
From Text to Safety: A Novel Framework for Mining Unsafe Aviation Events Using Advanced Neural Network and Feature Network

Abstract
1. Introduction
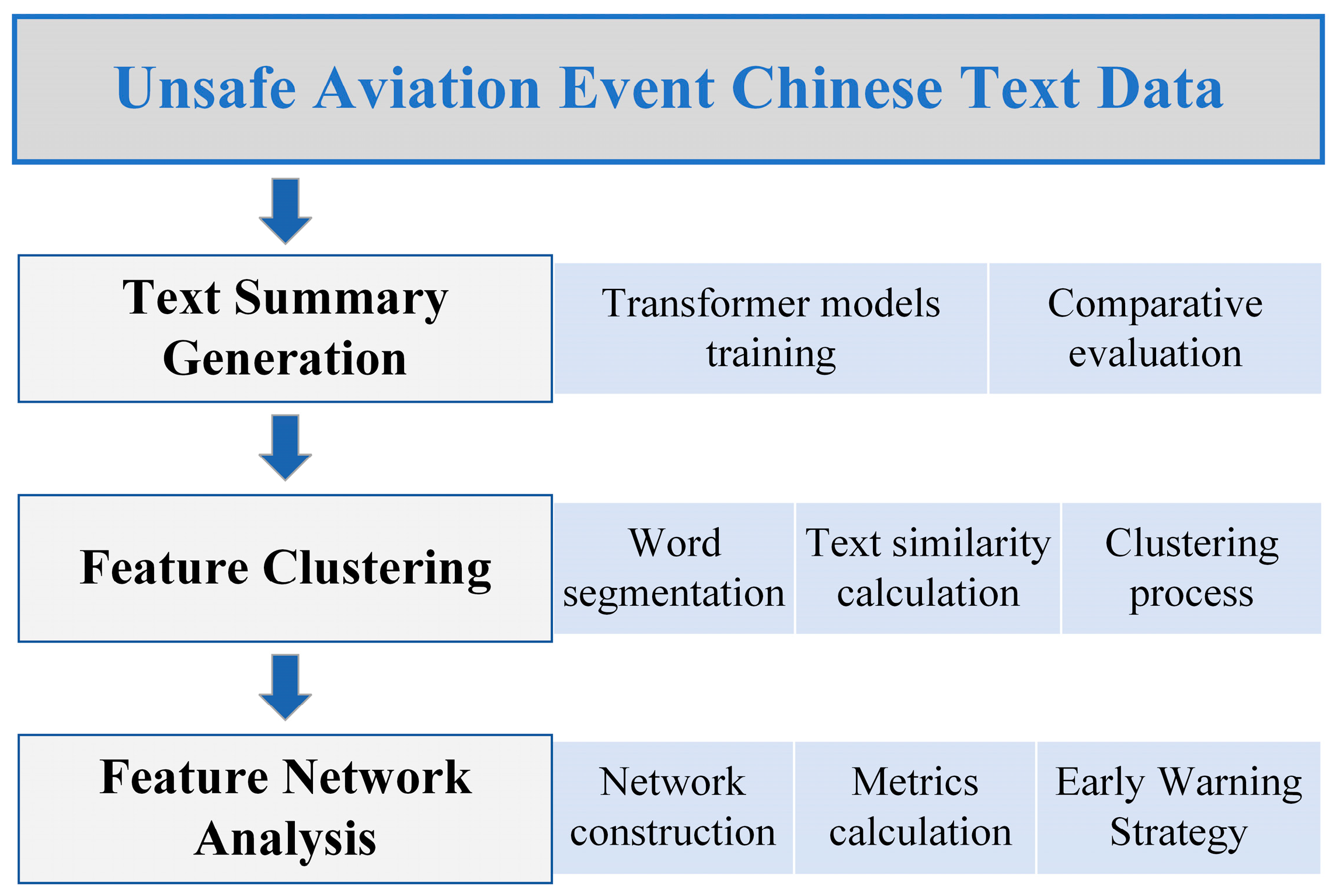
2. Summary Generation by Neural Network Model
2.1. Dataset Creation
2.2. Model Deployment
2.2.1. Model Introduction
- T5 Model (Text-to-Text Transfer Transformer): This model employs a unified text-to-text framework capable of handling a variety of Seq2Seq tasks by unifying multiple NLP tasks into a text-to-text format;
- GLM Model (General Language Model): This model integrates auto-encoding and auto-regressive pre-training methods, enabling it to construct output text progressively, which aids in generating coherent and fluent text;
- BART Model (Bidirectional and Auto-Regressive Transformers): Leveraging the strengths of both BERT and GPT, this model introduces random perturbations to the input text data, allowing it to better learn the semantic and structural information of the text.
2.2.2. Local Model Deployment
2.3. Model Training and Evaluation
2.3.1. Training Parameters Setting
2.3.2. Evaluation Method
2.3.3. Experiment Results
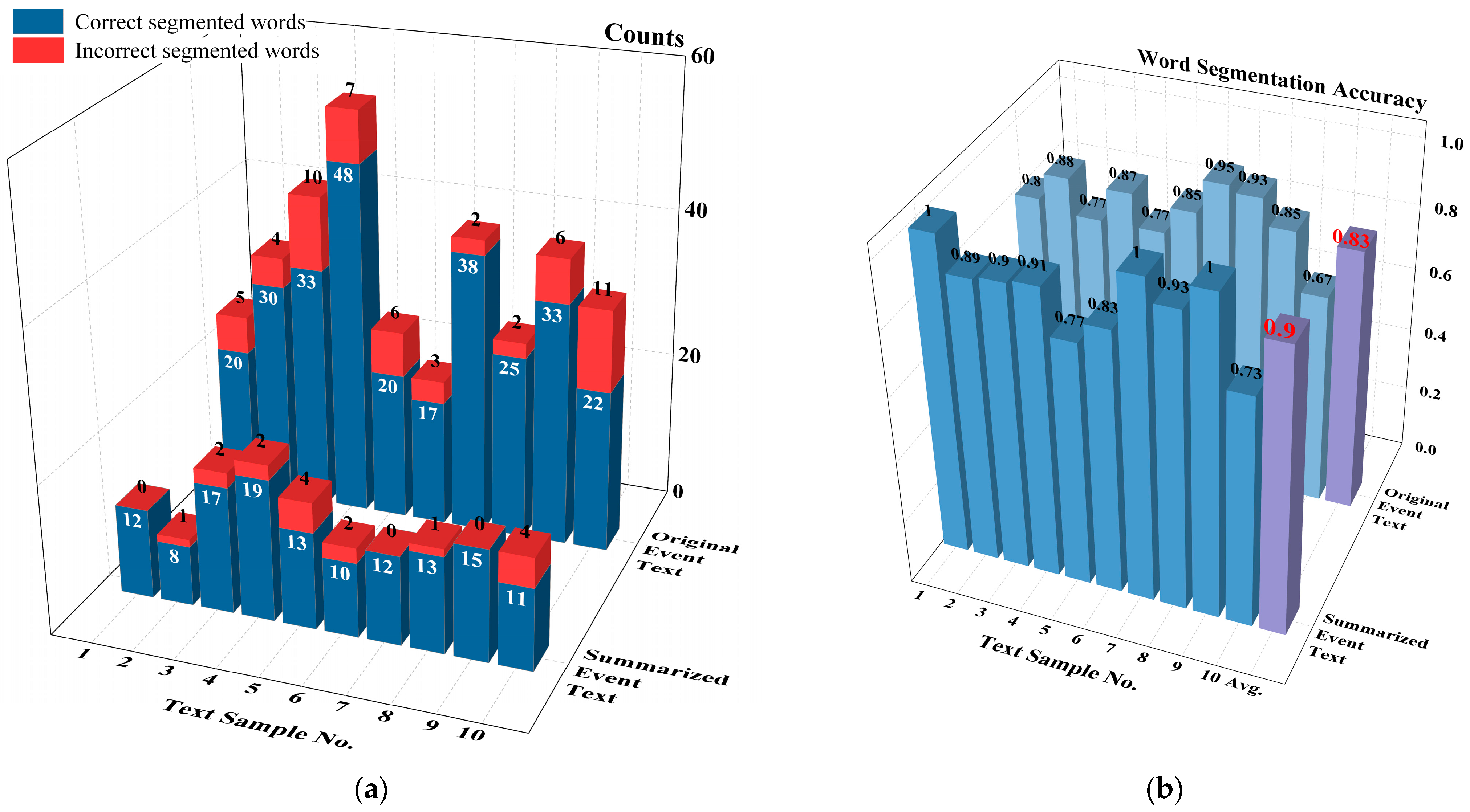
2.4. Impact Assessment of Summarization on Text Segmentation
3. Cluster Analysis of Summarized Text
3.1. Text Feature Extraction
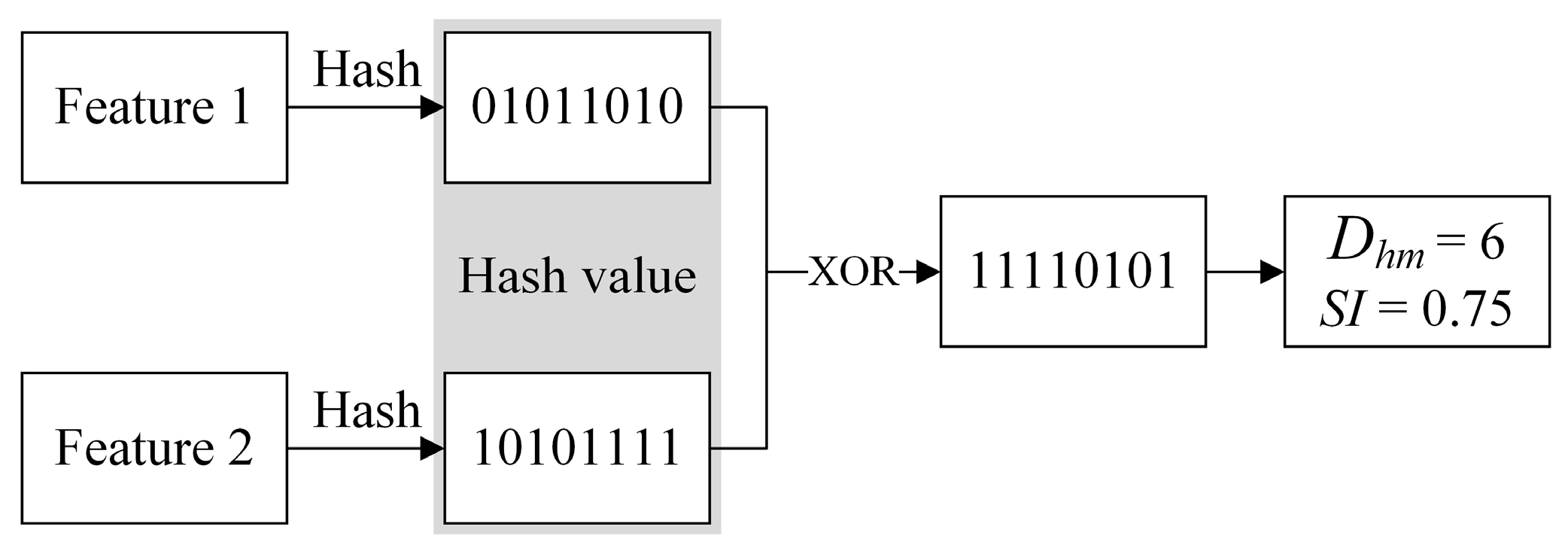
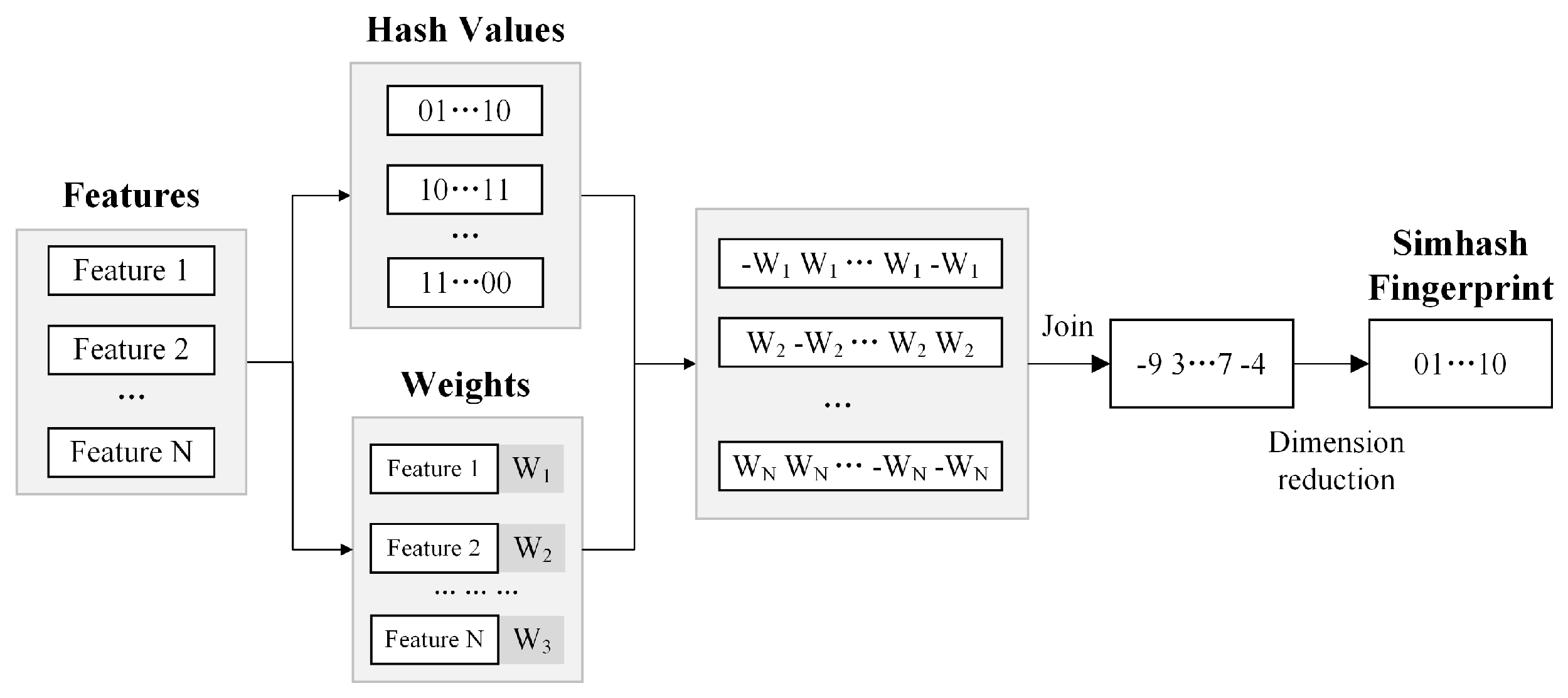
3.2. Hash-Mapping Text Similarity Calculation
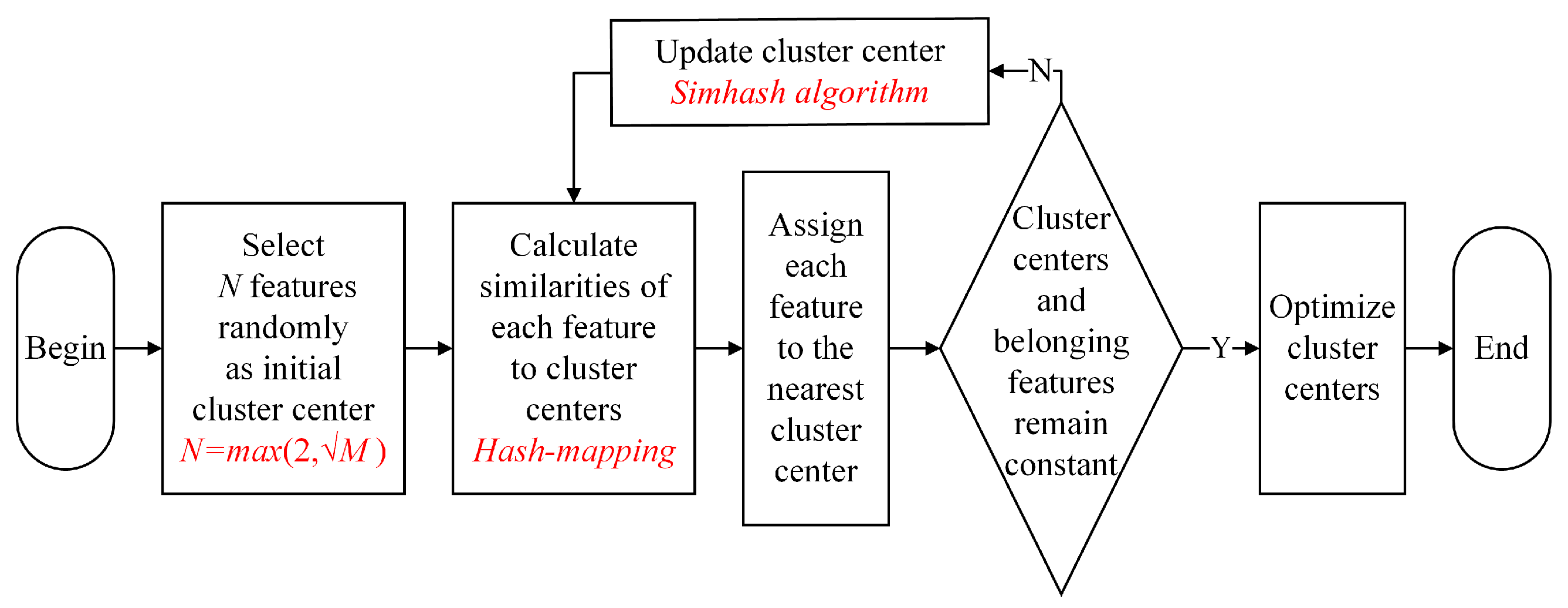
3.3. Clustering Process Based on Simhash Algorithm
3.4. Clustering Results
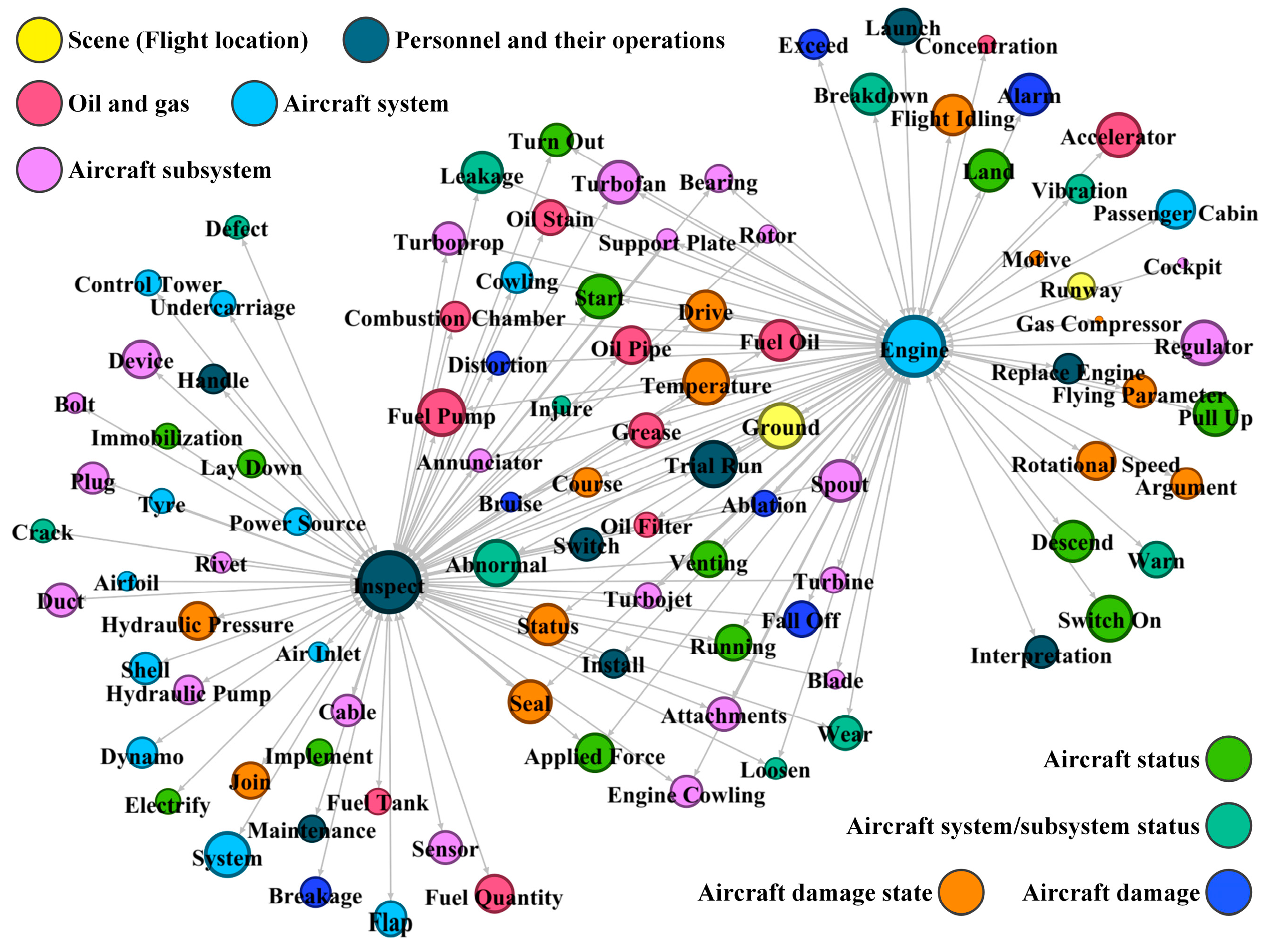
4. Unsafe Feature Network Analysis
4.1. Feature Correlation Matrix
4.2. Feature Network Construction
4.3. Network Metrics Calculation
4.4. Data-Driven Risk Early Warning Strategy
5. Conclusions
6. Discussion
- Generalizability of the Model: Although the Transformer models used in this study have performed well on specific datasets, their generalizability to other languages or domains may decline. This means that the model may require retraining and adjustment for new datasets to maintain its effectiveness;
- Consumption of Computational Resources: Transformer models with rather large-scale parameters typically require substantial computational resources for training and inference. This may limit their application in environments with limited resources, especially in scenarios that require real-time or near-real-time analysis;
- Limitations of Cluster Analysis: Although cluster analysis is used in this study for feature categorization, the method may be influenced by initial conditions and algorithm choices, leading to different clustering results. And that is why clustering results need manual adjustments;
- Inherent Limitations of Data-Driven Approaches: The method proposed in this study relies on historical data to predict and identify potential risk patterns. However, this approach may not fully capture emerging risk factors or those events that do not occur frequently but have significant impacts.
- Cross-Linguistic Application: To extend the methodology to other languages requires the adaptation of language-specific pre-trained transformer models and word segmentation tools. This expansion will enable the application of the method to a broader range of aviation reports, enhancing its global relevance;
- Model Updating Strategy Optimization: As aviation activities continue to evolve, the associated data and risk patterns will also change. Therefore, how to optimize the information update strategy according to the new-coming unsafe events, and the goal is to manage to achieve the timeliness of information updates under limited computational resources;
- Temporal Analysis of Unsafe Features: Analyzing the evolution and distribution patterns of unsafe features over time is another area for future exploration. This temporal analysis will provide insights into the dynamics of aviation safety, potentially revealing trends and patterns that can inform proactive safety measures.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- International Civil Aviation Organization. Doc9859 Safety Management Manual, 4th ed.; 999 Robert-Bourassa Boulevard: Montréal, QC, Canada, 2018. [Google Scholar]
- Aviation Safety Reporting System Database. Available online: https://asrs.arc.nasa.gov/search/dbol.html (accessed on 2 February 2024).
- National Transportation Safety Board Aviation Database. Available online: https://www.ntsb.gov/Pages/AviationQueryV2.aspx (accessed on 2 February 2024).
- Aviation Safety Network. Available online: https://aviation-safety.net/database/databases.php (accessed on 2 February 2024).
- Rose, R.L.; Puranik, T.G.; Mavris, D.N. Natural Language Processing Based Method for Clustering and Analysis of Aviation Safety Narratives. Aerospace 2020, 7, 143. [Google Scholar] [CrossRef]
- Garcia, J.S.D.; Jaedicke, C.; Lim, G.L.; Truong, D. Predicting the Severity of Runway Excursions from Aviation Safety Reports. J. Aerosp. Inf. Syst. 2023, 20, 555–564. [Google Scholar] [CrossRef]
- Madeira, T.; Melício, R.; Valério, D.; Santos, L. Machine Learning and Natural Language Processing for Prediction of Human Factors in Aviation Incident Reports. Aerospace 2021, 8, 47. [Google Scholar] [CrossRef]
- Chen, C.J.; Huang, C.N.; Yang, S.M. Application of Deep Learning to Multivariate Aviation Weather Forecasting by Long Short-term Memory. J. Intell. Fuzzy Syst. 2023, 44, 4987–4997. [Google Scholar] [CrossRef]
- Gong, W.; Guan, Z.; Sun, Y.; Zhu, Z.; Ye, S.; Zhang, S.; Yu, P.; Zhao, H. Civil Aviation Travel Question and Answer Method Using Knowledge Graphs and Deep Learning. Electronics 2023, 12, 2913. [Google Scholar] [CrossRef]
- Han, S.; Khatir, S.; Wahab, M.A. A deep learning approach to predict fretting fatigue crack initiation location. Tribol. Int. 2023, 185, 108528. [Google Scholar] [CrossRef]
- Zhang, X.; Srinivasan, P.; Mahadevan, S. Sequential deep learning from NTSB reports for aviation safety prognosis. Saf. Sci. 2021, 142, 105390. [Google Scholar] [CrossRef]
- Dong, T.; Yang, Q.; Ebadi, N.; Luo, X.R.; Rad, P. Identifying Incident Causal Factors to Improve Aviation Transportation Safety: Proposing a Deep Learning Approach. J. Adv. Transport. 2021, 2021, 5540046. [Google Scholar] [CrossRef]
- Monika; Verma, S.; Kumar, P. Generic Deep-Learning-Based Time Series Models for Aviation Accident Analysis and Forecasting. SN Comput. Sci. 2024, 5, 32. [Google Scholar] [CrossRef]
- Andrade, S.R.; Walsh, H.S. SafeAeroBERT: Towards a Safety-Informed Aerospace-Specific Language Model. AIAA Aviation Forum. 2023, 2023–3437. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arxiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Aviation Safety Information System of Civil Aviation Administration of China. Available online: https://safety.caac.gov.cn/index/initpage.act (accessed on 2 February 2024).
- Sino Confidential Aviation Safety Reporting System. Available online: http://scass.huahangxinyan.com/pcToReportQuery.do (accessed on 2 February 2024).
- González, J.; Hurtado, L.-F.; Pla, F. TWilBert: Pre-trained deep bidirectional transformers for Spanish Twitter. Neurocomputing 2021, 426, 58–69. [Google Scholar] [CrossRef]
- Choi, Y.-S.; Park, Y.-H.; Lee, K.J. Building a Korean morphological analyzer using two Korean BERT models. PeerJ Comput. Sci. 2022, 8, e968. [Google Scholar] [CrossRef] [PubMed]
- Kawara, Y.; Chu, C.; Arase, Y. Preordering Encoding on Transformer for Translation. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 644–655. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, H.; Chen, K.; Guo, Y.; Hua, J.; Wang, Y.; Zhou, M. Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese. arXiv 2021, arXiv:2110.06696. [Google Scholar] [CrossRef]
- Du, Z.; Qian, Y.; Liu, X.; Ding, M.; Qiu, J.; Yang, Z.; Tang, J. GLM: General Language Model Pretraining with Autoregressive Blank Infilling. arXiv 2021, arXiv:2103.10360. [Google Scholar] [CrossRef]
- Shao, Y.; Geng, Z.; Liu, Y.; Dai, J.; Yan, H.; Yang, F.; Qiu, X. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation. Sci. China Inf. Sci. [CrossRef]
- Lin, C.-Y.; Hovy, E.H. Automatic evaluation of summaries using N-gram co-occurrence statistics. In Proceedings of the The 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, Edmonton, AB, Canada, 27 May–1 June 2003. [Google Scholar] [CrossRef]
- Qin, J.; Cao, Y.; Xiang, X.; Tan, Y.; Xiang, L.; Zhang, J. An encrypted image retrieval method based on simhash in cloud computing. CMC-Comput. Mater. Con. 2020, 63, 389–399. [Google Scholar] [CrossRef]
- Kwon, Y.-M.; An, J.-J.; Lim, M.-J.; Cho, S.; Gal, W.-M. Malware Classification Using Simhash Encoding and PCA (MCSP). Symmetry 2020, 12, 830. [Google Scholar] [CrossRef]
- Deng, T.; Huang, Y.; Yang, G.; Wang, C. Pointwise mutual information sparsely embedded feature selection. Int. J. Approx. Reason. 2022, 151, 251–270. [Google Scholar] [CrossRef]
- Kucuk, S.; Yukse, S.E. Pointwise Mutual Information-Based Graph Laplacian Regularized Sparse Unmixing. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aviation Unsafe Event Text | Chinese | XX飞机执行XX-XX航班,落地后航班进入M11机位后,机务检查发现飞机右水平尾翼前缘被外物击伤,有3个凹坑(100毫米 × 50毫米 × 5.5毫米、60毫米 × 70毫米 × 3.5毫米、70毫米×40毫米×4.0毫米),机务确认飞机损伤超标,停场执行修理工作。23:49–23:58,飞行区管理部检查跑道及滑行道均未见异常,该飞机无后续出港计划。 |
| English | XX aircraft, operating flight XX-XX, was found to have suffered impact damage to the leading edge of the right horizontal stabilizer after landing and parking at the M11 gate. The damage consisted of three indentations (100 mm × 50 mm × 5.5 mm, 60 mm × 70 mm × 3.5 mm, 70 mm × 40 mm × 4.0 mm). The maintenance crew determined that the damage exceeded acceptable limits, and the aircraft was grounded for repairs. From 23:49 to 23:58, the Flight Area Management Department inspected the runway and taxiway and found no abnormalities. The aircraft had no subsequent departure plans. | |
| Manually Labeled Summary | Chinese | XX飞机落地后机务检查发现,飞机右水平尾翼前缘被外物击伤,损伤超标,执行修理工作。 |
| English | After landing, maintenance inspection of XX aircraft revealed impact damage to the leading edge of the right horizontal stabilizer, exceeding acceptable limits, and repairs were performed. |
| Hardware | Software | ||
|---|---|---|---|
| CPU | Intel Core i7-7700HQ | Environment | Anaconda |
| GPU | NVIDIA GTX 1070 8 GB | Python Version | 3.9.18 |
| RAM | 32 GB @2400 MHz | CUDA Version | 11.6 |
| ROM | 1 TB SSD | Deep Learning Platform | Pytorch 1.13.1 |
| OS | Windows 10 22H2 | Transformer Library Version | 4.32.1 |
| Model Name | Parameter Scale | Training Duration | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|---|---|
| mengzi-t5-base (T5) | 220 M | 3 min 30 s | 0.644 | 0.555 | 0.573 |
| glm-large-chinese (GLM) | 335 M | 135 min 39 s | 0.832 | 0.729 | 0.748 |
| bart-base-chinese (BART) | 110 M | 13 min 4 s | 0.690 | 0.559 | 0.611 |
| Original Text of Event #1 | Chinese text: 2021年3月30日,XXX公司XXX飞机执行XXX(XXX-XXX)航班。在XXX机场26号跑道着陆过程中,无线电高度10英尺以下遭遇低空风切变:风向风速急剧变化,飞机状态出现较大偏差,机组执行复飞。在复飞过程中出现“BANK ANGLE”(坡度角)语音警告,左坡度最大峰值20.92度,左翼尖擦地。再次进近后在26号跑道正常落地。地面检查发现左大翼翼尖处损伤,部分材料缺失。 |
| English translation: On 30 March 2021, XXX company’s XXX aircraft was performing the XXX (XXX-XXX) flight. During the landing process on runway 26 at XXX airport, below 10 feet of radio altitude, the aircraft encountered low-altitude wind shear: there was a sudden change in wind direction and speed, and the aircraft’s state deviated significantly, leading the crew to execute a go-around. During the go-around, a “BANK ANGLE” voice warning occurred, with the maximum peak of the left bank angle reaching 20.92 degrees, and the left wingtip scraped the ground. After the second approach, the aircraft landed normally on runway 26. Ground inspection found damage at the tip of the left wing, with some materials missing. | |
| T5 Summary | Chinese text: XXX飞机着陆过程中,飞机状态偏差,复飞出现警告,最大峰值20.92度,材料缺失。 |
| English translation: During the XXX aircraft’s landing process, there was a significant deviation in the aircraft’s state, and a warning occurred during the go-around, with a maximum peak of 20.92 degrees, and some materials were missing. | |
| GLM Summary | Chinese text: XXX飞机着陆复飞过程中,左翼尖擦地,左大翼翼尖处损伤,部分材料缺失。 |
| English translation: During the XXX aircraft’s landing and go-around process, the left wingtip scraped the ground, resulting in damage at the tip of the left wing, with some materials missing. | |
| BART Summary | Chinese text: XXX飞机跑道着陆过程复飞过程中,无线电高度低空风切变,出现坡度角,左翼尖擦地。 |
| English translation: During the XXX aircraft’s runway landing and go-around process, low-altitude wind shear was encountered at a low radio altitude, a bank angle occurred, and the left wingtip scraped the ground. | |
| Original Text of Event #2 | Chinese text: 2020年8月29日,XXX航空有限公司XXX号直升机在江西省赣州市龙南县境内执行果树农喷作业。执行任务过程中坠机,机体受损严重。机上共一名人员(飞行员)经现场抢救无效死亡。该事件最大可能是飞行员飞行时未能观察到高压线位置,在从高压线下方经过时,旋翼桨叶挂断高压线一片桨叶断裂(断裂飞出桨叶长约1.5米),直升机失去平衡、失控翻转坠落在山坡上,并翻滚倒扣。 |
| English translation: On 29 August 2020, a helicopter operated by XXX Aviation Limited Company, with registration number XXX, crashed while conducting agricultural spraying for fruit trees in Longnan County, Ganzhou City, Jiangxi Province. During the mission, the helicopter suffered a severe crash, resulting in extensive damage to the aircraft. There was one person on board (the pilot) who was pronounced dead after rescue efforts at the scene were unsuccessful. The most likely cause of the incident was that the pilot failed to observe the position of the high-voltage power lines during flight. As the helicopter passed underneath the power lines, a rotor blade struck the high-voltage line, causing one of the blades to break off (the broken blade, approximately 1.5 m in length, flew off). The helicopter lost balance, went out of control, flipped over, and fell onto a hillside, rolling over and landing upside down. | |
| T5 Summary | Chinese text: XXX号直升机执行果树农喷作业任务过程中坠机,机体受损严重,飞行时未能观察到高压线位置。 |
| English translation: Helicopter XXX, while performing a fruit tree spraying mission, crashed, resulting in severe damage to the aircraft body due to failure to observe the location of high-voltage power lines during flight. | |
| GLM Summary | Chinese text: XXX号直升机坠机,旋翼桨叶挂断高压线一片桨叶断裂,直升机失去平衡、失控翻转坠落。 |
| English translation: Helicopter XXX crashed, with the rotor blade hitting and breaking a high-voltage power line, causing one of the blades to fracture. The helicopter lost balance and control, flipping and falling out of control. | |
| BART Summary | Chinese text: XXX号直升机执行果树农喷作业,现场抢救无效死亡,翻转坠落在山坡上,并翻滚倒扣。 |
| English translation: During the fruit tree spraying mission, Helicopter XXX experienced an accident that led to death after ineffective on-site rescue efforts. The helicopter flipped and fell onto a hillside, rolling over and landing upside down. | |
| Original Text of Event #3 | Chinese text: 2023年7月30日,XXX有限公司XXX号机执行XXX航班,在XX机场19号跑道着陆过程中偏出跑道,导致跑道边灯和飞机受损,机上人员安全。经调查,该事件是由于机组对夜间大雨天气运行风险管控能力不足,进近和着陆准备不充分,SOP执行不到位;飞机穿过决断高度以后,机长主要依靠HUD指示控制飞行,至30英尺跟丢HUD指引未及时复飞;30英尺以下,机长视线尚未及时完全散开,对飞机状态不清晰不掌握,导致飞机带左坡度(5.4度)、左交叉(7度)和左侧滑惯性在着陆区中线左侧(约9米)接地(1.55 G);接地后机长虽然立即持续蹬右满舵修正,但已无法制止飞机左偏趋势,飞机向左侧偏出跑道。 |
| English translation: On 30 July 2023, XXX Limited Company’s aircraft XXX, performing XXX flight, veered off the runway during the landing process on runway 19 at XX Airport, resulting in damage to the runway edge lights and the aircraft, with the crew and passengers remaining safe. The investigation found that the incident was due to the flight crew’s insufficient ability to control the operational risks in heavy rain at night, inadequate approach and landing preparation, and incomplete execution of Standard Operating Procedures (SOPs). After the aircraft passed the decision height, the captain mainly relied on the HUD (Head-Up Display) indications to control the flight and did not initiate a go-around in time after losing the HUD guidance at 30 feet. Below 30 feet, the captain’s vision had not fully cleared in time, resulting in unclear and uncontrolled awareness of the aircraft’s state, leading the aircraft to touch down with a left bank (5.4 degrees), left crab (7 degrees), and a left skid inertia on the left side of the landing zone’s centerline (about 9 m) with a vertical force of 1.55 G. After touchdown, although the captain immediately and continuously applied full right rudder to correct, it was impossible to stop the aircraft’s tendency to deviate to the left, causing the aircraft to veer off the runway to the left. | |
| T5 Summary | Chinese text: XXX号机着陆过程中偏出跑道,跑道边灯和飞机受损,30英尺跟丢HUD指引未及时复飞,飞机状态不清晰不掌握。 |
| English translation: Aircraft XXX veered off the runway during the landing process, resulting in damage to the runway edge lights and the aircraft. The aircraft lost the HUD guidance at 30 feet and failed to initiate a go-around in time, with the aircraft’s state being unclear and not under control. | |
| GLM Summary | Chinese text: XXX号机着陆过程中偏出跑道,跑道边灯和飞机受损,是由于机组运行风险管控能力不足,进近和着陆准备不充分。 |
| English translation: Aircraft XXX veered off the runway during the landing process, with damage to the runway edge lights and the aircraft. This was due to the flight crew’s insufficient ability to manage operational risks and inadequate preparation for approach and landing. | |
| BART Summary | Chinese text: XXX号机着陆过程中偏出跑道,机上人员安全,SOP执行不到位,飞机在着陆区中线左侧(约9米)接地(1.55 G)。 |
| English translation: Aircraft XXX veered off the runway during the landing process, with all crew and passengers on board safe. SOPs were not executed properly, and the aircraft touched down on the left side of the landing zone’s centerline (approximately 9 m) with a vertical force of 1.55 G. |
| Original Text | Chinese | 维修部中XXX飞机更换右发,装机前孔探发现低压涡轮叶片进气边根部磨损,该发动机XXXX年XX月第X次大修出厂,修后使用XXX小时XX分,总使用时间XXX小时XX分。 |
| English | In the maintenance department, during the replacement of the right engine for the XXX aircraft, a pre-installation borescope inspection revealed wear at the root of the inlet edge of the low-pressure turbine blade. The engine left the factory for the X overhaul in XXXX, XX month, XXX hours, and XX minutes after repair, and the total use time is XXX hours and XX minutes. | |
| Segmentation Result | 维修部中/XXX/飞机/更换/右发/,装机/前孔/探发现/低压/涡轮/叶片/进气/边根部/磨损/,该发动机/XXXX年XX月/第X次/大修/出厂/,修后/使用/XXX小时XX分,总使用/时间/XXX小时XX分。 | |
| Comments | 25 segmented words in total, 5 incorrect words (in red color), 20 correct words. | |
| summarized Text | Chinese | 飞机换发装机前发现,涡扇发动机低压涡轮叶片进气边根部磨损。 |
| English | Before the replacement and installation of the aircraft engine, it was found that the inlet edge of the low-pressure turbine blade of the turbofan engine was worn at the root. | |
| Segmentation Result | 飞机/换发/装机前/发现/,涡扇/发动机/低压/涡轮/叶片/进气边/根部/磨损。 | |
| Comments | 12 segmented words in total, all correct. | |
| Unsafe Events Feature | Word Frequency | Part of Speech | Unsafe Events Feature | Word Frequency | Part of Speech |
| 发动机 (Engine) | 1398 | noun | 检查 (Inspect) | 1167 | verb |
| 裂纹 (Crack) | 656 | noun | 故障 (Fail) | 377 | verb |
| 工作 (Work) | 557 | noun | 试车 (Trial Run) | 285 | verb |
| 叶片 (Blade) | 547 | noun | 告警 (Warn) | 183 | verb |
| 机务 (Maintenance) | 383 | noun | 断裂 (Breakage) | 155 | verb |
| 涡扇 (Turbofan) | 361 | noun | 超过 (Exceed) | 138 | verb |
| 客舱 (Cabin) | 109 | noun | 起飞 (Take off) | 133 | verb |
| 起落架 (Undercarriage) | 123 | noun | 脱落 (Fall off) | 104 | verb |
| 空中 (Midair) | 122 | noun | 刹车 (Brake) | 90 | verb |
| 导航 (Navigation) | 115 | noun | 渗漏 (Leakage) | 38 | verb |
| No. | Cluster Name | Examples of Unsafe Event Features | Number of Features | Comments |
|---|---|---|---|---|
| 1 | Scene (The location of the flight) | “空中” “地面” “跑道” midair, ground, runway | 3 | The relatively low number of features in this cluster suggests that unsafe events related to location may be rare or easily identifiable. |
| 2 | Personnel and their operations | “机组” “检查” crew, check | 15 | The significance and diversity of personnel operations in aviation safety is highlighted as indicated by the higher number of features. |
| 3 | Oil and gas | “渗漏” “油管” “油箱” leakage, tubing, fuel tank | 15 | The moderate number of features in this cluster indicates that the safe management of fuel systems is crucial for aviation safety. |
| 4 | Aircraft system | “发动机” “机身” “机翼” engine, airframe, wing | 17 | The high number of features in this cluster underscores the prevalence and importance of the main aircraft systems in safety events. |
| 5 | Aircraft subsystem | “涡轮” “轴承” “叶片” turbine, bearing, blade | 23 | With the highest number of features, this cluster suggests that meticulous monitoring of aircraft subsystems may be key to preventing accidents. |
| 6 | Aircraft damage state | “失效” “裂纹” failure, crack | 10 | The moderate number of features indicates that early identification of aircraft damage is crucial for preventing accidents. |
| 7 | Aircraft system/subsystem status | “温度” “密封” temperature, seal | 14 | This cluster serves as a reminder of the necessity to monitor system statuses to prevent failures and accidents. |
| 8 | Aircraft damage | “断裂” “打伤” “脱落” break, hurt, falloff | 7 | Although there are not many features in this cluster, the potential impact of each event can be very serious. |
| 9 | Aircraft status | “发生” “停车” “中转” occurrence, stop, transfer | 17 | With a higher number of features, which may be related to the state changes during aircraft operations, requiring real-time monitoring and management |
| Global Metrics | Formula | Description |
|---|---|---|
| Connects actual edges to possible maximum, indicating closeness of connections between nodes. | ||
| High transitivity means that nodes in the network tend to form tight clusters. | ||
| Note | is the actual total edge number of the network/node xi, k is the number of adjacent nodes to node xi. | |
| Individual Metrics | Formula | Description |
| Counts direct connections to a node. | ||
| Accounts for a node’s connections and their importance. | ||
| Indicates how close a node is to all others, affecting information flow. | ||
| Note | is the shortest path length between node xi and xj. | |
| No. | Event Feature | CC | DC | EC | No. | Event Feature | CC | DC | EC |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Inspect | 0.638 | 0.600 | 21.624 | 8 | Turbofan | 0.556 | 0.367 | 14.611 |
| 2 | Engine | 0.622 | 0.558 | 21.476 | 9 | Fuel Pump | 0.553 | 0.367 | 16.309 |
| 3 | Landing | 0.561 | 0.383 | 14.641 | 10 | Trial Run | 0.553 | 0.358 | 16.233 |
| 4 | Ground | 0.558 | 0.375 | 15.866 | 11 | Switch On | 0.553 | 0.358 | 15.918 |
| 5 | System | 0.558 | 0.375 | 15.526 | 12 | Temperature | 0.553 | 0.358 | 15.910 |
| 6 | Crew | 0.558 | 0.375 | 13.890 | 13 | Pressure | 0.553 | 0.375 | 15.780 |
| 7 | Abnormal | 0.556 | 0.367 | 15.986 | 14 | Alarm | 0.553 | 0.358 | 14.425 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Xia, R.; Yu, J.; Liu, Q.; Tong, S.; Xu, Z. From Text to Safety: A Novel Framework for Mining Unsafe Aviation Events Using Advanced Neural Network and Feature Network. Aerospace 2024, 11, 843. https://doi.org/10.3390/aerospace11100843
Wang Q, Xia R, Yu J, Liu Q, Tong S, Xu Z. From Text to Safety: A Novel Framework for Mining Unsafe Aviation Events Using Advanced Neural Network and Feature Network. Aerospace. 2024; 11(10):843. https://doi.org/10.3390/aerospace11100843
Chicago/Turabian StyleWang, Qiang, Ruicong Xia, Jiayang Yu, Qiuhan Liu, Sirong Tong, and Ziling Xu. 2024. "From Text to Safety: A Novel Framework for Mining Unsafe Aviation Events Using Advanced Neural Network and Feature Network" Aerospace 11, no. 10: 843. https://doi.org/10.3390/aerospace11100843
APA StyleWang, Q., Xia, R., Yu, J., Liu, Q., Tong, S., & Xu, Z. (2024). From Text to Safety: A Novel Framework for Mining Unsafe Aviation Events Using Advanced Neural Network and Feature Network. Aerospace, 11(10), 843. https://doi.org/10.3390/aerospace11100843