
Smooth Signals and Syntactic Change



Abstract
1. Introduction
1.1. Information Uniformity in Language
1.2. Current Study
- (1) a.
- …og sannleikurinn mun yður frelsa…and the truth will you free“…and the truth will set you free.”(Oddur Gottskálksson’s New Testament, date: 1540; ID 1540.NTJOHN.REL-BIB, 204.662 from Icelandic Parsed Historical Corpus (IcePaHC))
- b.
- …en eg skal sjá yður aftur.but I shall see you-pl again“…but I shall see you again”(Oddur Gottskálksson’s New Testament, date: 1540; ID 1540.NTJOHN.REL-BIB, 223.1305 from IcePaHC)
- (2)
- Mi feader & Mi moder for-þi þt ich nule þe forsaken; habbe forsake me.My father and my mother because that I not+would you forsake have forsaken me“Because I would not forsake you, my father and mother have forsaken me”(St. Juliana, northern Herefordshire/southern Shropshire, date: c1225; ID CMJULIA-M1,106.172 from the Penn Parsed Corpus of Middle English 2 (PPCME2))
1.3. Predictions
- Pronouns are closed-class and frequent, and so are low information content, (cf. Shannon 1948) in comparison with nominal DPs (e.g., you vs. the politician). For example, the average information content value for pronouns in the Penn Parsed Corpus of Modern British English (PPCMBE; Kroch et al. 2016) is 11.7 bits.
- Nominal DP Objects are high information content in general, because any particular DP will be low probability. There are more common noun lexemes than any other part of speech, and so any given noun is lower probability by virtue of belonging to a very large set. The probability of a given noun combined with a determiner and/or modifiers is necessarily lower than the probability of the noun alone. For example, the average information content for nouns in PPCMBE is 13.7 bits, and we can reasonably expect the average information content is much higher for nominal DPs, since they can be of arbitrary complexity.
- Verbs are mid-level in frequency and so also in information content: lower than nominal DPs, on average, but higher than pronouns. For example, the average information content for lexical verbs in the PPCMBE is 13.5 bits.
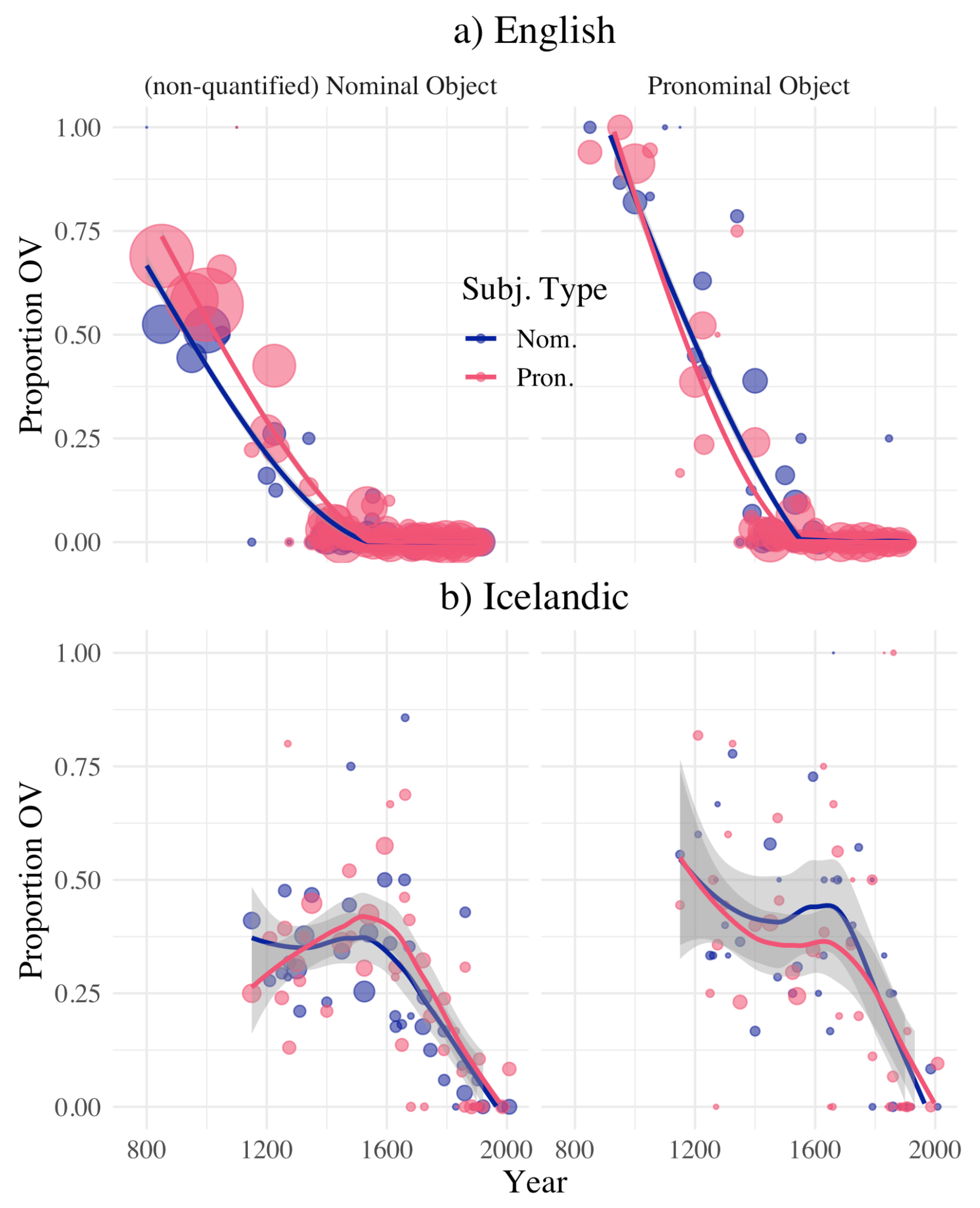
- When Subject and Object are of the same type (i.e., both pronominal or both nominal), VO clause structure is statistically favored.
- Otherwise, OV clause structure is favored.
- These effects are orthogonal to the OV to VO change, but apply as constants throughout the course of the change.
- (3)
- grátur mun þryngva ina efstu hluti fagnaðarWeeping will throng the highest parts joy-gen“Weeping will crowd into even the very last bits of joy”(Íslensk Hómilíubók, date: c. 1150; ID 1150.HOMILIUBOK.REL-SER,.1408 from IcePaHC)HIGH-mid-HIGH is the information distribution shape produced, on average, by the above clause structure.
- (4)
- …og sannleikurinn mun yður frelsa…and the truth will you free“…and the truth will set you free.”(Repeated from above, ID 1540.NTJOHN.REL-BIB,204.662 from IcePaHC)HIGH-low-mid is the information distribution shape produced, on average, by the above clause structure.
- (5)
- Ne maʒʒ he nohht rihht cnawenn meneg may he not right know me“He may not rightly know me”(Ormulum, Lincoln, date: 1200; ID CMORM-M1,II,241.2491 from PPCME2)low-mid-low is the information distribution shape produced, on average, by the above clause structure.
- (6)
- tu mihht ec gastlike laf Onn oþerr wise ʒarrkennyou might also spiritual loaf in another way prepare“You might also prepare a spiritual loaf in another way.”(Ormulum, Lincoln, date: 1200; ID CMORM-M1,I,49.493 from PPCME2)low-HIGH-mid is the information distribution shape produced, on average, by the above clause structure.
2. Materials and Methods
- (7)
- ef þeir vilja trú taka, …if they want faith take …“…if they wish to convert, …”(Jómsvíkinga saga, date: 1260; ID 1260.JOMSVIKINGAR.NAR-SAG,.765 from IcePaHC)
- (8)
- (IP-SUB(NP-SBJ (PRO-N þeir))(MDPI vilja)(NP-OB1(N-A trú))(VB taka))Token ID: 1260.JOMSVIKINGAR.NAR-SAG,.765
- (9)
- define:clause IP-(MAT|SUB).*finaux (MD|HV|BE|DO|RD)[PD][IS]mainverb (VB|VAN|VBN)object NP-OB[12]clause idoms finauxclause idoms NP-SBJov:1finaux sprec objectobject sprec mainverbov:0finaux sprec mainverbmainverb sprec object
- (10)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
- (11)
- meta:text genretext yearnode label clause
3. Results
- When Subject and Object are of the same type (i.e., both pronominal or both nominal), VO clause structure is statistically favored.
- Conversely, when Subject and Object are of different types, OV clause structure is favored.
- –
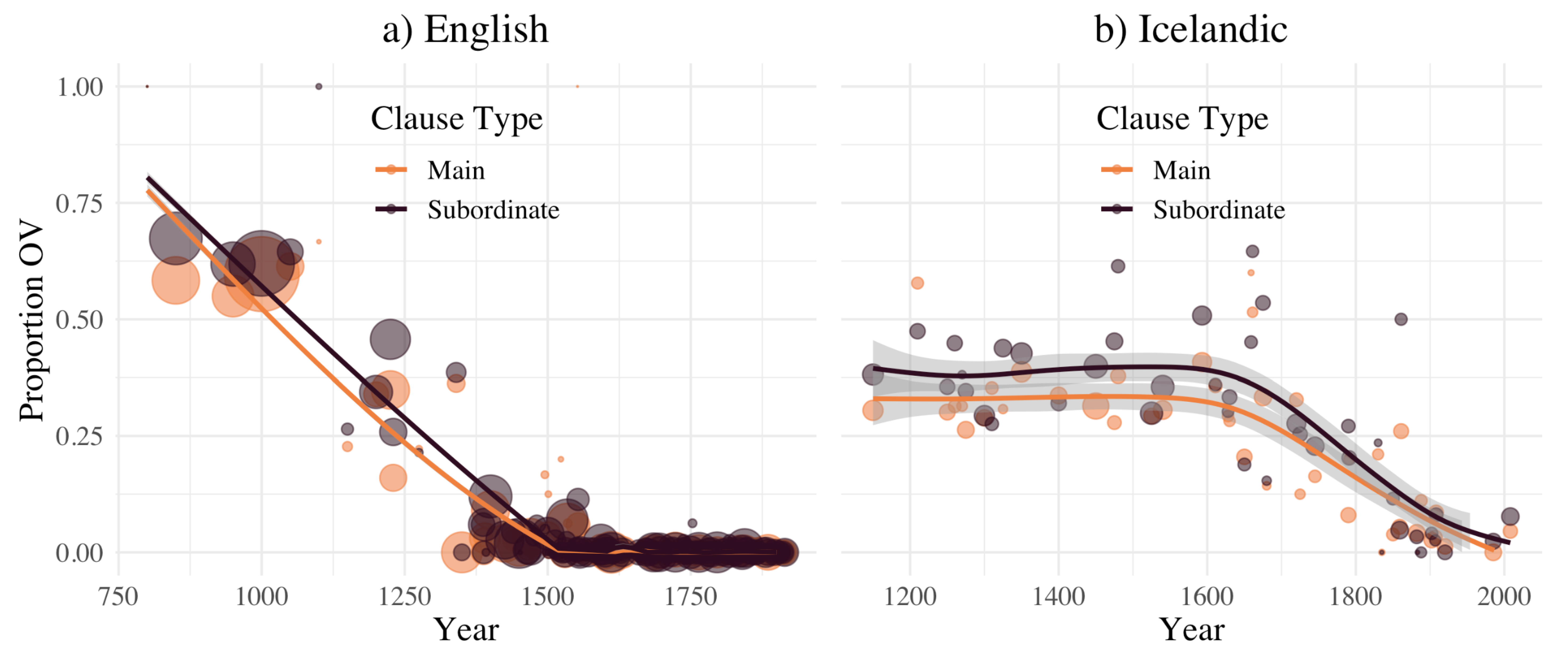
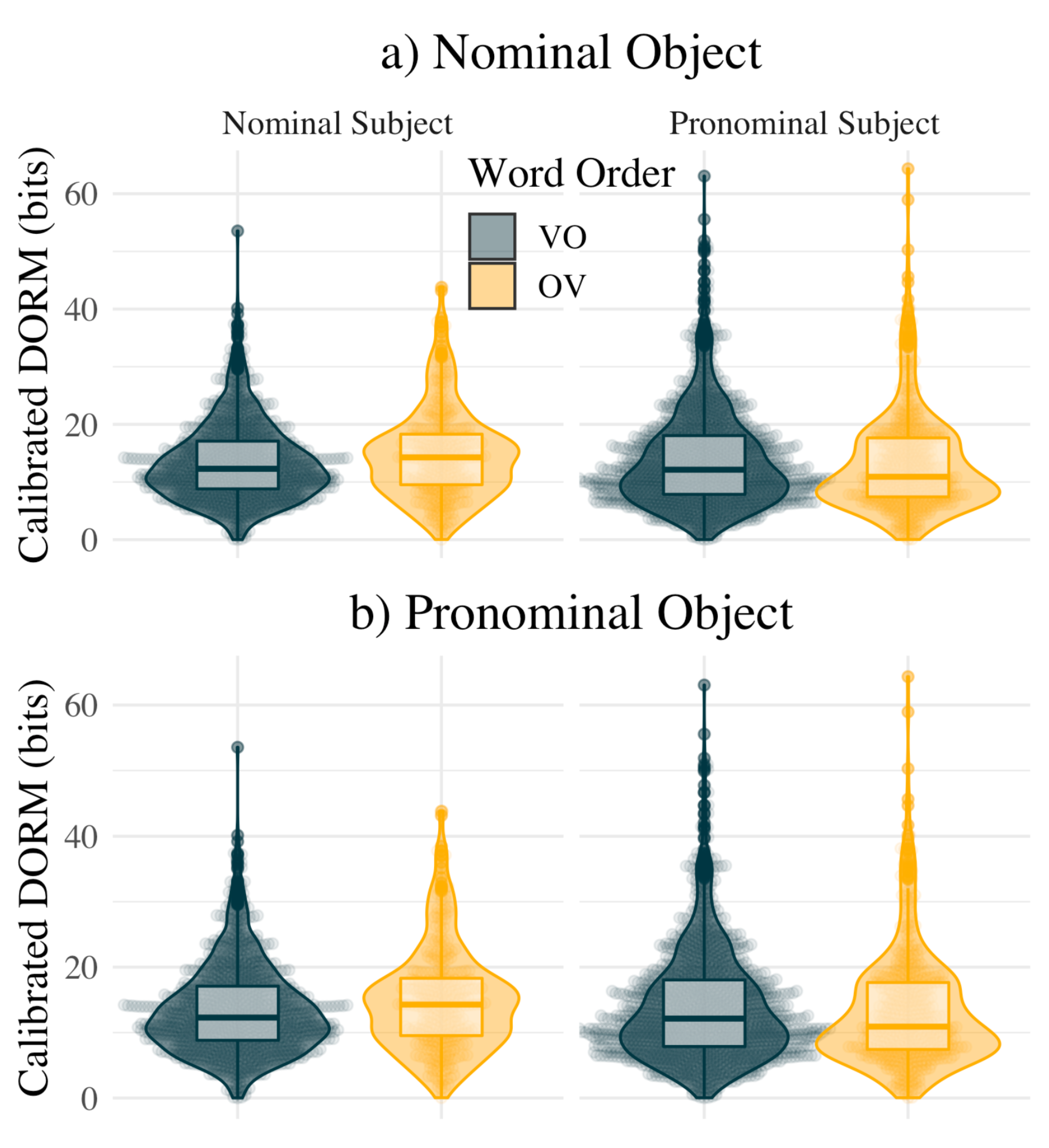
- These complementary results are summarized in Section 3.1 below, and illustrated by Figure 2. That this pattern of clause structure results in more uniform information distributions is summarized in Section 3.2 and illustrated by Figure 3.
- These effects are orthogonal to the OV to VO change, but apply as constants throughout the course of the change.
- –
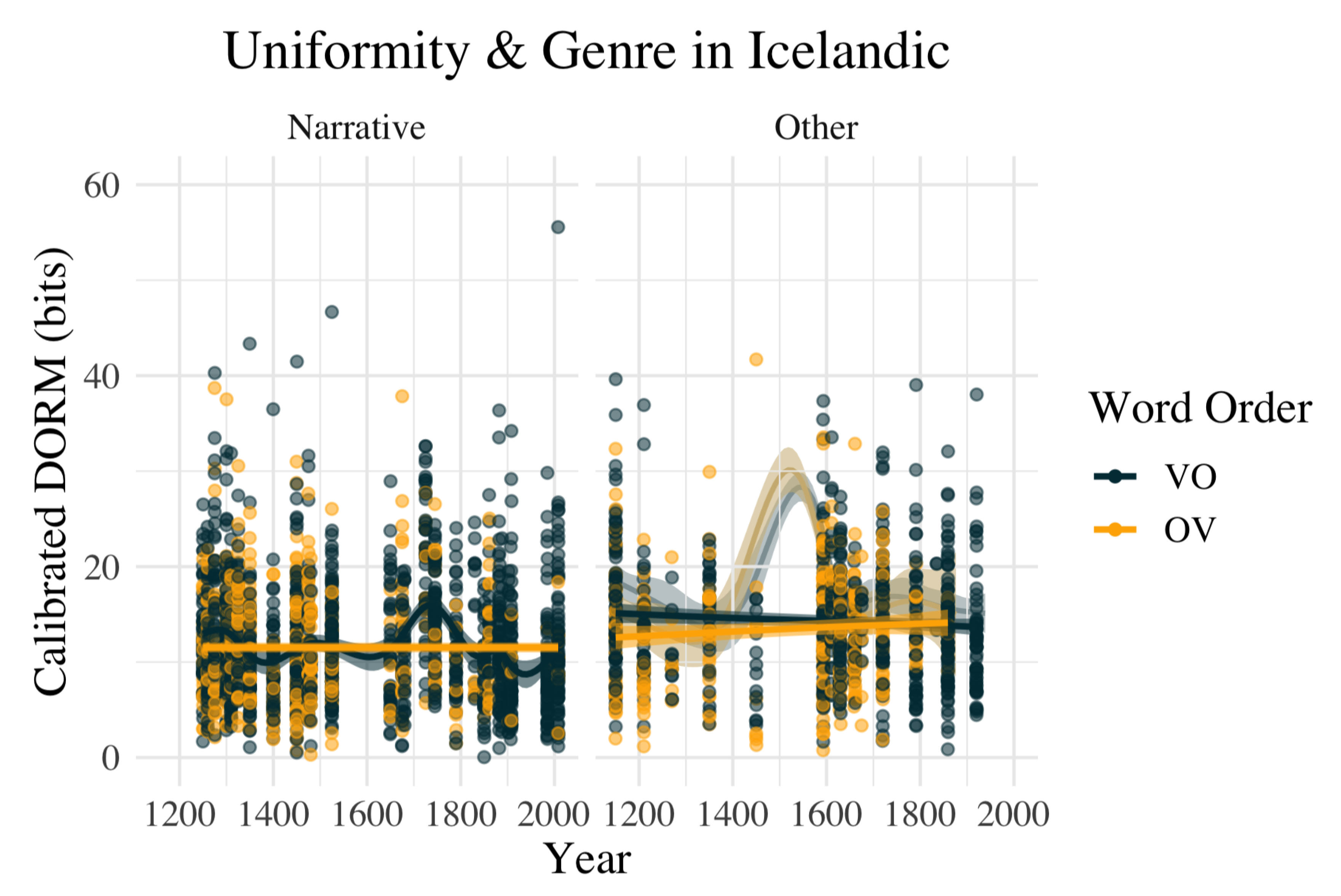
- This result is indicated in Section 3.1 below and illustrated by Figure 2. That information density remains stable given the OV to VO change is summarized in Section 3.3, and is illustrated by Figure 4.
3.1. Effect of Syntactic Context on OV/VO Diachrony
3.2. OV/VO and Information Density in Icelandic
3.3. Stability of Information Density over Time
4. Discussion
4.1. Effect of Syntactic Context on OV/VO Diachrony
4.2. OV/VO and Information Density in Icelandic
4.3. Stability of Information Density over Time
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| OV/VO | Object Verb/Verb Object |
| DORM | Deviation of Rolling Mean |
| IcePaHC | Icelandic Parsed Historical Corpus |
| YCOE | York Corpus of Old English Prose |
| PPCME2 | Penn Parsed Corpus of Middle English, Second Edition |
| PPCEME | Penn Parsed Corpus of Early Modern English |
| PPCMBE | Penn Parsed Corpus of Modern British English |
| AIC | Akaike Information Criterion |
| BIC | Bayesian Information Criterion |
References
- Aylett, Matthew. 1999. Stochastic suprasegmentals: Relationships between redundancy, prosodic structure and syllabic duration. Paper presented at the ICPhS–99, San Francisco, CA, USA, August 1–7. [Google Scholar]
- Aylett, Matthew, and Alice Turk. 2004. The smooth signal redundancy hypothesis: A functional explanation for relationships between redundancy, prosodic prominence, and duration in spontaneous speech. Language and Speech 47: 31–56. [Google Scholar] [CrossRef] [PubMed]
- Bergen, Leon, and Noah D. Goodman. 2015. The strategic use of noise in pragmatic reasoning. Topics in Cognitive Science 7: 336–50. [Google Scholar] [CrossRef] [PubMed]
- Biber, Douglas, and Bethany Gray. 2013. Nominalizing the verb phrase in academic science writing. The Verb Phrase in English: Investigating Recent Language Change with Corpora 9: 1–27. [Google Scholar]
- Bizzoni, Yuri, Stefania Degaetano-Ortlieb, Peter Fankhauser, and Elke Teich. 2020. Linguistic variation and change in 250 years of English scientific writing: A data-driven approach. Frontiers in Artificial Intelligence, Section Language and Computation. [Google Scholar] [CrossRef]
- Cuskley, Christine, Rachael Bailes, and Joel C. Wallenberg. 2020. Noise Resistance in Communication: Quantifying Uniformity and Optimality. Available online: https://psyarxiv.com/wpvq4 (accessed on 11 March 2021).
- Degaetano-Ortlieb, Stefania. 2018. Stylistic variation over 200 years of court proceedings according to gender and social class. Paper presented at the 2nd Workshop on Stylistic Variation collocated with NAACL HLT 2018, New Orleans, LA, USA, June 1–6; pp. 1–10. [Google Scholar]
- Degaetano-Ortlieb, Stefania, and Elke Teich. 2019. Toward an optimal code for communication: The case of scientific English. Corpus Linguistics and Linguistic Theory (Open Access), 1–33. [Google Scholar] [CrossRef]
- Einarsson, Sigurbjörn. 1988. Oddur Gottskálksson. In Nýja testamenti Odds Gottskálkssonar. Edited by Sigurbjörn Einarsson, Guðrún Kvaran, Gunnlaugur Ingólfsson and Jón Aðalsteinn Jónsson. Reykjavík: Lögberg, pp. VII–XX. [Google Scholar]
- Fenk, August, and Gertraud Fenk. 1980. Konstanz im kurzzeitgedächtnis-konstanz im sprachlichen informationsfluß. Zeitschrift für Experimentelle und Angewandte Psychologie 27: 402. [Google Scholar]
- Ferrer-i-Cancho, Ramon. 2017. The placement of the head that maximizes predictability. An information theoretic approach. arXiv arXiv:1705.09932. [Google Scholar]
- Frank, Austin F., and T. Florian Jaeger. 2008. Speaking Rationally: Uniform Information Density as an Optimal Strategy for Language Production. In Proceedings of the Annual Meeting of the Cognitive Science Society. Volume 30, Available online: https://escholarship.org/uc/item/7d08h6j4 (accessed on 11 March 2021).
- Fruehwald, Josef, Jonathan Gress-Wright, and Joel C. Wallenberg. 2013. Phonological Rule Change: The Constant Rate Effect. In Proceedings of the 40th Annual Meeting of the North East Linguistic Society. Edited by Seda Kan, Claire Moore-Cantwell and Robert Staubs. Amherst: GLSA (Graduate Linguistic Student Association) Publications. [Google Scholar]
- Genzel, Dmitriy, and Eugene Charniak. 2002. Entropy rate constancy in text. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, pp. 199–206. [Google Scholar]
- Gundel, Jeanette K. 1988. Universals of Topic-Comment Structure. pp. 209–39. Available online: https://benjamins.com/catalog/tsl.17.16gun (accessed on 11 March 2021).
- Helgadóttir, Sigrún, Ásta Svavarsdóttir, Eiríkur Rögnvaldsson, Kristín Bjarnadóttir, and Hrafn Loftsson. 2012. The tagged Icelandic corpus (MÍM). In Proceedings of the Workshop on Language Technology for Normalisation of Less-Resourced Languages—SaLTMiL 8. Istanbul: European Language Resources Association (ELRA), pp. 67–72. [Google Scholar]
- Helgason, Jón. 1929. Málið á Nýja Testamenti Odds Gottskálkssonar. Copenhagen: Hið íslenska fræðafjelag. [Google Scholar]
- Heycock, Caroline, and Joel C. Wallenberg. 2013. How variational acquisition drives syntactic change: The loss of verb movement in Scandinaviation. The Journal of Comparative Germanic Linguistics 16: 127–57. [Google Scholar] [CrossRef][Green Version]
- Hróarsdóttir, Thorbjörg. 2000. Word Order Change in Icelandic. From OV to VO. Number 35 in Linguistik Aktuell. Amsterdam: John Benjamins. [Google Scholar]
- Ingason, Anton Karl. 2016. PaCQL: A new type of treebank search for the digital humanities. Italian Journal of Computational Linguistics 2: 51–66. [Google Scholar] [CrossRef]
- Ingason, Anton Karl, Einar Freyr Sigurðsson, and Joel Wallenberg. 2012. A Paper Presented at DiGS. Antisocial Syntax. Disentangling the Icelandic VO/OV Parameter and its Lexical Remains. Available online: https://www.staff.ncl.ac.uk/joel.wallenberg/papers/antisocial2012.pdf (accessed on 11 March 2021).
- Jaeger, T. Florian. 2010. Redundancy and reduction: Speakers manage syntactic information density. Cognitive Psychology 61: 23–62. [Google Scholar] [CrossRef]
- Kauhanen, Henri, and George Walkden. 2018. Deriving the Constant Rate Effect. Natural Language & Linguistic Theory 36: 483–521. [Google Scholar]
- Kiparsky, Paul. 1996. The Shift to Head-Initial VP in Germanic. In Studies in Comparative Germanic Syntax II. Edited by Höskuldur Thráinsson, Samuel David Epstein and Steve Peter. Dordrecht: Kluwer Academic Publishers, pp. 140–179. [Google Scholar]
- Kroch, Anthony, Beatrice Santorini, and Lauren Delfs. 2004. Penn-Helsinki Parsed Corpus of Early Modern English, Release 3. Size 1.8 Million Words. Available online: https://www.ling.upenn.edu/hist-corpora/PPCEME-RELEASE-3/index.html (accessed on 11 March 2021).
- Kroch, Anthony S. 1989. Reflexes of grammar in patterns of language change. Language Variation and Change 1: 199–244. [Google Scholar] [CrossRef]
- Kroch, Anthony S., Beatrice Santorini, and Ariel Diertani. 2016. Penn Parsed Corpus of Modern British English 2nd Edition, Release 1. Size ∼ 2.8 Million Words. Available online: https://www.ling.upenn.edu/hist-corpora/PPCMBE2-RELEASE-1/index.html (accessed on 11 March 2021).
- Kroch, Anthony S., and Ann Taylor. 2000a. Penn-Helsinki Parsed Corpus of Middle English. CD-ROM. Second Edition, Release 4. Size: 1.3 Million Words. Available online: https://www.ling.upenn.edu/hist-corpora/PPCME2-RELEASE-4/index.html (accessed on 11 March 2021).
- Kroch, Anthony S., and Ann Taylor. 2000b. Verb-complement order in Middle English. In Diachronic Syntax: Models and Mechanisms. Edited by Susan Pintzuk, George Tsoulas and Anthony Warner. Oxford: Oxford University Press, pp. 132–63. [Google Scholar]
- Kvaran, Guðrún, Gunnlaugur Ingólfsson, and Jón Aðalsteinn Jónsson. 1988. Um þýðingu Odds og útgáfu þessa. In Nýja testamenti Odds Gottskálkssonar. Edited by Sigurbjörn Einarsson, Guðrún Kvaran, Gunnlaugur Ingólfsson and Jón Aðalsteinn Jónsson. Reykjavík: Lögberg, pp. XXI–XXXII. [Google Scholar]
- Levy, Roger P., and Florian T. Jaeger. 2007. Speakers optimize information density through syntactic reduction. In Advances in Neural Information Processing Systems. Boston: MIT Press, pp. 849–56. [Google Scholar]
- Maurits, Luke, Dan Navarro, and Amy Perfors. 2010. Why are some word orders more common than others? A uniform information density account. In Advances in Neural Information Processing Systems. New York: Curran Associates Inc, pp. 1585–93. [Google Scholar]
- Ortmann, Katrin, and Stefanie Dipper. 2019. Variation between different discourse types: Literate vs. oral. Paper presented at the NAACL-Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial), Minneapolis, MN, USA, June 7; pp. 64–79. [Google Scholar]
- Ortmann, Katrin, and Stefanie Dipper. 2020. Automatic orality identification in historical texts. In Proceedings of The 12th Language Resources and Evaluation Conference (LREC). Marseille: European Language Resources Association, pp. 1293–302. [Google Scholar]
- Ottósson, Kjartan. 1990. Íslensk málhreinsun. Reykjavík: Íslensk málnefnd. [Google Scholar]
- Pierce, John R. 1980. An Introduction to Information Theory: Symbols, Signals and Noise, 2nd ed. Kent: Dover. [Google Scholar]
- Pintzuk, Susan. 1991. Phrase Structures in Competition: Variation and Change in Old English Word Order. Ph.D. thesis, University of Pennsylvania, Pennsylvania, PA, USA. [Google Scholar]
- Pintzuk, Susan, and Ann Taylor. 2004. Objects in Old English: Why and how Early English is not Icelandic. In York Papers in Linguistics. Edited by Jonny Butler, Davita Morgan, Leendert Plug and Gareth Walker. Series 2; Heslington York: University of York, Department of Language and Linguistic Science. Issue 1. [Google Scholar]
- Pintzuk, Susan, and Ann Taylor. 2006. The loss of OV order in the history of English. In Blackwell Handbook of the History of English. Edited by Ans van Kemenade and Bettelou Los. Oxford: Blackwell, pp. 247–78. [Google Scholar]
- Pluymaekers, Mark, Mirjam Ernestus, and Harald Baayen. 2005. Articulatory planning is continuous and sensitive to informational redundancy. Phonetica 62: 146–159. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. 2017. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. [Google Scholar]
- Randall, Beth. 2013. Corpussearch 2: A Tool for Linguistics Research. Available online: http://sourceforge.net/projects/corpussearch/ (accessed on 11 March 2021).
- Rögnvaldsson, Eiríkur. 1984. Rightward displacement of NPs in Icelandic—formal and functional characteristics. In The Nordic Languages and Modern Linguistics. Edited by Kristian Ringgaard and Viggo Sørensen. Århus: Nordisk Institut, Åarhus Universitet, Number 5. pp. 361–268. [Google Scholar]
- Rögnvaldsson, Eiríkur. 1987. OV word order in Icelandic. In Proceedings of the Seventh Biennial Conference of Teachers of Scandinavian Studies in Great Britain and Northern Ireland. London: University College, pp. 33–49. [Google Scholar]
- Rögnvaldsson, Eiríkur. 1994. Breytileg orðaröð í sagnlið. Íslenskt mál 16–17: 27–66. [Google Scholar]
- Rögnvaldsson, Eiríkur. 1996. Word Order Variation in the VP in Old Icelandic. Working Papers in Scandinavian Syntax 58: 55–86. [Google Scholar]
- Rögnvaldsson, Eiríkur, Anton Karl Ingason, Einar Freyr Sigurðsson, and Joel Wallenberg. 2012. The Icelandic Parsed Historical Corpus (IcePaHC). In Proceedings of LREC. Istanbul: European Language Resources Association (ELRA), pp. 1977–84. [Google Scholar]
- Rögnvaldsson, Eiríkur, Anton Karl Ingason, Einar Freyr Sigurðsson, and Joel C. Wallenberg. 2011. Creating a dual-purpose treebank. Journal for Language Technology and Computational Linguistics 2: 141–52. [Google Scholar]
- Santorini, Beatrice. 1993. The rate of phrase structure change in the history of Yiddish. Language Variation and Change 5: 257–83. [Google Scholar] [CrossRef]
- Shannon, Claude Elwood. 1948. A mathematical theory of communication. The Bell System Technical Journal 27: 379–423. [Google Scholar] [CrossRef]
- Sigurðsson, Halldór Ármann. 1983. Um frásagnarumröðun og grundvallarorðaröð í forníslensku. Cand.mag. thesis, University of Iceland, Reykjavík, Iceland. [Google Scholar]
- Steinþórsson, Atli Freyr. 2015. Bækurnar í fjósinu. Um fyrirmyndir Nýja testamentis Odds Gottskálkssonar. BA thesis, University of Iceland, Reykjavík, Iceland. [Google Scholar]
- Taylor, Ann, and Susan Pintzuk. 2011. The interaction of syntactic change and information status effects in the change from OV to VO in English. Catalan Journal of Linguistics 10: 71–94. [Google Scholar] [CrossRef]
- Taylor, Ann, and Susan Pintzuk. 2012. Rethinking the OV/VO Alternation in Old English: The Effect of Complexity, Grammatical Weight and Information Status. Volume The Oxford Handbook on the History of English. Oxford: Oxford University Press, pp. 1199–213. [Google Scholar]
- Thráinsson, Höskuldur. 2007. The Syntax of Icelandic. Cambridge: Cambridge University Press. [Google Scholar]
- Turk, Alice. 2010. Does prosodic constituency signal relative predictability? A smooth signal redundancy hypothesis. Laboratory Phonology 1: 227–62. [Google Scholar] [CrossRef]
- Wallenberg, Joel C. 2013. Scrambling, LF, and Phrase Structure Change in Yiddish. Lingua 133: 289–318. [Google Scholar] [CrossRef]
- Wallenberg, Joel C., Anton K. Ingason, Einar F. Sigurðsson, and Eiríkur Rögnvaldsson. 2011. Icelandic Parsed Historical Corpus (IcePaHC). Version 0.9. Size: 1 Million Words. Available online: http://www.linguist.is/icelandic_treebank (accessed on 11 March 2021).
- Wickham, Hadley. 2009. ggplot2: Elegant Graphics for Data Analysis. New York: Springer. [Google Scholar]
- Yang, Charles. 2000. Internal and external forces in language change. Language Variation and Change 12: 231–50. [Google Scholar] [CrossRef]
- Yang, Charles. 2006. The Infinite Gift: How Children Learn and Unlearn the Languages of the World. New York: Scribner. [Google Scholar]
- Zarcone, Alessandra, Marten van Schijndel, Jorrig Vogels, and Vera Demberg. 2016. Salience and attention in surprisal-based accounts of language processing. Frontiers in Psychology 7. [Google Scholar] [CrossRef]
- Zhan, Meilin, and Roger P. Levy. 2018. Comparing Theories of Speaker Choice Using a Model of Classifier Production in Mandarin Chinese. Stroudsburg: Association for Computational Linguistics. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wallenberg, J.C.; Bailes, R.; Cuskley, C.; Ingason, A.K. Smooth Signals and Syntactic Change. Languages 2021, 6, 60. https://doi.org/10.3390/languages6020060
Wallenberg JC, Bailes R, Cuskley C, Ingason AK. Smooth Signals and Syntactic Change. Languages. 2021; 6(2):60. https://doi.org/10.3390/languages6020060
Chicago/Turabian StyleWallenberg, Joel C., Rachael Bailes, Christine Cuskley, and Anton Karl Ingason. 2021. "Smooth Signals and Syntactic Change" Languages 6, no. 2: 60. https://doi.org/10.3390/languages6020060
APA StyleWallenberg, J. C., Bailes, R., Cuskley, C., & Ingason, A. K. (2021). Smooth Signals and Syntactic Change. Languages, 6(2), 60. https://doi.org/10.3390/languages6020060