
The Effect of Ethnicity on Identification of Korean American Speech


Abstract
:1. Introduction
1.1. Perception of Ethnic Identity in Speech
1.2. Asian American Identity and Speech Perception
1.3. Korean Americans and English
2. Materials and Methods
3. Results
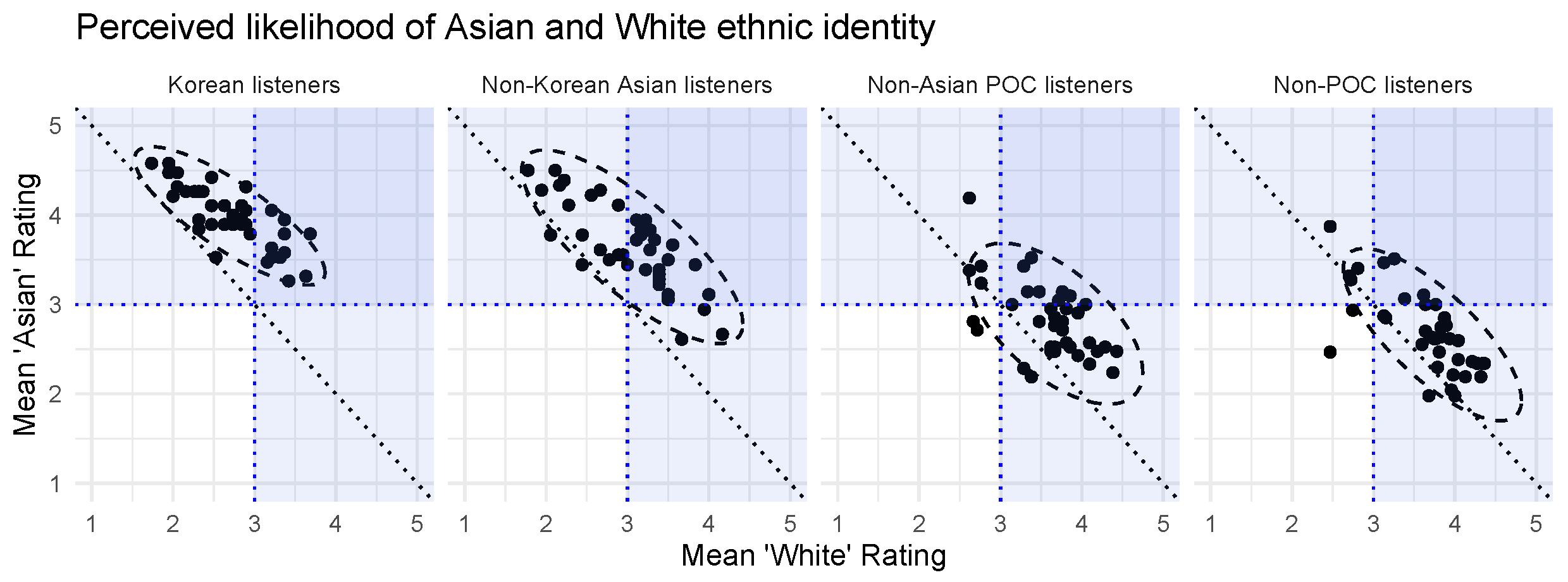
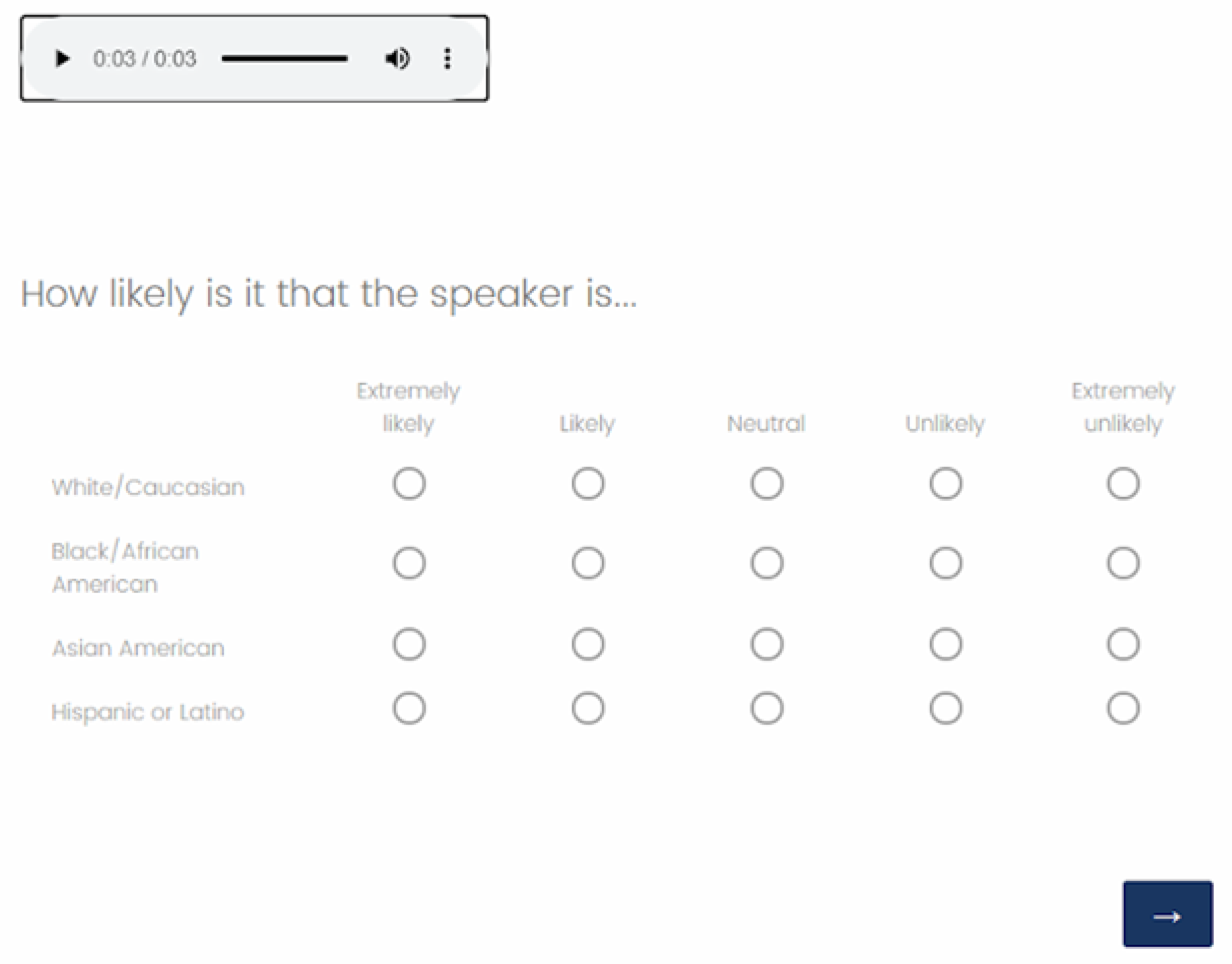
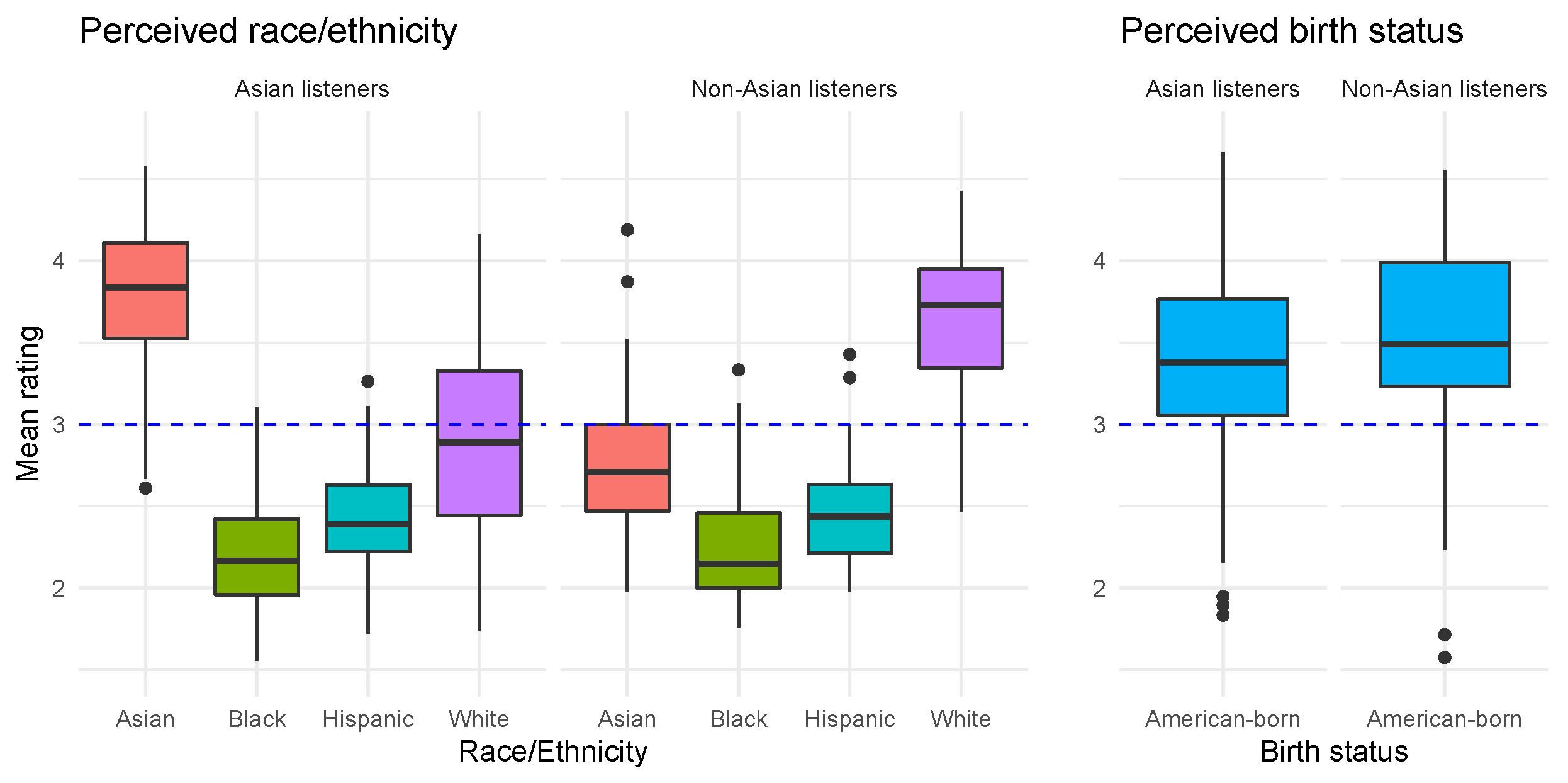
3.1. Perception of Race/Ethnicity
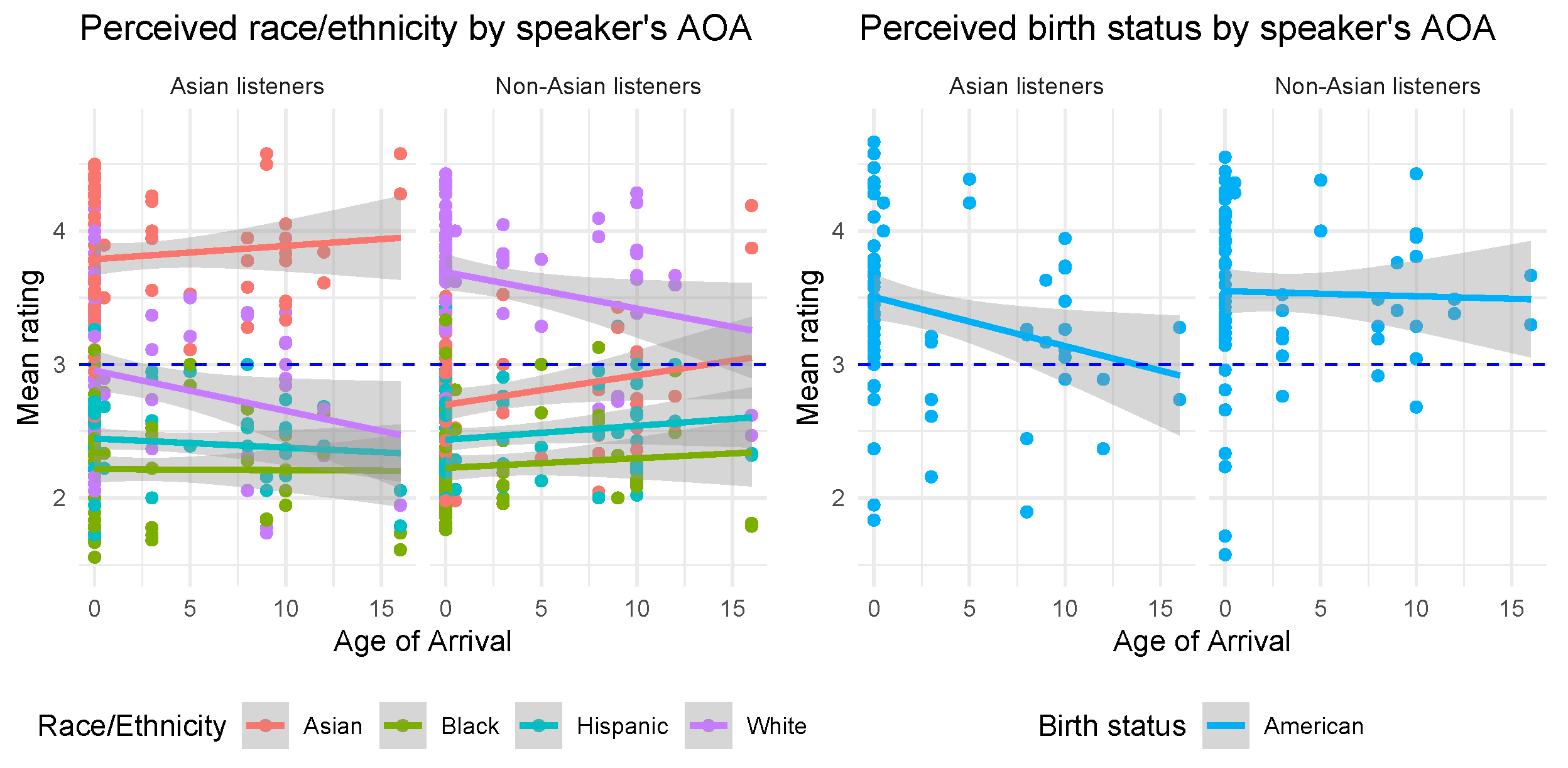
3.2. Perception of Race and Foreign-Born Status
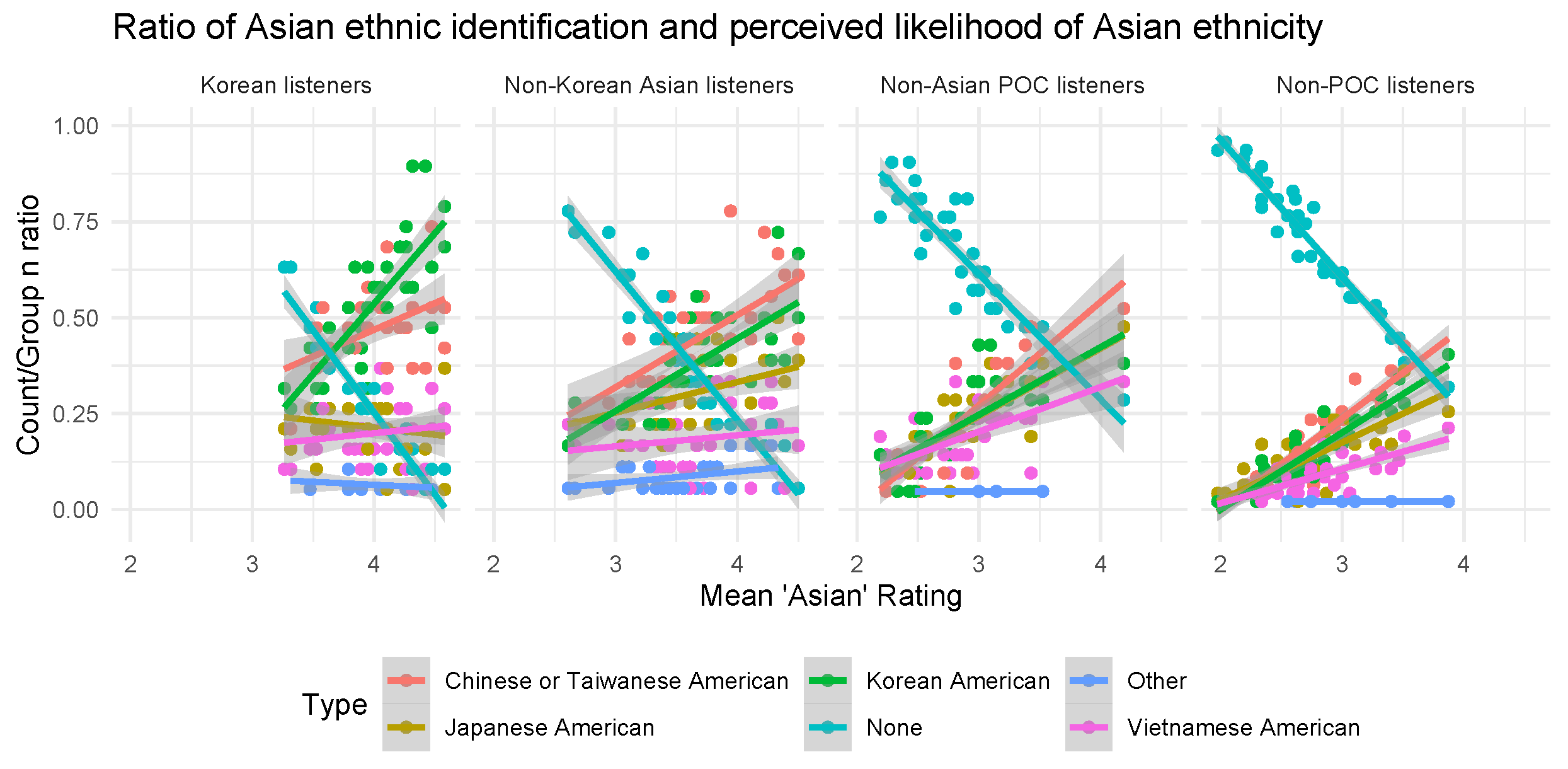
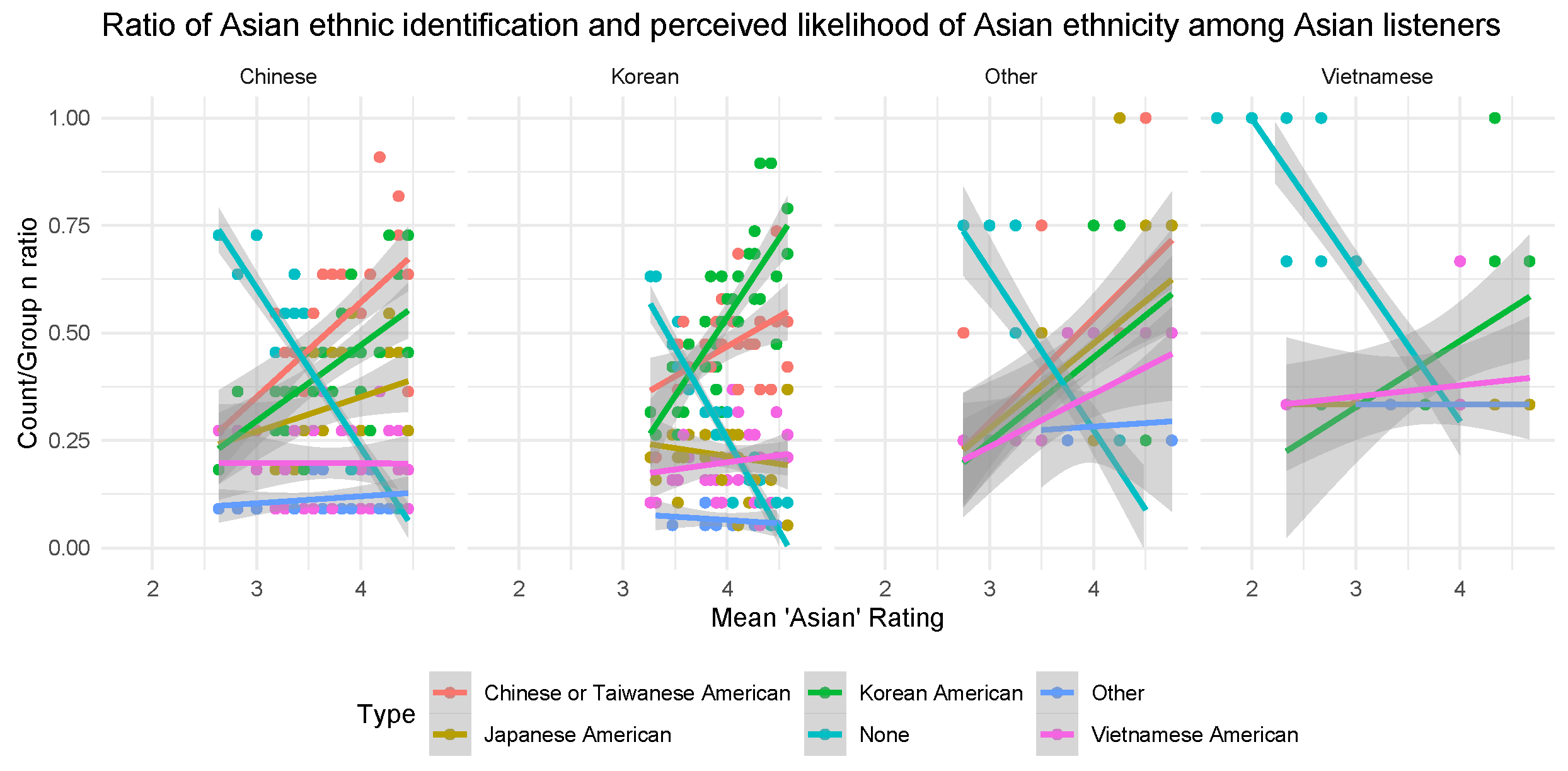
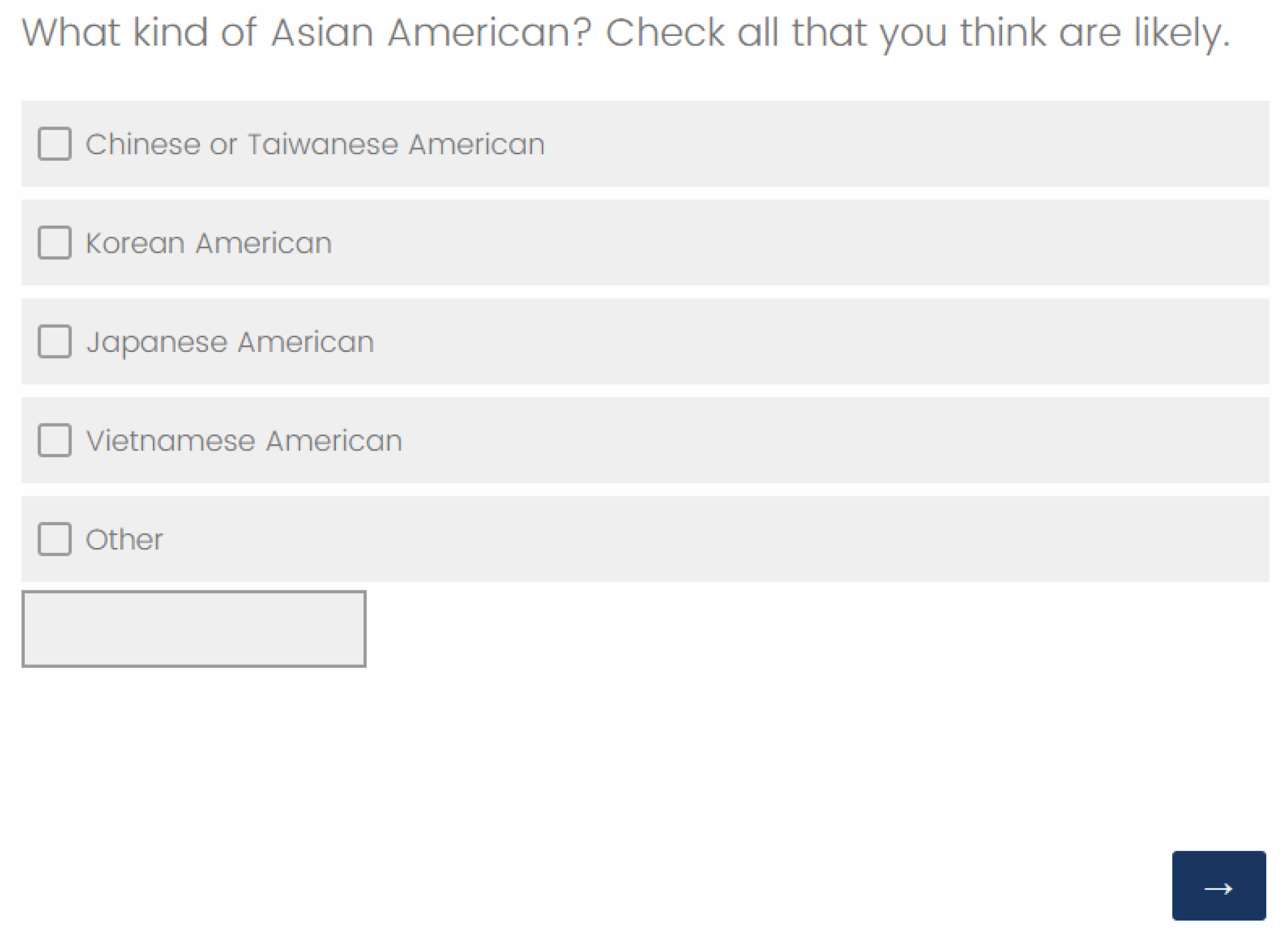
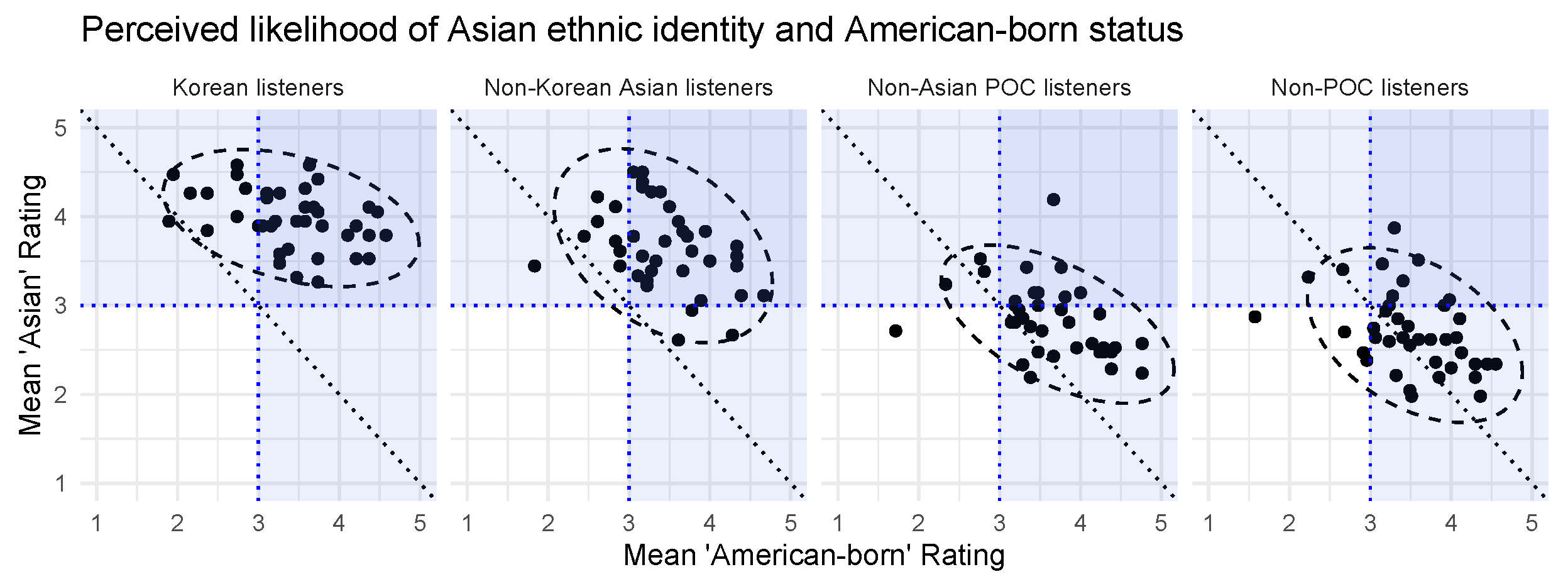
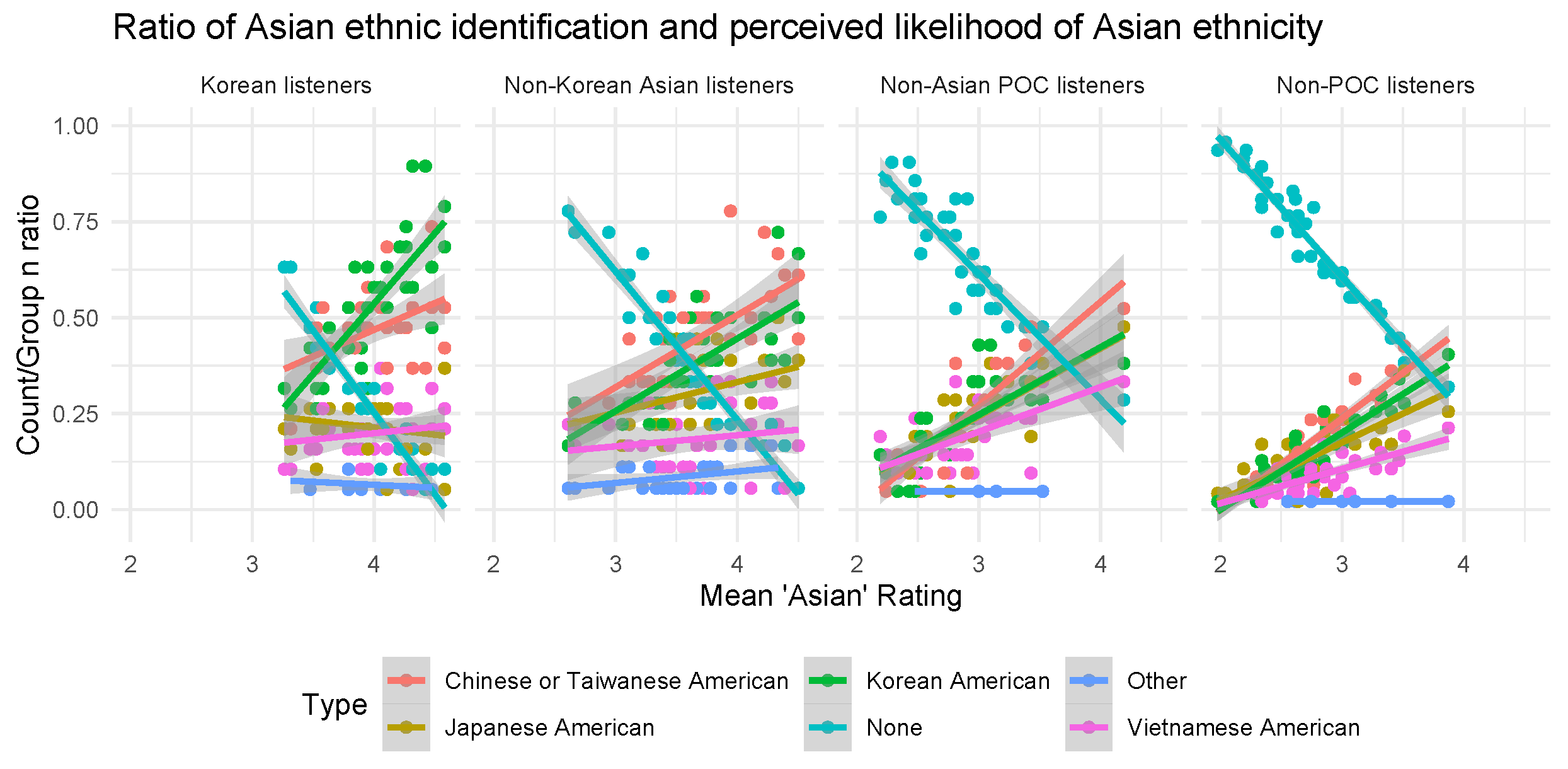
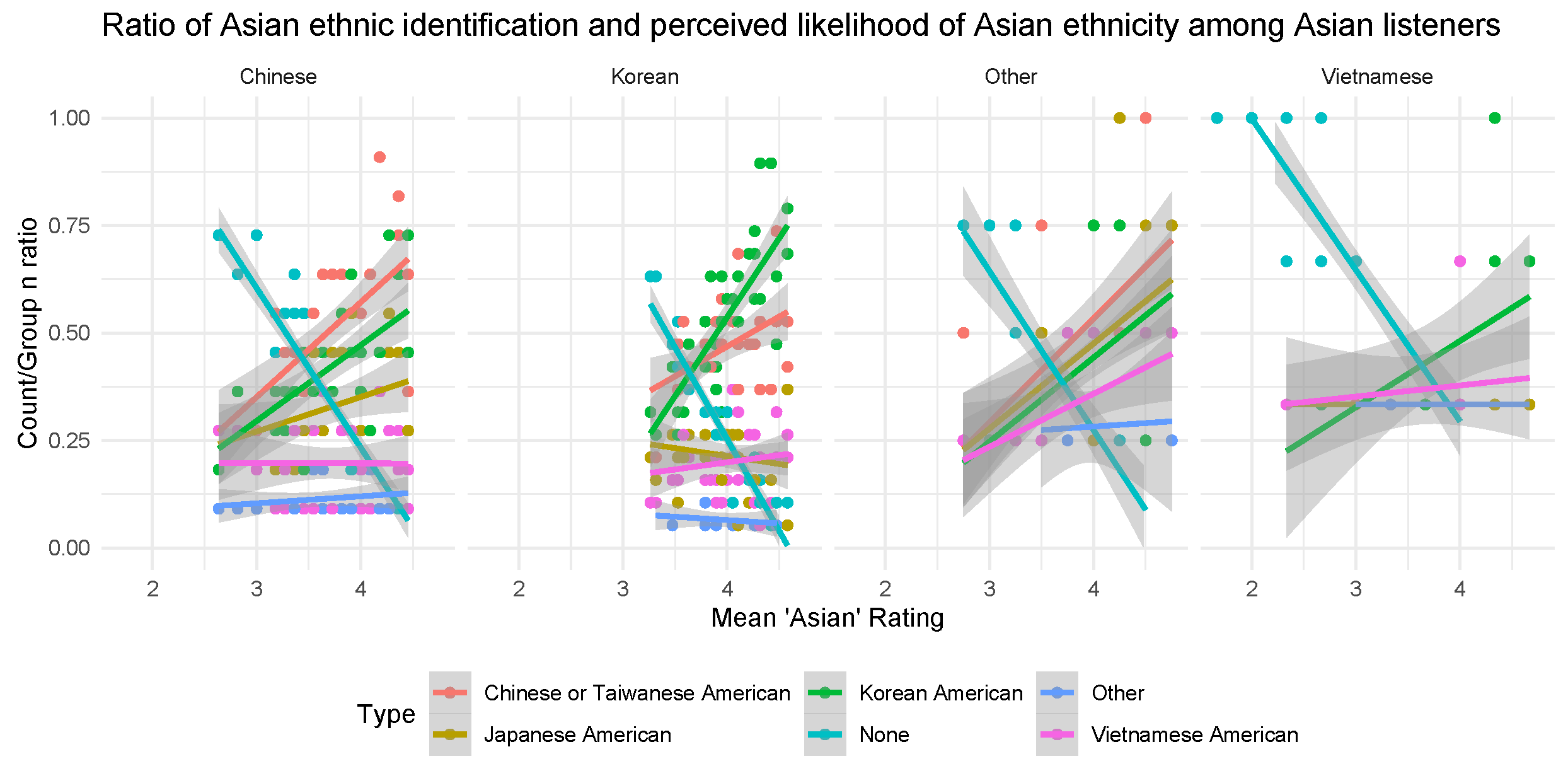
3.3. Perception of Specific Asian Ethnicity
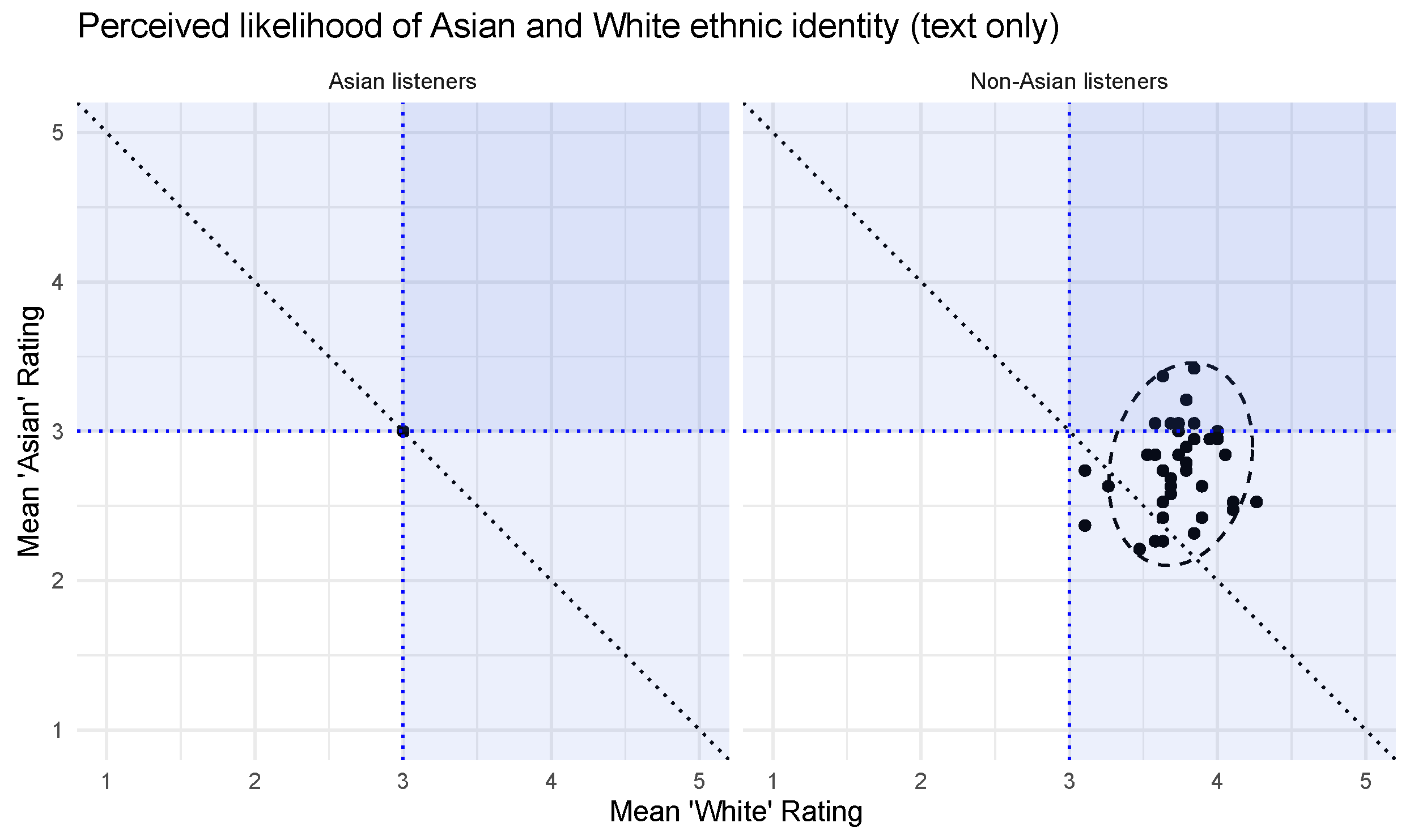
3.4. Post-Hoc Test of Text Stimuli
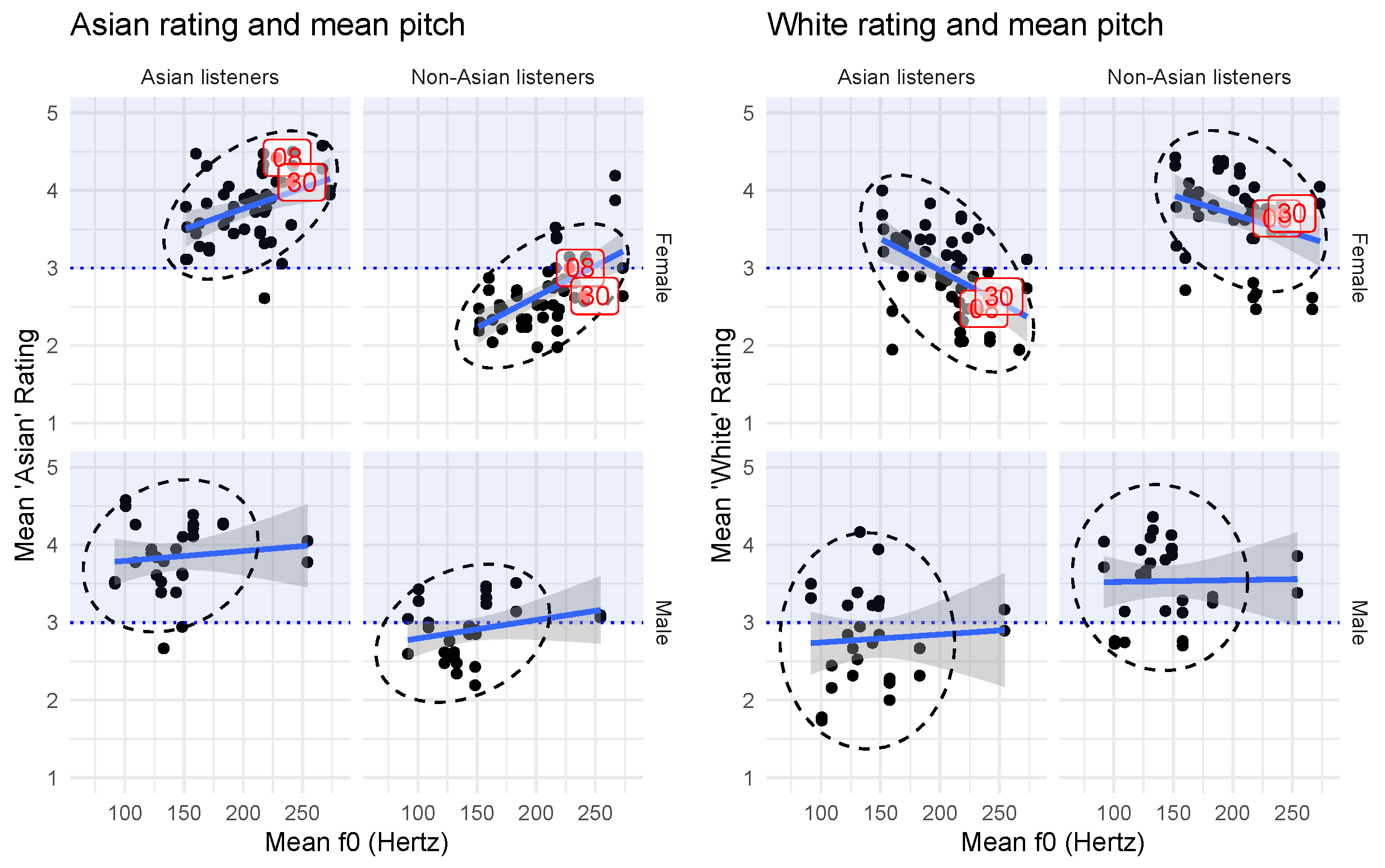
3.5. Listener Metalinguistic Commentary and Acoustic Case Studies
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Audio Stimulus Transcriptions
Appendix B. Speaker Ratings by Listener Ethnic Group
| Subj. | Age | Gender | Cal. | AOA | Gen. | Dominant Lang. | KAS | Listener Ethnic Group | White | Asian | American |
| 01 | 20 | Male | Yes | 0 | 2nd | English | 3.1 | Asian_Korean_POC | 2.947368 | 3.789474 | 4.578947 |
| Asian_Not Korean_POC | 4.166667 | 2.666667 | 4.277778 | ||||||||
| Not Asian_Not Korean_POC | 4.190476 | 2.47619 | 4.285714 | ||||||||
| Not Asian_Not Korean_White | 4.361702 | 2.340426 | 4.297872 | ||||||||
| 02 | 21 | Male | Yes | 9 | 1.5 | English | 6.35 | Asian_Korean_POC | 1.736842 | 4.578947 | 3.631579 |
| Asian_Not Korean_POC | 1.777778 | 4.5 | 3.166667 | ||||||||
| Not Asian_Not Korean_POC | 2.761905 | 3.428571 | 3.761905 | ||||||||
| Not Asian_Not Korean_White | 2.723404 | 3.276596 | 3.404255 | ||||||||
| 03 | 19 | Female | Yes | 0 | 2nd | English | 4.1 | Asian_Korean_POC | 2.894737 | 4.315789 | 3.578947 |
| Asian_Not Korean_POC | 3.277778 | 3.833333 | 3.666667 | ||||||||
| Not Asian_Not Korean_POC | 3.857143 | 2.52381 | 4.285714 | ||||||||
| Not Asian_Not Korean_White | 3.808511 | 2.468085 | 4.12766 | ||||||||
| 04 | 25 | Female | Yes | 0.5 | 1.5 | English | 2.7 | Asian_Korean_POC | 2.894737 | 3.894737 | 4.210526 |
| Asian_Not Korean_POC | 2.777778 | 3.5 | 4 | ||||||||
| Not Asian_Not Korean_POC | 3.619048 | 2.52381 | 4.285714 | ||||||||
| Not Asian_Not Korean_White | 4 | 1.978723 | 4.361702 | ||||||||
| 05 | 20 | Female | Yes | 3 | 1.5 | English | 5.6 | Asian_Korean_POC | 2.368421 | 4.263158 | 2.157895 |
| Asian_Not Korean_POC | 2.555556 | 4.222222 | 2.611111 | ||||||||
| Not Asian_Not Korean_POC | 3.380952 | 3.52381 | 2.761905 | ||||||||
| Not Asian_Not Korean_White | 3.765957 | 3 | 3.234043 | ||||||||
| 06 | 18 | Female | No | 5 | 1.5 | English | 4.3 | Asian_Korean_POC | 3.210526 | 3.526316 | 4.210526 |
| Asian_Not Korean_POC | 3.5 | 3.111111 | 4.388889 | ||||||||
| Not Asian_Not Korean_POC | 3.285714 | 2.285714 | 4.380952 | ||||||||
| Not Asian_Not Korean_White | 3.787234 | 2.297872 | 4 | ||||||||
| 07 | 19 | Female | Yes | 8 | 1.5 | Both | 5.75 | Asian_Korean_POC | 2.315789 | 3.947368 | 1.894737 |
| Asian_Not Korean_POC | 2.055556 | 3.777778 | 2.444444 | ||||||||
| Not Asian_Not Korean_POC | 2.666667 | 2.809524 | 3.190476 | ||||||||
| Not Asian_Not Korean_White | 2.468085 | 2.468085 | 2.914894 | ||||||||
| 08 | 20 | Female | Yes | 0 | 2nd | English | 5.7 | Asian_Korean_POC | 2.473684 | 4.421053 | 3.736842 |
| Asian_Not Korean_POC | 2.888889 | 4.111111 | 3.5 | ||||||||
| Not Asian_Not Korean_POC | 3.761905 | 3.142857 | 4 | ||||||||
| Not Asian_Not Korean_White | 3.638298 | 3 | 3.914894 | ||||||||
| 09 | 20 | Male | Yes | 0 | 2nd | English | 5 | Asian_Korean_POC | 2.736842 | 3.947368 | 3.578947 |
| Asian_Not Korean_POC | 3.222222 | 3.388889 | 3.277778 | ||||||||
| Not Asian_Not Korean_POC | 3.809524 | 2.952381 | 3.761905 | ||||||||
| Not Asian_Not Korean_White | 3.148936 | 2.851064 | 3.340426 | ||||||||
| 10 | 22 | Female | Yes | 0 | 2nd | English | 5.35 | Asian_Korean_POC | 2.736842 | 3.894737 | 3 |
| Asian_Not Korean_POC | 3.111111 | 3.722222 | 2.833333 | ||||||||
| Not Asian_Not Korean_POC | 3.761905 | 2.809524 | 3.142857 | ||||||||
| Not Asian_Not Korean_White | 4.042553 | 2.382979 | 2.957447 | ||||||||
| 11 | 21 | Male | Yes | 10 | 1.5 | English | 6.5 | Asian_Korean_POC | 2.894737 | 4.052632 | 3.736842 |
| Asian_Not Korean_POC | 3.166667 | 3.777778 | 3.722222 | ||||||||
| Not Asian_Not Korean_POC | 3.857143 | 3.095238 | 3.809524 | ||||||||
| Not Asian_Not Korean_White | 3.382979 | 3.06383 | 3.978723 | ||||||||
| 12 | 23 | Male | No | 0 | 2nd | English | 5.55 | Asian_Korean_POC | 2.263158 | 4.263158 | 2.368421 |
| Asian_Not Korean_POC | 2.277778 | 4.111111 | 2.833333 | ||||||||
| Not Asian_Not Korean_POC | 2.761905 | 3.238095 | 2.333333 | ||||||||
| Not Asian_Not Korean_White | 2.702128 | 3.319149 | 2.234043 | ||||||||
| 13 | 20 | Female | Yes | 0 | 2nd | English | 3.85 | Asian_Korean_POC | 2.631579 | 3.894737 | 3.157895 |
| Asian_Not Korean_POC | 3.333333 | 3.722222 | 3.444444 | ||||||||
| Not Asian_Not Korean_POC | 3.619048 | 2.952381 | 3.238095 | ||||||||
| Not Asian_Not Korean_White | 3.893617 | 2.765957 | 3.468085 | ||||||||
| 14 | 25 | Female | Yes | 0 | 2nd | English | 6.5 | Asian_Korean_POC | 3.421053 | 3.263158 | 3.736842 |
| Asian_Not Korean_POC | 3.388889 | 3.222222 | 3.222222 | ||||||||
| Not Asian_Not Korean_POC | 3.666667 | 2.47619 | 3.47619 | ||||||||
| Not Asian_Not Korean_White | 3.978723 | 2.212766 | 3.319149 | ||||||||
| 15 | 26 | Female | No | 10 | 1.5 | Both | 4.6 | Asian_Korean_POC | 2.473684 | 3.894737 | 3.052632 |
| Asian_Not Korean_POC | 3.388889 | 3.333333 | 3.111111 | ||||||||
| Not Asian_Not Korean_POC | 3.666667 | 2.857143 | 3.285714 | ||||||||
| Not Asian_Not Korean_White | 3.638298 | 2.702128 | 2.680851 | ||||||||
| 16 | 19 | Female | No | 3 | 1.5 | English | 4.8 | Asian_Korean_POC | 2.736842 | 4 | 2.736842 |
| Asian_Not Korean_POC | 3.111111 | 3.944444 | 2.611111 | ||||||||
| Not Asian_Not Korean_POC | 4.047619 | 3 | 3.190476 | ||||||||
| Not Asian_Not Korean_White | 3.829787 | 2.638298 | 3.404255 | ||||||||
| 17 | 18 | Female | No | 10 | 1.5 | Both | 6.75 | Asian_Korean_POC | 3.157895 | 3.473684 | 3.263158 |
| Asian_Not Korean_POC | 3 | 3.444444 | 2.888889 | ||||||||
| Not Asian_Not Korean_POC | 3.666667 | 2.52381 | 3.952381 | ||||||||
| Not Asian_Not Korean_White | 3.829787 | 2.744681 | 3.042553 | ||||||||
| 19 | 20 | Male | Yes | 0 | 2nd | English | 3.85 | Asian_Korean_POC | 3.315789 | 3.526316 | 3.736842 |
| Asian_Not Korean_POC | 3.5 | 3.5 | 3.333333 | ||||||||
| Not Asian_Not Korean_POC | 3.714286 | 3.047619 | 3.190476 | ||||||||
| Not Asian_Not Korean_White | 4.042553 | 2.595745 | 3.234043 | ||||||||
| 20 | 19 | Female | No | 0 | 2nd | English | 5.35 | Asian_Korean_POC | 2.052632 | 4.473684 | 2.736842 |
| Asian_Not Korean_POC | 2.166667 | 4.333333 | 3.166667 | ||||||||
| Not Asian_Not Korean_POC | 2.619048 | 3.380952 | 2.809524 | ||||||||
| Not Asian_Not Korean_White | 2.808511 | 3.404255 | 2.659574 | ||||||||
| 21 | 27 | Female | No | 0 | 2nd | English | 2.8 | Asian_Korean_POC | 3.368421 | 3.789474 | 4.368421 |
| Asian_Not Korean_POC | 3.833333 | 3.444444 | 4.333333 | ||||||||
| Not Asian_Not Korean_POC | 4.380952 | 2.238095 | 4.761905 | ||||||||
| Not Asian_Not Korean_White | 4.340426 | 2.340426 | 4.446809 | ||||||||
| 22 | 29 | Male | Yes | 0 | 2nd | English | 3.8 | Asian_Korean_POC | 2 | 4.210526 | 3.105263 |
| Asian_Not Korean_POC | 2.222222 | 4.388889 | 3.166667 | ||||||||
| Not Asian_Not Korean_POC | 3.285714 | 3.428571 | 3.333333 | ||||||||
| Not Asian_Not Korean_White | 3.12766 | 3.468085 | 3.148936 | ||||||||
| 23 | 28 | Female | Yes | 0 | 2nd | English | 7.3 | Asian_Korean_POC | 3.210526 | 4.052632 | 4.473684 |
| Asian_Not Korean_POC | 3.555556 | 3.666667 | 4.333333 | ||||||||
| Not Asian_Not Korean_POC | 4.380952 | 2.238095 | 4.761905 | ||||||||
| Not Asian_Not Korean_White | 4.276596 | 2.340426 | 4.553191 | ||||||||
| 24 | 18 | Male | Yes | 0 | 2nd | English | 3.75 | Asian_Korean_POC | 2.315789 | 4.263158 | 3.105263 |
| Asian_Not Korean_POC | 2.666667 | 4.277778 | 3.388889 | ||||||||
| Not Asian_Not Korean_POC | 3.333333 | 3.142857 | 3.428571 | ||||||||
| Not Asian_Not Korean_White | 3.255319 | 3.510638 | 3.595745 | ||||||||
| 25 | 24 | Female | Yes | 0 | 2nd | Both | 7.15 | Asian_Korean_POC | 1.947368 | 4.473684 | 1.947368 |
| Asian_Not Korean_POC | 2.444444 | 3.444444 | 1.833333 | ||||||||
| Not Asian_Not Korean_POC | 2.714286 | 2.714286 | 1.714286 | ||||||||
| Not Asian_Not Korean_White | 3.12766 | 2.87234 | 1.574468 | ||||||||
| 26 | 26 | Male | Yes | 0 | 2nd | English | 5.6 | Asian_Korean_POC | 2.842105 | 4.105263 | 3.578947 |
| Asian_Not Korean_POC | 3.277778 | 3.611111 | 3.777778 | ||||||||
| Not Asian_Not Korean_POC | 3.952381 | 2.904762 | 4.238095 | ||||||||
| Not Asian_Not Korean_White | 3.87234 | 2.851064 | 4.106383 | ||||||||
| 27 | 23 | Male | Yes | 12 | 1.5 | English | 5.4 | Asian_Korean_POC | 2.315789 | 3.842105 | 2.368421 |
| Asian_Not Korean_POC | 2.666667 | 3.611111 | 2.888889 | ||||||||
| Not Asian_Not Korean_POC | 3.666667 | 2.761905 | 3.380952 | ||||||||
| Not Asian_Not Korean_White | 3.595745 | 2.553191 | 3.489362 | ||||||||
| 28 | 21 | Female | Yes | 0 | 2nd | English | 4 | Asian_Korean_POC | 2.473684 | 4.105263 | 3.684211 |
| Asian_Not Korean_POC | 3.5 | 3.055556 | 3.888889 | ||||||||
| Not Asian_Not Korean_POC | 3.47619 | 2.809524 | 3.857143 | ||||||||
| Not Asian_Not Korean_White | 3.744681 | 2.617021 | 3.595745 | ||||||||
| 29 | 25 | Male | Yes | 0 | 2nd | English | 4.65 | Asian_Korean_POC | 2.842105 | 3.894737 | 3.789474 |
| Asian_Not Korean_POC | 3.222222 | 3.944444 | 3.611111 | ||||||||
| Not Asian_Not Korean_POC | 3.619048 | 2.47619 | 4.238095 | ||||||||
| Not Asian_Not Korean_White | 3.93617 | 2.617021 | 3.744681 | ||||||||
| 30 | 30 | Female | Yes | 0 | 2nd | English | 6.56 | Asian_Korean_POC | 2.631579 | 4.105263 | 4.368421 |
| Asian_Not Korean_POC | 2.944444 | 3.555556 | 4.333333 | ||||||||
| Not Asian_Not Korean_POC | 3.809524 | 2.571429 | 4.761905 | ||||||||
| Not Asian_Not Korean_White | 3.702128 | 2.638298 | 4.06383 | ||||||||
| 31 | 25 | Male | Yes | 0 | 2nd | English | 6.2 | Asian_Korean_POC | 2.526316 | 3.526316 | 4.368421 |
| Asian_Not Korean_POC | 3.388889 | 3.388889 | 3.666667 | ||||||||
| Not Asian_Not Korean_POC | 4.095238 | 2.571429 | 4.142857 | ||||||||
| Not Asian_Not Korean_White | 3.765957 | 2.617021 | 3.93617 | ||||||||
| 32 | 26 | Male | Yes | 0 | 2nd | English | 3.65 | Asian_Korean_POC | 2.157895 | 4.263158 | 3.263158 |
| Asian_Not Korean_POC | 2.444444 | 3.777778 | 3.055556 | ||||||||
| Not Asian_Not Korean_POC | 3.142857 | 3 | 3.47619 | ||||||||
| Not Asian_Not Korean_White | 2.744681 | 2.93617 | 3.191489 | ||||||||
| 33 | 30 | Female | No | 3 | 1.5 | English | 5.6 | Asian_Korean_POC | 3.368421 | 3.947368 | 3.210526 |
| Asian_Not Korean_POC | 2.888889 | 3.555556 | 3.166667 | ||||||||
| Not Asian_Not Korean_POC | 3.761905 | 2.714286 | 3.52381 | ||||||||
| Not Asian_Not Korean_White | 3.808511 | 2.638298 | 3.06383 | ||||||||
| 34 | 32 | Female | Yes | 10 | 1.5 | English | 5.15 | Asian_Korean_POC | 2.842105 | 3.947368 | 3.473684 |
| Asian_Not Korean_POC | 3.166667 | 3.833333 | 3.944444 | ||||||||
| Not Asian_Not Korean_POC | 4.285714 | 2.52381 | 4.428571 | ||||||||
| Not Asian_Not Korean_White | 4.212766 | 2.361702 | 3.808511 | ||||||||
| 35 | 28 | Female | Yes | 0 | 2nd | English | 4.6 | Asian_Korean_POC | 3.684211 | 3.789474 | 4.105263 |
| Asian_Not Korean_POC | 4 | 3.111111 | 4.666667 | ||||||||
| Not Asian_Not Korean_POC | 4.428571 | 2.47619 | 4.380952 | ||||||||
| Not Asian_Not Korean_White | 4.319149 | 2.191489 | 4.297872 | ||||||||
| 36 | 31 | Female | Yes | 0 | 2nd | English | 5.15 | Asian_Korean_POC | 2.052632 | 4.315789 | 2.842105 |
| Asian_Not Korean_POC | 2.111111 | 4.5 | 3.055556 | ||||||||
| Not Asian_Not Korean_POC | 3.47619 | 3.142857 | 3.47619 | ||||||||
| Not Asian_Not Korean_White | 3.617021 | 3.106383 | 3.276596 | ||||||||
| 37 | 36 | Female | Yes | 0 | 2nd | English | 6.25 | Asian_Korean_POC | 3.631579 | 3.315789 | 3.473684 |
| Asian_Not Korean_POC | 3.666667 | 2.611111 | 3.611111 | ||||||||
| Not Asian_Not Korean_POC | 3.380952 | 2.190476 | 3.380952 | ||||||||
| Not Asian_Not Korean_White | 3.680851 | 1.978723 | 3.510638 | ||||||||
| 38 | 25 | Male | Yes | 0 | 2nd | English | 4.4 | Asian_Korean_POC | 3.210526 | 3.631579 | 3.368421 |
| Asian_Not Korean_POC | 3.944444 | 2.944444 | 3.777778 | ||||||||
| Not Asian_Not Korean_POC | 3.952381 | 2.428571 | 3.666667 | ||||||||
| Not Asian_Not Korean_White | 4.12766 | 2.191489 | 3.851064 | ||||||||
| 39 | 32 | Female | Yes | 16 | 1.5 | Both | 5.5 | Asian_Korean_POC | 1.947368 | 4.578947 | 2.736842 |
| Asian_Not Korean_POC | 1.944444 | 4.277778 | 3.277778 | ||||||||
| Not Asian_Not Korean_POC | 2.619048 | 4.190476 | 3.666667 | ||||||||
| Not Asian_Not Korean_White | 2.468085 | 3.87234 | 3.297872 | ||||||||
| 40 | 55 | Female | Yes | 8 | 1.5 | Both | 5.15 | Asian_Korean_POC | 3.368421 | 3.578947 | 3.263158 |
| Asian_Not Korean_POC | 3.388889 | 3.277778 | 3.222222 | ||||||||
| Not Asian_Not Korean_POC | 4.095238 | 2.333333 | 3.285714 | ||||||||
| Not Asian_Not Korean_White | 3.957447 | 2.042553 | 3.489362 |
| 1 | However, it is often construed as a fundamental pillar of the uniquely U.S. American “ethnoracial pentagon” Torres-Saillant 2003: White, Black, Asian, Hispanic/Latino, and Native American/Indigenous, including Alaska Native and Native Hawaiian. |
| 2 | With several exceptions, including Hmong and Kurdish. |
| 3 | Note that it is also common for out-group members to have different associations between signals and categories compared to in-group members, rather than to have no associations at all, as has been shown in Johnstone and Kiesling (2008) and Villarreal (2016), inter alia. |
| 4 | Despite the variation, any audio sampled at these rates and a bit depth of 16 is considered standard for most speech perception experiments. |
| 5 | Thanks to an anonymous reviewer for noting the potential bias that could be introduced this way: due to the task design, over time, participants may have begun to intuit that the experiment was specifically targeting perception of Asian American voices. Great care was taken to ensure participant naivety to the goal of the task, but the possibility of this intuition always remains. |
| 6 | To account for potential variability in the 1.5 group due to the wide range of ages of arrival, the same tests were run with the speakers separated into three groups: second generation, “early” 1.5-generation arrivals (who immigrated prior to age 6) and “late” 1.5-generation arrivals (who immigrated between 6 and 16). The differences were similarly insignificant. |
| 7 | This category included those who identified as Hispanic/Latino, African American, Indigenous, and non-Asian mixed race. |
References
- Agha, Asif. 2005. Voice, footing, enregisterment. Journal of Linguistic Anthropology 15: 38–59. [Google Scholar] [CrossRef]
- Albury, Nathan John. 2017. How folk linguistic methods can support critical sociolinguistics. Lingua 199: 36–49. [Google Scholar] [CrossRef]
- Alfaraz, Gabriela G. 2014. Dialect perceptions in real time: A restudy of miami-cuban perceptions. Journal of Linguistic Geography 2: 74–86. [Google Scholar] [CrossRef]
- Baugh, John. 2003. Linguistic profiling. Black Linguistics: Language, Society, and Politics in Africa and the Americas 1: 155–68. [Google Scholar]
- Bauman, Carina. 2016. Speaking of Sisterhood: A Sociolinguistic Study of an Asian American Sorority. Ph.D. thesis, New York University, New York, NY, USA. [Google Scholar]
- Boersma, Paul, and David Weenink. 2021. Praat: Doing Phonetics by Computer [Computer Program]. Available online: http://www.praat.org/ (accessed on 1 October 2021).
- Bucholtz, Mary. 2004. Styles and stereotypes: The linguistic negotiation of identity among Laotian American youth. Pragmatics 14: 127–47. [Google Scholar] [CrossRef]
- Burdin, Rachel Steindel, Nicole Holliday, and Paul E. Reed. 2018. Rising above the standard: Variation in L+H* contour use across 5 varieties of American English. Paper presented at 9th International Conference on Speech Prosody, Poznań, Poland, June 13–16; pp. 354–58. [Google Scholar]
- Campbell-Kibler, Kathryn. 2007. Accent, (ING), and the social logic of listener perceptions. American Speech 82: 32–64. [Google Scholar] [CrossRef] [Green Version]
- Campbell-Kibler, Kathryn. 2010. Sociolinguistics and perception. Language and Linguistics Compass 4: 377–89. [Google Scholar] [CrossRef]
- Carter, Phillip M., Lydda López Valdez, and Nandi Sims. 2020. New Dialect Formation Through Language Contact: Vocalic And Prosodic Developments In Miami English. American Speech 95: 119–48. [Google Scholar] [CrossRef]
- Cheng, Andrew. 2020a. Cross-linguistic f0 differences in bilingual speakers of English and Korean. The Journal of the Acoustical Society of America 147: EL67–EL73. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Andrew. 2020b. Accent and Ideology among Bilingual Korean Americans. Ph.D. thesis, University of California, Berkeley, CA, USA. [Google Scholar]
- Cheryan, Sapna, and Benoît Monin. 2005. Where are you really from?: Asian Americans and identity denial. Journal of Personality and Social Psychology 89: 717. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Choi, Jinny K. 2015. Identity and language: Korean speaking Korean, Korean-American speaking Korean and English? Language and Intercultural Communication 15: 240–66. [Google Scholar] [CrossRef]
- Chun, Elaine W. 2001. The construction of white, black, and Korean American identities through African American Vernacular English. Journal of Linguistic Anthropology 11: 52–64. [Google Scholar] [CrossRef]
- Craft, Justin T., Kelly E. Wright, Rachel Elizabeth Weissler, and Robin M. Queen. 2020. Language and discrimination: Generating meaning, perceiving identities, and discriminating outcomes. Annual Review of Linguistics 6: 389–407. [Google Scholar] [CrossRef] [Green Version]
- Cundiff, Jessica L. 2012. Is mainstream psychological research “womanless” and “raceless”? An updated analysis. Sex Roles 67: 158–73. [Google Scholar] [CrossRef]
- Devos, Thierry, and Mahzarin R. Banaji. 2005. American = white? Journal of Personality and Social Psychology 88: 447. [Google Scholar] [CrossRef]
- D’Onofrio, Annette. 2015. Persona-based information shapes linguistic perception: Valley Girls and California vowels. Journal of Sociolinguistics 19: 241–56. [Google Scholar] [CrossRef]
- Drager, Katie. 2010. Sociophonetic variation in speech perception. Language and Linguistics Compass 4: 473–80. [Google Scholar] [CrossRef]
- Dragojevic, Marko, Christofer Berglund, and Timothy K. Blauvelt. 2018. Figuring out who’s who: The role of social categorization in the language attitudes process. Journal of Language and Social Psychology 37: 28–50. [Google Scholar] [CrossRef] [Green Version]
- Eckert, Penelope. 2008. Variation and the indexical field. Journal of Sociolinguistics 12: 453–76. [Google Scholar] [CrossRef]
- Espiritu, Yen. 1992. Asian American Panethnicity: Bridging Institutions and Identities. Philadelphia: Temple University Press, vol. 171. [Google Scholar]
- Flege, James Emil, and Kathryn L. Fletcher. 1992. Talker and listener effects on degree of perceived foreign accent. The Journal of the Acoustical Society of America 91: 370–89. [Google Scholar] [CrossRef]
- Font-Santiago, Cristopher B. 2021. Puerto Rican Island English (PRIE): On the Emergence of a New Dialect of American English. Madison: The University of Wisconsin-Madison. [Google Scholar]
- Foreman, Christina Gayle. 2000. Identification of African-American English from prosodic cues. In Texas Linguistic Forum. Austin: University of Texas, vol. 43, pp. 57–66. First published 1998. [Google Scholar]
- Fought, Carmen. 2002a. California students’ perceptions of, you know, regions and dialects. In Handbook of Perceptual Dialectology. Amsterdam: John Benjamins Publishing, vol. 2, pp. 113–34. [Google Scholar]
- Fought, Carmen. 2002b. Chicano English in Context. Berlin: Springer. [Google Scholar]
- Hall-Lew, Lauren. 2010. Ethnicity and sociolinguistic variation in San Francisco. Language and Linguistics Compass 4: 458–72. [Google Scholar] [CrossRef] [Green Version]
- Hanna, David B. 1997. Do I sound “Asian” to you?: Linguistic markers of Asian American identity. University of Pennsylvania Working Papers in Linguistics 4: 10. [Google Scholar]
- Hawkins, Francine Dove. 1993. Speaker Ethnic Identification: The Roles of Speech Sample, Fundamental Frequency, Speaker and Listener Variations. Ph.D. thesis, University of Maryland, College Park, MD, USA. [Google Scholar]
- Hinton, Leanne, Birch Moonwomon, Sue Bremner, Herb Luthin, Mary Van Clay, Jean Lerner, and Hazel Corcoran. 1987. It’s not just the Valley Girls: A study of California English. In Annual Meeting of the Berkeley Linguistics Society. Berkeley: The Linguistic Society of America’s Digital Publishing, vol. 13, pp. 117–28. [Google Scholar]
- Hoffman, Michol F., and James A. Walker. 2010. Ethnolects and the city: Ethnic orientation and linguistic variation in Toronto English. Language Variation and Change 22: 37–67. [Google Scholar] [CrossRef]
- Holliday, Nicole, and Dan Villarreal. 2020. Intonational variation and incrementality in listener judgments of ethnicity. Laboratory Phonology: Journal of the Association for Laboratory Phonology 11: 1–21. [Google Scholar] [CrossRef] [Green Version]
- Ito, Rika. 2010. Accommodation to the local majority norm by Hmong Americans in the Twin Cities, Minnesota. American Speech 85: 141–62. [Google Scholar] [CrossRef]
- Ito, Rika. 2021. ‘Not a white girl’ and speaking ‘English with slang’: Negotiating Hmong American identities in Minneapolis-St. Paul, Minnesota, USA. Multilingua 40: 339–66. [Google Scholar] [CrossRef]
- Jaspers, Jürgen. 2008. Problematizing ethnolects: Naming linguistic practices in an antwerp secondary school. International Journal of Bilingualism 12: 85–103. [Google Scholar] [CrossRef] [Green Version]
- Jeon, Lisa. 2017. Korean Ethnic Orientation and Regional Linguistic Variability in the Multiethnic Context of Houston. In Korean Englishes in Transnational Contexts. Berlin: Springer, pp. 93–114. [Google Scholar]
- Johnstone, Barbara, and Scott F. Kiesling. 2008. Indexicality and experience: Exploring the meanings of/aw/-monophthongization in Pittsburgh. Journal of Sociolinguistics 12: 5–33. [Google Scholar] [CrossRef]
- Kang, Kyoung-Ho, and Susan G. Guion. 2006. Phonological systems in bilinguals: Age of learning effects on the stop consonant systems of Korean-English bilinguals. The Journal of the Acoustical Society of America 119: 1672–83. [Google Scholar] [CrossRef]
- Kang, Okim, and Donald L. Rubin. 2009. Reverse linguistic stereotyping: Measuring the effect of listener expectations on speech evaluation. Journal of Language and Social Psychology 28: 441–56. [Google Scholar] [CrossRef]
- Lee, Jinsok. 2016. The participation of a northern New Jersey Korean American community in local and national language variation. American Speech 91: 327–60. [Google Scholar] [CrossRef]
- Lee, Jin Sook. 2002. The Korean Language in America: The Role of Cultural Identity in Heritage Language Learning. Heritage Language Learning, Language, Culture and Curriculum 15: 117–33. [Google Scholar] [CrossRef]
- Levon, Erez. 2014. Categories, stereotypes, and the linguistic perception of sexuality. Language in Society 43: 539–66. [Google Scholar] [CrossRef] [Green Version]
- Meissner, Christian A., and John C. Brigham. 2001. Thirty years of investigating the own-race bias in memory for faces: A meta-analytic review. Psychology, Public Policy, and Law 7: 3. [Google Scholar] [CrossRef]
- Nagy, Naomi, Michol Hoffman, and James A. Walker. 2020. How do Torontonians hear ethnic identity? Toronto Working Papers in Linguistics 42. [Google Scholar] [CrossRef]
- Newman, Michael, and Angela Wu. 2011. “Do you sound Asian when you speak English?” Racial identification and voice in Chinese and Korean Americans’ English. American Speech 86: 152–78. [Google Scholar] [CrossRef]
- Park, Kyeyoung. 1999. “I Really Do Feel I’m 1.5!”: The Construction of Self and Community by Young Korean Americans. Amerasia Journal 25: 139–64. [Google Scholar] [CrossRef]
- Park, Kyeyoung, and Jessica Kim. 2008. The contested nexus of Los Angeles Koreatown: Capital restructuring, gentrification, and displacement. Amerasia Journal 34: 126–50. [Google Scholar] [CrossRef]
- Perrachione, Tyler K., Joan Y. Chiao, and Patrick C. M. Wong. 2010. Asymmetric cultural effects on perceptual expertise underlie an own-race bias for voices. Cognition 114: 42–55. [Google Scholar] [CrossRef] [Green Version]
- Podesva, Robert J. 2011. The California vowel shift and gay identity. American Speech 86: 32–51. [Google Scholar] [CrossRef] [Green Version]
- Purnell, Thomas, William Idsardi, and John Baugh. 1999. Perceptual and phonetic experiments on American English dialect identification. Journal of Language and Social Psychology 18: 10–30. [Google Scholar] [CrossRef]
- Reed, Paul E. 2018. The importance of Appalachian identity: A case study in rootedness. American Speech 93: 409–24. [Google Scholar] [CrossRef]
- Reyes, Angela, and Adrienne Lo. 2009. Beyond Yellow English: Toward a Linguistic Anthropology of Asian Pacific America. New York: OUP USA. [Google Scholar]
- Rickford, John R., and Sharese King. 2016. Language and linguistics on trial: Hearing rachel jeantel (and other vernacular speakers) in the courtroom and beyond. Language 92: 948–88. [Google Scholar] [CrossRef]
- Rosa, Jonathan, and Nelson Flores. 2017. Unsettling race and language: Toward a raciolinguistic perspective. Language in Society 46: 621–47. [Google Scholar] [CrossRef] [Green Version]
- Rubin, Donald L. 1992. Nonlanguage factors affecting undergraduates’ judgments of nonnative English-speaking teaching assistants. Research in Higher Education 33: 511–31. [Google Scholar] [CrossRef]
- Rubin, Donald L., and Kim A. Smith. 1990. Effects of accent, ethnicity, and lecture topic on undergraduates’ perceptions of nonnative English-speaking teaching assistants. International Journal of Intercultural Relations 14: 337–53. [Google Scholar] [CrossRef]
- Salter, Phia, and Glenn Adams. 2013. Toward a critical race psychology. Social and Personality Psychology Compass 7: 781–93. [Google Scholar] [CrossRef]
- Sanchez, Jared, Mirabai Auer, Veronica Terriquez, and Mi Young Kim. 2012. Koreatown: A Contested Community at a Crossroads. Available online: https://dornsife.usc.edu/pere/koreatowncommunity/ (accessed on 1 January 2021).
- Schuld, Danielle, Joseph Salmons, Thomas Purnell, and Eric Raimy. 2016. “Subliminal accent”: Reactions to the rise of Wisconsin English. Journal of Linguistic Geography 4: 15–30. [Google Scholar] [CrossRef]
- Sharma, Devyani. 2011. Style repertoire and social change in British Asian English. Journal of Sociolinguistics 15: 464–92. [Google Scholar] [CrossRef]
- Shin, Jeeweon. 2016. Hyphenated Identities of Korean Heritage Language Learners: Marginalization, Colonial Discourses and Internalized Whiteness. Journal of Language, Identity and Education 15: 32–43. [Google Scholar] [CrossRef]
- Shin, Sarah J. 2005. Developing in Two Languages: Korean Children in America. Clevedon: Multilingual Matters. [Google Scholar]
- Thomas, Erik R. 2007. Phonological and phonetic characteristics of African American vernacular English. Language and Linguistics Compass 1: 450–75. [Google Scholar] [CrossRef]
- Thomas, Erik R., and Jeffrey Reaser. 2004. Delimiting perceptual cues used for the ethnic labeling of African American and European American voices. Journal of Sociolinguistics 8: 54–87. [Google Scholar] [CrossRef]
- Torres-Saillant, Silvio. 2003. Inventing the race: Latinos and the ethnoracial pentagon. Latino Studies 1: 123–51. [Google Scholar] [CrossRef]
- Tuan, Mia. 1998. Forever Foreigners or Honorary Whites?: The Asian Ethnic Experience Today. New Brunswick: Rutgers University Press. [Google Scholar]
- Villarreal, Dan. 2016. “Do I sound like a Valley Girl to you?” Perceptual dialectology and language attitudes in California. Publication of the American Dialect Society 101: 55–75. [Google Scholar] [CrossRef]
- Wong, Amy Wing-mei, and Lauren Hall-Lew. 2014. Regional variability and ethnic identity: Chinese Americans in New York City and San Francisco. Language & Communication 35: 27–42. [Google Scholar]
- Wong, Phoebe, and Molly Babel. 2017. Perceptual identification of talker ethnicity in Vancouver English. Journal of Sociolinguistics 21: 603–28. [Google Scholar] [CrossRef] [Green Version]
- Wright, Kelly E. 2021. Linguistic inequities: An audit study of three American dialects in the housing market. Presented at the Annual Meeting of the Linguistic Society of America, Online, January 7–10. [Google Scholar]
- Yogeeswaran, Kumar, and Nilanjana Dasgupta. 2010. Will the “real” American please stand up? The effect of implicit national prototypes on discriminatory behavior and judgments. Personality and Social Psychology Bulletin 36: 1332–45. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Speaker Gender | Speaker ID | Listener ID | Corr. (Mean f0) | Corr. (f0 Range) |
|---|---|---|---|---|
| Female | Asian rating | Asian | = 0.30, p = 0.002 | = 0.21, p = 0.034 |
| Not Asian | = 0.41, p < 0.001 | = 0.31, p = 0.002 | ||
| White rating | Asian | = −0.37, p < 0.001 | = −0.08, p = 0.42 | |
| Not Asian | = −0.27, p = 0.007 | = −0.002, p = 0.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, A.; Cho, S. The Effect of Ethnicity on Identification of Korean American Speech. Languages 2021, 6, 186. https://doi.org/10.3390/languages6040186
Cheng A, Cho S. The Effect of Ethnicity on Identification of Korean American Speech. Languages. 2021; 6(4):186. https://doi.org/10.3390/languages6040186
Chicago/Turabian StyleCheng, Andrew, and Steve Cho. 2021. "The Effect of Ethnicity on Identification of Korean American Speech" Languages 6, no. 4: 186. https://doi.org/10.3390/languages6040186
APA StyleCheng, A., & Cho, S. (2021). The Effect of Ethnicity on Identification of Korean American Speech. Languages, 6(4), 186. https://doi.org/10.3390/languages6040186