
Pose Estimation for Cross-Domain Non-Cooperative Spacecraft Based on Spatial-Aware Keypoints Regression

Abstract
1. Introduction
- 1.
- By integrating PVT and SAR, we propose a novel network for monocular camera space non-cooperative target keypoints detection. This network is well suited for combining with PnP methods to obtain the target pose and for rapidly adapting to new domains through self-training techniques.
- 2.
- We propose a local data augmentation strategy for stereoscopic perception established through keypoints and target geometric structures, which effectively enhances the generalization capability of the source domain training model.
- 3.
- We achieved promising results on the SPEED+ and SHIRT datasets and successfully deployed the method on a mobile device. In the lightbox domain, which is a focal point of the research, our method achieves a 37.7% improvement over the baseline method SPNv2. Compared with the VPU using a heatmap for keypoint detection, a 24.7% performance improvement is obtained.
2. Methods
2.1. Overview
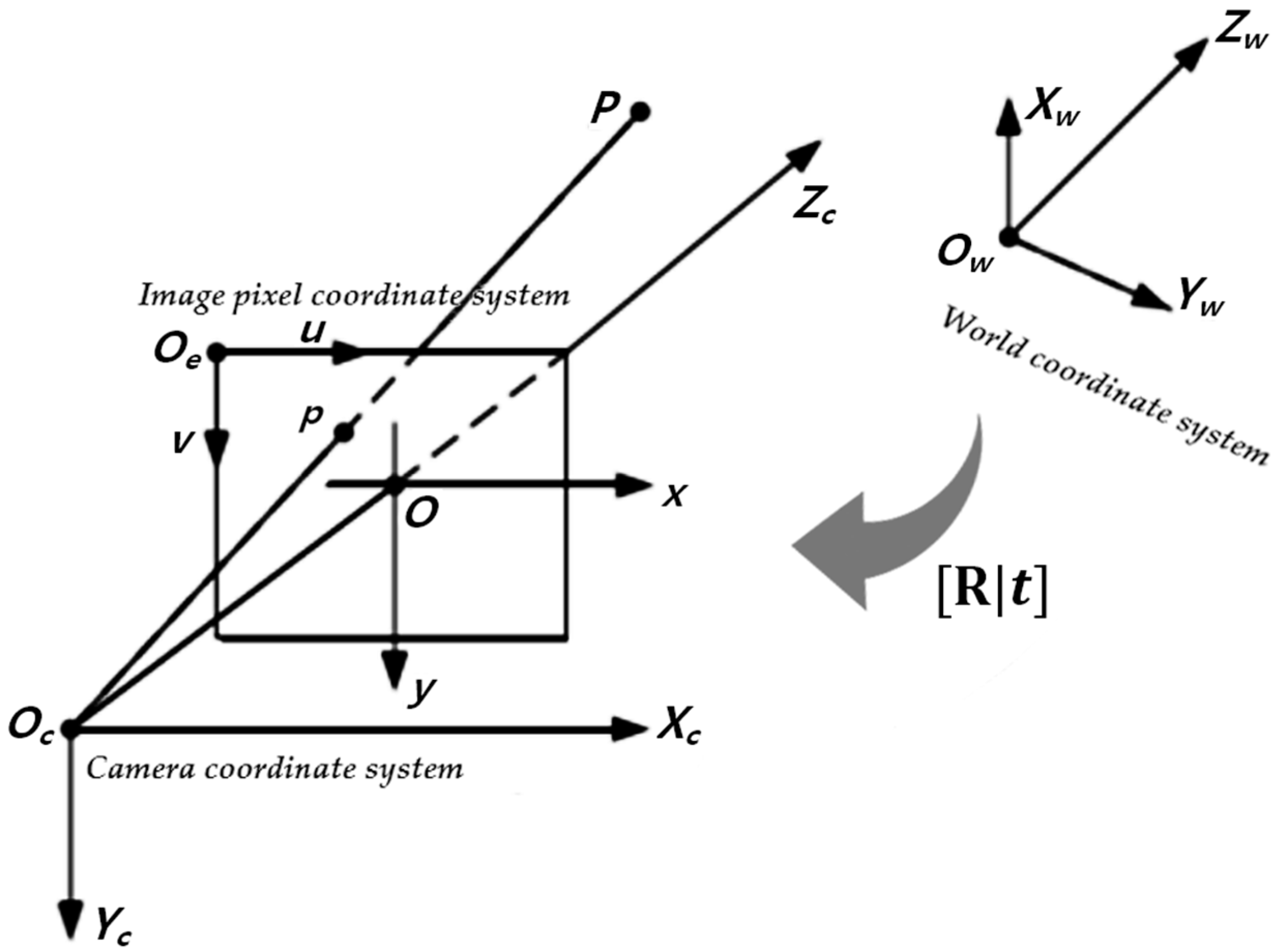
2.2. Three-Dimensional Reconstruction and Reprojection
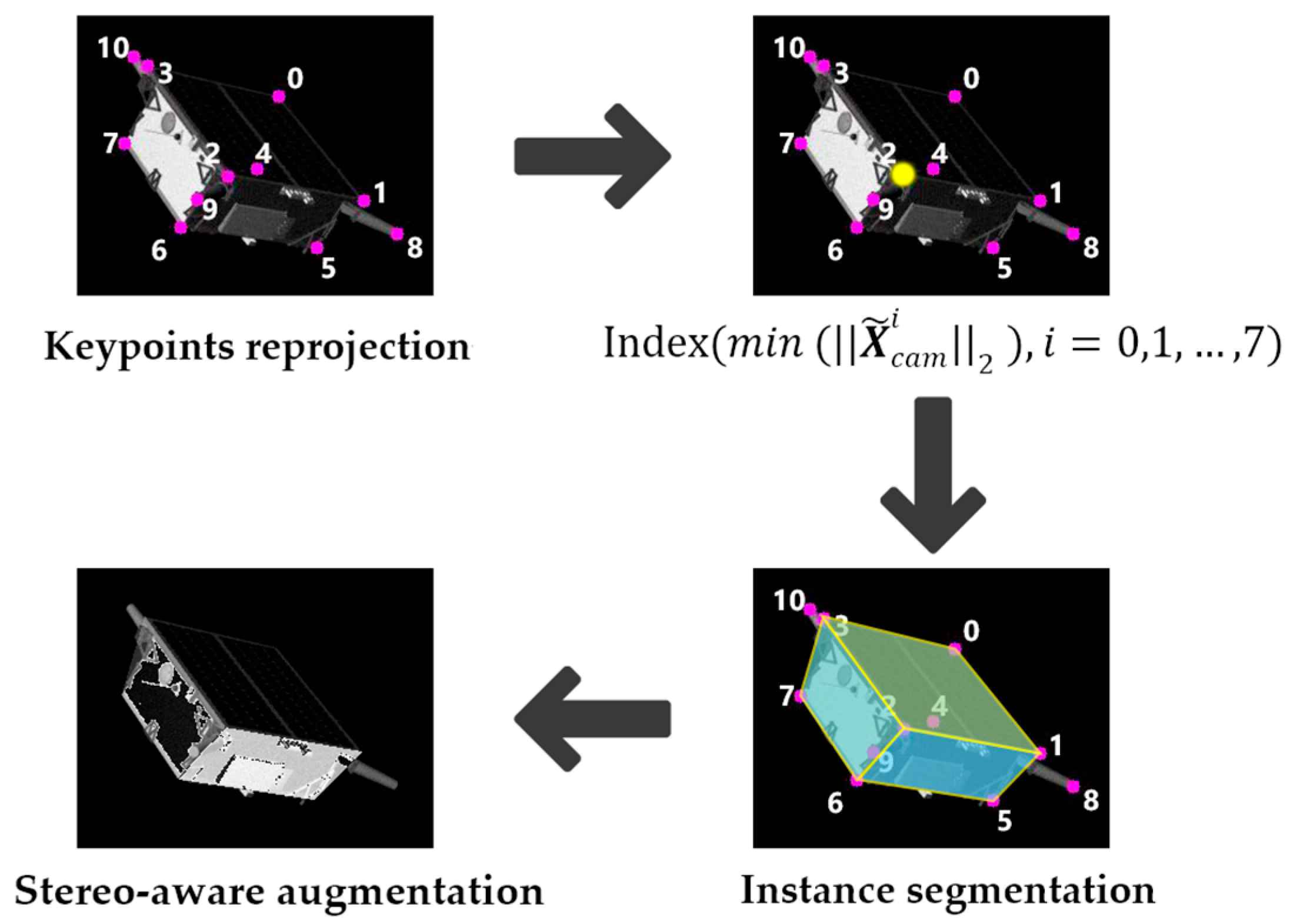
2.3. Data Augmentation
2.4. PVSAR Network
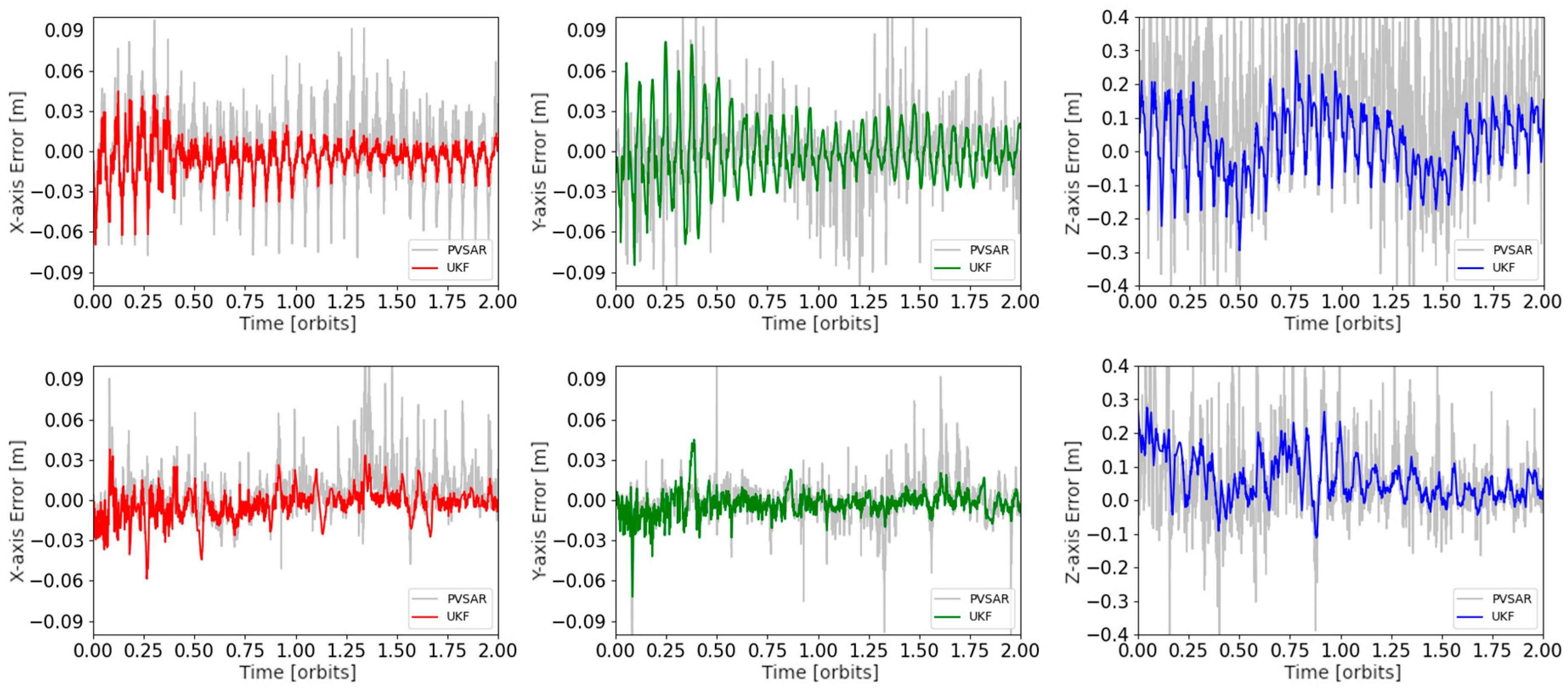
2.5. PnP and Online Self-Training
3. Experiments
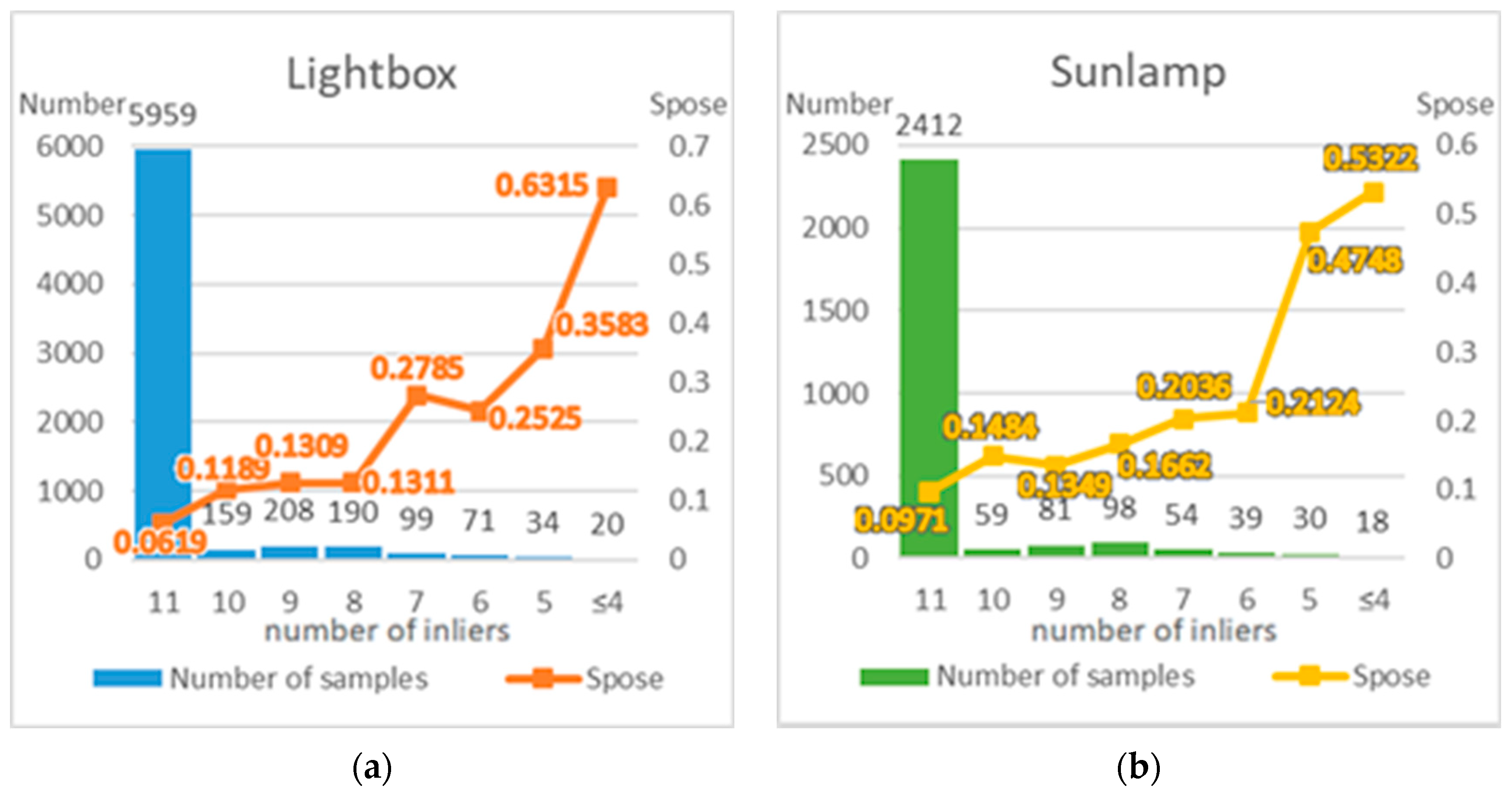
3.1. Dataset Analysis
3.2. Evaluation Metrics and Implementation Details
3.3. Results and Discussion
3.3.1. Offline Training Results
3.3.2. Self-Training Results
3.3.3. Validation on SHIRT
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- ESA—ESA Space Environment Report 2024. Available online: https://www.esa.int/Space_Safety/Space_Debris/ESA_Space_Environment_Report_2024 (accessed on 15 September 2024).
- Park, T.H.; D’Amico, S. Robust multi-task learning and online refinement for spacecraft pose estimation across domain gap. Adv. Space Res. 2024, 73, 5726–5740. [Google Scholar] [CrossRef]
- Kisantal, M.; Sharma, S.; Park, T.H.; Izzo, D.; Martens, M.; D’Amico, S. Satellite pose estimation challenge: Dataset, competition design, and results. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 4083–4098. [Google Scholar] [CrossRef]
- Park, T.H.; Märtens, M.; Jawaid, M.; Wang, Z.; Chen, B.; Chin, T.-J.; Izzo, D.; D’amico, S. Satellite pose estimation competition 2021: Results and analyses. Acta Astronaut. 2023, 204, 640–665. [Google Scholar] [CrossRef]
- Oza, P.; Sindagi, V.A.; Vs, V.; Patel, V.M.; Sharmini, V.V. Unsupervised Domain Adaptation of Object Detectors: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 4018–4040. [Google Scholar] [CrossRef] [PubMed]
- SPARK 2024 CVI2. Available online: https://cvi2.uni.lu/spark2024/ (accessed on 15 September 2024).
- Chen, B.; Cao, J.; Parra, A.; Chin, T.J. Satellite pose estimation with deep landmark regression and nonlinear pose refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Pérez-Villar, J.I.B.; García-Martín, Á.; Bescós, J.; Escudero-Viñolo, M. Spacecraft Pose Estimation: Robust 2D and 3D-Structural Losses and Unsupervised Domain Adaptation by Inter-Model Consensus. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 2515–2525. [Google Scholar] [CrossRef]
- Chen, S.; Yang, W.; Wang, W.; Mai, J.; Liang, J.; Zhang, X. Spacecraft Homography Pose Estimation with Single-Stage Deep Convolutional Neural Network. Sensors 2024, 24, 1828. [Google Scholar] [CrossRef]
- Yang, H.; Xiao, X.; Yao, M.; Xiong, Y.; Cui, H.; Fu, Y. PVSPE: A pyramid vision multitask transformer network for spacecraft pose estimation. Adv. Space Res. 2024, 74, 1327–1342. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, M.; Guo, Y.; Li, Z.; Yu, Q. Bridging the Domain Gap in Satellite Pose Estimation: A Self-Training Approach Based on Geometrical Constraints. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 2515–2525. [Google Scholar] [CrossRef]
- Ulmer, M.; Durner, M.; Sundermeyer, M.; Stoiber, M.; Triebel, R. 6d object pose estimation from approximate 3d models for orbital robotics. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 10749–10756. [Google Scholar]
- Legrand, A.; Detry, R.; De Vleeschouwer, C. Domain Generalization for 6D Pose Estimation Through NeRF-based Image Synthesis. arXiv 2024, arXiv:2407.10762. [Google Scholar]
- Huo, Y.; Li, Z.; Zhang, F. Fast and Accurate Spacecraft Pose Estimation From Single Shot Space Imagery Using Box Reliability and Keypoints Existence Judgments. IEEE Access 2020, 8, 216283–216297. [Google Scholar] [CrossRef]
- Lotti, A.; Modenini, D.; Tortora, P.; Saponara, M.; Perino, M.A. Deep learning for real time satellite pose estimation on low power edge tpu. arXiv 2024, arXiv:2204.03296. [Google Scholar]
- Huang, H.; Song, B.; Zhao, G.; Bo, Y. End-to-end monocular pose estimation for uncooperative spacecraft based on direct regression network. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 5378–5389. [Google Scholar] [CrossRef]
- Jin, Y.; Mishkin, D.; Mishchuk, A.; Matas, J.; Fua, P.; Yi, K.M.; Trulls, E. Image matching across wide baselines: From paper to practice. Int. J. Comput. Vis. 2021, 129, 517–547. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, S. Spatial-Aware Regression for Keypoint Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Li, Y.; Guo, L.; Ge, Y. Pseudo Labels for Unsupervised Domain Adaptation: A Review. Electronics 2023, 12, 3325. [Google Scholar] [CrossRef]
- COLMAP. Available online: https://colmap.github.io/ (accessed on 16 September 2024).
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Peng, S.; Zhou, X.; Liu, Y.; Lin, H.; Huang, Q.; Bao, H. PVNet: Pixel-Wise Voting Network for 6DoF Object Pose Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 3212–3223. [Google Scholar] [CrossRef]
- Yuan, H.; Chen, H.; Wu, J.; Kang, G. Non-Cooperative Spacecraft Pose Estimation Based on Feature Point Distribution Selection Learning. Aerospace 2024, 11, 526. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, W.; Wang, H. Reflection characteristics of on-orbit satellites based on BRDF. Opto-Electron. Eng. 2011, 38, 6–12. [Google Scholar]
- Park, T.H.; Bosse, J.; D’Amico, S. Robotic testbed for rendezvous and optical navigation: Multi-source calibration and machine learning use cases. arXiv 2021, arXiv:2108.05529. [Google Scholar]
- Park, T.H.; D’Amico, S. Adaptive neural-network-based unscented kalman filter for robust pose tracking of noncooperative spacecraft. J. Guid. Control. Dyn. 2023, 46, 1671–1688. [Google Scholar] [CrossRef]
- Liu, K.; Yu, Y. Revisiting the Domain Gap Issue in Non-cooperative Spacecraft Pose Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Zhou, Y.; Barnes, C.; Lu, J.; Yang, J.; Li, H. On the continuity of rotation representations in neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Augmentation Methods | Synthetic | Lightbox | Sunlamp | ||||||
|---|---|---|---|---|---|---|---|---|---|
| St | SR | Spose | St | SR | Spose | St | SR | Spose | |
| Only Normalize | 0.0024 | 0.0105 | 0.0129 | 0.2412 | 0.5629 | 0.8041 | 0.1997 | 0.7185 | 0.9183 |
| +Sun Flare, Noise, etc. | 0.0037 | 0.0141 | 0.0178 | 0.0423 | 0.151 | 0.1933 | 0.1398 | 0.4678 | 0.6076 |
| +Stereo-aware Aug. | 0.0037 | 0.0144 | 0.0182 | 0.0344 | 0.1087 | 0.1431 | 0.1471 | 0.4206 | 0.5677 |
| Methods | Additional Model | Num. of Param. | Lightbox | Sunlamp | ||||
|---|---|---|---|---|---|---|---|---|
| St | SR | Spose | St | SR | Spose | |||
| EagerNet [12] | - | >88 M | 0.009 | 0.031 | 0.039 | 0.013 | 0.046 | 0.059 |
| haoranhuang_njust [16] | - | - | 0.014 | 0.051 | 0.065 | 0.011 | 0.048 | 0.059 |
| TangoUnchained [4] | Object detection | - | 0.017 | 0.056 | 0.073 | 0.015 | 0.075 | 0.090 |
| Legrand et al. [13] | NeRF | - | 0.021 | 0.064 | 0.085 | 0.033 | 0.136 | 0.169 |
| VPU [8] | / | 190.1 M | 0.021 | 0.080 | 0.101 | 0.012 | 0.049 | 0.061 |
| PVSPE [10] | / | - | 0.017 | 0.084 | 0.101 | 0.022 | 0.156 | 0.178 |
| prow | - | - | 0.019 | 0.094 | 0.114 | 0.013 | 0.084 | 0.097 |
| SPNv2 [2] | Style Aug. | 52.5 M | 0.025 | 0.097 | 0.122 | 0.027 | 0.170 | 0.197 |
| Liu et al. [28] | Object detection | - | 0.03 | 0.12 | 0.15 | 0.03 | 0.10 | 0.13 |
| lava1302 [11] | NeuS, CycleGAN | - | 0.046 | 0.116 | 0.163 | 0.007 | 0.048 | 0.055 |
| Ours | / | 30.6 M | 0.018 | 0.057 | 0.076 | 0.023 | 0.089 | 0.112 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Liu, Y.; Zhang, E. Pose Estimation for Cross-Domain Non-Cooperative Spacecraft Based on Spatial-Aware Keypoints Regression. Aerospace 2024, 11, 948. https://doi.org/10.3390/aerospace11110948
Wang Z, Liu Y, Zhang E. Pose Estimation for Cross-Domain Non-Cooperative Spacecraft Based on Spatial-Aware Keypoints Regression. Aerospace. 2024; 11(11):948. https://doi.org/10.3390/aerospace11110948
Chicago/Turabian StyleWang, Zihao, Yunmeng Liu, and E Zhang. 2024. "Pose Estimation for Cross-Domain Non-Cooperative Spacecraft Based on Spatial-Aware Keypoints Regression" Aerospace 11, no. 11: 948. https://doi.org/10.3390/aerospace11110948
APA StyleWang, Z., Liu, Y., & Zhang, E. (2024). Pose Estimation for Cross-Domain Non-Cooperative Spacecraft Based on Spatial-Aware Keypoints Regression. Aerospace, 11(11), 948. https://doi.org/10.3390/aerospace11110948