1. Introduction
Oral proficiency in a second and/or foreign language (L2) is “at the very heart of what it means to be able to use a foreign language” (
Alderson and Bachman 2004, p. ix), but it is also the language skill that is the most difficult to assess in a reliable way (ibid.). One of the challenges raters of L2 oral proficiency face is the fact that numerous aspects of quality need to be considered simultaneously by raters (
Bachman 1990). Furthermore, as assessment of L2 oral proficiency (henceforth OP) is generally tested in different social interactional formats, such as paired/small group conversations or interviews with an examiner, standardizing testing conditions for learners’ L2 OP is particularly challenging (
Bachman 2007). Likewise, as convincingly demonstrated in the literature, the indisputable co-constructedness of the product for
assessment, the actual interaction in L2 oral tests (see e.g.,
Young and He 1998;
May 2009), entails a realization that each interaction is unique in terms of context and co-participants and that, as such, generalizations regarding individual proficiency are virtually impossible. Adding to these difficulties, raters will inevitably make different professional judgments of the same candidate’s performance in an interaction-based test, to the extent that some scholars have argued that “aiming for perfect agreement among raters in paired speaking assessment is not feasible” (
Youn and Chen 2021, p. 123). However, a strive for equity and fair grading in high-stakes contexts is, and should be, of central concern to stakeholders in language testing and assessment.
While many well-known large-scale OP tests rely on trained examiners for their assessment (e.g., the Test of English as a Foreign Language (TOEFL) and the Cambridge ESOL Examinations, including the International English Language Testing System (IELTS)), some national assessment systems use teachers for assessing their students’ performance (
Sundqvist et al. 2018). In New Zealand, an assessment reform—
interact—has been implemented in which teachers are required to collect several instances of interaction output from students for grading purposes, using guidelines for the assessment (
East 2015). Norway implemented a system where teachers could choose between assessing their students’ language proficiency (OP included) in a testing or classroom context (
Hasselgren 2000). In Sweden, which constitutes the empirical case of the present study, the National Test of English is compulsory in years 6 and 9, and teachers both administer and assess the test of OP with assessment guidelines provided by the Swedish National Agency for Education (SNAE) (
Borger 2019;
University of Gothenburg 2021). While the setup has many advantages, voices have also been raised about the role of teachers as examiners for achieving equity and assessment standardization (
Sundqvist et al. 2018). Furthermore, as studies focusing explicitly on uncovering the rating process for speaking assessment have demonstrated, raters differ in both their understandings of assessment criteria and in their application of those understandings to authentic speech/interaction samples (e.g.,
Borger 2019;
Ducasse and Brown 2009;
May 2011;
Sandlund and Sundqvist 2019,
2021). In line with such observations,
Youn and Chen (
2021) call for additional research on the rating process as such. Similarly,
Ducasse and Brown (
2009) and
Sandlund and Sundqvist (
2019) emphasize the need for empirical work uncovering how raters orient to interaction as they conceptualize assessment. In response to these calls, the present study examines how teachers, as raters of L2 OP in the Swedish national test of English in compulsory school, conceptualize and “do” assessment of L2 OP. In contrast to studies examining post-assessment rating protocols, stimulated recall, rater interviews (
May 2009,
2011;
Youn and Chen 2021), or recorded rater discussions (
Sandlund and Greer 2020;
Sandlund and Sundqvist 2019,
2021), we target scoring rubrics created by raters themselves for notetaking during actual test situations. The study thus contributes to filling a research gap in terms of uncovering raters’ conceptualizations of the construct at hand as they prepare and organize their actual assessment work.
In Sweden, students in school years 6 (ages 12–13) and 9 (ages 15–16) take a high-stakes, summative, three-part proficiency test in English, whose aim is to support equity in assessment and the grading of students’ knowledge and skills (
Swedish National Agency for Education 2021). Our focus is on part A (Speaking)—the National English Speaking Test (NEST), where L2 English OP is tested by the test construct
oral production and interaction. Students are divided into pairs or small groups and instructed to discuss pre-set topics from the test material with their peers. As mentioned, the students’ own teacher also administers and assesses the NEST (
Sundqvist et al. 2018). Teachers do not receive specific rater training; instead, they are provided with extensive rater guidelines and benchmark examples, which they are instructed to review before operationalizing assessment of the test. In the present article, the term
teacher-as-rater is used to reflect the dual role of the teachers, as they serve as raters/examiners of the NEST while, at the same time, they are the test-takers’ own teacher. Despite extensive rater guidelines and benchmark examples from SNAE, some teachers construct their own scoring rubric that they use when assessing the NEST. As teachers-as-raters are faced with the task of assessing a standardized test of L2 English OP in a fair, valid, and reliable manner, while also taking into consideration different local conditions, examining their self-made scoring rubrics might reveal how teachers-as-raters adapt to this particular assessment situation and, consequently, whether alterations of the test construct are made when operationalizing assessment in this particular context. An issue arising from this research problem is how assessment policy (in this case, SNAE’s holistic view) is conceptualized and operationalized in scoring rubrics created by teachers-as-raters. Thus, the aim of the study is to unveil teachers-as-raters’ conceptualizations of the NEST construct as these emerge from teachers’ self-made scoring rubrics, to examine whether, and possibly how, policy is
transformed (
Chevallard 2007) in the process.
The following research questions (RQs) guided the study:
RQ1: What sub-skills of oral proficiency are in focus for assessment in teachers’ own scoring rubrics, and in what ways is transformation of the test construct possibly reflected in sub-skills chosen for assessment?
RQ2: How are oral proficiency sub-skills to be assessed organized in teachers’ own scoring rubrics? In what ways are teachers’ conceptualizations of the test construct reflected in this organization?
RQ3: What similarities and differences are there between conceptualizations as reflected in the scoring rubrics when it comes to sub-skills to be in focus for assessment?
The present case study, in a high-stakes context in Sweden, can shed light on teachers-as-raters’ conceptualizations of the process of assessing L2 OP, as well as on whether raters in other settings conceptualize assessment of L2 OP in a similar way, despite its multi-faceted and context-dependent nature. Furthermore, the study aims to provide insights into whether the use of rubrics for assessment of L2 OP affects conceptualizations and, thus, knowledge on what stands out as salient to teachers-as-raters as they operationalize policy for assessment. These insights, in turn, can inform test constructors and contribute to construct development as well as rater training efforts.
1.1. Assessing L2 Oral Proficiency
For the assessment of “complex” performances, such as free-written or spoken production, the “individualized uniqueness and complexity” (
Wang 2010, p. 108) of the tasks and performances to be assessed present a challenge in terms of ensuring that raters understand and apply rating scales in the same way. As
Papajohn (
2002) observes, raters may arrive at the same score on the same learner response for different reasons, and, with such inherently subjective scoring of complex language abilities, disagreement between raters is to be expected (
Meadows and Billington 2005). Additional challenges with test constructs for linguistic and interactional skills include the deeply collaborative nature of conversations between individuals (
Sert 2019), as raters are forced to attempt to separate the performances of test-takers, although they are, in fact, inter-dependent.
Traditionally, the assessment of L2 speaking performance has been based on several core components making up L2 proficiency, such as the CAF framework of
complexity,
accuracy, and
fluency (
Skehan and Foster 1999;
Housen et al. 2012), or divided up into further analytic criteria such as
fluency,
appropriateness,
pronunciation,
control of formal resources of grammar, and
vocabulary (
McNamara 2000). However, whether raters are asked to assess these different components separately (analytic rating) or to consider all in assessing a single impression of performance (holistic rating, see
McNamara 2000, p. 43) varies between different tests. While there is agreement in testing research that OP is multi-faceted, the jury is still out on exactly which components should be weighed in and relative importance for proficiency measurements of these components. The communicative movement in language teaching and testing (
Canale and Swain 1980;
Bachman 1990) brought about an increased focus on learners’ use of language for communicative purposes, and more recently, the framework of interactional competence (
Kramsch 1986;
Young and He 1998;
Kasper and Ross 2013;
Salaberry and Kunitz 2019;
Salaberry and Burch 2021) has also made its way into speaking tests, and many speaking tests now include interactional abilities along with proficiency in their constructs.
Needless to say, as most speaking tests are conducted in the form of interaction between either an interviewer and a candidate (
oral proficiency interviews, OPIs) or in pairs or small groups (see
Sandlund et al. 2016; or
Ducasse and Brown 2009 for an overview), raters of L2 speaking tests face a challenging task when considering multiple aspects of proficiency
and interaction when assessing an individual speaking performance. As
McNamara (
1996) noted, judgments of complex language skills “will inevitably be complex and involve acts of interpretation on the part of the rater and thus be subject to disagreement” (p. 117).
Ducasse and Brown (
2009) point out that studies of raters’ perceptions of L2 test interactions are essential in understanding how assessment plays out in practice, “because it is their view of interaction which finds its reflection in the test scores” (
Ducasse and Brown 2009, p. 425).
1.2. Raters’ Conceptualizations of L2 OP Assessment
As the act of speaking an L2 involves not only purely linguistic but also pragmatic competence, raters have at their disposal a range of aspects of learner performances to be weighed against criteria or which contribute to an overall impression of learner’s L2 linguistic and interactional skills. Empirical studies of raters’ understandings of scoring rubrics have emphasized this complexity for assessment.
Ang-Aw and Goh (
2011), for instance, show that raters have conflicting ideas about the importance of the various criteria in the rating scales and that aspects of learner performances both within and at the outskirts of the scoring rubrics may be weighed into assessment decisions, such as effort (
Ang-Aw and Goh 2011). Other studies demonstrate how raters of oral L2 tests pay attention to different aspects of performance (see, e.g.,
Orr 2002) and that raters focus on different aspects of performance depending on what level the test-takers are at (
Sato 2012). As such, the salience of particular aspects may vary—between raters but also in their application to test-taker proficiency levels.
In a study of raters’ perceptions of interaction in tests using test discourse, written rater protocols, rater discussions, and stimulated recall,
May (
2011) demonstrates that many features of L2 interaction that were salient to raters fell under the scope of what test-takers co-construct in a test, such as understanding and responding to the interlocutor’s message, cooperating interactionally, and contributing to the quality and perceived authenticity of the interaction. The issue of co-construction and assessment was also raised by
May (
2009), who points out that, given raters’ apparent struggles in separating the individual performances of interlocutors when scoring, “it seems counter-intuitive to ask raters to award separate marks to candidates for interaction” (ibid., p. 417). Relatedly, both
May (
2011) and
Sandlund and Sundqvist (
2016) note that raters sometimes tend to compare test-takers against each other rather than against criteria. In a Swedish high-stakes L2 English testing context,
Borger (
2019) examined rater perceptions of interactional competence based on raters’ NEST scoring and notes about test-takers. Three aspects of interaction seemed to stand out to raters in their assessment: topic development moves, turn-taking management, and interactive listening strategies. Raters also considered test-takers’ interactional roles. Further, Borger observes that the raters attended to features both within and beyond the assessment guidelines, indicating that guidelines for raters “have to be elaborated, including conceptually grounded reasoning as well as commented examples” (2019, p. 167).
In most research studies, raters use a pre-defined set of criteria, or scoring rubric, from which they draw their conclusions about what, or what not, to include in assessment of OP. However, there are also examples of research on the assessment of oral proficiency where no common rating scale is used (
Bøhn 2015). Results from this study show that raters generally have similar thoughts regarding what aspects to include in the assessment of OP but that they differ when it comes to the relative importance of these aspects and results that are in line with studies where common rating scales are being used.
In Sweden, an examination of raters’ orientations to L2 English oral tests shows that raters using national performance standards and raters using the Common European Framework of Reference for Languages (CEFR) (
Council of Europe 2018) seem to understand and interpret the categories to be assessed in a similar way, and therefore a broad level of agreement regarding the test construct
oral production and interaction seems to be reached (
Borger 2014). However, another study in the area (
Frisch 2015) indicates that teachers have different orientations toward OP and that differences in orientations stem from “which criteria from the national test guidelines they mostly referred to” (
Frisch 2015, p. 102). In other words, there seems to be broad consensus among Swedish teachers about what categories assessment of L2 OP should encompass; however, there also seem to be conflicting ideas about what is stated about such assessment in the national test guidelines and, as a consequence, what to focus on when assessing these categories. The present study aims at generating new knowledge when it comes to how teachers-as-raters conceptualize the categories to assess, as well as whether there are differences or similarities between their conceptualizations. In relation to Frisch’s study, an interesting question is whether teachers-as-raters’ conceptualizations, as reflected in their scoring templates, mirror different views of what is stated about assessment of the test construct in the NEST guidelines.
In summary, raters face a tough task when assessing L2 OP, and there is often a “lack of meaningful descriptors” for guidance, particularly with asymmetric dyads (
May 2009, p. 416). Adding to previous research on rater perceptions, this study focuses on some ways in which raters deal with such complexity. This study also aims to add to previous research on how raters’ conceptualizations of assessment are possibly affected by the actual practice of carrying out assessment. It contributes as such to filling a knowledge gap identified by
Tsagari (
2021, p. 27): “there is a lot yet to be learnt about the protagonists of assessment—students and teachers, and how they enact assessment policy mandates in their daily practices”.
1.3. Scoring Rubrics
A
rubric is generally viewed as an assessment tool that consists of two parts: criteria in focus for assessment and descriptive text for different performance levels for each criterion (
Brookhart 2018;
Brown 2012;
Sadler 2009). The descriptive text typically consists of a “qualitative description of the corresponding ‘standard’, often with reference to sub-attributes of the main criterion” (
Sadler 2009, p. 163).
Rubrics are often confused with other rubric-like instruments such as
checklists and
rating scales that also list criteria. Although definitions of
checklists and
rating scales vary somewhat in the literature (e.g.,
Brookhart 2018;
Brown 2012), a common denominator is that they, unlike
rubrics, contain little descriptive text to inform the raters what varying qualities of each criterion are. Instead, a
checklist typically consists of criteria that target details of a performance, where raters make rough estimations whether the criteria listed are absent/present or rate the performance according to a scale that indicates the quality of the feature listed (e.g.,
ok,
good,
great). A
rating scale lists criteria (although they are usually fewer compared with those in checklists) and also ask raters to assess the performance along a scale, but “characteristics of performance at each level are not described” (
Brown 2012, p. 40).
Rubrics can be categorized as
analytical or
holistic, where the former consists of criteria that are considered one at a time during assessment and the latter of all criteria considered simultaneously (
Brookhart 2018;
Brown 2012). The content of an analytic rubric and a holistic rubric might be identical; what distinguishes the two is mainly the format, something that might fundamentally change both the purpose and utility of the rubric used (
Brown 2012). Therefore, the choice between using one or the other depends on the assessment situation (
Davis 2018), as they are “representations of what is considered important in performance” (
Khabbazbashi and Galaczi 2020, p. 336). Each has its strengths and weaknesses. Since analytic rubrics list different criteria of a multi-dimensional performance, using them for assessment can give an indication of test-takers’ potentially jagged performance profiles (
Davis 2018;
Khabbazbashi and Galaczi 2020), and analytic rubrics are therefore beneficial for formative feedback purposes (
Jönsson and Svingby 2007). The main advantage of a holistic rubric is that it is practical: only one grading decision needs to be made (
Brookhart 2018;
Brown 2012;
Davis 2018), which makes it less cognitively demanding for raters (
Xi 2007). Holistic rubrics are often used in large-scale assessment and standardized testing (
Brown 2012;
Jönsson and Svingby 2007).
Particularly in relation to assessing written and spoken proficiency, holistic and analytic scoring seem to be widely used human-mediated marking methods, and their respective strengths and weaknesses have been both documented and discussed (
Khabbazbashi and Galaczi 2020). In comparison, analytic scoring rubrics allow for a more systematic assessment process where qualities are made explicit. Further, raters are given a clearer picture of the focus for assessment, which may improve reliability (ibid.). However, both
Lee et al. (
2010) and
Xi (
2007) found a clear correlation between analytic and holistic scores and concluded that analytic scoring might be psychometrically redundant. Moreover, since analytic assessment is cognitively more challenging,
Xi (
2007) argues that rigorous rater training is necessary if raters are to reliably distinguish between criteria listed in an analytic scoring method.
According to
Khabbazbashi and Galaczi (
2020), choice of marking method has been shown to affect grades awarded, but there is little empirical research on how different marking methods compare. In their study (
Khabbazbashi and Galaczi 2020), they examined the impact of holistic, analytic, and part marking models on measurement properties and CEFR classifications in a speaking test. Although there were strong correlations between the three different marking models, the choice of model impacted significantly on the CEFR levels awarded to candidates, with half of the candidates being awarded different levels depending on the scoring model used. The authors conclude that, of the three models examined, the part marking model had superior measurement qualities.
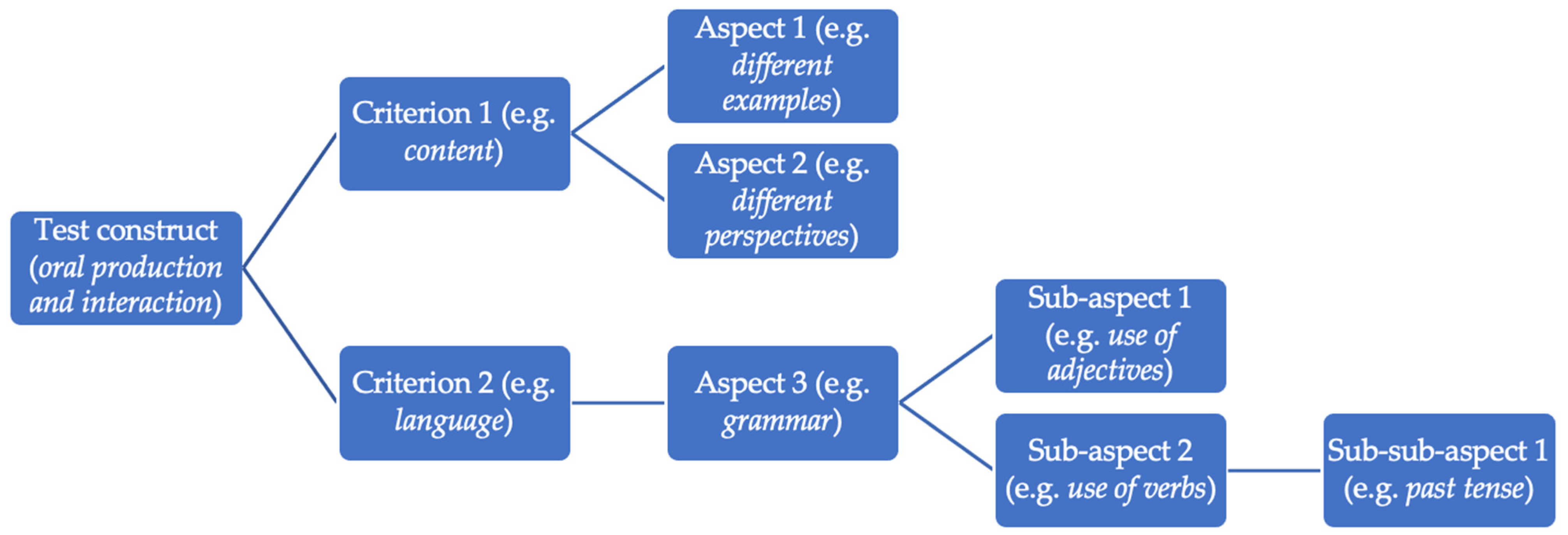
In relation to rubrics for assessment of L2 spoken interaction,
Ducasse (
2010) reports on a study of scale development based on raters’ perceptions of salient interactional features. Scale development was thus empirically developed by raters following a method for developing task-specific rubrics. However, although rubrics are extensively used as guides for scoring (
Lindberg and Hirsh 2015), no studies have to our knowledge examined what is included or excluded from assessment in teacher-generated scoring rubrics and in what ways content is organized. The present study aims to contribute to filling this gap of knowledge, particularly when it comes to what
content teachers decide to include in an L2 OP assessment rubric. Since
content is a representation of what is of importance in the assessment situation (
Khabbazbashi and Galaczi 2020) and since organization of content can greatly affect the outcome of scoring (
Brown 2012;
Davis 2018;
Khabbazbashi and Galaczi 2020), studying teacher-generated rubrics used for standardized testing of L2 OP can shed light on
what is being assessed as well as
how. We use the unifying term
scoring templates for all the teacher-generated assessment documents analysed, including documents where performance level descriptors are lacking. We categorize the data by applying
Brookhart’s (
2018) definitions of
rubric, rating scale, and
checklist. She makes a distinction between the three different scoring instruments as follows: “A
rubric articulates expectations for student work by listing criteria for the work and performance level descriptions across a continuum of quality […].
Checklists ask for dichotomous decisions (typically has/doesn’t have or yes/no) for each criterion.
Rating scales ask for decisions across a scale that does not describe the performance” (
Brookhart 2018, p. 1).
1.4. Transformations of Subject Content: The ATD Framework
As we are interested in possible transformations of the construct of
oral production and interaction in teachers’ operationalization of policy, we draw on the theoretical framework Anthropological Theory of Didactics (ATD) (
Chevallard 2007) and the
didactic transpositions that the content to be taught and learnt is subject to. According to ATD, there is a dialectic relationship between institutions and the people within these institutions in which content is co-determined on a hierarchy of levels (
Achiam and Marandino 2014). At the core of didactic transposition theory lies the assumption that knowledge is a changing reality, as it is affected and formed by the conditions prevalent in the institution in which knowledge is taught and learnt. Thus, knowledge is adapted to the institution it exists within, and in the ATD framework, this is called
the institutional relativity of knowledge (
Bosch and Gascón 2014).
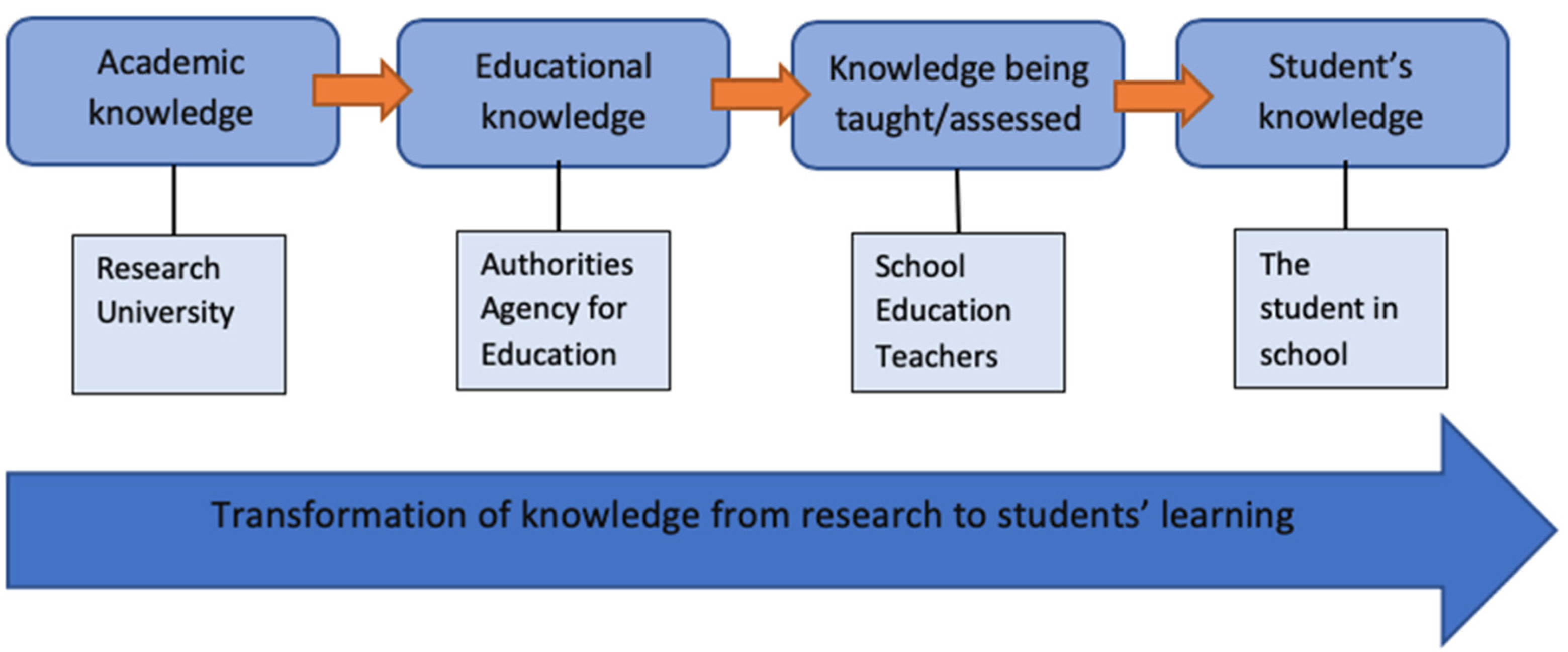
Figure 1 shows how knowledge, according to ATD, undergoes a transformation process in order to become (institutionally) operable. Knowledge generated in academia thus needs to be transformed by stakeholders and authorities (for instance, the SNAE) to become policy (for instance, assessment guidelines for the NEST). Policy, in turn, needs to be interpreted by stakeholders at the institutional level and transformed to become operable (for instance, into teaching material). Finally, each student’s knowledge will be formed by the teaching and assessment activities they are being subjected to and partake in. Here, the ATD framework is used to explain potential transformations of the test construct
oral production and interaction as it emerges when influenced and formed by operationalization.
The idea of
praxeologies is part of the ATD framework. Praxeologies are entities consisting of
praxis and
logos. Both these parts need to be taken into account “in order to explain the fate of ‘true’ knowledge” (
Chevallard 2007, p. 133).
Praxis consists of a type of task and a technique for carrying out the task, whereas
logos consists of technology (i.e., the discourse of the technique, such as why a particular technique is beneficial for carrying out a task) and a theory supporting the use of technology. Following this idea, the scoring templates generated by teachers-as-raters can be seen as the
technique supporting the
task of assessing L2 OP. Teachers-as-raters’ reasons for creating the scoring templates as well as the theory supporting their use are viewed as the
logos of the praxeology. Data generated in the present study do not allow us to analyse the
logos behind the use of scoring templates for the assessment of L2 English OP; however, examining the
technique, and conceptualizations of the test construct as reflected therein, should reveal teachers-as-raters’
relative institutional knowledge of
oral production and interaction. This
knowledge, generated at the “school level” in
Figure 1, is compared and contrasted to
knowledge of L2 English OP generated at the “authority” level (which is reflected in the assessment guidelines for the test). By comparing knowledge generated at these two different levels, transformations of the test construct when using scoring templates for assessment can emerge.
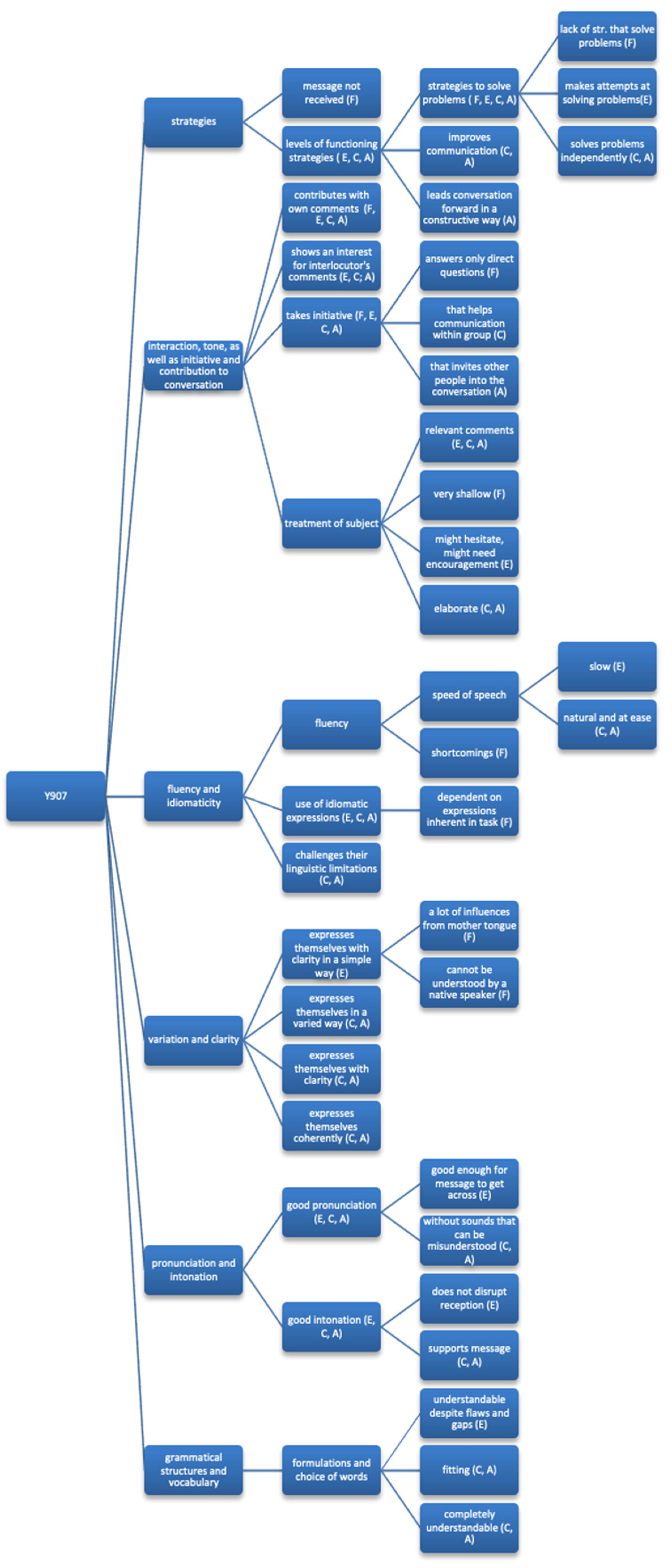
4. Discussion
The purpose of this study was to unveil teachers-as-raters’ conceptualizations of the NEST construct
oral production and interaction as these emerge from teachers’ self-made scoring rubrics and to examine whether, and possibly how, policy is transformed in the process. To avoid confusion, we have referred to these self-made scoring rubrics as
scoring templates. Since teachers-as-raters are provided with extensive assessment guidelines for the test in lieu of specific rater training, it is particularly interesting to analyse how teachers-as-raters conceptualize and transform guidelines when preparing for test assessment. When applying the ATD framework to our empirical findings, teachers-as-raters’
institutional relativity of knowledge emerged regarding assessment of L2 English OP. The
technique (i.e., the scoring templates) teachers-as-raters have created to perform the
task (assessment of a high-stakes test) displayed conceptualizations of the
praxis. We clearly saw how policy documents, in our case the NEST assessment guidelines for the NEST, influenced teachers-as-raters’ decisions on what to include in their scoring templates. We also saw how policy is transformed by teachers-as-raters when scoring rubrics/templates were used for operationalization of the test, since only parts of the SNAE guidelines, more specifically the
assessment factors, were in focus for assessment. As
Khabbazbashi and Galaczi (
2020) point out, the content of scoring rubrics mirrors what is made important in assessment. The results of our study suggest that SNAE’s
assessment factors played a particularly important role for the content of the scoring templates examined and, thus, assessment of L2 English proficiency when teacher-generated scoring templates were used in this context. As a result, our study shows that teachers-as-raters were in broad agreement on what aspects should be in focus for assessment, which is in line with both national and international studies (
Borger 2014,
2019;
Bøhn 2015;
Frisch 2015). SNAE’s
assessment factors are introduced to teachers in relation to the assessment of the NEST specifically, which can be a reason why they caught teachers’ attention. Even though SNAE instructs teachers to assess holistically based on the
knowledge requirements, the inclusion of the analytic
assessment factors in the NEST assessment guidelines may send a signal to teachers-as-raters that the assessment of the test construct in fact is analytic, as our analysis of the teacher-generated STs suggests. If so, instructions to teachers-as-raters to grade students’ L2 OP on the
knowledge requirements expressed in holistic terms, while at the same time considering a number of analytic criteria specific to this test situation, might conflate different meanings of what holistic assessment is. The end-result of the assessment—the grade—is indeed holistic, yet the underlying decision is based on a number of criteria and/or qualities not necessarily mirrored in the grade awarded.
When applying the ATD framework, our results do not allow us to analyse the
technology (i.e., the
logos) behind the
technique. However, our study indicates possible explanations as to why this particular
technique might be beneficial for carrying out the
task. All STs in our study were analytic, despite the fact that all were used for summative assessment in an assessment situation where quick decisions about grades need to be taken (
Sundqvist et al. 2018). In addition, holistic scales are quicker and less cognitively demanding to use when grading compared to analytic scales (
Brookhart 2018;
Brown 2012;
Davis 2018;
Xi 2007). Since analytic rubrics are more beneficial for formative feedback to students (
Jönsson and Svingby 2007), it is possible that teachers are more familiar with analytic rather than holistic STs in their daily work and therefore prone to use an analytic rubric as a template when designing their own. SNAE’s analytic
assessment factors can, therefore, fit this type of ST well. An explanation as to why teachers-as-raters decide to construct their own analytic scoring rubric/template could be to improve inter-reliability, as a more systematic assessment process allows for a clearer picture of the criteria underlying the holistic grade (
Khabbazbashi and Galaczi 2020), which might facilitate comparisons between raters of the same student performance. Moreover, since the choice between using a holistic and an analytic scoring rubric depends on the assessment situation (
Davis 2018), another explanation why teachers decided to use an analytical tool for a summative assessment situation could be that the templates also serve the purpose of displaying students’ jagged performance profiles (
Davis 2018), enabling for formative feedback to students (
Jönsson and Svingby 2007) or for information to parents. This could explain construct-irrelevant concepts found in some of the STs, for instance, the
criterion argue found in ST Y607. It is possible that teachers have designed analytical, task-specific rubrics used for formative classroom-based task assessment and found these STs also useful for assessing the NEST.
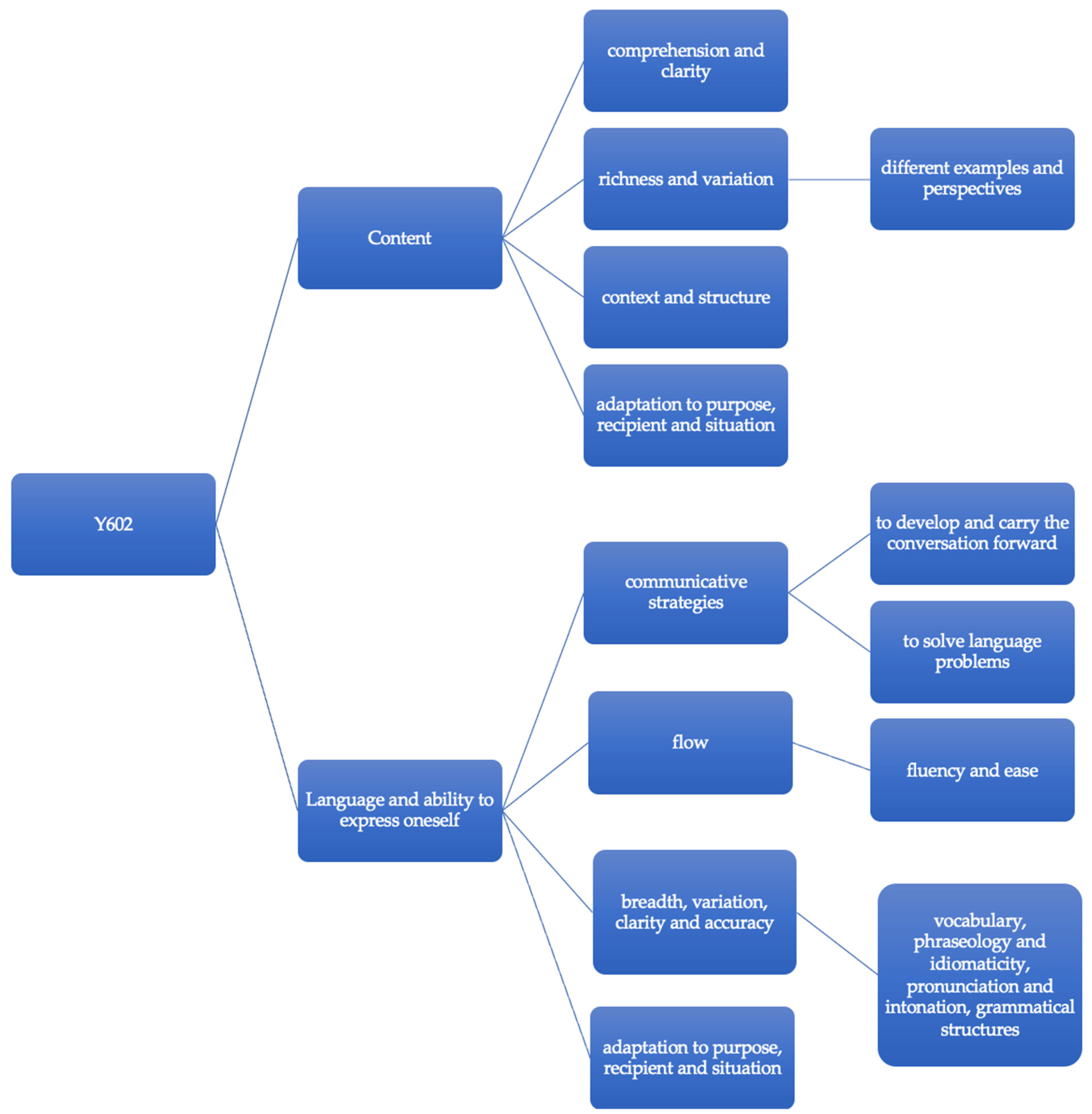
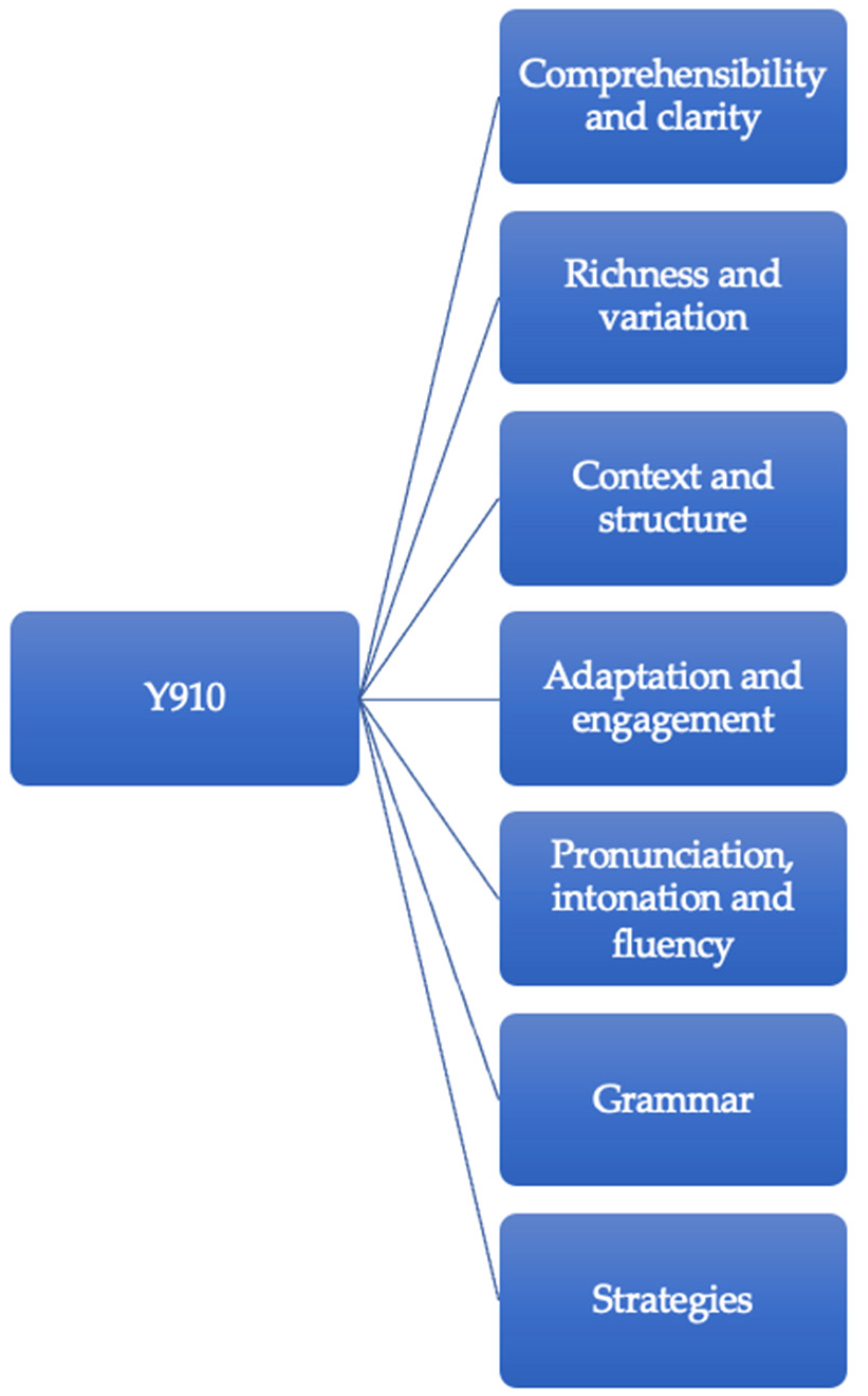
Although the assessment factors have clearly influenced both the content and design of the teacher-generated STs, several STs indicate a need for more in-depth descriptions of criteria than the assessment factors offer. A case in point for this type of specification is when specific phrases are noted down as indicative of the assessment factor different perspectives, something that might seem peculiar. However, these phrases might be used as markers for when students express different perspectives. In an assessment situation where many decisions must be made more or less instantly, it might be difficult to focus on what students say as well as on how they say it. It is possible that access to notes about specific words and phrases facilitates for teachers-as-raters to assess whether different perspectives and examples are presented by the students in their treatment of the topic.
As themes emerging through content analysis of STs were heavily influenced by SNAE’s
assessment factors, no additional focal themes were added by teachers-as-raters. However, the theme
interaction represented a strong exception.
Interaction (or
interactive skills) was included in the STs, but this sub-skill seemed particularly troublesome to define. It is part of the test construct yet nearly not visible at all in the templates for Y6, and in the templates for Y9, it was present in several themes as disparate as
richness and variation and
adaptation. There are several possible explanations for why Y6 and Y9 templates differ regarding
interaction. One is that raters consider the level of the test-takers when focusing on criteria to assess (cf.
Sato 2012) and expect Y9 students to have more elaborated interactional skills than Y6 students. Another explanation could be that Y6 and Y9 raters orient to different criteria from the assessment guidelines (cf. Frisch 2015, and a third could be the fact that our data consist of fewer STs from Y6 than Y9, which makes comparison troublesome. However, what our results show is that teachers-as-raters consider Y9 students’ interactive skills as essential in the assessment of the test construct, even though their conceptualizations vary a lot about the definition (in line with
Borger 2019; and
May 2009). A reason for this could be that
interaction lacks a definition in SNAE’s
assessment factors. Both
May (
2009) and
Borger (
2019) point to the importance of developing more elaborated guidelines for assessing interactional skills, since access to such guidelines could facilitate the recognition of interactional skills in test-taker performances, as well as stronger guidance on how to award individual grades for a co-constructed performance. Our study supports this view, as the results indicate that more elaborated guidelines lead to broader consensus in teachers-as-raters’ conceptualizations.
Ang-Aw and Goh (
2011) show that students were given credit for
effort regardless of whether such test conduct was part of the test construct or not. Although the word
engagement is not found in the SNAE
assessment factors, teachers clearly base their assessment on an action-oriented approach to language teaching and testing, something SNAE instructs them to do. In light of the communicative movement to language teaching and assessment (
Bachman 1990,
2007;
Canale and Swain 1980), the extent to which students are engaged or show an effort to participate in communication (see
willingness to communicate,
MacIntyre et al. 1998), is conceptualized as a criterion for assessment of the test construct (cf.
Sandlund and Greer 2020). However, ideas on how to spot
engagement or
effort in students’ performances differ between teachers-as-raters in their respective STs, which suggests they might need more elaborate guidelines when it comes to whether
engagement and/or
effort should be part of assessment, and if so, how to assess it.
Transformations of the test construct also emerged when analysing the design of the STs, as most of them were designed to enable differentiation between the quality of test-takers’ oral production and interaction. Differentiation, therefore, seemed to be an important feature in using STs for summative assessment, which is not surprising since teachers are expected to come up with a grade as the “end-product”. However, as several of the
rubrics STs included relatively extensive descriptions of what quality looked/sounded like on the three grade levels, these STs appear more beneficial for formative feedback to students than for summative grading. Further, the results showed that, the more teachers-as-raters attempted to describe quality, the more their conceptualizations of oral sub-skills differed. A very detailed ST does not necessarily entail that a teacher-as-rater assesses differently than a teacher-as-rater who uses an ST consisting of more general formulations. The latter teacher-as-rater might very well implicitly know what an E, C, and A performance looks/sounds like, and their assessment might, therefore, be just as de-constructed as one made by a teacher-as-rater who uses an ST that, on paper, is very detailed. The more de-constructed/detailed STs in our study can, therefore, be seen as teachers-as-raters’ tacit assessment knowledge verbalised. However, due to the fact that organization of content in a scoring rubric can greatly affect the outcome of grading (
Brown 2012;
Davis 2018;
Khabbazbashi and Galaczi 2020), further studies should examine whether scoring is affected when teacher-generated analytic scoring templates are used, as well as the ways in which they are put to practical use. STs in our data showed two ways of notetaking.
Checklists STs left room for spontaneous comments relating to pre-determined criteria, and
rubrics STs were filled with pre-printed descriptive text relating to pre-determined criteria, leaving little or no room left for comments. A question that this study raises is how teachers use such STs in the actual assessment situation. Are STs that leave room for comments used for holistic assessment, while STs filled with pre-printed text are employed for analytic assessment? When using the latter, do teachers-as-raters mainly assess performance by “ticking off” the boxes, and do they assign different values to different criteria? Further research might shed light on how raters of L2 OP use rating scales and if these processes are similar to rater processes of L2 written proficiency (see
Lumley 2005).
While this study is fairly small and examines a limited dataset of scoring templates, it nevertheless yielded results and new questions that deserve scholarly attention. In particular, our study sheds light on teachers-as-raters’
institutional relativity of knowledge of L2 English OP when preparing and conducting assessment in practice. Beyond the scope of the present study was to examine policy documents for assessment with the same scrutiny that was applied for the STs in order for the
institutional relativity of knowledge inherent in policy to emerge. Therefore, further research is necessary in order to compare and contrast these two different kinds of knowledge in depth. Our results revealed a broad consensus between teachers-as-raters when it comes to
what to assess but not with regard to
how to assess. Discrepancies in conceptualizations are particularly salient for
interactive skills, which is in line with previous studies of rater conceptualizations of assessment of L2 English OP (
Borger 2014,
2019). While assessment guidelines for the test seem to have been conceptualized in a similar way regarding what criteria to focus on, when information was missing from
assessment factors (as is the case for
interaction), consensus was also missing among our teachers-as-raters.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}