1. Introduction
In contemporary space exploration, the Moon, as Earth’s sole natural satellite, holds paramount significance for scientific investigation. Lunar exploration not only facilitates resource development initiatives, such as the in situ utilization of lunar mineral resources to provide material support for deep space exploration and alleviate terrestrial resource constraints, but also drives technological innovation. The advancement of critical technologies, including lunar rover systems and path planning algorithms, exemplifies this dual-purpose development: these innovations not only fulfill mission-specific requirements for lunar exploration but also demonstrate significant potential to feed back into terrestrial engineering domains, thereby catalyzing industrial upgrading and technological transformation.
Lunar rover path planning stands as one of the critical technologies for lunar exploration missions. The objective of path planning is to identify an optimal trajectory from a starting point to a destination for mobile entities (e.g., robots, vehicles) in a given environment. An optimal path constitutes a core requirement for ensuring precise and efficient task execution by robotic systems [
1]. In offline scenarios, path planning is typically implemented using predefined maps, where the environment is modeled as a grid-based maze and addressed through search algorithms such as A* [
2] and Dijkstra [
3]. Early research focused on enhancing traditional path planning algorithms. Tang et al. [
4] proposed an improved A* algorithm integrated with environmental mapping techniques to optimize lunar rover path planning in rugged terrains, achieving significant reductions in path length and turning angles. Chen et al. [
5] developed a Particle Swarm Optimization-based approach for autonomous waypoint selection, resolving inefficiencies in manual waypoint intervention and enabling efficient path exploration. Mamdapur et al. [
6] constructed a lunar terrain model incorporating craters and steep slopes, compared the performance of Differential Evolution and Ant Colony Optimization in lunar rover path optimization, and analyzed the adaptability of these algorithms in complex topographies. However, the lunar surface environment presents significant challenges. Its complex terrain features include impact craters, steep slopes, and loose regolith; dynamic obstacles (e.g., moving meteoroids) and sudden environmental changes (e.g., abrupt local illumination shifts) demand real-time responsiveness; and potential path conflicts in multi-vehicle collaborative missions further exacerbate planning complexity. These challenges necessitate path planning algorithms that balance global optimality, dynamic adaptability, and multi-agent coordination. In recent years, researchers have proposed diverse local path planning methodologies, including the Artificial Potential Field (APF) [
7], hybrid APF-Adaptive Dynamic Programming frameworks [
8], Convolutional Neural Networks [
9], and Reinforcement Learning (RL) [
10], which have demonstrated efficacy in addressing obstacle avoidance in dynamic environments. Despite these advancements, existing planning systems in dynamic path planning environments often fail to respond promptly to unexpected scenarios (e.g., limited visibility).
Reinforcement Learning and deep reinforcement learning (DRL) have garnered significant attention in online path planning due to their adaptability to environmental changes and dynamic obstacles. As RL requires no predefined training data, it is particularly suited for scenarios demanding autonomous exploration. For instance, when training robots to perform specific tasks, the system incrementally adjusts action selection through trial and error: behaviors that increase reward signals are reinforced and executed more frequently. This learning paradigm mimics the conditioning of animals via reward-punishment mechanisms, ultimately enabling agents to autonomously optimize decision sequences in uncertain environments [
11]. DRL integrates RL with deep learning, leveraging deep neural networks to enhance traditional RL algorithms (e.g., Q-learning), thereby overcoming performance limitations imposed by the curse of dimensionality. For example, in complex scenarios such as airports, mobile robots can utilize DRL to adapt to dynamically distributed pedestrians and sudden obstacles, achieving efficient navigation. This technology employs an end-to-end training mechanism that directly maps raw inputs to control policies, significantly enhancing the generalization capabilities of agents in open environments [
12]. The Deep Q-Network (DQN) model proposed by Mnih et al. [
13] represents a milestone in the integration of deep learning and RL, catalyzing advancements in RL methodologies. The applicability of DRL has gained widespread acceptance across multidisciplinary research communities. Yu et al. [
14] demonstrated the application of safety-constrained DRL to end-to-end path planning for lunar rovers. Park et al. [
15] implemented DRL for fault-tolerant motion planning of four-wheel dual-steering lunar rovers, though the long-term planning efficacy requires further validation. Lu et al. [
16] developed a multi-rover collaborative path planning method combining DRL with Artificial Potential Field heuristics, addressing challenges such as obstacle avoidance across varying sizes and time-constrained target arrival. These innovative approaches have markedly improved the adaptability and responsiveness of lunar rover path planning strategies.
However, a more formidable challenge lies in the multidimensional characteristics of the lunar environment: motion uncertainties caused by lunar soil slippage, sensor drift induced by extreme temperature fluctuations, and emergent obstacles formed by dynamic meteorite impacts. These factors render pure deep reinforcement learning simulation training inadequate for ensuring algorithmic reliability in practical missions. For instance, while the LSTM-DRL framework developed by Hu et al. [
17] achieved a 92% obstacle avoidance success rate in laboratory environments, its failure rate surged to 41% in unforeseen lunar shadow terrain, revealing a significant modeling gap between simulation and real-world scenarios. Digital twin (DT) technology provides critical support to address these limitations. Initially proposed by Professor Grieves [
18], digital twin technology aims to create highly synchronized digital replicas of physical entities in virtual space. In aerospace applications, DT enables high-fidelity simulation environments for path planning in complex scenarios through real-time mapping of lunar rovers’ geometric characteristics, kinematic parameters, and environmental constraints. Specifically, digital twin models of lunar rovers incorporate not only static attributes like mechanical structures and sensor configurations but also dynamically simulate their motion postures, energy consumption, and obstacle interaction behaviors on lunar terrain. Through virtual-physical interactions, DT technology enables pre-validation of path planning strategies, thereby reducing operational risks and trial costs in real missions. With recent advancements in digital twin theory and technology, increasing research efforts have explored its applications in path planning. For example, Gan et al. [
19] employed SPIS to construct 3D models simulating lunar rovers’ charging potential distributions in flat regions, shadowed areas, and near impact craters, analyzing solar incidence angles to mitigate threats posed by complex polar environments to electronic systems and sampling tasks. Yakubu et al. [
20] developed a single-motor-driven wheel-legged lunar rover mobility system, addressing the high energy consumption and low fault tolerance of traditional multi-motor systems through DT simulations. Xia et al. [
21] utilized DT to simulate system behaviors and predict process failures while integrating deep reinforcement learning into industrial control workflows, expanding system-level DT applications. Lee et al. [
22] validated the potential of DT-driven DRL in robotic construction environments, demonstrating DRL’s adaptability in dynamic settings. These studies collectively indicate that the integration of digital twin technology with deep reinforcement learning can effectively bridge the gap between simulation and real-world implementation. These methodologies have proven effective in addressing obstacle avoidance challenges in dynamic environments.
Recent research has predominantly focused on navigation and obstacle avoidance in dynamic environments. Hu et al. [
23] proposed a hierarchical framework combined with deep reinforcement learning for rapid path planning of planetary rovers in complex extraterrestrial environments, aiming to generate safe and efficient trajectories. Polykretis et al. [
24] investigated mobile robot navigation in mapless environments by deploying a self-supervised cognitive map learner on edge devices, enabling autonomous environmental perception and cognitive map construction for navigation without prior maps. These studies have successfully accomplished navigation tasks through the development of DRL algorithms and their variants. Despite significant advancements in DRL, most approaches exhibit suboptimal performance in scenarios involving obstacles or multi-robot systems. For instance, Wei et al. [
16] employed independent Q-learning, but their algorithm’s convergence speed degrades markedly as the number of robots increases, and it struggles to handle complex collaborative tasks requiring synchronized actions (e.g., scenarios demanding coordinated maneuvers). Their study explicitly notes that “an increase in robot count amplifies policy conflicts”, a critical concern given the potential for lunar rovers to obstruct one another. Pai et al. [
25] discretized indoor environments into grids (e.g., 10 cm×10 cm), but such discretization may introduce collision risks when obstacles exhibit complex geometries (e.g., cylindrical shapes). R. Lowe et al. [
26] introduced the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm, significantly enhancing agent decision-making in mixed cooperative-competitive environments. While MADDPG demonstrates efficacy in certain scenarios, the authors also highlight its limitations in highly competitive or obstacle-dense environments (e.g., in “predator-prey” tasks, agents may fall into cyclic strategies, resulting in inefficiency). To address these challenges, this study proposes a novel lunar rover path planning framework, termed A*-D3QN-Opt. The research adopts the Deep Q-Network, a subfield of DRL, to resolve dynamic path planning problems by integrating an A*-algorithm-based static path planner with the D3QN algorithm. Here, A* generates initial paths in static environments, while D3QN optimizes trajectories and makes real-time decisions in dynamic settings. As an advanced DRL algorithm, D3QN combines the Double Q-Learning framework with a Dueling Network architecture, effectively mitigating traditional DQN limitations such as value overestimation and unstable convergence. Hasselt et al. [
27] experimentally demonstrated that the dual-network structure reduces Q-value overestimation errors by 37%. By minimizing value function estimation bias through this architecture, D3QN enables rapid policy adaptation in dynamic obstacle scenarios (e.g., moving meteorites or other rovers). Furthermore, D3QN’s network design facilitates flexible integration of multimodal inputs, enhancing adaptability to complex perceptual environments. To further optimize the DRL model, this work enhances D3QN’s prioritized experience replay and reward function mechanisms. Additionally, the proposed method leverages a digital twin model to simulate lunar environments. Depth maps acquired from depth cameras and directional distance information from RGB cameras serve as model inputs, constructing a comprehensive state space to support agent decision-making and navigation.
The contributions of this paper are as follows:
1. Innovative Integration of the Two-Layer Path Planning Architecture: This study proposes a hierarchical path planning framework based on the A* algorithm and the improved D3QN algorithm. This architecture overcomes the limitations of traditional single-algorithm approaches by achieving efficient path planning in complex environments through a collaborative mechanism of static global planning and dynamic local adjustment. The A* algorithm is responsible for generating the global optimal path, addressing the low search efficiency of deep reinforcement learning in static environments. The D3QN algorithm, on the other hand, performs real-time adjustments to deal with dynamic obstacles and sudden environmental changes, enhancing the system’s adaptability. This layered design retains the global optimality of A* while leveraging the dynamic decision-making capability of deep reinforcement learning.
2. Multidimensional Optimization Strategy for the D3QN Algorithm: To address the issues of slow convergence and low sample utilization common in traditional deep reinforcement learning algorithms, this study optimizes the reward function and experience replay mechanism. A five-dimensional reward system was developed, incorporating path progress, obstacle avoidance, direction, energy consumption, and time penalties. This system effectively balances path efficiency and safety. Additionally, a priority sampling strategy based on TD-error is proposed, which dynamically adjusts the weight of experience samples, significantly improving the utilization efficiency of key experiences.
3. Improvement of the YOLOv5-DisNet Multi-Modal Perception System: To solve the challenges of target detection and distance estimation for the lunar rover in complex terrains, this study proposes a multi-modal perception approach integrating target detection and depth estimation. The traditional YOLOv3 is replaced by YOLOv5 [
28], and obstacle detection is performed using the improved CSPDarknet53 backbone network and CIoU (Complete Intersection over Union) loss function. The data is then input into DisNet [
29], where the target distance is precisely estimated by fusing object bounding box information with depth images. This information is provided as input to the path planning method for real-time obstacle avoidance.
Section 2 provides a detailed description of the proposed method,
Section 3 presents the experimental results, and
Section 4 concludes the study.
2. Methods
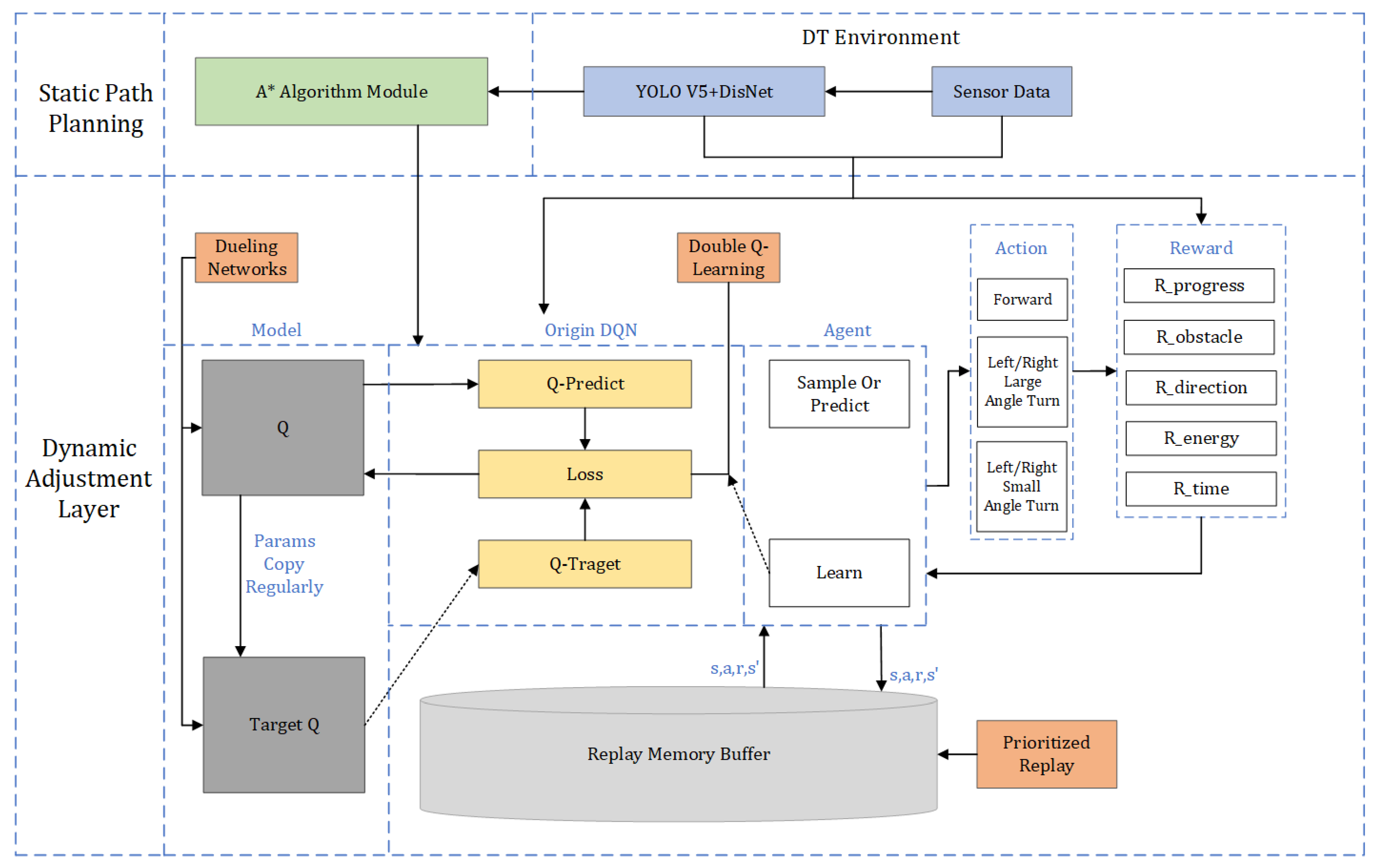
2.1. System Framework
The lunar rover path planning system proposed in this paper is divided into a static global planning layer and a dynamic local adjustment layer, with the A* algorithm responsible for static path planning and the D3QN algorithm responsible for dynamic path optimization.
The initial module of the system is the static path planning, which employs the A* algorithm. This module is responsible for generating an initial global path in a static environment. The A* algorithm calculates the shortest path based on a predefined terrain map and avoids static obstacles. It lays the foundation for global path planning, ensuring the optimality of the path under ideal conditions.
Real-time sensor data, such as depth images and RGB images, provide crucial information regarding obstacles, terrain features, and distances. This data serves as input to both the static and dynamic planning modules. The proposed system integrates YOLOv5 with DisNet architecture [
30], establishing a multimodal perception framework that synergizes target detection and depth estimation capabilities, enabling real-time environmental data acquisition.
The dynamic adjustment layer enhances the system’s responsiveness to environmental changes through D3QN (Dueling Double Deep Q-Network). This layer adjusts the path planning in real time based on sensor inputs. D3QN combines the dueling network architecture (which improves the stability of Q-value estimation) and double Q-learning (which reduces the bias caused by overestimation of Q-values) to handle dynamic obstacles. The agent module is responsible for decision-making. It selects actions based on the current state, which includes sensor data and terrain information. Actions include moving forward or turning at different angles (large or small turns). The agent learns from the environment through reinforcement learning to maximize long-term rewards. The Q-network predicts the Q-values for different possible actions, guiding the agent’s decision-making process. The target Q-network periodically updates its parameters to ensure learning stability. The Q-value is used to calculate both the Q-prediction (predicted Q-value) and the Q-target (target value computed through rewards and the next state). To optimize the learning process, a priority experience replay mechanism is used. This mechanism adjusts the sampling probability based on the temporal difference error (TD-error) of experiences, ensuring that important experiences are prioritized in the sampling process, thus accelerating learning. The system is designed with a detailed reward structure to guide the agent toward optimal path planning. The reward system consists of five components: path progress, obstacle avoidance, direction, energy consumption, and time consumption. Through these reward terms, the agent can balance path advancement, safe obstacle avoidance, and time efficiency. The replay memory buffer stores the agent’s past experiences (state, action, reward, and next state), which are used to train the Q-network. This allows the agent to learn from diverse experiences, improving decision-making quality. By combining static path planning and dynamic adjustment modules and employing deep reinforcement learning techniques, this architecture successfully addresses the challenges of autonomous navigation and obstacle avoidance for the lunar rover in complex terrains. The digital twin environment, advanced sensor data processing, and optimized reward functions and experience replay mechanisms enable efficient and safe path planning.
The system architecture of this paper is shown in
Figure 1.
2.2. Digital Twin Environment Model Construction
In this section, we constructed a digital twin environment, including the lunar surface environment, lunar rover model, and sensor perspective views. To ensure the consistency between the digital twin environment and the real lunar surface, after injecting Gaussian noise into the simulation environment, the mean and standard deviation of the DisNet distance estimation error, as well as the mean and standard deviation of the target orientation angle deviation, meet the precision requirements for lunar rover obstacle avoidance decision-making. The root-mean-square (RMS) position tracking error and velocity error of dynamic obstacles are controlled within allowable ranges, ensuring the physical consistency of obstacle motion in the simulation environment, as shown in
Figure 2.
2.2.1. Lunar Terrain Model
Based on lunar remote sensing data and elevation models, a three-dimensional lunar terrain grid is constructed. Terrain features (such as crater slopes and rock distributions) are generated using Gaussian random fields, with dynamic obstacles introduced to simulate the uncertainty of real-world environments. The terrain data is stored in a raster map format, with a spatial resolution of 0.1 m per pixel, ensuring the accuracy of path planning.
Gaussian noise with a mean of 0.1 m and a standard deviation of 0.05 m is injected into the simulation environment. Tests show that the root-mean-square error (RMSE) of distance estimation by DisNet is controlled within 0.08 m, and the standard deviation of target azimuth angle deviation does not exceed 0.5°. The position tracking error (RMSE) of dynamic obstacles is ≤0.15 m, and the velocity error is ≤0.05 m/s, meeting the precision requirements for lunar rover obstacle avoidance decisions.
Table 1 demonstrates the validation of quantitative parameters for the digital twin environment.
2.2.2. Lunar Rover Model
The modeling of the lunar rover includes both the three-dimensional rover model and the rover’s dynamic model. To study the rover’s driving performance on complex terrain, related research has explored the topic from multiple perspectives. Watanabe et al. [
31] investigated the effect of wheel speed on the performance of a small two-wheeled lunar rover on lunar soil, including slip, sinkage, and power consumption. Through experiments, they tested the driving time, slip rate, power consumption, and sinkage at different wheel speeds and analyzed the relationship between wheel speed and ground reaction force. Chen et al. [
32] established a forward and inverse kinematics model for an eight-wheeled torsion bar rocker-arm steering lunar rover, solving the relationship between rover body pose and wheel speed, providing a theoretical basis for motion control and autonomous navigation. Yang et al. [
33] proposed a torque coordination control strategy, combining a wheel-ground interaction model to optimize the distribution of driving force for a six-wheeled rover on soft terrain, reducing energy consumption and improving mobility. Takehana et al. [
34] analyzed the rutting characteristics of planetary rover gears on simulated lunar soil (Toyoura sand) through single-wheel test rigs and LiDAR scanning, quantifying the effect of load on rut depth and tilt. These studies collectively provide multidimensional theoretical and experimental foundations for the dynamic modeling and performance optimization of lunar rovers.
Based on the lunar rover’s geometric model and mechanical structure, a 3D physical model of the lunar rover is created. This model includes various components of the lunar rover, such as the wheels, rocker arms, and body. The kinematic model of the lunar rover describes the relationship between the wheel speed and the body speed. The lunar rover features an eight-wheel configuration with four steerable wheels and four fixed wheels, providing enhanced maneuverability on uneven terrain.
Figure 3 shows the 3D model of the lunar rover. The kinematic model of the lunar rover can be expressed as follows:
Here, and are the velocities of the lunar rover in the x and y directions, is the angular velocity of the lunar rover, is the linear velocity of the i-th wheel and its unit is m/s, is the wheelbase of the lunar rover unit: m, and is the heading angle of the lunar rover and its unit is rad.
The dynamics model of the lunar rover takes into account factors such as the rover’s mass, inertia, and the interaction forces between the wheels and the ground. The dynamics model can be described by the following system of equations:
Here, is the mass of the lunar rover, and its unit is kg; is the moment of inertia of the lunar rover about the z-axis, and its unit is kg; and are the driving forces of the lunar rover in the x and y directions; is the steering torque; is the gravitational acceleration on the lunar surface ; is the pitch angle of the lunar rover, and its unit is rad; and is the roll angle of the lunar rover, and its unit is rad.
2.2.3. Sensor Simulation
The stereo vision principle is used to simulate the RGB-D camera, with key parameters including focal length, principal point coordinates, baseline distance, and resolution.
Parameters of the RGB-D camera: focal length
f = 0.05 m, baseline distance
B = 0.1 m, resolution 640 × 480. The sensor end-to-end latency is 80 ms (including 20 ms for image acquisition, 50 ms for YOLOv5 detection, and 10 ms for DisNet distance calculation), which meets the real-time control requirements.
Table 1 demonstrates the validation of quantitative parameters for the digital twin environment.
The formula for generating depth images is as follows:
where
is the disparity map (in pixels),
is the baseline distance, and
is the equivalent focal length (in meters).
RGB Image Generation: The texture mapping algorithm projects the material properties of the lunar terrain model onto the camera coordinate system to produce a color image. The output of YOLOv5 includes bounding box coordinates and class confidence. Based on the bounding box output from YOLOv5, DisNet calculates the target distance using the depth image. The depth image, RGB image, target orientation angle, and distance are integrated into the state vector
. The formula for generating the state vector is as follows:
where
is the target orientation angle calculated from the image, with the unit of rad, and
is the target distance computed by DisNet, with the unit of m.
With the above model, the digital twin environment can accurately simulate the sensor data collection process and provide reliable input for the path planning algorithm.
2.3. Path Planning Algorithm Based on D3QN
The path planning method proposed in this study adopts a two-tier architecture, dividing the path planning task into static global path planning and dynamic local path adjustment. This approach fully leverages the advantages of both the A* algorithm and the D3QN algorithm.
2.3.1. Static Path Planning Layer
The A* [
2] algorithm is a classic heuristic search algorithm used to find the shortest path from the start point to the goal point in a graph. It combines the optimality of Dijkstra’s [
3] algorithm with the efficiency of the greedy best-first search algorithm. The algorithm selects the next node to expand based on an evaluation function
. The evaluation function
consists of two parts. The first part, the actual cost
, represents the actual path cost from the start point to the current node. In lunar rover path planning, the actual cost can be calculated based on factors such as path length and terrain complexity. The second part is the heuristic estimate
, which represents the estimated cost from the current node n to the goal node. To ensure the optimality of the A* algorithm, the heuristic function must satisfy the consistency (or monotonicity) condition. This means that for any node n and its neighboring node m, the following inequality must hold:
c(
n,
m)
, where
c(
n,
m) is the actual cost of moving from node
n to node
m. In this study, the Manhattan distance is used as the heuristic function, which calculates the sum of the horizontal and vertical distances between the current node and the goal node. It is simple and computationally efficient.
The core formula is as follows:
where
represents the actual cost from the start point to the current node, and
is the heuristic function, which in this case is the Manhattan distance. The formula for the Manhattan distance is given by the following:
The coordinates of the goal node are (, ), and the coordinates of the current node are (, ).
2.3.2. Dynamic Path Adjustment Layer
Deep Q-Network is a reinforcement learning algorithm that combines deep neural networks with Q-learning. It uses neural networks to approximate the Q-value function, which addresses the limitations of traditional Q-learning when dealing with high-dimensional state spaces. However, DQN suffers from issues such as overestimating Q-values and slow convergence. The Duel Deep Q-Network effectively mitigates these issues by introducing a dueling network architecture and double Q-learning mechanism. In this study, the D3QN algorithm is used to handle path adjustment in dynamic environments, enabling intelligent decision-making based on real-time environmental and sensor data.
To further enhance the performance of the D3QN algorithm, this study improves its reward function and prioritized experience replay mechanism. The design of the reward function directly affects the learning behavior of the agent. A well-designed reward function can guide the agent to learn the optimal strategy more efficiently. The prioritized experience replay mechanism adjusts the sampling probability based on the importance of experience samples, allowing the network to make more effective use of valuable experiences, thus accelerating convergence.
The design of the state space needs to comprehensively consider the environmental information and task objectives of the lunar rover. In this study, multi-source sensor data is used to construct the state vector , which includes depth images, target direction angles, and target distances. Depth images provide 3D geometric information about the lunar surface, helping the lunar rover identify the position and shape of obstacles. The target direction angle and target distance clarify the relative position of the lunar rover to the target point, offering directional guidance for path planning.
Depth images acquired from depth cameras typically exhibit high resolution and rich detail. To reduce computational load and enhance network training efficiency, the images undergo preprocessing steps. First, the image dimensions are resized to 80 × 64 pixels to align with the neural network’s input requirements. Subsequently, pixel values are normalized to the range [0, 1] to accelerate network convergence.
The target distance is calculated using an RGB camera integrated with the YOLOv5 object detection algorithm and the DisNet distance estimation algorithm, which provides distance information between the lunar rover and the target. The process begins by detecting the target’s bounding box (,,,) using YOLOv5. Based on the depth map and bounding box data, the actual distance dd is computed via DisNet using the formula , where H represents the predefined physical height of the target, and h denotes the height of the target’s bounding box in pixels.
The target orientation angle , reflecting the required steering direction for the rover, is derived by calculating the angular difference between the rover’s current position and the target location. This angle is obtained by first localizing the target in the image coordinate system using RGB data. The camera’s intrinsic parameters—focal length f and principal point )—are then applied to convert the target’s pixel coordinates into its relative azimuth angle. Finally, the angle value is normalized to the range [−π, π].
The speed actions .2 m/s and .4 m/s represent low-speed and high-speed movement, respectively. Under different terrain and environmental conditions, the lunar rover can choose the appropriate speed to improve driving efficiency and safety.
The steering actions /4, /8, 0, /8, and /4 represent a large left turn, a small left turn, moving straight, a small right turn, and a large right turn, respectively. Through these steering actions, the lunar rover can flexibly adjust its driving direction.
The action space comprises seven discrete actions combining velocity and steering angle configurations, defined as follows:
Low-speed sharp left turn: velocity = 0.2 m/s, steering angle = π/4.
Low-speed gentle left turn: velocity = 0.2 m/s, steering angle = π/8.
Low-speed straight motion: velocity = 0.2 m/s, steering angle = 0.
Low-speed gentle right turn: velocity = 0.2 m/s, steering angle = π/8.
Low-speed sharp right turn: velocity = 0.2 m/s, steering angle = π/4.
High-speed straight motion: velocity = 0.4 m/s, steering angle = 0.
Emergency stop: velocity = 0 m/s, activated for obstacle avoidance or mission termination.
For action selection, an ε-greedy strategy is implemented with an initial exploration rate (ε) of 0.5, which decays exponentially to a minimum value of 0.05 at a decay rate of 0.99. During later training phases, when the policy transitions toward exploitation, the strategy prioritizes selecting actions with the highest Q-values.
2.3.3. Improved Reward Function
The design of the reward function is a critical component of reinforcement learning, as it directly influences the agent’s learning performance and behavioral strategy. In this study, the principle for designing the composite reward function is to encourage the lunar rover to move towards the target while avoiding collisions with obstacles, improving driving efficiency and safety. By considering multiple factors, including path progress, obstacle avoidance, driving direction, energy consumption, and time consumption, a comprehensive reward function is designed.
In lunar rover path planning, the improved composite reward function guides the agent to learn the optimal strategy from multiple dimensions.
Path Progress Reward R_{progress}: This reward term is used to encourage the lunar rover to move towards the target. By comparing the current position with the previous position’s distance to the target, the path progress reward is calculated. If the rover is closer to the target, a positive reward is given; if it is farther from the target, a negative reward is given. The magnitude of the reward is proportional to the change in distance, allowing the rover to move towards the target more quickly. The calculation method is as follows:
is the distance from the lunar rover to the target point at the previous time step, and is the current distance to the target point. If < , it indicates that the lunar rover is approaching the target, and will be a positive reward. The larger the difference, the higher the reward. If the distance has not decreased or even increased, the reward will be negative, prompting the agent to adjust its strategy.
Obstacle Avoidance Reward R_{obstacle}: To prevent the lunar rover from colliding with obstacles, an obstacle avoidance reward term is designed. The distance to obstacles is detected using depth images and sensor data, and the weighted sum of obstacle distances in 8 directions is computed to obtain the obstacle avoidance reward. If an obstacle is detected to be nearby, a larger negative reward is given, encouraging the lunar rover to adjust its direction in time. The calculation method is as follows:
represents the distance to obstacles detected in the 8 directions around the lunar rover (obtained through depth cameras and other sensors), and is the predefined maximum detection distance. The closer the obstacle is (the smaller is), the smaller the value becomes, and after applying the negative sign, the absolute value of increases. This results in a stronger negative reward, which strongly penalizes behaviors that bring the rover closer to obstacles, forcing the agent to actively avoid them.
Direction reward R_{direction}: The direction reward is designed to guide the lunar rover towards the target direction. By calculating the cosine value of the angle between the current travel direction and the target direction, the direction reward is obtained. When the angle is small, the cosine value approaches 1, and a positive reward is given; when the angle is large, the cosine value approaches −1, and a negative reward is given. This ensures that the lunar rover moves more accurately towards the target direction. The calculation is as follows:
is the angle between the lunar rover’s current travel direction and the target direction. The value of ranges from [−1, 1], where the smaller the angle (the more accurate the direction), the closer is to 1, resulting in a higher reward. The larger the angle, the lower the reward, or even negative, which encourages the agent to adjust its direction to align with the target.
Energy Consumption Reward R_{energy}: Considering the limited energy of the lunar rover, an energy consumption reward term is designed. The reward is calculated by comparing the difference between the current travel speed and the optimal speed. If the travel speed deviates significantly from the optimal speed, a negative reward is given, encouraging the lunar rover to operate in a more energy-efficient manner. The calculation is as follows:
is the current travel speed, is the preset optimal energy-efficient speed, and is the maximum speed of the lunar rover. The larger the deviation between and , the greater the absolute value of , resulting in a more significant negative reward. This encourages the agent to travel at a reasonable speed, thereby conserving energy.
Time penalty R_{time}: To improve the efficiency of path planning, a time penalty term is designed. As time increases, a negative reward is given, encouraging the lunar rover to reach the target point as quickly as possible and minimize unnecessary time consumption. The calculation is as follows:
is the total time steps from the starting point to the current time. As time increases, the negative penalty accumulates, motivating the agent to plan the path efficiently, reduce time consumption, and improve task execution efficiency.
Through the collaborative effect of the five reward components, the agent (D3QN) can achieve a balance between path progress, obstacle avoidance, direction, energy consumption, and time efficiency, learning an efficient path planning strategy that adapts to the complex lunar environment.
2.3.4. Prioritized Experience Replay Mechanism
The traditional experience replay mechanism randomly samples experiences from the experience pool for training. This approach may cause the network to learn from some less important experiences while neglecting critical ones. The prioritized experience replay mechanism adjusts the sampling probability based on the importance of experience samples, enabling the network to more effectively learn from valuable experiences. In this study, the temporal difference (TD) error is used to measure the importance of experience samples. A larger TD error indicates that the experience sample is more valuable for updating the network.
TD-error Calculation: The TD-error
represents the difference between the current estimated Q-value and the target Q-value. The calculation formula is as follows:
where
r is the reward at the current time step,
is the discount factor,
target is the maximum Q-value of the next state estimated by the target network, and
is the Q-value estimated by the current network.
To avoid sampling issues caused by a TD-error of 0, a small positive value
is added to the TD-error, resulting in the priority
.
Sampling probability calculation: The sampling probability
) of an experience sample is directly proportional to its priority
, and is calculated as follows:
where
is the parameter that controls the priority level, with
= 0 indicating random sampling and
= 1 indicating sampling entirely based on priority.
During the training process, the experience replay buffer (ERB) is used in the following stages. When the agent interacts with the environment and executes an action, it collects relevant state information, the action taken, the reward obtained, and the next state, which are stored in the ERB. Specifically, after each action executed by the agent in the environment, a tuple (current state , action , reward r, next state , and termination flag) is stored in the ERB. This process continues from the start to the end of training, recording all historical experiences of the agent-environment interactions. In each training cycle, a mini-batch of experience samples is randomly sampled from the ERB to train the Q-network. These samples update the network’s weights and biases to improve the agent’s policy. For example, in the early training phase, once the ERB accumulates sufficient samples, 64 samples are randomly drawn for training in each cycle, enabling the agent to learn from past experiences and gradually enhance decision-making.
The prioritized experience replay (PER) mechanism introduces special usage of ERB. Experience samples are assigned priorities based on the TD error, i.e., the difference between the current predicted Q-value and the target Q-value. A larger TD error indicates higher importance of the sample, hence a higher priority. Sampling from ERB is performed according to these priorities rather than randomly, with high-priority samples having a higher selection probability to ensure the agent learns more from critical experiences. As training progresses, sample priorities are dynamically updated based on new TD errors. For instance, after each training cycle, the TD errors of sampled experiences are recalculated to update their priorities, allowing the ERB to continuously reflect the latest learning focus and facilitate more efficient learning.
2.4. Environmental Perception and Data Processing
The depth images are obtained using an RGB-D camera and provide 3D geometric information about surrounding objects. In this study, in addition to using the current depth image, the previous three depth images are also used to acquire 3D information about surrounding objects. Considering computational costs, all depth images are resized to 80×64. While the depth images provide essential information for the mobile robot to avoid both static and dynamic obstacles under the control of the agent, additional inputs are necessary for the robot to reach a given target. The first of these additional inputs is the direction of the target. In addition to providing this information as extra input to the fully connected layer of the model, it is also utilized within the reward-punishment system structure. The target direction information is obtained using the RGB camera and the OpenCV library in this study.
In the autonomous path planning task of the lunar rover, target detection and distance calculation are among the key technologies for achieving autonomous navigation and obstacle avoidance. In addition to the direction of the target, another additional input to the model is the target’s distance. First, the target must be detected to obtain the distance. A YOLOv3-based DisNet is used to detect the target and estimate the distance [
35]. DisNet is a deep neural network designed to extract depth information from images and estimate the distance to the target. The main goal of DisNet is to calculate the actual distance between the target object and the lunar rover based on the target’s bounding box in the image. In the path planning of the lunar rover, accurate distance estimation is crucial for determining path selection and obstacle avoidance effectiveness. YOLOv5, using the PyTorch (version 1.12.1) framework, provides higher detection accuracy and speed [
36]. Compared to YOLOv3, YOLOv5 offers improved detection precision and speed and performs better in complex scenes, providing more accurate target bounding boxes. Specifically, YOLOv5 utilizes an improved neural network architecture, achieving a better balance between processing speed and accuracy. The bounding box coordinates and the confidence scores for the target classes output by the model have been optimized, allowing for more precise target localization, making YOLOv5 particularly suitable for autonomous navigation of lunar rovers in complex environments. Furthermore, in the same lunar simulation scenario, we compared the performance of YOLOv3 and YOLOv5 using the mean average precision (mAP) at an Intersection over Union (IoU) threshold of 0.5. The dataset comprised 2000 annotated RGB images (synthetic + real lunar surface data), including lunar terrain obstacles such as craters and rocks. The results showed that YOLOv3 achieved an mAP of 72.3%, while YOLOv5 achieved 83.1%, representing a 15% relative improvement. The training data we use is a 1:1 mixture of real and simulation-generated data and is labeled using labeling. Therefore, in this study, the target detection implementation code was modified to adopt the YOLOv5 output results, and the target detection results were parsed based on YOLOv5’s optimizations. These results were then used as input for DisNet to estimate the distance. DisNet takes the target bounding boxes output by YOLOv5 and depth images as inputs. Its core task is to calculate the actual distance
between the target and the lunar rover based on the target’s size in the image and camera parameters through Equation (7). The feature calculation module is responsible for fusing multi-source data to integrate the feature vector
, including depth images, distance calculation
, and direction angle
. Finally, this information is provided as input data to the Deep Q-Network model, ultimately achieving path planning for the lunar rover.
Figure 4 illustrates the environmental perception and data processing system architecture.
In this study, YOLOv5 is used for real-time detection of objects (obstacles and target locations) around the lunar rover, while DisNet is employed to calculate the actual distance between the target and the rover, providing more accurate spatial perception information. In the digital twin environment, DisNet’s distance estimation results were validated against LiDAR measurements as ground truth, with the error metric being relative error (i.e., the difference between DisNet’s estimation and LiDAR measurements). Among 1500 test samples (distance range 1–20 m), 95% of errors fell within ±5% (with a maximum error of 6.2% at 20 m). Within the typical operational range of the lunar rover (1–10 m), the relative error is less than 5%. YOLOv5 takes pre-processed RGB images as input and outputs the bounding box coordinates and class confidence for each detected target object. Specifically, the output includes the bounding box coordinates
:(
,
,
,
) for the target, as shown in the following Formula (14), and the class confidence
for each target, as shown in Formula (15).
is the confidence of the i class target in the j detection box, is the coordinates of the target bounding box processed by the Sigmoid function, where σ represents the Sigmoid function, and is the confidence of the target.
YOLOv5 outputs the bounding box coordinates and class information of the target objects, while DisNet combines this information with the depth data of the image. Each detection box output by YOLOv5 not only contains the class of the target but also provides its position in the image. Therefore, DisNet estimates the depth of the target objects using the bounding box information provided by YOLOv5. The input channels of the DisNet network receive the target areas output by YOLOv5 and further extract depth features through convolutional layers.
In this study, DisNet estimates the target distance using the depth map, with the calculation formula given by Equation (16).
is the actual distance of the target object, is the focal length of the camera, is the actual height of the target object, and is the image height of the target obtained through DisNet, which corresponds to the height of the bounding box.
The feature calculation module constructs the feature vector
by combining the actual target distance
calculated by DisNet, the target direction angle
parsed from the image, and the processed depth image. The formula is shown as Equation (17).
where
is the target orientation angle calculated from the image, and
is the target distance calculated by DisNet.
By combining YOLOv5 and DisNet, the lunar rover is capable of precise target detection and distance calculation.
In summary, for depth images, the input layer of the D3QN neural network architecture accepts an 80 × 64 × 4 depth map sequence. The convolutional layers are structured as follows: Layer 1: 32 8 × 8 convolutional kernels with a stride of 4, activated by ReLU. Layer 2: 64 4 × 4 convolutional kernels with a stride of 2, activated by ReLU. Layer 3: 64 3 × 3 convolutional kernels with a stride of 1, activated by ReLU. Depth images are processed through these three CNN layers to automatically extract spatial features, such as edges, shapes, and relative positions of obstacles. The features extracted by the convolutional layers are flattened and concatenated with two additional features: target orientation angle and target distance , forming a comprehensive feature vector.
The fused feature vector is fed into a 512-dimensional fully connected layer, which further processes and integrates the features to enable the network to learn complex relationships among them. The output of the fully connected layer branches into two streams: the Value Stream and the Advantage Stream. The Value Stream evaluates the quality of the current state, while the Advantage Stream assesses the relative advantages of different actions in the current state. The output layer consists of seven neurons corresponding to the Q-values of seven discrete actions. Each neuron’s output represents the expected return of the corresponding action in the current state. The lunar rover selects the optimal action (e.g., forward movement or steering) based on these Q-values to achieve efficient path planning.
4. Conclusions
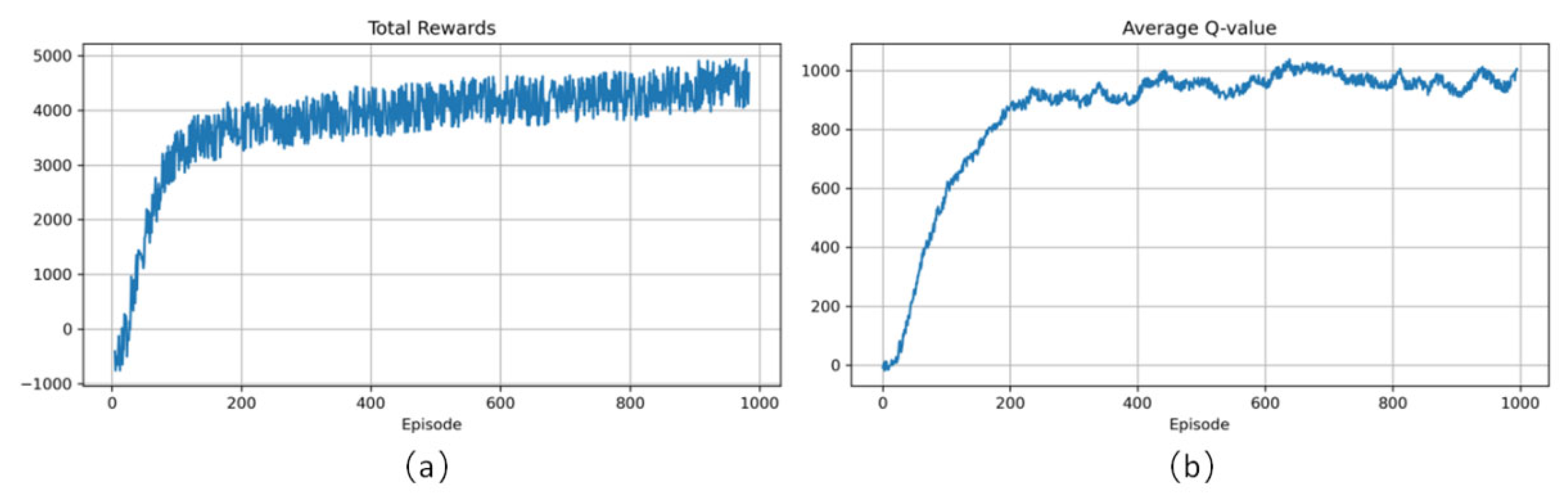
This study addresses the path planning challenges of lunar rovers in complex dynamic environments by proposing an A*-D3QN-Opt method that integrates digital twin technology with improved deep reinforcement learning. By constructing a hierarchical path planning architecture, optimizing deep reinforcement learning algorithms, and designing a multimodal perception system, the study achieves efficient navigation of the lunar rover under multiple constraints. The proposed A*-D3QN-Opt method significantly improves path planning efficiency and robustness through a synergistic mechanism of static global planning and dynamic local adjustments. The A* algorithm provides prior knowledge of the globally optimal path for deep reinforcement learning, effectively alleviating the exploration blindness (when the lunar rover performs path exploration in a complex and dynamic environment, due to the absence of effective prior knowledge or global guidance, its exploration behavior demonstrates blindness and inefficiency) inherent in reinforcement learning in complex environments. The improved D3QN algorithm, through a quintuple reward function and prioritized experience replay mechanism, enhances the rover’s real-time response capability to dynamic obstacles and sudden environmental changes. Experiments show that the method reduces path lengths by 50.7%, 24.2%, and 26.3% in low-, medium-, and high-complexity environments, respectively, compared to the traditional D3QN, verifying the superiority of the hierarchical architecture. The improved D3QN algorithm achieves multi-objective optimization through the quintuple reward function (path progress, obstacle avoidance, direction, energy consumption, and time penalty), successfully reducing collision counts to zero in high-complexity environments and increasing the average Q-value to 299.87. The prioritized experience replay mechanism, by dynamically adjusting the weight of experience samples, accelerates model convergence by approximately 30%, reducing training time by one hour in medium-complexity environments. The YOLOv5-DisNet multimodal perception system improves target detection accuracy by 15%, with distance estimation errors controlled within ±5%, providing reliable environmental information for path planning. The constructed digital twin model achieves high-fidelity mapping of lunar terrain, motion control, and task constraints, providing a safe and controllable simulation training environment for reinforcement learning. Through virtual-real interaction validation, the lunar rover, after completing 1000 training episodes in the virtual environment, quickly adapts to dynamic changes in real-world scenarios, significantly reducing trial-and-error costs in actual missions. This research provides an innovative solution for lunar rover path planning, although there is still room for improvement. Future work will focus on the development of multi-rover collaborative path planning algorithms and enhancing model robustness in extreme environments such as lunar nights with low temperatures and high radiation.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}