1. Introduction
With the increasing frequency of commercial activities since the 1960s, spacecraft numbers continue to grow rapidly. Unavoidably, there has also been an increase in the spacecraft with launch and on-orbit operation failure [
1]. Once spacecrafts, with autonomous maneuvering and decision-making capabilities, are out of control, their potential unconventional and irregular maneuvers endanger the safe operation of spacecraft on orbit, and the losses would be difficult to estimate. Therefore, in the research of on-orbit service in recent years, the safe approach and processing of out-of-control spacecraft have been paid more attention. In general, the disposal of satellites can be completed by analyzing the orbital data towards its end of mission, if it carries de-orbiting devices. However, once a satellite is out of control, its disposal has to be on-orbit processed by an active debris removal spacecraft.
In this paper, an approach method for a class of uncontrolled satellites with space situation awareness is studied. Such satellites have the ability to avoid obstacles and can make autonomous decisions to keep on-orbit service spacecraft away. Since the target can automatically perceive space information and make unconventional maneuver strategies, a bilateral optimal strategy, which considers target irregular maneuvers, based on game theory, is more suitable than the traditional unilateral optimal control strategy [
2]. In addition, the out-of-control satellite has unknown maneuvers. Consequently, the pursuer cannot obtain the complete information of the target through traditional means, such as two-line elements (TLE), which leads to the problem of incomplete information game. Therefore, it is of great significance to study the pursuit game problem of the out-of-control spacecraft with obstacle avoidance capability under incomplete information. We explored the problem of space rendezvous and approach of out-of-control spacecraft within the problem of game without considering non -peaceful purpose.
There have been many studies on the two-side game, where the target has maneuverability, and most of these are based on differential game theory and applied in the military field [
3]. Ye [
4] derived vector guidance for satellite proximate interception. The formula for calculating the intercept time was given, by which the interception with the desired miss distance could be achieved. Stupik [
5] derived the optimal thrust angle for the satellite game, based on the Hill-Clohessy-Wilshire (HCW) equation. The particle swarm optimization was used to obtain an open-loop solution, while closed-loop control strategy was given by interpolating and extrapolating a series of trajectories. For the game with complex dynamics of the two players, the problem evolved into the two-point boundary value problem (TPBVP) with coupled nonlinear equations, which is difficult to solve. Aiming at this problem, authors in Refs. [
6,
7,
8] used the genetic algorithm to approximately calculate initial value of the adjoint state so that, then, the exact value could be calculated by nonlinear programming. In Ref. [
9], the thrust configurations of the two players were assumed to be different. Then the pursuit–evasion game was transferred into a TPBVP with four unknowns and four nonlinear equations. Based on the indirect method, a numerical algorithm for solving the TPBVP was proposed. Gutman [
10] derived the missile vector guidance laws in the polar coordinate and in the spherical coordinate, respectively. Furthermore, a quadratic equation on time-to-go was proposed to determine the terminal intercept time, and the bifurcation of this equation was discussed in Refs. [
11,
12]. With this method, the shortest intercept time could be calculated and rapid interception could be achieved.
Game theory also provides a suitable frame to study the sophisticated optimal decision and control problems, where the performance index function of each player depends on the control strategies of itself and all other players. In Ref. [
13], the two-side game was considered first and the target strategy could be optimized based on the attacking missile strategy. In addition, the author analyzed the game with three players. The target evasion strategy and the defender pursuit strategy were derived cooperatively. Simulations indicated that the defender could intercept the attacking missile using the cooperative strategy. Perelman [
14] considered the three-player game and derived a closed-loop game strategy based on continuous dynamics and discrete dynamics, respectively. Then, the guidance gains and the condition of the saddle-point existence were analyzed under the different game cases. Simulations showed that the pursuer could be attacked by the defender, and the target was used as a bait to lure the pursuer. Literature [
15] proposed a differential game method to stabilize a combined spacecraft composed of multiple microsatellites and a failed spacecraft, in which each microsatellite could independently calculate its own control strategy. Numerical simulations verified the effectiveness of the differential game method in the attitude takeover control of the failed spacecraft.
These literatures mentioned above were the application of complete information game strategy under idealized conditions. This paper will focus on the safe approach of uncontrolled spacecraft with continuous and dynamic obstacle avoidance ability under incomplete information. In a practical pursuit process, some players have private information, and others should consider this fact when forming expectations of these players’ behaviors. The pursuer may not obtain game information completely due to lost contact and component damage of the target. Aiming at the incomplete information problem, Ref. [
16] considered the evasion defense problem for a given interceptor strategy. For the target and the defender, the optimal strategy of single-direction communication and the game strategy of two-direction communication were derived, respectively. Refs. [
17,
18] investigated the incomplete-information and imperfect-information situations based on double integral dynamics. The missing information was treated as the extended state, and then the observer was applied to estimate the information. Satak [
19,
20] used series extension to approximate the unknown game value function, which played a key role in strategy derivation, and the series coefficients were updated by the observable target information. In Refs. [
21,
22], authors used the multiple mode adaptive estimator to identify the unknown guidance law of the pursuer. Several filters matched to possible guidance laws were applied to obtain estimated posterior probability. By fusing guidance laws in probability, the target strategy and the defender strategy could be derived. Wang [
23] proposed a method to degenerate the game into a strong tracking problem. The extended Kalman Filter was used to obtain relative state of the target, the observability was analyzed under different measurement methods, based on linear quadratic differential game theory. Similar to the optimization object considered in this paper, one of the goals of our paper is to approach the target with minimal fuel consumption.
We should consider not only the completeness and symmetry of the information during the dynamic game scenario, but also the potential unconventional and irregular changes of the target maneuver strategies. The pursuer can adopt hybrid game strategies to cope with the capricious changes of the target maneuver strategy effectively. Hafer [
24] considered the scenario where the spacecraft needed a hybrid strategy to avoid obstacles and evade another spacecraft. By comparing game value and obstacle value, the spacecraft would switch its strategy to balance the two missions. Turesky [
25] derived evasion strategy for hybrid pursuit dynamics. If the switch information was available to the target, the evasion strategy could be given as a bang-bang form, which relied on the switch function and the zero-effort miss (ZEM). On the other hand, the matrix game was formulated for the incomplete-information scenario. Through the Nash equilibrium, the mixed saddle-point solution could be given, which guaranteed the low bound of ZEM. Shinar [
26,
27] considered the pursuit-evasion game with hybrid pursuer dynamics and evader dynamics. On this basis, the corresponding opponent’s strategies were derived and the capture zone was constructed.
In summary, in the current research methods of the game problem in aerospace, the theory of differential game accounts for the majority [
28,
29,
30]. Although there is much research on pursuit–evasion, most of the discussions are about a situation in which the pursuer can obtain complete information of the target. However, due to lost contact of the target or the failure of its components, the target information is not completely available to the pursuer in practice, which makes the pursuit not achievable. Moreover, in Refs. [
17,
22], although the authors consider the incomplete-information situation, the player dynamics are simplified, which is not consistent with the actual scenario of spacecraft pursuit. All in all, the formation of the game relationship requires conflict of interests between spacecrafts. A large amount of literatures have studied the application of differential game in the field of target interception. However, this paper focuses on its application in the field of on-orbit services. Thus, this paper applies differential game theory to space rendezvous and the approach of runaway spacecraft, regardless of its non-peaceful uses. We assume that the pursuer can change its maneuver strategies during the game process, and that the target knows the maneuver strategies that the pursuer may take, that is, the target has complete information during the game process, but does not know the actual game strategy taken by the pursuer. In this scenario, we propose the optimal hybrid game strategy in pursuit of the out-of-control spacecraft using its incomplete information. The designed hybrid game strategy can achieve a rapid approach while saving fuel consumption. This approach strategy, based on game theory, can also deal with failed targets with dynamic avoidance capability in the future constellation.
This paper is organized as follows: the relative dynamics model is first established in
Section 2, the complete information game strategy pairs and the game strategies under incomplete information are subsequently derived in
Section 3. The target missing information is estimated by the disturbance estimator and the corresponding optimal hybrid strategy is then presented in
Section 4. Simulation study has been conducted to verify the proposed hybrid game strategy and evaluate the satellite safe approach performance in
Section 5. Lastly, conclusions are presented in
Section 6.
2. Relative Dynamics Model
For the spacecraft terminal approach, we can establish a moving orbital coordinate to derive the relative dynamics for the pursuer [
4]. As shown in
Figure 1, we can establish a satellite near the pursuer as the reference satellite
O1, with
P as a pursuer. A non-inertial orbital coordinate frame
O1xyz, known as the local vertical local horizon (LVLH) coordinate [
31] can be established by setting the center of the reference satellite as the origin. The
O1x axis is directed from the Earth’s center to the reference satellite. The
O1z axis is orientated to the direction of the orbital angular momentum of the reference satellite, and the
O1y axis completes the right-hand rule.
Let
,
be the positions of the reference satellite and the pursuer in the earth inertial coordinate frame
OXYZ. Then, the dynamics of the two satellites can be given as
where
μ is the earth gravitational constant,
is the thrust acceleration of the pursuer.
Defining the relative position between the pursuer and the reference satellite as
and differentiating it, we can obtain the dynamic of the pursuer as
Since the orbital coordinate rotates with the motion of the reference satellite, the relative position derivatives can be derived from the vector differentiation relations as follows:
where
,
are the first and the second derivatives of
in orbital coordinate, and
ω represents the angular velocity of the orbital coordinate frame.
Therefore, the dynamic of the pursuer in the orbital coordinate frame can be rewritten as:
Under the assumption that the reference satellite moves along a circular orbit and the relative distance between the pursuer and the reference satellite is far less than the geocentric distance of the reference satellite, namely,
.
The dynamic of the pursuer in the LVLH coordinate can be simplified to the Clohessy-Wiltshire (CW) equations as:
where
,
,
are position components of the pursuer in the LVLH coordinate, and
,
,
represent the three-axis thrust accelerations of the pursuer.
Defining the state variable
, and the control acceleration variable
, we can rewrite Equation (6) in the state space form as:
with the matrices:
We select another satellite as our target
. For the terminal approach, the pursuer
is close to the target
in position. As the formula deduces, a satellite near them is chosen as the reference satellite to establish the LVLH frame. Thus, the relative dynamics for the two players in the LVLH coordinate are as follows:
where
denotes the state of the pursuer
or the target
in the orbital coordinate, respectively.
denotes the thrust accelerations of the pursuer
and the target
, and satisfies the magnitude constraint, namely,
.
We define the relative state between the pursuer and the target as .
By differentiating the state equation and combining with Equation (8), the relative dynamics can be written as:
where
.
3. Game Strategies under Incomplete Information
From Ref. [
4], the necessary condition for successful interception is that the thrust magnitude of the pursuer is higher than that of the target. When the target thrust is higher than the pursuer, the target will successfully escape. In practical application, due to private information or sensor constraints, the pursuit–evasion game information may not be completely known to the pursuer. Therefore, based on the complete information game strategy pairs, this section studies the pursuit game strategies under incomplete information. The proposed norm-based game strategy can achieve fast approach, while the linear quadratic game strategy can save fuel consumption.
3.1. Norm-Based Game Strategy
The goal of the pursuer is to compete with the target in terms of terminal approach distance. In the norm-based game strategy, it is sufficient to consider only the relative displacements between the pursuer and the target. In order to facilitate later analysis, we define the terminal zero effort misse (ZEM) between the pursuer and the target as .
Thus, the norm-based strategy with ignoring fuel optimization is derived.
where
with
,
is the terminal time of the interception.
is the state-transition matrix of the system (9), with its explicit form being given in [
4], and satisfies:
Differentiating Equation (10) and using Equations (9) and (11) yield:
where
.
Throughout the pursuit-evasion game process, the pursuer expects the target to enter one of the pursuit zones in a limited time, while the target tries to avoid it by increasing the distance with maximum thrust. Therefore, we define the cost function
as:
Define the cost function along a solution as:
Differentiating it and combining with Equation (12), we have:
Since the pursuer
has the intention to minimize
, the strategy
satisfies
. Therefore, the control strategy of the pursuer
with the maximal magnitude constraint can be derived as:
On the contrary, the target
tries its effort to maximize
and its strategy
satisfies
. Therefore, the control strategy of the target
with the maximal magnitude constraint can be derived as:
For the norm-based strategy, the cost function only takes into account the relative position between the pursuer and the target, that is, the pursuer uses its strategy instead of the target strategy. Thus, the absence of the target strategy information has no impact on the norm-based strategy.
3.2. Linear Quadratic Game Strategy
First, we make an assumption that both players can obtain the complete information of the game in the zero-sum equilibrium game. The pursuer has the goal to pursuit the target with minimal cost, while the target increases the distance with the pursuer with minimal cost. Thus, we define the linear quadratic cost function as follows:
where
,
and
are all symmetric positive definite cost matrices, and
is symmetric positive semidefinite cost matrix,
is the terminal time of the game.
Different from the norm-based game strategy, the cost function of the linear quadratic game strategy takes into account fuel consumption. If both sides in the game have complete information about the opponent, the game is zero-sum and associates with a saddle-point strategy pair.
To derive the saddle-point strategy pair, a Hamiltonian function is introduced as:
where
is the adjoint variable.
Thus, the game saddle-point strategy pair is obtained as:
where
can be determined by:
with
satisfies the terminal condition:
Next, to derive the target strategy under incomplete information. The pursuit information may not be completely known to the pursuer in practice, which causes the strategies derived in Equation (20) not be applicable. Thus, the approach strategy under incomplete information is studied, and we make an assumption as follows:
Assumption 1. The pursuer can obtain the target state information, instead of the target maneuver information. On the contrary, the target can perceive the complete information of the whole game.
Under this assumption, the pursuer considers the target strategy to be
, and the relative dynamics can be written as:
Thus, the pursuit strategy can be derived by minimizing the one-side cost function
where
,
and
are identical to that in Equation (18).
The Hamiltonian function is defined as:
From the optimal control condition
, we have
The necessary condition for the optimal saddle-point solution includes the adjoint equation
, namely:
in conjunction with the boundary condition:
Assuming the adjoint variable and the relative state also satisfy the linear relationship as follows:
where
is also a symmetric positive definite matrix, namely,
. Then, the assumption given in Equation (30) is valid.
Differentiating Equation (30) and combing with Equations (23), (27) and (28), we can obtain the Ricatti equation as follows:
From the boundary condition in Equation (29),
also satisfies the terminal condition:
Thus, the one-side pursuit strategy is determined by Equations (27) and (30)–(32), namely:
For the target, the target knows the maneuver strategy that the pursuer may take, that is, the target has the complete information about the game process, but does not know the actual strategy taken by the pursuer after estimating the incomplete information. Therefore, the target’s game strategy can be optimized by considering the pursuer’s game strategy to obtain better avoidance performance.
Thus, with the pursuer using strategy (33), the relative dynamics can be rewritten as:
where
is a time-varying matrix and defined as
.
The target one-side optimization cost function is defined as:
where
,
,
are identical to Equation(18).
Similar to the derivation of the pursuer strategy, the optimal strategy of the target is given as:
where
is symmetric positive definite, and satisfies:
with the terminal condition:
4. Optimal Hybrid Game Strategies
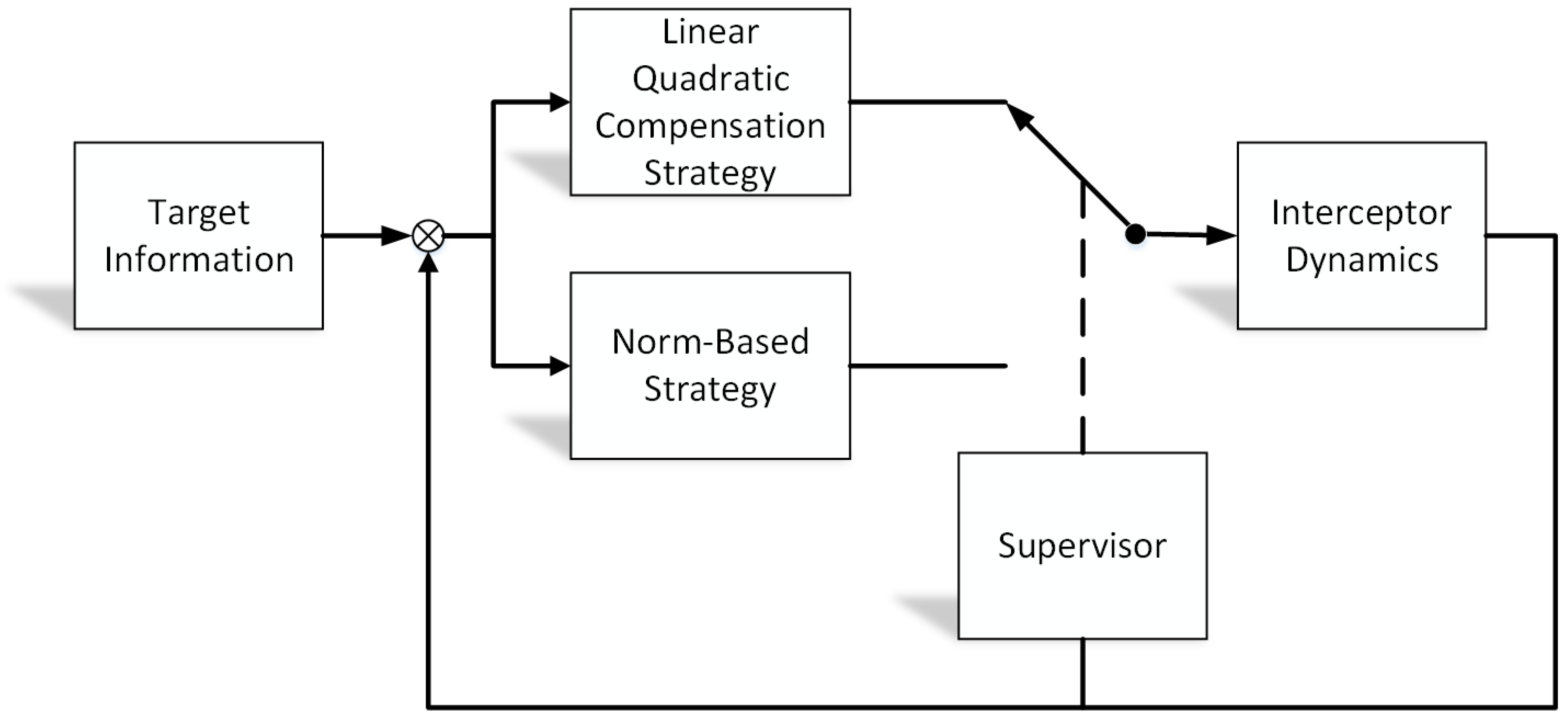
For the norm-based strategy, the interception can be guaranteed, as long as the thrust amplitude is greater than the target. Nevertheless, the fuel consumption term is not optimized, which leads to an increase in fuel consumption. On the other hand, the linear quadratic strategy can reduce fuel consumption, although the pursuit may not be realized because of the target’s strong maneuverability or the changeable maneuvering law. Thus, the hybrid game strategy, combining the linear quadratic compensation strategy with the norm-based strategy, is proposed to guarantee the approach and reduce fuel consumption. The proposed hybrid game strategy has the inherent ability to combine multiple game algorithms under a single coherent framework as shown in
Figure 2. The designed hybrid game strategy can achieve rapid approach and save fuel consumption, even under the condition that the target can perceive complete information of the pursuer and obtain better evasion performance in the game strategy.
To model the system dynamics in hybrid framework, the hybrid systems state is defined as:
where
is the game control logic variable and
is the timer variable. The value of
specifies which game strategy is currently being used, with
, where
represents the linear quadratic compensation strategy, and
represents the norm-based strategy. The property of
introduces discrete dynamics into the system. For this problem, the hybrid system
is defined as:
where
is the flow map,
is the jump map,
is the flow set, and
is the jump set. That is,
is defined as the set of the state of
in which the system will follow the continuous time dynamics defined by
. Similarly,
and
are defined for the discrete dynamics.
The definition of the continuous dynamics of the flow map
follows:
The definition of the discrete dynamics of the flow map
follows:
The flow set and the jump set are defined later. For the norm-based strategy, the strategy is given in Equation (16).
For the linear quadratic strategy, the disturbance observer is designed to estimate the unavailable target maneuver information, and the compensation strategy is derived. To simplify the analysis later, an assumption is given as follows:
Assumption 2. The target perceives the pursuer maneuver strategy with incomplete information, namely, Equation (33), rather than knows that the pursuer uses the disturbance estimator.
To apply the disturbance estimator, defining the minus of the target strategy as the disturbance
, namely,
, and combing with
, the relative dynamics can be written as:
Decomposing the relative state as
, we can obtain the relative dynamics on
with
,
.
Thus, we design the disturbance estimator as follows:
with the disturbance observer gain
being positive definite, and the
satisfying
.
is the estimated value of using to compensate the target strategy,
is the internal additional variable of the system.
Thus, we define the estimation error of the system (45) as .
If the disturbance defined in this paper
is continuous and satisfies
, then, according to the input-to-state stable (ISS) criterion, the estimation error
is uniformly ultimately bounded, as known from Ref. [
32].
For the well estimation, the pursuer applies a strategy combining an interception term with a compensation term. Thus, the pursuer’s strategy can be given as:
where
satisfies the Ricatti differential equation as follows:
with
.
Remark 1. To derive the approach strategy above, we make an assumption that the target does not know the estimated value of the pursuer. If a rational target knows the estimated value, it may use the strategy as follows:
In this case, substituting the pursuer strategy and the target strategy into Equation (9), the estimation can be offset and the relative dynamics can be rewritten as:
For the incomplete information game, substituting Equations (33) and (36) into Equation (9) yields an equation which is identical to Equation (49). Therefore, the case where the target knows the estimated value of the pursuer is not discussed.
If the target strategy changes slowly, the disturbance observer achieves a well estimation performance. Nevertheless, the target may adjust its strategy fast to avoid being intercepted in practice. In this case, the estimation error is large and the effective estimation cannot be achieved, and, as a result, the pursuer is still unavailable to the game information. In this case, the pursuer applies the norm-based strategy. From Ref. [
4], we know that if the pursuer applies the norm-based strategy, the approach can be guaranteed as long as the thrust magnitude of the pursuer is larger than that of the target. Thus, the pursuer uses this strategy if the estimation error is large. To obtain the switch logic, and evaluate the strategy estimation performance, an auxiliary system is defined as:
Defining state error
, subtracting the actual system yields:
Integrating Equation (51), we have:
Choosing the initial state of the auxiliary system as the same one of the actual system, we have
. Thus,
Therefore, the estimation error
can be substituted by
. Predesign an estimation error bound as:
If
, a well estimation is obtained and the linear quadratic compensation strategy is implemented. On the other hand, if
, the norm-based strategy is used. Thus, the flow set
and the jump set
are defined as:
with
and
Remark 2. If the error boundis large, the pursuer may always use the linear quadratic strategy. On the other hand, the pursuer always uses the norm-based strategy with a small error bound.
5. Simulation Analysis
To demonstrate the performance of the hybrid strategy under different information scenarios, several simulations were carried out. We assumed that the pursuer and the target moved around the geocentric orbit (GEO). Thus, a satellite near them was chosen as the reference satellite that moved along the GEO. We knew that the orbital angular velocity was
. The initial positions of the pursuer and the target were [1.5; 0.5; 0] km, [0; 0; 0] km. The initial velocities they had were [0; 0; 0] km/s, [−0.05; 0; 0.01] km/s, respectively. The parameters in cost function were chosen as:
The maximal thrust of the pursuer was . The maximal thrust of the target was . The gain of the disturbance estimator was chosen as .
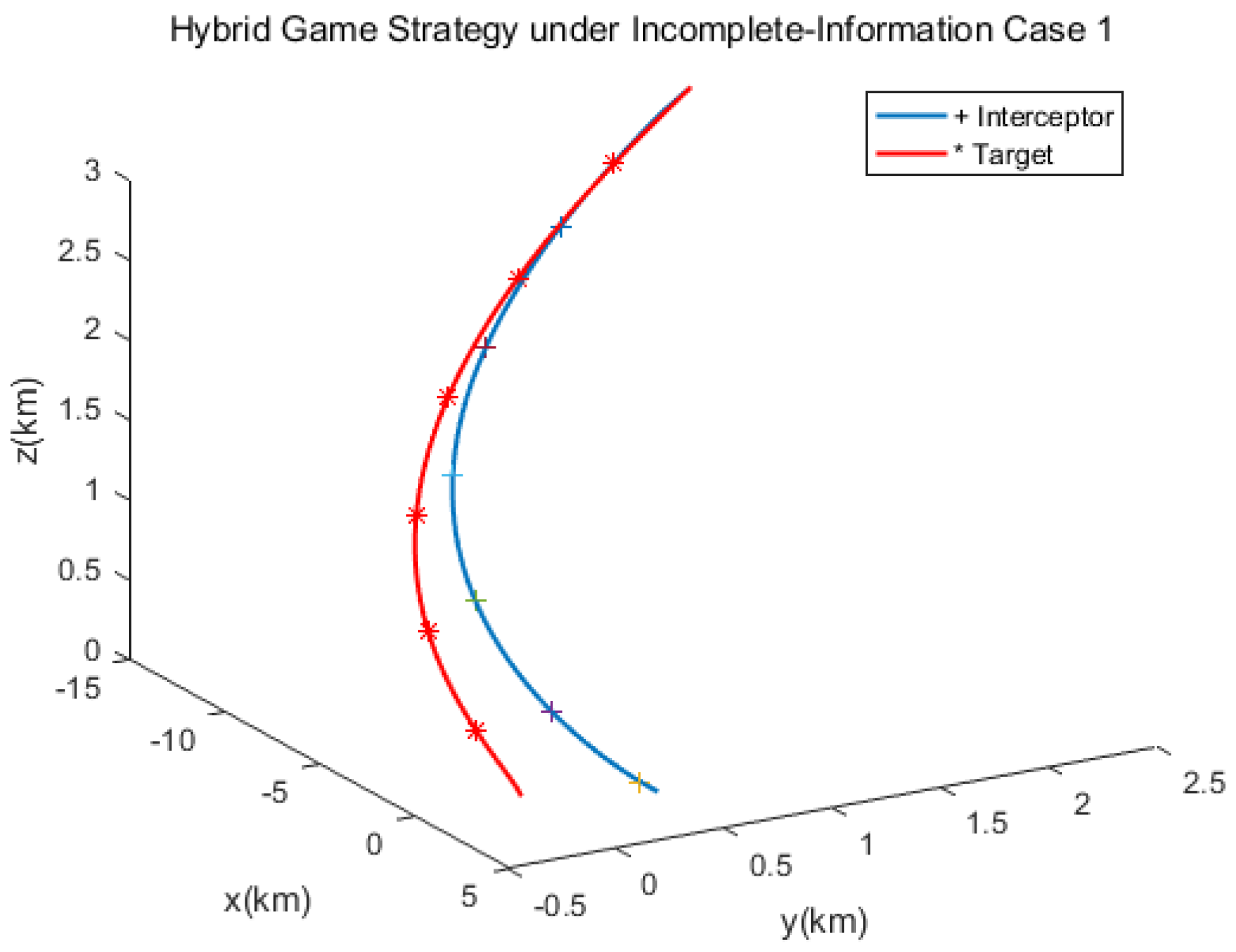
In the first scenario, the target applied the linear quadratic strategy.
Figure 3 gives the trajectories of the pursuer and the target, and
Figure 4 shows the relative distance between them, from which we can find that the target was approached in 134 s.
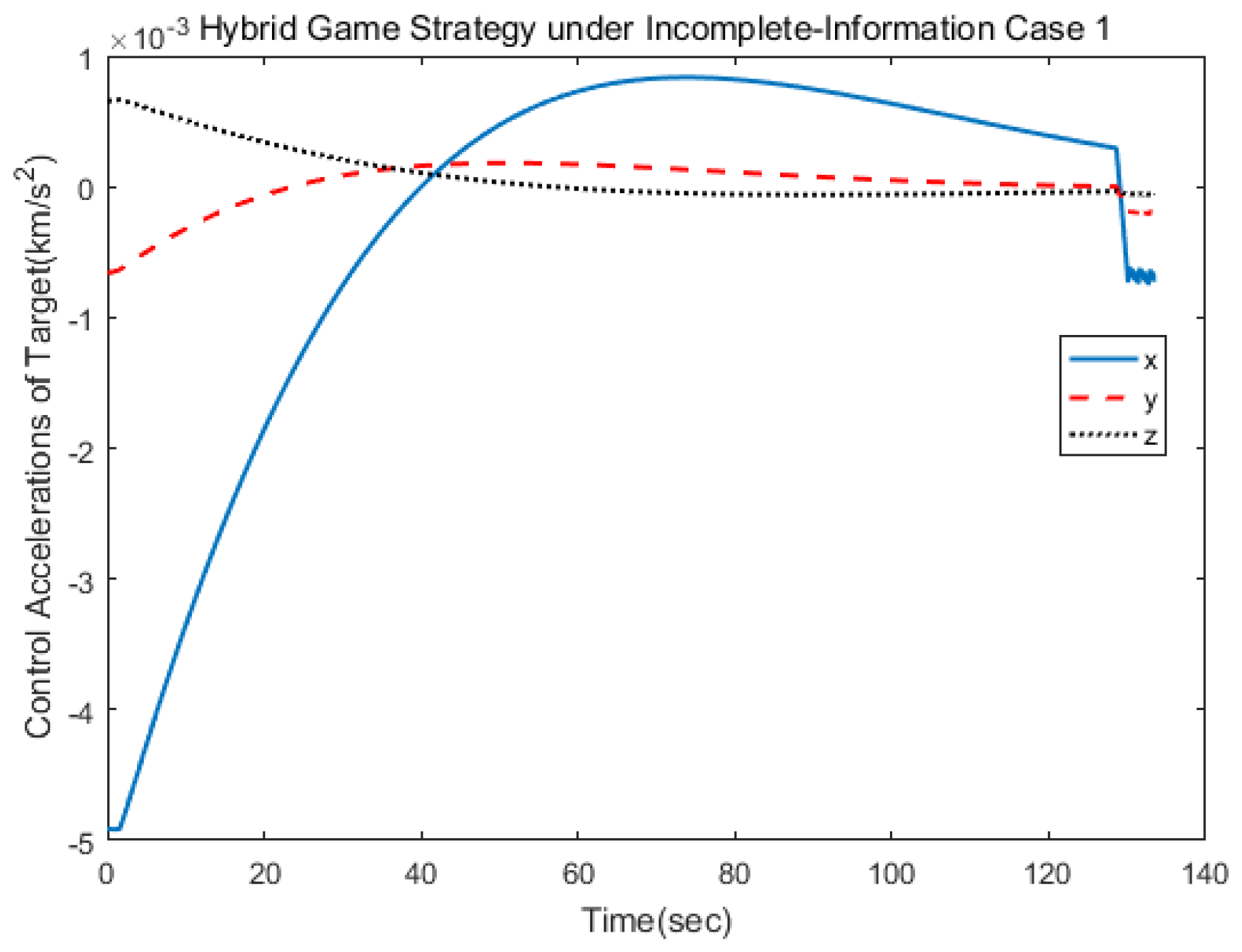
Figure 5 and
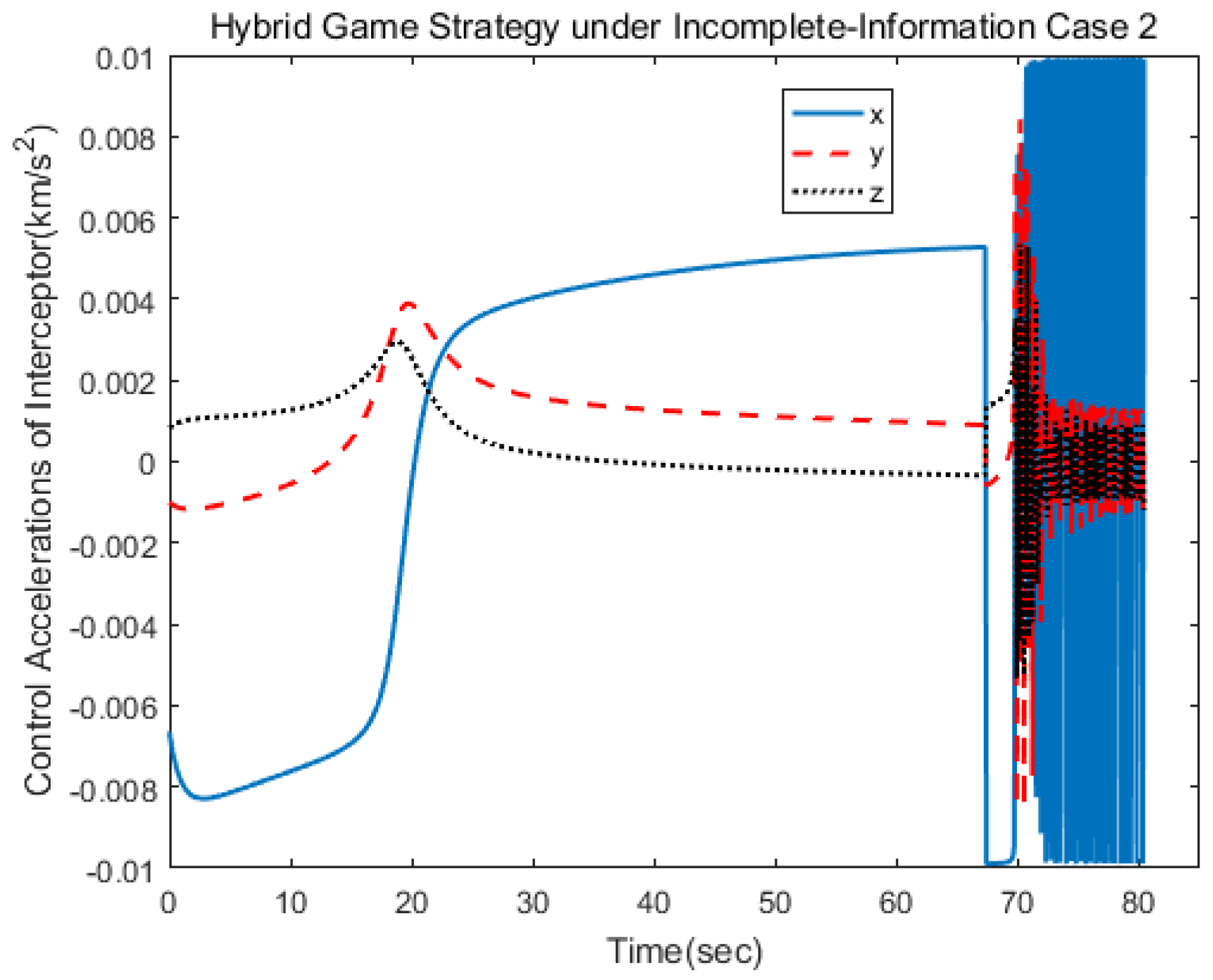
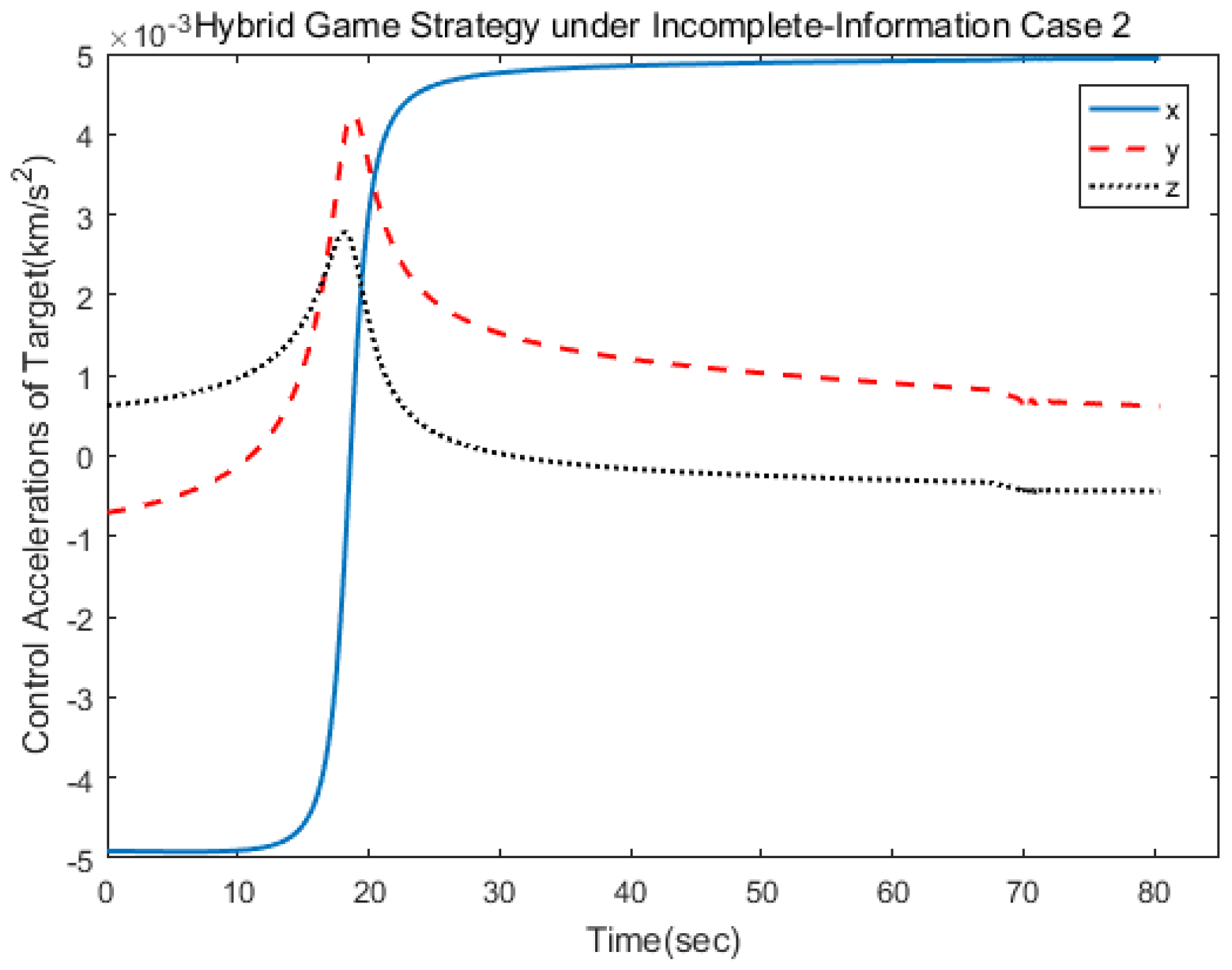
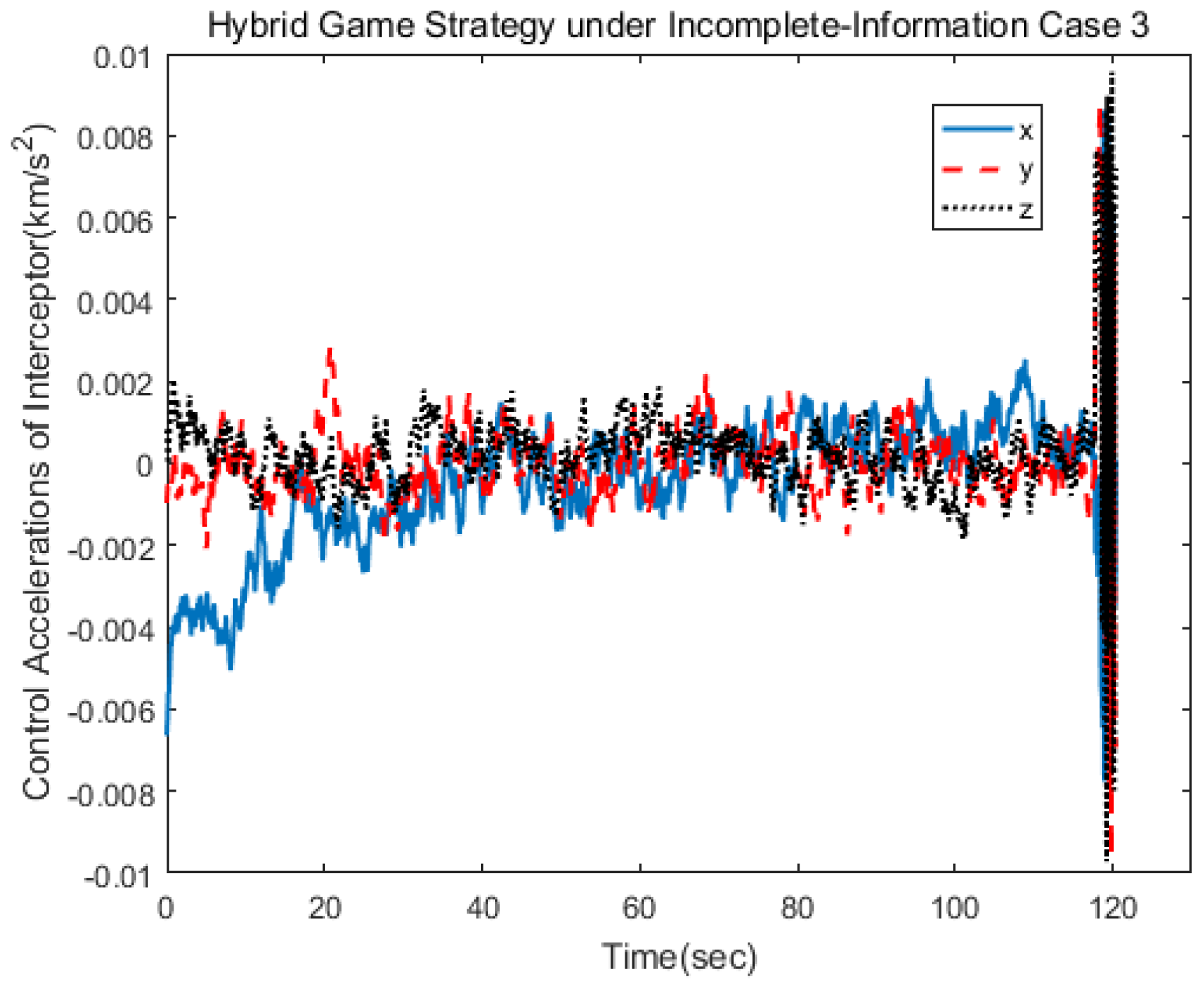
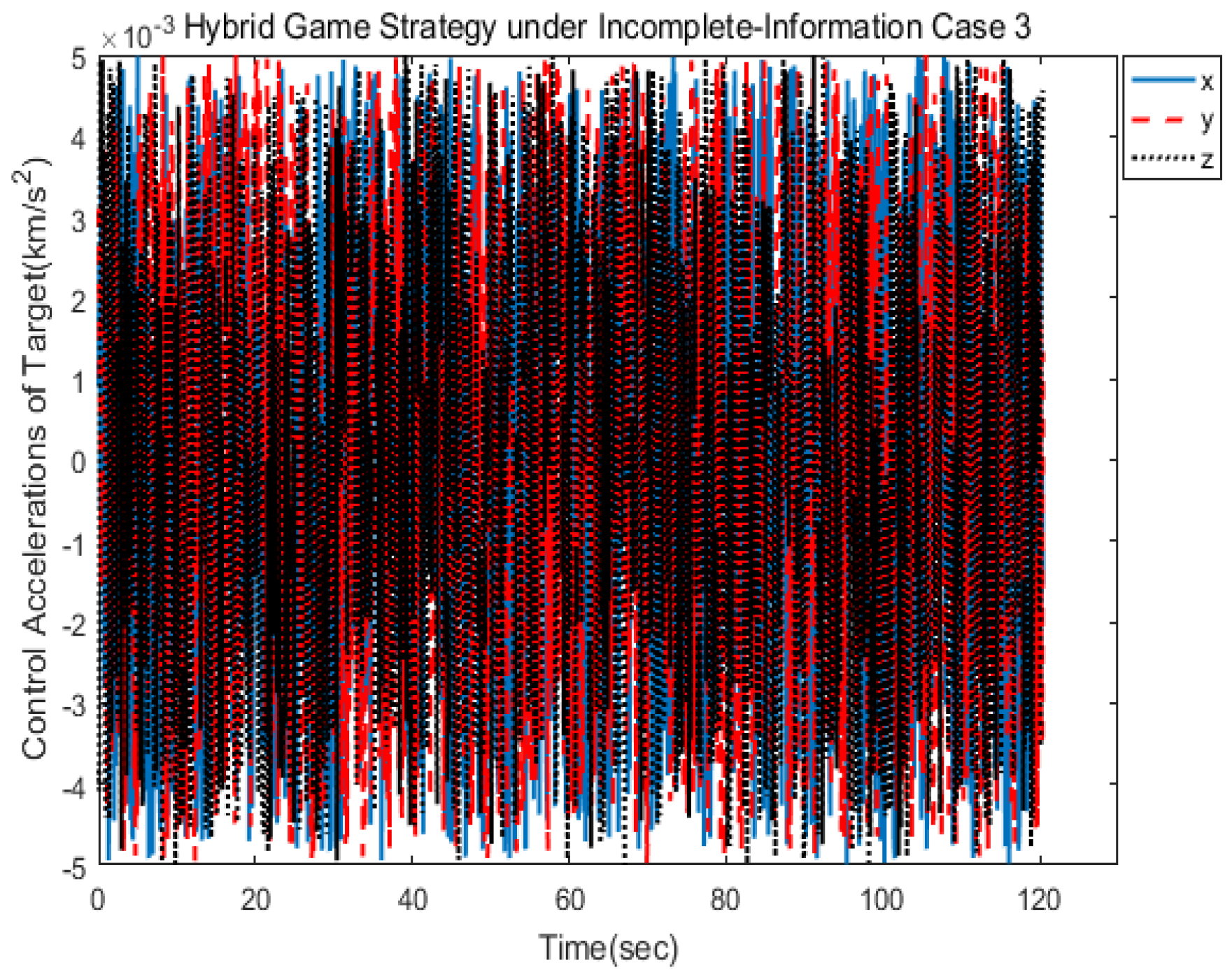
Figure 6 show the three-axis thrust accelerations of the spacecrafts. It can be seen that the acceleration of the pursuer was larger than that of the target, and their accelerations varied slowly.
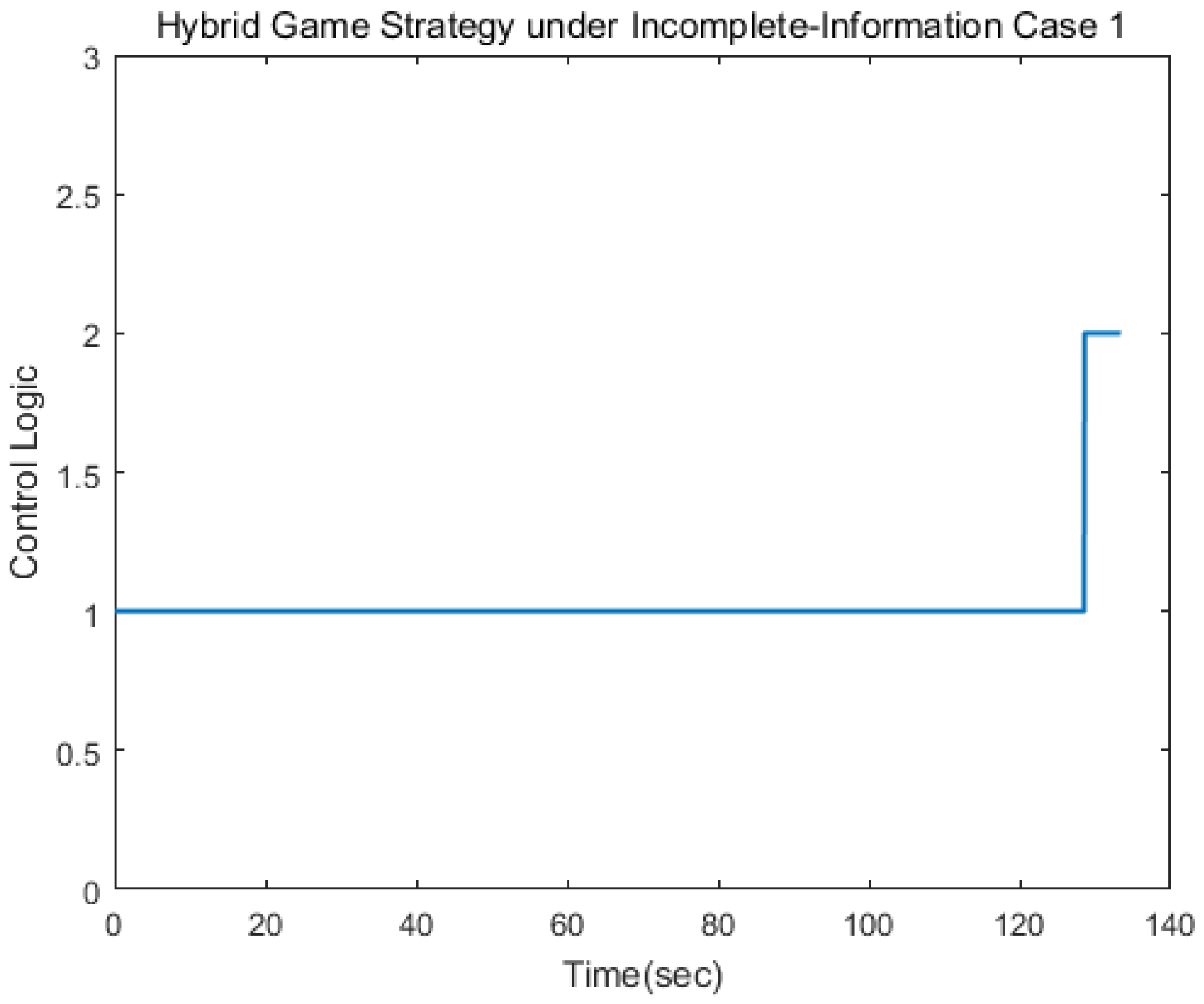
Figure 7,
Figure 8 and
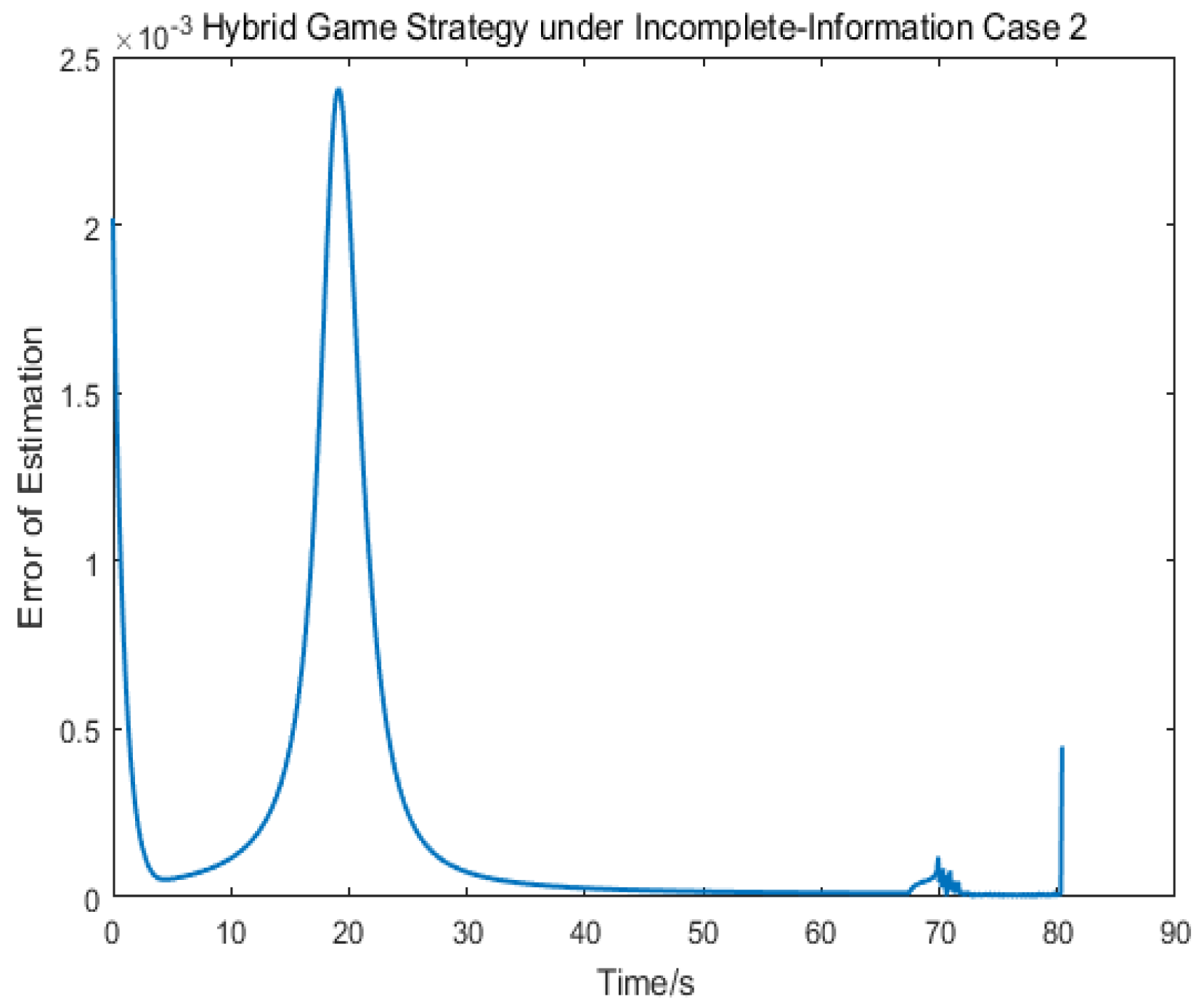
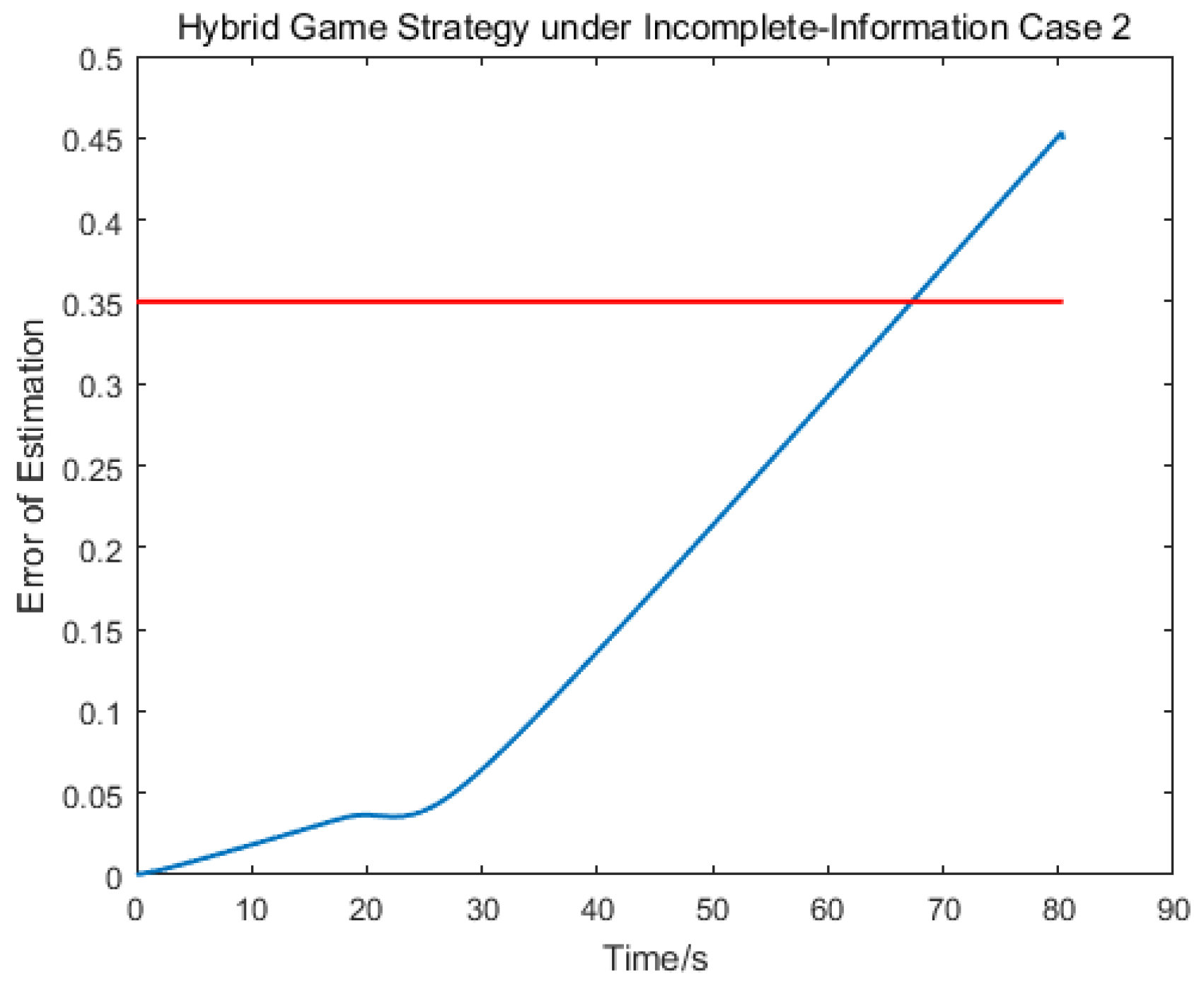
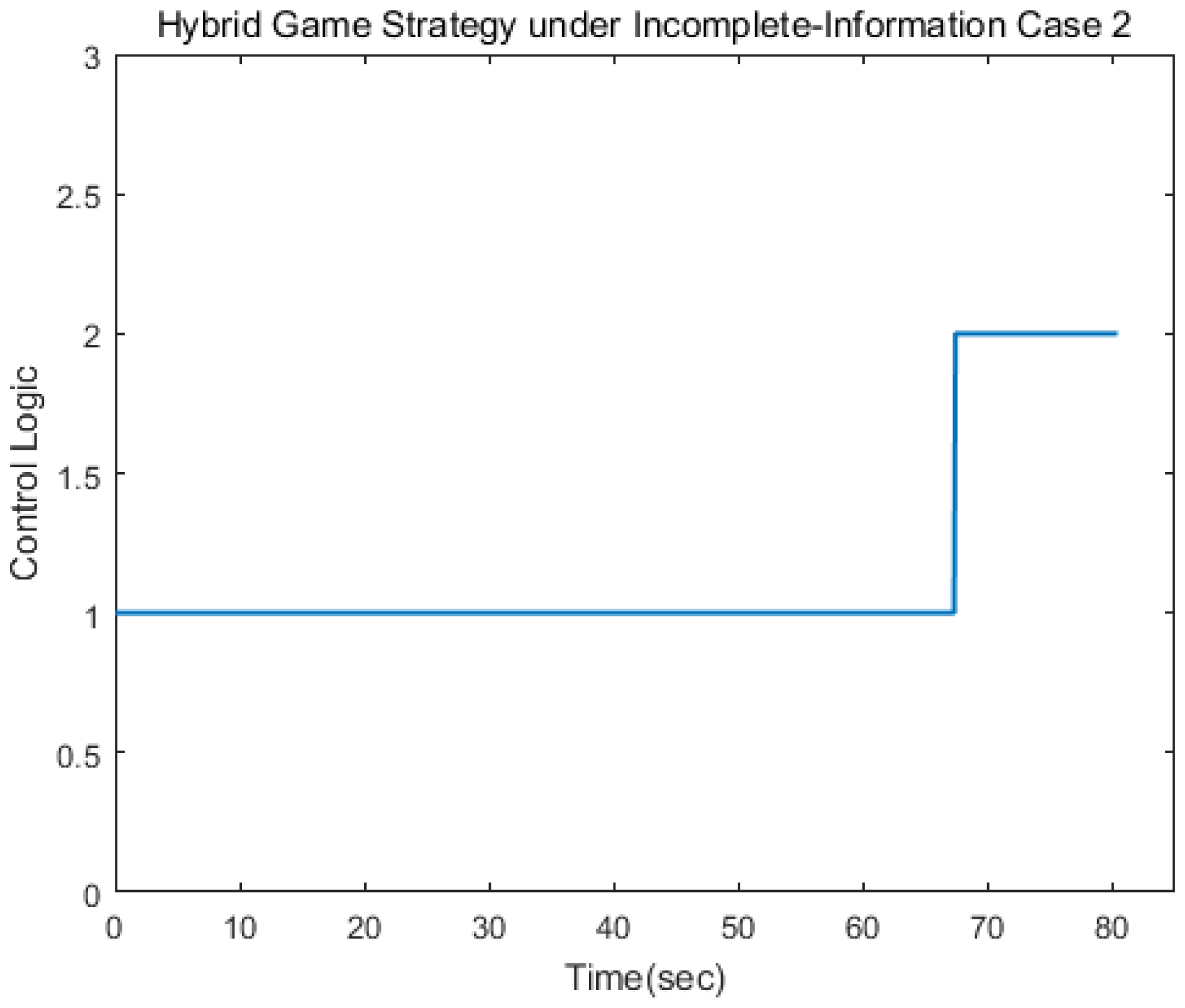
Figure 9 depict the control logic and error of estimation, from which we knew that the pursuer used the linear quadratic compensation strategy, and, then, used the norm-based strategy after 128 s. Via the hybrid strategy, the approach could be achieved.
The second scenario was that the target used the norm-based strategy. Simulation results are shown as
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15 and
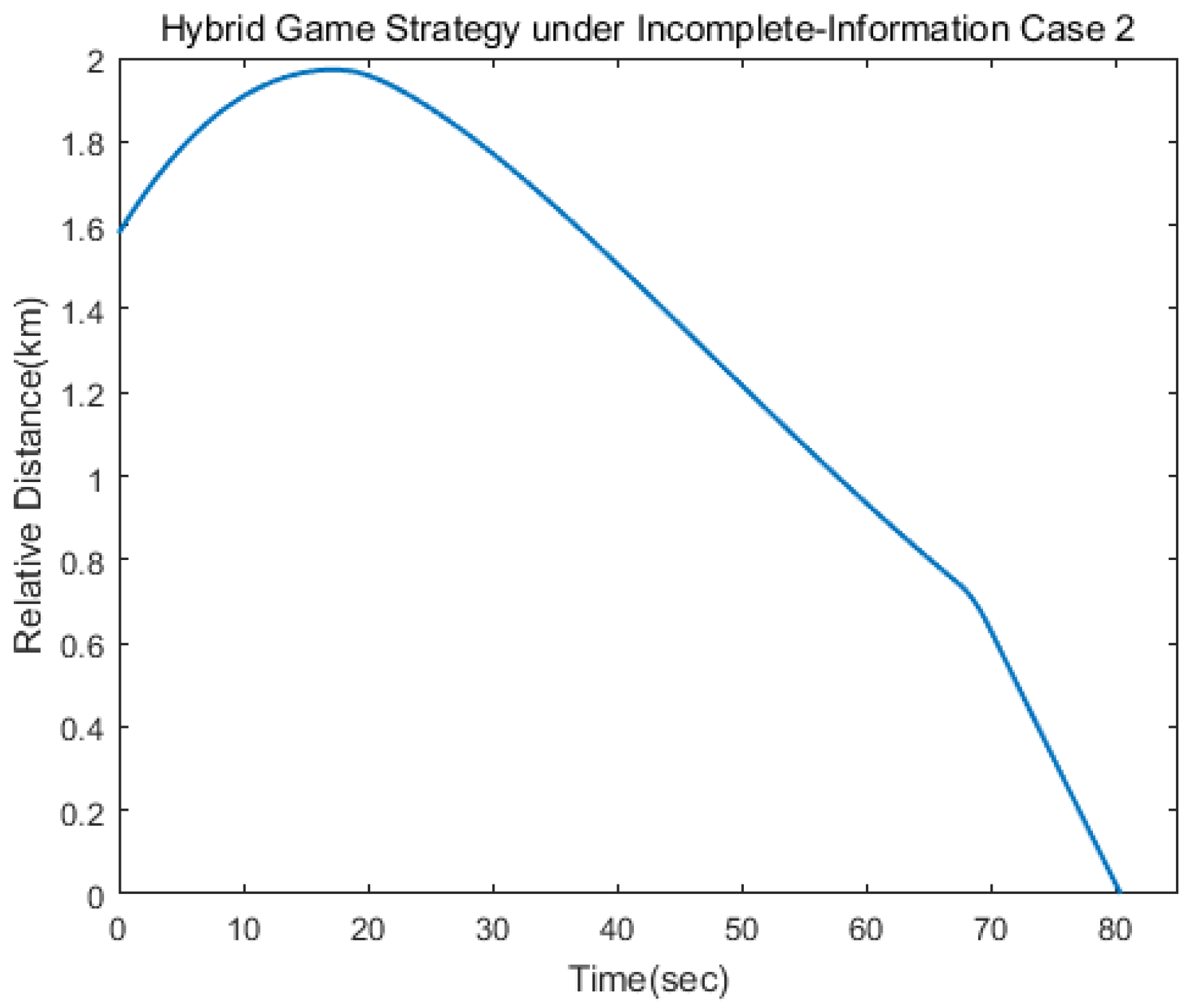
Figure 16. Different from the first case, the target adopted the strategy of ignoring fuel consumption, and so the limit value of change hybrid strategy would be reached faster. The control logic changed from 1 to 2 at 68 s, which indicated that the pursuer applied the linear quadratic strategy within 70 s and, then, applied the norm-based strategy. The results show that the approach could be achieved in 81 s.
Finally, to demonstrate the effectiveness of the disturbance estimator to the target strategy, we supposed the target employed random strategy, which is a non-optimal and irregular strategy. This situation simulated a real-world scenario for handling dangerously out-of-control spacecraft. The strategy is given as:
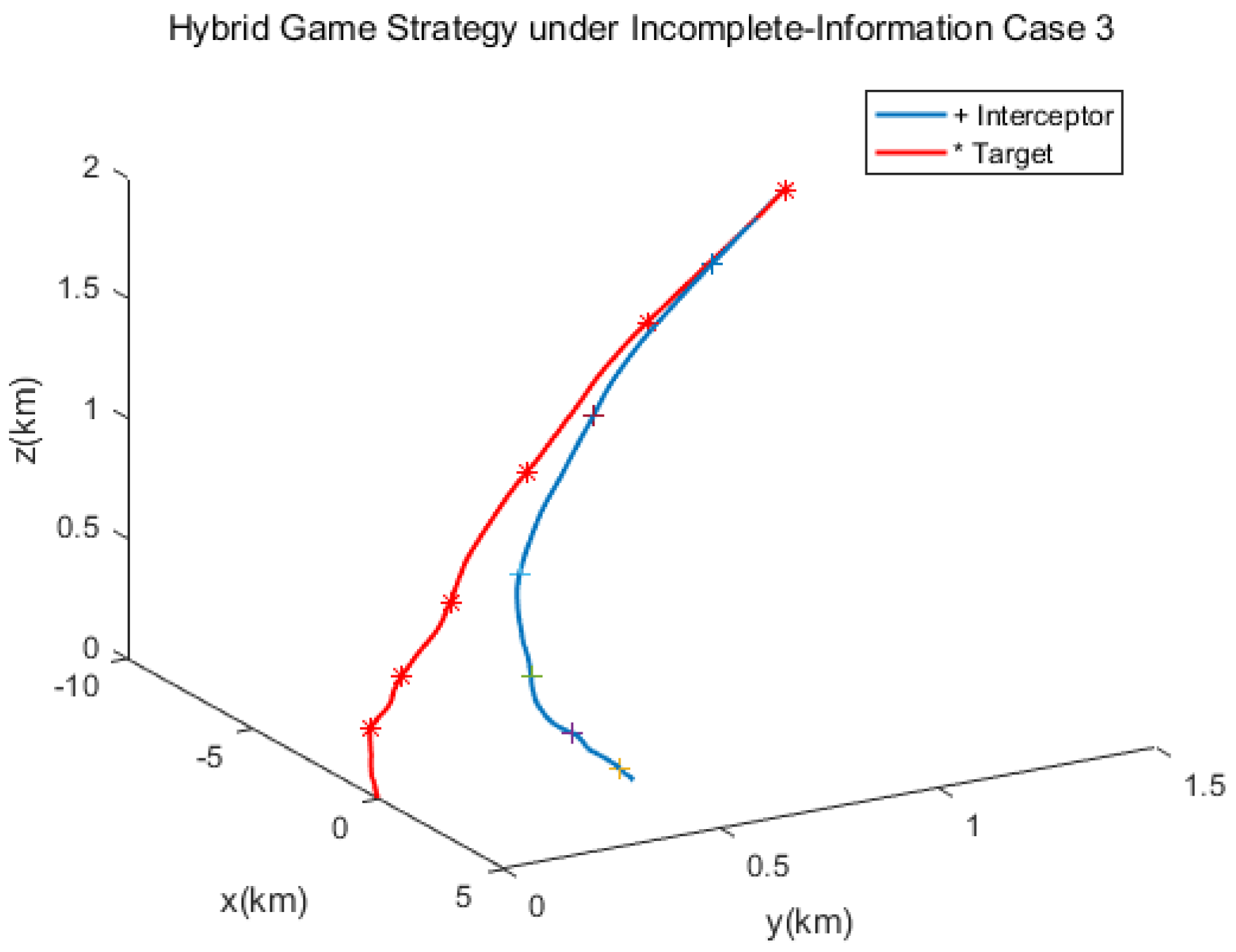
The spacecraft trajectory of hybrid game strategy is shown in
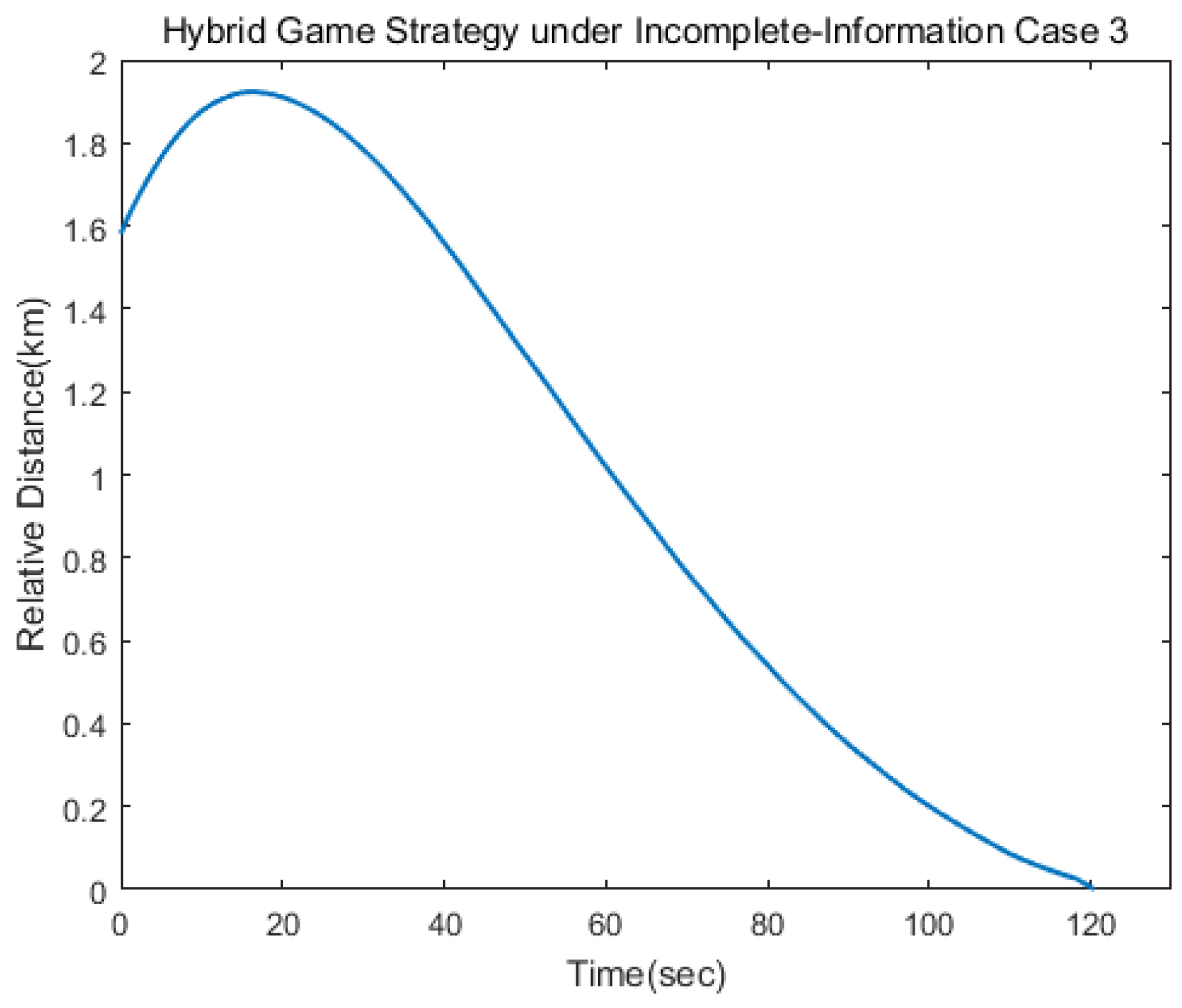
Figure 17, from which we can find that the target maneuvered irregularly in the whole process. The following
Figure 18 shows the relative distance between the pursuer and the target. After 120 s, the target spacecraft was approached. As can be seen from
Figure 19 and
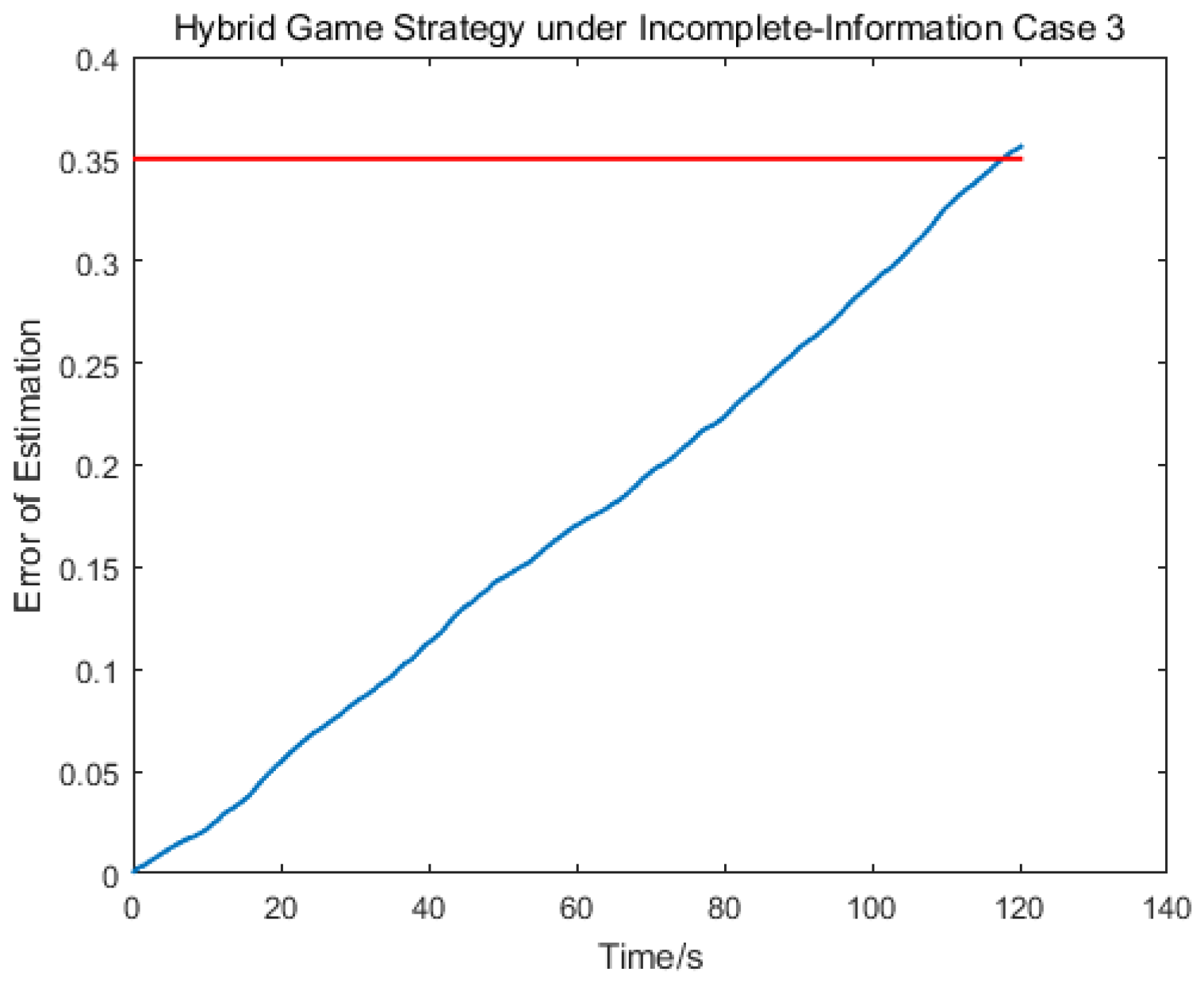
Figure 20, if there was no hybrid strategy in the situation of incomplete information, approach could not be realized, so the estimation of target strategy was very meaningful. As can be seen from
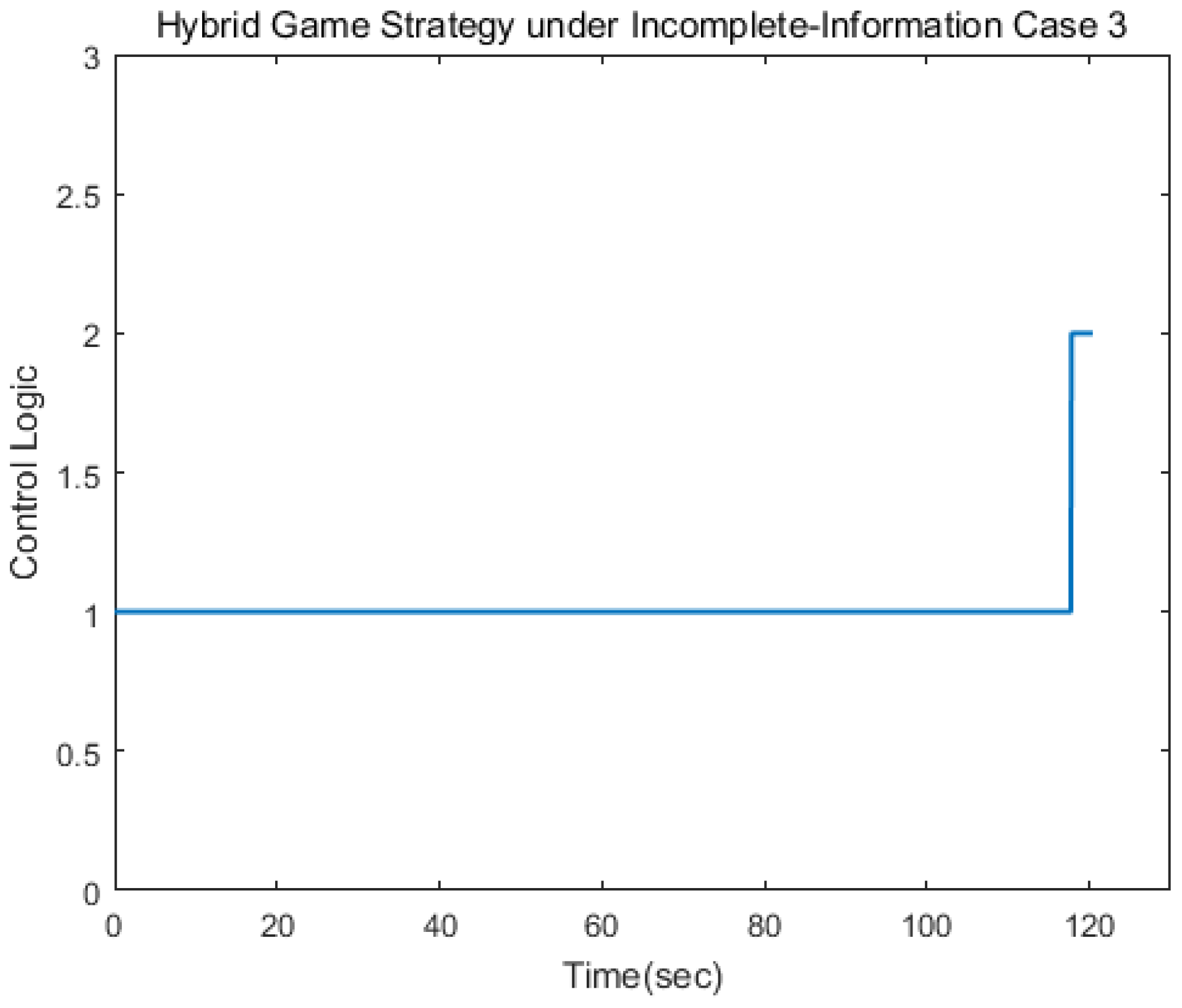
Figure 21, since the maneuvering strategy of the out-of-control target was random and disordered, the error estimated oscillation constantly to match the true value of the target control strategy. In this scenario, the pursuer took the disturbance observer to estimate the target control matrix information, and then established the hybrid game strategy and completed the change of control logic after 117 s as shown in
Figure 22 and
Figure 23.
When the pursuer took the estimation behavior, the bilateral game problem turned into a unilateral optimization problem, so the pursuer could get better approaching effect by adopting the corresponding strategy. The proposed hybrid game strategy could intercept a dangerous spacecraft which is out of control in a finite time, which shows the effectiveness of information estimation in incomplete information game. Nevertheless, it was noted that when the target’s maneuver varied slowly, the disturbance estimator showed the well estimation performance. However, if the target’s maneuver was performed randomly, which meant at a fast-changing rate, the estimation performance would be degraded, which would also affect the pursuit performance.
From
Table 1 on the comparison of fuel consumption, it was observed that the designed hybrid game strategy could achieve rapid approach, while saving fuel consumption in different scenarios. Compared with the traditional unilateral optimal control strategy, considering the complex situation of pursuit–evasion of spacecrafts with the ability of perceiving information, the application of hybrid game strategy had more advantages.
6. Conclusions
This paper investigated the hybrid game strategies of an out-of-control spacecraft with incomplete-information. Firstly, the impact of hybrid game strategy on both sides was analyzed, and the complete-information intercept game switching strategy was derived from differential game theory. Furthermore, the asymmetric-information situation, where the target information was not available to the pursuer, was discussed. The incomplete-information game strategy and information-estimation strategy were derived, respectively. The method of interference estimator is proposed to improve the estimation performance, and, embedded in hybrid game strategy, is consideration of both interception effectiveness and fuel consumption in estimating unknown target maneuver information. Finally, simulations were performed to assess the effectiveness and pursuit performance.
Compared with traditional unilateral optimal control strategy, the complex situation of the out-of-control spacecraft with the ability of sensing space information was considered. The simulation verified the effectiveness of the hybrid game strategy under different information scenarios. Simulation results showed that if the out-of-control target’s maneuver was unknown to the pursuer, the difficulty of approach would increase. Using the proposed disturbance estimator, the target information could be estimated effectively and the control logic could be changed quickly to minimize fuel consumption while quickly approaching the target, which indicated the effectiveness of the proposed scheme in this paper. Therefore, the proposed hybrid game strategy can be applied in practical pursuit scenarios for dangerous spacecraft disposal missions with incomplete-information. In the future, the authors will focus on stochastic-game problems for complex dynamics of the out-of-control spacecraft.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}