1.1. Approaching Code-Switching
Since its first use by Vogt in 1954 [
2], the term CS was adopted by different fields in linguistics. Following Gumperz’ much cited definition, CS can be described as the “juxtaposition within the same speech exchange of passages of speech belonging to two different grammatical systems or subsystems” [
3] (p. 59). However, depending on the theoretical approach (formal, sociolinguistic, interactional etc.), the unity of analysis in question (sentence, turns in talk, sequences of interaction), and sometimes on the specific extralinguistic context, what can all be referred to as CS, can prove to be very differing phenomena (see [
4,
5] for a discussion). In fact, both facets of the term CS (
code and
switching) raise important questions as to their precise definition.
Firstly, it is not straightforward to define without ambiguities what a ”code” exactly is. It is a subject to debate whether a given linguistic material can always be attributed to a labeled language or whether it can be legitimately assumed to belong to different languages or varieties of languages [
6,
7,
8]; the type of data studied here (written, mainly informal interaction) and the social activities that are often conducted in this context (playful language use, see
Section 1.4) may even amplify these challenges [
7,
8].
Secondly, it is not evident what represents an actual instance of switching, even if the codes are unambiguously labelled: Which criteria (sociopragmatic, morphological, etymological/lexicographic) and which perspective (the researcher’s or the participants’) is more appropriate to identify a switch?
Thirdly, the mere impossibility of finding a widely accepted definition of CS goes hand in hand with the difficulty in distinguishing CS from other linguistic contact phenomena, especially from borrowing [
4,
9]. The lack of a clear-cut distinction leaves us with a continuum ranging from clear instances of CS to clear instances of borrowings shared by a larger linguistic community. In the corpus of text messages under analysis (see
Section 2), many allogenic items appear to be neither used completely spontaneously, nor to be really integrated into the repertoire shared by a larger community, hence belonging to the grey zone of the continuum between the two categories [
4,
8,
10].
These caveats being formulated, we underline the fact that the present paper focuses on the formal analysis of CS based on two syntactic principles formulated by González Vilbazo [
1], which we test without any theoretical presupposition on what grammatical CS entails. It is based on the empirical identification of two or more constituents that expose the morphological material of what appears-to researchers-as different languages or varieties inside the relevant syntactic boundaries. This may also imply simple word insertions, which are not considered to be CS by any of the theoretical approaches (see [
4] for a discussion).
1.2. Code-Switching and Grammar
Since the seminal work of Poplack [
11], research on syntactic restrictions in CS has grown to a large body of works, which we will not be able to address in detail here; for the sake of brevity, we focus on the research that is particularly relevant to the principles tested, see
Section 1.3.
In the generative framework, CS has become popular with Poplack’s proposal of an Equivalence Constraint on CS [
11]. However, this constraint stating that parallel structures in two languages are needed in order to switch from one language to the other
1 has repeatedly been shown not to hold up to scrutiny (cf. [
1] (p. 30) and [
8] (pp. 40–54)). Other constraints have been proposed to overcome the shortcomings of the Equivalence Constraint, such as Belazi et al.’s Functional Head Constraint (FHC) [
12]. Instead of focusing on the surface structure, the FHC takes into account the syntactic structure of phrases; it supposes that it is impossible to switch language between a functional head and its complement because of the strong relation between the two constituents. Yet, this would imply that CS is not possible between a determiner and its complement, as González Vilbazo points out [
1] (p. 41), a fact that is not confirmed in his corpus, neither by our examples, as we will see in
Section 3.2. Then, MacSwan’s minimalist approach is based on the selectional properties of lexical items [
13], since according to early minimalism, the relevant linguistic properties are all encoded in the lexicon. As a consequence, CS would only be constrained by feature mismatches of lexical items during computation. On this account, CS should be possible regardless of the heads involved, an assumption that does not seem to hold either. For instance, a relative pronoun must be followed by functional material of the same language, as shown by the following example taken from [
1] (p. 79); the Spanish relative
que ‘who’ has to be followed by the Spanish inflected verb
da ‘gives’ (1a), while it is not possible to combine the German relative
der ‘who’ with Spanish verbal morphology, be it in the Spanish (2b) or the German (2c) word order.
| 1. | a. | El Lehrer, | que da | schlechte | mündliche | Noten...2 | |
| | the teacher | who gives | bad | oral | marks | |
| | | | | | | |
| b. | *El Lehrer, | der
da | schlechte | mündliche | Noten | |
| | the teacher | who gives | bad | oral | marks | |
| | | | | | | |
| c. | *El Lehrer, | der | schlechte | mündliche | Noten | da |
| | the teacher | who | bad | oral | marks | gives |
| | ‘The teacher who gives bad oral marks…” | | [1] (p. 79) |
In this approach, it is not clear how different word order properties (cf. example 10 below) are dealt with.
The last model we want to mention is the Matrix Language Frame (MLF) model [
14], of which the 4-M model, named after four distinctive morpheme classes, i.e. content morphemes and three types of system morphemes, whose characteristics play a crucial role when it comes to CS, (e.g., [
15,
16]) is a refined version. This model takes its origin in the assumption that there is a matrix language defined for a whole CP. Inside a CP, only the so-called “outsider late system morphemes” have to be in the matrix language (ML). This includes all functional morphemes showing a grammatical relation with constituents that are outside the immediate maximal projection, e.g., subject-agreeing morphemes on verbs. The MLF also allows for embedded language (EL) islands in which a whole chunk appears in the EL without being affected by the ML. This last component of the model is at the same time its weak point, since EL occurrences that do not confirm the expectations can be regarded as such islands. A more promising approach would be to propose alternative explanations for examples which, at first sight, do not seem to fit into the model.
Given the fact that the models discussed in this section seem to all have their downsides, we will test two principles more recently proposed by González Vilbazo [
1], for which little research has been done so far. These principles are presented in more detail in the next section.
1.3. Presentation of the Principle of Agreement and the Principle of Functional Restriction
The principles we are going to test on our corpus are the Principle of Agreement (PA), and the Principle of Functional Restriction (PFR):
The PA states that:
All the morphosyntactic requirements of all the lexical and functional entities have to be satisfied in the sentence. Among these there is selection, agreement in the narrow sense, and the attribution of case and theta roles. The language of the lexical entities does not matter, as long as they satisfy the requirements.
3[
1] (p. 157, our translation)
The second principle, the PFR, is about where CS can occur, stating that:
Two functional heads X° and Y° have to be filled by lexical material of the same language if the functional category of YP is the complement of X° and both heads are part of the same extended projection.
4[
1] (p. 94, our translation)
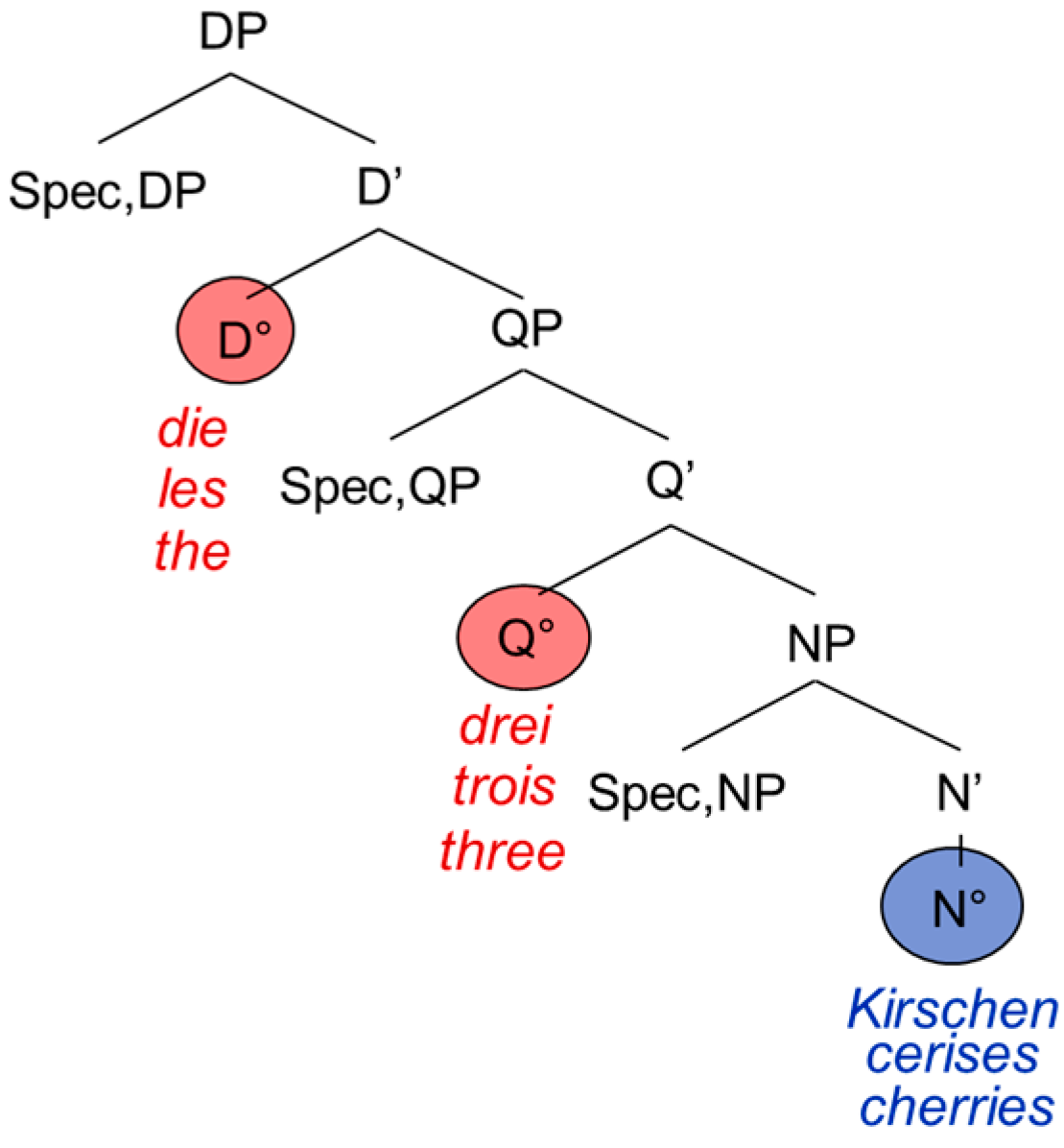
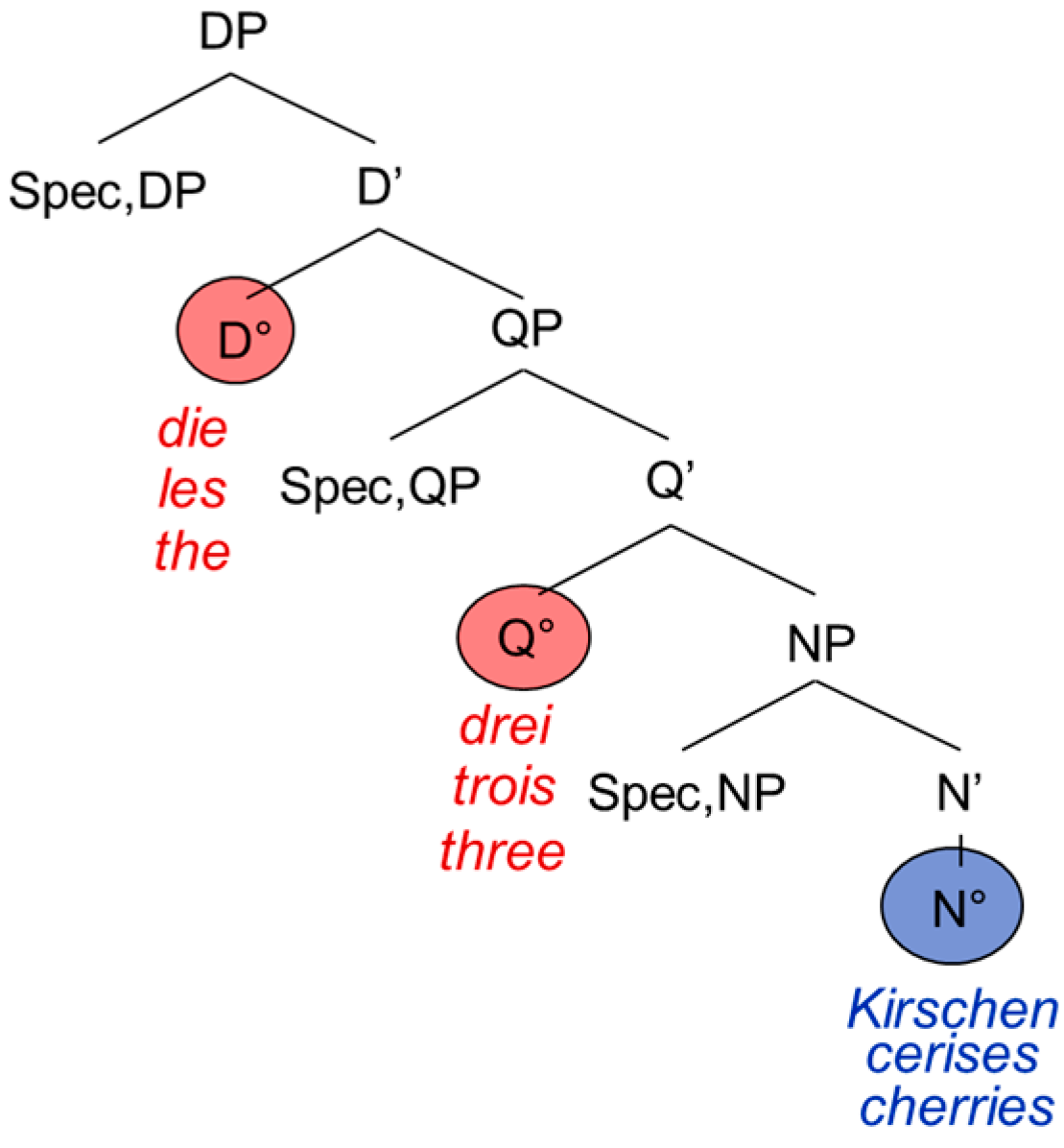
Because the PFR applies to extended projections, we focus our analysis on two extended projections, namely the extended projection of the noun (the DP) and the extended projection of the verb (CP). Extended projections form the functional overhead of the lexical categories. Hence, besides the lexical noun head N°, the DP contains at least a quantifier head Q° as well as a determiner head D°.
5 Following González Vilbazo [
1] (p. 108) and Bhatt [
17], the DP can be represented as in
Figure 1:
The determiner occupies the D°-head, the numeral the Q°-head, and the nominal expression the N°-head. It is not uncontroversial whether quantifiers have to be analyzed as heads or as phrases (or even as “semi-functional or semi-lexical categories” [
18] (p. 408; for a general discussion, see Part III, Chap. 2)); for reasons that will become clear later, we follow [
1], which considers them as heads. The DP can be modified by adjectives, which according to Cinque are phrases (occupying the specifier position of the adjective phrase) [
19]. The adjective phrase is left-adjoined to the noun phrase as in
Figure 2:
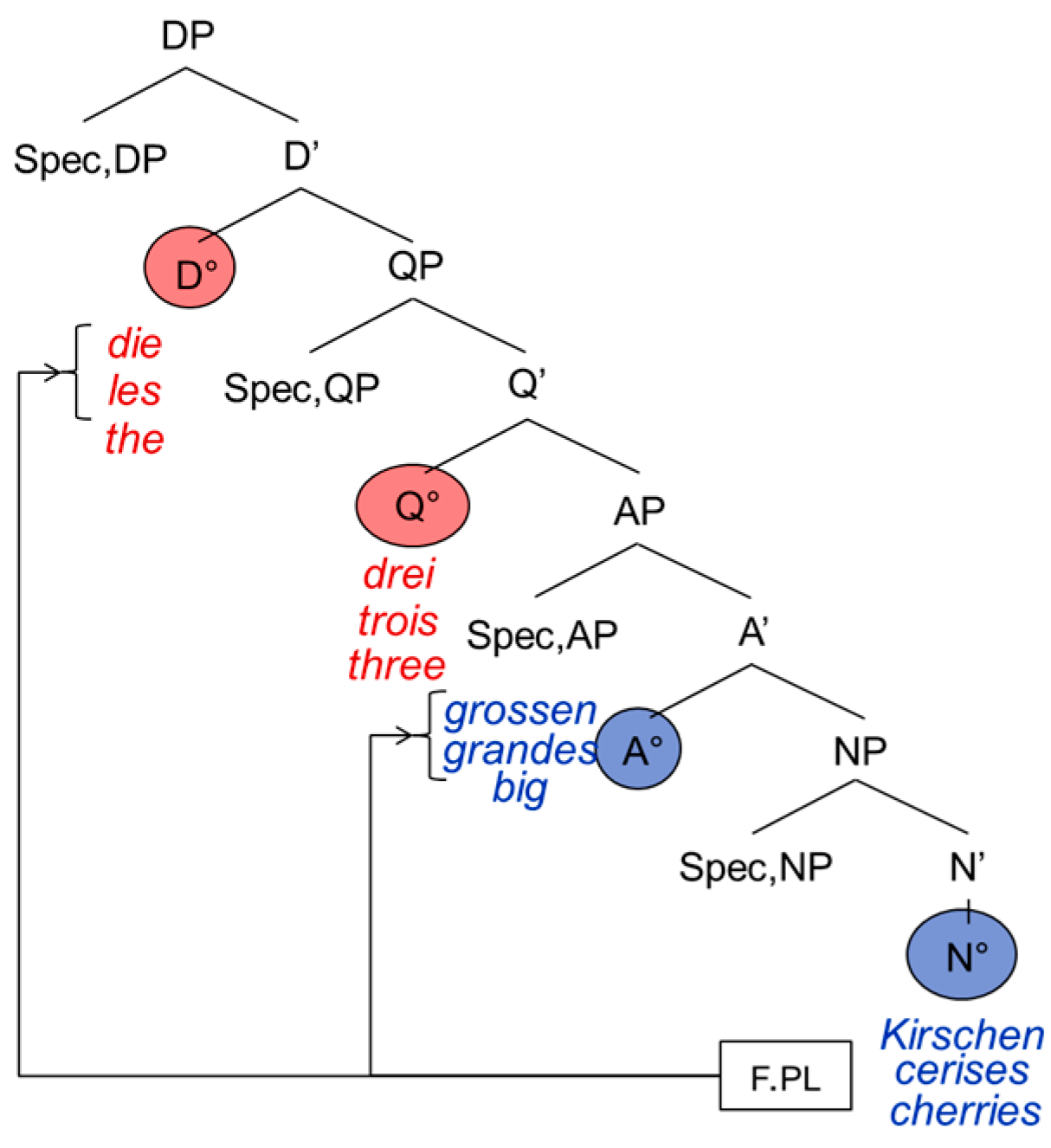
Coming back to the PA, the prediction is that inside, the DP agreement must be preserved regardless of the lexical item’s origin language. So, in
Figure 2 we can see the feminine plural agreement on both the German and the French determiner as well as on the adjectives, triggered by the feminine plural
cherries (
Kirschen and
cerises, respectively). It would be ungrammatical not to have agreement on lexical items that usually display it:
| 2. | die | drei | gross*(e)*(n) | Kirschen |
| the.pl | three | big(f)(pl) | cherries |
| 3. | les/*la | trois | grand*(e)*(s) | cerises |
| the.pl/the.f | three | big(f)(pl) | cherries |
Taking the determiner and the quantifier to be functional heads, a CS from the determiner to the quantifier is banned according to the PFR, since they are two functional heads of the same extended projection. The adjectival lexical item on the other hand, can originate from a different language, since it constitutes a lexical phrase:
| 4. | die | drei/trois | grossen/grandes | Kirschen/cerises |
| the.pl | three | big.f.pl | cherries |
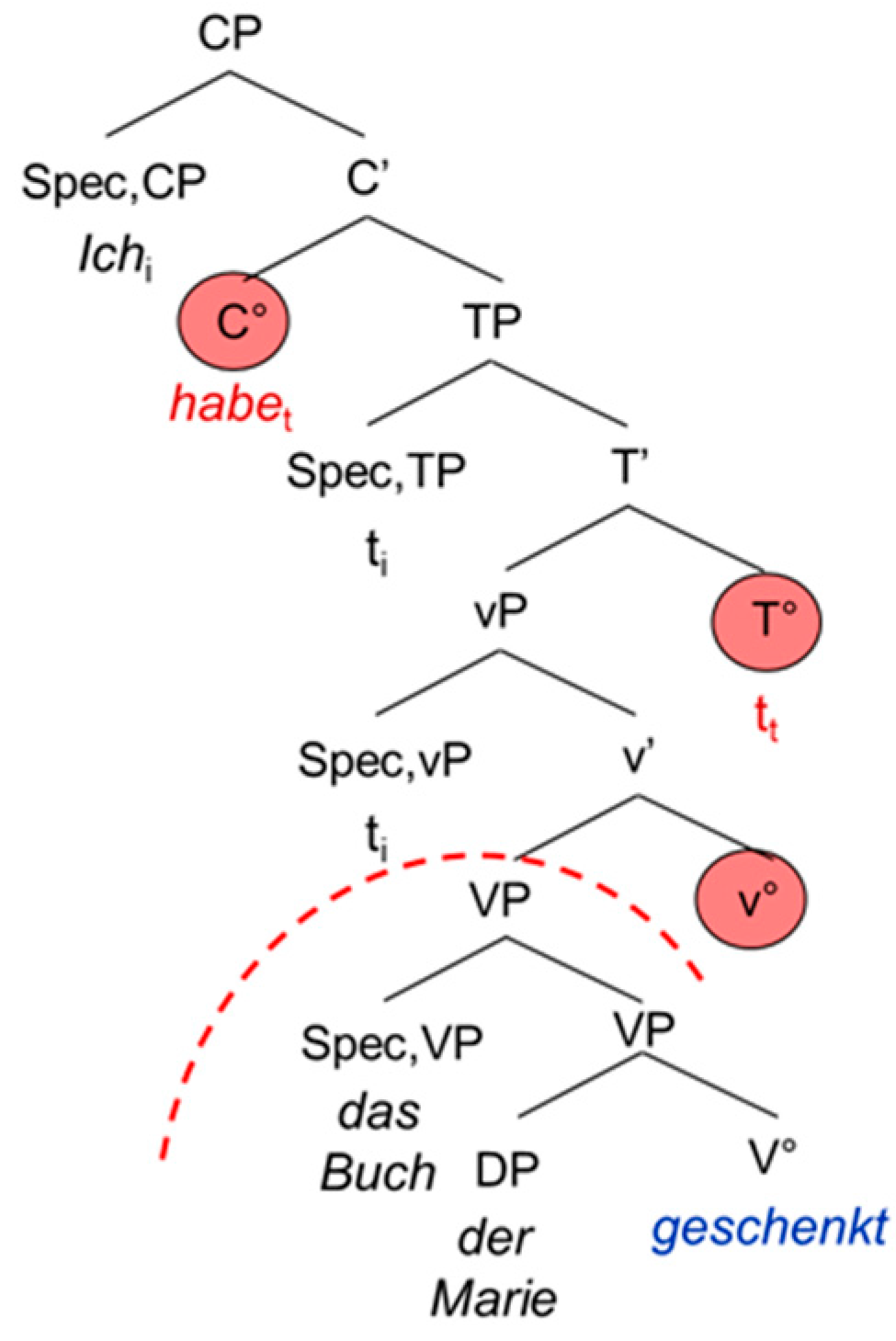
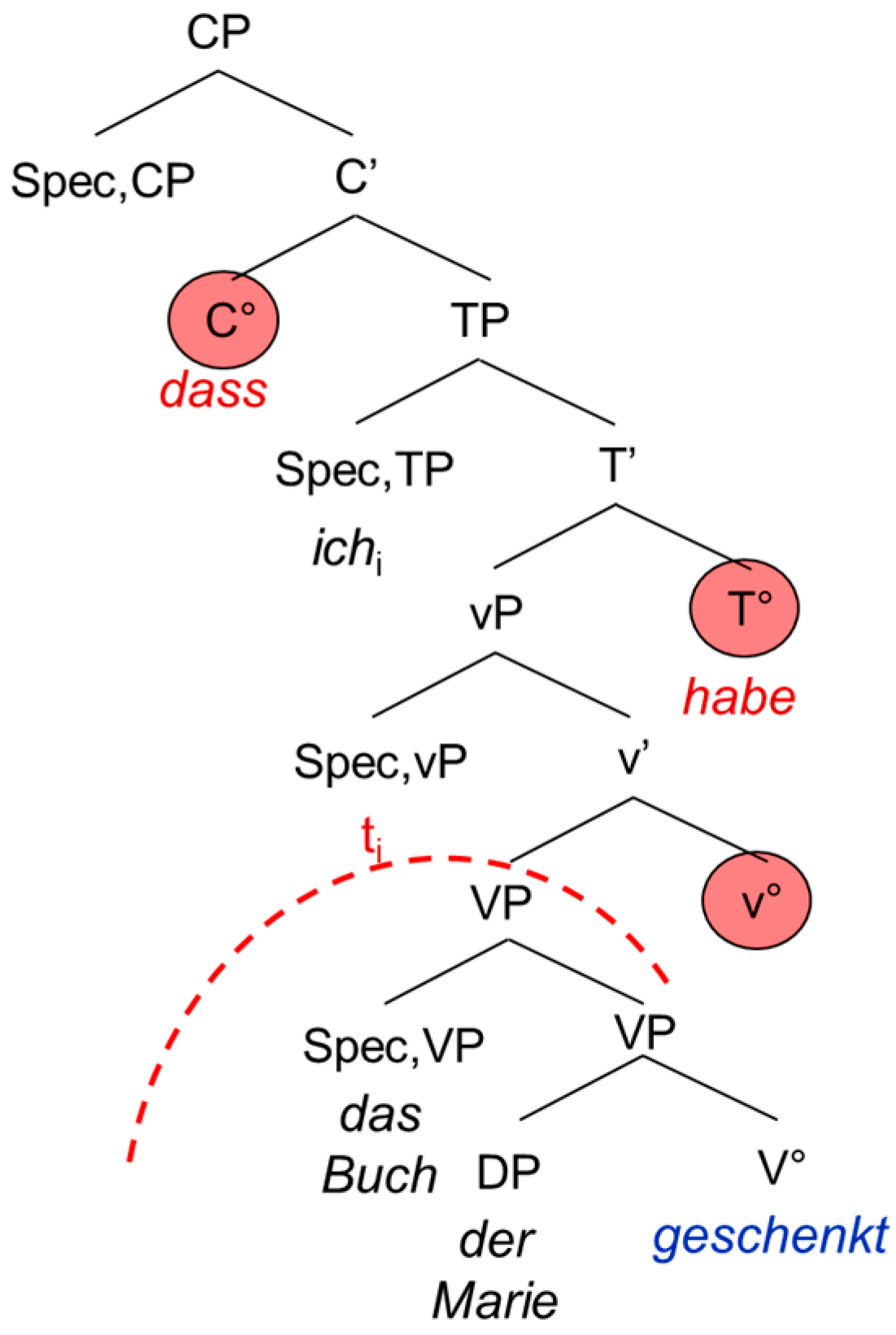
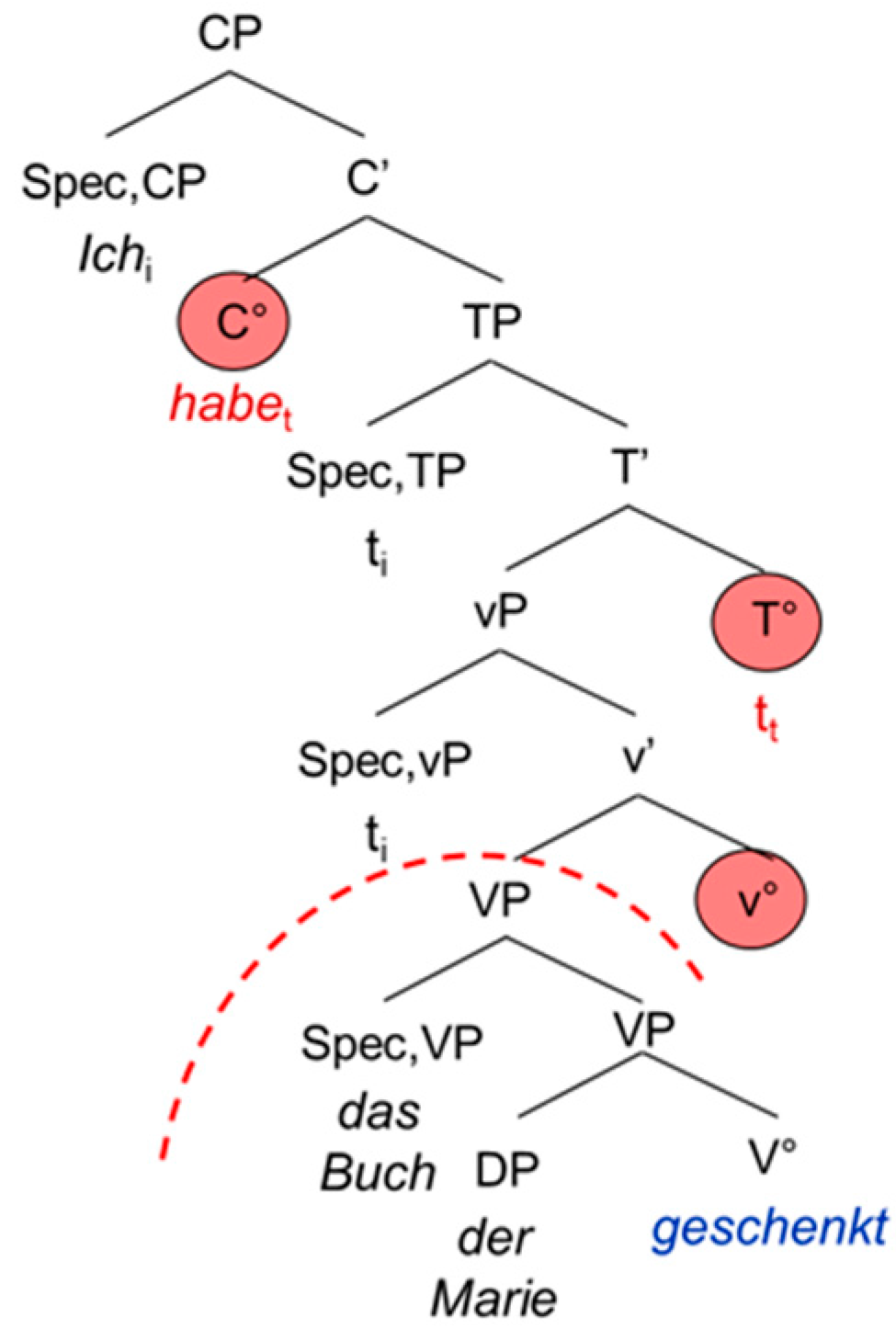
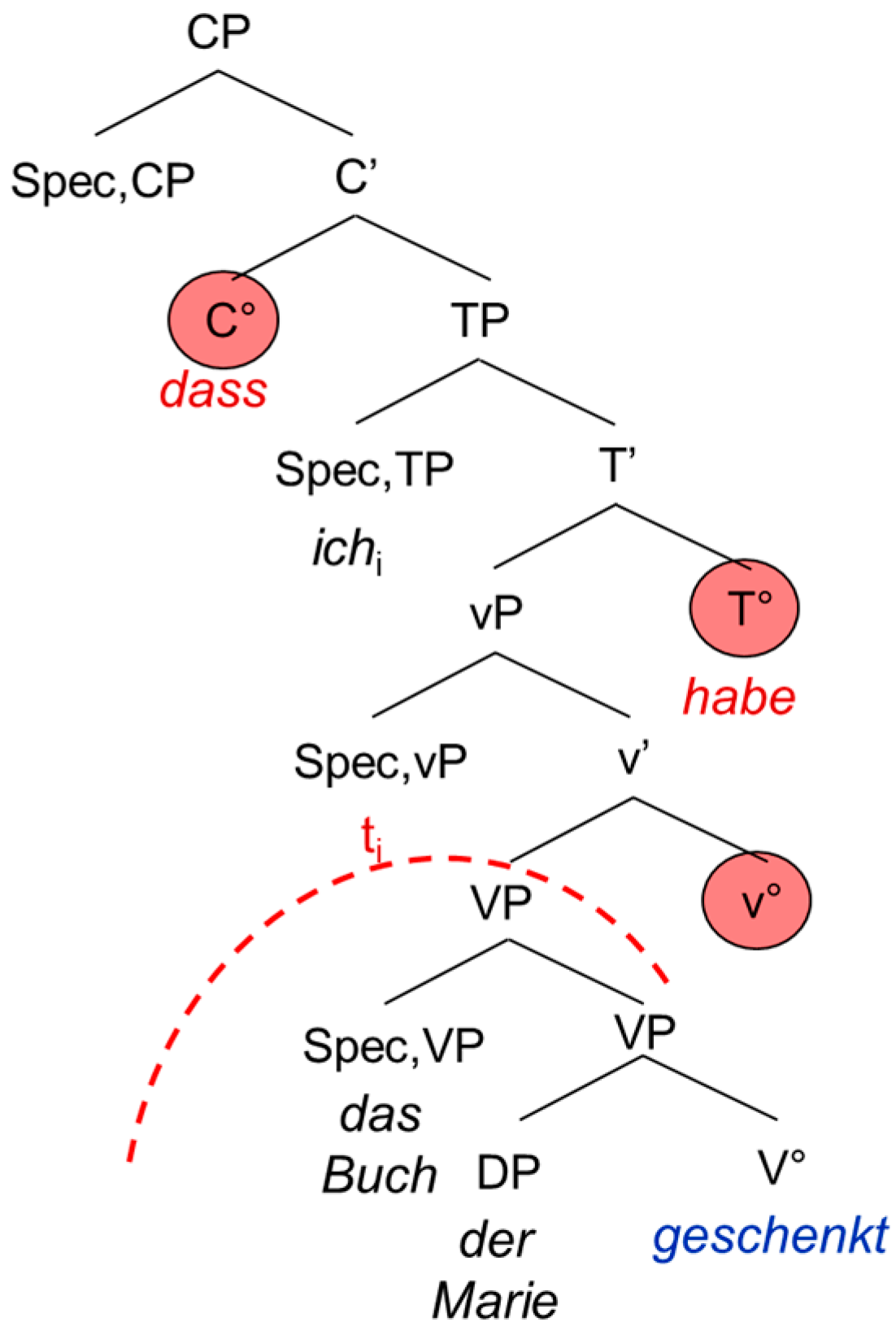
The second extended projection we look at is the complementizer phrase CP, the functional overhead of the verb. The CP consists of the lexical verb V°, the “functional” verb little v°, the temporal head T° and the complementizer C°. In German, the CP does not show exactly the same configuration as in the Romance languages and English. This is mainly due to the fact that German is a verb-second language displaying a V2 word order in the main clause and a V-final word order in the embedded clause, whereas the Romance languages and English show a rather consistent SVO word order. This has two main consequences: in the main clause, the German inflected verb raises to C°, hence triggering the V2 word order. In the embedded clause on the other hand, it remains in T° because C° is occupied by the complementizer. Since German shows a head-final configuration, the inflected verb will appear at the end of the embedded clause. Moreover, it has been shown that the German participle does not move out of V°. This means that it remains in the lexical domain, not entering the functional (extended) projection of the verb [
1] (p. 86).
| 5. | Ich | habe | das Buch | der | Marie | geschenkt. |
| I | have | the book | the.dat | Mary | given |
| ‘I have given the book to Mary.’ | |
| 6. | …dass | ich | das Buch | der | Marie | geschenkt | habe. |
| that | I | the book | the.dat | Mary | given | have |
| ‘… that I have given the book to Mary.’ | | |
The examples in (5) and (6) are schematized in the tree-structures in
Figure 3 and
Figure 4. The trees are not meant to represent antisymmetric trees; we adopt the representation proposed by [
1]. The discontinuing arch delimits the functional from the lexical domain of the verb.
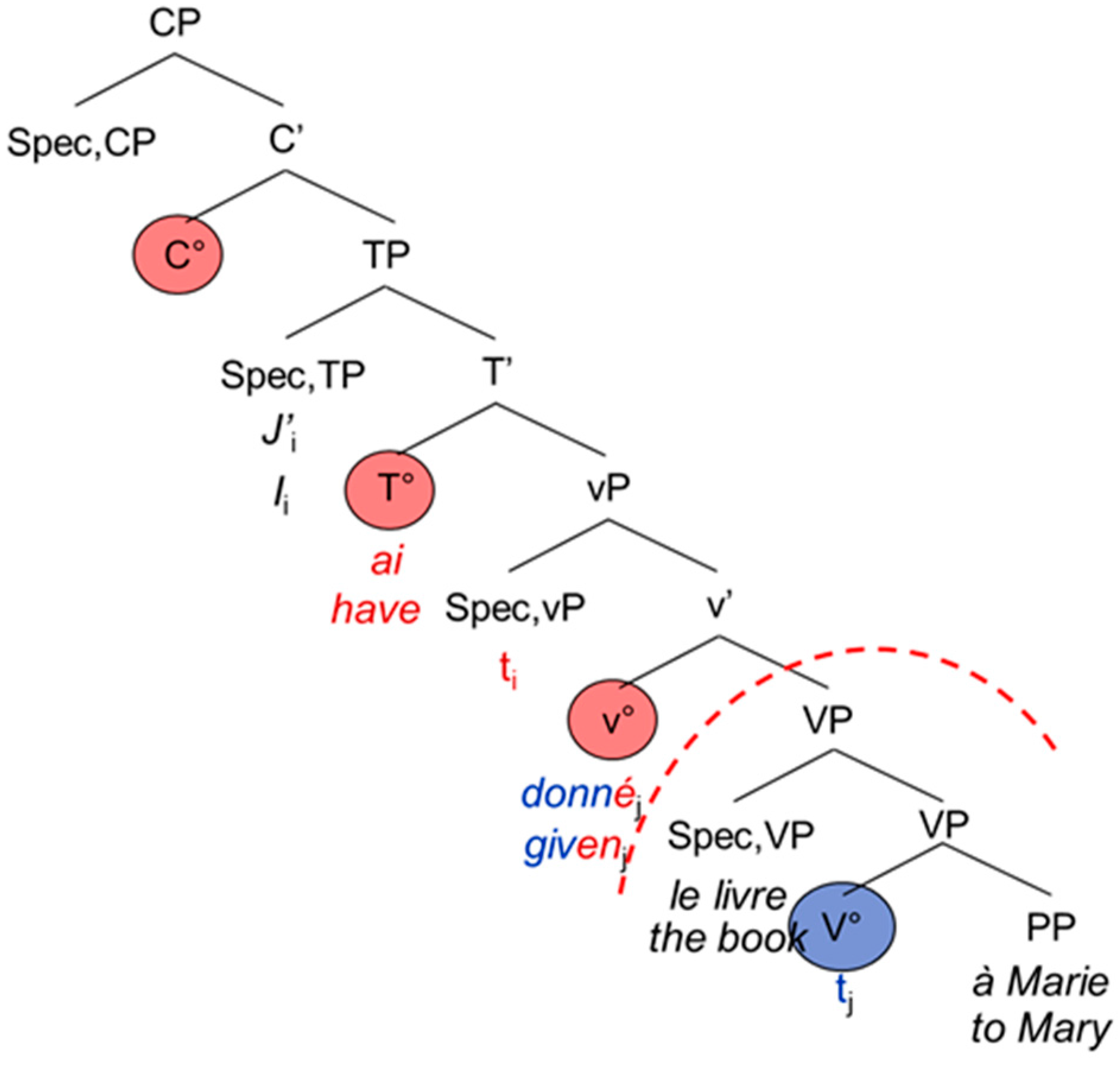
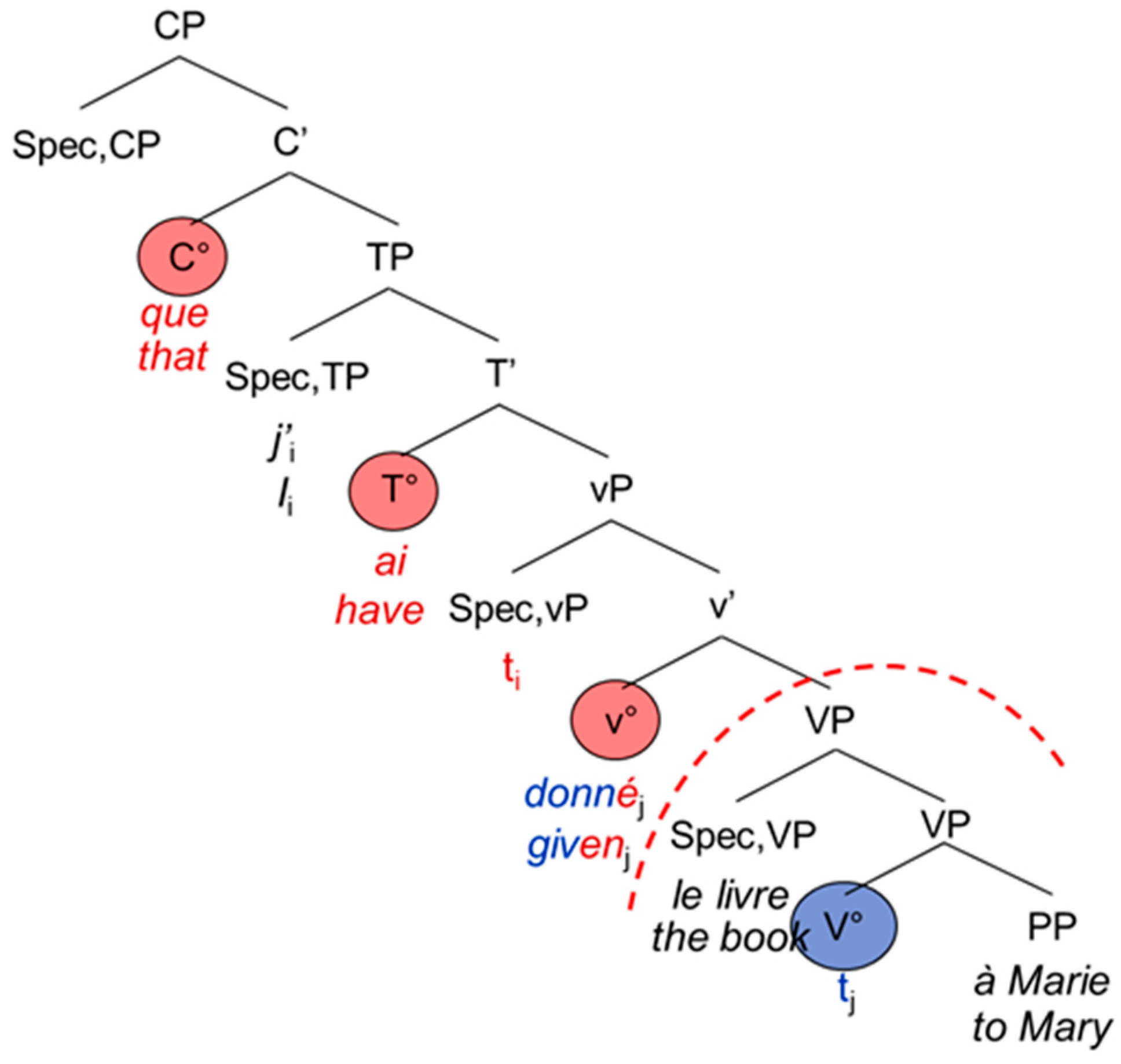
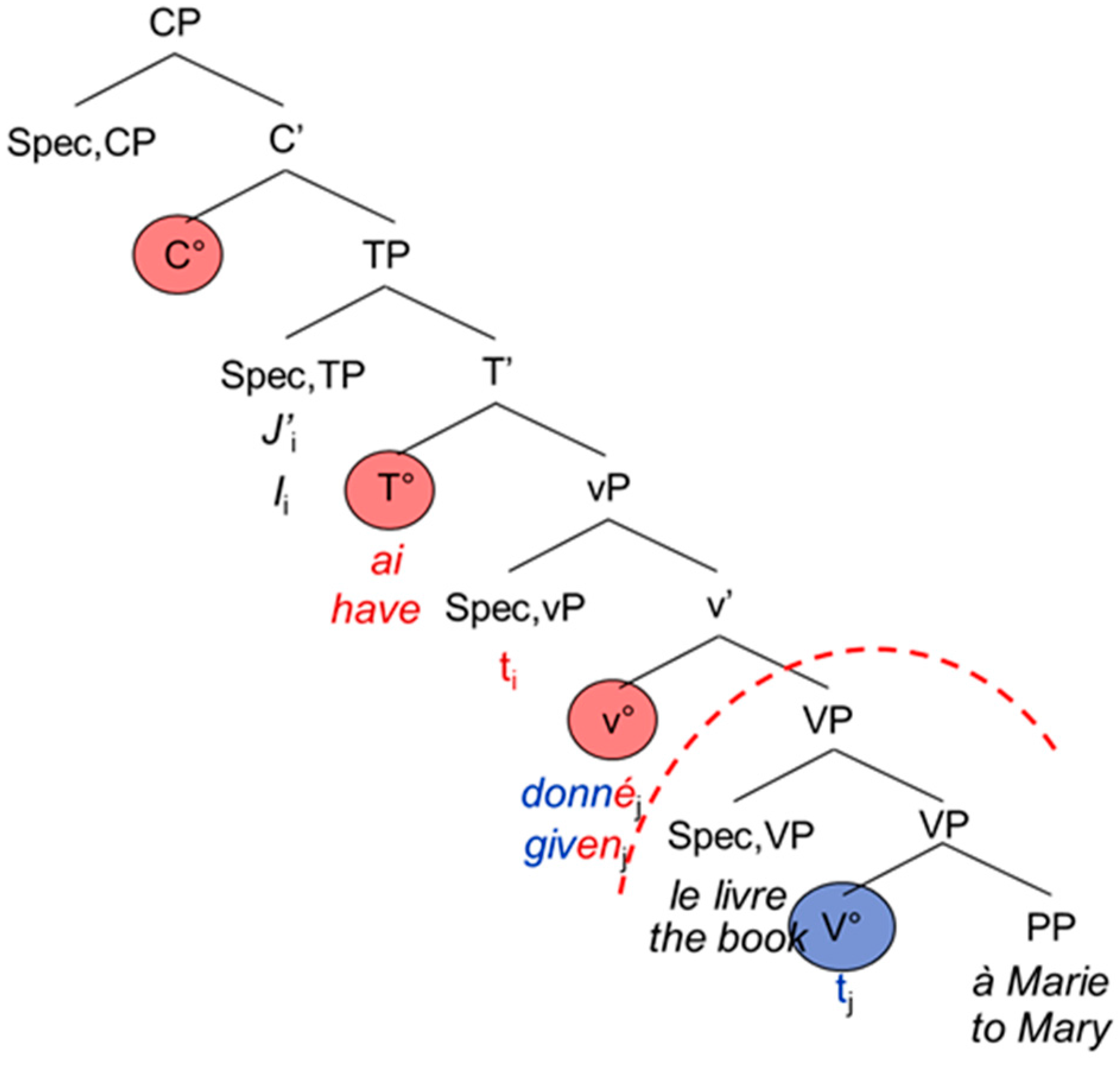
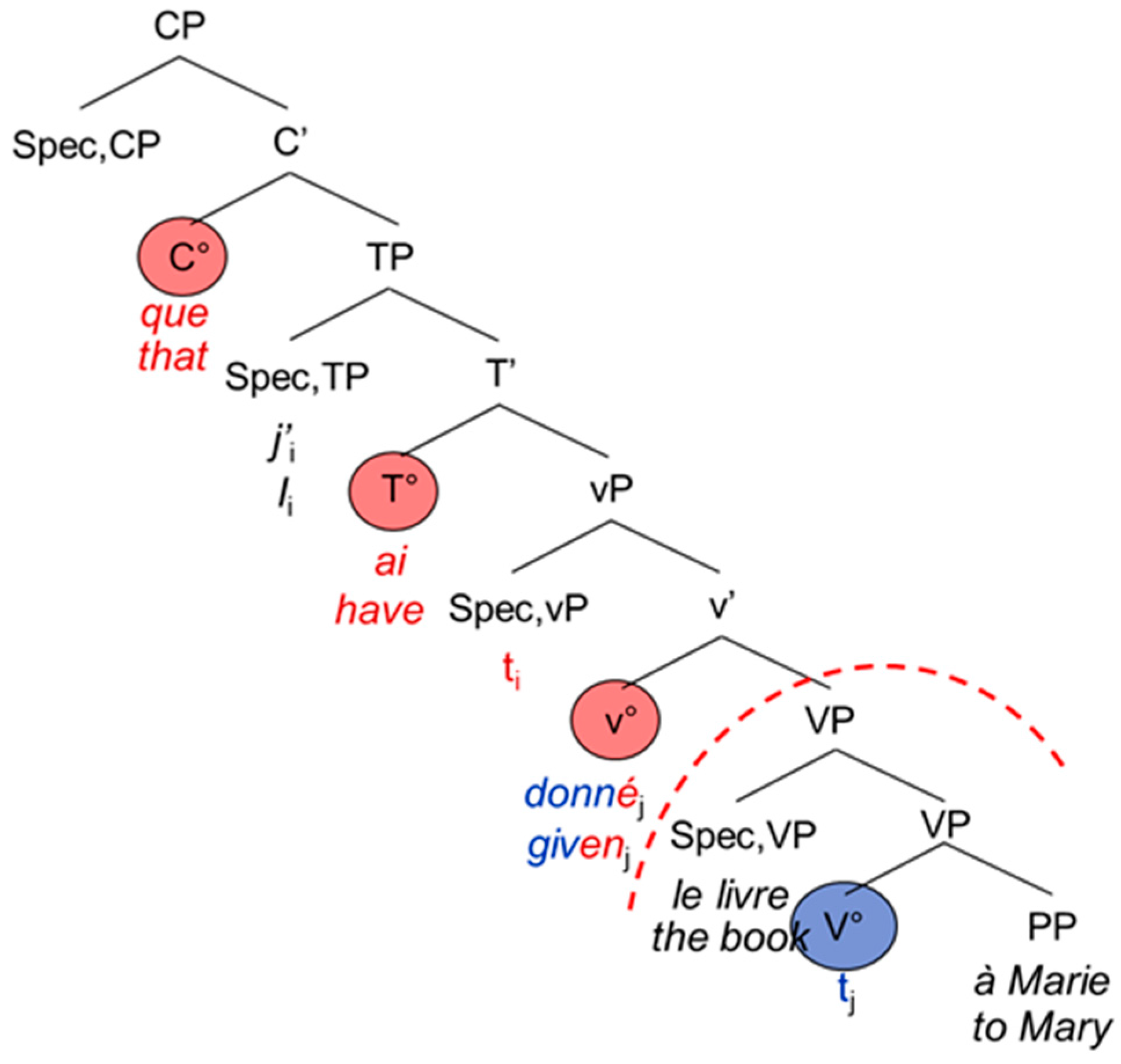
The French and English main and embedded clauses do not differ from each other apart from the complementizer that usually introduces the embedded clause: Both are head-initial with the inflected verb staying in T°. The participle moves to v°, hence entering the functional domain of the verb [
1] (p. 95) (see also [
20]). Again, examples (7) and (8) are represented by the tree-structures in
Figure 5 and
Figure 6 below.
| 7. | J’ | ai | donné | le livre | à | Marie. |
| I | have | given | the book | to | Mary |
| 8. | …que | j’ | ai | donné | le livre | à | Marie. |
| …that | I | have | given | the book | to | Mary |
According to the PA, the theta filter (thematic roles, cf. [
21]) must be satisfied and there is agreement (person, number) inside the CP (e.g., between the subject and the verb). The PFR further states that there should not be any CS in the functional domain, namely between the morphological exponents of the complementizer (C°) and the verbal morphology (the exponents of T° and v°). The differences between the syntactic architecture of German and that of French and English lead to interesting asymmetries in the possibility for CS, as [
1] has been observed for German-Spanish bilinguals. Since the participle enters the functional domain in Spanish, but not in German, it is possible to switch the code for the German participle (9b), but not for the Spanish one (9a):
| 9. | a. | Er | hat | *contado. |
| | | | |
| b. | | Ha | erzählt. |
| | ‘(He) has told.’ |
Our grammaticality judgments as native German-French bilinguals reflect the same asymmetry. If we try to switch the code inside the periphrastic verbal construction of examples (6) and (8) above, we obtain the possible combinations in (10) of which only the alternative (10a) with the German lexical item
schenk- endowed with the French past participle morphology
-é is perfectly fine. Alternative (10b) does not seem completely impossible but is very marked; acceptability improves without a following indirect object (like in example (9b) above). This contrast is probably induced by the fact that the German participle, which remains in V°, follows all objects in the syntax of German (recall that it displays a V-final word order in embedded clauses). The two last alternatives with a French participle integrated in a German clause, both with French or German morphology are excluded.
| 10. | a. | …que j’ai schenké le livre à Marie. |
| | |
| b. | …que j’ai ??/*geschenkt le livre à Marie. |
| | |
| c. | …dass ich das Buch der Marie *donné habe. |
| | |
| d. | …dass ich das Buch der Marie *gedonnt habe. |
This pattern is expected under the PFR: we assume that lexical material merged in a low position can take part in syntactic operations (namely the German participle that can be endowed with French morphology by moving to v°), while it is not possible to have a functional exponent (namely the French participle in v°) of a different language than the complementizer.
What sets González Vilbazo’s analysis [
1] apart from the MLF, the MLF being arguably the most promising model for the last decade, is the claim that a ML is set on the level of extended projections instead of the whole CP. As a consequence, no language has to dominate since the phrase structure of every extended projection can be built according to a different grammar. González Vilbazo’s PFR differs also form the 4-M model (a refinement of the MLF, see
Section 1.2) in the theoretical assumption about the “outsider late system morphemes” of the 4-M model [
15,
16]. Theoretically, the 4-M model predicts that structural case markers (i.e., for the nominative and accusative cases) should in fact originate from the same language as the verb’s functional morphemes, since these cases depend on the functional properties of the verb. According to the PFR on the other hand, it suffices that the features match. González Vilbazo himself does not discuss this point, but gives example (1), repeated as example (11), in which there is a German direct complement (
schlechte mündliche Noten ‘bad oral marks’) paired with a Spanish inflected verb (
da ‘gives’) [
1]. Unfortunately, with plural nouns, the nominative and accusative cases are syncretic in German. However, if we replace the complement by a masculine singular noun in (12), the accusative morphology is apparent (
einen guten Kurs ‘a good course’ vs. nom:
ein guter Kurs).
| 11. | El Lehrer, | que | da | schlechte | mündliche | Noten… |
| the teacher | which | gives | bad.f.pl.nom/acc | oral.f.pl.nom/acc | grade.f.pl.nom/acc |
| ‘The teacher, which gives bad oral grades…’ | [1] (p. 79) |
| 12. | El Lehrer, | que | da | einen | guten | Kurs… |
| the teacher | which | gives | a.m.sg.nom | good.m.sg.nom | course.m.sg.nom |
| ‘The teacher, which gives a good course…’ | (our adaption) |
Moreover, in more recent publications, Myers-Scotton and Jake argue that complementizers are not all of the same kind, since their classification is based on a conceptually relevant versus system-relevant distinction [
16] (pp. 351–354). Some complementizers are claimed to be late system morphemes (the “outsiders”) while others are content morphemes or both. The former usually appear in the ML (even if different from the CP they introduce) while the latter are more likely to occur in the language of the CP they introduce. As a consequence, and in contrast to González Vilbazo’s approach [
1], the C° head could appear in a different language than the functional elements of the CP it introduces. But again, since it is not clearly defined which complementizers are outsiders and because there seems to be variation according to the languages involved in CS, this prediction is difficult to prove or falsify. However, if there is indeed a case of mismatch between a complementizer and the following functional material, this could falsify the PFR, but only if the connector is really a head. This last restriction is fundamental, as González Vilbazo points out [
1] (pp. 81–84). For example, connectors conveying the same meaning in two languages are not automatically C-heads in both of them. There exist also different kinds of connectors bearing the same meaning in one and the same language, as is shown by the complementizer
weil contrasting with the coordinating connector
denn, both meaning ‘because, since’ in German, but only the first being a subordinating device, as can easily be seen by the German word order.
Having said that, Myers-Scotton and Jake also give some examples which are challenging for González Vilbazo’s claims [
1], since they show that bridge connectors like English
that vary according to whether they are morphological exponents of the language of the matrix CP, such as in (13) from a Palestinian Arabic–English CS, or of the embedded CP [
16] (pp. 352–353).
| 13. | […] kaan | el-doctor | yišuk | it is not reliable |
| […] perf.3masc.be | the-doctor | imperf.3masc.doubt | it is not reliable |
| ‘[he] was, the doctor, doubting that it was not reliable.’ | | [22] (p. 71), in [16] (p. 353) |
In the former case, Myers-Scotton and Jake propose to analyze the “entire multi-clausal constituent in one language” [
16] (p. 353), i.e., the language of the matrix CP, and the following TP-clause is an embedded island, and not the ML of the embedded CP. A CS from a complementizer to its following TP is unexpected under the PFR and has been argued several times (cf. [
12], (pp. 224–225) among others) to be ungrammatical. Interestingly, the examples given in [
16] are all with saying verbs like
say,
confirm or
doubt. Now, it is well known that the bridge following this type of verb is a rather loose connector, introducing sentences that are less integrated in the matrix sentence. According to Haegeman [
23], the relation between the matrix sentence and these loosely embedded sentences is more one of coordination than of subordination, which could explain the unexpected CS here: coordinating linking words are not subject to the PFR.
It is also worth considering that in the reported examples of CS between English and Arabic in [
16], the Arabic complementizers equivalent of
that show morphological agreement. We cannot discuss this issue in detail here, but it could point towards a difference in CS depending on whether the subordinating head expresses the Force-head or the Fin-head in Rizzi’s split-CP hypothesis [
24]. Rizzi [
24] (p. 312) and Rizzi and Shlonsky [
25] argue that only the Fin-head, but not the Force-head, can be associated with agreement. If the complementizers which do not match the language of the following TP are instances of Fin°, we could speculate that it is Force° which sets the ML of the CP and Fin° might not be bound to the PFR since it carries more lexical features (besides functional ones). If there can be shown such a correlation across languages, this would be welcome, otherwise, no principle can be stated for the complementizer’s language in CS. However, these considerations have to remain speculative for the time being.
1.4. Code-Switching in Texting
The formal analysis discussed in this paper aims to complement and build on previous work pertaining to CS in text messaging, which now comprises a rather large number of studies on different contexts (for a more complete literature review see [
8,
26,
27]; for research on texting in general see [
28]).
A first body of research focuses on CS of individuals who regularly use different languages in all their everyday activities, including text messages, in language combinations like Tagalog–English in the Philippines [
29], Spanish–English in the U.S. [
30], English–isiXhosa in South Africa [
31], English–Arabic in Kuwait [
32], Nigerian English-standard English-vernaculars in Niger [
33] and French–Wolof (and other languages) in Senegal [
34]. Particular attention has been given to the influence of CS on the length of messages [
29], assuming that CS leads to shorter messages, although this hypothesis has since been falsified [
30,
31]. These studies illustrate diversified and culturally specific CS practices and interpret them on a sociolinguistic background, assuming ‘sociosymbolic values’ of certain languages. However, they generally disregard formal aspects of CS and do not explicitly refer to any theoretical CS framework.
6A second body of research relates to work carried out within the project “sms4science”, especially in Belgium [
36], La Réunion [
37] and Switzerland; in the Swiss context, CS was analyzed in text messages with Swiss German [
26], French [
8,
27], Italian [
38] and Romansh [
39] as main text language (see also [
7,
40] for transversal and comparative elements).
These contributions use linguistic categories to describe the data mainly in a variational [
8,
26,
40] and/or interactional [
8,
27] approach to language contact phenomena, but pay less attention to syntactic constrains on CS. Based on Poplack [
11], the authors distinguish between intersentential and intrasentential CS. For the latter they further use Muysken’s CS typology [
41] to discriminate the insertion of elements originating from a language
x into the utterance (or proposition) whose base language is
y (called “transfer” by Auer [
42] and “embedding” by Myers-Scotton [
43]) and the alternation between two distinct base languages.
The results from analyses of language-specific subcorpora in the context of the Swiss sms4science project show that even though CS is quite frequent (57% of the Romansh messages, 23% of the Italian messages, 22% of the Swiss German messages and 18% of the French messages contain at least one switch), the patterns are minimal in nature, as most of the elements are very short, potentially formulaic intersentential alternations (e.g., hola ‘hi’, ti amo ‘I love you’, besos ‘kisses’, what else?).
Overall, more complex intrasentential alternations, intersentential CS and language change from one message to another are mainly found with older participants who consider themselves to be plurilingual.
7 Due to the high proportion of short and recurrent intersentential alternations, often combined with recurrent language play, the usefulness of syntactic analyses of CS has been questioned for the corpus at hand (e.g., [
8]) and syntactic constraints were not tested on any subpart of the corpus so far. However, in spite of the fact that the sequences of CS with which it is dealt are rather short and relevant cases perhaps limited in number, this does not imply that they could not be used to test hypotheses, especially if these focus on the transition point from one variety to the other in CS, since syntactic principles should apply to every kind of CS, regardless of their length or communicative intention.
Apart from that, a corpus of Swiss text messages seems to be an ideal ground for testing hypotheses on CS for two reasons. Firstly, the informal context, in which most of the text messages are written, facilitates CS with respect to other more formal contexts where CS is stigmatized. Secondly, in Switzerland, people not only switch from their mother tongue to English (which is taught as a foreign language at school)
8, but also to other languages spoken (and regionally taught as L2) in the country, namely (Swiss) German, French, Italian and Romansh (see
Section 2 for further details). This particular sociolinguistic situation allows us to test if the syntactic restrictions under study (the PA and the PFR, see
Section 1.3) hold across different types of (informal) communication and different language pairs. If this is the case, it may be a strong hint towards the interlinguistic, if not universal validity of the principles.
As mentioned above, we are going to test the two proposed principles on a corpus of multilingual Swiss text messages. In the next section, we introduce the corpus and the methodology we used; the results are presented and discussed in
Section 3.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}