1. Introduction
In recent years, the regional coverage problem has garnered substantial research attention. The acceleration-based coverage interception algorithm that controls flight angle [
1] is mainly applicable in two-dimensional space, using acceleration coverage to intercept the target. However, acceleration coverage does not equate to regional coverage in three-dimensional space; it only covers the maneuvering range of the target, unable to effectively cover the target’s activity range in three-dimensional space. Moreover, the collaborative allocation interception strategy proposed in [
2] is based on multi-missile coverage in two-dimensional space. However, this strategy is also limited to two dimensions and cannot be applied in three-dimensional space, potentially creating escape vulnerabilities. Another three-dimensional cooperative coverage interception strategy for intercepting highly maneuverable targets [
3] achieves all-around coverage by calculating the arc length of the interception region, but it does not account for the influence of interception time, which could cause the target to exit the interception region. In [
4,
5,
6], several cooperative guidance strategies based on coverage range were proposed, where each missile’s interception region is pre-allocated based on zero-control miss distance, ensuring that all missile interception regions cover the target. However, the zero-control miss distance is computed using a linearized guidance model, and significant linearization errors may lead to coverage failure.
In [
7], a differential game strategy was proposed to solve the multiple-to-one pursuit problem, but the control input in this strategy is based on angles. This paper considers normal acceleration as the control input, as relying solely on angle changes significantly differs from the actual situation, leading to large miss distances that prevent the pursuers from successfully intercepting the target. In [
8,
9], differential game strategies are also used for interception, but the control input remains angle-based, while for missiles, normal acceleration is typically used as the control input [
10].
The guidance strategies in the aforementioned literature contain errors and mismatches between the control inputs and the actual conditions, making them unsuitable for multi-to-one missile interception. In three-dimensional space, miss distance is closely related to errors, and reinforcement learning training can effectively reduce errors. Therefore, this paper proposes the Q-learning-cover algorithm to compute the missile guidance strategy. There has been substantial research in the field of reinforcement learning, addressing the optimal problem of systems through experience [
11]. Reinforcement learning was initially introduced in [
12] and is one of the most common and fundamental reinforcement learning algorithms used to describe unknown systems via Markov decision processes. The convergence of Q-learning has been extensively studied and proven through various methods, including the original proof [
13], random approximation and contraction mapping methods [
14], and ordinary differential equation approaches [
15]. In [
16], a minimax Q-learning-based algorithm was proposed to solve zero-sum games between two players. However, this algorithm involves significant computation and usually requires rapid iteration in pursuit problems, making it unsuitable for such scenarios. The algorithm designed in this paper aims to achieve iteration within 200ms. Although the training time is longer, the model used for encirclement needs to complete an iteration quickly. In [
17], a new control theory framework is provided to analyze Q-learning’s convergence, introducing bias terms and Lyapunov functions for analyzing the algorithm’s convergence in switched systems. This paper also adopts this approach to analyze the impact of encirclement and time coordination on the convergence of the pursuit system. Similarly, in [
18,
19], new Q-learning update schemes are proposed. To ensure convergence in finite time, Reference [
20] used Lyapunov theory to analyze the convergence of finite-time sampling algorithms. This paper also uses Lyapunov functions, but it focuses on proving the iteration upper bound and ensuring finite-time convergence by establishing the existence of the iteration upper bound.
Regarding synchronous time interception, many scholars have conducted in-depth research, and a new guidance method provides a computational approach for interception time [
21]. This method is mainly applied in two-dimensional planes, where the normal acceleration is calculated by determining the deviation between the expected and actual arrival times. Similar to the aforementioned references, pre-time prediction methods are used to solve the interception of anti-ship missiles in maritime environments. These methods are primarily suited for two-dimensional planes, and multi-to-one missile interception designs analyze changes in expected interception time based on angle variations [
22]. In contrast to the idealized conditions considered in the aforementioned literature, this paper introduces a time prediction-based method to address the interception of anti-ship missiles in maritime environments. The derived guidance strategy can achieve precise interception within a specified time window [
23]. Notably, all three referenced works rely on iterative methods to compute flight times, whereas [
24] proposes a recursive time calculation method, updating time non-iteratively. Furthermore, Reference [
25] introduces a recursive time estimation method that compensates for errors caused by non-zero initial heading errors and non-iteratively updates the missile’s remaining flight time.
In [
26], flight time is calculated by dividing relative distance by relative speed, whereas [
27] uses relative distance, target and missile speeds, and missile heading angles to calculate flight time. However, in many cases, these estimation methods fail to predict lead time accurately, resulting in the missile not achieving synchronous interception under CPN guidance laws.
To effectively intercept highly maneuverable targets, a multi-to-one cooperative interception strategy presents an effective solution. In recent years, numerous advanced cooperative guidance methods have emerged. Several cooperative interception strategies have been proposed in two-dimensional space. For example, a geometric-based synchronous target interception method was introduced in [
28], and a time-constrained guidance law was designed in [
29] to control missiles to attack synchronously at a specified time. For non-maneuvering targets, Reference [
30] designed a new two-dimensional impact time guidance law for zero-error interception. Reference [
31] proposed a sliding mode-based interception time guidance rate to solve the synchronous interception problem under large navigation angle errors. Furthermore, Reference [
32] proposed two cooperative guidance schemes with impact angles and time constraints, designed to intercept maneuvering targets, either with or without lead missiles.
Reference [
33] proposed an improved combined navigation guidance law that integrates proportional navigation, angle acceleration, and fixed lead navigation. Reference [
34] introduced a multi-to-one cooperative proportional guidance law that enables missiles of different speeds to intercept synchronously based on remaining flight time. Reference [
35] proposed a cooperative salvo guidance strategy using fixed finite-time consensus.
For the aforementioned two-dimensional cooperative guidance laws, References [
36,
37] proposed three-dimensional space guidance law design methods. In Reference [
38], an optimal strategy for solving non-collision games in three-dimensional space is introduced, including an optimal state feedback strategy for solving two-to-one interception problems. However, in non-collision games, both players must have complete information to compute the game strategy. In practice, some information (e.g., angle of view) may not be accessible. To address this issue, Reference [
39] proposed a two pursuers–one evader differential game cooperative strategy that analyzes the positional relationship between the two pursuers and one evader. Using the solution of the HJI equation in differential games, the optimal equations for pursuers and evaders are derived [
40]. In [
41], a new non-maneuvering aircraft air defense missile guidance law is proposed to solve the cooperative interception problem between pursuers. This solution is based on dynamic games and provides real-time optimal trajectories. Reference [
1] introduced a cooperative navigation strategy based on covering the flight line-of-sight angle.
The application of deep reinforcement learning in autonomous guidance systems has been widely discussed, especially in missile and UAV domains [
42]. These systems improve performance through real-time decision-making optimization, sensor fusion, and path planning. Reference [
43] proposed a missile trajectory control system based on artificial neural networks, which adapts to various operational environments, improving missile accuracy. Similarly, Reference [
44] introduced an adaptive missile guidance method, where a neural network adjusts guidance laws in real time based on environmental changes (e.g., wind speed or target maneuvering).
Neural networks have also been used in sensor fusion for guidance and navigation systems [
45], integrating data from radar, infrared, and GPS sensors to enhance system accuracy and robustness. Reference [
46] discussed the challenges faced by autonomous vehicles in real-time path planning and obstacle avoidance. Using deep learning algorithms (e.g., CNNs and reinforcement learning), neural networks optimize UAV navigation and control. Reference [
47] proposed a novel missile guidance method where neural networks adapt in real-time based on environmental conditions, improving missile accuracy and performance in uncertain environments.
Regarding the guidance rate in three-dimensional space, this paper proposes a proportional guidance law based on time deviation to achieve the synchronous interception of virtual targets. Unlike the previous methods, regarding stability analysis, Reference [
48] proposed a Lyapunov candidate function for analyzing the stability of neural networks in control systems. This Lyapunov function helps prove that, in the presence of interference, the weight norm of the neural network is always constrained by system design parameters. Similar Lyapunov methods are applied to analyze the interception performance of pure proportional navigation guidance laws in three-dimensional space.
In this paper, we aim to solve the problem of the strategic interception of a moving target in three-dimensional space by multiple pursuers using reinforcement learning techniques. Specifically, we focus on the multi-on-one pursuit scenario, where a set of pursuers must intercept a single evader while accounting for the evader’s dynamic motion and evasive strategies. The challenge lies in efficiently planning the pursuers’ trajectories in a complex 3D environment while minimizing computational costs and ensuring real-time decision-making.
The proposed Q-learning-cover algorithm integrates reinforcement learning with geometric covering methods to optimize the interception strategy. By leveraging the Q-learning framework, the algorithm enables pursuers to learn and adapt their behavior based on the evader’s movements. Furthermore, the use of a complex plane projection reduces the computational burden typically associated with real-time 3D trajectory planning, making the algorithm suitable for practical applications in real-time systems.
This paper introduces the Q-learning-cover algorithm, which combines regional coverage interception with time synchronization algorithms. The reward–punishment mechanism incorporates coverage probability and time penalty terms. The algorithm is trained based on various escapee motion patterns, generating new models to guide each pursuer’s strategy. In practical scenarios, the trained model can be loaded onto hardware to enable multiple pursuers to encircle a single evader.
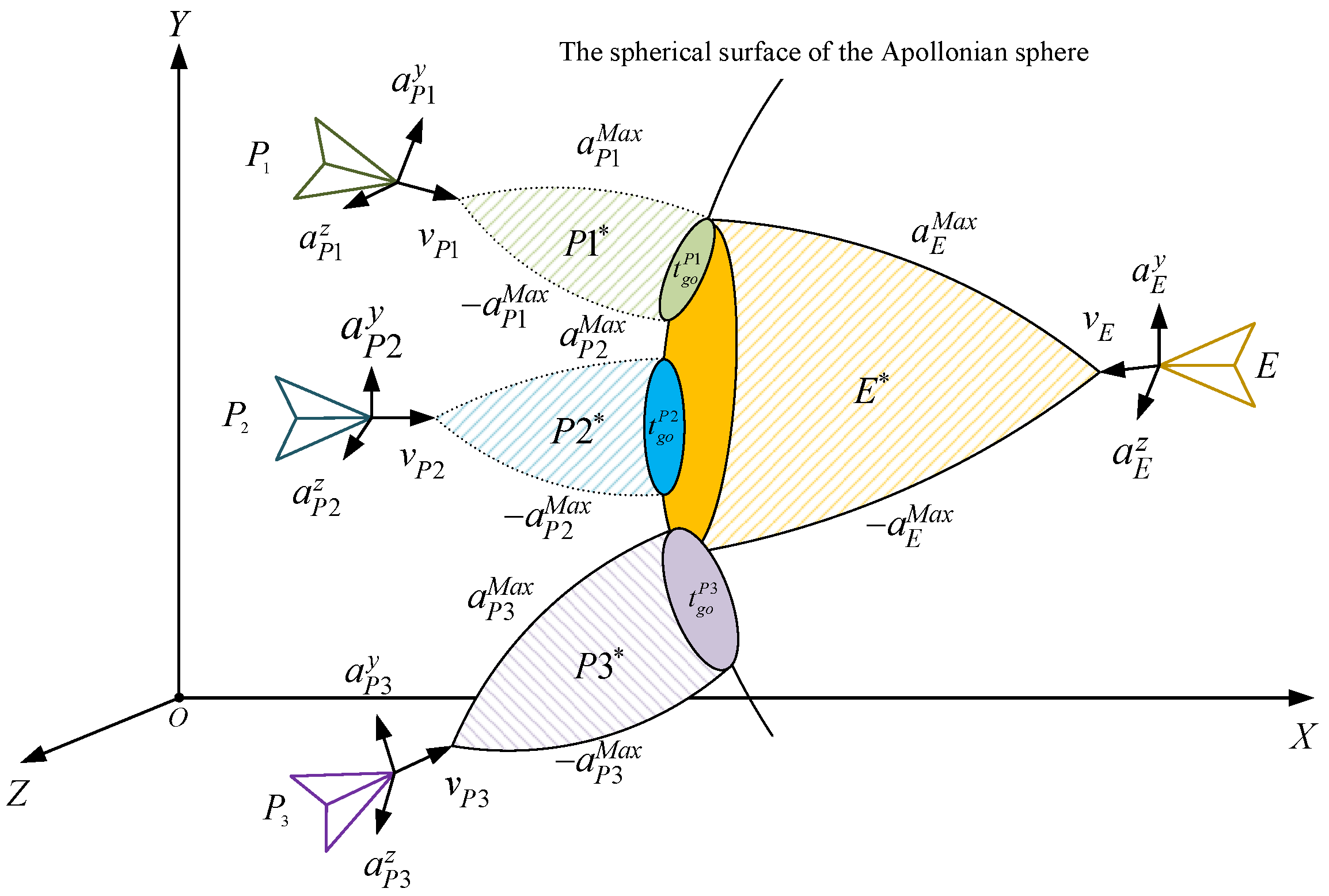
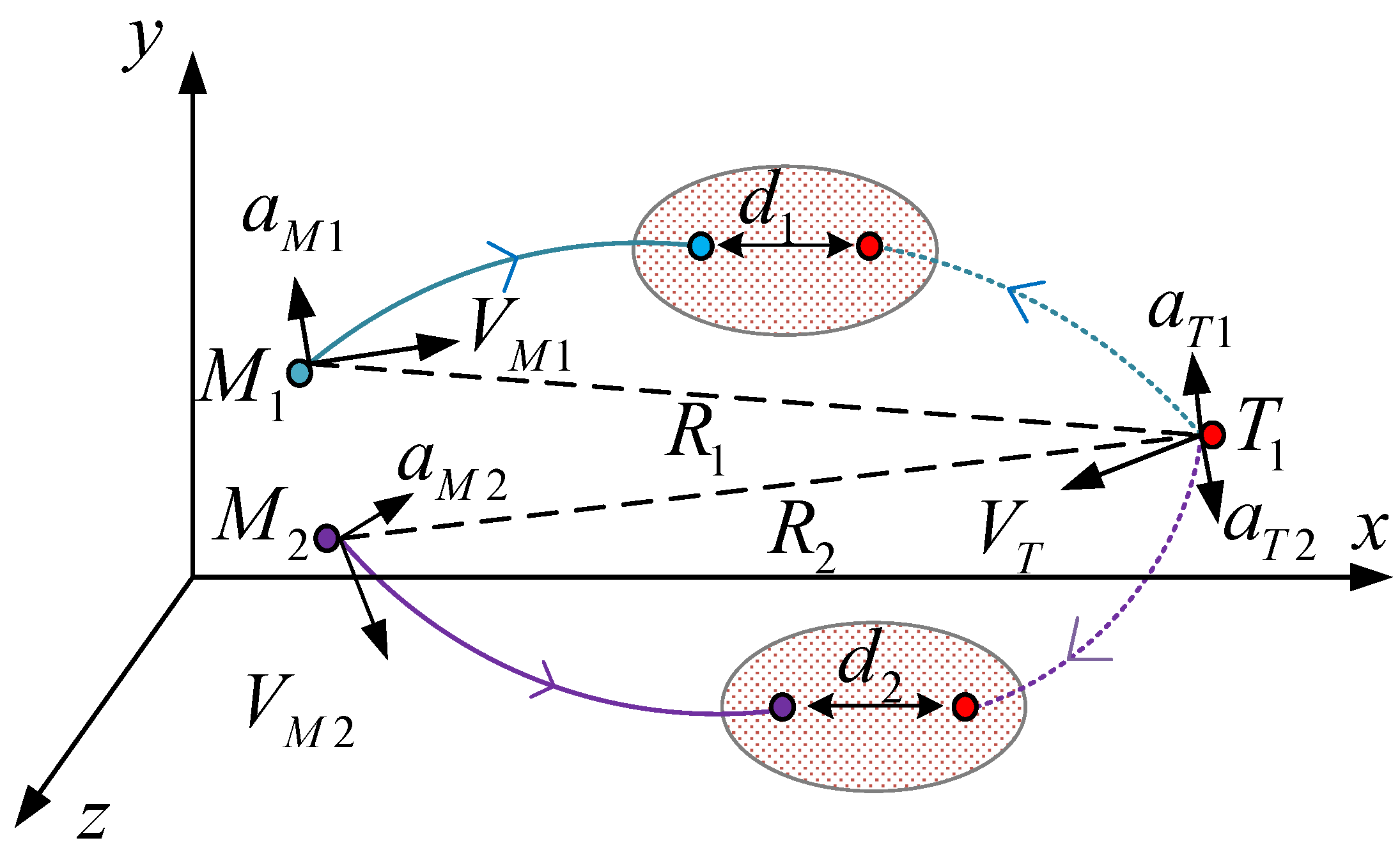
A schematic diagram of regional coverage interception is shown in
Figure 1.
The main contributions of this paper are as follows:
1. Introduction of the Q-learning-cover regional coverage interception algorithm: This paper innovatively proposes the Q-learning-cover algorithm, combining regional coverage with time coordination. By integrating the geometric relationship between the pursuers and evaders and the coverage strategy of reinforcement learning, the algorithm increases the pursuit coverage area with each iteration in three-dimensional space, thus improving the pursuers’ interception efficiency.
2. Simplification of calculations using spherical-to-complex plane mapping: By introducing projection mapping, this paper projects the maneuvering range of the pursuers and evaders on a three-dimensional sphere onto the complex plane, simplifying arc surface calculations. This approach converts the coverage problem in three-dimensional space into a geometric mapping problem on the plane, significantly reducing computation complexity and improving the algorithm’s operability and efficiency.
3. Convergence analysis of the Q-learning-cover algorithm: Based on the assumption of iteration limits, this paper proves the convergence of the Q-learning-cover algorithm. By optimizing the iteration process, it ensures that pursuers can quickly find the optimal strategy to effectively cover and intercept the evader, guaranteeing convergence within a finite time.
In this paper, we propose a novel Q-learning-cover algorithm that combines geometric coverage in 3D space with temporal synchronization. Unlike traditional methods, our approach utilizes offline training of the Q-learning algorithm, where the model is trained in a simulation environment on various escapee motion patterns. Once trained, the model is then deployed online for the real-time guidance of the pursuers. This allows the system to leverage the computational efficiency of offline training while still enabling dynamic, online application during interception. The Q-learning algorithm is trained offline on a powerful computing platform, and the trained model is subsequently loaded onto the embedded hardware for online execution in real-world scenarios.
The structure of this paper is as follows:
Section 2 describes the missile interception model in three-dimensional space;
Section 3 discusses spherical-to-complex plane projection mapping for calculating the maneuvering range of pursuers and evaders;
Section 4 presents the calculation method for interception time;
Section 5 provides the update formula and iteration limit constraints for the Q-learning-cover algorithm;
Section 6 presents the simulation platform used for missile interception.
Section 7 shows numerical simulation and hardware-in-the-loop simulation experiments;
Section 8 concludes the paper.
3. Coverage Interception Based on Spherical Polar Projection Mapping
The coverage probability calculation method designed in this paper primarily involves calculating the intersection point of the velocity vector with the Ahlswede ball in space, which corresponds to the center of an ellipse. By using the current normal acceleration, we compute the components along the
Y-axis and
Z-axis in the velocity coordinate system, thereby determining the major and minor axes of the ellipse. When the normal acceleration is zero, a small positive number is used as a substitute to ensure the validity of the coverage probability calculation. We assume that the Ahlswede ball between the pursuer and the evader is as follows:
where
Let
represent the velocity of the pursuer in three-dimensional space and
represent the velocity of the evader in three-dimensional space.
In this formula, we define the Apollonian sphere as the set of points in three-dimensional space that are bounded by a radius dependent on the velocities of both the pursuer and the evader. The variables represent the coordinates in space, while are the weighted averages of the pursuer’s positions in three-dimensional space, given by the following summations:
We assume that the pursuer’s velocity vector in the inertial reference frame follows the line equation:
where
are the position coordinates of the pursuer,
are the velocity components of the pursuer in three-dimensional space, and
is the time step.
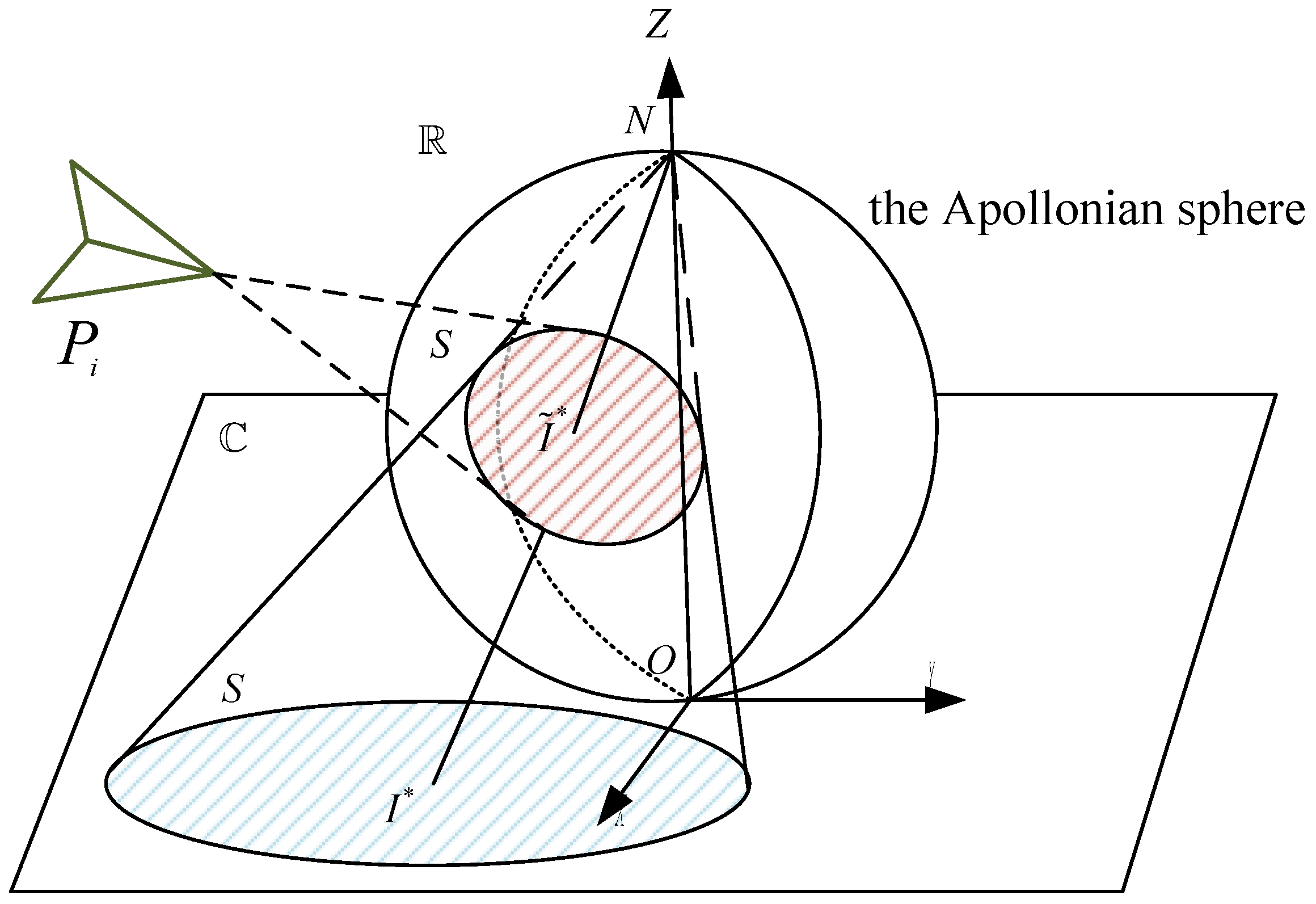
Spherical Polar Projection Mapping
When the pursuer’s velocity vector extends to the surface of the Ahlswede ball, it will cover the evader. To achieve this, we first need to allocate local coordinate systems on the sphere to describe the entire sphere through these local coordinate systems. This approach ensures that every point on the sphere has a unique corresponding coordinate. By combining these local coordinate systems, the entire sphere can be fully described. Next, we use spherical polar projection mapping to project these local regions from the three-dimensional real space onto a two-dimensional complex plane, as shown in
Figure 3. Overlapping regions: The local coordinate systems of the coverage regions projected by different pursuers often overlap, leading to intersecting small areas. In these overlapping regions, we need to ensure that the local coordinate systems are correctly transformed to maintain consistency between different areas. Coverage of the sphere: Since the sphere is a closed surface, multiple local coordinate systems are required to cover the entire sphere. For example, on the unit sphere
in three-dimensional space, multiple small regions can be formed through the pursuer’s region coverage, and a local coordinate system is defined for each small region. Ultimately, these local coordinate systems will work together to ensure maximum coverage of the area where the evader is located.
Select the coordinate system
such that
and
coincide with the
and
axes on the complex plane and
is perpendicular to the complex plane, with
aligned along the diameter
. The complex number
corresponds to the point
, and the center of the sphere has coordinates
. We can calculate the coordinates of point
N using the center of the sphere’s coordinates as follows:
This formula represents the calculation of the coordinates of point N in three-dimensional space, based on the center coordinates of the sphere . The coordinates represent the position of point P, and is an adjustment factor that scales the difference between point P and the sphere’s center. Specifically, influences the variation in the coordinates in relation to the center of the sphere. The denominator ensures the proper scaling and normalization of the coordinates, which is essential for maintaining the geometric relationships between the points in three-dimensional space. As varies, the calculated coordinates of point N adjust accordingly, reflecting the influence of the center’s position and the relative distance between the points.
This formula represents the calculation of the coordinates of point
N in three-dimensional space based on the sphere’s center coordinates
. The parameter
is an adjustment factor that influences the variation in
.
This equation calculates the new coordinates of point N by adding a correction term to the previous formula. The correction term is multiplied by the distance between the coordinates of the point P and the sphere’s center. The distance is represented by the Euclidean norm, which is the square root of the sum of the squared differences between the coordinates of the sphere center and point P. This term adjusts the calculated coordinates of point N, making it more accurate by accounting for the relative motion between the pursuer and evader.
Thus, the expression for the line
is as follows:
This formula describes the line equation , which represents the relationship between point N and the complex number . The coordinates are calculated based on the sphere’s center coordinates and the adjustment factor , which influences the geometry of the problem. The correction term is applied to the z-coordinate to account for the distance and improve the accuracy of the model.
Therefore, the line equation can be expressed as follows:
This represents the ratio form of the line equation, which is used to express the relationship between the points on the sphere and the complex plane. Each of the three equations in the ratio form corresponds to the normalized difference between the coordinates and the respective coordinates of the point N on the sphere. This form is essential for modeling the geometric relationship between the positions of the pursuer and the evader in three-dimensional space, ensuring that the calculations remain consistent and accurate.
To simplify subsequent calculations, we define the following:
Here, we define new variables , and to simplify the subsequent calculations. These variables are derived from the previous expressions for the coordinates of point N and the correction term. The variables represent the adjusted coordinates of point P, while represents a correction factor that accounts for the distance between the points on the sphere. By introducing these simplified variables, we reduce the complexity of the formulas and make the upcoming steps in the calculation more manageable.
At this point, the line equation can be rewritten as follows:
This represents the simplified form of the line equation, using to represent the parameters of the line. By expressing the equation in terms of these new variables, we streamline the process of calculating the corresponding points on the sphere and the complex plane. The simplified equation reduces the complexity and allows for easier manipulation in subsequent calculations.
We can express the correspondence between points on the sphere and points on the complex plane as follows:
These formulas illustrate the correspondence between points on the sphere and points on the complex plane. They provide the relationships between the coordinates on the complex plane and the corresponding coordinates on the sphere, adjusted by the values of . This correspondence is crucial for converting between the two coordinate systems and analyzing their geometric relationship.
Furthermore, the correspondence between points on the complex plane and points on the sphere is given by the following:
These formulas provide expressions for solving the coordinates on the sphere based on the known coordinates on the complex plane. They demonstrate the precise relationship between the sphere and the complex plane, allowing for the conversion between the two coordinate systems. These equations are essential for mapping the points on the sphere to the complex plane and vice versa, which is key to understanding the geometric relationship between the two systems.
Through spherical polar projection, a circle not passing through point
N is mapped to a circle on the complex plane. Suppose the equation of the spherical circle is
The equation of the circle on the complex plane can be written as
This equation is used to represent the relationship between the circle on the sphere and the circle on the complex plane. In the simulation process, by solving the system of equations, we obtain the expressions for each parameter, which leads to the equation of the circle on the complex plane.
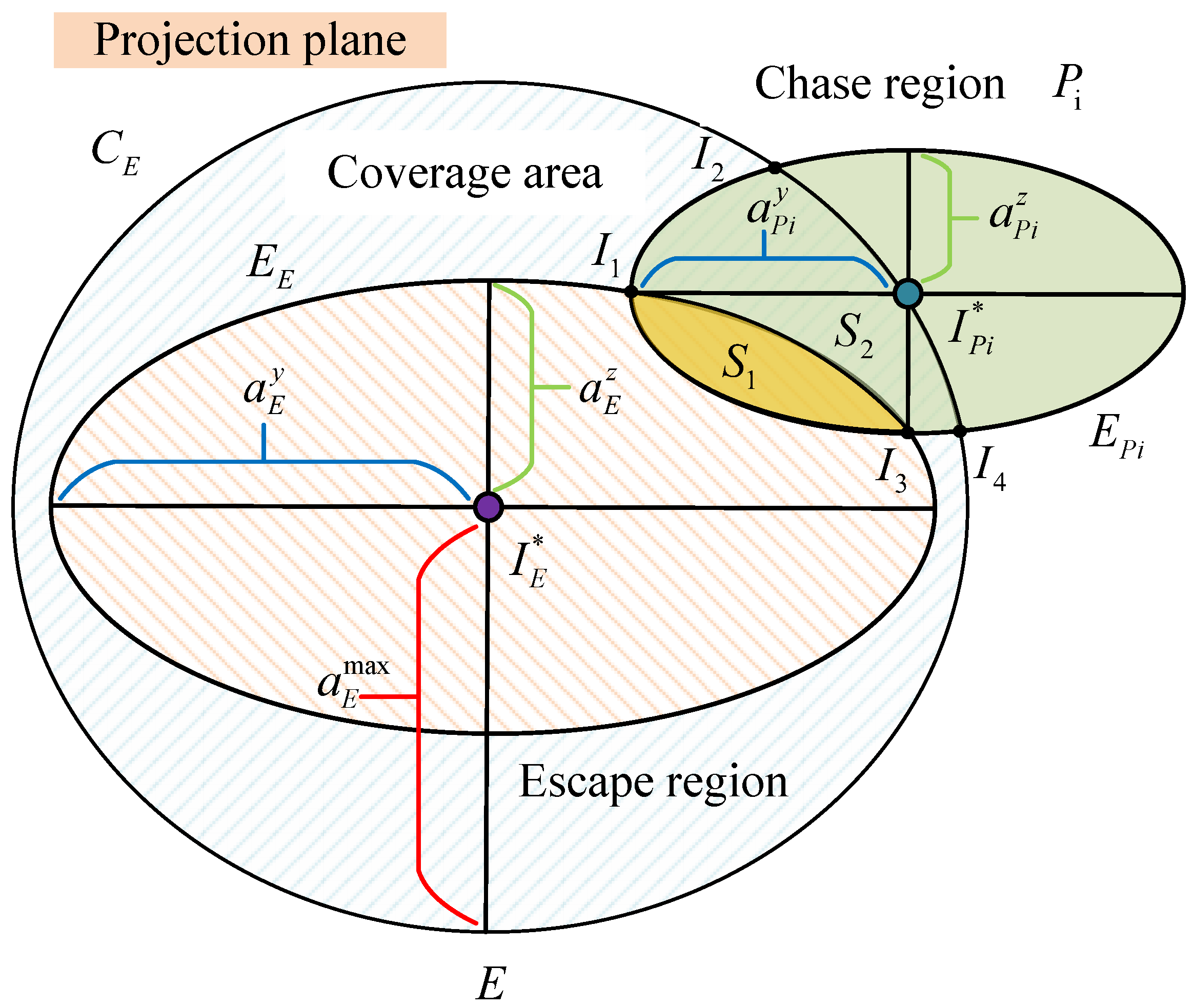
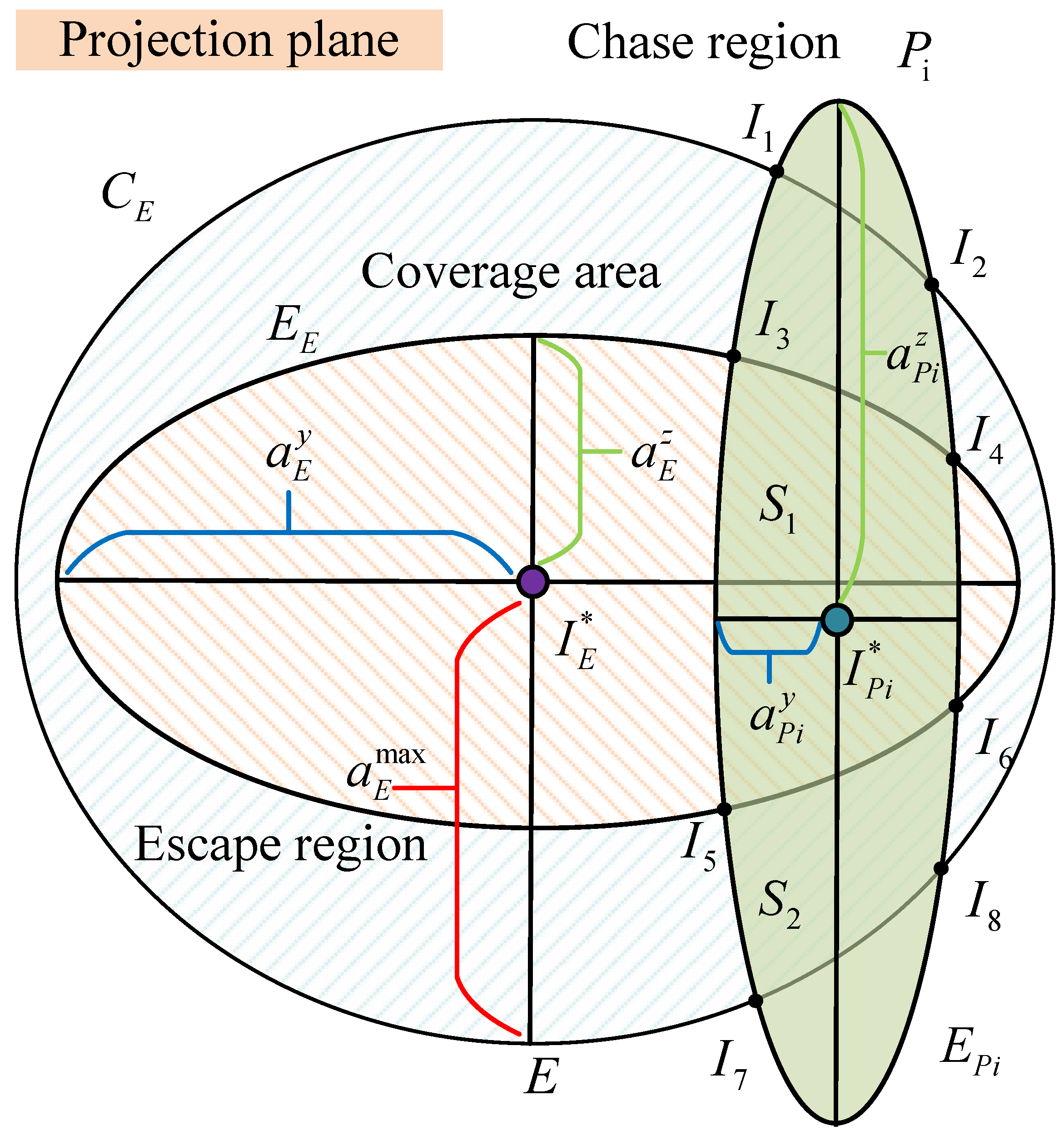
By solving the Ahlswede ball equation and the line equation, we obtain the intersection points of the pursuer
and the evader
. Based on this, the normal accelerations of both parties serve as the major and minor axes of two ellipses. We then project these two ellipses onto the complex plane and calculate their intersection points. For the intersection points of these two ellipses, there are two possible cases. The first case is shown in
Figure 4, and the second case is shown in
Figure 5.
The projection plane represents the projection of the current player’s information onto the
plane in the inertial frame, which facilitates the calculation of the coverage area. The choice of the projection plane is related to the distance between the pursuer and the evader. The projection plane in the inertial system is parallel to the
plane, with the
-axis given by
Circle represents the maximum normal cutoff coverage area of the evader E, where the center of the circle is the optimal game point of the evader , and the radius is the maximum normal cutoff of the evader.
Ellipse represents the current normal cutoff coverage area of the evader, with the two axes of the ellipse defined as follows: is the normal acceleration along the Y-axis in the evader’s velocity system, and is the normal acceleration along the Z-axis in the evader’s velocity system. The center of the ellipse is the same as the center of circle .
Ellipse represents the normal cutoff coverage area of the pursuer . The center of the ellipse is the optimal game point of the pursuer , and the two axes of the ellipse are set as follows: is the normal acceleration along the Y-axis in the pursuer’s velocity system, and is the normal acceleration along the Z-axis in the pursuer’s velocity system.
The coverage areas of the pursuer and evader intersect at four focal points. This is simply for illustrative purposes, and different forms of the focal points will be given later. The intersection points and represent the intersections of the current acceleration coverage areas of the pursuer and evader. The coverage area is formed by the trajectory from to the lower trajectory . The intersection points and represent the intersections of the current velocity coverage area of the pursuer and the maximum velocity coverage area of the evader. The coverage area is formed by the trajectory from to the lower trajectory .
4. Calculation of Interception Time
In this section, we first introduce a method for calculating the interception time in two-dimensional space. Based on this, we extend the method to three-dimensional space and propose a method for calculating interception time under three-dimensional conditions. Additionally, we design a guidance method based on time deviation, which uses a variable proportional coefficient to adjust the proportional guidance rate.
The schematic diagram of the synchronous interception of two-to-one missiles is shown in
Figure 6.
represent the set flight ranges of the missiles at their termination time. We use two missiles intercepting two virtual motions of the target simultaneously, where these two virtual points are defined at the initial moment. Apart from the acceleration, all other initial parameters are the same. In this way, two missiles can intercept the same batch of targets, thus achieving batch interception. If the two missiles can pass the acceleration determination values to the virtual point commands of the same batch of targets, it can be assumed that when one missile reaches its maximum acceleration, both missiles can successfully intercept the target. This way, a complex interception of the target can be achieved.
As shown in
Figure 6, during the interception process, the missiles are modeled using virtual points. This method can effectively simplify the complex interaction between the missile and the target. Next, we will derive more detailed expressions based on these models and use mathematical formulas to optimize the interception time and path planning.
Lemma 1. The launch time of a missile intercepting a moving target in two-dimensional space is given by [23]where is the angle between the missile’s velocity system and the line-of-sight system; is the forward time of missile attack on the virtual stationary target calculated by the PN guidance law; is a constant related to the viewing angle; α is a constant related to the proportional coefficient, and ; N is the proportional coefficient. When calculating interception time in three-dimensional space, we improve Lemma 1. First, we calculate the attack time
of the missile along a straight path. Then, compared to the two-dimensional case, the interception time calculation in three-dimensional space must consider the influence of the
z-axis. For the straight path, the calculation process is as follows:
The equation for
can be derived as
Next, the time required for the missile to attack along the straight path is calculated as follows:
where
is the derivative of the distance between the target and the missile. The expression for
is
where
is the component of the target’s velocity along the
Y-axis in the target velocity coordinate system. Additionally, the value of
n is
where
represents the distance between the target and the missile. Next, we calculate the time required for the missile to reach the virtual point. After determining the attack time
along the straight line, we assume the target moves to a virtual point
in the velocity coordinate system. Through the transformation matrix, we can obtain the position of the virtual point
in the ground reference system, thus calculating the terminal velocity of the target. The missile’s speed is then converted to the virtual line-of-sight system. At the virtual target point, the angles
and
represent the angle between the missile’s line-of-sight system and velocity system, and
and
represent the angle between the target’s velocity system and the line-of-sight system. The angles
and
are calculated as follows:
The angles
and
are intermediate variables and do not have actual physical meaning. The time for the missile to reach the virtual position is given by
where
is the distance between the missile and the virtual point.
The constant represents a constant related to the missile’s velocity and the angle , where is the missile’s velocity, is the distance from the missile to the virtual point, and is the missile’s lift-to-drag ratio constant.
The constant , where is the missile’s lift-to-drag ratio.
The deviation time can be calculated as
where
represents a term involving the missile’s lift-to-drag ratio, the proportional coefficient
N, and the angle
.
The missile’s velocity after correction is given by , where is the missile’s initial velocity and is a correction factor based on the missile’s lift-to-drag ratio.
Additionally, , where is the forward time for missile attack, and is the time to reach a stationary target.
In Lemma 1, during each iteration, we consider a stationary target. However, in this paper, we need to consider the target’s movement with random acceleration. Therefore, we need to subtract the target’s movement impact from the time calculated in each iteration.
where
t is the current time and
is the interception time.
The difference between the current estimated interception time and the actual interception time can be obtained.
is the error time,
.
In the aforementioned methods for calculating coverage probability and interception time, we primarily focus on the spatial relationship and coverage probability between the pursuer and the evader. However, this is a static analysis of the pursuit–evasion game, while in practice, the behavior of the pursuer and the evader is dynamic and there are strategic interactions between them. To address this complex dynamic game, we introduce the Q-learning-cover algorithm.
The Q-learning-cover algorithm uses reinforcement learning to train the strategies of the pursuer and evader, combining area cover and time coordination problems to optimize the solution to the pursuit–evasion game. The key to this algorithm is to gradually optimize the strategy through Q-value updates, so that the pursuer maximizes the probability of capturing the evader, while the evader tries to escape the pursuit by adjusting its strategy. Through this method, the Q-learning-cover algorithm not only considers the actions of both parties in the game but also effectively adapts to the changing game environment.
Next, we will provide a detailed introduction to the design and implementation of the Q-learning-cover algorithm and analyze its application effectiveness in the pursuit–evasion game.
5. Q-Learning-Cover Algorithm
In this section, we present the Q-learning-cover algorithm, which is based on the previously described coverage probability calculation method. The algorithm trains both the pursuer and the evader separately, thereby solving the pursuit–evasion game. In the pursuit–evasion game, the actions of the pursuer and evader are interdependent. Therefore, both must be trained individually to allow the model to effectively learn how to make optimal decisions based on real-time states and environments.
The Q-learning-cover algorithm combines the Q-learning algorithm from reinforcement learning with the concept of area cover. By iteratively training the behavior of each participant (the pursuer and the evader), the strategy is gradually optimized. Specifically, the goal of the pursuer is to maximize the probability of capturing the evader by continuously adjusting its behavior, while the evader tries to adjust its strategy to maximize its chances of escaping the pursuit.
In this algorithm, the training of the reinforcement learning model considers not only the actions of the participants but also integrates the area coverage probabilities and the synergistic effects of both parties’ behaviors at different points in time. The specific training process gradually improves the expected return of each participant in each state by updating the Q-values. To achieve this, the Q-learning-cover algorithm incorporates area coverage and time factors into the Q-value updating process, forming a bilateral game strategy.
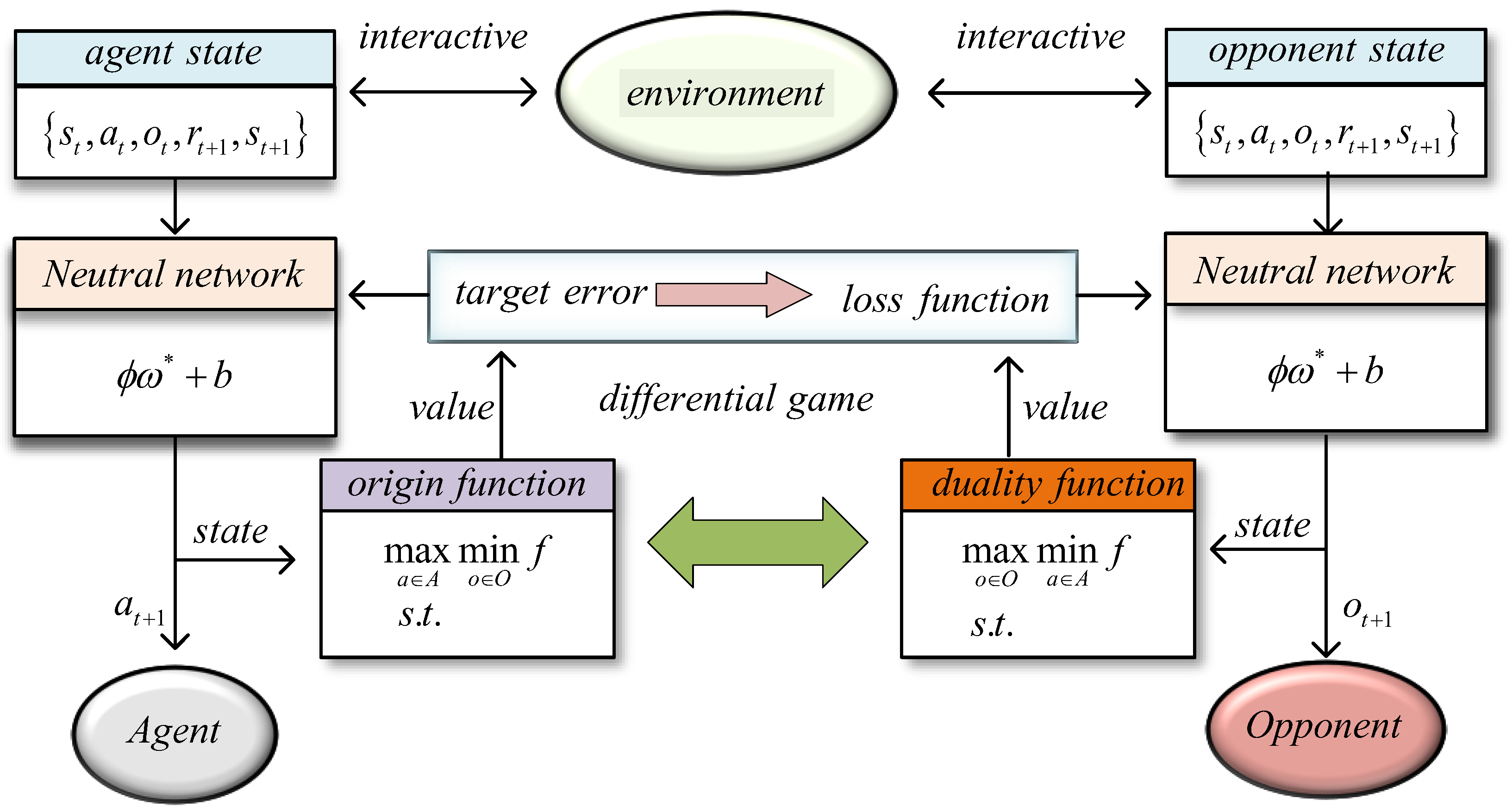
Figure 7 shows the game strategy of the Q-learning-cover algorithm. On the left side is the strategy diagram for the pursuer, and on the right side is the strategy diagram for the evader. The two interact in different game states and adjust according to the feedback from reinforcement learning. Through this method, both the pursuer and evader can find the optimal pursuit–evasion strategy in complex environments.
By incorporating area coverage and time coordination, the Q-learning-cover algorithm is able to provide a more accurate solution to the pursuit–evasion game in dynamic environments. The behavior patterns of both the pursuer and the evader are continuously optimized during the training process, eventually reaching the optimal strategy. This enables the algorithm to effectively address complex pursuit–evasion problems encountered in real-world applications. The update formula for Q-learning-cover is shown below:
The Q-learning-cover algorithm is designed to efficiently plan the trajectories of multiple pursuers to intercept a single evader. The following pseudo-code outlines the main steps of the algorithm, incorporating both the interception time and regional coverage calculation before the algorithm iterations begin. Algorithm 1 shows the steps of the Q-learning-cover algorithm.
| Algorithm 1 Q-learning-cover algorithm |
- 1:
Initialize the state space S, action space A, and Q-table - 2:
Set learning parameters: (learning rate), (discount factor), and (exploration rate) - 3:
(Interception Time Calculation) - 4:
Calculate the interception time based on the positions and velocities of pursuers and the evader. - 5:
(Regional Coverage Calculation) - 6:
Calculate the regional coverage based on the positions of the pursuers and the evader’s trajectory, using geometric covering techniques such as the Ahlswede sphere. - 7:
for each episode do - 8:
Initialize the environment (pursuer and evader positions) - 9:
while not converged do - 10:
Select action a using an epsilon-greedy policy: - 11:
Execute action a and observe new state and reward r - 12:
Update Q-value using the formula: - 13:
end while - 14:
end for - 15:
Return the optimized policy
|
Theorem 1. When the Q-learning-cover algorithm satisfies the selection upper bound condition in Equation (28), then convergence is achieved. - -
: This term represents the average error in the Q-values over N iterations. is the Q-value at time t, and is the optimal Q-value. The error is measured using the infinity norm (), which refers to the maximum difference between the current Q-values and the optimal Q-values. This term gives the expected error across all iterations.
- -
: This factor is the convergence rate. It ensures that as the algorithm progresses, the error decreases over time. The parameter controls how quickly the algorithm converges—lower values of result in faster convergence.
- -
: This term is the second moment of the error. It measures the average squared error of the Q-values. The second moment provides a more detailed view of how the error evolves over time, which is crucial for understanding the stability of the algorithm.
- -
: This term accounts for the discount factor , which determines how much weight is given to future rewards. represents the maximum reward, and this term adjusts the impact of future rewards on the convergence.
- -
: This is the policy error, which measures how far the current policy deviates from the optimal policy . This term represents the gap between the learned policy and the optimal policy.
This theorem shows that the Q-learning-cover algorithm will converge to the optimal
Q-values and optimal policy as long as the algorithm satisfies the upper bound condition specified in Equation (
28). The convergence is guaranteed by controlling the
Q-value error, policy error, and the impact of future rewards through the discount factor
. Each term on the right-hand side of the equation ensures that as the algorithm progresses, the error will decrease, ultimately leading to convergence.
Proof. Our proof starts from the following elementary analysis and inverse recursion formula:
where for any
, the first line comes from the update rule of the Q-learning algorithm, which computes the
Q-value update based on the previous
Q-value, the reward, and the transition probabilities. The term
is the current
Q-value, and
is the optimal
Q-value. The second-to-last line comes from the Bellman equation, which represents the optimal
Q-value function as
[
17], where
r is the reward,
is the discount factor,
P is the transition probability matrix, and
is the optimal policy. The Bellman equation is used to express the recursive relationship between the
Q-values, the reward, and the future state values.
In this formula, we are defining the infinity norm of a matrix A, which is calculated by taking the maximum of the row sums of the absolute values of the elements. The first line expresses the definition of the infinity norm for matrix A. The second line represents the same norm, expressed in terms of the elements of matrix A, where is the element in the i-th row and j-th column of the matrix. In the third line, we use the identity , which is a difference between the identity matrix and a matrix , and the absolute values of its elements are summed to calculate the norm. The fourth line assumes that the maximum of these sums is bounded by , where is a parameter. Finally, the last line indicates that the norm is bounded by a constant , which is a convergence parameter. This bound ensures that the norm does not grow unbounded as the algorithm proceeds.
Next, we design the Lyapunov function
, where for any
,
. We assume the existence of a positive definite matrix
, such that
and
In this part of the proof, we define a Lyapunov function , where M is a positive definite matrix. The Lyapunov function is a key tool in proving stability and convergence of dynamic systems. The term ensures that the energy-like quantity is non-negative and decreases over time. We introduce a condition on the matrix M such that it is positive definite (), ensuring that M has strictly positive eigenvalues. The first equation defines a relationship between M, the matrix A, and the identity matrix I, where is a factor controlling the contraction or expansion behavior of the system. The second inequality states that the minimum eigenvalue of M is greater than or equal to 1, ensuring that the matrix is not degenerate and that the Lyapunov function behaves correctly. The third inequality provides an upper bound on the maximum eigenvalue of M. This bound is critical in determining the stability of the system, as it ensures that M does not grow too large, maintaining the desired convergence properties.
Then, by substituting these formulas into the Lyapunov function, we can obtain
In this part of the proof, we are calculating the expected value of the Lyapunov function , which captures the change in the error at the next time step . We expand the equation by substituting the previous terms into the Lyapunov function. The first line is the expression for , which involves the error at time , and we compute its expectation. The subsequent lines expand this function, considering the evolution of , the effect of the transition probabilities , and the impact of the perturbation terms and . The inequality in the third line introduces the term , which governs the contraction of the Lyapunov function over time. It shows how the system’s error reduces based on the parameters and , and the impact of the rewards and perturbations. The term controls the scaling of the error, with its maximum eigenvalue affecting the convergence. In the later lines, we apply the assumption that the system is stable, meaning that the error diminishes as the iterations progress. The terms involving and represent the expected values of the optimal policy and Q-values, which further guide the convergence analysis of the system.
We assume that
, and we can obtain
In this part of the proof, we are computing the expected change in the Lyapunov function over time. The left-hand side of the inequality represents the difference between the Lyapunov function at time and at time t. We are showing how this difference evolves based on the current error and other terms such as perturbations and , as well as the optimal policy . The first line of the inequality expresses the change in the Lyapunov function as a combination of the current error term and additional terms involving the optimal Q-values and policies. The second line represents the bounding term that ensures the error is controlled. The third line simplifies the expression by combining terms and adjusting for the maximum eigenvalue of the matrix M, which is used to control the growth of the error. In subsequent lines, we apply the assumption that is a small contraction factor, leading to the error reduction. The inequality shows that the error term will eventually become negative, implying that the error decreases over time, ensuring convergence. Finally, the right-hand side of the inequality bounds the error by terms involving the perturbations and the maximum eigenvalue of M, ensuring that the system’s stability holds as the iteration progresses.
According to the initial assumption,
Taking the expectation on both sides, we can obtain
In this part, we start by assuming that the infinity norm of the optimal policy is bounded by , where is the maximum reward, and is the discount factor. This bound is important for controlling the range of policy values. The second assumption involves the squared error between the current policy and the optimal policy . The expectation on the left-hand side represents the squared difference of the policy, while the right-hand side expresses this difference in terms of the infinity norm squared. This inequality helps in bounding the policy error. Next, we define , which controls the convergence rate. We use as a contraction factor that governs the convergence speed of the algorithm. The term ensures that lies between 0 and 1, helping us control the system’s error reduction over time. The inequality in the main equation expresses the change in the error in terms of the Lyapunov function , the perturbation terms and , and the optimal policy. The expectation is taken over these terms, and the error bound is influenced by the maximum eigenvalue of the matrix M, which ensures that the error decreases over time. The right-hand side of the equation includes several terms that account for the following: The contribution from the policy error between and . The contribution from the perturbations and , which are factors that introduce noise or uncertainty into the system. The convergence rate controlled by the parameter , which ensures that the system converges to the optimal policy.
In this part, we start by using the relationship between the Lyapunov function and the squared norm of x. Specifically, we know that the Lyapunov function is bounded between the minimum and maximum eigenvalues of the matrix M, which are and , respectively. This relationship helps us control the magnitude of the Lyapunov function in terms of the vector norm. The inequality is important for bounding the error. The next step is to bound the expected value of the squared error , which is the difference between the Q-values and the optimal Q-values. We break down the bound into several terms: The first term represents the contribution of the initial error at to the total error, scaled by the maximum eigenvalue of M. The second term involves the policy error, which is the squared difference between the learned policy and the optimal policy . The expectation is averaged over all iterations and gives a measure of the convergence of the policy. The third term accounts for the influence of perturbations and , which represent noise or uncertainty in the system. These perturbations contribute to the overall error, and their impact is scaled by the maximum eigenvalue of M. The final term includes the reward terms and their impact on the total error. The term captures the effect of the maximum reward and the discount factor , while ensures that the error remains bounded over time. This inequality provides a clear upper bound for the error in terms of the initial error, the policy error, the perturbations, and the system’s parameters.
Taking the square root on both sides and applying the subadditivity of square roots, we can obtain
and
In this section, we apply the relationship between the Lyapunov function and the squared norm of x, and we introduce the bounds for in terms of the minimum and maximum eigenvalues of the matrix M. The inequality helps control the growth of the Lyapunov function based on the norms of x. We then consider the expected value of the squared error , which is the difference between the current Q-values and the optimal Q-values. The expectation is averaged over all iterations. The first term on the right-hand side represents the contribution from the initial error , scaled by the maximum eigenvalue of M, which controls how the error propagates over time. The second term involves the policy error , which is the squared difference between the learned policy and the optimal policy . The policy error is crucial for understanding how well the system converges to the optimal policy. The third term accounts for perturbations and , which introduce noise or uncertainty into the system. These perturbations contribute to the overall error, and their impact is scaled by the maximum eigenvalue of M. Finally, we apply the convergence factor , which ensures that the error decreases over time. The inequality bounds the total error by accounting for the initial error, policy error, perturbations, and the convergence parameters.
Finally, we prove the relationship between the Q-value vector at the iteration limit and the initial value vector when the system is stable. □
The purpose of this paper is to demonstrate the convergence of the Q-learning algorithm using a Lyapunov function and error bound analysis. By defining an appropriate Lyapunov function , we can control the system’s state and error, ensuring that the error decreases over time as the iterations progress, and the system ultimately converges to the optimal solution. Throughout the analysis, we define error bounds using a series of inequalities and employ the properties of the Lyapunov function. The error is decomposed into initial error, policy error, and perturbation error, each of which is scaled by the maximum eigenvalue of matrix M. Each error term is related to other system parameters such as the maximum reward , the discount factor , and perturbation terms and . Further derivation leads to an upper bound on the change in error, which takes into account all possible sources of error, including policy deviation and system perturbations. Finally, by introducing a convergence factor , we ensure that the error gradually decreases over time, guaranteeing the system’s convergence. This analysis not only demonstrates the stability of the Q-learning algorithm in multi-step learning but also provides a theoretical foundation for error control in practical applications. With this approach, we can effectively learn the optimal policy in complex environments and ensure that the system converges within a finite amount of time.
6. Simulation Platform
This paper constructs a simulation platform suitable for the interception strategy, where the system model applies the proposed algorithm to an autonomously developed platform. By distributing the pursuers and evaders onto different physical hardware, the platform achieves interoperability between pursuers, while data communication between the pursuers and the evader can only occur through the server. This design aims to simulate a real interception scenario as closely as possible and validate the feasibility of the proposed algorithm through this platform. A missile interception model is used in the simulation.
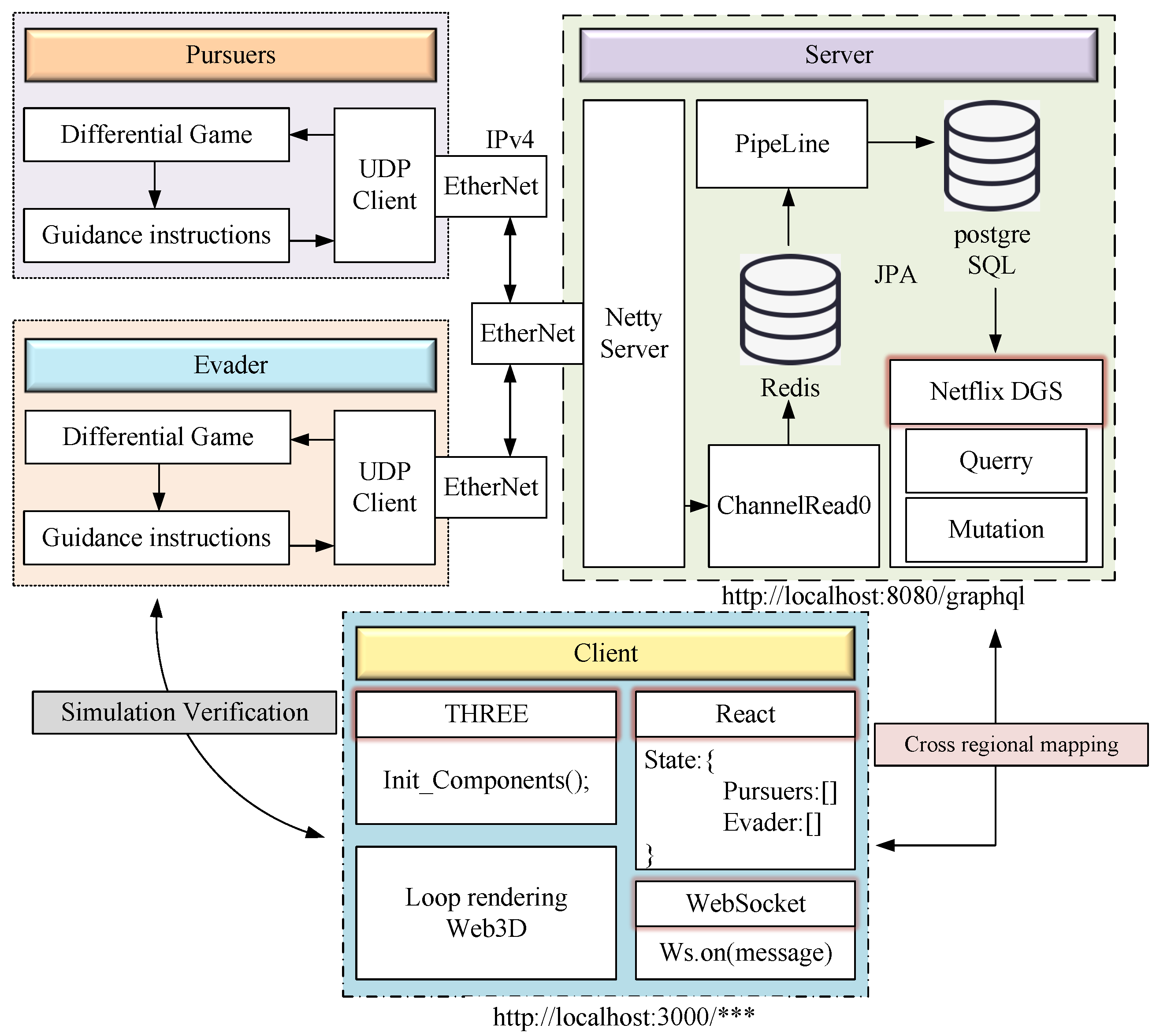
The simulation platform consists of three parts: the embedded hardware section, the backend built using a server, and the frontend presented by the browser. The overall framework design is shown in
Figure 8.
In the embedded hardware, we used the Nvidia-developed Jetson Nano development board as the pursuer in the differential game, and the Raspberry Pi as the evader in the differential game. These two embedded development boards are connected to a switch via Ethernet ports, and the switch is connected to the local server. The backend server uses the Java programming language with the Spring Boot framework, which internally supports the Tomcat server. The asynchronous communication framework is Netty. The data from the underlying hardware is sent to the backend server via UDP communication. The embedded hardware in the second part makes the already small memory even more limited. In terms of database management, we use Redis as a caching database, which caches and updates data via pipeline stream technology. Additionally, we use PostgreSQL as the relational storage database to store the data of both parties in the game. This pipeline stream technology and asynchronous framework help prevent data packetization issues.
For the frontend, we use React, with Netflix DGS providing methods for querying and modifying data. The DGS framework’s main feature is its annotation-based Spring Boot programming model, which has lower server overhead compared to traditional Restful APIs. GraphQL is mainly used for temporary queries and operations. Queries are used to fetch data and return the found data, while mutations are used to modify data. The entire technology stack is based on a B/S structure, with communication conducted through HTTP protocols. The application includes methods for processing data and mapping the data of the pursuers and evaders. Three-dimensional modeling uses Three.js and Cesium.js.
Firstly, the pursuers and the evader upload their positions and attitude angles to the server through UDP communication. Once the server receives the data, it calls the asynchronous program ‘Channelread0’ to write the data into the Redis cache database and uses pipeline stream technology to update the data in real-time to the PostgreSQL database. Netty sends messages between them. After receiving each other’s information, the pursuers and the evader calculate the optimal strategy through differential game theory, give guidance commands, and calculate the next moment’s position and attitude through the motion model, then update the data again. Since UDP communication can sometimes lose data, no multithreading solution is used to ensure real-time data reception.
On the frontend, the page rendering is completed when the application is launched. When the server writes data for the PostgreSQL database and updates it, a long connection between the frontend and backend is triggered, and the updated data are sent through Mutation. After receiving the updated information, the frontend uses a data mapping scheme to write the updated data into the state. At the same time, the position and attitude of the pursuers and evaders are updated in real-time. Both the Jetson Nano and Raspberry Pi development boards support the Python 3.9 compiler. The paper attempts to use hardware development boards with identical configurations.
The Q-learning algorithm is trained offline using a simulated environment where the pursuers learn to intercept the evaders based on various escape patterns. The offline training phase allows for computationally intensive processes, such as model optimization and fine-tuning, to be performed without the constraints of real-time processing. After training, the model is deployed on an embedded platform, such as Jetson Nano or Raspberry Pi, for online use, where it guides the pursuers in real-time interception. By separating the training and execution phases, our approach reduces the computational load during real-time operations. This allows the system to run on less powerful embedded hardware, such as the Jetson Nano or Raspberry Pi, while still benefiting from the rich training data and complex computations performed offline.
This paper validates the feasibility of the proposed algorithm through the simulation platform. To simulate this process more accurately, the observation coordinate system is projected onto the geocentric coordinate system for analysis. Hardware parameters are shown in
Table 2. The data transmission protocol is shown in
Figure 9.
Figure 10 shows the 3D visualization effect of the system, clearly presenting the interaction and interception process between the pursuer and the evader. This page greatly enhances the user experience through vivid dynamic effects and interactive feedback, making the system’s state and behavior more intuitive and understandable.
Figure 11 presents the structure and functionality of the backend server, which is responsible for processing core data calculations and interactive operations, ensuring the stable operation of the system and supporting real-time communication with the frontend and the database.
Figure 12 and
Figure 13 show real-time data from the database, reflecting the dynamic changes of the evader and the pursuer. These figures accurately reflect key data and real-time states during the entire pursuit process, providing detailed monitoring information.
7. Experimental Results
Next, this paper presents three different examples to demonstrate the interception process using the proposed Q-learning-cover algorithm.
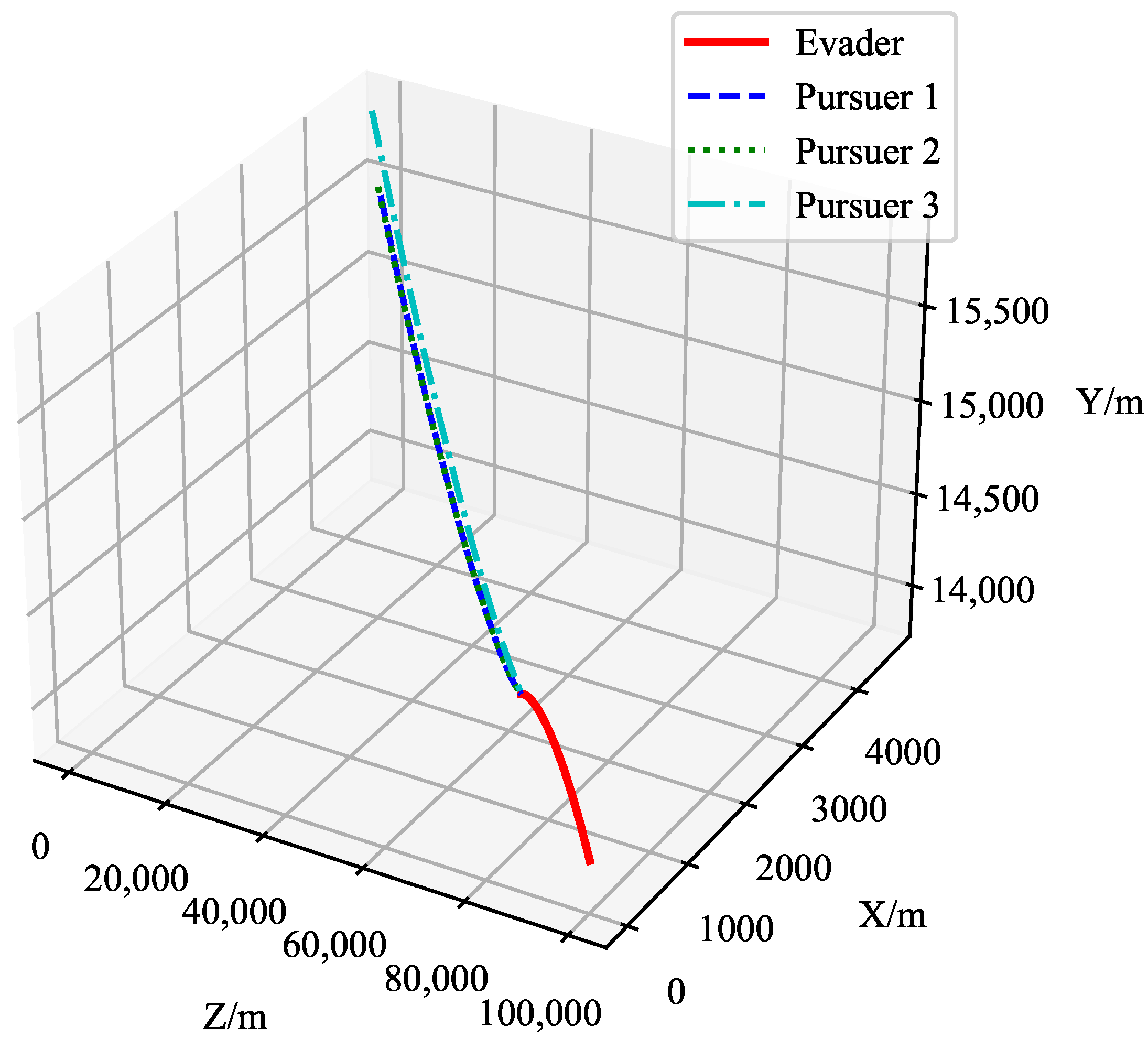
Example 1: The initial position of pursuer 1 is [0, 14,005, 4546], the initial position of pursuer 2 is [0, 15,892, 5025], and the initial position of pursuer 3 is [0, 14,543, 5072]. The pursuers’ speed is 4000 m/s. The initial position of the target is [100,000, 14,000, 0], and the target tries to evade the pursuers with a speed of 3000 m/s. The
y- and
z-coordinates of the pursuers’ initial positions are random. The initial distance between the pursuers and the evader is approximately 100,000 m, and the initial angle is random. The motion trajectories are shown in
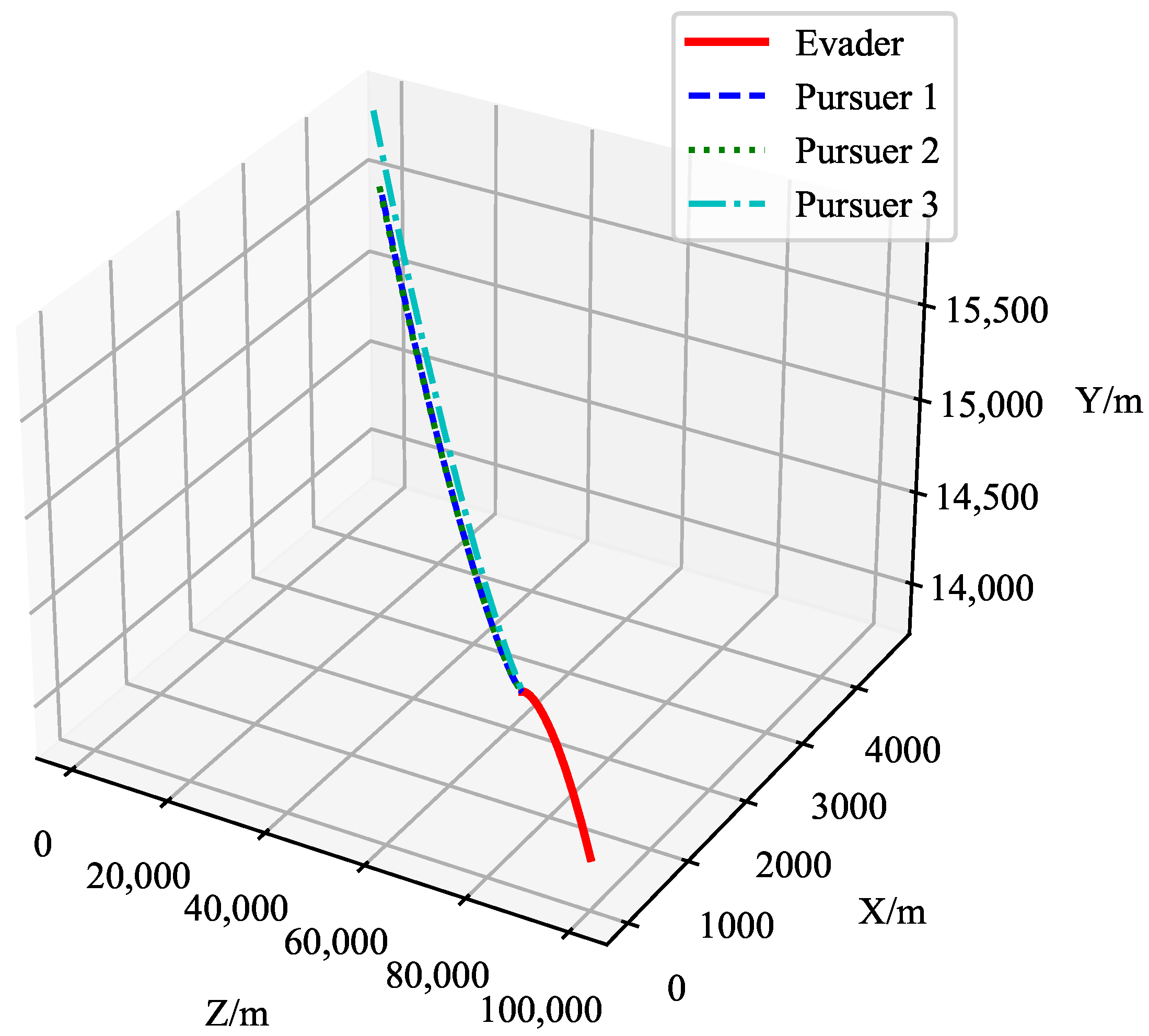
Figure 14.
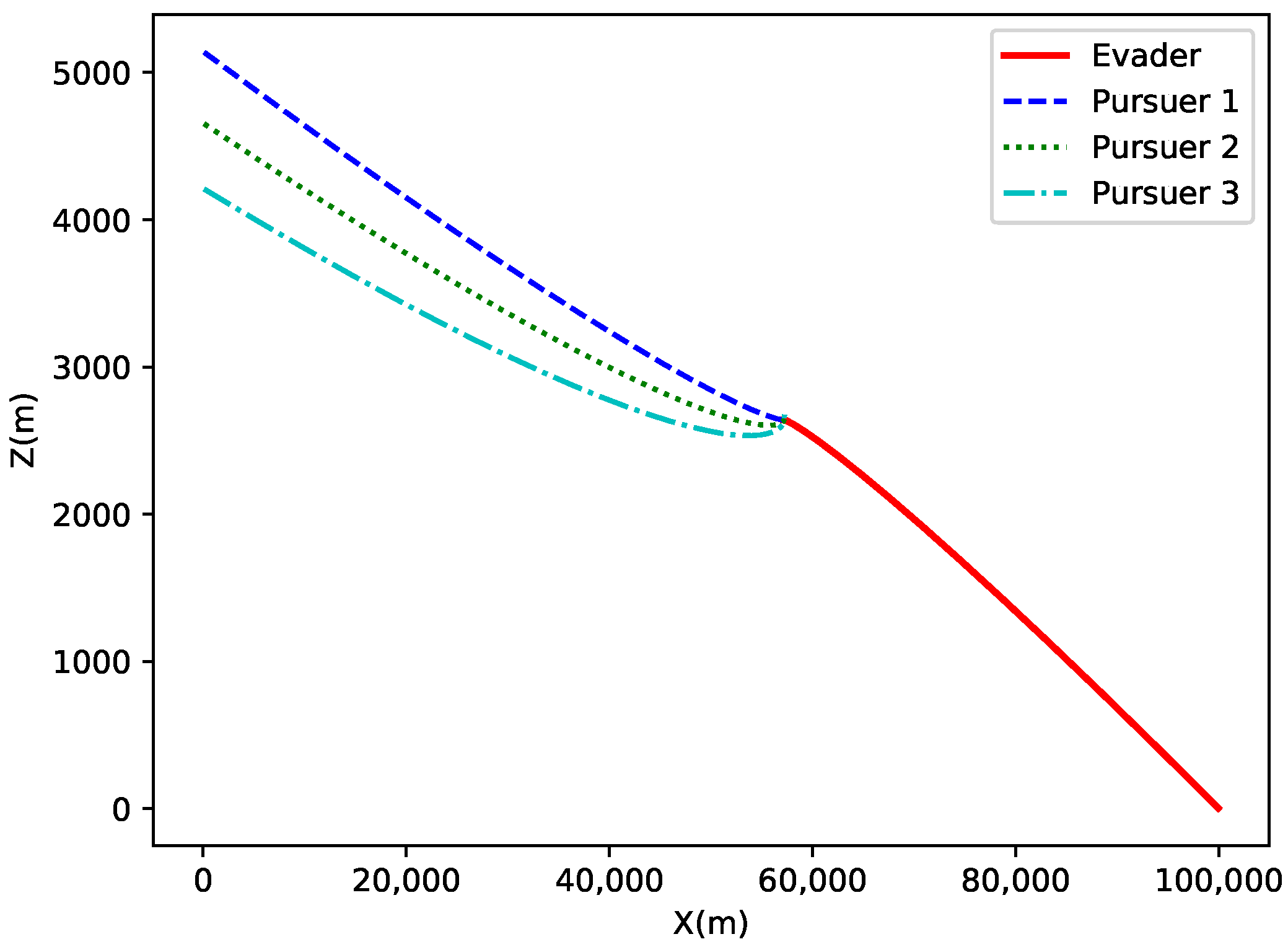
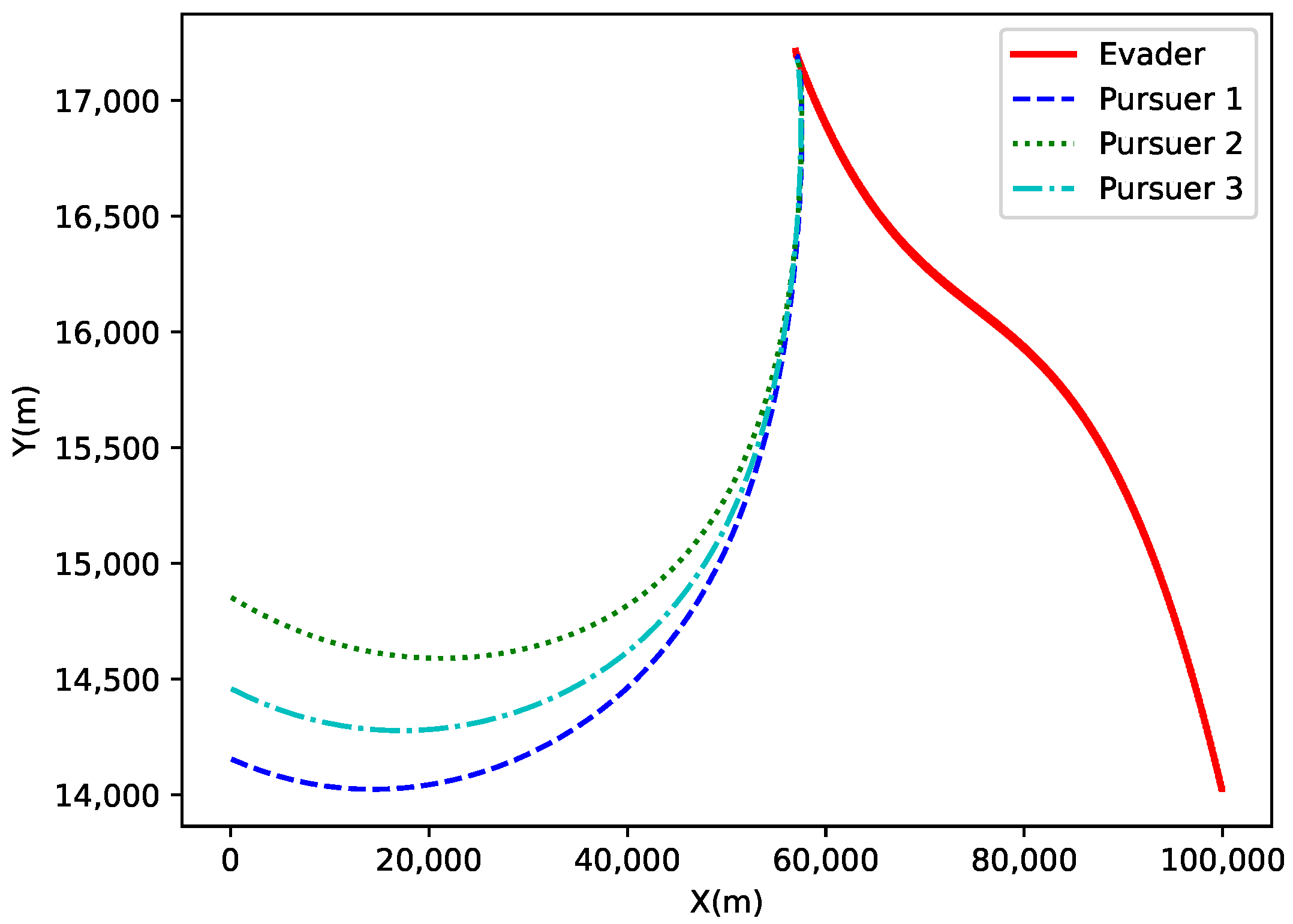
Figure 14 shows the motion trajectories of the target and the pursuers in three-dimensional space. The red line represents the trajectory of the evader, while the blue, green, and cyan dashed lines represent the trajectories of the three pursuers. The figure demonstrates the relative position between the pursuers and the evader, as well as the distance variation between the target and the pursuers. Using the Q-learning-cover algorithm, the pursuers gradually reduce the distance to the target and ultimately capture it.
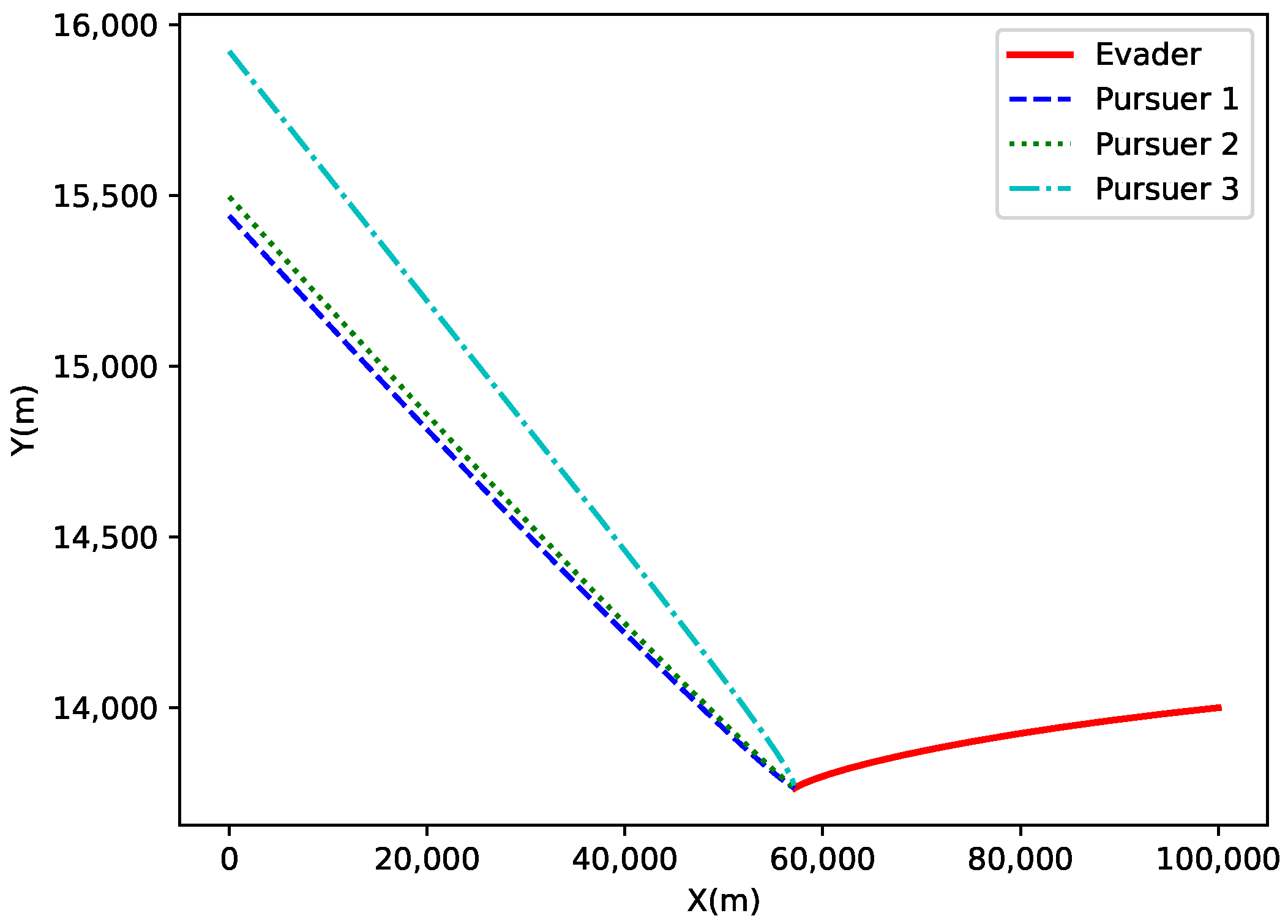
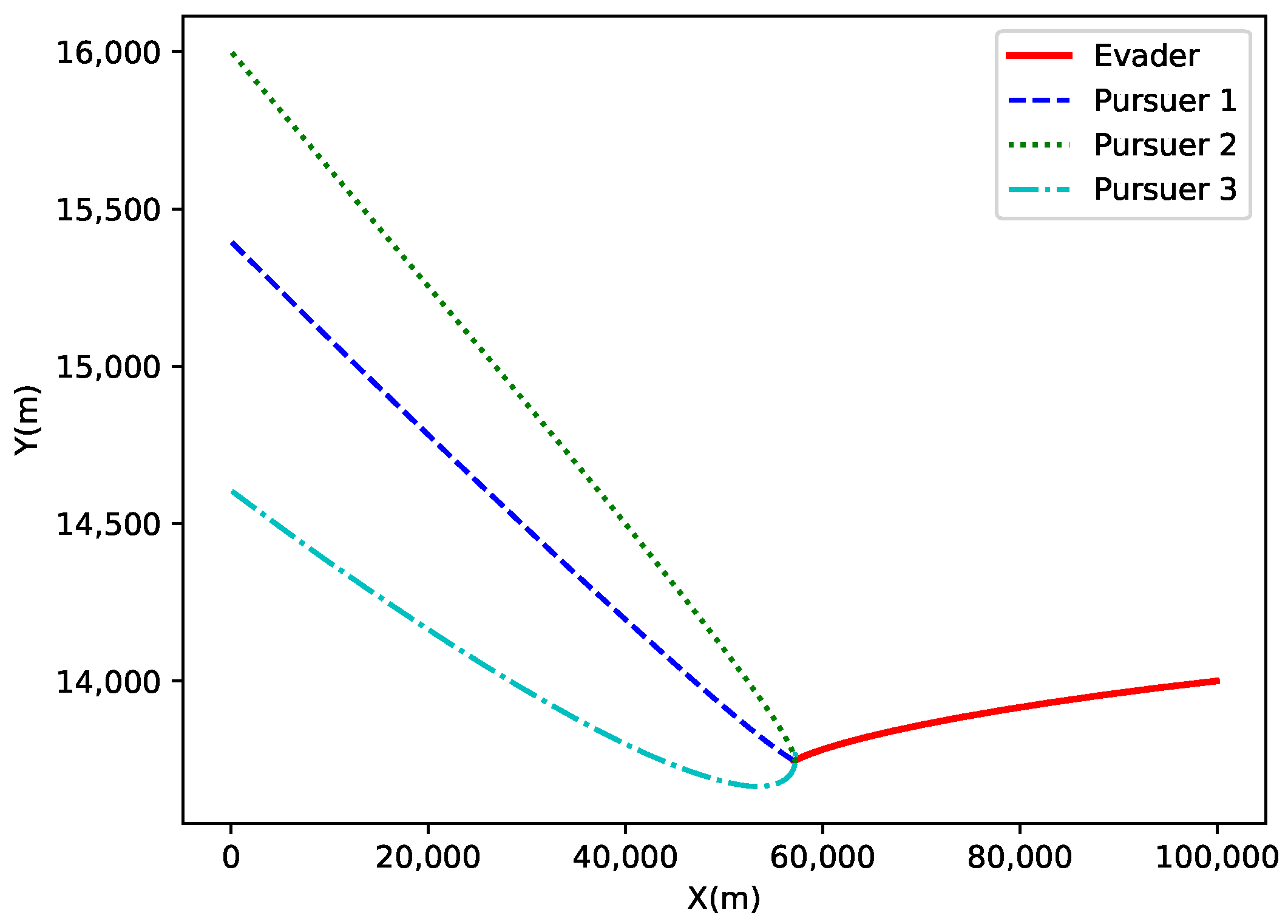
The
X-
Y axis projection is shown in
Figure 15. This figure presents the projection of the target and the three pursuers on the
X-
Y plane. The trajectories of the evader and the pursuers are distinct in the
X-
Y plane due to their different initial positions. The evader’s trajectory shows a rapid offset, while the pursuers’ trajectories gradually converge towards the target based on their initial positions and motion directions.
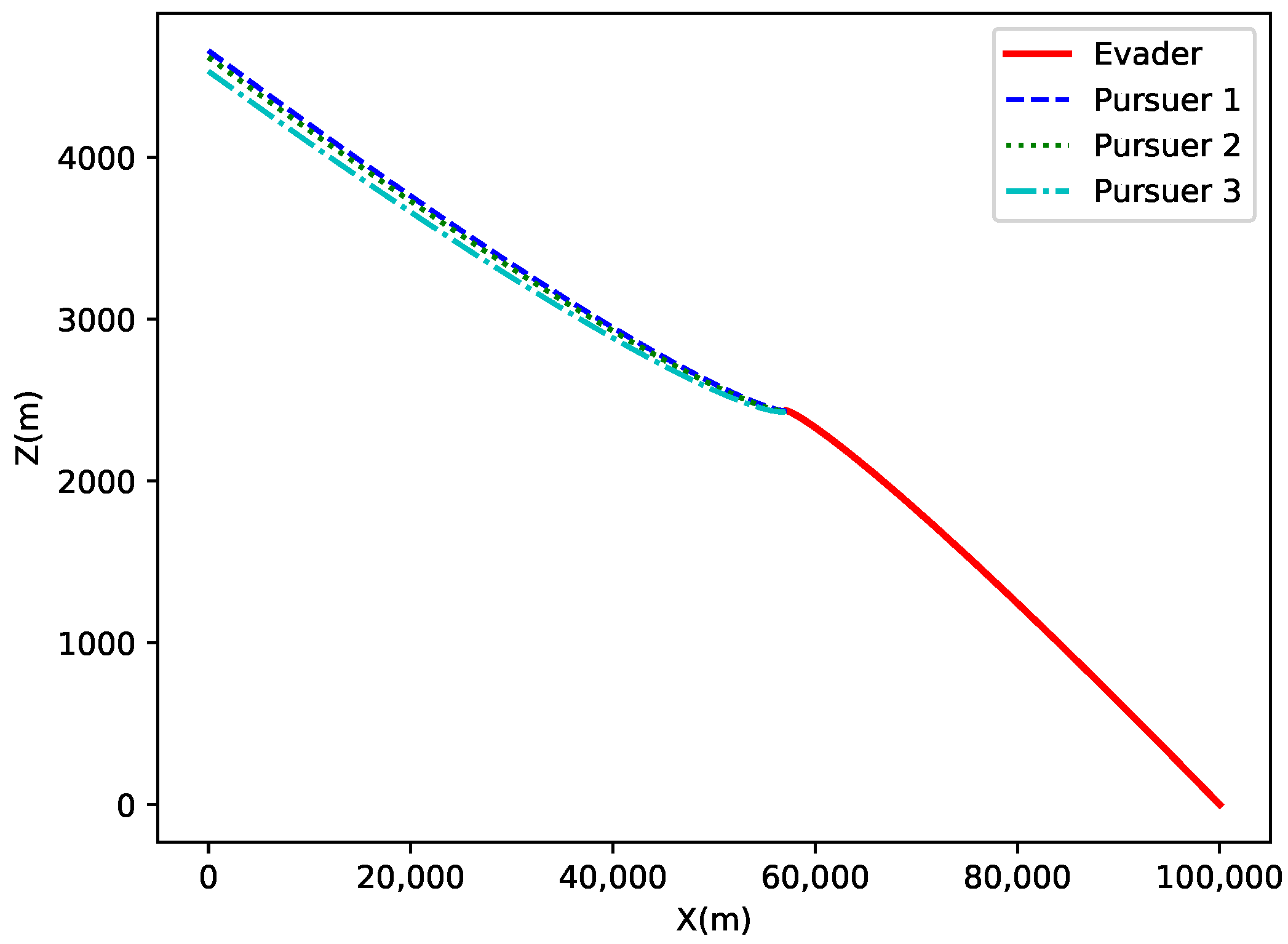
The
X-
Z axis projection is shown in
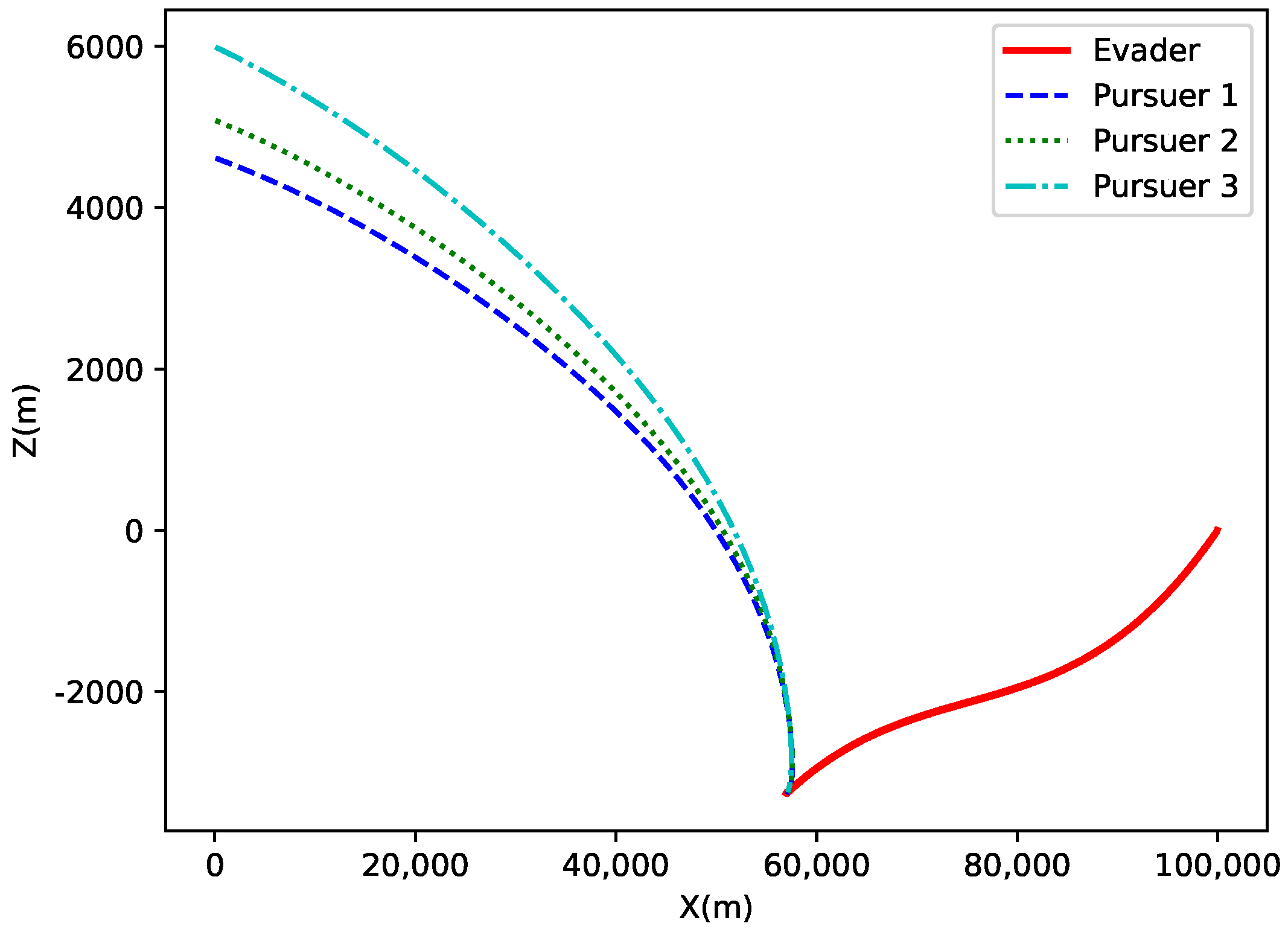
Figure 16. This figure presents the projection of the target and the three pursuers on the
X-
Z plane. The evader’s trajectory shows a rapid displacement along the
X-axis, while the pursuers’ trajectories gradually approach the target, demonstrating the motion characteristics of different pursuers and the effectiveness of the algorithm.
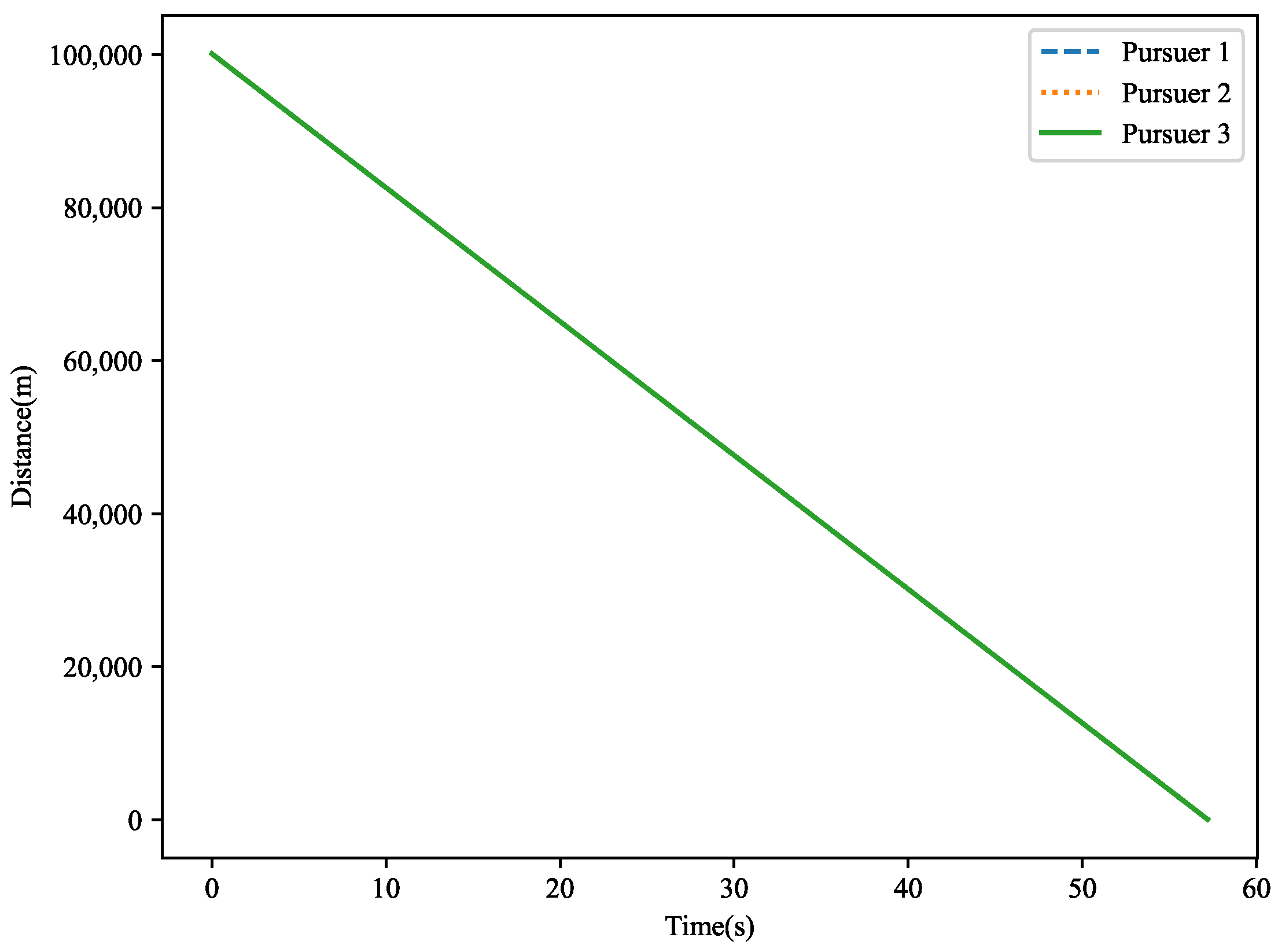
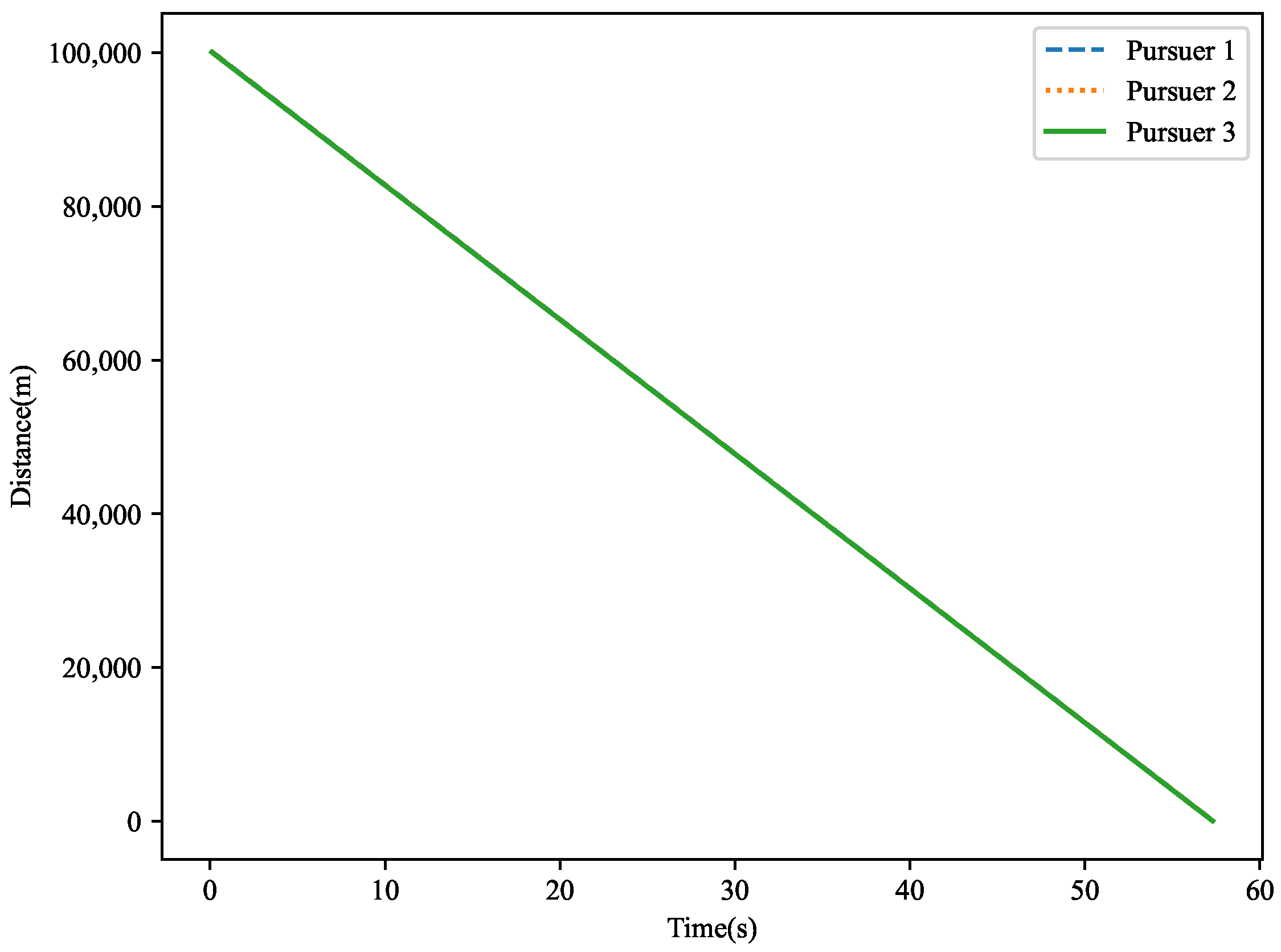
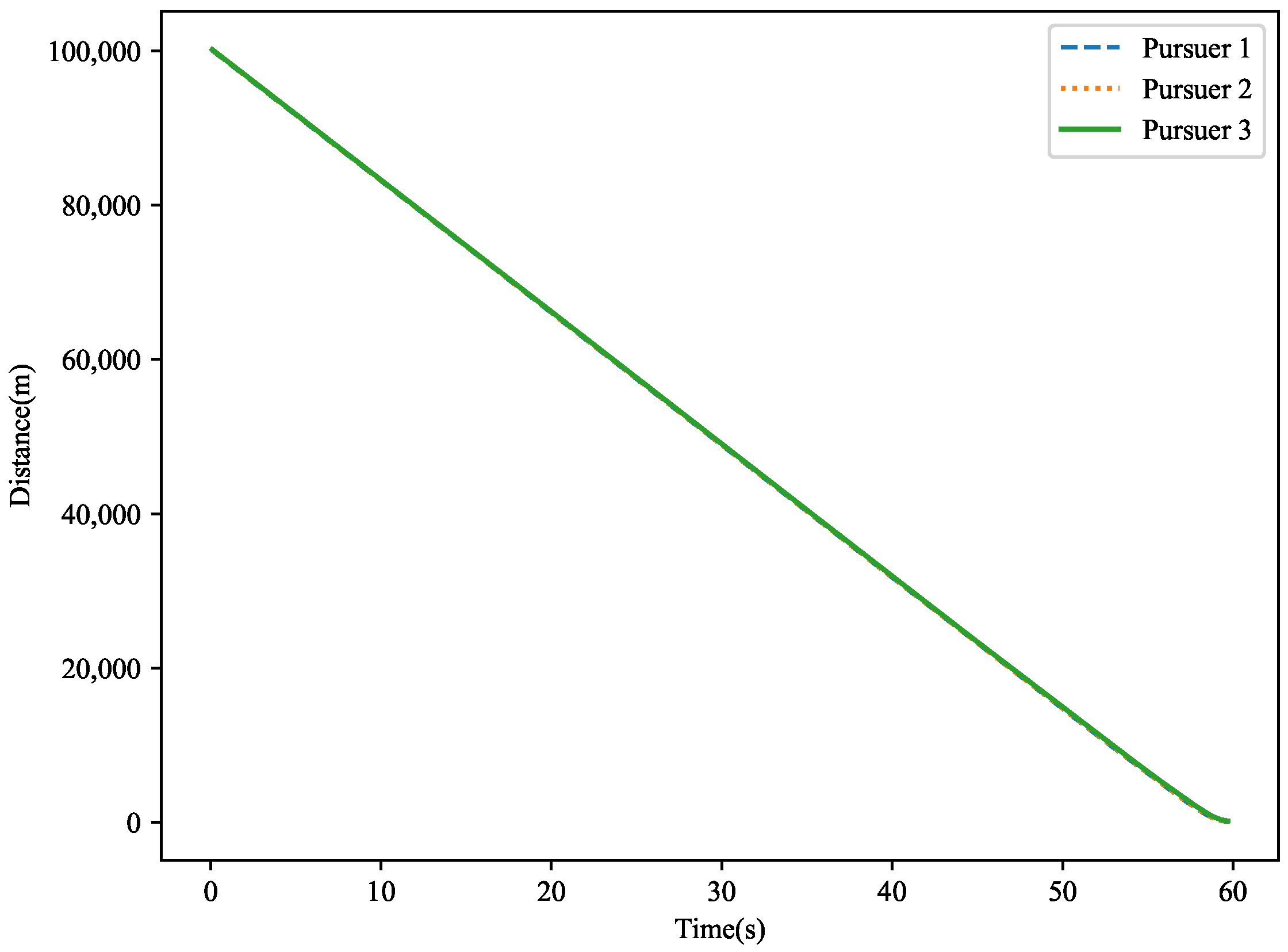
The distance variation is shown in
Figure 17. This figure illustrates the distance changes between the target and the three pursuers in three-dimensional space. Over time, the target is gradually approached by the pursuers. Ultimately, the miss distances are
,
, and
, with the target being successfully captured by pursuer 2.
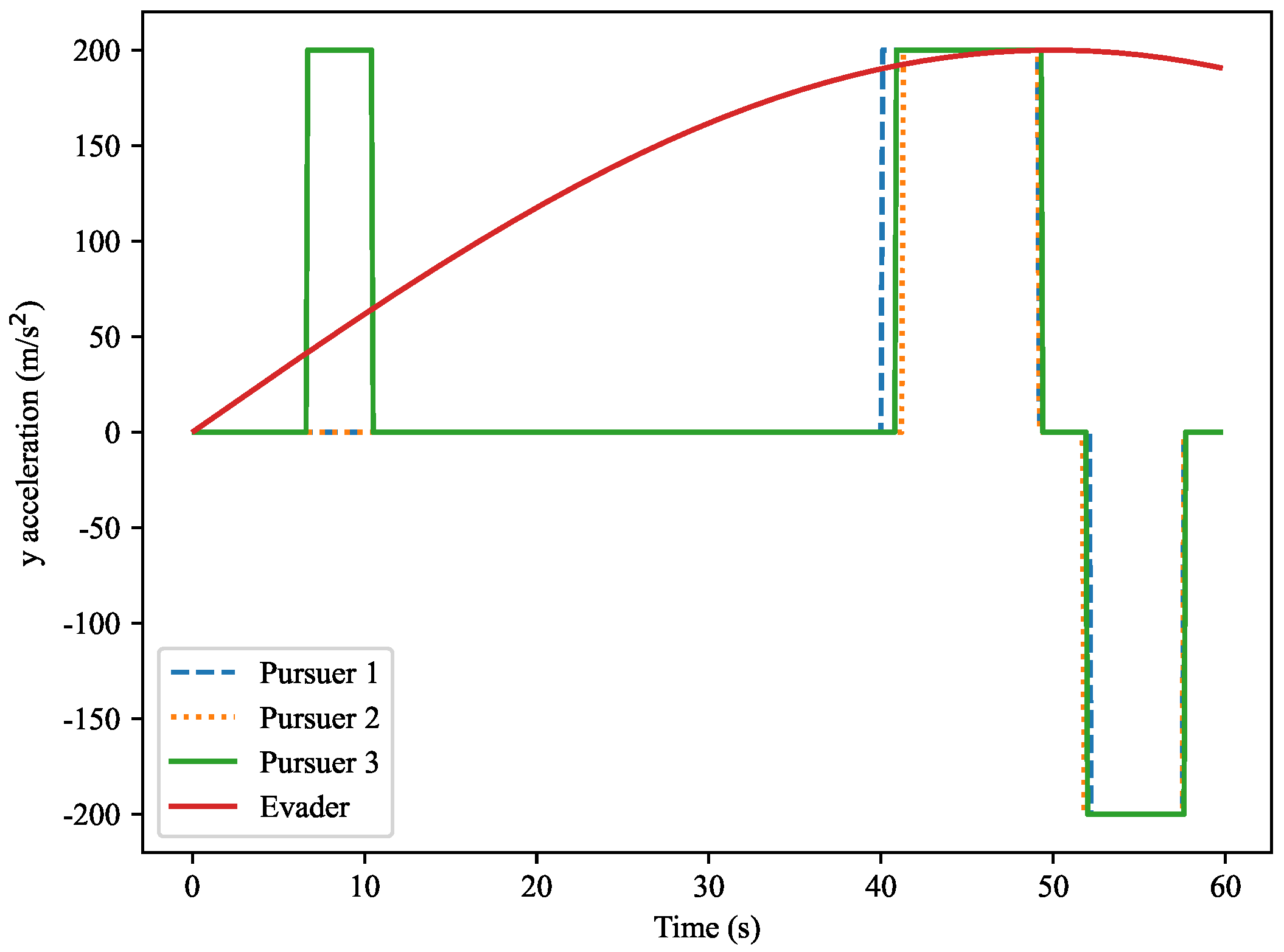
The
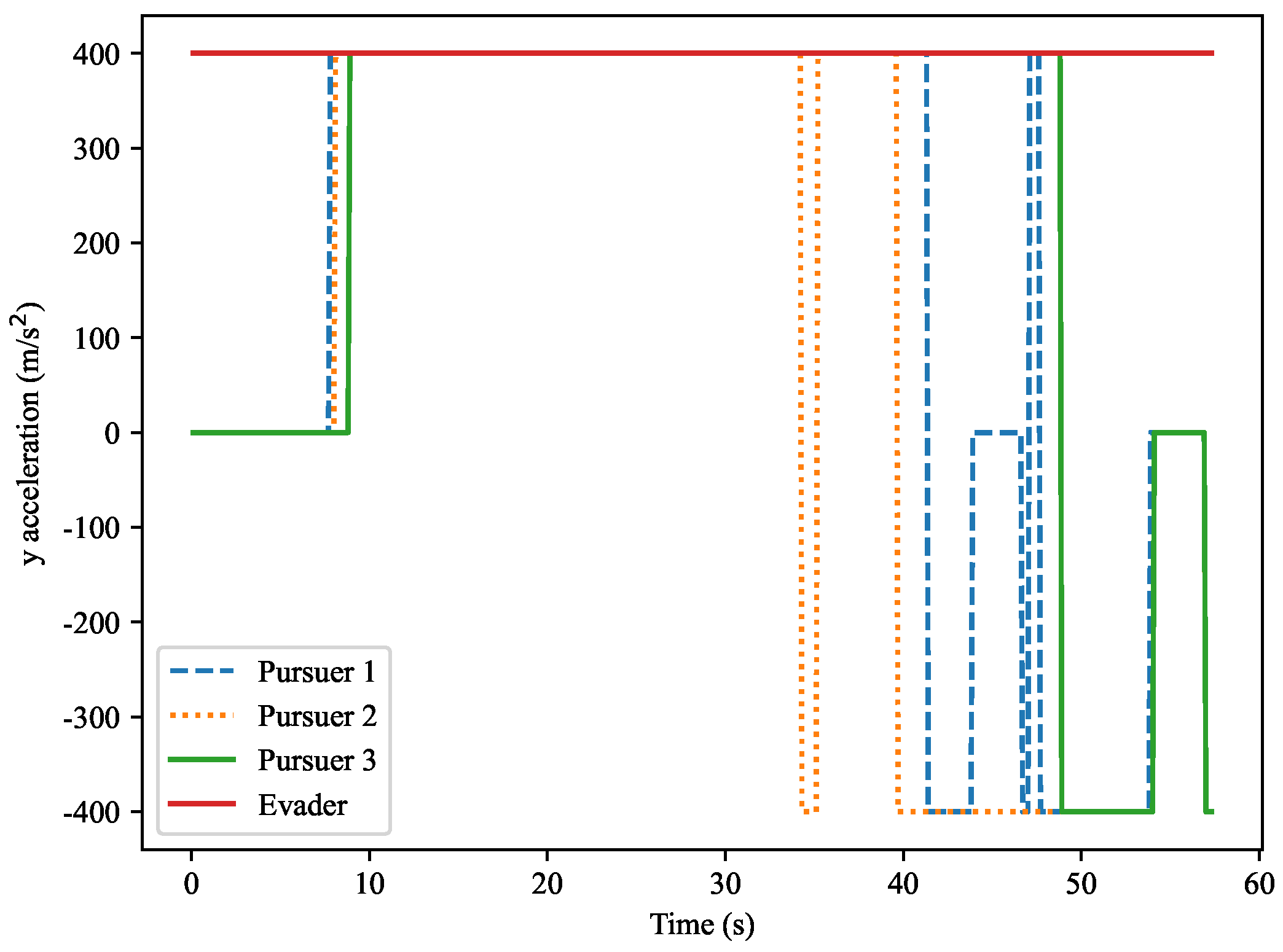
Y-axis normal acceleration variation is shown in
Figure 18. This figure presents the variation in normal accelerations along the
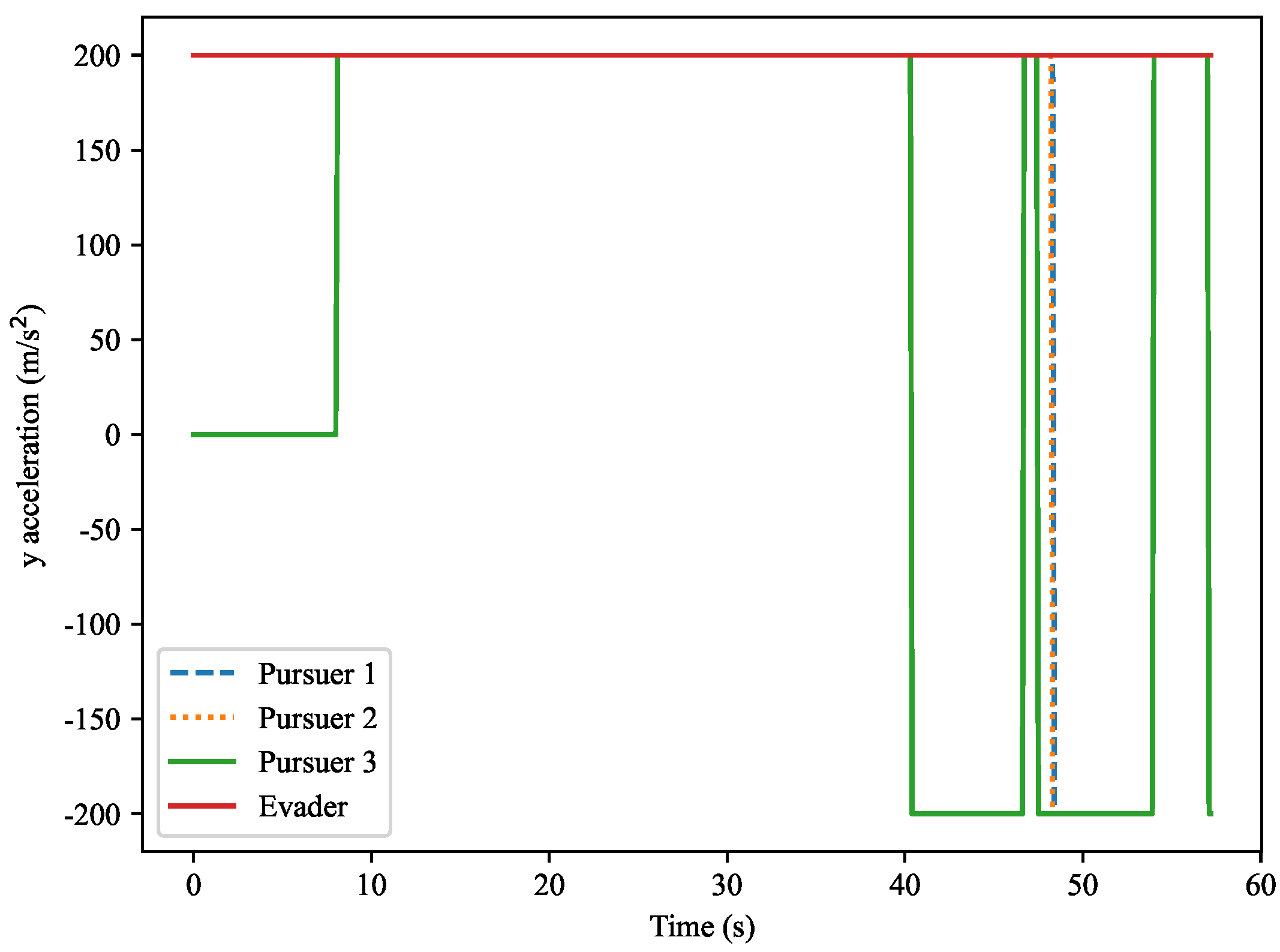
Y-axis for the evader and the three pursuers. Over time, the accelerations of the pursuers fluctuate significantly, especially during the capture process. The evader’s acceleration remains relatively stable, close to zero. The curves in the figure show the acceleration changes required by each pursuer based on their current motion trajectory.
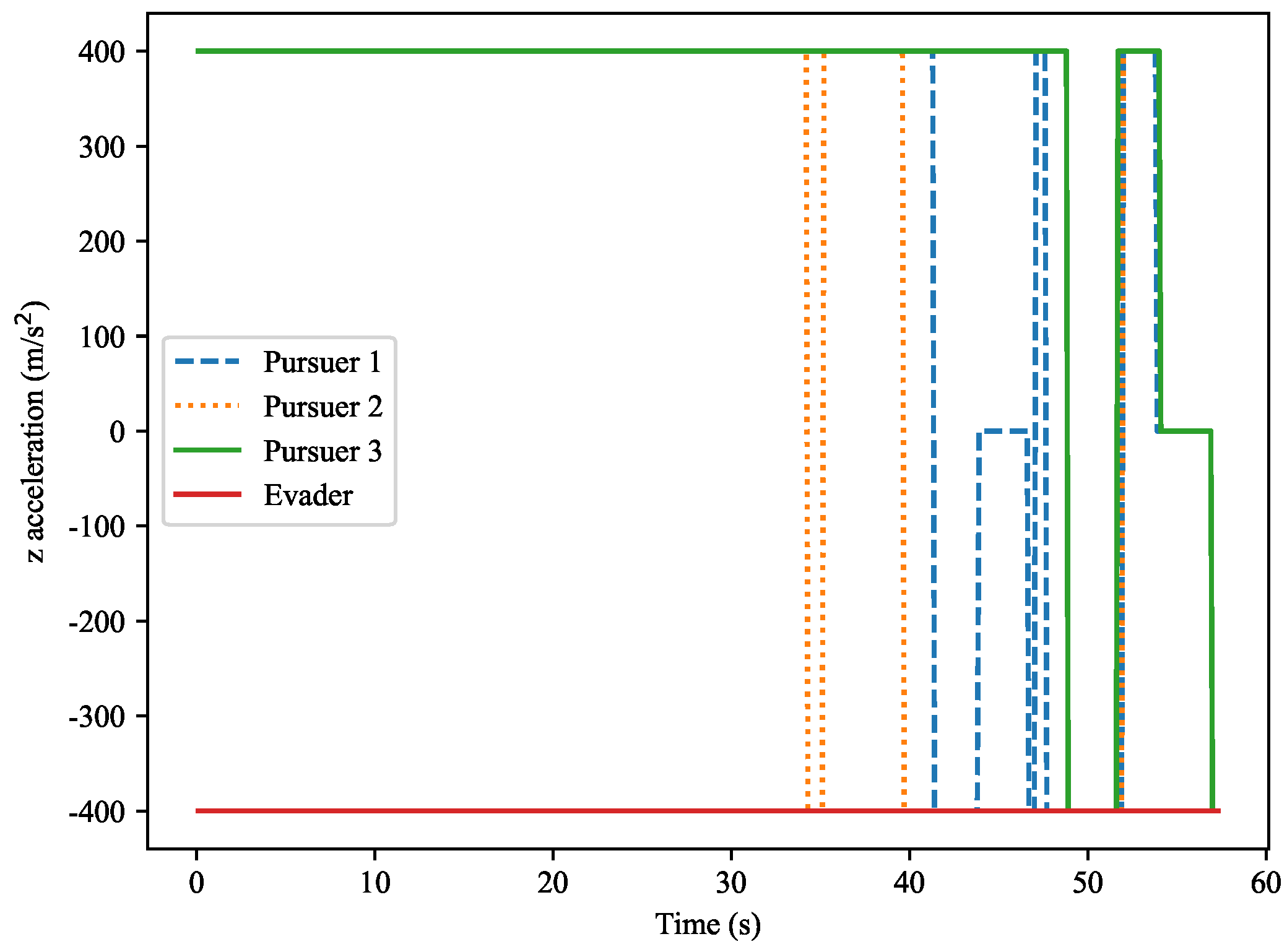
The
Z-axis normal acceleration variation is shown in
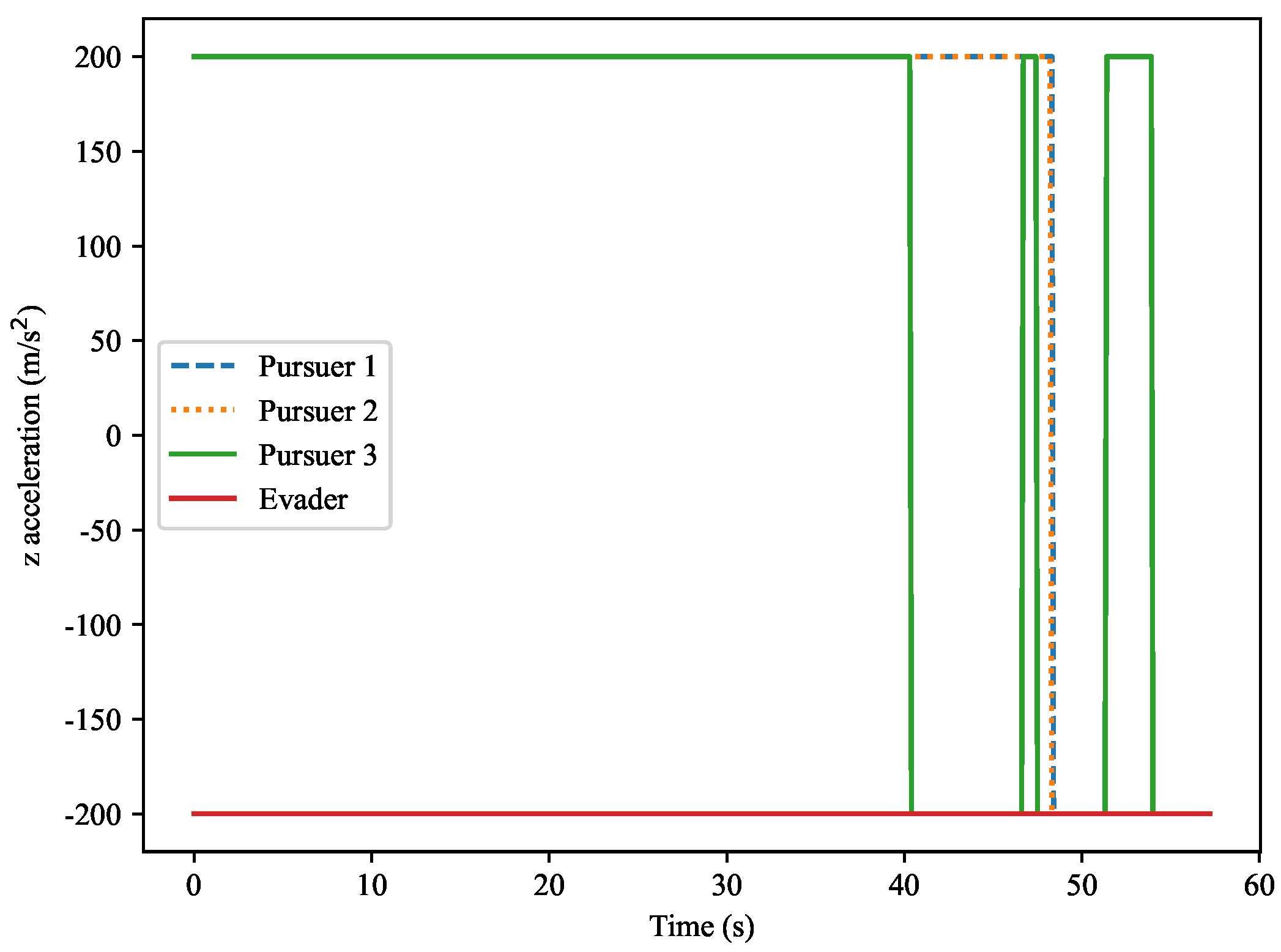
Figure 19. This figure shows the normal acceleration along the
Z-axis for both the target and the pursuers. Similarly to the
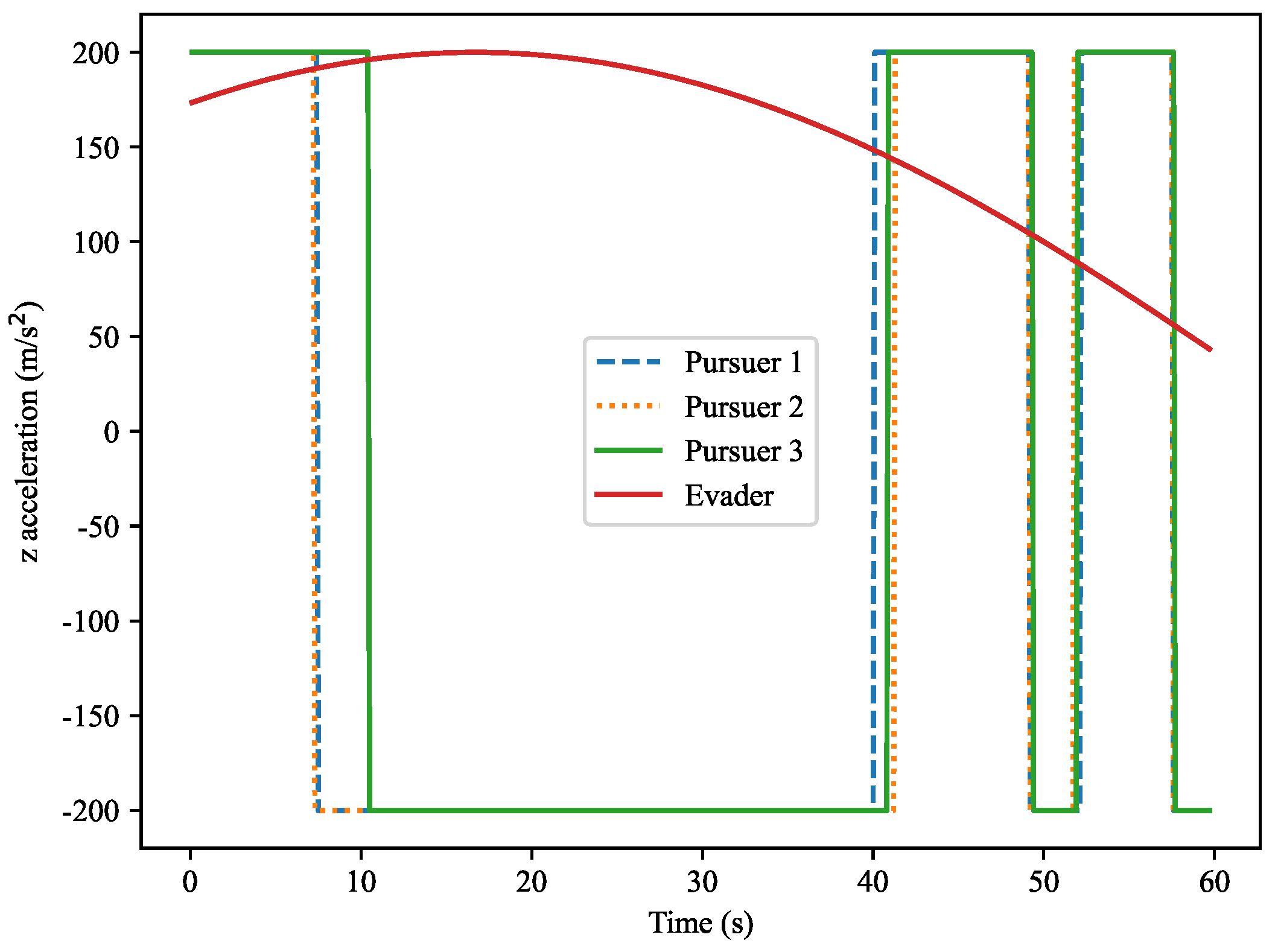
Y-axis acceleration, the pursuers’ accelerations exhibit significant fluctuations during the capture process, while the evader’s acceleration remains relatively small and close to zero. The figure shows that as the distance between the pursuers and the target changes, the fluctuations in acceleration become more pronounced.
Example 2: The maximum normal acceleration of the pursuers and the evader is set to 40 g, while other conditions remain the same as in Example 1. The initial position of pursuer 1 is [0, 14,399, 5250], the initial position of pursuer 2 is [0, 15,481, 4543], and the initial position of pursuer 3 is [0, 14,324, 5211]. The target’s initial position is [100,000, 14,000, 0], and the maximum normal acceleration is set to 40 g, which means that the pursuers’ acceleration is restricted to a higher value, thus affecting their efficiency and strategy in capturing the target.
The motion trajectory is shown in
Figure 20. The figure displays the motion trajectories of the evader and the three pursuers in three-dimensional space. The trajectories of the pursuers and the evader differ from those in Example 1, especially after the change in the acceleration limit. The pursuers’ trajectories show more significant changes. Through the Q-learning-cover algorithm, the pursuers gradually approach the target and ultimately capture it.
The
X-
Y plane projection is shown in
Figure 21. This figure presents the projection of the target and the three pursuers on the
X-
Y plane. Compared to Example 1, the motion trajectories of the pursuers and the evader exhibit different changes in this plane. Particularly, with the normal acceleration limit set to 40 g, the pursuers’ movement becomes more intense, and the trajectory changes are more pronounced. The evader maintains a relatively stable path in the
X-
Y plane, while the pursuers’ trajectories show their continuous approach toward the target. By comparing the trajectories of the pursuers, the dynamic changes during the pursuit process are clearly observed.
The
X-
Z plane projection is shown in
Figure 22. This figure presents the projection of the target and the three pursuers on the
X-
Z plane. With the normal acceleration limit set to 40 g, the pursuers’ trajectories show more complex dynamic changes on this plane, especially during the capture process. The pursuers’ paths exhibit larger fluctuations, while the evader’s trajectory remains more stable, despite the pursuers closing in. Comparing the projections of the pursuers in the
X-
Z plane helps in understanding the impact of acceleration on the pursuers’ movement paths.
The distance variation is shown in
Figure 23. This figure displays the distance variations between the evader and the three pursuers. As the pursuers gradually approach the target, the final miss distances are
,
, and
. The curves in the figure show the dynamic changes during the pursuit. In this example, due to the normal acceleration being set to 40 g, the pursuers’ acceleration is significantly increased, leading to more dramatic trajectory changes during the capture process. By comparing the distance variation curves of the pursuers, one can clearly see the acceleration and deceleration processes at different stages of the pursuit.
The
Y-axis acceleration variation is shown in
Figure 24. This figure presents the variation in acceleration along the
Y-axis for the evader and the three pursuers. In this example, the acceleration of the pursuers fluctuates significantly, especially as they approach the target. As their acceleration increases, the pursuers’ trajectories gradually close in on the target. In contrast, the evader’s acceleration remains relatively stable, staying at a low level. By comparing the acceleration variations of the pursuers and the evader, the effect of acceleration on the pursuit strategy is clearly observable.
Z-axis acceleration variation is shown in
Figure 25. This figure presents the variation in acceleration along the
Z-axis for the target and the pursuers. Similar to the
Y-axis acceleration, the pursuers’ acceleration fluctuates more significantly as they approach the target, showing obvious variations. The evader’s acceleration remains relatively stable, with consistent values. By comparing the acceleration differences between the pursuers and the evader, the impact of acceleration on the capture process is intuitively observed.
Experiment 3: The pursuers use the optimal strategy, and the evader uses a composite sine maneuver. Other conditions are the same as in Example 1. The initial position of pursuer 1 is [0, 14,399, 5250], the initial position of pursuer 2 is [0, 15,481, 4543], and the initial position of pursuer 3 is [0, 14,324, 5211]. The initial position of the target is [100,000, 14,000, 0]. Unlike the previous two examples, the evader in this example adopts a composite sine maneuver strategy, making its trajectory more complex and unpredictable, thereby increasing the difficulty for the pursuers to capture the target. The 3D trajectory is shown in
Figure 26.
The initial distance between the pursuers and the evader is approximately 100,000 m. The initial angle is random. The figure displays the motion trajectories of the evader and the three pursuers in three-dimensional space. Due to the composite sine maneuver of the evader, the trajectory shows more complex and variable characteristics. With the optimal strategy, the pursuers gradually close the distance to the target and eventually capture it.
X-
Y plane projection is shown in
Figure 27. This figure presents the motion trajectories of the evader and the three pursuers in the
X-
Y plane. Compared to Example 1, the motion trajectories of the pursuers and the evader exhibit different changes in this plane. Particularly, with the normal acceleration limit set to 40 g, the pursuers’ movement becomes more intense, and the trajectory changes are more pronounced. The evader maintains a relatively stable path in the
X-
Y plane, while the pursuers’ trajectories show their continuous approach toward the target. By comparing the trajectories of the pursuers, the dynamic changes during the pursuit process are clearly observed.
The
X-
Z plane projection is shown in
Figure 28. This figure presents the motion trajectories of the evader and the three pursuers in the
X-
Z plane. With the normal acceleration limit set to 40 g, the pursuers’ trajectories show more complex dynamic changes on this plane, especially during the capture process. The pursuers’ paths exhibit larger fluctuations, while the evader’s trajectory remains more stable, despite the pursuers closing in. Comparing the projections of the pursuers in the
X-
Z plane helps in understanding the impact of acceleration on the pursuers’ movement paths.
The distance variation is shown in
Figure 29. This figure displays the distance variations between the evader and the three pursuers over time. As the pursuers gradually approach the target, the final miss distances are 3.6 m (pursuer 1), 0.92 m (pursuer 2), and 2.3 m (pursuer 3). The curves in the figure display the dynamic changes during the pursuit. In this example, with the normal acceleration being set to 40 g, the pursuers’ acceleration is significantly increased, leading to more dramatic trajectory changes during the capture process. By comparing the distance variation curves of the pursuers, one can clearly see the acceleration and deceleration processes at different stages of the pursuit.
The
Y-axis acceleration variation is shown in
Figure 30. This figure presents the variation in acceleration along the
Y-axis for the evader and the three pursuers during the pursuit. The evader’s
Y-axis acceleration curve (red solid line) shows an overall increasing trend, which then stabilizes, reflecting the sustained control signals applied during its evasion or turning maneuvers. The pursuers’ acceleration curves exhibit significant jumps, especially for pursuer 3 (green dashed line), where acceleration spikes are observed during multiple periods, likely due to its rapid path correction behavior. Pursuers 1 and 2 show relatively smoother acceleration curves, indicating stable control strategies, contributing to higher precision tracking.
The
Z-axis acceleration variation is shown in
Figure 31. The figure shows the acceleration variations along the
Z-axis for both the target and the pursuers. Similar to the
Y-axis acceleration, the pursuers’ acceleration fluctuates more significantly as they approach the target, with obvious spikes in their acceleration. The evader’s acceleration remains relatively steady, with consistent values. Comparing the acceleration differences between the pursuers and the evader provides a more intuitive understanding of how acceleration differences impact the capture process.
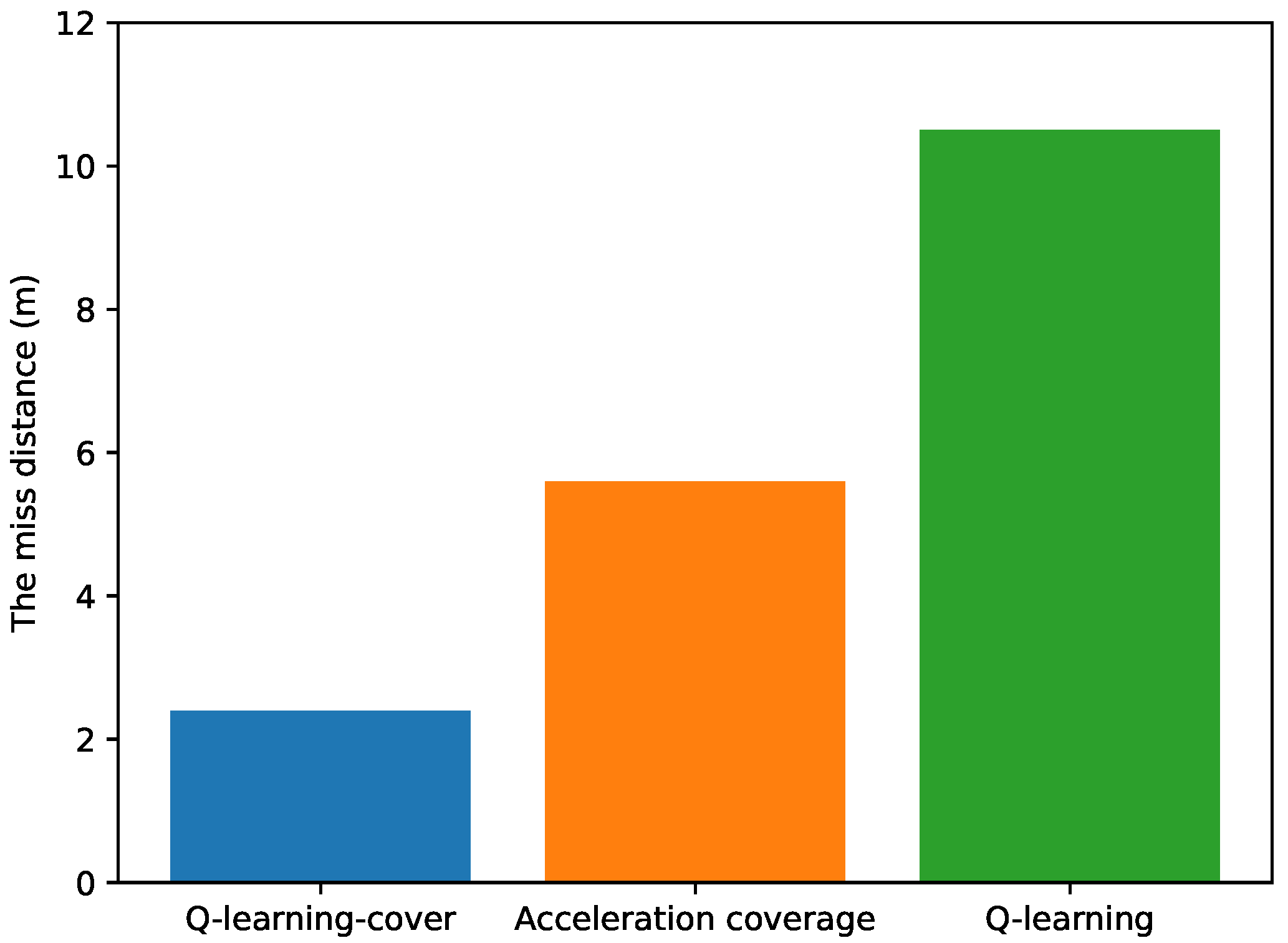
Comparison of three algorithms: This paper compares the Q-learning-cover algorithm with the acceleration coverage algorithm in terms of miss distance. The experiment was repeated 100 times, and the average miss distance for the three pursuers was calculated, as shown in
Figure 32. The experimental results show that the Q-learning-cover algorithm’s average miss distance is 2.4 m, the acceleration coverage algorithm’s average miss distance is 5.8 m, and the Q-learning algorithm’s miss distance is 10.4 m. This demonstrates that the Q-learning-cover algorithm has a clear advantage in improving interception accuracy.
In
Figure 33, we present an analysis of the experimental results. The left side of the figure shows the process of three pursuers successfully intercepting one evader, while the right side presents the real-time feedback of the browser monitoring data. Unlike the experimental setup in
Section 2, this experiment was conducted in the Earth coordinate system and used advanced Cesium technology for visualization, achieving more precise and dynamic monitoring displays.
Tabular comparison of existing approaches: As per the recommendation, we have included a tabular comparison (
Table 3) between existing methods (PN, ZCMD, and DDPG) and the Q-learning-cover algorithm. This comparison presents the results based on accuracy, convergence time, and computational complexity, providing a clearer perspective on how our method compares to others in the field.
Table 3 presents a comparison of the Q-learning-cover algorithm with other existing methods, namely PN, ZCMD, and DDPG, based on three key metrics: interception success rate, convergence time, and memory requirement.
Interception success rate: The Q-learning-cover algorithm achieved the highest interception success rate at 97%, significantly outperforming the other methods, with PN at 87%, ZCMD at 92%, and DDPG at 89%. This indicates that the Q-learning-cover algorithm excels in accuracy, making it a highly effective approach for strategic interception.
Convergence time: The Q-learning-cover algorithm also demonstrated the shortest convergence time (0.002 s), suggesting that it is computationally efficient compared to the other methods. In contrast, DDPG took the longest (0.021 s), followed by ZCMD (0.004 s) and PN (0.003 s).
Memory requirement: Regarding memory usage, the Q-learning-cover algorithm required 54 MB, which is the least among all methods. This efficiency is critical for real-time applications, especially when hardware resources are constrained. DDPG required 96 MB, ZCMD 120 MB, and PN 82 MB.
Overall, these results show that the Q-learning-cover algorithm offers a promising balance between high interception accuracy, fast convergence, and low memory usage, making it an attractive option for real-world applications in pursuit–evasion scenarios.
The parameter plays a crucial role in adjusting the proportional coefficients of the algorithm. As increases, the accuracy of the interception improves, but this comes at the cost of increased computation time. We observe that larger values of result in slower convergence times, suggesting a trade-off between accuracy and efficiency.
The parameter , which is related to the discount factor in the reinforcement learning setup, influences the weight given to future rewards. Increasing leads to better long-term planning but may cause slower adaptation in dynamic environments. In our experiments, we found that varying significantly affects the algorithm’s convergence speed.
Finally, the parameter is crucial for scaling the velocity difference between the pursuer and evader. As increases, the algorithm’s memory usage decreases, but at the cost of reduced accuracy in interception. The relationship between and efficiency highlights a balance between resource consumption and interception precision.
In addition to the performance metrics presented in
Table 3, we further analyze the algorithm’s efficiency by evaluating the computation time and the number of iterations required for convergence.
Computation time: The computation time is measured for each iteration of the algorithm, and we observe that the Q-learning-cover algorithm outperforms other methods in terms of speed, as shown in
Table 4.
Number of iterations: The number of iterations required for the algorithm to reach convergence is also reported. We found that the Q-learning-cover algorithm requires fewer iterations compared to the other methods, which contributes to its faster convergence time.
The results show that the Q-learning-cover algorithm is both computationally efficient and fast in converging to the optimal solution with fewer iterations compared to other algorithms.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}