
Pixel-Wise and Class-Wise Semantic Cues for Few-Shot Segmentation in Astronaut Working Scenes

 ,
,
Abstract
1. Introduction
- (1)
- We propose a novel and effective FSS network, termed PCNet, to solve the semantic segmentation with a limited number of annotated samples in AWSs.
- (2)
- Pixel-wise semantic correlations and reverse-distill class-wise semantic cues are used to deal with the complexity of AWSs.
- (3)
- We create a scientific and practical dataset for the CSS simulator, which will be used for further research and in-orbit applications.
- (4)
- Experiments demonstrate that our network is the most effective method for solving AWSs’ FSS task.
2. Related Work
2.1. Semantic Segmentation
2.2. Few-Shot Learning
2.3. Few-Shot Segmentation
3. Materials and Methods
3.1. Problem Definition
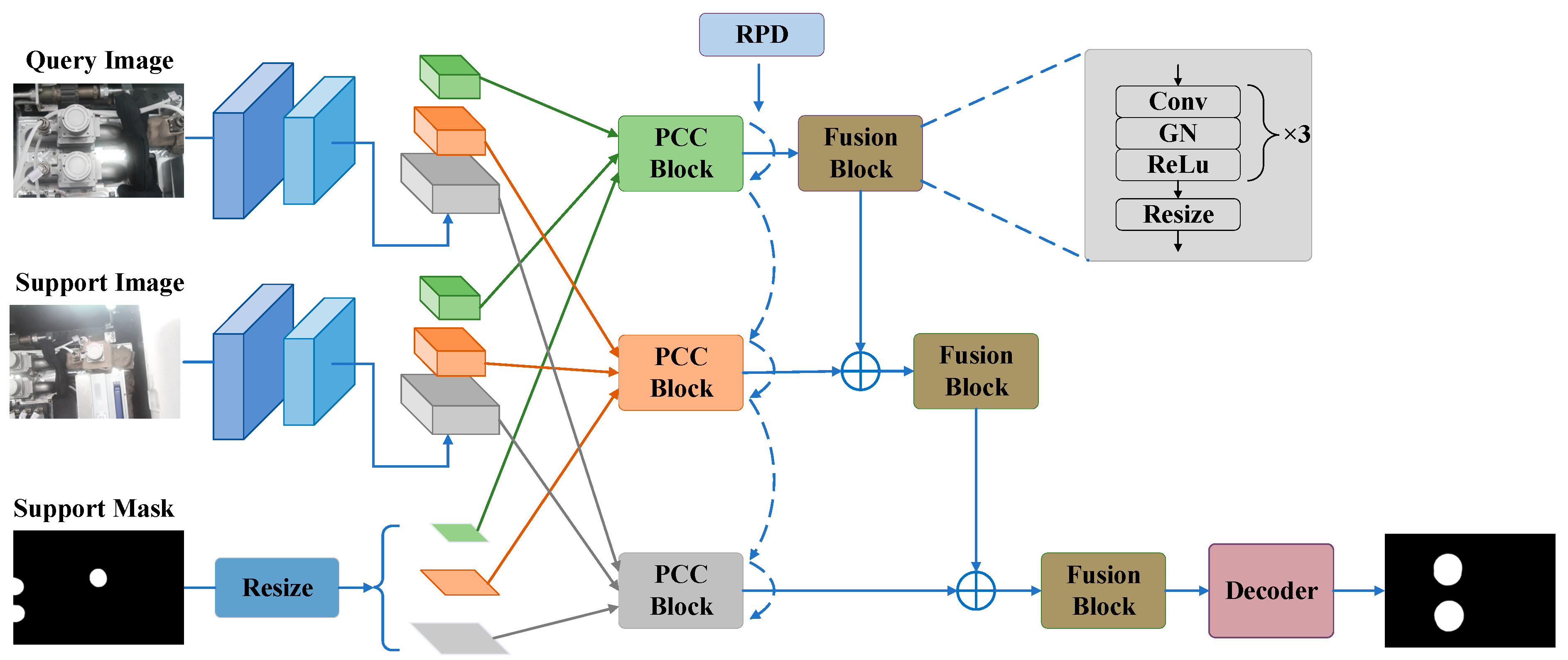
3.2. Method Overview
3.3. Feature Preparation
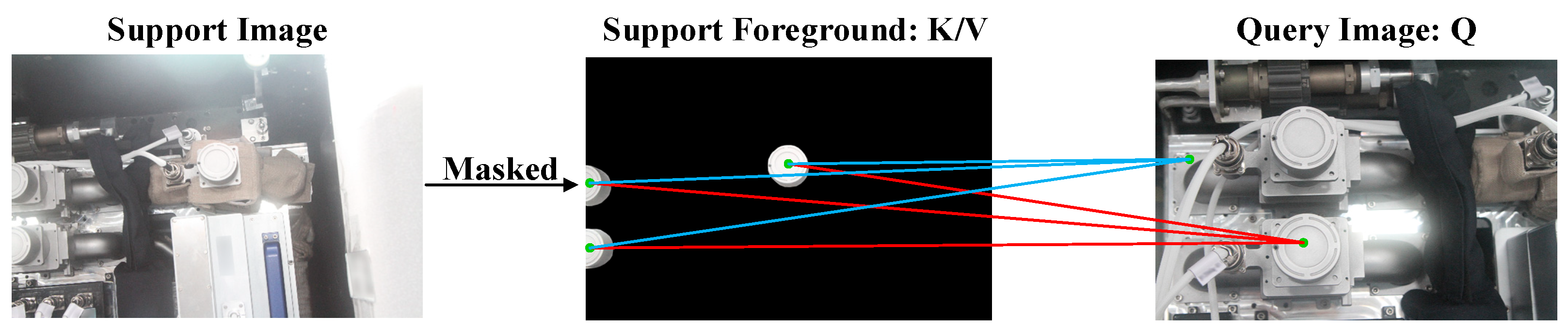
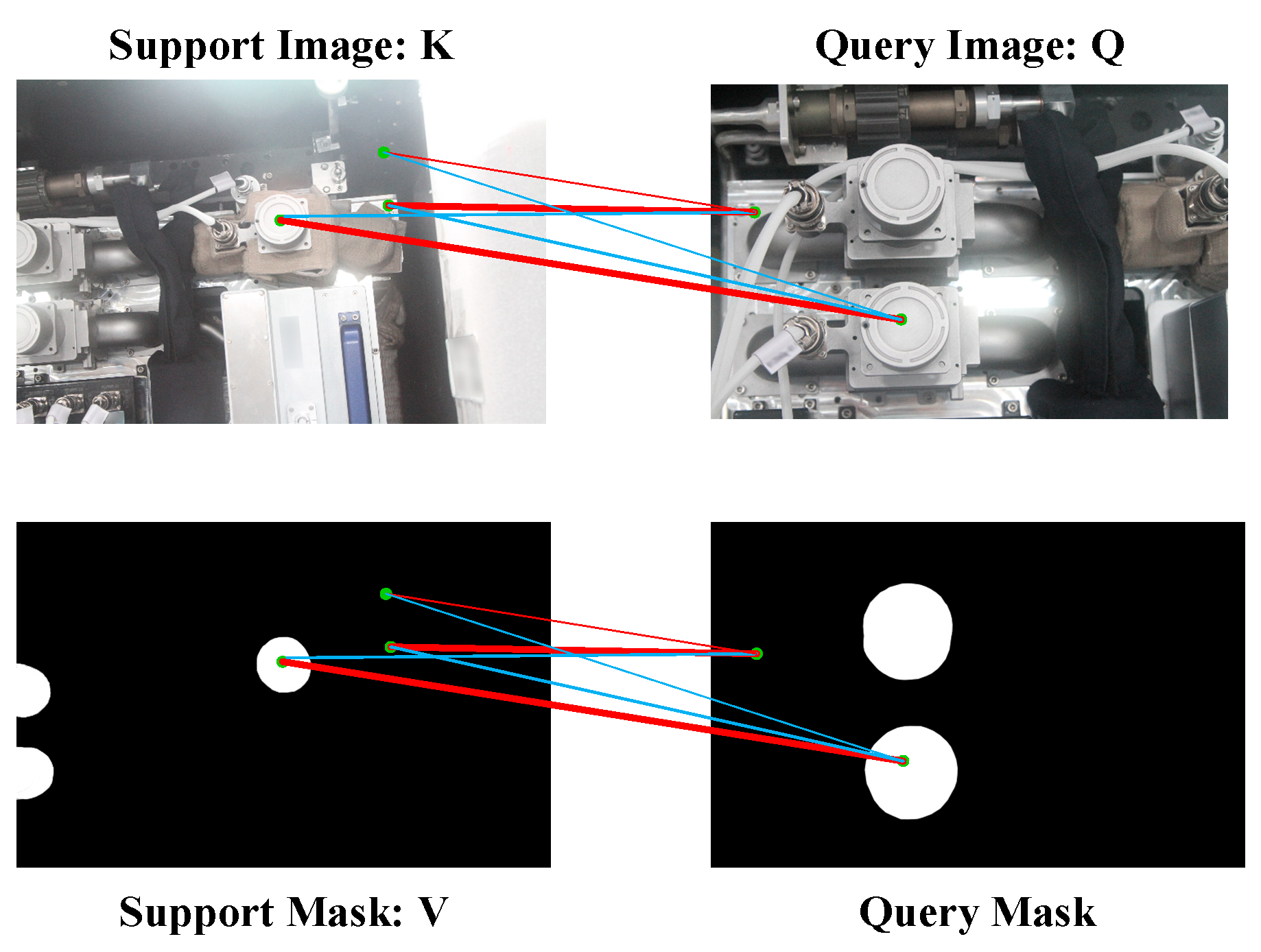
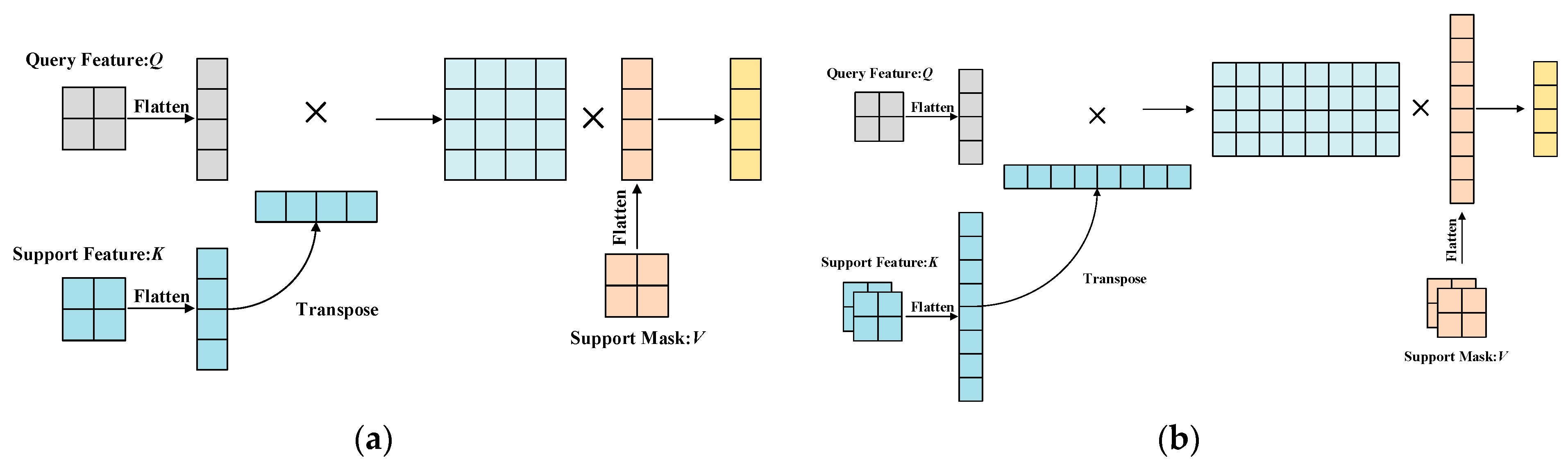
3.4. Rational Application of the Cross-Attention
3.5. Pixel-Wise and Class-Wise Correlation Block (PCC Block)
3.6. Reverse Prototype Distillation (RPD)
3.7. Feature Fusion and Decoder
3.8. Extension to K-Shot Setting
4. Experimental Settings
4.1. Dataset
4.2. Metrics
4.3. Implementation Details
5. Results and Discussion
5.1. Comparison with the SOTA Methods
5.2. Qualitative Results
5.3. Ablation Studies
5.3.1. Effects of the Proposed Modules
5.3.2. Effects of Different Forms of Cross-Attention
5.3.3. Effects of the Distillation Temperature
5.3.4. SS vs. FSS
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bertrand, R. Conceptual design and flight simulation of space stations. Aerosp. Sci. Technol. 2001, 5, 147–163. [Google Scholar] [CrossRef]
- Li, D.; Liu, H.; Sun, Y.; Qin, X.; Hu, X.; Shi, L.; Liu, Q.; Wang, Y.; Cheng, T.; Yi, D.; et al. Active Potential Control Technology of Space Station and Its Space-ground Integrated Verification. J. Astronaut. 2023, 44, 1613–1620. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, B.; Xing, T. Preliminary integrated analysis for modeling and optimizing space stations at conceptual level. Aerosp. Sci. Technol. 2017, 71, 420–431. [Google Scholar] [CrossRef]
- Shi, L.; Yao, H.; Shan, M.; Gao, Q.; Jin, X. Robust control of a space robot based on an optimized adaptive variable structure control method. Aerosp. Sci. Technol. 2022, 120, 107267. [Google Scholar] [CrossRef]
- Yuan, H.; Cui, Y.; Shen, X.; Liu, Y.; Wang, Z.; Zhang, L.; Zhang, C.; Shi, F. Technology and Development of Sub-System of Docking and Transposition Mechanism for Space Station Laboratory Module. Aerosp. Shanghai (Chin. Engl.) 2023, 40, 71–77. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Pan, Z.; Jiang, P.; Wang, Y.; Tu, C.; Cohn, A.G. Scribble-Supervised Semantic Segmentation by Uncertainty Reduction on Neural Representation and Self-Supervision on Neural Eigenspace. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 7396–7405. [Google Scholar] [CrossRef]
- Lang, C.; Cheng, G.; Tu, B.; Han, J. Learning What Not to Segment: A New Perspective on Few-Shot Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8047–8057. [Google Scholar] [CrossRef]
- Shaban, A.; Bansal, S.; Liu, Z.; Essa, I.; Boots, B. One-Shot Learning for Semantic Segmentation. arXiv 2017, arXiv:1709.03410. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. In Proceedings of the International Conference on Neural Information Processing Systems (NeurlPS), Barcelona, Spai, 5–10 December 2016; pp. 3637–3645. [Google Scholar]
- Yang, B.; Liu, C.; Li, B.; Jiao, J.; Ye, Q. Prototype Mixture Models for Few-shot Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar] [CrossRef]
- Peng, B.; Tian, Z.; Wu, X.; Wang, C.; Liu, S.; Su, J.; Jia, J. Hierarchical Dense Correlation Distillation for Few-Shot Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 23641–23651. [Google Scholar] [CrossRef]
- Zhang, G.; Kang, G.; Yang, Y.; Wei, Y. Few-Shot Segmentation via Cycle-Consistent Transformer. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Online, 6–14 December 2021; pp. 21984–21996. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar] [CrossRef]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Cham, Switzreland, 23–28 August 2020; pp. 173–190. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-Time Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 334–349. [Google Scholar] [CrossRef]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vision 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J.; Wei, X. Rethinking BiSeNet For Real-time Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 9711–9720. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Cham, Switzerland, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 6–14 December 2021; pp. 12077–12090. [Google Scholar]
- Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting Local Descriptor Based Image-To-Class Measure for Few-Shot Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7253–7260. [Google Scholar] [CrossRef]
- Qiao, L.; Shi, Y.; Li, J.; Tian, Y.; Huang, T.; Wang, Y. Transductive Episodic-Wise Adaptive Metric for Few-Shot Learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3602–3611. [Google Scholar] [CrossRef]
- Wu, Z.; Li, Y.; Guo, L.; Jia, K. PARN: Position-Aware Relation Networks for Few-Shot Learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6658–6666. [Google Scholar] [CrossRef]
- Ye, H.J.; Hu, H.; Zhan, D.C.; Sha, F. Few-Shot Learning via Embedding Adaptation With Set-to-Set Functions. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8805–8814. [Google Scholar] [CrossRef]
- Li, H.; Eigen, D.; Dodge, S.; Zeiler, M.; Wang, X. Finding Task-Relevant Features for Few-Shot Learning by Category Traversal. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Jamal, M.A.; Qi, G.J. Task Agnostic Meta-Learning for Few-Shot Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11711–11719. [Google Scholar] [CrossRef]
- Chen, Z.; Fu, Y.; Wang, Y.X.; Ma, L.; Liu, W.; Hebert, M. Image Deformation Meta-Networks for One-Shot Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8672–8681. [Google Scholar] [CrossRef]
- Zhang, C.; Lin, G.; Liu, F.; Yao, R.; Shen, C. CANet: Class-Agnostic Segmentation Networks With Iterative Refinement and Attentive Few-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5212–5221. [Google Scholar] [CrossRef]
- Dong, N.; Xing, E.P. Few-Shot Semantic Segmentation with Prototype Learning. In Proceedings of the British Machine Vision Conference, Northumbria, UK, 3–6 September 2018; p. 79. [Google Scholar]
- Fan, Q.; Pei, W.; Tai, Y.-W.; Tang, C.-K. Self-support Few-Shot Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 701–719. [Google Scholar] [CrossRef]
- Luo, X.; Tian, Z.; Zhang, T.; Yu, B.; Tang, Y.Y.; Jia, J. PFENet++: Boosting Few-Shot Semantic Segmentation With the Noise-Filtered Context-Aware Prior Mask. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 1273–1289. [Google Scholar] [CrossRef] [PubMed]
- Tian, Z.; Lai, X.; Jiang, L.; Liu, S.; Shu, M.; Zhao, H.; Jia, J. Generalized Few-shot Semantic Segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11553–11562. [Google Scholar] [CrossRef]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. PANet: Few-Shot Image Semantic Segmentation With Prototype Alignment. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9196–9205. [Google Scholar] [CrossRef]
- Li, G.; Jampani, V.; Sevilla-Lara, L.; Sun, D.; Kim, J.; Kim, J. Adaptive Prototype Learning and Allocation for Few-Shot Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8330–8339. [Google Scholar] [CrossRef]
- Zhang, C.; Lin, G.; Liu, F.; Guo, J.; Wu, Q.; Yao, R. Pyramid Graph Networks With Connection Attentions for Region-Based One-Shot Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9586–9594. [Google Scholar] [CrossRef]
- Lu, Z.; He, S.; Zhu, X.; Zhang, L.; Song, Y.Z.; Xiang, T. Simpler is Better: Few-shot Semantic Segmentation with Classifier Weight Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 8721–8730. [Google Scholar] [CrossRef]
- Min, J.; Kang, D.; Cho, M. Hypercorrelation Squeeze for Few-Shot Segmenation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 6921–6932. [Google Scholar] [CrossRef]
- Xu, Q.; Zhao, W.; Lin, G.; Long, C. Self-Calibrated Cross Attention Network for Few-Shot Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1 August 2023; pp. 655–665. [Google Scholar] [CrossRef]
- Shi, X.; Wei, D.; Zhang, Y.; Lu, D.; Ning, M.; Chen, J.; Ma, K.; Zheng, Y. Dense Cross-Query-and-Support Attention Weighted Mask Aggregation for Few-Shot Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 151–168. [Google Scholar] [CrossRef]
- Liu, H.; Peng, P.; Chen, T.; Wang, Q.; Yao, Y.; Hua, X.S. FECANet: Boosting Few-Shot Semantic Segmentation with Feature-Enhanced Context-Aware Network. IEEE Trans. Multimed. 2023, 25, 8580–8592. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Red Hook, NY, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhang, X.; Wei, Y.; Yang, Y.; Huang, T.S. SG-One: Similarity Guidance Network for One-Shot Semantic Segmentation. IEEE Trans. Cybern. 2020, 50, 3855–3865. [Google Scholar] [CrossRef] [PubMed]
- Tian, Z.; Zhao, H.; Shu, M.; Yang, Z.; Li, R.; Jia, J. Prior Guided Feature Enrichment Network for Few-Shot Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1050–1065. [Google Scholar] [CrossRef] [PubMed]
- Lang, C.; Wang, J.; Cheng, G.; Tu, B.; Han, J. Progressive Parsing and Commonality Distillation for Few-Shot Remote Sensing Segmentation. IEEE Trans. Geosci. 2023, 61, 1–10. [Google Scholar] [CrossRef]
- Zhang, B.; Xiao, J.; Qin, T. Self-Guided and Cross-Guided Learning for Few-Shot Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8308–8317. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Piscataway, NJ, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Type | 1-Shot | 5-Shot | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Split0 | Split1 | Split2 | Split3 | Mean | Split0 | Split1 | Split2 | Split3 | Mean | |||
| PFENet | Class-wise | 28.76 | 37.24 | 37.83 | 30.49 | 33.58 | 34.33 | 38.93 | 39.08 | 33.09 | 36.36 | |
| BAM | 40.17 | 44.79 | 51.36 | 38.84 | 43.79 | 43.29 | 45.20 | 52.96 | 41.84 | 45.82 | ||
| BAM * | 37.24 | 42.38 | 42.11 | 33.78 | 38.88 | 39.08 | 43.89 | 43.75 | 33.84 | 40.14 | ||
| HSNet | Pixel-wise | 4D-conv | 46.45 | 49.79 | 45.43 | 45.85 | 46.88 | 54.58 | 58.99 | 55.15 | 52.68 | 55.35 |
| FECANet | 50.22 | 50.19 | 49.78 | 46.10 | 49.07 | 54.75 | 57.29 | 52.69 | 52.17 | 54.23 | ||
| CyCTR | Cross-att. w/o mask | 33.92 | 39.27 | 40.99 | 32.49 | 36.67 | 34.68 | 41.17 | 43.58 | 34.23 | 38.42 | |
| SCCAN | 42.90 | 42.49 | 45.22 | 36.68 | 41.82 | 45.41 | 43.42 | 47.48 | 38.46 | 43.70 | ||
| HDMNet | 53.85 | 45.25 | 42.51 | 37.00 | 44.65 | 56.98 | 50.28 | 47.24 | 42.04 | 49.14 | ||
| HDMNet * | 47.25 | 35.42 | 43.61 | 32.75 | 39.76 | 51.04 | 39.33 | 52.43 | 36.46 | 44.82 | ||
| DCAMA | Cross-att. w/mask | 52.99 | 51.61 | 54.55 | 53.95 | 53.28 | 59.90 | 63.28 | 60.96 | 61.36 | 61.38 | |
| PCNet | 57.33 | 54.69 | 57.50 | 52.83 | 55.59 | 66.19 | 67.65 | 62.50 | 61.83 | 64.54 | ||
| Method | 1-Shot | 5-Shot | FPS |
|---|---|---|---|
| PFENet | 67.95 | 69.90 | 11.02 |
| BAM | 72.48 | 74.13 | 36.45 |
| BAM * | 69.44 | 70.68 | 37.87 |
| HSNet | 74.03 | 78.00 | 18.28 |
| FECANet | 75.50 | 78.09 | 8.42 |
| CyCTR | 68.23 | 69.62 | 9.30 |
| SCCAN | 69.62 | 70.86 | 13.85 |
| HDMNet | 71.32 | 74.40 | 15.46 |
| HDMNet * | 70.44 | 73.61 | 15.82 |
| DCAMA | 77.38 | 81.92 | 19.49 |
| OURs | 78.18 | 82.85 | 17.73 |
| Prototype | RPD | Split0 | Split1 | Split3 | Mean | Δ |
|---|---|---|---|---|---|---|
| 52.34 | 51.67 | 50.31 | 51.58 | 0 | ||
| √ | 55.08 | 53.25 | 52.26 | 53.82 | +2.24 (4.34%) | |
| √ | √ | 57.33 | 54.69 | 52.83 | 55.59 | +4.01 (7.77%) |
| Temperature (T) | Split0 | Split1 | Split2 | Split3 | Mean | Δ |
|---|---|---|---|---|---|---|
| 0.5 | 57.33 | 54.69 | 57.50 | 52.83 | 55.59 | 0 |
| 1 | 56.93 | 54.33 | 56.17 | 52.90 | 55.08 | −0.51 |
| 2 | 56.78 | 54.05 | 56.15 | 52.02 | 54.75 | −0.84 |
| 3 | 56.38 | 53.48 | 55.21 | 51.66 | 54.18 | −1.41 |
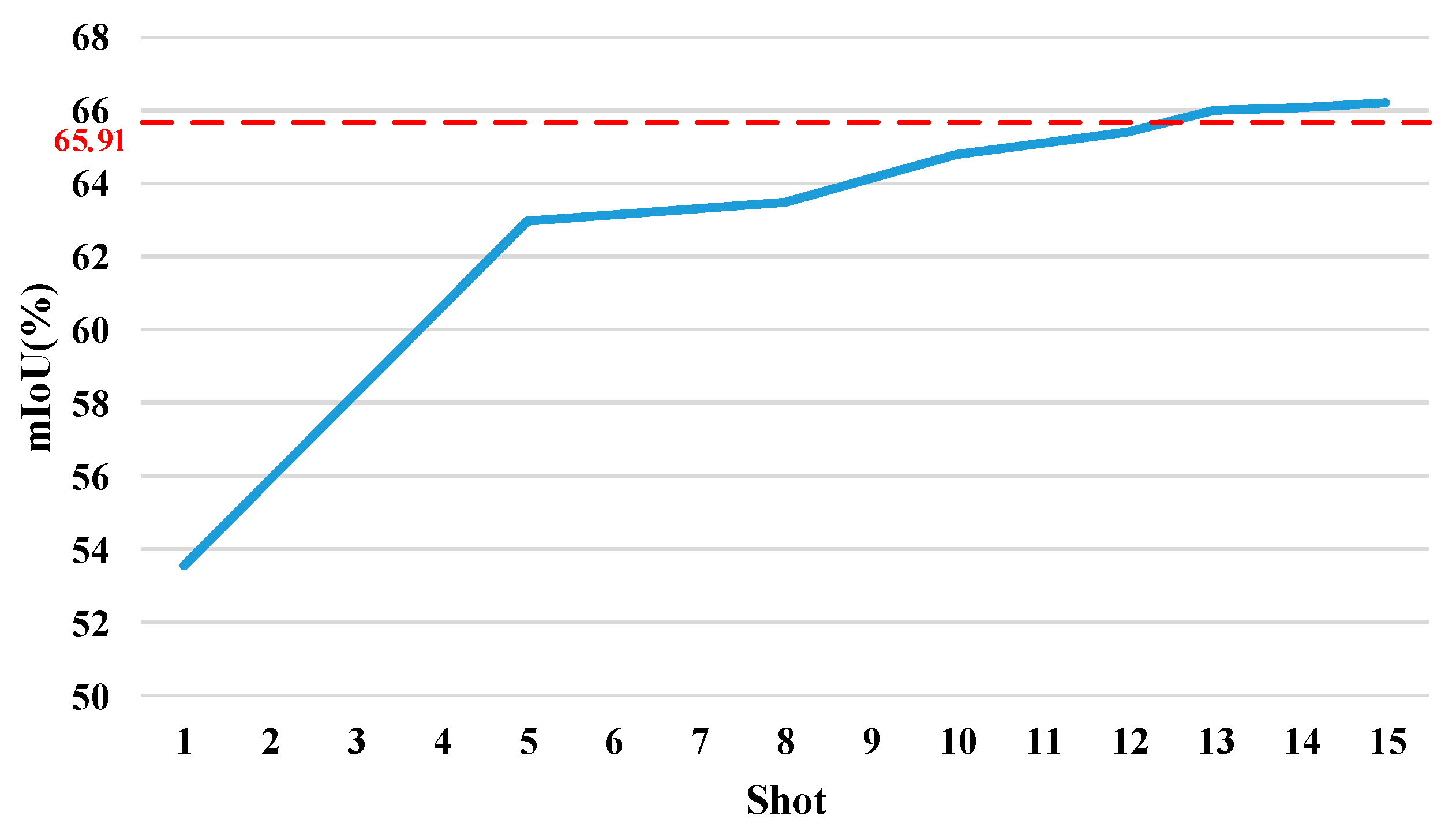
| PSPNet | 59.75 | 71.41 | 70.36 | 62.12 | 65.91 | 0 |
|---|---|---|---|---|---|---|
| Shot | Split0 | Split1 | Split2 | Split3 | Mean | Δ |
| 1 | 55.15 | 51.21 | 55.75 | 52.08 | 53.55 | −12.36 |
| 5 | 64.01 | 64.59 | 61.45 | 61.85 | 62.98 | −2.93 |
| 8 | 66.44 | 61.17 | 62.26 | 64.10 | 63.49 | −2.42 |
| 10 | 65.20 | 67.56 | 62.69 | 63.71 | 64.79 | −1.12 |
| 12 | 66.20 | 67.60 | 62.40 | 65.45 | 65.41 | −0.5 |
| 13 | 66.30 | 68.31 | 63.19 | 66.20 | 66.00 | +0.09 |
| 14 | 66.68 | 67.46 | 62.99 | 67.14 | 66.07 | +0.16 |
| 15 | 67.37 | 68.03 | 63.12 | 66.36 | 66.22 | +0.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Q.; Chao, J.; Lin, W.; Wang, D.; Chen, W.; Xu, Z.; Xie, S. Pixel-Wise and Class-Wise Semantic Cues for Few-Shot Segmentation in Astronaut Working Scenes. Aerospace 2024, 11, 496. https://doi.org/10.3390/aerospace11060496
Sun Q, Chao J, Lin W, Wang D, Chen W, Xu Z, Xie S. Pixel-Wise and Class-Wise Semantic Cues for Few-Shot Segmentation in Astronaut Working Scenes. Aerospace. 2024; 11(6):496. https://doi.org/10.3390/aerospace11060496
Chicago/Turabian StyleSun, Qingwei, Jiangang Chao, Wanhong Lin, Dongyang Wang, Wei Chen, Zhenying Xu, and Shaoli Xie. 2024. "Pixel-Wise and Class-Wise Semantic Cues for Few-Shot Segmentation in Astronaut Working Scenes" Aerospace 11, no. 6: 496. https://doi.org/10.3390/aerospace11060496
APA StyleSun, Q., Chao, J., Lin, W., Wang, D., Chen, W., Xu, Z., & Xie, S. (2024). Pixel-Wise and Class-Wise Semantic Cues for Few-Shot Segmentation in Astronaut Working Scenes. Aerospace, 11(6), 496. https://doi.org/10.3390/aerospace11060496