Focus Prosody Varies by Phrase-Initial Tones in Seoul Korean: Production, Perception, and Automatic Classification

Abstract
1. Introduction
2. Production
2.1. Method
2.1.1. Stimuli
| A: | mina-ɰi | bʌnho-ga | 887-412-4699-ja. | matɕi? |
| Mina-POSS | number-NOM | 887-412-4699-DEC | right | |
| ‘Mina’s number is 887-412-4699. Right?’ | ||||
| B: | anija, mina-ɰi | bʌnho-nɯn | 787-412-4699-ja. | |
| no | Mina-POSS | number-TOP | 787-412-4699-DEC | |
| ‘No, Mina’s number is 787-412-4699.’ | ||||
2.1.2. Subjects
2.1.3. Recording Procedure
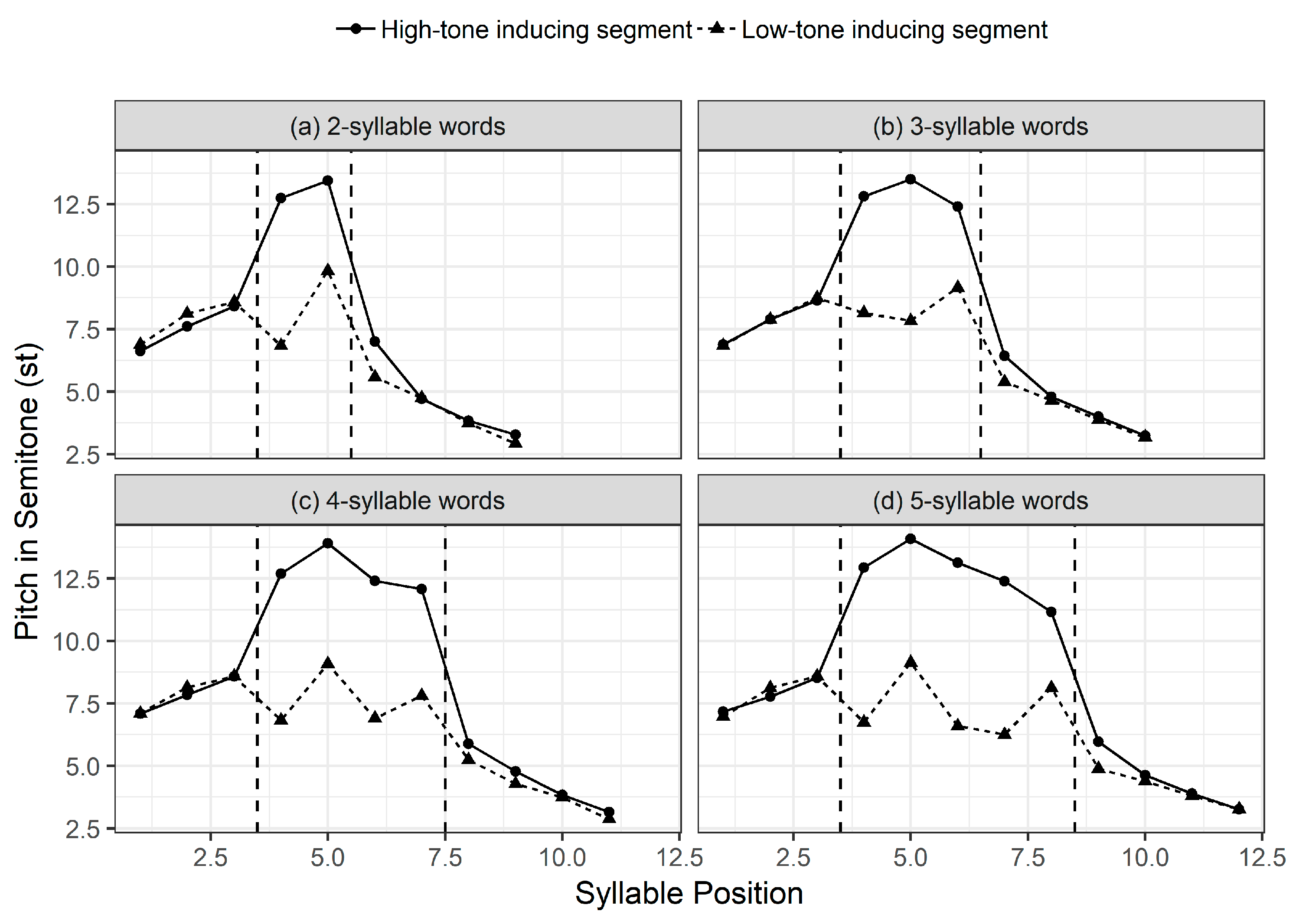
2.1.4. A Sketch of Pitch Contours
2.2. Analyses
2.3. Results
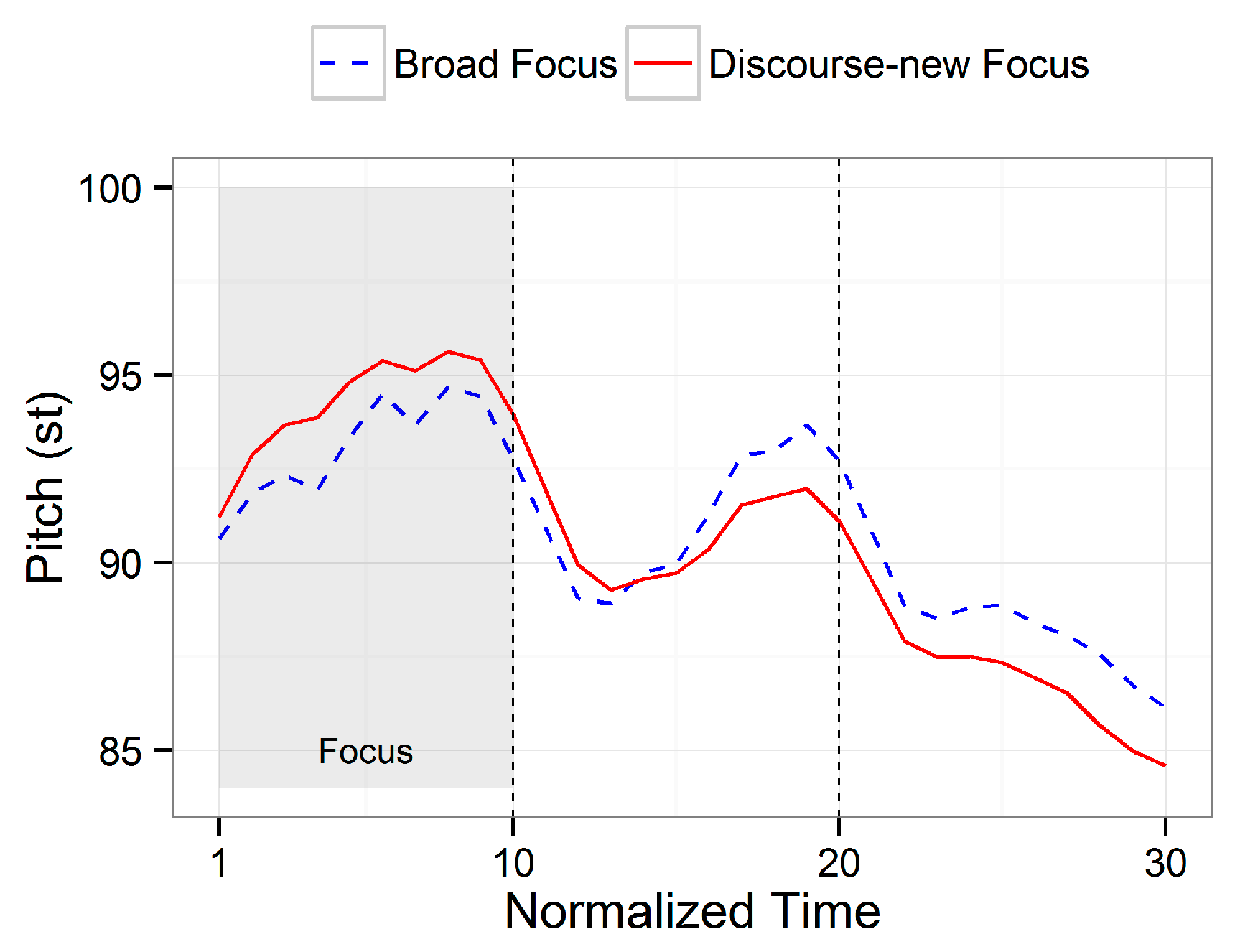
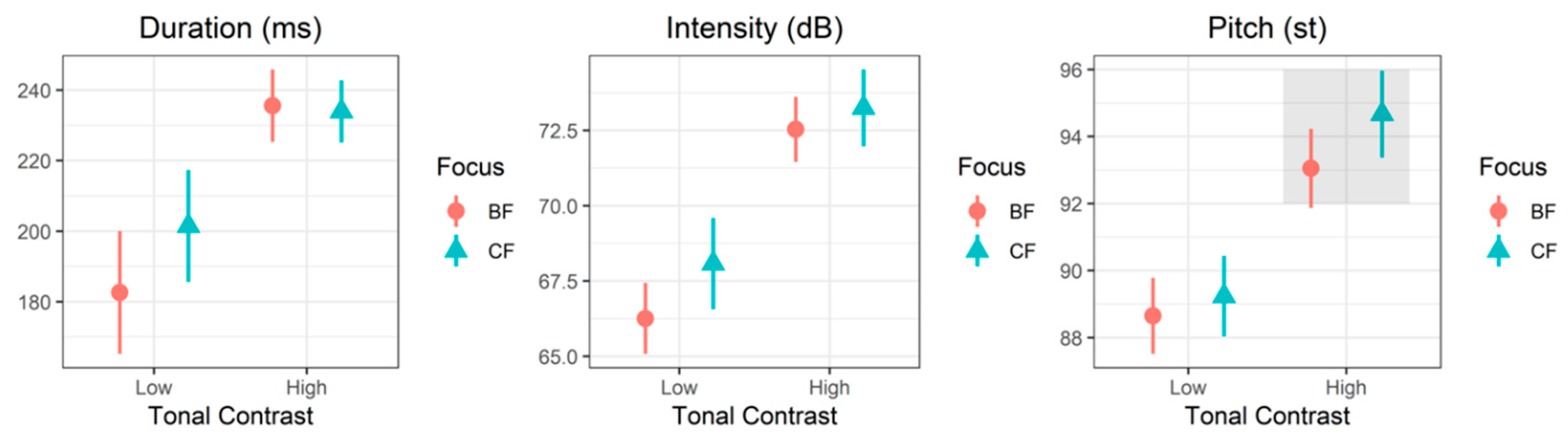
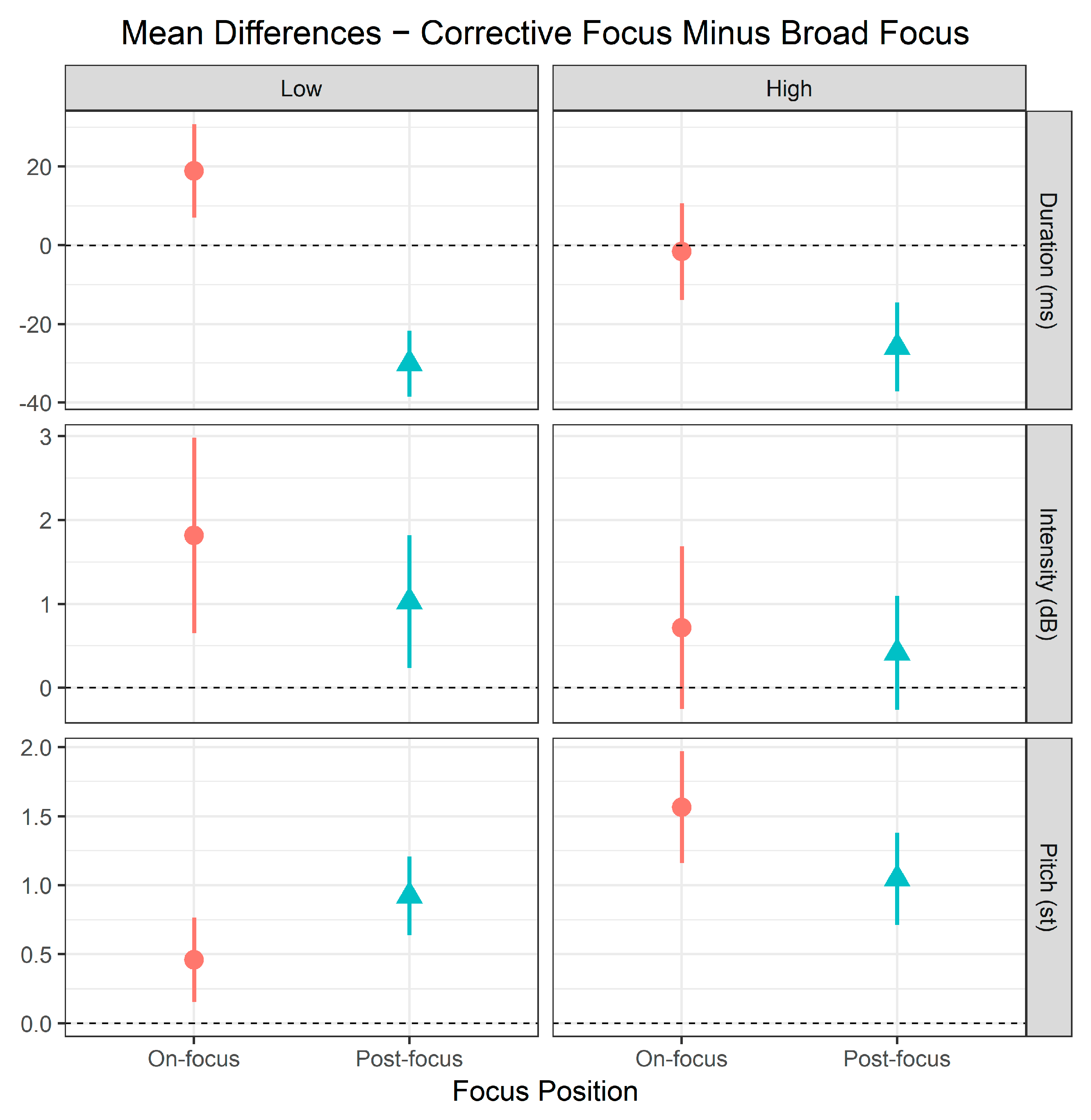
2.3.1. On-Focus Effects
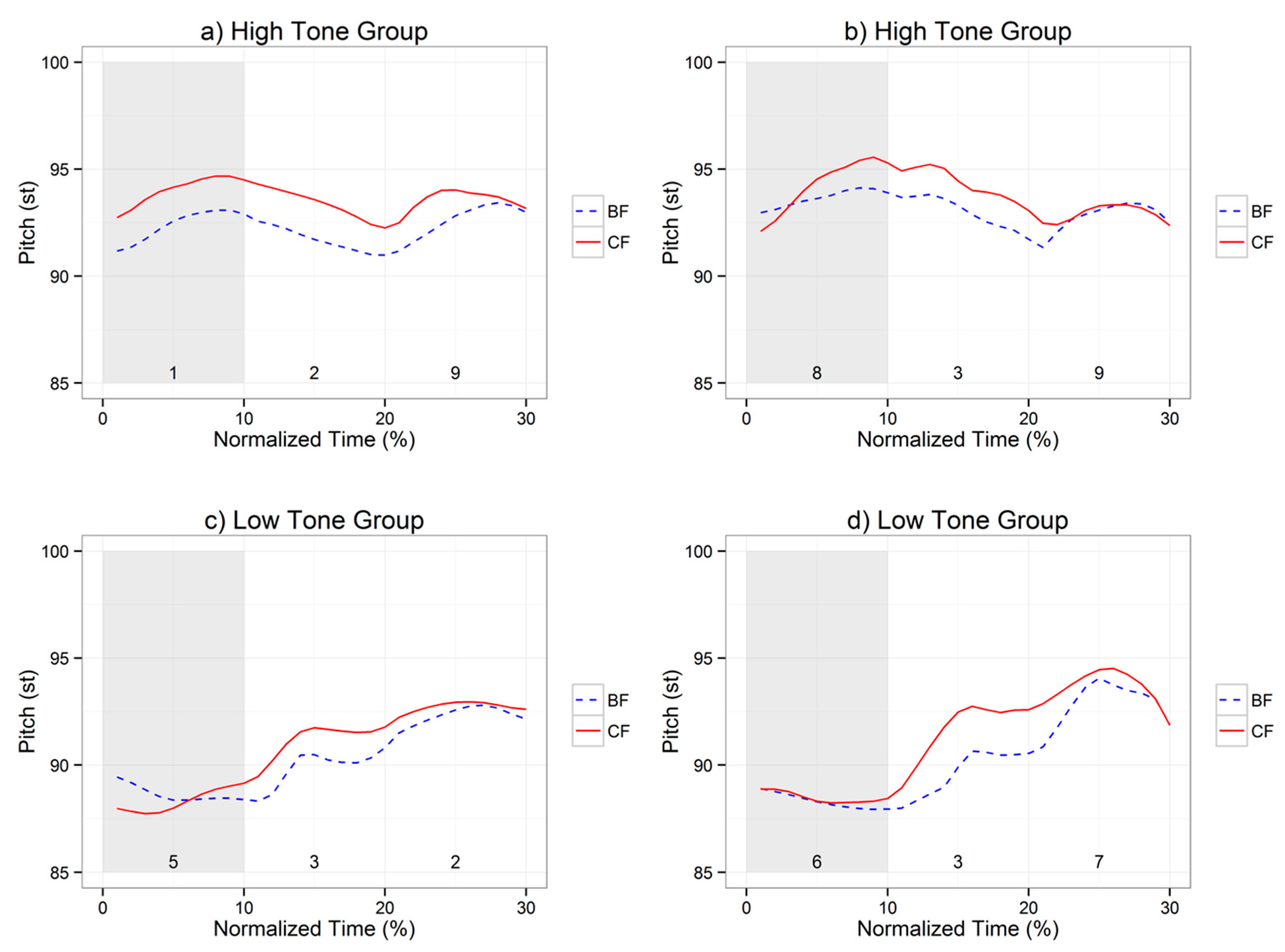
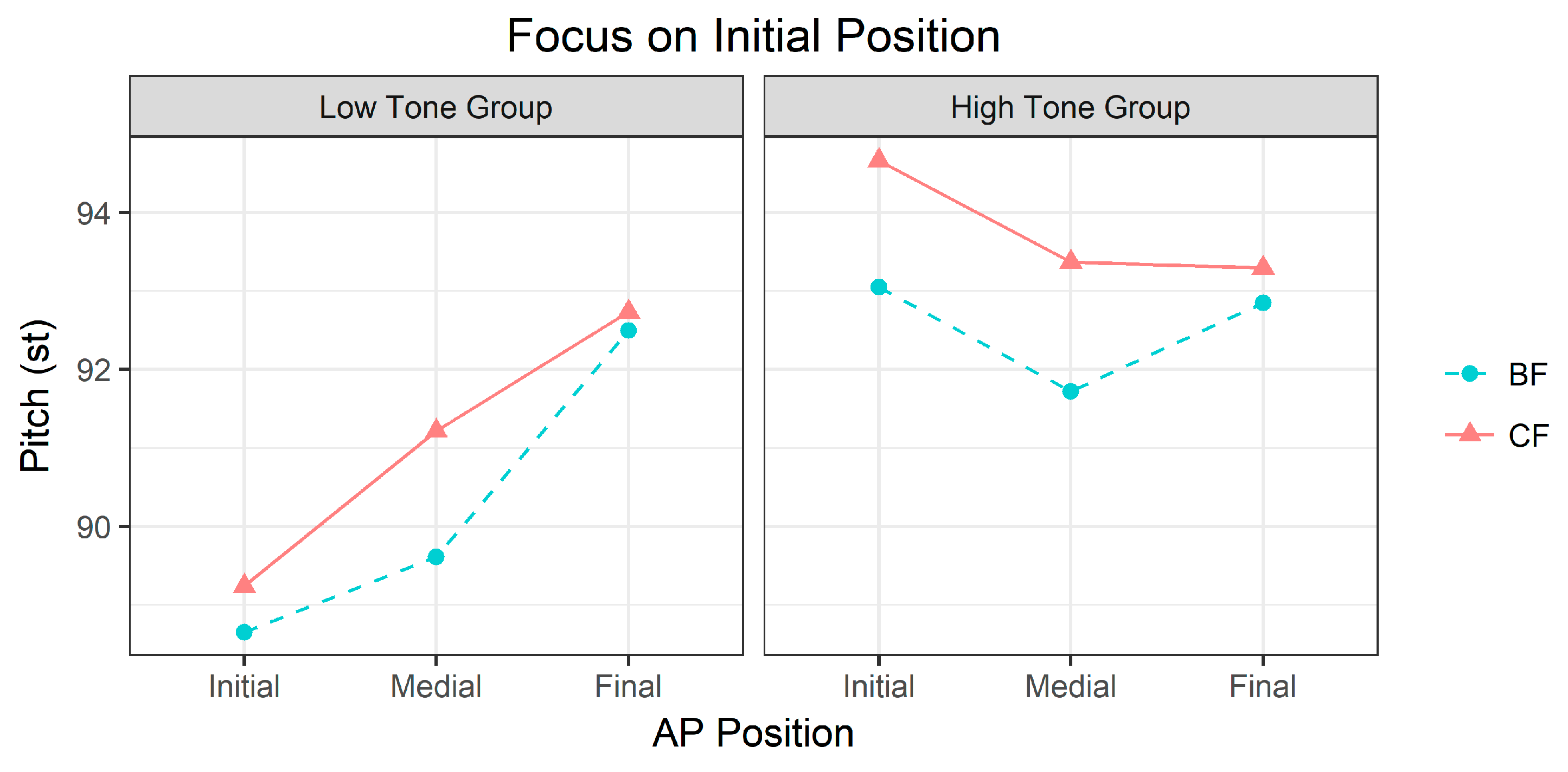
2.3.2. Focus Effects within APs
2.3.3. SK’s AP Tonal Constraints on Focus Prosody
3. Human Perception
3.1. Data Collection
3.2. Analyses
3.3. Results
4. Automatic Classification
4.1. Features and Model Training
4.2. Model Performance
5. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Beckman, Mary E., and Janet B. Pierrehumbert. 1986. Intonational structure in Japanese and English. Phonology Yearbook 3: 255–309. [Google Scholar] [CrossRef]
- Bolinger, Dwight. 1972. Accent is predictable (if you’re a mind-reader). Language 48: 633–44. [Google Scholar] [CrossRef]
- Cho, Sunghye, and Yong-cheol Lee. 2016. The effect of the consonant-induced pitch on Seoul Korean intonation. Linguistic Research 33: 299–317. [Google Scholar]
- Cho, Sunghye, Mark Liberman, and Yong-cheol Lee. 2019. Automatic detection of prosodic focus in American English. Proceedings of Interspeech 2019: 3470–74. [Google Scholar]
- Cho, Sunghye. 2017. Development of Pitch Contrast and Seoul Korean Intonation. Ph.D. dissertation, University of Pennsylvania, Philadelphia, PA, USA. [Google Scholar]
- Cho, Sunghye. 2018. The production and perception of High-toned [il] by young speakers of Seoul Korean. Linguistic Research 35: 533–65. [Google Scholar]
- Cohan, J. Ballantyne. 2000. The Realization and Function of Focus in Spoken English. Ph.D. dissertation, The University of Texas at Austin, Austin, TX, USA. [Google Scholar]
- Hair, Joseph, Rolph Anderson, Barry Babin, and William Black. 2010. Multivariate Data Analysis: A Global Perspective. Boston: Pearson. [Google Scholar]
- Hothorn, Torsten, Frank Bretz, and Peter Westfall. 2008. Simultaneous inference in general parametric models. Biometrical Journal 50: 346–63. [Google Scholar] [CrossRef] [PubMed]
- Jeon, Hae-sung, and Francis Nolan. 2017. Prosodic marking of narrow focus in Seoul Korean. Laboratory Phonology 8: 1–30. [Google Scholar] [CrossRef]
- Jo, Jung-Min, Seok-Keun Kang, and Taejin Yoon. 2006. A rendezvous of focus and topic in Korean: Morpho-syntactic, semantic, and acoustic evidence. The Linguistics Association of Korean Journal 14: 167–96. [Google Scholar]
- Jun, Sun-Ah, and Hee-Sun Kim. 2007. VP focus and narrow focus in Korean. Paper presented at the 16th The International Congress of Phonetic Sciences, Saarbrücken, Germany, August 6–10; pp. 1277–80. [Google Scholar]
- Jun, Sun-Ah, and Hyuck-Joon Lee. 1998. Phonetic and phonological markers of contrastive focus in Korean. Paper presented at the 5th International Conference on Spoken Language Processing, Sydney, Australia, November 30–December 4; pp. 1295–98. [Google Scholar]
- Jun, Sun-Ah, and Jihyeon Cha. 2011. High-toned [il] in Seoul Korean Intonation. Paper presented at the 17th The International Congress of Phonetic Sciences, Hong Kong, China, August 17–21; pp. 990–93. [Google Scholar]
- Jun, Sun-Ah, and Jihyeon Cha. 2015. High-toned [il] in Korean: Phonetics, intonational phonology, and sound change. Journal of Phonetics 51: 93–108. [Google Scholar] [CrossRef]
- Jun, Sun-Ah. 1998. The Accentual Phrase in the Korean prosodic hierarchy. Phonology 15: 189–226. [Google Scholar] [CrossRef]
- Jun, Sun-Ah. 2005. Korean intonational phonology and prosodic transcription. In Prosodic Typology: The Phonology of Intonation and Phrasing. Edited by Sun-Ah Jun. New York: Oxford University Press, pp. 201–29. [Google Scholar]
- Jun, Sun-Ah. 2011. Prosodic markings of complex NP focus, syntax, and the pre-/post-focus string. Paper presented at the 28th West Coast Conference on Formal Linguistics (WCCFL 28), Los Angeles, CA, USA, February 12–14; pp. 214–30. [Google Scholar]
- Jun, Sun-Ah. 2014. Prosodic typology: By prominence type, word prosody, and macro-rhythm. In Prosodic Typology II: The Phonology of Intonation and Phrasing. Edited by Sun-Ah Jun. Oxford: Oxford University Press, pp. 520–40. [Google Scholar]
- Kuznetsova, Alexandra, Per B. Brockhof, and Rune H. B. Christensen. 2017. lmerTest Package: Tests in Linear Mixed Effects Models. Journal of Statistical Software 82: 1–26. [Google Scholar] [CrossRef]
- Ladd, D. Robert. 1996. Intonational Phonology. Cambridge: Cambridge University Press. [Google Scholar]
- Lee, Yong-cheol, and Yi Xu. 2010. Phonetic realization of contrastive focus in Korean. Paper presented at Proceedings of Speech Prosody 2010, Chicago, IL, USA, May 10–14; p. 100033. [Google Scholar]
- Lee, Yong-cheol, Dongyoung Kim, and Sunghye Cho. 2019. The effect of prosodic focus varies by phrasal tones: The case of South Kyungsang Korean. Linguistics Vanguard 5: 20190010. [Google Scholar] [CrossRef]
- Lee, Yong-cheol, Satoshi Nambu, and Sunghye Cho. 2018. Focus prosody of telephone numbers in Tokyo Japanese. Journal of the Acoustical Society of America 143: EL340–46. [Google Scholar] [CrossRef] [PubMed]
- Lee, Yong-cheol, Ting Wang, and Mark Liberman. 2016. Production and perception of tone 3 focus in Mandarin Chinese. Frontiers in Psychology 7: 1058. [Google Scholar] [CrossRef] [PubMed]
- Lee, Yong-cheol. 2009. The Phonetic Realization of Contrastive Focus and its Neighbors in Korean and English: A Cross-Language Study. Master’s thesis, Hannam University, Daejeon, Korea. [Google Scholar]
- Lee, Yong-cheol. 2012. Prosodic correlation between the focusing adverb ozik ‘only’ and focus/givenness in Korean. Journal of Speech Sciences 2: 85–111. [Google Scholar]
- Lee, Yong-cheol. 2015. Prosodic Focus within and across Languages. Ph.D. dissertation, University of Pennsylvania, Philadelphia, PA, USA. [Google Scholar]
- Liberman, Mark, and Janet Pierrehumbert. 1984. Intonational invariance under changes in pitch range and length. In Language Sound Structure. Edited by Mark Aronoff and Richard Oehrle. Cambridge: MIT Press, pp. 157–233. [Google Scholar]
- Liu, Fang. 2009. Intonation Sytems of Mandarin and English: A Functional Approach. Ph.D. dissertation, University of Chicago, Chicago, IL, USA. [Google Scholar]
- Nolan, Francis. 2003. Intonational equivalence: An experimental evaluation of pitch scales. Paper presented at 15th International Congress of Phonetic Sciences, Barcelona, Spain, August 3–9; pp. 771–74. [Google Scholar]
- Oh, Miran, and Dani Byrd. 2019. Syllable-internal corrective focus in Korean. Journal of Phonetics 77: 100933. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, Fabian, Gael Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, and et al. 2011. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research 12: 2825–30. [Google Scholar]
- R Core Team. 2020. R: A Language and Environment for Statistical Computing. Version 4.0.2. Available online: http://www.r-project.org (accessed on 1 July 2020).
- Rietveld, Toni, and Carlos Gussenhoven. 1985. On the relation between pitch excursion size and prominence. Journal of Phonetics 13: 299–308. [Google Scholar] [CrossRef]
- Song, Jae Jung. 2005. The Korean Language: Structure, Use and Context. Abingdon: Routledge. [Google Scholar]
- Ueyama, Motoko, and Sun-Ah Jun. 1998. Focus realization in Japanese English and Korean English intonation. Japanese and Korean Linguistics 7: 629–45. [Google Scholar]
- Xu, Yi, and Ching X. Xu. 2005. Phonetic realization of focus in English declarative intonation. Journal of Phonetics 33: 159–97. [Google Scholar] [CrossRef]
- Xu, Yi, and Maolin Wang. 2009. Organizing syllables into groups—Evidence from F0 and duration patterns in Mandarin. Journal of Phonetics 37: 502–20. [Google Scholar] [CrossRef] [PubMed]
- Xu, Yi. 2013. ProsodyPro—A Tool for large-scale systematic prosody analysis. Paper presented at Tools and Resources for the Analysis of Speech Prosody, Aix-en-Provence, France, August 30; pp. 7–10. [Google Scholar]
- Yuan, Jiahong. 2004. Intonation in Mandarin Chinese: Acoustics, Perception, and Computational Modeling. Ph.D. dissertation, Cornell University, Ithaca, NY, USA. [Google Scholar]
| 1 | In this study, we used the International Phonetic Alphabet (IPA) symbols for Korean examples. |
| 2 | A sample size of 200 may not be sufficient to statistically determine the differences in focus prosody between the two tone groups: Low and high tone. Nevertheless, since digit and position were treated as random samples, we had 50 tokens for each focus type (broad and corrective) in each tone group. According to Hair et al. (2010), the general rule is to have a minimum of five observations per variable (5:1), and an acceptable sample size would have ten observations per variable (10:1). Since we had 50 tokens for each focus type, it should be noted that the ratio in our study was just above the rule of thumb. |
| 3 | We would like to thank the reviewer for bringing this issue to our attention. |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Digit (IPA) | Onset Consonant Type | Post-Lexical Tone Group |
|---|---|---|
| 0 (/koŋ/) | lenis | Low |
| 1 (/il/) | vowel-initial | High |
| 2 (/i/) | vowel-initial | Low |
| 3 (/sam/) | aspirated | High |
| 4 (/sa/) | aspirated | High |
| 5 (/o/) | vowel-initial | Low |
| 6 (/juk/) | glide | Low |
| 7 (/tɕhil/) | aspirated | High |
| 8 (/phal/) | aspirated | High |
| 9 (/ku/) | lenis | Low |
| Estimate | SE | z-Value | p-Value | ||
|---|---|---|---|---|---|
| Low tone | AP-initial vs. AP-medial | −2.12 | 0.24 | −8.94 | <0.001 |
| AP-initial vs. AP-final | −3.64 | 0.24 | −15.37 | <0.001 | |
| High tone | AP-initial vs. AP-medial | 1.28 | 0.29 | 4.46 | <0.001 |
| AP-initial vs. AP-final | 1.36 | 0.29 | 4.73 | <0.001 |
| Perceived | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th | 9th | 10th | |||
| Target | Low | 1st | 21.2 | 20.4 | 31.5 | 3.8 | 1.2 | 3.8 | 6.9 | 1.2 | 6.2 | 3.8 |
| 4th | 6.9 | 11.5 | 13.8 | 25.8 | 8.1 | 18.5 | 8.5 | 1.5 | 4.2 | 1.2 | ||
| High | 1st | 35.4 | 19.2 | 12.3 | 12.3 | 7.3 | 4.6 | 5.4 | 2.3 | 1.2 | 0.0 | |
| 4th | 5.4 | 2.7 | 10.4 | 44.6 | 4.6 | 8.5 | 12.7 | 0.8 | 10.0 | 0.4 | ||
| Predicted | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th | 9th | 10th | |||
| Target | Low | 1st | 52 | 0 | 8 | 8 | 8 | 0 | 16 | 0 | 0 | 8 |
| 4th | 0 | 0 | 0 | 84 | 0 | 4 | 8 | 0 | 0 | 4 | ||
| High | 1st | 80 | 8 | 0 | 4 | 0 | 4 | 0 | 0 | 0 | 4 | |
| 4th | 4 | 4 | 0 | 92 | 0 | 0 | 0 | 0 | 0 | 0 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.-c.; Cho, S. Focus Prosody Varies by Phrase-Initial Tones in Seoul Korean: Production, Perception, and Automatic Classification. Languages 2020, 5, 64. https://doi.org/10.3390/languages5040064
Lee Y-c, Cho S. Focus Prosody Varies by Phrase-Initial Tones in Seoul Korean: Production, Perception, and Automatic Classification. Languages. 2020; 5(4):64. https://doi.org/10.3390/languages5040064
Chicago/Turabian StyleLee, Yong-cheol, and Sunghye Cho. 2020. "Focus Prosody Varies by Phrase-Initial Tones in Seoul Korean: Production, Perception, and Automatic Classification" Languages 5, no. 4: 64. https://doi.org/10.3390/languages5040064
APA StyleLee, Y.-c., & Cho, S. (2020). Focus Prosody Varies by Phrase-Initial Tones in Seoul Korean: Production, Perception, and Automatic Classification. Languages, 5(4), 64. https://doi.org/10.3390/languages5040064