

Distributional Learning and Language Activation: Evidence from L3 Spanish Perception Among L1 Korean–L2 English Speakers


Abstract
1. Introduction
2. Review of the Literature
3. Materials and Methods
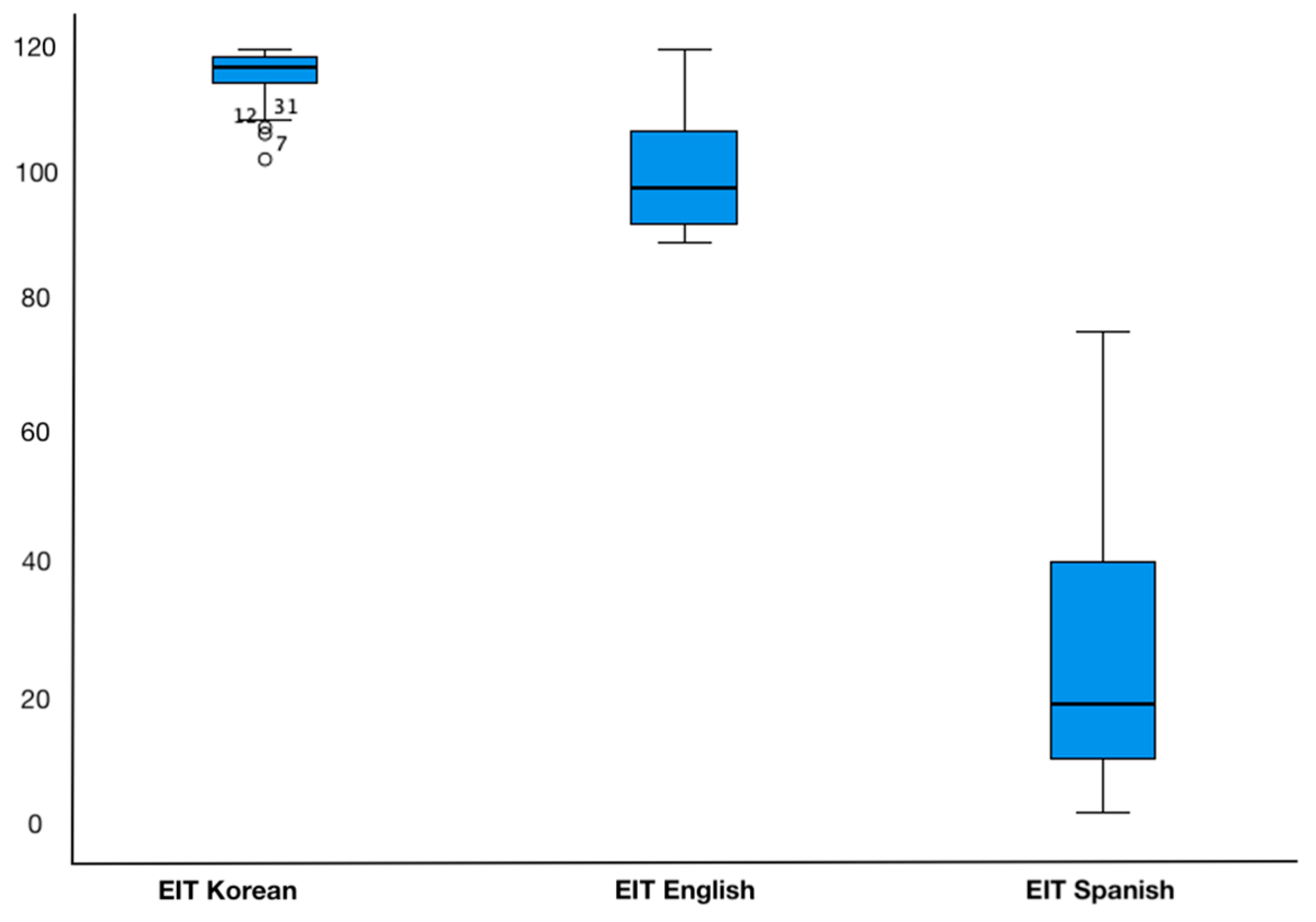
3.1. Participants
3.2. Tasks
3.2.1. Discrimination (Oddity) Task
- L3 /p/-L2 /p/: Matching at the phonological level but differing phonetically, with positive VOT as the key cue.
- L3 /p/-L2 /b/: Different at both the phonological and phonetic levels, with no reliable cue since neither VOT nor F0 shows sufficient differentiation.
- L3 /p/-L1 fortis /p*/: Different at both levels, with F0 serving as the key phonetic cue.
- L3 /b/-L2 /b/: Matching phonologically but differing phonetically, where negative VOT is the key cue.
- L3 /b/-L1 lenis /p/: Different at both levels, with both positive and negative VOT serving as the key cues.
3.2.2. Identification Task with Rating
3.2.3. Elicited Imitation Task
3.3. Procedure
3.4. Data Analysis
3.4.1. Discrimination Task
a. If H > FA, then A′ = 0.5 + [(H-FA)(1+H-FA)]/[4H(1-FA)]b. If H = FA, then A′ = 0.5c. If H < FA, then A′ = 0.5 + [(FA-H)(1+FA-H)]/[4FA(1-H)]
3.4.2. Identification Task
4. Results
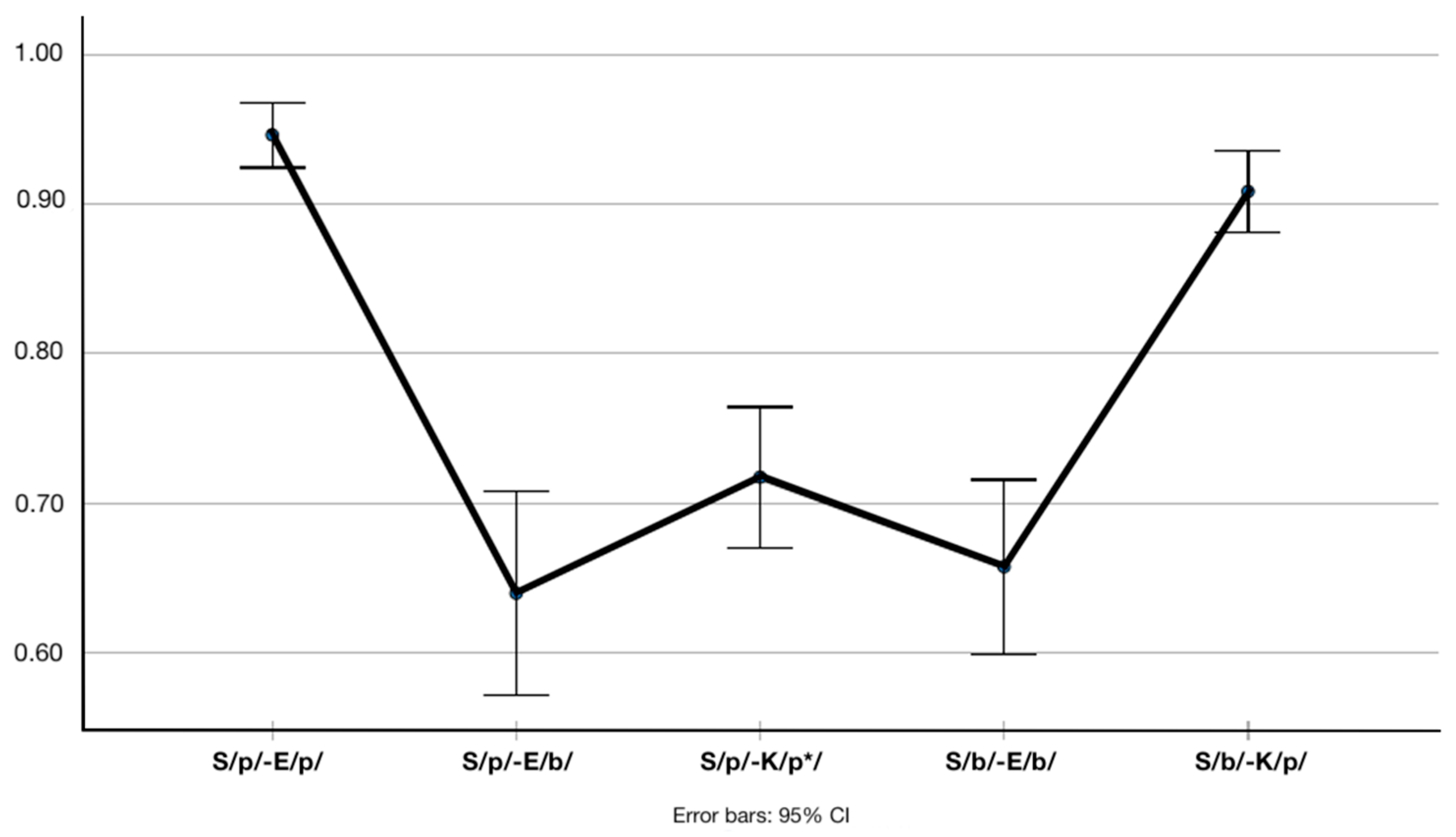
4.1. Discrimination Task
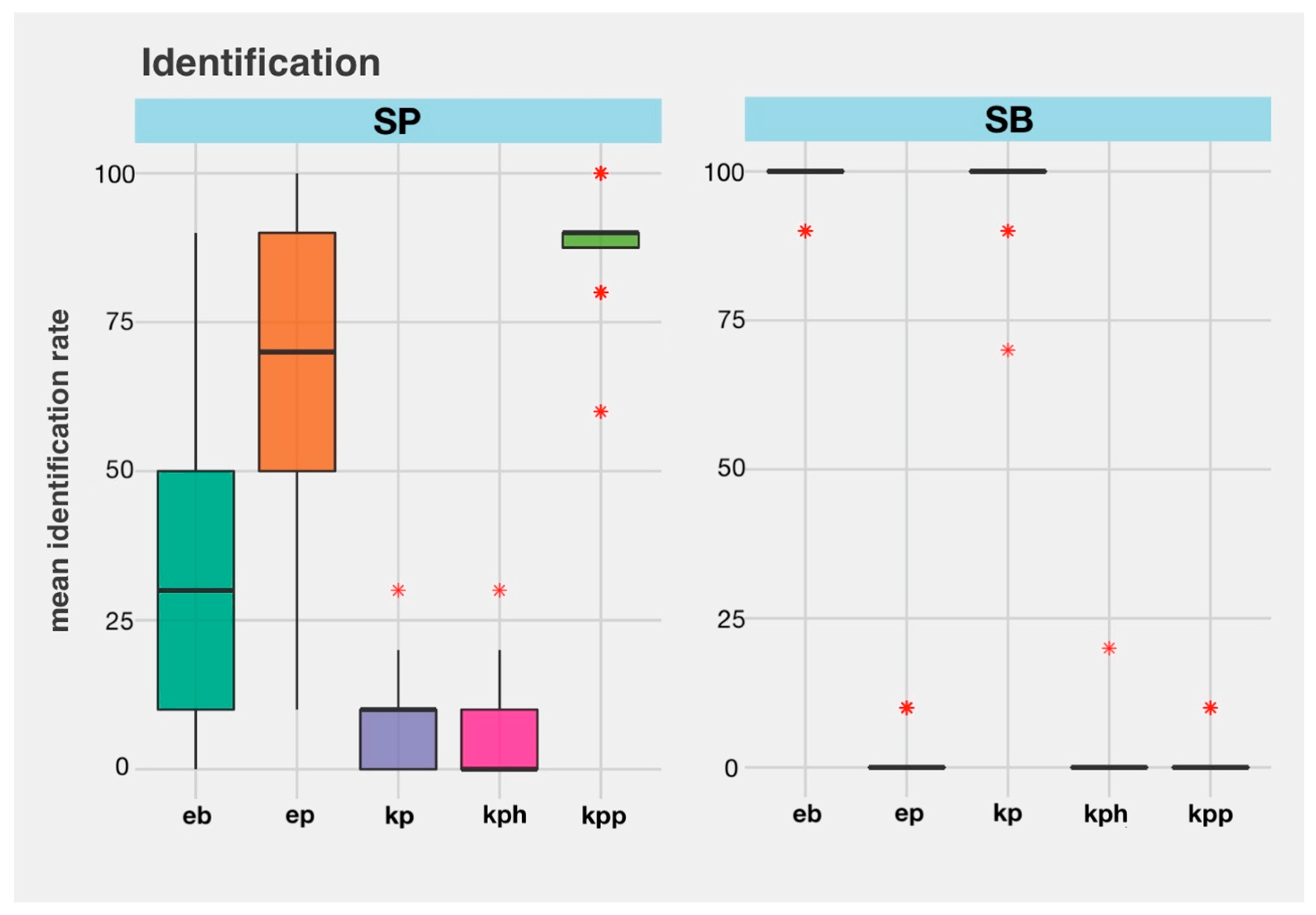
4.2. Identification Task with Rating
5. Discussion
6. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Cross-Language Oddity Task Stimuli
| Different | Same | ||||
| S/ba/-E/ba/ | M | S/ba/-E/ba/-E/ba/ | E/ba/-S/ba/-E/ba/ | E/ba/-E/ba/-S/ba/ | S/ba/-S/ba/-S/ba/ S/ba/-S/ba/-S/ba/ E/ba/-E/ba/-E/ba/ |
| F | E/ba/-S/ba/-S/ba/ | S/ba/-E/ba/-S/ba/ | S/ba/-S/ba/-E/ba/ | S/ba/-S/ba/-S/ba/ E/ba/-E/ba/-E/ba/ E/ba/-E/ba/-E/ba/ | |
| S/ba/-K/pa/ | M | K/pa/-S/ba/-S/ba/ | S/ba/-K/pa/-S/ba/ | S/ba/-S/ba/-K/pa/ | S/ba/-S/ba/-S/ba/ K/pa/-K/pa/-K/pa/ K/pa/-K/pa/-K/pa/ |
| F | S/ba/-K/pa/-K/pa/ | K/pa/-S/ba/-K/pa/ | K/pa/-K/pa/-S/ba/ | S/ba/-S/ba/-S/ba/ S/ba/-S/ba/-S/ba/ K/pa/-K/pa/-k/pa/ | |
| S/pa/-E/pa/ | M | S/pa/-E/pa/-E/pa/ | E/pa/-S/pa/-E/pa/ | E/pa/-E/pa/-S/pa/ | S/pa/-S/pa/-S/pa/ S/pa/-S/pa/-S/pa/ E/pa/-E/pa/-E/pa/ |
| F | E/pa/-S/pa/-S/pa/ | S/pa/-E/pa/-S/pa/ | S/pa/-S/pa/-E/pa/ | S/pa/-S/pa/-S/pa/ E/pa/-E/pa/-E/pa/ E/pa/-E/pa/-E/pa/ | |
| S/pa/-E/ba/ | M | E/ba/-S/pa/-S/pa/ | S/pa/-E/ba/-S/pa/ | S/pa/-S/pa/-E/ba/ | S/pa/-S/pa/-S/pa/ E/ba/-E/ba/-E/ba/ E/ba/-E/ba/-E/ba/ |
| F | S/pa/-E/ba/-E/ba/ | E/ba/-S/pa/-E/ba/ | E/ba/-E/ba/-S/pa/ | S/pa/-S/pa/-S/pa/ S/pa/-S/pa/-S/pa/ E/ba/-E/ba/-E/ba/ | |
| S/pa/-K/p*a/ | M | S/pa/-K/p*a/-K/p*a/ | K/p*a/-S/pa/-K/p*a/ | K/p*a/-K/p*a/-S/pa/ | S/pa/-S/pa/-S/pa/ S/pa/-S/pa/-S/pa/ K/p*a/-K/p*a/-K/p*a/ |
| F | K/p*a/-S/pa/-S/pa/ | S/pa/-K/p*a/-S/pa/ | S/pa/-S/pa/-K/p*a/ | S/pa/-S/pa/-S/pa/ K/p*a/-K/p*a/-K/p*a/ K/p*a/-K/p*a/-K/p*a/ | |
| Based on the counterbalance of stimuli in (Nagle, 2021); M-male speaker, F-female speaker. | |||||
Appendix B. An Example of the Oddity Task
Appendix C. English Version of the Identification Task
Appendix D. Korean Version of the Identification Task

Appendix E. Pseudo-Word Stimuli Used in the Different Versions of the Identification Task
| Spanish Consonant | /p/ | /b/ |
| Stimuli (word-initial position, pseudo-words) | pafe | bafe |
| pame | bame | |
| pasi | basi | |
| pado | bado | |
| pafo | bafo | |
| pano | bano | |
| pamo | bamo | |
| pamu | bamu | |
| panu | banu | |
| paru | baru |
Appendix F. Study Procedure
| Informed Consent Form |
| ↓ |
| Elicited Imitation Tasks (Kor, Eng, Sp) |
| ↓ |
| Discrimination Task |
| ↓ |
| Identification Task + Goodness-of-Fit Task |
| ↓ |
| Informal Interview and Language Background Questionnaire |
Appendix G. Language Background Questionnaire
- Age (in years): ____________________
- Sex (choose one): Male/Female/Other
- Please give your current or most recent educational level, even if you have not yet finished the degree:
- Freshman
- Sophomore
- Junior
- Senior
- Graduate School—Masters
- Graduate School—Ph.D./M.D./J.D
- None of the above. Please explain: __________________________________________________________
- Indicate your native language(s) and any other languages you have studied or learned, the age at which you started using each language in terms of listening, speaking, reading, and writing, and the total number of years you have spent using each language.
- 5a.
- Country of residence: _______________
- 5b.
- Country of origin: _______________
- 5c.
- If 5a and 5b are different, then at what age did you first move to the country where you currently live? _______________
- 6.
- If you have lived or travelled in countries other than your country of residence or country of origin for one month, then indicate the name of the country, your length of stay, the language you used, and the frequency of your use of the language for each country.
| Never | Rarely | Sometimes | Regularly | Often | Usually | Always | |||
| Country | Length of Stay [mth] | Language(s) | Frequency of Use of Language(s) | ||||||
| You may have been to the country on multiple occasions, each for a different length of time. Add all the trips together. | |||||||||
- 7.
- Indicate the language used by your teachers for instruction at each educational level. (e.g., English, Spanish, Korean, etc.)
| Language | |
| Elementary school | |
| Middle school | |
| High school | |
| College/university |
- 8.
- Indicate the language used by your Spanish teachers for instruction at each educational level if applicable. If the teachers used Spanish during class, then indicate what dialects of Spanish they used.
| Language | Spanish dialects (e.g., Argentine, Puerto Rican, Andalusian, etc.) | |
| Elementary school | ||
| Middle school | ||
| High school | ||
| College/university |
- 9.
- Rate your language learning skill. In other words, how good do you feel you are at learning new languages relative to your friends or other people you know? (Choose one.)
| Very poor | Poor | Limited | Average | Good | Very good | Excellent |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
- 10.
- Rate your current ability in terms of listening, speaking, reading, and writing in each of the languages you have studied or learned. Please rate according to the following scale (choose the number below):
| Very poor | Poor | Limited | Functional | Good | Very good | Native-like |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Language | Listening | Speaking | Reading | Writing |
| 1 2 3 4 5 6 7 | 1 2 3 4 5 6 7 | 1 2 3 4 5 6 7 | 1 2 3 4 5 6 7 | |
| 1 2 3 4 5 6 7 | 1 2 3 4 5 6 7 | 1 2 3 4 5 6 7 | 1 2 3 4 5 6 7 | |
| 1 2 3 4 5 6 7 | 1 2 3 4 5 6 7 | 1 2 3 4 5 6 7 | 1 2 3 4 5 6 7 | |
| 1 2 3 4 5 6 7 | 1 2 3 4 5 6 7 | 1 2 3 4 5 6 7 | 1 2 3 4 5 6 7 |
- 11.
- If you have taken any standardized language proficiency tests (e.g., TOEFL), then indicate the name of the test, the language assessed, and the score you received for each. If you do not remember the exact score, then indicate an “Approximate score” instead.
| Test | Language | Score | (Approximate score) |
- 12.
- Estimate how many hours per day you spend engaged in the following activities in each of the languages you have studied or learned (hrs).
| Language: | Language: | Language: | |
| Watching TV, Netflix, Youtube, etc. | ______ | ______ | ______ |
| Listening for/at school/work: | ______ | ______ | ______ |
| Reading for school/work: | ______ | ______ | ______ |
| Reading for fun: | ______ | ______ | ______ |
| Writing emails or texts to friends: | ______ | ______ | ______ |
| Writing for school/work: | ______ | ______ | ______ |
- 13.
- Estimate how many hours per day you spend speaking with the following groups of people in each of the languages you have studied or learned.
| Language: | Language: | Language: | |
| Family members: | (hrs) | (hrs) | (hrs) |
| Friends: | (hrs) | (hrs) | (hrs) |
| Classmates: | (hrs) | (hrs) | (hrs) |
| Coworkers: | (hrs) | (hrs) | (hrs) |
- 14a.
- Do you feel that you are bicultural or multicultural? (This includes, for example, growing up with parents or relatives from different cultures or living in different cultures for extensive periods of time.) (Choose one.)Yes/No
- 14b.
- If you answered “Yes” to 16a, then which cultures/languages do you identify with more strongly? Rate the strength of your connection in the following categories for each culture/language. Choose the number in the table according to the following scale.
| None | Very weak | Weak | Moderate | Strong | Very strong | Extreme |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Culture/Language | Identity |
| 1 2 3 4 5 6 7 | |
| 1 2 3 4 5 6 7 | |
| 1 2 3 4 5 6 7 | |
| 1 2 3 4 5 6 7 |
- 15.
- Phonetics/Linguistics Training
| (1) a. Have you taken any Linguistics courses? | Yes/No |
| (1) b. If yes, please indicate which language you learned during the courses. | _________ |
| (2) a. Have you taken any Phonetics courses? | Yes/No |
| (2) b. If yes, please indicate which language you learned during the courses. | _________ |
| (3) a. In your Spanish courses, have any of your professors talked about pronunciation (or phonetics)? | Yes/No |
| (3) b. If yes, please explain briefly what the professor(s) discussed (e.g., the differences in pronunciation (or phonetics) between Spanish and English). | _________ |
- 16.
- Parents’ information:
- How old are your parents?Father:Mother:
- At what age were they when they moved to the U.S. or Canada?Father:Mother:
- Where are your parents from?Father:Mother:
| Father’s hometown: ___________________________ | Mother’s hometown: ___________________________ | ||||||||||||||
| None (1) | Very Weak (2) | Weak (3) | Moderate (4) | Strong (5) | Very Strong (6) | Extreme (7) | None (1) | Very Weak (2) | Weak (3) | Moderate (4) | Strong (5) | Very Strong (6) | Extreme (7) | ||
| Dialect | Strength of Foreign Accent | Dialect | Strength of Foreign Accent | ||||||||||||
- 17.
- How do you identity yourself in terms of Korean dialect? Do you think you are a speaker of Seoul Korean? yes/no
| Your dialect: ___________________________ | |||||||
| None (1) | Very Weak (2) | Weak (3) | Moderate (4) | Strong (5) | Very Strong (6) | Extreme (7) | |
| Dialect | Strength of Foreign Accent | ||||||
- 18.
- Please comment below to indicate any additional answers to any of the questions above that you feel better describe your language background or usage.
- 19.
- Please comment below to provide any other information about your language background or usage.
References
- Balas, A., Kopečková, R., & Wrembel, M. (2019). Perception of rhotics by multilingual children. In S. Calhoun, P. Escudero, M. Tabain, & P. Warren (Eds.), Proceedings of the 19th international congress of phonetic sciences (pp. 3725–3729). Australasian Speech Science and Technology Association Inc. [Google Scholar]
- Bardel, C., & Falk, Y. (2007). The role of the second language in third language acquisition: The case of germanic syntax. Second Language Research, 23(4), 459–484. [Google Scholar] [CrossRef]
- Bardel, C., & Falk, Y. (2012). The L2 status factor and the declarative/procedural distinction. In J. Cabrelli, S. Flynn, & J. Rothman (Eds.), Third language acquisition in adulthood (Vol. 46, pp. 61–78). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Bardel, C., & Sánchez, L. (2017). The L2 Status Factor Hypothesis revisited. In T. Angelovska, & A. Hahn (Eds.), L3 syntactic transfer: Models, new developments and implications (Vol. 5, pp. 85–101). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Barzilai, M. L. (2020). The relative effects of phonetic and phonological salience in speech sound processing [Unpublished doctoral dissertation]. Georgetown University.
- Beckman, J., Helgason, P., McMurray, B., & Ringen, C. (2011). Rate effects on Swedish VOT: Evidence for phonological overspecification. Journal of Phonetics, 39(1), 39–49. [Google Scholar] [CrossRef]
- Berkes, É., & Flynn, S. (2012). Further evidence in support of the Cumulative-Enhancement Model. In J. Cabrelli, S. Flynn, & J. Rothman (Eds.), Third language acquisition in adulthood (Vol. 46, pp. 61–78). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Berry, K. J., Johnston, J. E., Zahran, S., & Mielke, P. W. (2009). Stuart’s Tau measure of effect size for ordinal variables: Some methodological considerations. Behavior Research Methods, 41(4), 1144–1148. [Google Scholar] [CrossRef]
- Best, C. T., McRoberts, G. W., & Goodell, E. (2001). Discrimination of non-native consonant contrasts varying in perceptual assimilation to the listener’s native phonological system. The Journal of the Acoustical Society of America, 109(2), 775–794. [Google Scholar] [CrossRef]
- Best, C. T., & Tyler, M. D. (2007). Nonnative and second-language speech perception. In O.-S. Bohn, & M. J. Munro (Eds.), Language experience in second language speech learning (Vol. 17, pp. 13–34). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Black, M., Rato, A., & Rafat, Y. (2024). Effect of perceptual training without feedback on bilingual speech perception: Evidence from approximant-stop discrimination in L1 Spanish and L1 English late bilinguals. Journal of Monolingual and Bilingual Speech, 6, 127–150. [Google Scholar] [CrossRef]
- Bradlow, A. R., & Bent, T. (2008). Perceptual adaptation to non-native speech. Cognition, 106(2), 707–729. [Google Scholar] [CrossRef]
- Cabrelli Amaro, J., & Wrembel, M. (2016). Investigating the acquisition of phonology in a third language—A state of the science and an outlook for the future. International Journal of Multilingualism, 13(4), 395–409. [Google Scholar] [CrossRef]
- Caramazza, A., Yeni-Komshian, G. H., Zurif, E. B., & Carbone, E. (1973). The acquisition of a new phonological contrast: The case of stop consonants in French-English bilinguals. The Journal of the Acoustical Society of America, 54(2), 421–428. [Google Scholar] [CrossRef]
- Cenoz, J., Hufeisen, B., & Jessner, U. (2001). Cross-linguistic influence in third language acquisition: Psycholinguistic perspectives. Multilingual Matters Ltd. [Google Scholar] [CrossRef]
- Cho, T., Jun, S., & Ladefoged, P. (2002). Acoustic and aerodynamic correlates of Korean stops and fricatives. Journal of Phonetics, 30(2), 193–228. [Google Scholar] [CrossRef]
- Darcy, I., Mora, J. C., & Daidone, D. (2016). The role of inhibitory control in second language phonological processing. Language Learning, 66(4), 741–773. [Google Scholar] [CrossRef]
- Davidson, L. (2016). Variability in the implementation of voicing in American English obstruents. Journal of Phonetics, 54, 35–50. [Google Scholar] [CrossRef]
- De Angelis, G. (2007). Third or additional language acquisition. Multilingual Matters. [Google Scholar] [CrossRef]
- Díaz, B., Mitterer, H., Broersma, M., & Sebastián-Gallés, N. (2012). Individual differences in late bilinguals’ L2 phonological processes: From acoustic-phonetic analysis to lexical access. Learning and Individual Differences, 22(6), 680–689. [Google Scholar] [CrossRef]
- Dmitrieva, O., Llanos, F., Shultz, A. A., & Francis, A. L. (2015). Phonological status, not voice onset time, determines the acoustic realization of onset f0 as a secondary voicing cue in Spanish and English. Journal of Phonetics, 49, 77–95. [Google Scholar] [CrossRef]
- Escudero, P. (2005). Linguistic perception and second language acquisition: Explaining the attainment of optimal phonological categorization. LOT. [Google Scholar]
- Escudero, P., & Boersma, P. (2004). Bridging the gap between L2 speech perception research and phonological theory. Studies in Second Language Acquisition, 26(4), 551–585. [Google Scholar] [CrossRef]
- Falk, Y., & Bardel, C. (2010). The study of role of the background languages in third language acquisition. International Review of Applied Linguistics in Language Teaching (IRAL), 48, 185–220. [Google Scholar] [CrossRef]
- Falk, Y., & Bardel, C. (2011). Object pronouns in German L3 syntax: Evidence for the L2 status factor. Second Language Research, 27(1), 59–82. [Google Scholar] [CrossRef]
- Faretta-Stutenberg, M., & Morgan-Short, K. (2018). Contributions of initial proficiency and language use to second-language development during study abroad: Behavioral and event-related potential evidence. In C. Sanz, & A. Morales-Front (Eds.), The routledge handbook of study abroad research and practice (pp. 421–435). Routledge. [Google Scholar] [CrossRef]
- Flege, J. E. (1995). Second language speech learning: Theory, findings, and problems. In W. Strange (Ed.), Speech perception and linguistic experience: Issues in cross-language research (pp. 233–272). York Press. [Google Scholar]
- Flege, J. E. (2003). A method for assessing the perception of vowels in a second language. In E. F.-A. Mioni (Ed.), Issues in clinical linguistics (pp. 5–18). Unipress. [Google Scholar]
- Flege, J. E., & Bohn, O. (2021). The revised speech learning model (SLM-r). In R. Wayland (Ed.), Second language speech learning (pp. 3–83). Cambridge University Press. [Google Scholar] [CrossRef]
- Flege, J. E., Bohn, O., & Jang, S. (1997). Effects of experience on non-native speakers’ production and perception of English vowels. Journal of Phonetics, 25(4), 437–470. [Google Scholar] [CrossRef]
- Flege, J. E., & Liu, S. (2001). The effect of experience on adults’ acquisition of a second language. Studies in Second Language Acquisition, 23(4), 527–552. [Google Scholar] [CrossRef]
- Flege, J. E., MacKay, I. R. A., & Meador, D. (1999). Native Italian speakers’ perception and production of English vowels. The Journal of the Acoustic Society of America, 106(5), 2973–2987. [Google Scholar] [CrossRef]
- Flynn, S., Foley, C., & Vinnitskaya, I. (2004). The Cumulative-Enhancement Model for language acquisition: Comparing adults’ and children’s patterns of development in first, second and third language acquisition of relative clauses. International Journal of Multilingualism, 1(1), 3–16. [Google Scholar] [CrossRef]
- Green, D. W. (1998). The Language Control Model: The role of inhibition in bilingual language processing. Bilingualism: Language and Cognition, 1(2), 151–163. [Google Scholar]
- Grosjean, F. (2001). The bilingual’s language modes. In Janet Nicol (Ed.), One mind, two languages: Bilingual language processing (pp. 1–22). Blackwell. [Google Scholar]
- Guion, S. G., Flege, J. E., Akahane-Yamada, R., & Pruitt, J. C. (2000). An investigation of current models of second language speech perception: The case of Japanese adult’s perception of English consonants. The Journal of the Acoustical Society of America, 107(5), 2711–2724. [Google Scholar] [CrossRef] [PubMed]
- Han, M., & Weitzman, R. (1970). Acoustic features of Korean /P, T, K/, /p, t, k/, /ph, th, kh/. Phonetics, 22, 112–128. [Google Scholar] [CrossRef]
- Hardcastle, W. J. (1973). Some observation on the tense-lax distinction in initial stops in Korean. Journal of Phonetics, 2, 263–272. [Google Scholar] [CrossRef]
- House, A. S., & Fairbanks, G. (1953). The influence of consonant environment upon the secondary acoustical characteristics of vowels. The Journal of Acoustic Society of America, 25, 105–113. [Google Scholar] [CrossRef]
- Hualde, J. I. (2005). The sounds of Spanish. Cambridge University Press. [Google Scholar]
- Jang, H. 장혜진. (2011). Acoustic properties and perceptual cues of Korean word-initial obstruents 국어 어두 장애음의 음향적 특성과 지각 단서 [Unpublished doctoral dissertation]. Korea University 고려대학교.
- Jurafsky, D., & Martin, J. H. (2022). Speech and language processing (3rd ed.). Pearson. Available online: https://web.stanford.edu/~jurafsky/slp3/ (accessed on 2 February 2025).
- Kang, K., & Guion, S. G. (2008). Clear speech production of Korean stops: Changing phonetic targets and enhancement strategies. The Journal of the Acoustical Society of America, 124(6), 3909–3917. [Google Scholar] [CrossRef]
- Kang, Y. (2014). Voice Onset Time merger and development of tonal contrast in Seoul Korean stops: A corpus study. Journal of Phonetics, 45, 76–90. [Google Scholar] [CrossRef]
- Keating, P. A. (1984). Phonetic and phonological representation of stop consonant voicing. Language, 60(2), 286–319. [Google Scholar] [CrossRef]
- Kerns, K. A., Don, M. J., & Fenton, A. R. (1994). The use of music to teach word recognition to children with learning disabilities. The Journal of Educational Research, 87(2), 85–94. [Google Scholar]
- Kędzierska, H., Rataj, K., Balas, A., Cal, Z., Castle, C., & Wrembel, M. (2023). Vowel perception in multilingual speakers: ERP evidence from Polish, English, and Norwegian. Frontiers in Psychology, 14, 1270743. [Google Scholar] [CrossRef] [PubMed]
- Kim, C. (1965). On the autonomy of the tensity feature in stop classification (with special reference to Korean stops). Word, 21(3), 339–359. [Google Scholar] [CrossRef]
- Kim, M., Beddor, P. S., & Horrocks, J. (2002). The contribution of consonantal and vocalic information to the perception of Korean initial stops. Journal of Phonetics, 30(1), 77–100. [Google Scholar] [CrossRef]
- Kim, S., Cho, T., & McQueen, J. M. (2012). Phonetic richness can outweigh prosodically-driven phonological knowledge when learning words in an artificial language. Journal of Phonetics, 40, 443–452. [Google Scholar] [CrossRef]
- Kim, Y., Tracy–Ventura, N., & Jung, Y. (2016). A Measure of proficiency or short-term memory? Validation of an Elicited Imitation Test for SLA Research. Modern Language Journal, 100(3), 655–673. [Google Scholar] [CrossRef]
- Kingston, J., & Diehl, R. L. (1994). Phonetic knowledge. Language, 70(3), 419–454. [Google Scholar] [CrossRef]
- Kuhl, P. K., & Miller, J. D. (1975). Speech perception by the chinchilla: Voiced-voiceless distinction in alveolar plosive consonants. Science, 190(4209), 69–72. [Google Scholar] [CrossRef] [PubMed]
- Lee, H., Politzer-Ahles, S., & Jongman, A. (2013). Speakers of tonal and non-tonal Korean dialects use different cue weightings in the perception of the three-way laryngeal stop contrast. Journal of Phonetics, 41(2), 117–132. [Google Scholar] [CrossRef] [PubMed]
- Li, P., Zhang, F., Tsai, E., & Puls, B. (2014). Language history questionnaire (LHQ 2.0), A new dynamic web-based research tool. Bilingualism: Language and Cognition, 17(3), 673–680. [Google Scholar] [CrossRef]
- Lisker, L., & Abramson, A. S. (1964). A cross-language study of voicing in initial stops: Acoustical measurements. Word, 20(3), 384–422. [Google Scholar] [CrossRef]
- Liu, J., & Lin, J. (2021). A Cross-linguistic study of L3 phonological acquisition of stop contrasts. SAGE Open, 11(1), 215824402098551. [Google Scholar] [CrossRef]
- Maye, J., & Gerken, L. (2001). Learning phonemes: How far can the input take us? In A. H.-J. Do, L. Domínguez, & A. Johansen (Eds.), BUCLD 25 Proceedings (pp. 480–490). Cascadilla Press. [Google Scholar]
- Maye, J., Werker, J. F., & Gerken, L. (2002). Infant sensitivity to distributional information can affect phonetic discrimination. Cognition, 82(3), B101–B111. [Google Scholar] [CrossRef] [PubMed]
- McClelland, J. L., & Elman, J. L. (1986). The TRACE model of speech perception. Cognitive Psychology, 18(1), 1–86. [Google Scholar] [CrossRef]
- Moorman, C. (2017). Individual differences and linguistic factors in the development of mid vowels in L2 Spanish learners: A longitudinal study [Unpublished doctoral dissertation]. Georgetown University.
- Morales-Front, A. (2018). Voice Onset Time in advanced SLA. In P. A. Malovrh, & A. G. Benati (Eds.), The handbook of advanced proficiency in second language acquisition (pp. 323–339). Wiley-Blackwell. [Google Scholar] [CrossRef]
- Mun, J. (2022). Contributions of cross-linguistic influence and language aptitude to the perception and production of l3 spanish labial stops among korean-english bilinguals of varying l3 proficiency [Unpublished doctoral dissertation]. Georgetown University.
- Nagle, C. L. (2021). Revisiting perception-production relationships: Exploring a new approach to investigate perception as a time-varying predictor. Language Learning, 71(1), 243–279. [Google Scholar] [CrossRef]
- Nelson, C. (2020). The younger, the better? Speech perception development in adolescent vs. adult L3 learners. Yearbook of the Poznan Linguistic Meeting, 6(1), 27–58. [Google Scholar] [CrossRef]
- Nittrouer, S., & Lowenstein, J. H. (2015). Relative perceptual recoverability of different phonemic contrasts by children and adults. Journal of Speech, Language, and Hearing Research, 58(1), 143–155. [Google Scholar]
- Oh, E. (2011). Effect of speaker gender on voice onset time in Korean stops. Journal of Phonetics, 39(1), 59–67. [Google Scholar] [CrossRef]
- Onishi, H. (2016). The effects of L2 experience on L3 perception. International Journal of Multilingualism, 13(4), 459–475. [Google Scholar] [CrossRef]
- Ortega, L., Iwashita, N., Norris, J. M., & Rabie, S. (2002). An investigation of elicited imitation tasks in crosslinguistic SLA research. The Second Language Research Forum, Toronto, October 3–6, 2002 [Unpublished handout retrieved from IRIS].
- Parrish, K. (2022). The categorization of L3 vowels near first exposure by Spanish-English bilinguals. Languages, 7, 226. [Google Scholar] [CrossRef]
- Peperkamp, S., Vendelin, I., & Dupoux, E. (2006). Prosodic cues to word boundaries: The role of stress and rhythm. Language and Speech, 49(4), 457–487. [Google Scholar] [CrossRef]
- Peterson, G. E., & Lehiste, I. (1961). Some basic considerations in the analysis of intonation. Journal of the Acoustical Society of America, 33(4), 419–425. [Google Scholar] [CrossRef]
- Riney, T. J., & Takagi, N. (1999). Global foreign accent and Voice Onset Time among Japanese EFL speakers. Language Learning, 49(2), 275–302. [Google Scholar] [CrossRef]
- Rosner, B. S., López-Bascuas, L. E., García-Albea, J. E., & Fahey, R. P. (2000). Voice-onset times for Castilian Spanish initial stops. Journal of Phonetics, 28, 217–224. [Google Scholar] [CrossRef]
- Rothman, J. (2010). On the typological economy of syntactic transfer: Word order and relative clause high/low attachment preference in L3 Brazilian Portuguese. IRAL—International Review of Applied Linguistics in Language Teaching, 48(2–3), 245–273. [Google Scholar] [CrossRef]
- Rothman, J. (2011). L3 syntactic transfer selectivity and typological determinacy: The typological primacy model. Second Language Research, 27(1), 107–127. [Google Scholar] [CrossRef]
- Rothman, J. (2013). Cognitive economy, non-redundancy and typological primacy in L3 acquisition: Evidence from initial stages of L3 Romance. In S. Baauw, F. Drijkoningen, L. Meroni, & M. Pinto (Eds.), Romance languages and linguistic theory 2011 (pp. 217–247). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Rothman, J., Alonso, J. G., & Puig-Mayenco, E. (2019). Third language acquisition and linguistic transfer. Cambridge University Press. [Google Scholar] [CrossRef]
- Rothman, J., Amaro, J. C., & de Bot, K. (2013). Third language acquisition. In J. Herschensohn, & M. Young-Scholten (Eds.), The Cambridge handbook of second language acquisition (pp. 372–393). Cambridge University Press. [Google Scholar] [CrossRef]
- Saffran, J. R., Aslin, R. N., & Newport, E. L. (1996). Statistical learning by 8-month-old infants. Science, 274(5294), 1926–1928. [Google Scholar] [CrossRef]
- Sánchez, L. (2020). From L2 to L3, verbs getting into place: A study on interlanguage transfer and L2 syntactic proficiency. In C. Bardel, & L. Sánchez (Eds.), Third language acquisition: Age, proficiency, and multilingualism (pp. 209–235). Language Science Press. [Google Scholar] [CrossRef]
- Schertz, J., Cho, T., Lotto, A., & Warner, N. (2015a). Individual differences in phonetic cue use in production and perception of a non-native sound contrast. Journal of Phonetics, 52, 183–204. [Google Scholar] [CrossRef]
- Schertz, J., Kim, H., & Vasiliev, A. (2015b, August 10–14). Korean stops: Production and perception. 18th International Congress of Phonetic Sciences (pp. 1–5), Glasgow, UK. [Google Scholar]
- Sebastián-Gallés, N., & Díaz, B. (2012). First and second language speech perception: Graded learning. Language Learning, 62, 131–147. [Google Scholar] [CrossRef]
- Shin, J. 신지영. (2011). 한국어의 말소리 [Korean sounds]. 지식과 교양 [Knowledge and General Education].
- Silva, D. J. (2006). Variation in voice onset time for Korean stops: A case for recent sound change. Korean Linguistics, 13(1), 1–16. [Google Scholar] [CrossRef]
- Silverman, D. (2003). On the rarity of pre-aspirated stops. Journal of Linguistics, 39, 575–598. [Google Scholar] [CrossRef]
- Solon, M., Park, H. I., Henderson, C., & Dehghan-Chaleshtori, M. (2019). Revisiting the Spanish elicited imitation task: A tool for assessing advanced language learners? Studies in Second Language Acquisition, 41, 1027–1053. [Google Scholar] [CrossRef]
- Song, Y. J., Kim, S., & Rhee, S. (2018). The role of VOT and f0 in production of Korean word-initial stops by non-native learners of the Korean language. Teaching Korean as a Foreign Language, 50, 95–113. [Google Scholar] [CrossRef]
- Sypiańska, J. (2016). L1 vowel of multilinguals: The applicability of SLM in multilingualism. Research in Language, 14(1), 79–94. [Google Scholar] [CrossRef]
- Werker, J. F., & Tees, R. C. (1984). Cross-language speech perception: Evidence for perceptual reorganization during the first year of life. Infant Behavior and Development, 7(1), 49–63. [Google Scholar] [CrossRef]
- Westergaard, M. (2019). Microvariation in multilingual situations: The Importance of property-by-property acquisition. Second Language Research, 37(3), 379–407. [Google Scholar] [CrossRef]
- Westergaard, M., Mitrofanova, N., Mykhaylyk, R., & Rodina, Y. (2017). Crosslinguistic influence in the acquisition of a third language: The linguistic proximity model. International Journal of Bilingualism, 21(6), 666–682. [Google Scholar] [CrossRef]
- Wilson, I., & Gick, B. (2011, August 17–21). Nonsense-syllable sound discrimination ability correlates with second language (L2) proficiency. 17th International Congress of Phonetic Sciences (ICPhS XVII), Hong Kong, China. [Google Scholar]
- Winn, M. B. (2020). Manipulation of Voice Onset Time in speech stimuli: A tutorial and flexible Praat script. The Journal of the Acoustical Society of America, 147(2), 852–866. [Google Scholar] [CrossRef]
- Wrembel, M., Gut, U., Kopečková, R., & Balas, A. (2020). Cross-linguistic interactions in Third Language Acquisition: Evidence from multi-feature analysis of speech perception. Languages, 5(4), 52. [Google Scholar] [CrossRef]
- Wrembel, M., Marecka, M., & Kopečková, R. (2019). Extending perceptual assimilation model to L3 phonological acquisition. International Journal of Multilingualism, 16(4), 513–533. [Google Scholar] [CrossRef]
- Wu, S., Tio, Y. P., & Ortega, L. (2022). Elicited imitation as a measure of L2 proficiency: New insights from a comparison of two L2 English parallel forms. Studies in Second Language Acquisition, 44(1), 271–300. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
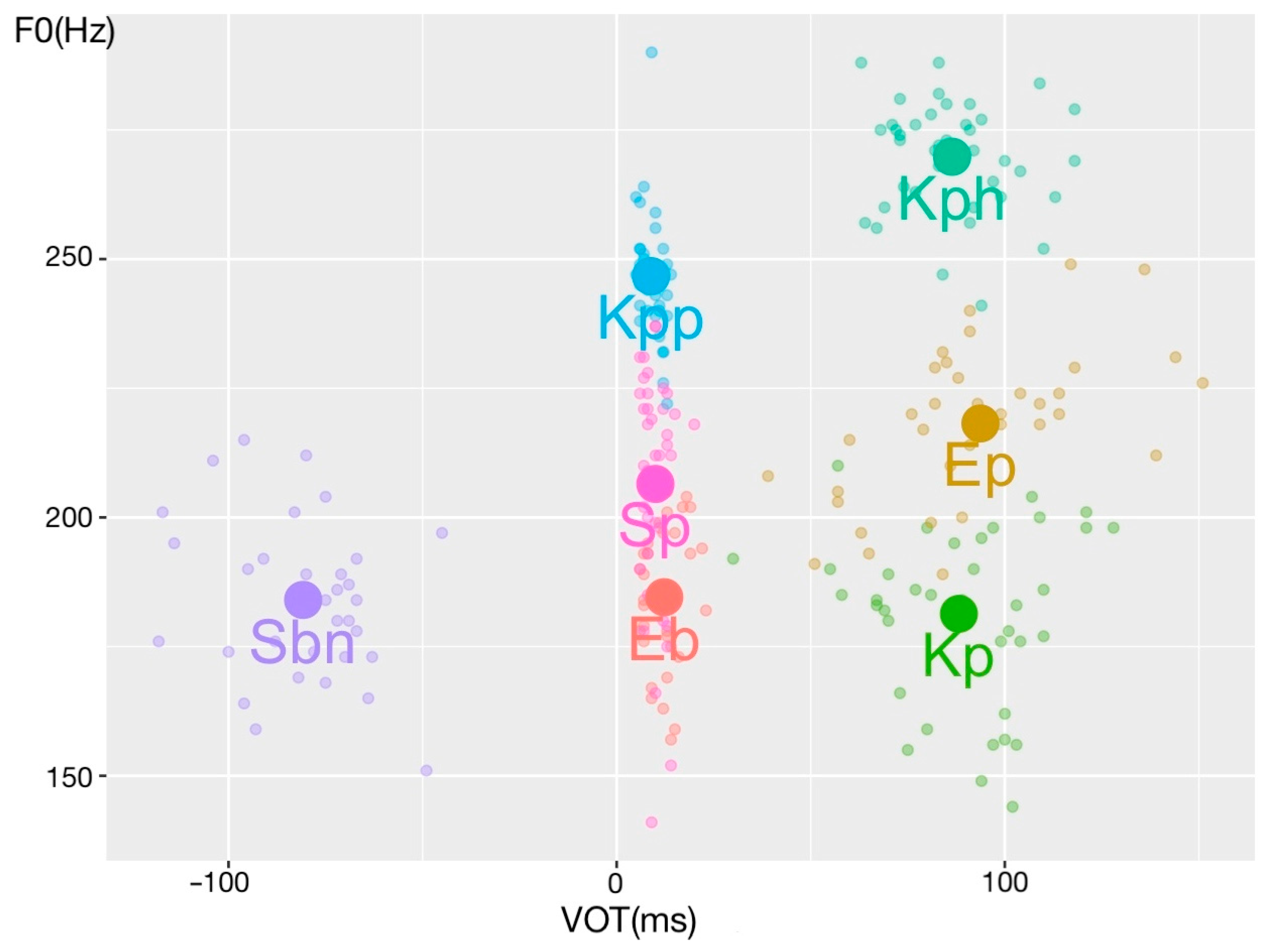
| VOT (ms) | F0 (Hz) | |||
|---|---|---|---|---|
| M | 95%CI | M | 95%CI | |
| Kpp | 8.85 | 7.97/9.73 | 246.71 | 242.90/250.52 |
| Kph | 86.43 | 81.76/91.09 | 269.80 | 266.40/273.20 |
| Kp | 88.18 | 81.44/94.91 | 181.34 | 175.88/186.80 |
| Ep | 93.72 | 85.36/102.09 | 218.19 | 213.33/223.05 |
| Eb | 12.25 | 10.54/13.96 | 184.56 | 179.57/189.56 |
| Sp | 9.97 | 8.99/10.96 | 206.49 | 199.06/213.92 |
| Sbn | −80.78 | −87.22/−74.34 | 184.03 | 178.40/189.66 |
| Inclusion Criteria | |
|---|---|
| Age | Between 18 and 40 Years of Age |
| L1 Korean |
Self-assessed language skills (1–7): between 5 and 7 |
| L2 English |
Self-assessed language skills (min: 1, max: 7): between 5 and 7 |
| L3 Spanish |
|
| Additional language (L4) |
|
| (N = 40) | |||||
| Undergrad | MA | PhD/MD/JD | |||
| Education level | 23 | 10 | 7 | ||
| Mean (SD) | 95% CI (lower/upper) | ||||
| Age | 28.18 (5.242) | 26.50 | 29.85 | ||
| Age of acquisition | Eng | 9.85 (4.704) | 8.35 | 11.35 | |
| Age of acquisition | Sp | 17.43 (5.168) | 15.77 | 19.08 | |
| Self-assessed language skills (min: 1, max: 7) | Kor | listening | 6.95 (0.316) | 6.85 | 7.05 |
| speaking | 6.90 (0.379) | 6.78 | 7.02 | ||
| reading | 6.88 (0.404) | 6.75 | 7.00 | ||
| writing | 6.65 (0.770) | 6.40 | 6.90 | ||
| Eng | listening | 6.38 (0.838) | 6.11 | 6.64 | |
| speaking | 6.28 (0.816) | 6.01 | 6.54 | ||
| reading | 6.33 (0.888) | 6.04 | 6.61 | ||
| writing | 6.30 (0.966) | 5.99 | 6.61 | ||
| Sp | listening | 2.53 (1.154) | 2.16 | 2.89 | |
| speaking | 2.15 (1.099) | 1.80 | 2.50 | ||
| reading | 2.60 (1.411) | 2.15 | 3.05 | ||
| writing | 1.90 (1.105) | 1.55 | 2.25 | ||
| Language | Carrier Sentence |
|---|---|
| Spanish | Digo, ‘ba’ porque sí (×5) |
| Digo, ‘pa’ porque sí (×5) | |
| English | I say, ‘ba’ just because (×5) |
| I say, ‘pa’ just because (×5) | |
| Korean | 그냥, ‘바’ 라고 말합니다 (×5) /kunyang, ‘pa’ lako malhapnita/ “Just because, ‘pa’ I say” which means “I say, ‘ba’ just because” |
| 그냥, ‘빠’ 라고 말합니다 (×5) /kunyang, ‘ppa’ lako malhapnita/ “Just because, ‘p*a’ I say” which means “I say, ‘p*a’ just because” |
| Pairs | τc | Sig |
|---|---|---|
| S/p/—E/p/ | −0.052 | 0.719 |
| S/p/—E/b/ | −0.051 | 0.653 |
| S/p/—K/p*/ | −0.062 | 0.526 |
| S/b/—E/b/ | −0.177 | 0.092 |
| S/b/—K/p/ | 0.092 | 0.446 |
| All pairs | −0.097 | 0.409 |
| Stimulus | Identified As | τc | Sig | |
|---|---|---|---|---|
| S/p/ | K/ph/ | % | −0.163 | 0.123 |
| goodness | 0.079 | 0.768 | ||
| S/p/ | K/p/ | % | 0.167 | 0.165 |
| goodness | −0.171 | 0.346 | ||
| S/p/ | K/p*/ | % | 0.032 | 0.773 |
| goodness | −0.146 | 0.275 | ||
| S/b/ | K/p/ | % | 0.030 | 0.757 |
| goodness | −0.001 | 0.992 |
| Stimulus | Identified As | τc | Sig | |
|---|---|---|---|---|
| S/p/ | E/p/ | % | −0.118 | 0.365 |
| goodness | −0.124 | 0.287 | ||
| S/p/ | E/b/ | % | 0.118 | 0.365 |
| goodness | 0.002 | 0.991 | ||
| S/b/ | E/b/ | % | −0.027 | 0.857 |
| goodness | −0.030 | 0.805 |
| Stimuli (Sp) | Identification in English | Identification in Korean | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| /p/ | /b/ | /p*/ | /ph/ | /p/ | ||||||
| % | Rating | % | Rating | % | Rating | % | Rating | % | Rating | |
| Sp /p/ | 66 | 3.17 | 34 | 2.89 | 88.8 | 4.49 | 3.5 | 3.8 | 7.3 | 4.08 |
| Sp /b/ | 1.13 | 0.45 | 98.7 | 4.06 | 0.7 | 2.66 | 0.5 | 3 | 98.4 | 4.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mun, J.; Morales-Front, A. Distributional Learning and Language Activation: Evidence from L3 Spanish Perception Among L1 Korean–L2 English Speakers. Languages 2025, 10, 147. https://doi.org/10.3390/languages10060147
Mun J, Morales-Front A. Distributional Learning and Language Activation: Evidence from L3 Spanish Perception Among L1 Korean–L2 English Speakers. Languages. 2025; 10(6):147. https://doi.org/10.3390/languages10060147
Chicago/Turabian StyleMun, Jeong, and Alfonso Morales-Front. 2025. "Distributional Learning and Language Activation: Evidence from L3 Spanish Perception Among L1 Korean–L2 English Speakers" Languages 10, no. 6: 147. https://doi.org/10.3390/languages10060147
APA StyleMun, J., & Morales-Front, A. (2025). Distributional Learning and Language Activation: Evidence from L3 Spanish Perception Among L1 Korean–L2 English Speakers. Languages, 10(6), 147. https://doi.org/10.3390/languages10060147