Abstract
Research on singing and language abilities has gained considerable interest in the past decade. While several studies about singing ability and language capacity have been published, investigations on individual differences in singing behavior during childhood and its relationship to language capacity in adulthood have largely been neglected. We wanted to focus our study on whether individuals who had sung more often during childhood than their peers were also better in language and music capacity during adulthood. We used questionnaires to assess singing behavior of adults during childhood and tested them for their singing ability, their music perception skills, and their ability to perceive and pronounce unfamiliar languages. The results have revealed that the more often individuals had sung during childhood, the better their singing ability and language pronunciation skills were, while the amount of childhood singing was less predictive on music and language perception skills. We suggest that the amount of singing during childhood seems to influence the ability to sing and the ability to acquire foreign language pronunciation later in adulthood.
1. Introduction
Singing is a very complex human vocal behavior which occurs in all cultures and has a large number of different social functions (Hutchins and Peretz 2012; Mithen 2007; Tsang et al. 2011). Singing facilitates the transfer of cultural knowledge (Tsang et al. 2011), has uniting characteristics (Patel 2007) and reveals basic emotions such as fear, happiness, and sadness (Fritz et al. 2009). Song is omnipresent in everyday life and even the vocalization of infants starts out more musical in its characteristics when compared to adult speech (McMullen and Saffran 2004; Tsang et al. 2011).
In the past decade, singing research has gained increasing attention since song consists of elements of both music and language (Crowder et al. 1990). Therefore, research on singing offers new perspectives in understanding the link between music and language learning processes. In recent times, singing and its relationship to language functions has been investigated in various ways. For instance, singing and its positive effect on speech recovery for therapeutic purposes have been investigated in detail (Norton et al. 2009). Other research on the relationship of song and speech have reported that languages can perceptually also be transformed into song by repetition (Deutsch et al. 2011). For instance, Deutsch et al. (2011) have noted that spoken utterances can be transformed to song by repeating the same language stimuli several times. This finding was taken up by Margulis et al. (2015) who investigated language pronunciation abilities. The findings of Margulis’ study have provided evidence that there is an association between how difficult a language is perceived to be and the song-like nature of a language. In another study, it has also been demonstrated that individuals who perceive languages to be more melodic than others also retrieve and pronounce more melodic-sounding utterances more accurately (Christiner et al. 2021).
Educational research has started looking at potential positive transfer effects from melody generation and singing to language functions and vice versa. With this in mind, singing has been employed as a tool in foreign language learning. Researchers have provided evidence that the ability to memorize new vocabulary improves if they are sung (Ludke et al. 2014). Studies on children have shown that learning new words together with a melody also relates to taking up new language material more accurately (Anton 1990). In early childhood, vocalization flows between speaking and singing modes (Snow and Balog 2002) which illustrates that both rest upon the same learning capacities early in life (McMullen and Saffran 2004). Research has outlined that children develop more elaborate vocal skills if they were engaged in vocal play and singing activities (Calì 2017; Snow and Balog 2002). This may also explain why singing ability is associated with foreign language pronunciation (Christiner 2018; Christiner and Reiterer 2018) and vocabulary learning (Thiessen and Saffran 2009). More recently, it was also possible to outline that singing to infants has a positive impact on vocabulary building in later ages (Franco et al. 2021). This shows that singing and language functions are highly intertwined on multiple domains.
On the other hand, psychological and linguistic research has focused on analyzing whether language ability and singing capacity show overlaps (Christiner 2018, 2020; Christiner et al. 2018, 2021; Christiner and Reiterer 2013, 2018, 2019; Coumel et al. 2019; Turker et al. 2018). The findings of these studies have illustrated that language ability and aptitude is indeed related to singing capacity in adults, adolescents, and children.
From a developmental perspective, the overlaps between song and speech are rather salient during infancy and early childhood when culture-specific music and language is acquired. Vocalization of infants can neither be categorized as speech nor as song. Singing, like language ability, is age-related (Davies and Roberts 1975; Goetze et al. 1990) and requires the integration of multiple abilities that depend on physical growth (Sergeant and Welch 2008) which develops alongside motor control (Iverson 2010). Regarding vocal ontogeny, researchers have different views about the relationship of song and speech. While some prefer to view both as separate faculties, others suggest that speaking develops out of singing, or vice versa (Stadler Elmer 2020). Canonical babbling, which starts between 5–10 months of age (Nathani et al. 2006), has more recently been defined to be the starting point for both singing and language development (Stadler Elmer 2020; Welch 2007). The vocalization of children shifts from more associated singing to higher frequency of speaking at the age of 2 years (Welch 2006)—a development which is also related to the fact that during this stage, children gain increasingly more control over their vocal-motor apparatus.
While infants seek to gain control over their vocal-motor apparatus in order to be able to speak and sing, trained singers represent the opposite extreme. Vocalists possess enhanced vocal-motor control and elaborate orofacial motor abilities. Voice experts stress the relationships between singing and speaking, as they are generated by the same vocal apparatus (García-López and Gavilán Bouzas 2010). Contrary to language research, singing research reveals that production processes are often in the foreground. For instance, voice experts analyze the impact of vocal-motor commands, i.e., laryngeal positions (Ekholm et al. 1998; McClellan 2011; Sundberg 1999) such as how vocal timbre and vowel quality is altered by the lowering and raising of the larynx (Ekholm et al. 1998; Sundberg 1999). Vocal instructions for singers are often based on generational instructions such as glottis closure, tongue coordination, breathing techniques, body posture, and intrinsic as well as extrinsic muscle control (García-López and Gavilán Bouzas 2010). Singing training focuses on refining the interplay between the individual components of the vocal organ, the respiratory system, the vocal folds, and the vocal tract (Sundberg 1999) with which vocalization is realized. The basis of vocal instructions is physical training which enhances vocal skills and vocal flexibility. This has also been offered as a possible explanation as to why professional singers perform also better than instrumentalists in language pronunciation tasks of unfamiliar languages (Christiner and Reiterer 2013, 2015).
Brain research mirrors singing research and has provided evidence that vocal-motor training seems to enhance singing and language capacity. Intense vocal training has been found to enhance the connectivity of specific white matter tracts (Halwani et al. 2011), which are associated with language ability (Ocklenburg and Güntürkün 2018). For instance, trained singers show structural adaptations in the left arcuate fasciculus which are relevant for both musical and linguistic functions (Halwani et al. 2011), while reduced density of the arcuate fasciculus has been found in individuals with speech production disorders (Chang and Zhu 2013). Even though neuroscientific studies have provided evidence that general musical training also stimulates non-auditory regions such as pre-motor and supplementary motor areas (Altenmüller 2008; Bangert et al. 2006; Baumann et al. 2005; Chen et al. 2008; Koelsch et al. 2005; Zatorre et al. 2007), vocal training seems to be a special case that leads to the development of fine vocal-motor skills (Kleber et al. 2010).
Studies on foreign language perception and production have noted that speech perception and production can partially be dissociated on a behavioral as well as on an anatomical basis (Christiner 2020; Golestani and Pallier 2007). Thus, individuals who perceive foreign speech sounds more precisely do not necessarily pronounce them better. In the light of linguistic models, several assumptions about the relationship between speech perception and production have been put forward. For instance, the TRACE Model of Speech Perception suggests that perception and production can largely be separated (McClelland and Elman 1986), while other models such as the Perceptual Assimilation Model (Best 1995) and the Motor Theory of Speech Production (Liberman and Mattingly 1985) propose that perception and production are interrelated to a certain extent. The Motor Theory of Speech Production model is based on the assumption that the perception of an utterance is to perceive a specific pattern of intended gesture. This involves the understanding that acoustic speech sounds are transformed gestures and consequently, that speech perception and production are, in two ways, motor (Liberman and Mattingly 1985). Contrary to the general concept that perception precedes production of utterances, research has also noted that this process can be reversed. For instance, researchers developed a robotic device that altered the jaw position while participants articulated specific utterances. The findings of this study have revealed that only the participants who adapted to the new motor commands showed a perceptual shift (Nasir and Ostry 2009).
Research on music perception and singing have come to conclusions similar to those of language research on the perception and production of speech. Specifically, contradictory results in musicological research about the relationship between singing and pitch perception have been found. In a study by Zarate (2013), training-induced neural plasticity within the functional network for audio-vocal integration was assessed. Participants received auditory discrimination training, which aimed at improving singing accuracy. Findings revealed that auditory training alone could not account for improving vocal accuracy. In contrast, other studies have delineated a relationship between music perception and singing (Estis et al. 2009). Despite the miscellaneous findings, inaccuracy in singing has often been related to perception deficits (Hutchins et al. 2014; Tremblay-Champoux et al. 2010). In order to uncover interactions between music processing and production, researchers have focused on studying individuals who suffer from congenital amusia—a lifelong deficit in perceptual musical ability (Tillmann et al. 2009). Amusics are poor singers (Hutchins and Moreno 2013) which creates the impression that poor singing ability is caused by perception deficits. However, researchers have provided alternative reasons for poor singing of individuals such as deficits in implementing motor ability (Tremblay-Champoux et al. 2010; Groß et al. 2022), and in sensorimotor translations of the vocal system affecting (vocal) imitation in general (Pfordresher and Mantell 2014). These notions are also illuminated in a model on singing ability and pitch perception: the Linked Dual Representation Model by Hutchins and Moreno (2013). This model proposes that vocal information can be processed in two different ways. First, conscious perception enables individuals to distinguish between low or high tones, and second, to encode vocal information as the motoric representation necessary for all generative vocal processes. The authors assume that this model is potentially applicable to all vocal behaviors. If such a model could be sustained, there are at least two ways in which all vocal behaviors can be processed, namely perceptual and motoric. The motoric and direct way may be more effective for generational processes, which may explain why individuals who sing well can mimic accents (Coumel et al. 2019) and pronounce new languages better than individuals with lower singing skills (Christiner 2020; Christiner and Reiterer 2013, 2015; Ludke et al. 2014). It appears that individuals with elaborate singing skills encode vocal information more likely as motoric representation rather than as conscious perception.
Since language acquisition processes shape vocal behavior in general, it could be assumed that individuals who sing more often during childhood may acquire more elaborate vocal-motor skills than individuals who sing seldom. In language research, it is a commonly accepted notion that the earlier foreign languages are acquired, the better the foreign language proficiency. It is well-observed that late foreign language learners often show poor ability to take up foreign accents (Reiterer et al. 2011; Skehan 2012), and it has been suggested that only 5 percent of late foreign language learners reach native-like pronunciation skills. While there is a considerable amount of literature about the benefit of learning foreign languages at a young age, studies on the impact of singing behavior during childhood on language capacity, in particular, pronunciation, have largely been neglected. Only a few attempts have been made to analyze the impact of childhood singing, i.e., individuals who tended to sing more often than their peers, on language functions during adulthood. Individual differences in singing behavior during childhood has been related to language pronunciation skills and voice quality (Christiner 2013) which is seen as the marker of a professional voice (Sundberg 1988). In another study, similar findings have been made showing that singing frequency during childhood can be related to the ability to repeat unfamiliar language in six out of eight languages, instrument playing, singing ability, and performance anxiety (Christiner 2013, 2020). The few existing studies suggest that there appears to be a relationship between language, singing, and music acquisition processes that develop during childhood.
In developmental terms, singing and speaking derive from a common source which is why it is plausible to assume that both influence each other beyond childhood. However, while various language-related factors influencing language acquisition processes have been studied in detail, little is known about whether the amount of singing during childhood also influences language capacity during adulthood.
Therefore, we wanted to address this research field in more detail and developed questionnaires in which the participants were asked to assess their singing behavior during childhood. Three distinct categories emerged: individuals, who as children had sung very often, on average, and seldom. In addition, we used an already established multi-item scale concept about the singing behavior during childhood as a second childhood singing measurement. Furthermore, we tested them for their ability to pronounce and perceive five unfamiliar languages as well as their music perception ability and their singing capacity. We speculated that if the relationship between singing ability and language functions are largely based on motor ability, we assumed that individuals who sang more often during childhood will be better at language pronunciation and singing ability (Q1) but not necessarily in speech and music perception (Q2).
1.1. Measuring Language Perception and Production Ability
Measuring individual differences in the ability to perceive and to pronounce languages can be executed in several ways. Existing validated language ability tests such as the LLAMA (Meara 2005), the MLAT (Carroll 1989), or the PLAB (Pimsleur 1966) are available but are not suitable measurements to assess language perception and production since none of the tests include a pronunciation task. Existing language perception tasks are based on sound discrimination. For instance, individuals have to discriminate almost identical words in Ewe (Pimsleur 1966). Another way of assessing language perception ability has been developed by Meara (2005). He invented a sound recognition task (LLAMA D) where short stretches of spoken utterances in a British Columbian Indian language should be recognized (Meara 2005). This measurement is usually used to assess the ability to perceive and discriminate unfamiliar languages. Since established tests do not include production (pronunciation) and perception tasks of the same languages, we developed our own language pronunciation and perception tasks. The language perception tasks we developed shows similarities to the LLAMA D measurement and consisted of strings of language elements followed by a response which is either included in the string, before or not, in five different languages (see Section 2.3)
For assessing individual differences in pronunciation ability, we used language measurements of previous research (Christiner 2020; Christiner et al. 2021). Presenting individual differences in language pronunciation skills is achieved best by developing short sequences of unfamiliar language material which individuals have to repeat. The performances of the participants can subsequently be evaluated by experts or native speakers for their accuracy. This way of measuring individual differences in pronunciation skills is also of high ecological validity as it resembles a situation in which new languages are acquired, and has been used and assessed in various previous studies (Christiner 2020; Christiner et al. 2021; Christiner and Reiterer 2013). Since we used this approach in earlier research, the nature of the measurements was studied in more detail in several sessions. Findings have revealed that, on the one hand, short sequences of different language material more likely reflect general pronunciation ability, even if they are typologically different. On the other hand, this suggests that different languages as a single language pronunciation measurement represent a more reliable and stronger approach to assess individual differences in the ability to reproduce unfamiliar languages (Christiner 2020; Christiner et al. 2021).
1.2. Measuring Music and Singing Ability
Musical ability tests are rather diverse and multiple measurements have been established to assess different musical capacities. Most of them are discrimination tasks which mainly focus on rhythmic and melodic parameters (Gordon 1965, 1979, 1982; Gordon 1989; Law and Zentner 2012; Wallentin et al. 2010). One very frequently used measurement to assess tonal and rhythmic ability is the Advanced Measures of Music Audiation (AMMA) by Gordon (1989). This test has often been used in the scientific context to assess the ability to discriminate musical statements and provides information about tonal and rhythmic perceptual abilities. Therefore, we also used, beside a tone frequency task (high versus low tones), the AMMA test in our study. While the AMMA test is already accepted, no unified methods have been established for measuring singing ability. In general, two main singing tasks are distinguished: imitation tasks (repeating new, unfamiliar melodies or songs) and familiar song singing tasks (Christiner 2020). The assessment of singing tasks can be achieved by computerized methods and by rating scales (Salvador 2010). Since rating scales can easily be adjusted to the criteria to be evaluated, they are often preferred. Rating scales are also often used if singing criteria of voice experts such as vocal range or voice quality are assessed because longer sequences of songs can also be evaluated (Christiner 2020). In this investigation, we used singing tasks (imitation and familiar song singing tasks) and expert (vocal range, voice quality, volume, and focus) and non-expert singing rating criteria (rhythm and melody) based on previous research (Christiner 2013, 2020; Christiner et al. 2021; Christiner and Reiterer 2019).
2. Materials and Methods
2.1. Participants
We recruited 92 informants who voluntarily participated in this study. Informed consent was obtained from all subjects involved in the study. The sample included 39 male and 53 female participants. Their mean age was M = 34.69, SD = 13.40.
The participants were all monolingually grown-up German native speakers who started acquiring foreign languages at schools. None of the participants reported to speak or comprehend any of the five languages which we included in the research design. The most frequently spoken foreign language was English, followed by Spanish, French, Italian, Dutch, and Croatian. The participants were instructed to indicate the foreign languages which they spoke, at least on a B1 level or higher. Ten of the participants reported to have learnt English in school but felt unable to communicate in English, while thirty-one participants indicated their ability to speak one foreign language on a B1 level or higher. Forty participants indicated an ability to speak two foreign languages, while eleven participants reported their ability to speak three foreign languages on a B1 level or higher.
2.2. Educational and Musical Status
The educational status of the participants revealed that forty-five participants completed secondary academic school (general qualification for university entrance), seventeen had a bachelor’s degree, thirty had a master’s or a doctoral degree. The participants reported their musical proficiency as either advanced musical practitioners, basic musical practitioners, or non-musicians. It was explained that being an advanced musical practitioner meant that they play musical instruments or sing every week on a regular basis. Being a basic musical practitioner meant that they play a musical instrument or sing occasionally, while being a non-musician meant that they rarely and are not capable of playing a musical instrument.
2.3. Language Perception
For measuring aptitude in phonetic perception, a speech perception task was developed which consisted of five unintelligible (for the participants) foreign languages (Thai, Tagalog, Mandarin, Farsi, Japanese). The task consisted of language strings (Stimline) of eight, ten or twelve different words or short phrases (Stims), followed by a comparative string (Stimcompare) which consisted of one, two or three words or short phrases. The Stims of the Stimline are separated from each other by a pause of 50 ms while the Stimcompare is separated from the string by a pause of 2 s. Additionally, the change from the Stimline to Stimcompare is supported by a change in the color of the screen. To the participants, the samples sounded like a sequence of foreign speech since the Stims always were spoken by the same speaker. The participants were asked to indicate whether the Stimcompare was included in the Stimline they were listening before or not. In the condition where the Stimcompare consisted of two or three Stims, the answer “correct” is only given if all comparative phrases were included in the string. A detailed test description is contained in the Supplementary Materials (see Section S3). This phonetic measurement was programmed online and consists of a familiarity task which was practiced as often as the participants wanted. After the familiarity session, the 25 tasks (five tasks for each of the five languages) were performed in a single sitting. The participants listened to each of the tasks once. The sum of all 25 items represented the language perception score.
2.4. Language Production
For measuring the ability to pronounce new words, language tasks consisted of short sequences of nine to eleven syllables long in the same foreign languages that were used for the language perception tasks. The samples were spoken by native speakers in the standard language version of the respective languages (Thai, Mandarin, Tagalog, Farsi, and Japanese). For each language, four samples spoken by four different speakers have been used. This type of measuring phonetic aptitude is of high ecological validity because it simulates a foreign language situation in which new words, phrases, or sentences are acquired. The participants had to repeat the samples in a single sitting. Before testing, the participants performed a familiarization program for which samples in the Polish language were provided, and each sample was played three times and separated by a pause of 50 ms. Afterwards, the participants were instructed to repeat the sample once in the accent as best they could. Their responses were recorded before the next sample followed. For the recordings, the participants were given Beyerdynamic, DT 290 headphones with integrated microphone. The trials from the familiarization task were discarded from the analysis. After the participants were introduced to their task, testing took place.
The recordings of the participants were re-assessed before they were uploaded to the rating platform. First, we ensured that the recordings were of similar length. Therefore, pauses at the beginning and the end of the recordings were cut and removed. Then, the loudness of the samples was normalized. The performances which were uploaded to an online rating platform were rated by native speakers of the respective languages. The raters were informed that the speakers did not speak or had been taught in any of the five languages. They were also provided with the original sound files which were spoken by native speakers of the respective languages. Then, the raters were introduced to evaluate how well the language samples were pronounced and whether the speakers sound native-like or not. Raters were asked to focus on accuracy in intonation, fluency, and intelligibility. In addition, the raters were instructed to evaluate the performances of the participants on a scale between 0 and 10 where 10 was the highest possible score and 0 the lowest one could receive—an approach which has been used several times in previous research (Christiner 2018; Christiner et al. 2018, 2021; Christiner and Reiterer 2018). Although ratings of native speakers do not deviate from phoneticians (Bongaerts 1999), we decided to consult raters who were native speakers of the respective languages and linguists. For their work, we offered them compensation. We consulted five raters for Thai, four raters for Tagalog, five for Mandarin, four for Farsi, and six for Japanese. For the assessment of the ratings, we followed previous research in which the nature and interpretation of the rating scales of various language pronunciation tasks were discussed and analyzed in detail (Christiner 2020). We therefore applied an inter-rater reliability Cronbach’s α for assessing the internal consistency of the ratings for this study. Results have revealed that the ratings showed high interrater reliability, and the Cronbach’s α varied between 0.86 and 0.93 for the five different languages. The sum of all 20 items represents the language pronunciation score.
2.5. Singing Measures
The singing ability was tested and measured in two different ways: singing an unknown and a familiar song. The familiar song was “Happy Birthday” and the second singing task consisted of two imitation tasks where parts of an unfamiliar song had to be learnt. We used singing tasks which were successfully used in previous studies (Christiner 2013, 2020; Christiner et al. 2021). Therefore, we knew that the familiar song singing and the short sequences of the song learning task were completed by all participants regardless of whether they were advanced, basic musical practitioners or non-musicians. The participants had to sing “Happy Birthday” to the best of their ability, before they were introduced to the unfamiliar song. This song singing task was divided into two components, with increasing difficulty. Lyrics were provided since singing with lyrics demonstrates the full vocal repertoire and makes it possible to address more rating criteria (Larrouy-Maestri et al. 2013). The participants had to sing the original part of the song after they had listened to the original sound file three times in a row separated by a pause of 2 s. Additionally, the participants had to sing the song for the recording without background music and only from memory to the best of their ability. In this respect, the participants were also required to use a key which they found pleasurable since key was not considered in the ratings but only the internal consistency of how well they sang the constituent of the song.
For the evaluation of the singing performances, we used the same approach we had used in previous studies (Christiner 2013, 2020; Christiner et al. 2018, 2021). We then consulted singing experts (two male and two female raters) who rated the singing performances for the six criteria: voice quality, vocal range, volume, clarity/focus, melodic, and rhythmic ability. We used common singing criteria (rhythm and melody) and expert singing criteria (voice quality, vocal range, volume, clarity/focus) since we wanted to assess all elements of the performances as precise as possible for the creation of our singing ability complex. However, since singing criteria are rather closely interrelated, we do not discuss the individual parameters but use the composite score which consists of all six criteria in this study.
Although the raters were experts in their fields, they received additional instructions in respect to the six evaluation criteria. For a detailed description about the singing criteria, we used works by Wapnick and Ekholm (1997) or Gupta et al. (2018) to introduce the raters. The ratings were conducted online where the evaluators had to listen to all performances of all participants. Since it was not possible to do the ratings within a single sitting, the ratings were always performed on just one of the six criteria before the next criteria was rated. Each criterion was assessed in a separate sitting and the performances of the participant appeared in random order. The first six performances in all rating sections were familiarization tasks for which we used samples of participants of previous research who had achieved high, average, and low scores. Then, the performances were presented in randomized order where the raters had to indicate their assessment on a scale ranging from 0, “minimum”, to 10, “maximum”.
The ratings form the basis of the singing complex which consists of all six criteria of both singing tasks. This approach was based on the findings of former research where different singing tasks and singing rating criteria were assessed. Interrater reliability and factor analysis showed that familiar and unfamiliar song singing tasks were highly interrelated and can be treated as a single singing complex. This was also shown to be consistent after a follow-up reliability analysis (Christiner 2020). Therefore, we also applied an interrater reliability by means of using Cronbach’s alpha coefficients to assess the internal consistency of the performances of our raters. This was determined for all rating criteria. The Cronbach’s alpha coefficients for the six rating criteria were rather high and ranged between 0.86 and 0.93.
The participants were also asked to estimate how many hours per week they had been singing over the last five years (Singing Hours Per Week (HPW). Therefore, they were introduced that any form of singing (e.g., in the car, in the bathroom, etc.) should be considered.
2.6. AMMA Test and Tone Frequency
Participants’ music perception abilities were measured with the AMMA test (Advanced Measures of Music Audiation, Gordon 1989). This measurement requires the participants to determine whether two musical statements differ rhythmically, tonally, or whether they are the same. In the different conditions, tempo, meter, duration, or notes can be altered. While the latter assesses tonal discrimination ability, the other conditions provide information about the ability to detect rhythmic changes. The entire test consists of 33 items. The first three items are discarded from the analysis since they belong to the familiarization tasks. The 30 paired statements represent the test stimuli (music perception: AMMA total score).
To test basic sound perception abilities, the subtest tone frequency of the primary auditory threshold measure KLAWA (Klangwahrnehmug) was used. KLAWA is an inhouse computer-based threshold measurement. Difference limes are measured for tone frequency (“low vs. high”). Based on an “alternative-forced choice” (Jepsen et al. 2008), this method to measure individual perceptual thresholds can be used for scientific investigations to study auditory processing. In this computer-aided test procedure of exact scientifically measured quantities (cent = 1/100 semitone for recording the pitch, and milliseconds (ms) for time measurements), the above-mentioned hearing performance was determined, which can largely vary from subject to subject (>factor 100). In an alternative forced-choice paradigm, reference, and test tones (sinusoids) separated by an interstimulus interval of 500 ms were presented. Participants were asked to decide, per mouse-click, which of the presented tones sounded higher or longer in the tone frequency subtests. If the answers were correct, the differences become smaller in small steps; if the answers were incorrect, they become larger again. In this procedure, which automatically adapts to the performance of the tested subjects with increasing difficulty, the individual threshold values were finally calculated based on the convergence behavior.
2.7. Singing Behavior during Childhood
We collected the information about childhood singing during two different sessions. The participants had to fill in an online questionnaire on singing behavior during childhood. Additional information was provided to assure that the participants referred to the same period they received further information, which was a definition of childhood as an age prior to 11 years. It has been suggested that the singing voice reaches around two octaves at the age of 10 (Welch et al. 2011) which is similar to adults without vocal training (Christiner 2020). After the participants filled in the online questionnaire, they were invited to a soundproof room for the recording and execution of the language and music tasks where they were also provided with the second childhood singing measurement with the three response options.
To assess how often the participants had sung during childhood, two distinct questionnaires were used. One reflected the concept of a multi-item scale which introduced the participants to the topic; additionally, this questionnaire allowed the retesting of the reliability of the main response options. The second childhood singing measurement defined three distinct categories: “I sang very often (often)”, “I sang an average amount (average)”, and “I sang very seldom (seldom)”.
In general, it has been recommended that multi-item scales should include fewer than four questions in order to ask for a particular concept (Dörnyei and Taguchi 2010). The internal consistency of a multi-item scale concept should show at least a Cronbach’s α value of 0.70 (Warner 2013). Therefore, we developed eight questions based on previous research (Christiner 2013, 2020), and assessed the internal consistency of the statements by applying means of Cronbach’s α. All Cronbach’s α = 0.90 (see Supplementary Materials Section S2.1) which is well above the accepted value. The questions are contained in the Supplementary Materials (see Table S1).
The second childhood singing measures consisted of response options such as “I sang very often (often)”, “I sang an average amount (average)”, and “I sang very seldom (seldom)”. Since these statements without detailed instructions would have been too vague, we carefully introduced the participants to what we call the three categories. The participants received detailed instructions about the meaning of the three options as additional information in their mother tongue (German). Option 1 “often” was described in the following way: “As a child I used to sing whenever I could”. “As a child I used to sing more often than my friends”. “As a child I enthusiastically joined in with the singing whenever the possibility arose”. “I suggest that I sang very frequently when I was a child. I can clearly say that I sang very often during my childhood”. Option 2 “average” singing was described in the following way: “As a child I used to sing like most of my friends did”. “On average I think that I sang as often as most of my friends”. “As a child I joined in with the singing like everyone else”. “I think that I would describe the amount of singing during my childhood to be average”. “There were of course people in my near surrounding who sang more or less frequently”. “I can clearly say that I was an average singer when I was a child”. Option 3 “seldom” was indicated in the following way: “As a child I used to sing less often than my friends”. “As a child I didn’t like to join in with the singing. I suggest that I sang very seldom when I was a child”. “In general, most of my friends sang more often than me”. “I can clearly say that I sang seldom when I was a child”.
Based on the response options, 34 participants classified themselves as belonging to the “often group”, 29 participants to the “average” group, and 29 participants to the “seldom” singing group. The statistical analyses in the Results and Methods sections are based on the response option. However, as a retest, we also used the multi-item scale concept singing behavior during childhood and analyzed the concept’s relationship to the second childhood singing variable by applying correlational analysis. In addition, we performed cluster analysis to establish groups based on the eight statements of the multi-item scale concept and ran the same statistical analyses again. Since both the multi-item scale concept, and the response options have provided almost identical findings, the statistical analyses of the multi-item scale concept, including a short description of the statistical approach, have only been included in the Supplementary Materials Sections S2.3 and S2.4.
3. Results
3.1. Statistical Analysis
The statistical analysis is divided into three main sections. First, we performed a MANOVA where we wanted to reveal whether singing behavior during childhood based on the three options (often, average, and seldom) predicts individual differences in language perception, language pronunciation, singing ability, singing hours per week, music perception (AMMA), and the number of foreign languages. As a follow-up analysis, we performed separate ANOVAs and discriminant analysis to illustrate how well our variables predict group membership. As there were sightly unequal group sizes, we ran Welch-ANOVAs followed by Games-Howell post-hoc analyses for pairwise group comparisons. We also included the linear term of the ANOVA as it provides information about whether the means increase across groups in a linear way. The separate ANOVAs are provided below (see Section 3.2.1, Section 3.2.2, Section 3.2.3, Section 3.2.4, Section 3.2.5, Section 3.2.6 and Section 3.2.7). The statistical approach which consists of MANOVA followed by discriminant analysis has been decided since this procedure takes relationships among variables into account, corrects for multiple comparisons, and provides information about which of the variables discriminate, for instance, a specific group best. Second, we run correlations followed by regression analysis. As the language pronunciation score was beside singing ability, the best predictor with which the three groups could be differentiated, we used the pronunciation score as the dependent variable. For the regression model, a stepwise method was chosen, and the ordering of the variables was based on purely mathematical decisions. Third, we also assessed whether there was an association between the grouping of variable singing behavior during childhood, gender, and the musical status (advanced musical practitioner, basic musical practitioners, and non-musicians) of the participants by means of using chi-square analyses. The results revealed that both chi-square tests were non-significant (see Supplementary Materials Section S1). Before we show the results of the statistical analyses, we provided the descriptives of the variables in Table 1 below first.

Table 1.
Descriptives of the variables of interest.
The scores for the speech perception task range between 0 and 1. Zero means that none of the tasks were correctly answered, while 1 indicates that all tasks were correctly answered. The values represent percentages of correct answers in decimal numbers. The speech pronunciation score like the singing score range between 0 and 10. Whereas 0 represents the worst score one can receive, 10 is the highest. While the full scaling range of the scoring is expected for singing, the pronunciation scores tend to be lower. Ratings of native speakers’ pronunciation performances are expected to range between 8 and 10. Since the participants did not speak or have learnt any of the language before, a mean value of around 3 has been expected and represents scorings of previous research (e.g., Christiner et al. 2021). For the AMMA test, we used the raw score which can vary between 0 and 80. While 0 is the lowest score one can receive, 80 is the highest score. In addition, Singing hpw represents the score for how many hours the participants estimated to sing per week over the last five years (Singing Hours Per Week (HPW), and the number of foreign languages represent the foreign languages which the participants spoke at least on a B1 level or higher. The tone frequency score represents measures in cents.
3.2. MANOVA
We performed a MANOVA to understand whether our language perception, language pronunciation, singing ability, singing hours per week, the number of foreign languages, and the music perception variables AMMA and tone frequency differ in their mean values based on the singing behavior grouping variable (often, average, and seldom). Using Pillai’s trace, there was a significant effect of singing frequency during childhood and language pronunciation and perception V = 0.47, F(14, 154) = 3.37, p < 0.001. Since the MANOVA was significant, we ran separate ANOVAs for all four dependent variables and afterwards, a discriminant analysis.
3.2.1. ANOVA: Language Pronunciation
There was a significant main effect of the amount of singing during childhood and the performance of the pronunciation tasks, F(2, 89) = 6.98, p < 0.002, ω = 0.34. There was also a linear trend, F(1, 89) = 13.75, p < 0.01, ω = 0.35, indicating that the more the participants sang during childhood, the better they performed in the language pronunciation tasks. Planned contrasts also revealed that the group which sang most often performed significantly better in the language tasks than the group which sang seldom t(89) = 3.71, p < 0.001, r =0.37. For the other groups, no statistical difference was observed, but the linear trend shows that the “often” group (M = 2.97, SD = 1.01) performed best, followed by the “average” (M = 2.52, SD = 0.76) and the “seldom” (M = 2.19, SD = 0.67) groups (see Figure 1).
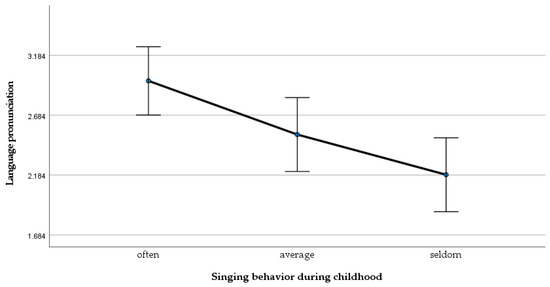
Figure 1.
Mean differences of the language pronunciation measure across groups.
3.2.2. ANOVA: Language Perception
A separate ANOVA for the speech perception tasks revealed that no significant effect on the amount of singing during childhood and language perception could be detected F(2, 89) = 0.92, p > 0.05 (see Figure 2).
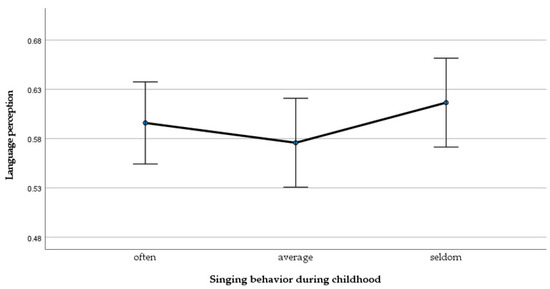
Figure 2.
Mean differences of the language perception measure across groups.
3.2.3. ANOVA: Singing Ability
There was a significant main effect of the amount of singing during childhood and singing ability, F(2, 89) = 20.20, p < 0.001, ω = 0.54. There was also a linear trend, F(1, 89) = 39.95, p < 0.01, ω = 0.57, indicating that the more the participants sang during childhood, the better they performed in the singing tasks. Planned contrasts also revealed that the group which sang most often performed significantly better in the language tasks than the group which sang seldom t(89) = 6.32, p < 0.001, r = 0.56. For the other groups, no statistical difference was observed, but the linear trend shows that the “often” group (M = 6.66, SD = 1.22) performed best, followed by the “average” (M = 5.78, SD = 0.76) and the “seldom” (M = 5.08, SD = 0.87) groups (see Figure 3).
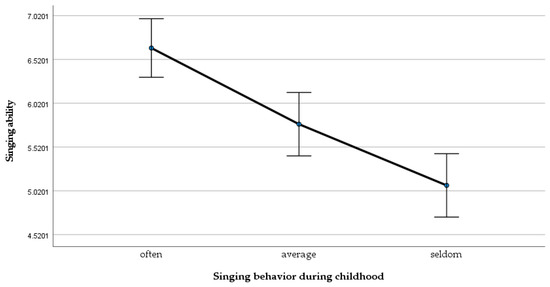
Figure 3.
Mean differences of the singing ability across groups.
3.2.4. ANOVA: AMMA Perception
A separate ANOVA for the speech perception tasks revealed that no significant effect on the amount of singing during childhood and language perception could be detected F(2, 89) = 1.17, p > 0.05 (see Figure 4).
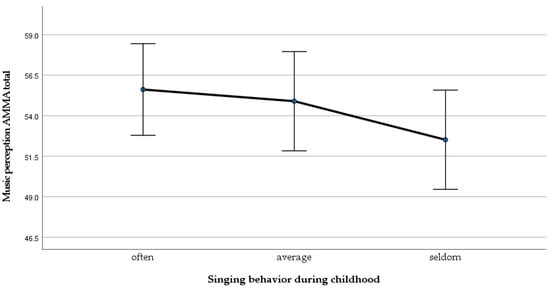
Figure 4.
Mean differences of the music perception measure (AMMA total) across groups.
3.2.5. ANOVA: Singing Hours per Week
There was a significant main effect on the singing hours and the amount of singing during childhood (often, average, seldom), F(2, 89) = 6.18, p < 0.003, ω = 0.32. There was also a linear trend, F(1, 89) = 11.25, p < 0.001, ω = 0.30, indicating that the more the participants sang during childhood, the more hours they sing per week. Planned contrasts also revealed that the group which sang most often sang significantly more hours than the group which sang an average amount t(89) = 2.470, p < 0.015, r = 0.25 and the group which sang seldom t(89) = 3.358, p < 0.001, r = 0.34. For the average versus seldom group, no statistical difference was observed (see Figure 5).
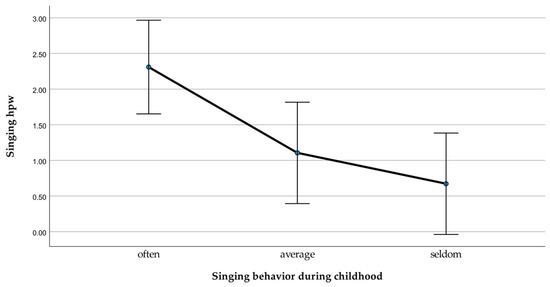
Figure 5.
Mean difference of the singing hours per week measure across groups.
3.2.6. ANOVA: Number of Foreign Languages
A separate ANOVA for the amount of foreign languages revealed that no significant effect on the number of foreign languages and the amount of childhood singing (often, average, seldom) could be detected F(2, 89) = 0.55, p = 0.577 (see Figure 6).
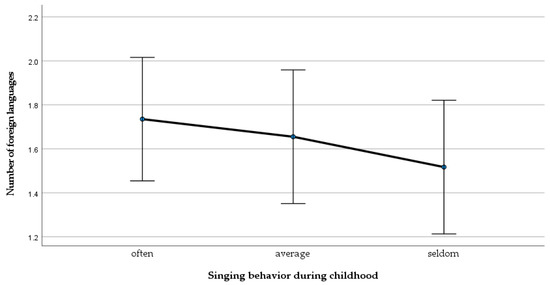
Figure 6.
Mean differences of the number of foreign languages across groups.
3.2.7. ANOVA: Tone Frequency
A separate ANOVA for the tone frequency measurement revealed that no significant effect on the tone frequency ability and the amount of childhood singing (often, average, seldom) could be detected F(2, 89) = 0.66, p = 0.519 (see Figure 7).

Figure 7.
Mean differences of the music perception measure (tone frequency) across groups.
3.3. Discriminant Analysis
The MANOVA was followed by a discriminant analysis, which revealed two discriminant functions. The first explained 96.3% of the variance, canonical R2 = 0.44, whereas the second explained only 3.7%, canonical R2 = 0.02. In combination, these discriminant functions significantly discriminated the groups, Λ = 0.54, χ²(14) = 48.20, p < 0.001, but removing the first function indicated that the second function did not significantly differentiate the three groups Λ = 0.97, χ²(6) = 2.33, p = 0.89. The correlations between the outcomes and the discriminant functions revealed that the loads onto the first function are rather high for the singing ability (r = 0.90) and the language pronunciation (r = 0.53), while they showed rather low loads onto the second non-significant function; singing ability (r = 0.13) and the language pronunciation (r = 0.15). If the statistically recommended cutoff of value of 0.50 is used to decide which of the standardized discriminant coefficients are large (Warner 2013), the singing ability and the language pronunciation highly discriminate the groups. In the second non-significant function the singing hours per week (r = −0.59), tone frequency (r = −0.52), the AMMA test (r = −0.17), and the language perception measurement (r = −0.39) showed the largest correlation between each variable and discriminant function 2. Based on the singing ability and the pronunciation score, the group which sang very often in childhood can be differentiated from both of the other groups. The discriminant plot illustrates the finding (see Figure 8).
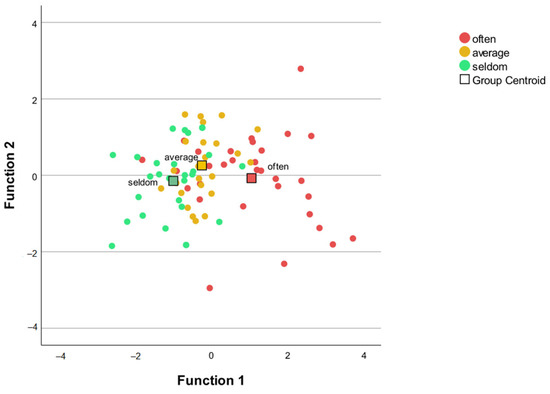
Figure 8.
Discriminant plot of the singing behavior during childhood groups.
Figure 8 Discriminant function of the language and music variables. Function 1 discriminates the often group from both other groups. The correlations between the outcomes and the discriminant functions revealed that the loads onto the first function are high for singing ability (r = 0.90) and for language pronunciation (r = 0.53).
3.4. Correlational Analysis
Pearson’s correlational analysis was applied to outline the relationships between the music and the language variables. The results of the correlations are provided below in Table 2.
Table 2.
Correlations of the variables of interest.
3.5. Regression Analysis
The correlational analysis provided the basis for the regression analysis. In the regression analysis, all variables which correlated to the language pronunciation score were entered into a multiple linear regression as independent variables. We decided for a stepwise method in which the ordering of the variables is based on mathematical decisions. The results revealed that singing ability, the number of foreign languages, and the multi-item concept singing behavior during childhood predicted 43 percent of the variance in the pronunciation. The only predictor which did not contribute was the AMMA score. Table 3 below illustrates the results of the regression models.
Table 3.
Multiple regression models explaining the variance in Language pronunciation.
4. Discussion
The findings of the statistical analyses have shown that participants who sang more often during childhood were better at singing and better at pronouncing unfamiliar languages (Q1), while differences in music and language perception across groups were not detected (Q2). In addition, we performed a regression model which has shown that 43 percent of the variances of the pronunciation skills can be explained by the number of foreign languages spoken, singing ability, and childhood singing. Research on speaking multiple languages and its positive influence on learning new languages has been intensively studied and will not be further discussed. For details, the following work could be consulted: (Gathercole et al. 1997; Christiner et al. 2021; Gathercole 2006; Gathercole and Baddeley 1990; Papagno and Vallar 1995). In the following, we will mainly focus on the musical and language variables which we included in the research design. Language, music, and singing acquisition processes include a number of critical and sensitive periods which are age-related (Birdsong and Vanhove 2016; Cohen 2008; Gordon 2013; Hernandez and Li 2007; Patel 2007; Sloboda 2005). Infants acquire their native language and music simultaneously which illustrates that both processes are intertwined by their nature. In general, infants are virtually open to learn any language. However, the input infants receive shapes and manifests their linguistic competence throughout their lives. This kind of specification for the native language is at the expense of plasticity towards the ability to acquire unfamiliar languages during adulthood. Therefore, only few individuals gain native speaker competences in foreign languages during adulthood. Adult learners of new languages have difficulties, for instance, in discriminating and producing phonetic contrasts which are not rooted in the mother tongue (Werker and Tees 2005). Other difficulties arise in the beginning stages where individuals often fail to hear where a word begins or ends. As a result, language learners face segmentation difficulties since learners apply the same segmentation strategy of their native language (Patel 2007).
Most often, it is suggested that difficulties in the acquisition of foreign languages mainly stem from perception difficulties and therefore also affect pronunciation skills. This is motivated by dominating views which suggest that perception of acoustic input precedes its reproduction (Hutchins and Moreno 2013). We found that childhood singing was associated with singing ability and pronunciation skills in our adult participants. This may indicate that early childhood singing has an influence on the vocalization later in life. This reflects common notions about music acquisition processes. Musical ability is a composition between innate and early acquired skills, and a rich musical environment during childhood that increases the chances to develop high musical talent (Gordon 2013). Whereas musical talent is associated with multiple abilities, singing is a musical phenomenon which is highly dependent on vocal-motor training. While it is a commonly accepted notion that early musical exposure and training leads to higher musical proficiency, there is no equivalent research focusing on vocal-motor training during childhood and its effect on the vocalization of language and singing ability during adulthood is available.
Individuals who sing more often than others during childhood continually train their vocal-motor apparatus which, according to our findings, leads to enhanced singing and language pronunciation skills later in life. This finding seems to correspond to observations in previous research on the relationships between language production and musical abilities (singing and music perception). Good singers seem to retain a certain plasticity to generate new sound combinations (Christiner and Reiterer 2013, 2019) which may be partly based on their vocal flexibility and which are achieved by long-term vocal-motor training, while perceptual musical abilities played an inferior role in pronunciation skills (Christiner 2020; Christiner and Reiterer 2015). Evidence for vocal-motor ability and vocal flexibility as an explanation for enhanced language pronunciation skills also comes from singing and brain research. Singing and speaking are based on the same principles such as body posture, breathing, resonance and articulation (García-López and Gavilán Bouzas 2010; Rutkowski 1996), and rely on the same physical aspects since both are generated in the larynx (Berke and Long 2010). Vocal instructions for singers include tongue coordination, breathing techniques, body posture, and intrinsic as well as extrinsic muscle control (García-López and Gavilán Bouzas 2010).
Like for singers, similar findings have been provided for children who engage in vocal play. They possess enhanced vocal skills in comparison to their peers who did not engage in vocal play (Calì 2017). It could be suggested that early childhood singing may lead to experience-dependent fine-tuning of any form of vocalization. While the latter has not been studied and found for children, this has indeed been outlined for adult professional singers. In addition, research has shown that the impact of vocal-motor training on the brain structure can even be differentiated from more general musical effects. Intensive vocal-motor training of singers increases the volume and microstructural complexity of specific white-matter tracts such as the left arcuate fasciculus which connects regions that are fundamental to the production and perception of sound. This is an effect which has not been detected for individuals who are pure instrumentalists (Halwani et al. 2011). The left arcuate fasciculus is a fiber tract which is not only involved in musical functions, but also plays an important role in language processing (Ocklenburg and Güntürkün 2018). Structural adaptations of the left arcuate fasciculus have been noted for individuals who learn new languages (Ashtari et al. 2007) and therefore have been understood as a marker for enhanced vocal-motor and auditory-motor integration (Halwani et al. 2011). In another study on classical singers, “[…] increased functional activation of bilateral primary somatosensory cortex [has been detected], representing proprioceptive feedback from the articulators and the larynx, in concert with increased involvement of the cerebellum and implicit motor memory areas at the subcortical level” (Kleber et al. 2010). Increased functional activation in singers have been associated to represent improved kinesthetic motor ability. In marked contrast, individuals with speech production disorders show abnormal activation patterns in motor-associated brain areas (Falk et al. 2020). For instance, conduction aphasia has been viewed as a deficit in sensory-motor integration (Buchsbaum et al. 2011); improvements of stuttering is associated with gaining enhanced motor control (Falk et al. 2020). Singing has been introduced for therapeutical purposes and improves fluency of speech in individuals who stutter. Speech production improvements have been associated with the ability to self-monitor, and to integrate sensory and vocal tract-related motor representations which enhance motor control while articulating (Stager et al. 2003).
In consideration of the findings of this study, it could be suggested that childhood singing enhances the vocal-motor ability and manifests elaborate vocal-motor skills like those in language acquisition processes: a person’s native language leaves a deep imprint in their minds (Patel 2007). While the imprint of the native language makes it more difficult to acquire new foreign languages at the expense of plasticity, childhood singing, as a vocal-motor training, probably counteracts the loss of plasticity to generate new sounds. This may be one reason why our adult participants who sang more often during childhood outperformed those who sang less often in both vocal behaviors.
As an alternative explanation to vocal-motor ability linking singing behavior during childhood and language pronunciation during adulthood, performance anxiety has been investigated in more detail. A study by Christiner (2020) on singing behavior during childhood as measured via a multi-item scale concept was interrelated to performance anxiety and pronunciation skills. Since the same study has revealed that instrumentalists and singers both were less anxious than amateur musicians and non-musicians, it was assumed that the relationship between singing behavior during childhood and pronunciation skill may be biased by performance anxiety. However, partial correlational analysis revealed that performance anxiety has no impact on the relationship between childhood singing and language pronunciation (Christiner 2020). Consequently, reduced performance anxiety was ultimately not determined to be the reason why singing behavior during childhood was related to foreign language pronunciation skills.
In this investigation, we also detected that participants who sang more than their peers during childhood were not better in respect to their perception of music and speech (Q2). Since it is plausible to assume that motor ability seems to link singing and speech production, this finding provides additional evidence why miscellaneous findings for the relationship between perception and production in speech and language are probably found. The discriminant analysis has illustrated that the group which sang often during childhood could be differentiated from both other groups who reported to sing less often during childhood. The predictors (singing ability and pronunciation skills) which separate the groups best are production predictors and more prominent than the perceptual parameters. This finding could possibly be explained by considering the Linked Dual Representation Model by Hutchins and Moreno (2013). This model proposes that vocal information can be encoded in two ways: the conscious perception and motoric representation. It could be suggested that individuals with enhanced vocal abilities encode vocal information as motoric information. This would explain why singing ability is more likely related to language pronunciation than the latter is to language and music perception in this study. In addition, it would also explain why researchers find miscellaneous results for perception and production in music and language since individuals may encode vocal information in different ways.
5. Conclusions
The findings of this investigation have shown that individuals who sing more often during childhood were better at singing ability and the ability to pronounce unfamiliar languages, while speech and music perception variables played an inferior role in explaining group membership. A multiple regression revealed similar findings, and 43 percent of the variances in the ability to pronounce unfamiliar languages could be explained by singing ability, singing behavior during childhood, and the number of foreign languages spoken. The main link between singing ability and language pronunciation is that both rely on vocal-motor skills and sensorimotor ability. It could be assumed that childhood singing may positively influence vocal ability in adult life. While language research postulates that the native language leaves a deep imprint in the mind and makes the acquisition of new foreign languages more difficult, future research should focus on whether singing during childhood as vocal motor training has the potential to counteract the loss of plasticity to generate new sounds. Since the participants who sang more often during childhood were better at both productive vocal behaviors (singing and language pronunciation), future research could focus on whether individuals who sing often or sang very often during their childhood tend to decode vocal information more likely as motoric representation rather than as conscious perception. If this were to be found, it would also explain why language pronunciation most often yields stronger relationships to singing performance.
It must also be considered that childhood singing is based on questionnaires and therefore, the study has its limitations. Future research is necessary which should re-assess our findings and include more refined ways of measuring childhood singing, as well as studies to assess the impact of childhood singing on language capacity in more detail. For example, longitudinal studies which focus on the effects of childhood singing and the brain may provide novel insights in the overlaps of song and speech across ages.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/languages7020072/s1. Section S1 describes the chi-square results of gender and singing behavior during childhood as well as musical status and singing behavior during childhood. Section S2: second statistical approach on the multi-item scale singing behavior during childhood. This section illustrates the questions which were used to assess singing behavior during childhood and includes additional statistical procedures. Finally, a cluster analysis has been provided in order to compare the results of response options (see Section 2.7 to the cluster-based approach. Table S1: Translated questions of the multi-item scale concept singing behavior during childhood, Table S2: Welch’s F-test ANOVA singing concept, Table S3: Descriptives of the questions Q1–Q8, Table S4: Games-Howell post-hoc analysis on the questions regarding singing behavior during childhood. Section S3 includes the structure of the language perception measurement.
Author Contributions
Conceptualization, M.C.; Data curation, M.C. and C.G.; Formal analysis, M.C., V.B., and C.G.; Investigation, M.C.; Methodology, M.C., V.B., and C.G.; Project administration, M.C.; Resources, M.C.; Supervision, M.C., V.B., and C.G.; Writing—review and editing, M.C., V.B., and C.G. All authors have read and agreed to the published version of the manuscript.
Funding
Open Access Funding by the University of Graz.
Institutional Review Board Statement
The study was conducted according to the guidelines of the Declaration of Helsinki, and approved by the Institutional Review Board of the Medical Association of Homburg (Saarland) Ha-55/2021.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Data is contained in the article or Supplementary Materials.
Acknowledgments
M.C. is funded within the Post-DocTrack Programme of the OeAW. The authors acknowledge the financial support of the University of Graz.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Altenmüller, Eckart. 2008. Neurology of Musical Performance. Clinical Medicine 8: 410–13. [Google Scholar] [CrossRef] [PubMed]
- Anton, Ronald J. 1990. Combining Singing and Psychology. Hispania 73: 1166. [Google Scholar] [CrossRef]
- Ashtari, Manzar, Kelly L. Cervellione, Khader M. Hasan, Jinghui Wu, Carolyn McIlree, Hana Kester, Babak A. Ardekani, David Roofeh, Philip R. Szeszko, and Sanjiv Kumra. 2007. White Matter Development During Late Adolescence in Healthy Males: A Cross-Sectional Diffusion Tensor Imaging Study. NeuroImage 35: 501–10. [Google Scholar] [CrossRef]
- Bangert, Marc, Thomas Peschel, Gottfried Schlaug, Michael Rotte, Dieter Drescher, Hermann Hinrichs, Hans-Jochen Heinze, and Eckart Altenmüller. 2006. Shared Networks for Auditory and Motor Processing in Professional Pianists: Evidence from FMRI Conjunction. NeuroImage 30: 917–26. [Google Scholar] [CrossRef] [PubMed]
- Baumann, Simon, Susan Koeneke, Martin Meyer, Kai Lutz, and Lutz Jäncke. 2005. A Network for Sensory-Motor Integration: What Happens in the Auditory Cortex During Piano Playing Without Acoustic Feedback? Annals of the New York Academy of Sciences 1060: 186–88. [Google Scholar] [CrossRef]
- Berke, Gerald S., and Jennifer L. Long. 2010. Functions of the larynx and production of sounds. In Handbook of Mammalian Vocalization: An Integrative Neuroscience Approach (Handbook of Behavioral Neuroscience 19). London: Academic, vol. 19, pp. 419–26. [Google Scholar]
- Best, Catherine. 1995. A Direct Realist Perspective on Cross-Language Speech Perception. In Speech Perception and Linguistic Experience: Theoretical and Methodological Issues in Cross-Language Speech Research. Edited by Winifred Strange. Baltimore: York Press, pp. 171–204. [Google Scholar]
- Birdsong, David, and Jan Vanhove. 2016. Age of Second Language Acquisition: Critical Periods and Social Concerns. In Bilingualism Across the Lifespan: Factors Moderating Language Proficiency. Edited by Elena Nicoladis and Simona Montanari. Language and the Human Lifespan Series; Washington, DC: American Psychological Association, Berlin: Walter de Gruyter, pp. 163–81. [Google Scholar]
- Bongaerts, Theo. 1999. Ultimate Attainment in L2 Pronunciation: The Case of Very Advanced Late L2 Learners, in Second Language Acquisition and the Critical Period Hypothesis. In Second Language Acquisition and the Critical Period Hypothesis. Edited by David Birdsong. Second Language Acquisition Research. Mahwah: Erlbaum, pp. 133–59. [Google Scholar]
- Buchsbaum, Bradley R., Juliana Baldo, Kayoko Okada, Karen F. Berman, Nina Dronkers, Mark D’Esposito, and Gregory Hickok. 2011. Conduction Aphasia, Sensory-Motor Integration, and Phonological Short-Term Memory—An Aggregate Analysis of Lesion and FMRI Data. Brain and Language 119: 119–28. [Google Scholar] [CrossRef] [Green Version]
- Calì, Claudia. 2017. Creating Ties of Intimacy Through Music: The Case Study of a Family as a Community Music Experience. International Journal of Community Music 10: 305–16. [Google Scholar] [CrossRef]
- Carroll, John B. 1989. The Carroll Model: A 25-Year Retrospective and Prospective View. Educational Researcher 18: 26–31. [Google Scholar] [CrossRef]
- Chang, Soo-Eun, and David C. Zhu. 2013. Neural Network Connectivity Differences in Children Who Stutter. Brain a Journal of Neurology 136, Pt 12: 3709–26. [Google Scholar] [CrossRef] [Green Version]
- Chen, Joyce L., Virginia B. Penhune, and Robert J. Zatorre. 2008. Moving on Time: Brain Network for Auditory-Motor Synchronization Is Modulated by Rhythm Complexity and Musical Training. Journal of Cognitive Neuroscience 20: 226–39. [Google Scholar] [CrossRef]
- Christiner, Markus. 2013. Singing Performance and Language Aptitude: Behavioural Study on Singing Performance and Its Relation to the Pronunciation of a Second Language. Master’s Thesis, University of Vienna, Vienna, Austria. [Google Scholar]
- Christiner, Markus. 2018. Let the Music Speak: Examining the Relationship Between Music and Language Aptitude in Pre-School Children. In Exploring Language Aptitude: Views from Psychology, the Language Sciences, and Cognitive Neuroscience. Edited by Susanne M. Reiterer. English Language Education 16. Cham: Springer Nature, vol. 16, pp. 149–66. [Google Scholar]
- Christiner, Markus. 2020. Musicality and Second Language Acquisition: Singing and Phonetic Language Aptitude Phonetic Language Aptitude. Ph.D. thesis, Department of Linguistics, University of Vienna,, Vienna, Austria. [Google Scholar]
- Christiner, Markus, and Susanne M. Reiterer. 2013. Song and Speech: Examining the Link Between Singing Talent and Speech Imitation Ability. Frontiers in Psychology 4: 874. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Christiner, Markus, and Susanne M. Reiterer. 2015. A Mozart Is Not a Pavarotti: Singers Outperform Instrumentalists on Foreign Accent Imitation. Frontiers in Human Neuroscience 9: 482. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Christiner, Markus, and Susanne M. Reiterer. 2018. Early Influence of Musical Abilities and Working Memory on Speech Imitation Abilities: Study with Pre-School Children. Brain Sciences 8: 169. [Google Scholar] [CrossRef] [Green Version]
- Christiner, Markus, and Susanne Reiterer. 2019. Music, Song and Speech. Bilingual Processing and Acquisition 8. In The Internal Context of Bilingual Processing. Edited by John Truscott and Michael Sharwood Smith. Amsterdam: John Benjamins, vol. 3, pp. 131–56. [Google Scholar]
- Christiner, Markus, Stefanie Rüdegger, and Susanne M. Reiterer. 2018. Sing Chinese and Tap Tagalog? Predicting Individual Differences in Musical and Phonetic Aptitude Using Language Families Differing by Sound-Typology. International Journal of Multilingualism 15: 455–71. [Google Scholar] [CrossRef] [Green Version]
- Christiner, Markus, Christine Gross, Annemarie Seither-Preisler, and Peter Schneider. 2021. The Melody of Speech: What the Melodic Perception of Speech Reveals About Language Performance and Musical Abilities. Languages 6: 132. [Google Scholar] [CrossRef]
- Cohen, Annabel J. 2008. Advancing Interdisciplinary Research in Singing Through a Shared Digital Repository. Journal of the Acoustical Society of America 123: 3380. [Google Scholar] [CrossRef]
- Coumel, Marion, Markus Christiner, and Susanne M. Reiterer. 2019. Second Language Accent Faking Ability Depends on Musical Abilities, Not on Working Memory. Frontiers in Psychology 10: 257. [Google Scholar] [CrossRef] [PubMed]
- Crowder, Robert G., Mary Louise Serafine, and Bruno Repp. 1990. Physical Interaction and Association by Contiguity in Memory for the Words and Melodies of Songs. Memory & Cognition 18: 469–76. [Google Scholar] [CrossRef] [Green Version]
- Davies, Ann D. M., and Emlyn Roberts. 1975. Poor Pitch Singing: A Survey of Its Incidence in School Children. Psychology of Music 3: 24–36. [Google Scholar] [CrossRef]
- Deutsch, Diana, Trevor Henthorn, and Rachael Lapidis. 2011. Illusory Transformation from Speech to Song. Journal of the Acoustical Society of America 129: 2245–52. [Google Scholar] [CrossRef]
- Dörnyei, Zoltán, and Tatsuya Taguchi. 2010. Questionnaires in Second Language Research: Construction, Administration, and Processing, 2nd ed. Second Language Acquisition Research Series; New York: Routledge. [Google Scholar]
- Ekholm, Elizabeth, Georgios C. Papagiannis, and Françoise P. Chagnon. 1998. Relating Objective Measurements to Expert Evaluation Ofvoice Quality in Western Classical Singing: Critical Perceptual Parameters. Journal of Voice 12: 182–96. [Google Scholar] [CrossRef]
- Estis, Julie M., Joana K. Coblentz, and Robert E. Moore. 2009. Effects of Increasing Time Delays on Pitch-Matching Accuracy in Trained Singers and Untrained Individuals. Journal of Voice 23: 439–45. [Google Scholar] [CrossRef] [PubMed]
- Falk, Simone, Ramona Schreier, and Frank A. 2020. Russo. Singing and Stuttering. In The Routledge Companion to Interdisciplinary Studies in Singing: Volume III: Wellbeing. Edited by Rachel Heydon, Daisy Fancourt and Annabel J. Cohen. New York: Routledge, pp. 50–60. [Google Scholar]
- Franco, Fabia, Chiara Suttora, Maria Spinelli, Iryna Kozar, and Mirco Fasolo. 2021. Singing to Infants Matters: Early Singing Interactions Affect Musical Preferences and Facilitate Vocabulary Building. Journal of Child Language, 1–26. Available online: https://www.cambridge.org/core/article/singing-to-infants-matters-early-singing-interactions-affect-musical-preferences-and-facilitate-vocabulary-building/103D68368DDDCB6B80D2939C5667FD7F (accessed on 27 December 2021). [CrossRef] [PubMed]
- Fritz, Thomas, Sebastian Jentschke, Nathalie Gosselin, Daniela Sammler, Isabelle Peretz, Robert Turner, Angela D. Friederici, and Stefan Koelsch. 2009. Universal Recognition of Three Basic Emotions in Music. Current Biology 19: 573–76. [Google Scholar] [CrossRef] [Green Version]
- García-López, Isabel, and Javier Gavilán Bouzas. 2010. La voz cantada. [The Singing Voice] Acta Otorrinolaringologica Espanola 61: 441–51. [Google Scholar] [CrossRef]
- Gathercole, Susan E. 2006. Nonword Repetition and Word Learning: The Nature of the Relationship. Applied Psycholinguistics 27: 513–43. [Google Scholar] [CrossRef]
- Gathercole, Susan E., and Alan David Baddeley. 1990. The Role of Phonological Memory in Vocabulary Acquisition: A Study of Young Children Learning New Names. British Journal of Psychology 81: 439–54. [Google Scholar] [CrossRef]
- Gathercole, Susan E., Graham J. Hitch, Elisabet Service, and Amanda J. Martin. 1997. Phonological Short-Term Memory and New Word Learning in Children. Developmental Psychology 33: 966–79. [Google Scholar] [CrossRef]
- Goetze, Mary, Nancy Cooper, and Carol J. Brown. 1990. Recent Research on Singing in the General Music Classroom. Bulletin of the Council for Research in Music Education 104: 16–37. [Google Scholar]
- Golestani, Narly, and Christophe Pallier. 2007. Anatomical Correlates of Foreign Speech Sound Production. Cerebral Cortex 17: 929–34. [Google Scholar] [CrossRef]
- Gordon, Edwin. 1965. Musical Aptitude Profile Manual. Boston: Houghton Mifflin. [Google Scholar]
- Gordon, Edwin. 1979. Primary Measures of Music Audiation. Chicago: GIA. [Google Scholar]
- Gordon, Edwin. 1982. Intermediate Measures of Music Audiation. Chicago: GIA. [Google Scholar]
- Gordon, Edwin. 1989. Advanced Measures of Music Audiation. Chicago: GIA. [Google Scholar]
- Gordon, Edwin E. 2013. Music Learning Theory for Newborn and Young Children. Chicago: GIA. [Google Scholar]
- Groß, Christine, Bettina L. Serrallach, Eva Möhler, Jachin E. Pousson, Peter Schneider, Markus Christiner, and Valdis Bernhofs. 2022. Musical Performance in Adolescents with ADHD, ADD and Dyslexia—Behavioral and Neurophysiological Aspects. Brain Sciences 12: 127. [Google Scholar] [CrossRef] [PubMed]
- Gupta, Chitralekha, Haizhou Li, and Ye Wang. 2018. A Technical Framework for Automatic Perceptual Evaluation of Singing Quality. APSIPA Transactions on Signal and Information Processing 7: 1. [Google Scholar] [CrossRef] [Green Version]
- Halwani, Gus F., Psyche Loui, Theodor Rüber, and Gottfried Schlaug. 2011. Effects of Practice and Experience on the Arcuate Fasciculus: Comparing Singers, Instrumentalists, and Non-Musicians. Frontiers in Psychology 2: 156. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hernandez, Arturo E., and Ping Li. 2007. Age of Acquisition: Its Neural and Computational Mechanisms. Psychological Bulletin 133: 638–50. [Google Scholar] [CrossRef]
- Hutchins, Sean, and Sylvain Moreno. 2013. The Linked Dual Representation Model of Vocal Perception and Production. Frontiers in Psychology 4: 825. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hutchins, Sean Michael, and Isabelle Peretz. 2012. A Frog in Your Throat or in Your Ear? Searching for the Causes of Poor Singing. Journal of Experimental Psychology 141: 76–97. [Google Scholar] [CrossRef] [Green Version]
- Hutchins, Sean, Pauline Larrouy-Maestri, and Isabelle Peretz. 2014. Singing Ability Is Rooted in Vocal-Motor Control of Pitch. Attention Perception & Psychophysics 76: 2522–30. [Google Scholar] [CrossRef] [Green Version]
- Iverson, Jana M. 2010. Developing Language in a Developing Body: The Relationship Between Motor Development and Language Development. Journal of Child Language 37: 229–61. [Google Scholar] [CrossRef]
- Jepsen, Morten L., Stephan D. Ewert, and Torsten Dau. 2008. A computational model of human auditory signal processing and perception. Journal of the Acoustical Society of America 124: 422–38. [Google Scholar] [CrossRef] [Green Version]
- Kleber, Boris, Ralf Veit, Niels Birbaumer, John Gruzelier, and Martin Lotze. 2010. The Brain of Opera Singers: Experience-Dependent Changes in Functional Activation. Cerebral Cortex 20: 1144–52. [Google Scholar] [CrossRef] [Green Version]
- Koelsch, Stefan, Thomas C. Gunter, Matthias Wittfoth, and Daniela Sammler. 2005. Interaction Between Syntax Processing in Language and in Music: An ERP Study. Journal of Cognitive Neuroscience 17: 1565–77. [Google Scholar] [CrossRef]
- Larrouy-Maestri, Pauline, Yohana Lévêque, Daniele Schön, Antoine Giovanni, and Dominique Morsomme. 2013. The Evaluation of Singing Voice Accuracy: A Comparison Between Subjective and Objective Methods. Journal of Voice 27: 259.e1–259.e5. [Google Scholar] [CrossRef] [PubMed]
- Law, Lily N. C., and Marcel Zentner. 2012. Assessing Musical Abilities Objectively: Construction and Validation of the Profile of Music Perception Skills. PLoS ONE 7: e52508. [Google Scholar] [CrossRef] [Green Version]
- Liberman, Alvin M., and Ignatius G. Mattingly. 1985. The Motor Theory of Speech Perception Revised. Cognition 21: 1–36. [Google Scholar] [CrossRef]
- Ludke, Karen M., Fernanda Ferreira, and Katie Overy. 2014. Singing Can Facilitate Foreign Language Learning. Memory & Cognition 42: 41–52. [Google Scholar] [CrossRef]
- Margulis, Elizabeth H., Rhimmon Simchy-Gross, and Justin L. Black. 2015. Pronunciation Difficulty, Temporal Regularity, and the Speech-to-Song Illusion. Frontiers in Psychology 6: 48. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McClellan, Josef William. 2011. Comparative Analysis of Speech Level Singing and Traditional Vocal Training in the United States. Ph.D. Thesis, University of Memphis, Memphis, TN, USA. [Google Scholar]
- McClelland, James L., and Jeffrey L. Elman. 1986. The TRACE Model of Speech Perception. Cognitive Psychology 18: 1–86. [Google Scholar] [CrossRef]
- McMullen, Erin, and Jenny R. Saffran. 2004. Music and Language: A Developmental Comparison. Music Perception 21: 289–311. [Google Scholar] [CrossRef]
- Meara, Paul. 2005. LLAMA Language Aptitude Tests. Swansea: Lognostics. [Google Scholar]
- Mithen, Steven. 2007. The Singing Neanderthals: The Origins of Music, Language, Mind and Body. 1, Harvard University Press Paperback ed. Cambridge: Harvard University Press. [Google Scholar]
- Nasir, Sazzad M., and David J. Ostry. 2009. Auditory plasticity and speech motor learning. Proceedings of the National Academy of Sciences USA 106: 20470–75. [Google Scholar] [CrossRef] [Green Version]
- Nathani, Suneeti, David J. Ertmer, and Rachel E. Stark. 2006. Assessing Vocal Development in Infants and Toddlers. Clinical Linguistics & Phonetics 20: 351–69. [Google Scholar] [CrossRef]
- Norton, Andrea, Lauryn Zipse, Sarah Marchina, and Gottfried Schlaug. 2009. Melodic Intonation Therapy: Shared Insights on How It Is Done and Why It Might Help. Annals of the New York Academy of Sciences 1169: 431–36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ocklenburg, Sebastian, and Onur Güntürkün. 2018. Structural Hemispheric Asymmetries. In The Lateralized Brain: The Neuroscience and Evolution of Hemispheric Asymmetries. Edited by Sebastian Ocklenburg and Onur Güntürkün. London: Elsevier Academic Press, pp. 239–62. [Google Scholar]
- Papagno, Costanza, and G. Vallar. 1995. Verbal Short-Term Memory and Vocabulary Learning in Polyglots. Quarterly Journal of Experimental Psychology Section A 48: 98–107. [Google Scholar] [CrossRef] [PubMed]
- Patel, Aniruddh D. 2007. Music, Language, and the Brain. Oxford: Oxford University Press, Available online: http://gbv.eblib.com/patron/FullRecord.aspx?p=415568 (accessed on 23 October 2020).
- Pfordresher, Peter Q., and James T. Mantell. 2014. Singing with Yourself: Evidence for an Inverse Modeling Account of Poor-Pitch Singing. Cognitive Psychology 70: 31–57. [Google Scholar] [CrossRef] [PubMed]
- Pimsleur, Paul. 1966. Pimsleur Language Aptitude Battery. New York: Harcourt Brace Javanovich. [Google Scholar]
- Reiterer, Susanne Maria, Xiaochen Hu, Michael Erb, Giuseppina Rota, Davide Nardo, Wolfgang Grodd, Susanne Winkler, and Hermann Ackermann. 2011. Individual Differences in Audio-Vocal Speech Imitation Aptitude in Late Bilinguals: Functional Neuro-Imaging and Brain Morphology. Frontiers in Psychology 2: 271. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rutkowski, Joanne. 1996. The Effectiveness of Individual/small-Group Singing Activities on Kindergartners’ Use of Singing Voice and Developmental Music Aptitude. Journal of Research in Music Education 44: 353–68. [Google Scholar] [CrossRef]
- Salvador, Karen. 2010. How Can Elementary Teachers Measure Singing Voice Achievement? A Critical Review of Assessments, 1994–2009. Update: Applications of Research in Music Education 29: 40–47. [Google Scholar] [CrossRef]
- Sergeant, Desmond, and Graham Frederick Welch. 2008. Age-Related Changes in Long-Term Average Spectra of Children’s Voices. Journal of Voice 22: 658–70. [Google Scholar] [CrossRef]
- Skehan, Peter. 2012. Language Aptitude. In The Routledge Handbook of Second Language Acquisition. Edited by Susan Gass and Alison Mackay. Routledge Handbooks in Applied Linguistics. Milton Park, Abingdon, Oxon and New York: Routledge, pp. 381–95. [Google Scholar]
- Sloboda, John. 2005. Exploring the Musical Mind: Cognition, Emotion, Ability, Function. Oxford: Oxford University Press. [Google Scholar]
- Snow, David, and Heather L. Balog. 2002. Do Children Produce the Melody Before the Words? A Review of Developmental Intonation Research. Lingua 112: 1025–58. [Google Scholar] [CrossRef]
- Stadler Elmer, Stefanie. 2020. From Canonical Babbling to Early Singing and Its Relation to the Beginnings of Speech. In The Routledge Companion to Interdisciplinary Studies in Singing: Volume I: Development. Edited by Frank A. Russo, Beatriz Ilari and Annabel J. Cohen. Routledge Companion to Interdisciplinary Studies in Singing. New York and London: Routledge. [Google Scholar]
- Stager, Sheila V., Keith J. Jeffries, and Allen R. Braun. 2003. Common Features of Fluency-Evoking Conditions Studied in Stuttering Subjects and Controls: An H215O PET Study. Journal of Fluency Disorders 28: 319–36. [Google Scholar] [CrossRef]
- Sundberg, Johan. 1988. The Science of the Singing Voice. Dekalb: Northern Illinois University. [Google Scholar]
- Sundberg, Johan. 1999. The Perception of Singing. In The Psychology of Music, 2nd ed. Edited by Diana Deutsch. Academic Press Series in Cognition and Perception. San Diego: Academic Press, pp. 171–212. [Google Scholar]
- Thiessen, Erik D., and Jenny R. Saffran. 2009. How the Melody Facilitates the Message and Vice Versa in Infant Learning and Memory. Annals of the New York Academy of Sciences 1169: 225–33. [Google Scholar] [CrossRef]
- Tillmann, Barbara, Katrin Schulze, and Jessica M. Foxton. 2009. Congenital Amusia: A Short-Term Memory Deficit for Non-Verbal, but Not Verbal Sounds. Brain and Cognition 71: 259–64. [Google Scholar] [CrossRef] [PubMed]
- Tremblay-Champoux, Alexandra, Simone Dalla Bella, Jessica Phillips-Silver, Marie-Andrée Lebrun, and Isabelle Peretz. 2010. Singing Proficiency in Congenital Amusia: Imitation Helps. Cognitive Neuropsychology 27: 463–76. [Google Scholar] [CrossRef] [PubMed]
- Tsang, Christine D., Rayna H. Friendly, and Laurel J. Trainor. 2011. Singing Development as a Sensorimotor Interaction Problem. Psychomusicology 21: 31–44. [Google Scholar] [CrossRef]
- Turker, Sabrina, Sabine Sommer-Lolei, and Markus Christiner. 2018. Sprachtalent Und Musikgenie—Zwei Seiten Einer Münze? Zusammenspiel Musikalischer Und Sprachlicher Fähigkeiten Durch Umsetzungsnahe Ideen Im Schulischen Und Familiären Bereich. Journal für Begabtenförderung 2: 53–60. [Google Scholar]
- Wallentin, Mikkel, Andreas Højlund Nielsen, Morten Friis-Olivarius, Christian Vuust, and Peter Vuust. 2010. The Musical Ear Test, a New Reliable Test for Measuring Musical Competence. Learning and Individual Differences 20: 188–96. [Google Scholar] [CrossRef] [Green Version]
- Wapnick, Joel, and Elizabeth Ekholm. 1997. Expert Consensus in Solo Voice Performance Evaluation. Journal of Voice 11: 429–36. [Google Scholar] [CrossRef]
- Warner, Rebecca M. 2013. Applied Statistics: From Bivariate Through Multivariate Techniques, 2nd ed. Los Angeles: Sage. [Google Scholar]
- Welch, Graham F. 2006. Singing and Vocal Development. In The Child as Musician: A Handbook of Musical Development. Edited by Gary McPherson. Oxford and New York: Oxford University Press, pp. 311–30. [Google Scholar]
- Welch, Graham F. 2007. Singing as Communication. In Musical Communication. Edited by Dorothy M. Repr. Oxford: Oxford University Press, pp. 239–60. [Google Scholar]
- Welch, Graham F., Evangelos Himonides, Jo Saunders, Ioulia Papageorgi, Tiija Rinta, Costanza Preti, Claire Stewart, Jennifer Lani, and Joy Hill. 2011. Researching the First Year of the National Singing Programme Sing up in England: An Initial Impact Evaluation. Psychomusicology 21: 83–97. [Google Scholar] [CrossRef]
- Werker, Janet F., and Richard C. Tees. 2005. Speech Perception as a Window for Understanding Plasticity and Commitment in Language Systems of the Brain. Developmental Psychobiology 46: 233–51. [Google Scholar] [CrossRef]
- Zarate, Jean Mary. 2013. The Neural Control of Singing. Frontiers in Human Neuroscience 7: 237. [Google Scholar] [CrossRef] [Green Version]
- Zatorre, Robert J., Joyce L. Chen, and Virginia B. Penhune. 2007. When the Brain Plays Music: Auditory-Motor Interactions in Music Perception and Production. Nature Reviews. Neuroscience 8: 547–58. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).