1. Introduction
Aircraft maintenance is the repair, modification, overhaul, inspection, and determination of the condition of aircraft systems, components, and structures that aims at providing aircraft airworthiness for operations [
1].
Maintenance in aviation is usually defined using preventive strategies, which means that each aircraft must be grounded to perform a maintenance check at certain intervals. This strategy aims at constantly guaranteeing the airworthiness of the aircraft, reducing the risk of unexpected failures that are caused by a deterioration of components, and keeping a consistent maintenance program for the entire aircraft fleet. The maintenance check intervals that indicate when a new check is needed are dependent on the utilization as well as the aircraft aging. They are defined with respect to the aircraft usage parameters, which are defined in flight hours (
FH), flight cycles (
FC), and calendar days (
DY). An
FC corresponds to a complete take-off and landing sequence. Whenever an aircraft reaches the usage limit in one of the metrics, it must be grounded to perform the corresponding check. There are three major maintenance checks: A-checks, C-checks, and D-checks [
2]. An A-check is a lighter check that is performed approximately every two to three months and it usually lasts one day. A C-check is a heavier check that is performed every 18 to 24 months and lasts between one and three weeks. A D-check, or structural check, is the heaviest check. It is performed every six to ten years and it lasts for three weeks to two months. In some literature, a B-check is also mentioned, although, in practice, most airlines opt to incorporate B-checks tasks into A-checks [
3]. Because of the large impact these checks have on aircraft availability for flying and the amount of resources allocated to perform these checks, they are typically planned months ahead for a time horizon of three to five years [
3].
Maintenance costs represent around 10–20% of the total operating costs of an airline [
4]. Despite this, the scheduling of aircraft maintenance is currently mostly based on a manual approach. Airlines rely on the experience of the maintenance personnel to plan the checks for fleets of aircraft, solving schedule conflicts that inevitably occur by shifting checks back and forth until a feasible calendar is found. Generally, this process is very time consuming, since it can take days or even weeks to develop a feasible maintenance plan. It also leads to sub-optimal solutions, which can affect aircraft availability, resulting in financial losses for the airline. Therefore, it is important to improve the current existing procedures and look towards maintenance optimization.
The literature on long-term aircraft maintenance scheduling is limited, as most of the research focus is on short-term aircraft maintenance routing. One of the main reasons is that the gains of optimizing the scheduling of checks can only be observed in the long term, and airlines usually aim for more rapid benefits. There are only two references in the literature addressing the long-term check scheduling problem. In [
5], a simulation model was developed to reduce the maintenance costs and the time required to generate a maintenance plan. A second work is proposed in [
3], where a Dynamic Programming (DP) based approach is used to schedule A and C-checks for a time horizon of four years while considering several maintenance constraints. The problem has a structure that follows the Markov Decision Process (MDP), and the goal is to schedule checks as close as possible to their due date, which is, the date when the respective interval is reached. By doing this, a higher FH utilization is achieved, which results in a lower amount of checks in the long run.
The aircraft maintenance routing problem consists in assigning aircraft to a sequence of flights that allow them to be routed to a maintenance station within a given number of days to perform a daily check [
6]. One of the first studies on this topic is presented in [
7], in which the goal is to build flight schedules that satisfy maintenance constraints, such as the maintenance base locations for the fleet. Over the years, several other approaches have been proposed. A polynomial time algorithm is developed in [
8] to solve a maintenance routing problem, where each aircraft must visit a maintenance station every three days. In [
9], the authors propose a solution for fleet allocation and maintenance scheduling using a DP approach and a heuristic technique. An Integer Linear Programming (ILP) model to generate feasible aircraft routes is developed in [
10], to maximize fleet utilization. A set-partitioning problem was presented in [
11] to minimize maintenance costs without violating the flight hour limit intervals of each aircraft. An approach for maximizing aircraft utilization by defining routes that satisfy the scheduled maintenance checks was proposed in [
12]. A model to optimize the inventory management regarding the components and spare parts needed for maintenance was developed in [
13]. The use of RL in maintenance scheduling problems was studied in [
14]. The authors use the value function approximation and design policies for a dynamic maintenance scheduling problem, where the goal is to minimize the costs of expired maintenance tasks. In [
15], RL algorithms were used to optimize the scheduling of maintenance for a fleet of fighter aircraft. The goal was to maximize availability and maintain it above a certain level. The results indicate that RL algorithms can find efficient maintenance policies, which have increased performance compared to heuristic policies.
In this paper, we develop a Deep Q-learning algorithm to solve the same check scheduling problem that is defined in [
3]. By using RL, we can address some of the limitations found in the previous work. For instance, the time that is required to obtain a solution can be heavily reduced once the model is trained. RL can also answer some "curse of dimensionality” problems found with the DP-based method, and its adaptability is a relevant factor when dealing with this complex environment. At the same time, the check scheduling problem continues to be defined as an MDP. The model is trained using real maintenance data and, to evaluate the quality of the maintenance plans generated, we perform a comparison with the work that was done in [
3] and with airline estimations. One of the main advantages of RL is the possibility to adapt to changes over time without needing to restart the training process. This characteristic is verified by introducing disturbances in the initial conditions of the fleet and training the model with these simulated scenarios. The obtained results with this method indicate that RL can continue to produce good maintenance plans.
This paper is organized, as follows:
Section 2 provides relevant background on RL, focusing on the Deep Q-learning algorithm used in this study.
Section 3 presents the scheduling problem formulation.
Section 4 describes the experimental setup.
Section 5 depicts the key results that were obtained and their comparison with other approaches. Finally,
Section 6 summarizes the research and addresses directions for future research on this topic.
2. Reinforcement Learning
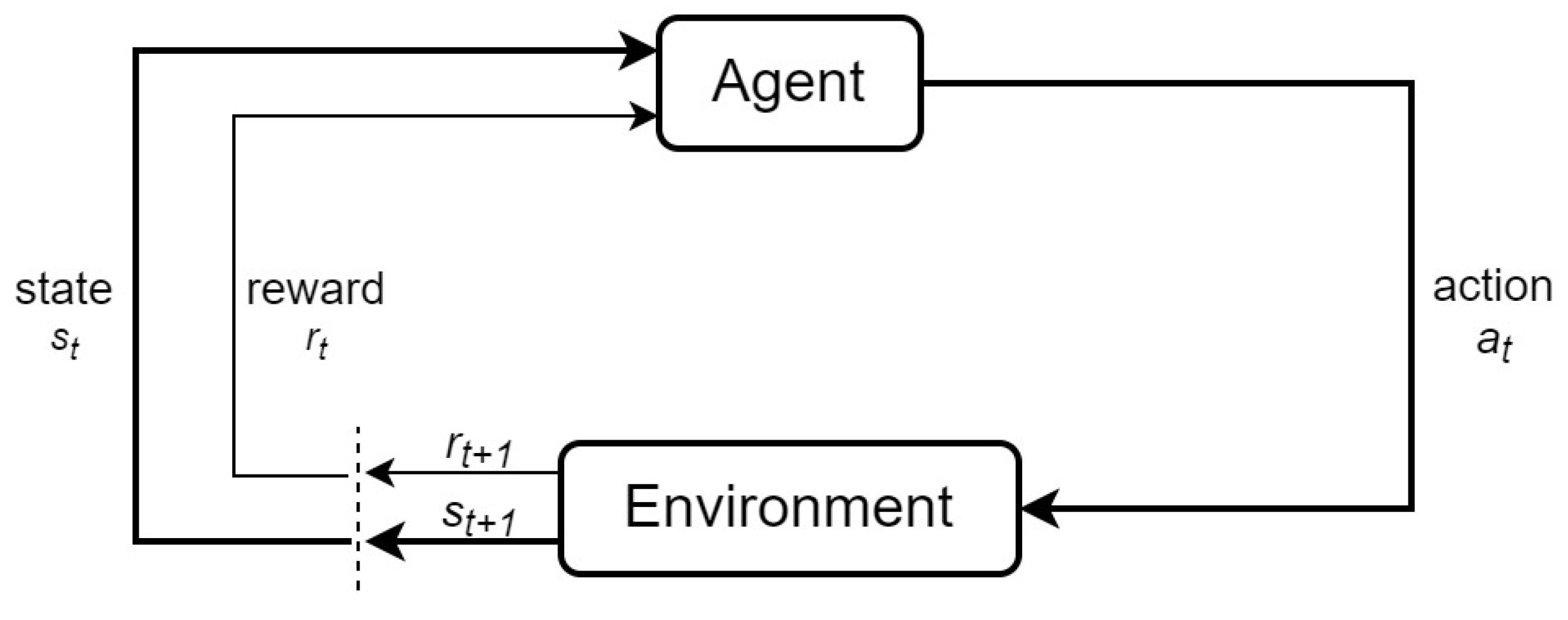
In RL, an agent interacts with an environment by performing a series of subsequent decisions to reach a particular goal, receiving a reward depending on the quality of the action chosen [
16]. The idea is that the agent will continuously learn by selecting actions that grant bigger rewards. The training of the RL agent occurs in several episodes. An episode is a sequence of states that starts on an initial state and ends on a terminal state.
Formally, RL can be described as a Markov Decision Process (MDP) and defined as a tuple (S, A, P, R,
), where S is the set of states, A is the action set, P is the transition function, R is the reward function, and
is a discount factor, which is used to give less relevance to rewards occurring far into the future. At each time step
t, the agent is in a state
and it selects an action
. It then moves to the next state
and receives a reward
, which indicates how good the selected action was. This interaction is represented in
Figure 1. To select an action, the agent follows a policy, which is a mapping from states to actions. The policy defines the behavior of the agent.
The goal is to find an optimal policy that corresponds to a sequence of actions that maximize the expected return,
. This return corresponds to the sum of discounted rewards over time and it can be defined with:
where
is the reward obtained at time
t and
is the discount factor.
Another important element of RL is the value function, which defines the value of being in a given state. The value of a state
s when following a policy
, denoted
, is the expected return when starting at state
s and following policy
thereafter, and it can be formally defined as:
There are two main methods for obtaining the optimal policy: policy iteration and value iteration. The first one aims to manipulate the policy directly, while the second one aims to find an optimal value function and adopt a greedy policy.
2.1. Q-Learning
Q-Learning [
17] is based on value iteration and it is one of the most popular RL algorithms. It makes use of a look-up table, called Q-table, which, in most cases, has the shape [states, actions]. Each number in the Q-table represents the quality of taking an action,
a, in a state,
s, and it is named as the Q-value,
. The RL agent, at each time step, observes the current state and chooses the action with a higher Q-value in that state. After acting, the agent receives a reward, which will be used to update the Q-table using (
3), where
is the learning rate.
The RL agent learns from his own decisions, which means that he must perform a large number of actions and collect a wide variety of experiences to be able to achieve a big reward and find the optimal policy. Suppose the agent adopts a greedy strategy by constantly choosing the action with the highest value. In that case, there is a risk of obtaining a suboptimal solution by converging to a local minimum. This is known as the exploration-exploitation trade-off, where the exploration corresponds to the agent choosing a random action, and the exploitation corresponds to the agent selecting the best action in the current state. The -greedy is a widely known strategy for ensuring a proper exploration of the state-action space. The variable represents the probability of choosing a random action and it is usually initialized to 1 with a decay rate over time. This ensures ahigh exploration at the beginning, with exploitation rising over time.
While a look-up table can be a simple and efficient solution for state-action spaces of reduced size, the same is not true for bigger and more complex problems. The traditional solution in these cases is the Deep Q-learning variant, which uses Artificial Neural Networks (ANN) to obtain approximations for the Q-values. Experience replay is a relevant feature frequently used with Deep Q-learning. Instead of training the network with the sequence of experiences as they occur during the simulation, those experiences are saved in what is usually called the replay memory. After each action of the agent, a random batch of experiences is sampled from the replay memory and used for training [
18]. This helps to overcome two common problems of Deep Q-learning: the agent forgetting past experiences as time passes, and the correlation between consecutive experiences.
3. Problem Formulation
In the aviation industry, each aircraft must be grounded to perform maintenance checks at certain intervals, as specified in the aircraft Maintenance Planning Document (MPD). These intervals are defined in flight hours (FH), flight cycles (FC), and calendar days (DY), which are the three metrics that represent the aging of the aircraft. Usually, each check type has its own maximum defined interval, and the corresponding usage metrics are reset to 0 immediately after a check is performed.
It is possible to schedule maintenance checks beyond the maximum interval by using a tolerance, which is also defined in the aircraft MPD. However, the use of this tolerance should be avoided since permission has to be requested from the civil aviation authorities. Furthermore, the FH, FC, and DY that are used from the tolerance have to be deducted from the maximum interval metrics of the next check.
In cases where a lighter check is scheduled near a heavier one, airlines frequently opt to merge the two of them. For instance, it is common for an A-check to be merged into a C-check if both of them reach their interval within a certain number of days from each other. This merging prevents the same aircraft from being grounded twice in a short period without necessarily increasing the duration of the C-check. The disadvantage of doing this is the increase in the number of A-checks in the long term.
Some airlines also require a minimum number of days between the start dates of two checks of the same type. This is mainly related to resource preparation, such as workforce, tools, aircraft spare parts, or the hangar itself.
3.1. Assumptions
We consider the following assumptions to define our long-term maintenance check scheduling approach:
- A1
The minimum time unit for the scheduling of maintenance is 1 DY.
- A2
Aircraft utilization can be measured in FH, FC, and DY.
- A3
The daily utilization of each aircraft can be defined by the airline or can be estimated using historical data.
- A4
The duration of each check can be defined by the airline or can be estimated using historical data.
- A5
There is a limited amount of hangar slots each day to perform A/C-checks.
- A6
Each A/C-check uses only one hangar slot for its total duration.
- A7
C-checks have a higher priority than A-checks.
- A8
An A-check can be merged in a C-check without increasing the C-check duration and without occupying an A-check slot.
- A9
The fleet operation plan does not influence the scheduling of maintenance.
In addition to A5, it is relevant to know that the available maintenance slots can vary during the year. For instance, during commercial peak seasons, the amount of maintenance performed is greatly reduced, and heavy maintenance can even be suspended. These peak seasons usually consist of Christmas, New Year, Easter, and Summer periods.
The priority that is given to the scheduling of C-checks mentioned in A7 has two main reasons. The first one is related to the possibility of merging checks. When planning the A-checks, it is important to know the exact starting and ending days of the C-checks to decide whether the merging is possible. The second reason is related to the fact that the A-check usage parameters are not increased when the aircraft is performing a C-check (due to it being grounded). Because a C-check usually involves several weeks of ground time, it has great influence on the scheduling of the A-checks.
There is a deviation from traditional state-of-the-art problems by not considering the operation plan, as mentioned in A9. The reason is that maintenance checks have intervals of several months/years, while the airline only plans aircraft routes for the next few days. Consequently, the geographic location of the aircraft is also not considered.
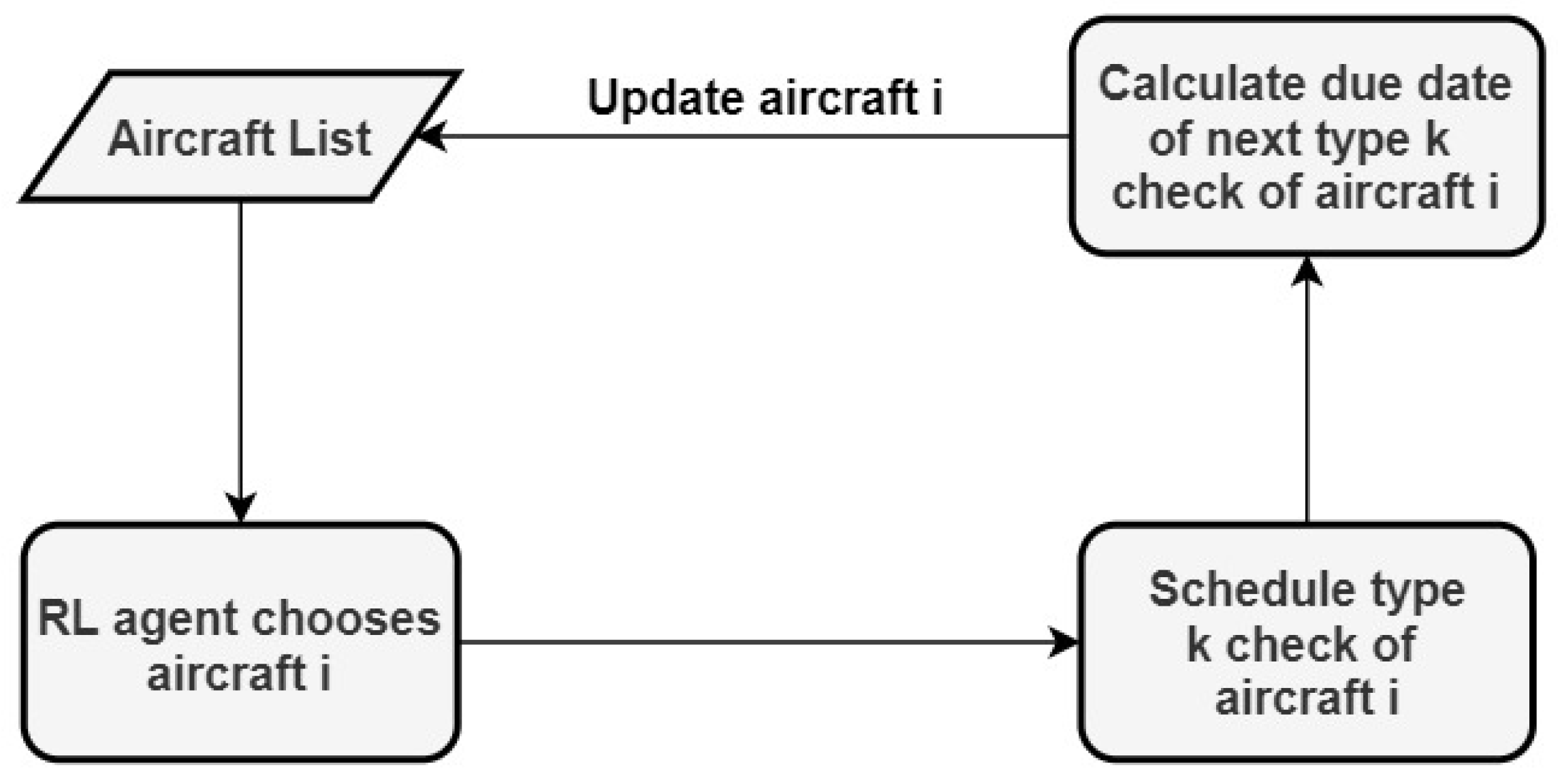
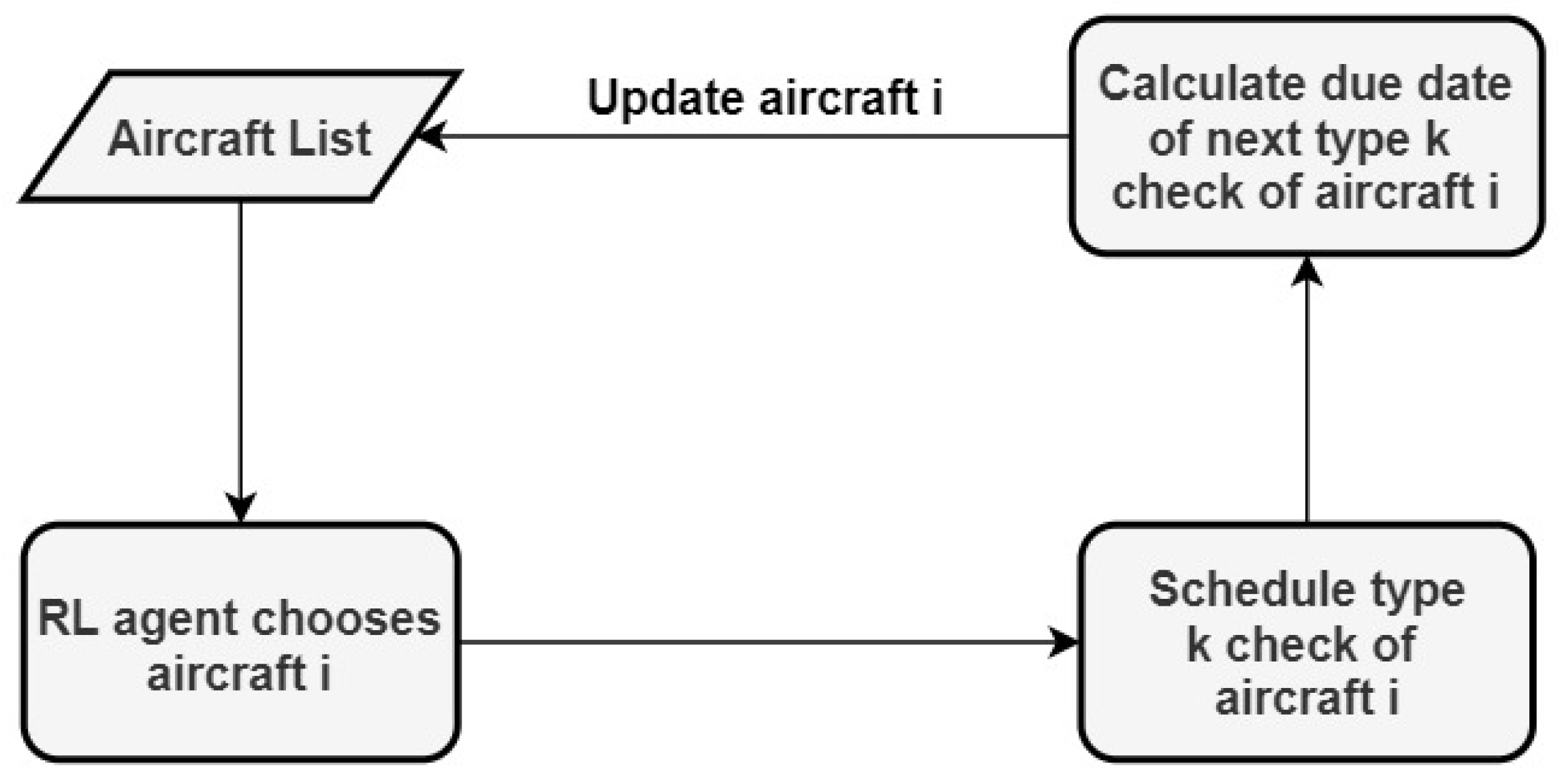
3.2. Decision Variable
The decision variable in this problem corresponds to selecting an aircraft to have its next check scheduled (giving priority to C-checks). At each step
j, the decision variable
can be defined with (
4), where
i is the chosen aircraft index.
3.3. State Variables
The state vector
includes a set of attributes that influence the decisions:
where each attribute contains information of aircraft
, on a specific day
, with respect to a check type
. These attributes are defined for each aircraft for the entire time horizon. It is important to note that only working days are considered, that is, days in which hangar maintenance can be performed.
is a binary variable to indicate if a type k check can be performed in hangar h on day t.
is the hangar capacity for type k checks on day t.
, , and correspond to the cumulative usages in DY, FH, and FC, respectively, of aircraft i on day t for a type k check.
, , and correspond to the tolerance used in the last type k check of aircraft i, with respect to the same three metrics.
is the next due date for type k check of aircraft i, that is, the day in which the respective interval is reached.
is the next due date for type k check of aircraft i using the tolerance.
is the ending day of the last type k check for aircraft i.
is the scheduled day of the next type k check for aircraft i
is a binary variable to indicate if aircraft i is grounded on day t performing a type k check.
is a binary variable to indicate if there is a type k check starting on day t for aircraft i.
is the duration (in working days) of the next type k check for aircraft i.
is the amount of FH lost in the last scheduled check of aircraft i.
There are also fixed attributes, such as check intervals and tolerances, aircraft average utilization, and others that are predefined by the airline, such as the minimum number of days between the start of two type k checks, and other constraint variables. All of these attributes are described in the Nomenclature section at the end of the document.
3.4. State Transition
The state transition defines a set of equations that determine how the state attributes evolve along each step. With every new action, an aircraft is selected and its next A/C-check is scheduled. Several conditions must be verified to choose the day in which to schedule the check. The first one is that there needs to be hangar availability during the entire duration of the check. We define the capacity for a particular hangar
h as:
This variable is used to calculate whether there is enough hangar availability for type
k checks on a specific day
t:
Finally, the hangar capacity for the entire duration of the check can be defined with:
where
t is the candidate day to schedule the check.
A second condition is related to the minimum number of days between the start dates of two consecutive type
k checks,
. We can use
to calculate the total number of checks starting in the range
, with
t being the candidate day to schedule the check. If this sum is equal to 0, then a type
k check for aircraft
i can be scheduled on day
t:
With Equations (
8) and (
9), it is possible to select the day in which to schedule the next
k check of aircraft
i, defined as
:
where
and
. By default, the use of tolerance should always be avoided in the planning phase. Therefore, the goal with Equation (
10) is to choose the maximum day possible, which is, the closest possible day to the check due date, so that we minimize the unused
FH of the aircraft. If the value of
obtained is equal to 0, then there are no possible days to schedule the check before the due date. This can happen when there is not enough hangar availability and/or the spacing rule between checks is not verified. In this case, the tolerance can be used and the check scheduled day is defined with (
11):
where
and
. Similarly, the goal is to choose a day as close as possible to the check due date, but this time, with the goal of reducing the amount of tolerance used.
Several attributes need to be updated after calculating the scheduled day for the next check of aircraft
i. The hangar capacity during the check is reduced since a new aircraft is now occupying a slot:
Attributes
, which indicates the check start days for aircraft
i, and
, which indicates the days in which aircraft
i is grounded, are updated with:
Now that a new type
k check is scheduled for aircraft
i, we can set
to the last day of this recently scheduled check:
The amount of
FH that is lost as a result of this scheduling, defined as
, can be computed with Equation (
16).
Subsequently, the cumulative utilization attributes of aircraft
i,
,
, and
, are set to 0 on day
. The duration of the next check,
, is updated according to a lookup table that contains the duration of future checks specified by the airline.
The last step in the state transition is to calculate the new due date for a type
k check. We start by updating the amount of tolerance used in the last type
k check, which must be deducted from the next interval:
where
and
correspond to the average daily utilization of aircraft
i estimated by the airline in
FH and
FC, respectively, and
. We also need to consider the number of days in which the aircraft is grounded and its utilization does not increase. For instance, the grounded days to perform the C-check do not count to compute the next A-check due date if a C-check is scheduled after the last A-check. We define the day in which the interval for the next type
k check is reached as
,
, and
, with respect to each usage metric, without yet considering the aircraft ground time:
where
,
, and
are the type
k check intervals in
DY,
FH, and
FC, respectively. Subsequently, the due date of the next type
k check is defined with:
This due date corresponds to the day in which the first usage interval is reached with the addition of the aircraft ground time since the last type k check.
The last attribute to update is the due date for the next
k check when the tolerance is used,
:
where
,
, and
are the maximum tolerances that are allowed for a type
k check, with respect to
DY,
FH, and
FC, respectively.
3.5. Problem Constraints
There are multiple constraints in this check scheduling problem and some of them were already defined in the previous subsections. One of the most important conditions in this problem is to guarantee that the aircraft usage conditions relative to each check type never exceed the maximum allowed. This maximum corresponds to the sum of the check interval with the fixed tolerance while deducting the amount of tolerance that is used in the last check. This constraint can be formulated for each usage metric with the following three equations:
It is also necessary to guarantee that the number of checks occurring in parallel in each day does not exceed the available number of hangar slots:
where
is a binary variable to indicate if aircraft
i is grounded on day
t performing a type
k check, and
is a binary variable to indicate if a type
k check can be performed in hangar
h on day
t.
Finally, we formulate the constraint relative to the minimum number of days between the start of two consecutive type
k checks:
where
is a binary variable to indicate whether there is a type
k check starting on day
for aircraft
i, and
is the minimum number of
DY between the start of two type
k checks.
3.6. Objective Function
Cost reduction is one of the main goals in aviation maintenance. In a long term maintenance scheduling problem, the best way to meet this goal is to minimize the unused
FH of the fleet. This results in a reduction of the number of checks scheduled in the long run, which can have a significant impact since each day out of operations has a great cost for the airline. At each step of the scheduling algorithm, we can calculate the cost of choosing action
on state
,
, with:
where
i is the selected aircraft,
is the unused
FH in the last scheduled check of aircraft
i, and
P is a penalty for using the tolerance.
The objective function corresponds to minimizing this cost and can be defined with Equation (
31), where
is the optimal scheduling policy function. This optimal scheduling policy consists of selecting the best action in any given state, which is, the action that yields a lower cost.
5. Results
This section presents the results that were obtained in both test cases. A set of Key Performance Indicators (KPI) is defined to evaluate the quality of the maintenance plan generated and it consists of:
the number of A and C-checks scheduled during the entire horizon,
the average FH used between two consecutive A and C-checks,
the number of A and C-checks scheduled using the tolerance, and
the number of A-checks merged into C-checks.
These KPIs are all relevant in evaluating the maintenance plan, since they can all influence maintenance costs, which airlines aim to minimize. Regarding the RL algorithm, one of the most important elements to evaluate the performance of the agent is the learning process. Therefore, the sum of rewards obtained by the agent at the end of each training episode is a good performance indicator.
5.1. Real Scenario
In order to evaluate the quality of the maintenance plan generated for the real scenario, a comparison to the work done in [
3] is performed, in which the authors developed a practical DP methodology to solve the same problem. The results are also compared with airline estimations for the period. However, the A-check metrics were not available for the airline, because they only plan A-checks for the next year.
Table 3 presents the comparison of the three approaches.
The results indicate an improvement of both the DP and the RL approaches over the airline in all of the KPI considered, meaning that both methods can generate a better maintenance plan much faster.
For the C-checks, the results show that the RL solution produces better results. The higher C-check average FH means that the average usage of the fleet in between two consecutive C-checks is higher, leading to two fewer checks scheduled in the time horizon. This outcome has great significance if we think that each C-check represents several days of ground time for an aircraft, without generating any profit. Regarding the A-checks, the results of the RL and DP solutions are very similar in both the total number of A-checks scheduled and in the average usage of the fleet.
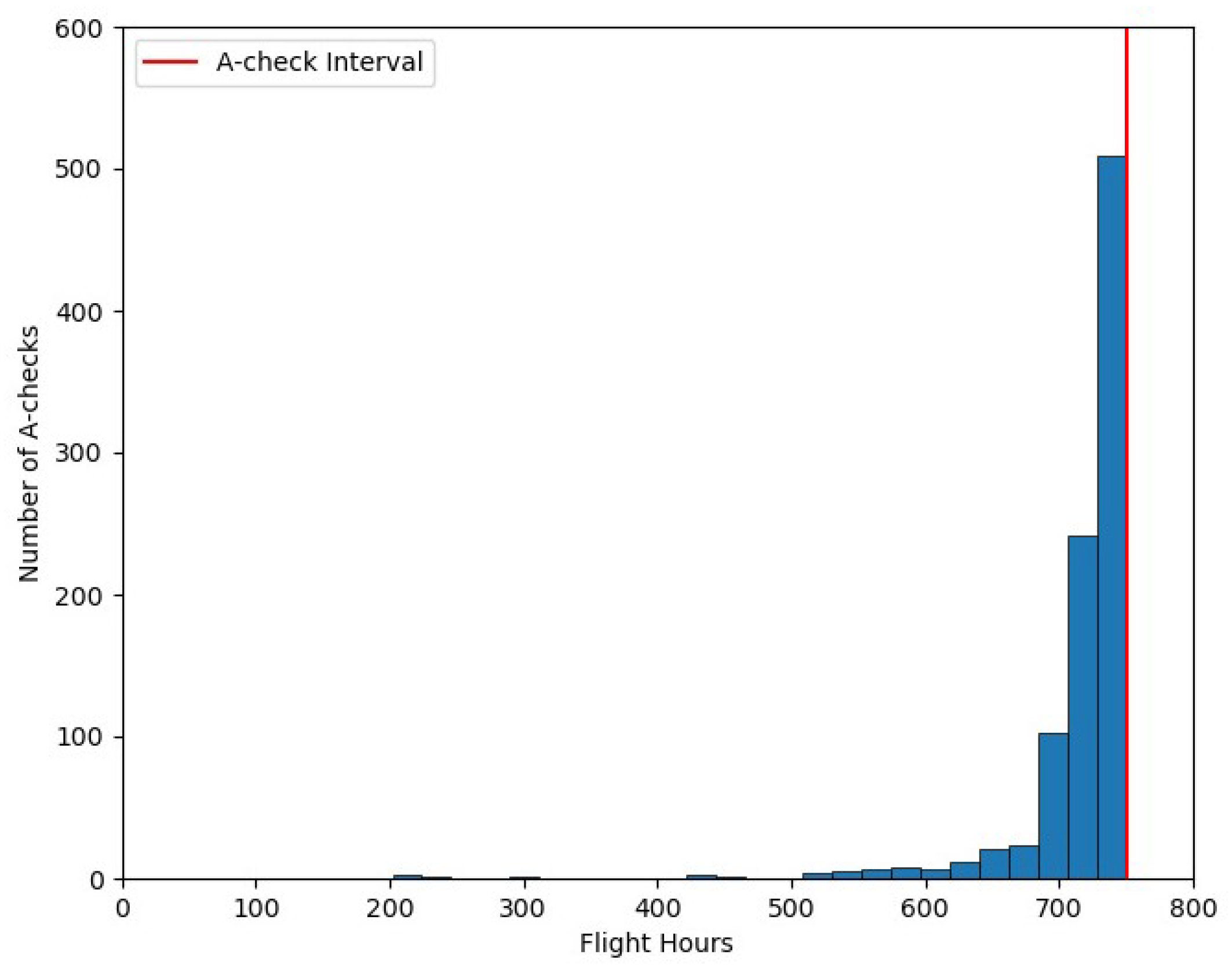
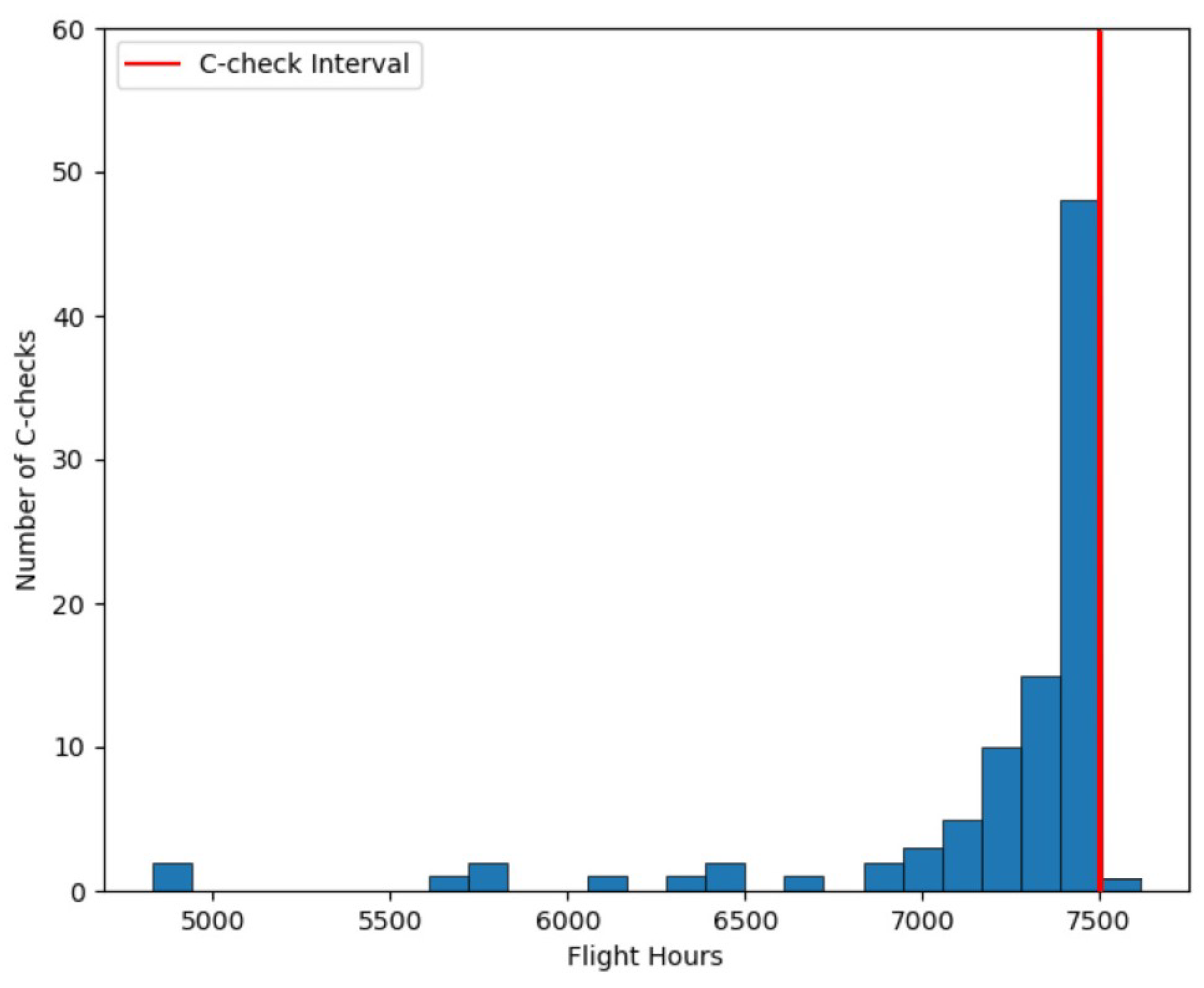
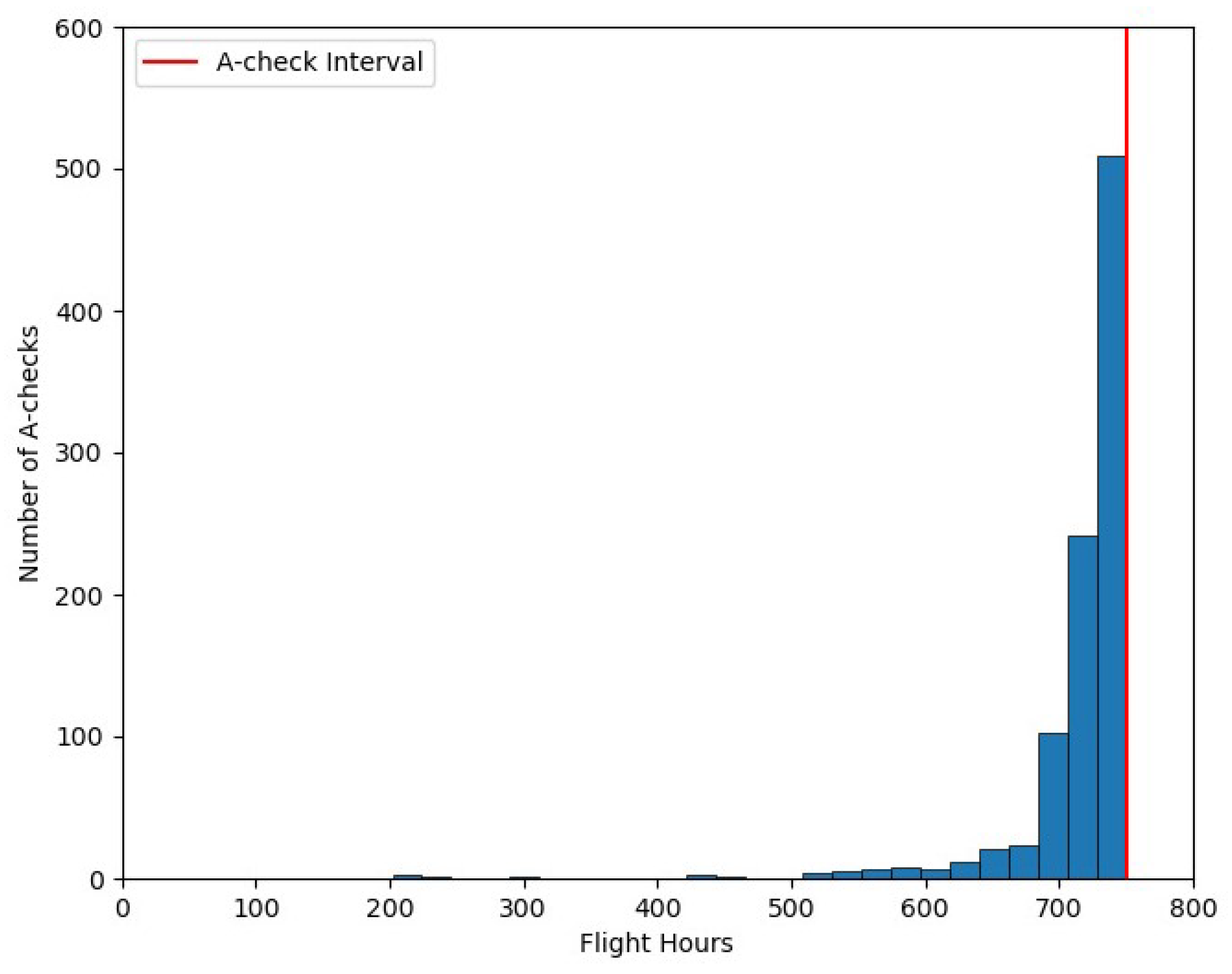
Figure 3 and
Figure 4 show the distribution of A and C-check usages for the entire fleet. As we can see, in the optimal maintenance plan generated by the RL solution, the majority of A and C-checks are scheduled close to their interval.
There are a few checks with lower utilization due to limitations in hangar maintenance at some periods. For instance, there are two C-checks with less than 5000 FH, which had their due date during the Christmas period. The C-check constraints during this period and the Summer season lead the algorithm to schedule them several months before their due date.
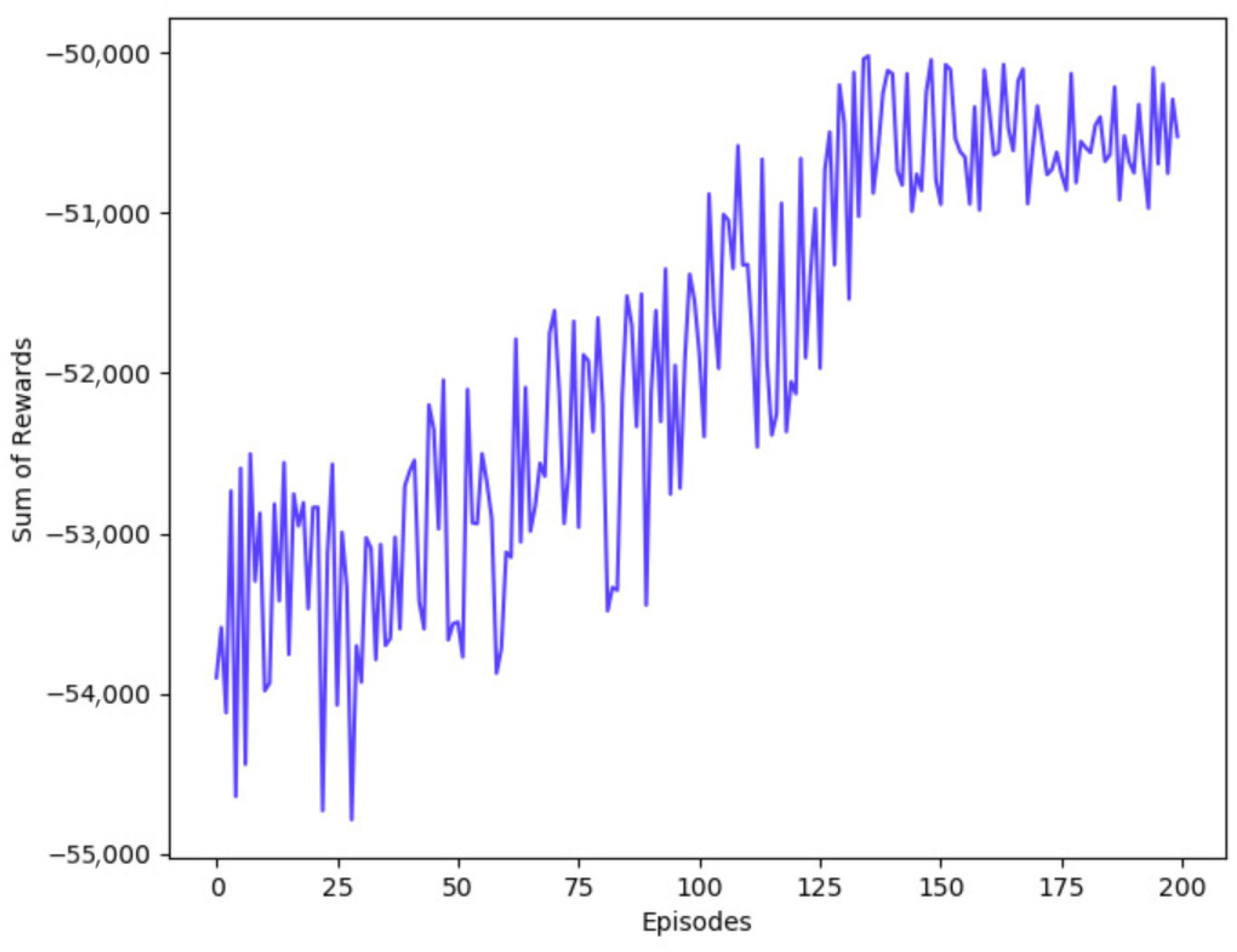
Figure 5 presents the sum of rewards that were obtained by the agent over each training episode. In the beginning, the lack of experiences collected by the agent, combined with higher exploration rates, results in lower rewards. Although, as the agent learns, the obtained rewards get higher over time, until it reaches convergence around episode 140.
5.2. Simulated Scenarios
In this stage, small disturbances were introduced in the initial fleet conditions to generate different maintenance scenarios. In particular, aircraft usages since their last A and C-check were randomized according to the three previously explained levels. The same RL algorithm is used to train a model with these simulated scenarios. The idea is to evaluate the ability of the RL solution in generating good maintenance plans when the fleet conditions change.
Table 4 presents the mean and standard deviation that were obtained for the set of scenarios used for testing, regarding the established KPIs.
If we analyze these results with the RL results for the real scenario, we see a decrease in the quality of the solution. This is more noticeable when scheduling C-checks due to the higher number of constraints. The decrease in quality is to be expected since the model is not specialized in a single scenario. Although, the average FH of the fleet for both A and C-checks remains close to the respective intervals. The low amount of tolerance events means that the use of tolerance when scheduling the checks is being avoided. Finally, the number of merged checks also remains consistent. Overall, it is safe to say that the RL solution can produce quality maintenance plans for different fleet scenarios.
An advantage of RL over other traditional approaches in solving this type of problem is the computation time for generating a solution after the model is trained. In this case, the training of the model lasted close to 20 h. After that, a new solution could be only be obtained in a few seconds. A fast planning tool can add significant value in such a high uncertainty environment in dealing with operation disruptions or other unexpected events. Furthermore, the agent can continue to learn and improve the maintenance plans that are produced over time.
6. Conclusions
This paper proposed a reinforcement learning solution to optimize the long-term scheduling of A and C-checks for an aircraft fleet. The goal was to maximize the FH usage between checks, which allows for an increase in aircraft availability in the long run. The proposed approach uses a Deep Q-learning algorithm with experience replay and the Double Q-learning variant. At each decision step, the RL agent selects an aircraft to have its next check scheduled on the best available day, prioritizing the scheduling of C-checks.
This approach is evaluated in a real scenario using data from a fleet of 45 aircraft from three sub-fleets (A319, A320, and A321). A comparison with airline estimations for the same period shows that the RL solution produces more efficient maintenance plans. The higher fleet usage for both A and C-checks results in a lower amount of checks being scheduled during the entire time horizon, which has significant financial benefits for the airline. The RL results are also promising when compared to the DP approach, achieving better results in the C-check scheduling.
A second test case is defined to evaluate the ability of RL in dealing with different initial conditions of the fleet. Multiple scenarios are simulated by introducing disturbances in the initial usage metrics of each aircraft. These scenarios are used to train the RL agent with different fleet conditions. The results obtained with several testing scenarios show that this approach can generate quality maintenance plans in a short amount of time.
There are not many studies regarding long-term maintenance problems in aviation despite its great relevance, which encourages future research on this topic. A potential opportunity is to extend the check scheduling algorithm by defining the set of maintenance tasks to be performed in each one of them. This task allocation problem would produce an optimal maintenance plan with a combination of maintenance checks and tasks.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}