In previous research on mood selection in relative clauses, difficulty with mood selection is widely attested in Spanish L2ers, especially with English as an L1 (
Borgonovo et al. 2006,
2008,
2015). Thus, we expect participants to rate the indicative higher than the subjunctive in contexts where the indicative is expected (i.e., with a specific antecedent). With nonspecific antecedents, however, we do not expect the subjunctive to be preferred or at least to be preferred to the same degree as the indicative in specific relative clauses. This result would be consistent with the indicative extension, in particular, the loss of association with specificity, previously reported in the literature.
Research Question 2 (Language mode): Is L2 sensitivity to mood selection requirements impacted by language mode (i.e., code-switched versus monolingual Spanish sentences)?
Previous research has reported differences in the speech of bilinguals when they are codeswitching, as opposed to when they are in Spanish monolingual mode, an effect that we refer to here as a CS effect. In particular, previous research has identified a CS effect in subject expression (e.g.,
Prada Pérez 2018;
Toribio 2004;
Torres Cacoullos and Travis 2011,
2016), increased indeterminacy in copula selection in Spanish–English Cuban HSs (
Prada Pérez and Hernández 2017), and in mood choice in nominal and adjectival clauses (
Prada Pérez et al. 2021;
Raymond 2012). To the best of our knowledge, there is no comparable previous research with L2ers. Thus, we adhere to the null hypothesis and anticipate no CS effect. Assuming that these CS preferences are not derived from grammatical knowledge in each of the languages and that exposure to the CS community is necessary (
Torres Cacoullos and Travis 2018), no CS effect is expected for L2ers, particularly since our participants do not seem to interact with a bilingual speech community.
3.1. Participants
A total of 20 Spanish L2ers (14 females; mean age 20.9 years; range 20–22) were recruited from a large research institution in the U.S., who, at the time of data collection, were enrolled in third and fourth year Spanish courses and who had acquired Spanish after the age of 11 and in a classroom context. Learners from third and fourth year classes were recruited, as these individuals had already met the basic language requirements from lower-level courses and had likely already been taught about the subjunctive in relative clauses (which, at the institution, is typically taught in the third semester). Informed consent was obtained from all participants involved in the study.
The participants were born in the U.S., except for three who were born abroad (non-Spanish speaking countries) but moved to the U.S. before age 6. Two participants reported having studied a third language, Portuguese and Chinese, respectively, and one participant reported also being a native speaker of Haitian Creole. All the participants learned Spanish in school, with 13 of them being first exposed to it in middle/high school (ages 11–15), 5 in elementary school (ages 6–10), and 1 in college at age 18. When they were offered
Gumperz’ (
1982) definition of CS, an example of what would be CS vs. loanwords (e.g.,
lunchear ‘to eat lunch,’
parquear ‘to park’,
chompear ‘to chomp’), 11 participants reported engaging in CS. With our question being rather vague, we are unable to ascertain whether participants who reported CS indeed engaged in CS or were exposed to it in the community or were referring of switches for a lexical gap (cf.
Koronkiewicz 2018, for a methodology to better attain this information from participants). Thus, this predictor was not included in the main analyses.
Results from an independent measure of proficiency (a 50-item section of the DELE typically used in the field,
Montrul and Slabakova 2003) indicated that 1 participant scored above 40 and was classified as advanced, 10 scored between 30 and 40 and were classified as intermediate, and 9 scored below 30 and were classified as of low proficiency (all participants:
M = 29.1 (11–44),
SD: 8.0). For the analyses, proficiency was included as a continuous variable based on mean-centered scores.
3.2. Materials
In addition to the proficiency measure and the language background questionnaire, participants completed two written AJTs, depending on language mode: one in Spanish and one in Spanish–English CS, administered via the online platform Qualtrics. Participants were instructed to read and judge the acceptability of sentences on a 4-point Likert scale (1= totally unacceptable; 2 = unacceptable; 3 = acceptable; 4 = totally acceptable), according to their intuitions. Specifically, they were told to judge the sentences in terms of how they are accepted ‘under normal circumstances’ and not based on whether they conform to standard usage of grammar. Target sentences were manipulated for mood (half of the embedded verbs were in the subjunctive mood and the other half were in the indicative) and specificity of the antecedent (half of the target sentences contained a definite/specific antecedent, via the use of specificity markers, and the other half contained a negative antecedent). Participants completed the AJT in two modes: a Spanish-only and a CS one, distributed on separate sessions. All target sentences were controlled for tense of the subordinate verb (all were in the present tense) and the relativizing pronoun (always
que). Across conditions there were similar ratios of regular and irregular verb forms (11 regular and 13 irregular in the Spanish-only conditions and 9 regular and 15 irregular in the CS conditions) (
Table 1). The verbs used in the relative clause were controlled for frequency across language mode conditions, based on frequency rankings from
Davies (
2006). A Wilcoxon–Mann–Whitney test revealed there were no significant differences in the verb frequency used for Spanish-only (
Mdn: 92) versus the codeswitching sentences (
Mdn: 57) (
W = 244.5,
p = 0.667). Experimental stimuli are included in the
Supplementary Material.
There were eight experimental conditions in total: four in Spanish-only (monolingual mode) and four in English–Spanish CS (bilingual mode), where the matrix clause was in English and the relative clause was in Spanish. Examples of the four CS conditions are listed below. Comparable sentences in Spanish-only were presented in the first session.
(3) CS conditions
Condition 5.
Codeswitched sentences, Specific antecedent, Indicative mood| This summer | I am going to visit my friend [que vive | en California]. |
| This summer | I am going to visit my friend who lives-ind | in California. |
| ‘This summer I’m going to visit my friend who lives in California.’ |
*Condition 6.
Codeswitched sentences, Nonspecific antecedent (Nadie/Nada/Ninguno), Indicative mood| Stephanie doesn’t know | anybody here | [que es | una | buena persona]. |
| Stephanie doesn’t know | anybody here | who is-ind | a | good person. |
| ‘Stephanie doesn’t know anybody here who is a good person.’ |
*Condition 7.
Codeswitched sentences, Specific antecedent, Subjunctive mood| My best friend Lauren | is a person [que me quiera | por lo que soy]. |
| My best friend Lauren | is a person who me loves-subj | for what | am. |
| ‘My best friend Lauren is a person who loves me for what I am.’ |
Condition 8.
Codeswitched sentences, Nonspecific antecedent (Nadie/Nada/Ninguno), Subjunctive mood| In the book, there is no chapter [que explique | la velocidad | de la | luz]. |
| In the book there is no chapter that explains-subj the speed | of the | light. |
| ‘In the book, there is no chapter that explains the speed of light.’ |
Conditions 1–4 were entirely in Spanish, and conditions 5–8 contained sentences that were code-switched between English and Spanish. Participants completed the Spanish-only (monolingual mode) AJT first and were provided with the link to the CS (bilingual mode) AJT at least 24 h after taking the first survey. Lastly, they were not allowed to go back and change their responses. Participants were sent experiment links to their email and, thus, were able to complete the surveys from their own laptop or mobile devices.
1Each condition contained 6 items, resulting in a total of 48 target sentences. The task additionally presented 48 filler sentences (24 monolingual Spanish and 24 Spanish/English code-switched), none of which contained a relative clause, but which contained varying instances of the subjunctive and indicative in nominal and adverbial clauses to not restrict the presentation of the subjunctive to experimental conditions only. The target sentences and fillers in each task were presented in a randomized order generated by Qualtrics.
3.3. Results
Survey ratings were analyzed in
R (
R Core Team 2017) by fitting cumulative link mixed effects models with a specified
probit link function (clmm function in package ordinal;
Christensen 2019). The
probit link function models the z-score (i.e., changes in standard deviation units) of the probability of increasing the rating by 1 on the Likert scale (e.g., rating a sentence as 4 over 3, or as 3 over 2, etc.), and thresholds between each Likert value were set to
flexible (which is also the default in
clmm), given that ratings may not be treated equally across the scale. For example, on a 4-point Likert scale, individuals may not perceive the difference between a 3 and a 4 (‘Acceptable’ and ‘Totally acceptable’, respectively) the same as that between a 2 and a 3 (‘Unacceptable’ and ‘Acceptable’). In interpreting the model, the coefficients represent the effect of predictors on the probability that the ratings will increase and not directly on the ratings per se.
Model fitting began by including a maximal fixed-effects structure (i.e., all main effects and interaction terms), given the interest of the interaction between Mood, Mode, and Specificity. Fixed effects were dummy coded and included Mood (Indicative [reference], Subjunctive), Mode (Spanish-only [reference], Codeswitched), and Specificity (Specific [reference], Nonspecific). Random intercepts of Participant and Item were also included. Regression coefficients represent whether a particular level of one of the factors differs significantly from the reference level (e.g., specific antecedents vs. nonspecific antecedents, in sentences that are Spanish-only and in the indicative mood). For testing main effects, we used log-likelihood ratio tests and compared nested models with and without the factor of interest (
Meteyard and Davies 2020), and comparisons across conditions were analyzed using
emmeans (
Lenth 2020). The final equation is provided below:
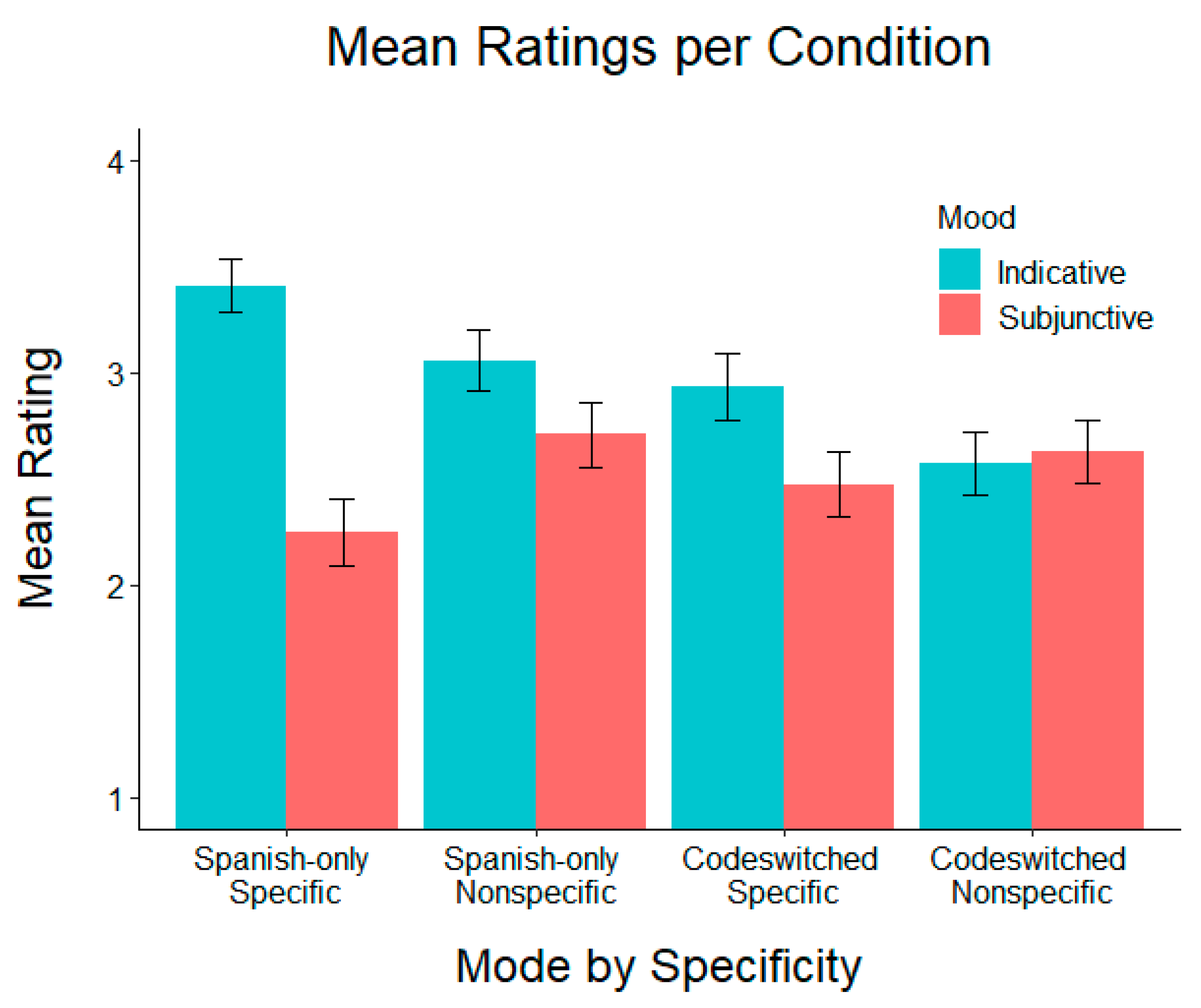
Mean ratings per condition are shown in
Figure 1. The analysis revealed significant effects of Mood (
χ2(4) = 57.289,
p < 0.001), Mode (
χ2(4) = 26.560,
p < 0.001), and Specificity (
χ2(4) = 24.233,
p < 0.001), as well as a significant interaction of Mood × Specificity (
χ2(2) = 23.272,
p < 0.001) and Mood × Mode (
χ2(2) = 18.116,
p < 0.001), but not Mode × Specificity (
χ2(2) = 2.618,
p = 0.270) or Mood × Mode × Specificity (
χ2(1) = 1.753,
p = 0.186). The interaction between Mood and Specificity revealed that sentences in the indicative mood were rated higher with specific than nonspecific antecedents (
β = 0.536,
SE = 0.126,
z = 4.270,
p < 0.001), while the subjunctive mood was rated higher with nonspecific than specific antecedents (
β = 0.390,
SE = 0.123,
z = 3.176,
p = 0.002). These patterns are consistent with specificity requirements for verbal mood in Spanish. Comparisons of verbal moods revealed that the indicative mood was rated higher than the subjunctive with specific antecedents (
β = 1.142,
SE = 0.128,
z = 8.953,
p < 0.001), while this preference was only marginal with nonspecific antecedents (
β = 0.215,
SE = 0.123,
z = 1.746,
p = 0.081). Crucially, the lack of a three-way interaction among Mood × Mode × Specificity suggests that L2ers’ sensitivity to verbal mood and specificity requirements is not affected by whether sentences are presented in Spanish-only or in Spanish–English CS. The final model is presented in
Table 2.
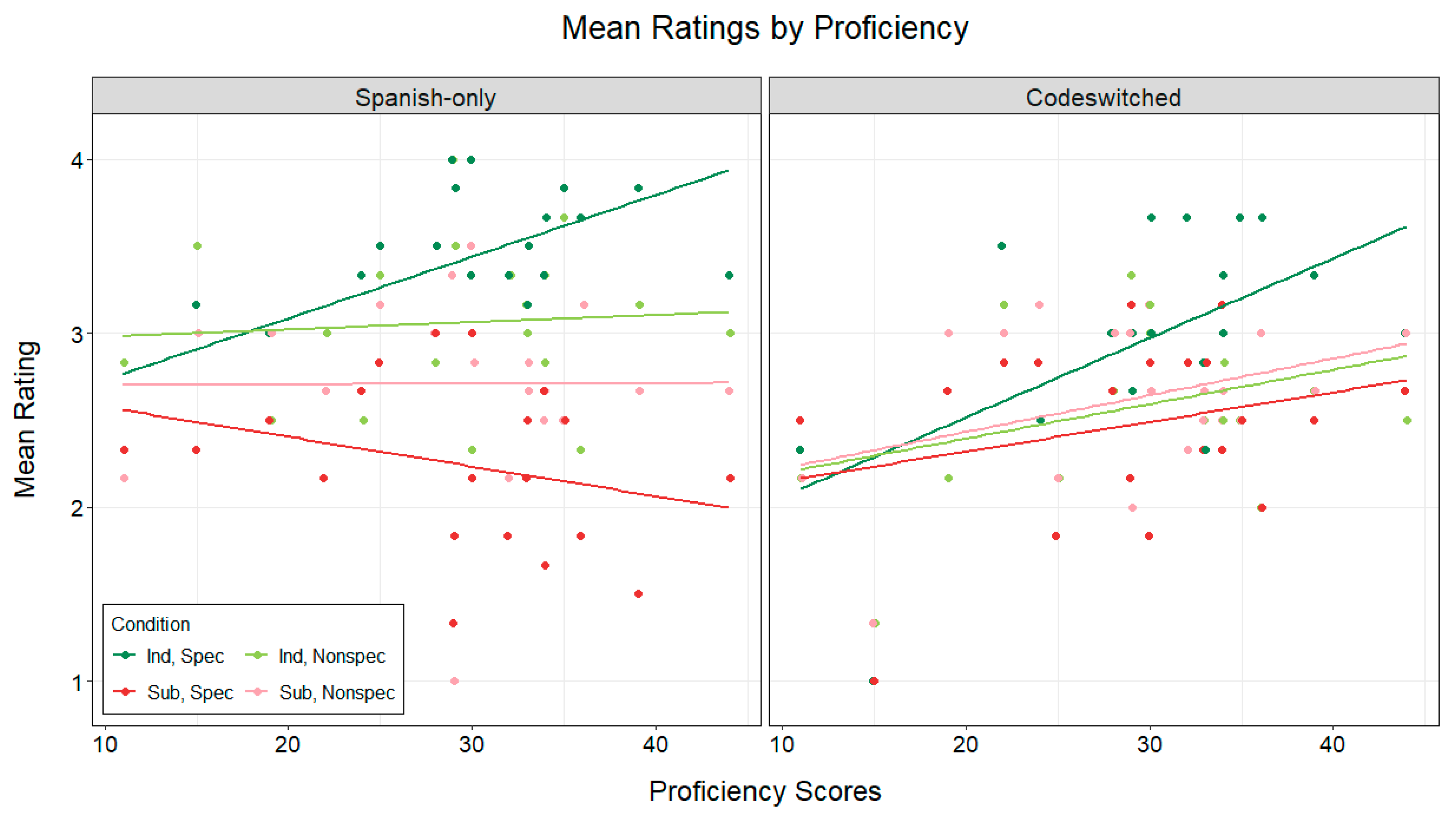
We also explored the role of proficiency by incorporating it as a factor within a maximal fixed-effects structure. Proficiency scores were mean-centered, and data analyses followed the same methods as the analysis without proficiency. The final model is presented below, and final model output is presented in
Table 3:
We report results here only for terms involving Proficiency. The analysis revealed that there was a significant effect of Proficiency (
χ2(8) = 41.324,
p < 0.001), Mood × Proficiency (
χ2(4) = 23.883,
p < 0.001), Specificity × Proficiency (
χ2(4) = 13.984,
p = 0.007), and Mood × Specificity × Proficiency (
χ2(2) = 11.211,
p = 0.004), a marginal interaction of Mode × Proficiency (
χ2(4) = 9.267,
p = 0.055), and no significant effects of Mode × Specificity × Proficiency (
χ2(2) = 0.746,
p = 0.689), Mood × Mode × Proficiency (
χ2(2) = 2.283,
p = 0.319), or Mood × Mode × Specificity × Proficiency (
χ2(1) = 0.744,
p = 0.389). The lack of a significant four-way interaction suggests that proficiency did not modulate ratings differently across conditions based on language mode. However, the interaction of Mood × Specificity × Proficiency suggests that sensitivity to verbal mood and specificity constraints may differ based on proficiency. Specifically, for a person of average proficiency, a 1 unit increase in proficiency was associated with higher rating likelihood for sentences with specific antecedents and the indicative mood (
β = 0.061,
SE = 0.011,
z = 5.526,
p < 0.001) but not for any other conditions (
p’s > 0.145). To examine the simple effects of Mood × Specificity at different proficiency levels, proficiency scores were recentered based on quartiles (Q1: 25th percentile on the lower end; Q3: 75th percentile on the higher end). This revealed that L2ers rated the indicative mood higher with specific than nonspecific antecedents, and this distinction increases with proficiency (Q1:
β = 0.362,
SE = 0.139,
z = 2.599,
p = 0.009; Q3:
β = 0.782,
SE = 0.146,
z = 5.374,
p < 0.001). For the subjunctive mood, participants were more likely to rate sentences higher with nonspecific than specific antecedents, and this also increases with proficiency (Q1:
β = 0.339,
SE = 0.138,
z = 2.461,
p = 0.014; Q3:
β = 0.465,
SE = 0.140,
z = 3.313,
p = 0.001). Additionally, verbal mood comparisons show that with specific antecedents, participants rated the indicative higher than the subjunctive (Q1:
β = 0.911,
SE = 0.140,
z = 6.487,
p < 0.001; Q3:
β = 1.472,
SE = 0.148,
z = 9.936,
p < 0.001). In contrast, for nonspecific antecedents, there was no difference between the indicative and subjunctive ratings at either lower or higher proficiency levels (Q1:
β = 0.210,
SE = 0.138,
z = 1.526,
p = 0.127; Q3:
β = 0.225,
SE = 0.140,
z = 1.604,
p = 0.109).
Figure 2 depicts the relationship between average ratings per condition and proficiency scores; for transparency and reader’s convenience, we show the trends for both Spanish-only and Codeswitched sentences.
The trends reported in the results are summarized in
Table 4.





{kind=link}
{kind=link}