Abstract
This study investigates the relative weighting of morphosyntactic and visual cues in spoken-language comprehension, and whether this varies systematically within and between first (L1) and second language (L2) speakers of German. In two experiments, 45 L1 and 39 L2 speakers answered probe questions targeting the action direction of subject- and object-extracted relative clauses, which were presented either in isolation (Experiment 1) or alongside scene depictions either matching or mismatching the action direction expressed in the sentence (Experiment 2). We hypothesized that visual cues contribute to shaping meaning representations in sentence comprehension, and that sensitivity to morphosyntactic cues during interpretation may predict reliance on visual cues in both L1 and L2 comprehension. We found reliable effects of visual cues in both groups, and in response to both relative-clause types. Further, proxies of morphosyntactic sensitivity were associated with higher agent-identification accuracy, especially in response to object-extracted relative clauses presented with mismatching visual cues. Lastly, morphosyntactic sensitivity was a better predictor of accuracy rates than L1–L2 grouping in our dataset. The results extend the generalizability of models of visuo-linguistic integration across populations and experimental settings. Further, the observed sentence-comprehension differences can be explained in terms of individual cue-weighting patterns, and thus point to the crucial role of sensitivity to distinct cue types in accounting for thematic-role assignment success in L1 and L2 speakers alike.
Keywords:
sentence comprehension; second language; individual differences; case; visual cues; German 1. Introduction
To understand sentences, listeners or readers need to process morphosyntactic cues that encode, among other things, sentence constituents’ grammatical roles (e.g., subject, object), which helps in determining the direction of the action (i.e., ‘who does what to whom’, ). For instance, German makes extensive use of morphological case by marking pre-nominal determiners, adjectives, and nouns to indicate which grammatical function and possible thematic role (e.g., agent, patient) should be assigned to a noun phrase (NP).
Psycholinguistic research has shown that comprehenders may consider cues to interpretation from a variety of linguistic and non-linguistic information sources (). Here, we use the term ‘(morpho)syntactic cue’ to refer to interpretation cues that are encoded within the grammar. In contrast, ‘non-syntactic’ refers to all non-grammatical cues, which may be linguistic (e.g., semantic, pragmatic) or extra-linguistic in nature (e.g., visual context, world knowledge).
The relative weighting of different cue types, i.e., the extent to which comprehenders rely upon each type of cue to derive meaning, has been argued to differ between populations (e.g., , ; ) and individuals (e.g., ). Evidence from sentence comprehension in a second language (L2) suggests that non-grammatical information might be weighted more strongly in L2 than in the first language (L1). At the same time, morphosyntax might be relied on to a narrower extent, as captured by theoretical proposals such as the Shallow Structure Hypothesis (SSH, , ) and Cunnings’ Interference Hypothesis ().
There is evidence that even L1 speakers may interpret language in a way that is merely ‘good enough’ for the current situation. That is, meaning representations may sometimes be computed that are incompatible with the linguistic input, especially if the linguistic stimuli represent marked structures (such as object extractions or passives), and if information from non-grammatical cues supports the misinterpretation (). Evidence for the misinterpretation of noncanonical sentences has been interpreted as supporting dual-route models of sentence processing (), in which meaning can be derived either based on ‘deep’ grammatical parsing or on lexico-semantic and pragmatic information.
The core ideas of the dual-route approach to comprehension can be recast in terms of multiple-constraint models that allow for different weightings of information sources (see for a review), as has been argued by () for L2 processing. Conflicts between linguistic cues—where different types of co-occurring cues support different interpretations—have often been used to gauge the relative importance or weighting of each cue type for comprehension in L1 (; ) and L2 speakers (, ). However, the interaction of linguistic and visual cues has not systematically been modeled in terms of competition in L1 or L2 processing. Moreover, the role of individual differences in cue weighting for L2 sentence comprehension has rarely been focused on ().
In the present study, based on accounts of visuo-linguistic integration () and situated language processing (, ; ; ), we assume that both visual and morphosyntactic information contribute to shaping mental representations. This study aims to test the robustness of visual effects on comprehension outcomes, and whether such effects vary between L1 and L2 speakers. We further explore the possibility that morphosyntactic sensitivity (i.e., the ability to interpret morphosyntactic cues to derive meaning) might predict to what extent the same individual makes use of visual information in spoken sentence comprehension.
2. Background
While earlier, ‘syntax-first’ accounts of sentence comprehension have typically assumed that (morpho)syntactic information is temporally prioritized over non-syntactic cues (; ; ; ; ), constraint-based approaches have proposed that all types of linguistic cues are integrated as they become available to shape mental representations (e.g., ). In both accounts, however, all linguistic information is assumed to be eventually considered for interpretation. The present study remains agnostic as to the temporal precedence of one cue type over others and assumes that non-linguistic (visual) cues are considered alongside linguistic cues for sentence interpretation. In the following we review the evidence supporting the latter assumption. We then provide an overview of prior work on the processing of noncanonical sentences by L1 and L2 speakers, focusing on approaches which model conflicts between unambiguous syntax and other types of linguistic cues. Finally, we review evidence for the role of individual variability in cue-weighting patterns in L1 and L2 speakers.
2.1. The Role of Visual Cues in L1 Sentence Comprehension
Language has increasingly been considered as naturally multimodal (especially in the spoken modality, , ), i.e., as immersed in and constantly interacting with the visual environment (for reviews, see ; ). Early research on visuo-linguistic integration has typically used sentence–picture verification tasks to study speakers’ preferences during language-mediated visual attention (, ; ; ). Early models of visuo-linguistic integration, such as the Constituent Comparison Model (CMM, ) were put forth to account for response-time data from sentence–picture verification, and specifically for a facilitation in response to matching (i.e., ‘true’) relative to mismatching (i.e., ‘false’) trials (e.g., ). For instance, the CMM proposed that both the spoken and the visual components of the input are stored in terms of constituents and serially verified against one another. However, further research has painted a more complex picture.
For one, sentence–picture mismatches have been found to yield increases in verification accuracy. For example, in both experiments, () found that verification accuracy was higher for sentence–picture mismatches (vs. matches). This seems hard to reconcile with the CMM’s claim that encountering a mismatching feature triggers the sentence–picture comparison process to be re-initiated (), as it is unclear how re-initiating the process may benefit verification success. Further, it has been debated whether a verification mechanism underlies situated language processing with no verbatim comparisons to be performed. For instance, () found no match–mismatch differences in sentence–picture verification times when visual scenes and written sentences were presented successively. This suggested that the process of extracting comparable components from visual and linguistic input for serial comparison may have been associated with the specific task settings in previous research (e.g., simultaneous presentation) and might not generalize. () addressed this issue by measuring word-by-word reading times of SVO/OVS sentences preceded by depictions that either matched or mismatched the sentences’ thematic roles (e.g., SVO: Die Oma filmt soeben den Handelskaufmann, “TheNOM/ACC granny is filming theACC businessman right now”). Interestingly, however, the authors found selective slowdowns in reading times in mismatching trials, but no difference in total reading times (as in ). This showed not only that a verification process was indeed taking place, though unrequired by the task, but also that mismatch effects were time locked to the specific cue that caused the sentence to mismatch the depictions. The replication of Underwood et al.’s results further suggested that mismatch effects might only be measured with finer-grained temporal measures (vs. total response times), as such effects may be short lived. These results support the fundamental validity of claims from the CCM, contribute to extending its generalizability across tasks, and further point to the role of recency in modulating visual effects.
Visual cues have often been used as a means for measuring linguistic processing in the ‘visual-world’ eye-tracking paradigm (VWP), based on the assumption that oculomotor behavior and linguistic processing are coupled in a tightly time-locked fashion (e.g., ). The VWP uses eye movements to visual displays to infer the time course and dynamics of the processing of particular cues during, e.g., word recognition (e.g., ; ) and incremental sentence processing (e.g., , ; ; ). For example, () examined the role of morphosyntactic and semantic cues in anticipating upcoming referents in unambiguous SVO/OVS sentences in German (e.g., OVS: Den Hasen frißt gleich der Fuchs ‘TheACC hareACC will soon eat theNOM fox’). Participants were more likely to look at the fox when the first-mentioned NP ‘the hare’ was in the accusative (i.e., den Hasen, object role) in comparison to the nominative form (i.e., der Hase, subject role). This indicated that case-marking cues were integrated with lexical information and world knowledge to anticipate upcoming items.
Manipulating the visual input can also affect sentence processing (), indicating a complex interaction of cross-modal information in sentence comprehension (; , ). For example, () showed that eye movements while processing temporarily ambiguous instructions (e.g., 'Put the apple on the towel in the box') were contingent on the visual display—for example, whether one or two apples were presented visually. Subsequent studies have provided ample evidence to support the claim that the integration of linguistic and visual cues plays a crucial role in determining language processing in context. For instance, () monitored eye-movements to visual scenes while participants listened to simple SVO/OVS sentences in German with initial thematic-role ambiguities (e.g., Die Prinzessin malt gleich den Fechter ‘TheNOM/ACC princess will soon paint theACC fencer’). Crucially, the ‘princess’ character was depicted as though painting one character and being washed by another character. Participants were found to integrate morphosyntactic and visual cues incrementally to assign thematic roles at the verb, i.e., before the disambiguating case marker appeared on the second NP’s determiner. ’s () results provide strong evidence that visually encoded role relations are used to guide incremental interpretation of thematic roles in the face of syntactic ambiguity.
Yet, generalizing findings from studies with syntactically ambiguous stimuli to sentence processing at large may lead us to overestimate the role of non-syntactic cues for the processing of unambiguous structures (see, e.g., ; ; ; ). This is because ambiguous syntax allows for two or more interpretations, at least up to a point, such that participants may need to rely on non-syntactic cues to derive unambiguous mental representations. Thus, it may be hypothesized that non-syntactic cues are relied upon less if they are unnecessary for comprehension. Addressing this issue, () presented unambiguous structures, which allows for a more conservative estimation of the contribution of non-syntactic cues. Using a similar design to (), () recorded participants’ eye movements as they listened to unambiguous OVS structures in German and inspected depictions of three referents carrying out actions. The results showed that the depicted characters were attended to as soon as they were identified as potentially upcoming agents, extending the role for visual-scene information to the processing of syntactically unambiguous stimuli.
Building on and extending the CCM, the Coordinated Interplay Account (CIA, ) was proposed as a model of visuo-linguistic integration able to capture findings from recent research on situated language processing. The CIA defines the time course and boundary conditions of visuo-linguistic integration by describing a cyclic mechanism in two steps. First, as utterances are understood, comprehenders direct their visual attention towards the entities mentioned, to bind them to their referents and ground them in the real world. Second, the entities that are being visually attended to are integrated with spoken-language cues and contribute to the interpretation of the utterance.
The current study fundamentally assumes the premises of the CIA and seeks to extend the evidence supporting it. Different from previous research, we measured the effects of conflicting (instead of compatible) visual-scene information on post-sentence comprehension, using unambiguous (instead of ambiguous) spoken sentences and a linguistic task unrelated to sentence–picture congruence. Sentence–picture verification tasks do not seem to be well suited to investigating the weighting of visual cues in shaping mental representations, because the visual input must be considered to verify a match or a mismatch. Thus, visual information can be assumed to contribute as much as linguistic information towards verification outcomes. Similarly, the VWP is often uninformative about how conflicting visual and linguistic cues contribute to shaping mental representations. This is because the conflict being modeled is often induced by syntactic ambiguity rather than by competing cues from distinct sources, as the visual displays are typically compatible with one or more possible interpretations. Similar to (), we presented sentences with unambiguous thematic roles assigned to referents. We reasoned that, if visual influence on sentence processing is robust, effects of the visual context should emerge even when morphosyntactic cues suffice to derive fully specified meaning representations. Evidence for the integration of task-unrelated visual scenes on the comprehension of unambiguous sentences would strengthen claims regarding the robustness of visual influence on linguistic processes.
2.2. Syntactic and Non-Syntactic Cues in L1 vs. L2 Sentence Comprehension
The question as to the relative weighting of distinct linguistic cues has been the focus of the Competition Model (CM, ; ; ) and the dual-route approach (e.g., ). Similar to the present study, both of these accounts have typically inferred patterns of cue weightings by pitching cues of different types against one another, usually using agent-identification tasks.
The CM is a constraint-based model of language acquisition and processing. It presupposes that sentence interpretation is based on functional relations between form and meaning that are learnt probabilistically and can be implemented in a connectionist network. The model was put forth specifically to account for thematic-role-assignment preferences and introduced computable dimensions of linguistic cues. For instance, the dimension of cue reliability is computed as the proportion of times a cue leads to correct thematic-role assignment over its total occurrence. Crucially, cue dimensions are thought to take on language-specific values (or ‘weightings’), based on which types of cues are prioritized for sentence interpretation. For example, () tested L1 English, German and Italian sentence comprehension while manipulating word-order, agreement, animacy and stress cues. The results showed that speakers’ reliance on each type of cue varied systematically across languages. English L1 speakers used mainly word order, Italian L1 speakers relied mostly on agreement cues, and German L1 speakers attended to both agreement and animacy. The results were interpreted as evidence for cross-linguistic differences in cue weighting. Similarly, () manipulated case-marking and animacy cues to test thematic-role assignment using a speeded picture-choice task with L1 German and L1 Russian speakers. The reaction-time data showed that German but not Russian speakers relied on animacy cues, whilst Russian speakers relied on case marking to a larger extent than German speakers did. This suggests that case-marking cues are relied on more if they are more reliable for thematic-role assignment (as in Russian vs. German), although the inflectional paradigm is more complex in Russian (vs. German). Of relevance for our study is the authors’ finding that less reliance on the morphosyntactic cue was associated with stronger reliance on the non-syntactic cue.
The CM has been extended to L2 sentence interpretation with the hypothesis that L1 cue weightings are transferred to L2 comprehension, especially at low levels of proficiency. For instance, () found that L1 English speakers learning Russian relied on Russian case markings earlier than L1 English speakers learning German relied on German case markings. Instead, the learners of German tended to consider both animacy and case cues, even though the latter unambiguously indicated the sentence participants' thematic roles. These findings strongly suggest that differences in cue weighting might underlie L1 vs. L2 comprehension strategies. However, the experimental setup in CM studies often resulted in the presentation of ungrammatical stimuli alongside (semi-)grammatical ones (). This design choice has been sharply criticized as it may influence participants' response strategies, or be confusing to participants, thus limiting the conclusions to be drawn from these designs (e.g., ). Further, due to the large number of conditions resulting from the manipulation of several cues at once, and to relatively small sample sizes, CM studies have been systematically underpowered.
Effects of conflict between syntactic and non-syntactic cues on comprehension accuracy have also been the focus of dual-route approaches to sentence comprehension. Within this research, comprehenders have been found to mis-assign the thematic roles of noncanonical sentences (). Such misinterpretations are facilitated when non-syntactic cues, such as semantic plausibility, support the incorrect reading. Linear word-order heuristics underlie the ‘agent-before-patient’ preference, by which speakers overwhelmingly interpret Noun–Verb–Noun (NVN) structures as Subject–Verb–Object (SVO, e.g., ; ). For instance, () examined the comprehension of unambiguous English sentences containing subject and object clefts as a manipulation of linear word order (e.g., subject cleft: It was the dog that bit the man). Pragmatic plausibility was manipulated to convey plausible and implausible readings (e.g., implausible object cleft: It was the dog the man bit). The results showed that agent-identification accuracy was higher for subject clefts overall, and the effect of implausible (vs. plausible) relations was evident in participants responses to object (but not subject) clefts. To account for this and further evidence, comprehenders have been argued to construe meaning either based on the algorithmic parsing of syntactic cues, including case markings, or on heuristics relying on non-syntactic information such as plausibility and word-order cues (; ). Thus, especially in the face of noncanonical syntactic structures, comprehenders may endorse interpretations that are inconsistent with the linguistic input as computed algorithmically (; ). The core ideas of the dual-route approach can be remapped onto a multiple-constraint framework in which distinct cues are assumed to take on different weightings. The present study adopts an analogous rationale to the dual-route approach in that it models situations in which morphosyntactic and visual cues convey competing interpretations, but without assuming a dichotomous division of (algorithmic vs. shallow) routes to interpretation (e.g., ).
Relative to English, German has a more flexible word order due to the use of morphological case markings. Thus, German linear word order is not a reliable cue, because an NVN structure cannot always be mapped onto an SVO structure (as in English). Case markers may provide more reliable indicators of thematic roles, allowing for the argument phrases that carry them to be mapped onto a verb’s thematic grid. In particular, masculine case markings present unambiguous nominative vs. accusative cues (der vs. den) for grammatical role assignment, which are used for prediction () and may eliminate the 'agent-before-patient’ preference observed for German ambiguous NVN clauses (e.g., ). Yet, L1 German speakers have also been shown to have problems interpreting unambiguous, noncanonical sentences in agent-identification tasks (; ). For example, () found that agent-identification accuracy rates significantly decreased in response to OS (vs. SO) sentences, regardless of whether the thematic roles were reversible (e.g., ‘The father hugs the uncle’), biased (e.g., ‘The chef ruined the roast’), or non-reversible (e.g., ‘The chef cleaned the pan’). These results suggest a crucial role of linear word order (giving rise to the agent-before-patient preference) for agent-identification success. Therefore, in the present study, word order is taken to represent a further heuristic for German sentence interpretation, one that will only be beneficial for the interpretation of more frequent, canonical structures. We manipulated the conflict between linear word-order-based thematic role biases and case cues by manipulating the relative ordering of nominative- and accusative-marked nominals.
As regards L2 comprehension, the Shallow Structure Hypothesis (SSH, , ) applies a similar rationale to the dual-route approach to understanding L1–L2 differences in sentence processing. The SSH was proposed to account for evidence showing that L2 morphosyntactic processing tends to be less automatized compared to L1 processing (, ). It is supported by findings showing persisting vulnerability in the use of morphosyntactic cues in an L2, which may be compensated for by an increased reliance on non-syntactic relative to syntactic information (e.g., ; ; ; ; ; ; ; ; ; ; ). ’s () Interference Hypothesis is similar in spirit but holds that L1–L2 differences in cue weightings specifically affect memory retrieval during processing. Support for differential cue weighting in L1–L2 comprehension is provided by studies exploring the extent to which L2 speakers at different proficiency levels integrate information from morphosyntax and, e.g., prosody (), pragmatic consistency (), semantic plausibility (; ), discourse context (; ; ; ) or focus (). However, little is known about the impact of visual information on L2 sentence comprehension.
2.3. Individual Variability in L1 and L2 Sentence Comprehension
While most previous research on sentence comprehension has analyzed group-level performance, essentially treating individual variability as a source of noise, there has been growing recognition of the fact that individual variability may be an important source of information to consider as well. Individual differences in L1 sentence comprehension have often been considered in terms of working-memory capacity (e.g., ; ) and reading speed (e.g., ). Results from this line of research demonstrate that individual differences in cognitive capacity or linguistic abilities might determine sensitivity to different information sources in L1 comprehension. However, our understanding of how individual-difference variables affect L2 performance is still rather limited (see ; , for review and discussion). While previous L2 research has often investigated the role of L2 proficiency, language background, age of acquisition, or cognitive or affective variables, few studies have examined variables related to individual differences in specific linguistic abilities (e.g., ; ; ). For instance, () measured speakers’ ability to integrate semantic and syntactic information using a word-monitoring task. Interestingly, semantic and syntactic-integration abilities were found to correlate negatively in L2 speakers, suggesting that the larger the advantage experienced by each participant in the presence (vs. absence) of semantic cues, the smaller the advantage experienced in the presence (vs. absence) of syntactic cues, and vice versa. This result seems compatible with the dual-route and SSH claims regarding a potential trade-off in the reliance on syntactic vs. non-syntactic cues.
Indirect support for a dual-route approach to sentence comprehension, as well as novel insights into individual variability, were brought about by electrophysiological findings showing systematic differences in speakers’ brain responses to grammatical and semantic violations at the individual level. These were interpreted as reflecting individual tendencies towards reliance on algorithmic versus superficial processing in L1 speakers (; ). Further studies have shown that the brain signatures of L2 speakers may show an increased reliance on a shallow processing strategy, and that increasing grammatical sensitivity is associated with increasing overlap with L1 speakers’ brain signatures (; ; ). This evidence suggests that graded differences in sensitivity to different cues may underlie individual patterns of linguistic performance beyond categorical grouping.
Summarizing, individual variability has been observed in both L1 and L2 comprehension, both at the behavioral and the neurophysiological level, but the degree to which different kinds of individual-difference measures can predict L1 and L2 performance patterns is still far from clear.
3. Aims and Research Questions
This study focused on the interplay of visual-scene and morphosyntactic cues for thematic-role assignment of canonical and noncanonical sentences in German L1 and L2 comprehension. Specifically, we investigated the following research questions:
- How do (task-unrelated) visual cues influence thematic-role assignment in unambiguous sentences in L1 and L2 speakers?
- Does individual sensitivity to morphosyntactic cues predict speakers’ sensitivity to visual cues?
The aim of Research Question 1 is to provide evidence for the robustness of visual-scene effects (as predicted by the CIA) in a maximally conservative setting, and to extend previous evidence on situated language to L2 speakers. It also explores the claim that that (morpho)syntactic and non-syntactic cues are differently weighted in L1 and L2 comprehension (e.g., ; ; ), extending previous research by investigating the relative impact of visual context information on comprehension. Research Question 2 builds on the SSH/dual-route claim for a potential trade-off in the reliance on syntactic and non-syntactic cues, and focuses on the role of individual differences in L1 and L2 sentence comprehension. Considering that traditional group-level analyses may mask graded differences in cue weightings between individuals (see Section 2.3 above), we test (i) whether reliance on syntactic and visual information are negatively associated at the participant level, and (ii) whether individual cue weighting can explain comprehension performance beyond categorical L1–L2 grouping.
To answer Research Question 2, we need to obtain a proxy of each participant’s sensitivity to morphosyntactic cues. Experiment 1 sought to replicate previous findings on the L1 and L2 comprehension of noncanonical sentences and to provide an individual index of sensitivity to use as a predictor in Experiment 2.
Here, we focus on morphological case marking as the syntactic cue under investigation. While case has been found to be less problematic in L2 acquisition and processing compared to, for example, agreement or tense marking (e.g., ; ), L2 comprehenders have shown reduced sensitivity to case cues compared to L1 comprehenders (e.g., ; ; —but cf. ).
We chose L2 speakers whose L1s present a strong case-marking system so as to minimize the possibility of negative cross-linguistic influence on the decoding of case information. Because the L1s of the participants included in the L2 group rely on case marking for grammatical role assignment, similarly to German (; ; ; ; ), any patterns signaling that L2 speakers weight morphosyntactic cues less heavily than L1 speakers cannot be easily attributed to the absence of case-marking cues in the L1.
4. Methods
4.1. Design
In two experiments, we manipulated the structure of unambiguous spoken relative clauses in German (subject-extracted and object-extracted relative clauses; SR and OR henceforth), which were presented in isolation (Experiment 1) and alongside scene depictions (Experiment 2). Scene depictions were manipulated either to convey the same (match) or the opposite (mismatch) role relations as the spoken sentence. Participants answered a forced-choice binary agent-identification question referring to the spoken sentence. Accuracy and response latencies were analyzed using mixed-effects logistic and linear regression models. All participants took part in both experiments.
4.2. Participants
Participants were recruited via the online participant recruitment platform of the University of Potsdam and via web-based adverts throughout Germany. Participants provided their informed consent to participating in this study and were compensated with either 10 EUR/h or university credit. Participants reported no perceptual, cognitive, or language-related impairments, and normal or corrected-to-normal vision (including unimpaired color vision).
Our L1 participants were speakers of German who had not learned another language before the age of 5. In our L2 group, we recruited L1 speakers of Balto-Slavic languages with a strong case-marking system (i.e., Bulgarian, Czech, Latvian, Lithuanian, Polish, Russian, Slovakian, Ukrainian) as well as Romanian speakers. What we refer to as strong case-marking system is one that does not only operate on pronouns, as, e.g., in English. Romanian was included as an eligible L1 because, although it does not belong to the Balto-Slavic languages, it differs from other Romance languages in that it has a case system comparable to that of German ().
Our sample included 84 participants from 19 to 50 years of age (mean = 28, SD = 8), of which 45 L1 and 39 L2 speakers of German. The same participants took part in both Experiments. Of the L2 speakers, one was scored as A2, 13 were scored as B1, 18 as B2 and seven as C1 on the Common European Framework of Reference for Languages (CEFR) scale. For all analyses, A2 and B1 speakers were collapsed into the same proficiency group. Further participant characteristics are reported in Table 1.

Table 1.
Participant information. Demographic information is reported for both groups under ‘Demographic information’. Under ‘L2 group’, we report the L2 speakers’ background of German learning and percentage of daily use. Under ‘Additional language information’, we report information on L1 and additional languages spoken in both groups.
4.3. Materials
4.3.1. Spoken Sentences (Experiments 1 and 2)
The linguistic stimuli included 80 spoken sentences recorded by a female speaker of German. They were identical for Experiments 1 and 2. Target sentences were distributed across two (Experiment 1) or four (Experiment 2) presentation lists using a Latin-Square design to counterbalance the experimental conditions across participants. Each presentation list contained eight practice items, 24 targets, 16 pseudo-fillers and 32 fillers. Item order within each list was randomized for each participant. The complete presentation lists are available as Supplementary Materials (https://osf.io/m5ujv/).
Target sentences were unambiguous copular sentences containing a modifying relative clause. The main clause introduced a human male referent denoted by a nominative case-marked NP. This was followed by a relative clause introducing a (human) female referent and a transitive verb. See Table 1 for examples. All characters were common nouns indicating grammatically gendered referents (e.g., die Braut ‘the bride’; der Prinz ‘the prince’) or professions (e.g., der Koch 'the cook'). For the manipulation of syntactic structure, half of the relative pronouns were in nominative (der ‘who’) and half in the accusative case (den ‘whom’), introducing subject-extracted (SR) and object-extracted (OR) relative clauses, respectively. Only masculine nouns were included as antecedents because masculine singular pronouns allow for unambiguous case marking in German. The argument order in SRs represents the canonical word order in German (NOM > ACC), whilst ORs are noncanonically ordered (ACC > NOM). To interpret OR sentences correctly, listeners need to associate the main clause subject (e.g., der Koch ‘the cook’) with the embedded verb's (e.g., verfolgt ‘follows’) object or patient role. An accusative-marked relative pronoun provides an unambiguous cue to this interpretation.
Pseudo-fillers were identical to target items, except that they included feminine, neuter, or plural relative pronoun antecedents. All items were globally unambiguous, but some fillers presented local syntactic ambiguity due to case syncretism. Such ambiguities were always resolved by subject-verb agreement or unambiguous case marking inside the relative clause, such that all stimuli were globally unambiguous, and participants did not need visual cues to solve the task (e.g., pseudo-filler sentence: Die sind die Damen, die der Dieb erschießt ‘These are the ladies whom the thief shoots dead’; probe question: Wird der Dieb erschossen? ‘Is the thief shot dead?’). Locally ambiguous fillers were introduced to prevent habituation, given that all target items contained masculine relative pronouns. To further increase variety, pseudo-fillers also included non-human animate referents (e.g., Hund ‘dog,’ Pferd ‘horse’) and inanimate referents (e.g., Vase ‘vase,’ Tisch ‘table’). Pseudo-fillers included an equal number of subject-relative and object-relative clauses to replicate the symmetrical distribution of sentence structures in the critical items. Filler sentences included a main clause and a causal or temporal subordinate clause. In half of the fillers, the subordinate clause preceded the main clause, while in the other half, it followed it (e.g., Der Hund verfolgt den Mann, weil er mit ihm gehen möchte ‘The dog follows the man because it wants to walk with him’; Weil sie einen Schatz gefunden haben, freuen sich die Kinder sehr ‘Because they found a treasure, the children are very happy’).
4.3.2. Picture Stimuli (Experiment 2)
Scene depictions consisted of photos of Playmobil© figurines performing actions against a white background. The photos were taken in a brightly lit room with a Canon EOS 40D digital camera and edited with the open-source software GIMP (GNU Image Manipulation Program) software (version 2.10.20; ). All pictures were cropped to a 1:1 width-to-height ratio, and their visual features were kept as similar as possible to one another (e.g., characters’ size and location on the screen, their respective position, brightness, and saturation of color features).
Each image depicted only the two referents mentioned in the sentence. For target sentences, visual cues in mismatching conditions deviated from the meaning of the sentence only with regard to the conveyed role relations, i.e., the action direction, with half of the pictures matching the thematic roles in the auditory stimulus sentence (match condition), and the other half presenting them as reversed (mismatch condition). See Table 2 for examples of target pictorial stimuli.
Table 2.
Experimental design and sample stimuli. NOM = nominative case, ACC = accusative case.
As was the case for target items, fillers and pseudo-fillers were presented half with matching and half with mismatching depictions. In order to dissuade participants from paying attention specifically to the thematic roles depicted in the image, context mismatches for fillers and pseudo-fillers were (in equal parts) due to either the verb (i.e., picture and sentence described two different actions), locative prepositional phrases (i.e., the sentence stated that an object was in a different position from how it was depicted), or a number mismatch (i.e., the sentence stated that a different number of referents were present than were depicted).
4.3.3. Probe Questions (Experiments 1 and 2)
Each sentence was directly followed by a slide presenting a written probe question (in the passive voice) which targeted agent identification. Half of the probe questions required a Yes and half a No response. See Table 2 for example questions. Half of the questions referred to the male and half to the female character. Thus, responding accurately required participants to deeply parse the target clause structures, as the most reliable cue was case marking information on the relative pronoun. Although errors in delayed agent-identification tasks may be associated with memory failures rather than parsing difficulty (), presenting probe questions targeting the processing of case-marking information has been shown to encourage speakers’ reliance on morphosyntactic cues ().
4.4. Procedure
The experiment was programmed in E-Prime 3.0 (, Pittsburgh, PA) and conducted online using E-Prime Go (, Pittsburgh, PA). All participants completed an online screening questionnaire and then received an e-mail with instructions, a download link for the experiment, and a subject ID number. The order of tasks was arranged in two sentence-comprehension blocks (Experiments 1 and 2) in counterbalanced order.
4.4.1. Screening Questionnaire
Participants filled out a demographic background questionnaire, asking about their gender, date of birth, number of years of education, L1, other spoken languages (for each, specifying age-of-acquisition and acquisition context), handedness, vision and/or hearing deficits, and (past or current) language and/or neurological impairments. If participants were L2 speakers of German, they were additionally asked to indicate their age of acquisition of German, the context in which they learned German, and the extent to which they used German in their daily life on a percentage scale. The language history section of the questionnaire for L2 participants followed the guidelines outlined in ().
4.4.2. German Proficiency Assessment
All L2 participants were asked to complete an online test to measure their proficiency level in German (https://www.sprachtest.de/einstufungstest-deutsch, accessed on 19 November 2021). The test is a freely available online tool containing language tasks aimed at assessing reading- and listening-comprehension skills, as well as grammar and vocabulary. The test is timed, and its duration is 15 minutes. The evaluation of the participants’ skills is based on the points obtained for each category: reading (max. 5 points), listening (max. 7 points) and grammar and vocabulary (max. 28 points; total = 40 points). Participants’ proficiency levels were derived automatically from the raw scores according to the Common European Framework of Reference’s guidelines ().
4.4.3. Comprehension Task
Each trial in the sentence-comprehension tasks consisted of two steps: first, participants heard a spoken sentence; then, a written binary forced-choice probe question was presented which participants were asked to answer through keypress within 4000 ms. As mentioned above, the task was administered in two consecutive blocks. Experiment 1 presented sentences in isolation and Experiment 2 presented sentence alongside matching/mismatching visual cues. The order in which both experiments were administered was counterbalanced across participants. Participants were allowed to take a break between both experiments. Target items were presented in a Latin-Square design, such that each participant only saw target items once within and across both experiments. In contrast, filler and pseudo-filler sentences were presented identically twice, though the correct response was counterbalanced across experiments to prevent habituation. This was achieved by altering the probe question. Participants completed eight practice trials before each experiment. Of the practice trials, four resembled target and pseudo-filler items, and four resembled filler items. Practice trials were distributed symmetrically across conditions: half of target-like trials presenting subject-relatives and half object-relative clauses; in addition, in Experiment 2, both filler- and target-type practice trials were presented alongside half matching, half mismatching depictions. Practice probe questions required an equal number of Yes and No responses. All items were presented to participants in randomized order. The total duration of the procedure was about 25 min.
4.5. Data Analyses
All analyses were conducted in R Studio (version: 2021.09.0, ). The analysis code is available as Supplementary Materials. All trials to which no response had been provided and with response times below and above two standard deviations from the mean were removed from the dataset. This operation resulted in the exclusion of all trials from two participants and altogether 419 trials, corresponding to 9.59% of the whole dataset. Further, one participant had to be excluded from Experiment 2 because they provided no responses to Experiment 1.
We collected accuracy rates and RTs (for correct responses) in response to the probe questions. We fitted mixed-effects logistic regression models (binomial family) for analysis of accuracy and linear mixed-effects regression models for RTs (natural log). Mixed-effects logistic and linear regression analyses were carried out with the lme4 R package (). The effects of individual-level variables (e.g., proficiency, age of acquisition) on sensitivity scores were assessed with simple linear regressions. Models were plotted using sjPlot () and ggplot2 (). Follow-up analyses were performed with the emmeans package ().
Sentence structure (SR, OR), visual cue (match, mismatch), and group (L1, L2) were sum-coded with ±0.5 weights, which allows us to compare the effect of an OR (0.5) relative to an SR clause (−0.5), the effect of a mismatch (0.5) relative to a match (−0.5), and the effect of belonging to the L2 group (0.5) compared to the L1 (−0.5). Note that the intercept represents the grand mean, i.e., the average response outcome across conditions for the whole sample.
Accuracy rates in Experiment 1 were averaged at the individual level and used as proxies of sensitivity to morphosyntax (‘sensitivity scores’ henceforth), as high sensitivity to case information would result in higher accuracy overall. This is because participants who are not sensitive to case marking but rather rely on surface-level heuristics (such as word order and pattern frequency), will assign thematic roles correctly only 50% of the times. () followed a similar rationale to estimate ‘case-marking mastery’ (p. 560) and used it as a predictor for further analyses.
To answer Research Question 1, we fitted a mixed-effects logistic regression (binomial family) to accuracy rates from Experiment 2, which included sentence structure, visual cue and group as fixed factors. To answer Research Question 2, we fitted an identical model but replaced the group factor with continuous sensitivity scores (centered). In both of the latter models, the random-effects structure included by-item and by-participant intercepts, and by-participant slopes for sentence structure and visual cue. Finally, we compared both models with ANOVA comparisons. This allowed us to assess whether sensitivity scores represent a better predictor for thematic-role assignment success than L1–L2 grouping.
5. Experiment 1
5.1. Predictions
5.1.1. Replication of Subject Preference and L1 Advantage
On the group level, we expect canonical SR (vs. OR) clauses to yield higher accuracy and shorter reaction times (RTs) across both groups. This is based on findings for less accurate agent-identification outcomes for German object- (vs. subject-) extracted relative clauses (, ; ). We assume that the subject preference reflects an overwhelming reliance on an agent-before-patient strategy (see ; ), facilitated through the considerably higher occurrence frequency of SO vs. OS order in German (e.g., ). We use the subject preference as a testbed to evaluate predictions from dual-route approaches for both L1 and L2 speakers. Specifically, we explore whether visual cues modulate the ease with which unambiguous syntax can successfully be interpreted in sentences with canonical and noncanonical ordering of thematic roles.
Overall, L1 speakers are expected to respond faster and more accurately than L2 speakers overall, based on evidence for L1–L2 differences in sensitivity to case information (e.g., ; ; ; ). Specifically, if L2 speakers are less able to make use of case information (i.e., have low morphosyntactic sensitivity), they might show disproportionate accuracy decreases in response to OR (vs. SR) clauses, in line with the SSH. This is because correct thematic-role assignment in SR trials may either be performed via deep syntactic parsing or via surface-level heuristics, as both routes convey the same reading. In contrast, in response to OR clauses, successful thematic-role assignment can only happen through the parsing and integration of morphosyntactic cues into a mental representation.
5.1.2. Individual Proxies of Sensitivity to Morphosyntax
We expect L1–L2 differences in morphosyntactic sensitivity scores, which should be significantly higher in L1 than L2 speakers overall, as indicated by the effect of group on accuracy scores in Experiment 1. Increasing L2 proficiency might be associated with higher sensitivity to morphosyntactic cues. Further, based on previous evidence in favor of a role for maturational processes in the mechanisms underlying both morphological () and syntactic processing (; ), increasing age of acquisition of German might be associated with lower sensitivity to morphosyntactic cues.
5.2. Results
5.2.1. Descriptives
Average proportions of accurate responses and RTs in milliseconds to correctly answered trials from Experiment 1 are reported for each group and condition in Table 3. While accuracy rates were numerically similar in L1 and L2 speakers in response to SR clauses, we noticed larger group differences in response to OR clauses, as well as higher variability.
Table 3.
Average proportions of accuracy and RTs in milliseconds to correctly answered trials for L1 and L2 speakers.
5.2.2. Replication of Group-Level Subject-Preference and L1 Advantage
The models fitted to accuracy and response times included random by-item and by-participant intercepts. The logistic regression fitted to accuracy data also included by-participant sentence-structure slopes, which were excluded from the RT model due to convergence errors. The coefficients of the models are reported in Table 4.
Table 4.
Mixed-effects regression coefficients from linear and logistic regressions fitted to the natural log of response times of correctly answered trials and accuracy rates. Sentence structure, visual cue, and group were sum-coded with ±0.5 weights, comparing the effect of OR (0.5) versus SR clauses (−0.5), of mismatch (0.5) versus match (−0.5), and of pertaining to the L2 (0.5) versus the L1 (−0.5) group. The intercept represents the grand mean.
The model fitted to the RT data showed main effects of sentence structure, with SR clauses yielding faster responses than OR clauses, and of group, as L2 speakers responded more slowly than L1 speakers. We found no evidence for an interaction of both factors. The model fitted to the accuracy data revealed a main effect of sentence structure, showing that accuracy was higher in response to SR than OR clauses. The main effect of group shows that L2 speakers’ accuracy was lower overall than the German controls'. Further, the significant interaction of sentence structure × group indicates that L2 comprehension accuracy was reduced specifically for OR clauses, as compared to L1 speakers (Figure 1). Post hoc tests revealed significant between-group differences in accuracy responding to OR (b = 1.25, SE = 0.29, z = 4.27, p < 0.001) but not SR clauses (b = 0.39, SE = 0.30, z = 1.30, p = 0.192). These patterns confirmed our predictions by replicating previously reported accuracy decreases for OR clauses in German (e.g., , ) and L1–L2 differences in the comprehension of noncanonical syntax (e.g., ; ; ).
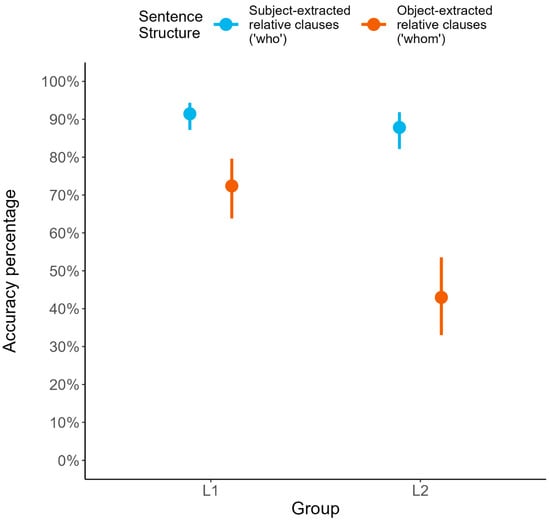
Figure 1.
Interaction of sentence structure by group on accuracy rates in Experiment 1. Error bars represent 95% confidence intervals.
5.2.3. Individual Differences in Sensitivity to Morphosyntactic Cues
By-participant sensitivity scores are plotted in Figure 2 as a function of group. After computing sensitivity scores, we examined their relation to individual-level variables with simple regressions. As suggested by the group analysis, belonging to the L2 (vs. L1) group was associated with lower sensitivity scores (b = −0.14, SE = 0.03, t = −4.28, p < 0.001). Proficiency in German1 contributed to determining sensitivity, which was significantly decreased in C1 (vs. L1) speakers (b = −0.46, SE = 0.11, t = −4.03, p < 0.001), and in B1 (vs. the average of L1, C1 and B2) speakers (b = −0.09, SE = 0.04, t = −2.09, p = 0.039). Moreover, increasing age of acquisition of German (centered) was strongly associated with lower sensitivity scores (b = −0.01, SE < 0.01, t = −4.18, p < 0.001). Both latter patterns are in line with previous evidence for the negative effect of increasing age of acquisition on the automatized ability to make use of subtle morphological and morphosyntactic cues to derive meaning (e.g., ), which in turn is closely reflected by measures such as proficiency (e.g., ).
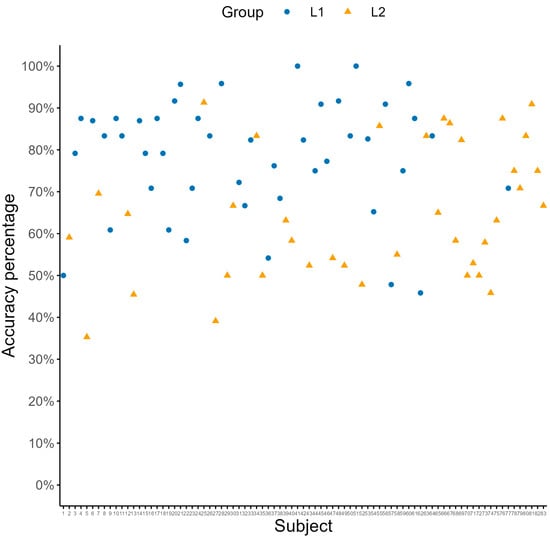
Figure 2.
By-participant accuracy rates from Experiment 1 (i.e., sensitivity scores) as a function of group.
To summarize, the results of Experiment 1 show that sentence structure influenced both dependent variables, with SR clauses being answered more accurately and faster than OR clauses across groups. This finding is compatible with evidence for decreased agent-identification accuracy of German OS (vs. SO) clauses (, ; ). Further, the results confirmed that L2 speakers were slower and less accurate at comprehending the spoken sentences than L1 speakers, and their accuracy rates were especially low in response to OR clauses. The latter results replicate the L1 advantage and suggest that L2 speakers may have greater difficulty at comprehending noncanonical structures than L1 speakers. These conclusions are in line with previous evidence for a decreased tendency to rely on morphosyntactic information to process the L2 (vs. L1, e.g., ; ).
6. Experiment 2
6.1. Predictions
Overall, we expect to replicate the results from Experiment 1: SR (vs. OR) clauses should be understood faster and more accurately, and L1 speakers are expected to respond faster and more accurately than L2 speakers. L2 speakers may also show selective decreases in accuracy rates in response to OR (vs. SR) clauses. However, the sentence structure × group interaction detected in Experiment 1 may be modulated by the presence of visual cues (see below). As sensitivity scores were computed as the mean individual accuracy in Experiment 1, we expect such scores to be associated with more accurate performance in Experiment 2.
6.1.1. Research Question 1: Visual Influences on L1 and L2 Sentence Comprehension
We expect sentence–picture congruence (vs. incongruence) to yield faster and more accurate responses overall (i.e., across clause types and groups). This hypothesis is in line with evidence in favor of the interplay of visual and morphosyntactic cues in (i) the processing of ambiguous syntax with tasks unrelated to sentence–picture congruence (e.g., ), and (ii) the processing of unambiguous syntax (e.g., ; ). We specifically add to () by examining whether visually driven representations are retained and influence comprehension post-sentence. Because the CIA predicts a role of recency in determining the strength of visual effects, these may be too weak to be detected on post-sentence comprehension (). To increase the recency of the visual inspection relative to the probe question, we opted for simultaneous presentation of spoken and visual stimuli. In sum, the present setting enables us to test the robustness of visual influences across stimuli, tasks, and populations, and thus to extend the generalizability of models such as the CCM and the CIA.
In both speaker groups, the comprehension of noncanonical (vs. canonical) clauses may be influenced by visual cues to a larger extent. Specifically, for the comprehension of OR clauses, matching visual cues may make it easier for comprehenders to overcome the general subject preference, while mismatching visual cues may render it more difficult. This is because in mismatching OR trials, both visual and word-order cues support an incorrect reading. This pattern should be indexed by an interaction of sentence structure × visual cue (in the direction of larger visual-cue differences in response to OR vs. SR clauses). This finding would align with previous evidence from the dual-route framework (e.g., ) and extend it by including visual information as a relevant non-syntactic cue.
Lastly, the SSH predicts L2 speakers’ reliance on visual cues to be at least comparable to L1 speakers’, whilst L1 speakers should be more adept at using case cues during comprehension than L2 speakers. As in Experiment 1, this expected group difference should be especially pronounced in response to OR clauses, as responding accurately to canonical (SR) sentences can be achieved either via deep syntactic parsing or superficial comprehension heuristics. In contrast, relying on an agent-before-patient strategy will lead to incorrect thematic-role assignment in noncanonical sentences.
6.1.2. Research Question 2: The Effect of Morphosyntactic Sensitivity on Visual-Cue Weighting
Based on evidence for the role of individual-level profiles underlying cue weighting in L1 and L2 sentence processing (; ; ), we assume that individuals vary in their cue-weighting preferences even at the highest levels of proficiency (including L1 speakers). We hypothesize that the weighting of morphosyntactic and visual cues might be negatively correlated. Thus, participants who are more sensitive to case cues may be less sensitive to visual cues, and participants who are less sensitive to case cues may be more sensitive to visual cues. If so, increasing sensitivity scores should be associated with smaller differences between matching and mismatching trials, and vice versa.
6.2. Results
6.2.1. Descriptives
Average proportions of accuracy and RTs to correctly answered trials are reported per group and condition in Table 5. Descriptively, accuracy was relatively high for SR clauses across groups and visual-cue levels. Nonetheless, mismatching scenes caused accuracy rates to drop about 20% even in response to SR clauses in the L1 group, a difference that was smaller in the L2 group (~12%). In the L1 group, OR (vs. SR) clauses were associated with a 20% drop in accuracy, even with matching scenes, and for L2 speakers, accuracy dropped as much as 30%. These patterns are similar to those seen in Experiment 1. In the L1 group, accuracy dropped to the same extent for OR (vs. SR) clauses as in Experiment 1 in the match condition, while L2 speakers’ performance dropped more steeply in Experiment 1 (40%) than in Experiment 2's match condition. In mismatching OR conditions, L1 speakers performed at chance level, whilst L2 speakers scored as low as less than a third of the total. The numerical differences between matches and mismatches were larger in OR (vs. SR) trials, and in L2 compared to L1 speakers. A descriptive comparison of the mean accuracy rates across clause types in both Experiments reveals both increased accuracy in response to matching scenes, and decreased accuracy in the presence of mismatching scenes, as compared to the same sentences presented without accompanying visual scenes. RTs are reported for completeness, but due to the low number of trials that would have been included in the RT analyses, these were not performed on the data from Experiment 2.
Table 5.
Average proportions of accuracy and RTs in milliseconds to correctly answered trials in Experiment 2 for L1 and L2 speakers.
6.2.2. Research Question 1: Visual Influences on L1 and L2 Sentence Comprehension
To answer Research Question 1, we examined the effects of sentence structure, visual cue, group, and their interactions, which were added as fixed factors in the logistic regression fitted to accuracy data. The model’s random-effects structure included by-item and by-participant intercepts, as well as by-participant Sentence and visual-cue slope adjustments. The coefficients of the model are reported in Table 6.
Table 6.
Mixed-effects regression coefficients from the logistic regression fitted to accuracy rates from Experiment 2 (RQ1). sentence structure, visual cue, and group were sum-coded with ±0.5 weights, comparing the effect of OR (0.5) versus SR clauses (−0.5), of mismatch (0.5) versus match (−0.5), and of belonging to the L2 (0.5) versus L1 (−0.5) group. The intercept represents the grand mean.
As expected, we detected simple effects of sentence structure, visual cue, and group. In line with results from Experiment 1, SR clauses were answered more accurately than OR clauses, and belonging to the L2 (vs. L1) group was associated with lower accuracy rates. In line with our predictions, matching trials were answered more accurately than mismatching trials. Further, we found some indication that L2 (vs. L1) speakers’ performance was lower especially in response to OR trials, but in contrast to Experiment 1, the sentence structure × group interaction only reached marginal significance. However, post hoc tests indicated that group differences were significant in response to OR (b = 1.06, SE = 0.33, z = 3.16, p = 0.002) but not SR clauses (b = 1.13, SE = 0.48, z = 2.34, p = 0.019). Finally, the numerical tendency for L2 speakers to show selective accuracy decreases in mismatching OR trials did not reach significance at an alpha level of p < 0.05.
6.2.3. Research Question 2: Role of Morphosyntactic Sensitivity for Visual-Cue Weighting
To answer Research Question 2, we fitted the same model as to answer Question 1, but we replaced L1–L2 group with the sensitivity scores obtained from Experiment 1. The model’s coefficients are reported in Table 7.
Table 7.
Mixed-effects regression coefficients from the logistic regression fitted to accuracy rates from Experiment 2 (RQ2). Sentence structure and visual cue were sum-coded with ±0.5 weights, comparing the effect of OR (0.5) versus SR clauses (−0.5) and of mismatch (0.5) versus match (−0.5). sensitivity scores were centered. The intercept represents the grand mean.
In addition to similar effects of sentence structure and visual cue as in the previous analysis, higher sensitivity scores were associated with higher accuracy overall, indicating that individual accuracy in Experiment 1 predicted accuracy in Experiment 2. Further, the interactive effects with group that were marginal or non-significant in the previous analysis reached significance as a function of sensitivity score: increasing sensitivity scores were associated with smaller sentence-structure differences in accuracy. This finding confirms our assumption that high levels of accuracy in Experiment 1 were associated with better ability to make use of subtle morphosyntactic cues for interpretation in the face of noncanonical structures. Moreover, sensitivity scores were significantly modulating match–mismatch differences depending on sentence structure (Figure 3). Post hoc tests showed that match–mismatch differences were greatest when participants at the lower end of the sensitivity range responded to OR clauses (b = 2.62, SE = 0.56, z = 4.67, p < 0.001). Match–mismatch differences were also significant, yet less pronounced, when participants at either end of the sensitivity range responded to SR clauses (lower end: b = 1.17, SE = 0.58, z = 2.02, p = 0.043; upper end: b = 1.47, SE = 0.69, z = 2.12, p = 0.034). In contrast, match–mismatch differences were not significant when participants at the upper end of the sensitivity range responded to OR clauses (b = 0.50, SE = 0.55, z = 0.91, p = 0.362).2 We discuss this result in detail in the following section.
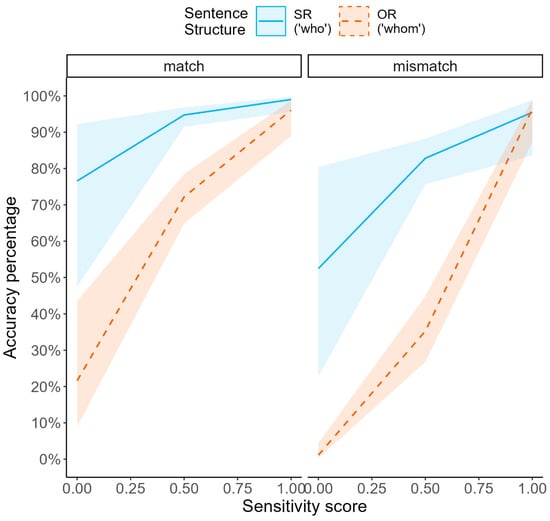
Figure 3.
Interaction of sentence structure × visual cue × sensitivity scores across speakers. Error bands represent 95% confidence intervals.
Finally, we contrasted the model including group to the model including sensitivity score with an ANOVA model comparison. The Akaike Information Criterion (AIC) of the ‘sensitivity-score’ model was lower (1765.7) than the AIC of the ‘group’ model (1805.1). This result confirms that sensitivity scores had more explanatory power as a predictor of comprehension differences in our dataset than L1–L2 grouping.
To summarize, we found that both our sentence structure and visual cue manipulations influenced performance, yielding higher accuracy for SR (vs. OR) clauses and for matching (vs. mismatching) visual cues. L1 speakers were more accurate than L2 speakers overall in both experiments, a pattern that was more pronounced in response to OR clauses (significant in Experiment 1, marginal in Experiment 2). Across groups, sensitivity scores modulated reliance on visual cues as a function of sentence structure. Low morphosyntactic sensitivity was associated with larger match–mismatch differences, particularly in response to OR clauses, while high sensitivity was associated with larger match–mismatch differences in response to SR than OR clauses. Finally, sensitivity scores were found to be a better predictor than group in modeling agent-identification accuracy.
7. Discussion
The present study investigated the processing of visual and morphosyntactic cues for thematic-role assignment of unambiguous German sentences in L1 and L2 comprehension. Further, we took an individual-difference approach to investigating the relationship between morphosyntactic sensitivity and the use of visual cues across L1 and L2 speakers. We asked (i) how (task-unrelated) visual cues influence thematic-role assignment of unambiguous sentences in L1 and L2 speakers, and (ii) whether a proxy of individual sensitivity to morphosyntax predicts sensitivity to visual information.
The novel findings from the current study (discussed in detail below) can be summarized as follows: first, visual-scene cues influenced agent-identification accuracy of L1 and L2 speakers alike, even though case marking unambiguously indicated thematic relations, and although the task was unrelated to sentence–picture congruence. Second, morphosyntactic sensitivity modulated reliance on visual-scene cues as a function of sentence structure: Individuals with low morphosyntactic sensitivity tended to rely on visual-scene cues for thematic-role assignment in noncanonically ordered (and to a lesser extent, canonically ordered) relative clauses. In contrast, individuals with high morphosyntactic sensitivity relied on visual-scene cues for thematic-role assignment of canonical structures only. Third, we found that morphosyntactic sensitivity scores were a better predictor of agent-identification accuracy than categorical L1–L2 grouping.
7.1. Replication of Agent-Before-Patient Preference and L1 Advantage
In both experiments, noncanonical OR structures yielded lower accuracy (and in Experiment 1, slower RTs) than canonical SR structures. Our results, showing relatively high error rates in L1 speakers irrespective of syntactic ambiguity, align with previous evidence for accuracy decreases in the face of noncanonical but unambiguous sentences, particularly as measured by agent-identification tasks (; ). In the dual-route framework, accuracy decreases in response to unambiguous noncanonical structures are attributed to reliance on ‘fast-and-frugal’ comprehension heuristics (e.g., word-order, frequency) that strongly favor interpretations that correspond to the ‘agent-before-patient’ pattern. In multiple-constraint models, the same basic finding is interpreted in terms of relative cue weightings. Crucially, replicating previous evidence for decreased agent-identification accuracy in response to noncanonical sentences in German (e.g., , ; ) enables us to use the phenomenon as a testbed for assessing to what degree the reliance on morphosyntactic versus word-order cues to interpretation predicts reliance on visual cues.
In Experiment 1, L1 speakers were faster and more accurate at responding than L2 speakers, replicating well-established findings in L2 research. Further, we found more pronounced L1–L2 differences in accuracy to OR (vs. SR) clauses, in line with previous findings of disproportional difficulties triggered by noncanonical structures in L2 (vs. L1) comprehension (e.g., ; ; —but cf. ). The latter interaction was only significant in the absence of visual cues, only reaching marginal significance when visual-scene cues were available. However, the group and sentence structure factors were involved in a relatively strong, higher-level numerical tendency including the visual-cue factor in Experiment 2. The discrepancy between the sentence structure × group interactions in Experiments 1 and 2 may be due to the modulation of co-occurring visual-scene information in Experiment 2. This conclusion is supported by the significant interaction obtained as a function of sentence structure, visual cue, and sensitivity scores in Experiment 2, reflected by a large numerical tendency when group was included as predictor instead of sensitivity (discussed below).
In line with the SSH, our finding of accuracy decreases in the L2 group’s responses to OR clauses can be explained in terms of reduced sensitivity to case-marking cues, and correspondingly greater reliance on linear word-order, in L2 vs. L1 comprehension. In response to canonical SR clauses, we found no difference between L1 and L2 speakers’ performance, indicating that comprehension should be unproblematic for L2 speakers when word-order and case cues converge. In contrast, selective difficulties in L2 comprehension of noncanonical structures may be ascribed to L2 speakers’ enhanced reliance on shallower, word-order-based heuristics.
7.2. Research Question 1: Influence of Visual Cues on L1 and L2 Sentence Comprehension
In line with predictions from the CIA, mismatching (vs. matching) visual scenes yielded lower agent-identification accuracy in both L1 and L2 speakers. This confirms that visual cues are relied upon in both the L1 and L2 comprehension of unambiguous structures. As mentioned above, this finding complements and extends existing evidence on the integration of visual and morphosyntactic cues. First, the present study assessed the influence of visual cues on final interpretations, whereas previous studies using unambiguous linguistic stimuli assessed the time course of visuo-linguistic integration during processing using the VWP (e.g., ). Contrary to the VWP, however, our setting enabled us to present visual-scene cues that were incompatible with the action direction conveyed linguistically. We further measured comprehension using a linguistic task unrelated to sentence–picture congruence, unlike studies using sentence–picture verification (e.g., ). Though () have provided evidence for a role of sentence–picture congruence using reading times as a purely linguistic outcome measure, their study differed from the current investigation in that they presented ambiguous sentences in written form.
In short, the present study’s design choices were justified by the attempt to provide evidence for the effects of visual cues on sentence comprehension in a ‘maximally conservative’ setting. In other words, we strove to provide a potentially unfertile ground for visual influences on comprehension to emerge. The fact that we nevertheless found reliable effects of visual-scene cues in the present setting provides strong support for the robustness of visual influences on sentence processing. Descriptively, we found that matching scenes increased, whilst mismatching scenes decreased, comprehension accuracy relative to conditions in which no accompanying visual information was presented. This observation supports the view that matching visual input can be advantageous for comprehension. It is possible that matching scenes allowed participants to form richer mental representations as compared to language alone, thus improving post-sentence recall of thematic-role relations. In contrast, mismatching scenes should have triggered an attempt to re-analyze (CCM) or reconcile (CIA) spoken and visual input, which we found to negatively influence post-sentence recall of the role-relations in the sentence. Thus, the abstract relations depicted in the visual scenes were integrated in the computation of meaning representations, irrespective of task requirements or syntactic ambiguity.
The effect of visual cue was not significantly modulated by sentence structure. Rather, morphosyntactic and visual cues seemed to contribute additively to agent-identification accuracy. This result contrasts with evidence in favor of the influence of visual cues (e.g., speaker gaze, visual scenes) on the comprehension and processing of noncanonical structures (e.g., ; ). In this research, matching visual cues were found to neutralize the preference for canonical over noncanonical syntax in anticipating upcoming referents, which was not the case in our results. Instead, the additive patterns in our results seem to support the view that linguistically and visually derived representations might be stored in a modality-dependent fashion, rather than in a common representational format. However, this null result is only suggestive, and conclusive insights in this regard would have to be based on positive evidence. Further, the lack of an interaction of visual cue and sentence structure contrasts with dual-route claims about increased reliance on non-syntactic cues in the face of noncanonical syntax in L1 processing (; ).
To our knowledge, the current study represents a novel attempt to explore the applicability of visuo-linguistic integration models (such as the CIA) to L2 sentence comprehension. Our results therefore add to the generalizability of CIA claims across populations. Interestingly, we found that the size of the visual effects overall was statistically indistinguishable between the L1 and L2 groups. This indicates that L2 speakers were as able as L1 speakers to utilize visual cues to interpretation.
7.3. Research Question 2: Role of Morphosyntactic Sensitivity for Visual-Cue Weighting
We found that comprehension accuracy in Experiment 1 (used as a proxy of morphosyntactic sensitivity) was also associated with higher accuracy in Experiment 2, both overall and specifically in response to noncanonical sentences. First, participants who relied on case cues in Experiment 1 also relied on this type of interpretation cue in Experiment 2. Second, the selective effect of sensitivity score on comprehension of OR sentences suggests that surface-level heuristics were underlying thematic-role mis-assignment. This is because SR clauses present no conflict between the agent-before-patient preference on the one hand, and case cues on the other. Thus, SR-OR differences were minimal in participants who were able to use case cues for interpretation (i.e., participants with a high sensitivity score). Lastly, the finding that sensitivity to morphosyntactic cues explains L1–L2 variability better than L1–L2 grouping indicates that L1–L2 processing differences are not necessarily categorical but may be gradient (compare, e.g., ).
We now turn to the observed three-way interaction of sentence structure × visual cue × sensitivity scores. This interaction confirms our hypotheses as to the negative association of morphosyntactic sensitivity and reliance on visual-scene information: the less participants were able to use morphosyntactic information, the more they relied on visual-scene information for comprehension. The interaction reflects the following: While the visual-cue effect size was similar in high and low-sensitivity participants in SR trials, in OR trials the visual-cue effect was absent in high-sensitivity participants. In low-sensitivity participants, in contrast, the visual-cue effect size almost doubled (as compared to SR trials). These patterns broadly confirm our prediction of a negative association between sensitivity to case and visual cues, thus adding to current efforts to understand the role of individual variability in L1 and L2 sentence comprehension. This evidence aligns with the results from (), where speakers’ ability to integrate syntactic versus semantic cues for sentence processing was found to correlate negatively at the individual level. In the present study, speakers’ sensitivity scores were found to determine comprehension success across both L1 and L2 speakers, as reflected by the disproportional influence of visual cues on the comprehension of noncanonical clauses at lower levels of morphosyntactic sensitivity.
Our finding that highly sensitive participants showed greater visual-cue effects in SR than OR trials, however, seems counterintuitive. One possibility is that processing OR clauses, where the agent-before-patient preference conflicts with case cues, takes up more cognitive resources than processing SR trials, where there is no such conflict. This would then leave them with fewer cognitive resources in OR trials for taking into account visual context information, in comparison to SR trials and to participants with lower morphosyntactic sensitivity.
To summarize, our results confirm the claims made by the CIA and extend their generalizability by testing them in a strictly conservative experimental setting, as well as providing evidence for their validity from a novel population. Further, our results support our hypothesis as to a trade-off in the reliance on morphosyntactic and visual cues across speakers. Our results demonstrate that differences in successful thematic-role assignment can be better accounted for by individual differences in cue weighting (; ) than in terms of L1–L2 grouping.
8. Conclusions
Our findings expand on previous evidence for the influence of visual cues on the comprehension of syntactically unambiguous sentences in L1 and L2 speakers, emphasizing the need for the integration of visual cues in research on language comprehension. Our results further support the view that differences in the weighting of syntactic and non-syntactic cues underlie L1–L2 group differences, whilst highlighting the usefulness of determining individual cue-weighting profiles for explaining within-group differences in sentence comprehension. Future research should address individual differences within L2 speakers with larger samples and seek to identify potential cognitive or environmental factors underlying cue-weighting profiles in L1 and L2 comprehension.
Supplementary Materials
The complete set of materials, presentation lists, analysis code and the raw data are available on OSF at https://osf.io/m5ujv/.
Author Contributions
Conceptualization, C.I.Z. and C.F.; methodology, C.I.Z. and C.F.; software, C.I.Z.; validation, C.I.Z. and C.F.; formal analysis, C.I.Z.; investigation, C.I.Z.; resources, C.I.Z. and C.F.; data curation, C.I.Z.; writing—original draft preparation, C.I.Z.; writing—review and editing, C.I.Z. and C.F.; visualization, C.I.Z.; supervision, C.F.; project administration, C.I.Z. and C.F.; funding acquisition, C.I.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported through a Ph.D. scholarship by the German Academic Scholarship Foundation (Studienstiftung des deutschen Volkes) to C.I.Z.
Institutional Review Board Statement
This study was conducted in accordance with the Declaration of Helsinki and approved by the Ethics Committee of the University of Potsdam (Reference number 37/2011).
Informed Consent Statement
Informed consent was obtained from all subjects involved in this study.
Data Availability Statement
The data are available on the study’s OSF repository at the link https://osf.io/m5ujv/.
Acknowledgments
We are grateful to Laura Ciaccio and Anna Laurinavichyute for their guidance with data analysis and to the IT service of the University of Potsdam for their technical assistance in creating the materials.
Conflicts of Interest
The authors declare no conflict of interest.
Notes
| 1 | By coding proficiency with Helmert contrasts, we compared sensitivity scores at each proficiency level (native, C1, B2 and B1+A2) to the average scores of all preceding levels (i.e., native vs. C1, native+C1 vs. B2, etc.). |
| 2 | For the follow-up analyses on the effect of sensitivity, the effect of interest was measured at the lowest and highest values of the continuous sensitivity scale. This is achieved with the argument cov.reduce = range in the emmeans function (). Follow-up analyses of categorical predictors are instead performed at the mean value of the sensitivity range across the whole sample. |
References
- Allopenna, Paul D., James S. Magnuson, and Michael K. Tanenhaus. 1998. Tracking the time course of spoken word recognition using eye movements: Evidence for continuous mapping models. Journal of Memory and Language 38: 419–39. [Google Scholar] [CrossRef]
- Altmann, Gerry T. M., and Yuki Kamide. 1999. Incremental interpretation at verbs: Restricting the domain of subsequent reference. Cognition 73: 247–64. [Google Scholar] [CrossRef] [PubMed]
- Altmann, Gerry T. M., and Yuki Kamide. 2009. Discourse-mediation of the mapping between language and the visual world: Eye movements and mental representation. Cognition 111: 55–71. [Google Scholar] [CrossRef] [PubMed]
- Arnaudova, Olga, Wayles Browne, María Luisa Rivero, and Danijela Stojanovic. 2004. Relative clause attachment in Bulgarian. In Annual Workshop on Formal Approaches to Slavic Languages. Ann Arbor: Michigan Slavic Publications. [Google Scholar]
- Bader, Markus, and Jana Häussler. 2010. Word order in German: A corpus study. Lingua 120: 717–62. [Google Scholar] [CrossRef]
- Bader, Markus, and Michael Meng. 2018. The misinterpretation of noncanonical sentences revisited. Journal of Experimental Psychology: Learning Memory and Cognition 44: 1286–1311. [Google Scholar] [CrossRef]
- Bader, Markus, and Michael Meng. 2023. Processing noncanonical sentences: Effects of context on online processing and (mis)interpretation. Glossa Psycholinguistics 2: 1–45. [Google Scholar] [CrossRef]
- Barsalou, Lawrence W. 1999. Perceptual symbol systems. Behavioral and Brain Sciences 22: 577–660. [Google Scholar] [CrossRef] [PubMed]
- Barsalou, Lawrence W. 2008. Grounded cognition. Annual Review of Psychology 59: 617–45. [Google Scholar] [CrossRef]
- Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Bates, Elizabeth, and Brian MacWhinney. 1982. Functionalist approaches to grammar. In Language Acquisition: The State of the Art. Edited by Eric Wanner and Lila Gleitman. New York: Cambridge University Press. [Google Scholar]
- Bates, Elizabeth, and Brian MacWhinney. 1989. Functionalism and the Competition Model. In The Crosslinguistic Study of Sentence Processing. Edited by Elizabeth Bates and Brian MacWhinney. New York: Cambridge University Press, pp. 3–76. [Google Scholar]
- Bates, Elizabeth, Sandra McNew, Brian MacWhinney, Antonella Devescovi, and Stan Smith. 1982. Functional constraints on sentence processing: A cross-linguistic study. Cognition 11: 245–99. [Google Scholar] [CrossRef]
- Benţea, Anamaria. 2012. Does “Case” Matter in the Acquisition of Relative Clauses in Romanian? Proceedings of the 26th Annual Boston University Conference on Child Language Development, Boston, MA, USA, November 2–4; Edited by Alia Biller, Esther Chung and Amelia Kimball. Somerville: Cascadilla Press, pp. 1–12. [Google Scholar]
- Carpenter, Patricia A., and Marcel A. Just. 1975. Sentence comprehension: A psycholinguistic processing model of verification. Psychological Review 82: 45–73. [Google Scholar] [CrossRef]
- Chambers, Craig G., Michael K. Tanenhaus, and James S. Magnuson. 2004. Actions and affordances in syntactic ambiguity resolution. Journal of Experimental Psychology: Learning Memory and Cognition 30: 687–96. [Google Scholar] [CrossRef] [PubMed]
- Christianson, Kiel, Steven G. Luke, and Fernanda Ferreira. 2010. Effects of plausibility on structural priming. Journal of Experimental Psychology: Learning Memory and Cognition 36: 538–44. [Google Scholar] [CrossRef] [PubMed]
- Christianson, Kiel. 2016. When language comprehension goes wrong for the right reasons: Good-enough, underspecified, or shallow language processing. Quarterly Journal of Experimental Psychology 69: 817–28. [Google Scholar] [CrossRef]
- Chromý, Jan. 2022. When readers fail to form a coherent representation of garden-path sentences. Quarterly Journal of Experimental Psychology 75: 169–90. [Google Scholar] [CrossRef]
- Citko, Barbara. 2016. Types of appositive relative clauses in Polish. Studies in Polish Linguistics 11: 85–110. [Google Scholar] [CrossRef]
- Clahsen, Harald, and Claudia Felser. 2006. Grammatical processing in language learners. Applied Psycholinguistics 27: 3–42. [Google Scholar] [CrossRef]
- Clahsen, Harald, and Claudia Felser. 2018. Some notes on the Shallow Structure Hypothesis. Studies in Second Language Acquisition 40: 1–14. [Google Scholar] [CrossRef]
- Clark, Herbert H., and William G. Chase. 1972. On the process of comparing sentences against pictures. Cognitive Psychology 3: 472–517. [Google Scholar] [CrossRef]
- Coltheart, Max. 1999. Modularity and cognition. Trends in Cognitive Sciences 3: 115–20. [Google Scholar] [CrossRef]
- Cooper, Roger M. 1974. Control of Eye Fixation By the Meaning of Spoken Language. Cognitive Psychology 107: 166–68. [Google Scholar] [CrossRef]
- Council of Europe. 2011. Common European Framework of References for Languages: Learning, Teaching, Assessment. Cambridge: Cambridge University Press. Available online: https://rm.coe.int/1680459f97 (accessed on 16 November 2022).
- Cunnings, Ian, and Hiroki Fujita. 2021. Similarity-based interference and relative clauses in second language processing. Second Language Research 39: 1–25. [Google Scholar] [CrossRef]
- Cunnings, Ian, Georgia Fotiadou, and Ianthi Tsimpli. 2017. Anaphora resolution and reanalysis during L2 sentence processing. Studies in Second Language Acquisition 39: 621–52. [Google Scholar] [CrossRef]
- Cunnings, Ian. 2017. Parsing and working memory in bilingual sentence processing. Bilingualism 20: 659–78. [Google Scholar] [CrossRef]
- den Ouden, Dirk-Bart, Michael Walsh Dickey, Catherine Anderson, and Kiel Christianson. 2016. Neural correlates of early-closure garden-path processing: Effects of prosody and plausibility. Quarterly Journal of Experimental Psychology 69: 926–49. [Google Scholar] [CrossRef] [PubMed]
- Deniz, Nazik Dinçtopal. 2022. Processing syntactic and semantic information in the L2: Evidence for differential cue-weighting in the L1 and L2. Bilingualism 25: 713–25. [Google Scholar] [CrossRef]
- Díaz, Begoña, Kepa Erdocia, Robert F. De Menezes, Jutta L. Mueller, Núria Sebastián-Gallés, and Itziar Laka. 2016. Electrophysiological correlates of second-language syntactic processes are related to native and second language distance regardless of age of acquisition. Frontiers in Psychology 7: 133. [Google Scholar] [CrossRef]
- Farmer, T. A., J. B. Misyak, and M. H. Christiansen. 2012. Individual differences in second language sentence processing. In The Cambridge Handbook of Psycholinguistics. Edited by Michael J. Spivey, Marc F. Joannisse and Ken McRae. Cambridge: Cambridge University Press, pp. 353–64. [Google Scholar] [CrossRef]
- Felser, Claudia, and Ian Cunnings. 2012. Processing reflexives in a second language: The timing of structural and discourse-level constraints. Applied Psycholinguistics 33: 571–603. [Google Scholar] [CrossRef]
- Felser, Claudia, Leah Roberts, Theodore Marinis, and Rebecca Gross. 2003. The processing of ambiguous sentences by first and second language learners of English. Applied Psycholinguistics 24: 453–89. [Google Scholar] [CrossRef]
- Ferreira, Fernanda, and Nikole D. Patson. 2007. The ‘Good Enough’ approach to language comprehension. Language and Linguistics Compass 1: 71–83. [Google Scholar] [CrossRef]
- Ferreira, Fernanda. 2003. The misinterpretation of noncanonical sentences. Cognitive Psychology 47: 164–203. [Google Scholar] [CrossRef] [PubMed]
- Fodor, Jerry A. 1983. The Modularity of Mind. Cambridge: MIT Press. [Google Scholar]
- Folk, Jocelyn R., and Robin K. Morris. 2003. Effects of syntactic category assignment on lexical ambiguity resolution in reading: An eye movement analysis. Memory and Cognition 31: 87–99. [Google Scholar] [CrossRef] [PubMed]
- Foucart, Alice, Xavier Garcia, Meritxell Ayguasanosa, Guillaume Thierry, Clara Martin, and Albert Costa. 2015. Does the speaker matter? Online processing of semantic and pragmatic information in L2 speech comprehension. Neuropsychologia 75: 291–303. [Google Scholar] [CrossRef] [PubMed]
- Frazier, Lyn, and Janet Dean Fodor. 1978. The sausage machine: A new two-stage parsing model. Cognition 6: 291–325. [Google Scholar] [CrossRef]
- Frazier, Lyn, and Keith Rayner. 1982. Making and correcting errors during sentence comprehension: Eye movements in the analysis of structurally ambiguous sentences. Cognitive Psychology 14: 178–210. [Google Scholar] [CrossRef]
- Friederici, Angela D. 2002. Towards a neural basis of auditory sentence processing. Trends in Cognitive Sciences 6: 78–84. [Google Scholar] [CrossRef]
- Gerth, Sabrina, Constanze Otto, Claudia Felser, and Yunju Nam. 2017. Strength of garden-path effects in native and non-native speakers' processing of subject-object ambiguities. International Journal of Bilingualism 21: 125–44. [Google Scholar] [CrossRef]
- Gibson, Edward. 1992. On the Adequacy of the Competition Model. Language 68: 812–30. [Google Scholar] [CrossRef]
- Grüter, Theres, Elaine Lau, and Wenyi Ling. 2020. How classifiers facilitate predictive processing in L1 and L2 Chinese: The role of semantic and grammatical cues. Language, Cognition and Neuroscience 35: 221–34. [Google Scholar] [CrossRef]
- Hagoort, Peter. 2003. Interplay between syntax and semantics during sentence comprehension: ERP effects of combining syntactic and semantic violations. Journal of Cognitive Neuroscience 15: 883–99. [Google Scholar] [CrossRef]
- Hahne, Anja, and Jörg D. Jescheniak. 2001. What’s left if the Jabberwock gets the semantics? An ERP investigation into semantic and syntactic processes during auditory sentence comprehension. Cognitive Brain Research 11: 199–212. [Google Scholar] [CrossRef] [PubMed]
- Hopp, Holger. 2015. Individual differences in the second language processing of object-subject ambiguities. Applied Psycholinguistics 36: 129–73. [Google Scholar] [CrossRef]
- Jackson, Carrie N., and Susan C. Bobb. 2009. The processing and comprehension of wh-questions among second language speakers of German. Applied Psycholinguistics 30: 603–36. [Google Scholar] [CrossRef] [PubMed]
- Jackson, Carrie. 2008. Proficiency level and the interaction of lexical and morphosyntactic information during L2 sentence processing. Language Learning 58: 875–909. [Google Scholar] [CrossRef]
- Jacob, Gunnar, and Claudia Felser. 2016. Reanalysis and semantic persistence in native and non-native garden-path recovery. Quarterly Journal of Experimental Psychology 69: 907–25. [Google Scholar] [CrossRef]
- Kamide, Yuki, Christoph Scheepers, and Gerry T. M. Altmann. 2003. Integration of Syntactic and Semantic Information in Predictive Processing: Cross-Linguistic Evidence from German and English. Journal of Psycholinguistic Research 32: 37–55. [Google Scholar] [CrossRef]
- Karimi, Hossein, and Fernanda Ferreira. 2016. Good-enough linguistic representations and online cognitive equilibrium in language processing. Quarterly Journal of Experimental Psychology 69: 1013–40. [Google Scholar] [CrossRef]
- Kempe, Vera, and Brian MacWhinney. 1998. The acquisition of case marking by adult learners of Russian and German. Studies in Second Language Acquisition 20: 543–87. [Google Scholar] [CrossRef]
- Kempe, Vera, and Brian MacWhinney. 1999. Processing of morphological and semantic cues in Russian and German. Language and Cognitive Processes 14: 129–71. [Google Scholar] [CrossRef]
- Kidd, Evan, Seamus Donnelly, and Morten H. Christiansen. 2018. Individual differences in language acquisition and processing. Trends in Cognitive Sciences 22: 154–69. [Google Scholar] [CrossRef]
- Kilborn, Kerry. 1992. On-line integration of grammatical information in a second language. Advances in Psychology 83: 337–50. [Google Scholar] [CrossRef]
- King, Jonathan, and Marcel Adam Just. 1991. Individual differences in syntactic processing: The role of working memory. Journal of Memory and Language 30: 580–602. [Google Scholar] [CrossRef]
- Knoeferle, Pia, and Helene Kreysa. 2012. Can speaker gaze modulate syntactic structuring and thematic role assignment during spoken sentence comprehension? Frontiers in Psychology 3: 1–15. [Google Scholar] [CrossRef] [PubMed]
- Knoeferle, Pia, and Matthew W. Crocker. 2005. Incremental effects of mismatch during picture-sentence integration: Evidence from eye-tracking. Paper present at 26th Annual Conference of the Cognitive Science Society, Nashville, Tennessee, August 1–4; pp. 1166–71. [Google Scholar]
- Knoeferle, Pia, and Matthew W. Crocker. 2006. The coordinated interplay of scene, utterance, and world knowledge: Evidence from eye tracking. Cognitive Science 30: 481–529. [Google Scholar] [CrossRef]
- Knoeferle, Pia, and Matthew W. Crocker. 2007. The influence of recent scene events on spoken comprehension: Evidence from eye movements. Journal of Memory and Language 57: 519–43. [Google Scholar] [CrossRef]
- Knoeferle, Pia, Matthew W. Crocker, Christoph Scheepers, and Martin J. Pickering. 2005. The influence of the immediate visual context on incremental thematic role-assignment: Evidence from eye-movements in depicted events. Cognition 95: 95–127. [Google Scholar] [CrossRef]
- Knoeferle, Pia, Thomas P. Urbach, and Marta Kutas. 2011. Comprehending how visual context influences incremental sentence processing: Insights from ERPs and picture-sentence verification. Psychophysiology 48: 495–506. [Google Scholar] [CrossRef]
- Knoeferle, Pia, Thomas P. Urbach, and Marta Kutas. 2014. Different mechanisms for role relations versus verb-action congruence effects: Evidence from ERPs in picture-sentence verification. Acta Psychologica 152: 133–48. [Google Scholar] [CrossRef]
- Knoeferle, Pia. 2007. Comparing the time course of processing initially ambiguous and unambiguous German Svo/ovs sentences in depicted events. In Eye Movements: A Window on Mind and Brain. Edited by Roger P. G. van Gompel, Martin H. Fischer, Wayne S. Murray and Robin L. Hill. Amsterdam: Elsevier, pp. 517–33. [Google Scholar] [CrossRef]
- Knoeferle, Pia. 2016. Characterising visual context effects: Active, pervasive, but resource-limited. In Visually Situated Language Comprehension. Edited by Pia Knoeferle, Pirita Pyykkönen-Klauck and Matthew W. Crocker. Amsterdam: John Benjamins Publishing Company, pp. 227–60. [Google Scholar] [CrossRef]
- Knoeferle, Pia, and Ernesto Guerra. 2016. Visually Situated Language Comprehension. Language and Linguistics Compass 10: 66–82. [Google Scholar] [CrossRef]
- Knoeferle, Pia. 2019. Predicting (variability of) context effects in language comprehension. Journal of Cultural Cognitive Science 3: 141–58. [Google Scholar] [CrossRef]
- Kreysa, Helene, Eva Nunnemann, and Pia Knoeferle. 2018. Distinct effects of different visual cues on sentence comprehension and later recall: The case of speaker gaze versus depicted actions. Acta Psychologica 188: 220–29. [Google Scholar] [CrossRef] [PubMed]
- Kuperberg, Gina R. 2007. Neural mechanisms of language comprehension: Challenges to syntax. Brain Research 1146: 23–49. [Google Scholar] [CrossRef] [PubMed]
- Lardiere, Donna. 1998. Case and tense in a ‘fossilized’ steady state. Second Language Research 14: 1–26. [Google Scholar] [CrossRef]
- Leal, Tania, Roumyana Slabakova, and Thomas A. Farmer. 2017. The fine-tuning of linguistic expectations over the course of L2 learning. Studies in Second Language Acquisition 39: 493–525. [Google Scholar] [CrossRef]
- Lee, Juyoung, and Jeffrey Witzel. 2022. Plausibility and structural reanalysis in L1 and L2 sentence comprehension. Quarterly Journal of Experimental Psychology 76: 319–37. [Google Scholar] [CrossRef]
- Lenth, Russell. 2022. emmeans: Estimated Marginal Means, aka Least-Squares Means. Available online: https://cran.r-project.org/package=emmeans (accessed on 12 December 2022).
- Levy, Roger, Evelina Fedorenko, and Edward Gibson. 2013. The syntactic complexity of Russian relative clauses. Journal of Memory and Language 69: 461–95. [Google Scholar] [CrossRef]
- Lüdecke, Daniel. 2018. sjPlot: Data Visualization for Statistics in Social Science. Available online: https://cran.r-project.org/package=sjPlot (accessed on 28 February 2021).
- MacWhinney, Brian, and Csaba Pleh. 1997. Double agreement: Role identification in Hungarian. Language and Cognitive Processes 12: 67–102. [Google Scholar] [CrossRef]
- MacWhinney, Brian, Elizabeth Bates, and Reinhold Kliegl. 1984. Cue validity and sentence interpretation in English, German, and Italian. Journal of Verbal Learning and Verbal Behavior 23: 127–50. [Google Scholar] [CrossRef]
- MacWhinney, Brian. 2002. Extending the Competition Model. In Bilingual Sentence Processing. Edited by Roberto R. Heredia and Jeanette Altarriba. Amsterdam: Elsevier Science B. V., pp. 31–57. [Google Scholar]
- MacWhinney, Brian. 2005. Second language acquisition and the Competition Model. In Tutorials in Bilingualism: Psycholinguistic Perspectives. Edited by Annette M. B. de Groot and Judith F. Kroll. Mahwah: Lawrence Erlbaum Associates, pp. 113–42. [Google Scholar]
- Marian, Viorica, Henrike K. Blumenfeld, and Margarita Kaushanskaya. 2007. The Language Experience and Proficiency Questionnaire (LEAP-Q): Assessing language profiles in bilinguals and multilinguals. Journal of Speech Language and Hearing Research 50: 940. [Google Scholar] [CrossRef]
- McRae, Ken, and Kazunaga Matsuki. 2013. Constraint-based models of sentence processing. In Sentence Processing, 1st ed. Edited by Roger P. G. van Gompel. New York: Psychology Press, pp. 51–77. [Google Scholar]
- Meng, Michael, and Markus Bader. 2021. Does comprehension (sometimes) go wrong for noncanonical sentences? Quarterly Journal of Experimental Psychology 74: 1–28. [Google Scholar] [CrossRef]
- Mirman, Daniel, and James S. Magnuson. 2009. Dynamics of activation of semantically similar concepts during spoken word recognition. Memory and Cognition 37: 1026–39. [Google Scholar] [CrossRef] [PubMed]
- Mitsugi, Sanako, and Brian MacWhinney. 2016. The use of case marking for predictive processing in second language Japanese. Bilingualism 19: 19–35. [Google Scholar] [CrossRef]
- Morgan-Short, Kara, Cristina Sanz, Karsten Steinhauer, and Michael T. Ullman. 2010. Second language acquisition of gender agreement in explicit and implicit training conditions: An event-related potential study. Language Learning 60: 154–93. [Google Scholar] [CrossRef] [PubMed]
- Osterhout, Lee. 1997. On the brain response to syntactic anomalies: Manipulations of word position and word class reveal individual differences. Brain and Language 59: 494–522. [Google Scholar] [CrossRef] [PubMed]
- Pakulak, Eric, and Helen J. Neville. 2010. Proficiency differences in syntactic processing of monolingual native speakers indexed by event-related potentials. Journal of Cognitive Neuroscience 22: 2728–2744. [Google Scholar] [CrossRef]
- Pakulak, Eric, and Helen J. Neville. 2011. Maturational constraints on the recruitment of early processes for syntactic processing. Journal of Cognitive Neuroscience 23: 2752–65. [Google Scholar] [CrossRef]
- Pan, Hui-Yu, and Claudia Felser. 2011. Referential context effects in L2 ambiguity resolution: Evidence from self-paced reading. Lingua 121: 221–36. [Google Scholar] [CrossRef]
- Pan, Hui-Yu, Sarah Schimke, and Claudia Felser. 2015. Referential context effects in non-native relative clause ambiguity resolution. International Journal of Bilingualism 19: 298–313. [Google Scholar] [CrossRef]
- Papadopoulou, Despina, and Harald Clahsen. 2003. Parsing strategies in L1 and L2 sentence processing. Studies in Second Language Acquisition 25: 501–28. [Google Scholar] [CrossRef]
- Patterson, Clare, Yulia Esaulova, and Claudia Felser. 2017. The impact of focus on pronoun resolution in native and non-native sentence comprehension. Second Language Research 33: 403–29. [Google Scholar] [CrossRef]
- Pearlmutter, Neal J., and Maryellen C. MacDonald. 1995. Individual differences and probabilistic constraints in syntactic ambiguity resolution. Journal of Memory and Language 34: 521–42. [Google Scholar] [CrossRef]
- Pozzan, Lucia, and John C. Trueswell. 2016. Second language processing and revision of garden-path sentences: A visual word study. Bilingualism 19: 636–43. [Google Scholar] [CrossRef] [PubMed]
- Psychology Software Tools, Inc. 2016. E-Prime 3.0. Available online: https://pstnet.com/ (accessed on 3 April 2023).
- Psychology Software Tools, Inc. 2020. E-Prime Go. Available online: https://pstnet.com/ (accessed on 3 April 2023).
- Puebla, Cecilia, and Claudia Felser. 2022. Discourse prominence and antecedent mis-retrieval during native and non-native pronoun resolution. Discours, 29. [Google Scholar] [CrossRef]
- Rankin, Tom. 2014. Word order and case in the comprehension of L2 German by L1 English speakers. EuroSLA Yearbook, 201–24. [Google Scholar] [CrossRef]
- Roberts, Leah, and Claudia Felser. 2011. Plausibility and recovery from garden paths in second language sentence processing. Applied Psycholinguistics 32: 299–331. [Google Scholar] [CrossRef]
- Rosenblum, Lawrence D. 2005. Primacy of multimodal speech perception. In The Handbook of Speech Perception. Edited by David B. Pisoni and Robert E. Remez. Malden: Blackwell, pp. 51–78. [Google Scholar]
- Rosenblum, Lawrence D. 2008. Speech perception as a multimodal phenomenon. Current Directions in Psychological Science 17: 405–409. [Google Scholar] [CrossRef]
- Rossi, Sonja, Manfred F. Gugler, Angela D. Friederici, and Anja Hahne. 2006. The impact of proficiency on syntactic second-language processing of German and Italian: Evidence from event-related potentials. Journal of Cognitive Neuroscience 18: 2030–2048. [Google Scholar] [CrossRef]
- RStudio Team. 2021. RStudio: Integrated development environment for R. Boston: RStudio, PBC. Available online: http://www.rstudio.com/ (accessed on 1 October 2019).
- Sato, Mikako, and Claudia Felser. 2010. Sensitivity to morphosyntactic violations in English as a second language. Second Language 9: 101–18. [Google Scholar] [CrossRef]
- Schlenter, Judith, and Claudia Felser. 2021. L2 prediction ability across different linguistic domains: Evidence from German. In Prediction in Second Language Processing and Learning. Edited by Edith Kaan and Theres Grüter. Amsterdam: John Benjamins, pp. 48–68. [Google Scholar] [CrossRef]
- Schriefers, Herbert, Angela D. Friederici, and Katja Kuhn. 1995. The processing of locally ambiguous relative clauses in German. Journal of Memory and Language. [Google Scholar] [CrossRef]
- Sedivy, Julie C., Michael K. Tanenhaus, Craig G. Chambers, and Gregory N. Carlson. 1999. Achieving incremental semantic interpretation through contextual representation. Cognition 71: 109–47. [Google Scholar] [CrossRef]
- Service, Elisabet, Päivi Helenius, Sini Maury, and Riitta Salmelin. 2007. Localization of syntactic and semantic brain responses using magnetoencephalography. Journal of Cognitive Neuroscience 19: 1193–1205. [Google Scholar] [CrossRef] [PubMed]
- Sevcenco, Anca, Larisa Avram, and Ioana Stoicescu. 2013. Subject and direct object relative clause production in child Romanian. In Topics in Language Acquisition and Language Learning in a Romanian Context. Edited by Larisa Avram and Anca Sevcenco. Bucharest: Editura Universităţii din Bucureşti, pp. 51–85. [Google Scholar]
- Swets, Benjamin, Timothy Desmet, Charles Clifton, and Fernanda Ferreira. 2008. Underspecification of syntactic ambiguities: Evidence from self-paced reading. Memory and Cognition 36: 201–16. [Google Scholar] [CrossRef] [PubMed]
- Tanenhaus, Michael K., Michael J. Spivey-Knowlton, Kathleen M. Eberhard, and Julie C. Sedivy. 1995. Integration of visual and linguistic information in spoken language comprehension. Science 268: 1632–34. [Google Scholar] [CrossRef]
- Tanner, Darren, Judith McLaughlin, Julia Herschensohn, and Lee Osterhout. 2013. Individual differences reveal stages of L2 grammatical acquisition: ERP evidence. Bilingualism 16: 367–82. [Google Scholar] [CrossRef]
- Tanner, Darren, Kayo Inoue, and Lee Osterhout. 2014. Brain-based individual differences in online L2 grammatical comprehension. Bilingualism 17: 277–93. [Google Scholar] [CrossRef]
- The GIMP Development Team. 2019. GIMP. Available online: https://www.gimp.org (accessed on 26 January 2017).
- Traxler, Matthew J. 2011. Parsing. Wiley Interdisciplinary Reviews: Cognitive Science 2: 353–64. [Google Scholar] [CrossRef]
- Trueswell, John C., Michael K. Tanenhaus, and Susan M. Garnsey. 1994. Semantic influences on parsing: Use of thematic role information in syntactic ambiguity resolution. Journal of Memory and Language 33: 285–318. [Google Scholar] [CrossRef]
- Underwood, Geoffrey, Lorraine Jebbett, and Katharine Roberts. 2004. Inspecting pictures for information to verify a sentence: Eye movements in general encoding and in focused search. Quarterly Journal of Experimental Psychology Section A: Human Experimental Psychology 57: 165–82. [Google Scholar] [CrossRef]
- Van Gompel, Roger P. G., and Martin J. Pickering. 2006. Syntactic parsing. In The Oxford Handbook of Psycholinguistics, 2nd ed. Edited by Matthew Traxler and Morton A. Gernsbacher. Cambridge: Academic Press, pp. 455–503. [Google Scholar] [CrossRef]
- Veríssimo, João, Vera Heyer, Gunnar Jacob, and Harald Clahsen. 2018. Selective effects of age of acquisition on morphological priming: Evidence for a sensitive period. Language Acquisition 25: 315–26. [Google Scholar] [CrossRef]
- Wannemacher, Jill T. 1974. Processing strategies in picture-sentence verification tasks. Memory & Cognition 2: 554–60. [Google Scholar] [CrossRef]
- Wickham, H. 2016. Elegant Graphics for Data Analysis Second Edition (vol. 35, pp. 10–1007). Available online: http://www.springer.com/series/6991 (accessed on 12 October 2019).
- Yadav, Himanshu, Dario Paape, Garrett Smith, Brian W. Dillon, and Shravan Vasishth. 2022. Individual differences in cue weighting in sentence comprehension: An evaluation using approximate Bayesian computation. Open Mind 6: 1–24. [Google Scholar] [CrossRef] [PubMed]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).