1. Introduction
In flight control, the problem of finite-horizon optimization for pitching attitude tracking control of aircraft can be treated as the pitching attitude tracking the command signal with the desired finite-horizon optimal index. To resolve the above problem, both the tracking control and finite-horizon optimization should be taken into consideration, which makes the overall problem significantly difficult.
In order to achieve attitude tracking for aircraft, much research has been conducted. In [
1], an adaptive second order sliding model control method was presented in order to improve the performance in the presence of external disturbances. In [
2], a gain-scheduling control method was proposed for linear parameter-varying systems with multi-input multi-output in order to obtain a satisfactory performance in the bank-to-turn control of aircraft. In [
3], nonlinear dynamic inversion technology was proposed for the design of a supermaneuverable aircraft control. In [
4], backstepping control was employed to execute the attitude tracking control of a mini unmanned aerial vehicle.
Among the control methods above, the backstepping control scheme is widely used owing to some advantages. First, virtual control is designed separately for each subsystem in the process of backstepping control to reduce the complexity of high-order system control. Subsequently, the backstepping control can be combined with other control methods such as sliding mode control, NN, adaptive control method, and disturbance observer to improve the control performance. In [
5], a robust backstepping control scheme combining sliding mode control and neural network (NN) was proposed to achieve the reentry attitude tracking control of a near-space hypersonic vehicle in the presence of parameter variations and external disturbances. In [
6], a deep convolutional NN-based backstepping method was used to identify system uncertainties and hidden states in attitude control in order to enhance the robustness. In [
7], an auxiliary system-based backstepping control was constructed for the aircraft subject to the input saturation problem caused by wing rock. In [
8], a finite-time convergence backstepping control scheme was designed. In the scheme, a finite-time observer and finite-time auxiliary system were used to suppress the effects of unsteady aerodynamic disturbances and compensate for the effect of input saturation, respectively. However, the aforementioned attitude control methods do not take into account the optimal control that meets some desired index. Actually, the optimal control problem is intractable, especially for a nonlinear system. Hence, there is relatively little research on the attitude control of aircraft in an optimal way, which is a nonlinear optimization problem in nature, not to mention the finite-horizon optimization for attitude tracking control. Thus, how to control the aircraft attitude in an optimal way should be further studied.
Quadratic optimal control is an optimal control method applied earlier in flight control. A given quadratic index is used to control the system with a desired optimal performance. In [
9], a nonlinear system was divided into two parts of a linear nominal system and compound disturbances. Then, a linear quadratic regulator was designed to control the linear nominal system, while a robust control was derived to compensate for the effects caused by compound disturbances. In order to cope with the problem of recovering open-loop singular values in the quadratic optimal control, the LQG/LTR technique was applied for a multivariable vertical short take-off and landing aircraft linear system in [
10]. However, the above control methods can only be applied to linear systems. For a nonlinear system, Hamilton–Jacobi–Bellman (HJB) equations without analytical solutions need to be solved, which makes it intractable to execute optimal control.
To cope with the problem of solving HJB equations for a nonlinear system, some numerical methods were applied to approximate the solution. In [
11], a dynamic programming algorithm was presented, which is supposed to be solved in an off-line manner. In [
12], a recursive optimization approach was proposed for a nonlinear system. In [
13], a state-dependent Riccati equation (SDRE) method, which used a parameterization technique to convert the nonlinear system into a linear structure with state-dependent coefficients, was proposed to deal with the problem of nonlinear optimization. Nevertheless, a heavy computational burden is the main obstacle to applying the above three methods to nonlinear optimization. Inspired by the dynamic programming algorithm, the ADP algorithm was proposed in [
14]. Compared with the dynamic programming algorithm, a critic NN was constructed to approximate the value function in order to solve the HJB equation forward-in-time in the ADP algorithm. Thus, the heavy computational burden was avoided, and on-line optimization was achieved.
The ADP algorithm, characterized by strong abilities of self-learning and adaptivity, has received significantly increased attention and has become an important intelligent optimal control method for nonlinear systems [
15]. Due to its advantage of a low calculation cost, ADP has been applied in flight control. In [
16], an adaptive critic design (ACD)-based optimal control algorithm was proposed. Under the premise of ensuring system stability, the ACD algorithm was utilized to improve the control performance of the system. In [
17], a constrained ADP approach and linear parameter-varying technique were employed to guarantee the closed-loop stability and excellent control performance of the flight with aerodynamic parameter uncertainties and actuator failures. In [
18], an incremental ADP algorithm was proposed to control the attitude tracking of spacecraft. In [
19], an integral sliding-mode control based adaptive actor–critic algorithm was developed to guarantee the optimal control for sliding-mode dynamics online. As discussed above, the backstepping control method is favored by researchers due to its advantages. Because of its feature of easy combination with other control methods, the backstepping-based ADP scheme has been applied in many works. In [
20], a backstepping-based ADP algorithm was developed to solve the problem of missile-target interception with state and input constraints. In the scheme of backstepping, a barrier Lyapunov function was used in the virtual controller design process for each subsystem to guarantee the state constraints, and an auxiliary system was designed to compensate for the constrained input. In [
21], a backstepping-based ADP algorithm with zero-sum differential game method was applied to the zero-sum game problem for a missile and target. The zero-sum differential game technique was applied in the scheme of ADP algorithm in order to control the missile and target in an optimal way, and a critic network was constructed to approximate the value function in Hamilton–Jacobi–Isaacs (HJI) in order to achieve optimization online. In [
22], an NN-based optimal control scheme was proposed for the near-space vehicle attitude tracking control. In the scheme, the NN and NDO were designed in a backstepping scheme to approximate the system uncertainties and external disturbances, while the critic network was constructed to approximate the value function in the HJB equation. However, it should be noted that the developments of the ADP algorithm above mainly address only the problem of infinite-horizon optimization. In fact, it is required to control in a finite-horizon optimal way for many systems, especially for flight systems.
Compared with infinite-horizon optimal control, finite-horizon optimal control is considered to be more challenging. First, the value function of the finite-horizon optimal control system is time-to-go-dependent, which leads to a time-varying associated HJB equation. Hence, it is more difficult to solve the HJB equation. Second, the terminal constraint should be taken into account for infinite-horizon optimization [
23]. For the purpose of addressing the issues above, some research has been conducted. In [
24], time-dependent weights and state-dependent feature functions were incorporated to construct an NN in order to approximate the time-to-go-dependent value function, and the least-square-based gradient descent method was utilized to update the weights off-line. In contrast, an NN consisting of constant weights and time-state-dependent feature functions was designed to achieve the approximation of the value function in the HJB function online in [
25]. Nevertheless, the constrained input and system uncertainties were not taken into account. Considering input constraints, a non-quadratic function was utilized to eliminate the input constraints in [
26]. Regarding system uncertainties, an online NN identifier was designed to approximate system uncertainties, and an actor–critic algorithm was introduced to solve the HJB equation to guarantee that the system was controlled with the optimal index in finite-horizon in [
27]. Unfortunately, most of the research considered discrete systems. Furthermore, the constrained input, system uncertainties, and external disturbances are not considered in the finite-horizon optimal control together, which limits its application in flight control.
In order to address the problem of finite-horizon optimization pitching attitude tracking with system uncertainties, external disturbances, and input constraints, a novel backstepping-based finite-horizon optimization is developed in this work. The backstepping scheme, in which NN and NDO are employed to estimate the value of system uncertainties and external disturbances and an auxiliary system is designed to compensate for the constrainted input, is introduced to ensure the stability of systems. The ADP algorithm with a critic NN that consists of constant weights and time-state-dependent feature functions is employed to obtain finite-horizon optimal control. A novel updating law of the critic NN weights is derived to solve the HJB equation and minimize the terminal constraints. Furthermore, the Lyapunov stability method is applied to prove that the signals in the control system are UUB. Finally, simulation results illustrate the effectiveness of the proposed control scheme.
The main contributions of this paper include the following:
- (1)
A backstepping-based ADP scheme is used to achieve finite-horizon optimal control. In the backstepping control scheme, NN is applied to approximate system uncertainties, while NDO is employed to estimate external disturbances. The ADP is used to control the nominal system in a finite-horizon optimal manner. Due to the integration of the backstepping method and the advantages of ADP, the backstepping-based finite-horizon optimization ADP scheme is promising for pitching attitude tracking control.
- (2)
A novel updating law of the critic NN weights is derived in order to satisfy the terminal constraints, relaxing the requirement of an initial admissible control and guarantee the stability of system.
The rest of the paper is organized as follows.
Section 2 formally states the preliminaries of the research object of this paper. The desigsn for backstepping control and finite-horizon optimal control are given in
Section 3 and
Section 4, respectively. Then, the stability analysis is developed in
Section 5. The simulation results are presented in
Section 6. Finally, the conclusions of the paper are given in the last section.
Notations. Throughout the paper, stands for the set of all real matrices. stands for the gradient of f with respect to x such as . stands for the sign function.
4. Design for Finite-Horizon Optimal Control
In this section, an ADP based finite-horizon optimal control method is designed to make the nominal system (
43) controlled in a finite-horizon optimal manner. In order to approximate the value function in the HJB equation, an NN consisting of constant weights and a time-state-dependent feature function is constructed. A novel weight updating law is proposed in order to minimize the objective function, remove the requirement for the initial admissible control, and guarantee the Lyapunov stability.
The objective of the finite-horizon optimal control is to maximize the finite-horizon cost function defined as
where
is the terminal constraint of the terminal state
.
is the cost-to-go function defined as
where
,
are symmetric positive matrices.
Similarly, the terminal cost function is defined as
Considering Equation (
50), the Hamiltonian function of the nominal system (
43) is given as
Then, the optimal cost function
satisfies the equation as [
20]
According to Equation (
54), the optimal control input
meets the conditions as
Hence, the optimal control input
can be obtained as
Invoking Equation (
56) into (
53) and considering (
54) yields
We rewrite the optimal cost function
by NN as
where
is the basis functions vector,
L is the number of the basis functions.
is the weights vector.
is the approximate error.
Similarly, the terminal optimal cost function
can be written as
The gradients of
with respect to
t and
Z are
Assumption 5 ([
20,
22,
25,
26,
29,
30]).
, , , , , , and are all bounded such as , , , , , , .Invoking Equation (61) into (56) yields Invoking Equations (60)–(62) into (57) yieldswhere Lemma 1 ([
31]).
For nominal system (43), it is asymptotically stable under the control aswhere . Assumption 6. and are both bounded as and .
Since is unknown, a critic NN is constructed to approximate the optimal cost function aswhere is the estimation of . We define the estimation error Invoking Equation (67), the gradients of the optimal cost function with respect to t and Z can be approximated as Invoking Equations (56) and (70), the estimation of the optimal control input can be written aswhere . Similar to Equation (57), the estimation of the Hamiltonian function can be expressed as Then, the optimal terminal cost function can be estimated aswhere is the estimation of [25,26,32]. We define the terminal constraints estimation error as Invoking Equations (72) and (74), a total squared error is defined as Prior to designing the weight updating law for the critic NN, an assumption is given.
Assumption 7. Considering system (43) with the optimal control input (56), we can always find a Lyapunov function that satisfies . Furthermore, there is always a positive function that satisfies the following inequality. In order to minimize the total squared error (75), a novel weight updating law based on the gradient descent theory is developed aswhere is the parameter to be designed. is designed in Remark 4. , are the vector and matrix to be designed, respectively. , , , are expressed as , , , , where and are written as
Φ
is given as Remark 3. Considering the optimal approximation property of the NN, Assumption 5 is reasonable. In addition, the optimal control can be obtained when in Equation (66). Taking Lemma 1 into account, can stabilize the nominal system (43); that is, is bounded. Simultaneously, considering Assumptions 1 and 5, Assumption 6 is reasonable. Taking Remark 3 into consideration, the optimal control input can stabilize the nominal system (43). Hence, we can always find a Lyapunov function where the derivative of with respect to t is negative and bounded. In general, can be designed as . Thus, Assumption 7 is reasonable. Remark 4. According to the expression of , and , we have that , and are bounded as , , , respectively.
Remark 5. The first and second terms in Equation (77) are employed to minimize the total squared error based on gradient descent theory. Moreover, the third term is used to enhance the stabilizing ability of the controller. In more detail, according to Equation (80), the third term disappears when , which can be treated as a stability characteristic of the system, while the third term is activated to reinforce the stability of the system when the stability characteristic is gone. Thus, the requirement of an initial admissible control is avoided. In addition, the fourth term is designed for the UUB stability of the system in the subsequent process of the proof. 6. Simulation Results
In this section, the simulation of the pitching attitude tracking of the aircraft controlled by the backstepping finite-horizon optimal control is described to illustrate the effectiveness of the proposed scheme. The parameters of the aircraft model and the designed control system are given in
Table 2 and
Table 3, respectively. The finite-horizon is selected as
. The terminal constraint is chosen as
. The basis functions are designed as
and
. The objective of the designed control law is to obtain an optimized performance in the finite-horizon
under the guarantee of basic tracking ability.
In order to simulate system uncertainties
,
, aerodynamic parameter variations are set to 1.1 times the nominal value. The disturbances are given as
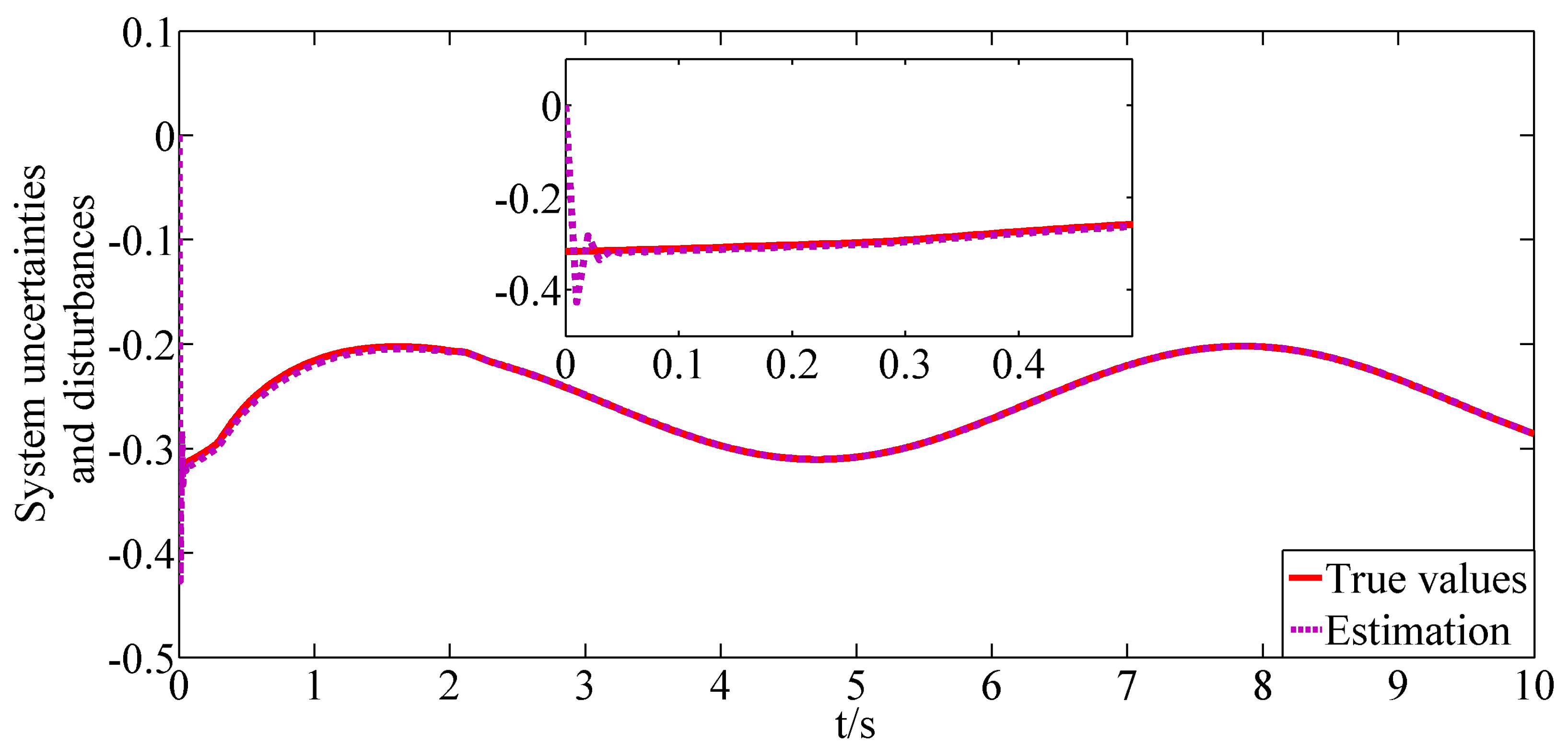
. NN and NDO are designed as the estimators of the system uncertainties and external disturbances, respectively. In order to illustrate the effectiveness of the NN and NDO, the estimations of the sums of
,
and
,
are shown as
Figure 2 and
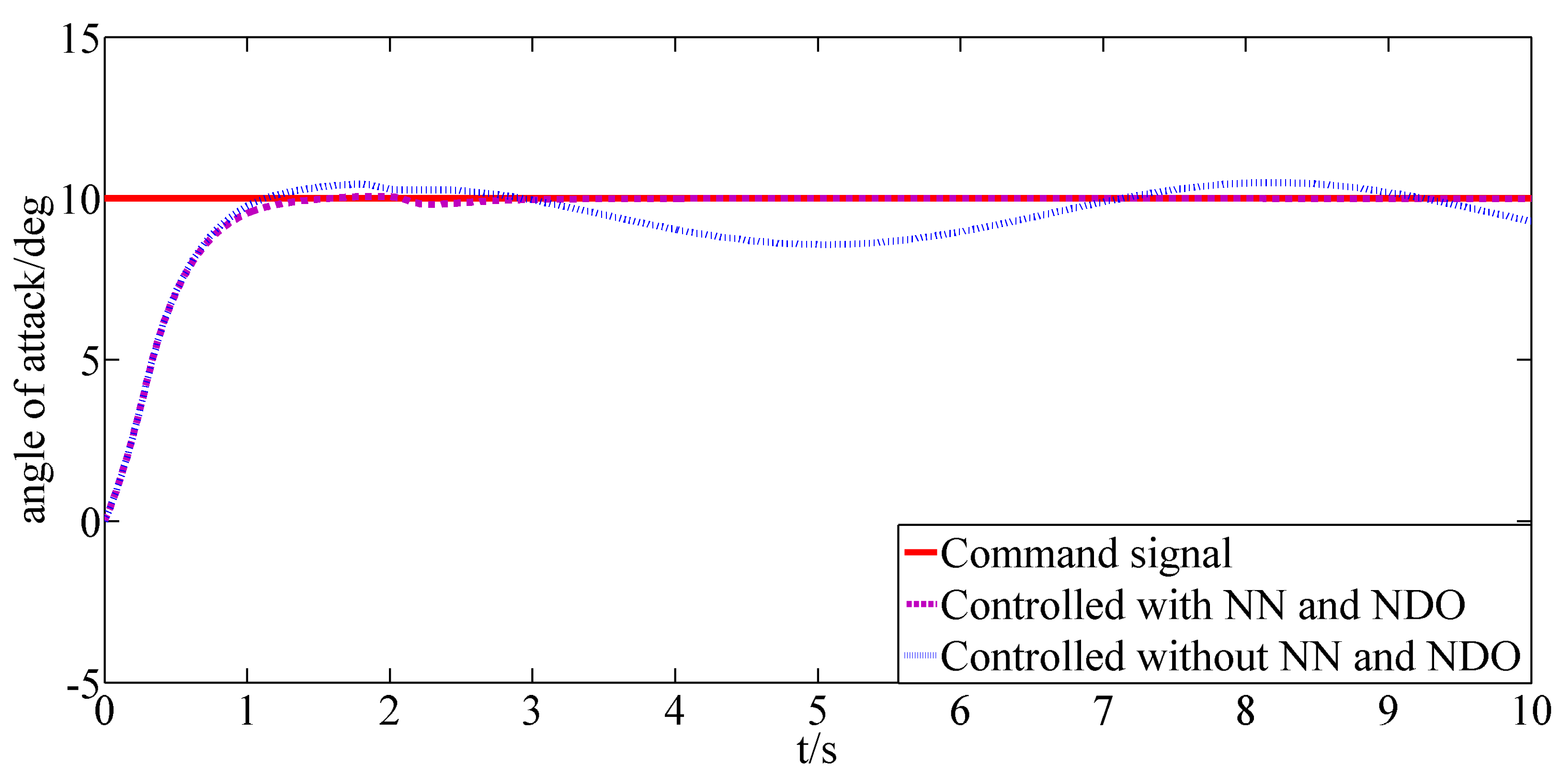
Figure 3, respectively. In addition, the comparison of the response of the angle of attack controlled with and without the designed estimators are shown in
Figure 4. As shown in
Figure 2 and
Figure 3, the system uncertainties and external disturbances can be estimated accurately and quickly under the utility of NN and NDO. From
Figure 4, it can be depicted that owing to the designed estimators, the adverse effects caused by the system uncertainties and external disturbances are greatly reduced so that the angle of attack can track the command signal more precisely.
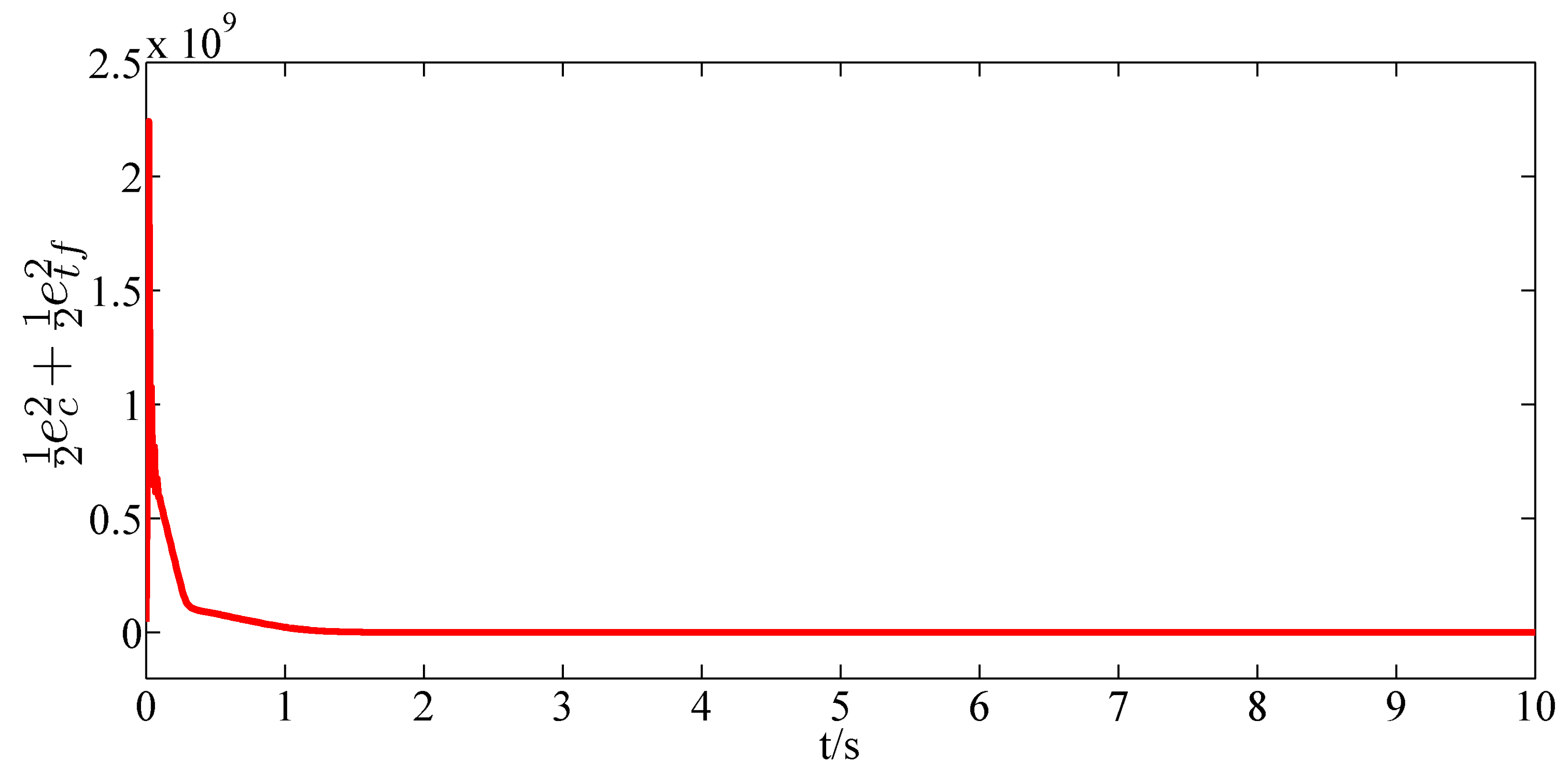
In order to achieve the finite-horizon optimal control, the ADP algorithm is applied. The objective function is given as
in Equation (
75). The objective of the ADP algorithm is to minimize the objective function. For the purpose of illustrating the effectiveness of the designed ADP algorithm, the response of
is shown in
Figure 5. It can be observed that
gradually decreases and eventually converges to zero. Hence, the designed ADP algorithm is efficient.
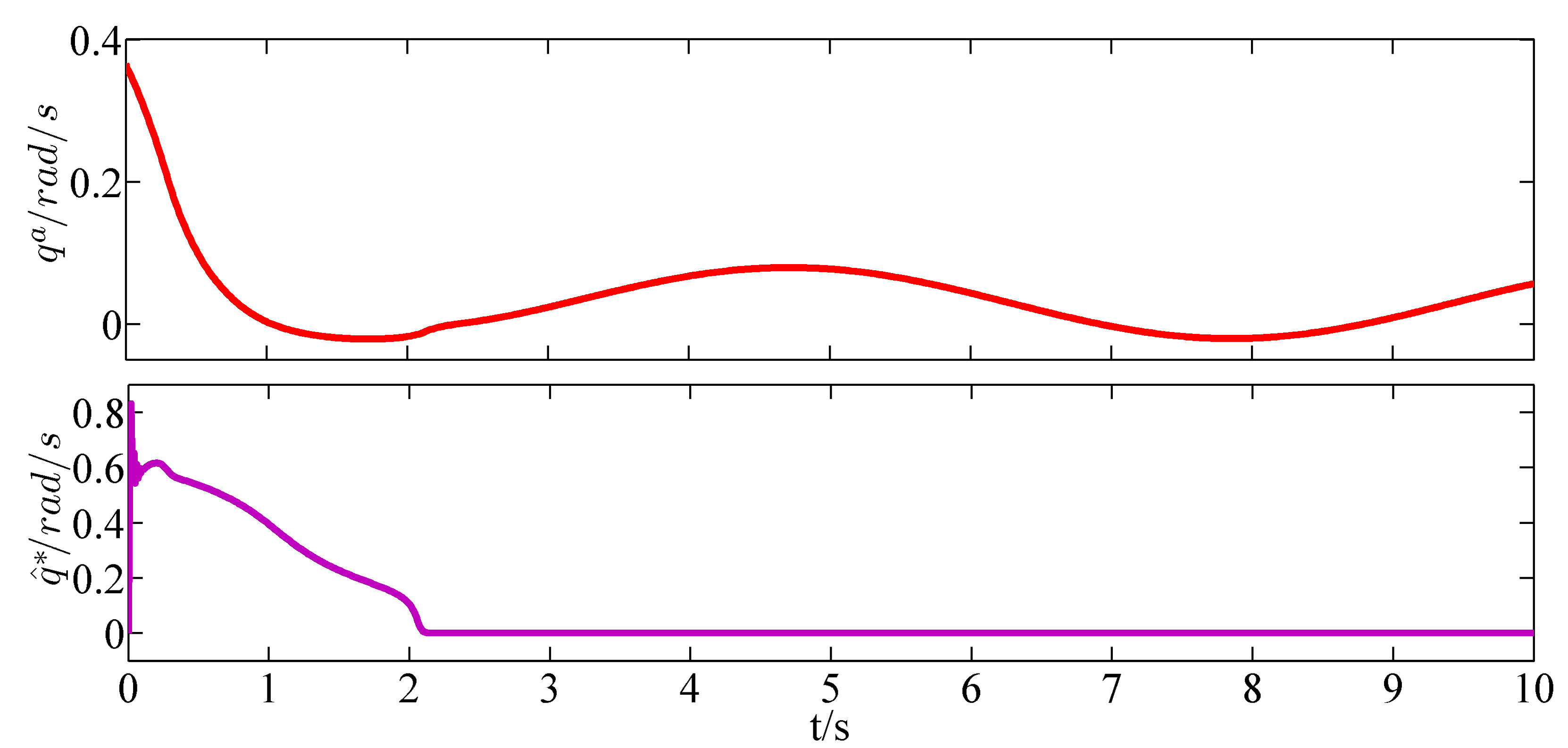
The virtual control inputs
defined in Equation (
26), the control inputs
defined in Equation (
36), and
and
defined in Equation (
71) are shown in
Figure 6 and
Figure 7, respectively. Under the action of the backstepping based finite-horizon optimal control inputs, the response of the angle of attack is shown in
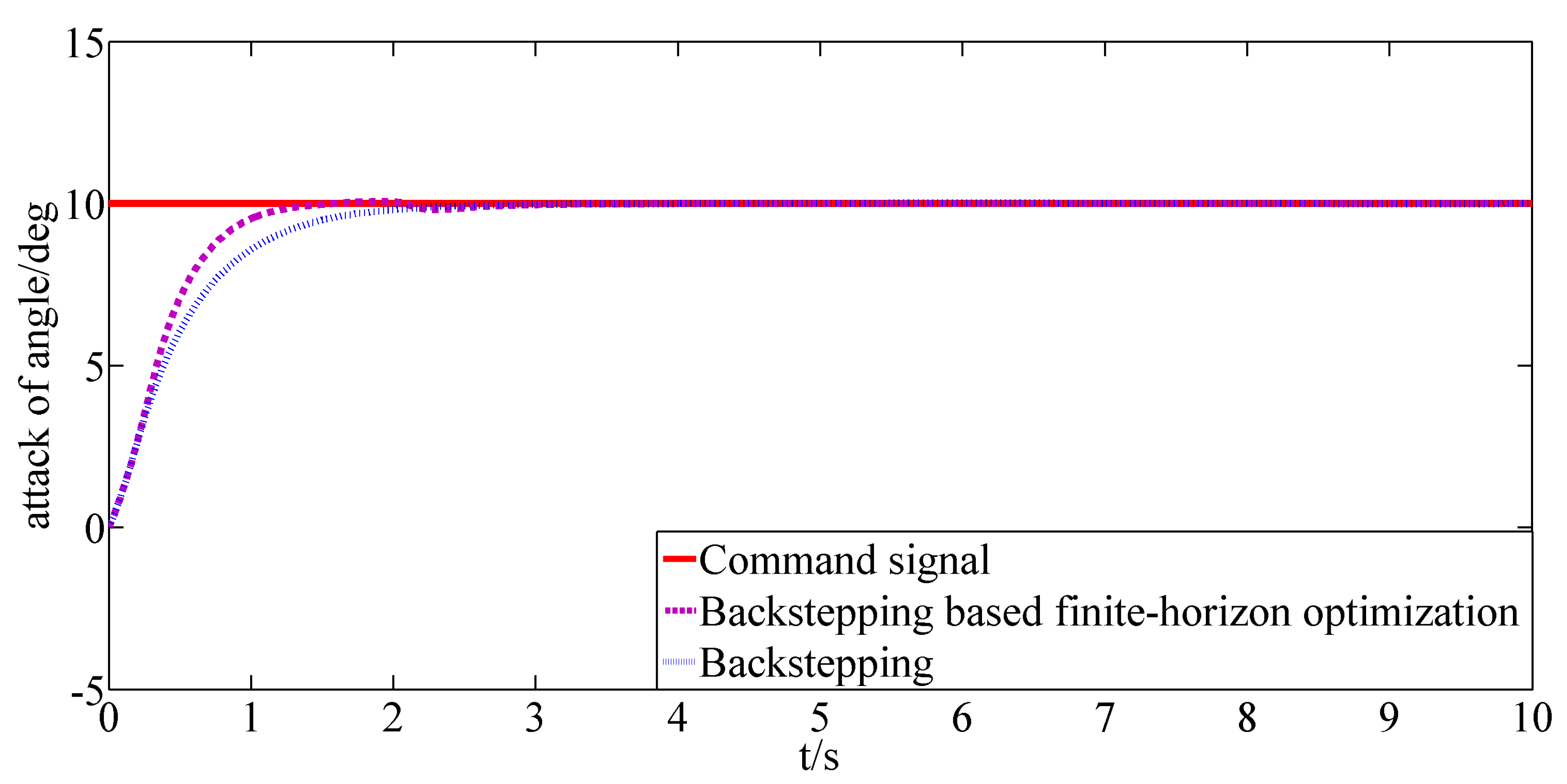
Figure 8. Furthermore, the response of the angle of attack controlled by the backstepping method with the same parameters is given in
Figure 8 as a contrast. It can be illustrated that the system controlled by the designed backstepping based finite-horizon optimal control method can evolve in a finite-horizon optimal way. Thus, the conclusion can be drawn that a better performance can be obtained under the control of the backstepping-based finite-horizon optimal control method.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}