The extent to which language influences thinking has been a focus of study for decades in the fields of anthropology, linguistics and first language (L1) acquisition, psychology, and recently in second and bilingual acquisition research. Focusing on the influence of language on online thinking, Slobin’s thinking-for-speaking hypothesis (TFS) [
1,
2,
3] has provided new insights into this topic and attracted substantial research that explores issues pertaining to conceptual changes in language learning (e.g., [
4,
5,
6,
7,
8]). This hypothesis suggests that speakers are habitually attuned to aspects of an event that are readily codable in the language while they are formulating speech. This TFS process varies cross-linguistically and can be observed in all forms of production and reception such as thinking for speaking/writing, listening/reading for understanding, thinking for translating, or listening for imaging [
2,
9]. Although Slobin’s TFS framework underscores the online effects of language on thought processes, there have been very limited experimental methods employed to study the real time processing of TFS, especially for second language (L2) learners. It remains unclear whether or how well L2 learners can acquire the thought patterns of the L2 while processing the language online. This study filled the gap by adopting a simulation-based approach [
10,
11] to examine patterns of mental simulation produced by L1 speakers and L2 learners in real-time processing of motion language containing deictic paths.
1.1. Language and Thought in Motion Language Processing
Slobin’s TFS hypothesis [
1,
2,
3] claims that because each language provides a limited set of linguistic options to its speakers, instead of reflecting a direct representation of a situation, the activity of thinking takes a particular quality when one is engaging in the activity of speaking. He called this dynamic process “thinking for speaking”, which involves attending to aspects of objects or events that are readily codable in the language when preparing, producing, and interpreting verbal messages. Following Talmy’s [
12,
13] two-way motion event typology, Slobin [
9,
14] examined narratives produced by speakers of satellite-framed and verb-framed languages (S-languages and V-languages, respectively) and identified distinct characteristics between the two groups. Because of the large differentiated manner verb lexicons offered in S-languages, their speakers are habitually attuned to the fine-grained distinctions of manner, so as to capture features of manner. By contrast, V-languages do not encode manner in the main verbs but require their speakers to encode the path information. While V-languages also provide speakers the option of encoding manner via an adverbial or gerund outside of the main verb, this means requires more processing effort. Consequently, when describing the same motion events, speakers of S-languages encode manner information more frequently than speakers of V-languages. The same patterns were also found in mental imagery in Slobin [
9]. He gave English (S-language) and Spanish (V-language) speakers the same passages to read and asked them to report mental imagery for the protagonist’s movement. The passages were extracted from Spanish novels, in which manner verbs were not used but can be inferred from descriptions of the terrain and the protagonist’s inner state. English speakers were given a literal translation of the Spanish texts. Interestingly, all English speakers reported mental imagery for the manner in which the protagonist moved using verbs such as
stagger,
stumble, or
dodge, whereas the Spanish speakers focused on the static surroundings of the scene. Other empirical studies also confirmed that speakers of S- and V-languages attend to different components of motion events while producing or interpreting linguistic communications about motion (e.g., [
6,
15]).
1.2. Listening for Imagery by Native Speakers
Other methods that have been used to study processing of motion language are behavioral experiments designed to study mental imagery or simulation as well as the activation of neural patterns corresponding to perceptual or motor experiences, which are grounded in a variety of experiential domains, including cognitive, physiological, biological, and cultural (cf. [
10]). Mental simulation or imagery as a basic form of cognition plays a crucial role in many thought processes such as communication, navigation, memory, and problem solving [
16]. Simulation-based theories of language processing claim that understanding language involves the automatic and unconscious running of mental simulation related to the content of the utterance [
10,
17,
18,
19,
20,
21,
22,
23]. Studies using neuroimaging technology, such as Positron Emission Tomography (PET) and functional Magnetic Resonance Imaging (fMRI), have provided convergent evidence concerning the localization of simulation (e.g., [
24,
25,
26]). In these studies, it was observed that mental simulation for understanding an utterance uses the same neural circuitry as those activated when one actually perceives or performs the action named in the utterance. That is, when a language learner runs a simulation in understanding a motion sentence such as
Throw the ball to me, the neural motor structures responsible for the action of throwing a ball are activated as well.
Two kinds of behavioral predictions are commonly made in simulation-based approaches: compatibility effects and interference effects [
10]. The distinction between these two effects lies in the timing of the presentation of stimuli. Compatibility effects are expected when the presentation of the sentence and a corresponding image/action
do not overlap temporally, and the presentation of the sentence appears before the image or action. In such a design, the simulation that occurs while processing the preceding sentence facilitates the response in the following task if the image or action matches the sentence in terms of orientation, shape, type of action, etc. Such a facilitation effect occurs because the neural regions responsible for comprehending the content of the sentence are activated, which primes the activation of the same neural regions for the subsequent compatible task. Zwaan et al. [
23] used an experimental design to elicit compatibility effects. Participants first heard a sentence describing the motion of a ball toward or away from the listener (e.g., toward condition:
The shortstop hurled the softball at you; away condition:
You hurled the softball at the shortstop). They then saw pictures of objects presented in a smaller-bigger sequence (suggesting movement toward) or a bigger-smaller sequence (suggesting movement away) and were asked to decide whether the two pictures displayed the same object. A compatibility effect was observed. Participants responded more quickly to visual stimuli that matched the direction of movement described in the sentence they had heard, showing that the participants constructed a visual simulation during sentence comprehension.
The second kind of behavioral prediction is that of an interference effect. When the presentation of the sentence and the image/action
overlap temporally, or the presentation of the sentence appears after the image or action, interference effects between the two tasks can be expected. In contrast to compatibility effects, the simultaneous presentation of the sentence and the image/action requires the same neural structures to process multiple tasks simultaneously, and thus processing is slowed for the two tasks. Kaschak et al. [
11] is an example of a method that was designed to elicit interference effects. Participants were asked to decide whether the sentence they heard was meaningful or not while simultaneously watching a visual presentation of motion. The critical sentences described events involving movement in one of the four directions (up, down, toward, or away), such as
The car approached you (toward condition) or
The car left you in the dust (away condition), and the visual presentation also depicted one of the four directions. It was found that participants took longer to decide on the meaningfulness of the sentence when the visual stimulus and the sentence both involved motion in the same direction, because the same cognitive structure was required to process two competing tasks.
Simulations evoked by linguistic input can reflect universally-shared human experiences, as well as language-specific differences in patterns of imagery [
10,
27]. Such differences in the construction of mental simulations can be illustrated by the following two scenarios, involving boiling water and chewing betel nuts. Most people are familiar with the perceptual experience of seeing and hearing boiling water. When hearing the sentence
The water on the stove is boiling, people unconsciously run a simulation depicting the heat, vapor, or bubbles rising from the bottom of the pot. However, some experiences can be specific to languages, cultures, and individuals. For instance, upon hearing the sentence
Chewing betel nuts brought him a burning sensation and made his teeth and mouth bloody red, the mental representation evoked by this linguistic input can vary profoundly, depending on whether one has had the experience of chewing betel nuts or has seen other people do so, or whether one has other factual knowledge of betel nuts. For example, a mouth cancer expert may have a simulation with more vivid details concerning the medical effects of betel nut chewing, which would be unlikely to take place for people who lack such knowledge or relevant experience. Given that mental simulations are specific to languages and experiences, the typologically different TFS patterns observed between speakers of S-languages and V-languages are likely to be implicated in the existence of different simulation patterns between such two types of speakers.
1.3. Listening for Imagery by L2 Learners
Few attempts have been made to investigate whether and how language-driven mental imagery developed in L2 learning. Following the method used in Bergen et al. [
19] with English NSs, Wheeler and Stojanovic [
28] used an image-verb forced-choice matching task to test if proficient L2 English learners show the same interference effects as L1 learners. They showed first an image depicting an action and then a verb describing an action (e.g.,
grab,
kick, or
lick). The image and verb either used the same effector (e.g.,
grab and
push both use hand) or different effectors (e.g.,
grab uses hand;
lick uses mouth). The participants’ task was to determine whether or not the image and the verb depicted the same action as quickly as possible. In the non-matching conditions, they found that it took the participants longer to decide when the image and verb used the same effector than when they did not. When processing the image and verb that used the same effectors (e.g., image of
jump followed by verb
kick), it required co-activation of the same neural representations for processing the image and the verb, which resulted in a longer response time for two competing inputs involving the same areas of motor cortex. By contrast, when the image and verb depicted actions using different effectors, there was less similarity in the neural representations and thus made the simultaneous processing easier (cf. [
29,
30]). The 40 L2 participants in Wheeler and Stojanovic [
28] were mostly international students studying in a public university in the United States and their mean length of English study was 14 years. Although the response times overall were longer than the NSs in Bergen et al. [
19], the results suggested that proficient L2 learners can perform automatic mental simulation while comprehending motion language in a way similar to NSs.
In another study on simulation with English prepositions, Shoen [
31] examined patterns of mental simulation in L1 and L2 English learners. The 36 L1 participants and 35 L2 participants first heard a sentence containing a preposition (e.g., the man went
up the mountain) and then saw animated geometrical shapes representing the semantic content of the preposition with a moving object and a fixed landmark. The visual display either matched or mismatched (i.e., match condition: upward display vs. mismatch condition: downward display) the preposition heard in the sentence. The participants’ task was to answer whether the moving object they saw was a square or a circle as fast as possible. The results suggested presence of compatibility effects for matching conditions, but was not statistically significant for the L1 group. The L2 group, by contrast, did not pattern with the L1 group and no statistically significant result was found.
While there have been a substantial number of studies on the role of mental simulation in sentence processing by L1 learners, little research has been conducted to explore L2 learners’ online performance in this regard. Focusing on L1 and L2 TFS, the present study aims to explore whether or how well L2 learners of heritage and foreign language backgrounds engage in mental simulation of deictic paths while processing motion language online.
1.4. Chinese Deictic Paths
According to Talmy’s motion event typology [
12,
13,
32], the Chinese language typically uses path satellites to denote path information, which falls in the classification of a satellite-framed language. Slobin [
14,
33] reanalyzed such constituents as full path verbs with an equal status as the preceding manner verb, and treated both the manner verb and the path verb together as a serial verb construction. He proposed serial-verb languages such as Chinese and Thai should be classified into a third type-equipollently-framed languages. The debate over whether or not Chinese should be considered an equipollently-framed language has been a topic of heated discussion with no general consensus being reached thus far (see discussions of different stances in [
32,
34,
35,
36,
37,
38,
39]. Nevertheless, it is generally agreed that Chinese encodes deictic paths more frequently than English. Chen [
35] (p. 53) reported that 55% of the motion event descriptions found in 59 Chinese frog stories encoded deictic paths. Wu [
40] examined 240 motion events that involved movement of an object produced by 40 Chinese speakers and found that 93% encoded deictic paths. Slobin [
14] also commented that space deixis seems to be more closely tied to conceptions of path for Chinese speakers, as compared to the other groups of speakers.
| 1. | a. | 小 | 王 | 走 | 進 | 來 | 了。 |
| | | Xiǎo | Wáng | zǒu | jìn | lái | le |
| | | Little | Wang | walk | into | hither | CRS |
| | | ‘Little Wang walked in [hither]’. |
| | b. | 他 | 把 | 椅子 | 搬 | 進 | 辦公室 | 去 | 了。 |
| | | Tā | bǎ | yǐzi | bān | jìn | bàngōngshì | qù | le. |
| | | he | Prep. | chair | move | into | office | thither | CRS |
| | | ‘He moved the chair into the office [thither]’. |
In addition to a path particle such as
into,
out, or
down that indicates direction of a movement, Chinese speakers frequently attach a deictic hither/thither path from the perspective of the speaker:
lái ‘moving toward the speaker’ or
qù ‘moving away from the speaker’. The deictic path informs the interlocutors of the relative location where one is standing and where the moving figure is heading. As shown in example (1a), the hither path
lái denotes that the agent Little Wang is walking into a space and moving toward the speaker. Substituting the hither path
lái with the thither path
qù would completely change the relative location of the two, where Little Wang is walking into another space further away from the speaker. If the deictic cue is overlooked or misinterpreted, the interlocutors would not be able to quickly construct the correct relative location between oneself and the moving figure. Such use of space deixis is habitually encoded when describing movement of objects as well. For instance, the thither path
qù in (1b) tells that the movement of the inanimate object
shū ‘book’ to the office is in a direction away from the interlocutors, suggesting that they are in a location other than the office. Note that the use of deictic paths is mostly a matter of choice, but there are occasions when it becomes a matter of grammaticality. Specifically, when the sentence does not have a location or object noun (e.g., removal of ‘office’ in example (1b)), it becomes necessary to encode the deictic path for the utterance to be grammatical (cf. [
7]).
Properly uttering deictic expressions involves several simultaneous dimensions of processing. Interlocutors need to resort to perception, proximity, and ongoing interaction in the context of utterance [
41,
42]. For two interlocutors to communicate effectively, they need to share not only the same grammar, but also the same pragmatically appropriate ways in orienting themselves verbally and perceptually in context. Encodings of deictic paths presents language-specific TFS patterns, in which the deictic path needs to be frequently attended to in different social situations. It has been noted that this conceptual restructuring presents considerable challenge for L2 learners whose L1 does not require such encodings of deictic relations. The deictic paths were often misused or ungrammatically omitted by English-speaking learners of L2 Chinese [
7,
40]. Wu [
7,
40] also reported that heritage language learners (HLLs) performed better than foreign language learners (FLLs) of the same proficiency level in supplying deictic paths, potentially because HLLs have more opportunities to use deictic paths in different social contexts in real-life situations. It is therefore important to examine whether there is a difference in processing deictic paths between these two types of learners.
As suggested by Slobin [
1], L2 learners may require a relatively long period of time to restructure their L1 TFS in order to be able to express motion events fluently in the L2. To explore the underlying cognitive processes that may not be obvious from speech, it would be desirable to apply methods developed in simulation-based research to explore the online processing of deictic paths in an L2. If L2 learners can process Chinese deictic paths in a way similar to L1 learners, which would require them to show similar simulation patterns as the L1 learners, this would suggest that they have successfully internalized the L2 TFS patterns.




{kind=link}
{kind=link}
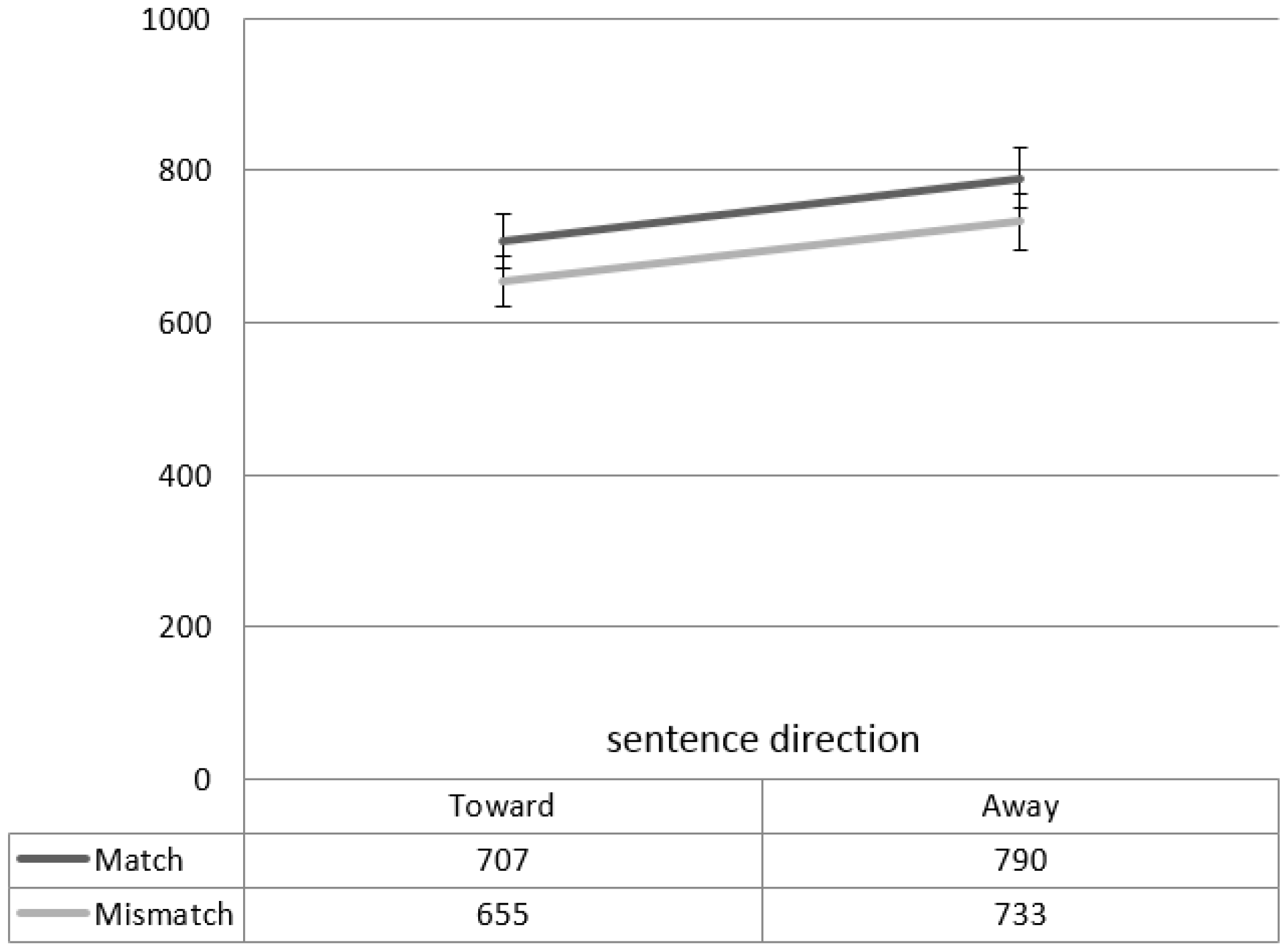{kind=link}
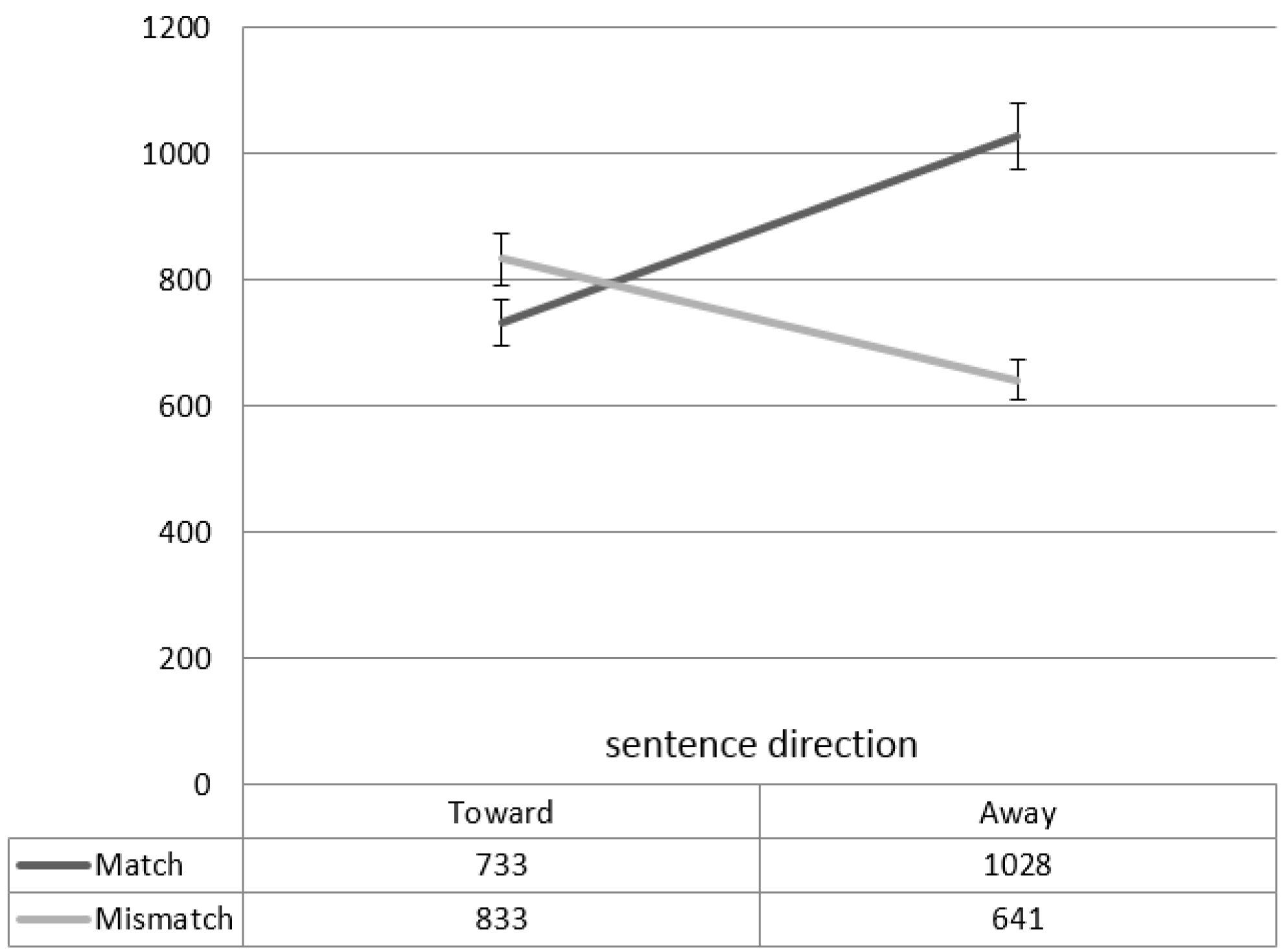{kind=link}