1. Introduction
Globally, aircraft maintenance, repair and overhaul (MRO) costs account for
of the total airline operational costs [
1]. To reduce these maintenance costs and, in particular, to reduce the costs of the maintenance needed in the case of an unexpected failure, MROs benefit from predictive maintenance. Here, the analysis of sensor health-monitoring data for aircraft components is central. By analyzing this data, the aim is to make predictions about the remaining-useful-life (RUL) of the components.
In the past, several RUL prognostic methodologies have been developed [
2], mainly using data-driven and model-based approaches. Examples of data-driven methodologies for RUL prediction are neural networks [
3,
4] and neural fuzzy networks and recurrent neural networks [
5,
6]. Model-based RUL prediction methodologies have employed Wiener processes [
7,
8], Kalman filters [
9], particle filtering [
10], physics-based models [
11,
12], and Markov models [
13].
In most such studies, an inherent assumption is made that there is only one degradation mechanism or trend that governs the failure of components [
14]. However, given that systems are often complex, with multiple interconnected components, and given that each component is subject to various operational and environmental factors, it is expected that the degradation of components follows more than one failure mechanism or trend [
14,
15]. As such, several degradation models should be integrated into the RUL prediction methodology, in order to capture the various degradation trends toward component failure.
Only a limited amount of studies developed RUL predictions using multiple degradation models. Data-driven approaches with multiple degradation models were considered in [
16,
17]. In [
16], a Long Short-Term Neural Network was developed such that degradation patterns under multiple operational conditions and belonging to several fault modes were detected. With this approach, the RUL of aircraft engines was estimated.
In [
17], a deep learning approach was combined with a genetic algorithm to predict the RUL of aircraft engines operating under multiple conditions and failing under several fault modes. Machine-learning approaches, however, are often seen by aircraft maintenance practitioners as “black-boxes” [
6]. This is an obstacle for the implementation of purely data-driven prognostic methods in practice [
18]. In this paper, we, therefore, focus on a model-based prognostic approach that considers multiple models to capture the degradation trends of components.
Model-based RUL prognostic approaches that incorporate multiple degradation models and fault modes were considered in [
14,
19,
20,
21,
22,
23]. In [
19], four physics-based failure models of subsea pipelines were incorporated into one dynamic Bayesian network. In [
14], the authors considered multiple resistance degradations for batteries, each with its own degradation trend. With these degradation models and a particle filtering algorithm, the authors predicted the RUL of batteries. A switching Kalman filter to model multiple degradation trends within one degradation process was used in [
22,
23] for bearings and in [
20] for aircraft engines. In contrast to these studies, where multiple degradation models are integrated in one comprehensive degradation model, we first cluster the degradation trends of components and propose cluster-specific degradation models. In this way, different components are associated with different degradation models.
For model-based RUL prognostic methods, two frequently considered models are the exponential and the linear degradation models [
2,
24]. Linear degradation models were developed in [
25,
26,
27,
28]. In [
25], a linear model with Brownian drift and random shocks, together with a particle filtering algorithm, was used to estimate the RUL of milling machines. A linear degradation model was also used in [
26] for batteries, in [
27] for aircraft engines, and in [
28] for engine bleed valves.
Exponential degradation models were used in [
29,
30,
31,
32,
33]. An exponential model was used together with a particle filtering algorithm to predict the RUL of bearings in [
29], and to predict the RUL of batteries in [
30]. An exponential model for the degradation of bearings was also considered in [
31], for batteries in [
32], and for railway turnout systems in [
33]. Similarly, in this paper, we consider clusters of components that degrade according to a linear or an exponential model.
In this paper, we propose an end-to-end approach to obtain online, model-based RUL prognostics for aircraft components by exploiting the knowledge obtained from clusters of component degradation trends. First, using sensor monitoring data, we construct a health indicator, which is used to diagnose components as being healthy or unhealthy. As soon as a component is diagnosed as unhealthy, a cluster-specific degradation model is selected for this component based on a dynamic time-warping clustering of a library of health indicators. These degradation models, together with a particle filtering algorithm, are further used to obtain RUL prognostics.
We illustrate our approach for the case of several aircraft Cooling Units, originating from a fleet of aircraft. We consider operational aircraft data, i.e., the sensor measurements were collected during actual operation of the aircraft. The results show that our proposed cluster-based RUL prognostics approach was robust and consistent across multiple components.
The main contributions of this paper are as follows:
- (i)
We propose an end-to-end methodology from sensor measurements to diagnostics of a component as healthy or unhealthy to RUL prognostics. Using a health indicator, a component is diagnosed as healthy or unhealthy. Once a component reaches the unhealthy stage, a degradation model is selected based on the similarity between the degradation trend of this component and clusters of a library of health indicators. This approach exploits the potential learning from degradation trends of other components.
- (ii)
We consider multiple degradation models. A generic clustering method of the degradation of components is proposed. Each obtained cluster is associated with one degradation model and a corresponding failure threshold.
- (iii)
Our proposed approach is illustrated using operational aircraft data, i.e., the sensor measurements were collected during the actual operation of the aircraft. In general, case studies are often conducted with simulated data or sensor data generated in a laboratory, which may not be as noisy as the aircraft operational data.
The remainder of this paper is organized as follows. In
Section 2, we provide a methodology for online, model-based RUL prognostics using dynamic time-warping and a particle filtering algorithm. For time-warping, we consider several, same-type components, which are clustered based on the similarity between their degradation trends. In
Section 3, we illustrate our methodology for several aircraft cooling units.
Section 4 provides our conclusions and recommendations for further research.
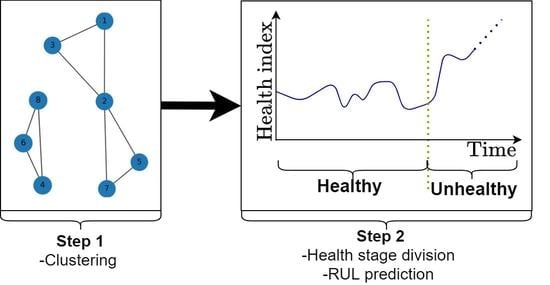
2. Online, Model-Based Rul Prognostics for Multiple Components
In this section, we provide an approach to obtain online RUL prognostics for aircraft components. We first construct a health indicator from the sensor monitoring data. Based on this health indicator, we online diagnose a component as being healthy or unhealthy (step 1). Once a component is diagnosed as being unhealthy, a degradation model and corresponding failure threshold are selected for this component using dynamic time-warping data clustering of a library of series of health indicators (steps 2 and 3). Having selected a degradation model, RUL prognostics are obtained using a particle filtering algorithm (step 4). This process is illustrated in
Figure 1.
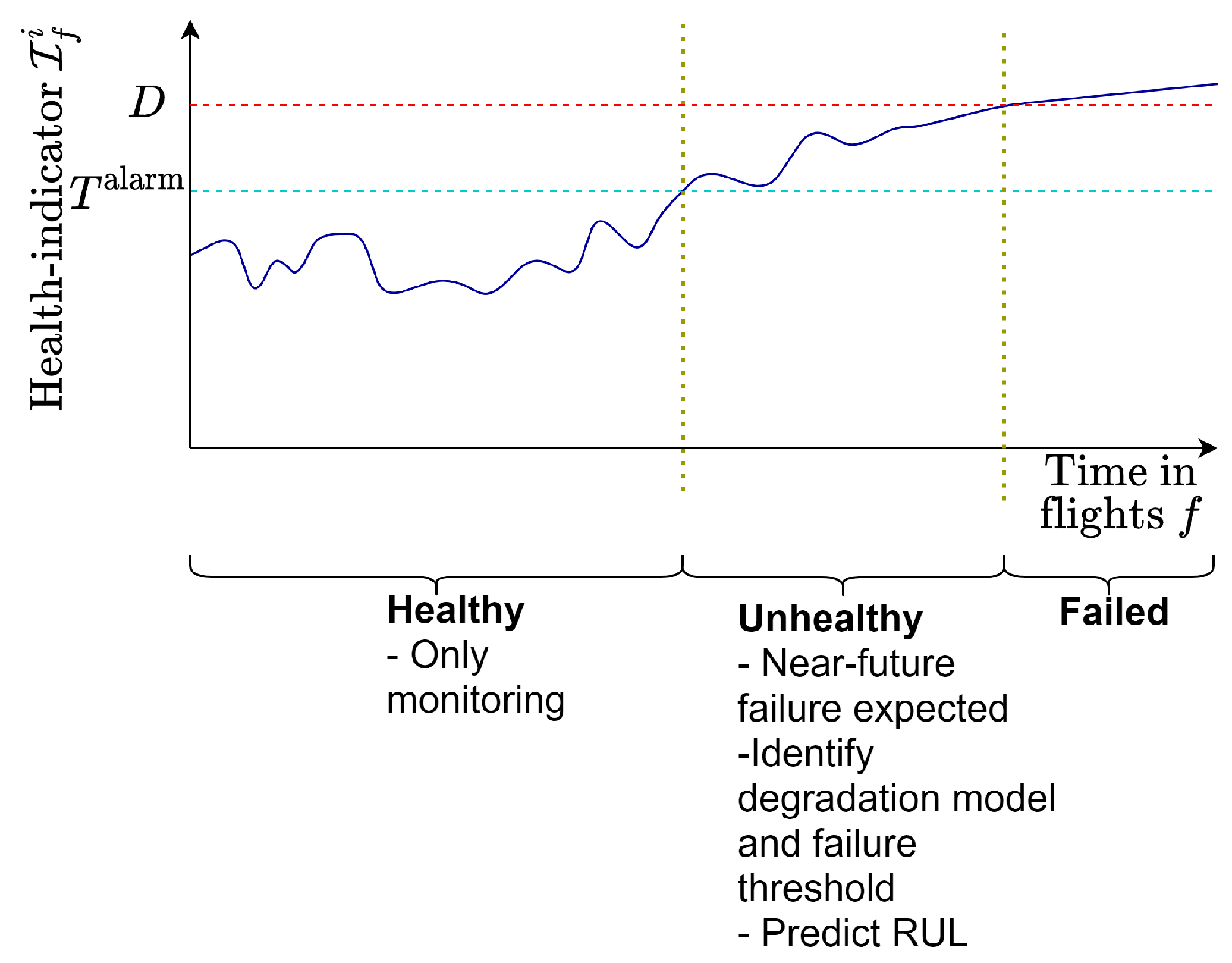
Let a stochastic process characterize the degradation over time of a component. Let denote the failure threshold. We define a component failure and the RUL of a component as follows.
Definition 1 (Component failure). For a component that degrades according to , we say that this component has failed if , .
Definition 2 (Component RUL)
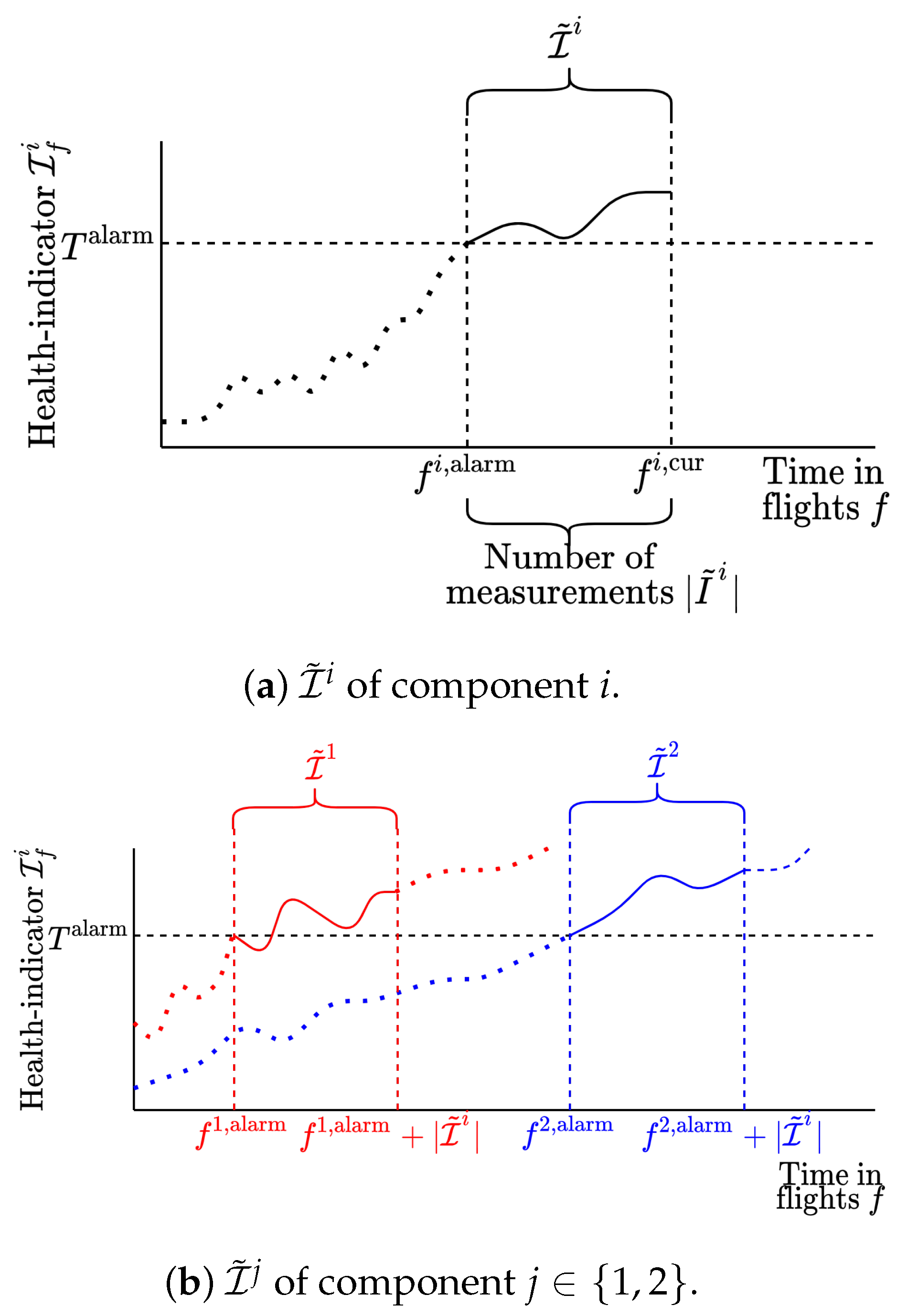
. Given a current time , the RUL of a component is defined as follows: 2.1. Step 1: Constructing a Health Indicator and Defining the Health Stage of the Component
Let
be a health indicator of component
i after flight
f. We assume that
is a function of the sensor measurements
, i.e.,
Here, a measurement depends on the degradation, with as the actual degradation of component i after flight f and , the noise.
We diagnose the component as being healthy or unhealthy by analyzing whether
exceeds an alarm threshold
defined by the Chebyshev’s inequality [
34,
35,
36], which specifies that, for any probability distribution with a specified mean
and standard deviation
, at most
percent of the values from this distribution fall outside the
interval,
. This implies that
where
is the mean and
is the standard deviation of the health indicator while it is healthy. We, thus, use the following alarm threshold
:
As soon as
, a component is diagnosed as
unhealthy (see
Figure 1).
Let denote the first flight when a component i is diagnosed as unhealthy. Let denote the flight when component i fails.
2.2. Step 2: Selecting a Degradation Model for a Component
As soon as a component is diagnosed as being unhealthy, we select a degradation model and a corresponding failure threshold D based on a similarity analysis of clusters in a library of health indicators. As a last step, we use this selected degradation model together with a particle filtering algorithm to obtain RUL prognostics.
We consider an offline library of n health indicators. Each health indicator is constructed starting m flights before the component is diagnosed as unhealthy (see Step 1) until the component fails.
Let the series of indicators denote the health levels recorded for component after flight . We are interested in clustering the set of time series into clusters where the underlying deterioration of the health indicators follows a similar path toward failure (similar degradation paths).
We propose (i) a Dynamic Time Warping (DTW) algorithm [
37,
38] to determine the minimum distance between any two condition series
and
of component
i and component
j, respectively, and, (ii) we cluster the
n series of health indicators based on this minimum distance metric.
2.2.1. (i) Dynamic Time-Warping for an Offline Library with Time-Series of Health Indicators
We define the following Euclidean distance between any two points
and
of the health indicators time series
and
:
Here, we see as the distance or the dissimilarity between points (health indicator values) and . The larger the distance, the more dissimilar the health indicator values are.
We next find a warping path of minimum distance between the two health indicator series and , where is the number of flights in the health indicator time-series of component i, and the number of flights in the health indicator time-series of component j. We define a warping path between and as follows:
Definition 3 (Warping path [
38])
. A warping path is a sequence with for such that:- (a)
and ;
- (b)
, and ;
- (c)
for .
Condition (a) in Definition 3 implies that the first and last elements of health indicator series and are warped (aligned), respectively. Condition (b) ensures that the time moments for both series are monotonically increasing. Last, condition (c) ensures that no element of and can be omitted or repeated in the warping (alignment), i.e., the elements in the sequence need to be contiguous.
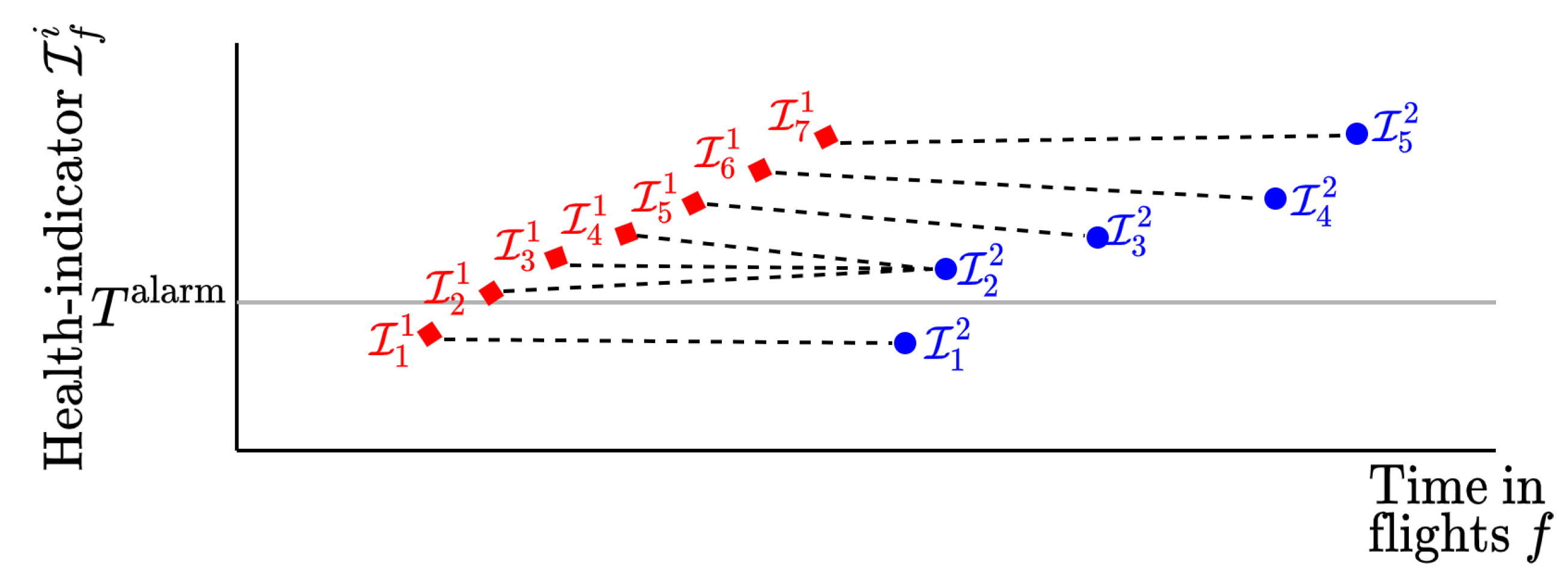
Figure 2 shows an example of a warping path for two time-series of health indicators,
and
. Here,
contains seven health indicator values, while
contains only five health indicator values. There are three health indicator values of the first component, namely
, and
, connected to the health indicator value
of the second component. The warping path
p for these two time-series is:
Let
p be a warping path between degradation series
and
. Let
, as introduced in Equation (
4), be a similarity metric between the degradation points
and
. Let
denote a similarity metric between two series of health indicators
and
with warping path
p, where
We are interested in a warping path
P between the two series
and
with a minimum cumulative Euclidean distance
, i.e, we are interested in obtaining:
Lastly, we obtain a warping path of minimum cumulative distance
using dynamic programming as follows [
38]. Let
be the minimum distance between a part of the time series
and a part of the time series
. Here,
and
. Then,
and
We can now solve the recursive equation to find the minimum distance between two health indicator time-series as:
2.2.2. (ii) Clustering Series of Health Indicators of a Library of n Components
Having determined the distance between the components , , we construct a graph , where a node corresponds to a series of health indicators for component , and thus . We construct an edge between a node to the closest nodes , i.e., the shortest distances between a component i and the rest of the components . Here, we normalize the distance with the maximum number of health indicator values in and . The connected components of this graph are considered to be the clusters of health indicator series (or equivalently, clusters of components with similar underlying degradation trends).
We assume that all components in the same cluster have a degradation trend according to a stochastic process that has the same functional form, and that all components in the same cluster have the same failure threshold D. These cluster-specific degradation models and failure thresholds are ultimately used to estimate the RUL for a component using a particle filtering algorithm.
2.3. Step 3: Online Clustering of (Non-Failed) Components
Let component
i be monitored online. Let an offline library consist of
n series of health indicators
. Let
C be the set of clusters in the offline libraries, which are obtained using dynamic time-warping (see
Section 2.2.2).
As soon as the health indicator of component
i exceeds an alarm threshold
(i.e., the component is diagnosed as unhealthy), the online monitored component
i is assigned to a cluster in the set
C using dynamic time-warping (
Section 2.2.1). Here, the series of health indicators for component
i consists of indicators obtained
m flights before the threshold
is reached (flight
) until the current, most recently available measurement at flight
.
We calculate the minimum distance
for the online component
i and each component
j in the offline library (
), where
Figure 3 illustrates
corresponding to an online monitored component
i.
The partial health indicator series
for component
j from the offline library is defined as:
where
is the length of series
.
Figure 3 shows an example for an online monitored component
i and a library with component
.
Lastly, we assign component
i to a cluster
such that the average minimum distance
to the series of health indicators of components
j in cluster
is minimised, i.e.,:
Now, component i assumes the same degradation model and failure threshold as the degradation model and a failure threshold specific to cluster . This degradation model is further used to estimate the RUL for component i.
2.4. Step 4: RUL Prognostics
Together with the degradation model and failure threshold
D identified in Step 3, we use a particle filtering algorithm [
39] to estimate the RUL of an online monitored component. Let us consider the following recurrence function:
where
is the actual degradation level of a component after flight
and
are i.i.d. Gaussian variables representing the noise in the degradation process. In general,
is assumed to have a certain functional form, which depends on the type of component and/or the type of degradation that the component is expected to undergo. In our case, we consider cluster-specific functional forms for all components in the same cluster (see Steps 2 and 3). The health indicator
is a function of
(see Equation (
1)):
To obtain RUL prognostics, the particle filtering algorithm has four steps [
39]: (i) prediction, (ii) updating, (iii) resampling, and (iv) prognostics.
- (i)
Prediction
We are interested in the conditional probabilities:
where Equation (12) is the conditional probability density function of the degradation level of the component after flight
, given the recorded degradation measurements
, whereas Equation (
11) is the transition probability density function to reach future degradation state
, given the current degradation state
.
Using the Chapman–Kolmogorov equation, we have the following probability density function for the state degradation after flight
f:
- (ii)
Updating
As soon as new measurements are available, the state probability density function is updated, using Bayes’ theorem, as:
- (iii)
Resampling
We approximate Equation (
13), the probability density function for the state degradation, numerically using Importance Sampling [
40] as follows. First, we sample
M particles from a probability density function
. Then, using importance sampling, the probability density function of the degradation state of the component after flight
f is approximated as:
where
is a Dirac function,
is the estimated degradation level of particle
j of the component after flight
f, and
is the weight of the
jth particle,
after flight
f, which is updated and normalized as follows:
In every re-sampling cycle, the particles are re-sampled proportionally to their weight. A new particle set is generated by re-sampling M new particles, where the probability to resample a particle j equals .
- (iv)
The RUL prognostic
Lastly, we consider a threshold
and define the RUL as the stopping time:
3. Numerical Case Study—Multiple Cooling Units from a Fleet Of Aircraft
To illustrate our approach from
Section 2, we considered eight cooling units (CUs) originating from a fleet of aircraft operated by a large European airline. For each CU, a time series of measurements was recorded during the operation of these aircraft until the components failed (run-to-failure data).
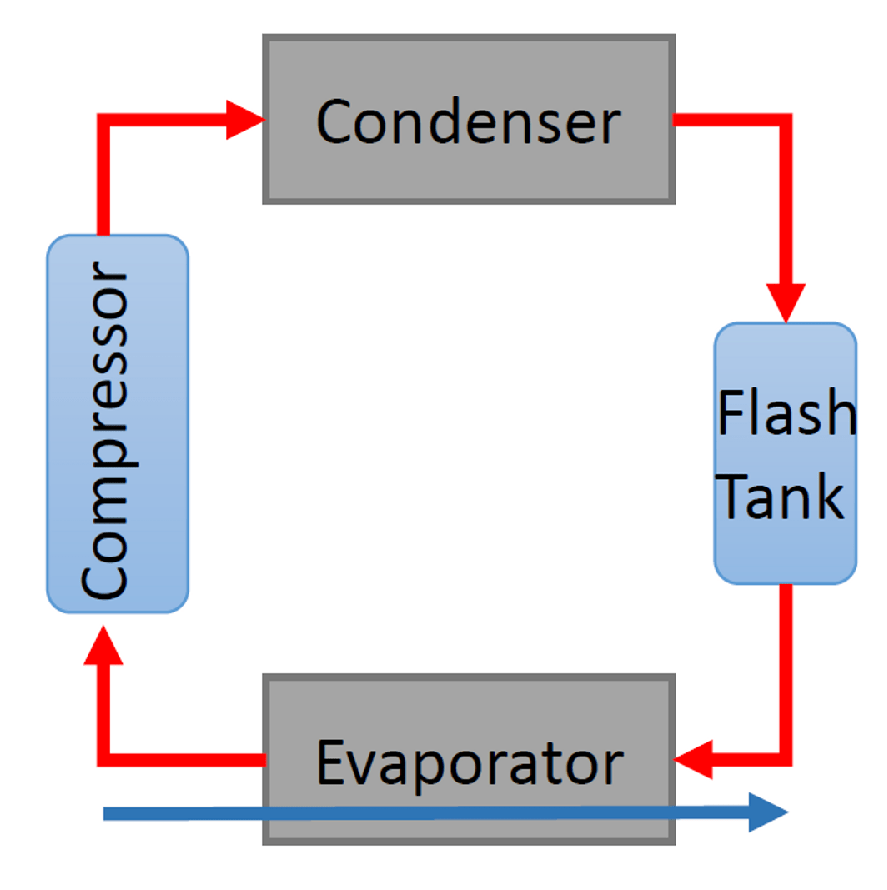
The CU is a vapor cycle refrigeration unit consisting of a compressor, a condenser, an evaporator and a flash tank (see
Figure 4). After many days of operations, the CU becomes clogged with burned oil, moisture, and sludge from the compressor. This accelerates the compressor wear. Long-term exposure to these conditions negatively affects the health of the CU, which, in time, leads to failure [
41].
3.1. Health Indicator For CUs
For each CU, run-to failure measurements were considered. These measurements were available after some initial usage of the component. The run-to-failure data series consists of sequences of 50 flights (short series) up to 390 flights (long series). For each CU, there were nine sensors
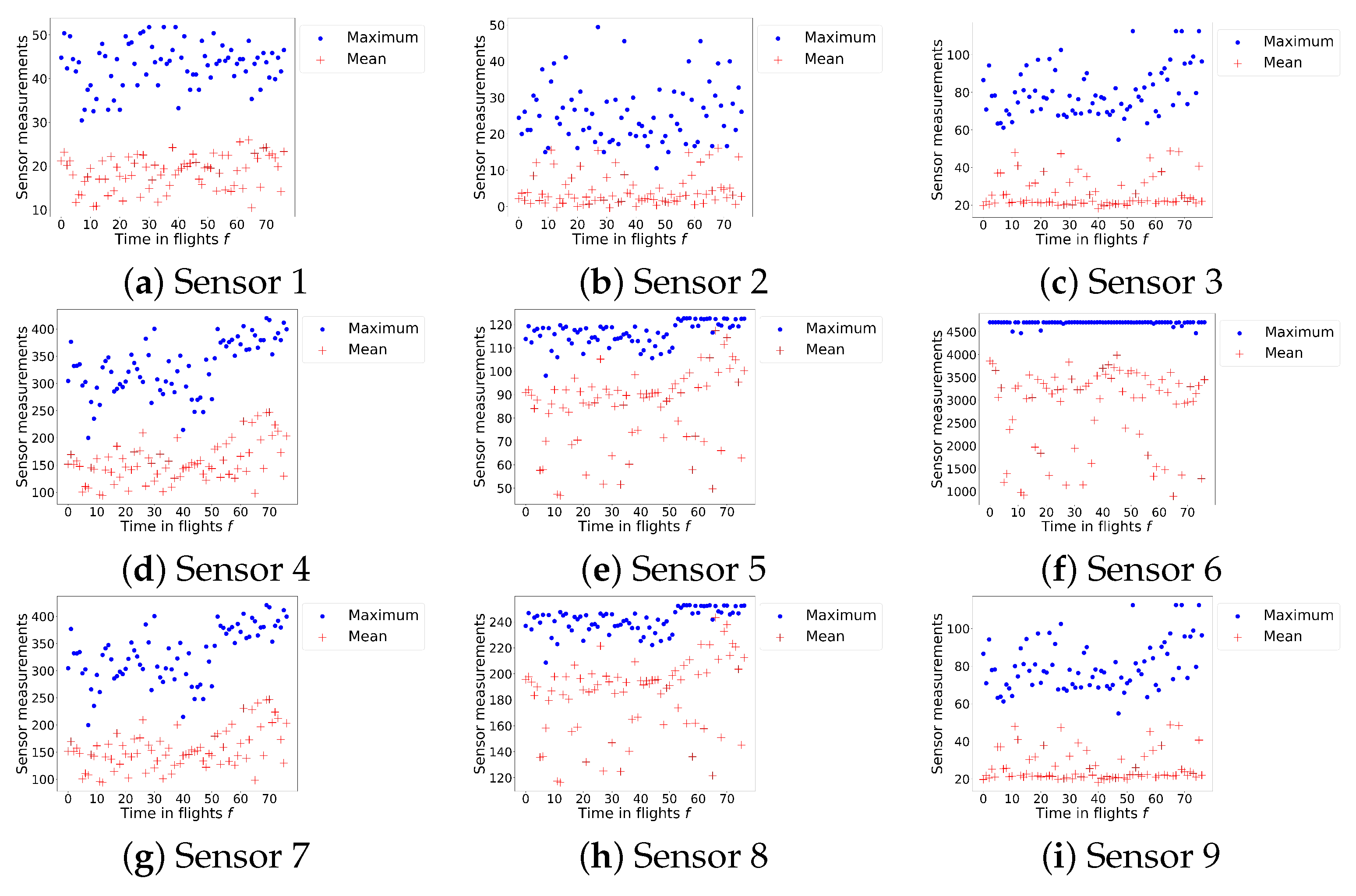
, each generating a measurement every 10 s during each flight. For the purpose of our analysis, the data sets are anonymized, and thus it is unknown the type of measurement each sensor generates. We observed, in the sensor data, an increasing trend in the mean and maximum sensor measurements toward failure. As an example,
Figure 5 shows the mean and maximum sensor measurements per day until the moment of failure for one CU and for each of the nine available sensors.
Let
denote the
measurement during flight
f for CU
i generated by sensor
s. We first normalize the sensor measurements as follows:
with the
and
the available minimum and maximum measurements generated by sensor
s, respectively, and
as the total number of measurements recorded during flight
f of CU
i.
With these normalized sensor measurements, we considered several health indicators, as described in [
2,
42]. We constructed each health-indicator for the measurements of each sensor and calculated, for each sensor, the correlation coefficient (trendability) between the health indicator and the time to failure for the last 50 flights before failure (length of the shortest serie).
Table 1 provides an overview of the considered health-indicators and the corresponding correlation coefficients. An extensive description of the health indicators can be found in [
42].
The highest correlation coefficients were obtained for the Root Mean Square (RMS) health indicator. We, thus, constructed a health indicator based on the RMS of the measurements [
10,
42,
43]. A health indicator based on the RMS of measurements was often employed in the literature [
2,
42], for example for the health monitoring of gearboxes [
44], turbine-cutting tools [
43], and rolling element bearings [
45]. The RMS of sensor
s of CU
i during flight
f is:
A health indicator
for CU
i during flight
f was obtained as the moving average of the maximum RMS obtained by the sensors
, as follows:
where
and where
is the set of sensors for which the moving average of the RMS of the measurements obtained in the last 50 flights before failure has a correlation coefficient with the time of failure of at least 0.70. We, therefore, included sensors 4, 5, 7, and 8 in the health-indicator. This final health indicator emphasizes the increase in the mean and the maximum measurements toward failure, which we observe in
Figure 5.
Figure 6 shows the health indicator and the alarm threshold
when considering the run-to-failure data of the eight CUs. For the alarm threshold, we assume
(see Equation (
3)), obtaining a threshold of
. When analyzing all CUs, the alarm threshold is reached between 2 to 40 flights before the actual failure time.
Figure 6 also shows that the degradation trends toward failure, which differed across components. The failure thresholds differed among the eight components. As such, in the next section, we cluster the series of health indicators to identify the main degradation models and the corresponding failure thresholds.
3.2. Clustering the Health Indicators and Determining Clustering-Specific Degradation Models
We performed dynamic time-warping (see
Section 2.2, Step 2) to cluster the
time series of health indicators and to identify cluster-specific degradation models for the CUs. For this, we used the run-to-failure data of the eight CUs, starting
flights before the CU reached the alarm threshold until failure time.
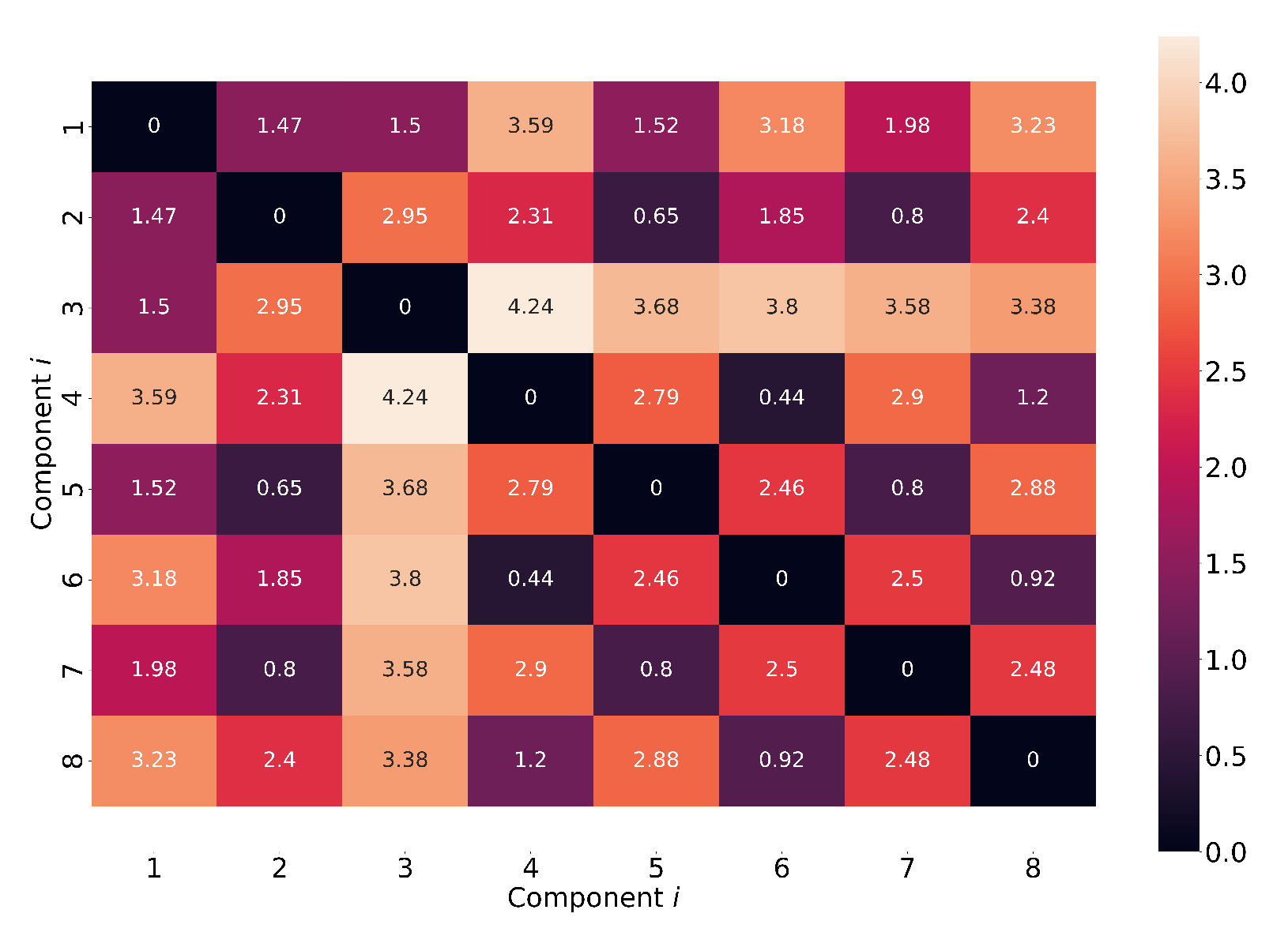
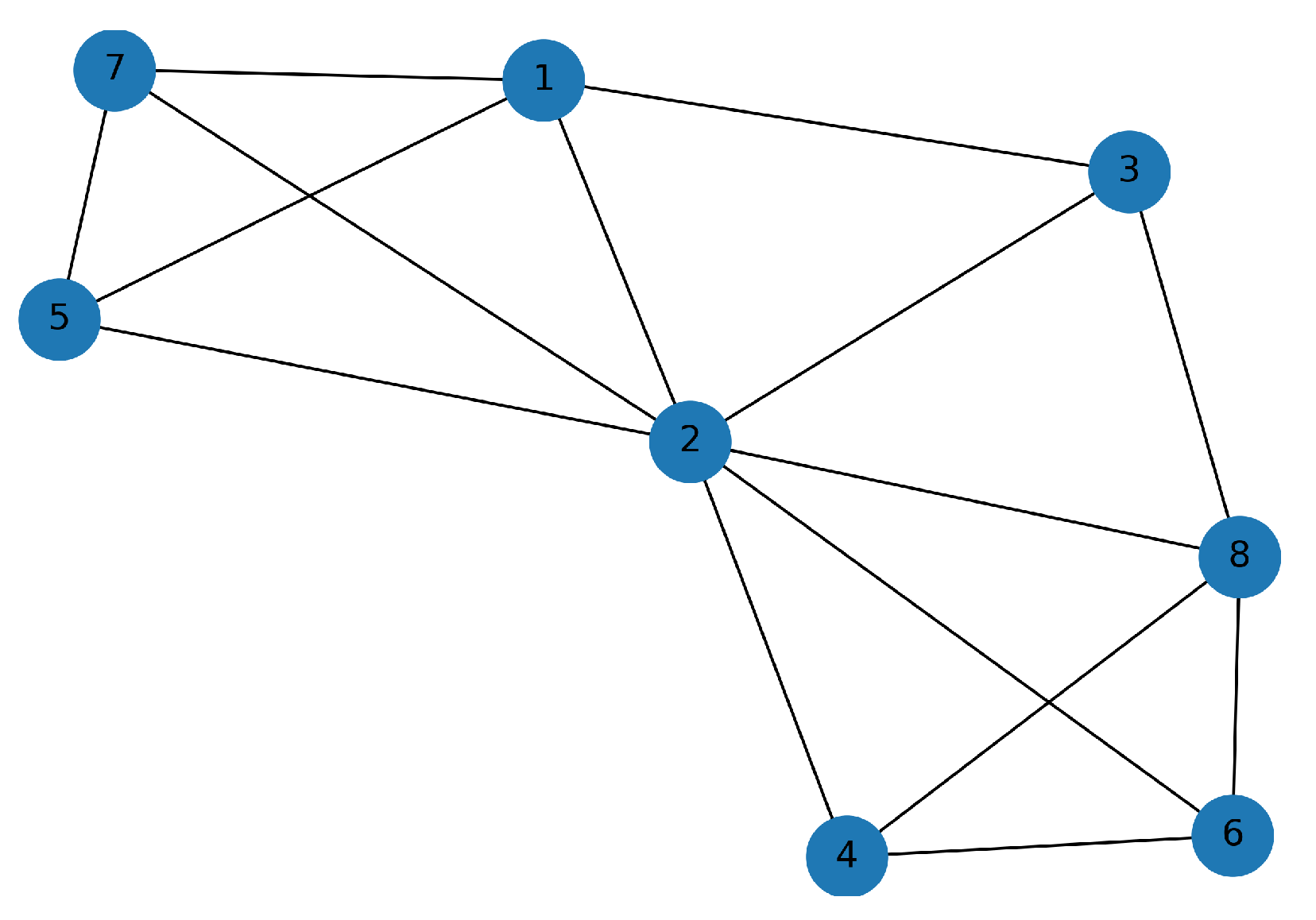
Figure 7 shows the minimum distance
,
, between the series of health indicators of the eight CUs, normalized with the maximum length of the series
and
. Here, the minimum distances
between the degradation of any two components varies from 0.44 (high similarity between the degradation trends) to 4.24 (large dissimilarities between the degradation trends).
Using
, between the eight series of health indicators, we constructed the graph
, with
. Here, a node
in the graph corresponds to the series of health indicators for component
. For each CU
i, and a given
, an edge was constructed between those
nodes (CUs) that have the smallest distance to node
(CU
i). For example, if
and we consider CU
, an edge was constructed between node
and node
and between node
and
, since the distances between node
and nodes
and
are the smallest (see
Figure 7).
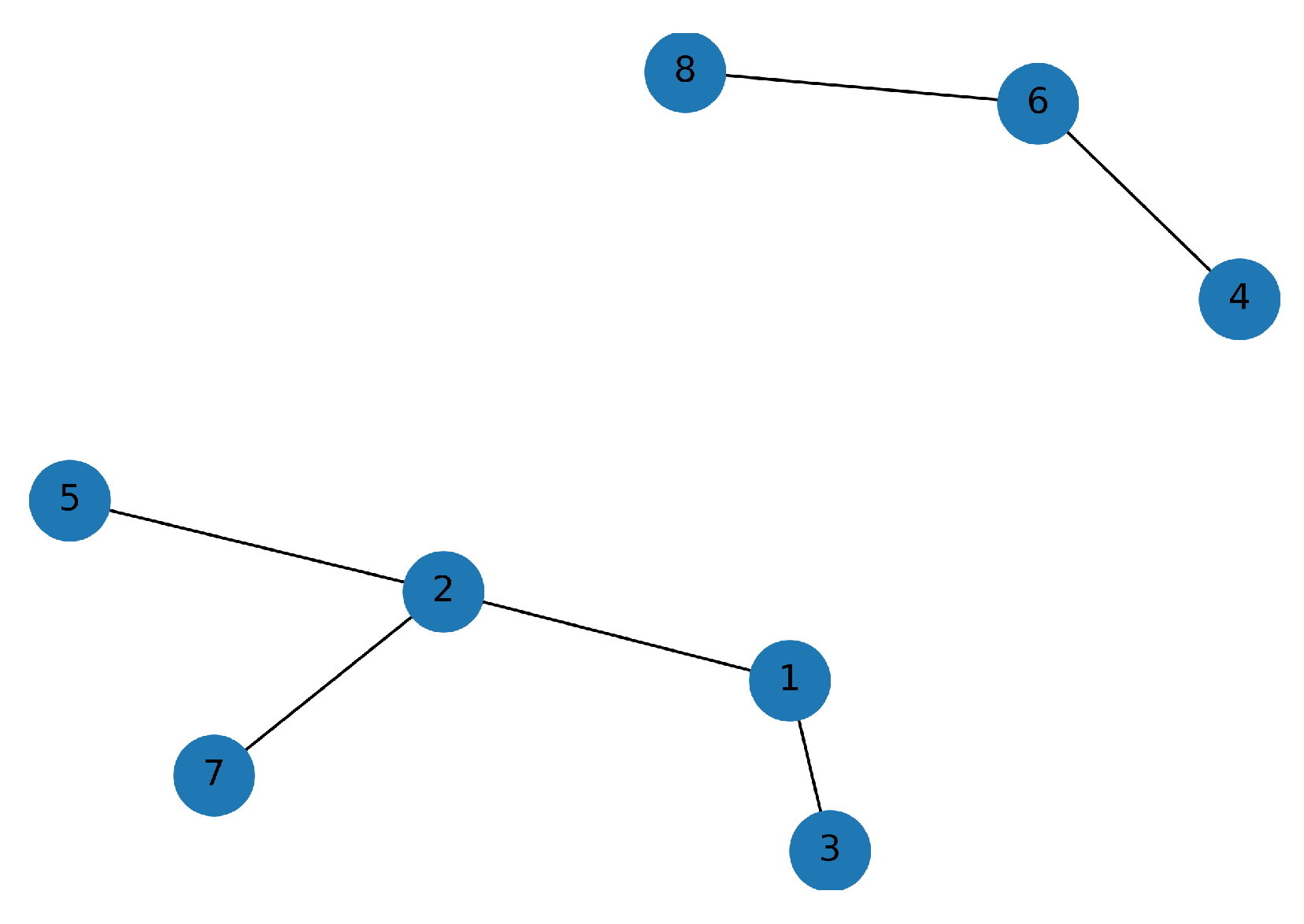
In
Figure 8, we set
. This results in two clusters of CUs:
, and CU
. The health indicator in
Figure 6 shows that the CUs 4, 6, and 8 failed soon after the health indicator reached the alarm threshold—when the health indicator reached a value of approximately 15. The degradation trend around failure showed a monotonic increase. In contrast, CUs 1,2,3,4,5, and 7 failed when the health indicator reached a value of 20. Furthermore, the degradation of these CUs often accelerated toward failure.
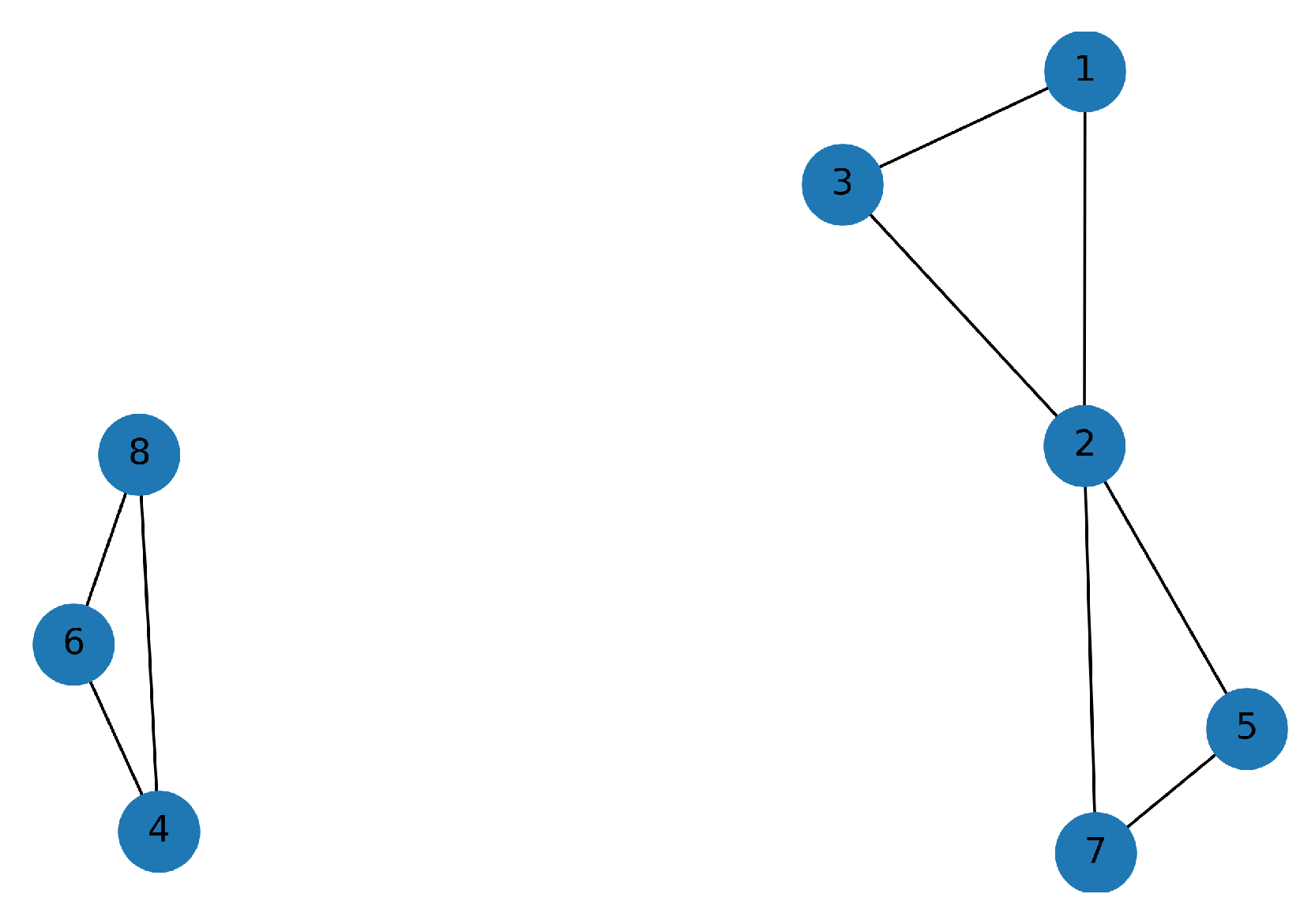
For
(see
Figure 9), the same two clusters
and
are maintained. The CUs in
Figure 9 are now connected by multiple edges. For
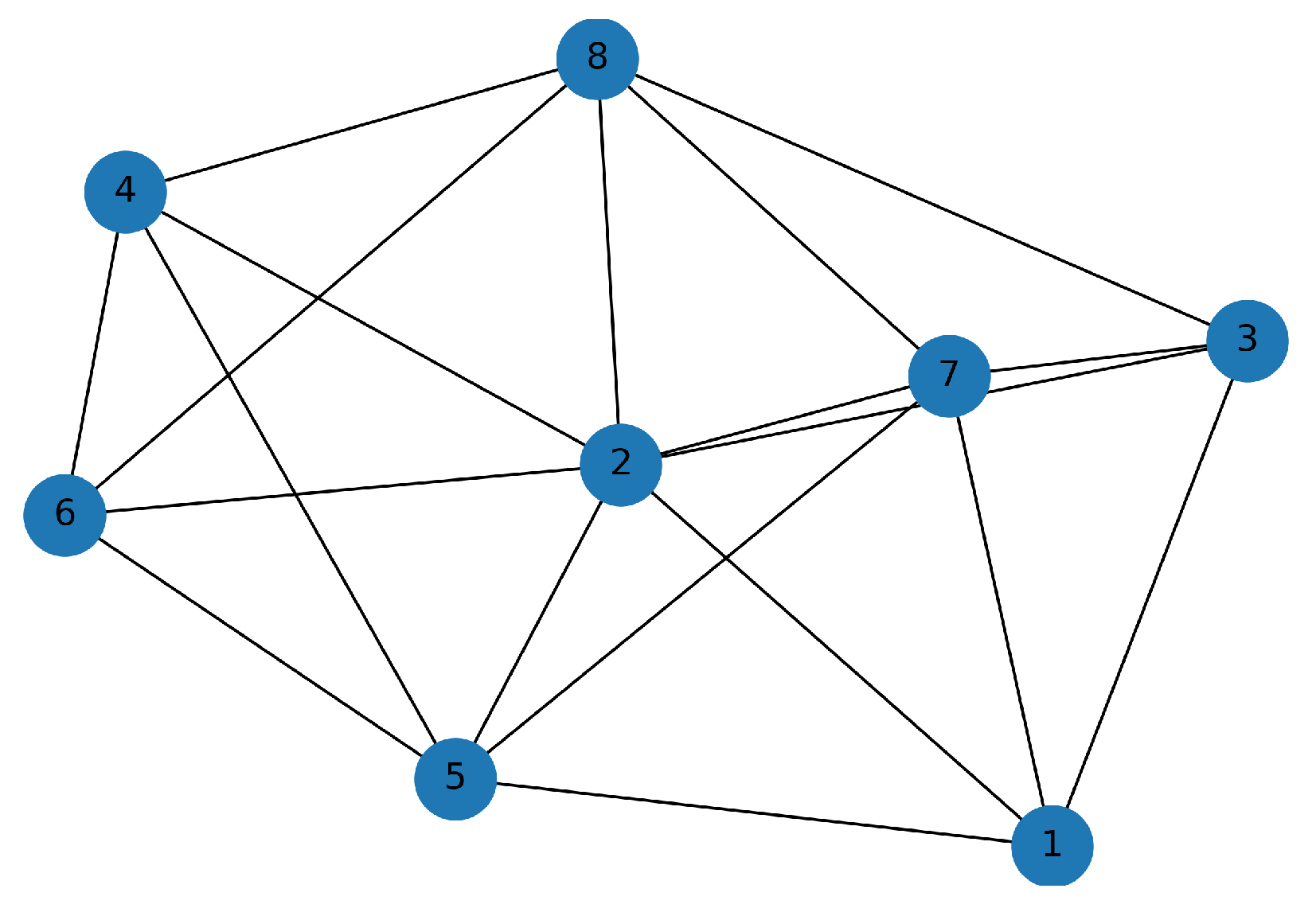
(see
Figure 10), only one large cluster emerges. Here, the CUs in cluster
and cluster
are still grouped together (see
Figure 8), and connected to each other through CU 2 and 3. Finally, for
(see
Figure 11), all CUs formed one large cluster with several edges between clusters
and
. Following the clustering for different
, we define the following two clusters:
For the two clusters in Equations (
21) and (22), we now define the following cluster-specific degradation models.
3.3. Cluster 1—Linear Degradation Model
The health indicators of CUs 4, 6, and 8 in Cluster 1 are given in
Figure 6d,f,h. All these CUs fail when their health indicator reached a value of approximately 15. Thus, we consider a failure threshold
for Cluster 1. Once the health indicator of the CUs in Cluster 1 reaches the alarm threshold
, the indicator had a sharply, but monotonic increasing, trend toward failure. We, thus, consider the following linear degradation model for the CUs in Cluster 1 [
8]:
where
is the degradation of component
i at time
t,
is the initial degradation,
is a model parameter, and
is the noise in the degradation process. As in [
30], we ignore the process noise because it is handled through the uncertainty in the model parameters and in the measurements [
46]. Linear degradation models are often considered for prognostics [
24], for example for milling machines [
25], batteries [
26], aircraft engines [
27], and engine bleed valves [
28].
Following the degradation model in Equation (
23), we consider the derivative:
Rewriting the above equation in the form of Equations (
10) and (
1) with
flight, we obtain:
where
is the measurement noise at flight
f. The distributions of the model parameters are initialized as
and
.
The parameter distributions are initialized such that sample impoverishment, the degeneracy problem and non-convergence of the particle filtering algorithm are avoided [
46].
3.4. Cluster 2—Exponential Degradation Model
The health indicators of CUs 1,2,3,5, and 7 in Cluster 2 are given in
Figure 6. All these CUs failed when their health indicator reached a value of approximately 20. Thus, we consider a failure threshold
for Cluster 2.
Moreover, the increments of the health indicator steadily increased toward failure for these CUs. We, thus, consider the following exponential degradation model for the CUs in Cluster 2:
where
is the degradation of component
i at time
t,
is the initial degradation,
is a model parameter, and
is the noise in the degradation process. As before, we ignore the process noise [
30]. Exponential degradation models have been considered in many prognostic studies [
24], for bearings [
29,
31], batteries [
30,
32], and railway turnout systems [
33].
Taking the logarithm of Equation (
27):
As in [
8], we assume that
. Following the degradation model in Equation (
28), we consider the derivative:
Rewriting the above equation in the form of Equations (
10) and (
1) with
flight, we obtain:
where
is the measurement noise at flight
f. The distributions of the model parameters are initialized as
and
. The parameter distributions are initialized such that sample impoverishment, the degeneracy problem, and the non-convergence of the particle filtering algorithm are avoided [
46].
Lastly, with the degradation models introduced above, we apply the particle filtering algorithm (see
Section 2, Step 4) to estimate the RUL of the CUs.
3.5. Rul Estimation Results
In this section, we estimate the RUL of the eight CUs using leave-one-out cross validation as follows. We select one CU
. We consider the (partial) health indicator of this CU
i up to the moment of generating a RUL prediction. We determine the minimum distance between this (partial) health indicator and the (partial) health indicators of the CUs in Cluster 1 and Cluster 2 (see Equations (
21) and (22)), which do not include CU
i. We assign CU
i to that cluster for which the average distance between the cluster and CU
i is the minimum (see Step 3,
Section 2). Then, CU
i assumes the degradation model and the failure threshold of this cluster. Lastly, we estimate the RUL of CU
i using particle filtering with 10,000 particles.
Table 2 shows for each CU the cluster it is assigned to as soon as
is reached, i.e., the CU is diagnosed as unhealthy, and there is a corresponding RUL prediction. CU 1 was diagnosed as unhealthy, and an alarm was triggered at an early stage at 40 flights before the actual failure time. CUs 2, 3, 4, 5, 6, and 7 were diagnosed as unhealthy up to six flights before the actual failure. For CU 8, an alarm was triggered only two flights before the actual failure.
CUs 1, 2, 5, and 7 were assigned to Cluster 2, which assumed an exponential degradation model, whereas CUs 3, 4, 6, and 8 were assigned to Cluster 1, which assumed a linear degradation model. Only CU 3 was assigned to a different cluster (namely cluster 1) than in the offline clustering, which led to underestimation of the RUL. These results show that, even when considering clustering with partial health indicators, i.e., up to the moment when a prediction is made, our approach can well identify the underlying linear or exponential degradation trend and the corresponding failure threshold.
Table 2 shows the RUL estimates 10 flights before the time of failure. CUs 4, 6, and 8 failed within less than 10 flights as soon as they were diagnosed as unhealthy, thus, no RUL predictions are made in this case. CUs 1, 2, 3, 5, and 7 were all assigned to the same exponential cluster as in the offline clustering.
Table 2 also shows that the RUL of the CUs was well estimated as soon as these CUs were diagnosed as unhealthy. The Root Mean Square Error (RMSE) was low as well. The fact that we were able to select appropriate degradation models and failure thresholds based on cluster-specific trends contributes to the accuracy of the RUL predictions.
4. Conclusions
We proposed an online, model-based RUL estimation approach for aircraft components using a clustering of component degradation trends. Using clustering, we determined cluster-specific degradation models and failure thresholds. Together with a particle filtering algorithm, these degradation models were used to estimate the RUL of multiple, same-type aircraft components.
As an illustration, we considered several aircraft Cooling Units for which sensor measurements were recorded during the operation of the aircraft. The results show that our proposed methodology was able to identify the degradation models of components and estimate their RUL. From a practical point of view, our RUL estimation results have the potential to support aircraft maintenance stakeholders with maintenance task scheduling.
For future work, we plan to extend our methodology for other aircraft components. At the same time, we plan to propose maintenance task scheduling algorithms to evaluate the impact of prognostic-driven maintenance on the maintenance costs and aircraft availability.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}