1. Introduction
Object tracking is a fundamental task in image processing with many applications in fields like robotics, autonomous vehicles, surveillance, and human–computer interaction. The goal of object tracking is to identify and monitor the position of a target in a sequence of video frames, despite the difficulties generated by occlusions, different types of variabilities and variances, illumination changes, weak contrast, motion blur, and background clutter.
In several types of unmanned aerial vehicle (UAV) guidance, object tracking is a primary requirement of the algorithm [
1,
2]. Primarily, guidance is the process of controlling the trajectory, or the path of a UAV, to a given point (the goal) based on several constraints, such as the shortest route, obstacle avoidance, and consumption optimization, among others. One of the primary goals of the various autopilots (PX4, ArduPilot, or INAV) is to guide the UAV along a predefined trajectory, based on GPS information [
3,
4]. Furthermore, various UAV systems employ alternative guidance systems that facilitate target tracking [
5,
6] to enable (1) maneuvering within a defined formation for multiple UAVs, (2) following and intercepting a moving system, or (3) avoiding potential collisions.
The most used and effective guidance laws for different UAV systems, designed to track a target, are the pure pursuit guidance law and the proportional navigation guidance law [
2,
6,
7].
In the pure pursuit (PP) guidance law [
2], the velocity vector of the follower UAV always heads to a point on the trajectory of the target (named lookahead point) that is ahead of the current position of the target but on the vehicle’s path or even in the line with the actual target position. Therefore, the direction of the velocity vector must be in line of sight (LOS) between the follower (the tracker) system and the lookahead point. The LOS is the direct line between the tracker and the target.
The guidance systems based on the proportional navigation law have several implementations [
2,
7], including pure proportional navigation (PPN), true proportional navigation (TPN), augmented proportional navigation (APN), optimal guidance law (OGL) or proportional navigation with optimal gain—to name only the most important proportional navigation laws.
There are several methods used in UAV detection based on [
8,
9]: (a) thermal detection, (b) the scanning and detection of radio frequency signals, (c) radars, (d) optical cameras, (e) acoustic signal detection, and (f) hybrid methods that use a combination of these methods.
Thermal UAV detection is based on the heat generated by different components placed on the UAV [
8,
9]. Especially motors, as well as components such as batteries, internal processors, or other internal electrical or electronic devices generate heat. In more complex approaches, even panoramic thermal image sensors are used [
10].
Each UAV system exchanges information through different radio frequency (RF) channels [
8,
9,
11]. The RF connections between the UAV and the ground control (remote control signals, video links, telemetry information, etc.) represent one of the vulnerabilities of these systems that can be exploited for their detection. However, detecting UAVs through the RF-generated signals is considered a complex operation because, in general, the different working bands of UAV systems are crowded with noise and other signal sources that generate many signals. To address this issue, [
11] proposes a hierarchical approach that utilizes four classification systems, operating under an ensemble concept. By following this approach, the developed system can detect even the flight mode of the UAV, including hovering and flying.
Despite being the most expensive method of UAV detection, radar systems are used for this purpose [
8,
9], even though these have small radar cross-sections (RCS) and, as a direct result, are difficult to detect [
12]. Analyzing three types of radars, based on experimental and theoretical results, it was demonstrated that Frequency-Modulated Continuous-Wave (FMCW) radars are the most suitable for detecting and tracking small RCS targets, such as UAVs [
12].
The utilization of the audio signal generated by the motors of a UAV constitutes an alternative method cited in the literature [
8,
9] for detecting a UAV. The main disadvantage of this method is its minimal detection range. Furthermore, accurately determining the distance to the drone and identifying the direction from which the sound emanates pose two additional significant challenges to a precise estimation of the 3D position [
8]. The literature examines the detection of UAVs based on acoustic signals through two methodologies [
13]: (a) a one-dimensional analysis focusing on the magnitude or phase of the sound sources, and (b) a two-dimensional analysis examining the spectrogram of the acoustic signals. Using the second approach and a custom deep neural network with 10 layers, the researchers from [
13] achieved a 97% accuracy with an error rate of 0.05, maintaining a distance of 3 m between the drone and the microphones. However, the paper notes that the most significant factor limiting accuracy is the distance between the drone and the microphones.
The final method, which involves the detection and tracking of UAVs, utilizes an optical camera. This approach was adopted during this research.
Using an image or several images, traditional object detection and tracking approaches include (a) template matching-based methods [
14]; (b) feature extraction, such as a histogram of oriented gradients (HOG) followed by a classical classification algorithm (ensemble learners trained with the AdaBoost algorithm) [
15,
16]; (c) Haar features [
16]; (d) knowledge-based methods [
14]; (e) optical flow [
17]; (f) a clustering algorithm and a Support Vector Machine (SVM) classifier [
18]; and (g) object-based image analysis (OBIA) for object detection [
14]. These classical approaches have demonstrated effective outcomes in constrained environments; however, they encounter significant challenges when applied to complex real environments.
Recent advancements in deep learning, especially in convolutional neural networks (CNNs) and transformer-based architectures, have significantly improved detection accuracy. Deep neural network (DNN) object detection algorithms are divided into two main classes: (1) one-stage (e.g., You Only Look Once (YOLO) [
19,
20], SSD [
21], RetinaNet [
22], DETR [
23,
24]), and (2) two-stage (e.g., R-CNN [
25], Faster R-CNN [
26], SPP-Net [
27], Feature Pyramid Network (FPN) [
28]).
The accuracy of DNN systems has been improved through various approaches.
In the first approach, different research teams have proposed different and novel conceptual strategies for object detection. This has led to the emergence of new architectures, such as SSD [
21], DETR [
23], or YOLO [
29]. For instance, for the first time, YOLO treats the detection as a single step in a unified detection paradigm [
29]. In another architecture, DETR treats object detection as a prediction problem that enforces unique predictions through a bipartite matching strategy [
23].
In the second approach, the existing architectures were continuously refined and improved to achieve superior performance. This is the case with the YOLO architecture, which, since its launch in 2016, YOLOv1 [
29], has undergone numerous variants, reaching YOLOv12 in 2025 [
30]. In this area, progress has continued to advance even further. Starting with an architecture like YOLOv5, as described in [
31], modifications are introduced by adding an ESTDL (Efficient Small Target Detection Layer) and a new bottleneck structure (MLCSP) to enhance feature representation. Ultimately, a new detection algorithm, YOLO-LSM, has emerged as a lightweight UAV target detection algorithm [
31]. In another study [
32], the framework YOLO-DCTI is proposed for the remote sensing of small or tiny object detection, such as UAVs. YOLO-DCTI is based on YOLOv7 and a new improved Context Transformer (CoT-I) block.
In the third approach, in addition to the main detection algorithm, other algorithms are employed to enhance detection performance. For instance, in [
33], a YOLOv5 algorithm enhanced with time-domain information, acquired through a Kalman filter, demonstrated improved detection performance.
This paper addresses the following question: How can a deep neural network tracking algorithm (powerful but with high computational requirements) be optimized and improved to meet the conflicting requirements of working in real-time in an embedded unit while enhancing detection performance and maintaining its computational efficiency?
The hypothesis examined in this study proposes that the above question can be positively addressed through the incorporation of a deep neural network (DNN)-based detection mechanism within a synergistic algorithmic framework. This framework is optimized for embedded hardware environments and supported by DPU and CPU units. Consequently, improved real-time drone tracking performance can be achieved despite computational constraints, while simultaneously promoting the development of a versatile open-source unmanned aerial system (UAS) platform.
The novel algorithm presented in this paper is based on a similar approach to the one presented above [
33]. The novel object tracking framework addresses the challenge of missed detection. The new algorithm is based on a DNN-type neural network, specifically a YOLO-type network, and its performance is enhanced by utilizing spatial correlation information (provided by a correlation tracking algorithm) along with temporal information provided by a Kalman filter. Ultimately, this approach yields superior detection results. The methodology was evaluated using a publicly accessible dataset collected during this research, demonstrating its effectiveness compared to existing techniques.
The remainder of this paper is organized as follows:
Section 2 presents the materials and methods employed in this research, including the UAV system that supports the algorithm, the database used, and the algorithms utilized. In
Section 3, the results obtained are discussed, encompassing both hardware and software components.
Section 4 examines the results and discusses their presentation in the context of prior studies. The final section concludes the paper.
2. Materials and Methods
2.1. The UAV Ssystem
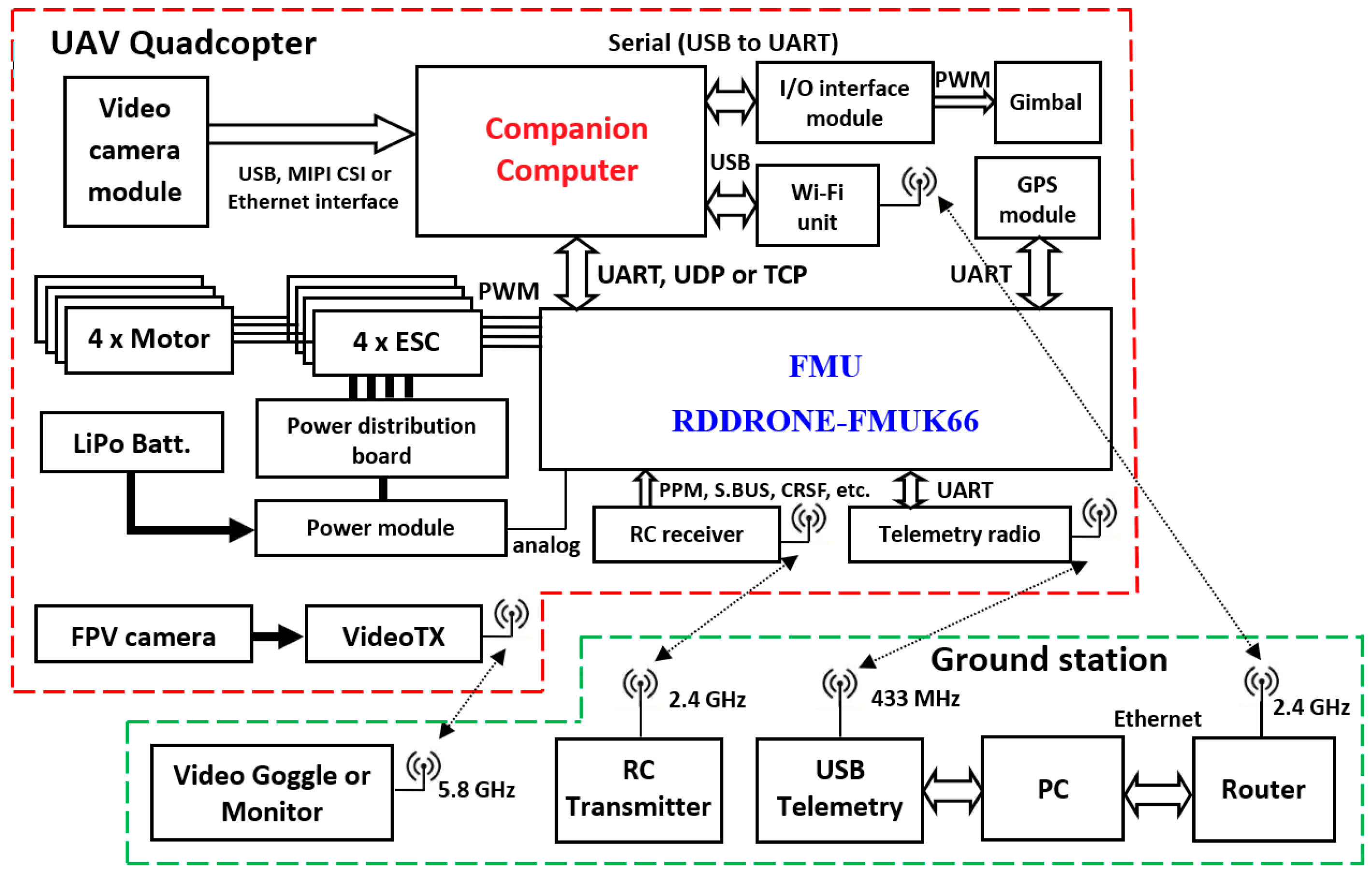
The UAV component of the UAS is based on an NXP HoverGame drone kit. The NXP HoverGame drone kit, known under the commercial name KIT-HGDRONEK66, is composed of all the main mechanical (carbon fiber frame, propellers), electrical (power distribution board (PDB), brushless direct current (BLDC) motors, electronic stability control (ESC) motor controllers), and electronic (the power management module, flight management unit (FMU)—RDDRONE-FMUK66, which also includes different sensors such as a gyroscope, accelerometer, magnetometer, barometer, etc., GPS unit) components needed to build a quadcopter.
The UAV system communicates with the ground control station through four distinct communication links (
Figure 1).
The first link is a video link done through a First Person View (FPV) system, allowing a real-time stream of information from the onboard camera. In this mode, the UAV system can be controlled from the pilot’s viewpoint. When the image database was acquired, this system was extensively used to control the quadcopter.
The second link is a radio controller link, which enables a human operator to take control of the UAV by switching from autonomous mode to manual mode. The reverse operation is also possible—by changing the system to offboard mode, the autonomous guidance system located in the companion computer takes control of the UAV. This link is implemented based on a TBS Crossfire 868 MHz long-range system.
The third link is a telemetry link. This is a link based on the Micro Air Vehicle Link (MAVLink) protocol, which enables ground control to communicate with and change the settings of the FMU, configure the flight path, and modify the mission on the fly, among other functions. In this research, the transceivers implementing this link work on 433 MHz. The system uses the 433 MHz wireless band mainly due to the legal constraints imposed by the European Union. In America, this band is on 915 MHz
A fourth link can be utilized and was employed during the system’s development phase. It is a short-range link based on Wi-Fi technology, operating at 2.4 GHz. Through this link, the different images were streamed in real-time using the ZeroMQ (ZMQ) messaging protocol from the companion computer to the ground station. In this mode, the developed algorithm was debugged in real time. ZMQ is a high-throughput, asynchronous, and low-latency protocol.
The NXP HoverGame drone professional kit does not include any software components for flight control or any other components capable of generating intelligent or adaptive behaviors.
The RDDRONE-FMUK66 FMU can run PX4 and ArduPilot autopilots. These two autopilots support a wide range of vehicles, including multi-copters, helicopters, VTOLs [
34], fixed-wing aircraft, boats, rovers, and more. In this research, the FMU utilizes the PX4 flight stack, which is built on top of the NuttX operating system (OS).
The guidance of the UAV system is accomplished through a companion computer. Based on the AMD Kria KR260 development board (produced by Advanced Micro Devices, Inc., Santa Clara, CA, USA), the companion computer runs the Ubuntu 22.04 operating system and ROS2 Humble. These two software components can support a wide range of algorithms. The AMD Kria KR260 development board is based on Zynq UltraScale+™ MPSoC, which is composed of the following:
A 64-bit quad-core Arm Cortex-A53 (up to 1.5 GHz) processor;
Two ARM Cortex-R5 real-time processors (up to 600 MHz);
One Mali-400 MP2 GPU;
One DPUCZDX8G B4096 (4096 MACs per clock cycle) Deep Learning Processor Unit (DPU).
The DPUCZDX8G engine is optimized for the efficient implementation of CNN. In our case, the YOLO DNN was executed on this unit to achieve real-time performance.
The companion computer connects to the FMU by utilizing (1) hardware through a universal asynchronous receiver–transmitter (UART) port; and (2) software based on uXRCE-DDS bridge (between the PX4 autopilot and robot operating system (ROS) 2), supported by the UART port.
From the presentation of the guidance laws, it is evident that a seeker must identify the target system and establish a lock. Using this system, the LOS can be determined. In our case, the seeker is a 3D gimbal system capable of autonomously pointing a camera at the target, as shown in
Figure 2. The 3D gimbal system is controlled by an interface system developed around the MSP430G2553 microcontroller, utilizing two pulse width modulation (PWM) signals to drive the SR431 servomotors. The companion computer controls the 3D gimbal using the RS232 serial protocol. This gimbal system was developed in the frame of this research.
2.2. Image Database
The database was acquired using a GEPRC CineLog35 drone equipped with a GoPro Hero 11 Black to capture the images. The image database used for training and cross-validation consisted of 5605 images, of which 1439 (25.67%) were negative samples. The images were acquired at a resolution of 1920 by 1080 pixels.
The DarkMark framework was used for image annotation. As a direct result, the database contains 2525 annotations with quadcopters and 1943 with planes—in this mode, there are 1.1 marks per image. The recorded quadcopter was the one previously presented in
Section 2.1. Three aircraft were used in the image acquisition process: a Cessna model, a Bixler V2, and a glider (
Figure 3).
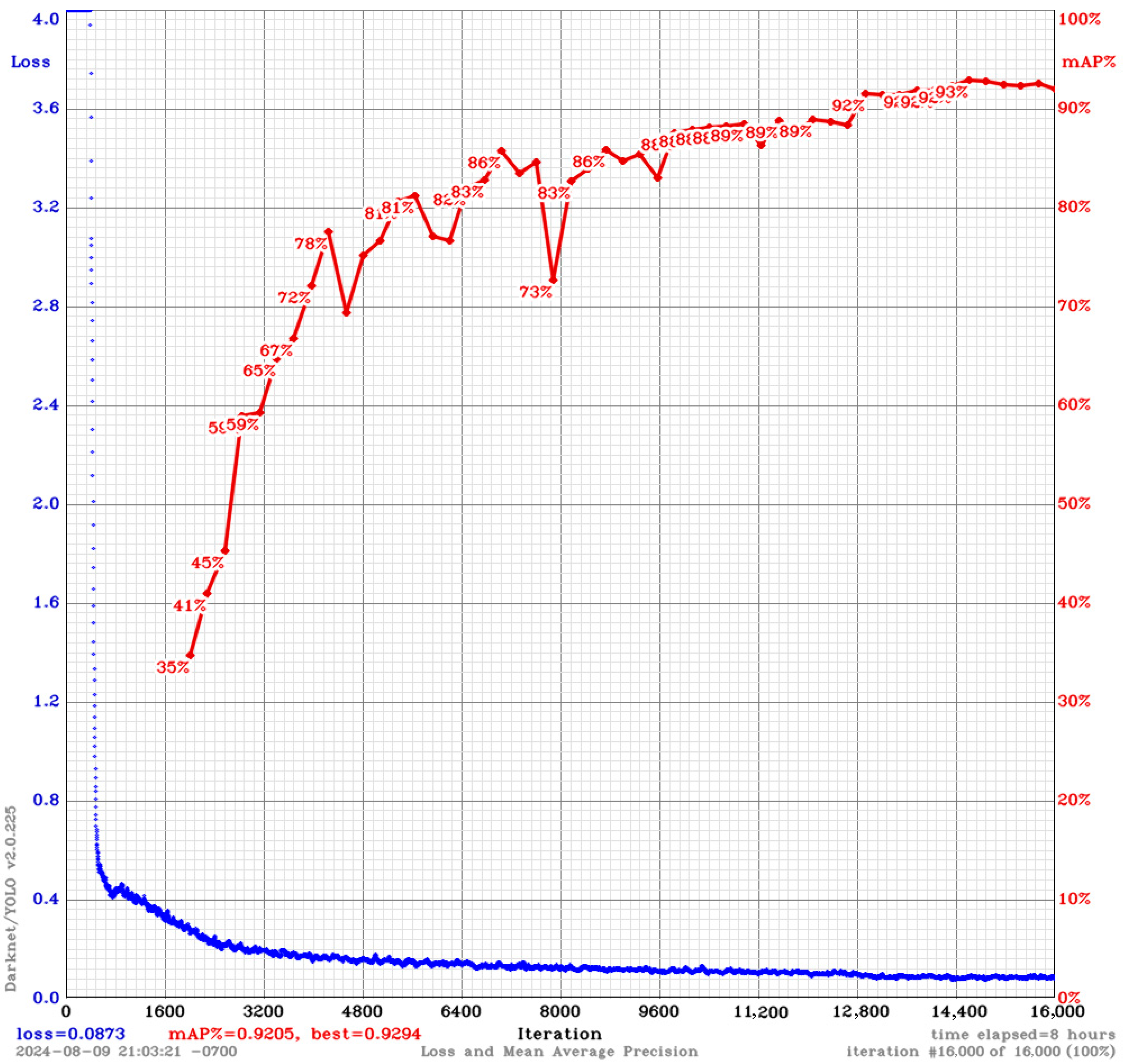
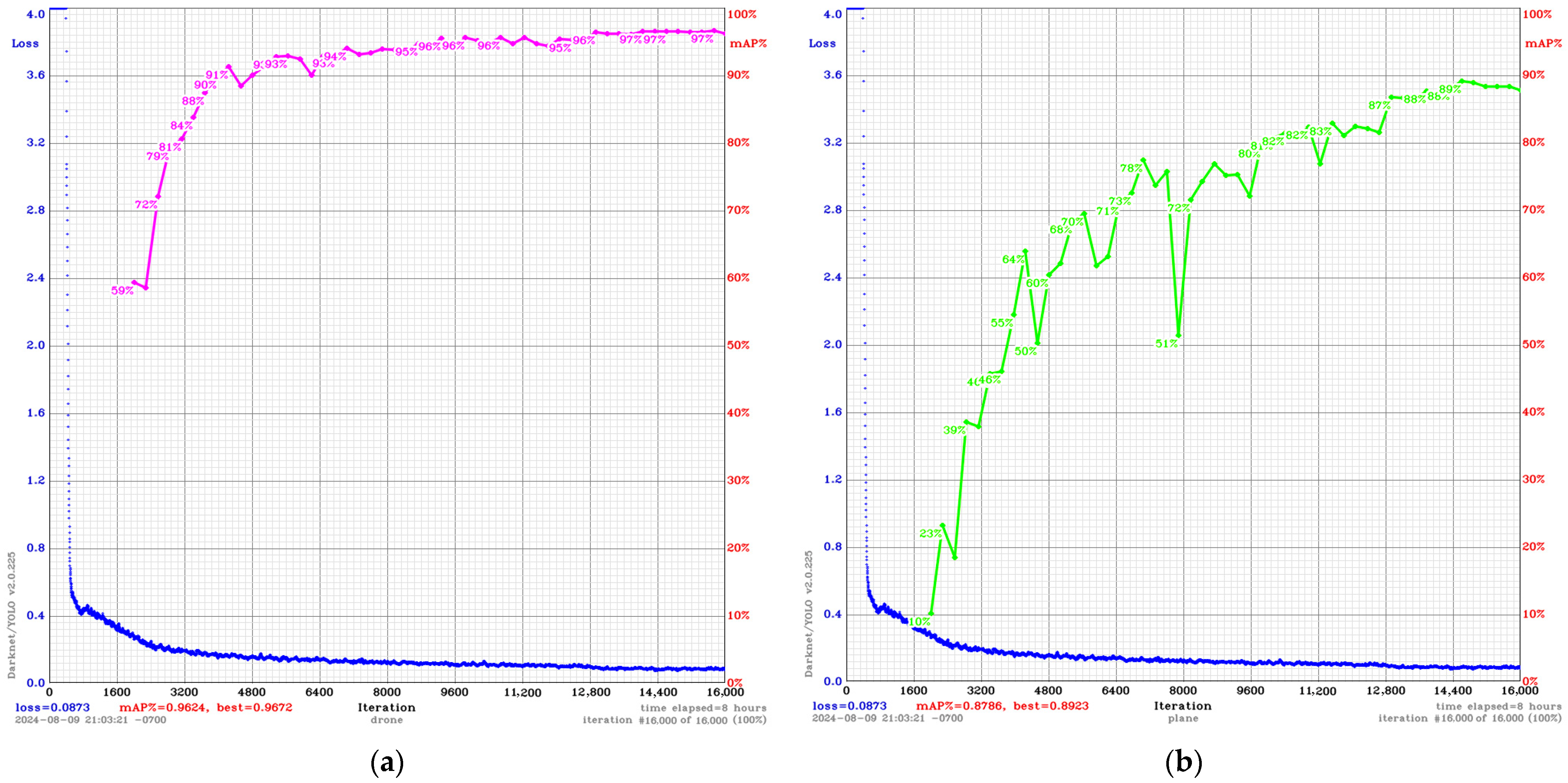
Following the dataset augmentation process, the initial set of 5605 images yielded 19,341 training images and 4835 validation images. Ultimately, 80% of the pictures were used for training, and 20% were reserved for cross-validation of the learning process to prevent overfitting.
Another set of 1524 images were used solely for testing. All accuracy performance analyses presented in the “Performance Analysis” section were conducted on this set. Since both tracking algorithms used in this research require a sequence of images (they need prior detection to predict the information in the next frame), this database includes images from six videos. The images were numbered in ascending order and correspond to the temporal unfolding of the associated videos.
The entire database, comprising images and annotations, occupies 4.85 GB and can be downloaded from the link provided in the Data Availability section.
2.3. DNN Detection Algorithm
2.3.1. YOLO Algorithm
YOLO (You Only Look Once) is a state-of-the-art real-time object detection algorithm able to process images in a single forward pass compared with traditional methods (e.g., R-CNN [
25], Faster R-CNN [
26], SPP-Net [
27], Feature Pyramid Network (FPN) [
28]), which use two stages. This approach is significantly faster than traditional methods. The YOLO DNN can simultaneously predict bounding boxes and class probabilities in a single step. Many aspects may be addressed concerning this type of neural network; however, a brief overview of the architectures utilized in this research will be provided: YOLOv3, YOLOv4, and YOLOv7.
The YOLO DNN family was introduced in 2016 when Joseph Redmon and his team proposed this type of DNN [
29], YOLOv1, for the first time. This type of DNN transitions to a regression-based approach for bounding boxes, departing from previous approaches based on sliding windows and classification.
YOLOv3 uses multi-scale predictions, allowing it to detect objects of different sizes more effectively [
35]. Additionally, the new architecture, Darknet-53, with 53 convolutional layers, improves YOLOv3’s learning capabilities [
35].
By utilizing Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Self-adversarial-training (SAT), Mosaic data augmentation, Cross mini-Batch Normalization (CmBN), Mish-activation functions, DropBlock regularization, and a new CIoU loss function, a new YOLO model was developed: YOLOv4 [
36]. The following year, 2021, saw the introduction of two new versions of this algorithm [
19]: YOLOv4-tiny, and YOLOv4-large.
YOLOv7 sets a new state-of-the-art, real-time object detection performance, outperforming all previously published YOLO detectors in terms of accuracy. These performances (56.8% on the Microsoft COCO dataset) were achieved by introducing new advanced E-ELAN (Extended Efficient Layer Aggregation Network) and Re-Parameterized Convolution (RepConvN) into the neural network backbone [
20].
2.3.2. Evaluation Metrics
The evaluation metrics employed in this research encompass the following: the number of model parameters, frames per second (FPS), precision, recall, specificity, false positive rate, average precision (AP), and mean average precision (mAP).
In previous equations, TP (True Positive) pertains to objects, such as planes or quadcopters, that are correctly detected by the deep neural network (DNN) and are indeed present. The True Negative (TN) value signifies objects that are neither detected nor present within the frame. FP (False Positive) refers to instances where objects are detected without existing in the image. Conversely, FN (False Negative) indicates cases in which objects are present within the frame but remain undetected by the algorithm. The average precision (AP), as defined in relation (2), is computed as the area beneath the Precision-versus-Recall curve [
37]. The mean average precision (mAP) represents the average precision evaluated across eleven equally spaced recall levels [
37].
2.4. Tracking Algorithms
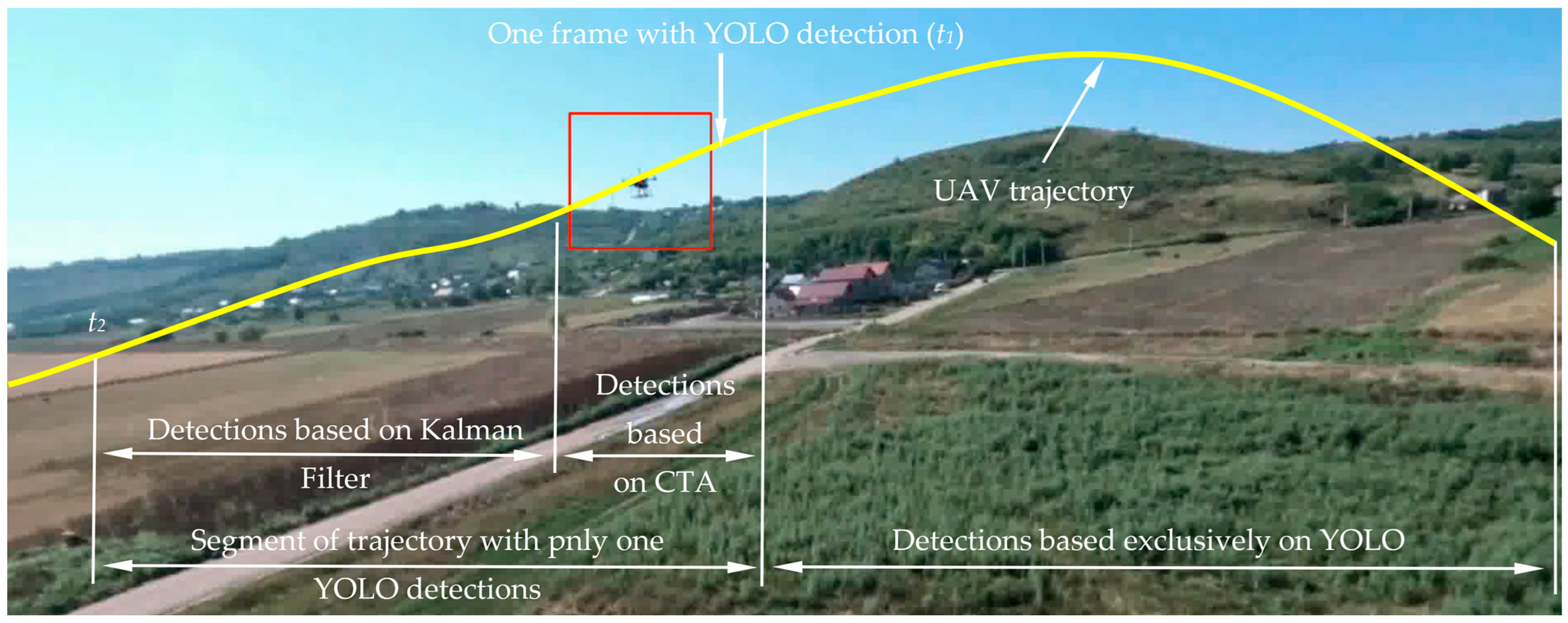
Even though YOLO is a state-of-the-art real-time object detection model, it cannot achieve 100% performance. Currently, no detection algorithms reach 100% performance—perhaps such performance can be accomplished only for small problems with few classes and in controlled laboratory environments. In real situations characterized by occlusions, illumination changes, motion blur, scale variation, intra-class variation, viewpoint variation, and background clutter, obtaining 100% detection performance is impossible.
Moreover, after training the DNN and obtaining the best neural model, it must be implemented in the UAV system. At this point, to achieve real-time performance, the DNN model must be executed in a DPU (Deep Learning Processing Unit), NPU (Neural Processing Unit), TPU (Tensor Processing Unit), or GPU (Graphics Processing Unit) system. However, these units have limited processing capacity, so the DNN must be quantized, or a weaker version of the model (nano or tiny, like YOLOv7 tiny) must be utilized. Ultimately, this leads to a drop in the performance of the neural model.
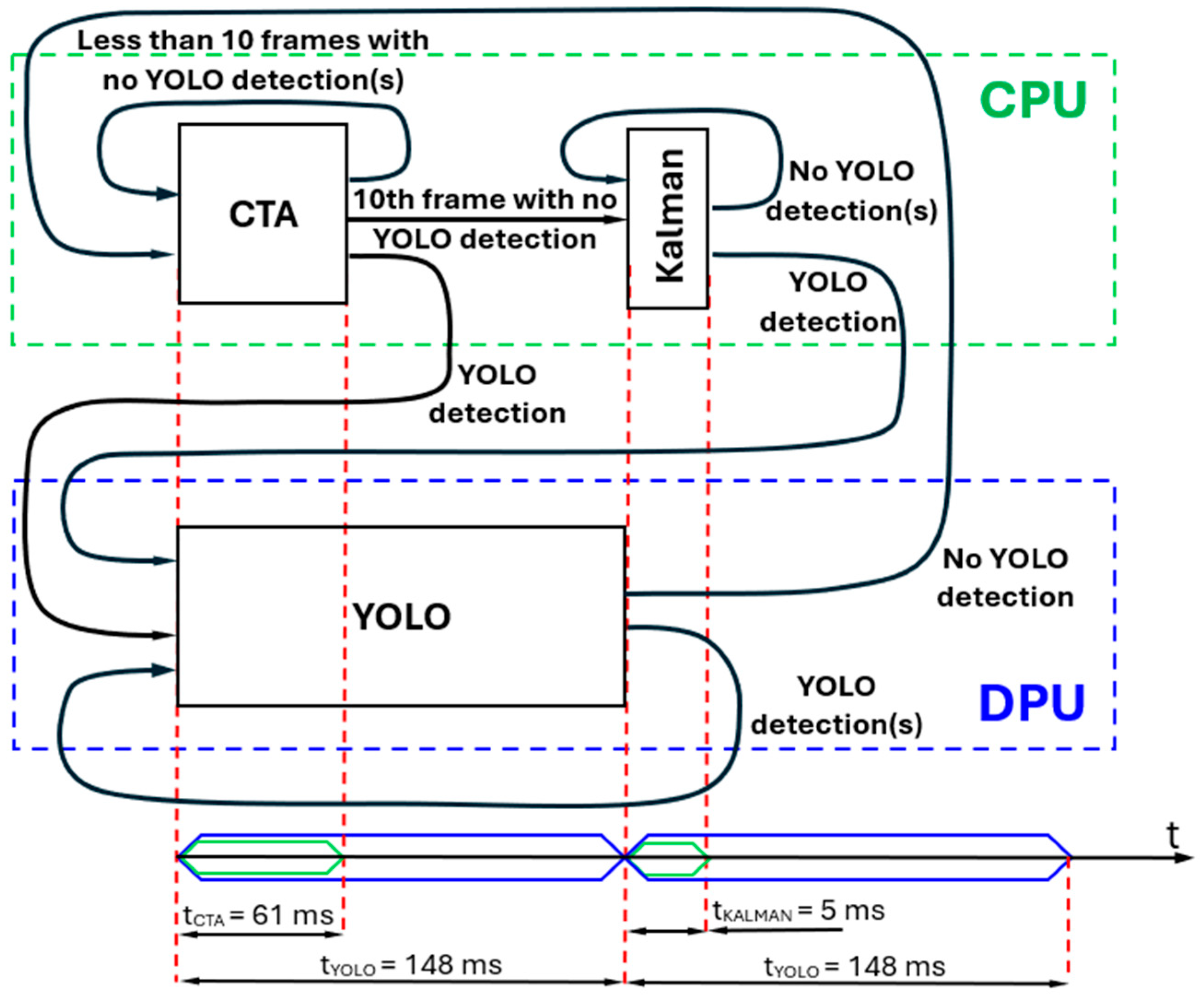
The inability of the YOLO model to achieve 100% detection performance means that, occasionally, it cannot detect the desired target in a frame or a series of frames. However, the flight path control guidance algorithm requires accurate target detection at each control step. To attain this objective, alternative methods must be employed to compensate for the lack of detections in frames or sequences of frames. A potential solution to this issue is to utilize a supplementary tracking algorithm when the YOLO algorithm fails to identify the desired object. To validate the robustness of this approach, the new algorithm used the correlation tracking algorithm (CTA) [
38], a Kalman filter, and the YOLO algorithm. Nevertheless, these algorithms also face challenges. For this reason, only the solution integrating all three algorithms has been shown to provide a very high target tracking performance.
2.4.1. Correlation Tracking Algorithm
The correlation tracking algorithm used is based on the implementation of Danelljan et al. [
38], and it can accurately track objects in real-time with significant scale variation.
This method extends the Minimum Output Sum of Squared Error (MOSSE) algorithm [
39] by learning several separate correlation filters, based on which the target is localized in the new frame. The discriminative correlation filters were extended to multidimensional features by using 1-dimensional filters for scale estimation, 2-dimensional filters for target translation based on Histogram of Oriented Gradients (HOG) features, and 3-dimensional filters for comprehensive scale–space localization of the target. Based on the observations that the scale difference is smaller than a translation of the target between two frames, the algorithm first applies the translation filter, followed by the scale filter. The image representation is based on Principal Component Analysis (PCA)-HOG. The HOG vector is augmented with greyscale image intensity values for robust target representation.
The higher detection accuracy of the CTA is based on HOG features, which significantly improve tracking performance over intensity-based approaches [
38]. This algorithm is also computationally efficient due to the decoupling mechanism between translation and scale estimation, which avoids exhaustive scale searches in this mode. Moreover, this CTA approach is modular and can be easily integrated into any tracking framework lacking scale adaptation, making it widely applicable in real-world scenarios.
2.4.2. Kalman Filter
The Kalman Filter estimates the current state based on (a) the estimated state from the previous time step and (b) the current measurement.
This research aims to track a UAV using the center coordinates of the detected bounding box obtained by the YOLO DNN as the measurement. The idea is to use a Kalman filter to continue tracking the UAV even when the YOLO detection fails. Based on the UAV’s estimated position and velocity, the new algorithm can accurately predict its position in the following frame.
The Kalman Filter is composed of two steps.
The first step is the prediction step, in which, by using the process model, the prior state estimate (
) is predicted. Also, the state estimate error covariance matrix (
) is computed. Based on
, the Kalman Filter estimates how much to trust the current values of the predicted state [
1].
The state vector is the position and velocity of the UAV on the
x and
y directions (
. The state transition matrix model was obtained from second-order equations of motion, and it has the following form (
is the time between two frames) [
1]:
B is the control input model matrix, which in our case is the zero matrix, and
is the predicted process noise, assumed to be a zero-mean multivariate normal distribution with covariance matrix
Q:
The second step is the update step, where the prior prediction is combined with the measurement (based on Kalman gain) to obtain the state estimation (
)—the output result of the Kalman Filter.
In relation (12),
is a measurement at the
k moment of the true state
, and v
k is the measurement noise, assumed to be also a zero-mean Gaussian white noise with covariance matrix
R.
The
H matrix is the observation model which maps the true state space into the measurement space, and in the case of our problem, has the following form:
The Kalman gain (
), see relation (13), is a measurement of the information existing in the sensors. The Kalman gain and the error in the sensors are inversely correlated—the higher the error in the measurement, the smaller the Kalman gain will be and vice versa.
is the new error covariance matrix after the measurement is embedded into the state estimation.
4. Discussion
Numerous previous studies have aimed to enhance the detection accuracy of systems implemented with either classical or deep learning algorithms. Considering that this research is based on a deep neural network (DNN) algorithm, the analysis will, therefore, be conducted exclusively on this category of detection system. Each of the previous works aims to enhance detection accuracy or optimize a specific aspect of deep neural networks (DNNs).
For example, in the first approach, accuracy is increased by employing a new type of DNN, such as the CFAMet neural network [
46], or by using a novel perceptual GAN model [
47]. In a second approach, different types of improvements are made to (a) the YOLOv5 algorithm, resulting in two new algorithms, YOLO-LSM [
31] and UA-YOLOv5s [
48]; (b) YOLOv7, resulting in YOLO-DCTI [
32]; and (c) YOLOv8, resulting in SP-YOLOv8s [
49]. However, these algorithms also have disadvantages, the most significant being the increase in computational load that accompanies the improvement in algorithm accuracy, as seen with the SP-YOLOv8s [
49] neural network.
No matter how robust a single detection algorithm is, it will be impossible for it to track a target in all the frames it acquires. There will inevitably be frames in which no detections occur or false-positive detections occur. Furthermore, when executing this algorithm on the UAV, due to its constrained computational resources, there will be supplementary performance degradation (attributable to model quantization, architectural modifications, or the utilization of a less complex variant of the DNN), which may result in the absence of detections in additional frames.
The algorithm proposed in this paper aims to address these issues. From
Table 4 and
Table 5, in the case of the detection algorithm presented in this paper, the number of ground truth bounded boxes is equal to the number of detected bounded boxes with the minimal distance between their centers. Therefore, there are no frames with missed detections.
Analyzing the data from
Table 4 and
Table 5, it can be observed that the CTA and Kalman Filter algorithms, used individually with YOLO or in combination, provide a performance boost over the YOLO detection algorithm. Moreover, our YOLO detection algorithm can be replaced with any of the previous algorithms [
31,
32,
46,
47,
48,
49]. Therefore, this new approach will undoubtedly enhance the performance of any initial algorithm employed in detection.
Among the similar works on this topic, Akyon et al. [
33] developed a detection algorithm that closely aligns with the approach presented in this paper. This algorithm represents the winning solution in the Drone vs. Bird Challenge, organized as part of the 17th IEEE International Conference on Advanced Video and Signal-Based Surveillance. As in our case, the data are augmented. The detection algorithm, the first step, is based on a YOLOv5 deep neural network (DNN), followed by a Kalman filter to enhance detection performance [
33]—the second step. At this point, a notable difference emerges compared to the algorithm presented in this paper; in [
33], the Kalman filter is used solely to eliminate false positive detections. In the third step, a tracking boosting method is used to increase the algorithm’s confidence. The results obtained are presented in
Table 6.
On the right side of
Table 6, the performances achieved by the proposed algorithm for both the entire test database and a single section are also shown. A direct comparison of the two algorithms based solely on the absolute mAP values is, therefore, not possible. Nevertheless, even within this context, the overall performance indicates the superiority of the algorithm proposed in this paper, with an mAP of 0.837 (or 0.905) in comparison to 0.794.
A comparison of absolute performance is inappropriate because, as referenced in [
33], a more recent iteration of the YOLO algorithm is utilized, which operates on a personal computer; thus, there are no constraints on real-time execution. Furthermore, YOLOv5 was not subjected to quantification; its architecture remained unaltered—no layers were diminished—and therefore employed the architecturally optimal configuration. Additionally, a reduced version of this algorithm was not utilized. Nonetheless, given the similarity between both algorithms, which are based on a combination of three distinct algorithms,
Table 7 illustrates the performance enhancement achieved by integrating the new detection capabilities with the previous results, using the YOLO algorithm as the reference point.
From
Table 7, the overall performance improvement achieved by the combination used in this paper (CTA and Kalman Filter) is superior (around 1.2 up to 1.4) to that of the combination used in [
33], which yields an mAP increase of only 1.0166.
The algorithm developed and presented in this paper shares the same deficiencies as all comparable algorithms [
14,
15,
16,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32]. In a real-world context, detection accuracy is influenced by factors such as lighting conditions, dynamic shadows, contrast levels, viewing angles, or scale variations. To mitigate these challenges, two distinct methodologies were employed. The first approach involved compiling an extensive and diverse training dataset, as illustrated in
Figure 10. The images were collected under various weather conditions: on sunny days (
Figure 10a), at dusk (
Figure 10b), during cloudy weather (
Figure 10d), and under a “gray” sky (
Figure 10c,e). To address scale discrepancies, images were captured from varying distances relative to the target, as exemplified in
Figure 10c,d,f. Additionally, to improve adaptability to different perspectives, images of the target were acquired from multiple viewpoints, including from above (
Figure 10a), below (
Figure 10e), and from various side angles (
Figure 10b–d,f).
The second approach was predicated on image augmentation. Through the augmentation process, starting from an initial set of 5605 images, a total of 19,341 training images were generated. The employed data augmentation techniques introduced new variations within the training dataset, such as random rotations, flips, cropping, and alterations in image color properties, including brightness, contrast, saturation, and hue. As a direct consequence, the deep learning model enhanced its robustness and its capacity for generalization.
The analysis of the algorithm’s detection capacity with altitude reveals that the background and proximity to the detected object predominantly influence it. Consequently, altitude is not an essential factor; an object situated at either low or high altitude against the sky is detected more readily than an object at the same altitude with a complex background, such as houses, forests, or fields. This observation is substantiated by both
Figure 8 and the video provided in the “
Supplementary Materials” section.
Based on the operation of the novel algorithm and the results presented in
Table 4 and
Table 5, it is evident that it is highly effective. For instance, analysis of the results in
Table 5 reveals a mean average precision (mAP) of 90.48%, with precision and recall values of 99.33% ± 1.31%. Nonetheless, these parameters (mAP, precision, and recall) also encompass information regarding the extent of overlap between the object’s bounding box annotation and the detection box generated by the algorithm, as demonstrated in
Figure 7. All results in
Table 5 were derived exclusively from the video included in the “
Supplementary Materials” section. In this video, no frame exhibits either a lack of high-quality detection or false positives. The reason for mAP not reaching 100% or a value very close to it is that the detected boxes tend to be larger than the ground truth bounding boxes, as illustrated in
Figure 7. Despite these high detection performance metrics, it remains plausible that, in the final stage, the Kalman algorithm may produce an erroneous output, or the YOLO may have a false positive detection. In such cases, these issues were partially mitigated through the implementation of “if” decision structures. For example, when a new detection is significantly distant from the previous one, the control algorithm relies on the prior detection to guide the drone. Moreover, in the absence of any detection, such as during the initial activation of the algorithm, the drone’s control is transferred to the operator. Alternatively, the drone ascends to a predetermined altitude, where a slow rotation around the vertical axis perpendicular to the ground begins until the first detection is achieved.
UAV control is accomplished via a velocity-based methodology utilizing an application developed and operated within the ROS2 environment. From this perspective, the application determines a specific set point, which in this instance, is a designated velocity. The internal PX4 control loops perpetually maintain the stability of the UAV system’s dynamics by utilizing this set point for subsequent updates. In offboard mode—when the vehicle adheres to setpoints supplied by an external source outside the flight stack—the companion computer is required to stream setpoints at a rate exceeding 2 Hz; failure to do so will result in the vehicle exiting offboard mode. In the worst case (with YOLOv3 detections), the developed algorithm produces setpoints at a rate of 5.8 Hz. This rate can increase to 15 Hz with CTA detections or 140 Hz with Kalman filter detections, see
Figure 4. During all field tests, both the tracking UAV system and target UAV were of the same types described in
Section 2.1 of this paper. This UAV system, based on the HoverGames drone, can attain a maximum speed of 68 km/h, approximately equivalent to 19 m/s. At their maximum velocity, the UAV systems operate, in the worst-case scenario, with a setpoint supplied 5.8 times per second, which corresponds to a correction for every 3.3 m of the drone’s travel. For these two deployed UAVs, this update frequency proved to be adequate, as the drone’s trajectory remained smooth, primarily due to the interplay between the current trajectory and the preceding one, integrated through the drone’s inertia. Clearly, as the speed of the tracking system increases, the 5.8 Hz trajectory modification rate of the tracking system can become insufficient in such scenarios. Therefore, additional optimizations of the detection system must be implemented. Alternatively, the operational frequency of the DPU system must be increased, or an alternative DNN system should be considered for replacement.
Through the utilization of the communication interface between the companion computer and the FMU, GPS coordinates can be acquired and employed. In this investigation, the proposed algorithm is capable of obtaining solely a position relative to the designated target. To establish the absolute position of the target, the depth information must be ascertained. Such information can be obtained via stereo cameras, LiDAR (Light Detection and Ranging), or radar systems. Future research will incorporate distance measurements and data fusion with the GPS unit to determine the absolute position of the tracked system.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}