1. Introduction
Compared with unmanned aerial vehicle (UAV), unmanned helicopter (UH) has lower requirements for airports and can take off and land in harsh environments [
1]. Therefore, they play an important role in the battlefield. The distinctive feature of UH is its strong maneuverability and good concealment, and it can evade radar detection by flying at ultra-low altitudes, thereby raiding important targets [
2]. Path planning technology is the basis for UH to safely reach the mission area. Therefore, it is of great significance to study the path planning of UH.
When UH performs raid missions in the low airspace, it will face a very complex airspace environment. First, mountains are a common static obstacle in low-airspace environments, and UH needs to maneuver to avoid mountains to prevent collisions. Then, due to factors such as the curvature of the earth and ground debris, the radar’s detection ability will attenuate with altitude in low airspace [
3]. In order to avoid radar detection, UH needs to fly at a low altitude for a long time. Since the probability of UH being detected by radar varies with the flight altitude, it is also difficult to accurately identify the radar area and avoid passing. Finally, the location of the vehicle radar can change at any time, and the coverage area of the radar will become highly dynamic, which also seriously threatens the safety of UH. The purpose of this paper is to seek a reliable path planning scheme to help UH to plan the optimal flight path in a complex dynamic environment.
Existing path planning research is usually conducted in a 2D environment [
4]. Since the cruising altitude of the UAV is usually fixed, the dimension of height can be ignored in the path planning research, and only the movement in the horizontal direction is considered. Considering that when UH performs raid missions in low airspace, the flight altitude will also change, and the dimension of flight altitude cannot be ignored. Therefore, it is very necessary to study the path planning of UH in a 3D environment. In previous work, the research on path planning in a 3D environment has also been addressed by related scholars [
5,
6,
7,
8]. However, most of these studies were carried out under simple environmental constraints, considering only static environmental constraints, but not highly dynamic complex environmental constraints.
The salient feature of the three-dimensional environment compared with the two-dimensional environment is that it has a huge state space, which brings a great burden to the algorithm for path search. Commonly used path planning algorithms such as the Dijkstra algorithm, A* algorithm, particle swarm algorithm, ant colony algorithm, genetic algorithm, and artificial potential field method all require a lot of calculations in the path search [
9,
10,
11,
12], so the application of these algorithms in the 3D environment is very limited.
Deep reinforcement learning technology is produced by the combination of reinforcement learning and deep learning, which inherits the ability of reinforcement learning to interact with the environment autonomously and the powerful state representation ability of deep learning [
13]. The application ability of deep reinforcement learning technology in large state space has been proved by related research [
14]. Therefore, using deep reinforcement learning techniques for path planning in 3D environments has significant advantages. First of all, deep reinforcement learning can dynamically adjust parameters by interacting with the environment independently, so as to find the optimal strategy, and this process does not require tedious operations. Second, deep reinforcement learning can store learning information through neural networks, and there is no state space explosion problem when processing large state space information. Finally, deep reinforcement learning is less dependent on prior knowledge of the environment, and has stronger adaptability to dynamic environments.
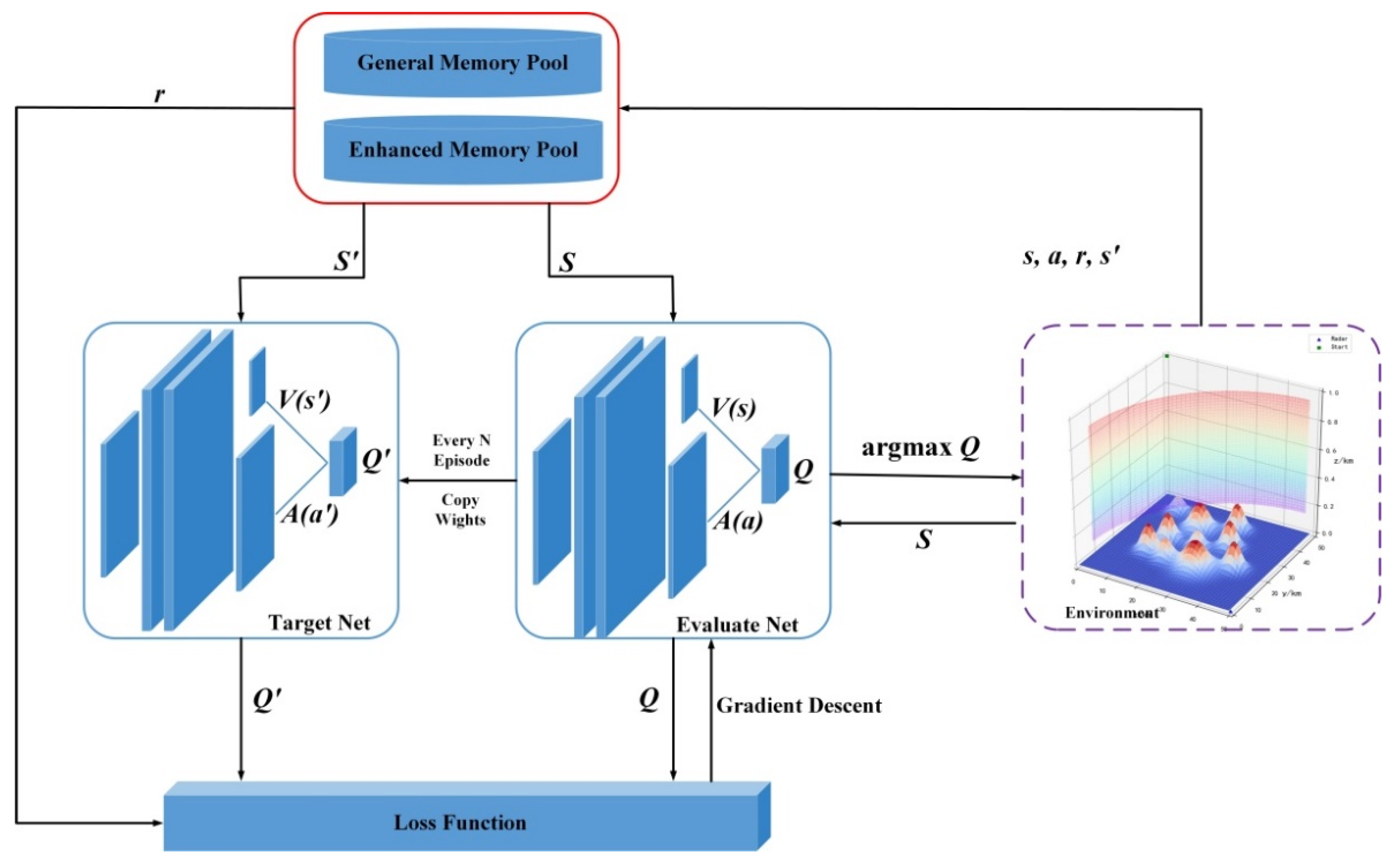
In this paper, a memory-enhanced dueling deep Q-network (ME-dueling DQN) algorithm is proposed, and it is embedded into the UH performing low-altitude raid mission model for path planning. Experimental results show that the proposed algorithm can converge quickly and plan a safe and effective flight path for UH in complex dynamic environments. The main contributions of this paper are as follows:
(1) Combined with the environment model, a comprehensive reward function is designed. On the basis of improving the sparse reward problem, the planning path is further optimized, and the convergence speed of the algorithm is improved.
(2) A memory-enhanced mechanism is proposed. The dual experience pool structure is introduced into the traditional dueling deep Q network structure, and the learning efficiency of the algorithm is improved by the memory-enhanced mechanism, making the learning process of the algorithm more stable.
(3) A three-dimensional environment model of UH’s raid missions in the low airspace is established. The whole process of embedding the proposed algorithm into the environment model to realize path planning is introduced in detail, and a new solution to the path planning problem is provided.
In general, this paper attempts to use deep reinforcement learning algorithms to solve the path planning problem in complex dynamic environments, which has certain significance for related research. First, the definition process of the reward function can be used for reference by related scholars. Then, the proposed memory-enhancing mechanism can also be extended to more general intelligent algorithms. Finally, the problem of path planning in complex 3D environments is relatively understudied, and this paper can enrich case studies in this area.
The remainder of this paper is structured as follows:
Section 2 presents related work. The establishment of the 3D environment model is introduced in
Section 3.
Section 4 introduces reinforcement learning theory and the traditional Dueling DQN algorithm. The details of the proposed algorithm and the implementation of path planning are presented in detail in
Section 5.
Section 6 presents the implementation results and discusses them.
Section 7 is the conclusion of this paper.
2. Related Works
Path planning refers to finding the optimal path from the starting point to the endpoint according to certain constraints [
15]. Usually, there are many feasible paths from the starting point to the endpoint, but the optimal path can be selected according to some criteria, such as the shortest distance, the straightest path, and the least energy consumption [
16]. Path planning can be divided into three parts: establishing an environment model, path search, and path generation [
17]. In these works, establishing an environment model is the basis of path planning, path search is the core work, and path generation is the presentation of the final planning results.
For a long time, the path search algorithm has been the focus of path planning research. The path search algorithm can be divided into a global path search algorithm and a local path search algorithm according to the situation of obtaining environmental information [
18]. In the global path search algorithm, the information of the environment model is required to be completely known, and the algorithm can quickly search for the optimal path based on this information. However, it is usually difficult to obtain complete environmental information, so the application of the global path search algorithm is relatively limited. Because the local path search algorithm can explore the optimal path based on limited environmental information, it has received more extensive attention [
19]. The reinforcement learning algorithm is a typical local path planning algorithm.
Path planning has always been a research hotspot in various fields. In [
20], the authors used the A* algorithm to generate a global path for UAVs, and then used the path results as input for task assignment, which improved the overall performance of UAV mission planning. An online path re-planning algorithm for autonomous underwater vehicles was proposed in [
21], where the authors used particle swarm optimization together with a cost function to enable the algorithm to operate efficiently in a cluttered and uncertain environment. A new hybrid algorithm for UAV 3D environment path planning was proposed in [
22], which combined metaheuristic ant colony algorithm and differential evolution algorithm to form a new path planning method, and had strong robustness and fast convergence. In [
23], a new genetic algorithm based on a probability graph was proposed, the author completed the path planning of the UAV by introducing a new genetic operator to select appropriate chromosomes for crossover operation. An improved artificial potential field algorithm for motion planning and navigation of autonomous grain carts was proposed in [
24], which combined an artificial potential field algorithm and fuzzy logic control to improve the robustness and work efficiency of the algorithm. It is worth noting that these traditional algorithms search for paths based on real-time environmental information. If the environmental information changes, the planned path obtained in this way has a certain lag and may not fully meet the needs. Therefore, the above-mentioned traditional algorithms are difficult to adapt to the complex and dynamic low-airspace environment faced by the UH’s mission.
The distinctive feature of reinforcement learning is that the search for the optimal strategy can be completed without prior knowledge. Therefore, the application of reinforcement learning to path planning has certain advantages [
25]. With appropriate reward settings, reinforcement learning algorithms can autonomously complete the path search task by interacting with the environment when the environmental information is unknown. A more representative and relatively mature reinforcement learning algorithm is the Q-Learning algorithm.
The application of the Q-Learning algorithm in the path planning problem has been widely studied. In the literature [
26], the author transformed environmental constraints such as distance, obstacles, and forbidden areas into rewards or punishments, and proposed a path planning and manipulation method based on the Q-Learning algorithm, which completed the autonomous navigation and control tasks of intelligent ships. A novel collaborative Q-Learning method using the Holonic Multi Agent System (H-MAS) was proposed in [
27]. The author used two different Q-tables to improve the traditional Q-Learning to solve the path planning problem of mobile robots in unknown environments. In the literature [
28], the author initialized the Q table by designing a reward function to provide the robot with prior knowledge, and designed a new and effective selection strategy for the Q-Learning algorithm, thus completing the task of optimizing the path for a mobile robot in a short time. However, the Q-Learning algorithm needed to constantly update the Q table in the process of working. A large number of operations of reading and storing the Q value greatly reduced the work efficiency of the algorithm, resulting in a very limited ability of the algorithm to deal with a large state space.
Deep reinforcement learning uses neural networks to fit the update process of reinforcement learning algorithms, which greatly enhances the ability of reinforcement learning algorithms to process large state space data. The deep Q network is the product of the combination of the Q-Learning algorithm and the neural network, which can effectively improve the Q-Learning algorithm’s ability to process large state space data while inheriting the advantages of the Q-Learning algorithm [
29].
In recent years, many scholars have tried to use the DQN algorithm for path planning. In [
30], the authors employed a dense network framework to compute Q-values using deep Q-networks. And according to the different needs for the depth and breadth of experience in different learning stages, they proposed an improved learning strategy, and completed the robot’s navigation and path planning tasks. Aiming at the problem of slow convergence and instability of traditional deep Q-network (DQN) algorithm in autonomous path planning of unmanned surface vehicles, an improved Deep Double-Q Network (IPD3QN) based on Prioritized Experience Replay was proposed in [
31]. The author used a deep double-Q network to decouple the selection and calculation of the target Q-value action to eliminate overestimation, and introduced a duel network to further optimize the neural network structure. A probabilistic decision DQN algorithm was proposed in [
32]. The authors combined the probabilistic dueling DQN algorithm with a fast active simultaneous localization and map creation framework to achieve autonomous navigation of static and dynamic obstacles of varying numbers and shapes in indoor environments. In [
33], the authors proposed ANOA, a deep reinforcement learning method for autonomous navigation and obstacle avoidance of USVs, by customizing the design of state and action spaces combined with a dueling deep Q-network. This algorithm completed the path planning tasks of unmanned surface vehicles in static and dynamic environments. Although the above research has proved the application ability of the DQN algorithm in large state space, its application ability in a highly complex and dynamic battlefield environment still needs to be further studied.
Dueling Deep Q-Network (Dueling DQN) is an improved algorithm of the DQN algorithm. In [
34], the author decomposed the model structure of the DQN algorithm into two parts, the state value function (V value) and the advantage function (A value), and proposed Dueling DQN, which made the model training pay more attention to high-reward actions and accelerated the convergence speed. Due to the stronger ability of Dueling DQN to process large state space information and the fast convergence speed, this paper conducts research on UH low-altitude raid path planning based on Dueling DQN.
3. System Model and Problem Definition
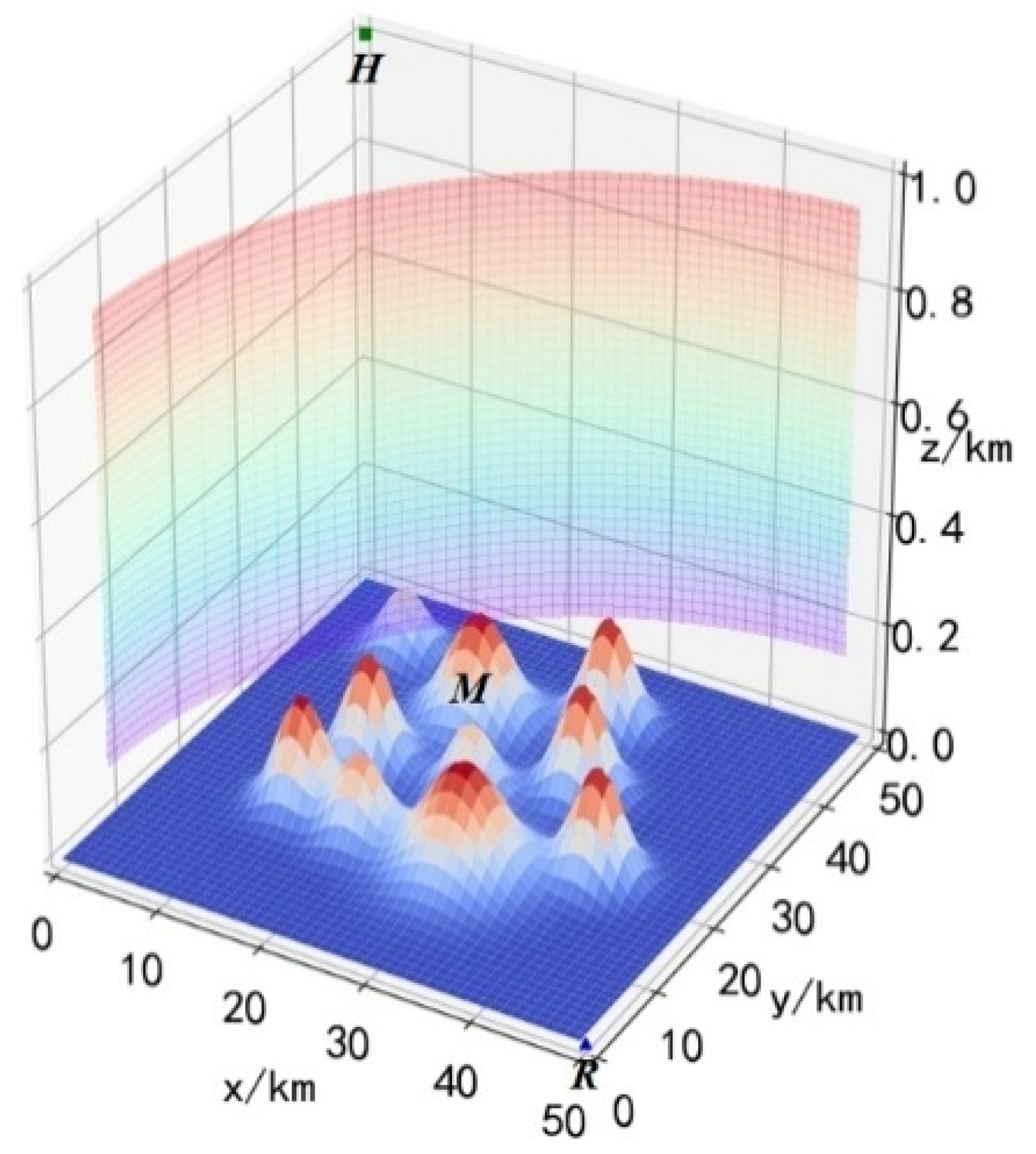
As shown in
Figure 1, a 3D battlefield environment
is established, whose length, width and height are 50 km, 50 km, and 1 km, respectively. Unmanned helicopter
, mountain range
and radar
are included in the battlefield environment
. The
can move freely in
, the position of
in
can be expressed as:
In Equation (1),
represents the position of the unmanned helicopter in the battlefield environment. The
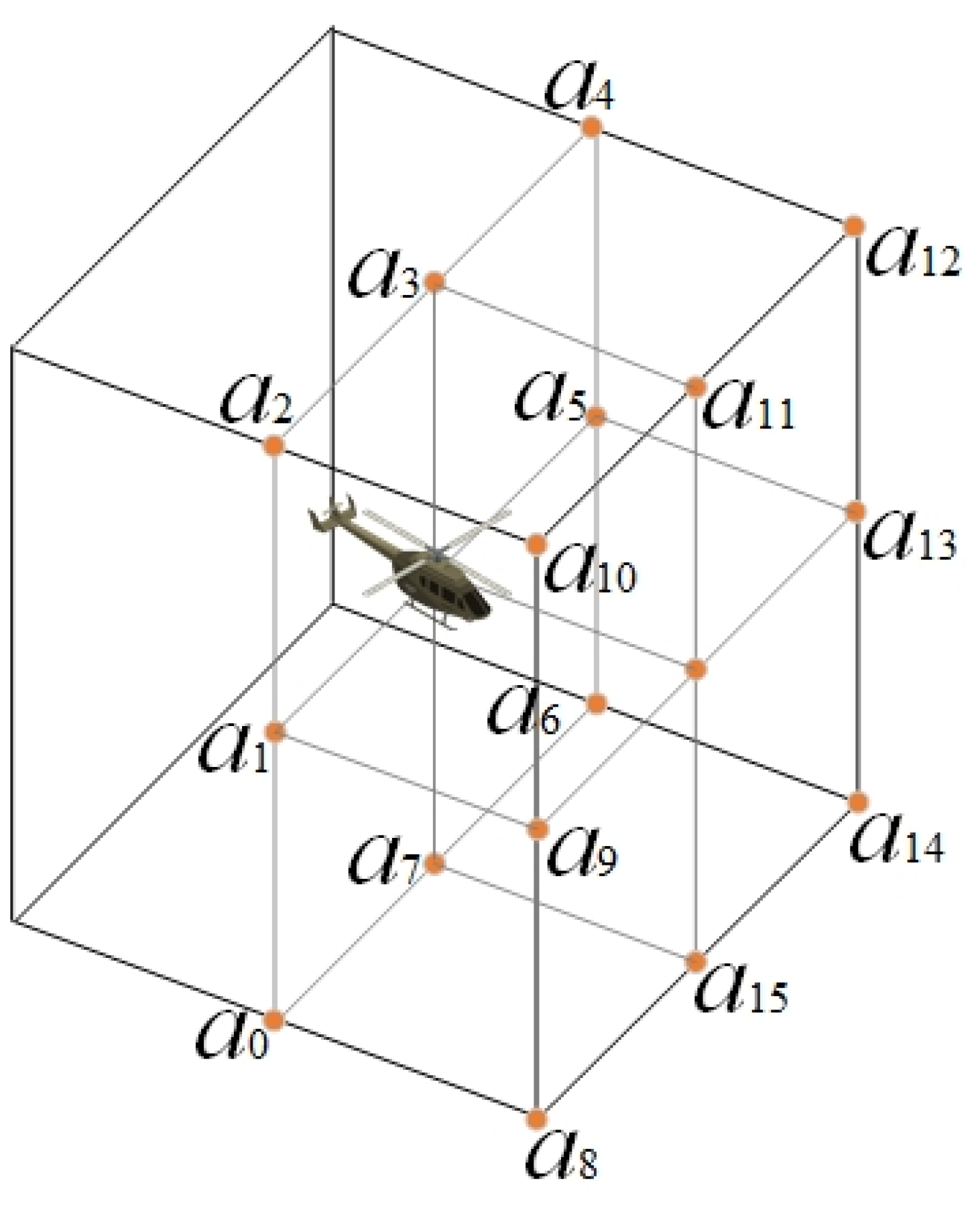
has flexible maneuverability, and it can choose to fly straight ahead in the horizontal direction, or choose to turn 45/90 degrees left or right. In the vertical direction, it can choose to climb up 45/90 degrees or descend 45/90 degrees. Then
can move with 17 degrees of freedom in
, as shown in
Figure 2.
cannot collide with mountains during flight, that is, the
cannot be contained within the
:
The mountain range
can be determined by the horizontal coordinates
and
, and the height of the mountain at the horizontal position
can be expressed as:
In Equation (3), is the height of the mountain at horizontal position , is the height coefficient, represents the center position of the mountain range , and can control the size of the mountain range .
The position of
can be determined by the
three-dimensional coordinates, but
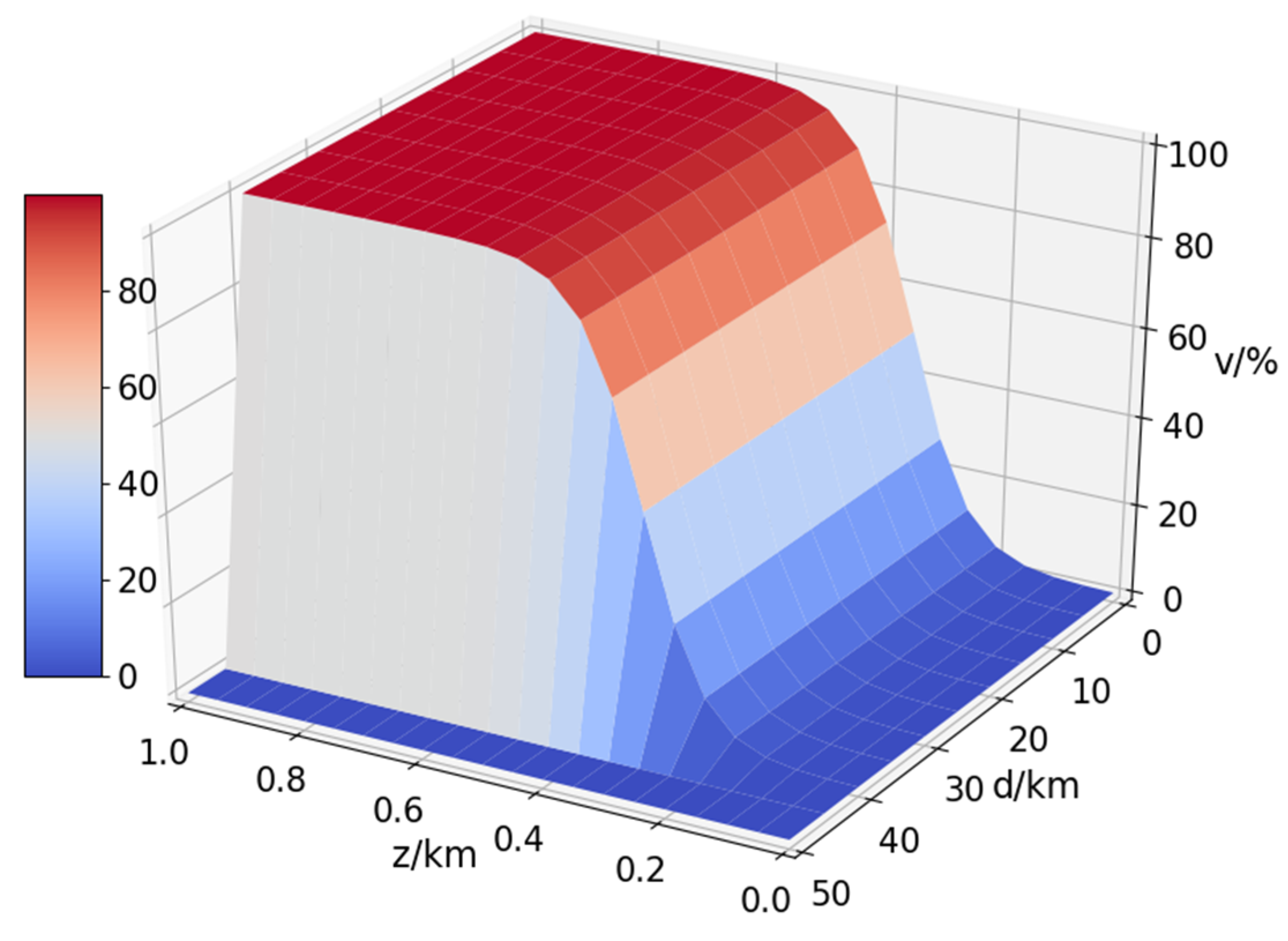
defaults to 0. Due to the influence of factors such as the curvature of the earth, it is difficult for radar to detect ultra-low-altitude flying targets, and the detection ability of radar will change with altitude. Assuming that the detection distance of the radar is up to 45 km, the radar detection probability formula can be expressed as:
In Equation (4),
is the relative distance between the UH and the radar, and
is the flying height of the UH. In order to observe the radar coverage more intuitively, the Equation (4) is drawn as a 3D probability distribution diagram to obtain
Figure 3.
In
Figure 3, the v-axis is the probability of being detected by the radar. Combining the Equation (4) and
Figure 3, it can be seen that when the UH passes through the radar coverage area, the flight height should be less than 0.2 km, and then it can ensure its own absolute safety. When the UH flight altitude
, it is not guaranteed to be detected by radar, but this behavior is also dangerous and should be avoided.
The UH’s mission is to raid and destroy the opponent’s radar. The maximum attack range of UH is 8 km, assuming that UH can find it and destroy it. Then the conditions for UH to complete the raid mission are: the relative distance
between UH and radar is less than 8 km, which can be expressed as:
In Equation (5), represents the position of the radar. Building a system model is an important step in path planning research. After the above discussion, we modeled and numerically analyzed the battlefield environment for UH to perform raid missions in low airspace, and clarified the environmental constraints and mission objectives. The purpose of this research is to plan a safe and reliable flight path for UH, and the evaluation indicators should be clearly defined to describe the pros and cons of the planned path. First, to ensure the safety of the UH, the planned path cannot collide with mountains and cross the radar coverage area. Then, in order to reduce the flight consumption of UH, the length of the planned path should be as short as possible. Finally, the planned path should be as straight as possible, and the number of turns should be as few as possible, which can further reduce flight consumption.
6. Experiments and Results
6.1. Experimental Environment and Algorithm Parameters
Carrying out a control experiment in the same experimental environment is the basis for ensuring the validity of the experimental results, and a clear description of the experimental conditions is also an important prerequisite for reproducing the experiment. This experiment was done on the same computer with twelve Intel(R) Core (TM) i7-8700 CPU @ 3.20 GHz processors and one NVIDIA GeForce GT 430 GPU with running memory RAM of 16 GB. All experimental codes were written in Python language on the PyCharm platform, and Python-3.6.10 was utilized. The construction of the neural network was based on Tensorflow-2.6.0, which was based on CPU work.
The setting of parameters is an important factor affecting the convergence of reinforcement learning algorithms. Among all the parameters of the ME-Dueling DQN algorithm, the learning rate , the decay factor , the exploration factor , the neural network parameter , the size of the memory pool , the sampling size and the target Net update frequency are the original of the Dueling DQN algorithm, while the straightness coefficient is unique to the proposed algorithm. The influence of these parameters on the performance of the algorithm is as follows: the larger the value of the learning rate is, the faster the training speed of the algorithm is, but it is easy to produce oscillation, and the smaller the value is, the slower the training speed is. The larger the decay factor is, the more the algorithm pays attention to past experience, and the smaller the value is, the more attention is paid to the current income. If the exploration factor is too large, the algorithm tends to maximize the current profit and loses the motivation to explore, which may miss the greater future benefits. If the value is too small, the algorithm is difficult to converge. If the number of hidden layer and hidden layer neurons of a neural network is too small, it cannot fit the data well, and if it is too many, it cannot learn effectively. The size of the experience pool and the sampling size will affect the learning efficiency of the algorithm. If the value is too small, the learning efficiency will be low, and if the value is too large, the algorithm will easily converge to the local optimal value. The larger the Target Net update frequency is, the more stable the algorithm is, and the smaller the is, the slower the algorithm converges. The straightness coefficient will affect the straightness of the planned path. The larger the value is, the straighter the path is, but it may affect the algorithm convergence. The smaller the value is, the more the planned path turns are. The impact of the value of on the performance of the algorithm will be discussed in the following Sections.
In order to obtain the most suitable parameters, a large number of adjustment parameter control experiments have been carried out. The experiment is done in Scenario 1, where the initial position of the UH is
and the position of the target radar is
. During the experiment, if the raid task is completed, UH will get 1 point, otherwise, it will not score. The score of the last 100 tasks performed by UH is used as an indicator to measure the performance of the algorithm, and UH has performed 2000 tasks for each set of parameter settings. The experimental results are shown in
Table 1. Combined with the experimental results in
Table 1, the final experimental parameters are shown in
Table 2.
6.2. Algorithm Comparative Analysis
In order to verify the performance of the proposed algorithm, three algorithms including Dueling DQN (without any improvement), C-Dueling DQN (introducing a comprehensive reward function) and ME-Dueling DQN (introducing a comprehensive reward function and a memory-enhanced mechanism) are utilized for control experiments. The experiment is done in Scenario 1, where the initial position of the UH is and the position of the target radar is . We have recorded the experimental process of 200 episodes, and the algorithm is updated 1000 times in each episode. Five independent experiments are performed for each algorithm, and the results of the five experiments are averaged as the final result.
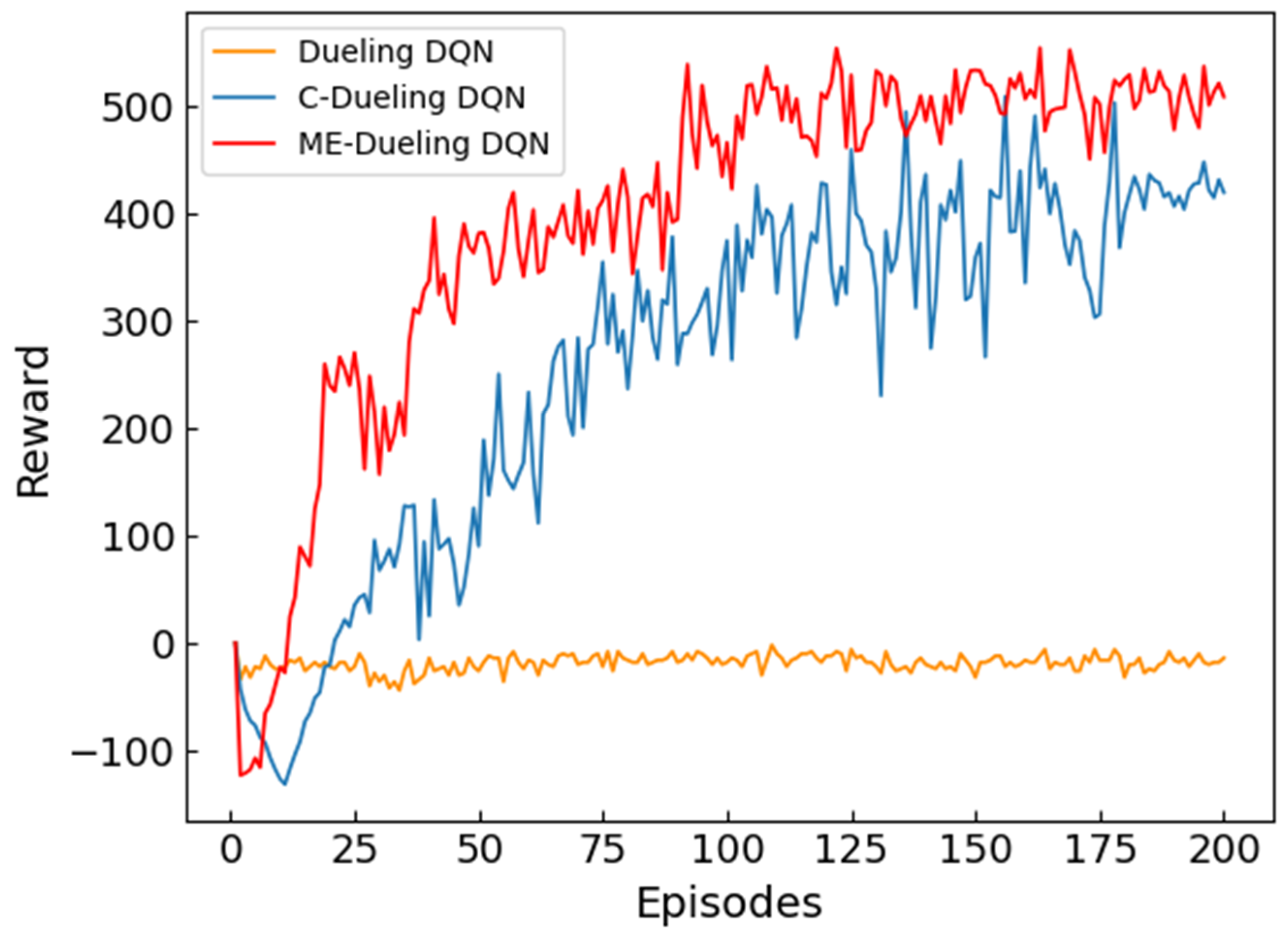
Since the goal of deep reinforcement learning algorithms is to maximize the cumulative reward, the reward situation is an important indicator for evaluating the performance of the algorithm.
Figure 5 records the cumulative situation of reward for each episode of the three algorithms. As shown in
Figure 5, the performance of Dueling DQN is the worst among the three algorithms, and the entire training process is completed without convergence. This shows that the traditional reward setting cannot be based on algorithm feedback in time in the face of a large state space environment, and the sparse reward makes the algorithm difficult to converge. After training, both C-Dueling DQN and ME-Dueling DQN converge smoothly, which shows that the comprehensive reward function effectively improves the sparse reward problem and promotes algorithm convergence. The comparative analysis shows that the reward accumulation process of the ME-Dueling DQN algorithm is faster than that of the C-Dueling DQN algorithm, which shows that the memory-enhanced mechanism can effectively reduce the meaningless exploration in the early stage of training, making the algorithm faster to maximize the cumulative reward. Orientation update. It is worth noting that the cumulative reward of the two algorithms is not stable enough, because the existence of the
strategy makes the algorithm have a certain probability to explore other non-optimal actions, which leads to the generation of oscillation.
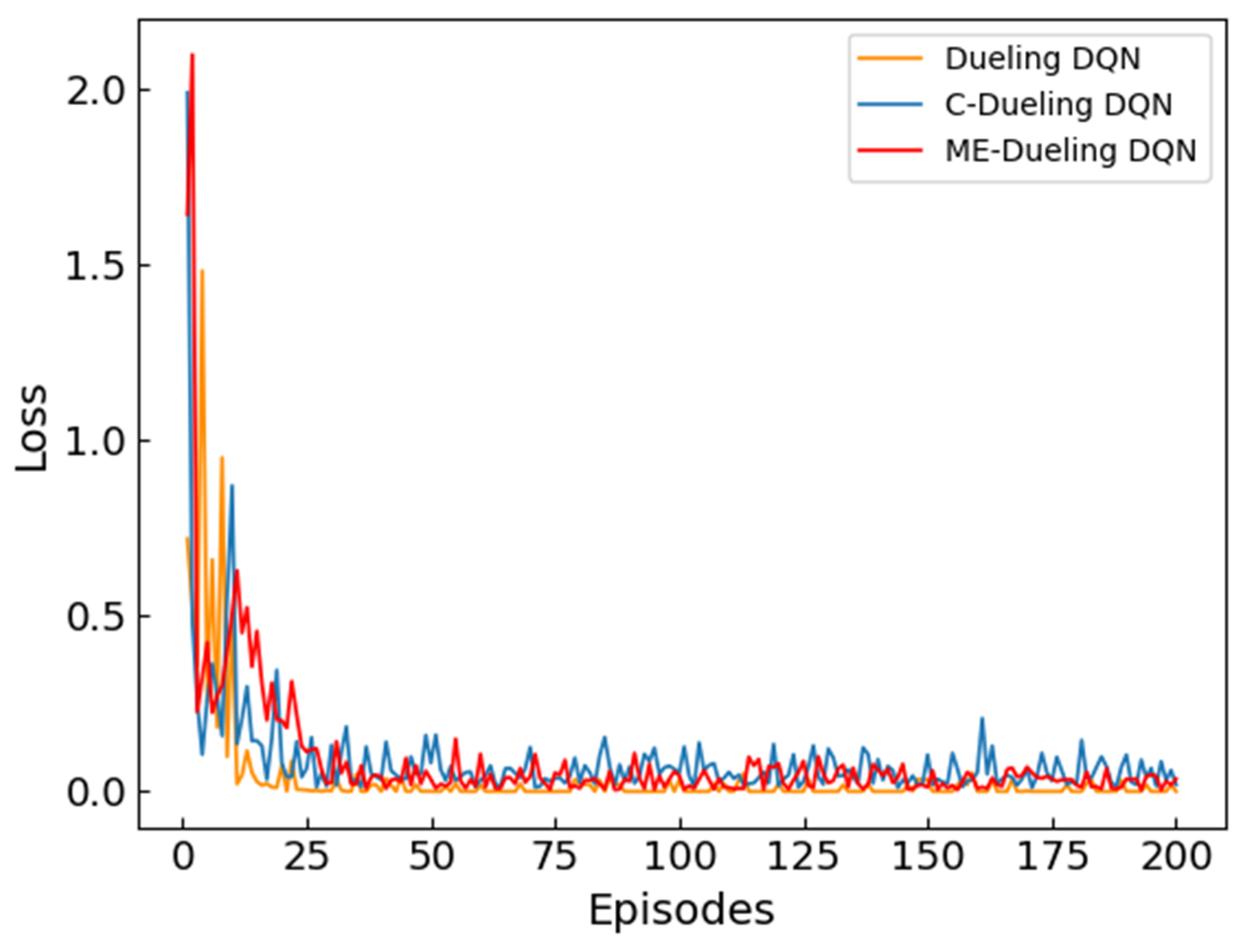
The loss value can reflect the update of the reinforcement learning algorithm and is another effective indicator to measure the performance of the algorithm.
Figure 6 records the loss change during the training of the algorithm. As shown in
Figure 6, the loss value of the Dueling DQN algorithm is 0 most of the time during the entire training process, indicating that it has not been effectively updated. The error values of the C-Dueling DQN and ME-Dueling DQN algorithms are at a large value in the initial stage of training, but they tend to be stable and maintain a small value after training. It shows that the comprehensive reward function can give feedback to the algorithm in time and prompt the algorithm to update quickly. Comparative analysis shows that in the initial stage of training, the loss value of the ME-Dueling DQN algorithm is larger than that of the C-Dueling DQN algorithm, indicating that the ME-Dueling DQN algorithm is updated faster in the early stage of training. This can indicate that the memory-enhanced mechanism can improve the learning ability of the algorithm in the early stage of training, because deep memory can promote learning more. In the later stage of training, the loss value of the ME-Dueling DQN algorithm is smaller and more stable than that of the C-Dueling DQN algorithm, indicating that the ME-Dueling DQN algorithm is more stable in the later stage of training. This shows that a memory-enhanced mechanism can improve the stability of the algorithm, because both good and bad memories are deepened, and meaningless exploration will be reduced.
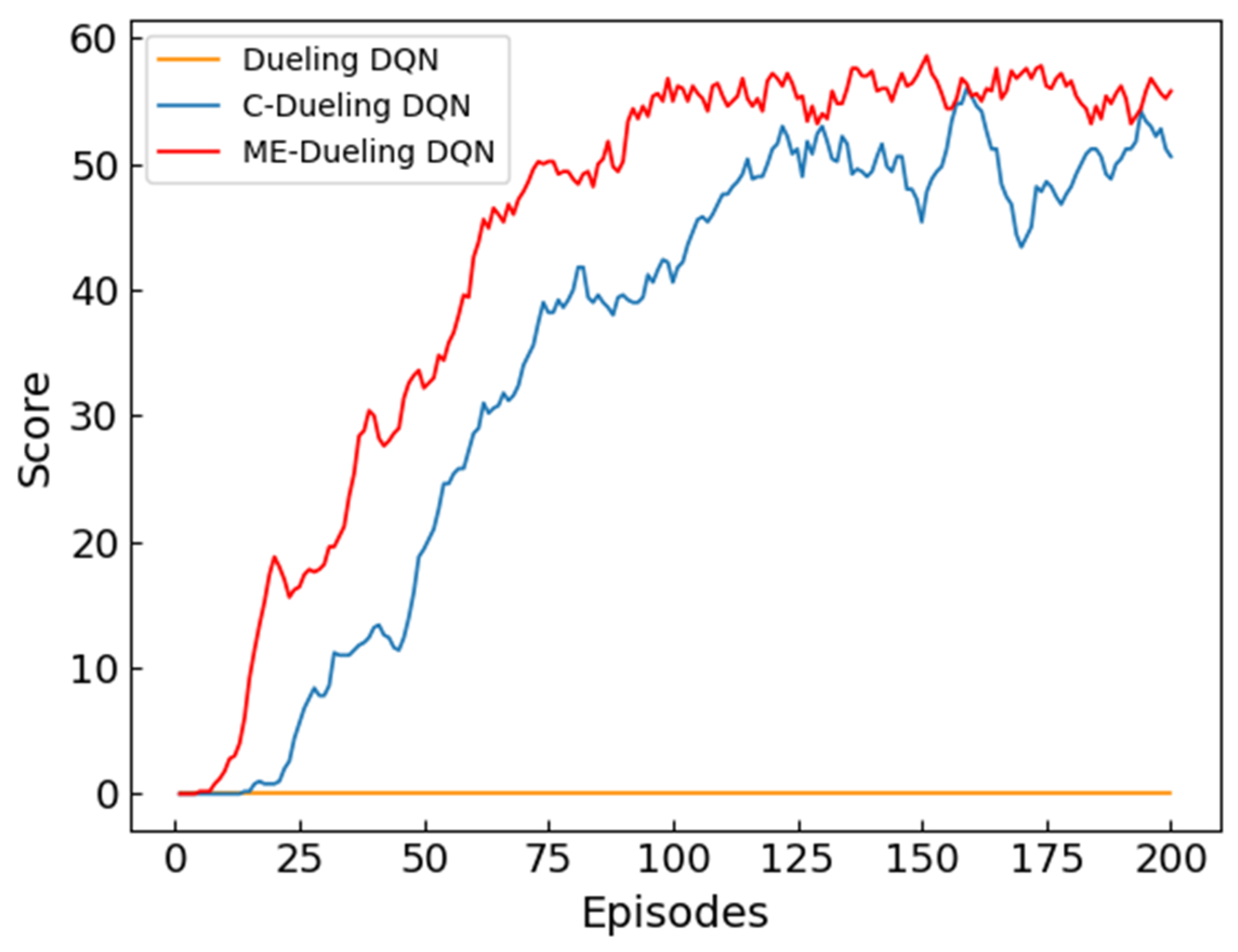
The score can be seen to be a good measure of the overall performance of the algorithm. The
Figure 7 records the score of the three algorithms. As shown in
Figure 7, the score of Dueling DQN is always 0 during the entire training process, indicating that it is difficult to complete the path planning task. After training, the score of C-Dueling DQN and ME-Dueling DQN eventually stabilizes within each episode. The comparative analysis shows that the overall score of the ME-Dueling DQN algorithm is higher than that of the C-Dueling DQN algorithm, indicating that the ME-Dueling DQN algorithm has a stronger ability to complete the path planning task. This shows that the memory-enhanced mechanism can effectively improve the algorithm’s ability to complete the task, because the memory of the crash and the memory of completing the task are repeatedly strengthened, which can promote the algorithm to avoid the threat area and complete the task as much as possible.
6.3. Influence of Straightness Coefficient
The purpose of introducing the straightness coefficient in the ME-Dueling DQN algorithm is to further optimize the planning path. Therefore, the effect of the straightness coefficient on the performance of the algorithm is a question worthy of discussion. We use the ME-Dueling DQN algorithm to analyze the effect of different values of the straightness coefficient on the performance of the algorithm and the planned path through multiple sets of control experiments. The experiment is done in Scenario 1, where the initial position of the UH is and the position of the target radar is . We recorded the experimental process of 200 episodes, and the algorithm was updated 1000 times in each episode. Five independent experiments are performed for each set of parameters, and the results of the five experiments are averaged as the final result.
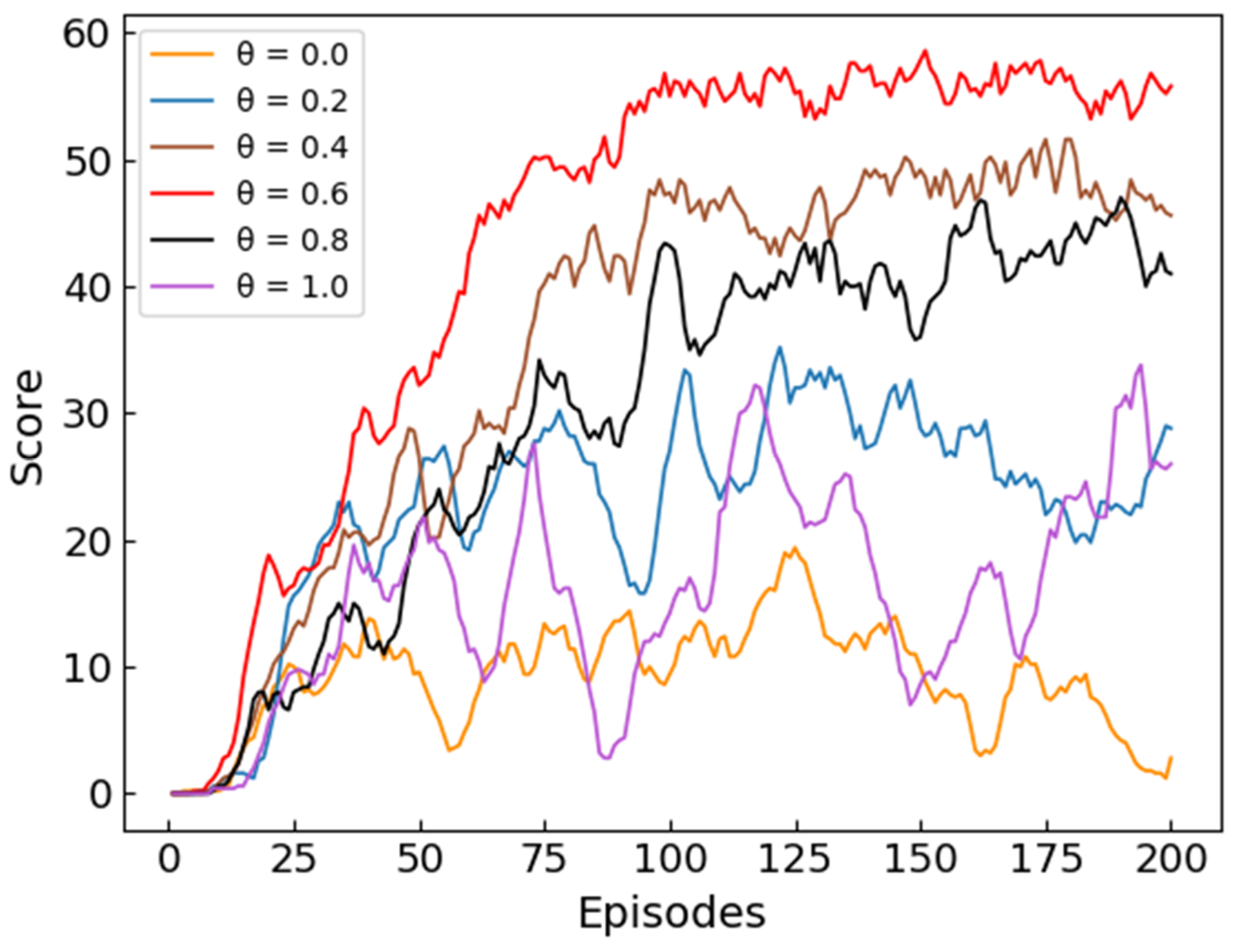
Figure 8 records the score of UH with different values of the straightness coefficient
. As shown in
Figure 8, when the straightness coefficient
takes different values, the convergence of the algorithm is different, and the final score is also different. This shows that the value of
can not only affect the convergence of the algorithm, but also affect the ability of the algorithm to complete the path planning task. It can be seen from
Figure 8 that when
, the performance of the algorithm is the worst in all cases, and the performance of the algorithm also improves as the value of
increases. When
, the performance of the algorithm is the best in all cases, and the performance of the algorithm starts to deteriorate as the value of
increases. The above situation can show that the introduction of the straightness coefficient
effectively improves the performance of the algorithm. Since there are many dangerous areas in the environment, it may be easier to enter the dangerous area by frequently changing the flight direction. The introduction of the straightness coefficient
can reduce the turning angle of the planned path, thereby reducing the possibility of UH encountering danger, thereby improving the performance of the algorithm. However, when the value of
is greater than a certain value, its impact on the algorithm gradually becomes negative, because an overly straight path may not be able to avoid the danger ahead. Therefore, the performance of the algorithm can be effectively improved only when
takes an appropriate value.
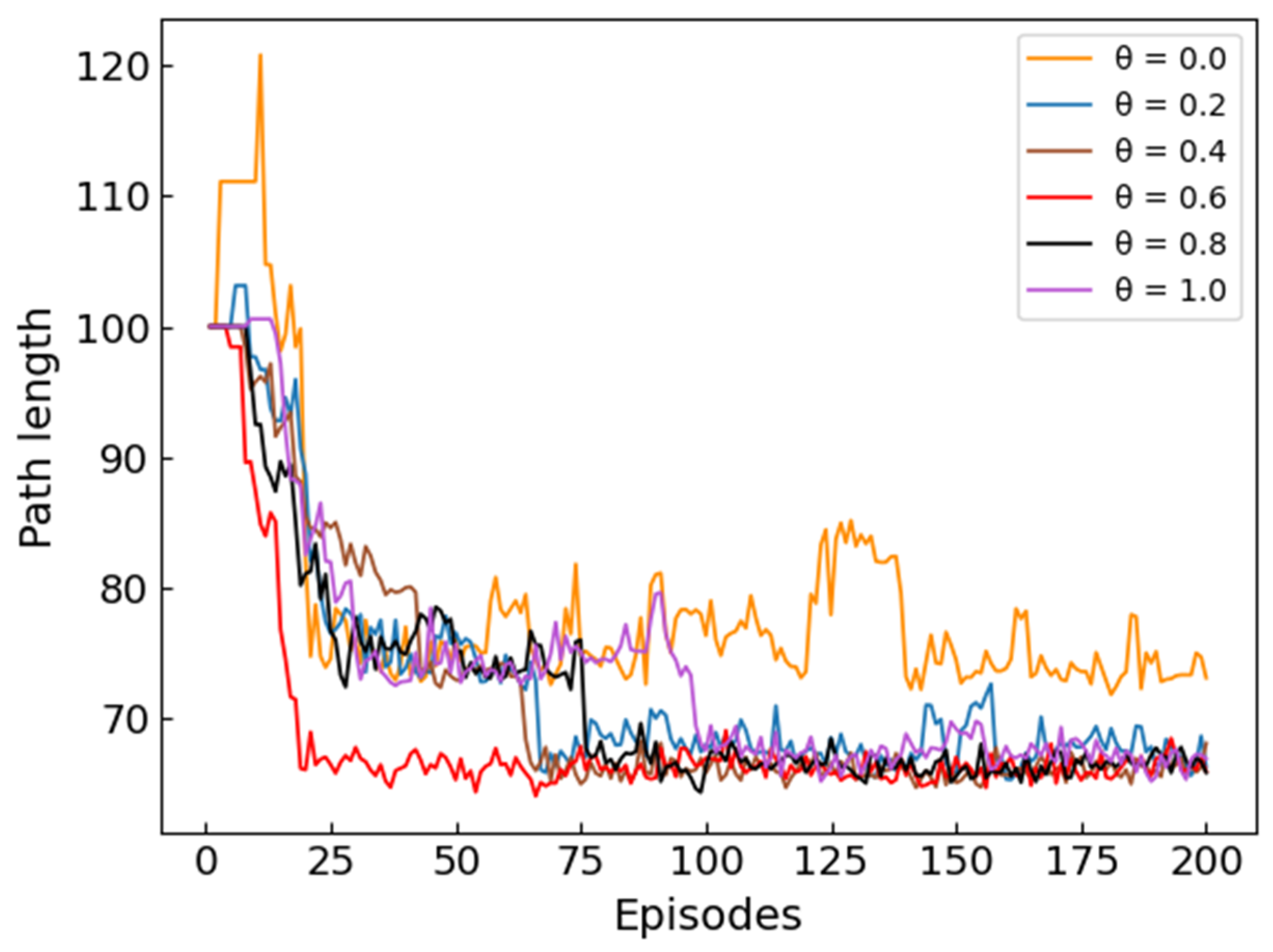
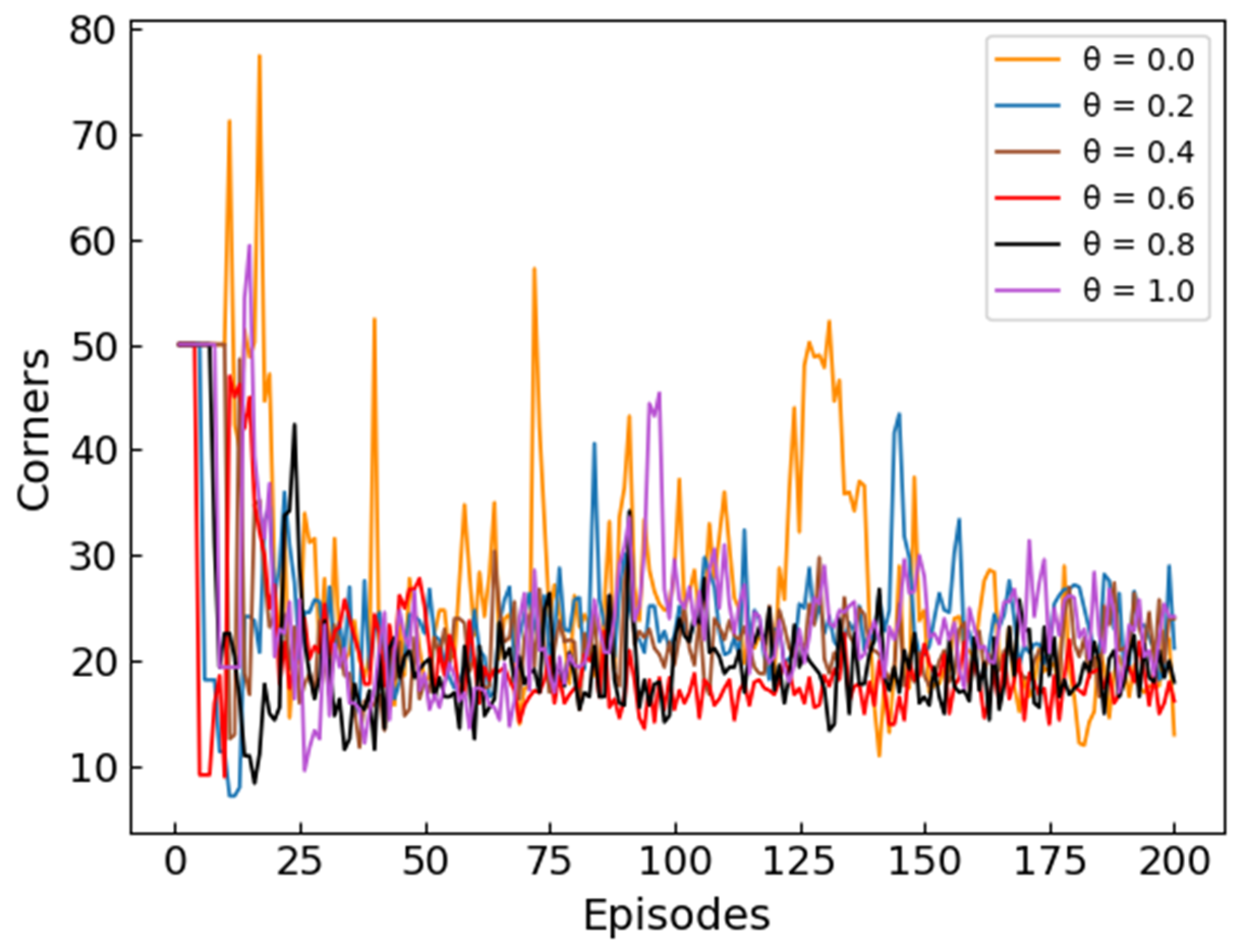
Figure 9 and
Figure 10 respectively record the length of the planned path and the number of corners when the straightness coefficient
takes different values. In order to make the changing trend of the curve clearer, the initial point of
Figure 9 is set to 100, and the initial point of
Figure 10 is set to 50. Combining
Figure 9 and
Figure 10, it can be seen that when
, the length of the planned path is the longest in all cases, and the number of corners is also the largest. As the value of
increases, the length of the planned path decreases and the number of turns decreases. When
is greater than a certain value, the length of the planned path begins to increase and the number of turns also increases. These situations can illustrate that the introduction of the straightness coefficient
can reduce the length and number of corners of the planned path, thereby making the planned path straighter. It is worth noting that the path length and the number of corners is not completely positively correlated. Since the movement distances of UH in the horizontal and vertical directions are not exactly equal (0.5 km in the horizontal direction and 0.05 km in the vertical direction), a higher number of corners does not mean a longer path length. Combining the experimental results of
Figure 8,
Figure 9 and
Figure 10, it can be seen that the ME-Dueling DQN algorithm can have the best performance when
.
6.4. Algorithm Suitability Test
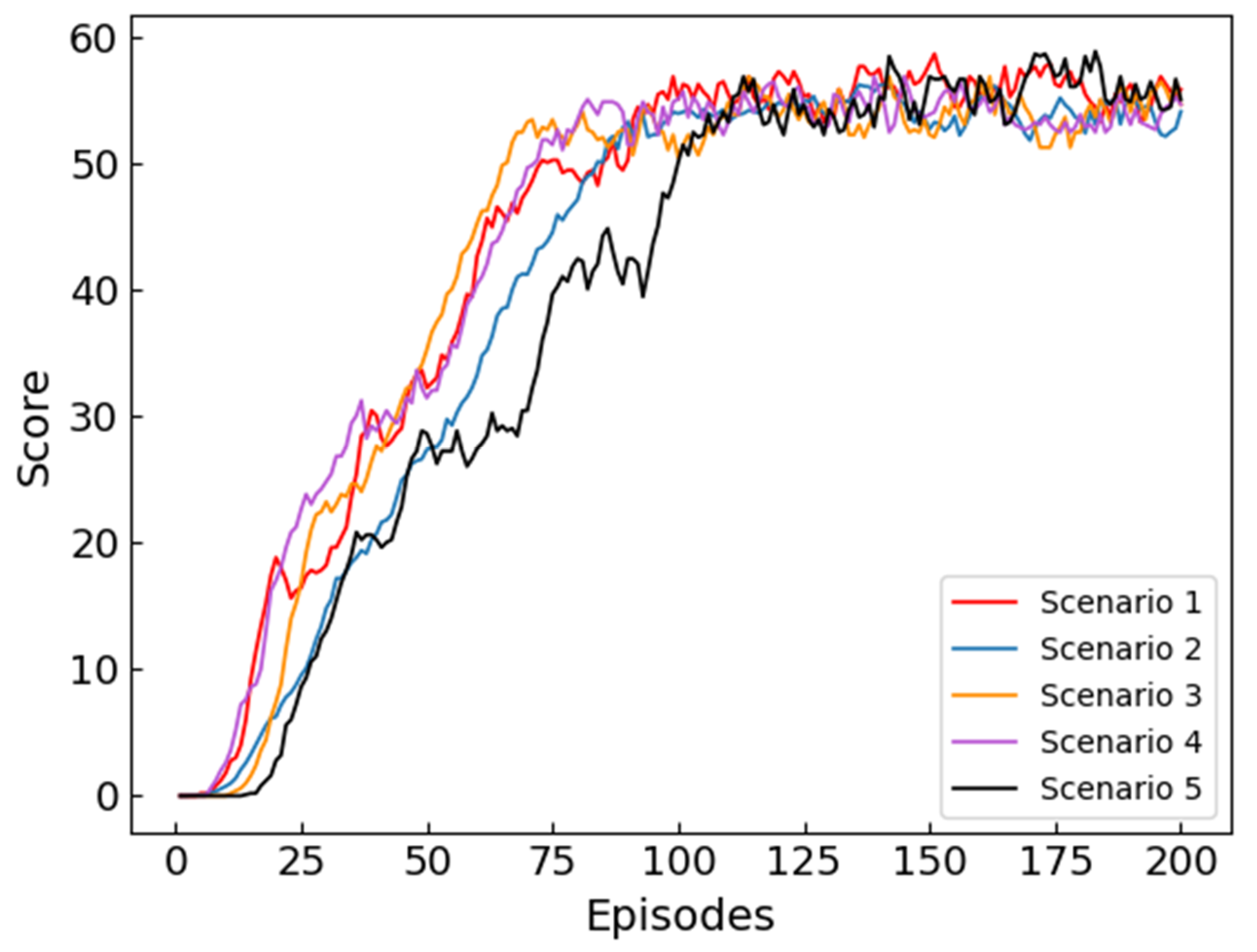
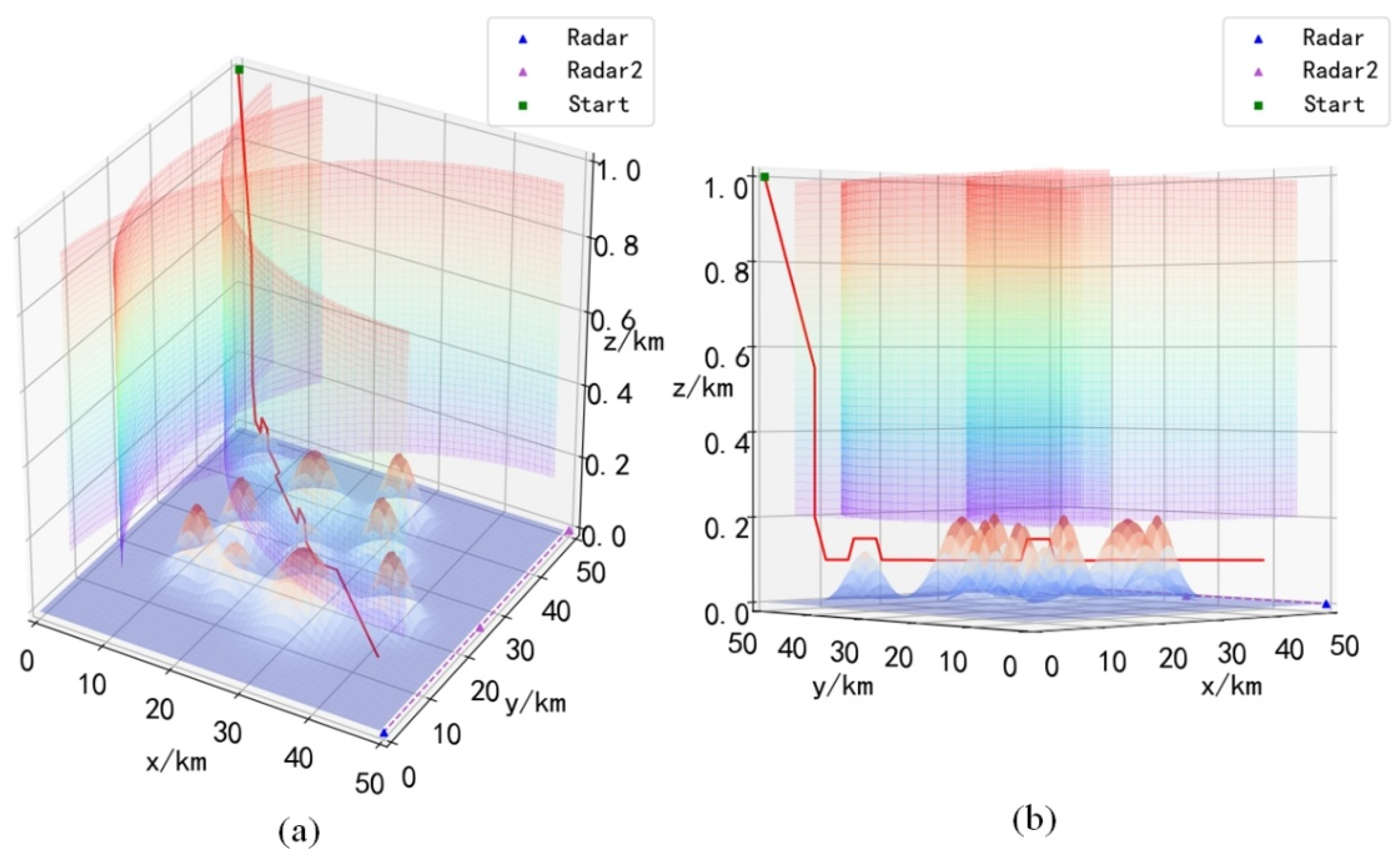
In order to verify the ability of the ME-Dueling DQN algorithm to adapt to various environments, we choose different environments for path planning tests. By changing the positions of the starting point and the target point, we construct four scenarios, Scenario 1: the initial position of the UH is , and the position of the target radar is . Scenario 2: The initial position of the UH is and the position of the target radar is . Scenario 3: The initial position of the UH is and the position of the target radar is . Scenario 4: The initial position of the UH is and the position of the target radar is . In addition, we construct a dynamic scene with variable radar coverage by introducing a second on-board radar that can move. Scenario 5: The initial position of the UH is , and the position of the target radar is . The moving vehicle radar will start from and make a round-trip motion along the y-axis to . Considering that the moving speed of the vehicle radar is much lower than that of the UH, it is set that the UH does two movements and the vehicle radar does one movement.
Figure 11 records the score of the path planning test using the ME-Dueling DQN algorithm in 5 scenarios. As shown in
Figure 11, the ME-Dueling DQN algorithm can converge quickly in all five scenarios. Comparative analysis shows that the convergence speed of the ME-Dueling DQN algorithm in scenario 5 is slower and more oscillating than in the other four scenarios. Since there are moving radar vehicles in scenario 5, the radar coverage area is changing, and it takes more time to accurately identify the radar coverage area.
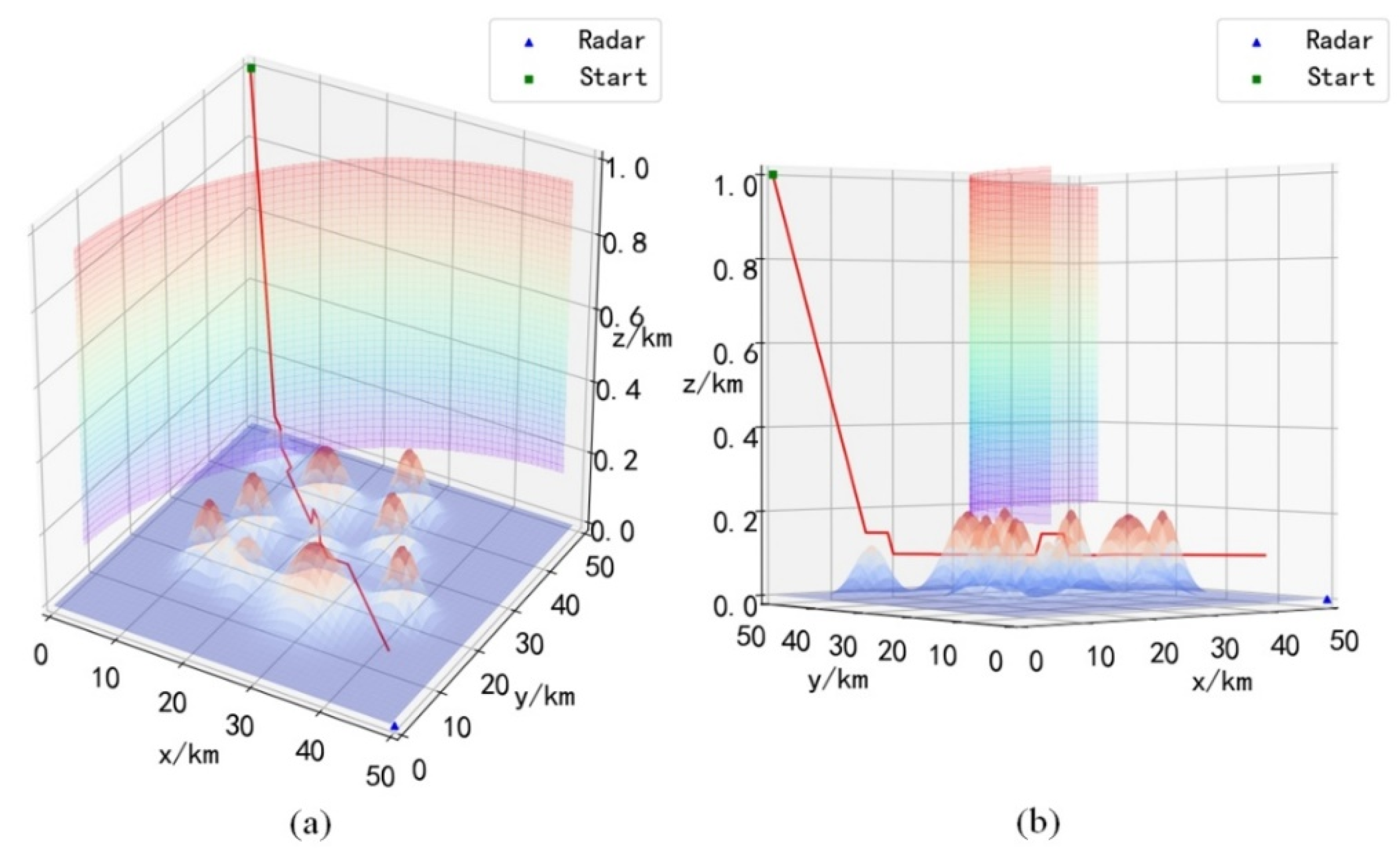
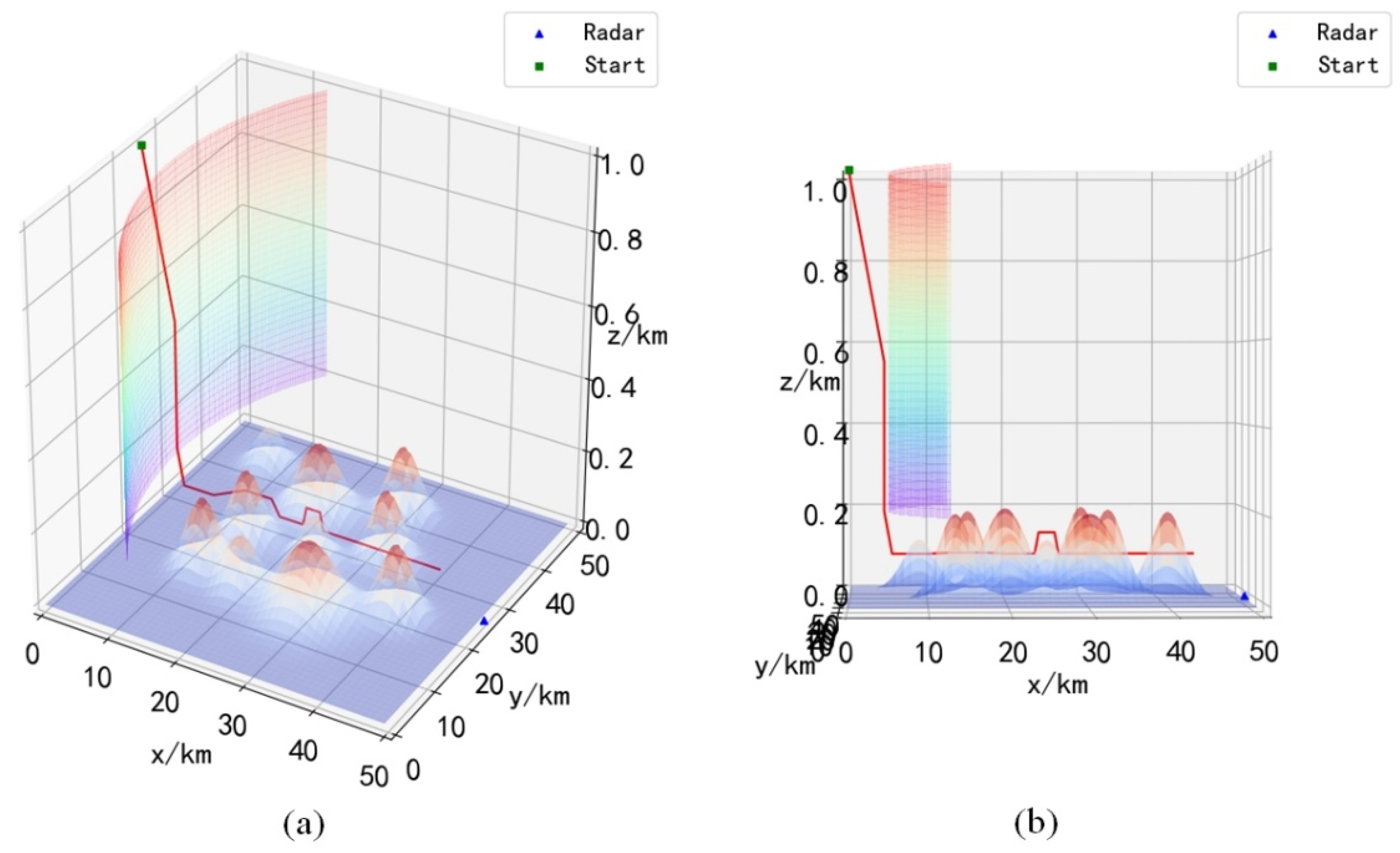
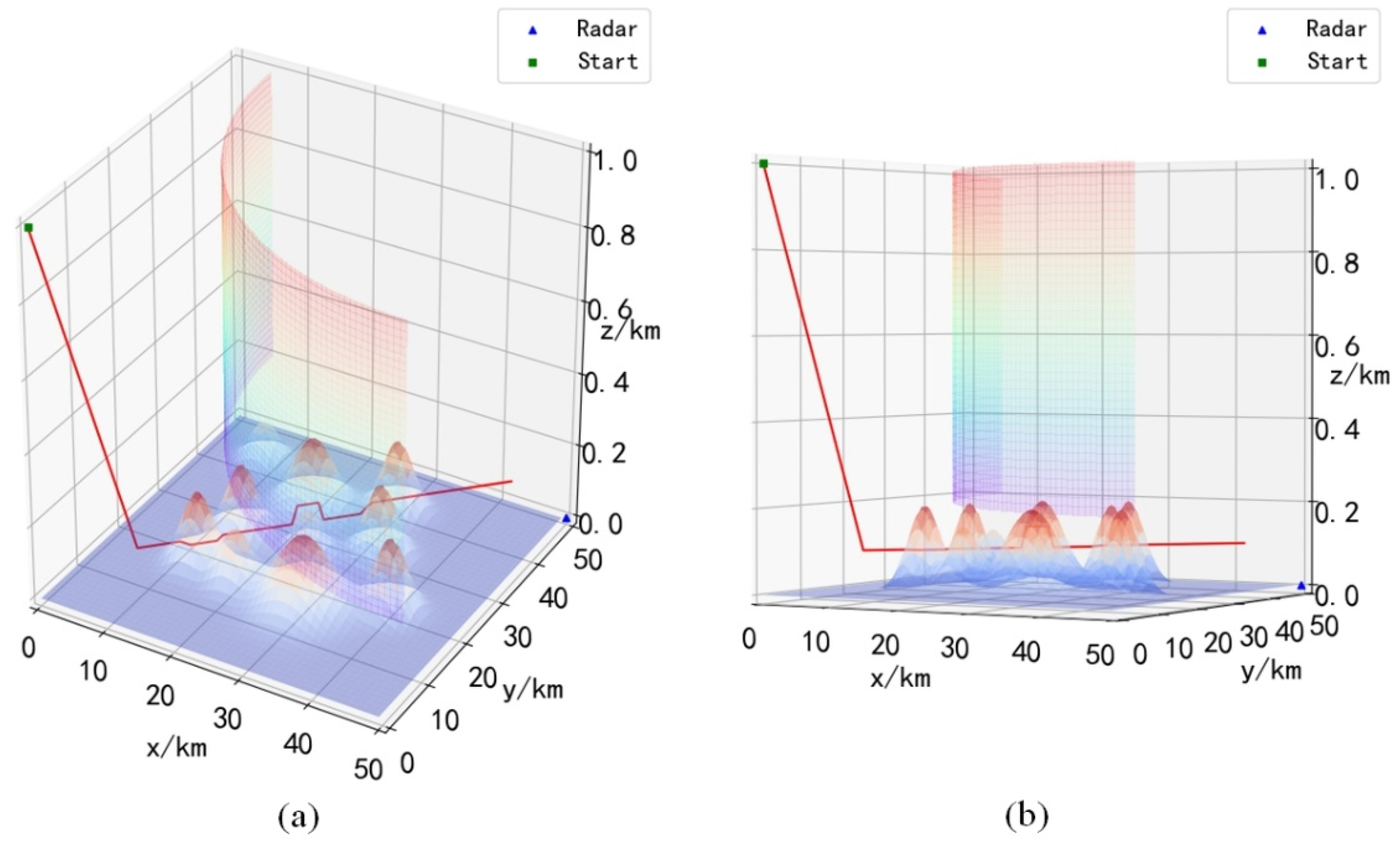
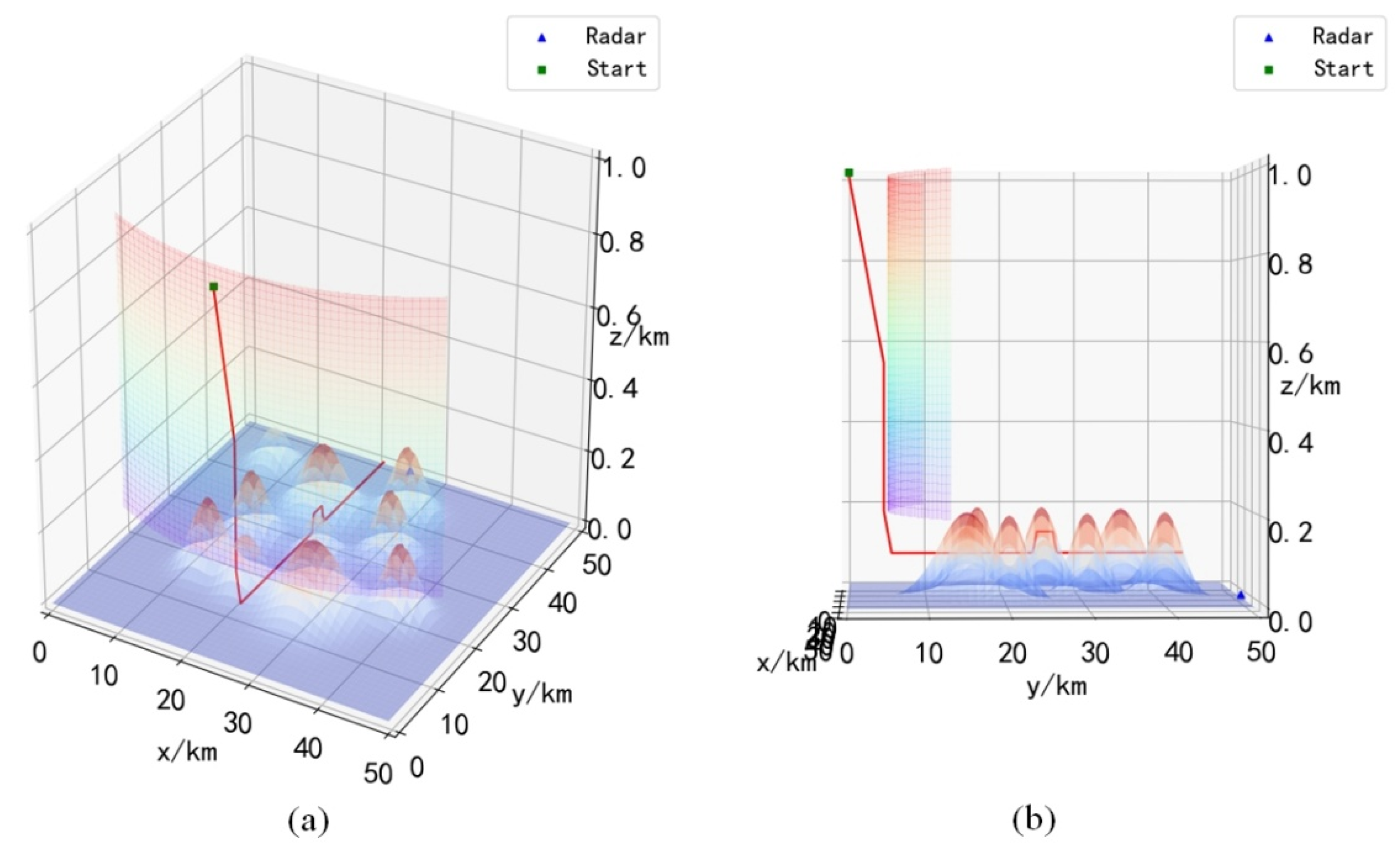
Combining
Figure 12,
Figure 13,
Figure 14 and
Figure 15, it can be seen that the UH after training will choose the descending height before entering the radar coverage area, and reach the strike area by flying at a low altitude, and the UH will choose the optimal action to avoid the mountains ahead during the flight. It is worth noting that during obstacle avoidance, the UH can fly over the obstacle, or go around the obstacle, which can be verified in
Figure 12a,
Figure 13a and
Figure 14a. This shows that the trained UH will autonomously choose the optimal path when avoiding obstacles. Since the rewards obtained when choosing different paths to avoid obstacles are different, only choosing the optimal path will maximize the cumulative reward.
In the process of the algorithm interacting with the environment, once the UH crashes (the UH hits the mountain or is detected by the radar), the current path will be considered unsafe, and the algorithm will receive a negative reward. Although detection by radar within the radar area is probabilistically distributed, the complete radar coverage area can also be explored after the algorithm has fully interacted with the environment. Since the purpose of the ME-Dueling DQN algorithm learning is to maximize the cumulative reward, after the algorithm converges, it will choose the optimal flight path to avoid crashes as much as possible. It can be seen from
Figure 16 that although the position of the mobile radar vehicle is changing, the ME-Dueling DQN algorithm still explores the optimal path. In
Figure 16, UH chooses to descend the flight height at the fastest speed, perfectly avoiding radar detection at all positions, indicating that it has accurately detected all potentially dangerous areas. To sum up, the ME-Dueling DQN algorithm has good environmental adaptability and can help UH successfully complete the raid mission.
6.5. Compared with Traditional Algorithms
In order to further verify the good performance of the ME-Dueling DQN algorithm, we select the Dijkstra and A* algorithms for control experiments. During the experiment, the
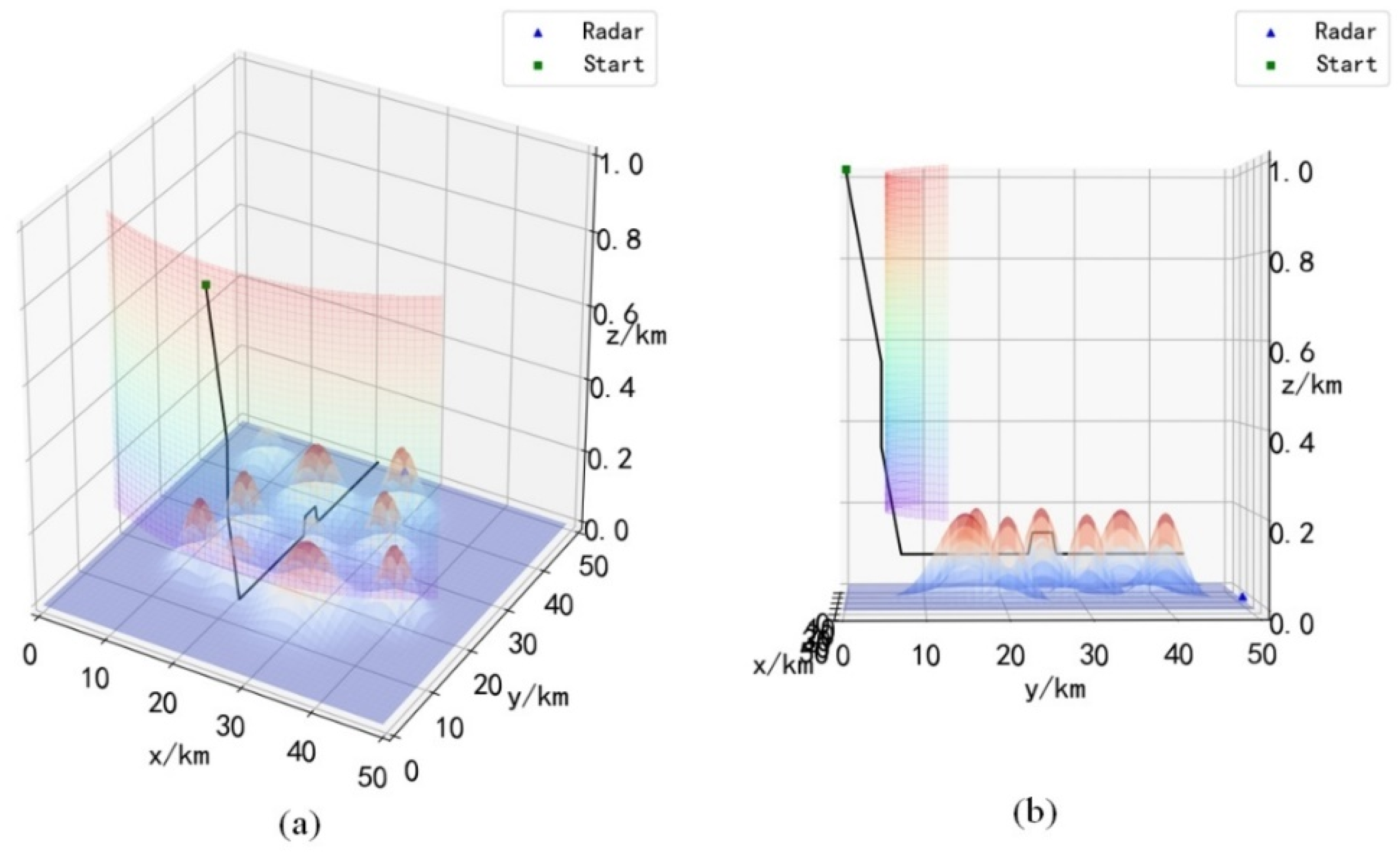
calculation of the A* algorithm uses the Manhattan distance. The Dijkstra and A* algorithms are used to conduct a large number of path planning tests in scenarios 1 to 5, respectively. The test results show that the Dijkstra and A* algorithms can successfully plan safe paths in scenarios 1 to 5, and in some cases these paths are the same as the path planned by the ME-Dueling DQN algorithm is consistent. However, the test results show that the safe paths planned by the Dijkstra and A* algorithms may cross the radar coverage area in some cases, as shown in
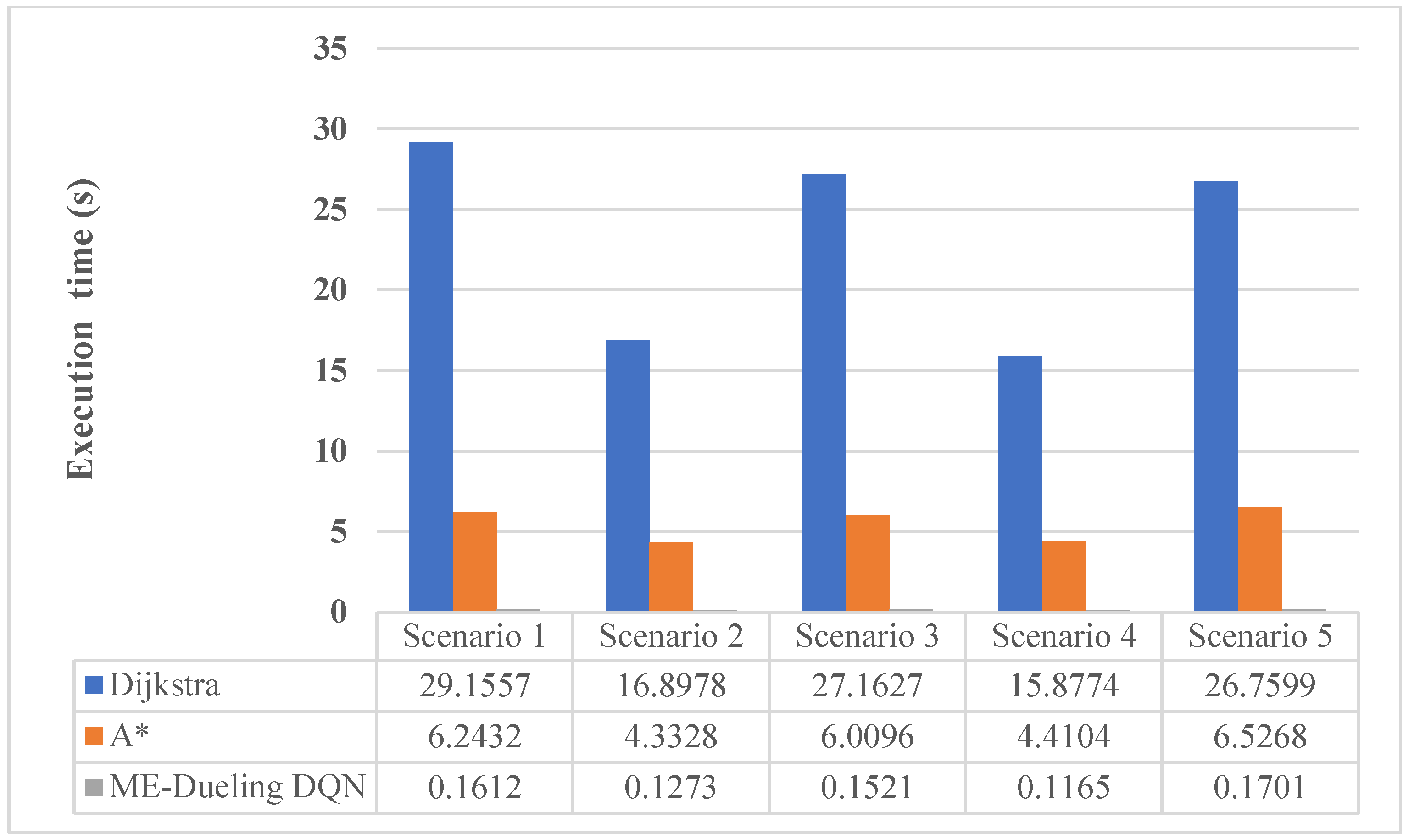
Figure 17. In addition, we recorded the execution time of the Dijkstra, A* and ME-Dueling DQN algorithms in the path planning test under various scenarios, as shown in
Figure 18. The execution time in the figures is obtained by averaging the results of five independent experiments.
Figure 17 is a special case we selected from multiple test results. Since the paths planned by the Dijkstra and A* algorithms are consistent in most cases,
Figure 17 can represent the test results of the two algorithms at the same time. It can be seen from
Figure 17 that the UH entered the radar coverage area during the process of descending the flight altitude in the early stage of the mission. The analysis shows that the radar cannot accurately detect the target within the height of 0.2–0.4 km, that is, this area is not completely covered by the radar. The Dijkstra and A* algorithms will consider the uncovered areas to be safe during the path search process, so they will pass through these areas. However, the radar coverage area is probabilistically distributed, and the location of the covered area will change. Therefore, absolute safety can only be guaranteed if the radar detection range is completely avoided. To sum up, the Dijkstra and A* algorithms cannot plan a safe and reliable flight path for UH in this complex battlefield environment.
It can be seen from
Section 6.4 that the path planned by Algorithm ME-Dueling DQN has not crossed the radar detection area. This is because, under the action of the reward mechanism, the ME-Dueling DQN algorithm will remember the position detected by the radar during the path search process. When the ME-Dueling DQN algorithm fully interacts with the environment, the radar detection range will be regarded as a restricted area and will no longer be entered. Therefore, the path planned by the ME-Dueling DQN algorithm can completely avoid the radar detection area, which can ensure that the UH will not be detected by the radar.
As can be seen from
Figure 18, in the test of each scenario, the execution time of the Dijkstra algorithm is the longest, and the execution time of the A* algorithm is much shorter than that of the Dijkstra algorithm. The ME-Dueling DQN algorithm has the shortest execution time among the three algorithms, and is much shorter than the other two algorithms. Analysis shows that the Dijkstra algorithm needs to calculate the shortest path length from the starting point to all other points in the iterative process, which is a divergent search algorithm. The A* algorithm is a heuristic search algorithm, which also calculates the expected cost from the current point to the endpoint. During the execution of the algorithm, the search space of the A* algorithm is much smaller than that of the Dijkstra algorithm, and so the execution time of its path search is smaller than that of the Dijkstra algorithm. In the process of path planning test, the ME-Dueling DQN algorithm only needs to judge the correct action corresponding to the current state through the neural network, and does not need to search for the path, so its path planning speed is naturally much faster than that of the Dijkstra and A* algorithms. It is worth noting that for the ME-Dueling DQN algorithm, the execution time of our comparison is performed using the already trained neural network, and the network training time is not calculated.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}