1. Introduction
With the progress of miniaturization technology, the inertial-stabilized gimbaled seeker is increasingly being supplanted by the strap-down seeker. This substitution is mainly attributed to the complex structure and high cost of the inertial-stabilized gimballed seeker [
1]. The strap-down seeker, rigidly mounted on the flight vehicle, offers significant advantages for various small flight vehicle platforms, including cost effectiveness, enhanced reliability, and improved stability. However, the fixed connection between the seeker and the flight vehicle body results in a complex coupling of the seeker’s measurement data with the vehicle’s attitude, which creates pronounced non-linearities and poses significant challenges for model decoupling, as described in [
2]. Furthermore, the inherently limited FOV characteristic of a strap-down seeker significantly increases the likelihood of exceeding the FOV during attitude adjustments for target tracking [
3]. Addressing the design issues of the guidance and control system under the constraints of intense coupling and FOV of the strap-down seeker is of paramount importance and persists as an urgent challenge in current research.
The first category of solutions to the aforementioned problems is to design guidance laws with FOV constraints. In this regard, the previous studies can be mainly divided into three categories: proportional navigation (PN)-based methods [
4,
5], sliding mode control (SMC)-based guidance laws [
6,
7], and optimal control-based guidance laws [
8]. For non-maneuvering targets, a biased PN algorithm that takes into account the FOV constraint was devised in [
4]. In reference [
5], a piece-wise design approach was implemented, and special switching logic was elaborately designed to ensure that the PN algorithm adheres to the FOV constraint. The SMC technique tackles the constraint issue by redefining both the sliding mode surface and the reaching law. In [
6], the sigmoid function was incorporated into the design of the sliding mode surface, effectively resolving the FOV constraint problem. Regarding the reaching law design, as presented in [
7], the FOV constraint problem is regarded as a state-constraint control problem, and an Integration Barrier Lyapunov Function (IBLF) is used to solve it effectively. In [
8], the optimal control theory was employed. By optimizing the positive weighting coefficient related to the constraint range, the performance index was minimized. Concurrently, both the impact angle and the FOV constraint were successfully regulated. Nonetheless, all the guidance laws mentioned above are formulated for two-dimensional (2D) scenarios and generally only find applicability to stationary or weakly maneuvering targets. These guidance laws fail to take into account the coupling relationships among diverse motion channels (e.g., pitch, yaw, and roll) in 3D dynamics, nor do they consider the impact of autopilot dynamics. Consequently, in 3D scenarios, the meticulous design of guidance laws subject to FOV constraint warrants further in-depth attention.
To design an FOV constraint guidance law in a 3D scenario, a back-stepping technique based on non-linear mapping was employed to develop a 3D guidance law considering both impact angle and FOV constraints. Yet, as shown in [
9], it still only works for stationary targets. In [
10], a 3D guidance law with impact time and the FOV constraints was proposed, based on the Barrier Lyapunov Function (BLF). It uses the time-to-go information of a flight vehicle to meet the FOV constraint. However, it demands additional information on the target, hindering practical implementation. In [
11], a time-varying function related to the line-of-sight (LOS) replaced the FOV constraint, converting it into an output constraint solved by a time-varying asymmetric BLF. Similarly, Ref. [
12] presented a 3D optimal guidance law based on biased proportional navigation, utilizing a non-linear function for FOV constraint satisfaction and impact time control. However, both methods apply only to stationary or weakly maneuvering targets. On the other hand, most of the above-mentioned studies assume a small but ideal angle of approach, which allows the FOV angle constraint problem to be converted into a velocity lead angle constraint problem for preliminary analysis. However, the rigid attachment of the strap-down seeker to the flight vehicle causes strong coupling between the measurement information of the seeker and flight vehicle’s attitude. This leads to a complex interaction between the guidance loop and the rotational dynamics. Given this, finding effective methods to address the coupling between the guidance and the attitude dynamics has now emerged as a crucial and urgent task in the field [
13].
The IGC design can alleviate the coupling problem between the guidance system and the attitude dynamics to a certain extent and has received extensive attention. In [
14], the small-gain theory was employed, while in [
15], the prescribed performance method was utilized to address the IGC problem. In [
16,
17,
18,
19], the sliding mode control theory was adopted to design IGC algorithm for a flight vehicle. In [
20], an adaptive block dynamic surface control algorithm was used to tackle the time-varying non-linear system problem of IGC design. However, these methods failed to consider the narrow FOV constraint problem inherent in the strap-down seeker. To achieve constraints on the impact angle, input, and system states, an IGC method integrating the back-stepping technique and IBLF was designed in [
21]. In [
22], an IGC method combining dynamic surface control with the IBLF was proposed for the Skid-to-Turn (STT) flight vehicles, thereby realizing the narrow FOV constraint. In [
23], an adaptive disturbance observer was designed using the adaptive gain super-twisting algorithm to estimate the uncertainties in the IGC system. The IBLF and time-varying sliding mode variables were combined to achieve the FOV constraint. In [
24], an integrated cooperative guidance and control method capable of achieving FOV constraints was derived by means of the BLF and dynamic surface control. In [
25], an adaptive IGC method under side-window constraint was proposed based on the asymmetric BLF, finite-time stability theory, and the modified dynamic surface technique. In [
13], an IGC method based on the IBLF and the adaptive algorithm was put forward, and the FOV constraint was achieved through state constraints. However, due to the intense guidance-control coupling in the IGC model, the above-mentioned methods present substantial challenges in terms of complex design and parameter tuning.
In contrast to traditional design methods, the DRL algorithm, a data-driven intelligent approach, substantially lessens the reliance on models and obviates the necessity for intricate model processing. By integrating the perception capacity of deep learning with the decision-making and optimization capabilities of reinforcement learning, it can extract features from vast amounts of data. This enables the agent to optimize strategies in accordance with the reward signals during environmental interactions [
26]. In [
27,
28,
29,
30], the DRL method was tailored to the guidance law design, thereby validating the feasibility of this concept. In [
31], the Deep Q-Network algorithm was applied to address the guidance problem. Nevertheless, as it can only generate a discrete action space, the TD3 algorithm was adopted in [
32] for enhancement. The TD3 algorithm can generate a continuous action space, rendering it more suitable for handling guidance and control issues. In [
33,
34,
35], the DRL algorithm was applied to the design of 3D guidance laws with constraints on impact angle, FOV, and approach time. It was shown that this method creates a direct mapping from states to actions via offline training, eliminating model dependence and effectively resolving the encountered constraint problems. In [
36], the DRL algorithm was applied to the design of the 2D IGC method. In [
37], the 3D IGC model was simplified, and an IGC method was formulated in the pitch and yaw directions, but no constraints were taken into account.
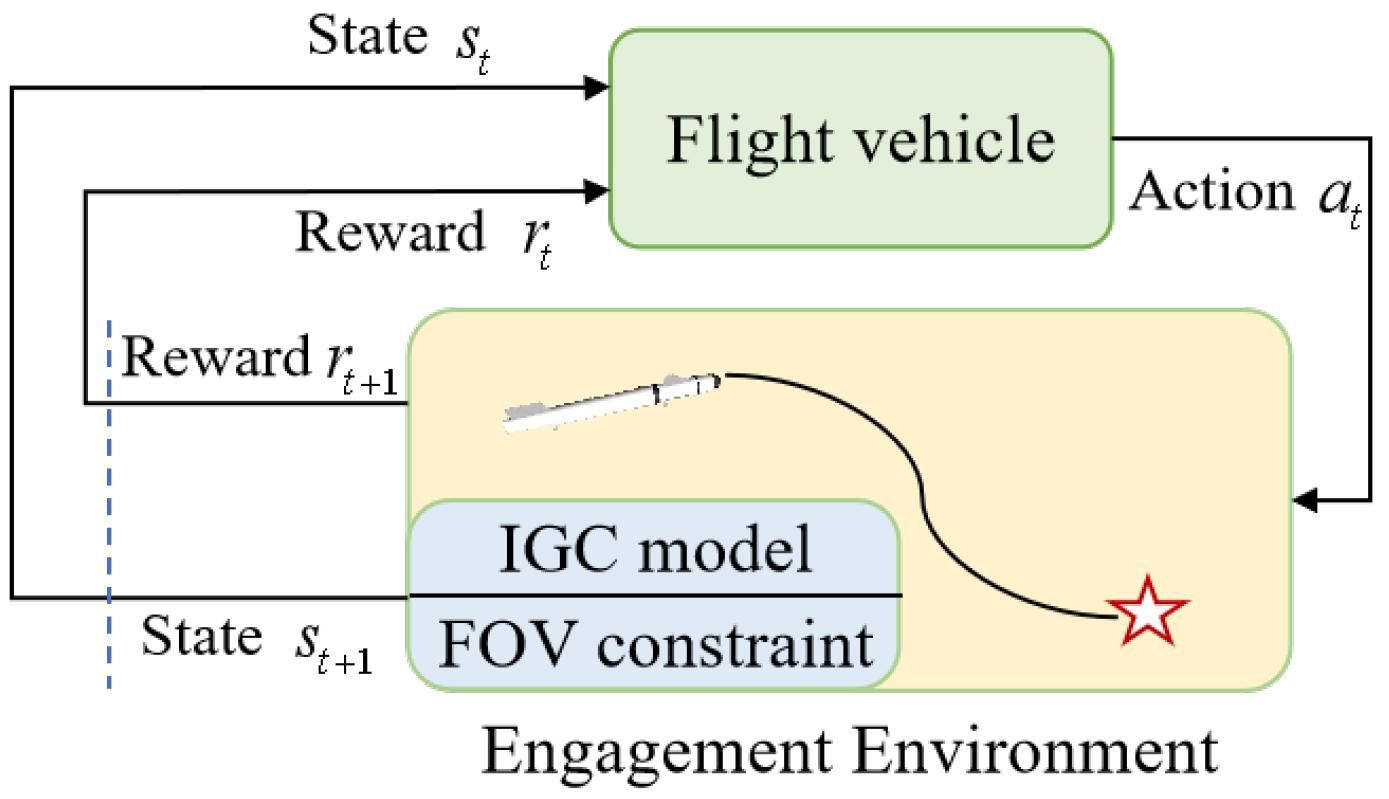
In the present technological context, research that employs DRL algorithms to solve the 3D IGC problem under the constraint of a narrow FOV remains relatively scarce. To devise an IGC method for STT flight vehicles within the narrow FOV constraint in three-dimensional scenario, this paper puts forward a DRLIGC approach founded on the TD3 algorithm. Specifically, the 6-DOF IGC model is transformed into Markov Decision Process (MDP) models channel by channel. Elaborate reward functions, which take into account both the FOV constraint and the hitting capability, are designed separately for the pitch and yaw channels.
Leveraging the data-driven characteristic of the DRL algorithm, a direct mapping from states to rudder deflection angles is established through training. This mapping can significantly mitigate the challenges associated with designing the guidance and control system, which are typically caused by the complex couplings that come with the strap-down seeker. The contributions of this paper are as follows:
- (1)
In contrast to existing methods, this paper introduces a DRLIGC algorithm capable of addressing the issue of accurately approaching maneuvering targets in 3D scenarios while adhering to the narrow FOV constraint of the strap-down seeker. Utilizing the DRL algorithm, this approach significantly reduces the complexity associated with the design of IGC methods and mitigates the challenges of parameter adjustment.
- (2)
In comparison to the three-channel coupling model training strategy, the DRLIGC algorithm proposed in this paper employs a channel-by-channel progressive training approach. This not only markedly decreases the training complexity arising from the coupling between the guidance and the attitude dynamics but also improves the training efficiency.
- (3)
Comprehensive reward functions are separately devised for the pitch and yaw channels. These functions effectively strike a balance between the FOV constraints and the hitting capability of the respective channels, thus alleviating the problem of sparse rewards.
The structure of this paper is organized as follows: In
Section 2, the 6-DOF IGC design model is presented, and the specific problems that this paper aims to resolve are also delineated. In
Section 3, the training procedure and specific algorithm of the DRLIGC method are detailed. In
Section 4, Monte Carlo simulations and comparative simulations are conducted to verify the effectiveness and superiority of the method proposed in this paper. And conclusions are drawn in
Section 5.
2. Problem Formulation
In this section, a 3D IGC model for the STT flight vehicle considering FOV constraint of the strap-down seeker is established. Based on this model, the design objective of this paper and the required preliminary concepts are presented.
Due to the data-driven characteristic of the DRL algorithm, which substantially lessens the reliance on the mathematical model, there is no need for intricate transformations of the entire model. Instead, training can be carried out directly using the 6-DOF model of the flight vehicle in the context of IGC design.
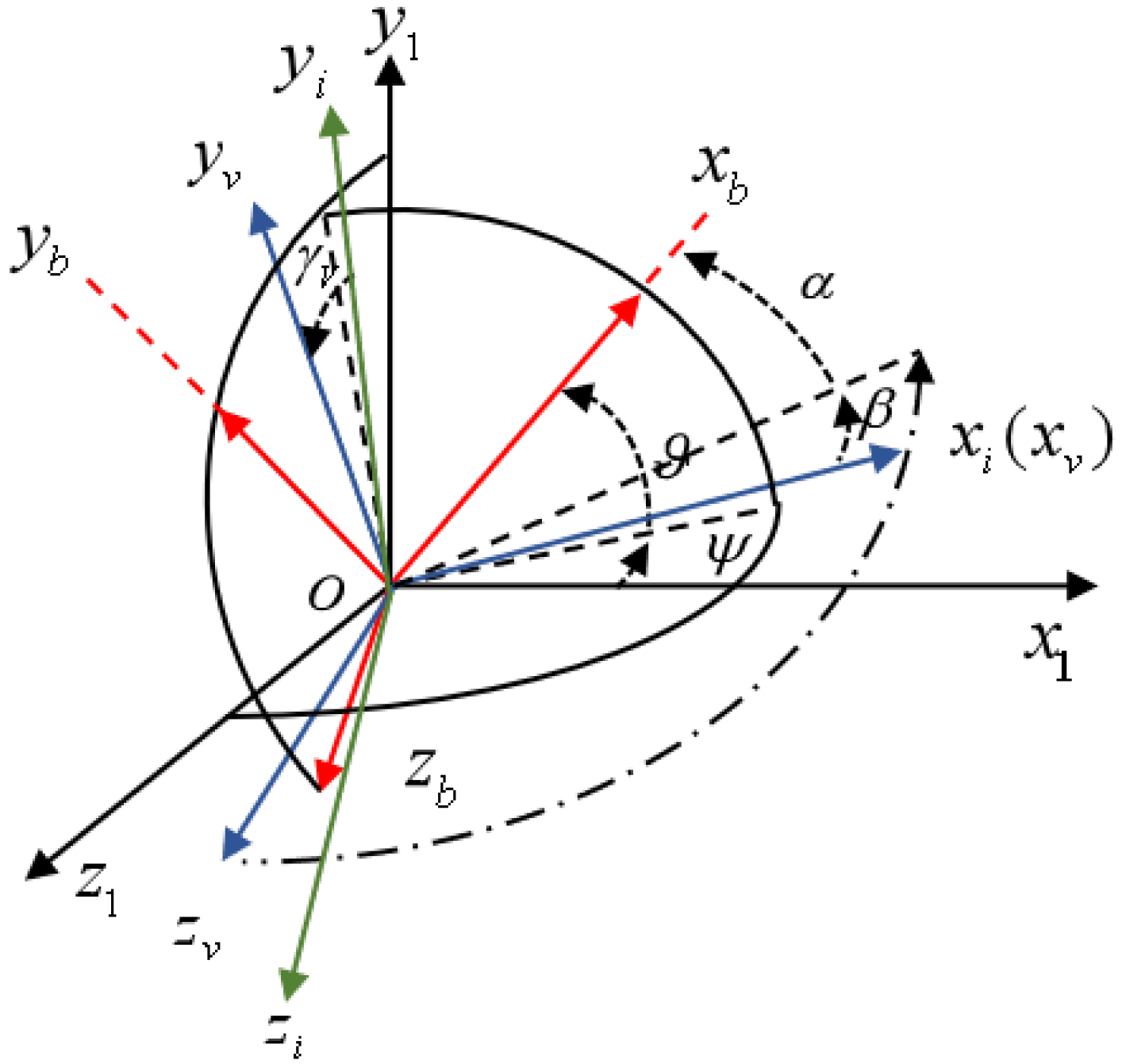
As shown in
Figure 1, the inertial coordinate system
, the body coordinate system
, the trajectory coordinate system
, and the velocity coordinate system
are presented, respectively;
and
represent the pitch angle and the yaw angle of the flight vehicle, respectively;
and
are the angle of attack and the sideslip angle of the flight vehicle, respectively, and
represents the velocity roll angle of the flight vehicle [
13].
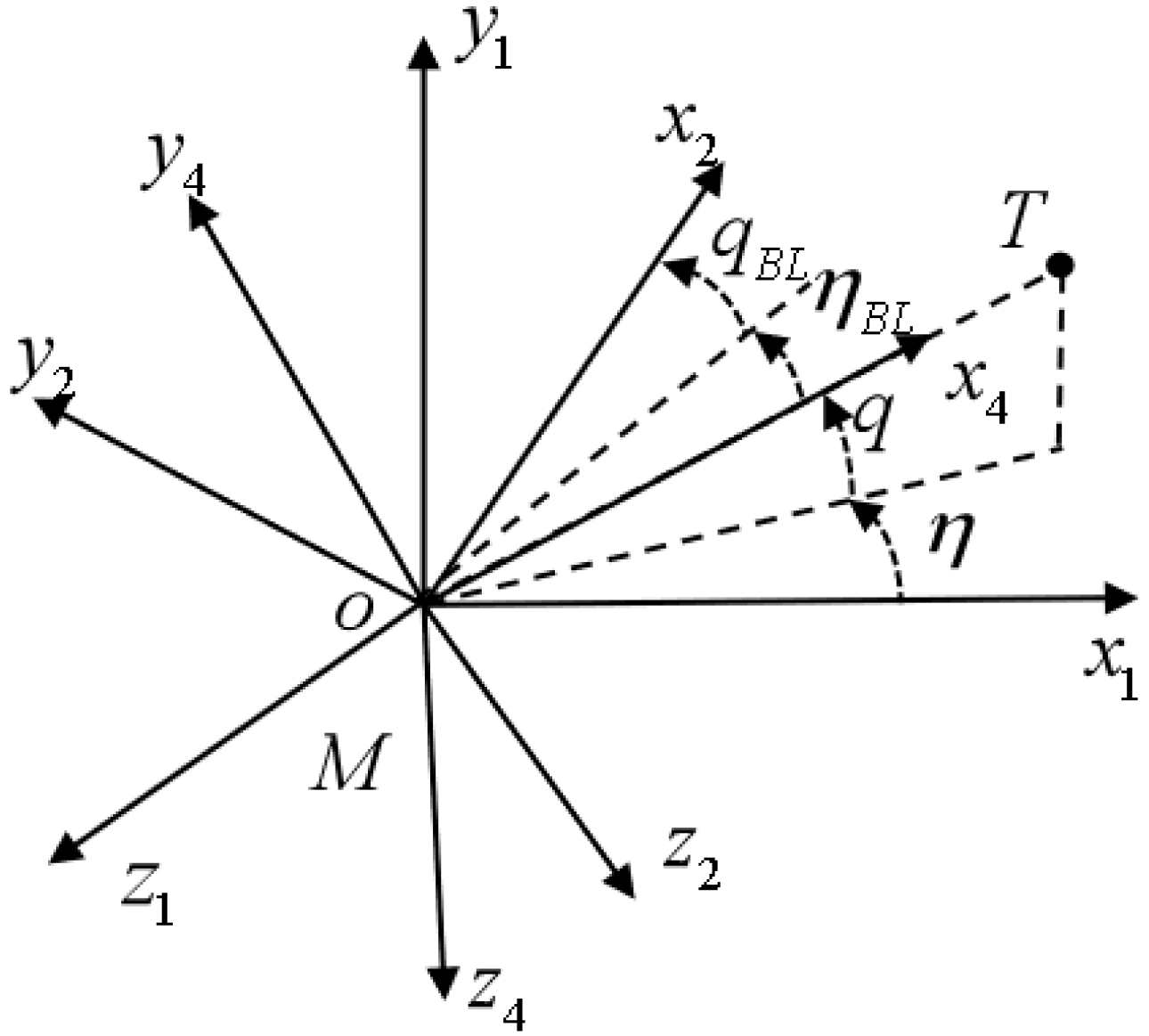
In
Figure 2, the flight vehicle and a moving target are represented by M and T, respectively;
and
represent the LOS coordinate system and the body-LOS (BLOS) coordinate system, respectively;
q and
represent the LOS elevation angle and LOS azimuth angle, respectively. To simplify the problem, the BLOS elevation angle
and the BLOS azimuth angle
are introduced to represent the FOV angles in the longitudinal plane and the lateral plane, respectively. Consequently, the seeker’s FOV constraint can be formulated in terms of the BLOS angles.
The kinematic equations of the flight vehicle can be expressed as [
13]:
where
denotes the roll angle of the flight vehicle;
represent the position of the flight vehicle;
V is the magnitude of the velocity of the center of mass of the flight vehicle;
is the angle between the velocity vector of the flight vehicle and the horizontal plane of the
coordinate system, and
is the angle between the projection of the velocity vector in the horizontal plane and the
axis. They are, respectively, called the flight path angle and the heading angle.
The dynamics equations are depicted as [
13]:
where
P represents the thrust;
X,
Y, and
Z are the components of the aerodynamic force in the directions of the respective coordinate axes of the velocity coordinate system, and they are, respectively, called the drag force, the lift force, and the side force;
,
, and
are the components of the aerodynamic moment along the three directions of the body coordinate system, and they are, respectively, called the rolling moment, the yawing moment, and the pitching moment. The specific calculations are as follows [
22]:
where
denote dynamic pressure, reference area, and reference length, respectively;
M is the mass of flight vehicle;
, and
are the components of the rotational angular velocity
of the body coordinate system relative to the inertial coordinate system on each axis of the missile body coordinate system;
, and
are the moments of inertia in the roll, yaw, and pitch directions, respectively;
and
represent the aerodynamic force and aerodynamic moment coefficients, respectively;
are the aileron, rudder, and elevator deflections.
Since this paper focuses on STT flight vehicles, the roll angle is typically kept close to zero. Additionally, for the strap-down flight vehicle facing the maneuvering target, it is of utmost importance to restrict the seeker’s BLOS angle to a very small region. Under these circumstances, the relationship between the angles of
and
is given by [
22]:
Therefore, the seeker’s FOV constraint can be transformed into , where is the maximum of the FOV of the strap-down seeker.
Taking the above-mentioned factors into account, the design objective of this paper is to achieve precise guidance for moving targets while maintaining the FOV constraint and keeping the roll angle stabilized at approximately zero.
Considering the inevitable signal transmission and processing delays in practical application scenarios, a first-order link is used to represent this time delay characteristic, ensuring that the simulation environment is more in line with the operating conditions of the real world. The formula for the time delay is shown in Equation (
5), where
represents the signal output by the intelligent agent, and
represents the signal actually used by the model. In addition,
is defined as the time constant.
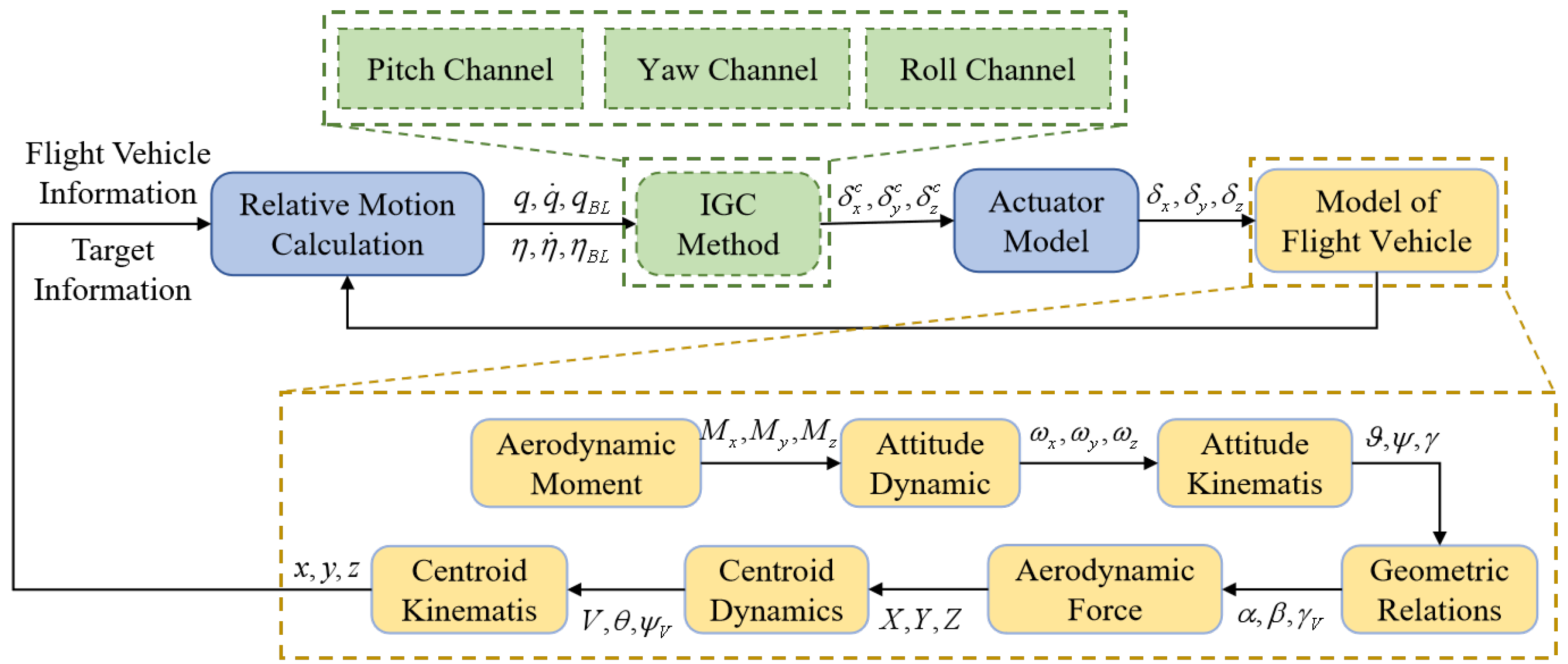
Based on the above mathematical models, the simulation process of the 6-DOF IGC model in this paper is shown in
Figure 3:
Remark 1. It should be noted that when the distance R between the flight vehicle and the target is less than a certain value , the seeker enters the working blind area. During this period, the output information of the seeker becomes invalid, and the flight vehicle is guided by its inertial guidance system. The inertial guidance system means that after analyzing the acceleration based on hardware systems such as accelerometers, kinematic calculation methods are directly used, and no target information is required.
Remark 2. All simulation training in this paper is conducted entirely based on the 6-DOF IGC design model.
3. The DRLIGC Method Design with FOV Constraint
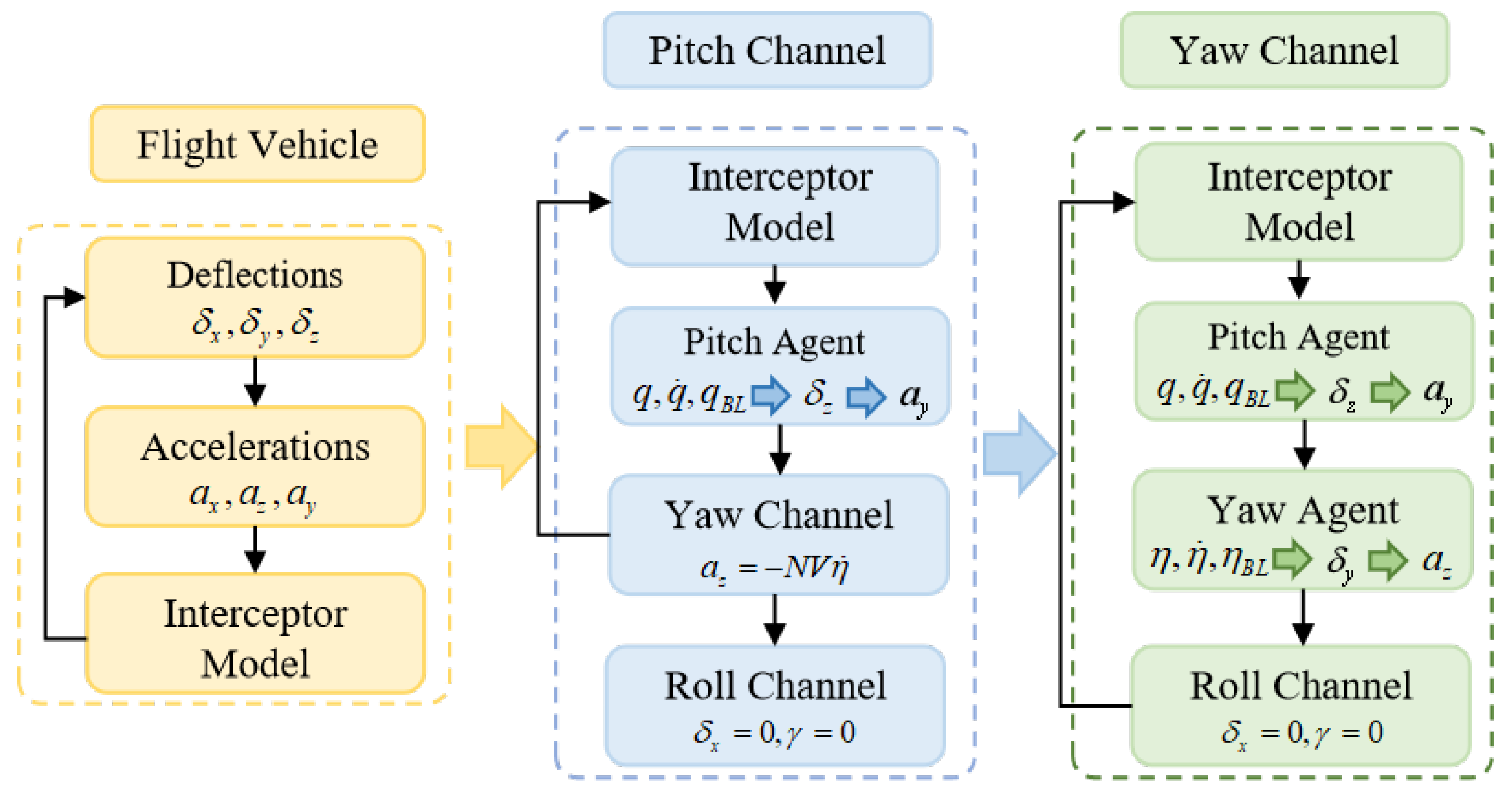
In this section, the IGC algorithm for the pitch, yaw, and roll channels of the STT flight vehicle are designed independently. A DRLIGC method is put forward to control the pitch and yaw channels of the flight vehicle while adhering to the FOV constraint of the seeker. Meanwhile, the back-stepping method is employed to maintain the roll angle at approximately zero.
3.1. Twin Delayed Deep Deterministic Policy Gradient Algorithm
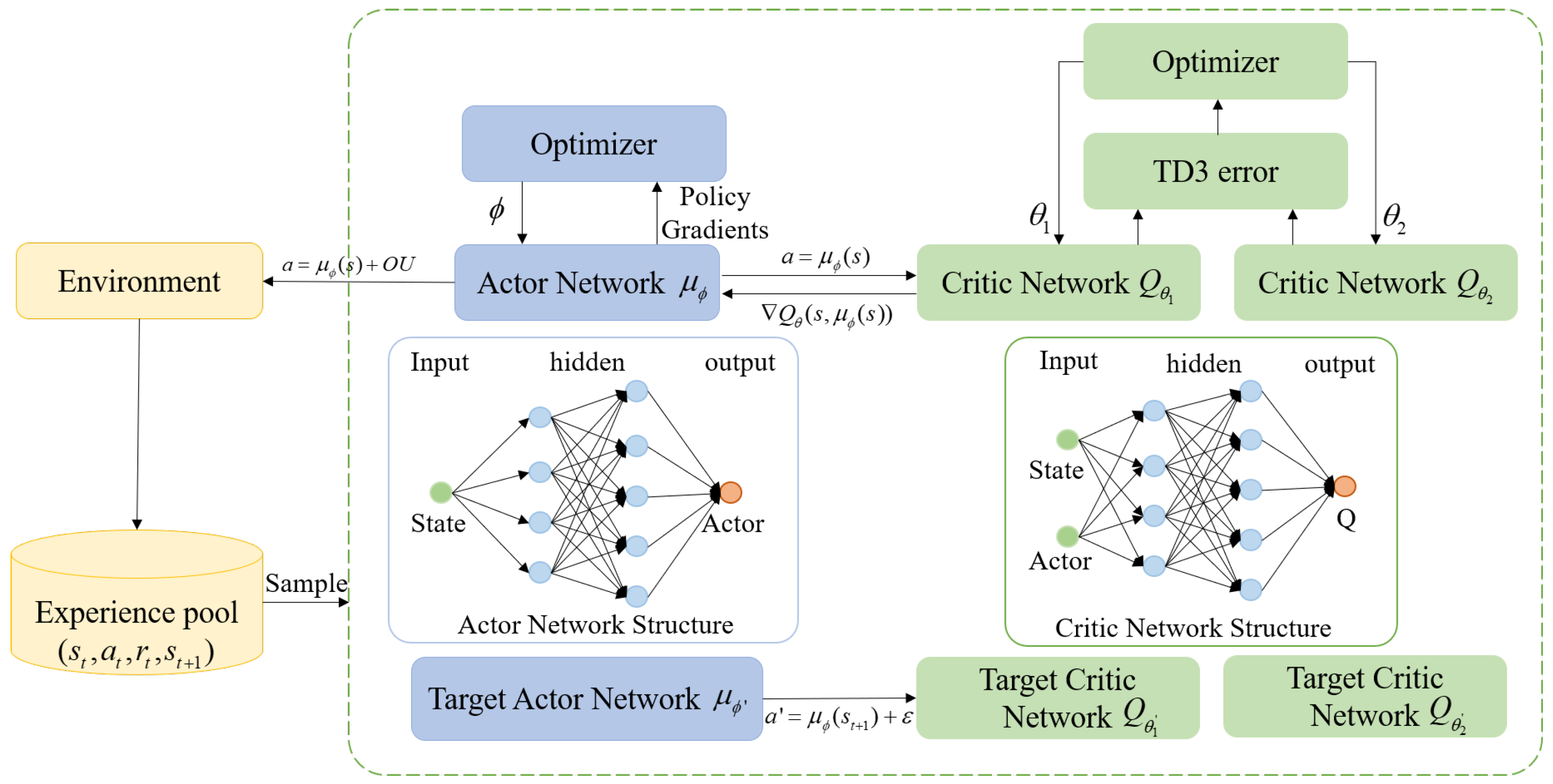
In this paper, the TD3 algorithm, a specific type of DRL algorithm, is harnessed for the design of the IGC method. Characterized as a data-driven intelligent algorithm, DRL refines its strategies via iterative trial-and-error processes. It is effectively applied to resolve a succession of issues within the MDP model. To leverage the capabilities of the DRL algorithm, it is imperative to cast the IGC issue into the form of an MDP model.
The MDP model includes a state space
that can describe the characteristics of the model, a suitable action space
, and a comprehensive reward function
that takes into account the objective of the problem. At each time step
t in the TD3 algorithm, the agent will select an action
based on the current environmental state
. The environment will transition to
according to the chosen action and provide the reward
according to the reward function
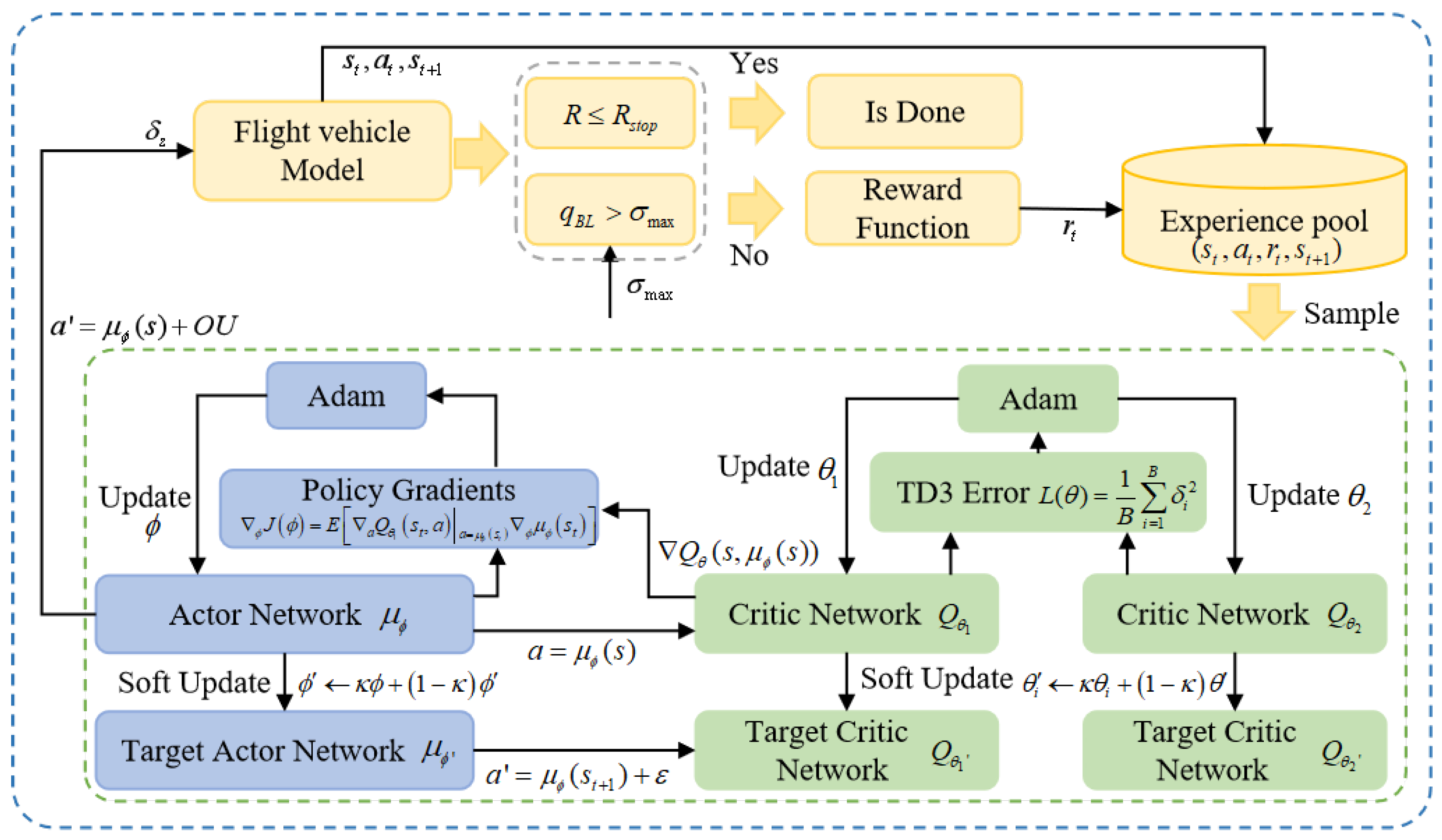
. Then, the agent will continuously adjust its own strategy based on the magnitude of the reward. The basic architecture of the TD3 algorithm including its network components is shown in
Figure 4, where
are the actor, target actor, critic network, and target critic networks, respectively;
are the corresponding network parameters, respectively.
As depicted in
Figure 4, the TD3 algorithm represents a classic Actor-Critic algorithm, as noted in [
34]. By incorporating two Q-networks and the target network update mechanism, it efficiently alleviates the overestimation problem that is intrinsic to policy gradient methods. This, in turn, significantly improves both the stability and the convergence rate of the algorithm. The twin delayed update mechanism ensures more stable parameter updates. Additionally, the smoothing of target networks reduces variance during the learning process. This architecture enables the TD3 algorithm to rapidly adapt and make efficient decisions in complex environments.
To address the IGC design challenge for STT flight vehicles with FOV constraints, the model ingeniously converts the FOV constraint into constraints on the BLOS angles.
This paper presents a high-precision approach IGC method that utilizes the TD3 algorithm. This method has the ability to enforce FOV constraints in the pitch and yaw channels. Through channel decomposition, the method significantly reduces the training complexity of the agent. Its objective is to directly establish a mapping from the state space to the action space obtained that the flight vehicle attains. By this way, it effectively alleviates the formidable multi-channel coupling problem inherent in the IGC issue.
Figure 5 vividly depicts the information interaction between flight vehicle and environment.
3.2. MDP Model Design in Pitch and Yaw Channels
In this subsection, the IGC design of the pitch channel and the yaw channel is carried out separately. Leveraging the model-agnostic nature of the DRL algorithm, our objective is to address the strong coupling relationship that exists between the pitch and yaw channels within the IGC design model.
According to Equations (
2) and (
3), it can be seen that the pitch channel involves a more complex balance among lift, drag, and gravity, and the uncertainty is much higher than that of the yaw channel. Training the pitch channel first represents a more effective curriculum learning strategy. By addressing the more complex pitch control problem initially, a more stable training environment is created for the subsequent yaw training. Therefore, in this paper, the training of the intelligent agent for the pitch channel is conducted first.
When devising the DRLIGC method for the pitch channel, the corresponding IGC design model is structured as an MDP model. The entire simulation environment is grounded in the 6-DOF IGC design model introduced in
Section 2. Relying on this model, the subsequent MDP model is developed.
The strap-down seeker can obtain the BLOS elevation angle and the BLOS azimuth angle . Through further calculation, the LOS elevation angle q and the LOS azimuth angle can be acquired. By utilizing the observable information obtained by the strap-down seeker and the information derivable from the observable data, a suitable state space is established. A well-chosen state space has the potential to mitigate the complexity of DRL training and expedite its convergence rate.
In light of the FOV angle constraint imposed on
that the pitch channel must satisfy, state variables that can comprehensively represent this channel are carefully selected to formulate the state space, which is defined as follows:
In order to further improve the convergence efficiency, the normalization method is employed to process the state space. Considering that the angle range within the model is
, the normalized state space is defined as follows:
The action space is selected as the elevator deflection corresponding to the pitch channel. This choice can make full use of the data-driven characteristics of the DRL algorithm to form a direct mapping from the state space to .
Finally, the construction of the MDP model can be finalized through careful selection of the most crucial reward function. The reward function represents the linchpin of the DRL algorithm. A well-designed reward function is capable of substantially accelerating the training of the agent and continuously fine-tuning it to conform to the specifications of the problem under consideration. This enables the agent to acquire a relatively optimal strategy.
In light of the constraints imposed on the BLOS angle within the pitch channel, as well as the ultimate necessity of attaining a high-precision target approach, and referring to the idea of achieving a quasi-parallel approach by suppressing the LOS angular rate in the classical PN guidance law, this paper determines the reward function of the pitch channel as:
where
represents the immediate reward function in the pitch channel;
denotes the penalty term generated when
exceeds the constraint;
is the terminal reward in the pitch channel. The specific calculation method of
is formulated as:
where
and
are the proportionality coefficients of each term, satisfying the condition that
;
and
are the corresponding scaling coefficients. The specific calculation method of
is defined as:
where
is the positive constant chosen for the penalty.
The terminal reward
is designed as:
where
is the hit reward obtained after a hit and is a selected positive constant.
When devising the reward function for the pitch channel, its content is essentially partitioned into three components. The underlying design concepts are elaborated on in the following manner:
- (1)
The immediate reward function yields the corresponding reward value at every time step. Its design intent is to minimize the LOS angular velocity . A non-linear function of the type is employed to obtain a reasonable distribution of the reward values.This approach endeavors to keep the LOS angular velocity within a relatively narrow range to the greatest extent possible, thereby emulating the effect of the PN guidance law. Furthermore, the function is crafted to maintain the BLOS angle within a relatively small range. This serves to enhance the detection performance of the seeker. Simultaneously, this component also contributes to accelerating the convergence speed.
- (2)
The FOV constraint penalty function takes effect when the BLOS elevation angle exceeds the constraint. It will impose a relatively substantial penalty value, compelling the agent to exert its utmost efforts to prevent the emergence of such a state.
- (3)
The terminal reward function is activated only upon the successful hit of the target. It will confer a relatively significant reward, informing the agent that this particular state yields greater rewards. This enables the agent to learn and gravitate towards a more optimal strategy.
Through the seamless integration of the state variables, action space, and the reward function with the established simulation model, a highly comprehensive and robust model for the pitch channel can be successfully constructed. This model can be utilized for agent training to derive the corresponding control strategy for the pitch channel, thereby forming an agent capable of directly obtaining the elevator deflection angle from the state values.
Analogously, in order to effectively tackle the FOV constraint issue within the yaw channel by means of the DRL algorithm, it is imperative to formulate the yaw channel model into an MDP model. Initially, it is crucial to establish that the FOV constraint in the yaw direction can be equivalently transformed into a constraint imposed on the LOS azimuth angle , i.e., . Based on this condition, the MDP model for the yaw channel is established.
The normalized state space constructed for the yaw channel is:
Based on the characteristics of the 6-DOF model of the flight vehicle, the rudder deflection
is chosen as the action space for the yaw channel. The reward function is crafted according to the principle of the PN guidance law. The specific form of the comprehensive reward function is designed as follows:
where
represents the immediate reward function in the yaw channel;
denotes the penalty term generated when
exceeds the constraint; and
stands for the terminal reward in the yaw channel. The specific calculation approach of
is formulated as:
where
and
are the proportionality coefficients, which meet the condition
. Meanwhile,
and
are the corresponding scaling coefficients. The specific calculation method for
is defined as:
where
is the positive constant chosen for penalizing behaviors that exceed the constraints.
The terminal reward
is selected as:
where
is a selected positive constant.
Similar to the design idea of , the comprehensive reward function for the yaw channel is divided into three parts: the immediate reward function , the penalty function for exceeding the FOV constraint, and the terminal reward function for target hitting. In the immediate reward function , aims to achieve a smaller LOS angular rate velocity, while is employed to reduce the BLOS azimuth angle. This design makes the behaviors to be constrained more explicit and accelerates the convergence rate.
Remark 3. The training episode terminates when any of the following conditions are met: the FOV penalty reward or the terminal reward is triggered, or the relative distance between the flight vehicle and the target starts to increase. Once the episode ends, a final comprehensive reward value is obtained.
Remark 4. Corresponding proportionality coefficients are used to strike a balance between target engagement and constraint satisfaction. As a result, the sum of these proportionality coefficients in the corresponding rewards must equal to one.
Remark 5. The scaling coefficients are utilized to adjust the magnitudes of the corresponding elements. They have a pronounced impact on the convergence of DRL training. Moreover, within the function , the scaling coefficients contribute to determining the magnitudes of the optimal values of the corresponding variables.
Remark 6. Differences in training step sizes lead to varying frequencies of obtaining immediate rewards. This variation directly impacts the influence exerted by the remaining components of the comprehensive reward function on the strategy formulation. As a result, different hyperparameters are required.
3.3. DRLIGC Method
In the DRLIGC method utilizing the TD3 algorithm, the training process commences with the independent training of the pitch channel. During this initial stage, the acceleration command of the yaw channel is directly determined according to the PN guidance law. Meanwhile, the roll angle and angular velocity of the roll channel are both set to zero. Under these conditions, the yaw channel achieves relatively high approach accuracy, which provides a stable environment for the separate training of the pitch channel. After the training phase, a highly effective engagement agent for the pitch channel is successfully obtained. The PN guidance law applied to the yaw channel is presented as follows:
where
N is the proportionality coefficient.
Once the pitch-channel agent is acquired, the yaw channel is switched to normal computation mode, and the yaw-channel agent is introduced into the training process. At this stage, the training effort is concentrated exclusively on the yaw-channel agent. Through this targeted training, a yaw-channel agent that disregards the roll factor can be obtained. By integrating this yaw-channel agent with the previously obtained pitch-channel agent, a DRLIGC method that does not take the roll factors into account can be developed. This approach streamlines the system design and potentially enhances the computational efficiency while maintaining an acceptable level of performance for the engagement task. The specific training process of the DRLIGC method is illustrated in
Figure 6, with the algorithm for the pitch channel shown in
Figure 7.
The DRLIGC procedure for the yaw channel is similar to that of the pitch channel, so it will not be repeated here. Through the process described above, the DRLIGC method that excludes the consideration of the roll channel is obtained. Regarding the roll channel, this paper adopts an adaptive control law based on the back-stepping method to carry out roll angle control. The model of the roll channel is as follows [
13]:
where
denotes the disturbance term, caused by aerodynamic moments.
Select the state variables as
and control input as
, the roll channel model can be transformed into:
where
The roll channel IGC method presented in [
13] is employed in this study and is defined as:
where
represent the designed parameters, where
stands for the estimation of
. Here,
denotes the unknown upper bound of
, satisfying the condition
.The proof of the stability of the roll IGC method can be retrieved in [
13]. By utilizing the above-mentioned roll IGC method, the objective of keeping the roll angle controlled around zero can be realized.
During the simulation process, when , the flight vehicle is guided using the DRLIGC algorithm proposed in this paper. When , it switches to inertial guidance. At this time, it can be regarded as an unguided section. The acceleration and its direction are provided by the acceleration measurement components inside the flight vehicle, and the subsequent motion trajectory is calculated through kinematic integration.
4. Numerical Simulation Analysis
In this section, a comprehensive account of the training scenarios, hyperparameters, and network parameters associated with the DRLIGC method is provided. Moreover, numerical simulations are carried out to verify the viability and effectiveness of this method.
4.1. DRLIGC Training Settings
To cultivate robust agents for the pitch and yaw channels within the DRLIGC method, variables are randomly initialized across a multitude of scenarios. The specific adjustments are comprehensively detailed in
Table 1, from which the corresponding parameters are selected.
The flight vehicle is initially positioned at (0, 200, 0) m, boasting an initial velocity of 400 m/s. The initial values of both its attitude angles and angular velocities are set to 0. The target starts at the position (, 0, 0) m, with an initial velocity of (, , ). The chosen maneuver acceleration is (4, 0, 2) m/. The FOV constraint size of the flight vehicle’s seeker is set to . Taking into account the detection frequency limitation of the seeker, the training step size is set at 0.05 s, while the simulation step size is fixed at 0.01 s. The time constant is randomly selected between 0.01 and 0.2. Given the simulation step size of 0.01 s and considering the velocities of the flight vehicle and the target, the value of is set to 30 m.
The network architectures of the pitch channel and the yaw channel are identical.
Table 2 details the specific number of layers and nodes in the Actor and Critic networks. For the Actor network, the activation layer employs the tanh function. Moreover, the target network shares the same architecture as the corresponding network.
The settings of the relevant hyperparameters in the reward function and the DRL algorithm are elaborated in
Table 3 and
Table 4, respectively.
Table 5 provides the aerodynamic characteristics of the flight vehicle, which are derived from the data reported in [
22]. Meanwhile,
Table 6 provides a detailed breakdown of the relevant parameters in Equation (
21).
4.2. DRLIGC Method Training
Based on the scenario settings and relevant parameter configurations in
Section 4.1, the DRLIGC method is applied to carry out DRL training for the pitch channel and the yaw channel separately. The training results of the pitch channel and yaw channel are presented in
Figure 8 and
Figure 9, respectively.
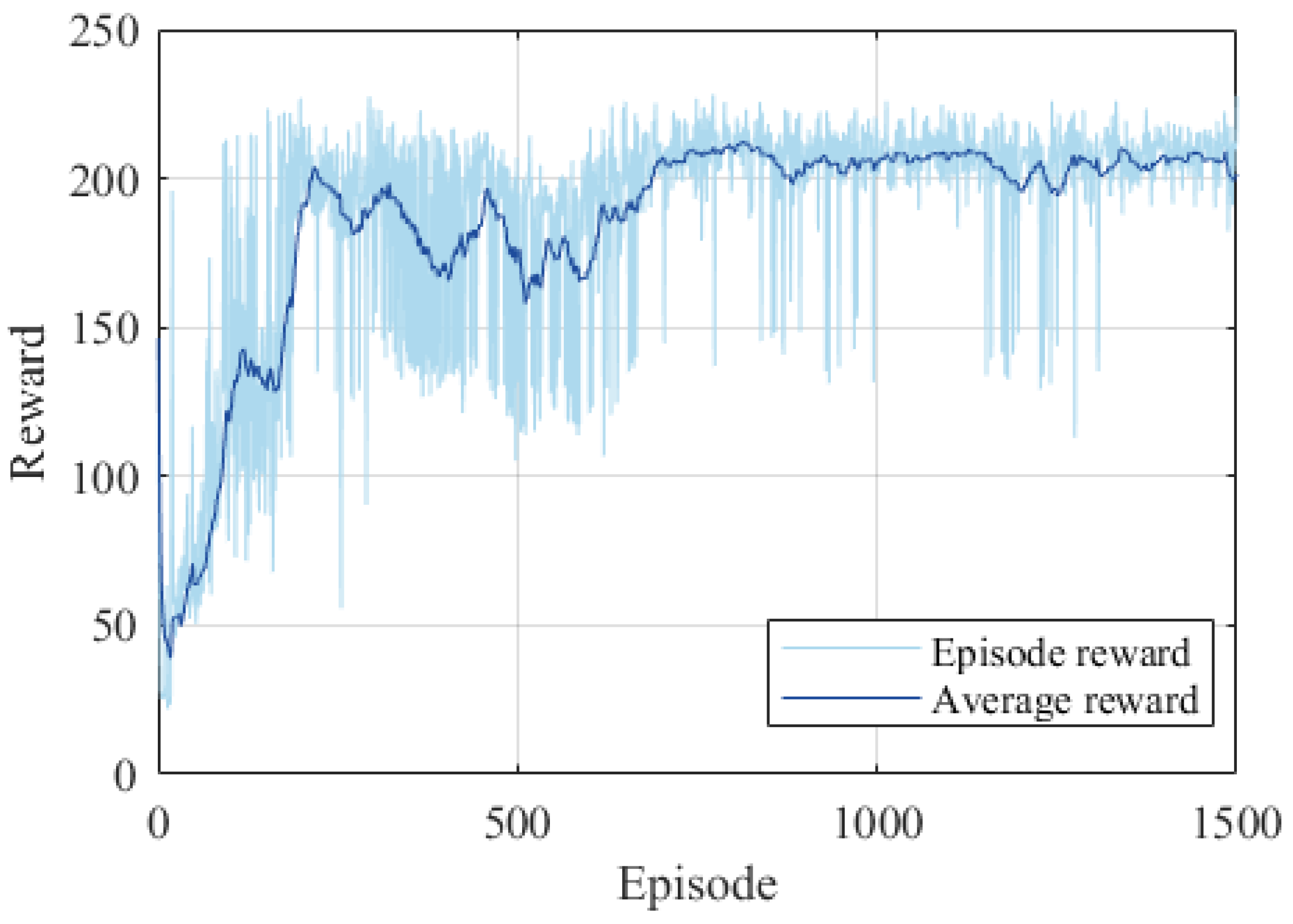
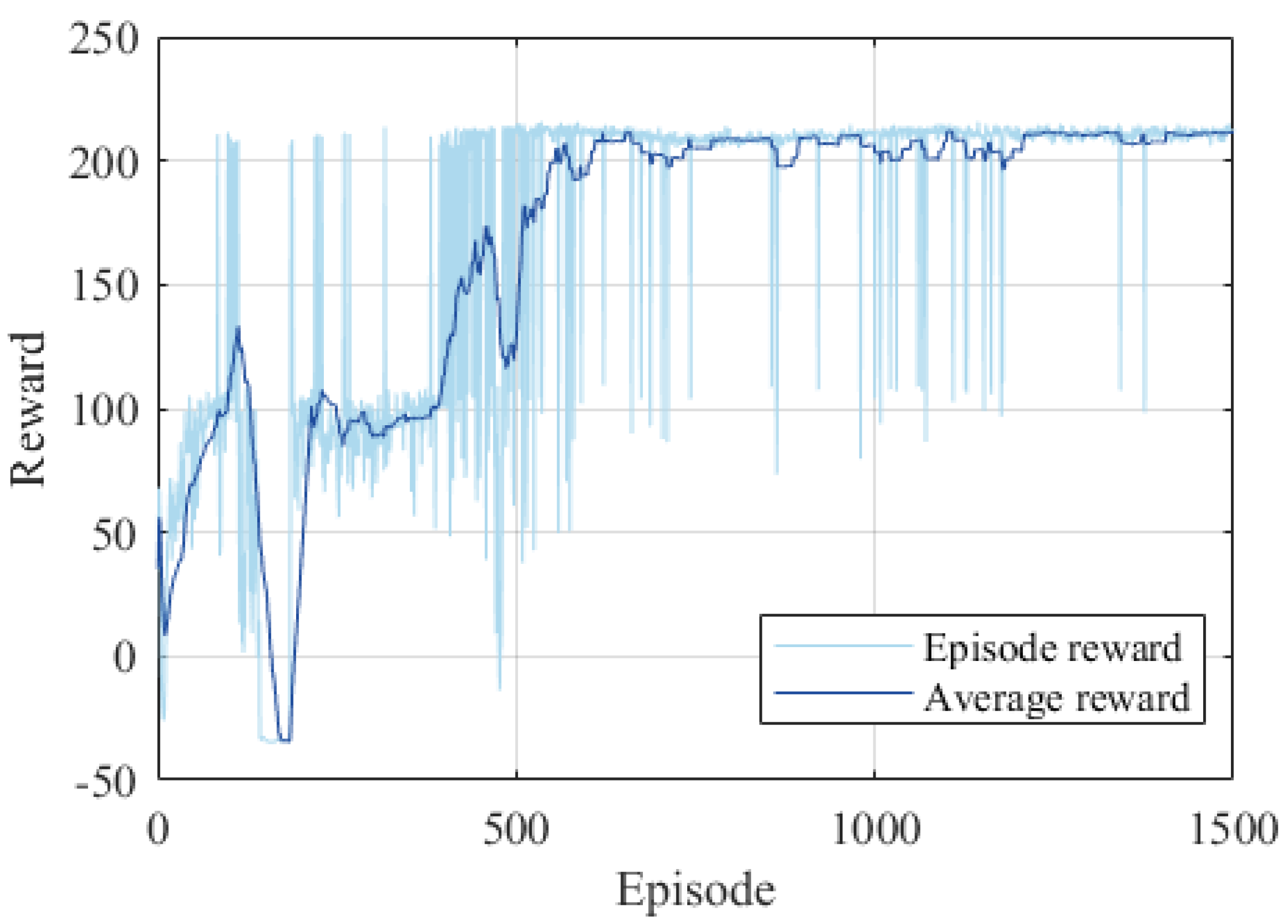
In
Figure 8 and
Figure 9, the average reward is calculated as the mean of the episode rewards from the adjacent 30 episodes. This metric serves as an indicator of the current agent’s stability.
We conducted an in-depth analysis of the curve in
Figure 8. The entire training process for the pitch channel spans 1500 episodes. Approximately at the 200th episode, the reward reaches its peak. This suggests that the agent has discovered a strategy that can successfully approach the target within the constraints of the FOV. Around the 700th episode, the reward value begins to stabilize. By the 1300th episode, convergence is attained, signifying that a relatively superior strategy has been formulated. It can be seen from
Figure 9 that the reward value hits its peak multiple consecutive times around the 400th episode for the yaw channel. This implies that, through continuous optimization, the strategy enables successful approaches in both channels. Convergence is achieved after the 1300th episode. When running on an Intel(R) Core(TM) i7-1065G7 CPU using the MATLAB R2023b Reinforcement Learning Toolbox, the total off-line training time for the pitch and yaw channels amounts to 7.3 h and 6.8 h, respectively.
An attempt was made to integrate the pitch and yaw channels into a single agent. This unified agent was designed with six inputs and two outputs, aiming to concurrently determine the rudder and elevator deflections of the flight vehicle. However, it was found that the coupling between the pitch and yaw channels was excessively severe. This high-level coupling made it extremely difficult for the agent to be trained and to converge. As a result, it was a great challenge to realize a successful approach. In contrast, the DRLIGC method proposed in this paper showcases certain advantages. It can effectively achieve target engagement, providing a more feasible and efficient solution for the engagement task.
4.3. Monte Carlo Simulation
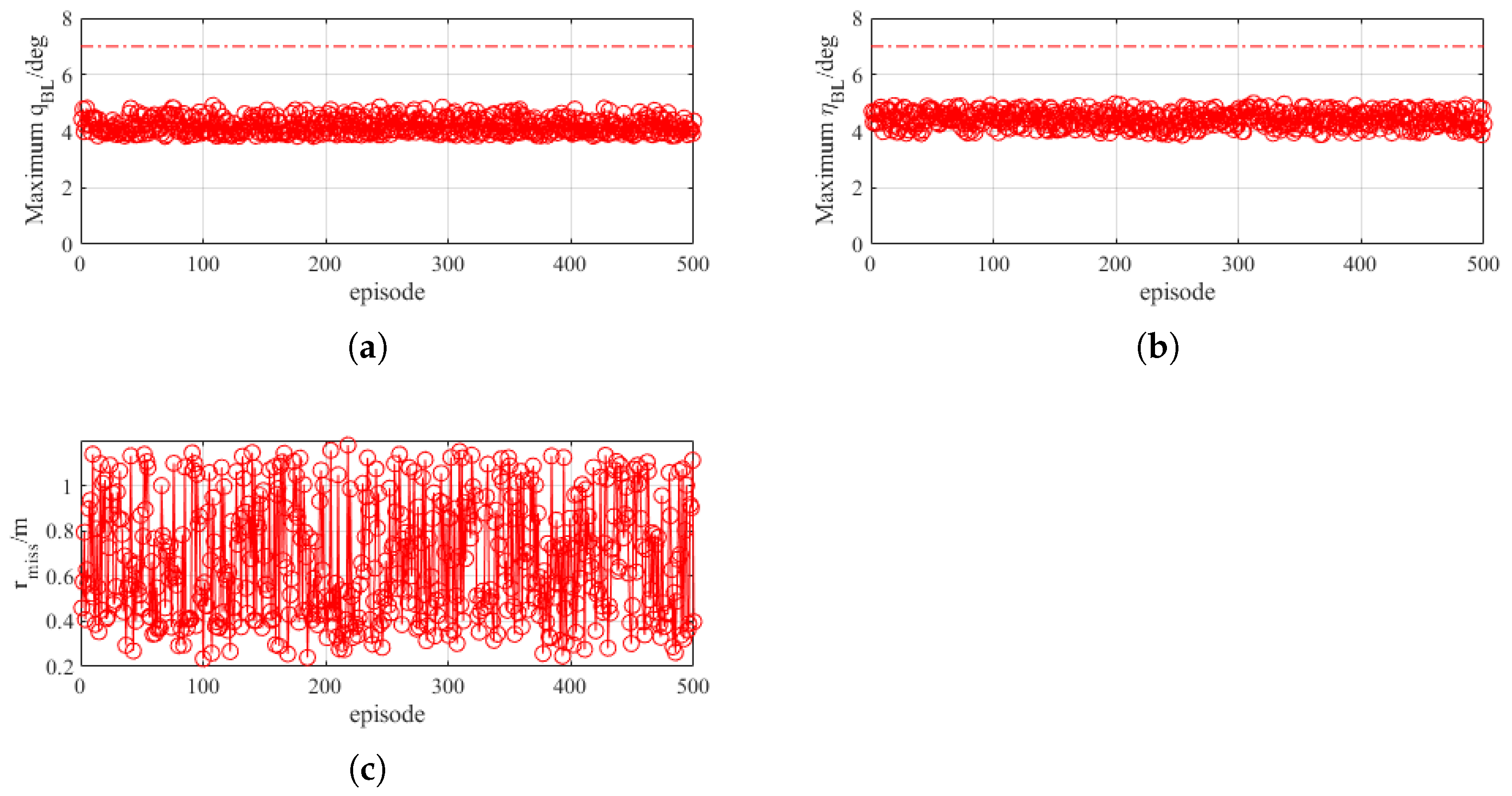
To validate the feasibility and robustness of the DRLIGC method put forward in this paper, a Monte Carlo simulation experiment encompassing 500 episodes was carried out. In this MC simulation experiment, scenarios were randomly chosen from those elaborated in
Table 1. The specific simulation results are presented in
Figure 10.
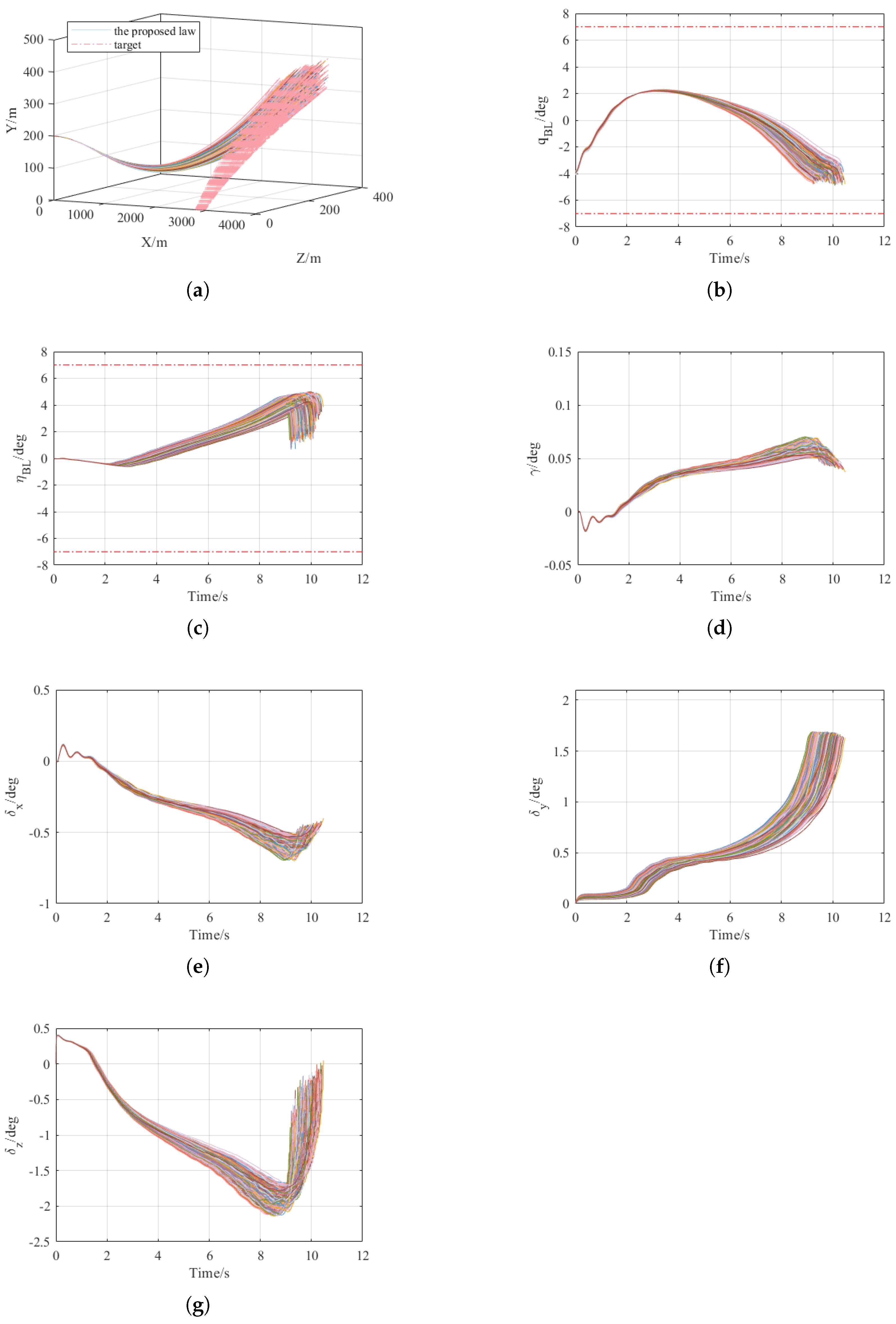
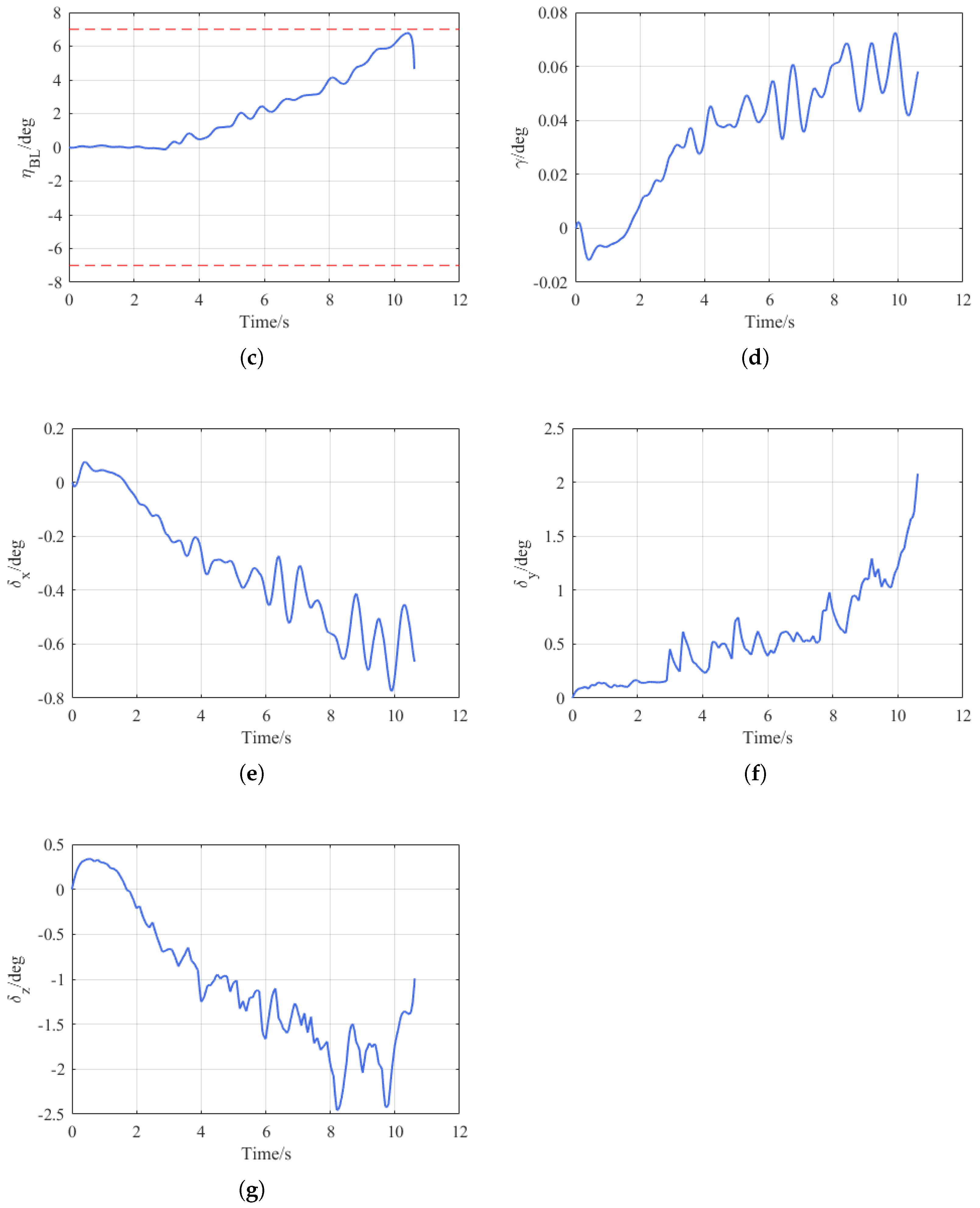
In
Figure 10a, the flight trajectories of the flight vehicle and the target are depicted. The solid line denotes the flight vehicle’s trajectory, while the dotted line represents that of the target. Evidently, the flight vehicle’s flight path appears normal.
Figure 10b,c, respectively, exhibit the curves of the flight vehicle’s BLOS elevation angle
and azimuth angle
. When combined with
Figure 11, it can be clearly observed that throughout the entire guidance process, both angles are within the FOV constraint range.
Figure 10d presents the roll angle curve of the flight vehicle. It is apparent that the roll angle remains close to zero with a relatively small amplitude, thus satisfying the design requirements.
Figure 10e–g, respectively, display the aileron, rudder, and elevator deflections of the flight vehicle.
Figure 11c represents the miss distance. Through statistical analysis, it is found that the mean value of the miss distance amounts to 0.6731 m, and the variance is 0.0699.
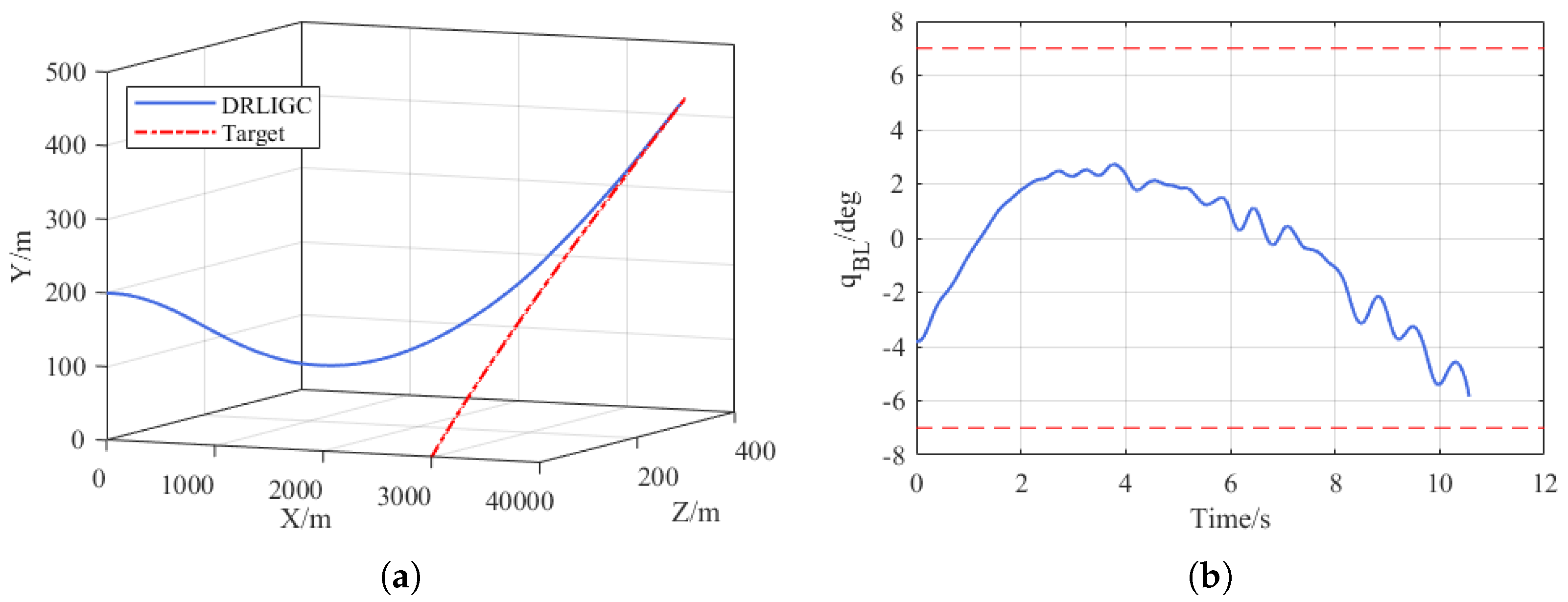
To study the impact of noise on the performance of the DRLIGC method proposed in this paper, a set of simulations is conducted while taking into account the influence of noise on the observed values. Random Gaussian noise with a mean value of 0° and a variance of 0.2 was added to
. The simulation results are shown in
Figure 12. After adding the noise, the FOV constraint can still be satisfied and the target can be successfully hit, with the miss distance being 0.70 m. The above simulation experiments further verified the feasibility of the DRLIGC method.
4.4. Comparison Study
To further substantiate the superiority of the proposed DRLIGC method, a comparative analysis is carried out in this subsection. The comparative algorithm employs the 3D IBLF-IGC algorithm presented in [
22]. The specific details of the IBLF-IGC algorithm are presented as follows:
where
The design parameters of the IBLF-IGC algorithm are given by , , .
The QLF-IGC algorithm, as elaborated on in [
22], is employed to illustrate the indispensability of FOV constraints within the present scenario. This algorithm bears resemblance to the IBLF-IGC algorithm yet incorporates the following modifications:
In order to further validate the robustness of the algorithm put forward in this paper, within the comparative simulation scenarios, the target maneuver is intensified to a certain degree. The specific scenarios are presented in
Table 7.
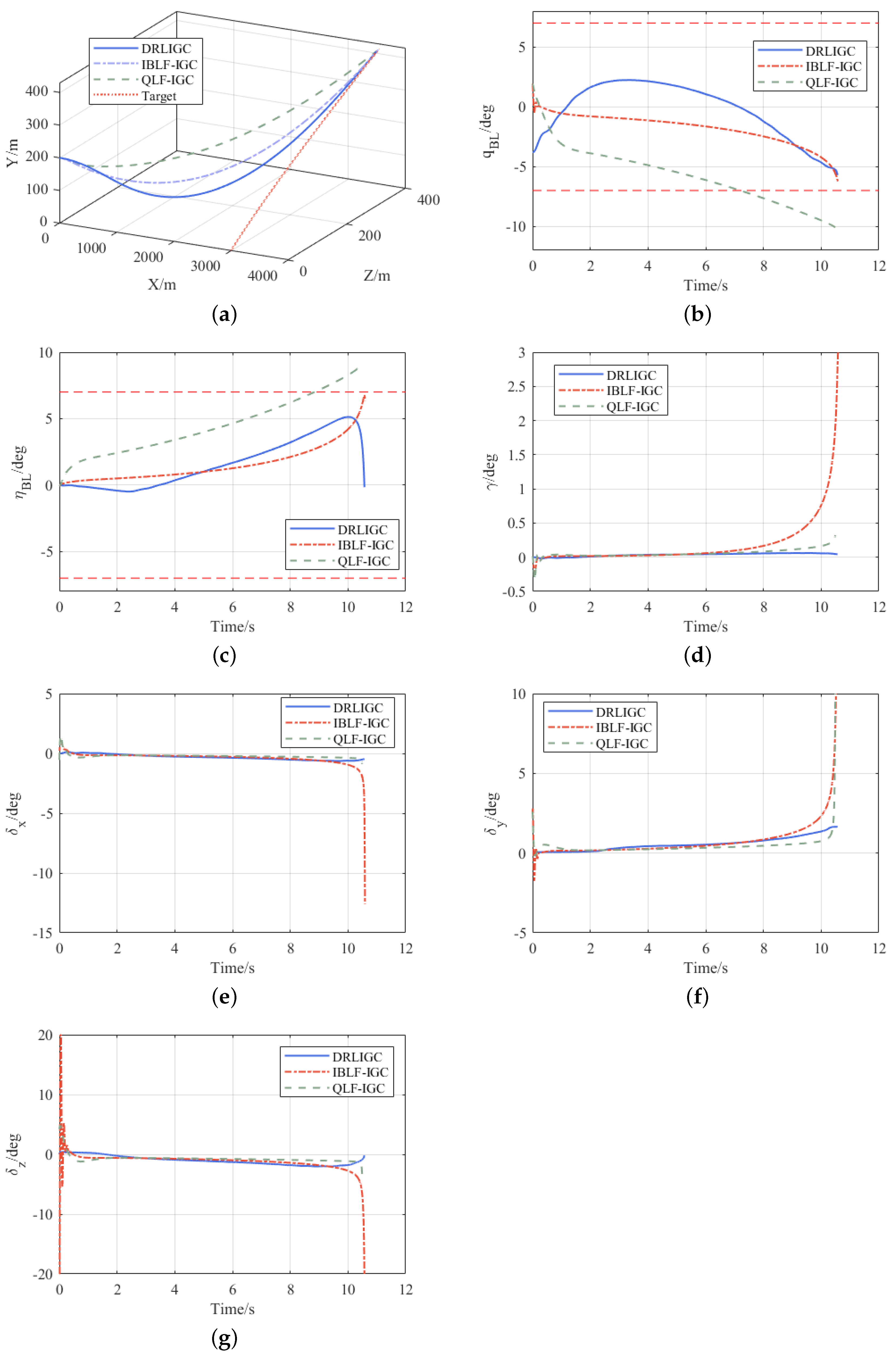
The results of the comparative simulation are shown in
Figure 13.
As illustrated in
Figure 13, the results of the comparative simulation reveal that the DRLIGC method, along with the IBLF-IGC and QLF-IGC algorithms, all accomplished successful target approach. Specifically, the miss distances were measured at 0.76 m for the DRLIGC method, 1.18 m for the IBLF-IGC algorithm, and 0.97 m for the QLF-IGC algorithm. Significantly, both the DRLIGC and IBLF-IGC algorithms strictly complied with the FOV constraint conditions. However, the QLF-IGC algorithm failed to meet these constraints, which powerfully emphasizes the indispensability of integrating FOV constraints within the current scenario. Furthermore, during the approach phase, the IBLF-IGC algorithm prematurely encountered divergence problems. Such issues have the potential to severely undermine the guidance effectiveness in particular circumstances, thus highlighting its relatively lower stability. In marked contrast, the DRLIGC method demonstrated outstanding stability, standing out as a more reliable and robust solution in comparison to the other algorithms under study.
Within the identical scenario described in
Section 4.3, 500 iterations of MC simulations are carried out for the IBLF-IGC algorithm. The obtained miss distance yielded an average value of 0.9715 m and a variance of 0.1273. This clearly indicates that the DRLIGC algorithm proposed in this study not only showcases higher approach accuracy but also exhibits superior overall performance, highlighting its effectiveness and reliability in comparison to other approaches in the context of target engagement tasks.
Remark 7. As the approach phase nears its end, divergence becomes evident in several simulation curves. This is because as the flight vehicle approaches and passes the target, it causes the angular velocity of the line of sight to diverge. This divergence leads to a sharp increase in some physical quantities. At this moment, the relative distance between the flight vehicle and the target has become close enough, enabling a successful approach.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}