
How Do Speakers of a Language with a Transparent Orthographic System Perceive the L2 Vowels of a Language with an Opaque Orthographic System? An Analysis through a Battery of Behavioral Tests


Abstract
1. Introduction
Greek and English Phonological and Orthographical Systems
2. Methodology
2.1. Participants
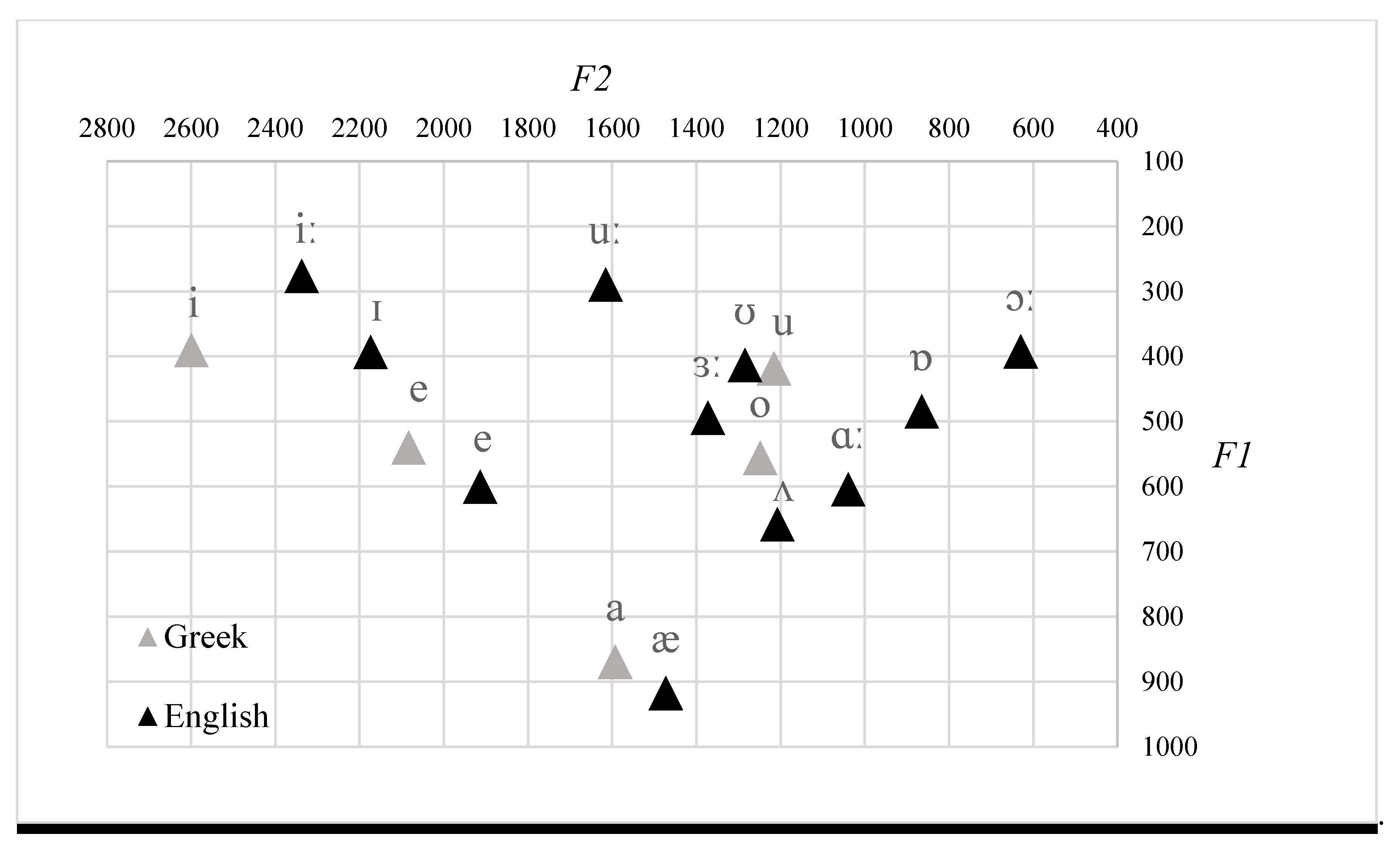
2.2. Stimuli
2.3. Procedure
2.3.1. Auditory Test
2.3.2. Orthography Test
3. Results
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Best, Catherine T. 1995. A direct realist view of cross-language speech perception: New Directions in Research and Theory. In Speech Perception and Linguistic Experience: Theoretical and Methodological Issues. Edited by Winifred Strange. Baltimore: York Press, pp. 171–204. [Google Scholar]
- Best, Catherine T., and Michael D. Tyler. 2007. Non-native and second-language speech perception: Commonalities and complementarities. In Second Language Speech Learning: In Honor of James Emil Flege. Edited by Ocke-Schwen Bohn and Murray J. Munro. Amsterdam and Philadelphia: John Benjamins, pp. 13–34. [Google Scholar]
- Best, Catherine T., and Winifred Strange. 1992. Effects of phonological and phonetic factors on cross-language perception of approximants. Journal of Phonetics 20: 305–30. [Google Scholar] [CrossRef]
- Best, Catherine T., Gerald W. McRoberts, and Elizabeth Goodell. 2001. Discrimination of non-native consonant contrasts varying in perceptual assimilation to the listener’s native phonological system. Journal of the Acoustical Society of America 109: 775–94. [Google Scholar] [CrossRef]
- Boersma, Paul, and David Weenink. 2020. Praat: Doing Phonetics by Computer [Computer Program]. Available online: http://www.fon.hum.uva.nl/praat/ (accessed on 14 March 2020).
- Castles, Anne, Virginia M. Holmes, Joanna Neath, and Sachiko Kinoshita. 2003. How does orthographic knowledge influence performance on phonological awareness tasks? Quarterly Journal of Experimental Psychology 56A: 445–67. [Google Scholar]
- Coutsougera, Photini. 2007. The impact of orthography on the acquisition of L2 phonology: Inferring the wrong phonology from print. In Proceedings of the Phonetics Teaching and Learning Conference 2007. London: University College London, pp. 1–5. [Google Scholar]
- Cutler, Anne, Andrea Weber, and Takashi Otake. 2006. Asymmetric mapping from phonetic to lexical representations in second-language listening. Journal of Phonetics 34: 269–84. [Google Scholar] [CrossRef]
- Dijkstra, Ton, Ardi Roelofs, and Steffen Fieuws. 1995. Orthographic effects on phoneme monitoring. Canadian Journal of Experimental Psychology 49: 264–71. [Google Scholar] [CrossRef] [PubMed]
- Erdener, V. Doǧu, and Denis K. Burnham. 2005. The role of audiovisual speech and orthographic information in nonnative speech production. Language Learning 55: 191–228. [Google Scholar] [CrossRef]
- Escudero, Paola, and Karin Wanrooij. 2010. The effect of L1 orthography on non-native and L2 vowel perception. Language and Speech 53: 343–65. [Google Scholar] [CrossRef] [PubMed]
- Escudero, Paola, Ellen Simon, and Karen E. Mulak. 2014. Learning words in a new language: Orthography doesn’t always help. Bilingualism-Language and Cognition 17: 384–95. [Google Scholar] [CrossRef]
- Flege, James E. 1995. Second language speech learning: Theory, findings and problems. In Speech Perception and Linguistic Experience: Theoretical and Methodological Issues. Edited by Winfield Strange. Baltimore: York Press, pp. 233–77. [Google Scholar]
- Frauenfelder, Uli H., Juan Segui, and Ton Dijkstra. 1990. Lexical effects in phonemic processing: Facilitatory or inhibitory? Journal of Experimental Psychology: Human Perception and Performance 16: 77–91. [Google Scholar] [CrossRef]
- Frost, Ram, Leonard Katz, and Shlomo Bentin. 1987. Strategies for visual word recognition and orthographical depth: A multilingual comparison. Journal of Experimental Psychology: Human Perception and Performance 13: 104–15. [Google Scholar] [CrossRef]
- Ganong, William F. 1980. Phonetic categorization in auditory word perception. Journal of Experimental Psychology: Human Perception and Performance 6: 110. [Google Scholar] [CrossRef]
- Georgiou, Georgios P. 2019. ‘Bit’ and ‘beat’ are heard as the same: Mapping the vowel perceptual patterns of Greek-English bilingual children. Language Sciences 72: 1–12. [Google Scholar] [CrossRef]
- Georgiou, Georgios P. 2021a. Effects of phonetic training on the discrimination of second language sounds by learners with naturalistic access to the second language. Journal of Psycholinguistic Research 50: 707–21. [Google Scholar] [CrossRef]
- Georgiou, Georgios P. 2021b. Toward a new model for speech perception: The Universal Perceptual Model (UPM) of Second Language. Cognitive Processing 22: 277–89. [Google Scholar] [CrossRef]
- Georgiou, Georgios P., Natalia Perfilieva, and Maria Tenizi. 2020. Vocabulary size leads to better attunement to L2 phonetic differences: Clues from Russian learners of English. Language Learning and Development 16: 382–98. [Google Scholar] [CrossRef]
- Georgiou, Georgios P., and Charalambos Themistocleous. 2021. Vowel Learning in Diglossic Settings: Evidence from Arabic-Greek Learners. International Journal of Bilingualism 25: 135–50. [Google Scholar] [CrossRef]
- Goswami, Usha, and Martin East. 2000. Rhyme and analogy in beginning reading: Conceptual and methodological issues. Applied Psycholinguistics 21: 63–93. [Google Scholar] [CrossRef]
- Goswami, Usha, Johannes C. Ziegler, Louise Dalton, and Wolfgang Schneider. 2003. Nonword reading across orthographies: How flexible is the choice of reading units? Applied Psycholinguistics 24: 235–47. [Google Scholar] [CrossRef]
- Hallé, Pierre A., Céline Chéreau, and Juan Segui. 2000. Where is the /b/ in “absurde” [apsyrd]? It is in French listeners’ minds. Journal of Memory & Language 43: 618–39. [Google Scholar]
- Katz, Leonard, and Ram Frost. 1992. The reading process is different for different orthographies: The orthographic depth hypothesis. In Orthography, Phonology, Morphology, and Meaning. Edited by Ram Frost and Leonard Katz. Amsterdam: Elsevier North Holland Press, pp. 67–84. [Google Scholar]
- Levy, Erika S., and Winifred Strange. 2008. Perception of French vowels by American English adults with and without French language experience. Journal of Phonetics 36: 141–57. [Google Scholar] [CrossRef]
- Norris, Dennis, James M. McQueen, and Anne Cutler. 2000. Merging information in speech recognition: Feedback is never necessary. Behavioral and Brain Sciences 23: 299–370. [Google Scholar] [CrossRef]
- Perry, Conrad, and Johannes C. Ziegler. 2000. Linguistic difficulties in childhood constrain adult reading. Memory and Cognition 28: 739–45. [Google Scholar] [CrossRef]
- Rastle, Kathleen, and Marc Brysbaert. 2006. Masked phonological priming effects in English: A critical review and two decisive experiments. Cognitive Psychology 53: 97–145. [Google Scholar] [CrossRef]
- Roach, Peter. 2004. British English: Received Pronunciation. Journal of the International Phonetic Association 34: 239–45. [Google Scholar] [CrossRef]
- Seidenberg, Mark S., and Michael K. Tanenhaus. 1979. Orthographic effects on rhyme monitoring. Journal of Experimental Psychology: Human Learning and Memory 5: 546–54. [Google Scholar] [CrossRef]
- Seidenberg, Mark S., Gloria S. Waters, Michael Sanders, and Pearl Langer. 1984. Pre-and postlexical loci of contextual effects on word recognition. Memory & Cognition 12: 315–28. [Google Scholar]
- Simon, Ellen, Della Chambless, and Ubiratã Kickhöfel Alves. 2010. Understanding the role of orthography in the acquisition of a non-native vowel contrast. Language Sciences 32: 380–94. [Google Scholar] [CrossRef]
- Taft, Marcus, Anne Castles, Chris Davis, Goran Lazendic, and Minh Nguyen-Hoan. 2008. Automatic activation of orthography in spoken word recognition: Pseudohomograph priming. Journal of Memory and Language 58: 366–79. [Google Scholar] [CrossRef]
- Timberlake, Alan. 2004. Sounds. A Reference Grammar of Russian. Cambridge: Cambridge University Press. [Google Scholar]
- Treiman, Rebecca, and Marie Cassar. 1997. Can children and adults focus on sound as opposed to spelling in a phoneme counting task. Developmental Psychology 33: 771–80. [Google Scholar] [CrossRef] [PubMed]
- Van Orden, Guy C. 1991. Phonologic mediation is fundamental to reading. In Basic Processes in Reading: Visual Word Recognition. Edited by Derek Besner and Glyn W. Humphreys. Hillsdale: Lawrence Erlbaum Associates, Inc, pp. 77–103. [Google Scholar]
- Ventura, Paulo, José Morais, Chotiga Pattamadilok, and Régine Kolinsky. 2004. The locus of the orthographic consistency effect in auditory word recognition. Language and Cognitive Processes 19: 57–95. [Google Scholar] [CrossRef]
- Vitevitch, Michael S., and Paul A. Luce. 1999. Probabilistic phonotactics and neighborhood activation in spoken word recognition. Journal of Memory and Language 40: 374–408. [Google Scholar] [CrossRef]
- Vitevitch, Michael S., David B. Pisoni, Karen Iler Kirk, Marcia Hay-McCutcheon, and Stacey L. Yount. 2000. Effects of Phonotactic Probabilities on the Processing of Spoken Words and Nonwords by Postlingually Deafened Adults with Cochlear Implants. Volta Review 102: 283–302. [Google Scholar]
- Vitevitch, Michael S., Paul A. Luce, Jan Charles-Luce, and David Kemmerer. 1997. Phonotactics and syllable stress: Implications for the processing of spoken nonsense words. Language and Speech 40: 47–62. [Google Scholar] [CrossRef]
- Vitevitch, Michael S., and Paul A. Luce. 2004. A web-based interface to calculate phonotactic probability for words and nonwords in English. Behavior Research Methods, Instruments, & Computers 36: 481–87. [Google Scholar]
- Weber, Andrea, and Anne Cutler. 2004. Lexical competition in non-native spoken-word recognition. Journal of Memory and Language 50: 1–25. [Google Scholar] [CrossRef]
- Ziegler, Johannes C., and Ludovic Ferrand. 1998. Orthography shapes the perception of speech: The consistency effect in auditory word recognition. Psychonomic Bulletin & Review 5: 683–89. [Google Scholar]



{kind=link}
{kind=link}
| English Grapheme | English Phoneme | Possible Association |
|---|---|---|
| <i> - <ee> | /ɪ/ - /iː/ | /i/ - /ee/ |
| <ea> - <a> | /ɑː/ - /æ/ | /ea/ - /a/ |
| <a> - <u> | /ɑː/ - /ʌ/ | /a/ - /u/ |
| <ou> - <o> | /ɔː/ - /ɒ/ | /u/ - /o/ |
| Auditory Test | Orthography Test | Significance of Difference | |
|---|---|---|---|
| Contrast | Mean (SD) | Mean (SD) | p Value |
| /ɪ/ - /iː/ | 69 (6.6) | 65 (4.6) | >0.05 |
| /ɑː/ - /æ/ | 66 (6) | 46 (9.4) | <0.05 |
| /ɑː/ - /ʌ/ | 57 (4.9) | 38 (5.3) | <0.05 |
| /ɔː/ - /ɒ/ | 59 (10) | 42 (6) | <0.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Georgiou, G.P. How Do Speakers of a Language with a Transparent Orthographic System Perceive the L2 Vowels of a Language with an Opaque Orthographic System? An Analysis through a Battery of Behavioral Tests. Languages 2021, 6, 118. https://doi.org/10.3390/languages6030118
Georgiou GP. How Do Speakers of a Language with a Transparent Orthographic System Perceive the L2 Vowels of a Language with an Opaque Orthographic System? An Analysis through a Battery of Behavioral Tests. Languages. 2021; 6(3):118. https://doi.org/10.3390/languages6030118
Chicago/Turabian StyleGeorgiou, Georgios P. 2021. "How Do Speakers of a Language with a Transparent Orthographic System Perceive the L2 Vowels of a Language with an Opaque Orthographic System? An Analysis through a Battery of Behavioral Tests" Languages 6, no. 3: 118. https://doi.org/10.3390/languages6030118
APA StyleGeorgiou, G. P. (2021). How Do Speakers of a Language with a Transparent Orthographic System Perceive the L2 Vowels of a Language with an Opaque Orthographic System? An Analysis through a Battery of Behavioral Tests. Languages, 6(3), 118. https://doi.org/10.3390/languages6030118