
UAV Imagery for Automatic Multi-Element Recognition and Detection of Road Traffic Elements



Abstract
:1. Introduction
2. Related Work
3. Research Method
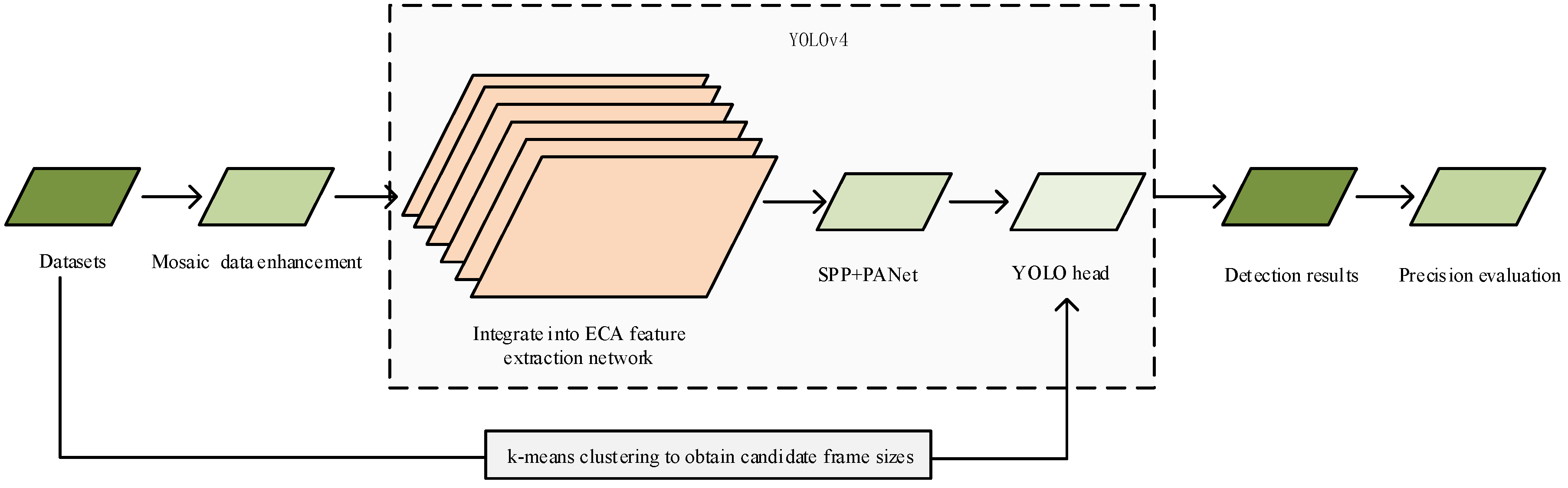
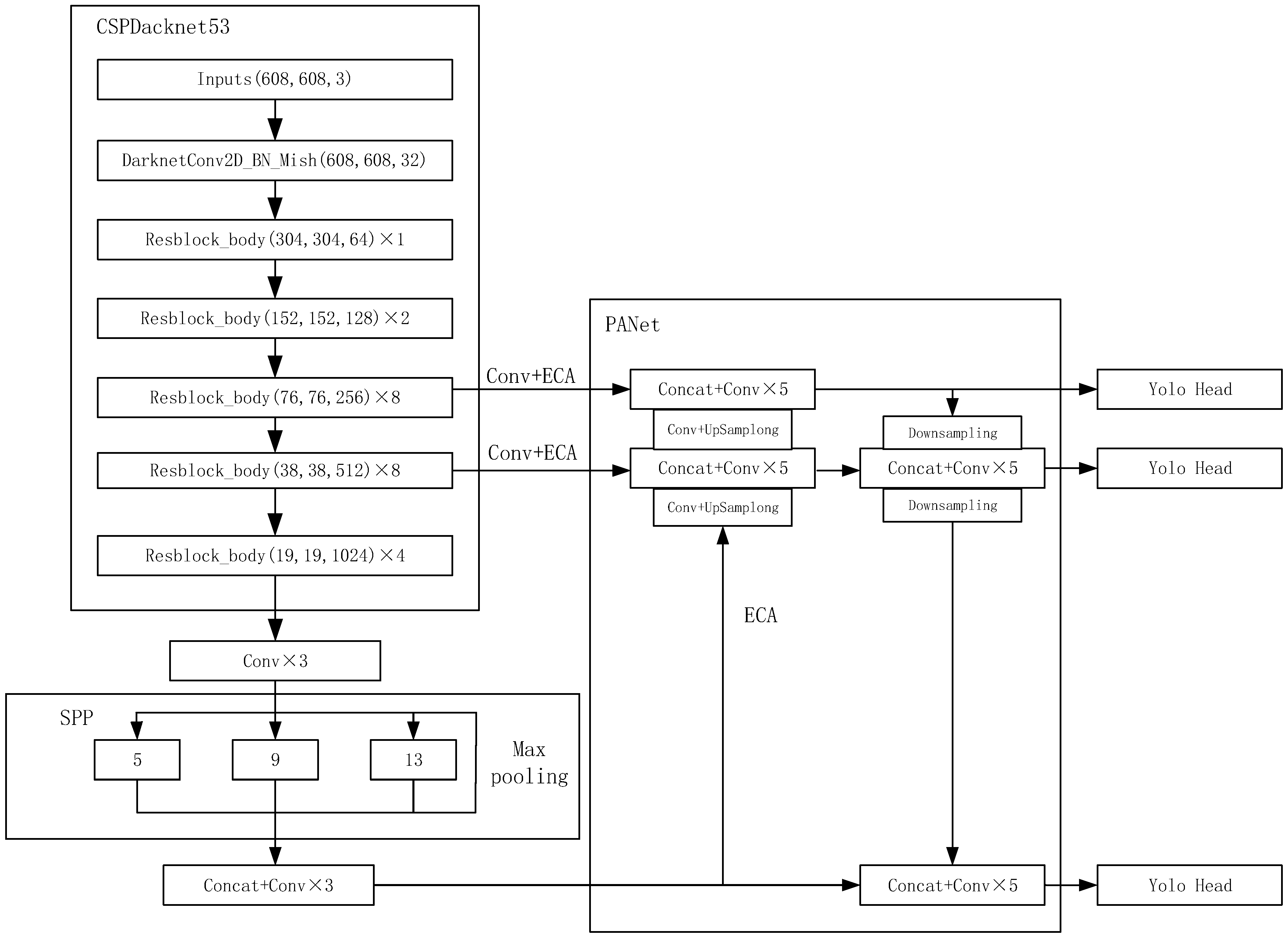
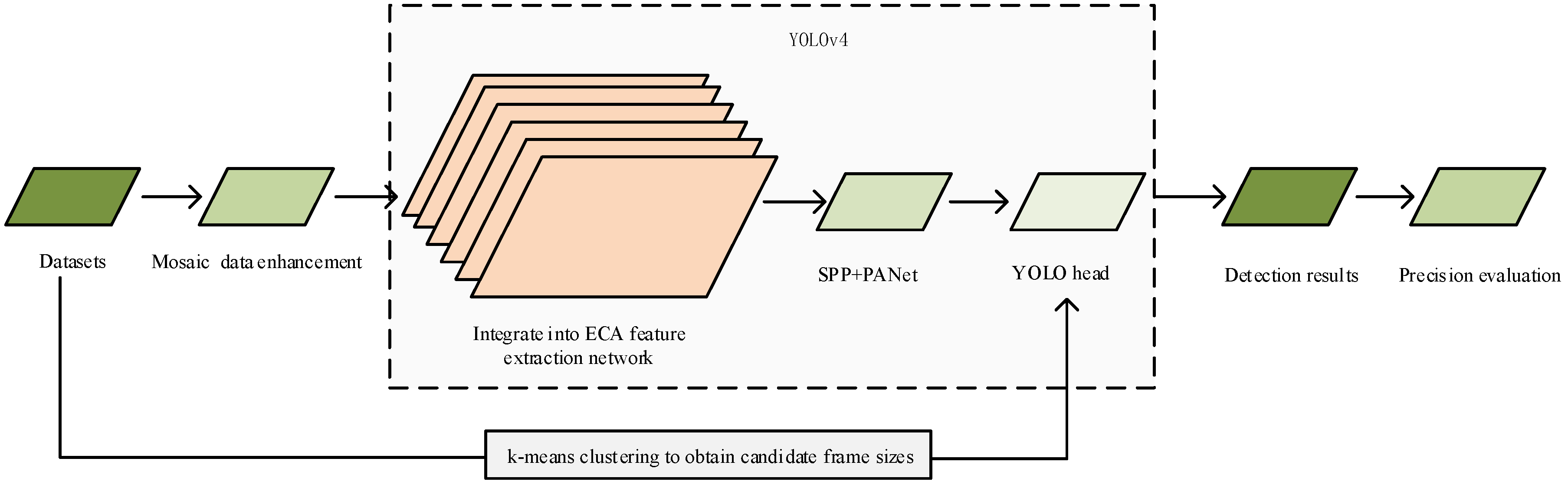
3.1. Overall Framework
3.2. Datasets and Scale Statistics
3.2.1. Introduction to the Datasets
3.2.2. Clustering of the Anchor Box
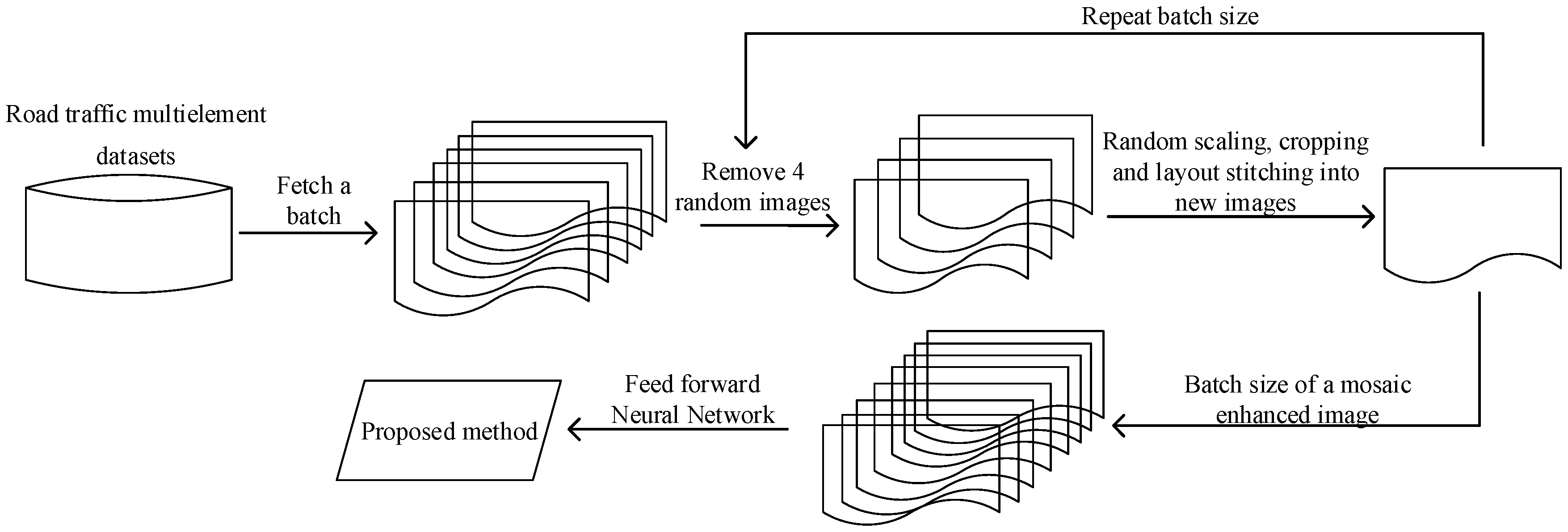
3.3. Data Augmentation
3.4. Efficient Channel Attention
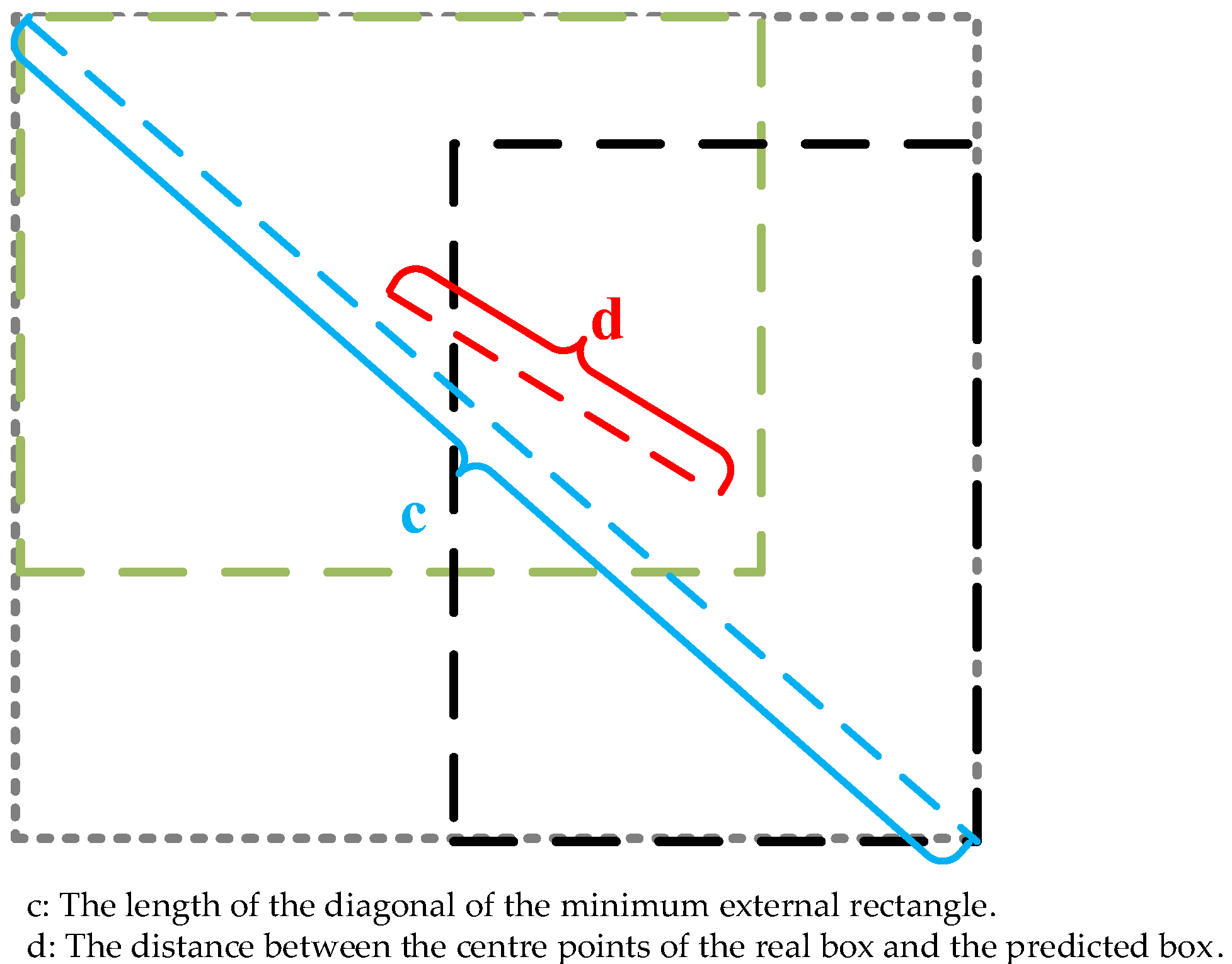
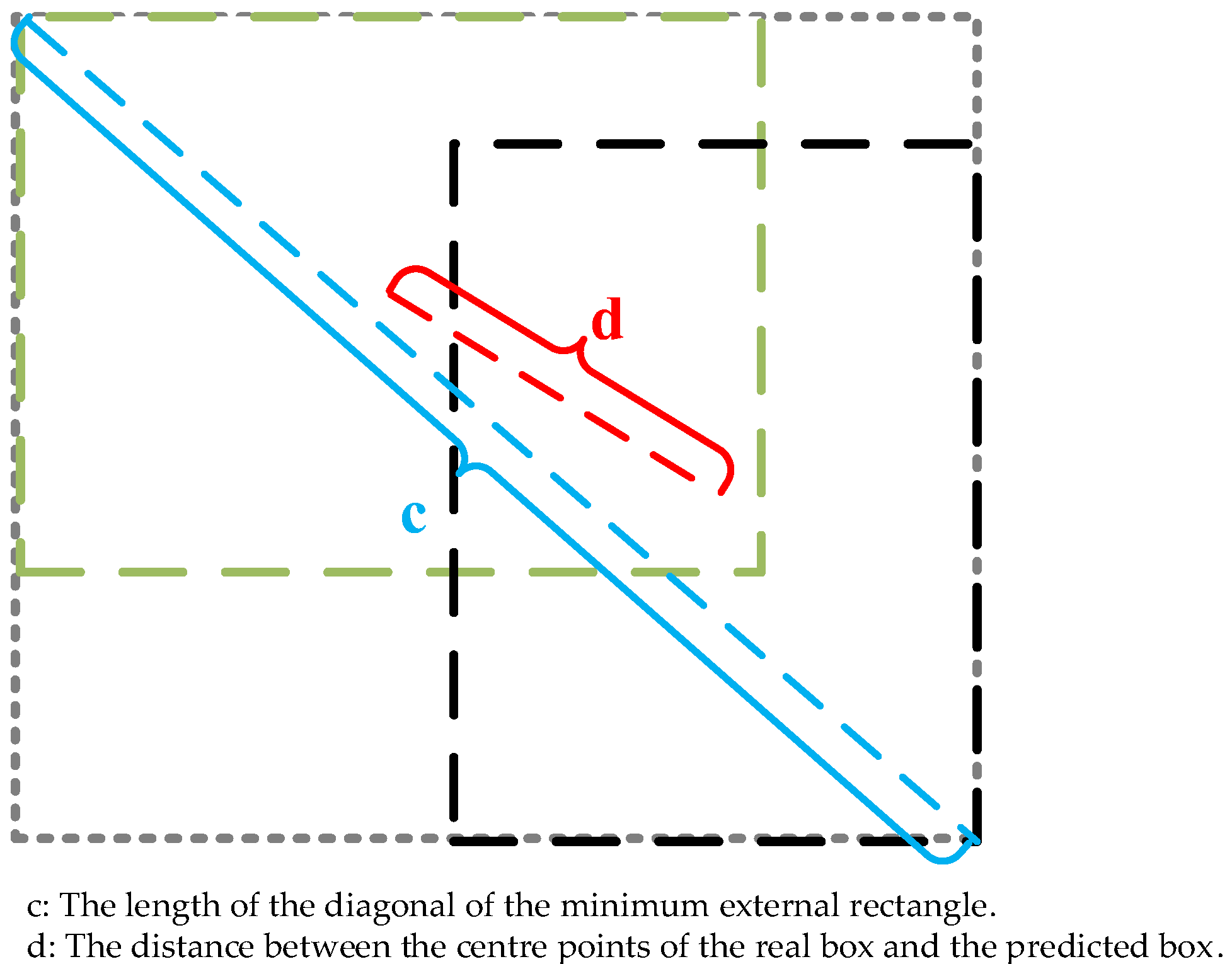
3.5. CIoU_Loss
4. Experimental Results and Analysis
4.1. Experimental Environment
4.2. Evaluation Indicators
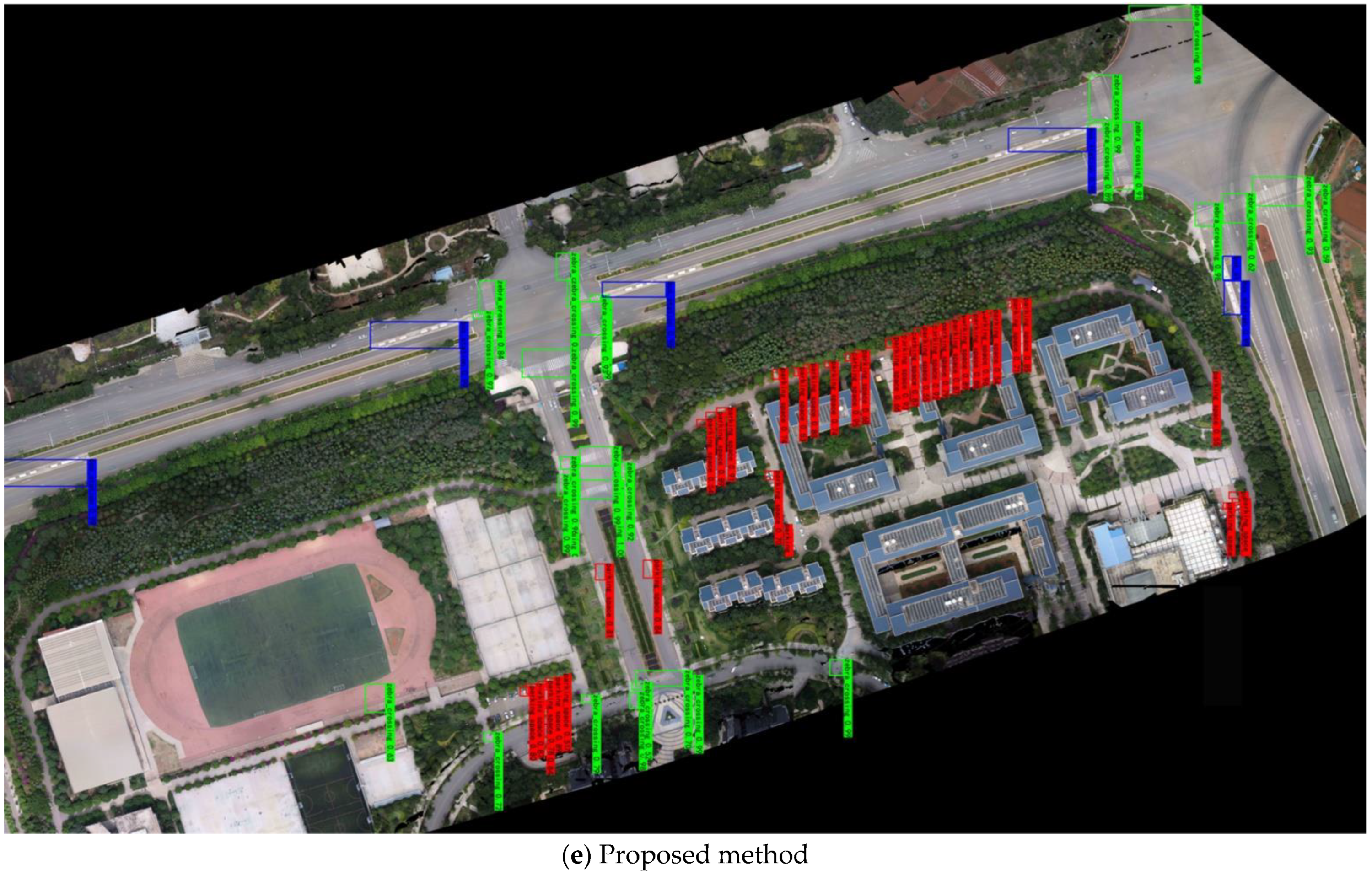
4.3. Comparison Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xiao, J. Design of urban basic traffic management system based on geographic information system. In Proceedings of the 29th Chinese Control Conference, Beijing, China, 29–31 July 2010. [Google Scholar]
- Wang, F.; Wang, J.; Li, B.; Wang, B. Deep attribute learning based traffic sign detection. Jilin Daxue Xuebao (Gongxueban) 2018, 48, 319–329. [Google Scholar]
- Li, H.J.; Sun, F.M.; Liu, L.J.; Wang, L. A novel traffic sign detection method via color segmentation and robust shape matching. Neurocomputing 2015, 169, 77–88. [Google Scholar] [CrossRef]
- Zhao, Y.W. Image processing based road traffic sign detection and recognition method. Transp. World 2018, 2018, 42–43. [Google Scholar]
- Zhang, S.F.; Zhu, X.Y.; Lei, Z.; Shi, H.L.; Wang, X.B.; Li, S.Z. Faceboxes: A cpu real-time face detector with high accuracy. In Proceedings of the IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017. [Google Scholar]
- Bagschik, G.; Menzel, T.; Maurer, M. Ontology based scene creation for the development of automated vehicles. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium, Suzhou, China, 26–30 September 2018. [Google Scholar]
- Liao, M.H.; Shi, B.G.; Bai, X.; Wang, X.G.; Liu, W.Y. TextBoxes: A fast text detector with a single deep neural network. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017. [Google Scholar]
- Meng, Y.B.; Shi, D.W.; Liu, G.H.; Xu, S.J.; Jin, D. Dense irregular text detection based on multi-dimensional convolution fusion. Guangxue Jingmi Gongcheng 2021, 29, 2210–2221. [Google Scholar] [CrossRef]
- Berkaya, S.K.; Gunduz, H.; Ozsen, O.; Akinlar, C.; Cunal, S. On circular traffic sign detection and recognition. Expert Syst. Appl. 2016, 48, 67–75. [Google Scholar] [CrossRef]
- Shi, X.P.; He, W.; Han, L.Q. A road edge detection algorithm based on the hough transform. Trans. Intell. Syst. 2012, 7, 81–85. [Google Scholar]
- He, J.P.; Ma, Y. Triangle Traffic sign detection approach based on shape information. Comput. Eng. 2010, 36, 198–199+202. [Google Scholar]
- Creusen, I.M.; Wijnhoven, R.; Herbschleb, E. Color exploitation in hog-based traffic sign detection. In Proceedings of the IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010. [Google Scholar]
- Hao, X.; Zhang, G.; Ma, S. Deep learning. Int. J. Semant. Comput. 2016, 10, 417–439. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. Available online: https://arxiv.org/abs/1804.02767 (accessed on 8 April 2018).
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. Available online: https://arxiv.org/abs/2004.10934 (accessed on 23 April 2020).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. Available online: https://arxiv.org/abs/2107.08430 (accessed on 6 August 2021).
- Girshick, R.; Donahue, J.; Darrell, T.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 15th IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Shan, H.; Zhu, W. A small traffic sign detection algorithm based on modified ssd. IOP Conf. Ser. Mater. Sci. Eng. 2019, 646, 012006. [Google Scholar] [CrossRef]
- Chen, P.D.; Huang, L.; Xia, Y.; Yu, X.N.; Gao, X.X. Detection and recognition of road traffic signs in uav images based on mask r-cnn. Remote Sens. Land Resour. 2020, 32, 61–67. [Google Scholar]
- Lodhi, A.; Singhal, S.; Massoudi, M. Car traffic sign recognizer using convolutional neural network cnn. In Proceedings of the 6th International Conference on Inventive Computation Technologies, Coimbatore, India, 20–22 January 2021. [Google Scholar]
- Guo, J.K.; Lu, J.Y.; Qu, Y.Y.; Li, C.H. Traffic-sign spotting in the wild via deep features. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium, Suzhou, China, 26–30 September 2018. [Google Scholar]
- Jin, Z.Z.; Zheng, Y.F. Research on application of improved yolov3 algorithm in road target detection. J. Phys. Conf. Ser. 2020, 1654, 012060. [Google Scholar]
- Wang, Q.L.; Wu, B.G.; Zhu, P.F.; Li, P.H.; Zuo, W.M.; Hu, Q.H. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, Online, 14–19 June 2020. [Google Scholar]
- Cgvict. RoLabelImg. Available online: https://github.com/cgvict/roLabelImg (accessed on 23 June 2020).
- Zheng, Z.H.; Wang, P.; Liu, W.; Li, J.Z.; Ye, R.G.; Ren, D.W. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Liu, X.F.; Guan, Z.W.; Song, Y.Q.; Chen, D.S. An optimization model of UAV route planning for road segment surveillance. J. Cent. South Univ. 2014, 21, 2501–2510. [Google Scholar] [CrossRef]
- Cheng, L.H.; Zhong, L.; Tian, S.S.; Xing, J.X. Task assignment algorithm for road patrol by multiple uavs with multiple bases and rechargeable endurance. IEEE Access 2019, 7, 144381–144397. [Google Scholar] [CrossRef]
- Elloumi, M.; Dhaou, R.; Escrig, B.; Idoudi, H.; Saidane, H. Monitoring road traffic with a uav-based system. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference, Barcelona, Spain, 15–18 April 2018. [Google Scholar]
- Yang, J.; Zhang, J.L.; Ye, F.; Cheng, X.H. A uav based multi-object detection scheme to enhance road condition monitoring and control for future smart transportation. In Proceedings of the 1st EAI International Conference on Artificial Intelligence for Communications and Networks, Harbin, China, 25–26 May 2019. [Google Scholar]
- Wang, X.; Ouyang, C.T.; Shao, X.L.; Xu, H. A method for uav monitoring road conditions in dangerous environment. J. Phys. Conf. Ser. 2021, 1792, 012050. [Google Scholar] [CrossRef]
- Huang, H.L.; Savkin, A.V.; Huang, C. Decentralised autonomous navigation of a uav network for road traffic monitoring. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 2558–2564. [Google Scholar] [CrossRef]
- Liu, X.F.; Peng, Z.R.; Zhang, L.Y. Real-time uav rerouting for traffic monitoring with decomposition based multi-objective optimization. J. Intell. Robot. Syst. Theor. Appl. 2019, 94, 491–501. [Google Scholar] [CrossRef]
- Pan, Y.F.; Zhang, X.F.; Cervone, G.; Yang, L.P. Detection of asphalt pavement potholes and cracks based on the unmanned aerial vehicle multispectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3701–3712. [Google Scholar] [CrossRef]
- Saad, A.M.; Tahar, K.N. Identification of rut and pothole by using multirotor unmanned aerial vehicle (UAV). Measurement 2019, 137, 647–654. [Google Scholar] [CrossRef]
- Roberts, R.; Inzerillo, L.; Mino, G.D. Using uav based 3d modelling to provide smart monitoring of road pavement conditions. Information 2020, 11, 568. [Google Scholar] [CrossRef]
- Wang, S.J.; Jiang, F.; Zhang, B.; Ma, R.; Hao, Q. Development of uav-based target tracking and recognition systems. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3409–3422. [Google Scholar] [CrossRef]
- Liu, H.; Mu, C.P.; Yang, R.X.; He, Y.; Wu, N. Research on object detection algorithm based on uva aerial image. In Proceedings of the 7th IEEE International Conference on Network Intelligence and Digital Content, Beijing, China, 17–19 November 2021. [Google Scholar]
- Pelleg, D.; Moore, A. X-means: Extending k-means with efficient estimation of the number of clusters. In Proceedings of the Seventeenth International Conference on Machine Learning, San Francisco, CA, USA, 29 June–2 July 2000. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, X.Q.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.F.; Shi, J.P.; Jia, J.Y. Path aggregation network for instance segmentatio. In Proceedings of the 31st Meeting of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Wang, C.Y.; Yuan, H.; Wu, Y.H.; Chen, P.Y. CSPNet: A new backbone that can enhance learning capability of cnn. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Virtual, Online, 14–19 June 2020. [Google Scholar]
- Everingham, M.; Eslami, S.; Gool, L.V.; Williams, C.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E.H. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial No. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| x | 11 | 13 | 17 | 25 | 28 | 57 | 60 | 96 | 117 |
| y | 22 | 14 | 33 | 77 | 20 | 119 | 45 | 99 | 59 |
| Network Model | Transport Elements | AP | Precision | Recall | mAP | Rise Points |
|---|---|---|---|---|---|---|
| Faster R-CNN | zebra crossings | 64.26 | 59.04 | 71.43 | 56.89 | 33.56 |
| bus stations | 71.46 | 73.33 | 70.97 | |||
| roadside parking spaces | 34.96 | 31.51 | 48.75 | |||
| Retinanet | zebra crossings | 70.01 | 87.82 | 61.16 | 57.27 | 33.18 |
| bus stations | 67.25 | 86.36 | 61.29 | |||
| roadside parking spaces | 34.54 | 74.28 | 24.38 | |||
| SSD | zebra crossings | 52.92 | 76.84 | 32.59 | 53.94 | 36.51 |
| bus stations | 75.09 | 100 | 54.84 | |||
| roadside parking spaces | 33.81 | 73.37 | 14.74 | |||
| YOLOv3 | zebra crossings | 84.25 | 87.38 | 80.36 | 81.52 | 8.93 |
| bus stations | 83.81 | 88.89 | 77.42 | |||
| roadside parking spaces | 76.49 | 76.13 | 75.86 | |||
| YOLOv4 | zebra crossings | 81.82 | 89.95 | 79.20 | 74.65 | 15.80 |
| bus stations | 76.77 | 90.48 | 61.29 | |||
| roadside parking spaces | 65.35 | 70.24 | 70.99 | |||
| YOLOv5 | zebra crossings | 93.61 | 91.82 | 93.50 | 86.84 | 3.61 |
| bus stations | 73.82 | 68.51 | 69.42 | |||
| roadside parking spaces | 93.10 | 91.41 | 90.11 | |||
| Proposed method | zebra crossings | 94.34 | 90.09 | 93.90 | 90.45 | |
| bus stations | 99.59 | 91.30 | 100 | |||
| roadside parking spaces | 77.44 | 80.95 | 78.14 |
| Network Model | Transport Elements | AP | Precision | Recall | mAP | Rise Points |
|---|---|---|---|---|---|---|
| YOLOv4+k-means | zebra crossings | 85.12 | 85.58 | 81.42 | 80.98 | 9.47 |
| bus stations | 83.52 | 88.89 | 77.42 | |||
| roadside parking spaces | 74.30 | 77.94 | 75.62 | |||
| YOLOv4+mosaic | zebra crossings | 88.31 | 87.95 | 87.17 | 82.44 | 8.01 |
| bus stations | 84.93 | 96.00 | 77.42 | |||
| roadside parking spaces | 74.08 | 74.85 | 75.39 | |||
| YOLOv4+SE | zebra crossings | 91.45 | 91.43 | 90.14 | 84.54 | 5.91 |
| bus stations | 81.00 | 79.31 | 82.14 | |||
| roadside parking spaces | 81.17 | 85.06 | 80.7 | |||
| YOLOv4+CBAM | zebra crossings | 92.07 | 89.63 | 90.95 | 86.92 | 3.53 |
| bus stations | 92.01 | 92.00 | 88.46 | |||
| roadside parking spaces | 76.68 | 81.62 | 77.47 | |||
| Proposed method | zebra crossings | 94.34 | 90.09 | 93.90 | 90.45 | |
| bus stations | 99.59 | 91.30 | 100 | |||
| roadside parking spaces | 77.44 | 80.95 | 78.14 |
| Network Model | Transport Elements | Single-Element | Multielement | Juxtaposed Dense-Element | |||
|---|---|---|---|---|---|---|---|
| Number | AP | Number | AP | Number | AP | ||
| YOLOv4+k-means | zebra crossings | - | - | 4 | 86.50 | - | - |
| bus stations | 2 | 89.50 | 0 | Leakage | - | - | |
| roadside parking spaces | - | - | 0 | Leakage | 17 | 95.71 | |
| YOLOv4+mosaic | zebra crossings | - | - | 4 | 95.50 | - | - |
| bus stations | 2 | 64.50 | 1 | 94.00 | - | - | |
| roadside parking spaces | - | - | 0 | Leakage | 17 | 99.88 | |
| YOLOv4+SE | zebra crossings | - | - | 4 | 95.50 | - | - |
| bus stations | 2 | 67.50 | 1 | 100 | - | - | |
| roadside parking spaces | - | - | 3 | 87.33 | 17 | 99.47 | |
| YOLOv4+CBAM | zebra crossings | - | - | 4 | 96.75 | - | - |
| bus stations | 1 | 77.00 | 1 | 82.00 | - | - | |
| roadside parking spaces | - | - | 3 | 87.68 | 17 | 96.29 | |
| Proposed method | zebra crossings | - | - | 4 | 98.25 | - | - |
| bus stations | 2 | 98.50 | 1 | 98.00 | - | - | |
| roadside parking spaces | - | - | 3 | 88.67 | 17 | 99.88 | |
| Network Model | Transport Elements | Number | AP |
|---|---|---|---|
| YOLOv4+k-means | zebra crossings | 17 | 89.26 |
| bus stations | 4 | 85.75 | |
| roadside parking spaces | 42 | 72.49 | |
| YOLOv4+mosaic | zebra crossings | 18 | 89.39 |
| bus stations | 4 | 86.00 | |
| roadside parking spaces | 54 | 77.02 | |
| YOLOv4+SE | zebra crossings | 18 | 89.48 |
| bus stations | 5 | 85.11 | |
| roadside parking spaces | 56 | 78.23 | |
| YOLOv4+CBAM | zebra crossings | 17 | 92.14 |
| bus stations | 5 | 89.33 | |
| roadside parking spaces | 43 | 73.03 | |
| Proposed method | zebra crossings | 18 | 92.17 |
| bus stations | 5 | 93.40 | |
| roadside parking spaces | 48 | 76.48 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, L.; Qiu, M.; Xu, A.; Sun, Y.; Zhu, J. UAV Imagery for Automatic Multi-Element Recognition and Detection of Road Traffic Elements. Aerospace 2022, 9, 198. https://doi.org/10.3390/aerospace9040198
Huang L, Qiu M, Xu A, Sun Y, Zhu J. UAV Imagery for Automatic Multi-Element Recognition and Detection of Road Traffic Elements. Aerospace. 2022; 9(4):198. https://doi.org/10.3390/aerospace9040198
Chicago/Turabian StyleHuang, Liang, Mulan Qiu, Anze Xu, Yu Sun, and Juanjuan Zhu. 2022. "UAV Imagery for Automatic Multi-Element Recognition and Detection of Road Traffic Elements" Aerospace 9, no. 4: 198. https://doi.org/10.3390/aerospace9040198
APA StyleHuang, L., Qiu, M., Xu, A., Sun, Y., & Zhu, J. (2022). UAV Imagery for Automatic Multi-Element Recognition and Detection of Road Traffic Elements. Aerospace, 9(4), 198. https://doi.org/10.3390/aerospace9040198