1. Introduction
The feature we explore in this article is the use of the word
anymore in positive-polarity clauses in English. This feature has often been referred to as “positive
anymore” (including in our previous work in (
Strelluf, 2019)). In this paper, we adopt
Horn’s (
2021) more recent label “non-polarity
anymore” (NPAM) (see
Horn, 2021, p. 6;
Blanchette & Keppenne, 2024). NPAM contrasts with the more general use of the
anymore as a negative polarity item (NPI). In the NPI construction,
anymore occurs at the end of a negative clause, as in sentence (1). Like most example sentences in this article, (1) is taken from a message that was posted to Twitter from an account associated with a city in the United States and is part of the larger corpus we describe below. In (1),
anymore is licensed by the negative particle
not. For most English users, a clause containing
anymore is considered ungrammatical if
anymore is not preceded by a trigger of non-positive polarity (i.e., if
not were omitted). However, some people use
anymore in positive-polarity clauses, such as in (2), exemplifying NPAM.
- (1)
I do not want to be on this phone anymore. (Birmingham, Alabama)
- (2)
Mizzou is a dumpster fire anymore. (Kansas City)
The regional distribution, persistence, and grammatical description of NPAM have attracted attention from American linguists periodically since the construction was first pointed out by
Malone (
1931). A particularly interesting feature proposed for NPAM is that it is associated with phrases signaling negative emotion (
Horn, 2013,
2014,
2021). Example (2) above demonstrates the basic idea: the negative connotation of the sentence may make NPAM more acceptable perceptually or more likely productively.
However, verification of this claim has been challenging. Descriptions and analyses of NPAM have generally been based on consciously elicited acceptability judgments. As we will detail below, this is because NPAM occurs infrequently and unpredictably in natural language and is difficult to elicit naturalistically. While such studies have undoubtedly offered insights into NPAM, linguists have warned that acceptability judgments of NPAM may be unreliable (
Labov, 1972, p. 309;
1973, p. 66;
Youmans, 1986;
Labov et al., 2006, p. 293).
One approach to solving this problem of infrequent occurrence is to leverage large-scale digital corpora of naturalistic language from social media. Such sources offer a solution to the problem of low-frequency variables like NPAM, enabling researchers to examine spontaneous productions that would otherwise be unavailable for quantitative study (e.g.,
Strelluf, 2019). Furthermore, once a sufficiently large social media dataset is compiled, an array of corpus linguistic tools may be leveraged to gain new insights into the variable. In the case of NPAM, emotional negativity can be examined via sentiment analysis, an approach that is used extensively in computational linguistics to characterize emotional and psychological features of language (e.g.,
Devitt & Ahmad, 2013;
Mohammad, 2016;
Taboada, 2016;
Liu & Lei, 2018). In this paper we use sentiment analysis to shed new light on NPAM while also demonstrating the potential value of sentiment analysis as a tool to study variability in low-frequency language features in social media datasets.
1.1. Anymore, Polarity, and American Englishes
NPIs, such as the standard form of
anymore, occur throughout the world’s languages and in a range of syntactic categories (see (
Tovena, 2020) for a brief review, but for a more comprehensive review, see (
Klima, 1964;
Ladusaw, 1980,
1996;
Edmondson, 1983;
von Bergen & von Bergen, 1993;
van der Wouden, 1997;
Zwarts, 1995,
1998;
Horn, 1970,
2002,
2016;
den Dikken, 2006;
Hoeksema, 2007,
2010;
Giannakidou, 2011)). The list of NPIs in English is long, but includes items like
yet (“I do
n’t know
yet”/*”I know
yet”),
ever (“I do
n’t ever go”/*”I
ever go”), and
give a damn (“Frankly my dear, I do
n’t give a damn”/*”Frankly my dear, I
give a damn”).
NPIs are united by their requirement for a negative (or, more accurately, non-positive) polarity trigger. The most canonical trigger is overt syntactic negation, as in (1) above, but a range of downward-entailing contexts may trigger NPIs, including inherently negative verbs, adjectives, and adverbs (3); negative prepositions (4); counterfactual statements (5); the semantic exclusivity of only (6); and too-comparatives (7). Question clauses (8) may also trigger NPIs.
- (3)
I refuse to lose in eight-ball anymore. (Indianapolis)
- (4)
This is beyond my ability to understand anymore. (Kansas City)
- (5)
Like you have any credibility anymore. (St. Louis)
- (6)
You’re the only thing that makes sense anymore. (Kansas City)
- (7)
I’m too stressed to care anymore. (Chicago)
- (8)
Do liberals even know what they stand for anymore? (Pittsburgh)
NPAM, however, occurs in positive-polarity clauses. This is exemplified by sentence (2) above, where no NPI trigger is present. In these cases, anymore is produced without being licensed by negative polarity. The removal of the requirement for a negative-polarity trigger is especially obvious in a sentence like (9), where NPAM occurs in a clause-initial position with no possibility for a polarity trigger preceding anymore to license the NPI form.
- (9)
Anymore, there’s Murphy’s Law, and then there’s the Bears. (Chicago)
Early citations glossed NPAM as ‘nowadays’ (
Krumpelmann, 1939, p. 156) or as ‘now’ with “a greater degree of finality to the contrast [with past events] and less likelihood of change” (
Carter & Cox, 1932, p. 236) or when
now is not “sufficiently expressive of a speaker’s attitude” (
Ferguson, 1932, p. 234). (Note, though, that these interpretations do not independently differentiate NPAM from NPI-
anymore, which can often also be replaced with
nowadays without drastically changing sentence meaning.) In the landscape of American Englishes, NPAM is typically associated with the American Midland (
Labov et al., 2006, pp. 293–294;
Murray & Simon, 2006;
Simon, 2006)—a dialect region of the United States that stretches from roughly Pittsburgh to Kansas City (
Labov et al., 2006, pp. 263–278). However, NPAM has also been identified as being acceptable to some people throughout much of the United States and Canada (e.g.,
Dunlap, 1945;
Vaux & Golder, 2003, Maps 54–57;
Maher & McCoy, 2011;
Horn, 2021). It was likely brought to North American English by Ulster Irish immigrants, and its presence in the Midland reflects westward settlement by the descendants of these immigrants along the Ohio and Missouri River valleys (
Eitner, 1949;
Montgomery & Hall, 2004).
1.2. NPAM and Negative Affect
While NPIs must occur in the syntactic scope of non-positive polarity, speakers are free to use syntactically negative clauses in affectively positive expressions. The fact that NPI-anymore can occur in emotionally positive clauses is illustrated in (10) and (11), where anymore presupposes that things were different in the past from their current state, but the utterer seems to be happy about the change.
- (10)
Happy birthday! You’re not a tween anymore! (St. Louis)
- (11)
You are a beautiful person and I’m glad you are not ashamed to embrace that anymore. (Chicago)
Technically, NPAM is differentiated from NPI-
anymore only in that it does not require a trigger of syntactic non-positive polarity to license it. However, linguists have posited that NPAM may also bear a semantic feature of negative emotional affect. For example,
Labov et al. (
2006) suggested that pragmatic factors influence judgments about the acceptability of NPAM:
In the eastern part of its range, positive anymore appears to be associated with the speech act of complaint. The cognitive dimension of “likelihood of occurrence” is then supplemented by the dimension of “speaker’s desire for the event to occur.”
(2006, p. 293, fn. 4)
Youmans (
1986, p. 73) confirmed that most instances of NPAM he informally observed seemed “to imply a negative evaluation,” meaning that
anymore might retain “some of its association with negation” for NPAM users. Laurence R. Horn, across a series of examinations of NPAM, has repeatedly observed that NPAM is associated with emotional negativity. For instance, while listing literary citations of NPAM,
Horn (
2013, p. 6) (see also
Horn, 2014, pp. 338–339) noted that the examples, “while not negative polarity occurrences, are nevertheless emotionally negative, amounting to an expression of regret at the change of state.” Horn extended this observation to say that most instances of NPAM in corpora reveal that affective negativity “is a characteristic (though not ineluctable) feature of positive
anymore.”
Horn (
2021) offers the only large-scale quantitative investigation we are aware of to examine emotional affect in NPAM. Acceptability judgments for five NPAM sentences were collected from 899 respondents to a Mechanical Turk survey. Across the United States, respondents were more likely to rate NPAM as grammatically acceptable when it occurred in a complaint than in sentences with positive emotional affect. Specifically, the sentence “It’s expensive to fly first-class
anymore” was judged to be acceptable across a large portion of the United States, while the sentence “It’s great to fly first-class
anymore” was judged to be acceptable (and acceptable at lower scalar ratings) in isolated patches of the Midland and areas of the Great Plains states. Likewise, the sentence, “
Anymore he’s spending too much time on Facebook” was rated as more acceptable than “
Anymore he watches what he eats.”
Negative affect may provide a pathway for the loosening of polarity requirements on anymore. Laurence Horn (pc.) identifies other cases where negative affect may make an NPI more acceptable without an NPI trigger. He notes that people are more likely to accept the NPI ever in a negative-affect sentence such as, “I curse the day I ever met you,” than in a sentence such as, “I bless the day I ever met you.” If NPAM is indeed associated with negative affect—i.e., if NPAM is more likely to be produced and/or accepted as grammatical when it is used in a complaint or otherwise emotionally “unhappy” utterance—it would not only be a unique semantic and emotive feature of the innovation but could also serve as the mechanism by which the innovation arose, shedding light on processes of change in polarity licensing.
1.3. The Paradox of NPAM Research
Labov (
1966/2006, p. 32) laid out the principle for linguistic variables that “the most useful items are those that are high in frequency, have a certain immunity from conscious suppression, are integral units of larger structures, and may be easily quantified on a linear scale.” Phonetic and phonological variables most naturally meet these criteria and have accordingly been a central focus of variationist sociolinguists. But other linguistic domains, including morphosyntax (
Tagliamonte, 2011, pp. 206–241) and discourse (
Pichler, 2016), have also provided variables that meet Labov’s criteria of high-frequency and quantifiability.
Low-frequency variables, however, pose methodological challenges.
Bailey et al. (
1997, p. 57), for instance, noted that some low-frequency variables “are extremely difficult to elicit” and “field workers cannot count on their appearing in conversation.” As a result, “any survey of these features that relies on observed behavior will surely under-report their occurrence” (pp. 57–58).
Murray and Simon (
2002, p. 34) similarly warned that collecting naturalistic productions of a low-frequency construction “requires an inordinate amount of time and offers no guarantee of success” because non-use “means only that an informant has not used it yet; the construction may appear in the next sentence or […] never.”
NPAM occurs rarely in natural speech and in corpora of edited texts and is difficult to elicit through traditional dialect and sociolinguistic survey methods. Sociolinguistic interviews conducted by the first author in the American Midland city of Kansas City offer an anecdotal illustration (see
Strelluf, 2018). During a grammaticality judgment task, 15 of 50 interviewees indicated they could use at least one of two NPAM sentences, and two others who rejected the sentences seemed to do so on the basis of propositional content rather than because of a violation in NPI licensing requirements. However, in nearly 30 h of spontaneous interview speech, just four interviewees used NPAM in a total of five utterances.
Because NPAM occurs infrequently in natural-language corpora, researchers have studied NPAM primarily through consciously elicited judgments (e.g.,
Dunlap, 1945;
Hindle & Sag, 1975;
Youmans, 1986;
Shields, 1997;
Murray, 1993;
Vaux & Golder, 2003;
Labov et al., 2006, pp. 293–294;
Coye, 2009;
Maher & McCoy, 2011;
Horn, 2021, but see
Blanchette & Keppenne, 2024 for an experimental approach targeting semantic interpretation of NPAM). However, language users seem to be unable to accurately assess whether NPAM is present in the speech around them or even a feature of their own grammars. In the anecdotal case of Strelluf’s sociolinguistic interviews and elicited grammaticality judgments, three of the four Kansas Citians who used NPAM in spontaneous speech rejected the survey prompt that syntactically matched their spontaneous usage. Their spontaneous utterances of NPAM appear as (12)–(15).
- (12)
My hips are so bad anymore. (Connie)
- (13)
This is a big deal anymore. (Cynthia)
- (14)
And [the school] is huge anymore. (Cynthia)
- (15)
It just draws so much notice anymore. (Robert)
They responded to the acceptability judgment prompt, “There’s a lot to do downtown anymore”:
- (16)
I don’t know that I’d say the anymore. I might say nowadays. (Connie)
- (17)
That doesn’t sound right. (Cynthia)
- (18)
I wouldn’t say that because it sounds, like, more like you’d say, “there isn’t much to do downtown anymore.” (Robert)
The fourth Kansas Citian conversationally used NPAM in a clause-medial position in (19):
- (19)
Out by the racetrack anymore is, you know, crazy built up. (Molly)
Molly’s NPAM is not structurally equivalent to the clause-initial and -final positions of NPAM for which judgments were directly elicited and therefore cannot be directly compared to elicited judgments. (As it happens, she judged clause-initial NPAM to be grammatical and clause-final NPAM to be ungrammatical, but something she heard others say.) The mismatches between these Kansas Citians’ conscious grammaticality judgments and actual observed productions undermine any insights into NPAM that could be drawn from elicited judgments.
Labov et al. (
2006, p. 293) similarly warned:
Positive anymore shows a disparity between intuitions and actual use. Long-term studies of positive anymore in Philadelphia show that the great majority of speakers will use [positive] anymore […] when enough spontaneous speech is recorded, but only about half will recognize this construction in response to direct questions.
Labov (
1972, p. 309;
1973, p. 66) offers additional instances of consciously elicited judgments of the acceptability of NPAM failing to match raters’ productions.
Youmans (
1986, p. 71) attributed the unreliability of elicited judgments to NPAM’s rarity: “Evidently, low-frequency phenomena such as positive
anymore can be heard for years without registering on a listener’s consciousness.”
Strelluf (
2019) turned to Twitter to overcome the “paradox of positive
anymore research” of data on low-frequency features being necessarily collected via elicited judgments and elicited judgments being unreliable because of the features’ low frequency. Thanks to the sheer volume of naturalistic language available at the time on Twitter,
Strelluf (
2019) collected 80,364 tweets containing
anymore, including 5642 where
anymore was not preceded by overt negation. By coding these tweets for their NPI trigger (or lack thereof) and regional origin,
Strelluf (
2019) confirmed that NPAM is a productive feature of grammars in the American Midland and that NPAM is produced rarely outside the Midland. However,
Strelluf (
2019) also revealed nuanced intra-regional differences within the Midland, as NPAM was more robustly a productive feature in Pittsburgh, Columbus, and Indianapolis in the eastern portion of the Midland than in the western cities of St. Louis and Kansas City. This provided a substantially more nuanced profile of NPAM as a regional syntactic feature than did studies based on consciously elicited acceptability judgments, which depicted the Midland as a region where NPAM was uniformly grammatical (e.g.,
Murray, 1993;
Vaux & Golder, 2003, Maps 54–57;
Labov et al., 2006, pp. 293–294;
Murray & Simon, 2006, p. 17;
Simon, 2006, p. 50;
Maher & McCoy, 2011).
Horn’s (
2021) study is an exception to this point, as his heat maps tend to show greater acceptability for NPAM in areas roughly around the Ohio River Valley, generally complementing production-based findings in
Strelluf (
2019).
While
Strelluf’s (
2019) use of tweets to study productions of NPAM introduced important nuance to dialectal and syntactic knowledge of the variable,
Strelluf (
2019, pp. 329–330) cautioned that it was not possible to study emotional affect in the Twitter corpus (pp. 329–330). Such research would have necessitated subjective judgments of messages, often with little or no context. For instance, we would read (20) as a complaint if we knew the author was working in a call center and tired of being unable to reach customers or was an annoyed recipient of calls from unknown numbers, but we would read it as neutral or optimistic if the author was a consultant giving marketing advice. On the other hand, in isolation we read (21) as carrying positive affect (i.e., they are satisfied with a situation), but it could also be an expression of resignation or sarcasm toward enduring unpleasantness.
- (20)
Cold calling anymore is frustrating for the receiver. People rarely answer numbers they don’t know. (Indianapolis)
- (21)
I’m cool on it anymore. (Columbus)
(See further examples of emotionally neutral or ambiguous NPAM citations in
Horn (
2021, p. 9). Note, too, that the examples of NPAM utterances in sociolinguistic interviews in examples 13–16 are not particularly emotionally negative. Even Connie’s apparent complaint about hip pain in 12, in the context of her interview, was an emotionally neutral rationale for her decision to buy a house without stairs.)
Messages scraped from social media routinely contain insufficient contextual information to reliably and replicably judge emotional affect. While in a small corpus it might be possible to probe conversational threads to make finer evaluations of emotional affect, this is impractical in large corpora of tens of thousands of messages.
Strelluf (
2019, p. 330) noted that the nature of tweets “would still leave emotional affect of a large number of tweets ambiguous (or scalar, i.e., necessitating establishing degree of emotional affect in a given tweet).” Moreover, in the times prior to Elon Musk’s acquisition and renaming of Twitter, when researchers could freely download huge amounts of user messages and account information through the platform’s developer API,
Fiesler and Proferes (
2018) questioned the ethics of researchers closely reviewing the content of tweets, as Twitter users were generally uncomfortable with researchers reading and analyzing individual tweets. As such, while
Strelluf (
2019) shed new light on previous claims about NPAM’s syntactic negative polarity by studying productions on Twitter, analysis could not be extended to examine affect.
1.4. Sentiment Analysis
Sentiment analysis focuses on computing a quantitative value of the emotional characteristics of a sample of language based on the words that occur in the sample. Canonical approaches associated with Charles Osgood and colleagues (e.g.,
Osgood et al., 1957,
1975) theorize that words can be emotionally categorized according to a finite set of discrete dimensions.
Osgood et al. (
1957) and
Russell and Mehabrian (
1977), for instance, distinguish three dimensions, as summarized by
Devitt and Ahmad (
2013, p. 477):
Good–bad axis (termed the dimension of “valence,” evaluation, or pleasantness);
Active–passive axis (termed the dimension of “arousal,” activation, or intensity);
Strong–weak axis (termed the dimension of “dominance” or submissiveness).
Dimensions vary across approaches, but
Watson and Tellegen (
1985) report valence and arousal being operationalized most consistently. In traditional approaches, human raters assign sentiment ratings to individual words, and these are compiled into lexica of ratings. Normed words are evaluated for validity and inter-rater reliability and, in the case of heavily researched languages like English, cover the majority of words that speakers produce (e.g.,
Warriner et al., 2013). These ratings can then be assigned to words that appear within a document, corpus, text, or other language sample and used to characterize the sentiment of the language that appears in the sample. Recent approaches to constructing sentiment lexica have relied on machine learning to automatically calculate sentiment ratings—for instance by calculating proximal relationships among words across time (e.g.,
Li et al., 2019)—or to bootstrap from a small sample of human-generated ratings to a larger sample of automated ratings. Large language model (LLM) artificial intelligence is also intuitively promising for assigning sentiment ratings, given LLMs’ abilities to analyze human-generated language according to patterns in training data, which might offer a solution to communicative devices such as sarcasm and irony, which are problematic for lexicon-based sentiment analysis (see (
Bamman & Smith, 2021) for relevant discussion in the context of Twitter and (
Gupta et al., 2024) in the context of sentiment analysis in LLMs). Results from initial applications of LLMs to sentiment analysis are so far mixed (e.g.,
Buscemi & Proverbio, 2024;
Zhang et al., 2024).
Fundamentally, though, all sentiment analytic approaches share the assumption that words carry categorizable and quantifiable emotional traits and that when a language user selects a set of words to construct a linguistic message they draw upon these emotional traits.
Taboada (
2016, p. 334) describes this perspective as an underlying principle of compositionality: “Researchers take for granted that the sentiment of a document, a sentence, or a tweet is the sum of its parts.” The sentimental characteristics of a linguistic message reflect the emotional state or affective stance of the message’s author at the time they constructed the message.
Sentiment analytic approaches have been shown to predict national wellbeing (
Dodds et al., 2011;
Hills et al., 2019), seasonal mood variation (
Nguyen et al., 2010;
Golder & Macy, 2011), depression in medical patients (
Eichstaedt et al., 2018), stock market trends (
Bollen et al., 2011), large-scale reactions to events (
Thelwall et al., 2011), and societal amenability to risk (
Li et al., 2020). In a number of cases, sentiment ratings of samples have been validated against the ground-truth ratings by the producers of those samples, or by independent metrics of emotional states. For example, Nguyen et al.’s (2010) large-scale study found simple unigram word-based methods to be surprisingly effective at capturing the ground-truth sentiment as provided by authors of texts (greater than 70 percent accuracy) despite words being detached out of the clauses in which they occur.
Hills et al. (
2019) used sentiment analysis to evaluate billions of words of historical texts to assess changes in national sentiment in Germany, Great Britain, the United States, and Italy. They showed that valence ratings for texts associated with each country align with measures derived from national surveys of wellbeing over approximately the last 50 years. Moreover, in historical texts that predated national wellbeing surveys, they found intuitive drops in valence coinciding with major national shocks such as wars, revolutions, and economic crashes.
We view sentiment analysis as an appealing approach to examining NPAM’s posited feature of negative affect—and indeed for exploring questions of areal and sociolinguistic variation more broadly. Sentiment analysis offers an objective and replicable metric for evaluating emotivity and affect. In the narrow context of NPAM, this addresses concerns raised by
Strelluf (
2019) about the impossibility of reliably determining the communicative and affective intent of authors in individual messages from social media. By providing a calculation of affect ratings attached to words in a message containing a form of
anymore, sentiment analysis should be able to assess emotional features of the message without demanding interpretation by a researcher. This approach will offer complementary evidence to
Horn’s (
2021) mappings of elicited judgments, informing whether language users’ naturalistic productions of NPAM match conscious evaluations in terms of emotivity and affect. And if sentiment analysis offers insight into features of NPAM, then it might be a useful tool for revealing the role that emotion and affect might play in sociolinguistic variability of other low-frequency (and other) linguistic features that can be effectively studied via social media corpora.
2. Materials and Methods
We utilize
Strelluf’s (
2019) Twitter
anymore corpus, which was compiled in 2016, in line with the platform’s terms of service at that time, via daily scrapes over one month using the twitteR package (
Gentry, 2015) in R (
R Core Team, 2023). Tweets containing the word
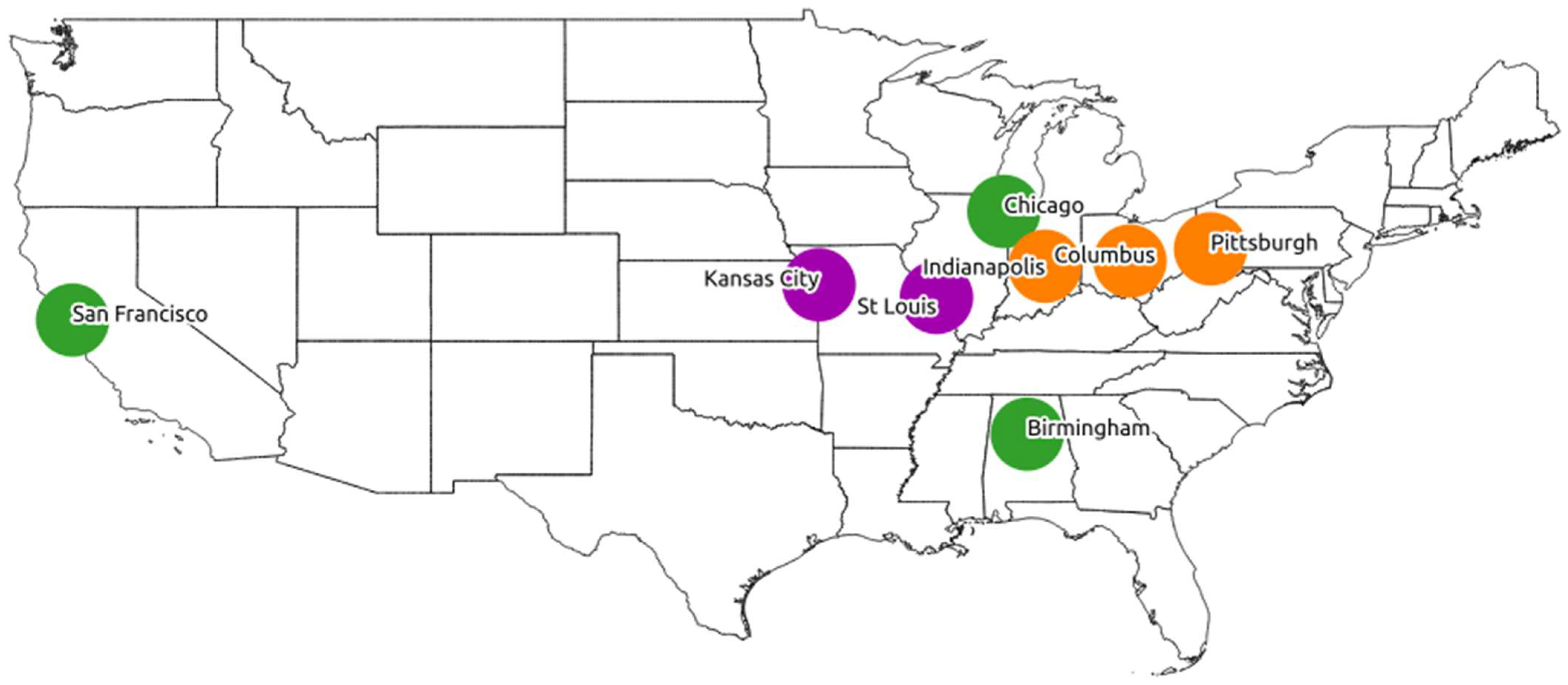
anymore were sampled from Twitter handles associated with areas within 75-mile radii of five cities in the US Midland (Pittsburgh; Columbus, OH; Indianapolis; St. Louis; and Kansas City) and three cities in other US dialect regions (Birmingham, AL; Chicago; and San Francisco) (see
Section 1.1 for discussion of NPAM as a regional dialect feature in US Englishes, associated especially with the US Midland). The search areas are mapped in
Figure 1. For the present study, following
Strelluf’s (
2019) identification of a three-way division among these cities in terms of NPAM productions, we combined the eight cities into three
anymore dialect areas: east Midland, where NPAM is used most frequently (Pittsburgh, Columbus, Indianapolis [mapped in orange]); non-Midland, where NPAM is used least (Birmingham, Chicago, San Francisco [green]); and west Midland, which sits between the other two areas in NPAM frequency (St. Louis, Kansas City [purple]).
Because NPI-anymore must occur after it has been licensed by a preceding trigger of negative polarity, we limited the dataset to 79,717 tweets where anymore occurred in a clause-final position.
Strelluf (
2019) hand-coded tweets for twenty NPI triggers based on lists in
van der Wouden (
1997),
Lawler (
2005), and
Giannakidou (
2011). (In cases of multiple NPI triggers being present in a single tweet,
Strelluf (
2019) coded for the “strongest” trigger, conceptually following
Edmondson’s (
1983) hierarchy of affective contexts (see also
Giannakidou, 2011, p. 1674). See
Strelluf (
2019) (2019, p. 328). Also see
Strelluf (
2019, p. 323) for details on quality control during hand-coding, including omitting tweets where polarity licensing was uninterpretable because a tweet containing
anymore appeared to be a continuation of a previous message, where
anymore occurred in quotations and titles, and where
anymore might describe quantity.) For the present study, we reduce
Strelluf’s (
2019) twenty triggers to six trigger categories, which we describe here with reference to example tweets for each category that appear throughout
Section 1 of this paper:
“Overt NEG,” where overt syntactic negation is present (1);
“Question,” including wh- and polar questions (8);
“Inherent NEG,” where a morphological feature or core semantic feature of a word always allows it to function as an NPI trigger. We borrow the label Inherent NEG from
Klima (
1964) as an umbrella for negative verbs such as
refuse in (3), negative quantifiers (e.g.,
nobody,
no one), adjectives with a negative affix (e.g.,
in-,
un-), and negative frequency adverbs (e.g.,
barely,
rarely). We include adversatives (22) in this category, following
Horn (
2021, pp. 5–6), who notes that constructions such as (22) are routinely rated as acceptable by speakers who otherwise reject sentences like (2) and (9).
- (22)
It’s hard to tell anymore. (Kansas City)
Sentences containing adversatives have often been cited by dialect dictionaries and linguists as examples of NPAM. We accept Horn’s evidence that adversatives license other NPIs (e.g., “It’s hard to give a damn”) as demonstrating that they are standard NPI triggers.
“Other Licensing,” which includes other downward entailing triggers, as in (4–7).
“Emotionally Charged” includes obviously negatively inflected adjectives and verbs (23).
- (23)
Weekends suck anymore. (Columbus)
- (24)
Kelce is dropping everything anymore. (Kansas City).
- (25)
Stafford is playing how we expect anymore. Looking good. (St. Louis)
Four categories—Overt NEG, Question, Inherent NEG, and Other Licensing—should license NPI-anymore for all English speakers. The categories of Emotionally Charged and Unlicensed should not normally license NPIs. For readers weary of checking intuitions with anymore, these general NPI licensing characteristics might be more apparent in constructed examples using the canonical English NPI such as ever:
Overt NEG: I do not ever eat pizza.
Question: Would you ever eat pizza?
Inherent NEG: I barely ever eat pizza.
Other Licensing: I only ever eat pizza.
The validity of
ever in the four NPI trigger categories and
ever’s invalidity in non-licensing categories illustrates the NPI licensing that will be present (or not) for NPI-
anymore and NPAM in these categories. While we acknowledge, as did
Strelluf (
2019, p. 330), that this is an imperfect coding scheme, it provides a framework for differentiating between clauses that license NPI-
anymore and clauses that could only contain NPAM.
We applied two complementary sentiment analytic approaches. First, we assigned a valence rating to each tweet based on the Valence Aware Dictionary for sEntiment Reasoning (VADER;
Hutto & Gilbert, 2014) using the R package vader (
Roehrick, 2020). VADER was built specifically for measuring valence in social media texts (
Hutto & Gilbert, 2014). It is based on a dictionary of crowd-sourced valence ratings for more than 9000 lexical items, including some emojis and common social media initialisms. VADER returns valence ratings for each word in a tweet and then an overall weighted valence measurement for the tweet.
In addition to being specialized for sentiment analysis in tweets, VADER is further suited to our dataset because it is polarity-sensitive. In some sentiment analysis approaches, a given word is always assigned the same rating regardless of facts about the clause in which it occurs. Because of this, potential effects of a polarity-switch in a clause are a methodological concern. For instance, the phrase “I am not happy” contains the same words as “I am happy” barring the negator
not, and traditional sentiment analyses miss the inversion of sentiment generated by
not (see
Taboada, 2016, pp. 332–333 for an overview of strategies for handling negation in sentiment analysis). This is of course of paramount concern as we distinguish between NPI-
anymore and NPAM, which will differ precisely in whether a trigger is present to flip polarity. VADER, however, does adjust sentiment on the basis of polarity, as demonstrated by the substantial increase in the valence assigned to (2) (reprinted here) when we add clausal negation, as in (2b):
- (2)
Mizzou is a dumpster fire anymore. (Kansas City—[VADER] valence: −0.459)
- (2b)
Mizzou isn’t a dumpster fire anymore. (constructed—[VADER] valence: 0.357)
While VADER’s training and polarity-sensitivity suit it to our Twitter corpus, we were concerned by the way VADER calculates valence on a by-tweet basis. Sentiment dimensions are normally calculated for relatively large passages of text. Because tweets are short, and because many words in tweets are not rated for sentiment (e.g., pronouns, copular verbs, articles, prepositions), it is typical that any given tweet might only contain one or two words that count toward the tweet’s valence. In (2), e.g., only dumpster and fire are rated. By calculating valence from just a few words, it is possible that VADER will generate spurious ratings.
As such, we also applied a more conventional approach of pooling text from many tweets to examine the overall emotional affect in words that were used when
anymore was produced with different NPI triggers (rather than the emotional affect of any single tweet). To do so, we conducted a second analysis by aggregating all words in our dataset and assigning ratings according to Osgood’s semantic differential (OSD;
Osgood et al., 1975). OSD posits that the prominent variance in word semantics is based on valence, arousal, and dominance. Our second study therefore allowed us not only to apply a more traditional sentiment analytic approach but also to extend our analysis to additional sentiment dimensions.
For our OSD analysis, we tokenized and lemmatized tweets into a list of 1,209,344 words using functions in the R packages tidytext (
Silge & Robinson, 2016) and textstem (
Rinker, 2018). We wrote scripts to assign ratings for valence, arousal, and dominance from Warriner et al.’s (2013) 13,915-word dictionary. For instance, the word
dumpster in (2) was assigned ratings of 3.48 for valence, 4 for arousal, and 4.44 for dominance. In contrast to VADER’s model, this approach cannot account for polarity, since words are detached from the clauses in which they were produced.
Dumpster, e.g., would be assigned the same rating whether it occurred in (2) or (2b). As is the case with most sentiment lexica, in
Warriner et al. (
2013) many high-frequency words (i.e., “stop words”) are not assigned sentiment ratings, and (as noted above) many words that were used in tweets were not rated. We were left with a final corpus of 416,248 words with ratings for all three OSD dimensions.
Roehrick’s (
2020) vader package scales overall valence from −1 to 1. To facilitate comparison against OSD ratings, we rescaled VADER valence ratings to run from 1.79 to 7.95, the range of ratings assigned to our corpus for valence by OSD.
We used the base statistical packages available in R to explore sentiment ratings assigned by the two frameworks to language associated with each of the six NPI trigger categories. Visual inspection of the data and Shapiro–Wilk tests showed that ratings assigned by either framework were generally not normally distributed. Accordingly, we tested whether trigger category was a significant predictor of any given sentiment rating by Kruskal–Wallis test (
Kruskal & Wallis, 1952) and then applied Dunn’s test of multiple comparisons (
Dunn, 1964) using the dunn.test package (
Dinno, 2017) in R. The dunn.test implementation makes pairwise comparisons using Dunn’s
z-test-statistic approximations of actual rank statistics, with the null hypothesis that for each pairwise comparison there is a 0.5 probability of observing a randomly selected value from the first group that is larger than a randomly selected value from the second group. We used this combination as a nonparametric equivalent to analysis of variation with post hoc Tukey Honest Significant Difference tests. We built separate models to examine our full corpus and for each of the three NPAM dialect regions. The full outputs of all models are downloadable as
Supplementary Materials. In the results below, we focus on the means of ratings associated with each trigger category and then between-trigger differences calculated from
z-statistics in the Dunn’s test pairwise comparisons (i.e., differences associated with a
p-value are the
z-statistic of one trigger category subtracted from the
z-statistic of a second trigger category).
We hypothesized that NPAM trigger categories would be associated with lower valence scores than NPI-
anymore trigger categories, corresponding to NPAM being produced with affectively negative language. We further hypothesized that NPAM categories would be associated with greater arousal than NPI-
anymore categories. This interpretation homed in on the specific speech act of complaint and assumes that complaining reflects emotional engagement. We also hypothesized that NPAM categories would be associated with lower dominance, focusing on complaints as a speech act performed from a standpoint of weakness. Finally, following
Strelluf’s (
2019) identification of inter- and intra-regional differences in the syntactic licensing of productions of NPAM, we will look for inter- and intra-regional differences in emotional affect.
We have posted scripts that were used to scrape Twitter, assign sentiment ratings, and build our models at
https://files.warwick.ac.uk/cstrelluf/browse/Big_Data (accessed on 15 May 2020). While the end of cost-free access to the pipeline of user content that accompanied Twitter’s rebranding to X has made the platform unavailable for automated scraping to most academic researchers, interested researchers might still use these scripts to assign sentiment ratings to existing corpora or to build scripts for scraping other social media sites, such as those gaining users as a result of the post-Elon-Musk “Twexit.” The
anymore corpus is available by request.
3. Results
3.1. Valence
As an initial view of the outputs of our approaches, we list the tweets that were assigned the lowest and highest valence scores by VADER (26–27) and lowest and highest scores for all three sentiment dimensions assigned by OSD (28–33).
- (26)
Holy shit he’s such a dickhead. Fucking dipshit. omg I am so gonna kill him. I can’t do this anymore. Holy fuck. (Pittsburgh—[VADER] valence: 1.79)
- (27)
Happy birthday to my best friend! So glad you don’t hate me anymore. Hope you have the best day and so excited to celebrate. (Birmingham—[VADER] valence: 7.95)
- (28)
I’m so stressed anymore. (Pittsburgh—[Osgood] valence: 1.79)
- (29)
I live on Pinterest anymore. (Columbus—[Osgood] valence: 7.95)
- (30)
It’s so common anymore. (Indianapolis—arousal: 2.43)
- (31)
My life is so fucked up anymore. (St. Louis—arousal: 6.365)
- (32)
I’m honestly just so lonely anymore. (Pittsburgh—dominance: 3.33)
- (33)
Weekends are boring anymore. (Columbus—dominance: 7.11)
Though individual tweets obviously show variation in sentiment based on the words they contain, the strength of this approach becomes clearer when data are aggregated across the corpus of tweets. Beginning with VADER’s valence ratings,
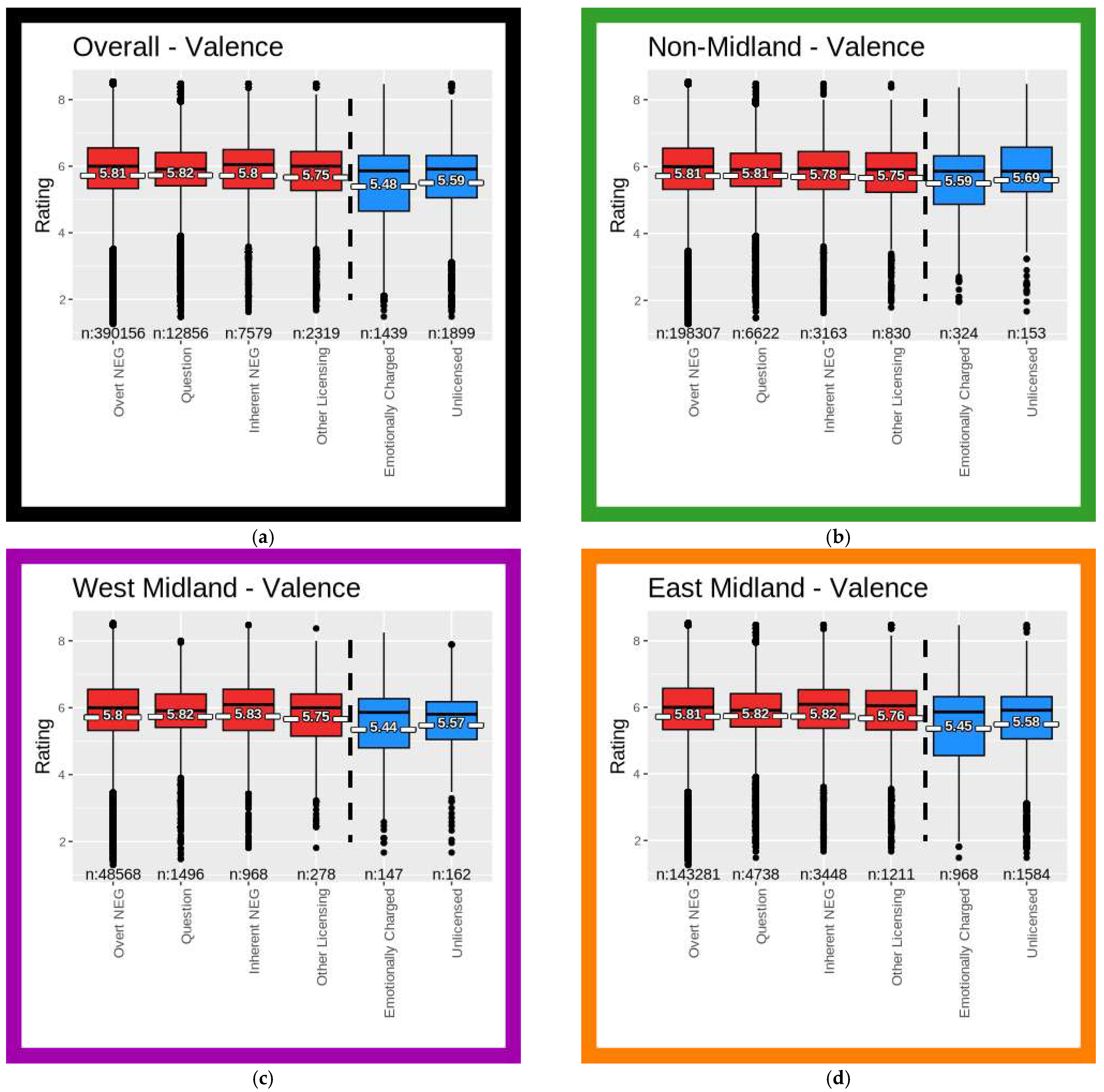
Figure 2 visualizes valence ratings for each trigger category, both across the entire corpus and within each dialect area. It was generated using the ggplot2 package (
Wickham, 2016) in R. A vertical dashed line demarcates the four NPI-
anymore trigger categories (which are also filled red) from the two NPAM categories (blue). Median values are plotted as a dark horizonal line in each box, and mean values are overlaid in white. Sample sizes for each trigger category are printed at the bottom of the boxplots. Colored outlines on the dialect area boxplots correspond to color-coding for cities in
Figure 1.
In the dataset as a whole and within each dialect area, valence measurements are generally, if slightly, lower in NPAM tweets than in NPI-anymore tweets. The lower valence measurements that are associated with NPAM indicate language that is more emotionally negative.
Trigger category is a significant predictor of valence ratings for the overall dataset (KW χ2(5) = 206.5757, p < 0.001). Crucially, differences between z-statistics calculated by Dunn’s test show valence ratings for each NPAM category to be significantly lower than for each NPI-anymore category (e.g., Overt NEG-Unlicensed = 4.373, p < 0.001). Emotionally Charged valence is also significantly lower than valence for Unlicensed (Unlicensed–Emotionally Charged = 4.038, p < 0.001). Given that tweets were coded for Emotionally Charged by virtue of their containing a word identified as intuitively emotionally negative, it is unsurprising that valence ratings for the Emotionally Charged category are lowest in the sample. The striking observation is that tweets coded as Unlicensed—despite not containing a marker of obvious negative affect—join the Emotionally Charged tweets in returning lower valence measurements. Overt NEG is also significantly different from each other trigger category, including its fellow NPI-anymore categories (e.g., Other Licensing-Overt NEG = 2.921, p = 0.003). These valence ratings indicate that when anymore is used with the most canonical NPI trigger of overt negation, it is used with relatively emotionally negative language compared with other standard triggers for medium-strength NPIs. However, NPAM is used with even greater emotional negativity.
Within dialect areas, some trigger categories contain few tweets. For instance, in the non-Midland, just 30 out of 39,915 total tweets were coded as Unlicensed. As such, we will only note general patterns in the three dialect areas. The patterns for the east Midland and non-Midland are essentially identical to the pattern for the overall dataset, with both NPAM trigger categories being significantly lower than all NPI-anymore categories. However, in the west Midland, Emotionally Charged valence is significantly lower than all other trigger categories (including Unlicensed; z difference = 2.080, p = 0.037), but differences between the small sample of Unlicensed and other NPI-anymore categories are not significant.
These by-area results raise the possibility of an intra-regional difference within the Midland in the degree to which NPAM occurs with emotionally negative language. However, the clear conclusion is that language in tweets with NPAM has lower valence than does language in NPI-anymore tweets. This confirms our initial hypothesis that NPAM is associated with affectively negative language.
We regard this result as particularly compelling because of VADER’s emphasis on measuring valence in social media texts and its sensitivity to polarity suit it well to our dataset. The statistical pattern from VADER is replicated, though, when we shift to a more conventional sentiment analytic approach of OSD, shown in
Figure 3,
Figure 4 and
Figure 5 for valence, arousal, and dominance, respectively. These figures follow the layout and color-coding of
Figure 2.
While differences in ratings across trigger categories are more subdued in OSD than in VADER, OSD valence remains consistently more negative in language that occurs with NPAM, both in the overall dataset and within each dialect area. Trigger category significantly predicts ratings (Kruskal–Wallis χ2(5) = 103.5394, p < 0.001). Dunn’s test measures the valence ratings of each NPAM category as significantly lower those of other NPI-anymore trigger categories (e.g., Other Licensing–Unlicensed = 3.583, p < 0.001). In the OSD ratings, the difference between Emotionally Charged and Unlicensed is not significant (z difference = 1.723, p = 0.085). Among the NPI-anymore trigger categories, valence ratings for Question are slightly but significantly higher than those of Overt NEG (z difference = 3.800, p < 0.001) and of Inherent NEG (z difference = 2.121, p = 0.034), but significant differences are not found among other NPI-anymore categories. As such, NPI-anymore and NPAM trigger categories form two relatively coherent clusters in terms of their valence ratings, with language occurring with NPAM categories being associated with lower valence. This indicates that language in tweets that contain NPAM is more emotionally negative than language in NPI-anymore tweets. As was the case with our VADER analysis, valence measured across all words based on OSD confirms the hypothesis that NPAM occurs more with affectively negative language.
This pattern broadly holds within each dialect area. NPAM trigger categories are consistently associated with lower valence than NPI-anymore categories. In the east Midland, as in the overall dataset, measurements for both NPAM categories are significantly lower than those of the four NPI-anymore categories. In the west Midland, Other Licensing is a bridge between the NPI-anymore and NPAM trigger categories, as the Dunn’s test z-statistic for Other Licensing is not significantly different from those of any other category. Otherwise, valence measurements for all NPAM trigger categories are significantly lower than those for NPI-anymore triggers in the west Midland. In the non-Midland, though, only the NPAM category of Emotionally Charged is reported to be significantly different from NPI-anymore trigger categories.
As with VADER, the OSD results may suggest that the semantic feature of negative affect differs across areas, with the strongest association between NPAM and negative affect occurring in the east Midland where NPAM is used most frequently. In the OSD framework, the association between NPAM and low valence is relatively weaker in the non-Midland and complicated by Other Licensing in the west Midland.
3.2. Arousal
Arousal indicates the extent to which language is exciting or engaging as opposed to calm or unstimulating.
Figure 4 shows that NPAM is associated with greater arousal than NPI-
anymore.
In the full sample (KW χ
2(5) = 106.5831,
p < 0.001), arousal ratings for the NPAM trigger categories of Emotionally Charged and Unlicensed are each significantly greater than arousal associated with any NPI-
anymore category (e.g., Unlicensed–Overt NEG = 2.402,
p = 0.016). Among the NPI-
anymore categories, the canonical NPI trigger of Overt NEG is associated with greater arousal than the NPI-
anymore categories of Question and Inherent NEG (e.g., Overt NEG–Inherent NEG = 4.185,
p < 0.001), and ratings for Question are significantly lower than for Other Licensing (
z difference = 2.147,
p = 0.032). As such, there are differences in the relative arousal of language occurring with NPI-
anymore, but arousal associated with NPI-
anymore in general is lower than arousal associated with NPAM. This indicates that NPAM is associated with increased emotional engagement. We speculate that the combination of low valence and high arousal is consistent with NPAM being used in complaints, as suggested by
Labov et al. (
2006).
Within the dialect areas, the east Midland and non-Midland pattern together with both NPAM categories having significantly greater arousal than NPI-anymore. To the extent that arousal reflects complaint, the heightened arousal of NPAM in the east Midland aligns with Labov et al.’s (2006, p. 293, fn. 4) note that “in the eastern part of its range, NPAM appears to be associated with the speech act of complaint.” It extends this association to occurrences of NPAM in the non-Midland.
NPAM is not significantly associated with greater arousal in the west Midland, however. Neither NPAM category is measured as significantly different from any other trigger category, and Other Licensing actually slightly exceeds the means for both NPAM categories.
As was the case with valence, mean measurements for arousal potentially reveal small inter- and intra-regional differences in emotional affect. Increased arousal may be a semantic feature of NPAM in the east Midland and non-Midland but not the west Midland.
3.3. Dominance
Dominance indicates the extent to which language is confident and forceful as opposed to submissive or passive. Looking at how dominance is associated with
anymore usage, we find that estimated means for dominance in
Figure 5 reflect a similar pattern to that found for valence in
Figure 3—though with especially tiny differences across triggers. In fact, in Warriner et al.’s (2013) ratings, valence, and dominance are highly correlated (
r(13,913) = 0.717), and in our corpus, ratings for valence and dominance match this correlation (
r(373,649) = 0.701). As such, dominance mostly reflects the same affective features as valence, and we will only highlight potential insights from the small differences between valence and dominance in OSD.
Within the full dataset, trigger category again significantly predicts dominance ratings (KW χ2(5) = 186.3439, p < 0.001), and measurements for the NPAM categories are significantly lower than those for each NPI-anymore trigger category (e.g., Other Licensing–Unlicensed = 4.222, p < 0.001). NPAM’s association with lower dominance ratings is consistent with NPAM being used with emotionally weak language.
The east Midland dominance ratings for each trigger category correspond to the pattern in the overall sample, with significantly lower dominance measurements for each NPAM category relative to each NPI-anymore trigger category. In the non-Midland and west Midland, a general pattern of the NPI-anymore category Question being associated with high dominance results in significantly reduced dominance for both Emotionally Charged and Unlicensed relative to Question. Emotionally Charged dominance is also significantly lower than Overt NEG dominance in both areas.
In general, then, NPAM is associated with weaker language than is NPI-anymore. This is most firmly entrenched in the east Midland. The west Midland and non-Midland generally follow the overall pattern of using NPAM with language that has lower dominance, but they do not straightforwardly differentiate NPI-anymore and NPAM trigger categories according to this dimension.
While the strength of this observation is limited by the relatively small samples of NPAM in the west Midland and non-Midland and by the correlatedness of valence and dominance in Warriner et al.’s (2013) ratings, the inter- and intra-regional differences in dominance ratings differ from those for valence. In the OSD ratings, the west Midland assigned significantly reduced valence to NPAM, while neither west nor non-Midland clearly associates NPAM with significantly reduced dominance. This nuanced difference in analyses of ratings supports interpretation of affective features varying inter- and intra-regionally.
4. Discussion
Our application of sentiment analysis to a corpus of tweets containing forms of
anymore shows that NPAM is used with language that is rated as unhappier (lower valence), more active (greater arousal), and weaker (lower dominance) than is NPI-
anymore. The association between NPAM and language with lower valence was confirmed in two complementary sentiment analytic approaches. These outcomes provide quantitative evidence that NPAM is associated with emotional negativity in naturalistic productions, complementing
Horn’s (
2021) report of greater acceptability of NPAM in affectively negative stimuli in elicited judgments and providing an essential picture of what language users do with a linguistic variable as a mirror to insights into what they consciously think they do with the variable. Moreover, NPAM is associated with weaker language in the east Midland and more active language in the east Midland and non-Midland, which we interpret as consistent with the speech act of complaining. We believe that our findings for NPAM carry broader implications for work in the semantics of NPIs, dialectology, micro-syntax, sentiment analysis, and variationist sociolinguistics, which we describe below.
4.1. Affect and Processes of Change in NPIs
Our findings support the suggestion in past work that a feature of grammatical negativity in NPI-anymore has shifted to one of emotional negativity in NPAM. This gives empirical credence to the possibility that affect-licensing may be part of the process that leads to the loss of the grammatical polarity-licensing requirement in NPAM. Negative affect could, for instance, support syntactic rescuing to license an utterance or interpretation of NPAM for a language user whose grammar contains only NPI-anymore. On encountering a sentence like (2), a person with an NPI-anymore-only grammar could use the emotionally negative affect in the sentence to prevent derivational crash, despite the lack of a negative polarity trigger. Conversely, a person with an NPI-anymore-only grammar could potentially generate (2) by rescuing the polarity requirement via affective licensing. Either way, emotional negativity would become a non-syntactic, affective trigger for NPAM. While Horn’s example of NPI ever (cited above from p.c.) being more acceptable in emotionally negative clauses establishes a precedent for affective rescuing, the pattern for NPAM seems to be robust and systematic in a way that, to our knowledge, has not been previously attested in the literature of NPIs. This is a promising pathway for understanding relationships between changes in polarity licensing and the cognitive processing of polarity and affect.
Syntactic rescuing via affective licensing could also help make sense of NPAM’s long-term endurance as a regional grammatical feature (i.e., surviving as a uniquely US Midland feature from Ulster Irish immigration in the eighteenth century—cf.
Eitner, 1949;
Montgomery & Hall, 2004;
Strelluf, 2019,
2020) despite the fact that language learners would likely encounter a low-frequency variable like NPAM rarely. If language users are able to rescue a feature via affect, then it might be able to occur at very low levels in language inputs and still persist in a language variety.
4.2. The Paradox of NPAM Research
The confirmation through sentiment analysis that productions of NPAM are associated with emotional negativity has implications for studying the linguistics of low-frequency variables. We detailed the paradox created by the necessity of studying low-frequency features like NPAM via consciously elicited acceptability judgments and the inability of respondents to accurately evaluate the acceptability of low-frequency features. However, like
Strelluf (
2019), which found that productions of NPAM confirmed the status of NPAM as a regional dialect feature, we found that productions also confirm the negative affect feature of NPAM previously posited on the basis of elicited acceptability judgments and (often unsystematic) scholarly observations.
Indeed, sentiment analysis bolsters relatively fine-grained descriptions of NPAM’s affect—including Labov et al.’s (2006, p. 293, fn 4) note that NPAM is associated with complaints in the area we have analyzed as the east Midland.
Horn’s (
2021) maps are inconclusive on this link between region and complaint: the positive-affect stimulus, “It’s great to fly first-class anymore,” appears to show slightly higher acceptability ratings in the area we have analyzed as the west Midland than in the east Midland, while “Anymore he watches what he eats” shows higher acceptability in the east. The nature of those stimuli as constructed may be relevant here;
Blanchette and Keppenne (
2024) collected ratings of the naturalness of NPAM statements and found that, among respondents from Pennsylvania, stimuli adapted from the NPAM tweets in
Strelluf (
2019) were rated as more natural than NPAM stimuli constructed by the researchers. While Blanchette and Keppenne’s purpose in collecting these ratings was to probe the role that exposure to NPAM played in knowledge of NPAM’s assertive and presuppositional content, the outcome also highlights that low-frequency features may be used and interpreted differently “in the wild.” In the
anymore corpus made possible by social media, the sentiment dimensions of arousal and dominance suggest that NPAM is indeed less strongly associated with complaints in the west Midland than in the east Midland or, to an extent, non-Midland.
We interpret these findings as affirming (following, e.g.,
Bailey et al., 1997) the validity of surveys of acceptability judgments for studying the semantics and usage of NPAM, and as extending this validity to the level of relatively fine-grained inter- and intra-regional differences in lexical semantics. However, we suggest that studies of judgments and productions of features like NPAM will only be reliable through the aggregation of large datasets and not at the level of individual judgments and productions. Methods for building large datasets—whether through massive acceptability surveys like the Yale Grammatical Diversity Project in
Horn (
2021) (see
Zanuttini et al., 2018, more generally) or datamining natural-language productions as here and in
Strelluf (
2019)—are crucial for understanding NPAM and other low-frequency variables of which speakers’ conscious knowledge is suspect. Furthermore, we believe that we have demonstrated that big data and corpus linguistic approaches like sentiment analysis can offer essential tools to uncover linguistic characteristics that will not necessarily be reliably observable at the utterance level but will be empirically revealed in aggregate.
4.3. Sentiment Analysis, Regional Dialectology, Variationist Sociolinguistics, and Micro-Syntax
Strelluf (
2019) discovered surprising inter- and intra-regional differences in the rates at which specific NPI-triggers licensed productions of
anymore. We mirror this finding by potentially revealing nuanced differences in affective licensing between and within regions. For instance, the west Midland showed anomalously high arousal for Other Licensing. This appears to align with
Strelluf’s (
2019, p. 343) observation in the west Midland city of Kansas City of “relatively elevated levels [of NPAM] in several NPI-licensing environments” that we included in the Other Licensing category.
Strelluf (
2019) pointed out that many of these instances of
anymore, while occurring after a trigger of NPI-
anymore, could be interpreted as NPAM. For instance, in the examples given in
Strelluf (
2019, p. 343), the gloss often used for NPAM in research, ‘nowadays,’ could easily be substituted for
anymore:
- (34)
Hard to tell anymore. (Kansas City; cf. Hard to tell nowadays.)
- (35)
I only write in cursive anymore. (Kansas City; cf. I only write in cursive nowadays.)
- (36)
Seems like all I do anymore on my days off is clean. (Kansas City; cf. Seems like all I do nowadays on my days off is clean.)
Strelluf (
2019, p. 343) suggested that a subset of triggers included in this paper under Inherent NEG and Other Licensing might operate “to transition interpretations and uses of
anymore from negative- to positive-polarity contexts.” Perhaps, then, the elevated arousal of Other Licensing in the west Midland (and non-significant differences generally between trigger categories in the west Midland in the dimensions of arousal and dominance) reflects the regional difference that
Strelluf (
2019) described, with
anymore being used according to the lexical semantics of NPAM in a syntactic condition where NPI-
anymore occurs. Or, as we noted above, it may be that the emotional negativity associated with NPAM simply differs within and between dialect regions.
NPAM is the type of linguistic variable that is increasingly treated under the frame of micro-syntax, which examines syntactic variability within ostensibly similar grammars (e.g.,
Horn, 2014;
Zanuttini & Horn, 2014;
Zanuttini et al., 2018;
Wood & Zanuttini, 2023). Sentiment analysis techniques applied to the micro-syntactic feature of NPAM revealed further variability within the micro-syntactic feature, suggesting differences not only between licensing in NPI-
anymore and NPAM grammars but also within NPAM grammars. Strelluf (2019, p. 344) argued that proportional differences in
anymore productions across syntactic polarity triggers inter- and intra-regionally were indicative of scalar differences in the strength of licensing requirements among speakers (as argued by Hindle and Sag, 1975, pp. 89–90; Horn, 2021, p. 8; Blanchette and Keppenne, 2024, p. 8). Our application of sentiment analysis extends findings of scalar differences inter- and intra-regionally in productions of
anymore to the semantic-affective domain. A crucial implication of this is that researchers examining NPAM—and potentially any other micro-syntactic feature—must consider that different speakers or dialects may land at different points along these continua. Put another way, sentiment analysis reveals that a given micro-syntactic feature might not actually be a single monolithic feature and might not actually be the same feature when compared between speakers and across dialects.
The potential value of sentiment analysis as a tool to reveal micro-syntactic variability extends more generally to variationist sociolinguistics. Simply put, sentiment analysis, particularly when applied to large datasets compiled from sources such as social media, offers a tool for exploring emotion and affect as predictors of why, when, where, and under what circumstances a language user might select one variant or another. As social media datasets can make low-frequency linguistic features available for variationist study, sentiment analysis can offer a new tool for studying linguistic variation.
The fact that sentiment analysis reveals features about regionally differentiated micro-syntactic variability also has implications for sentiment analysis. Traditionally, sentiment analysis has focused on “big” datasets, providing analyses at the level of documents or groups of people. While our study has still used a “big data”-style corpus for sentiment analysis, our work on NPAM has shown that once a large corpus is assembled, sentiment analysis is viable for examining very small features of language.
As such, our approach to NPAM points toward micro-sentiment-analytic or micro-semantic frameworks to be leveraged in the study of micro-syntax, regional dialectology, and language variation and change.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}