
Mars Exploration: Research on Goal-Driven Hierarchical DQN Autonomous Scene Exploration Algorithm

 , ,
, ,
Abstract
1. Introduction
- Addressing the current dependency of Mars rover motion control on ground-based remote operations, this study proposes a reinforcement learning method called GDH-DQN to enable the Mars rover to have autonomous movement and path planning capabilities.
- Given the vast scale of the Martian environment, the lack of prior maps, and the prevalence of numerous, densely packed, and irregularly-shaped obstacles, our GDH-DQN method effectively addresses the challenges of sparse rewards and the explosion of state dimensions in large-scale Mars exploration scenarios.
- Integrating the hindsight experience replay mechanism into the hierarchical reinforcement learning algorithm eliminates the need for complex reward function design, fully harnessing the intrinsic potential of the data, enhancing sample efficiency, and expediting model convergence. We conducted extensive training and testing experiments, demonstrating the high performance and robust adaptability of the GDH-DQN method in large-scale planet exploration scenarios.
2. Related Works
2.1. Deep-Reinforcement-Learning-Based Navigation Methods
2.2. Mars Rover Navigation Methods
3. Principles of Algorithms
3.1. Reinforcement Learning Theoretical Framework
- State space S: Represents all possible states of the environment.
- Action space A: Represents all possible actions that the agent can take in each state.
- State transition probability P (s′|s, a): Describes the probability of transitioning to the next state s′ after taking action a in state s.
- Reward function R (s, a): The immediate reward received by the agent for taking action a in state s. Reflects the agent’s progress toward its goal.
- Discount factor : Balances the importance of current and future rewards, with values between 0 and 1.
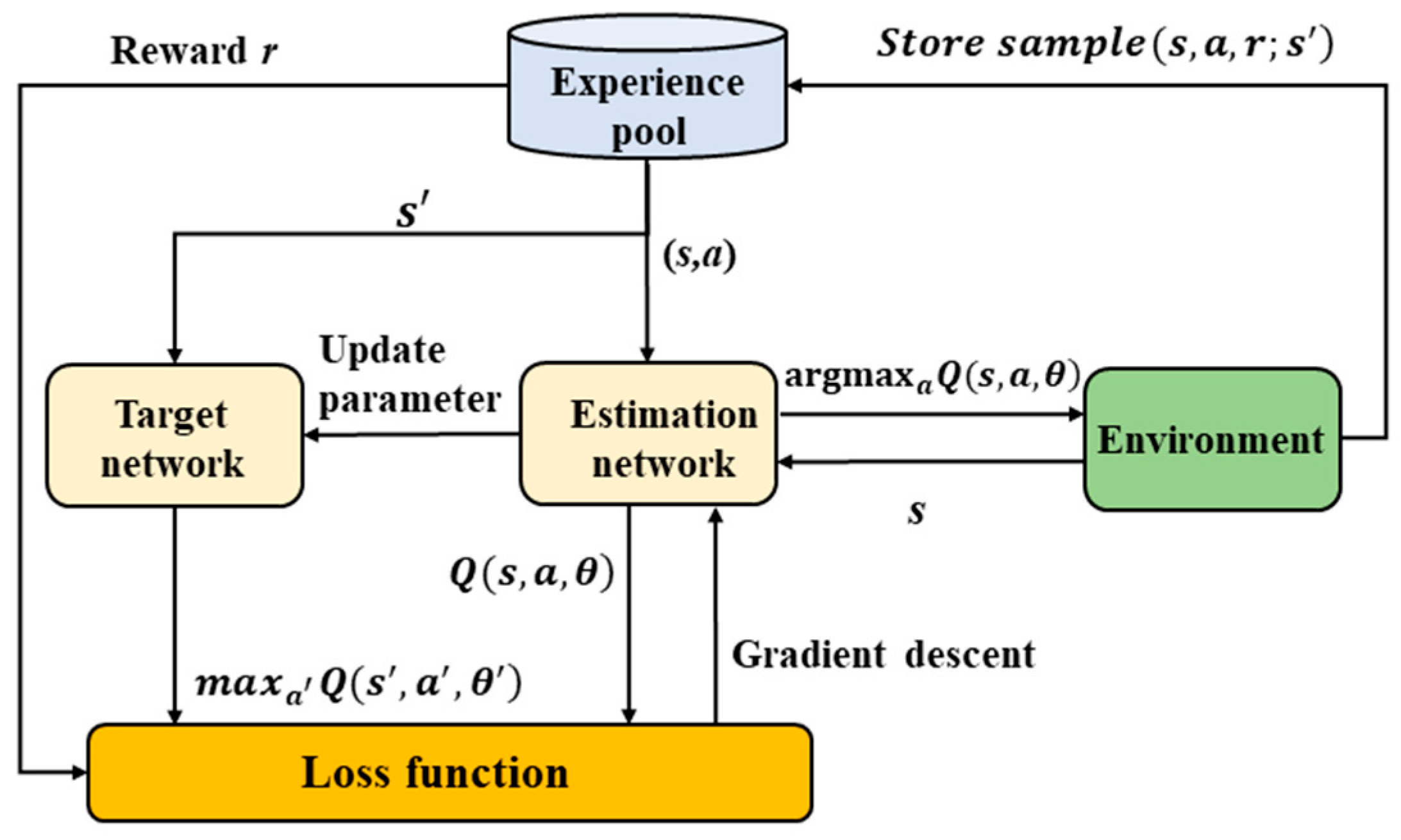
3.2. Deep Q-Network
3.2.1. Environment
3.2.2. Estimation Network
3.2.3. Target Network
3.2.4. Experience Pool
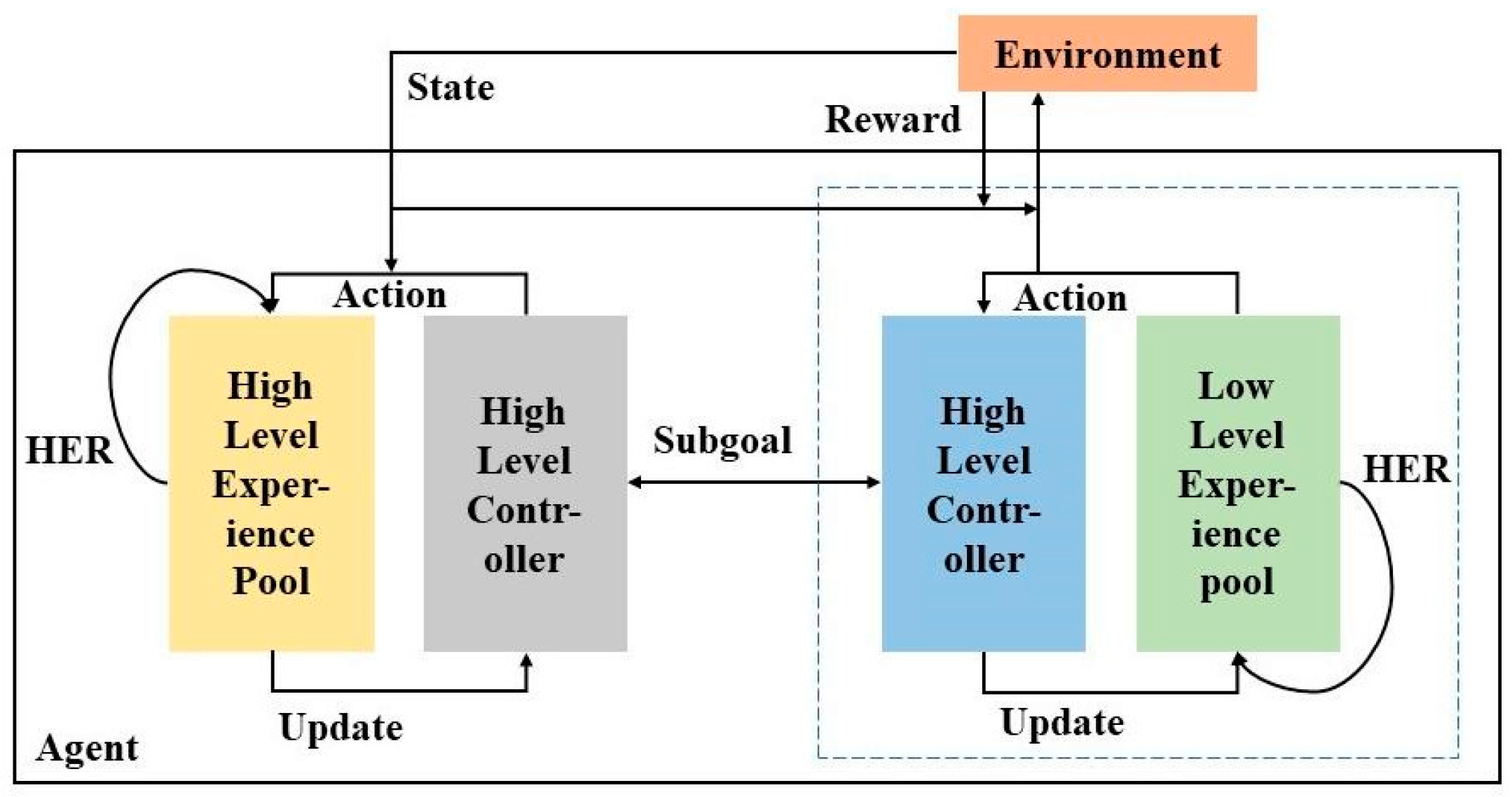
3.3. Hindsight Experience Replay Mechanism
3.4. Algorithm Structure
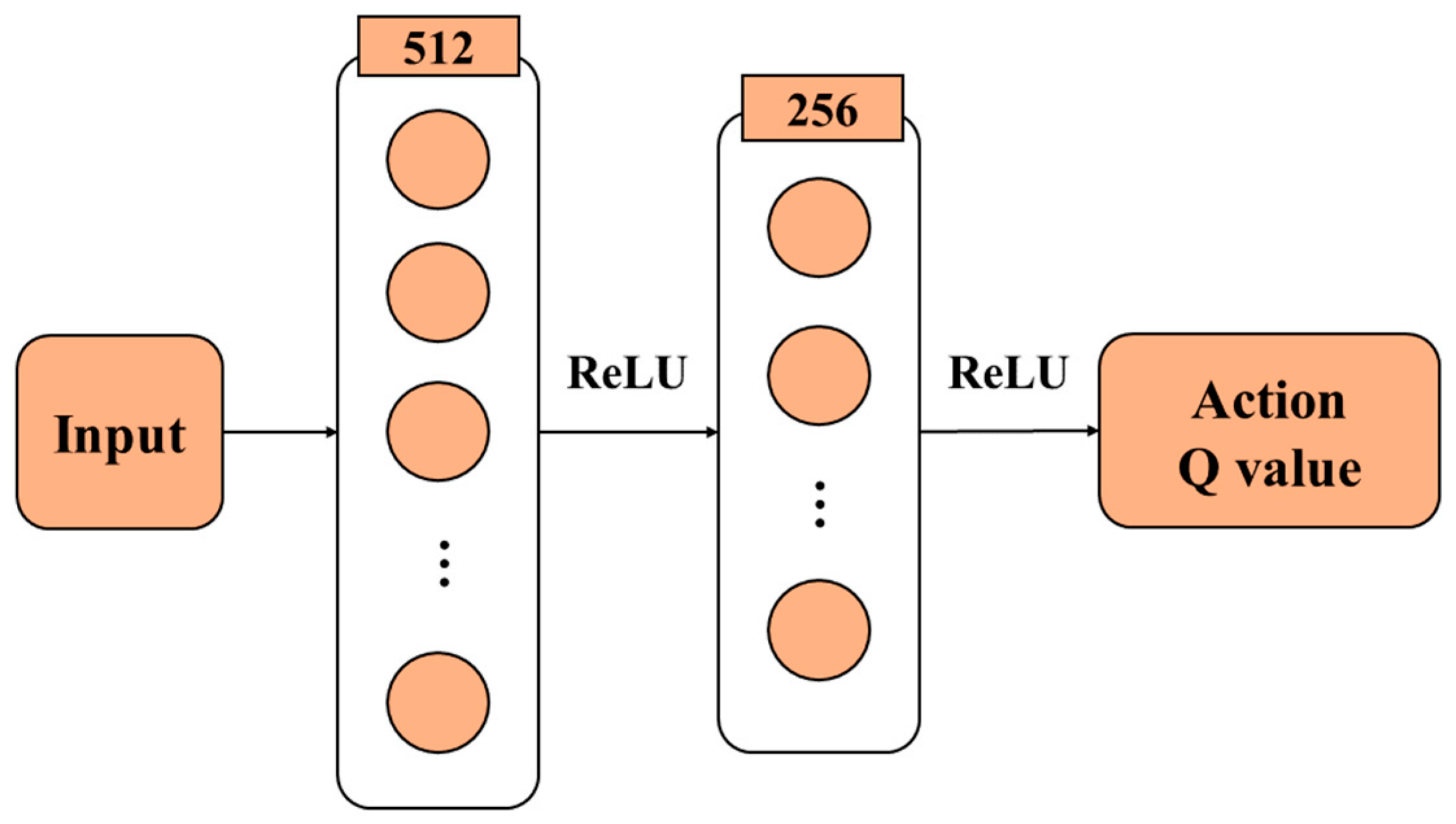
3.4.1. Low-Level Obstacle Avoidance Control Model
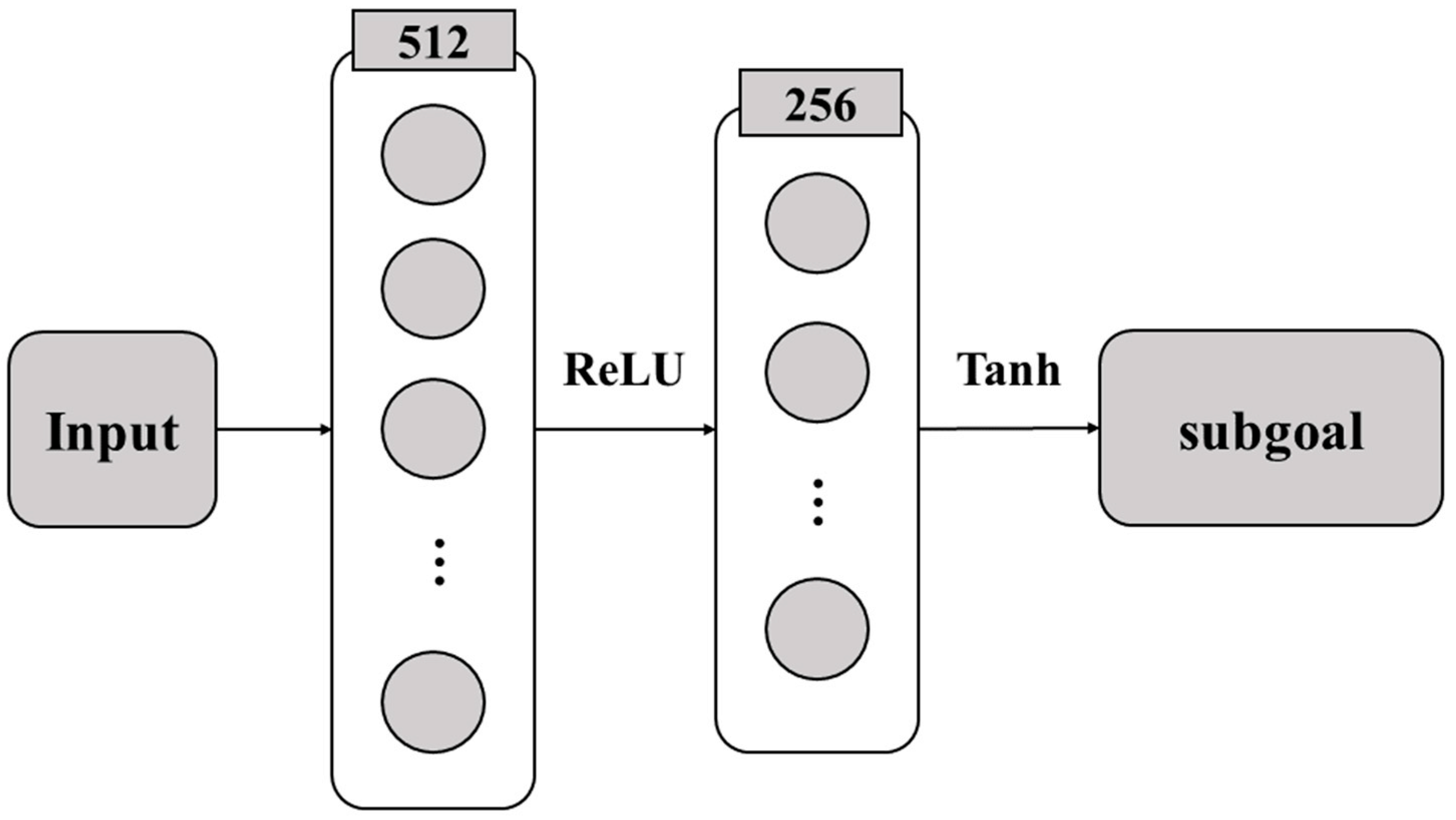
3.4.2. High-Level Target Selection Model
| Algorithm 1 GDH-DQN algorithm |
| 01: Initial high-level and low-level controller parameters |
| 02: Initialize the experience pool capacity and learning rate of each layer |
| 03: for episodes ← 1 to N do |
| 04: Initialization state , goal |
| 05: Execute the train function in layers and complete hindsight experience replay |
| 06: Network parameters are synchronized after an update period |
| 07: end for |
| 08: function Train () |
| 09: Initializes the layer state and goal |
| 10: for within exploration steps or have not yet reached the goal do |
| 11: The action is obtained using the ε-greedy strategy |
| 12: Take action and change the state to the next state |
| 13: The experience pool stores samples |
| 14: end for |
| 15: The low-level performs hindsight experience replay |
| 16: The high layer replays based on the low layer execution |
| 17: end function |
4. Experimental Verification
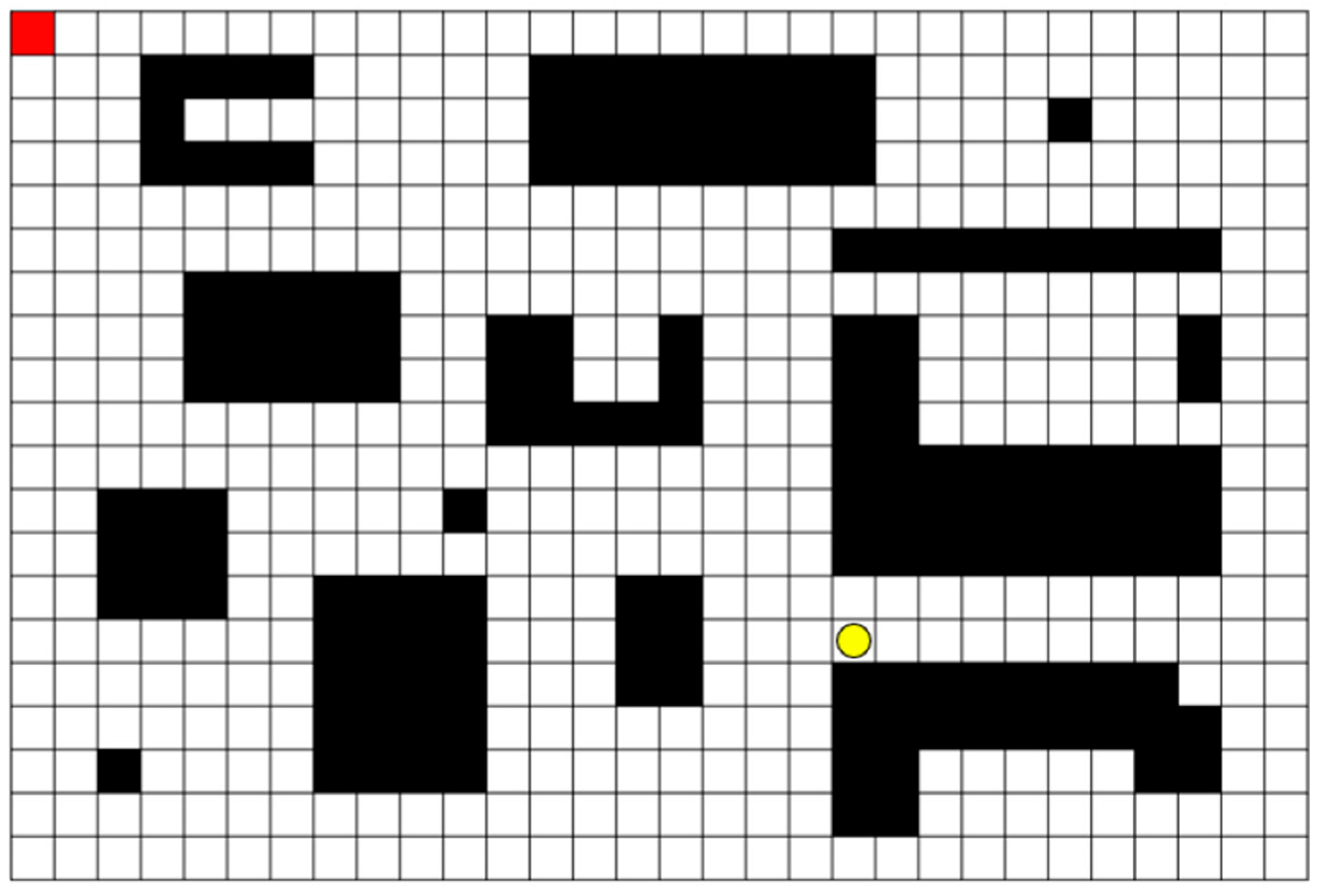
4.1. Experimental Environment
4.2. Neural Network and Parameter Design
4.3. Analysis of Computational Complexity and Resource Consumption
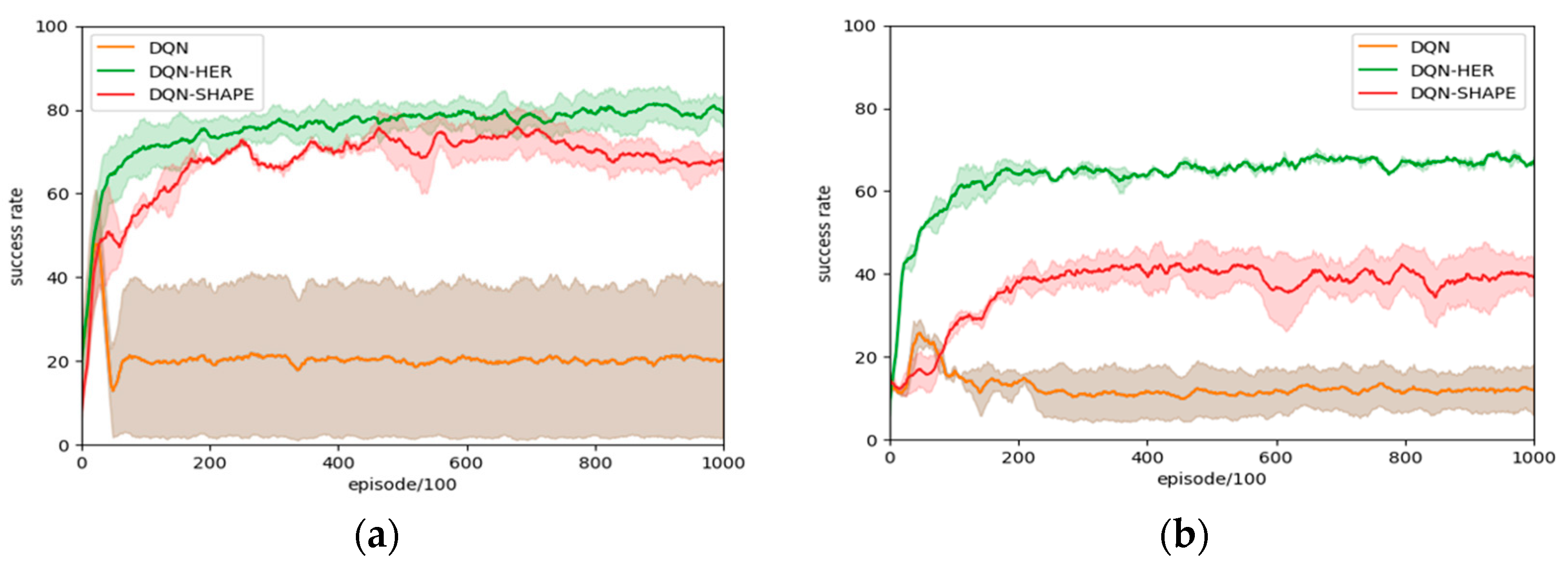
4.4. Single-Goal Experiment
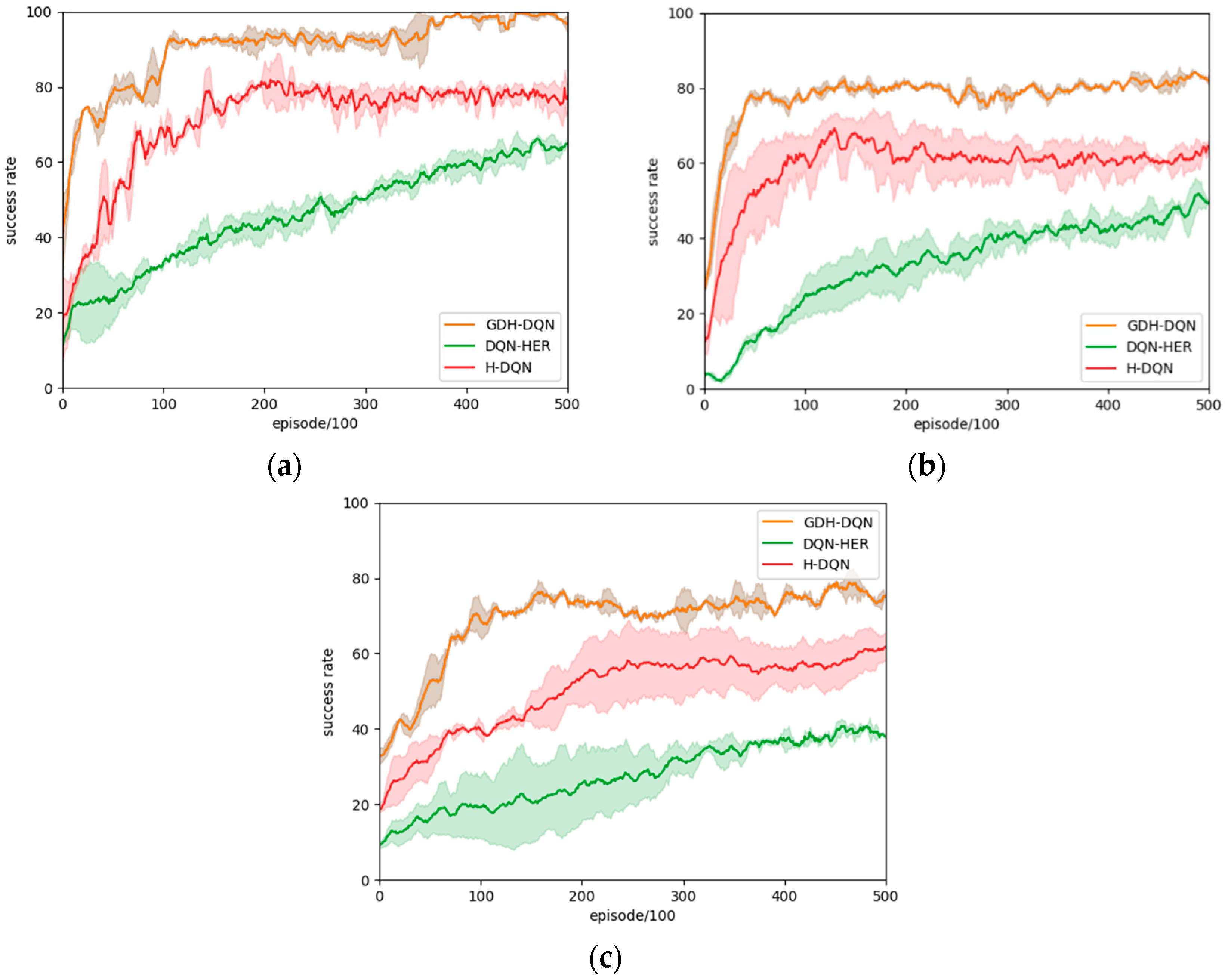
4.5. Multi-Goals Experiment
4.5.1. Comparative Experimental Design
4.5.2. Performance Index Design
4.6. Comprehensive Analysis of Performance Metrics
4.6.1. Navigation Success Rate
4.6.2. Collision Rate
4.6.3. Timeout Rate
4.6.4. Range of Success Rate Fluctuation
4.6.5. Convergence Speed
4.6.6. Average Steps to Reach the Target
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tao, Z.; Zhang, W.; Jia, Y.; Chen, B. Path Planning Technology of Mars Rover Based on Griding of Visibility-Graph Map Direction Search Method. In Proceedings of the CAC, Xiamen, China, 25–27 November 2022; pp. 6703–6707. [Google Scholar]
- Ropero, F.; Muñoz, P.; R-Moreno, M.D.; Barrero, D.F. A Virtual Reality Mission Planner for Mars Rovers. In Proceedings of the 2017 6th International Conference on Space Mission Challenges for Information Technology (SMC-IT), Madrid, Spain, 27–29 September 2017; pp. 142–146. [Google Scholar]
- Sun, S.; Wang, L.; Li, Z.P.; Gu, P.; Chen, F.F.; Feng, Y.T. Research on Parallel System for Motion States Monitoring of the Planetary Rover. In Proceedings of the 2020 5th International Conference on Communication, Image and Signal Processing (CCISP), Chengdu, China, 13–15 November 2020; pp. 86–90. [Google Scholar]
- Liu, J.; Li, H.; Sun, L.; Guo, Z.; Harvey, J.; Tang, Q.; Lu, H.; Jia, M. In-Situ Resources for Infrastructure Construction on Mars: A Review. Int. J. Transp. Sci. Technol. 2022, 11, 1–16. [Google Scholar] [CrossRef]
- Bell, J.F.; Maki, J.N.; Mehall, G.L.; Ravine, M.A.; Caplinger, M.A.; Bailey, Z.J.; Brylow, S.; Schaffner, J.A.; Kinch, K.M.; Madsen, M.B.; et al. The Mars 2020 Perseverance Rover Mast Camera Zoom (Mastcam-Z) Multispectral, Stereoscopic Imaging Investigation. Space Sci. Rev. 2021, 217, 24. [Google Scholar] [CrossRef] [PubMed]
- Ding, L.; Zhou, R.; Yu, T.; Gao, H.; Yang, H.; Li, J.; Yuan, Y.; Liu, C.; Wang, J.; Zhao, Y.-Y.S.; et al. Surface Characteristics of the Zhurong Mars Rover Traverse at Utopia Planitia. Nat. Geosci. 2022, 15, 171–176. [Google Scholar] [CrossRef]
- Zhou, R.; Feng, W.; Ding, L.; Yang, H.; Gao, H.; Liu, G.; Deng, Z. MarsSim: A High-Fidelity Physical and Visual Simulation for Mars Rovers. IEEE Trans. Aerosp. Electron. Syst. 2022, 59, 1879–1892. [Google Scholar] [CrossRef]
- Yang, G.; Liu, Y.; Guan, L. Design and Simulation Optimization of Obstacle Avoidance System for Planetary Exploration Mobile Robots. J. Phys. Conf. Ser. 2019, 1176, 032038. [Google Scholar] [CrossRef]
- Toupet, O.; Del Sesto, T.; Ono, M.; Myint, S.; vander Hook, J.; McHenry, M. A ROS-Based Simulator for Testing the Enhanced Autonomous Navigation of the Mars 2020 Rover. In Proceedings of the 2020 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2020; pp. 1–11. [Google Scholar]
- Zhu, D.; Yan, M. Survey on Technology of Mobile Robot Path Planning. Control Decis. 2010, 25, 961–967. [Google Scholar]
- Hart, P.; Nilsson, N.; Raphael, B. A Formal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE Trans. Syst. Sci. Cyber. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Khatib, O. Real-Time Obstacle Avoidance for Manipulators and Mobile Robots. In Proceedings of the 1985 IEEE International Conference on Robotics and Automation Proceedings, St. Louis, MO, USA, 25–28 March 1985; Volume 2, pp. 500–505. [Google Scholar]
- Hedrick, G.; Ohi, N.; Gu, Y. Terrain-Aware Path Planning and Map Update for Mars Sample Return Mission. IEEE Robot. Autom. Lett. 2020, 5, 5181–5188. [Google Scholar] [CrossRef]
- Daftry, S.; Abcouwer, N.; Sesto, T.D.; Venkatraman, S.; Song, J.; Igel, L.; Byon, A.; Rosolia, U.; Yue, Y.; Ono, M. MLNav: Learning to Safely Navigate on Martian Terrains. IEEE Robot. Autom. Lett. 2022, 7, 5461–5468. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Zhu, K.; Zhang, T. Deep Reinforcement Learning Based Mobile Robot Navigation: A Review. Tsinghua Sci. Technol. 2021, 26, 674–691. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-Level Control through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Devidze, R.; Kamalaruban, P.; Singla, A. Exploration-Guided Reward Shaping for Reinforcement Learning under Sparse Rewards. Adv. Neural Inf. Process. Syst. 2022, 35, 5829–5842. [Google Scholar]
- Cimurs, R.; Suh, I.H.; Lee, J.H. Goal-Driven Autonomous Exploration Through Deep Reinforcement Learning. IEEE Robot. Autom. Lett. 2022, 7, 730–737. [Google Scholar] [CrossRef]
- Riedmiller, M.; Hafner, R.; Lampe, T.; Neunert, M.; Degrave, J.; Wiele, T.; Mnih, V.; Heess, N.; Springenberg, J.T. Learning by Playing Solving Sparse Reward Tasks from Scratch. In Proceedings of the 35th International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4344–4353. [Google Scholar]
- Shaping as a Method for Accelerating Reinforcement Learning|IEEE Conference Publication|IEEE Xplore. Available online: https://ieeexplore.ieee.org/document/225046 (accessed on 15 July 2024).
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Pieter Abbeel, O.; Zaremba, W. Hindsight Experience Replay. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Jagodnik, K.M.; Thomas, P.S.; Van Den Bogert, A.J.; Branicky, M.S.; Kirsch, R.F. Training an Actor-Critic Reinforcement Learning Controller for Arm Movement Using Human-Generated Rewards. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 1892–1905. [Google Scholar] [CrossRef]
- Brito, B.; Everett, M.; How, J.P.; Alonso-Mora, J. Where to Go Next: Learning a Subgoal Recommendation Policy for Navigation in Dynamic Environments. IEEE Robot. Autom. Lett. 2021, 6, 4616–4623. [Google Scholar] [CrossRef]
- Liu, W.W.; Wei, J.; Liu, S.Q.; Ruan, Y.D.; Zhang, K.X.; Yang, J.; Liu, Y. Expert Demonstrations Guide Reward Decomposition for Multi-Agent Cooperation. Neural Comput. Appl. 2023, 35, 19847–19863. [Google Scholar] [CrossRef]
- Dai, X.-Y.; Meng, Q.-H.; Jin, S.; Liu, Y.-B. Camera View Planning Based on Generative Adversarial Imitation Learning in Indoor Active Exploration. Appl. Soft Comput. 2022, 129, 109621. [Google Scholar] [CrossRef]
- Luo, Y.; Wang, Y.; Dong, K.; Zhang, Q.; Cheng, E.; Sun, Z.; Song, B. Relay Hindsight Experience Replay: Self-Guided Continual Reinforcement Learning for Sequential Object Manipulation Tasks with Sparse Rewards. Neurocomputing 2023, 557, 126620. [Google Scholar] [CrossRef]
- Feng, W.; Ding, L.; Zhou, R.; Xu, C.; Yang, H.; Gao, H.; Liu, G.; Deng, Z. Learning-Based End-to-End Navigation for Planetary Rovers Considering Non-Geometric Hazards. IEEE Robot. Autom. Lett. 2023, 8, 4084–4091. [Google Scholar] [CrossRef]
- Verma, V.; Maimone, M.W.; Gaines, D.M.; Francis, R.; Estlin, T.A.; Kuhn, S.R.; Rabideau, G.R.; Chien, S.A.; McHenry, M.M.; Graser, E.J.; et al. Autonomous Robotics Is Driving Perseverance Rover’s Progress on Mars. Sci. Robot. 2023, 8, eadi3099. [Google Scholar] [CrossRef]
- Wong, C.; Yang, E.; Yan, X.-T.; Gu, D. Adaptive and Intelligent Navigation of Autonomous Planetary Rovers—A Survey. In Proceedings of the 2017 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), Pasadena, CA, USA, 24–27 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 237–244. [Google Scholar]
- Why—And How—NASA Gives a Name to Every Spot It Studies on Mars—NASA. Available online: https://www.nasa.gov/solar-system/why-and-how-nasa-gives-a-name-to-every-spot-it-studies-on-mars/ (accessed on 15 July 2024).
- Paton, M.; Strub, M.P.; Brown, T.; Greene, R.J.; Lizewski, J.; Patel, V.; Gammell, J.D.; Nesnas, I.A.D. Navigation on the Line: Traversability Analysis and Path Planning for Extreme-Terrain Rappelling Rovers. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 7034–7041. [Google Scholar]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.; Perez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transport. Syst. 2022, 23, 4909–4926. [Google Scholar] [CrossRef]
- Faust, A.; Oslund, K.; Ramirez, O.; Francis, A.; Tapia, L.; Fiser, M.; Davidson, J. PRM-RL: Long-Range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-Based Planning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 5113–5120. [Google Scholar]
- Al-Emran, M. Hierarchical Reinforcement Learning: A Survey. Int. J. Comput. Digit. Syst. 2015, 4, 137–143. [Google Scholar] [CrossRef] [PubMed]
- (PDF) Learning Representations in Model-Free Hierarchical Reinforcement Learning. Available online: https://www.researchgate.net/publication/335177036_Learning_Representations_in_Model-Free_Hierarchical_Reinforcement_Learning (accessed on 17 April 2024).
- Lu, Y.; Xu, X.; Zhang, X.; Qian, L.; Zhou, X. Hierarchical Reinforcement Learning for Autonomous Decision Making and Motion Planning of Intelligent Vehicles. IEEE Access 2020, 8, 209776–209789. [Google Scholar] [CrossRef]
- Trajectory Planning for Autonomous Vehicles Using Hierarchical Reinforcement Learning|IEEE Conference Publication|IEEE Xplore. Available online: https://ieeexplore.ieee.org/abstract/document/9564634 (accessed on 15 July 2024).
- Planning-Augmented Hierarchical Reinforcement Learning|IEEE Journals & Magazine|IEEE Xplore. Available online: https://ieeexplore.ieee.org/abstract/document/9395248 (accessed on 15 July 2024).
- Hierarchies of Planning and Reinforcement Learning for Robot Navigation|IEEE Conference Publication|IEEE Xplore. Available online: https://ieeexplore.ieee.org/abstract/document/9561151 (accessed on 15 July 2024).
- Between MDPs and Semi-MDPs: A Framework for Temporal Abstraction in Reinforcement Learning. Artif. Intell. 1999, 112, 181–211. [CrossRef]
- Han, R.; Li, H.; Knoblock, E.J.; Gasper, M.R.; Apaza, R.D. Joint Velocity and Spectrum Optimization in Urban Air Transportation System via Multi-Agent Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2023, 72, 9770–9782. [Google Scholar] [CrossRef]
- Han, R.; Li, H.; Apaza, R.; Knoblock, E.; Gasper, M. Deep Reinforcement Learning Assisted Spectrum Management in Cellular Based Urban Air Mobility. IEEE Wirel. Commun. 2022, 29, 14–21. [Google Scholar] [CrossRef]
- Yan, C.; Xiang, X.; Wang, C. Towards Real-Time Path Planning through Deep Reinforcement Learning for a UAV in Dynamic Environments. J. Intell. Rob. Syst. 2020, 98, 297–309. [Google Scholar] [CrossRef]
- Chen, J.P.; Zheng, M.H. A Survey of Robot Manipulation Behavior Research Based on Deep Reinforcement Learning. Robot 2022, 44, 236–256. [Google Scholar] [CrossRef]
- Biswas, A.; Anselma, P.G.; Emadi, A. Real-Time Optimal Energy Management of Multimode Hybrid Electric Powertrain with Online Trainable Asynchronous Advantage Actor–Critic Algorithm. IEEE Trans. Transp. Electrif. 2022, 8, 2676–2694. [Google Scholar] [CrossRef]
- Levy, A.; Konidaris, G.; Platt, R.; Saenko, K. Learning Multi-Level Hierarchies with Hindsight. arXiv 2018, arXiv:1712.00948. [Google Scholar]
- Ren, Y.Y.; Song, X.R.; Gao, S. Research on Path Planning of Mobile Robot Based on Improved A* in Special Environment. In Proceedings of the 2019 3rd International Symposium on Autonomous Systems (ISAS), Shanghai, China, 29–31 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 12–16. [Google Scholar]
- Yue, P.; Xin, J.; Zhang, Y.; Lu, Y.; Shan, M. Semantic-Driven Autonomous Visual Navigation for Unmanned Aerial Vehicles. IEEE Trans. Ind. Electron. 2024, 71, 14853–14863. [Google Scholar] [CrossRef]
- Images from the Mars Perseverance Rover—NASA Mars. Available online: https://mars.nasa.gov/mars2020/multimedia/raw-images/ (accessed on 15 July 2024).
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning Both Weights and Connections for Efficient Neural Network. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2015; Volume 28. [Google Scholar]
- He, K.; Sun, J. Convolutional Neural Networks at Constrained Time Cost. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar]
- Canziani, A.; Paszke, A.; Culurciello, E. An Analysis of Deep Neural Network Models for Practical Applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Parameter Value |
|---|---|
| Experience pool capacity | 100,000 |
| Batch size | 128 |
| Learning rate | 0.001 |
| Loss factor | 0.98 |
| Exploration factor | 1 to 0 |
| Sample proportion of HER | 4:1 |
| Exploration steps per round | L + W |
| Algorithm | DQN-HER | DQN | DQN-SHAPE |
|---|---|---|---|
| 10 × 10 Highest success rate | 94% | 77% | 88% |
| 10 × 10 Average success rate | 75.5% | 20.8% | 67.3% |
| 20 × 20 Highest success rate | 81% | 43% | 61% |
| 20 × 20 Average success rate | 63.6% | 12.6% | 36.7% |
| Test Environment | Algorithm | Highest Success Rate | Collision Rate | Timeout Rate | Average Success Rate |
|---|---|---|---|---|---|
| 10 × 10 | GDH-DQN | 100% | 0% | 0% | 90.3% |
| H-DQN | 99% | 0% | 1% | 71.0% | |
| DQN-HER | 77% | 8% | 15% | 45.9% | |
| 20 × 20 | GDH-DQN | 93% | 3% | 4% | 77.6% |
| H-DQN | 81% | 7% | 12% | 59.1% | |
| DQN-HER | 64% | 13% | 23% | 33.1% | |
| 20 × 30 | GDH-DQN | 93% | 2% | 5% | 68.9% |
| H-DQN | 74% | 10% | 16% | 49.9% | |
| DQN-HER | 51% | 20% | 29% | 27.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Chen, Y.; Yu, J.; Zu, B.; Wang, Q.; Zhou, X.; Duan, J. Mars Exploration: Research on Goal-Driven Hierarchical DQN Autonomous Scene Exploration Algorithm. Aerospace 2024, 11, 692. https://doi.org/10.3390/aerospace11080692
Zhou Z, Chen Y, Yu J, Zu B, Wang Q, Zhou X, Duan J. Mars Exploration: Research on Goal-Driven Hierarchical DQN Autonomous Scene Exploration Algorithm. Aerospace. 2024; 11(8):692. https://doi.org/10.3390/aerospace11080692
Chicago/Turabian StyleZhou, Zhiguo, Ying Chen, Jiabao Yu, Bowen Zu, Qian Wang, Xuehua Zhou, and Junwei Duan. 2024. "Mars Exploration: Research on Goal-Driven Hierarchical DQN Autonomous Scene Exploration Algorithm" Aerospace 11, no. 8: 692. https://doi.org/10.3390/aerospace11080692
APA StyleZhou, Z., Chen, Y., Yu, J., Zu, B., Wang, Q., Zhou, X., & Duan, J. (2024). Mars Exploration: Research on Goal-Driven Hierarchical DQN Autonomous Scene Exploration Algorithm. Aerospace, 11(8), 692. https://doi.org/10.3390/aerospace11080692