
Hybrid Machine Learning and Reinforcement Learning Framework for Adaptive UAV Obstacle Avoidance



Abstract

1. Introduction
Objective of the Review
2. Search Methodology
Literature Search Strategy
3. Machine Learning for Enhanced UAV Obstacle Avoidance
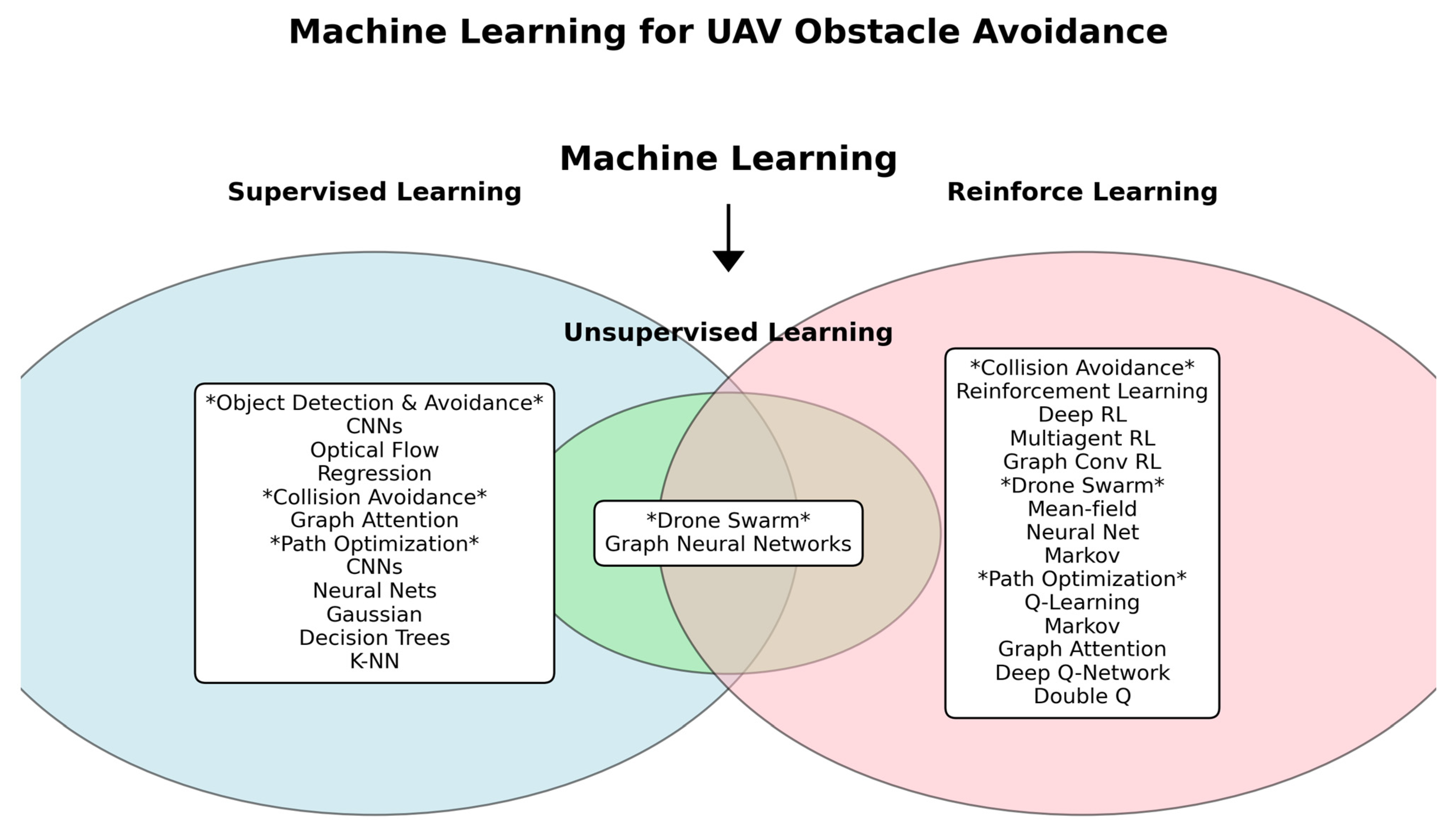
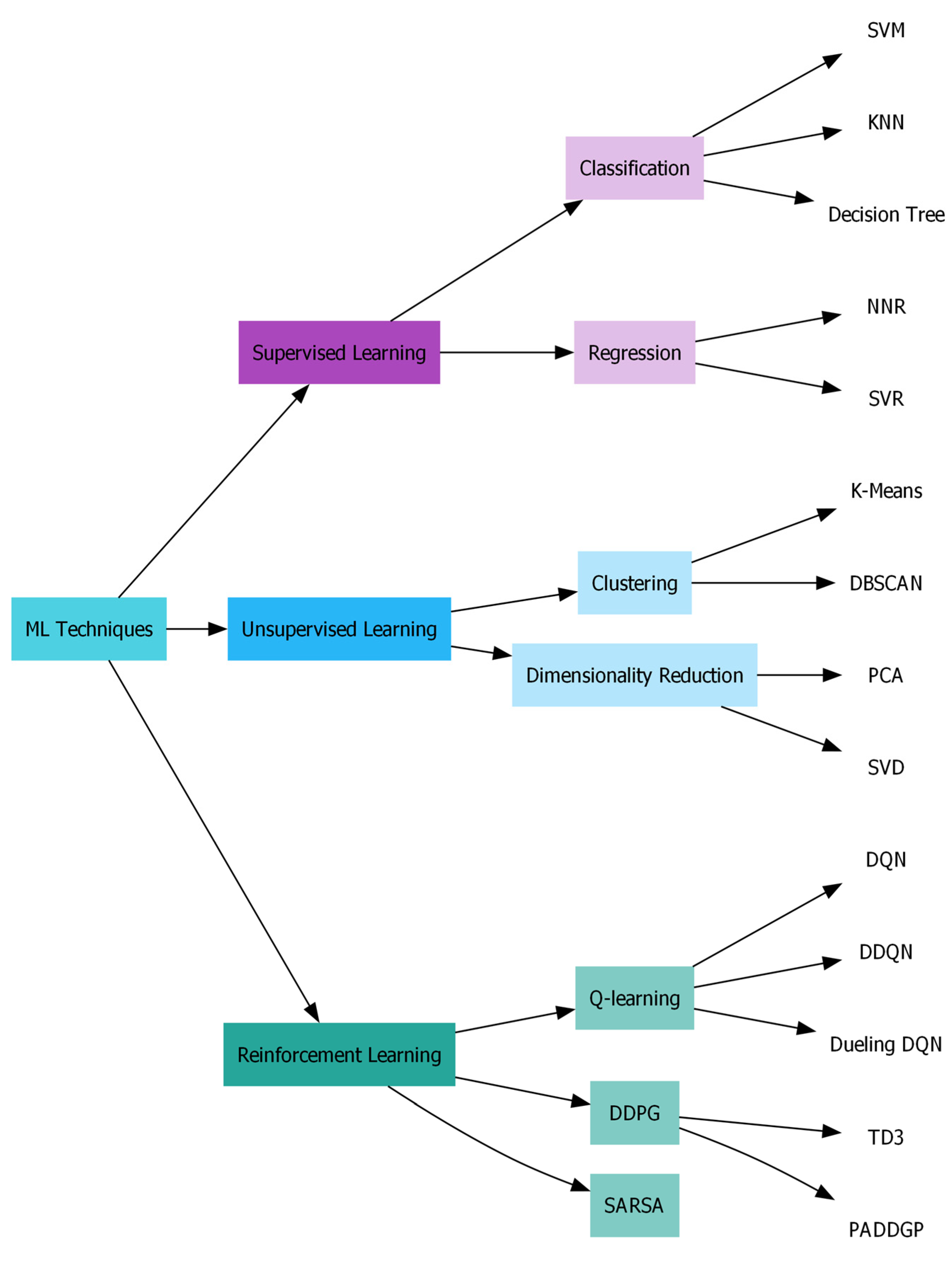
3.1. Overview of Machine Learning
3.2. Supervised Learning (SL)
3.3. Unsupervised Learning (UL)
3.4. Challenges in Machine Learning Techniques and the Need for Reinforcement Learning
4. Integrating Machine Learning and Reinforcement Learning for UAV Obstacle Avoidance
4.1. Path Planning with Reinforcement Learning
4.2. Reinforcement Learning for UAV Navigation
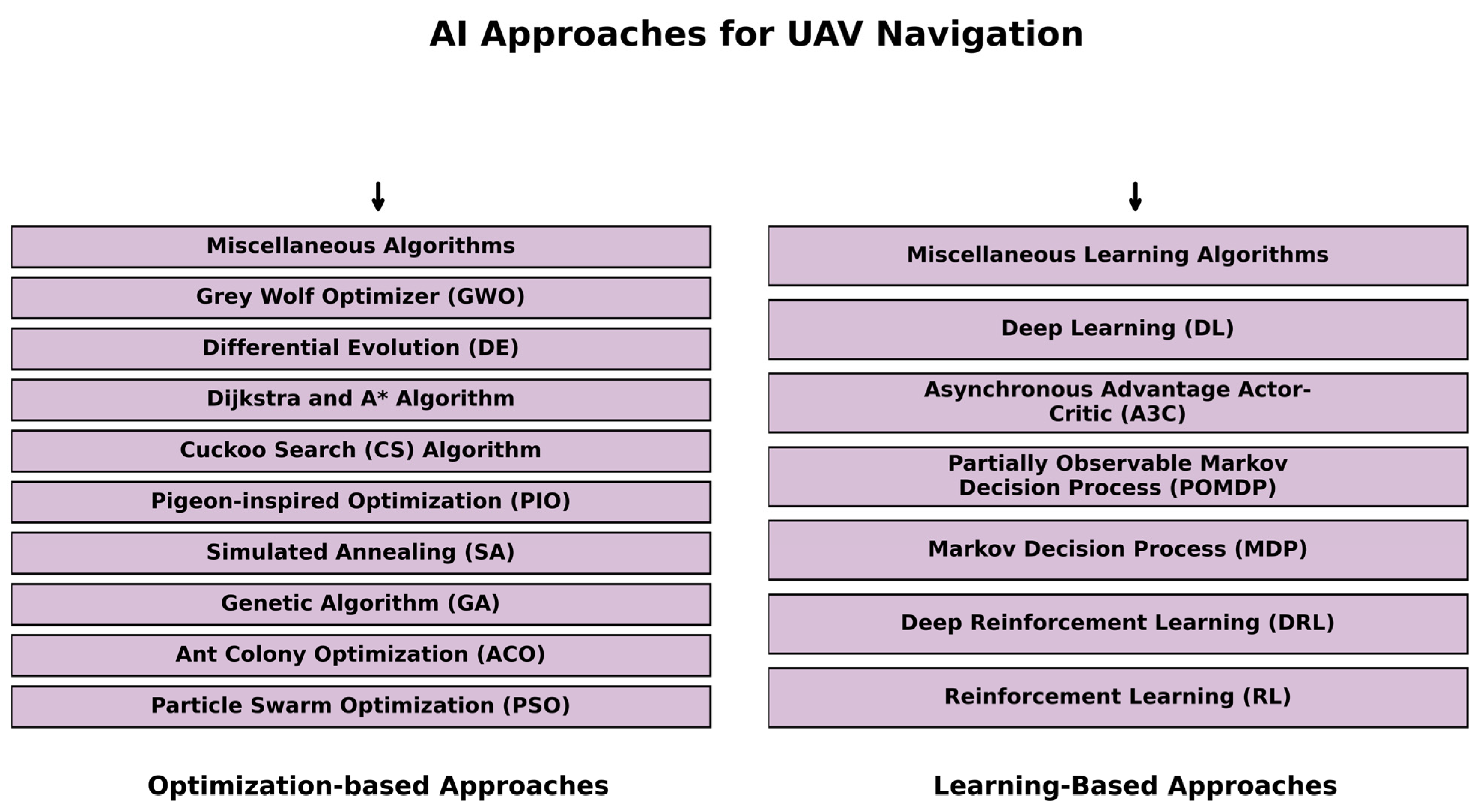
4.3. Learning-Based AI Approaches
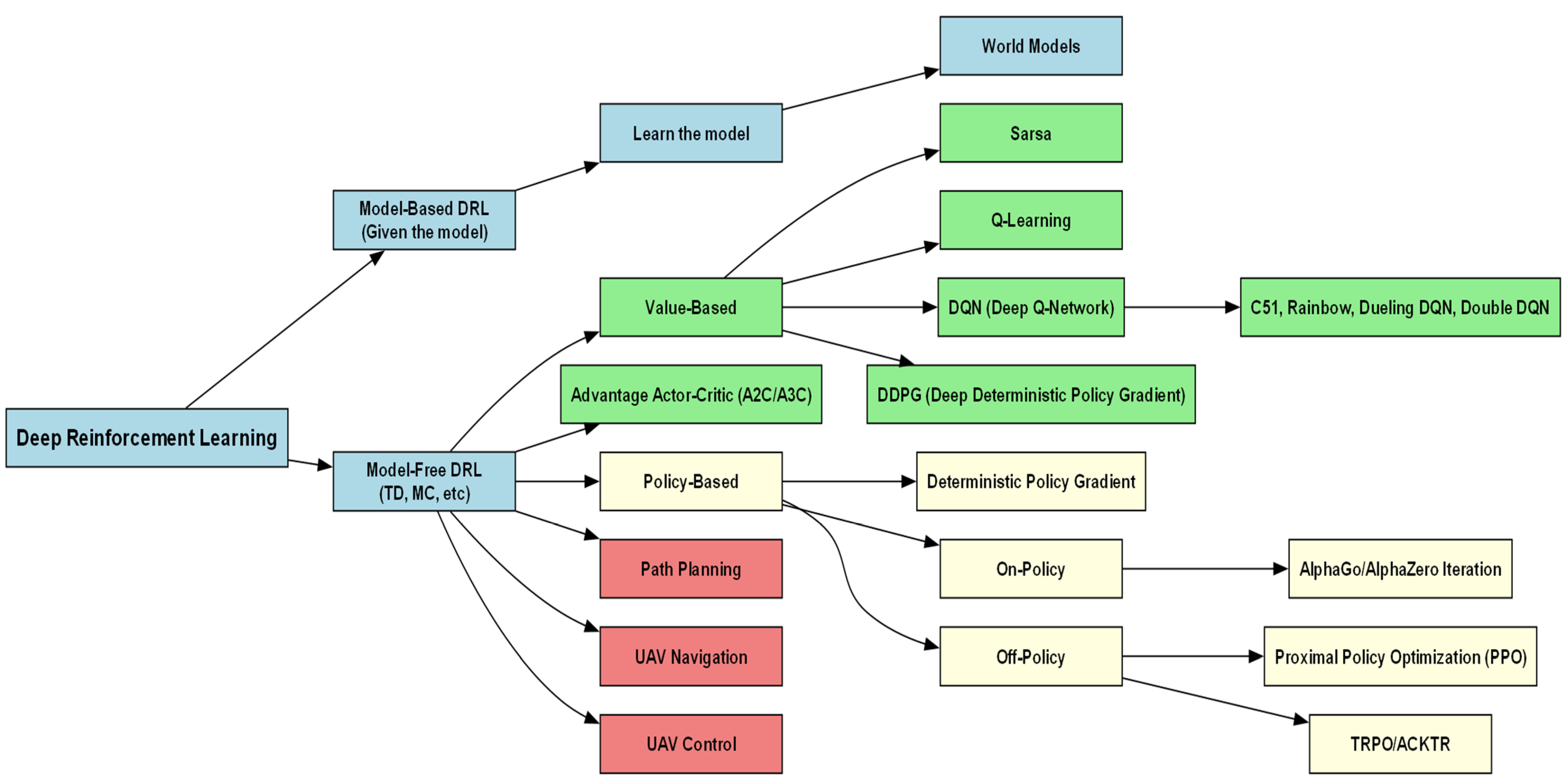
4.3.1. Reinforcement Learning
4.3.2. Deep Reinforcement Learning (DRL)
4.3.3. Deep Learning (DL)
4.4. Reinforcement Learning for UAV Control
5. Future Directions and Challenges
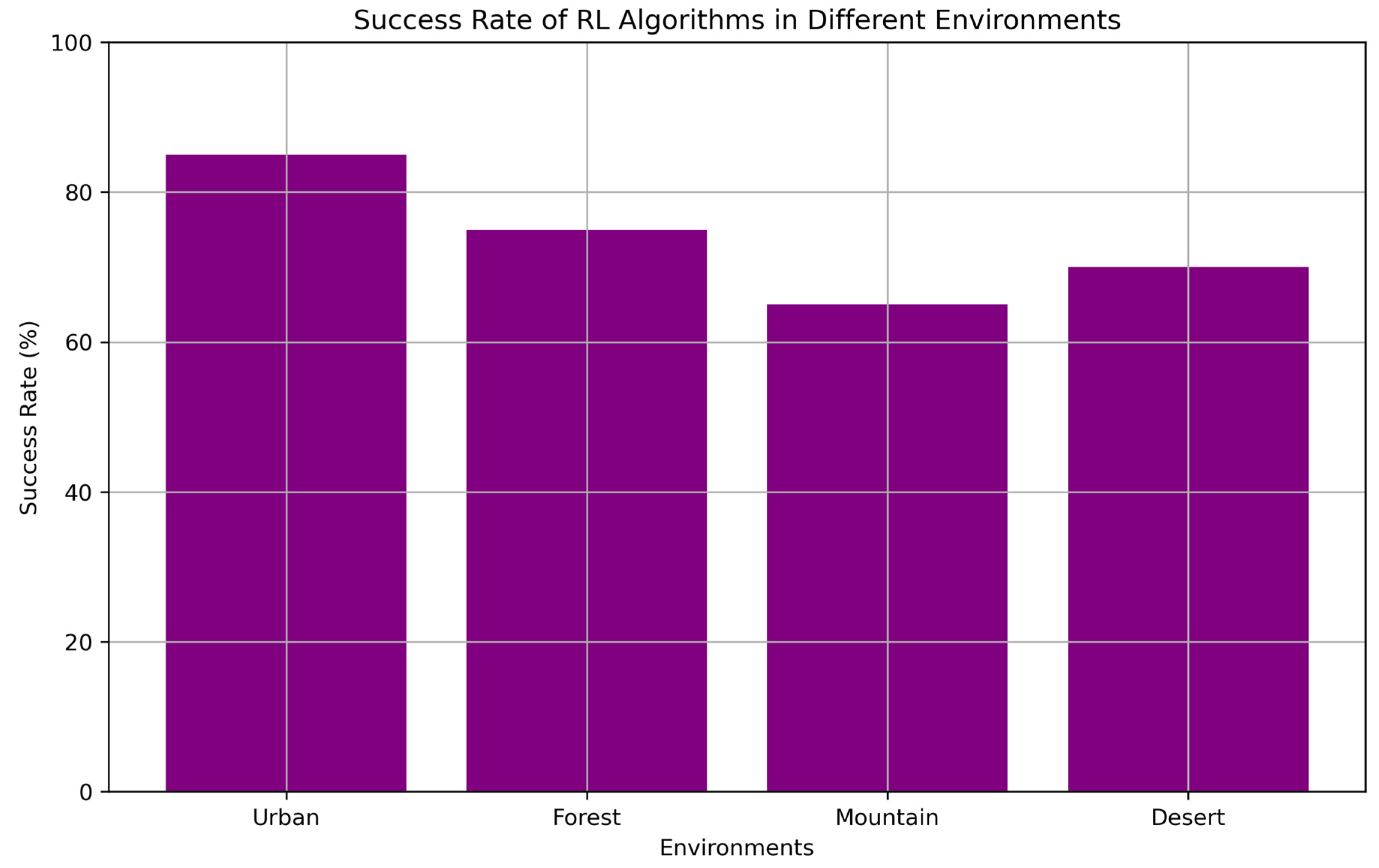
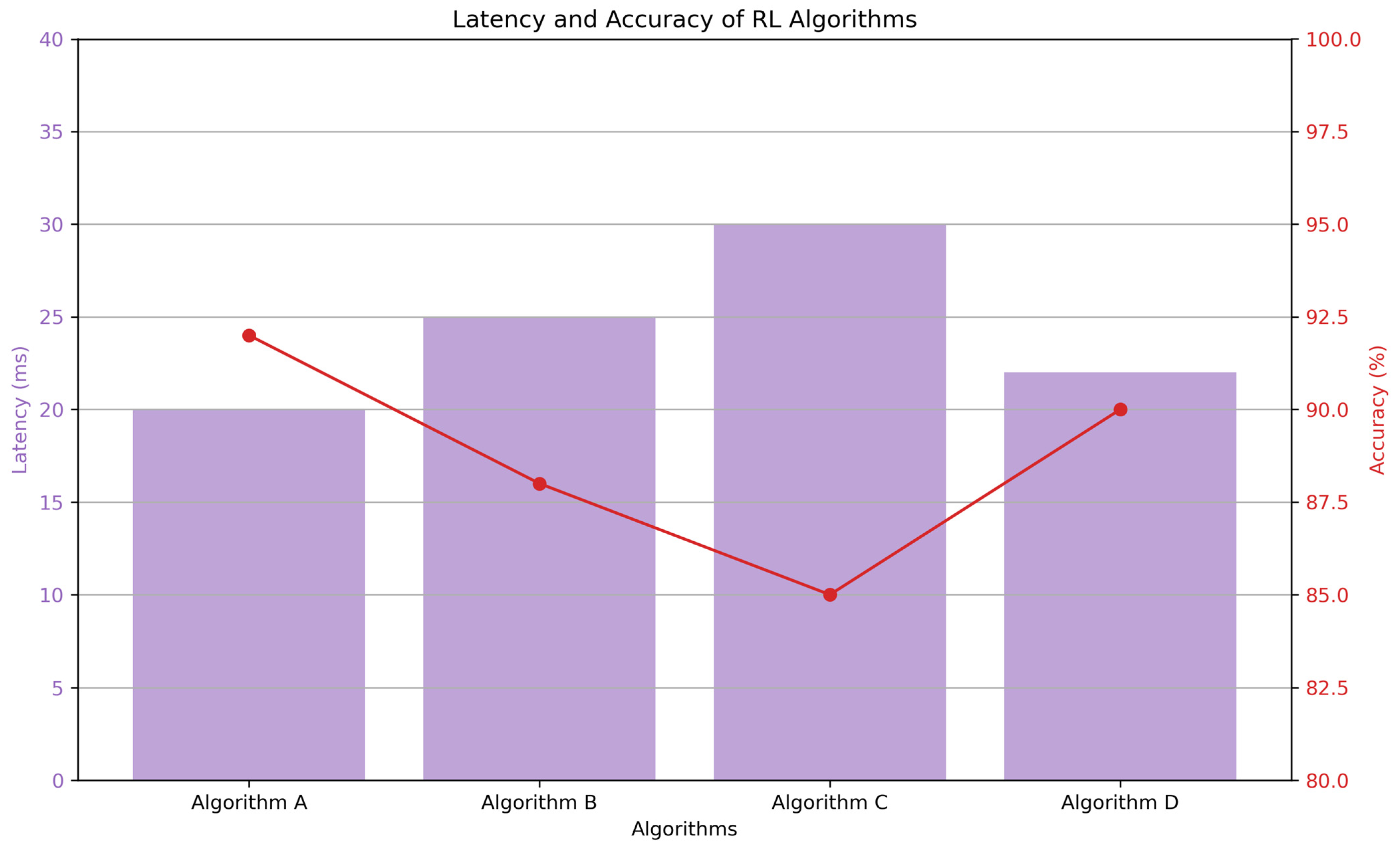
5.1. Comparative Analysis of Existing Studies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACKTR | Actor-Critic using Kronecker-Factored Trust Region |
| A3C | Asynchronous Advantage Actor-Critic |
| ACO | Ant Colony Optimization |
| ADE | Artificial Differential Evolution |
| AOQPIO | Adaptive Oppositional Quantum-behaved Particle Swarm Optimization |
| A* | Search Algorithm |
| ACER | Actor-Critic with Experience Replay |
| AoL | Age of Information |
| BKR | Bayesian Kernel Regression |
| CNN | Convolutional Neural Network |
| CGAN | Conditional Generative Adversarial Network |
| CL | Contrastive Learning |
| CDE | Coupled Differential Evolution |
| CS | Cuckoo Search |
| DNN | Deep Neural Network |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise |
| DRL | Deep Reinforcement Learning |
| DDQN | Double Deep Q-Network |
| DDPG | Deep Deterministic Policy Gradient |
| DAC | Differential Algebraic Constraint |
| DCNN-GA | Deep Convolutional Neural Network with Genetic Algorithm |
| DPSO | Dynamic Particle Swarm Optimization |
| DEAKP | Differential Evolution with Adaptive Knowledge Propagation |
| DCNNP | Deep Convolutional Neural Network Processor |
| DRL-EC3 | Deep Reinforcement Learning with Experience Cumulative Coefficient of Cooperation |
| ELM | Extreme Learning Machine |
| ESN | Echo State Network |
| EDDQN | Ensemble Deep Double Q-Network |
| ESCSO | Enhanced Semi-Continuous Scheduling Optimization |
| FNN | Feedforward Neural Network |
| FSR | Force Sensitive Resistor |
| FRDDM | Fuzzy Rough Dynamic Decision Making |
| G-FCNN | Gated Fully Convolutional Neural Network |
| GMM | Gaussian Mixture Model |
| GWO | Grey Wolf Optimizer |
| GNSS | Global Navigation Satellite System |
| GBPSO | Gaussian-Binary Particle Swarm Optimization |
| GA | Genetic Algorithm |
| GPS | Global Positioning System |
| HIER | Hierarchical Clustering |
| HR-MAGA | Hierarchical Representation-based Multi-Agent Genetic Algorithm |
| HSGWO-MSOS | Hybrid Shuffled Grey Wolf Optimizer with Modified Shuffle Operator Selection |
| ICA | Independent Component Analysis |
| IoT | Internet of Things |
| IDSIA | Dalle Molle Institute for Artificial Intelligence Research |
| IFDS | Iterative Flow Decomposition and Matching |
| IMUs | Inertial Measurement Units |
| JNN | Jump Neural Network |
| LSTM | Long Short-Term Memory |
| LiDAR | Light Detection and Ranging |
| LwH | Length-width-height |
| MARL | Multi-Agent Reinforcement Learning |
| MBO | Model-Based Optimization |
| MIMO | Multiple Input Multiple Output |
| MPP | Maximum Power Point |
| MRFT | Model Reference Adaptive Control with Tuning |
| NNP | Neural Network Pipeline |
| NAF | Normalized Advantage Function |
| OCGA | Optimized Cellular Genetic Algorithm |
| OBIA | Object-Based Image Analysis |
| PCA | Principal Component Analysis |
| PID | Proportional-Integral-Derivative |
| PPO | Proximal Policy Optimization |
| POMDP | Partially Observable Markov Decision Process |
| PFACO | Parallel Fuzzy Ant Colony Optimization |
| QoE | Quality of Experience |
| RDPG | Recurrent Deterministic Policy Gradient |
| RSS | Received Signal Strength |
| RWNN | Random Weight Neural Network |
| RBF | Radial Basis Function |
| RNN | Recurrent Neural Network |
| RL | Reinforcement Learning |
| SL | Supervised Learning |
| SVR | Support Vector Regression |
| SVM | Support Vector Machine |
| SOM | Self-Organizing Map |
| SLAM | Simultaneous Localization and Mapping |
| SFM | Structure from Motion |
| STAGE | Structured Temporal Attention Graph Ensemble |
| SAR | Synthetic Aperture Radar |
| SK | Sensitivity Kernel |
| SaR | Search and Rescue |
| SARSA | State-Action-Reward-State-Action |
| SAC | Soft Actor-Critic |
| SA-ACO | Simulated Annealing based Ant Colony Optimization |
| TRPO | Trust Region Policy Optimization |
| T-SNE | t-Distributed Stochastic Neighbor Embedding |
| UAV | Unmanned Aerial Vehicles |
| UL | Unsupervised Learning |
| UAV-BS | Unmanned Aerial Vehicle Base Station |
| WPCN | Wireless Powered Communication Network |
References
- Savkin, A.V.; Huang, H. Asymptotically optimal deployment of drones for surveillance and monitoring. Sensors 2019, 19, 2068. [Google Scholar] [CrossRef] [PubMed]
- Boucher, P. Domesticating the drone: The demilitarisation of unmanned aircraft for civil markets. Sci. Eng. Ethics 2015, 21, 1393–1412. [Google Scholar] [CrossRef] [PubMed]
- Clarke, R. Understanding the drone epidemic. Comput. Law Secur. Rev. 2014, 30, 230–246. [Google Scholar] [CrossRef]
- Lu, Y.; Xue, Z.; Xia, G.-S.; Zhang, L. A survey on vision-based UAV navigation. Geo-Spat. Inf. Sci. 2018, 21, 21–32. [Google Scholar] [CrossRef]
- Grippa, P.; Behrens, D.; Bettstetter, C.; Wall, F. Job selection in a network of autonomous UAVs for delivery of goods. arXiv 2016, arXiv:1604.04180. [Google Scholar]
- Huang, Z.; Chen, C.; Pan, M. Multiobjective UAV path planning for emergency information collection and transmission. IEEE Internet Things J. 2020, 7, 6993–7009. [Google Scholar] [CrossRef]
- Liu, M.; Yang, J.; Gui, G. DSF-NOMA: UAV-assisted emergency communication technology in a heterogeneous Internet of Things. IEEE Internet Things J. 2019, 6, 5508–5519. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Moh, S. Bio-inspired approaches for energy-efficient localization and clustering in UAV networks for monitoring wildfires in remote areas. IEEE Access 2021, 9, 18649–18669. [Google Scholar] [CrossRef]
- Bushnaq, O.M.; Chaaban, A.; Al-Naffouri, T.Y. The role of UAV-IoT networks in future wildfire detection. IEEE Internet Things J. 2021, 8, 16984–16999. [Google Scholar] [CrossRef]
- De Moraes, R.S.; De Freitas, E.P. Multi-UAV based crowd monitoring system. IEEE Trans. Aerosp. Electron. Syst. 2019, 56, 1332–1345. [Google Scholar] [CrossRef]
- Wan, M.; Gu, G.; Qian, W.; Ren, K.; Maldague, X.; Chen, Q. Unmanned aerial vehicle video-based target tracking algorithm using sparse representation. IEEE Internet Things J. 2019, 6, 9689–9706. [Google Scholar] [CrossRef]
- Chung, S.H.; Sah, B.; Lee, J. Optimization for drone and drone-truck combined operations: A review of the state of the art and future directions. Comput. Oper. Res. 2020, 123, 105004. [Google Scholar] [CrossRef]
- Wu, C.; Ju, B.; Wu, Y.; Lin, X.; Xiong, N.; Xu, G.; Li, H.; Liang, X. UAV autonomous target search based on deep reinforcement learning in complex disaster scene. IEEE Access 2019, 7, 117227–117245. [Google Scholar] [CrossRef]
- Wang, B.; Sun, Y.; Sun, Z.; Nguyen, L.D.; Duong, T.Q. UAV-assisted emergency communications in social IoT: A dynamic hypergraph coloring approach. IEEE Internet Things J. 2020, 7, 7663–7677. [Google Scholar] [CrossRef]
- Mohamed, N.; Al-Jaroodi, J.; Jawhar, I.; Idries, A.; Mohammed, F. Unmanned aerial vehicles applications in future smart cities. Technol. Forecast. Soc. Chang. 2020, 153, 119293. [Google Scholar] [CrossRef]
- AlMahamid, F.; Grolinger, K. Autonomous unmanned aerial vehicle navigation using reinforcement learning: A systematic review. Eng. Appl. Artif. Intell. 2022, 115, 105321. [Google Scholar] [CrossRef]
- Kim, D.K.; Chen, T. Deep neural network for real-time autonomous indoor navigation. arXiv 2015, arXiv:1511.04668. [Google Scholar]
- Crevier, D. AI: The Tumultuous History of the Search for Artificial Intelligence; Basic Books, Inc.: New Tork, NY, USA, 1993. [Google Scholar]
- Hu, S.; Chen, X.; Ni, W.; Hossain, E.; Wang, X. Distributed machine learning for wireless communication networks: Techniques, architectures, and applications. IEEE Commun. Surv. Tutor. 2021, 23, 1458–1493. [Google Scholar] [CrossRef]
- Pajares, G. Overview and current status of remote sensing applications based on unmanned aerial vehicles (UAVs). Photogramm. Eng. Remote Sens. 2015, 81, 281–330. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Barber, D. Bayesian Reasoning and Machine Learning; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Kurtz, V.; Lin, H. Toward verifiable real-time obstacle motion prediction for dynamic collision avoidance. In Proceedings of the 2019 American Control Conference (ACC), Philadelphia, PA, USA, 10–12 July 2019; pp. 2633–2638. [Google Scholar]
- Pedro, D.; Matos-Carvalho, J.P.; Fonseca, J.M.; Mora, A. Collision avoidance on unmanned aerial vehicles using neural network pipelines and flow clustering techniques. Remote Sens. 2021, 13, 2643. [Google Scholar] [CrossRef]
- Chen, J.; Zhou, Y.; Lv, Q.; Deveerasetty, K.K.; Dike, H.U. A review of autonomous obstacle avoidance technology for multi-rotor UAVs. In Proceedings of the 2018 IEEE International Conference on Information and Automation (ICIA), Wuyishan, China, 11–13 August 2018; pp. 244–249. [Google Scholar]
- Singla, A.; Padakandla, S.; Bhatnagar, S. Memory-based deep reinforcement learning for obstacle avoidance in UAV with limited environment knowledge. IEEE Trans. Intell. Transp. Syst. 2019, 22, 107–118. [Google Scholar] [CrossRef]
- Zhang, Z.; Xiong, M.; Xiong, H. Monocular depth estimation for UAV obstacle avoidance. In Proceedings of the 2019 4th International Conference on Cloud Computing and Internet of Things (CCIOT), Changchun, China, 6–7 December 2019; pp. 43–47. [Google Scholar]
- Wang, C.; Liang, X.; Zhang, S.; Shen, C. Motion parallax estimation for ultra low altitude obstacle avoidance. In Proceedings of the 2019 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 17–19 October 2019; pp. 463–468. [Google Scholar]
- Yijing, Z.; Zheng, Z.; Xiaoyi, Z.; Yang, L. Q learning algorithm based UAV path learning and obstacle avoidence approach. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 3397–3402. [Google Scholar]
- Kurdi, M.M.; Dadykin, A.; ElZein, I.; Ahmad, I.S. Proposed system of artificial Neural Network for positioning and navigation of UAV-UGV. In Proceedings of the 2018 Electric Electronics, Computer Science, Biomedical Engineerings’ Meeting (EBBT), Istanbul, Turkey, 18–19 April 2018; pp. 1–6. [Google Scholar]
- Liang, X.; Wang, H.; Li, D.; Liu, C. Three-dimensional path planning for unmanned aerial vehicles based on fluid flow. In Proceedings of the 2014 IEEE Aerospace Conference, Big Sky, MT, USA, 1–8 March 2014; pp. 1–13. [Google Scholar]
- Han, X.; Wang, J.; Xue, J.; Zhang, Q. Intelligent decision-making for 3-dimensional dynamic obstacle avoidance of UAV based on deep reinforcement learning. In Proceedings of the 2019 11th International Conference on Wireless Communications and Signal Processing (WCSP), Xi’an, China, 23–25 October 2019; pp. 1–6. [Google Scholar]
- Efe, M. Neural Network Assisted Computationally Simple PIλDμ Control of a Quadrotor UAV. IEEE Trans. Ind. Inform. 2011, 7, 354–361. [Google Scholar] [CrossRef]
- Gao, W.N.; Fan, J.L.; Li, Y.N. Research on neural network pid control algorithm for a quadrotor. Appl. Mech. Mater. 2015, 719–720, 346–351. [Google Scholar] [CrossRef]
- Kurnaz, S.; Cetin, O.; Kaynak, O. Adaptive neuro-fuzzy inference system based autonomous flight control of un-manned air vehicles. Expert Syst. Appl. 2010, 37, 1229–1234. [Google Scholar] [CrossRef]
- Chowdhary, G.V.; Johnson, E.N. Theory and flight-test validation of a concurrent-learning adaptive controller. J. Guid. Control Dyn. 2011, 34, 592–607. [Google Scholar] [CrossRef]
- Chowdhary, G.; Wu, T.; Cutler, M.; How, J.P. Rapid transfer of controllers between UAVs using learning-based adaptive control. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; pp. 5409–5416. [Google Scholar]
- Lin, C.-J.; Chin, C.-C. Prediction and identification using wavelet-based recurrent fuzzy neural networks. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2004, 34, 2144–2154. [Google Scholar] [CrossRef]
- Lin, C.-M.; Tai, C.-F.; Chung, C.-C. Intelligent control system design for UAV using a recurrent wavelet neural network. Neural Comput. Appl. 2014, 24, 487–496. [Google Scholar] [CrossRef]
- Punjani, A.; Abbeel, P. Deep learning helicopter dynamics models. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 3223–3230. [Google Scholar]
- Bansal, S.; Akametalu, A.K.; Jiang, F.J.; Laine, F.; Tomlin, C.J. Learning quadrotor dynamics using neural network for flight control. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 4653–4660. [Google Scholar]
- Shin, J.; Kim, H.J.; Kim, Y. Adaptive support vector regression for UAV flight control. Neural Netw. 2011, 24, 109–120. [Google Scholar] [CrossRef]
- Kan, E.M.; Lim, M.H.; Ong, Y.S.; Tan, A.H.; Yeo, S.P. Extreme learning machine terrain-based navigation for un-manned aerial vehicles. Neural Comput. Appl. 2013, 22, 469–477. [Google Scholar] [CrossRef]
- Loquercio, A.; Maqueda, A.I.; Del-Blanco, C.R.; Scaramuzza, D. Dronet: Learning to fly by driving. IEEE Robot. Autom. Lett. 2018, 3, 1088–1095. [Google Scholar] [CrossRef]
- Ross, S.; Melik-Barkhudarov, N.; Shankar, K.S.; Wendel, A.; Dey, D.; Bagnell, J.A.; Hebert, M. Learning monocular reactive UAV control in cluttered natural environments. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; pp. 1765–1772. [Google Scholar]
- Yang, S.; Konam, S.; Ma, C.; Rosenthal, S.; Veloso, M.; Scherer, S. Obstacle avoidance through deep networks based intermediate perception. arXiv 2017, arXiv:1704.08759. [Google Scholar]
- Kahn, G.; Villaflor, A.; Pong, V.; Abbeel, P.; Levine, S. Uncertainty-aware reinforcement learning for collision avoidance. arXiv 2017, arXiv:1702.01182. [Google Scholar]
- Zhang, T.; Kahn, G.; Levine, S.; Abbeel, P. Learning deep control policies for autonomous aerial vehicles with MPC-guided policy search. In Proceedings of the IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 528–535. [Google Scholar]
- Cherian, A.; Andersh, J.; Morellas, V.; Papanikolopoulos, N.; Mettler, B. Autonomous altitude estimation of a UAV using a single onboard camera. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 3900–3905. [Google Scholar]
- Scherer, S.; Rehder, J.; Achar, S.; Cover, H.; Chambers, A.; Nuske, S.; Singh, S. River mapping from a flying robot: State estimation, river detection, and obstacle mapping. Auton. Robot. 2012, 33, 189–214. [Google Scholar] [CrossRef]
- Guo, X.; Denman, S.; Fookes, C.; Mejias, L.; Sridharan, S. Automatic UAV forced landing site detection using machine learning. In Proceedings of the 2014 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Wollongong, Australia, 25–27 November 2014; pp. 1–7. [Google Scholar]
- Pérez-Ortiz, M.; Peña, J.M.; Gutiérrez, P.A.; Torres-Sánchez, J.; Hervás-Martínez, C.; López-Granados, F. Selecting patterns and features for between- and within- crop-row weed mapping using UAV-imagery. Expert Syst. Appl. 2016, 47, 85–94. [Google Scholar] [CrossRef]
- Rebetez, J.; Satizábal, H.F.; Mota, M.; Noll, D.; Büchi, L.; Wendling, M.; Cannelle, B.; Perez-Uribe, A.; Burgos, S. Augmenting a convolutional neural network with local histograms: A case study in crop classification from high-resolution UAV imagery. In Proceedings of the ESANN 2016, European Symposium on Artifical Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Giusti, A.; Guzzi, J.; Ciresan, D.C.; He, F.-L.; Rodriguez, J.P.; Fontana, F.; Faessler, M.; Forster, C.; Schmidhuber, J.; Di Caro, G.; et al. A Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robots. IEEE Robot. Autom. Lett. 2015, 1, 661–667. [Google Scholar] [CrossRef]
- Smolyanskiy, N.; Kamenev, A.; Smith, J.; Birchfield, S. Toward low-flying autonomous MAV trail navi-gation using deep neural networks for environmental awareness. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 4241–4247. [Google Scholar]
- Choi, S.Y.; Cha, D. Unmanned aerial vehicles using machine learning for autonomous flight; state-of-the-art. Adv. Robot. 2019, 33, 265–277. [Google Scholar] [CrossRef]
- Barták, R.; Vomlelová, M. Using machine learning to identify activities of a flying drone from sensor readings. In Proceedings of the the Thirtieth International Flairs Conference, Marco Island, FL, USA, 22–24 May 2017. [Google Scholar]
- Muñoz, G.; Barrado, C.; Çetin, E.; Salami, E. Deep reinforcement learning for drone delivery. Drones 2019, 3, 72. [Google Scholar] [CrossRef]
- Pham, H.X.; La, H.M.; Feil-Seifer, D.; Van Nguyen, L. Reinforcement learning for autonomous UAV navigation using function approximation. In Proceedings of the 2018 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Philadelphia, PA, USA, 6–8 August 2018; pp. 1–6. [Google Scholar]
- Zhong, W.; Wang, X.; Liu, X.; Lin, Z.; Ali, F. Joint optimization of UAV communication connectivity and obstacle avoidance in urban environments using a double-map approach. EURASIP J. Adv. Signal Process. 2024, 2024, 35. [Google Scholar] [CrossRef]
- Polvara, R.; Patacchiola, M.; Sharma, S.; Wan, J.; Manning, A.; Sutton, R.; Cangelosi, A. Toward end-to-end control for UAV autonomous landing via deep reinforcement learning. In Proceedings of the 2018 International Conference on Unmanned Aircraft Systems (ICUAS), Dallas, TX, USA, 12–15 June 2018; pp. 115–123. [Google Scholar]
- Tožička, J.; Szulyovszky, B.; de Chambrier, G.; Sarwal, V.; Wani, U.; Gribulis, M. Application of deep reinforcement learning to UAV fleet control. In Intelligent Systems and Applications: Proceedings of the 2018 Intelligent Systems Conference (IntelliSys); Springer International Publishing: Cham, Switzerland, 2019; Volume 2, pp. 1169–1177. [Google Scholar]
- Liu, C.H.; Chen, Z.; Tang, J.; Xu, J.; Piao, C. Energy-efficient UAV control for effective and fair communication coverage: A deep reinforcement learning approach. IEEE J. Sel. Areas Commun. 2018, 36, 2059–2070. [Google Scholar] [CrossRef]
- Peciak, M.; Skarka, W. Assessment of the Potential of Electric Propulsion for General Aviation Using Model-Based System Engineering (MBSE) Methodology. Aerospace 2022, 9, 74. [Google Scholar] [CrossRef]
- Mateja, K.; Skarka, W.; Peciak, M.; Niestrój, R.; Gude, M. Energy Autonomy Simulation Model of Solar Powered UAV. Energies 2023, 16, 479. [Google Scholar] [CrossRef]
- Peciak, M.; Skarka, W.; Mateja, K.; Gude, M. Impact Analysis of Solar Cells on Vertical Take-Off and Landing (VTOL) Fixed-Wing UAV. Aerospace 2023, 10, 247. [Google Scholar] [CrossRef]
- Tyczka, M.; Skarka, W. Optimisation of Operational Parameters Based on Simulation Numerical Model of Hydrogen Fuel Cell Stack Used for Electric Car Drive. In Transdisciplinary Engineering: Crossing Boundaries; IOS Press: Amsterdam, The Netherlands, 2016; pp. 622–631. [Google Scholar]
- Pham, H.X.; La, H.M.; Feil-Seifer, D.; Nguyen, L.V. Autonomous uav navigation using reinforcement learning. arXiv 2018, arXiv:1801.05086. [Google Scholar]
- Li, B.; Wu, Y. Path planning for UAV ground target tracking via deep reinforcement learning. IEEE Access 2020, 8, 29064–29074. [Google Scholar] [CrossRef]
- Koch, W.; Mancuso, R.; West, R.; Bestavros, A. Reinforcement learning for UAV attitude control. ACM Trans. Cyber-Physical Syst. 2019, 3, 1–21. [Google Scholar] [CrossRef]
- Nadimi-Shahraki, M.H.; Taghian, S.; Mirjalili, S.; Zamani, H.; Bahreininejad, A. GGWO: Gaze cues learning-based grey wolf optimizer and its applications for solving engineering problems. J. Comput. Sci. 2022, 61, 101636. [Google Scholar] [CrossRef]
- Qu, C.; Gai, W.; Zhong, M.; Zhang, J. A novel reinforcement learning based grey wolf optimizer algorithm for un-manned aerial vehicles (UAVs) path planning. Appl. Soft Comput. 2020, 89, 106099. [Google Scholar] [CrossRef]
- Jiang, S.; Jiang, C.; Jiang, W. Efficient structure from motion for large-scale UAV images: A review and a comparison of SfM tools. ISPRS J. Photogramm. Remote Sens. 2020, 167, 230–251. [Google Scholar] [CrossRef]
- He, L.; Aouf, N.; Whidborne, J.F.; Song, B. Deep reinforcement learning based local planner for UAV obstacle avoidance using demonstration data. arXiv 2020, arXiv:2008.02521. [Google Scholar]
- Bayerlein, H.; Theile, M.; Caccamo, M.; Gesbert, D. UAV path planning for wireless data harvesting: A deep reinforcement learning approach. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Hasheminasab, S.M.; Zhou, T.; Habib, A. GNSS/INS-assisted structure from motion strategies for UAV-based imagery over mechanized agricultural fields. Remote Sens. 2020, 12, 351. [Google Scholar] [CrossRef]
- Bouhamed, O.; Ghazzai, H.; Besbes, H.; Massoud, Y. Autonomous UAV navigation: A DDPG-based deep reinforcement learning approach. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar]
- Kim, I.; Shin, S.; Wu, J.; Kim, S.D.; Kim, C.G. Obstacle avoidance path planning for UAV using reinforcement learning under simulated environment. In Proceedings of the IASER 3rd International Conference on Electronics, Electrical Engineering, Computer Science, Okinawa, Japan, May 2017; pp. 34–36. [Google Scholar]
- Challita, U.; Saad, W.; Bettstetter, C. Interference management for cellular-connected UAVs: A deep reinforcement learning approach. IEEE Trans. Wirel. Commun. 2019, 18, 2125–2140. [Google Scholar] [CrossRef]
- Yan, C.; Xiang, X.; Wang, C. Towards real-time path planning through deep reinforcement learning for a UAV in dynamic environments. J. Intell. Robot. Syst. 2020, 98, 297–309. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Wang, Y.-M.; Peng, D.-L. A simulation platform of multi-sensor multi-target track system based on STAGE. In Proceedings of the 2010 8th World Congress on Intelligent Control and Automation (WCICA 2010), Jinan, China, 7–9 July 2010; pp. 6975–6978. [Google Scholar]
- Shin, S.-Y.; Kang, Y.-W.; Kim, Y.-G. Obstacle avoidance drone by deep reinforcement learning and its racing with human pilot. Appl. Sci. 2019, 9, 5571. [Google Scholar] [CrossRef]
- Tai, L.; Liu, M. A robot exploration strategy based on q-learning network. In Proceedings of the 2016 IEEE International Conference on Real-Time Computing and Robotics (RCAR), Angkor Wat, Cambod, 6–10 June 2016; pp. 57–62. [Google Scholar]
- Bamburry, D. Drones: Designed for product delivery. Des. Manag. Rev. 2015, 26, 40–48. [Google Scholar] [CrossRef]
- Hii, M.S.Y.; Courtney, P.; Royall, P.G. An evaluation of the delivery of medicines using drones. Drones 2019, 3, 52. [Google Scholar] [CrossRef]
- Altawy, R.; Youssef, A.M. Security, privacy, and safety aspects of civilian drones: A survey. ACM Trans. Cyber-Phys. Syst. 2016, 1, 1–25. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Liu, Y.; Nejat, G. Robotic urban search and rescue: A survey from the control perspective. J. Intell. Robot. Syst. 2013, 72, 147–165. [Google Scholar] [CrossRef]
- Tomic, T.; Schmid, K.; Lutz, P.; Domel, A.; Kassecker, M.; Mair, E.; Grixa, I.L.; Ruess, F.; Suppa, M.; Burschka, D. Toward a Fully Autonomous UAV: Research Platform for Indoor and Outdoor Urban Search and Rescue. IEEE Robot. Autom. Mag. 2012, 19, 46–56. [Google Scholar] [CrossRef]
- Jalal, L.D. Three-dimensional off-line path planning for unmanned aerial vehicle using modified particle swarm optimization. Int. J. Aerosp. Mech. Eng. 2015, 9, 1579–1583. [Google Scholar]
- Hoang, V.T.; Phung, M.D.; Dinh, T.H.; Ha, Q.P. System architecture for real-time surface inspection using multiple UAVs. IEEE Syst. J. 2019, 14, 2925–2936. [Google Scholar] [CrossRef]
- Huang, C.; Fei, J. UAV path planning based on particle swarm optimization with global best path competition. Int. J. Pattern Recognit. Artif. Intell. 2018, 32, 1859008. [Google Scholar] [CrossRef]
- Cekmez, U.; Ozsiginan, M.; Sahingoz, O.K. Multi colony ant optimization for UAV path planning with obstacle avoidance. In Proceedings of the 2016 International Conference on Unmanned Aircraft Systems (ICUAS), Arlington, VA, USA, 7–10 June 2016; pp. 47–52. [Google Scholar]
- Guan, Y.; Gao, M.; Bai, Y. Double-ant colony based UAV path planning algorithm. In Proceedings of the 2019 11th International Conference on Machine Learning and Computing, Zhuhai, China, 22–24 February 2019; pp. 258–262. [Google Scholar]
- Jin, Z.; Yan, B.; Ye, R. The flight navigation planning based on potential field ant colony algorithm. In Proceedings of the 2018 International Conference on Advanced Control, Automation and Artificial Intelligence (ACAAI 2018), Shenzhen, China, 21–22 January 2018; Atlantis Press: Dordrecht, The Netherlands, 2018. [Google Scholar]
- Bagherian, M.; Alos, A. 3D UAV trajectory planning using evolutionary algorithms: A comparison study. Aeronaut. J. 2015, 119, 1271–1285. [Google Scholar] [CrossRef]
- Tao, J.; Zhong, C.; Gao, L.; Deng, H. A study on path planning of unmanned aerial vehicle based on improved genetic algorithm. In Proceedings of the 2016 8th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 27–28 August 2016; Volume 2, pp. 392–395. [Google Scholar]
- Yang, Q.; Liu, J.; Li, L. Path planning of UAVs under dynamic environment based on a hierarchical recursive multiagent genetic algorithm. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Gao, M.; Liu, Y.; Wei, P. Opposite and chaos searching genetic algorithm based for uav path planning. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; pp. 2364–2369. [Google Scholar]
- Behnck, L.P.; Doering, D.; Pereira, C.E.; Rettberg, A. A modified simulated annealing algorithm for SUAVs path planning. IFAC-PapersOnLine 2015, 48, 63–68. [Google Scholar] [CrossRef]
- Liu, K.; Zhang, M. Path planning based on simulated annealing ant colony algorithm. In Proceedings of the 2016 9th Inter-national Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 10–11 December 2016; Volume 2, pp. 461–466. [Google Scholar]
- Xiao, S.; Tan, X.; Wang, J. A simulated annealing algorithm and grid map-based UAV coverage path planning method for 3D reconstruction. Electronics 2021, 10, 853. [Google Scholar] [CrossRef]
- Ghambari, S.; Idoumghar, L.; Jourdan, L.; Lepagnot, J. A hybrid evolutionary algorithm for offline UAV path planning. In Artificial Evolution: 14th International Conference, Évolution Artificielle, EA 2019, Mulhouse, France, 29–30 October 2019, Revised Selected Papers 14; Springer International Publishing: Cham, Switzerland, 2020; pp. 205–218. [Google Scholar]
- Yu, X.; Li, C.; Zhou, J.F. A constrained differential evolution algorithm to solve UAV path planning in disaster scenarios. Knowl.-Based Syst. 2020, 204, 106209. [Google Scholar] [CrossRef]
- Yu, X.; Li, C.; Yen, G.G. A knee-guided differential evolution algorithm for unmanned aerial vehicle path planning in disaster management. Appl. Soft Comput. 2021, 98, 106857. [Google Scholar] [CrossRef]
- Zhang, D.; Duan, H. Social-class pigeon-inspired optimization and time stamp segmentation for multi-UAV cooperative path planning. Neurocomputing 2018, 313, 229–246. [Google Scholar] [CrossRef]
- Hu, C.; Xia, Y.; Zhang, J. Adaptive operator quantum-behaved pigeon-inspired optimization algorithm with application to UAV path planning. Algorithms 2018, 12, 3. [Google Scholar] [CrossRef]
- Xie, C.; Zheng, H. Application of improved Cuckoo search algorithm to path planning unmanned aerial vehicle. In Intelligent Computing Theories and Application: 12th International Conference, ICIC 2016, Lanzhou, China, 2–5 August 2016, Proceedings, Part I 12; Springer International Publishing: Cham, Switzerland, 2016; pp. 722–729. [Google Scholar]
- Hu, H.; Wu, Y.; Xu, J.; Sun, Q. Cuckoo search-based method for trajectory planning of quadrotor in an urban environment. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2019, 233, 4571–4582. [Google Scholar] [CrossRef]
- Sundar, K.; Misra, S.; Rathinam, S.; Sharma, R. Routing unmanned vehicles in GPS-denied environments. In Proceedings of the 2017 International Conference on Unmanned Aircraft Systems (ICUAS), Miami, FL, USA, 13–16 June 2017; pp. 62–71. [Google Scholar]
- Ghambari, S.; Lepagnot, J.; Jourdan, L.; Idoumghar, L. UAV path planning in the presence of static and dynamic obstacles. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, ACT, Australia, 1–4 December 2020; pp. 465–472. [Google Scholar]
- Zhang, Z.; Wu, J.; Dai, J.; He, C. A novel real-time penetration path planning algorithm for stealth UAV in 3D complex dynamic environment. IEEE Access 2020, 8, 122757–122771. [Google Scholar] [CrossRef]
- Qu, C.; Gai, W.; Zhang, J.; Zhong, M. A novel hybrid grey wolf optimizer algorithm for unmanned aerial vehicle (UAV) path planning. Knowl.-Based Syst. 2020, 194, 105530. [Google Scholar] [CrossRef]
- Zhang, S.; Zhou, Y.; Li, Z.; Pan, W. Grey wolf optimizer for unmanned combat aerial vehicle path planning. Adv. Eng. Softw. 2016, 99, 121–136. [Google Scholar] [CrossRef]
- Dewangan, R.K.; Shukla, A.; Godfrey, W.W. Three dimensional path planning using Grey wolf optimizer for UAVs. Appl. Intell. 2019, 49, 2201–2217. [Google Scholar] [CrossRef]
- Ponsen, M.; Taylor, M.E.; Tuyls, K. Abstraction and generalization in reinforcement learning: A summary and framework. In International Workshop on Adaptive and Learning Agents; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–32. [Google Scholar]
- Colonnese, S.; Cuomo, F.; Pagliari, G.; Chiaraviglio, L. Q-SQUARE: A Q-learning approach to provide a QoE aware UAV flight path in cellular networks. Ad. Hoc. Netw. 2019, 91, 101872. [Google Scholar] [CrossRef]
- Chowdhury MM, U.; Erden, F.; Guvenc, I. RSS-based Q-learning for indoor UAV navigation. In Proceedings of the MILCOM 2019—2019 IEEE Military Communications Conference (MILCOM), Norfolk, VA, USA, 12–14 November 2019; pp. 121–126. [Google Scholar]
- Zeng, Y.; Xu, X. Path design for cellular-connected UAV with reinforcement learning. In Proceedings of the GLOBECOM 2019—2019 IEEE Global Communications Conference, Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Liu, X.; Liu, Y.; Chen, Y.; Hanzo, L. Trajectory design and power control for multi-UAV assisted wireless networks: A machine learning approach. IEEE Trans. Veh. Technol. 2019, 68, 7957–7969. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, H.; Song, L. Reinforcement learning for decentralized trajectory design in cellular UAV networks with sense-and-send protocol. IEEE Internet Things J. 2018, 6, 6177–6189. [Google Scholar] [CrossRef]
- Liu, X.; Chen, M.; Yin, C. Optimized trajectory design in UAV based cellular networks for 3D users: A double Q-learning approach. J. Commun. Inf. Netw. 2019, 4, 24–32. [Google Scholar] [CrossRef]
- Tu, G.-T.; Juang, J.-G. UAV path planning and obstacle avoidance based on reinforcement learning in 3d environments. Actuators 2023, 12, 57. [Google Scholar] [CrossRef]
- Kalidas, A.P.; Joshua, C.J.; Quadir, A.; Basheer, S.; Mohan, S.; Sakri, S. Deep Reinforcement Learning for Vision-Based Navigation of UAVs in Avoiding Stationary and Mobile Obstacles. Drones 2023, 7, 245. [Google Scholar] [CrossRef]
- Azzam, R.; Chehadeh, M.; Hay, O.A.; Humais, M.A.; Boiko, I.; Zweiri, Y. Learning-based navigation and collision avoidance through reinforcement for UAVs. IEEE Trans. Aerosp. Electron. Syst. 2023, 60, 2614–2628. [Google Scholar] [CrossRef]
- Zeng, Y.; Xu, X.; Jin, S.; Zhang, R. Simultaneous navigation and radio mapping for cellular-connected UAV with deep reinforcement learning. IEEE Trans. Wirel. Commun. 2021, 20, 4205–4220. [Google Scholar] [CrossRef]
- Huang, H.; Yang, Y.; Wang, H.; Ding, Z.; Sari, H.; Adachi, F. Deep reinforcement learning for UAV navigation through massive MIMO technique. IEEE Trans. Veh. Technol. 2019, 69, 1117–1121. [Google Scholar] [CrossRef]
- Oubbati, O.S.; Atiquzzaman, M.; Baz, A.; Alhakami, H.; Ben-Othman, J. Dispatch of UAVs for urban vehicular networks: A deep reinforcement learning approach. IEEE Trans. Veh. Technol. 2021, 70, 13174–13189. [Google Scholar] [CrossRef]
- Oubbati, O.S.; Atiquzzaman, M.; Lakas, A.; Baz, A.; Alhakami, H.; Alhakami, W. Multi-UAV-enabled AoI-aware WPCN: A multi-agent reinforcement learning strategy. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communica-tions Workshops (INFOCOM WKSHPS), Vancouver, BC, Canada, 10–13 May 2021; pp. 1–6. [Google Scholar]
- Wang, C.; Wang, J.; Wang, J.; Zhang, X. Deep-reinforcement-learning-based autonomous UAV navigation with sparse rewards. IEEE Internet Things J. 2020, 7, 6180–6190. [Google Scholar] [CrossRef]
- Theile, M.; Bayerlein, H.; Nai, R.; Gesbert, D.; Caccamo, M. UAV coverage path planning under varying power constraints using deep reinforcement learningg. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 1444–1449. [Google Scholar]
- Chen, Y.; González-Prelcic, N.; Heath, R.W. Collision-free UAV navigation with a monocular camera using deep reinforcement learning. In Proceedings of the 2020 IEEE 30th international workshop on machine learning for signal processing (MLSP), Espoo, Finland, 21–24 September 2020; pp. 1–6. [Google Scholar]
- Abedin, S.F.; Munir, S.; Tran, N.H.; Han, Z.; Hong, C.S. Data freshness and energy-efficient UAV navigation optimization: A deep reinforcement learning approach. IEEE Trans. Intell. Transp. Syst. 2020, 22, 5994–6006. [Google Scholar] [CrossRef]
- Walker, O.; Vanegas, F.; Gonzalez, F.; Koenig, S. A deep reinforcement learning framework for UAV navigation in indoor environments. In Proceedings of the 2019 IEEE Aerospace Conference, Big Sky, MT, USA, 2–9 March 2019; pp. 1–14. [Google Scholar]
- Maciel-Pearson, B.G.; Marchegiani, L.; Akcay, S.; Atapour-Abarghouei, A.; Garforth, J.; Breckon, T.P. Online deep reinforcement learning for autonomous UAV navigation and exploration of outdoor environments. arXiv 2019, arXiv:1912.05684. [Google Scholar]
- Theile, M.; Bayerlein, H.; Nai, R.; Gesbert, D.; Caccamo, M. UAV path planning using global and local map information with deep reinforcement learning. In Proceedings of the 2021 20th International Conference on Advanced Robotics (ICAR), Ljubljana, Slovenia, 6–10 December 2021; pp. 539–546. [Google Scholar]
- Wang, L.; Wang, K.; Pan, C.; Xu, W.; Aslam, N.; Nallanathan, A. Deep reinforcement learning based dynamic trajectory control for UAV-assisted mobile edge computing. IEEE Trans. Mob. Comput. 2021, 21, 3536–3550. [Google Scholar] [CrossRef]
- Wang, L.; Wang, K.; Pan, C.; Xu, W.; Aslam, N.; Hanzo, L. Multi-agent deep reinforcement learning-based trajectory planning for multi-UAV assisted mobile edge computing. IEEE Trans. Cogn. Commun. Netw. 2020, 7, 73–84. [Google Scholar] [CrossRef]
- Wang, C.; Wang, J.; Shen, Y.; Zhang, X. Autonomous navigation of UAVs in large-scale complex environments: A deep reinforcement learning approach. IEEE Trans. Veh. Technol. 2019, 68, 2124–2136. [Google Scholar] [CrossRef]
- Liu, C.H.; Ma, X.; Gao, X.; Tang, J. Distributed energy-efficient multi-UAV navigation for long-term communication coverage by deep reinforcement learning. IEEE Trans. Mob. Comput. 2019, 19, 1274–1285. [Google Scholar] [CrossRef]
- Gao, Y.; Ren, L.; Shi, T.; Xu, T.; Ding, J. Autonomous Obstacle Avoidance Algorithm for Unmanned Aerial Vehicles Based on Deep Reinforcement Learning. Eng. Lett. 2024, 32, 650–660. [Google Scholar]
- Wang, F.; Zhu, X.; Zhou, Z.; Tang, Y. Deep-reinforcement-learning-based UAV autonomous navigation and collision avoidance in unknown environments. Chin. J. Aeronaut. 2024, 37, 237–257. [Google Scholar] [CrossRef]
- Menfoukh, K.; Touba, M.M.; Khenfri, F.; Guettal, L. Optimized Convolutional Neural Network architecture for UAV navigation within unstructured trail. In Proceedings of the 2020 1st International Conference on Communications, Control Systems and Signal Processing (CCSSP), El Oued, Algeria, 16–17 May 2020; pp. 211–214. [Google Scholar]
- Back, S.; Cho, G.; Oh, J.; Tran, X.-T.; Oh, H. Autonomous UAV trail navigation with obstacle avoidance using deep neural networks. J. Intell. Robot. Syst. 2020, 100, 1195–1211. [Google Scholar] [CrossRef]
- Maciel-Pearson, B.G.; Carbonneau, P.; Breckon, T.P. Extending deep neural network trail navigation for unmanned aerial vehicle operation within the forest canopy. In Towards Autonomous Robotic Systems: 19th Annual Conference, TAROS 2018, Bristol, UK, 25–27 July 2018, Proceedings 19; Springer International Publishing: Cham, Switzerland, 2018; pp. 147–158. [Google Scholar]
- Chhikara, P.; Tekchandani, R.; Kumar, N.; Chamola, V.; Guizani, M. DCNN-GA: A Deep Neural Net Architecture for Navigation of UAV in Indoor Environment. IEEE Internet Things J. 2020, 8, 4448–4460. [Google Scholar] [CrossRef]
- Niu, Y.; Yan, X.; Wang, Y.; Niu, Y. 3D real-time dynamic path planning for UAV based on improved interfered fluid dynamical system and artificial neural network. Adv. Eng. Inform. 2024, 59, 102306. [Google Scholar] [CrossRef]
- Bohn, E.; Coates, E.M.; Moe, S.; Johansen, T.A. Deep reinforcement learning attitude control of fixed-wing uavs using proximal policy optimization. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019; pp. 523–533. [Google Scholar]
- Xu, J.; Du, T.; Foshey, M.; Li, B.; Zhu, B.; Schulz, A.; Matusik, W. Learning to fly: Computational controller design for hybrid uavs with reinforcement learning. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Xu, D.; Hui, Z.; Liu, Y.; Chen, G. Morphing control of a new bionic morphing UAV with deep reinforcement learning. Aerosp. Sci. Technol. 2019, 92, 232–243. [Google Scholar] [CrossRef]
- Wan, K.; Gao, X.; Hu, Z.; Wu, G. Robust motion control for UAV in dynamic uncertain environments using deep reinforcement learning. Remote Sens. 2020, 12, 640. [Google Scholar] [CrossRef]
- Passalis, N.; Tefas, A. Continuous drone control using deep reinforcement learning for frontal view person shooting. Neural Comput. Appl. 2020, 32, 4227–4238. [Google Scholar] [CrossRef]
- Yang, J.; You, X.; Wu, G.; Hassan, M.M.; Almogren, A.; Guna, J. Application of reinforcement learning in UAV cluster task scheduling. Future Gener. Comput. Syst. 2019, 95, 140–148. [Google Scholar] [CrossRef]
- Mandloi, Y.S.; Inada, Y. Machine learning approach for drone perception and control. In Engineering Applications of Neural Networks: 20th International Conference, EANN 2019, Xersonisos, Crete, Greece, 24–26 May 2019, Proceedings 20; Springer International Publishing: Cham, Switzerland, 2019; pp. 424–431. [Google Scholar]
- Lee, K.; Gibson, J.; Theodorou, E.A. Aggressive perception-aware navigation using deep optical flow dynamics and pixelmpc. IEEE Robot. Autom. Lett. 2020, 5, 1207–1214. [Google Scholar] [CrossRef]
- Yang, X.; Chen, J.; Dang, Y.; Luo, H.; Tang, Y.; Liao, C.; Chen, P.; Cheng, K.-T. Fast depth prediction and obstacle avoidance on a monocular drone using probabilistic convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2019, 22, 156–167. [Google Scholar] [CrossRef]
- Xu, Z.; Zhan, X.; Chen, B.; Xiu, Y.; Yang, C.; Shimada, K. A real-time dynamic obstacle tracking and mapping system for UAV navigation and collision avoidance with an RGB-D camera. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 10645–10651. [Google Scholar]
- Wakabayashi, T.; Suzuki, Y.; Suzuki, S. Dynamic obstacle avoidance for Multi-rotor UAV using chance-constraints based on obstacle velocity. Robot. Auton. Syst. 2023, 160, 104320. [Google Scholar] [CrossRef]
- Müller, H.; Niculescu, V.; Polonelli, T.; Magno, M.; Benini, L. Robust and efficient depth-based obstacle avoidance for autonomous miniaturized uavs. IEEE Trans. Robot. 2023, 39, 4935–4951. [Google Scholar] [CrossRef]
- Yasin, J.N.; Mohamed, S.A.S.; Haghbayan, M.-H.; Heikkonen, J.; Tenhunen, H.; Plosila, J. Unmanned aerial vehicles (uavs): Collision avoidance systems and approaches. IEEE Access 2020, 8, 105139–105155. [Google Scholar] [CrossRef]
- Gandhi, D.; Pinto, L.; Gupta, A. Learning to fly by crashing. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3948–3955. [Google Scholar]
- Santos MC, P.; Rosales, C.D.; Sarcinelli-Filho, M.; Carelli, R. A novel null-space-based UAV trajectory tracking con-troller with collision avoidance. IEEE/ASME Trans. Mechatron. 2017, 22, 2543–2553. [Google Scholar] [CrossRef]
- Al-Emadi, S.; Al-Senaid, F. Drone detection approach based on radio-frequency using convolutional neural network. In Proceedings of the 2020 IEEE International Conference on Informatics, IoT, and Enabling Technologies (ICIoT), Doha, Qata, 2–5 February 2020; pp. 29–34. [Google Scholar]
- Aldao, E.; González-Desantos, L.M.; Michinel, H.; González-Jorge, H. Uav obstacle avoidance algorithm to navigate in dynamic building environments. Drones 2022, 6, 16. [Google Scholar] [CrossRef]
- Ming, Z.; Huang, H. A 3d vision cone based method for collision free navigation of a quadcopter UAV among moving obstacles. Drones 2021, 5, 134. [Google Scholar] [CrossRef]
- Castillo-Lopez, M.; Sajadi-Alamdari, S.A.; Sanchez-Lopez, J.L.; Olivares-Mendez, M.A.; Voos, H. Model predictive control for aerial collision avoidance in dynamic environments. In Proceedings of the 2018 26th Mediterranean Conference on Control and Automation (MED), Zadar, Croati, 19–22 June 2018; pp. 1–6. [Google Scholar]
- Kouris, A.; Bouganis, C.-S. Learning to fly by myself: A self-supervised cnn-based approach for autonomous navigation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar]
- Zhao, J.; Wang, H.; Bellotto, N.; Hu, C.; Peng, J.; Yue, S. Enhancing LGMD’s looming selectivity for UAV with spatial–temporal distributed presynaptic connections. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 2539–2553. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Type | Description | References |
|---|---|---|---|
| LSTM RNN | SL | Improved prediction accuracy based on recent observations | [24] |
| Neural Network Pipeline (NNP) | SL | High accuracy (2%) and fast processing speed. | [25] |
| Neural Network | SL | Good real-time performance | [26] |
| Neural Network | SL | Created a depth map using the CGAN network to prevent more collisions. | [27] |
| Neural Network | SL | CNN network was used to forecast the depth map. | [28] |
| Neural Network | SL | Suggested a method that combines the epipolar geometry with the depth neural network. | [29] |
| Neural Network | SL | Utilized CNN to calculate the image’s optical flow. | [30] |
| Neural Network | SL | Suggested an ANN-based route planning method. | [31] |
| Neural Network | SL | Used the G-FCNN algorithm to assess the route. | [32] |
| Neural Network | SL | Utilizing the Q-learning method and neural network, the 3D collision avoidance problem was resolved. | [33] |
| Parameter FNN | SL | Attitude control | [34] |
| RBF NN | SL | Attitude control | [35] |
| Adaptive FNN | SL | Control of aerobatic maneuvers | [36] |
| CL | SL | Tracking trajectory | [37] |
| CL, BKR-CL | SL | Change of controller | [38] |
| RWNN | SL | Trajectory tracking | [39,40] |
| ReLU Network | SL | Aerobatic maneuver | [41] |
| NN | SL | Generalization of dynamics | [42] |
| SVR | SL | Attitude control | [43] |
| ELM | SL | Single UAV navigation | [44] |
| CNN | SL | Getting around a city | [45] |
| Imitation learning | SL | MAV flying over a woodland | [46] |
| CNN | SL | Trajectory prediction | [47] |
| NN, RL | SL | Estimating collisions | [48] |
| DNN, RL | SL | State estimation | [49] |
| Regression | SL | Estimation of altitude | [50] |
| SVM | SL | Mapping a river | [51] |
| GMM, SVM | SL | Detecting landing sites | [52] |
| OBIA | SL | Precision agriculture | [53] |
| Hybrid deep NN | SL | Classification of crops | [54] |
| DNN | SL | Perception of mountain trails | [55,56] |
| Algorithms, References | Type | Characteristics | Goals |
|---|---|---|---|
| PSO [92] | MPSO | PSO-generated infeasible paths are transformed into feasible ones through the integration of an error factor. | For the best collision-free 3D UAV route planning, use MPSO. |
| PSO [93] | DPSO | Discrete steps facilitate propagation, while multiple augmentations are utilized to improve convergence. | IoT and image processing in UAV control |
| PSO [94] | GBPSO | It assesses the current global path against alternative candidates to identify the most optimal choice. | GBPSO for enhanced 3D UAV routing |
| ACO [95] | Multi-ACO | It addresses the TSP problem, taking into account both intra-colony and inter-colony pheromone values. | ACO with many colonies for effective UAV path planning |
| ACO [96] | Double-ACO | It employs GA for generating the initial population. | Double-ant colony speeds UAV planning. |
| ACO [97] | PFACO | Achieves rapid convergence by utilizing MMAS and APF for enhanced global search capabilities. | PFACO for improved UAV path planning. |
| GA [98] | GA | The UAVs’ heading angle rate, acceleration, and rising angle rate make up their chromosomes. | Best possible 3D UAV route planning with GIS information. |
| GA [99] | Improved-GA | It comprises an encoding vector derived from the sequence of UAV yaw angles. | Using evolutionary algorithms to enhance UAV route planning. |
| GA [100] | HR-MAGA | It employs a hierarchical recursive procedure to establish a more detailed path. | Recursive hierarchical evolutionary algorithms for UAV route planning optimization. |
| GA [101] | OCGA | Uses OC and TLBO searches to achieve quick convergence. | Optimizing the OCGA algorithm for UAV route planning. |
| SA [102] | Modified-SA | Selection of the POIs is stochastic | Boost the effectiveness of UAV route planning. |
| SA [103] | SA-ACO | Hybrid algorithm | Enhance efficiency of underground path planning. |
| SA [104] | Grid-based SA | SA based on grid maps for 2D UAV navigation | Improve the coverage route planning of UAVs. |
| DE [105] | ADE | Selective mutation in hybrid algorithm. | In urban settings, maximize the effectiveness of UAV path planning. |
| DE [106] | CDE | Adaptive mutation limited differential evolution algorithm for catastrophe situational awareness in UAV path planning optimization. | Enhancing UAV route planning for disaster awareness using limited differential evolution. |
| DE [107] | DEAKP | Prioritize knee solutions over the Pareto front within a constrained multi-objective optimization context. | By optimizing distance, risk metrics, and operational limitations, a knee point-guided differential evolution method may be used to increase the efficiency of UAV path planning in catastrophe scenarios. |
| PIO [108] | SCPIO | The use of randomization, ergodicity of motion trajectories, strong sensitivity to beginning values, and hierarchical social class. | Creating a multi-UAV route planning model using SCPIO and TSS to improve efficiency and cooperation in challenging conditions. |
| PIO [109] | AOQPIO | The behavior of the system is highly sensitive to initial conditions, exhibits ergodic motion trajectories, and incorporates elements of randomization. | Adaptive QPIO improves UAV route planning in hazardous situations, outperforming PSO and its variations. |
| CS [110,111] | Improved-CS | Implement crossover and mutation operators within genetic algorithms and employ Chebyshev collocation points for representing coordinates. | Adaptive QPIO improves UAV route planning for better performance in difficult settings. |
| A* [112] | Dijkstra | Uses Hamiltonian and Eulerian path model and Dijkstra | Putting forward a unique GPS-free route planning and unmanned vehicle localization technique that makes use of cooperative algorithms. |
| A* [113] | DEA* | Hybrid DE and A* for urban UAV path planning. | Hybrid DE and A* for UAV collision-free path planning. |
| A* [114] | A* | Multi-step search with real-time A* | Stealth UAV real-time path planning. |
| GWO [115] | HSGWO-MSOS | Hybrid algorithm | Creating a hybrid HSGWO-MSOS algorithm to plan the best UAV route. |
| GWO [116] | 2D-GWO | Ensure minimum fuel usage and zero threat | Creating GWO to maximize the effectiveness of UCAV route planning. |
| GWO [117] | 3D-GWO | Localization and obstacle avoidance | Creating GWO to maximize the effectiveness of UCAV route planning. |
| Algorithms, References | Type | Characteristics | Goals |
|---|---|---|---|
| RL [60] | Q-Learning | A calibrated reward system, employing e-greedy policy, operates in a coordinate-based state-action space. Q-learning adjusts PID controller parameters for navigation in a 2D environment, with function approximation based on FSR for efficiency. | Indoor navigation |
| RL [119] | Q-Learning | An adaptive reward system, utilizing e-greedy policy, functions within a goal-oriented state-action space. Navigating a 2D environment, the system autonomously seeks out charging points. | Improving QoE |
| RL [120] | Q-Learning | Utilizing an RSS-driven state-action space, the system employs a dynamic reward system and e-greedy policy, while also integrating obstacle avoidance. | Indoor SaR |
| RL [121] | TD-Learning | Employing a discrete state-action space, the system utilizes linear function approximation using tile coding to handle large state-spaces, alongside an e-greedy policy. | UAV-BS navigation |
| RL [122] | Multi-agent Q-Learning | The system anticipates user movement trajectories within a coordinate-based state-action space, factoring in energy usage with gradual convergence and integrating a dynamic rewarding system. | Data transmission with minimum power |
| RL [123] | Multi-agent Q-Learning | Real-time decentralized path planning with a model-based reward system, e-greedy policy, and reduced state-action space, all within a 3D environment. | Perform sense and send tasks |
| RL [124] | Double Q-Learning | An evolving reward system, paired with an e-greedy policy, functions within a goal-centric state-action space in a 2D environment. | Temporary BS support |
| RL [125] | Q-learning and SARSA | Utilizing reinforcement learning, optimizing UAV energy consumption, enhancing path planning efficiency. | UAV Efficiency Enhancement |
| RL [126] | Proximal Policy Optimization (PPO), Soft Actor-Critic (SAC), and Deep Q-Networks (DQN) | Obstacle detection and avoidance via diverse reinforcement learning approaches, contrasts DQN, PPO, and SAC methodologies for addressing static and dynamic obstacles, conducts evaluations in a virtual environment using AirSim and Unreal Engine 4, demonstrates SAC’s superior performance, and highlights the effectiveness of off-policy algorithms (DQN and SAC) compared to on-policy counterparts (PPO) for autonomous drone navigation. | Develop a drone system for autonomous obstacle avoidance. |
| RL [127] | (DNN-MRFT) | RL agent integration, direct policy transfer, DNN-MRFT parameter identification, reward function design, and fusion of high-level velocity actions and low-level control validated through simulations and real-world experiments with a 90% success rate, ensuring originality. | Closing the sim2real gap in UAVs with RL transfer and integrated control. |
| Algorithms, References | Type | Characteristics | Goals |
|---|---|---|---|
| DRL [128] | MDP-based Dueling DDQN | Utilizing a discrete action space, action approximation is performed through Artificial Neural Networks (ANNs), employing dual neural network architecture. | Simultaneous UAV navigation and radio mapping |
| DRL [129] | MDP-based DQN | Employing an RSS-driven state space, alongside an E-greedy policy, the system integrates a dynamic rewarding mechanism. | MIMO-based UAV navigation |
| DRL [130] | MDP-based DQN | Operating within a discrete action space contingent upon dispatched UAVs, the system incorporates an e-greedy policy and prioritized replay memory. | Urban vehicular connectivity |
| DRL [131] | MDP-based MADQN | Training centrally with an e-greedy policy, multiple agents share their individual locations, operating within a discrete action space. | AoL-aware WPCN |
| DRL [132] | MDP-based DQN | Incorporating an exceedingly sparse rewarding system and obstacle avoidance, the system employs LwH to enhance convergence within intricate environments. | UAV navigation in complex environment |
| DRL [133] | MDP-based DDQN | The system leverages CNN for map-based navigation while taking into account energy consumption. | UAV Coverage Path Planning |
| DRL [134] | MDP-based DQN | Employing object detection assistance, the system navigates through an object-oriented state space, integrating a binary rewarding system alongside an e-greedy policy. | Collision free UAV navigation |
| DRL [135] | MDP-based DQN | The system integrates user data freshness, UAV power consumption, and coordinates into the state space for DRL training with stochastic gradient descent. | UAV-BS Navigation |
| DRL [75] | MDP-based DQN | Implementing TD3fD for policy enhancement, employing a CNN-based DQN, the system includes obstacle avoidance capabilities. | Obstacle free UAV navigation |
| DRL [136] | POMDP-based DRL | MDP and POMDP are both employed for global and local planning, with policy improvements managed by TRPO. | Indoor navigation |
| DRL [137] | EDDQN | Employing a CNN-based DQN for map-guided navigation, the system adapts a modified Q-function to ensure effective obstacle avoidance. | Autonomous UAV exploration |
| DRL [138] | POMDP-based DDQN | CNN-based DDQN, grid-based navigation and searching | UAV-assisted data harvesting |
| Advantage Actor-Critic (A3C) [139,140] | A3C-based DRL | Prioritized experience replay is applied based on A3C, while multi-agent DDPG handles policy enhancement, alongside a pre-determined UAV navigation pattern. | UAV-assisted MEC |
| Advantage Actor-Critic (A3C) [141] | Fast-RDPG | Utilizing Fast-RDPG with LSTM-based DRL, the system achieves rapid convergence through an online algorithm. | UAV navigation in complex environment |
| Advantage Actor-Critic (A3C) [142] | A3C-based DRL | Utilizing A3C with a tailored policy gradient, the system accounts for energy consumption via an e-greedy policy, enabling decentralized multi-UAV navigation. | Distributed multi-UAV navigation |
| DRL [143] | DAC-SAC | The DAC-SAC algorithm integrates dual experience buffers, a Convolutional Neural Network (CNN), and a self-attention mechanism to improve UAV obstacle avoidance. Simulated trials affirm their efficacy in diverse environments, including scenarios with depth image inputs. | UAV autonomous obstacle avoidance |
| DRL [61] | D3QN | The trajectory planning approach for UAVs with cellular connectivity employs deep reinforcement learning and integrates connectivity and obstacle data to ensure safe flight, effectively navigating obstacles without AI plagiarism concerns. | Unique trajectory planning approach for cellular-connected UAVs |
| DRL [144] | FRDDM-DQN | The study presents FRDDM-DQN, an advanced deep-reinforcement-learning algorithm that combines Faster R-CNN with a Data Deposit Mechanism. It improves obstacle extraction, agent training, and adjusts to dynamic scenarios. In experiments, FRDDM-DQN demonstrates autonomous navigation, collision avoidance, and superior performance compared to alternative algorithms. | UAV autonomous navigation and collision avoidance |
| Algorithms, References | Type | Characteristics | Goals |
|---|---|---|---|
| DL [145] | CNN | CNN using the IDSIA dataset and ReLU activation | UAV navigation within unstructured trail |
| DL [146] | CNN | Following trails, recovering from disturbances, and avoiding obstacles. | UAV trail navigation |
| DL [147] | DNN | IDSIA dataset, trail navigation, and guidance | UAV navigation within forest |
| DL [148] | DCNN-GA | Model based on Exception and hyper-parameter tweaking based on GA | Indoor UAV navigation |
| DL [149] | Dynamic path planning IFDS with ANN | Optimization using ESCSO, Enhanced path navigation in intricate settings, real-time processing, reliable obstacle avoidance, improved computational efficiency. | Real-time UAV path planning enhancement |
| Algorithm | Description |
|---|---|
| SARSA | SARSA, which stands for State–Action–Reward–State–Action, is an algorithm used in artificial intelligence (AI) that belongs to the class of model-free and on-policy temporal difference (TD) learning methods. It functions by learning an action-value function. |
| SARSA Lambda | SARSA Lambda extends SARSA by including eligibility traces, enabling it to learn from more extended rewards. Moreover, SARSA Lambda is an on-policy TD learning algorithm. |
| Deep Q Network (DQN) | DQN, called deep Q-network, merges Q-learning with deep learning methods and operates on-policy. |
| Double DQN | Double DQN, a variant of DQN, employs two separate neural networks to estimate the action-value function, mitigating overestimation bias. It follows an off-policy approach. |
| Noisy DQN | Noisy DQN, a variant of DQN, injects noise into the action-value function during training to foster exploration and prevent the agent from being trapped in local optima. It adheres to an off-policy strategy. |
| Prioritized Replay DQN | Prioritized Replay DQN, a modification of DQN, prioritizes experience replay based on significance, enhancing the agent’s learning by focusing on crucial experiences. This algorithm operates on an off-policy basis. |
| Categorical DQN | Categorical DQN, an adaptation of DQN, employs a categorical distribution to model the action-value function, particularly beneficial for environments featuring a multitude of actions. This algorithm operates on an off-policy basis. |
| Distributed DQN (C51) | The Distributed DQN (C51) modifies DQN by using a quantized distribution for the action-value function, which improves its performance in continuous environments. This algorithm works on an off-policy basis. |
| Normalized Advantage Functions (NAF) | Normalized Advantage Functions (NAF) is a policy gradient method that employs advantage functions to adjust the policy. This algorithm operates on an off-policy basis. |
| Continuous DQN | Continuous DQN is an adaptation of the DQN algorithm tailored for environments with continuous action spaces. This algorithm operates on an off-policy basis. |
| REINFORCE (Vanilla policy gradient) | REINFORCE is a policy gradient method that employs the REINFORCE estimator for policy updates. This algorithm operates on a policy-based approach. |
| Policy Gradient | A class of algorithms known as Policy Gradient is designed to learn policies by directly optimizing predicted rewards. This strategy uses a policy-based methodology. |
| TRPO | A trust region is used by the policy gradient algorithm Trust Region Policy Optimization (TRPO) to ensure the security of policy changes. The on-policy methodology is used by this algorithm. |
| PPO | A policy gradient approach called Proximal Policy Optimization (PPO) uses a clipping goal to limit the size of policy updates. The on-policy methodology is used by this algorithm. |
| A2C/A3C | Policy gradient methods A2C (Advantage Actor-Critic) and A3C (Asynchronous Advantage Actor-Critic) are made to train several agents at once. These two algorithms follow an on-policy approach. |
| DDPG | Deep Deterministic Policy Gradient (DDPG) is a policy gradient algorithm tailored for continuous action spaces. It follows an off-policy approach. |
| TD3 | In order to increase stability, TD3, a modified version of DDPG, uses two Q-networks and two target Q-networks in addition to an off-policy methodology. |
| SAC | A policy gradient algorithm that combines Q-learning and policy gradient approaches is called Soft Actor-Critic (SAC). It employs an off-policy strategy. |
| ACER | Actor-Critic with Experience Replay (ACER) is a policy gradient algorithm that incorporates experience replay to enhance efficiency. It follows an off-policy approach. |
| ACKTR | Actor-Critic with Kronecker Product Representation (ACKTR) is a policy gradient algorithm that utilizes a Kronecker product representation to train a factored policy. It follows an off-policy approach. |
| References | Year | Approach | Observations |
|---|---|---|---|
| [156] | 2019 | Obstacle detection in wooded areas and takeoff dynamics | considerable computational overhead |
| [165] | 2020 | using radio frequency signals to detect drones | comparatively high computational cost |
| [166] | 2022 | Avoiding collisions with stationary and moving objects within a structure | reduced UAV speed and obstacle detection using LiDAR sensors |
| [157] | 2020 | Estimate the movement of pertinent pixels in the robot’s intended path. | When it’s raining or gloomy outside, visual performance will be reduced. |
| [167] | 2021 | Obstacle identification and avoidance using vision | seeing just one side at a time and requiring a lot of processing power to see other orientations |
| [168] | 2018 | From trajectory tracking to model predictive control in 3D among several moving objects | NMPC is known to be computationally expensive. |
| [169] | 2018 | System for avoiding obstacles | High cost of calculation |
| [25] | 2021 | From trajectory prediction to vision-based collision avoidance with dynamic objects | High cost of processing hardware and computing |
| [170] | 2021 | Vision-based collision avoidance in maneuverable aircraft | Expensive processing costs and inability to identify tiny things |
| [159] | 2023 | Avoiding collisions with both moving and stationary objects using vision | High failure rate in complicated environments |
| [160] | 2023 | Taking into account the obstacle’s location and velocity, dynamic obstacle avoidance | Restricted to a 2D setting. Assumes UAV can determine position and velocity of every barrier and UAV. |
| [161] | 2023 | Avoiding obstacles with a Nano drone | A typical, untested indoor environment with 100% dependability at 0.5 m/s |
| [158] | 2019 | Monocular depth prediction in real time and obstacle detection and avoidance using a lightweight probabilistic CNN (pCNN) | The method is shown to be faster and more accurate than the state-of-the-art approaches on the devices such as TX2 and 1050Ti with increased accuracy from sparse depth from visual odometry. |
| [164] | 2017 | Trajectory tracking with collision avoidance using a potential function a null-space controller | Confirmed on a Parrot AR. Drone, works well in dynamic scenarios with a low-cost RGB-D sensor platform |
| [162] | 2020 | The following paper aims to present a thorough analysis of the current approaches to collision avoidance systems as applied to unmanned vehicles with particular regard to UAVs. | Compared several approaches and types of sensors in order to discuss the problem of avoiding collisions with UAVs. |
| [163] | 2017 | Gathered a massive repository of UAV crash incidents for developing a self-supervising navigation strategy | Uses crash data to provide evidence about organization of vehicle motion in crowded spaces |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Skarka, W.; Ashfaq, R. Hybrid Machine Learning and Reinforcement Learning Framework for Adaptive UAV Obstacle Avoidance. Aerospace 2024, 11, 870. https://doi.org/10.3390/aerospace11110870
Skarka W, Ashfaq R. Hybrid Machine Learning and Reinforcement Learning Framework for Adaptive UAV Obstacle Avoidance. Aerospace. 2024; 11(11):870. https://doi.org/10.3390/aerospace11110870
Chicago/Turabian StyleSkarka, Wojciech, and Rukhseena Ashfaq. 2024. "Hybrid Machine Learning and Reinforcement Learning Framework for Adaptive UAV Obstacle Avoidance" Aerospace 11, no. 11: 870. https://doi.org/10.3390/aerospace11110870
APA StyleSkarka, W., & Ashfaq, R. (2024). Hybrid Machine Learning and Reinforcement Learning Framework for Adaptive UAV Obstacle Avoidance. Aerospace, 11(11), 870. https://doi.org/10.3390/aerospace11110870