Proposals for a Discourse Analysis Practice Integrated into Digital Humanities: Theoretical Issues, Practical Applications, and Methodological Consequences


Abstract
:1. Introduction
DH is an area of scholarly activity at the intersection of computing or digital technologies and the disciplines of the humanities. It includes the systematic use of digital resources in the humanities, as well as the analysis of their application. DH can be defined as new ways of doing scholarship that involve collaborative, transdisciplinary, and computationally engaged research, teaching, and publishing. It brings digital tools and methods to the study of the humanities with the recognition that the printed word is no longer the main medium for knowledge production and distribution.
- Society’s digital turn changes and calls into question the conditions of knowledge production and distribution.
- For us, the digital humanities concern the totality of the social sciences and humanities. The digital humanities are not tabula rasa. On the contrary, they rely on all the paradigms, savoir-faire, and knowledge specific to these disciplines, while mobilizing the tools and unique perspectives enabled by digital technology.
- The digital humanities designate a “transdiscipline,” embodying all the methods, systems, and heuristic perspectives linked to the digital within the fields of the humanities and social sciences.
which long preceded the emergence of numerical technology and computing. It is the history of scholarly practices, but also and especially the history of tools for classifying and organizing thought and knowledge. Just as it is worth remembering that the history of hypertexts started before numerical technology and their well-known concrete manifestations within web browsers, digital humanities are part of a tradition of organized reading that goes outside the linearity of texts and documents.
In fact, it is inter-, poly-, and trans-disciplinarity complexes that have operated and played a fertile role in the history of science; we must remember the key concepts involved, namely, cooperation and, better still, articulation, common object and, better still, common project. Finally, it is not only the idea of inter- and trans-disciplinarity that is important. We must “environmentalize” disciplines, that is, take into account everything that is contextual, including cultural and social conditions, that is, see in which environment they are born, raise issues, ossify, and metamorphose. We also need meta-disciplinarity, where the term “meta” means to go beyond and preserve. We cannot break what has been created by disciplines, we cannot pull down every fence—this problem pertains to any discipline, science, and life; a discipline must be both open and closed. In conclusion, what would be the use of all our fragments of knowledge if not to be compared and contrasted in order to form a configuration that meets our expectations, our needs, and our cognitive questions.
2. Materials and Methods
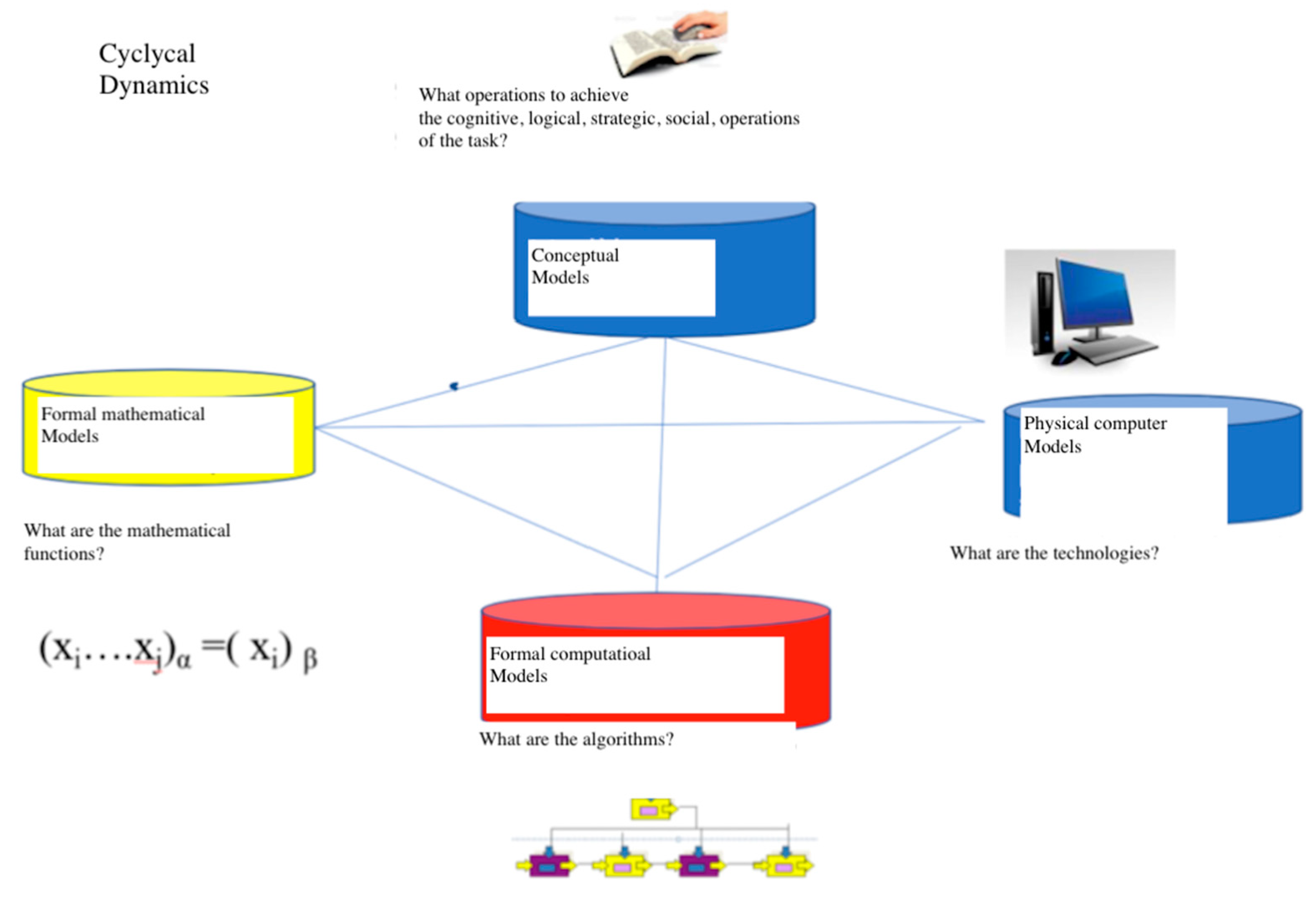
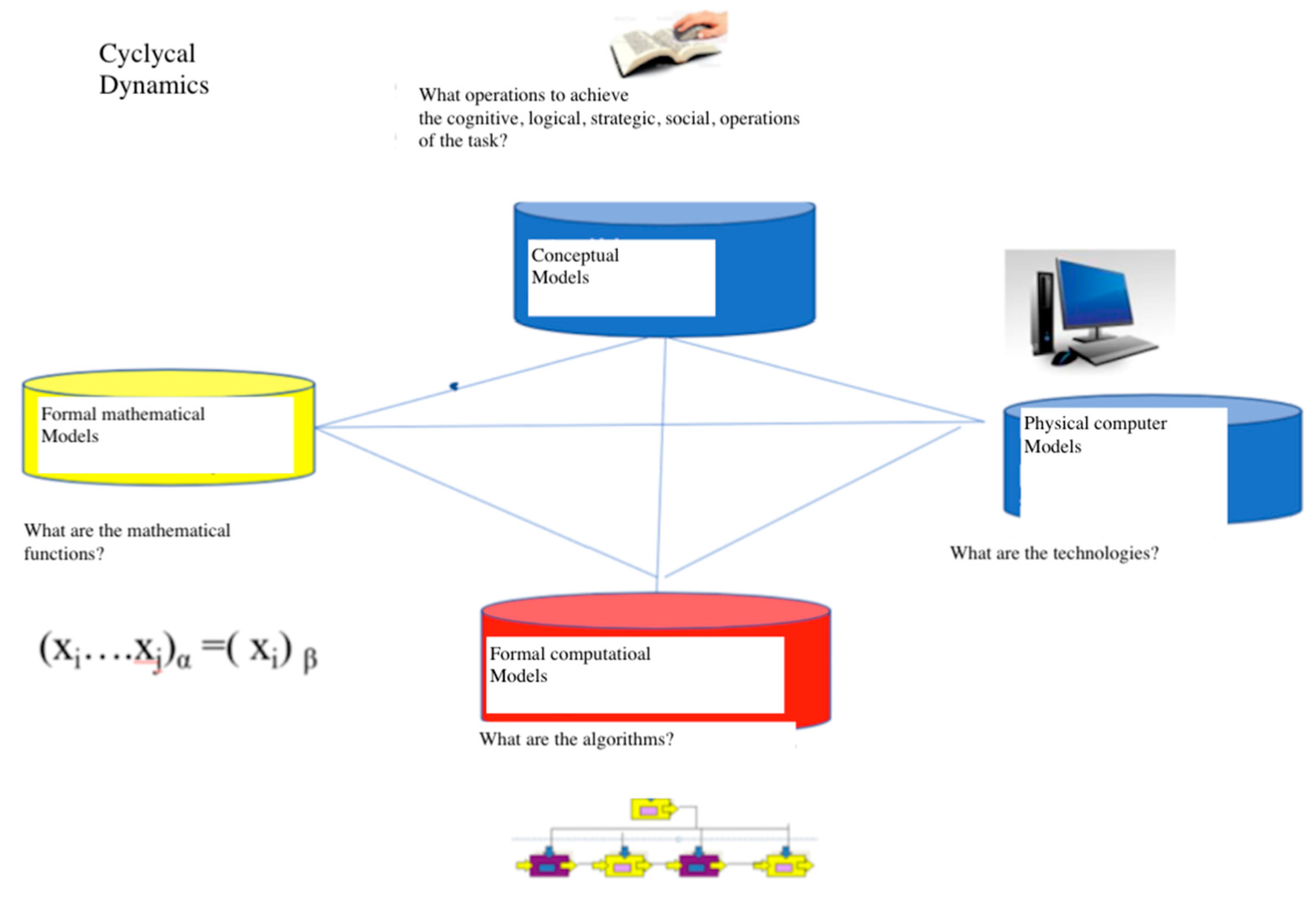
2.1. Models and Tools: Clarifications
2.1.1. The Conceptual Model
2.1.2. The Formal Model
2.1.3. The Computational Model
- -
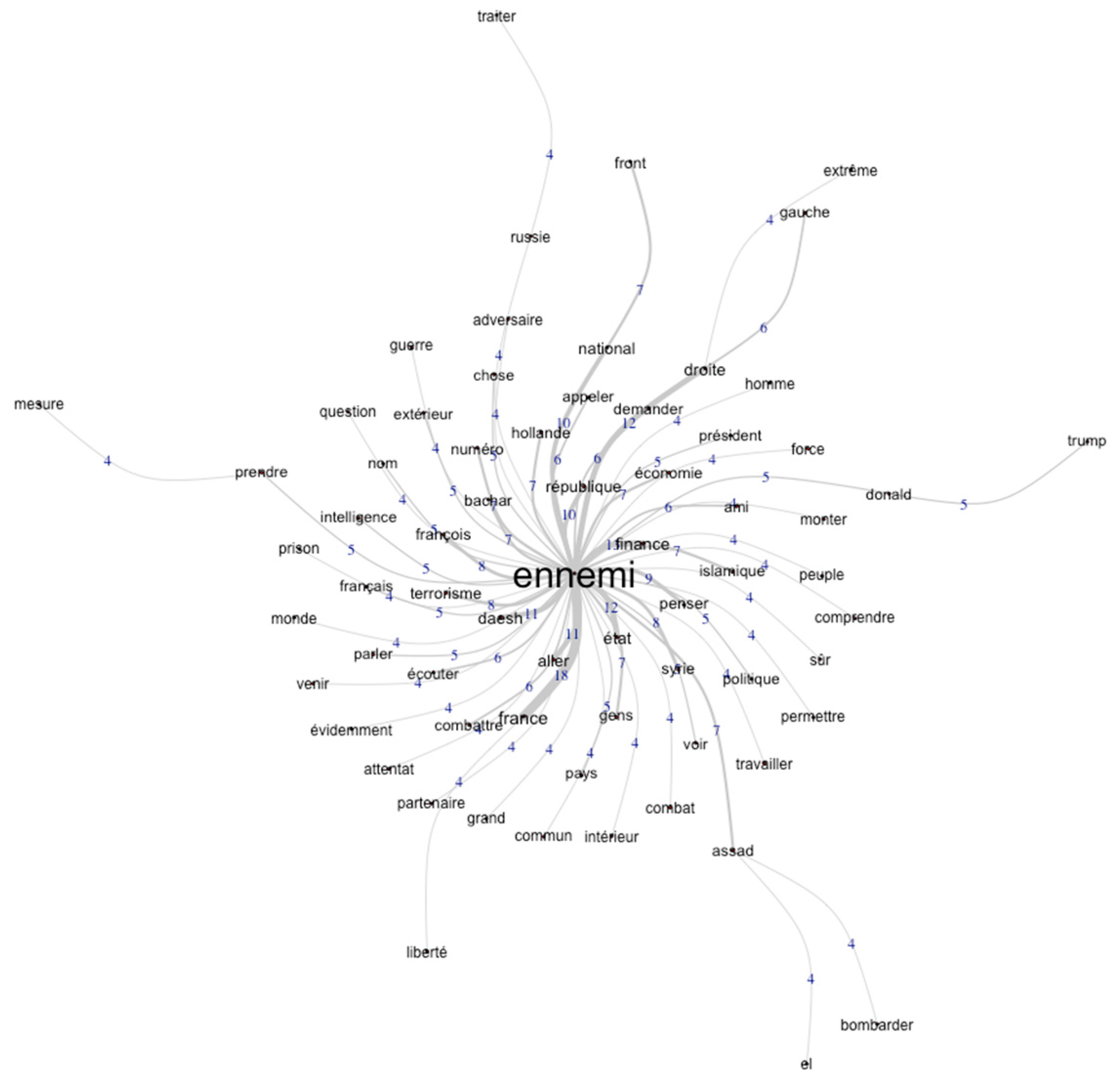
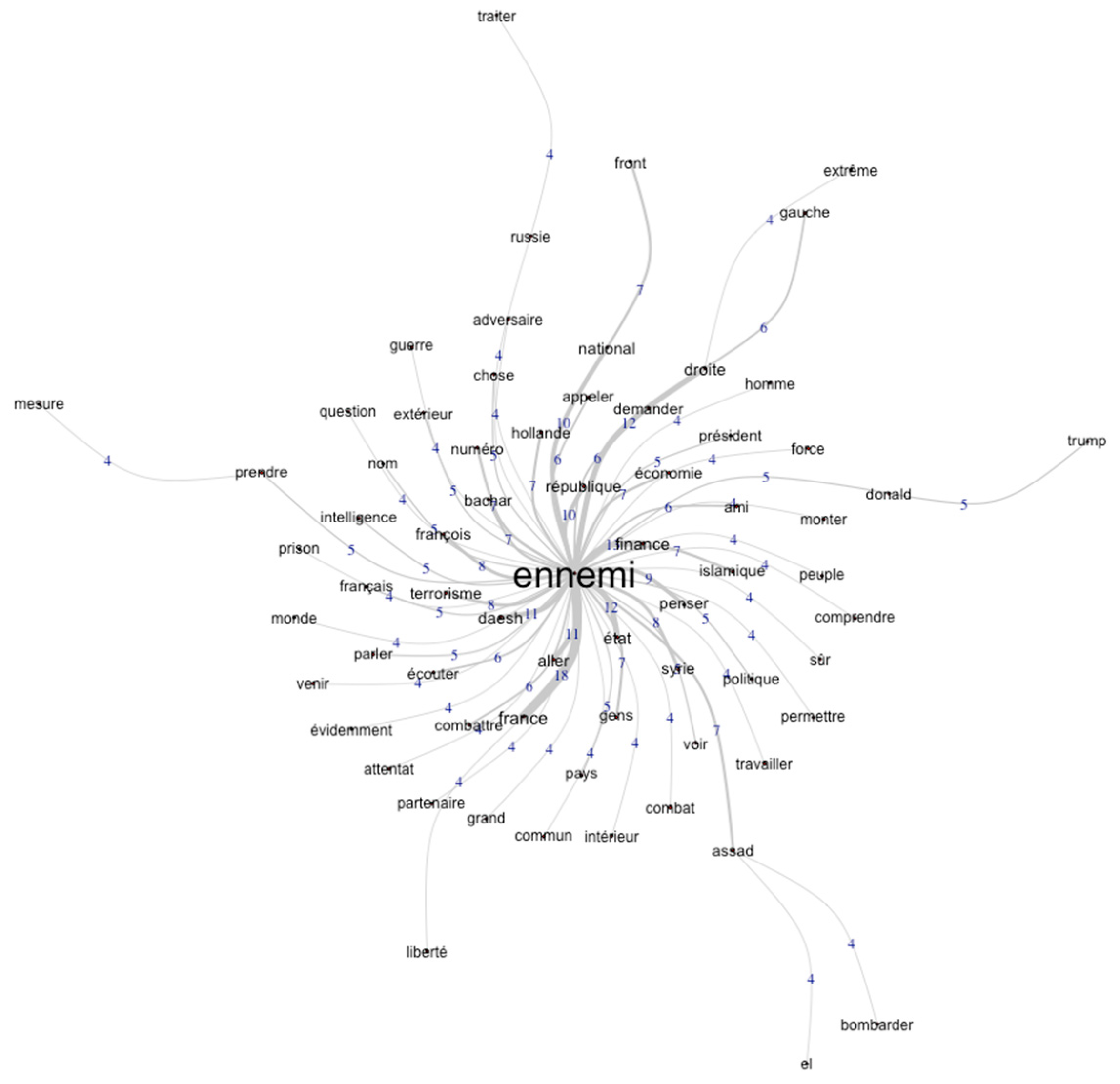
- With regard to similarity analyses, Loubère (2016) explains that this model stems from “graph theory (Flament 1962, 1981; Vergès and Bouriche 2001) and presents the structure of a corpus by schematizing these relationships, thus making it possible to highlight the links between forms in text segments.” More precisely, Marchand and Ratinaud (2012) explain that “after segmenting, recognizing, and lemmatizing forms, followed by ECU partitioning, the matrix of the overall corpus can be represented in various ways (linear or circular trees; form size proportional to frequency or statistical link, etc.). The tree of lexical links in the corpus is represented here (co-occurrence calculation and Fruchterman-Reingold algorithm).” The co-occurrence calculation and Fruchterman-Reingold algorithm1 are conceived here as a means to take into account the “profiles” since they reflect both the syntactic proximity and frequency of associations, and the force of the relationship between units.
- -
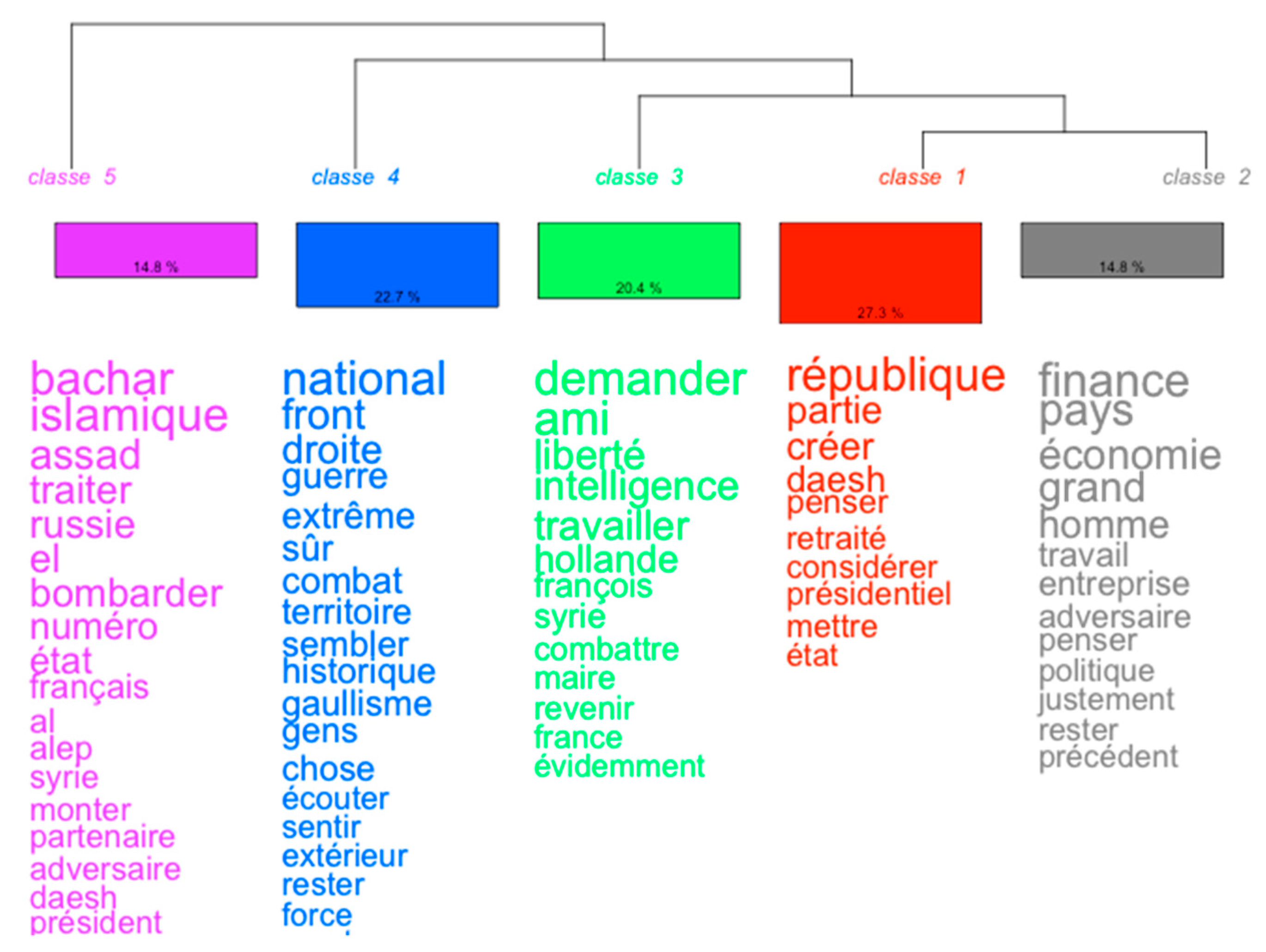
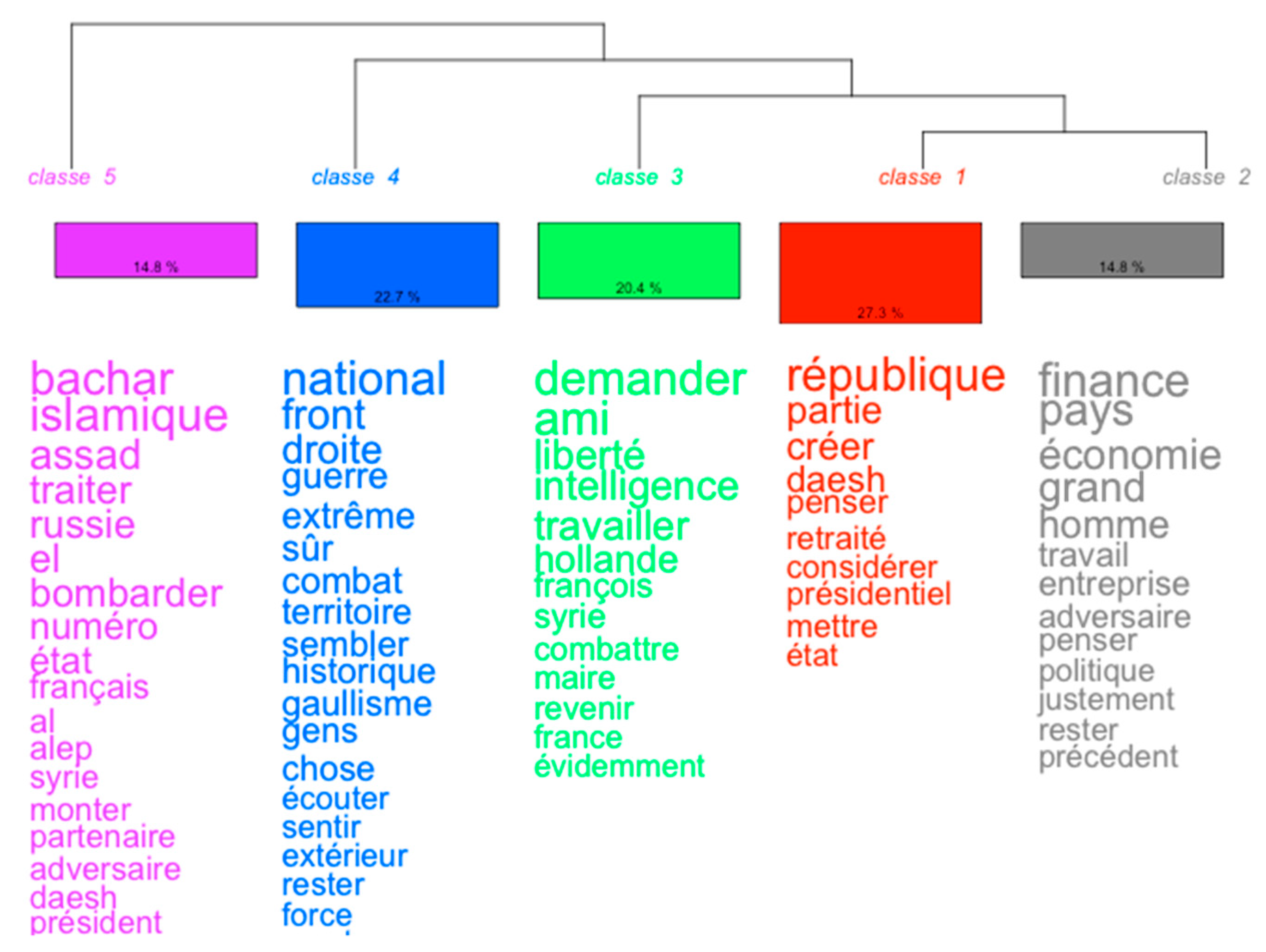
- With regard to descending hierarchical classifications, I have followed Loubère (2016) by choosing a Reinert-type classification proposed by the Iramuteq software: “this classification, implemented for the first time in the Alceste® software (Reinert 1983), makes it possible to highlight lexical worlds. These discourse structures assume that a statement is a stance that is dependent on the subject but also on its activity and context.” At a methodological level, as described by Loubère, the vocabulary of the corpus is “used to build a double-entry table listing the presence/absence of the full forms selected in/from the segments; a series of bi-partitions are [then] performed on this table based on a factorial analysis of correspondences.” These classifications are very useful for understanding the themes of a corpus through the lexical worlds that compose them.
- -
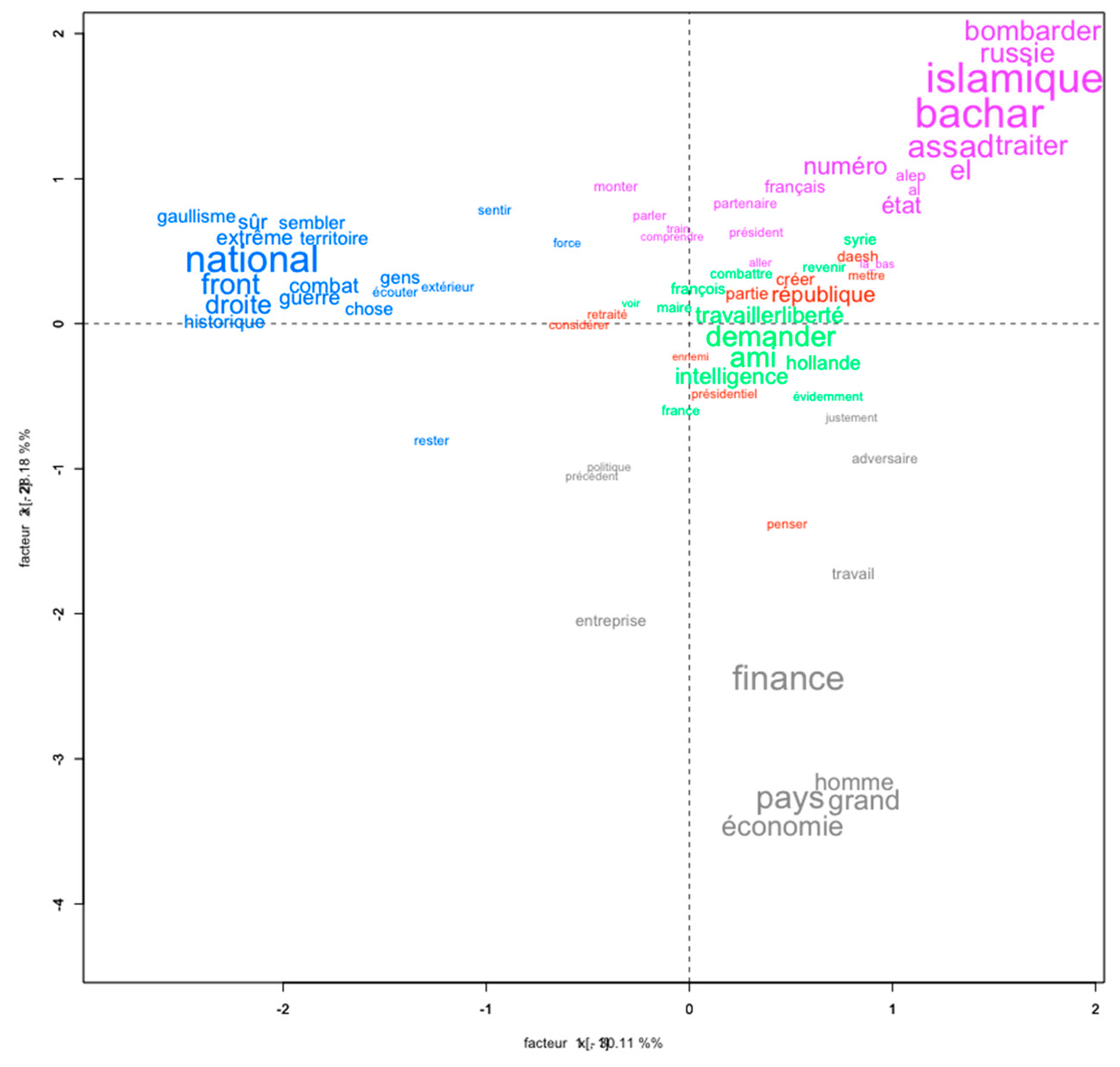
- In terms of the visualization and representation of the results, one can use the factorial analysis of correspondences (FAC): this is a statistical method “that can be applied to contingency tables such as tables resulting from counting different types of vocabulary (table rows) in different parts (table columns) of a corpus of texts” (Salem n.d. a, Lexico3 software tutorial). We start by “calculating a distance (known as the χ2 distance) between each pair of texts making up the corpus. These distances are then broken down into a hierarchical succession of factorial axes. … This method helps obtain synthetic representations of both the distances calculated between texts and those that can be calculated between the textual units that make them up.” It is nevertheless important to note that while “the main advantage of FAC lies in its ability to extract from vast data tables that are difficult to grasp simple structures that can approximately reflect large underlying oppositions within a corpus of texts,” this is only an “approximation” and the results of previous functions (calculations, tables of figures) must be precisely considered. These visualizations are an issue in the context of research in numerical humanities, which aim, in particular, to make complex results comprehensible through visualizations, which are based on metrics and rigorous calculations.
2.1.4. The Computer Model
2.2. From Theory to Tools: Profiling and Similarity Analysis, Themes and Lexical Classification
2.3. Material
3. Results
- c_est_à_dire que des gens qui reviennent de syrie qui sont allés égorger qui sont nos ennemis reviennent en france en liberté je suis là aussi un des rares à demander leur arrestation immédiate auprès du tribunal pour intelligence avec l ennemi (“That is to say that people who return from Syria, who went to slaughter people and are our enemies, return to France and keep their freedom. I am again one of the few asking for their immediate arrest and prosecution for colluding with the enemy.”)
- donc vous demandez vous aussi aux maires de france de ne pas accorder aux ennemis islamistes de la liberté la moindre parcelle de liberté mais évidemment (“So you too are asking the mayors of France not to grant the Islamist enemies of freedom the slightest ounce of freedom? Obviously.”)
- alors pour vous qui sont les rebelles d alep ce sont des amis ou des ennemis de la france on aurait dû les aider ou pas on les a aidés malheureusement (“Who are then, for you, the Aleppo rebels? Are they friends or enemies of France? Should we have helped them or not? Unfortunately, we did help them.”)
- 4.
- et que pour moi comme tous ceux qui étaient attachés au gaullisme historique ou comme ceux qui avaient une histoire centrée ou comme les humanistes de droite le front national l extrême droite était et reste un ennemi (“For me as for all those who subscribed to historical Gaullism or those with a centered background or the humanists of the right, the National Front, the far right was and remains an enemy.”)
- 5.
- moi mon ennemi c est le front national d_abord parce_que à paris vous ne le sentez pas mais en province ça monte et vous savez pourquoi ça monte parce_que les gens se sentent complètement abandonnés (“My enemy is the National Front, first because in Paris you don’t feel it but in the provinces it’s on the rise. And do you know why it’s on the rise? Because people feel completely abandoned.”)
- 6.
- notre ennemi à nous c est bien l extrême droite avant toute chose et bien sûr la droite représentée par françois fillon c est bien l extrême droite qui a le projet le plus dangereux pour la france et c est bien la droite qui a le projet le plus inégalitaire (“Our biggest enemy is first and foremost the far right and of course the right represented by François Fillon is very much the far right, which has the most dangerous plans for France, and it is very much the right whose ideas are most riddled with inequality.”)
4. Discussion
- -
- on the one hand, the humanities cannot keep using computing simply as a reservoir of tools without knowing how they are actually designed (the “black box”), or why and how they are relevant to their research—otherwise they will lose their own distinctive mark within them;
- -
- on the other hand, computer scientists cannot keep blindly applying tools which work properly elsewhere and are declared applicable in the humanities—otherwise results in the humanities will lose in quality. Indeed, the interpretation of textual data is subject to semiotic constraints (discursive practices, discourse genre, intertextuality, etc.) and it is necessary to be able to characterize, before any computer processing, the corpora. As we have seen, it is also fundamental to maintain coherence between the types of models called upon, in particular so that the results obtained are really answers to the scientific questions asked.
4.1. Humanities, Human Sciences, and Human and Social Sciences
A decree issued on 23 July 1958 (published in the Journal Officiel [official gazette] on 27 July 1958) turned faculties of arts [lettres] into faculties of arts and human sciences [lettres et sciences humaines] with the aim of encouraging some of the social sciences (psychology and sociology) to be taught in the proximity of arts and humanities subjects [humanités littéraires]. The phrase “human sciences” in this academic sense–which has come into widespread use–is a typically French idiomatic expression. The English language uses it in fairly loose contexts and speaks more commonly of “social sciences”.
- -
- Regarding the nature of the field, the HSS prism (or AHSS if we add the arts) leads us to conceive the digital either as an area or a means, not an approach angle, paying attention to what underlies this area or means (I will come back to this later);
- -
- Regarding practices, we are often faced with the use of generic tools that can be applied to the “humanities”; however, the computer sciences often develop specific projects on similar objects but from a perspective other than that of DH.
4.2. Computing, Numerical, Digital: The Data in Question
From computing (which has obviously not disappeared completely) to the numerical we go from one type of technicality, which is often exaggerated and cultivated for itself but requires a certain degree of technical skill, to more common uses requiring other skills which are put to use by a new online sociability built on texts and driven by “shares.” Nowadays, it is in relation to this popular numerical practice that the work of the numerical humanities also needs to be conceived.(711)
4.3. Qualitative/Quantitative, Conceptual/Formal, Semiotic/Numerical
In the 2000s there emerged, in conjunction with the emergence of computing technologies, an original and innovative research program deftly called the Digital Humanities [in English in original]. For the English-speaking world, this label took research in a more general direction than allowed by the previous label of Computers and the Humanities [in English in original]. In the French-speaking world, the English phrase which was translated as “humanités numériques” [“numerical humanities”] is more recent and raises questions not so much about the qualifier “digital” as about the noun “humanities.” As we know, the terms “humanités” and “humanities” do not cover the same disciplinary areas in the two languages.
a formal model does not necessarily have a quantitative dimension. Thus, we can have logical, geometrical, topological, grammatical, etc. formalisms. Some of them use iconic symbols (graphs, images, etc.). In all these formalisms, various types of symbols can be found, such as constants, variables, operators, etc.
5. Conclusions
Funding
Conflicts of Interest
Appendix A

References
- Cadiot, Pierre, and Yves-Marie Visetti. 2001. Pour une Théorie des Formes Sémantiques. Motifs, Profils, Thèmes. Paris: PUF. [Google Scholar]
- Dacos, Marin, and Pierre Mounier. 2014. Humanités Numériques. État des Lieux et Positionnement de la Recherche Française dans le Contexte International. Paris: Institut Français/Ministère des Affaires Étrangères pour L’action Culturelle, Available online: http://www.institutfrancais.com/sites/default/files/if_humanites-numeriques.pdf (accessed on 15 November 2019).
- Doueihi, Milad. 2015. Quelles humanités numériques? Critique 819–20: 704–11. [Google Scholar] [CrossRef]
- Evans, Vyvyan. 2018. Conceptual vs. inter-lexical polysemy. An LCCM theory approach. In Language Learning, Discourse and Cognition. Studies in the Tradition of Andrea Tyler. Amsterdam: John Benjamins Publishing Company. [Google Scholar]
- Flament, Claude. 1962. L’analyse de similitude. Cahiers du centre de recherche opérationnelle 4: 63–97. [Google Scholar]
- Flament, Claude. 1981. L’analyse de similitude: une technique pour les recherches sur les représentations sociales. Cahiers de Psychologie Cognitive/Current Psychology of Cognition 1: 375–95. [Google Scholar]
- Ganascia, Jean-Gabriel. 2015. Les big data dans les humanités. Critique 819–20: 627–36. [Google Scholar] [CrossRef]
- Le Deuff, Olivier. 2015. Les humanités digitales précèdent-elle le numérique? Les humanités digitales précèdent-elle le numérique? Jalons pour une histoire longue des humanités digitales. H2PTM 15. Available online: https://archivesic.ccsd.cnrs.fr/sic_01220978 (accessed on 15 November 2019).
- Longhi, Julien. 2015. La Théorie des objets discursifs: Concepts, méthodes, contributions. HDR Thesis, Cergy-Pontoise University, Cergy, France. [Google Scholar]
- Longhi, Julien, ed. 2017. Humanités numériques, corpus et sens. Questions de Communication 31. [Google Scholar]
- Longhi, Julien. 2018. Du discours comme champ au corpus comme terrain. Contribution méthodologique à l’analyse sémantique du discours. Paris: l’Harmattan. [Google Scholar]
- Longhi, Julien, and André Salem. 2018. Approche textométrique des variations du sens. Paper presented at the JADT 2018 Conference, Rome, Italy, June 12–15; pp. 452–58. Available online: http://lexicometrica.univ-paris3.fr/numspeciaux/special8/tutoriel2.pdf (accessed on 15 November 2019).
- Loubère, Lucie. 2016. L’analyse de similitude pour modéliser les CHD. Paper presented at the JADT 2016 Conference, Nice, France, June 7–10; Available online: http://lexicometrica.univ-paris3.fr/jadt/jadt2016/01-ACTES/83440/83440.pdf (accessed on 15 November 2019).
- Marchand, Pascal, and Pierre Ratinaud. 2012. L’analyse de similitude appliquée aux corpus textuels: Les primaires socialistes pour l’élection présidentielle française (septembre-octobre 2011). Paper presented at the JADT 2012 Conference, Liège, Belgium, June 13–15; Available online: http://lexicometrica.univ-paris3.fr/jadt/jadt2012/Communications/Marchand,%20Pascal%20et%20al.%20-%20L’analyse%20de%20similitude%20appliquee%20aux%20corpus%20textuels.pdf (accessed on 15 November 2019).
- Mayaffre, Damon. 2007. L’entrelacement lexical des textes. Cooccurrences et lexicométrie. Journées de Linguistique de Corpus, 91–102. [Google Scholar]
- Meunier, Jean-Guy. 2014. Humanités Numériques ou Computationnelles: Enjeux Herméneutiques. Sens Public. Available online: http://www.sens-public.org/spip.php?article1121 (accessed on 15 November 2019).
- Meunier, Jean-Guy. 2017. Humanités numériques et modélisation scientifique. Questions de Communication 31: 19–48. [Google Scholar] [CrossRef] [Green Version]
- Meunier, Jean-Guy. 2018. Vers une sémiotique computationnelle? Applied Semiotics 26: 75–107. [Google Scholar]
- Meunier, Jean-Guy. 2019a. Digital humanities: meaning engineering or material hermeneutics? Paper presented at Guest lecture of the Institute of advanced studies, Cergy-Pontoise, France, April 9. [Google Scholar]
- Meunier, Jean-Guy. 2019b. La rencontre du sémiotique et du “numérique”: Le rôle d’une modélisation conceptuelle. Semiotica. In press. [Google Scholar]
- Morin, Edgard. 1994. Sur L’interdisciplinarité. Available online: http://ciret-transdisciplinarity.org/bulletin/b2c2.php (accessed on 15 November 2019).
- Mounier, P. 2018. Les Humanités Numériques. Une Histoire Critique. Paris: Éditions de la Maison des Sciences de L’homme. [Google Scholar]
- Ortigues, Edmond. 1979. SCIENCES HUMAINES. Encyclopædia Universalis. Available online: http://www.universalis-edu.com/encyclopedie/sciences-humaines/ (accessed on 15 November 2019).
- Rastier, François. 2004. Doxa et Lexique en Corpus–Pour une Sémantique des Idéologies. Texto! Available online: http://www.revue-texto.net/Inedits/Rastier/Rastier_Doxa.html (accessed on 15 November 2019).
- Reinert, Max. 1983. Une méthode de classification descendante hiérarchique: Application à l’analyse lexicale par contexte. Les Cahiers de L’analyse des Données VIII: 187–98. [Google Scholar]
- Salem, André. 1988. Approches du temps lexical. Mots. Les langages du politique 17: 105–43. [Google Scholar]
- Salem, André. n.d. a. Séries Textuelles Chronologiques. Available online: http://lexicometrica.univ-paris3.fr/numspeciaux/special8/tutoriel2.pdf (accessed on 15 November 2019).
- Salem, André. n.d. b. Tutoriels pour L’analyse Textométrique. Available online: http://lexicometrica.univ-paris3.fr/numspeciaux/special8/tutoriel1.pdf (accessed on 15 November 2019).
- Vergès, Pierre, and Bouriche Boumédine. 2001. L’analyse des données par les graphes de similitude. Sciences Humaines. Available online: http://www.scienceshumaines.com/textesInedits/Bouriche.pdf (accessed on 15 November 2019).
- Visetti, Yves-Marie. 2003. Formes et Théories Dynamiques du Sens. Texto! Available online: http://www.revue-texto.net/Inedits/Visetti/Visetti_Formes1.html (accessed on 15 November 2019).
- Visetti, Yves-Marie. 2004. Le Continu en Sémantique: Une Question de Formes. Texto! Available online: http://www.revue-texto.net/Inedits/Visetti/Visetti_Continu.html (accessed on 15 November 2019).
| 1 | github.com/gephi/gephi/wiki/Fruchterman-Reingold: The Fruchterman-Reingold Algorithm is a force-directed layout algorithm. The idea of a force-directed layout algorithm is to consider a force between any two nodes. In this algorithm, the nodes are represented by steel rings and the edges are springs between them. The attractive force is analogous to the spring force and the repulsive force is analogous to the electrical force. The basic idea is to minimize the energy of the system by moving the nodes and changing the forces between them. For more details refer to the Force-Directed algorithm. |
| 2 | |
| 3 | Translation of the words: “enemy,” “finance,” “France,” “[the] right,” “Daesh,” (ISIS), “war,” “state,” “go,” “national,” “think,” “republic”. |
| 4 | Regarding the encounter between semiotics and computing, Meunier reminds us that “several formulations, often synthetic but sometimes simplistic or inadequate, can express this encounter between semiotics and computing as an opposition between: quantitative and qualitative, descriptive and interpretive, experimentation and interpretation, natural sciences and human sciences, Naturwissenschaften and Geisteswissenschaften, etc.” |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
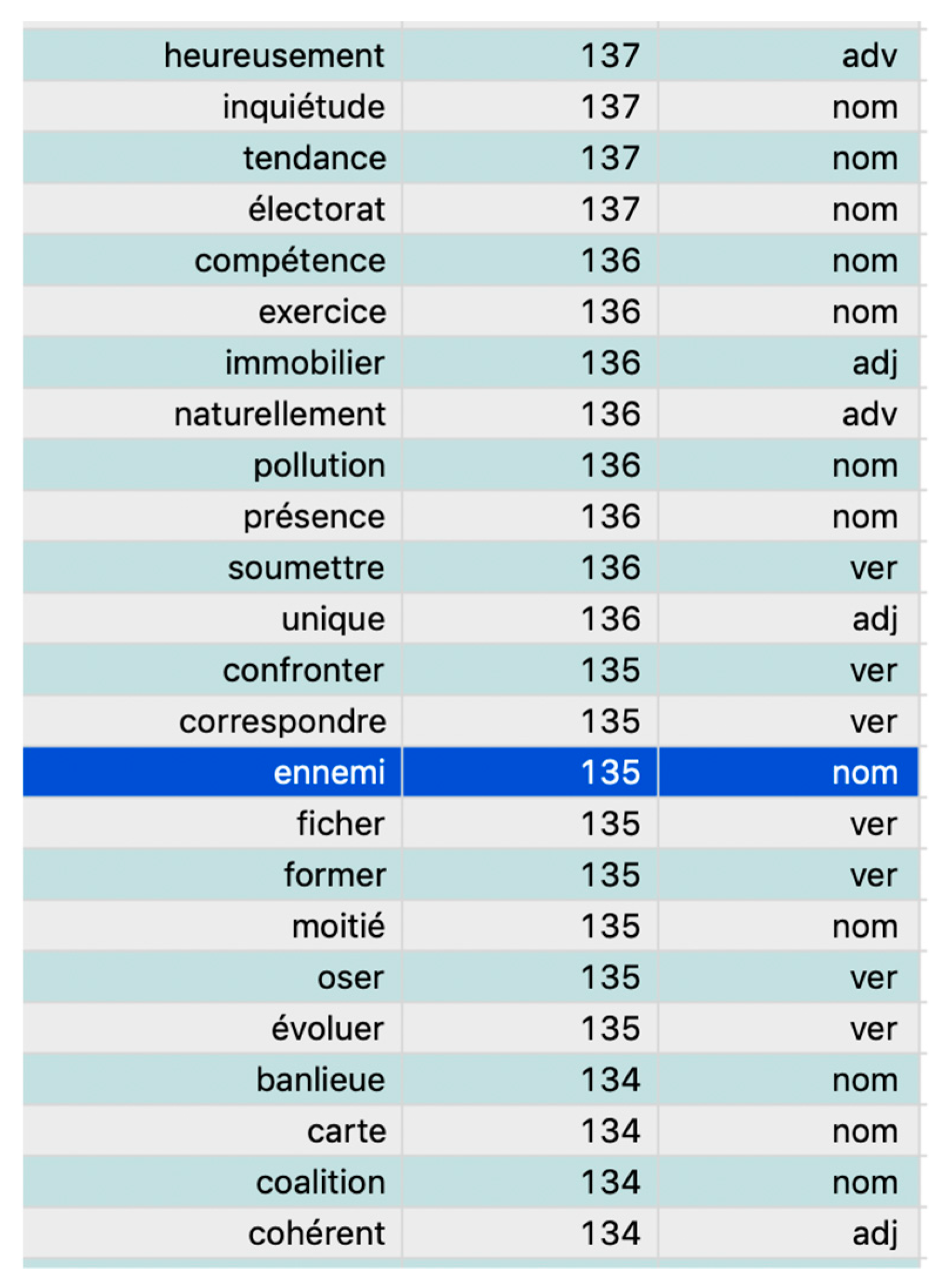
| Form | Freq. | Types |
|---|---|---|
| ennemi | 135 | common name |
| finance | 19 | common name |
| France | 19 | proper name |
| droite | 17 | common name |
| daesh | 16 | proper name |
| guerre | 13 | common name |
| état | 12 | common name |
| aller | 11 | verb |
| national | 10 | adjective |
| penser | 10 | verb |
| république | 10 | common name |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Longhi, J. Proposals for a Discourse Analysis Practice Integrated into Digital Humanities: Theoretical Issues, Practical Applications, and Methodological Consequences. Languages 2020, 5, 5. https://doi.org/10.3390/languages5010005
Longhi J. Proposals for a Discourse Analysis Practice Integrated into Digital Humanities: Theoretical Issues, Practical Applications, and Methodological Consequences. Languages. 2020; 5(1):5. https://doi.org/10.3390/languages5010005
Chicago/Turabian StyleLonghi, Julien. 2020. "Proposals for a Discourse Analysis Practice Integrated into Digital Humanities: Theoretical Issues, Practical Applications, and Methodological Consequences" Languages 5, no. 1: 5. https://doi.org/10.3390/languages5010005
APA StyleLonghi, J. (2020). Proposals for a Discourse Analysis Practice Integrated into Digital Humanities: Theoretical Issues, Practical Applications, and Methodological Consequences. Languages, 5(1), 5. https://doi.org/10.3390/languages5010005