything.’ |
| | b. | Step 0: input to morphology |
| | |  |
| | c. | Step 1: duplication |
| | |  |
| | d. | Step 2: bundling |
| | |  |
| (49) | Single negation reading in non-NC grammar (Dutch) | |
| | a. | Ik | heb | niemand | gezien. | (van der Auwera and Van Alsenoy 2018, p. 117) |
| | | I | have | n-person | seen | |
| | | ‘I haven’t seen anybody.’ |
| | b. | Step 0: input to morphology |
| | |  |
| | c. | Step 1: duplication |
| | |  |
| | d. | Step 2: deletion |
| | |  |
| | e. | Step 3: bundling |
| | |  |
In order to derive double negation readings, the semantic structure has to contain two
neg components. For non-NC grammars, this automatically leads to the spell out of two
neg components, matching the surface structure in (50a). The derivational steps are given in (50c) to (50e). In (50c),
neg-duplication applies due to the presence of the lower
neg operator. In (50d), this lower
neg operator is targeted by
neg-deletion. After bundling is applied, the output structure in (50e) predicts the realisation of the negative marker
niet in (50a).
| (50) | Double negation reading in non-NC grammar (Dutch) | |
| | a. | Ik | heb | niet | niets | gezegd. | (Giannakidou and Zeijlstra 2017, p. 8) |
| | | I | have | not | n-thing | said | |
| | | ‘I haven’t said nothing.’ (I have said something) |
| | b. | Step 0: input to morphology |
| | |  |
| | c. | Step 1: duplication |
| | |  |
| | d. | Step 2: deletion |
| | |  |
| | e. | Step 3: bundling |
| | |  |
The rationale so far allows for double negation readings in NC grammars, though with the negative marker spelled out twice. We will come back to this point at the end of this section.
Let us now discuss sentences with multiple NCIs. Sentences with more than one NCI receive single negation readings in NC grammars. In (52), we show how this surface structure is derived from an underlying semantic structure with only one
neg component. The key to capturing such structures is the assumption that morphological rules can iterate but always apply in an ordered block of rules, where each rule can only apply once and within the same DP, i.e., to the same indefinite. The iteration stops when the output structure is equal to the input structure, i.e., when none of the rules give rise to anymore changes. We visualize the rule block in (51). Given that negation may appear in a position other than the clause-initial one, a linearization algorithm will have to apply after the rule block (but before realization of concepts) which is capable of linearly reordering (certain) concepts thereby capturing the word order restrictions of a given language.
| (51) | Order of application of morphological rules |
| |  |
Since (52a) contains two indefinites, the semantic structure (52b) contains two choice functions. The duplicate created by
neg-duplication in (52c) forms a constituent with one of the choice function determiners, which is subsequently bundled with the choice function variable in (52d). This in turn creates a local configuration for
neg-duplication to apply again, this time in the context of the other choice function (52e), which initiates a second cycle of application of the rule block in (51). The constituent formed by the
neg duplicate and the other choice function determiner is bundled with the variable at the tail of the other dependency (52f). Any further iterations of (51) would not change the output structure, thus, the process is terminated.
| (52) | Multiple NCIs in NC grammar (Hungarian) | |
| | a. | Senki | nem | látott | semmit. | (Giannakidou and Zeijlstra 2017, p. 9) |
| | | n-person | not | saw | n-thing | |
| | | Noone said anything.’ |
| | b. | Step 0: input to morphology |
| | |  |
| | c. | Step 1: duplication |
| | |  |
| | d. | Step 2: bundling |
| | |  |
| | e. | Step 3: duplication |
| | |  |
| | f. | Step 4: bundling |
| | |  |
In non-NC grammars, each NCI introduces semantic negation. Hence, the sentence in (53a) receives a double negation reading. The semantic structure that derives this reading is given in (53b), which subsequently leads to neg-duplication (53c) for one of the choice function determiners, followed by neg-deletion (53d). The duplicate plus choice function determiner is bundled with the respective choice function variable in (53e). Since there is another local configuration that triggers neg-duplication to apply, the entire rule block applies again, this time with the other choice function determiner, see (53f)–(53h).
In contrast to (50a), no overt negative marker occurs in the surface structure in (52a), as both
neg operators are deleted before vocabulary insertion takes place. This crucially follows from the locality restrictions imposed by
neg-deletion. In (53d) and (53g), the
neg operator is local to an existential, thus can be targeted by
neg-deletion. In (50d), however, only the lower
neg operator is local enough to the existential to be targeted by
neg-deletion, resulting in the overt realisation of the negative marker.
| (53) | Multiple NIs in non-NC grammar (Dutch) | |
| | a. | Niemand | heeft | niets | gezegd. | (Giannakidou and Zeijlstra 2017, p. 8) |
| | | n-person | has | n-thing | said | |
| | | ‘Nobody has said nothing.’ (Everybody has said something) |
| | b. | Step 0: input to morphology |
| | |  |
| | c. | Step 1: duplication |
| | |  |
| | d. | Step 2: deletion |
| | |  |
| | e. | Step 3: bundling |
| | |  |
| | f. | Step 4: duplication |
| | |  |
| | g. | Step 5: deletion |
| | |  |
| | h. | Step 6: bundling |
| | |  |
It is not possible for (53a) to receive a single negation reading, due to the presence of
neg-deletion. We show the crucial derivation steps in (54). The semantic input for a single negation reading (54b) leads to duplication and deletion as shown in (54c). While subsequent bundling created a local configuration between
neg and the other choice function determiner in NC grammars (52e), it has no effect in non-NC grammars since
neg was deleted in a previous step, see (54d). Hence, no additional duplication is triggered which could potentially result in the surface structure in (53a). Instead, the output of (54) is:
Niemand heeft iets gezegd ‘Nobody said something’, after bundling
with
(thing) which produces a positive indefinite in object position.
20| (54) | No single negation reading for multiple NCIs in non-NC grammars |
| | a. | Intended output: Niemand heeft niets gezegd. |
| | b. | Step 0: input to morphology |
| | |  |
| | c. | Step 1 & 2: duplication, deletion |
| | |  |
| | d. | Step 3: bundling |
| | |  |
Now that we have derived the crucial contrasts between NC and non-NC grammars, we can finally turn to the availability of double negation readings in NC grammars.
Giannakidou and Zeijlstra (
2017, p. 8) report that many NC languages block double negation readings, while some allow it as a marked or less preferred alternative to a single negation reading, often with a special intonation contour and a dedicated information structure (see ex. (4) and Note 1, and also
de Swart 2010;
Déprez et al. 2015;
Espinal et al. 2015;
Fălăuş 2009;
Puskás 2012). Since we cannot do justice to the broad cross-linguistic variation in this area, we focus on the contrast in (55) and provide a solution within the reduplication account proposed in this section. The most intuitive way to trigger double negation readings in NC grammars is by producing the negative marker twice. As can be seen for the NC language BCS in (55a), this results in unacceptability. Interestingly, a NC language like Turkish is able to produce a double negation reading (55b) by making use of two morphologically distinct negative markers, the affixal
-mA and the negative auxiliary
deǧil.
| (55) | Double negation readings in NC grammars? | |
| | a. | * | Milan | ne | ne | vidi | ništa. | BCS |
| | | | Milan | not | not | sees | nothing | |
| | | | ‘Milan doesn’t see nothing.’ (Milan sees something) | |
| | b. | | Hiçbir şey | gör-me-müş | deǧil-di-m. | | | Turkish |
| | | | nothing | see-neg-prf | neg-pst-1sg | | | |
| | | | ‘It was not that I had not seen anything.’ | (Özdemir 2020 |
There is additional evidence that speaks in favour of attributing the lack of double negation readings to an OCP effect.
Fălăuş and Nicolae (
2016) observe that double negation readings are readily available in NC grammars in fragment answers to negative questions. They verified this observation for eight strict NC grammars, corroborating a previous study by
Espinal and Tubau (
2016) who made the same observation for non-strict NC languages (see also the Italian adult responses in
Moscati 2020 mentioned in
Section 2.1).
Fălăuş and Nicolae (
2016) illustrate the data with Romanian, a strict NC language, see (57). What these data reveal is that the OCP can be circumvented by ellipsis: If the two
neg concepts are elided before vocabulary insertion is taking place, no problem arises with the OCP and thus double negation readings are readily available.
| (57) | Double negation reading in fragment answers | (Fălăuş and Nicolae 2016, p. 586) |
| | A: | Cine | nu | a | venit? | Romanian |
| | | who | not | has | come | |
| | | ‘Who didn’t come?’ |
| | B: | Nimeni. | | | | |
| | | n-person | | | | |
| | | ‘Nobody.’ |
| | | Nobody came … You’re the first one here. |
| | | Nobody didn’t come … Everybody’s here. |
In this section, we have shown how the morphology of NCIs and NIs can be derived via the interaction of a reduplication and a deletion rule, thereby dispensing with the need for Upward and Multiple Agree. In contrast to the Agree accounts, this approach also provides a natural explanation for why negative markers obligatorily occur with NCIs in NC grammars. It is the negative marker that introduces semantic negation, thus its presence is required to derive a negative statement. There is no abstract negative operator (
Op) in this system which could take over this function. The only way to derive covert sentence negation is by a deletion rule, which targets the very same negative marker. This deletion rule is, as we propose, only operative in non-NC grammars. Moreover, the current account can readily explain why positive indefinites cannot co-occur with the negative marker in NC and non-NC languages. Since
neg-duplication applies before bundling, a
<neg> duplicate will be created as soon as the underlying semantic structure contains a negative operator scoping over an existential, ultimately turning the indefinite into a negative indefinite. In this sense, the morphological form of the indefinite is directly influenced by the presence of negation. Consequently, the absence of negation leads to positive indefinites, as no duplicates are created. Agree-based accounts, however, cannot explain why positive indefinites are blocked under sentence negation since the licensing of NCIs/NIs via Agree has no bearing on the occurrence of positive indefinites. Finally, as discussed earlier, the choice function analysis provides a new insight into why concord is tied to indefinite determiners cross-linguistically, and not for example definite determiners. For Agree approaches at least, there is nothing in these systems that prevents other types of determiners to come with a [
uNeg]- or [
nw]-feature.
22In the next section, we will discuss two extensions to the current approach. One is concerned with non-strict NC grammars, the other is devoted to capturing the patterns of English varieties.
4.2. Extensions of the Reduplication Approach
Non-strict NC grammars are like strict NC grammars in that they apply
neg-duplication and bundling to the exclusion of
neg-deletion. In order to account for the preverbal pattern of non-strict NC languages, we will make reference to allomorphy which we assume to operate under linear adjacency. In particular, we propose that non-strict NC languages display an additional zero allomorph for
neg which appears if
neg is linearized immediately following an existential. As this type of allomorphy is fairly uncontroversial (
Embick 2010) and easy to adjust across languages, we believe this approach is flexible enough to account for the considerable cross-linguistic variation and the general rarity of non-strict NC grammars (
Kahrel 1996;
van der Auwera and Van Alsenoy 2016). To illustrate our idea, we present the relevant minimal pairs for a non-strict NC grammar like Italian in (58). For post-verbal NCIs, Italian patterns with strict NC grammars like Hungarian, in that the negative marker has to be realised overtly (58a). Pre-verbal NCIs, however, lead to zero exponence of the negative marker like in non-NC grammars, see (58b) and (58c).
| (58) | Non-strict NC languages (Italian) | (Giannakidou and Zeijlstra 2017, pp. 9–11) |
| | a. | Non | ha | telefonato | nessuno. | | | |
| | | not | has | called | n-body | | | |
| | | ‘Nobody called.’ |
| | b. | Nessuno | | ha | telefonato. | | | |
| | | n-body | | has | called | | | |
| | | ‘Nobody called.’ |
| | c. | Nessuno | | ha | telefonato | a | nessuno. | |
| | | n-body | | has | called | to | n-body | |
| | | ‘Nobody has called anybody.’ |
We provide a representative set of vocabulary items (VIs) for a non-strict NC grammar like Italian in (59). Non-strict NC languages display a zero allomorph of
neg in the context of an indefinite (59a). This allomorphy operates on linear adjacency, which explains why the negative marker is overtly exponend only in (58a), but not in (58b) and (58c) where it is adjacent to the indefinite argument.
23 Note that the contextual restrictions on vocabulary items do not necessarily indicate scope (in contrast to
neg-duplication and
neg-deletion) since linearization of concepts applies before vocabulary insertion takes place. Hence, a scopal configuration can be made opaque by whatever is written into the linearization rules of the individual grammar. Thus, the entry in (59a) does not indicate that the existential takes scope above negation but rather that the existential is linearized before negation (which in such cases is not pronounced).
| (59) | VIs for non-strict NC grammar, Italian |
| | a. | /⌀/ ⇔ [neg] / ∃ __ |
| | b. | /non/ ⇔ [neg] |
| | c. | /nessuno/ ⇔ [neg,∃] |
Let us now turn to the English patterns. As was discussed in the previous sections, English (varieties) display NC utterances and non-NC utterances in free variation (
Blanchette 2015;
Robinson and Thoms 2021;
Tubau 2016). Some corpus examples from UK-based varieties of English are given in (60). Examples (60a) and (60d) are from the same variety and show the variation very clearly. Example (60e) shows a non-NC sentence shortly followed by an NC sentence. Utterances containing NCIs receive single negation and double negation readings, as is e.g., documented for Appalachian English by
Blanchette (
2015, p. 18).
| (60) | NC and non-NC sentences in UK-based varieties of English (Tubau 2016) | |
| | a. | But he had no music | (Outer Hebrides) |
| | b. | Well you got nothing | (Nottinghamshire, Midlands) |
| | c. | And beyond that nobody couldn’t go | (Glamorgan, Wales) |
| | d. | I didn’t say nothing | (Outer Hebrides) |
| | e. | Mi father had no work at all, and couldn’t get a job nowhere | (Lancashire, North) |
Given that both NC and non-NC variants exist, there seems to be enough evidence for learners to postulate a
neg-duplication and a
neg-deletion rule. Yet the system is less restricted than a non-NC grammar. We therefore propose that English varieties can be derived within the current system by a partial order of rules. An overview of the typology is shown in (61), repeating the rules and their orders that make up NC and non-NC grammars from the previous section, and adding the partial order for English varieties.
| (61) | Rule orders |
| | a. | NC grammar: neg-duplication ≺ bundling |
| | b. | non-NC grammar: neg-duplication ≺ neg-deletion ≺ bundling |
| | c. | English varieties: { neg-duplication, neg-deletion } ≺ bundling |
The variation observed in English varieties is the result of the availability of two orders, one being
neg-duplication ≺
neg-deletion ≺
bundling (the order for non-NC grammars) and the other being
neg-deletion ≺
neg-duplication ≺
bundling. The former derives utterances like (60a)–(60b) and double negation readings for (60c)–(60d), see the previous section for detailed derivations. The latter derives single negation readings for (60c)–(60d), in effect deriving the NC variants in English dialects. In (62), we illustrate how this data point can be derived based on the example in (60d). Given that we want to derive a single negation reading, only one
neg operator is present in the underlying semantic structure (62b). The first rule in the rule block is
neg-deletion. Note, however, that the context for
neg-deletion to apply is not given.
24 As is specified in (43b), this rule only applies in the presence of another
neg and an existential. Thus, we move on to the next rule which is
neg-duplication, see (62d). This creates a
neg duplicate, which will eventually be linearized together with the indefinite at the base position of the argument (62e). The output of the underlying structure corresponds to a sentence involving NC.
| (62) | Single negation reading of NC sentence in English dialect |
| | a. | I didn’t say nothing. |
| | b. | Step 0: input to morphology |
| | |  |
| | c. | Step 1: deletion (does not apply) |
| | |  |
| | d. | Step 2: duplication |
| | |  |
| | e. | Step 3: bundling |
| | |  |
With a minimal change in the order of application, we have now managed to extend our system of rule interaction to a more permissive pattern of NC that can be found in English varieties. The fact that
neg-deletion and
neg-duplication can apply in either order leads to a language that allows for more variation, where NIs on their own as well as NCIs can be found, and sentences with NCIs trigger single and double negation readings. Note that we have only discussed English varieties so far.
Blanchette and Lukyanenko (
2019a);
Blanchette (
2015,
2017);
Robinson (
2022);
Robinson and Thoms (
2021) argue that Standard English behaves just like the English varieties, but the NC variants, that is the output in (62e), are socially stigmatized. The difference between Standard English and English dialects is derived in our system by a strict order vs. a partial order of morphological operations.
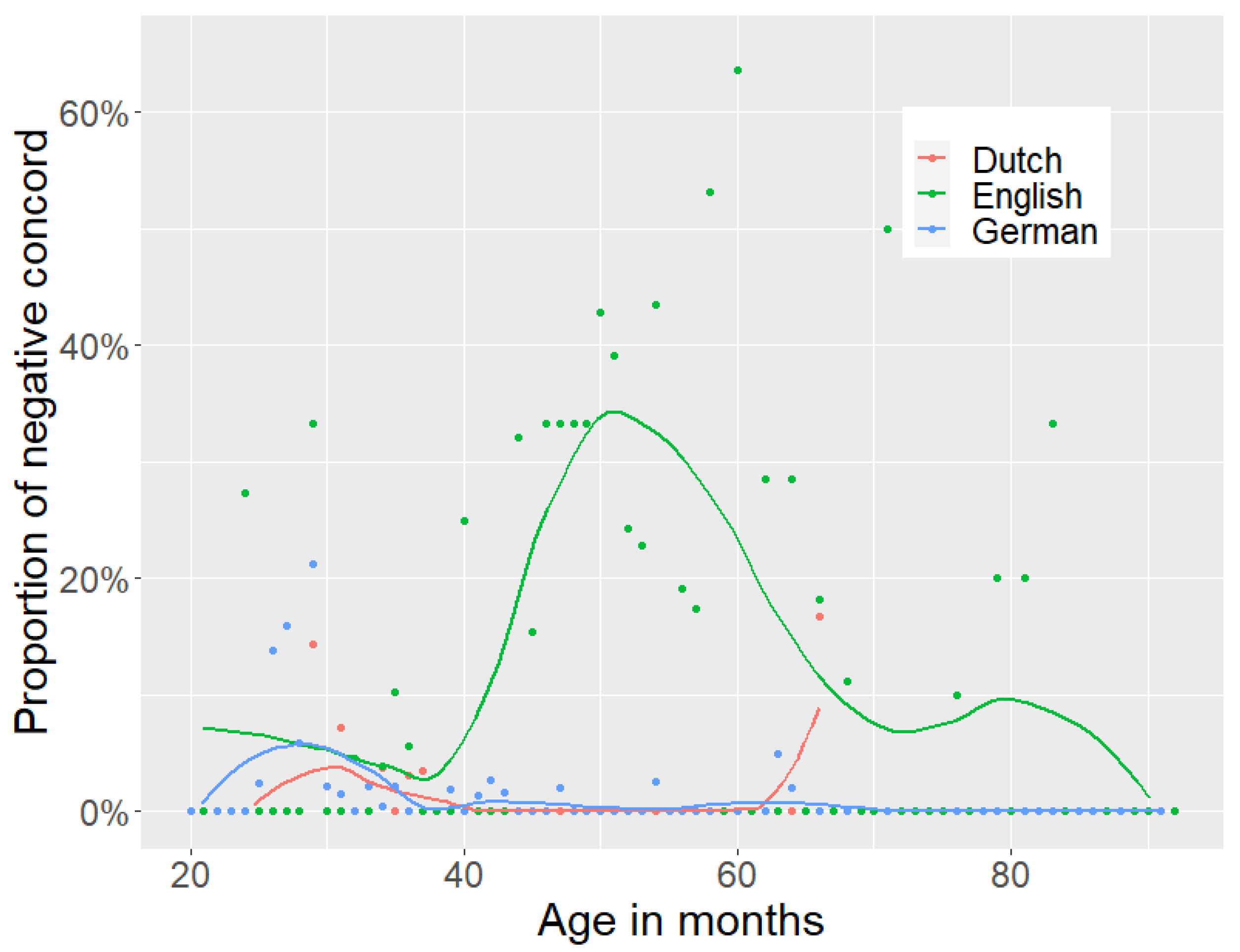
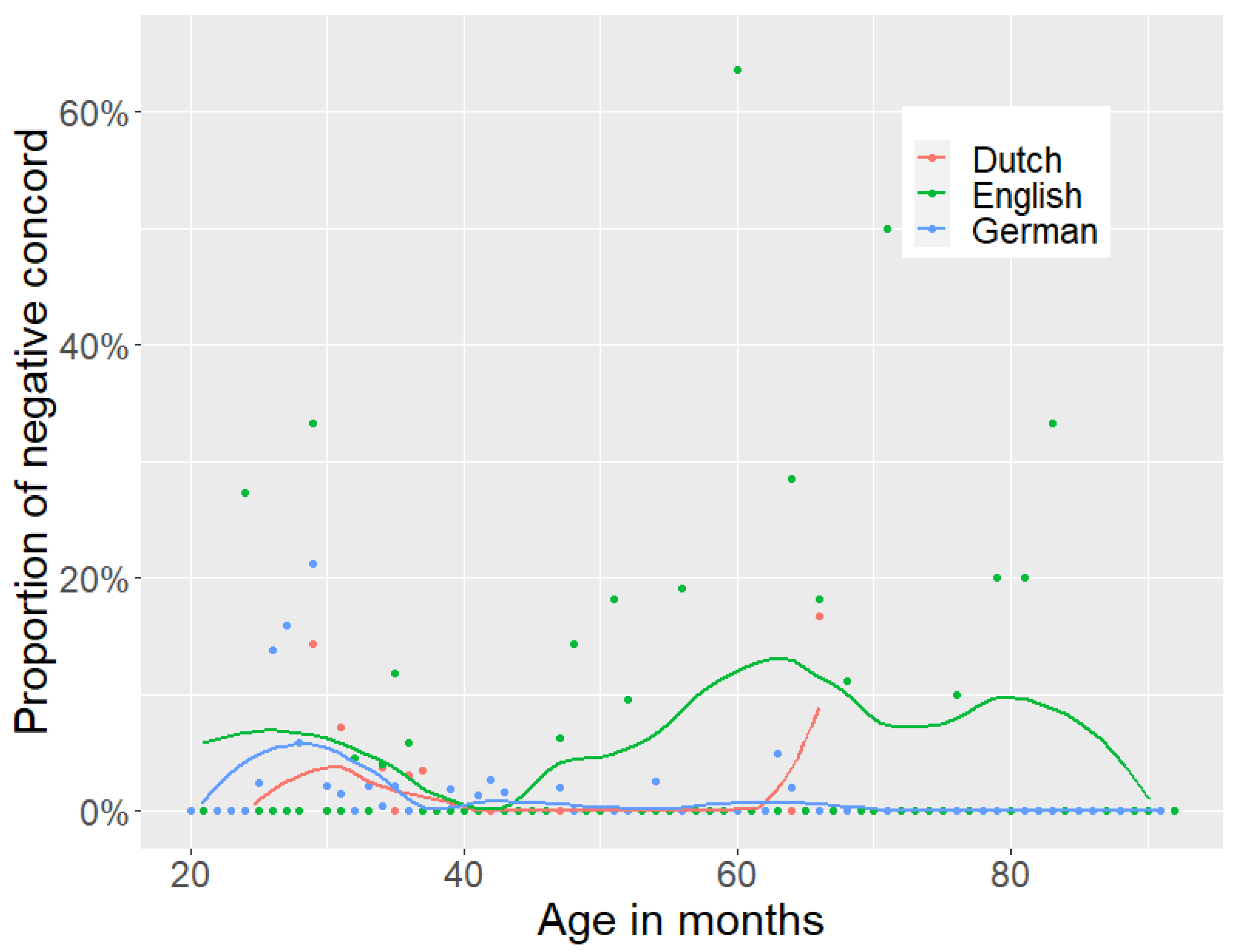
4.3. Children’s Production of Negative Concord
Finally, let us address the NC-type errors children make when acquiring non-NC languages like German, English, and Dutch. The Meaning First model takes commission errors made by children during acquisition as evidence for the underlying conceptual structure (
Guasti et al. 2023). Moreover, children are assumed to prefer a one-to-one correspondence with regard to the realisation of concepts, that is children are predicted to prefer the expression of each underlying semantic component overtly. While NC is a phenomenon that also introduces redundancy, specifically non-NC grammars additionally require children to learn
compression, that is they must learn to not overtly realise the
neg operator. Hence, we expect children to initially pronounce the
neg operator while acquiring non-NC grammars, resulting in the NC-type errors (11)–(13) reported in
Section 2.2, where the negative marker is produced together with the NI. We provide two further examples from the corpus study for illustration in (63) and (64).
| (63) | Kein | Teller | kann | s | net | sein. | German |
| | no | plate | can | it | not | be | |
| | ‘It can’t be a plate.’ | (Sebastian 5;04, Lieven and Stoll 2013) |
| (64) | Ik | zie | geen | andere | olifanten | niet | meer. | Dutch |
| | I | see | no | other | elephants | not | more | |
| | ‘I don’t see any other elephants anymore.’ | (Matthijs 3;01, Wijnen and Verrips 1998) |
The current system has a straightforward way to account for such commissive productions. Non-NC grammars display two rules which introduce opaqueness into the system. The
neg-duplication rule disrupts the one-to-one mapping and the
neg-deletion rule compresses a semantic operator. We provide the overview in (65).
| (65) | Compressor rules that disrupt one-to-one mapping |
| | a. | NC grammar: neg-duplication |
| | b. | non-NC grammar: neg-duplication ≺ neg-deletion |
| | c. | English varieties: { neg-duplication, neg-deletion } |
Let us start with the discussion of NC-type errors for German and Dutch, that is the data in (12), (13), (63), and (64). Recall from
Section 2.2 that children produce NC-type utterances alongside (target) non-NC utterances. A natural way to account for this pattern is to assume that in the acquisition of a non-NC grammar (65b), children do not apply
neg-deletion consistently. In such cases, the <
neg> duplicate is created but
neg itself is not deleted, leading to NC utterances (compare the derivations for NC grammars). If
neg-deletion is applied, a non-NC utterance is created. Following this rationale, we predict another type of error, namely when in children’s utterances neither
neg-deletion nor
neg-duplication is applied. Following the logic of our rule system, children would produce sentences containing sentential negation and a regular, that is, non-negatively marked indefinite taking narrow scope.
25 In the same context, the most natural way for adult speakers to express this meaning would be to use a NI. Indeed, we find such examples, shown in (66)–(68), where the child produces positive indefinites in the scope of sentence negation in the immediate context of the parent’s target-like production of a NI.
| (66) | CHI: | und | ich | wollte | xxx | nich(t) | eine | Pause | machen. | German |
| | | and | I | want | | not | a | pause | make | |
| | | ‘and I don’t want to take a break’ |
| | FAT: | nee, | da | machen | wir | keine | Pause. | | | |
| | | no | there | make | we | no | pause | | | |
| | | ‘No, we don’t take a break there.’ | Leo (3;08, Behrens 2006) |
| (67) | CHI: | die | haben | nich(t) | was | getut [: | getan][*]. | German |
| | | they | have | not | something | doed | done | |
| | | ‘they haven’t done anything.’ |
| | FAT: | was, | die | haben | dir | nichts | getan. | |
| | | what | they | have | you | nothing | done | |
| | | ‘what, they haven’t done anything to you.’ | Leo (2;06, Behrens 2006) |
| (68) | MOT: | omdat | je | geen | onderbroek | aan | had. | Dutch |
| | | because | you | no | pants | on | had | |
| | | ‘because you had no pants on’ |
| | CHI: | ja! | nee! | | | | | |
| | | yes | no | | | | | |
| | | ‘Yes! No!’ |
| | MOT: | doe | maar | gauw | een | onderbroek | aan. | |
| | | do | prt | quickly | a | pants | on | |
| | | ‘Put pants on quickly!’ |
| | CHI: | nee! | | | | | |
| | MOT: | ja. | | | | | | |
| | CHI: | wil | niet | een | onderbroek. | | | |
| | | want | not | a | pants | | | |
| | | ‘I don’t want pants on.’ | Abel (2;11, Wijnen and Verrips 1998) |
A search on this type of error in the corpora for German and Dutch investigated in
Section 2.2 revealed that they are overall more frequent than erroneous negative concord. We found 48 of these errors (which we call ‘decomposition errors’) in Dutch amounting to an overall error rate of 5.3%. For German, there were 67 of these errors which corresponds to an overall error rate of 2.5%.
26 Our account naturally derives the simultaneous presence of both types of errors, along with target-like productions.
We will now turn to the production errors from English children. As with the German and the Dutch data, NC-type utterances were produced alongside non-NC sentences, though the number of NC errors was much higher for English. Note that the children’s production data matches the output we derived from the partial order we proposed for English dialects, as is also shown in (65c). In the previous section, we hypothesized that the difference between English dialects and Standard English is derived by a partial vs. fixed order of
neg-duplication and
neg-deletion, where the fixed order can also be seen as a social stigma. A reasonable analysis of the NC-type utterances of children acquiring Standard English is therefore that children are not aware of the social stigma and thus apply the two operations in both orders. This can potentially explain why the number of NC errors is higher, or in any case different, for children acquiring English than for children acquiring Dutch and German. Such a developmental path would be consistent with grammar rules being acquired earlier than pragmatic or social-linguistic cues. More concretely, we can capture the first phase of errors, observed for all three languages in
Figure 2, as the acquisition of both rules and a fixed order of application such that
neg-duplication precedes
neg-deletion. The second phase in English then is due to the acquisition of NPIs, as discussed in
Hein et al. (
2023), but also to the fact that the English children reassess the order of rules to allow for partial ordering. This partial order enables NC and is only restricted (in Standard English) at later ages when children eventually master pragmatic factors such as the social stigma associated with NC.
One prediction that our account makes concerns possible errors made by children acquiring a (strict) NC language. Assuming that both rules, neg-duplication and neg-deletion, are learned from the input, those children have little to no reason to postulate a neg-deletion rule as their input negative sentences almost always include the negative marker that realizes the position of the original neg concept (cf. Note 24). In contrast, there is abundant evidence for the neg-duplication rule. Therefore, under the approach presented here they are expected to produce decomposition errors, either because they might not have acquired neg-duplication yet or because they fail to apply it consistently. In the absence of other sources for omission errors, however, they should not produce sentences that contain a NCI but lack the negation marker.
A further prediction is made about learning. Learners of a DN language like German or Dutch will have to acquire two rules (and their correct order of application) whereas learners of a NC language like Hungarian need to acquire only one rule (and no restriction on order of application). Therefore, NC languages should be in some sense easier to acquire than DN languages. Some support for this comes from
Maldonado and Culbertson (
2021) who show that an artificial language with NC is acquired faster and more reliably than a language with DN by adult learners. Languages that lack NC or NIs altogether and express their meaning by sentential negation and a regular indefinite (as mentioned in Note 25) should in turn be easier to acquire than NC languages as they involve no dedicated rule for the expression of negation. An indication that this learnability hierarchy between the three types of languages is correct comes from the typological study in
van der Auwera and Van Alsenoy (
2016). Based on a typologically balanced sample of 179 languages they show that 49.7% of them use a verbal negation marker plus a regular indefinite, 19% show negative concord and only 11.7% have NIs of the Dutch and German kind. If we accept that languages are more common across the world at least partly because they are easier to acquire than others,
van der Auwera and Van Alsenoy’s work corroborates our prediction. Despite these initial indications, a proper verification of these predictions requires further research. We leave this for future work here.






 ,
, 





























 for clarity. Vocabulary insertion is straightforward in this system, neg receives spell-out as the negative marker and neg+ as the NCI/NI. Since non-NC grammars have an additional impoverishment rule before vocabulary insertion, the negative marker is never realised in the context of an existential. Note that the addition of the <neg> duplicate does not lead to double negation readings, as neg-duplication counter-feeds semantic interpretation. This follows intrinsically from the Meaning First architecture since the morphological component is only responsible for realising the underlying semantic structure, thus no morphological rule can affect the meaning of a sentence.
for clarity. Vocabulary insertion is straightforward in this system, neg receives spell-out as the negative marker and neg+ as the NCI/NI. Since non-NC grammars have an additional impoverishment rule before vocabulary insertion, the negative marker is never realised in the context of an existential. Note that the addition of the <neg> duplicate does not lead to double negation readings, as neg-duplication counter-feeds semantic interpretation. This follows intrinsically from the Meaning First architecture since the morphological component is only responsible for realising the underlying semantic structure, thus no morphological rule can affect the meaning of a sentence.






































{kind=link}
{kind=link}