
AEM-D3QN: A Graph-Based Deep Reinforcement Learning Framework for Dynamic Earth Observation Satellite Mission Planning


Abstract
1. Introduction
2. Satellite Mission Planning Framework Based on GNNs and Deep Reinforcement Learning
2.1. Problem Definition
2.2. Problem Assumptions
- Only point targets are considered, with polygonal targets treated as multiple independent point targets.
- Each observation task is completed in a single imaging attempt.
- Each observation task is executed at most once, without considering multiple repetitions.
- Satellites are assumed to function normally during task execution.
- The data transmission process is not taken into account.
2.3. Modeling
- Objective Function
- Satellite Storage Capacity Constraint
- Satellite Energy Capacity Constraint
- Each Target Can Be Observed Only Once
- Composite Task Angular Constraint
- Task Time Constraint
- Task Visibility Constraint
3. Deep Reinforcement Learning Algorithm Based on Graph Neural Network
3.1. Overall Framework
3.2. Strip Synthesis
- First, sort all subtasks for each satellite in ascending order based on their earliest time window to generate the sequence , where represents the subtask of satellite (, m is the total number of satellites).
- Traverse each subtask in chronological order, setting as . Nest a loop through the remaining subtasks, setting as . Compare whether the time difference between the two subtasks is less than the maximum activation duration and whether their inclination angle ranges overlap. If the conditions are met, generate a strip with the two subtasks as the start and end points, indicating that satellite generates bands starting and ending at points and .
- Generate strip , where the start time of the composite strip’s visibility is time, the end time is time, and the composite strip’s effective inclination angle is the average of the two subtasks’ inclination angles, while the task priority is the sum of their priorities.
- Generate strip from subtask to (). Traverse all subtasks in between. If any subtask’s inclination angle intersects, it is included in the strip, and the strip task priority is increased. Repeat until all subtasks are processed.
- Set as and repeat Step (2) until becomes .
- Set as and repeat Step (2) until becomes .
- The satellite task sequence is transformed into ( represents the total number of satellites). Repeat Step (2) until all satellites are traversed, generating all observable task strips , where and .
3.3. Graph Structure Construction
- Filter observable tasks based on each satellite’s visibility for each task. Establish a virtual node A as the starting point for the current time step. Arrange all tasks in chronological order and eliminate those that do not satisfy observation constraints through constraint verification. This approach reduces computational complexity, as shown in Figure 6.
- Using the sorted sequence from the previous step, begin at the virtual node A and arrange all nodes according to the specified constraints. Identify valid child nodes and sort them chronologically. Since Tasks 1, 2, and 3 overlap in observation time, they cannot form a sequential observation sequence. In contrast, Tasks 4, 5, 6, and 7 exist as a continuous sequence and can be observed consecutively. Therefore, only Tasks 1, 2, and 3 qualify as child nodes of virtual node A, while Tasks 4, 5, 6, and 7 do not. Following this principle, child nodes for each node are identified and linked to construct all possible observation plans for each satellite. Figure 7 illustrates this node structure, which is further visualized in Figure 8. The purple boxes labeled with numbers are synthetic observation bands.
- (1)
- execution of an existing task;
- (2)
- arrival of new observation requests.
- Task execution.
- Emergency task insertion.
- (1)
- Temporal dependency: Task A must be executed before Task B due to time window alignment.
- (2)
- Resource conflict: Task A and Task B cannot be scheduled simultaneously due to limited imaging field-of-view or onboard energy.
- (3)
- Priority-based substitution: Task A and Task B target similar areas, but B has higher priority (e.g., emergency tasks), thus dominating the scheduling of A.
3.4. GNN Model Design
- (1)
- Input Encoding: Each task is represented by a feature vector containing: (i) observation priority (normalized between 0 and 1), (ii) visible time window length, (iii) task type (emergency or periodic), (iv) satellite identifier (one-hot encoded), and time urgency (derived from deadline proximity). These vectors form the node features of the input task graph, resulting in an input tensor of shape , where is the number of tasks and is the feature dimension.
- (2)
- Edge Encoding: Pairwise dependencies are encoded in an adjacency matrix , with each element representing the existence and type of dependency (temporal, conflict, or priority-based) between task pairs. This matrix guides the message passing in the GNN layer.
- (3)
- Intermediate Representation: During training, the GAT-based model dynamically updates node embeddings by aggregating neighborhood information, where attention coefficients reflect changing scheduling constraints—especially under fluctuating task urgency or satellite resource availability. Each node embedding captures contextual dependencies and is passed to the reinforcement learning agent.
- (4)
- Output Decoding: The final output is a scheduling action vector of length , where each element denotes the estimated Q-value of executing a specific task at a given time. These outputs are decoded into a ranked task list or an execution schedule via a greedy or softmax sampling strategy, which is compatible with satellite onboard planners.
3.5. Deep Reinforcement Learning Model Design
- State Space
- Action Space
- Reward Function
- Loss Function
4. Experiment Design and Result Analysis
4.1. Experimental Parameter Settings
- Periodic Task Planning
- Emergency mission planning
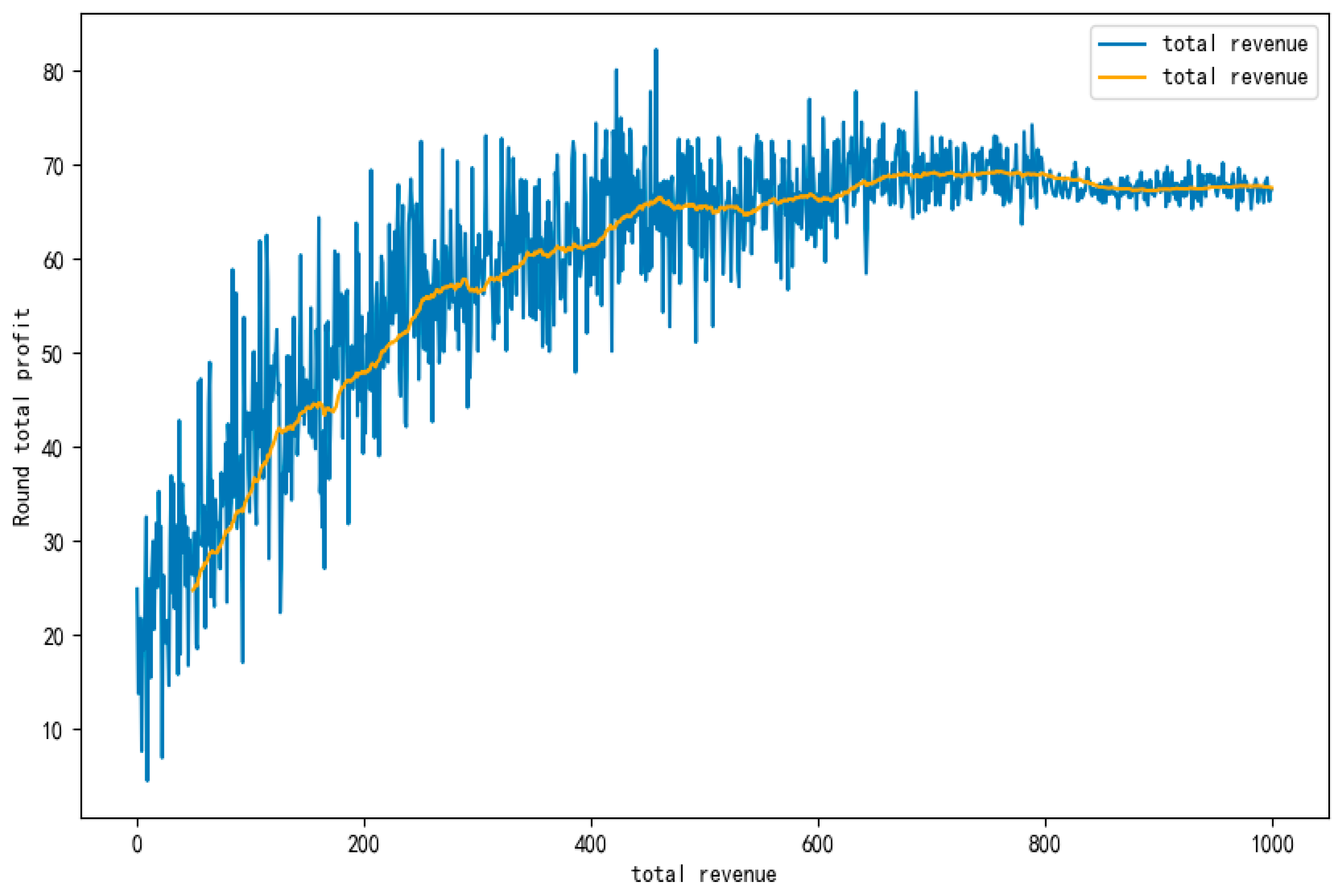
4.2. Experiment and Analysis
- Total Profit (F): It is defined as the ratio of the actual valid observation frequency of all emergency tasks to the required observation frequency. represents the set of completed tasks.
- Response Time (Latency): The time elapsed from the invocation of the algorithm to the generation of the schedule or decision. represents the algorithm invocation time, and represents the schedule generation time.
- Scheduling Rate (Task Completion Rate): It is defined as the ratio of the actual valid observation frequency of all emergency tasks to the required observation frequency.
4.2.1. Periodic Task Planning
4.2.2. Emergency Mission Planning
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, J. Earth Observation and Air Surveillance, 1st ed.; Science Press: Beijing, China, 2001. [Google Scholar]
- Li, G.; Xing, L.; Chen, Y. A hybrid online scheduling mechanism with revision and progressive techniques for autonomous Earth observation satellite. Acta Astronaut. 2017, 140, 308–321. [Google Scholar] [CrossRef]
- Jiang, B.T. Development and Prospect of China’s Space Earth—Observation Technology. Acta Geod. Cartogr. Sinica 2022, 51, 7. [Google Scholar] [CrossRef]
- Liao, X. Scientific and Technological Progress and Development of Earth Observation in China over the Past 20 Years. J. Remote Sens. 2021, 25, 267–275. [Google Scholar] [CrossRef]
- Schiex, T. Solution reuse in dynamic constraint satisfaction problems. In Proceedings of the Twelfth National Conference on Artificial Intelligence, Seattle, DC, USA, 31 July–4 August 1994. [Google Scholar]
- Pemberton, J.C. A constraint-based approach to satellite scheduling. In Proceedings of the DIMACS Workshop on Constraint Programming and Large Scale Discrete Optimization, Piscataway, NJ, USA, 14–17 September 2000. [Google Scholar]
- Dai, S. Research on Key Technologies of Spacecraft Autonomous Operation. Ph.D. Dissertation, Center for Space Science and Applied Research, Chinese Academy of Sciences, Beijing, China, 2002. [Google Scholar]
- Li, Y.; Wang, R.; Liu, Y.; Xu, M. Satellite range scheduling with the priority constraint: An improved genetic algorithm using a station ID encoding method. Chin. J. Aeronaut. 2015, 28, 789–803. [Google Scholar] [CrossRef]
- Habet, D.; Vasquez, M.; Vimont, Y. Bounding the Optimum for the Problem of Scheduling the Photographs of an Agile Earth Observing Satellite. Comput. Optim. Appl. 2010, 47, 307–333. [Google Scholar] [CrossRef]
- Sun, K.; Yang, Z.; Wang, P.; Chen, Y. Mission Planning and Action Planning for Agile Earth-Observing Satellite with Genetic Algorithm. J. Harbin Inst. Technol. 2013, 20, 51–56. [Google Scholar]
- Yuan, Z.; Chen, Y.; He, R. Agile earth observing satellites mission planning using genetic algorithm based on high quality initial solutions. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; IEEE: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Wang, M.; Dai, G.; Vasile, M. Heuristic Scheduling Algorithm Oriented Dynamic Tasks for Imaging Satellites. In Mathematical Problems in Engineering; Wiley: Hoboken, NJ, USA, 2014; pp. 1–11. [Google Scholar] [CrossRef]
- Xin, C.; Luo, Q.; Wang, C.; Yan, Z.; Wang, H. Research on Route Planning based on improved Ant Colony Algorithm. J. Phys. Conf. Ser. 2021, 1820, 012180. [Google Scholar] [CrossRef]
- Sangeetha, V.; Krishankumar, R.; Ravichandran, K.S.; Kar, S. Energy-efficient green ant colony optimization for path planning in dynamic 3D environments. Soft Comput. 2021, 25, 4749–4769. [Google Scholar] [CrossRef]
- He, W.; Qi, X.; Liu, L. A novel hybrid particle swarm optimization for multi-UAV cooperate path planning. Appl. Intell. 2021, 51, 7350–7364. [Google Scholar] [CrossRef]
- Yang, X.; Hu, M.; Huang, G.; Lin, P.; Wang, Y. A Review of Multi-Satellite Imaging Mission Planning Based on Surrogate Model Expensive Multi-Objective Evolutionary Algorithms: The Latest Developments and Future Trends. Aerospace 2024, 11, 793. [Google Scholar] [CrossRef]
- Peng, S.; Chen, H.; Du, C.; Li, J.; Jing, N. Onboard Observation Task Planning for an Autonomous Earth Observation Satellite Using Long Short-Term Memory. IEEE Access 2018, 6, 65118–65129. [Google Scholar] [CrossRef]
- Zhao, X.; Wang, Z.; Zheng, G. Two-Phase Neural Combinatorial Optimization with Reinforcement Learning for Agile Satellite Scheduling. J. Aerosp. Inf. Syst. 2020, 17, 1–12. [Google Scholar] [CrossRef]
- Wei, L.; Chen, M.; Chen, Y. Deep reinforcement learning and parameter transfer based approach for the multi-objective agile earth observation satellite scheduling problem. Appl. Soft Comput. 2021, 110, 107607. [Google Scholar] [CrossRef]
- Ma, Q.; Ge, S.; He, D.; Thaker, D.; Drori, I. Combinatorial Optimization by Graph Pointer Networks and Hierarchical Reinforcement Learning. arXiv 2019, arXiv:1911.04936. [Google Scholar] [CrossRef]
- Sun, H.; Chen, W.; Li, H.; Song, L. Improving learning to branch via reinforcement learning. In Proceedings of the 1st Workshop on Learning Meets Combinatorial Algorithms, Vancouver, BC, Canada, 11–12 December 2020; pp. 1–12. [Google Scholar]
- Li, K.; Zhang, T.; Wang, R.; Wang, L. Deep Reinforcement Learning for Online Routing of Unmanned Aerial Vehicles with Wireless Power Transfer. arXiv 2022, arXiv:2204.11477. [Google Scholar] [CrossRef]
- Li, C.; Chen, Y.; Lang, J. Data-driven onboard scheduling for an autonomous observation satellite. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, AAAI, Stockholm, Sweden, 13–19 July 2018; p. 20108. [Google Scholar]
- Wu, Y.L. Research on DAG Task Partitioning and Scheduling Algorithm for Multicore Real—Time Systems. Ph.D. Thesis, Harbin Institute of Technology, Harbin, China, 2024. [Google Scholar] [CrossRef]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In International Conference on Machine Learning; PMLR: Sydney, Australia, 2017; pp. 1263–1272. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar] [CrossRef]
- Gk, M. Dynamic path planning via Dueling Double Deep Q-Network (D3QN) with prioritized experience replay. Appl. Soft Comput. 2024, 158, 17. [Google Scholar] [CrossRef]
- Li, H.; Li, Y.; Liu, Y.; Zhang, K.; Li, X.; Li, Y.; Zhao, S. A Multi-Objective Dynamic Mission-Scheduling Algorithm Considering Perturbations for Earth Observation Satellites. Aerospace 2024, 11, 643. [Google Scholar] [CrossRef]
- Zhao, S.J. Research and Implementation of Satellite Autonomous Task Planning Method Based on Reinforcement Learning. Master’s Thesis, East China Normal University, Shanghai, China, 2023. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Node Feature Dimension Change | |
|---|---|---|
| Input layer | 12 × 32 | Feature extraction |
| Intermediate layer | 32 × 32 | |
| … | ||
| 32 × 32 | ||
| Pooling layer | Top-pooling | Decision making |
| Fully connected layer | (32n + 12) × 1024 | |
| 1024 × 512 | ||
| 512 × 9 |
| Parameter Name | Parameter Value | Meaning |
|---|---|---|
| 1000 | Training episodes | |
| 0.001 | Learning rate | |
| 64 | Hidden layer size | |
| 0.98 | Discount factor | |
| ReLU | Activation function | |
| 256 | Training batch size | |
| 5000 | Experience replay buffer size | |
| 12 | Initial node feature size | |
| 32 | Embedded node feature size | |
| 10 | Network depth | |
| 0.01 | Target network soft update |
| Scene Name | A | B | C | D |
|---|---|---|---|---|
| Number of meta-tasks | 500 | 1000 | 2000 | 3000 |
| Priority setting | 1–10 | 1–10 | 1–10 | 1–10 |
| Number of satellites | 8 | 8 | 8 | 8 |
| Energy storage | 10 | 10 | 10 | 10 |
| Storage space | 10 | 10 | 10 | 10 |
| Symbol | Range | Meaning |
|---|---|---|
| [2024-10-1 00:00:00, 2024-10-1 12:00:00] | The time window during which imaging is possible | |
| [0.05, 0.1] | The energy consumption required for imaging | |
| [0.05, 0.1] | The storage consumption required for imaging | |
| [0.05, 0.1] | The priority level of the task | |
| [0.05, 0.2] | The detection reward of the task |
| Algorithm Name | Scene A | Scene B | Scene C | Scene D |
|---|---|---|---|---|
| AEM-D3QN | 2.34 | 6.41 | 15.76 | 39.57 |
| MODMSA-INI | 5.18 | 38.18 | 84.19 | 381.34 |
| LSTM-DQN | 10.28 | 84.19 | 125.34 | 571.19 |
| AGI | 42.19 | 381.34 | 341.81 | 842.64 |
| Algorithm Name | Scene A | Scene B | Scene C | Scene D |
|---|---|---|---|---|
| AEM-D3QN | 73.18 | 70.26 | 71.36 | 67.71 |
| MODMSA-INI | 64.89 | 66.41 | 64.16 | 54.62 |
| LSTM-DQN | 67.42 | 65.32 | 66.31 | 57.17 |
| AGI | 62.19 | 60.14 | 60.67 | 48.44 |
| Case | AEM-D3QN | MODMSA-INI | LSTM-DQN | AGI |
|---|---|---|---|---|
| Case500_50 | 1.35 | 5.49 | 12.81 | 15.04 |
| Case500_100 | 1.74 | 8.34 | 18.91 | 23.18 |
| Case500_250 | 6.37 | 24.91 | 34.96 | 40.91 |
| Case1000_100 | 3.67 | 13.67 | 22.61 | 31.34 |
| Case1000_200 | 5.39 | 20.33 | 27.16 | 38.19 |
| Case1000_500 | 11.67 | 41.94 | 43.76 | 84.61 |
| Case2000_200 | 7.64 | 27.22 | 35.17 | 58.70 |
| Case2000_400 | 10.19 | 38.61 | 74.64 | 120.37 |
| Case2000_1000 | 18.35 | 79.16 | 341.73 | 574.61 |
| Case4000_400 | 12.76 | 44.63 | 246.38 | 267.09 |
| Case4000_800 | 19.36 | 82.34 | 637.81 | 943.37 |
| Case4000_2000 | 32.81 | 134.08 | 1867.40 | 3428.16 |
| Case | AEM-D3QN | MODMSA-INI | LSTM-DQN | AGI |
|---|---|---|---|---|
| Case500_50 | 88.16 | 84.10 | 83.91 | 80.19 |
| Case500_100 | 80.23 | 78.91 | 77.36 | 73.84 |
| Case500_250 | 62.18 | 59.14 | 58.61 | 53.91 |
| Case1000_100 | 86.16 | 82.36 | 79.14 | 77.43 |
| Case1000_200 | 79.18 | 74.93 | 74.64 | 67.29 |
| Case1000_500 | 60.94 | 56.17 | 55.39 | 52.57 |
| Case2000_200 | 87.34 | 84.34 | 84.13 | 76.94 |
| Case2000_400 | 78.43 | 74.93 | 72.64 | 68.61 |
| Case2000_1000 | 59.81 | 55.38 | 55.19 | 46.18 |
| Case4000_400 | 88.23 | 84.34 | 83.14 | 78.43 |
| Case4000_800 | 79.38 | 75.62 | 72.69 | 66.19 |
| Case4000_2000 | 58.16 | 54.64 | 52.67 | 43.73 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Wang, G.; Chen, J. AEM-D3QN: A Graph-Based Deep Reinforcement Learning Framework for Dynamic Earth Observation Satellite Mission Planning. Aerospace 2025, 12, 420. https://doi.org/10.3390/aerospace12050420
Li S, Wang G, Chen J. AEM-D3QN: A Graph-Based Deep Reinforcement Learning Framework for Dynamic Earth Observation Satellite Mission Planning. Aerospace. 2025; 12(5):420. https://doi.org/10.3390/aerospace12050420
Chicago/Turabian StyleLi, Shuo, Gang Wang, and Jinyong Chen. 2025. "AEM-D3QN: A Graph-Based Deep Reinforcement Learning Framework for Dynamic Earth Observation Satellite Mission Planning" Aerospace 12, no. 5: 420. https://doi.org/10.3390/aerospace12050420
APA StyleLi, S., Wang, G., & Chen, J. (2025). AEM-D3QN: A Graph-Based Deep Reinforcement Learning Framework for Dynamic Earth Observation Satellite Mission Planning. Aerospace, 12(5), 420. https://doi.org/10.3390/aerospace12050420