
Incomplete Information Pursuit-Evasion Game Control for a Space Non-Cooperative Target


Abstract
:1. Introduction
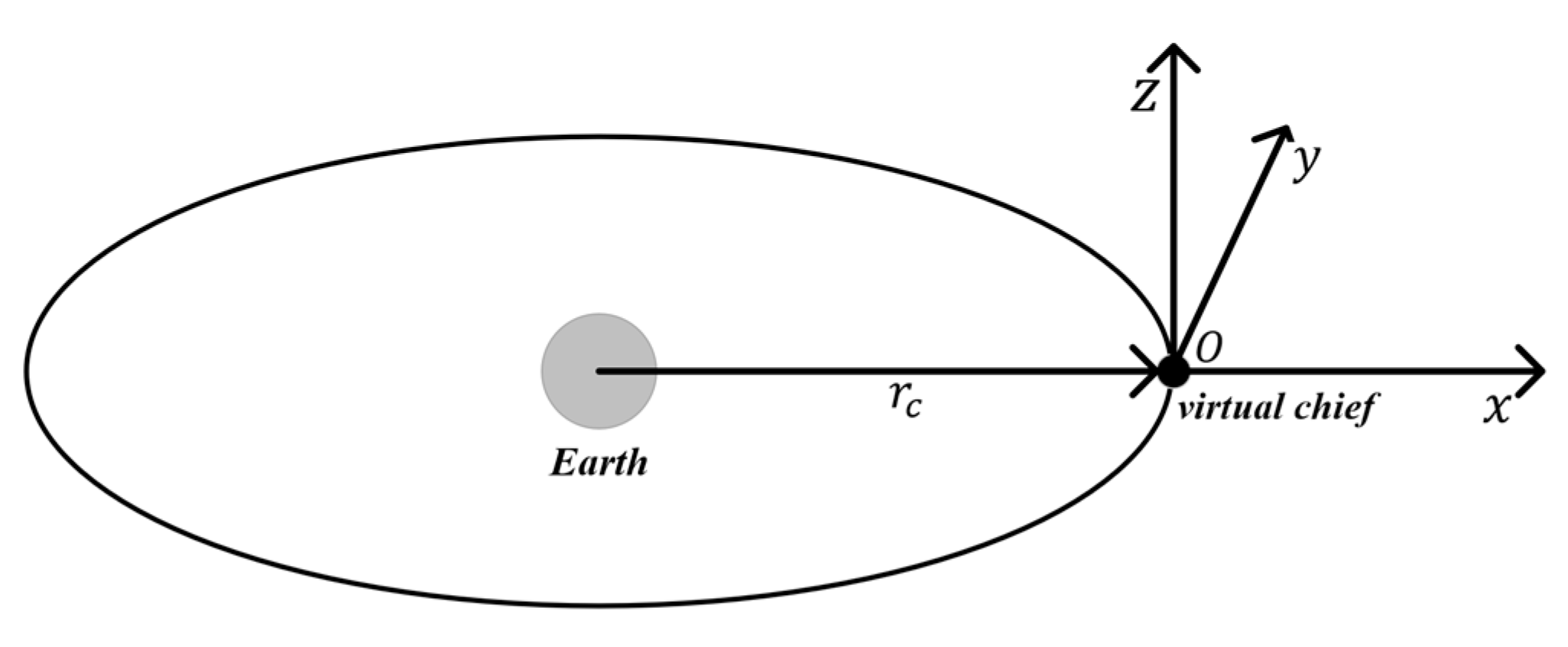
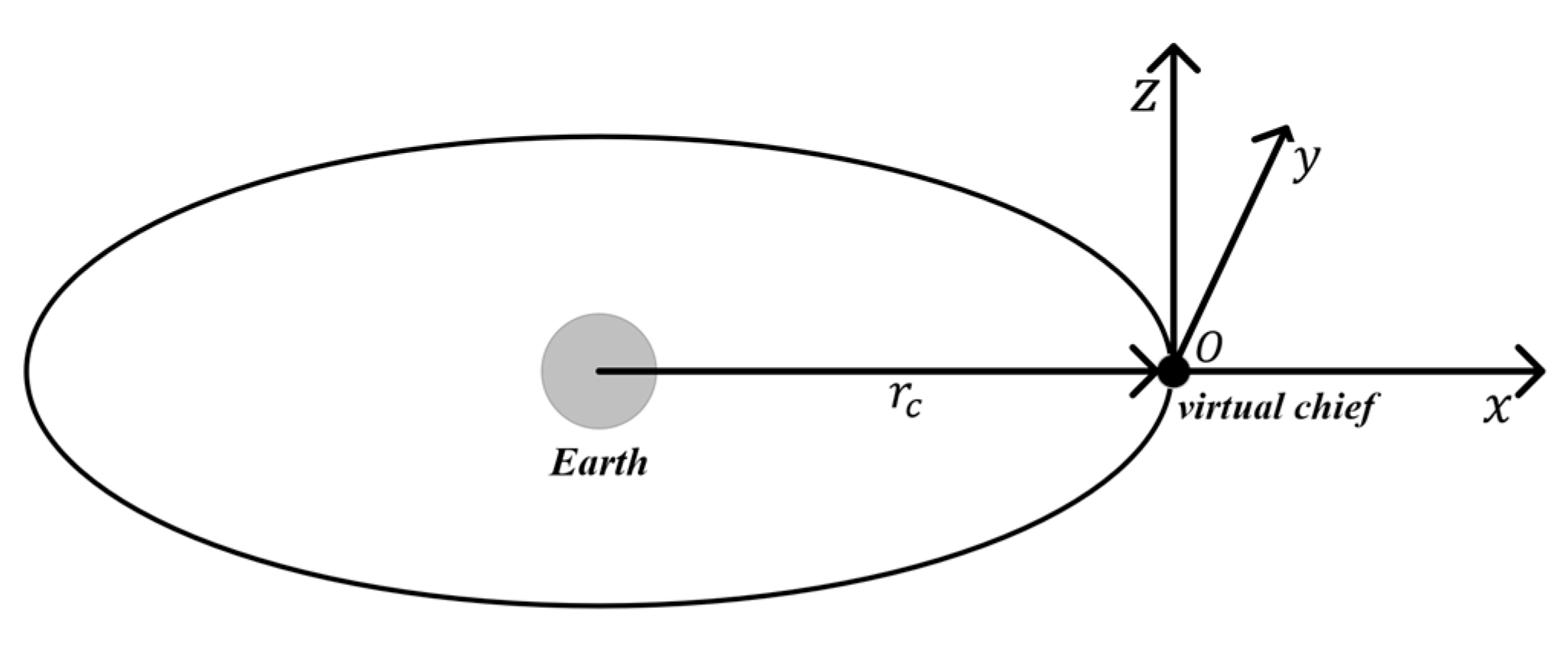
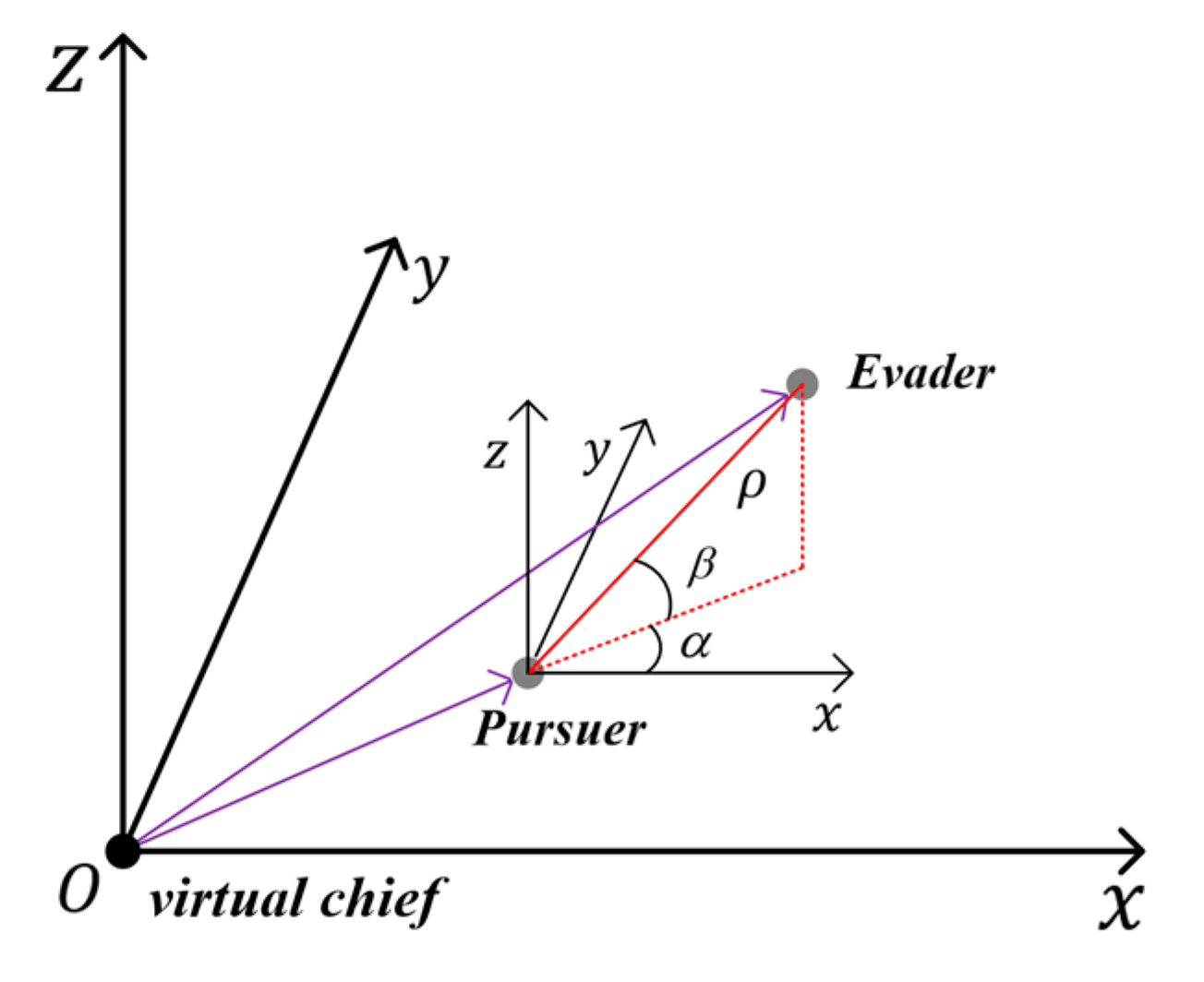
2. Relative Dynamics Model
3. Measurement Models
3.1. Single LOS Sensor Measurement
3.2. LOS Range Sensor Measurement
3.3. Double LOS Sensor Measurement
4. Observability Analysis
4.1. Observability Analysis in the Case of Single LOS Sensor Measurement
4.2. Observability Analysis with the LOS Range Measurement
4.3. Observability Analysis with Double LOS Measurements
5. Review of Differential Game Control Theory
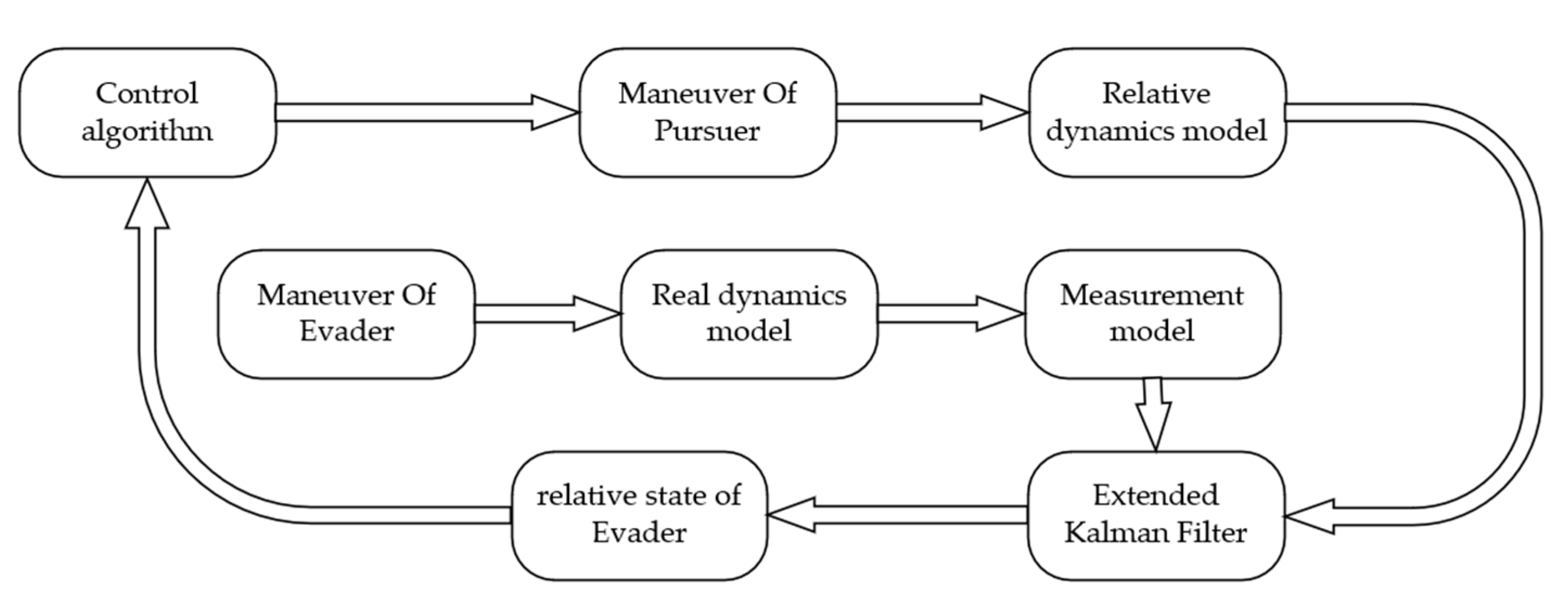
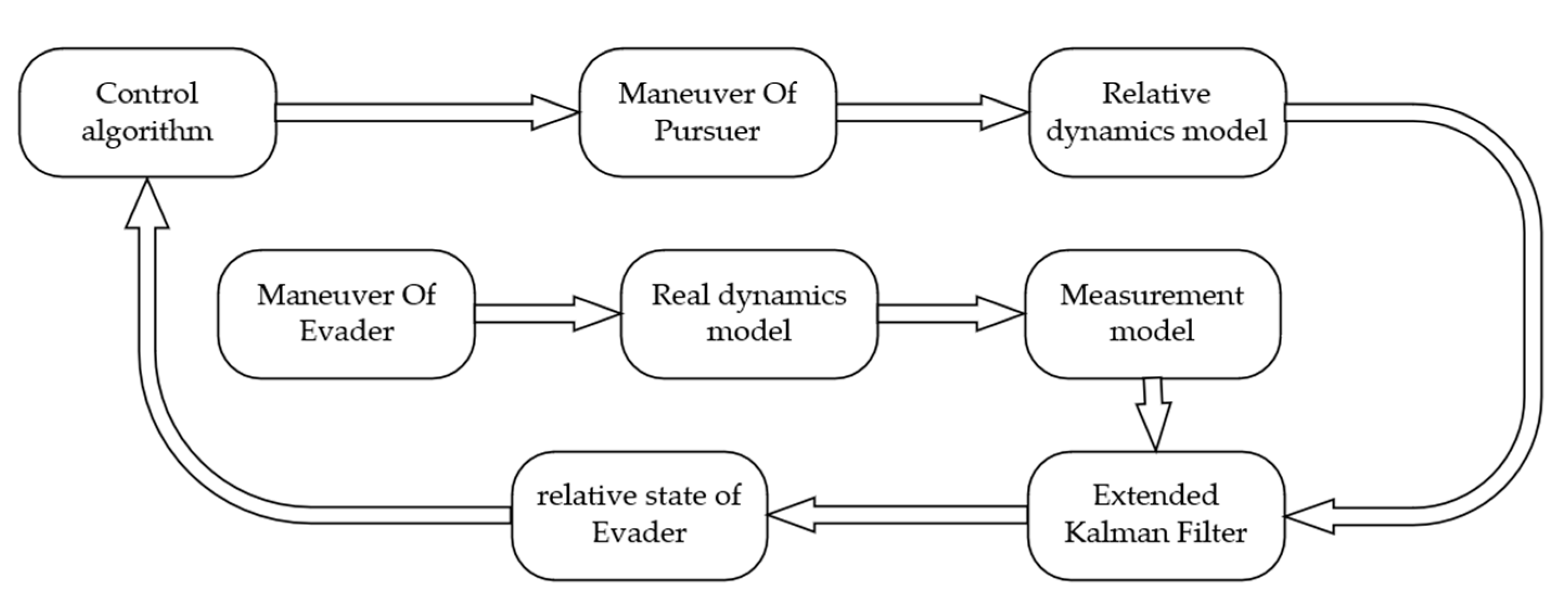
6. Control of Incomplete Information Pursuit-Evasion Games
6.1. Degradation of Pursuit-Evasion Games
- (1)
- The cost function of the non-cooperative target is not known, and its cost function is not necessarily the same as the form discussed above.
- (2)
- The weight matrix of the cost function is not known, that is, even if the non-cooperative target adopts the cost function as the form discussed above, its weight matrix is not necessarily known.
6.2. Control Restrictions
7. Numerical Simulations
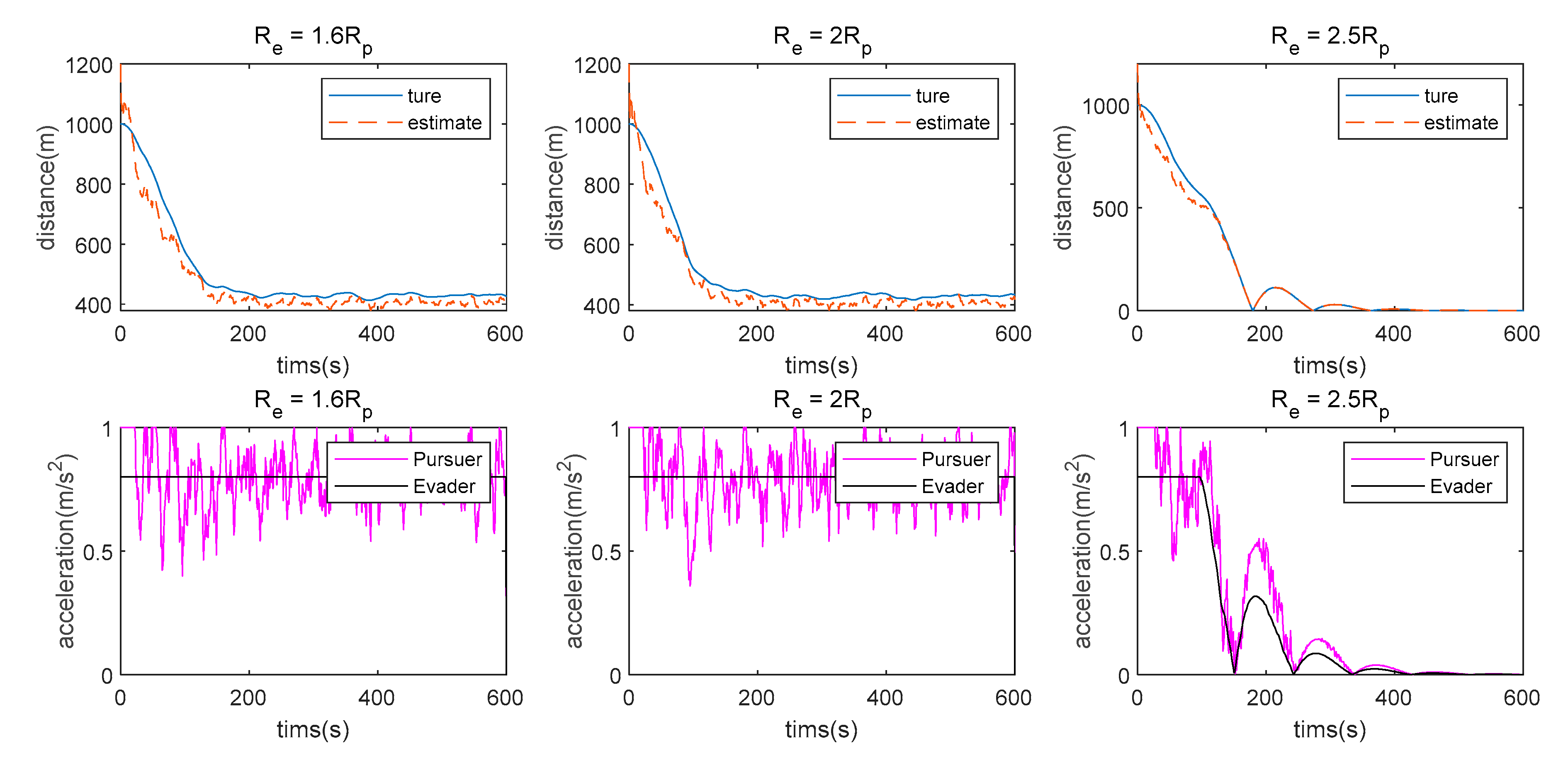
7.1. Single LOS Measurement Case
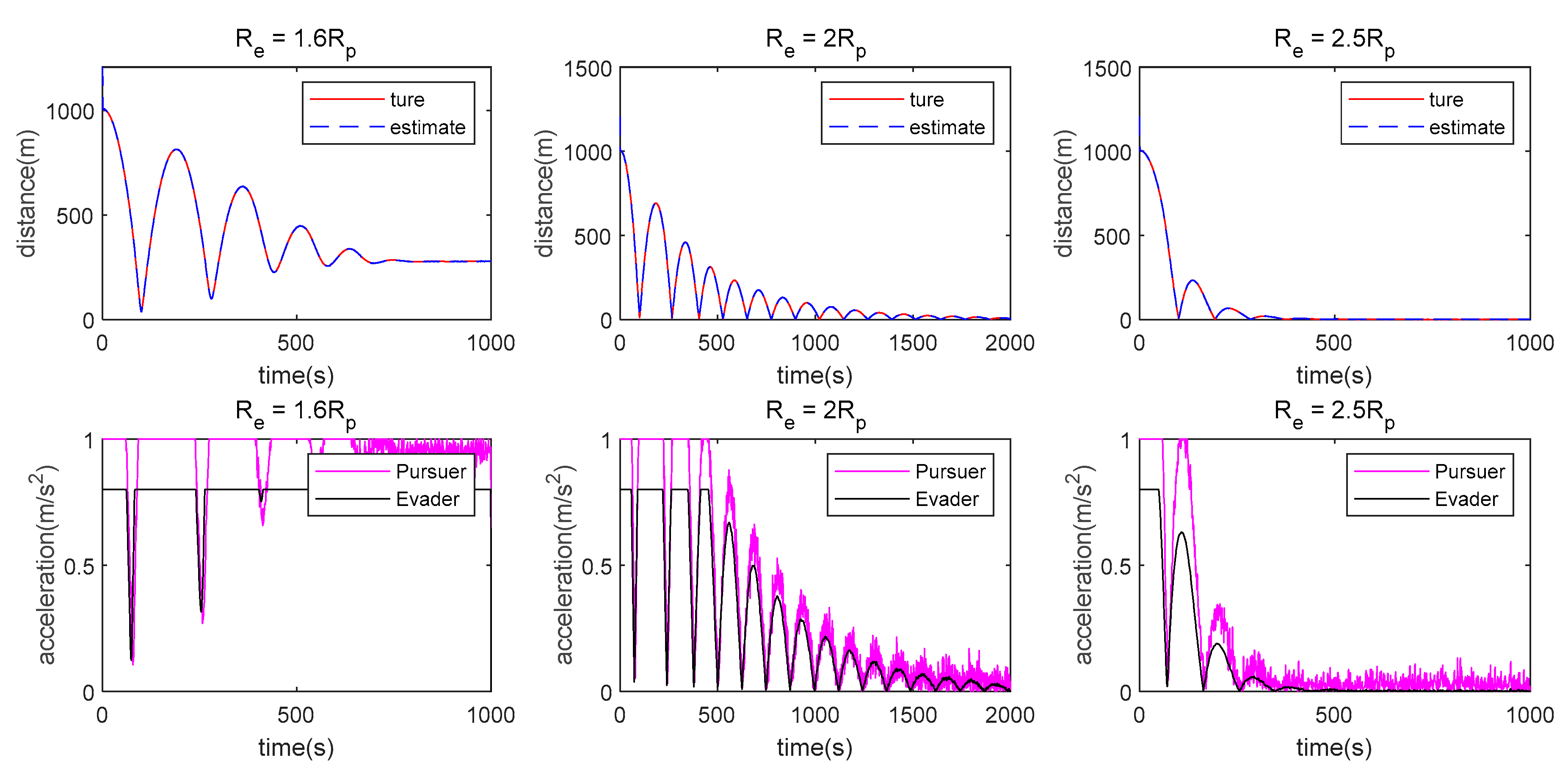
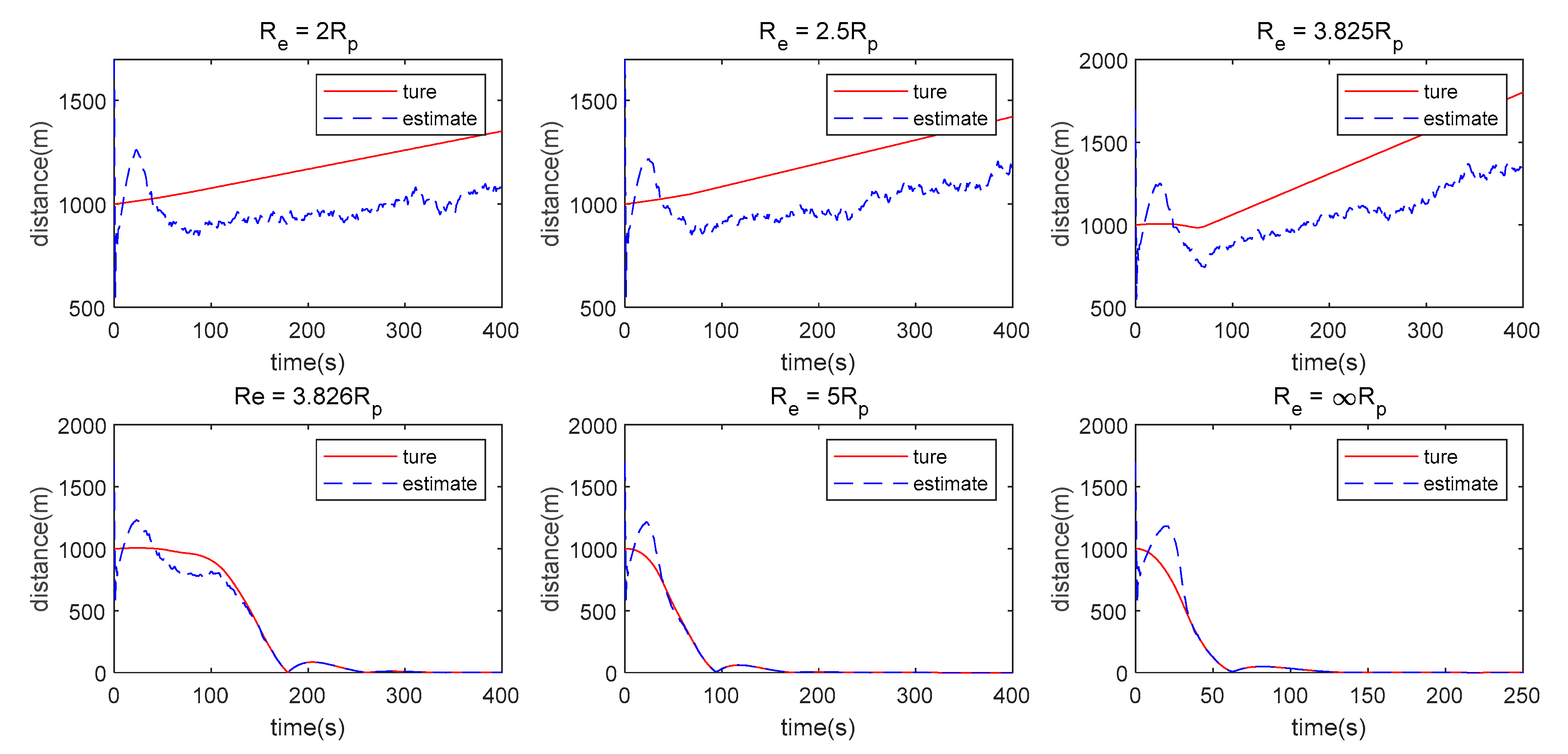
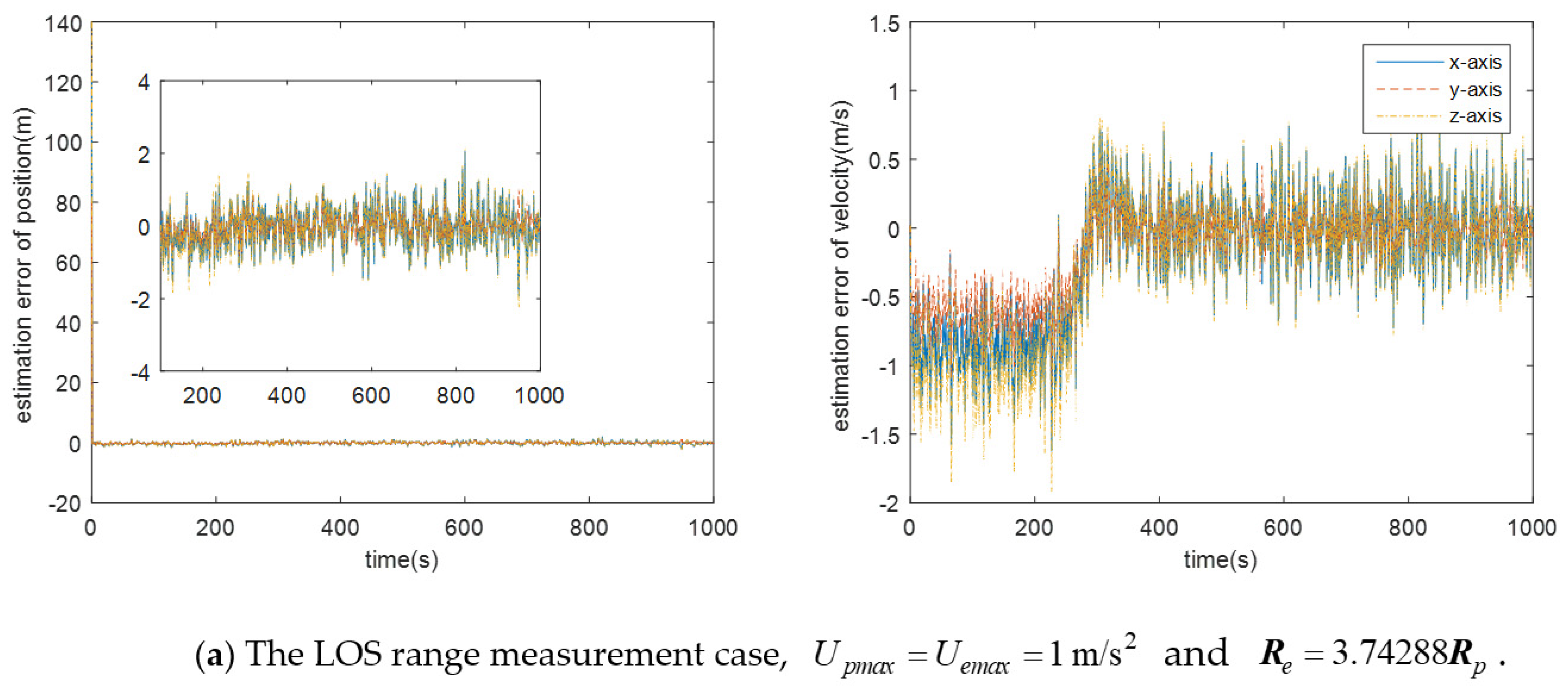
7.2. LOS Range Measurement Case
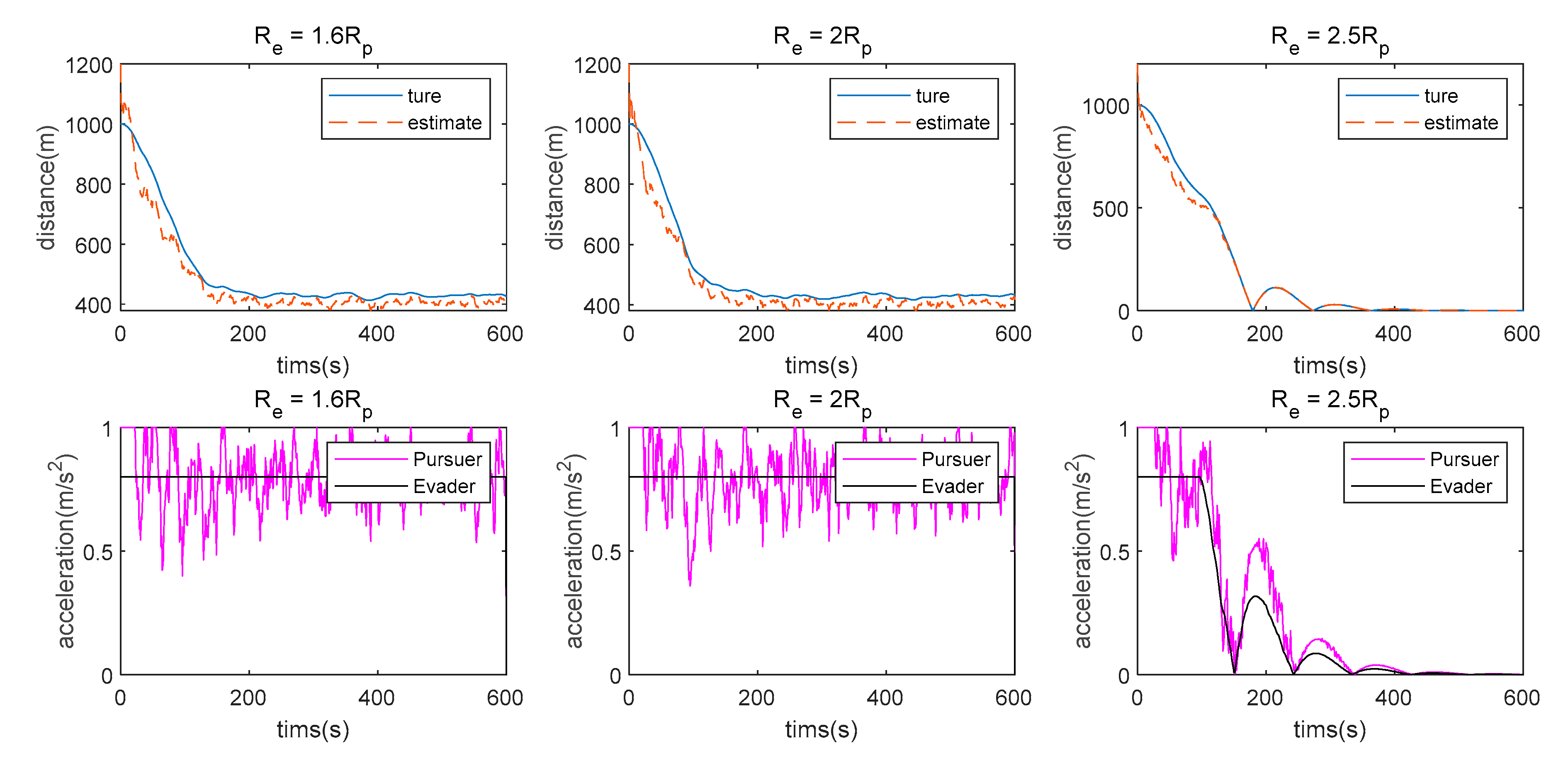
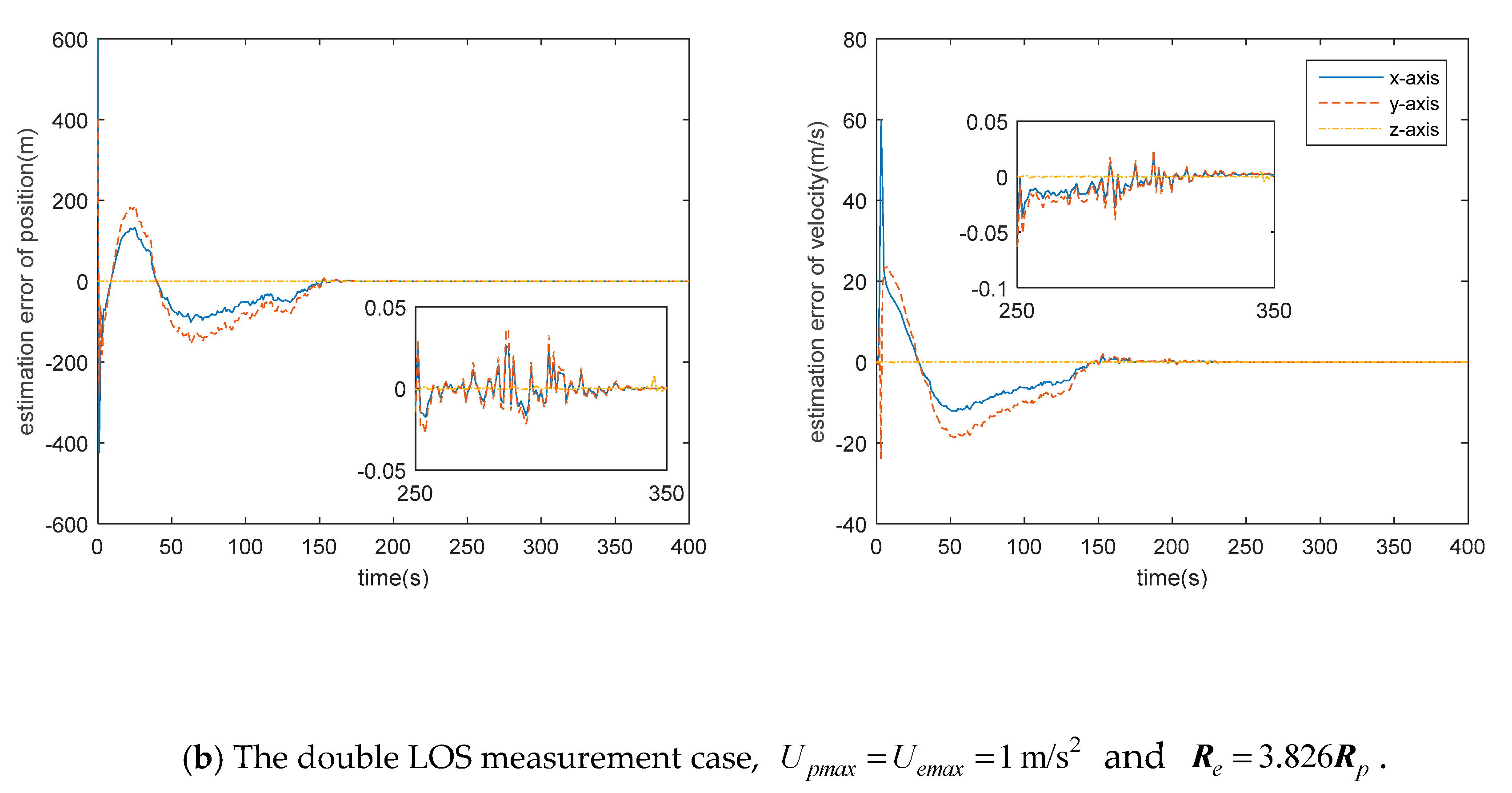
7.3. Double LOS Measurement Case
8. Conclusions
- (1)
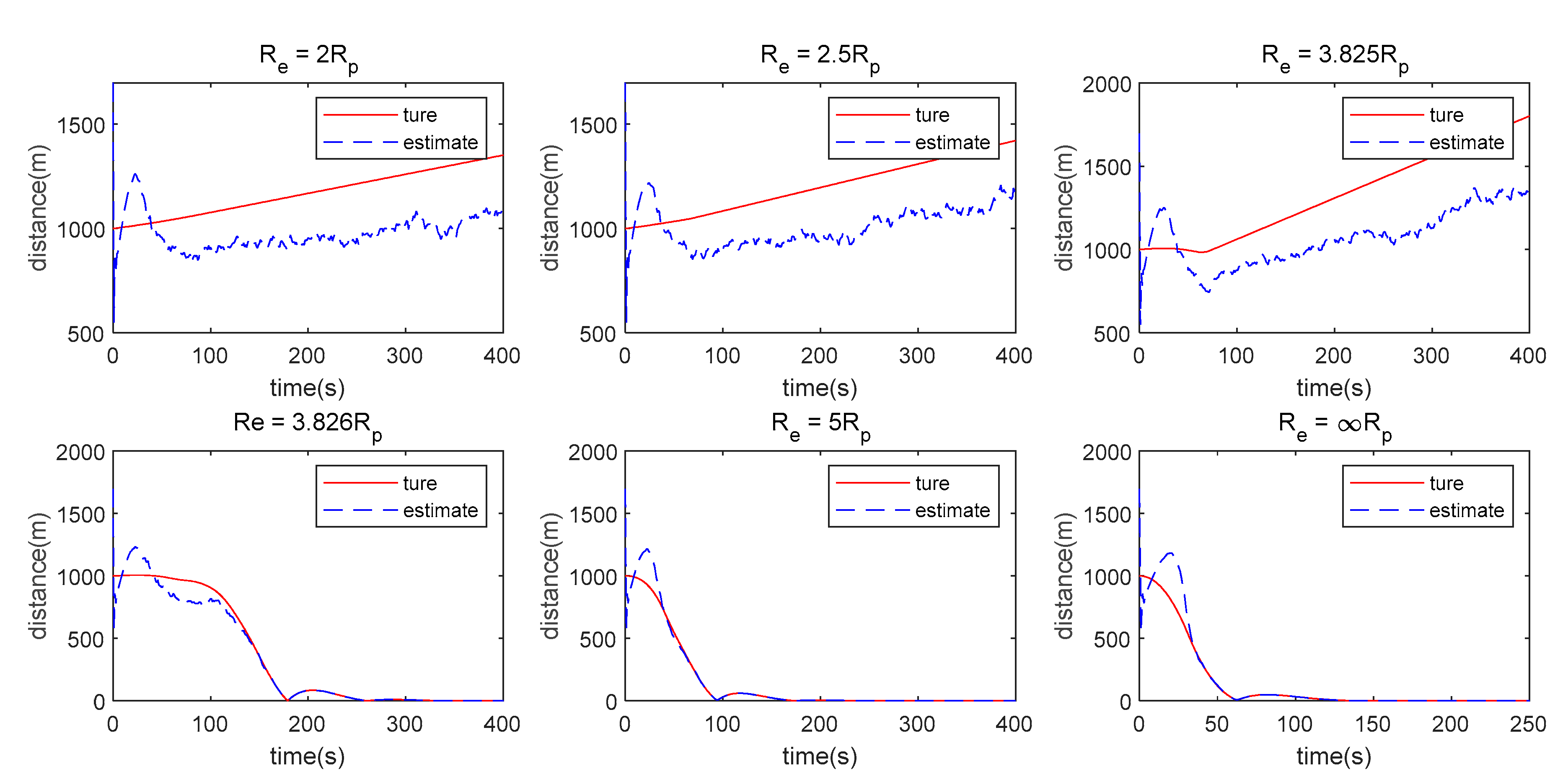
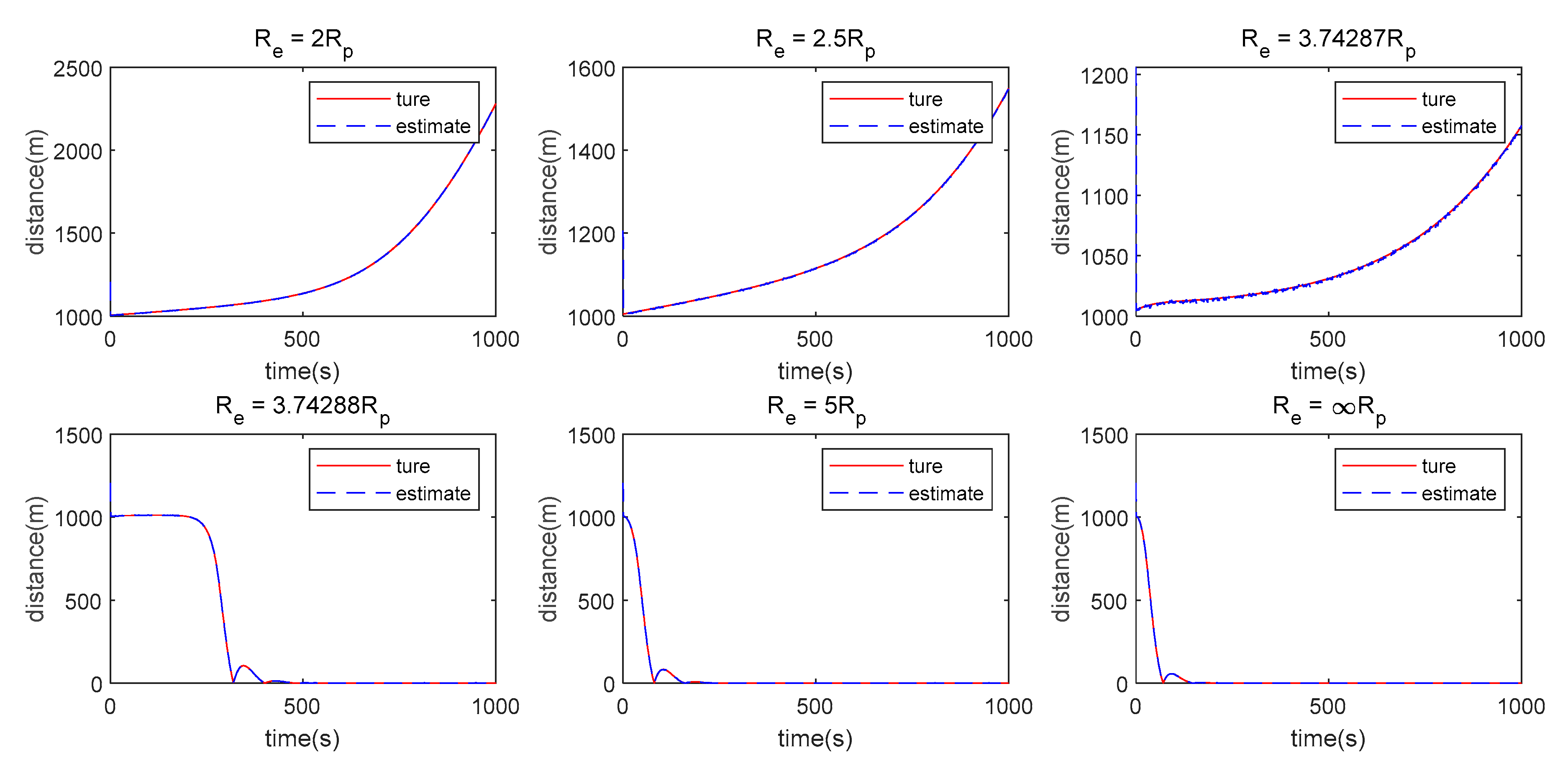
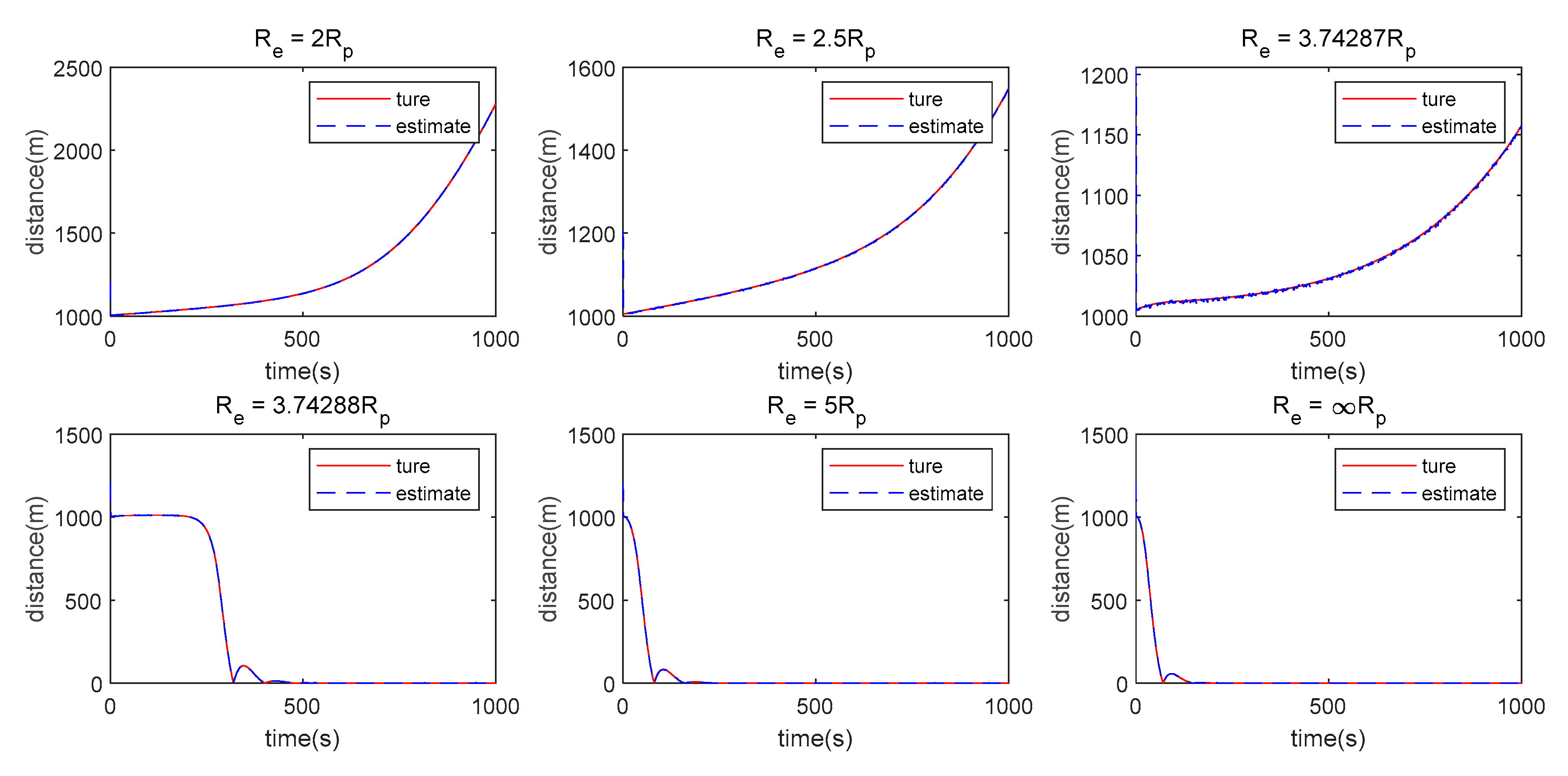
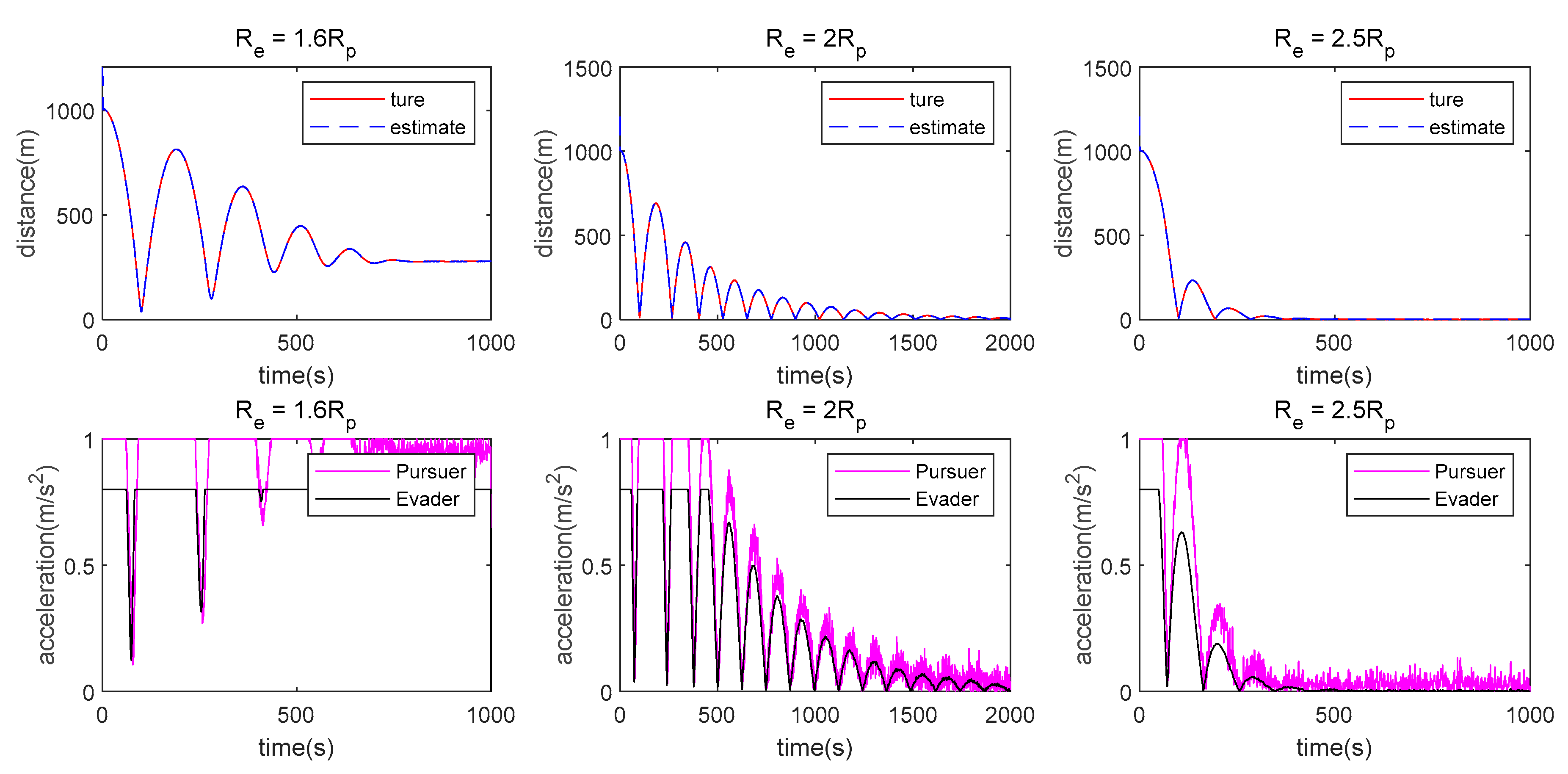
- The measurement method has a great influence on the algorithm proposed in this paper. When single angle measurement is used, the Pursuer can approach the Evader using observation information at the beginning, but the chasing process cannot be maintained because of weak observability. However, the Pursuer can approach the Evader when LOS range or double LOS sensor measurements are used by the Pursuer.
- (2)
- There is still some position/displacement/distance estimation error, although observability is improved by adding the distance measurement or when the double LOS sensor measurement is used, as shown in Figure 11. Thus, the Pursuer cannot catch the Evader when in the LOS range measurement case, or in the double LOS measurement case. The critical value of with which the Pursuer can catch the Evader will be smaller if .
- (3)
- The essence of the method proposed in this paper is that the Pursuer seeks the optimal control approaching the Evader under the assumption that the Evader’s maneuverability is lower than that of the Pursuer.
Author Contributions
Funding
Conflicts of Interest
References
- Geng, Y.Z.; Li, C.J.; Guo, Y.N.; James Douglas BIGGS. Rendezvous and docking of spacecraft with single thruster: Path planning and tracking control. Acta Aeronaut. Et Astronaut. Sin. 2020, 41, 323880. (In Chinese) [Google Scholar] [CrossRef]
- Xu, Z.Y.; Chen, Y.K.; Qi, N.M.; Yang, Y. Active disturbance rejection control for spacecraft rendezvous and docking simulation system during proximity operations. Acta Aeronaut. Et Astronaut. Sin. 2016, 37, 1552–1562. (In Chinese) [Google Scholar] [CrossRef]
- Sun, B.W.; Wang, D.Y.; Wang, J.Q.; Zhou, H.Y.; Ge, D.M.; Dong, T.S. Filter method for dimension reduction in spacecraft autonomous navigation based on sequence image. Acta Aeronaut. Et Astronaut. Sin. 2021, 42, 524971. (In Chinese) [Google Scholar] [CrossRef]
- Gong, B.; Li, S.; Zheng, L.; Zhou, W. Angles-only relative navigation algorithm for close-in proximity of space non-cooperative target. J. Chin. Inert. Technol. 2018, 26, 173–179. [Google Scholar] [CrossRef]
- Cohen, G.; Afshar, S.; Morreale, B.; Bessell, T.; Wabnitz, A.; Rutten, M.; van Schaik, A. Event-based Sensing for Space Situational Awareness. J. Astronaut. Sci. 2019, 66, 125–141. [Google Scholar] [CrossRef]
- Delande, E.; Frueh, C.; Franco, J.; Houssineau, J.; Clark, D. Novel Multi-Object Filtering Approach for Space Situational Awareness. J. Guid. Control Dyn. 2018, 41, 59–73. [Google Scholar] [CrossRef] [Green Version]
- Adurthi, N.; Singla, P.; Majji, M. Mutual Information Based Sensor Tasking with Applications to Space Situational Awareness. J. Guid. Control Dyn. 2020, 43, 767–789. [Google Scholar] [CrossRef]
- Chen, Y.; Tian, G.; Guo, J.; Huang, J. Task Planning for Multiple-Satellite Space-Situational Awareness Systems. Aerospace 2021, 8, 73. [Google Scholar] [CrossRef]
- Li, W.-J.; Cheng, D.-Y.; Liu, X.-G.; Wang, Y.-B.; Shi, W.-H.; Tang, Z.-X.; Gao, F.; Zeng, F.M.; Chai, H.; Luo, W.-B.; et al. On-orbit service (OOS) of spacecraft: A review of engineering developments. Prog. Aerosp. Sci. 2019, 108, 32–120. [Google Scholar] [CrossRef]
- Sabatini, M.; Volpe, R.; Palmerini, G.B. Centralized visual based navigation and control of a swarm of satellites for on-orbit servicing. Acta Astronaut. 2020, 171, 323–334. [Google Scholar] [CrossRef]
- Daneshjou, K.; Mohammadi-Dehabadi, A.A.; Bakhtiari, M. Mission planning for on-orbit servicing through multiple servicing satellites: A new approach. Adv. Space Res. 2017, 60, 1148–1162. [Google Scholar] [CrossRef]
- Rousso, P.; Samsam, S.; Chhabra, R. A Mission Architecture for On-Orbit Servicing Industrialization. In Proceedings of the 2021 IEEE Aerospace Conference (50100), Big Sky, MT, USA, 6–13 March 2021; pp. 1–14. [Google Scholar] [CrossRef]
- Isaacs, R. Differential Games; John Wiley & Sons: New York, NY, USA, 1965. [Google Scholar]
- Friedman, A. Differential Games; American Mathematical Society: Providence, RI, USA, 1974. [Google Scholar]
- Starr, A.W.; Ho, Y.C. Nonzero-sum differential games. J. Optim. Theor. Appl. 1969, 3, 184–206. [Google Scholar] [CrossRef]
- Roxin, E.; Tsokos, C.P. On the definition of a stochastic differential game. Math. Syst. Theor. 1970, 4, 60–64. [Google Scholar] [CrossRef]
- Nichols, W.G. Stochastic Differential Games and Control Theory. Dissertation for Doctoral Degree; Virginia Polytechnic Institute and State University: Blacksburg, VA, USA, 1971. [Google Scholar]
- Ciletti, M.D. Results in the theory of linear differential games with an information time lag. J. Optim. Theor. Appl. 1970, 5, 347–362. [Google Scholar] [CrossRef]
- Ciletti, M.D. New results in the theory of differential games with information time lag. J. Optim. Theor. Appl. 1971, 8, 287–315. [Google Scholar] [CrossRef]
- Ciletti, M.D. Differential games with information time lag: Norm-invariant systems. J. Optim. Theor. Appl. 1972, 9, 293–301. [Google Scholar] [CrossRef]
- Mori, K.; Shimemura, E. Linear differential games with delayed and noisy information. J. Optim. Theor. Appl. 1974, 13, 275–289. [Google Scholar] [CrossRef]
- Wang, J. A Stackelberg differential game for defence and economy. Optim. Lett. 2018, 12, 375–386. [Google Scholar] [CrossRef]
- Aumann, R.J.; Maschler, M.B. Repeated Games with Incomplete Information; MIT Press: Cambridge, UK, 1995. [Google Scholar] [CrossRef] [Green Version]
- Harsanyi, J.C. Games with Incomplete Information Played by “Bayesian” Players, I–III Part I. The Basic Model. Manag. Sci. 1967, 14, 159–182. [Google Scholar] [CrossRef]
- Kreps, D.; Wilson, R. Reputation and imperfect information. J. Econ. Theory 1982, 27, 253–279. [Google Scholar] [CrossRef] [Green Version]
- Woodbury, T.D.; Hurtado, J.E. Adaptive play via estimation in uncertain nonzero-sum orbital pursuit evasion games. In Proceedings of the AIAA SPACE and Astronautics Forum and Exposition, Orlando, FL, USA, 12–14 September 2017; p. 5247. [Google Scholar] [CrossRef]
- Woodbury, T.D.; Hurtado, J.E. Cooperative estimation in pursuit evasion games with bearing-only measurements. In Proceedings of the2018 AIAA Information Systems-AIAA Infotech@ Aerospace, Kissimmee, FL, USA, 8–12 January 2018; p. 0713. [Google Scholar] [CrossRef]
- Aures-Cavalieri, K.D. Incomplete Information Pursuit-Evasion Games with Applications to Spacecraft Rendezvous and Missile Defense. Ph.D. Thesis, Texas A&M University, College Station, TX, USA, 2014. [Google Scholar]
- Cavalieri, K.A.; Satak, N.; Hurtado, J.E. Incomplete information pursuit-evasion games with uncertain relative dynamics. In Proceedings of the AIAA Guidance, Navigation, and Control Conference, National Harbor, MD, USA, 13–17 January 2014; p. 0971. [Google Scholar] [CrossRef]
- Woodbury, T.D. Estimation-Based Solutions to Incomplete Information Pursuit-Evasion Games. Ph.D. Thesis, Texas A&M University, College Station, TX, USA, 2019. [Google Scholar]
- Liu, B.Y.; Ye, X.B.; Gao, Y.; Wang, X.; Ni, L. Strategy solition of non-cooperative target pursuit-evasion game based on branching deep rein-forcement learning. Acta Aeronaut. Et Astronaut. Sin. 2020, 41, 324040. (In Chinese) [Google Scholar] [CrossRef]
- Linville, D.; Hess, J. Linear Regression Models Applied to Spacecraft Imperfect Information Pursuit-Evasion Differential Games. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; p. 0952. [Google Scholar] [CrossRef]
- Ye, D.; Tang, X.; Sun, Z.; Wang, C. Multiple model adaptive intercept strategy of spacecraft for an incomplete-information game. Acta Astronaut. 2021, 180, 340–349. [Google Scholar] [CrossRef]
- Li, Z.Y.; Zhu, H.; Luo, Y.Z. An escape strategy in orbital pursuit-evasion games with incomplete information. Sci. China Technol. Sci. 2021, 64, 559–570. [Google Scholar] [CrossRef]
- Oshman, Y.; Davidson, P. Optimization of observer trajectories for bearings-only target localization. IEEE Trans. Aerosp. Electron. Syst. 1999, 35, 892–902. [Google Scholar] [CrossRef]
- Battistini, S.; Shima, T. Differential games missile guidance with bearings-only measurements. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 2906–2915. [Google Scholar] [CrossRef]
- Fonod, R.; Shima, T. Estimation enhancement by cooperatively imposing relative intercept angles. J. Guid. Control Dyn. 2017, 40, 1711–1725. [Google Scholar] [CrossRef]
- Battistini, S. A Stochastic Characterization of the Capture Zone in Pursuit-Evasion Games. Games 2020, 11, 54. [Google Scholar] [CrossRef]
- Curtis, H. Orbital Mechanics for Engineering Students; Elsevier Ltd.: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Grzymisch, J.; Fichter, W. Observability criteria and unobservable maneuvers for in-orbit bearings-only navigation. J. Guid. Control Dyn. 2014, 37, 1250–1259. [Google Scholar] [CrossRef]
- Jagat, A. Spacecraft Relative Motion Applications to Pursuit-Evasion Games and Control Using Angles-Only Navigation. Ph.D. Thesis, Auburn University, Auburn, AL, USA, 2015. [Google Scholar]
- Nash, J.F. Equilibrium points in n-person games. Proc. Natl. Acad. Sci. USA 1950, 36, 48–49. [Google Scholar] [CrossRef] [Green Version]
- Pontryagin, L.S.; Botyanskii, V.G.; Gamkrelidze, R.V.; Mishkenko, E.E. The theory of optimal processes I. The maximum principle. Izvest. Akad. Nauk SSSR Ser. Mat. 1960, 24, 3–42. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Observability | Single LOS | LOS Range | Double LOS |
|---|---|---|---|
| white noise | ✓ | ✓ | ✓ |
| colored noise | ✓ | ✓ |
| Parameters | Value |
|---|---|
| Semi-Major Axis | 16,000 km |
| Eccentricity | 0.02 |
| Right Ascension of the Ascending Node | 0 rad |
| Inclination | 0.1 rad |
| Argument of periapsis | 0 rad |
| True anomaly | 0.06 rad |
| Parameters | Value |
|---|---|
| Pursuer’s initial relative state | |
| Evader’s initial relative state | |
| Initial relative position | |
| Initial relative position estimate | |
| Initial status error covariance matrix | |
| Camera measurement error | |
| Angle measurement error covariance matrix | |
| Distance measurement error | 1 m |
| Equivalent position measurement error with angle and distance measurement | 1.2 m |
| Angle and distance measurement error covariance matrix | |
| Model error covariance matrix without maneuver limit | |
| Model error covariance matrix with maneuver limit |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Gong, B.; Yuan, Y.; Ding, X. Incomplete Information Pursuit-Evasion Game Control for a Space Non-Cooperative Target. Aerospace 2021, 8, 211. https://doi.org/10.3390/aerospace8080211
Wang Z, Gong B, Yuan Y, Ding X. Incomplete Information Pursuit-Evasion Game Control for a Space Non-Cooperative Target. Aerospace. 2021; 8(8):211. https://doi.org/10.3390/aerospace8080211
Chicago/Turabian StyleWang, Ziwen, Baichun Gong, Yanhua Yuan, and Xin Ding. 2021. "Incomplete Information Pursuit-Evasion Game Control for a Space Non-Cooperative Target" Aerospace 8, no. 8: 211. https://doi.org/10.3390/aerospace8080211
APA StyleWang, Z., Gong, B., Yuan, Y., & Ding, X. (2021). Incomplete Information Pursuit-Evasion Game Control for a Space Non-Cooperative Target. Aerospace, 8(8), 211. https://doi.org/10.3390/aerospace8080211