
Mobilizing Instruction in a Second-Language Context: Learners’ Perceptions of Two Speech Technologies


Abstract
:1. Introduction
2. Background
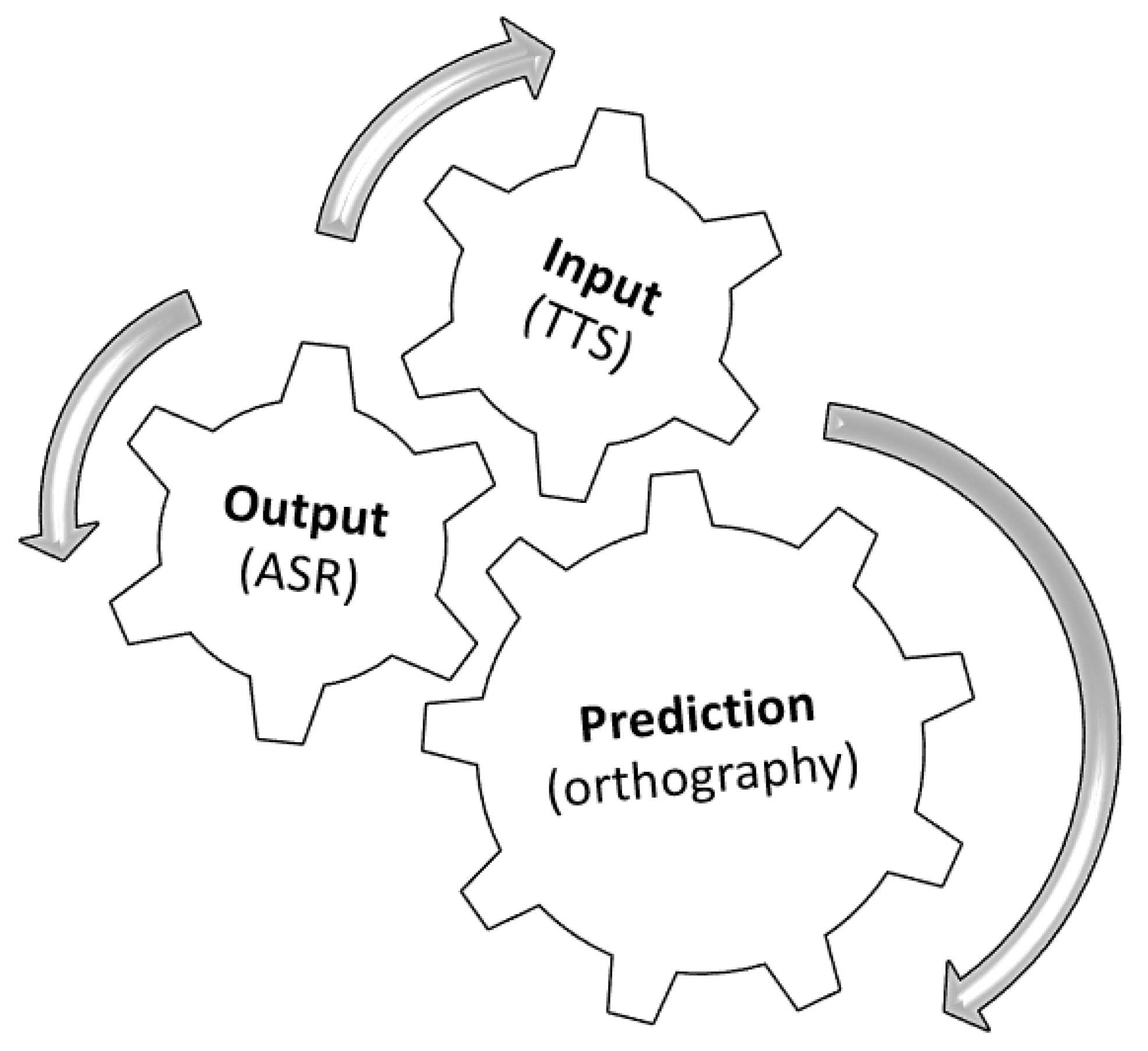
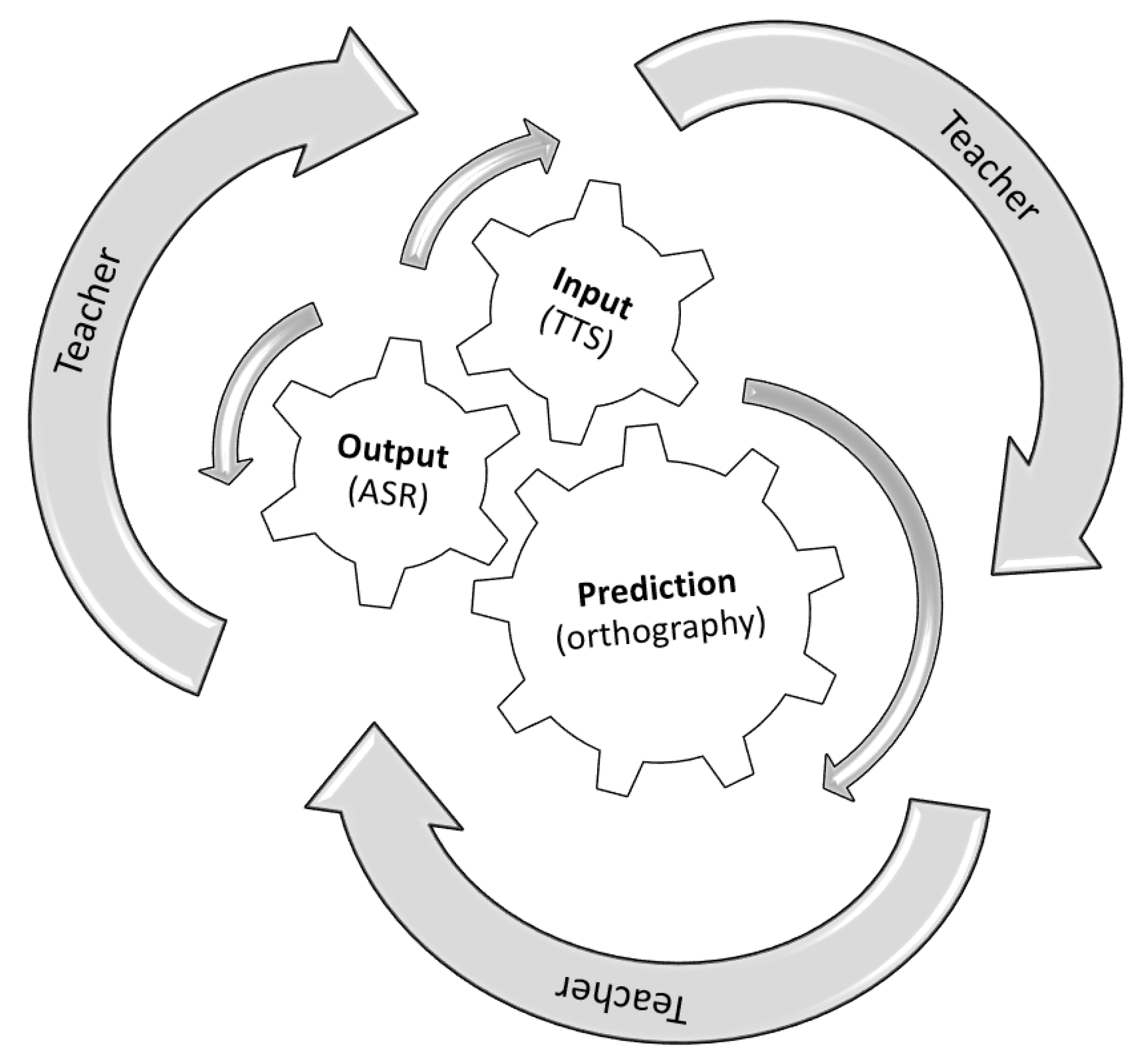
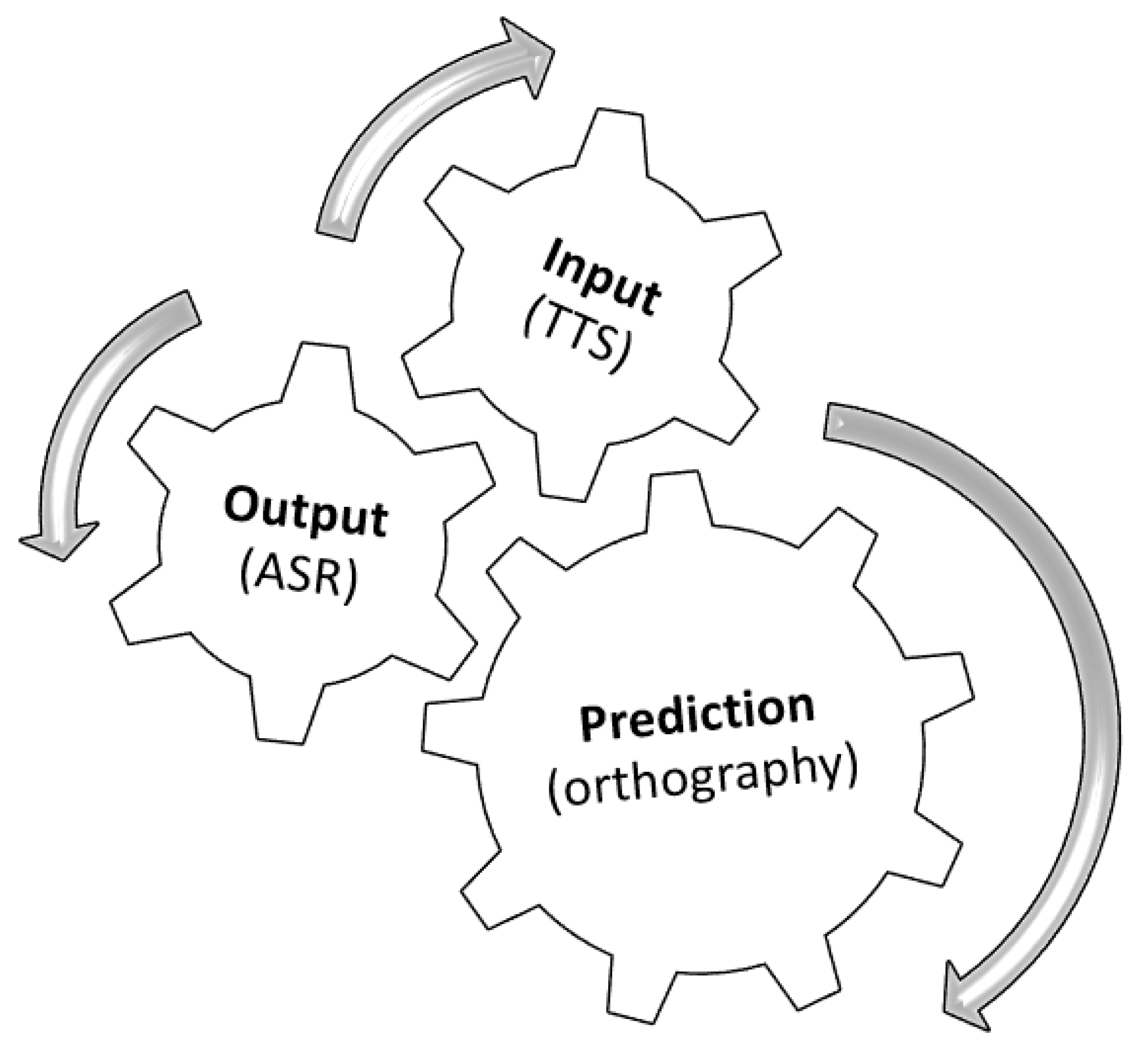
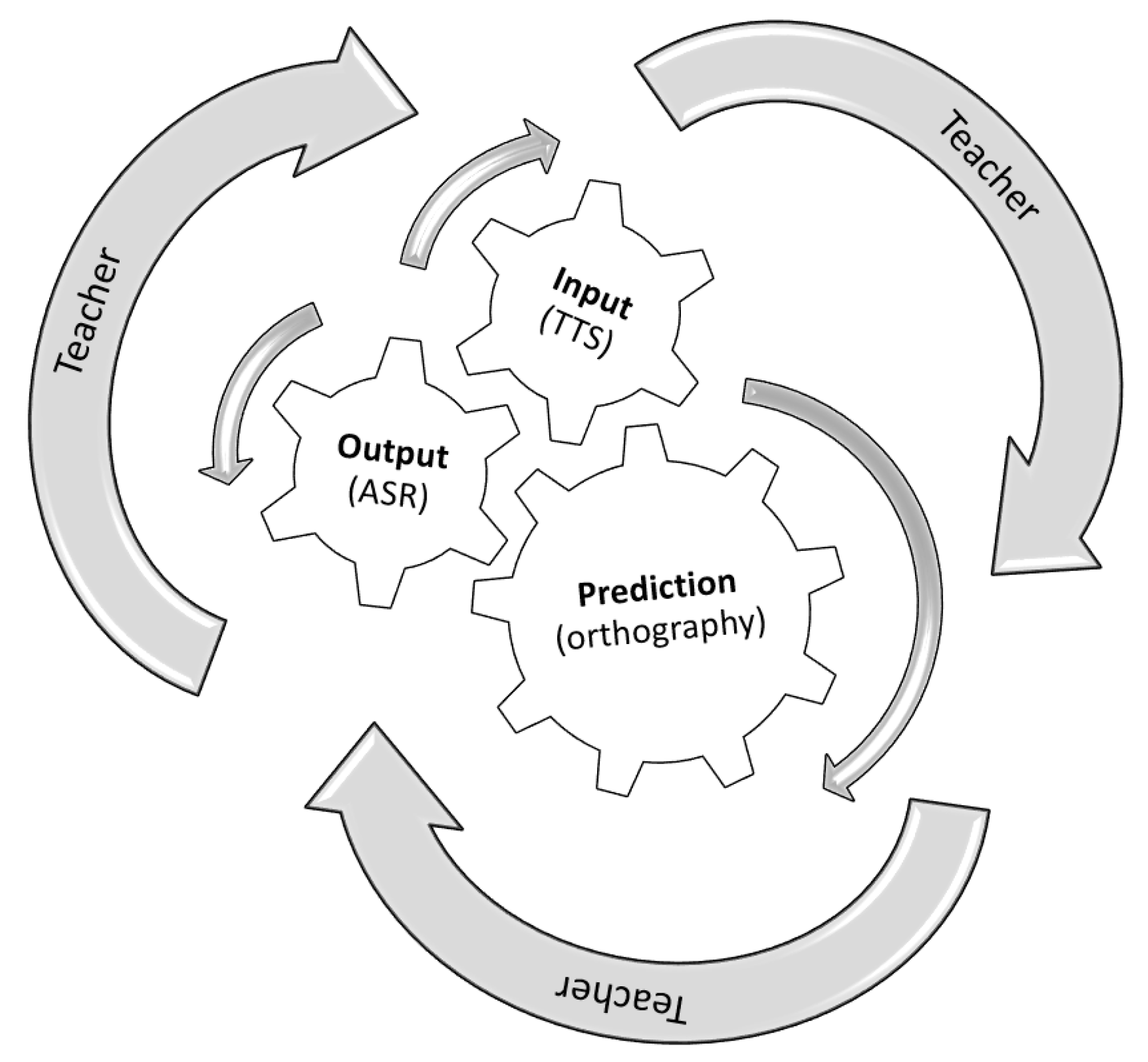
2.1. Input, Output, Prediction and Time Constraints
2.2. Text-to-Speech Synthesizers and Effects on L2 Learning
2.3. Automatic Speech Recognition and Effects on L2 Learning
2.4. Mobile Speech Technologies and L2 Learning: Automatic Speech Recognition and Text-to-Speech Synthesizers
- What are learners’ perceptions of the use of mobile TTS and ASR as pronunciation learning tools (based on a set of 10 pre-determined criteria, to be described later)?
- What are the perceived strengths and weaknesses of using TTS/ASR for learning pronunciation in a second language environment, particularly with respects to the tool’s ability to provide access to input, increase output opportunities, and develop learners’ prediction skills?
3. Method
3.1. Participants
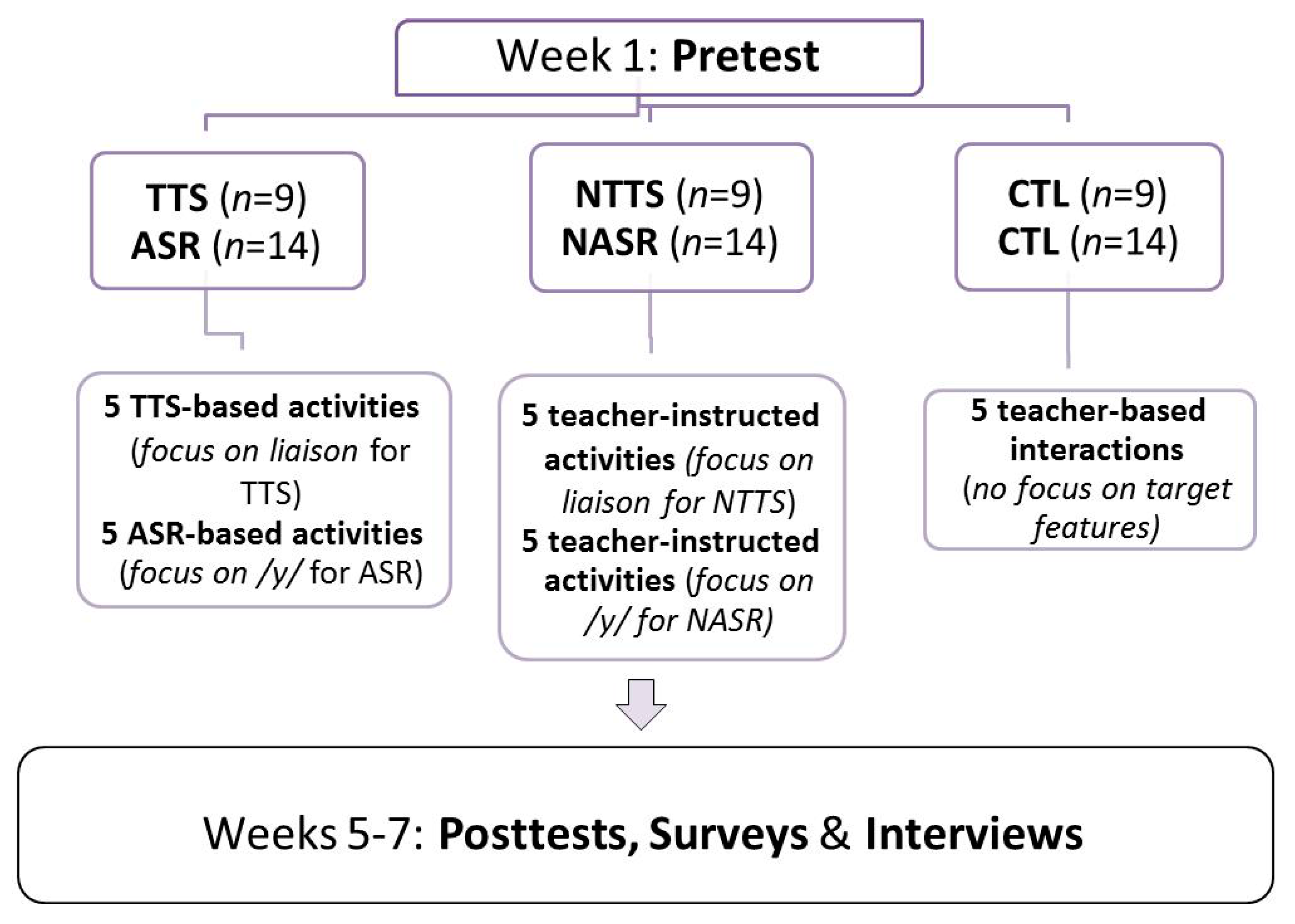
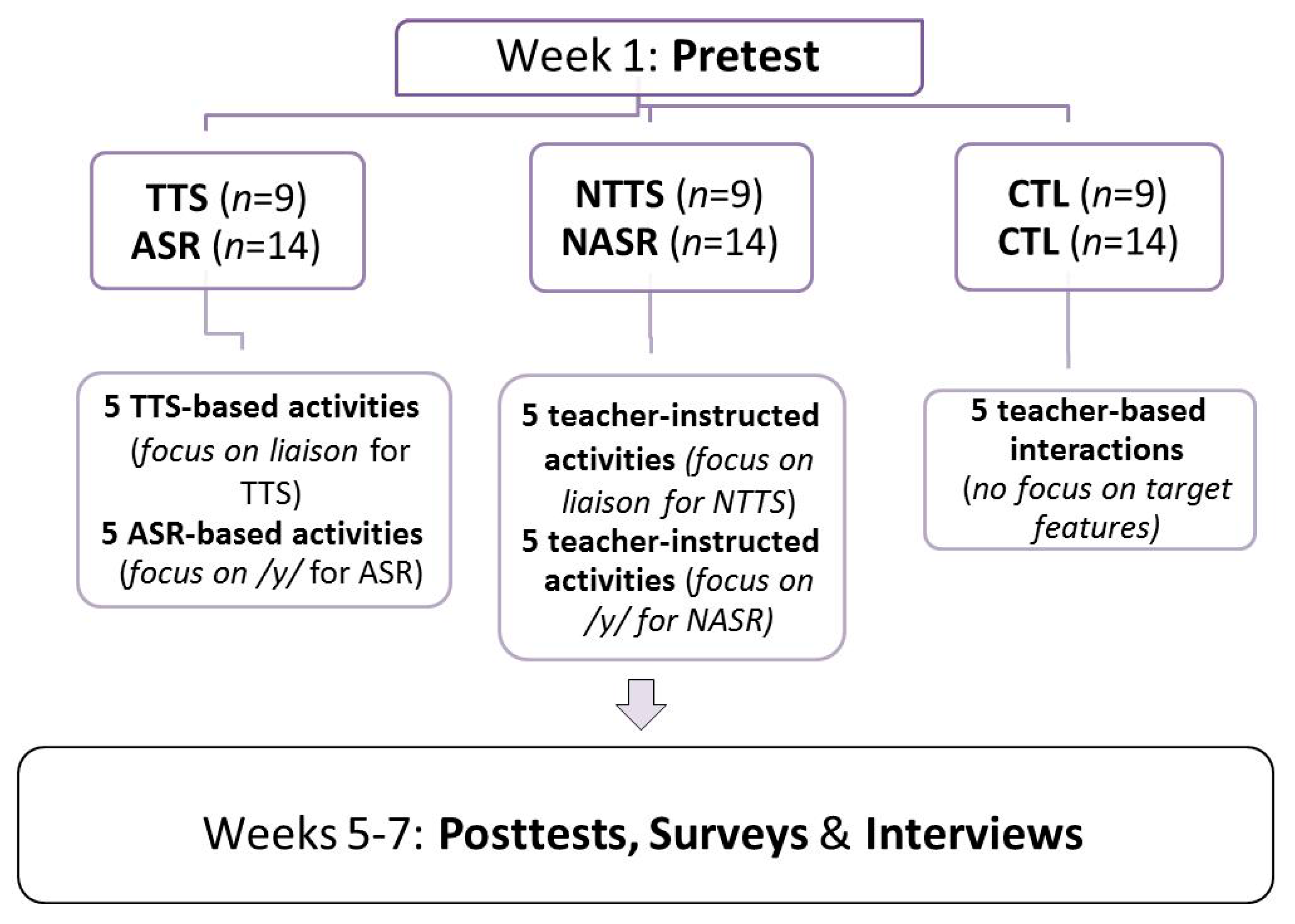
3.2. Design of the Study, Experimental Groups and Treatment
3.3. Materials
3.4. Procedure and Data Analysis
4. Results
4.1. Survey Analysis
4.2. Interview Analysis
5. Mobilizing Instruction: Discussion
5.1. Limitations and Future Research
5.2. Pedagogical Implications
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Celce-Murcia, M., D. Brinton, J. Goodwin, and B. Griner. 2010. Teaching Pronunciation: A Course Book and Reference Guide. Cambridge, UK: Cambridge University Press, ISBN 0521729769. [Google Scholar]
- Derwing, T.M., and M.J. Munro. 1997. Accent, intelligibility and comprehensibility: Evidence from four L1s. Stud. Sec. Lang. Acquis. 19: 1–16. [Google Scholar] [CrossRef]
- Levis, J. 2005. Changing contexts and shifting paradigms in pronunciation teaching. TESOL Quart. 39: 369–378. [Google Scholar] [CrossRef]
- Munro, M.J., and T.M. Derwing. 1999. Foreign accent, comprehensibility, and intelligibility in the speech of second language learners. Lang. Learn. 49: 285–310. [Google Scholar] [CrossRef]
- Collins, L., and C. Muñoz. 2016. The Foreign Language Classroom: Current Perspectives and Future Considerations. Mod. Lang. J. 100: 133–147. [Google Scholar] [CrossRef]
- Stockwell, G. 2008. Investigating learner preparedness for and usage patterns of mobile learning. ReCALL 20: 253–270. [Google Scholar] [CrossRef]
- Pearson Student Mobile Device Survey. 2015. National Report: College Students. Available online: http://www.pearsoned.com/wp-content/uploads/2015-Pearson-Student-Mobile-Device-Survey-College.pdf (accessed on 18 January 2017).
- UNESCO. 2014. Teaching and Learning: Achieving Quality for All. UNESCO. Available online: http://unesdoc.unesco.org/images/0022/002256/225660e.pdf (accessed on 12 January 2017).
- Duman, G., G. Orhon, and N. Gedik. 2015. Research trends in mobile assisted language learning from 2000 to 2012. ReCALL 27: 197–216. [Google Scholar] [CrossRef]
- Liakin, D., W. Cardoso, and N. Liakina. 2015. Learning L2 pronunciation with a mobile speech recognizer: French /y/. CALICO J. 32: 1–25. [Google Scholar]
- Liakin, D., W. Cardoso, and N. Liakina. 2017. The pedagogical use of mobile speech synthesis (TTS): Focus on French liaison. Comput. Assist. Lang. Learn. 30: 348–365. [Google Scholar] [CrossRef]
- Reinders, H., and M. Pegrum. 2016. Supporting Language Learning on the Move. An evaluative framework for mobile language learning resources. In Second Language Acquisition Research and Materials Development for Language. Edited by B. Tomlinson. London, UK: Taylor & Francis, pp. 116–141. ISBN 978-1441122933. [Google Scholar]
- Stockwell, G. 2012. Commentary: Working with constraints in mobile learning: A response to Ballance. Lang. Learn. Technol. 16: 24–31. [Google Scholar]
- Stockwell, G. 2013. Investigating an intelligent system for vocabulary learning through reading. JALTCALL J. 9: 259–274. Available online: http://journal.jaltcall.org/articles/9_3_Stockwell.pdf (accessed on 21 January 2017).
- Van Praag, B., and H.S. Sanchez. 2015. Mobile technology in second language classrooms: Insights into its uses, pedagogical implications, and teacher beliefs. ReCALL 27: 288–303. [Google Scholar] [CrossRef]
- Dickerson, W. 2013. Prediction in teaching pronunciation. In The Encyclopedia of Applied Linguistics. Edited by C. Chapelle. Hoboken, NJ, USA: Blackwell, ISBN 978-1405194730. [Google Scholar]
- Dickerson, W. 2015. Using orthography to teach pronunciation. In The Handbook of English Pronunciation. Edited by M. Reed and J. Levis. Chichester, UK: Wiley Blackwell, pp. 488–503. ISBN 978-1-118-31447-0. [Google Scholar]
- Ellis, N., and L. Collins. 2009. Input and second language acquisition: The roles of frequency, form, and function introduction to the special issue. Mod. Lang. J. 93: 329–335. [Google Scholar] [CrossRef]
- Fæerch, C., and G. Kasper. 1986. The role of comprehension in second-language learning. Appl. Linguist. 7: 257–274. [Google Scholar] [CrossRef]
- Chomsky, N., and H. Lasnik. 1993. The theory of principles and parameters. In Syntax: An International Handbook of Contemporary Research. Edited by J. von Stechow, A. Jacobs, W. Sternefeld and T. Vennemann. Berlin, Germany: de Gruyter, ISBN 978-3110142631. [Google Scholar]
- Flege, J.E. 1995. Second language speech learning: Theory, findings, and problems. In Speech Perception and Linguistic Experience: Theoretical and Methodological Issues in Cross-Language Speech Research. Edited by W. Strange. Timonium, MD, USA: York Press, pp. 233–277. ISBN 978-0912752365. [Google Scholar]
- Yanguas, I. 2012. Task-based oral computer-mediated communication and L2 vocabulary acquisition. CALICO J. 29: 507–531. [Google Scholar] [CrossRef]
- Swain, M. 2000. The output hypothesis and beyond: Mediating acquisition through collaborative dialogue. In Sociocultural Theory and Second Language Learning. Edited by J. Lantof. Oxford, UK: Oxford University Press, pp. 97–114. ISBN 978-0194421607. [Google Scholar]
- Nation, P., and J. Newton. 2009. Teaching ESL/EFL Listening and Speaking. New York, NY, USA: Routledge, ISBN 978-0415989701. [Google Scholar]
- Swain, M. 1998. Focus on form through conscious reflection. In Focus on Form in Classroom Second Language Acquisition. Edited by C. Doughty and J. Williams. Cambridge, UK: Cambridge University Press, ISBN 978-0521625517. [Google Scholar]
- Follick, M. 1965. The Case for Spelling Reform: With a Foreword by Sir William Mansfield Cooper. Manchester, UK: Manchester University Press, ISBN 978-0273419792. [Google Scholar]
- Tranel, B. 1987. The Sounds of French: An Introduction. Cambridge, UK: Cambridge University Press, ISBN 978-0521304436. [Google Scholar]
- Cardoso, W., L. Collins, and J. White. Phonological Input Enhancement via Text-to-Speech Synthesizers: The L2 Acquisition of English Simple Past Allomorphy. In Proceedings of the American Association of Applied Linguistics Conference, Boston, MA, USA, 24–27 March 2012. [Google Scholar]
- Cardoso, W., G. Smith, and C. Garcia Fuentes. 2015. Evaluating text-to-speech synthesizers. In Critical CALL—Proceedings of the 2015 EUROCALL Conference, Padova, Italy. Edited by F. Helm, L. Bradley, M. Guarda and S. Thouësny. Dublin, Ireland: Research-publishing.net, pp. 108–113. [Google Scholar]
- Soler-Urzua, F. 2011. The Acquisition of English /ɪ/ by Spanish Speakers via Text-to-Speech Synthesizers: A Quasi-Experimental Study. Master’s Thesis, Concordia University, Montreal, QC, Canada. [Google Scholar]
- Kirstein, M. 2006. Universalizing Universal Design: Applying Text-to-Speech Technology to English Language Learners’ Process Writing. Ph.D. Dissertation, University of Massachusetts, Boston, MA, USA. [Google Scholar]
- Guclu, B., and S. Yigit. 2015. Using Text to Speech Software in Teaching Turkish for Foreigners: The Effects of Text to Speech Software on Reading and Comprehension Abilities of African Students. J. Human. 4: 31–33. [Google Scholar]
- Proctor, C.P., B. Dalton, and D.L. Grisham. 2007. Scaffolding English language learners and struggling readers in a universal literacy environment with embedded strategy instruction and vocabulary support. J. Lit. Res. 39: 71–93. [Google Scholar] [CrossRef]
- Couper, M., P. Berglund, N. Kirgis, and S. Buageila. 2016. Using Text-to-speech (TTS) for Audio Computer-assisted Self-interviewing (ACASI). Field Methods 28: 28–95. [Google Scholar] [CrossRef]
- Cucchiarini, C., A. Neri, and H. Strik. 2009. Oral Proficiency Training in Dutch L2: The Contribution of ASR-based Corrective Feedback. Speech Commun. 51: 853–863. [Google Scholar] [CrossRef]
- Hardison, D. 2004. Generalization of computer-assisted prosody training: Quantitative and qualitative findings. Lang. Learn. Technol. 8: 34–52. [Google Scholar]
- Hirata, Y. 2004. Computer assisted pronunciation training for native English speakers learning Japanese pitch and durational contrasts. Comput. Assist. Lang. Learn. 17: 357–376. [Google Scholar] [CrossRef]
- McCrocklin, S. 2016. Pronunciation Learner Autonomy: The Potential of Automatic Speech Recognition. System 57: 25–42. [Google Scholar] [CrossRef]
- Neri, A., O. Mich, M. Gerosa, and D. Giuliani. 2008. The effectiveness of computer assisted pronunciation training for foreign language learning by children. Comput. Assist. Lang. Learn. 21: 393–408. [Google Scholar] [CrossRef]
- Strik, H., K. Truong, F. Wet, and C. Cucchiarini. 2009. Comparing different approaches for automatic pronunciation error detection. Speech Commun. 51: 845–852. [Google Scholar] [CrossRef]
- Strik, H., J. Colpaert, J. van Doremalen, and C. Cucchiarini. 2012. The DISCO ASR-based CALL system: Practicing L2 oral skills and beyond. In Proceedings of the Conference on International Language Resources and Evaluation (LREC 2012). Istanbul, Turkey: European Language Resources Association (ELRA), pp. 2702–2707. Available online: http://www.lrec-conf.org/proceedings/lrec2012/pdf/787_Paper.pdf (accessed on 29 January 2017).
- Stockwell, G. 2010. Using mobile phones for vocabulary activities: Examining the effect of the platform. Lang. Learn. Technol. 14: 95–110. [Google Scholar]
- Joseph, S., and M. Uther. 2009. Mobile devices for language learning: Multimedia approaches. Res. Pract. Technol. Enhanc. Learn. 4: 7–32. [Google Scholar] [CrossRef]
- Saldaña, J. 2009. The Coding Manual for Qualitative Researchers. Los Angeles, CA, USA: Sage, ISBN 978-1446247372. [Google Scholar]
- L’Écuyer, R. 1990. L’analyse de contenu: Notion et étapes. In Les Méthodes de la Recherche Qualitative. Edited by J.-P. Deslauriers. Sainte-Foy, QC, Canada: Presses de l’Université du Québec, pp. 54–63. ISBN 978-2760504295. [Google Scholar]
- Chapelle, C. 2001. Computer Applications in Second Language Acquisition: Foundations for Teaching, Testing, and Research. Cambridge, UK: Cambridge University Press, ISBN 9780521626460. [Google Scholar]
- Chapelle, C. Using Mixed-Methods Research in Technology-Based Innovation for Language Learning. Proceedings of Innovative Practices in Computer Assisted Language Learning Conference, University of Ottawa, Ottawa, ON, Canada, 26–27 April 2012. [Google Scholar]
- Cardoso, W. 2011. Learning a foreign language with a learner response system: The students’ perspective. Comput. Assist. Lang. Learn. 24: 393–417. [Google Scholar] [CrossRef]
- Pillay, H. 2002. Understanding learner-centredness: Does it consider the diverse needs of individuals? Stud. Contin. Educ. 24: 93–102. [Google Scholar] [CrossRef]
- Weimer, M. 2013. Learner-Centered Teaching, 2nd ed. San Francisco, CA, USA: Jossey Bass, ISBN 978-1118119280. [Google Scholar]
- Dupin-Bryant, P.A. 2004. Teaching Styles of Interactive Television Instructors: A Descriptive Study. Am. J. Distance Educ. 18: 39–50. [Google Scholar] [CrossRef]
- Doughty, C., and M. Long. 2003. Optimal psycholinguistic environments for distance foreign language learning. Forum Int. Dev. Stud. 23: 35–75. [Google Scholar]
- Swain, M. 2005. The output hypothesis: Theory and research. In Handbook of Research in Second Language Teaching and Learning. Edited by E. Hinkel. Mahwa, NJ, USA: Lawrence Erlbaum, pp. 471–483. ISBN 978-0805841817. [Google Scholar]
- Ducate, L., and L. Lomicka. 2009. Podcasting: An Effective Tool for Honing Language Students’ Pronunciation? Lang. Learn. Technol. 13: 66–86. [Google Scholar]
- Arnold, N. 2007. Reducing foreign language communication apprehension with computer-mediated communication: A preliminary study. System 35: 469–486. [Google Scholar] [CrossRef]
- Baralt, M., and L. Gurzynski-Weiss. 2011. Comparing learners’ state anxiety during task-based interaction in computer-mediated and face-to-face communication. Lang. Teach. Res. 15: 201–229. [Google Scholar] [CrossRef]
- Best, C.T., and M. Tyler. 2007. Nonnative and second-language speech perception: Commonalities and complementarities. In Second-Language Speech Learning: The Role of Language Experience in Speech Perception and Production. Edited by O.S. Bohn and M. Munro. Amsterdam, The Netherlands: John Benjamins, pp. 13–34. ISBN 978-9027219732. [Google Scholar]
- Nikolova, O. 2002. Effects of Students’ Participation in Authoring of Multimedia Materials on Student Acquisition of Vocabulary. Lang. Learn. Technol. 6: 100–122. [Google Scholar]
- Warschauer, M. 1996. Motivational aspects of using computers for writing and communication. In Telecollaboration in Foreign Language Learning: Proceedings of the Hawai’i Symposium. Edited by M. Warschauer. Honolulu, HI, USA: University of Hawai’i, Second Language Teaching and Curriculum Center, ISBN 978-0824818678. [Google Scholar]
- Clark, R.E. 1983. Reconsidering research on learning from media. Rev. Educ. Res. 53: 445–459. [Google Scholar] [CrossRef]
- Brandl, K. 2002. Integrating internet-based reading materials into the foreign language curriculum: From teacher- to student-centered approaches. Lang. Learn. Technol. 6: 87–107. [Google Scholar]
- Engin, M. 2014. Extending the flipped classroom model: Developing second language writing skills through student-created digital videos. J. Scholarsh. Teach. Learn. 14: 12–26. [Google Scholar] [CrossRef]
- McCombs, B.L. 2000. Assessing the role of educational technology in the teaching and learning process: A learner-centered perspective. In Proceedings of the Secretary’s Conference on Educational Technology: Measuring the Impacts and Shaping the Future. (ERIC Document Reproduction Service No. ED452830). Washington, DC, USA: Department of Education, Available online: http://files.eric.ed.gov/fulltext/ED452830.pdf (accessed on 10 January 2017).

{kind=link}
{kind=link}
{kind=link}
| Questions | Text to Speech Synthesizer (TTS) | Automatic Speech Recognition (ASR) | ||
|---|---|---|---|---|
| Mean | SD | Mean | SD | |
| 1. [App] increased my motivation to learn about French pronunciation. | 4.1 | 0.83 | 3.86 | 1.10 |
| 2. [App] allowed me to become aware of some of my pronunciation problems. | 4.1 | 0.35 | 3.86 | 0.77 |
| 3. [App] allowed me to evaluate my own pronunciation (for example, to decide whether my pronunciation was correct or incorrect). | 3.6 | 0.74 | 3.93 | 1.07 |
| 4. I felt more comfortable practicing pronunciation with [App] than I would in front of other students. | 3.8 | 1.28 | 3.64 | 1.28 |
| 5. I felt more comfortable practicing pronunciation with [App] than I would in front of the teacher. | 3.3 | 1.16 | 3.36 | 1.28 |
| 6. I learned more about French pronunciation using [App] than if I had not used it. | 3.8 | 0.89 | 3.64 | 0.93 |
| 7. In general, [App] helped me improve my pronunciation. | 3.6 | 0.74 | 4.14 | 0.77 |
| 8. I would like to use [App] in other language courses to improve my pronunciation. | 4.5 | 0.53 | 4.21 | 0.80 |
| 9. [App] is a great tool to learn pronunciation. | 4.3 | 0.71 | 3.86 | 0.95 |
| 10. I enjoyed using [App] in this study. | 4.6 | 0.52 | 4.21 | 0.58 |
| 1. Increased Involvement Outside of Class (Learning and Practicing Pronunciation Anytime, Anywhere) | |
| TTS (n = 5) | ASR (n = 3) |
| a. “… as long as I had a Wi-Fi connection, I can just take my tablet and listen to it anywhere.” b. “You can do it whenever you want, so … I used it when I was free.” c. “Mostly at home because I only had time on the weekend.” d. “It’s on the phone so you can carry it around anywhere.” e. “Instead of trying to track someone down to help you, uh, it could help a lot.” | a. “It’s good to have homework that you can take home and practice pronouncing on your own, instead of just in the lab. So, yeah. Especially when there’s no one else, different exercises.” b. “I don’t have much time to practice or much people to practice with and I really liked having these weekly assignments and to be able to practice at home.” c. “You can use it anywhere. Anytime like if you have a doubt you can always just take it out and start using it.” |
| 2. Usefulness for Any L2 Classroom | |
| TTS (n = 6) | ASR (n = 7) |
| a. “Yeah, I think it would be really useful. And if the sentences on the app match what we will learn in class, that would be so useful, especially for learning new vocabulary, because, it’s much easier to learn vocabulary when you can hear how it sounds and you can make the connection that way.” b. “Yes, I think it’s a good tool … I think, yeah, it’s actually better than the French lab, I think, probably.” | a. “They should definitely implement that in the grammar classes because it’s like you need to know how to pronounce things, like, it’s critical.” b. “As an additional tool, for sure! We don’t have much time to speak with other people or even with the teacher because we have a lot of students in the class. It’s difficult to practice the pronunciation. Actually, I think pronunciation is important. I don’t know why. Because the emphasis … during like general French class, not only the pronunciation class.” |
| 3. Increased Confidence (to Speak French) | |
| TTS (n = 0) | ASR (n = 2) |
| N/A | a. “I get nervous when it’s in person. So, it’s definitely easier, and then I can get more comfortable, and I don’t mess up so much, in person … you just get more confident.“ b. “It’s good because… maybe if someone is shy to speak, or even with the teacher ’cause sometimes we feel a little bit down when trying to speak and to pronounce … and with this application we can kind of try to do any sound, open your mouth and exaggerate and everything. It’s just you and the computer. You can do whatever you want. No one is going to see. No judgments.” |
| 4. Easy to Use/Usability and Portability | |
| TTS (n = 7) | ASR (n = 2) |
| a. “just how easy it is, you know, if you have a tablet, it’s right there, a couple of clicks and you can start listening.” b. “… the thing that I kind of liked about it …[is] that it’s portable” | a. “It’s really easy. You just have to press a button, and then it records. I liked it a lot, yeah.” b. “I think it’s very easy to use and it’s very portable.” |
| 1. Lack of Accuracy | |
| TTS (n = 5) | ASR (n = 6) |
| Pronunciation Accuracy (Different from Natural Voice): | Accuracy of Voice Recognition: |
| a. “The only thing is sometimes it makes weird sounds, like, automatic. You know, like, the computer voice thing? So, sometimes it’s harder to understand…” b. “…but in some cases with pronunciation, for example, it sounded, like, really, it was coming from a computer … a few of the words were really just not pronounced in a way that I could even hear it.” c. “Yes, I still feel like it’s pronounced by a machine ... even in Chinese … a machine talking in Chinese … I feel like it’s a bit weird … I’m not sure it’s a “natural” reader.” d. “It’s like with the GPS … ” e. “The only thing that was really a weakness for me, it’s probably just, like, the fact that it is, like, an electronic voice. It’s not, like, natural sound.” | a. “Well, I don’t know if it’s my pronunciation that is bad, or whether it was the technology of the instrument, but I didn’t think … some of the words that popped up to me weren’t even in the ballpark of what I was saying. Some of them were similar; some of them were completely out.” b. “I feel like it didn’t pick up what I was saying exactly. Some bizarre words came up that were just completely unrelated to what I was trying to tell my phone.” c. “Sentences. Maybe a negative point … I see when you try to speak with sentences they don’t recognize it very well. One word it’s okay but the same word in a sentence … I couldn’t get it right.” e. “it’s good. But it was all frustrating ’cause sometimes I’ve been so off.” |
| 2. Lack of Explicit Corrective Feedback | |
| TTS (n = 3) | ASR (n = 5) |
| a. “Then again, watching TV and that in French will help too. It’s on more or less the same level. It’s, like, you learn how to pronounce it, but at the same time you don’t get anyone correcting you.” b. “I guess it would be difficult to do, but … having the person record and then balancing it between the two sound files and seeing, how the pronunciation is, … see how it compares.” c. “Just thinking very hypothetically, maybe if there was a possibility to record your own pronunciation and then kind of hear how you sound after listening to your pronunciation.” | a. “It would be nice if it gave us examples of the words. For example, if you say something wrong, it says ‘Do you mean that?’ ‘This is what you pronounced …” b. “But sometimes I didn’t know what to change, so I just said the same thing over and over.” c. “I would have felt more motivated if I’d felt that I was learning something or improving… I didn’t even know what I was doing wrong, because it didn’t give any feedback.” d. “Maybe just … even a link or something … even like the IPA. I don’t know but when I was getting to the thirteenth, the fourteenth [try] and I’m just like ‘I don’t know how you want me to say it!’” e. “The one thing though would be to get the personal feedback, like after, and then like go through how to say each word. You say ‘No...’, what went wrong …” |
| 3. Time Consuming | |
| TTS (n = 0) | ASR (n = 3) |
| N/A | a. “You have to press it, and then record it, and sometimes it [takes a] very long time.” b. “It’s very time-consuming to use. You say and then it pops up, and then you’ve got to delete, then get back. And it’s a lot of manipulation of the device for very little reward.” c. “What I’d like is not to have to keep pushing buttons all the time. Every time you pronounce something, you have to press back. It would be nice if it recorded things automatically and continuously.” |
| 4. Lack of Interactivity | |
| TTS (n = 2) | ASR (n = 0) |
| a. “But, uh, chatting with people probably helped a bit more.” b. “Yeah, it’s a good app to let me practice, for pronunciation … listening actually … but for me the best part of learning French is communicating with people. (The app) is more listening than speaking.” | N/A |
| Input (TTS) | |
| Increased exposure to French (n = 7) | |
| a. “it’s very useful for me particularly, because I find … oral comprehension to be the most difficult part of learning French … In a class situation we don’t actually get a lot of listening practice … so just to hear sentences spoken really clearly, … and also using vocabulary that we’re actually learning in class, you know, was very useful for me.” b. “I think it was really useful because some words that I don’t know how to pronounce, like, I could read them, and also hear how to pronounce them.” c. “It was very helpful for me to hear. I found the pronunciation very good, because sometimes I would see a word and I wasn’t sure, but hearing them over and over I found was very helpful, and I feel like over the five weeks my pronunciation improved a little bit.” d. “If you have a text and you want to hear how someone else pronounces a word that you’ve never heard before … that’s actually one thing that I liked about it because, like, there’s sometimes words that I don‘t even know, like, know how to pronounce it… but if I hear at least someone else saying it, I can repeat it and I can understand, you know?” | |
| Input variability (n = 2) | |
| a. “… well, I think the fact that you can pick the speed and the speaker is very helpful. So if one speed is too much for you, you can bring it down.” b. “… have not just a female voice, but another voice [so] that maybe some sounds would be easier to hear … ‘cause [in] some pitches … [it] is harder to hear some sounds than others.” | |
| Output (ASR) | |
| Increased practice of French, pronunciation improvement (n = 6) | |
| a. “My pronunciation is getting better now but before it wasn’t very good. It’s a way of practicing ’cause it’s going to force you to practice.” b. “I like when the first time when I speak it gets [it] right. I’m like ‘Yeah, I can do it.’” c. “[app] helped me improve the pronunciation of the French sound in ‘u’.” d. “In general, [app] helped me improve my pronunciation.” e. “I learned more about French pronunciation using [app] than if I had not used it.” f. “[app] gave me an idea of how my pronunciation improved since I started taking this class.” | |
| Prediction (TTS and ASR, via Orthography) | |
| Helped me learn about pronunciation via spelling | |
| TTS (n = 5) | ASR (n = 4) |
| a. “… you can follow along. Also, in the paper there, I can just see how my pronunciation is, how it is like … if it’s strong enough towards, the actual application, or whatever … whatever they’re saying, I can repeat it and I can distinguish whether I sound [right] or not.” b. “… and then I realized, ok, I’m starting to get the gist of it and then, so, for the third, fourth, and fifth I started listening to it and then writing how it sounded after the first go, and then afterwards, like, re-reading it and listening to it a few times, so …, in that sense, yeah, it helps with catching the words and separating them.” c. “… it will help with hearing how stuff is pronounced.” d. “I can note … correct pronunciation … like if the teacher is around me. And … I can practice a little bit [before] a lesson.” e. “Well, I find it, like, really, um, interesting that you can read and follow the words.” | a. “[app] allowed me to become aware of some of my pronunciation problems.” b. “[app] allowed me to evaluate my own pronunciation (correct/incorrect).” c. “It gives you the answers, you can see … Because sometimes when I said some words, one of them was right, and then one of them was wrong, and then when one was wrong I was pronouncing it wrong …” d. “I like when the first time when I speak it gets [it] right.” |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liakin, D.; Cardoso, W.; Liakina, N. Mobilizing Instruction in a Second-Language Context: Learners’ Perceptions of Two Speech Technologies. Languages 2017, 2, 11. https://doi.org/10.3390/languages2030011
Liakin D, Cardoso W, Liakina N. Mobilizing Instruction in a Second-Language Context: Learners’ Perceptions of Two Speech Technologies. Languages. 2017; 2(3):11. https://doi.org/10.3390/languages2030011
Chicago/Turabian StyleLiakin, Denis, Walcir Cardoso, and Natallia Liakina. 2017. "Mobilizing Instruction in a Second-Language Context: Learners’ Perceptions of Two Speech Technologies" Languages 2, no. 3: 11. https://doi.org/10.3390/languages2030011
APA StyleLiakin, D., Cardoso, W., & Liakina, N. (2017). Mobilizing Instruction in a Second-Language Context: Learners’ Perceptions of Two Speech Technologies. Languages, 2(3), 11. https://doi.org/10.3390/languages2030011