LLM-ACNC: Aerospace Requirement Texts Knowledge Graph Construction Utilizing Large Language Model

Abstract
1. Introduction
- (1)
- This study proposes Large Language Model with Augmented Construction, Continual Learning, and Chain-of-Thought Reasoning (LLM-ACNC), a method for constructing KG from aerospace requirement texts. The proposed method automatically extracts key entities and relations from unstructured requirement texts and effectively constructs high-quality KG to support intelligent requirement management.
- (2)
- An efficient, domain-adaptive continual learning approach based on token index encoding is introduced. This approach enhances the model’s focus on key textual information through token index encoding and improves its understanding of aerospace-specific texts via LoRA fine-tuning.
- (3)
- A CoT reasoning framework for entity and relation extraction is developed, complemented by a dynamic few-shot strategy; this enables the model to adaptively select few-shot examples based on the characteristics of input texts, thereby enhancing stability and accuracy in NER and RE reasoning tasks.
- (4)
- Experimental results demonstrate substantial improvements in NER and RE performance on aerospace requirement texts, achieving F1 scores of 88.75% and 89.48%, respectively.
2. Background
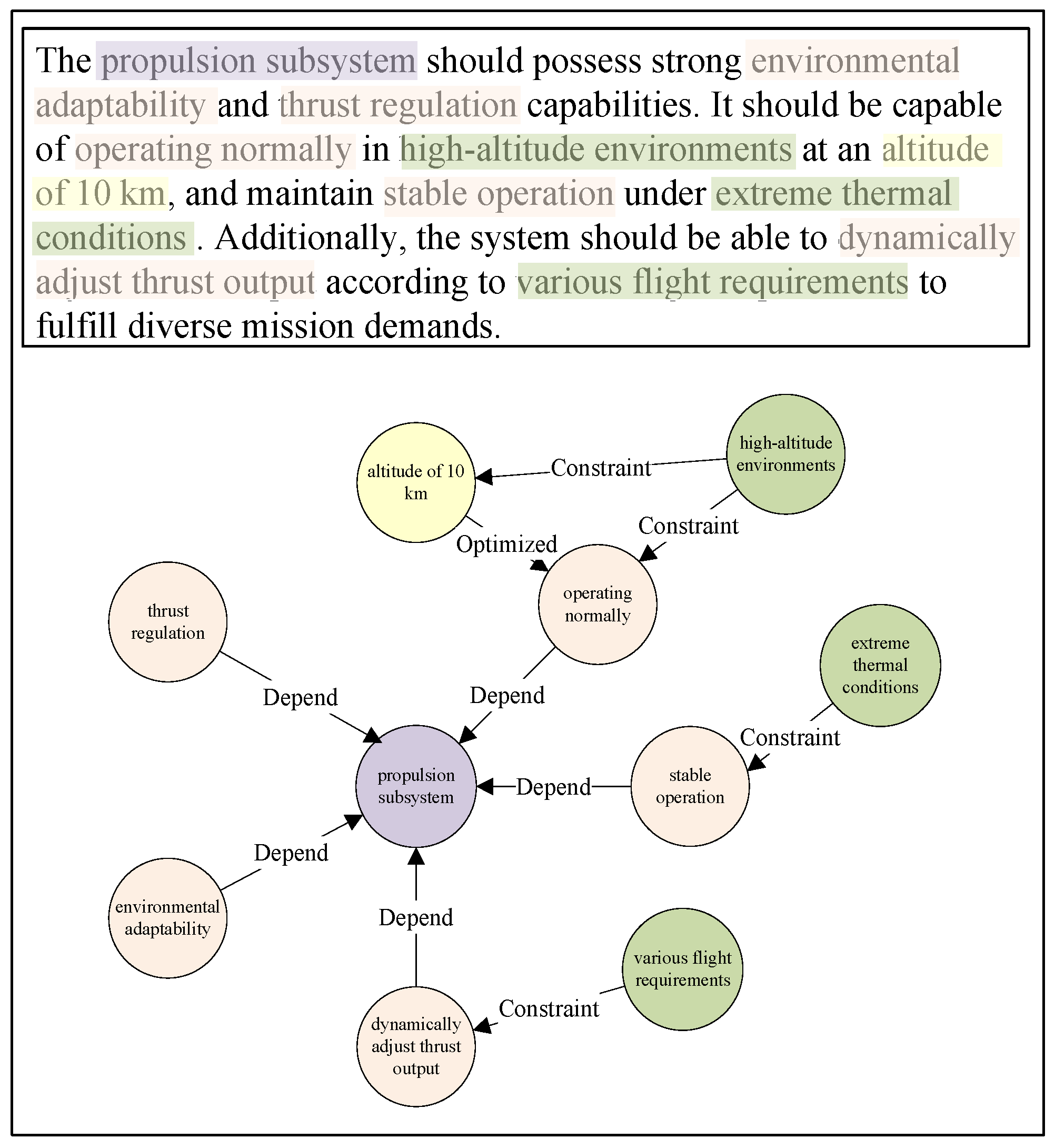
2.1. Motivation Example
2.2. LLM for KG
2.3. Continual Learning
2.4. Chain of Thought
3. Methods
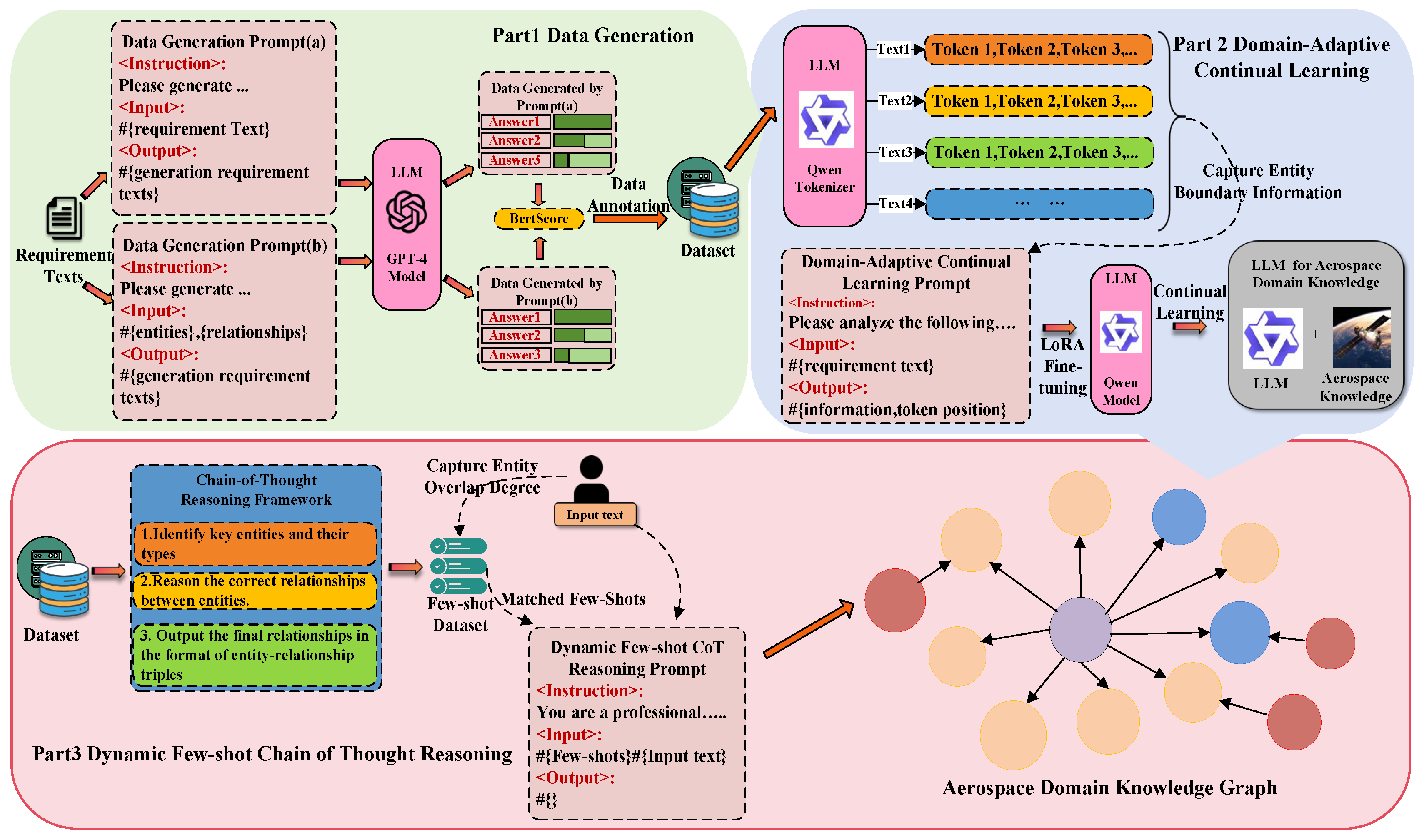
3.1. Overview of the Method
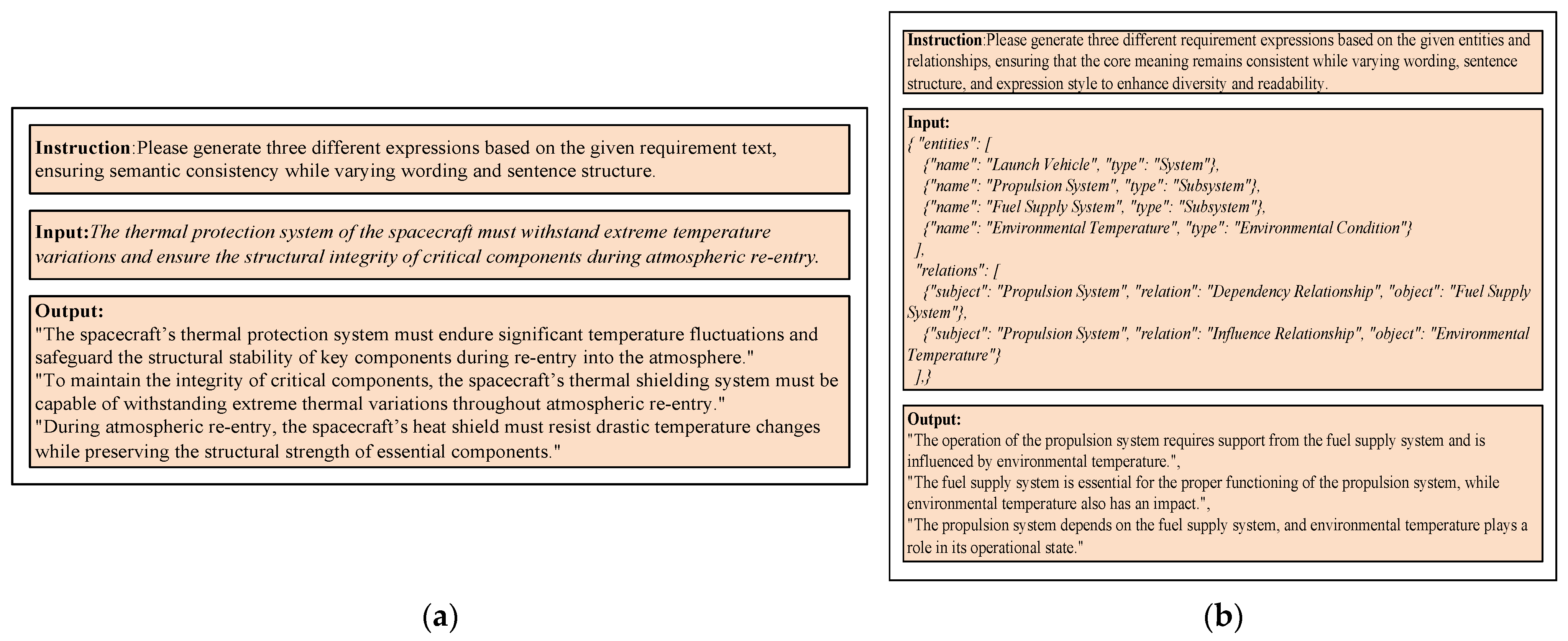
3.2. Data Generation
3.3. Domain-Adaptive Continual Learning
3.4. Dynamic Few-Shot Chain of Thought Reasoning
3.5. KG Generation
4. Experiment and Analysis
4.1. Evaluation of Model Performance
4.1.1. NER and RE Performance Evaluation
4.1.2. Evaluation of Domain-Adaptive Continual Learning Performance
4.1.3. Evaluation of Dynamic Few-Shot CoT Reasoning
4.2. Fine-Tuning Epoch Settings
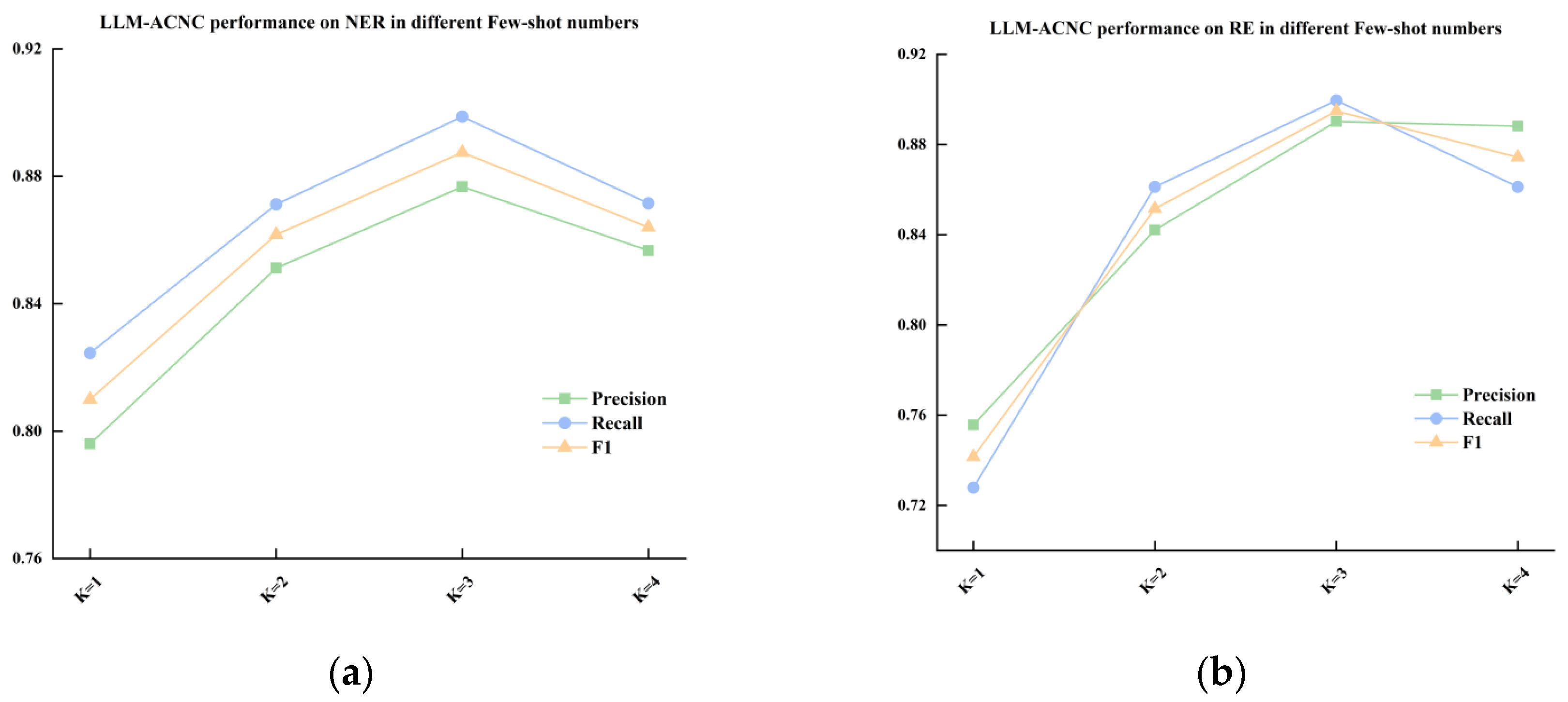
4.3. Few-Shot Example Number Configuration
4.4. Performance on Real Datasets
5. Case Study
6. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| KG | Knowledge Graph |
| SysML | Systems Modeling Language |
| NER | Named entity recognition |
| RE | Relation extraction |
| NLP | Natural Language Processing |
| LLM | Large Language Model |
| CoT | Chain of Thought |
| LoRA | Low-Rank Adaptation of Large Language Models |
| LLM-ACNC | Large Language Model with Augmented Construction, Continual Learning, and Chain-of-Thought Reasoning |
References
- INCOSE. INCOSE Systems Engineering Handbook; John Wiley & Sons: Hoboken, NJ, USA, 2023. [Google Scholar]
- Jia, J.; Zhang, Y.; Saad, M. An approach to capturing and reusing tacit design knowledge using relational learning for knowledge graphs. Adv. Eng. Inform. 2022, 51, 101505. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, K.; Li, Y.; Liu, Y. Data-driven concept network for inspiring designers’ idea generation. J. Comput. Inf. Sci. Eng. 2020, 20, 031004. [Google Scholar] [CrossRef]
- AlDhafer, O.; Ahmad, I.; Mahmood, S.J.I.; Technology, S. An end-to-end deep learning system for requirements classification using recurrent neural networks. Inf. Softw. Technol. 2022, 147, 106877. [Google Scholar] [CrossRef]
- Gao, Q.; Zhao, C.; Sun, Y.; Xi, T.; Zhang, G.; Ghanem, B.; Zhang, J. A unified continual learning framework with general parameter-efficient tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 11483–11493. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res. 2023, 24, 11324–11436. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Roumeliotis, K.I.; Tselikas, N.D. Chatgpt and open-ai models: A preliminary review. Future Internet 2023, 15, 192. [Google Scholar] [CrossRef]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D. Emergent abilities of large language models. arXiv 2022, arXiv:2206.07682. [Google Scholar]
- Li, Q.; Chen, Z.; Ji, C.; Jiang, S.; Li, J. LLM-based multi-level knowledge generation for few-shot knowledge graph completion. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, Jeju, Republic of Korea, 3–9 August 2024. [Google Scholar]
- Lan, J.; Li, J.; Wang, B.; Liu, M.; Wu, D.; Wang, S.; Qin, B. NLP-AKG: Few-Shot Construction of NLP Academic Knowledge Graph Based on LLM. arXiv 2025, arXiv:2502.14192. [Google Scholar]
- Zhang, J.; Wei, B.; Qi, S.; Liu, J.; Lin, Q. GKG-LLM: A Unified Framework for Generalized Knowledge Graph Construction. arXiv 2025, arXiv:2503.11227. [Google Scholar]
- Tian, S.; Luo, Y.; Xu, T.; Yuan, C.; Jiang, H.; Wei, C.; Wang, X. KG-adapter: Enabling knowledge graph integration in large language models through parameter-efficient fine-tuning. In Proceedings of the Findings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 3813–3828. [Google Scholar]
- Sun, L.; Zhang, P.; Gao, F.; An, Y.; Li, Z.; Zhao, Y. SF-GPT: A training-free method to enhance capabilities for knowledge graph construction in LLMs. Neurocomputing 2025, 613, 128726. [Google Scholar] [CrossRef]
- Chaudhry, A.; Dokania, P.K.; Ajanthan, T.; Torr, P.H. Riemannian walk for incremental learning: Understanding forgetting and intransigence. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 532–547. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef]
- Li, Z.; Hoiem, D. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2935–2947. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, J.; Ghosh, S.; Li, D.; Tasci, S.; Heck, L.; Zhang, H.; Kuo, C.-C.J. Class-incremental learning via deep model consolidation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1131–1140. [Google Scholar]
- Chen, T.; Goodfellow, I.; Shlens, J. Net2net: Accelerating learning via knowledge transfer. arXiv 2015, arXiv:1511.05641. [Google Scholar]
- Isele, D.; Cosgun, A. Selective experience replay for lifelong learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Qin, C.; Joty, S. Lfpt5: A unified framework for lifelong few-shot language learning based on prompt tuning of t5. arXiv 2021, arXiv:2110.07298. [Google Scholar]
- Razdaibiedina, A.; Mao, Y.; Hou, R.; Khabsa, M.; Lewis, M.; Almahairi, A. Progressive prompts: Continual learning for language models. arXiv 2023, arXiv:2301.12314. [Google Scholar]
- Madotto, A.; Lin, Z.; Zhou, Z.; Moon, S.; Crook, P.; Liu, B.; Yu, Z.; Cho, E.; Wang, Z. Continual learning in task-oriented dialogue systems. arXiv 2020, arXiv:2012.15504. [Google Scholar]
- Ke, Z.; Shao, Y.; Lin, H.; Konishi, T.; Kim, G.; Liu, B. Continual pre-training of language models. arXiv 2023, arXiv:2302.03241. [Google Scholar]
- Qin, Y.; Zhang, J.; Lin, Y.; Liu, Z.; Li, P.; Sun, M.; Zhou, J. Elle: Efficient lifelong pre-training for emerging data. arXiv 2022, arXiv:2203.06311. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large language models are zero-shot reasoners. Adv. Neural Inf. Process. Syst. 2022, 35, 22199–22213. [Google Scholar]
- Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Narang, S.; Chowdhery, A.; Zhou, D. Self-consistency improves chain of thought reasoning in language models. arXiv 2022, arXiv:2203.11171. [Google Scholar]
- Zhang, Z.; Zhang, A.; Li, M.; Smola, A. Automatic chain of thought prompting in large language models. arXiv 2022, arXiv:2210.03493. [Google Scholar]
- Fu, Y.; Peng, H.; Sabharwal, A.; Clark, P.; Khot, T. Complexity-based prompting for multi-step reasoning. arXiv 2022, arXiv:2210.00720. [Google Scholar]
- Xu, X.; Tao, C.; Shen, T.; Xu, C.; Xu, H.; Long, G.; Lou, J.-G. Re-reading improves reasoning in language models. arXiv 2023, arXiv:2309.06275. [Google Scholar]
- Wang, L.; Xu, W.; Lan, Y.; Hu, Z.; Lan, Y.; Lee, R.K.-W.; Lim, E.-P. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. arXiv 2023, arXiv:2305.04091. [Google Scholar]
- Norheim, J.J.; Rebentisch, E.; Xiao, D.; Draeger, L.; Kerbrat, A.; de Weck, O.L. Challenges in applying large language models to requirements engineering tasks. Des. Sci. 2024, 10, e16. [Google Scholar] [CrossRef]
- Ronanki, K. Enhancing Requirements Engineering Practices Using Large Language Models. Licentiate Thesis, University of Gothenburg, Gothenburg, Sweden, 2024. [Google Scholar]
- Vogelsang, A.; Fischbach, J. Using large language models for natural language processing tasks in requirements engineering: A systematic guideline. In Handbook on Natural Language Processing for Requirements Engineering; Springer: Berlin/Heidelberg, Germany, 2025; pp. 435–456. [Google Scholar]
- Tikayat Ray, A.; Pinon-Fischer, O.J.; Mavris, D.N.; White, R.T.; Cole, B.F. aeroBERT-NER: Named-Entity Recognition for Aerospace Requirements Engineering Using BERT. In Proceedings of the AIAA SciTech 2023 Forum, National Harbor, MD, USA, 23–27 January 2023; p. 2583. [Google Scholar]
- Tikayat Ray, A.; Pinon Fischer, O.J.; White, R.T.; Cole, B.F.; Mavris, D.N. Development of a language model for named-entity-recognition in aerospace requirements. J. Aerosp. Inf. Syst. 2024, 21, 489–499. [Google Scholar] [CrossRef]
- Zheng, Z.; Liu, M.; Weng, Z. A Chinese BERT-based dual-channel named entity recognition method for solid rocket engines. Electronics 2023, 12, 752. [Google Scholar] [CrossRef]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. Bertscore: Evaluating text generation with bert. arXiv 2019, arXiv:1904.09675 2019. [Google Scholar]
- Song, C.; Han, X.; Zeng, Z.; Li, K.; Chen, C.; Liu, Z.; Sun, M.; Yang, T. Conpet: Continual parameter-efficient tuning for large language models. arXiv 2023, arXiv:2309.14763. [Google Scholar]
- Wu, T.; Luo, L.; Li, Y.-F.; Pan, S.; Vu, T.-T.; Haffari, G. Continual learning for large language models: A survey. arXiv 2024, arXiv:2402.01364. [Google Scholar]
- Ding, N.; Chen, Y.; Han, X.; Xu, G.; Xie, P.; Zheng, H.-T.; Liu, Z.; Li, J.; Kim, H.-G. Prompt-learning for fine-grained entity typing. arXiv 2021, arXiv:2108.10604. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A novel cascade binary tagging framework for relational triple extraction. arXiv 2019, arXiv:1909.03227. [Google Scholar]
- Cabot, P.-L.H.; Navigli, R. REBEL: Relation extraction by end-to-end language generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 16–20 November 2021; pp. 2370–2381. [Google Scholar]
- Rossiello, G.; Chowdhury, M.F.M.; Mihindukulasooriya, N.; Cornec, O.; Gliozzo, A.M. Knowgl: Knowledge generation and linking from text. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 16476–16478. [Google Scholar]
- Laplante, P.A.; Kassab, M. Requirements Engineering for Software and Systems; Auerbach Publications: Boca Raton, FL, USA, 2022. [Google Scholar]
- Rolls-Royce, P. EARS (Easy Approach to Requirements Syntax). In Proceedings of the 17th IEEE International Requirements Engineering Conference, Atlanta, GA, USA, 31 August–4 September 2009. [Google Scholar]





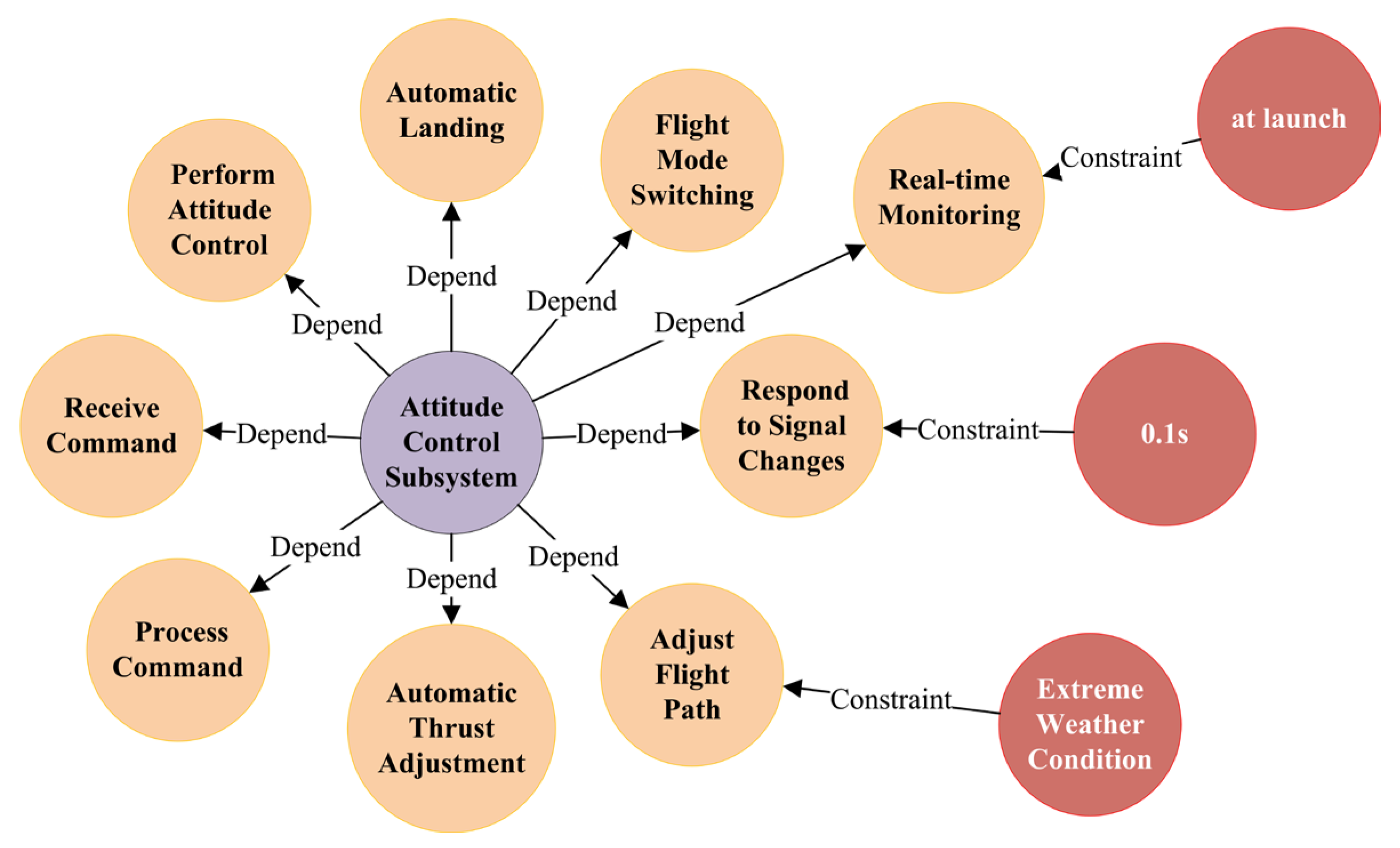


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity Type | Explanation |
|---|---|
| System | An integrated whole composed of multiple subsystems, typically designed to perform specific tasks or functions., e.g., launch vehicle |
| Subsystem | A component within a system; a system may contain multiple subsystems., e.g., control subsystem |
| Environment condition | External factors that affect the performance of a system or subsystem., e.g., under high-temperature environment |
| Functional requirement | A description of the functions that a system or subsystem must possess, specifying the tasks to be completed or the services to be provided., e.g., optimize launch sequence |
| Performance requirement | A description of the performance metrics that a system or subsystem must meet to ensure the expected operational efficiency and reliability., e.g., aerodynamic drag |
| Indicator parameter | Quantitative standards used to measure the functionality and performance of a system or subsystem., e.g., 100 Mpa |
| Relation Type | Explanation |
|---|---|
| Include | A hierarchical relationship indicating that one entity contains another entity. (System include Subsystem) |
| Support | A relationship where one entity provides functional support to another entity. (Subsystem support Subsystem) |
| Constraint | A relationship where one entity imposes limiting conditions on another entity, typically referring to mandatory design requirements. (Environment condition constraint Subsystem) (Environment condition constraint Functional requirement) |
| Depend | A relationship where one entity functionally or performance-wise depends on another entity. (Subsystem depend Functional requirement) |
| Optimized | A relationship indicating that one or more entities are optimized in terms of functionality or performance to improve efficiency or reduce costs. (Functional requirement optimized Indicator parameter) (System optimized Indicator parameter) (Performance requirement optimized Indicator parameter) |
| Satisfied | A relationship where one entity fulfills the requirements of another entity. (Subsystem satisfied Performance requirement) |
| Data Source | Numbers |
|---|---|
| Telemetry System | 2316 |
| Launch Support System | 1245 |
| Attitude Control Subsystem | 2347 |
| Ground Command Center | 942 |
| Propulsion System | 1073 |
| Total | 7923 |
| NER Precision | NER Recall | NER F1-Score | RE Precision | RE Recall | RE F1-Score | |
|---|---|---|---|---|---|---|
| CasRel | 0.5985 | 0.6746 | 0.6342 | 0.5321 | 0.4637 | 0.4955 |
| GPT-4 (Zero-shot) | 0.6418 | 0.6227 | 0.6321 | 0.6017 | 0.5168 | 0.5560 |
| GPT-4 (Few-shot) | 0.7212 | 0.6925 | 0.7065 | 0.7157 | 0.6974 | 0.7064 |
| REBEL | 0.6605 | 0.6423 | 0.6513 | 0.6275 | 0.6018 | 0.6144 |
| KnowGL | 0.6828 | 0.6722 | 0.6774 | 0.6436 | 0.6227 | 0.6330 |
| Our Proposed Method | 0.8767 | 0.8987 | 0.8875 | 0.8902 | 0.8995 | 0.8948 |
| NER Precision | NER Recall | NER F1-Score | RE Precision | RE Recall | RE F1-Score | |
|---|---|---|---|---|---|---|
| Without DACL | 0.6501 | 0.5531 | 0.5977 | 0.5483 | 0.6071 | 0.5762 |
| DACL-No TIE | 0.7852 | 0.8275 | 0.8058 | 0.7317 | 0.6927 | 0.7117 |
| Our Proposed Method | 0.8767 | 0.8987 | 0.8875 | 0.8902 | 0.8995 | 0.8948 |
| NER Precision | NER Recall | NER F1-Score | RE Precision | RE Recall | RE F1-Score | |
|---|---|---|---|---|---|---|
| Fixed Few-shot | 0.7169 | 0.6837 | 0.6999 | 0.6603 | 0.5814 | 0.6183 |
| Fixed Few-shot + CoT | 0.7682 | 0.8181 | 0.7924 | 0.7603 | 0.7142 | 0.7366 |
| Dynamic Few-shot | 0.7250 | 0.6981 | 0.7112 | 0.6792 | 0.6721 | 0.6756 |
| Our Proposed Method | 0.8767 | 0.8987 | 0.8875 | 0.8902 | 0.8995 | 0.8948 |
| Number | System Requirement Item Template |
|---|---|
| 1 | The <system> shall perform <function> (under <environmental conditions>). |
| 2 | The <system> shall accomplish <function> (under <parameter constraints>). |
| 3 | The <performance requirement> of the <system> shall meet <parameter constraints>(under <environmental conditions>). |
| 4 | The <subsystem> shall perform <function> (under <environmental conditions>). |
| 5 | The <subsystem> shall accomplish <function>(under <parameter constraints>). |
| 6 | The <performance requirement> of the <subsystem> shall meet <parameter constraints> (under <environmental conditions>). |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Hou, J.; Chen, Y.; Jin, J.; Wang, W. LLM-ACNC: Aerospace Requirement Texts Knowledge Graph Construction Utilizing Large Language Model. Aerospace 2025, 12, 463. https://doi.org/10.3390/aerospace12060463
Liu Y, Hou J, Chen Y, Jin J, Wang W. LLM-ACNC: Aerospace Requirement Texts Knowledge Graph Construction Utilizing Large Language Model. Aerospace. 2025; 12(6):463. https://doi.org/10.3390/aerospace12060463
Chicago/Turabian StyleLiu, Yuhao, Junjie Hou, Yuxuan Chen, Jie Jin, and Wenyue Wang. 2025. "LLM-ACNC: Aerospace Requirement Texts Knowledge Graph Construction Utilizing Large Language Model" Aerospace 12, no. 6: 463. https://doi.org/10.3390/aerospace12060463
APA StyleLiu, Y., Hou, J., Chen, Y., Jin, J., & Wang, W. (2025). LLM-ACNC: Aerospace Requirement Texts Knowledge Graph Construction Utilizing Large Language Model. Aerospace, 12(6), 463. https://doi.org/10.3390/aerospace12060463