1. Introduction
Satellites have the important task of promoting national economy, national defense security, and scientific research development. The in-orbit health assessment of satellite components can make use of limited computing resources for real-time information processing, improving the level of self-management of satellites in orbit. Concurrently, it furnishes a foundation for decision-making regarding in-orbit maintenance, system-level and full-satellite health assessment, and telemetry transmission optimization [
1]. The delicate structure of spacecraft components [
2,
3] and the complex orbital environment all pose significant challenges for satellite components to undergo in-orbit health assessment research [
4,
5].
With the rapid development of the aerospace industry and the increase in data from long-term satellite operations in orbit, data-based health assessment research has become a hot topic. Researchers have gradually applied intelligent algorithms such as feature extraction, data fusion, and transfer learning to the research of health assessment of satellite components. The research directions can be divided into three main categories: remaining life, probability of fault, and degree of condition deviation. Of these three directions, assessing components by predicting their remaining life [
6,
7,
8,
9,
10,
11] and their probability of fault [
12,
13,
14,
15,
16] is currently the dominant health assessment perspective [
17]. Islam et al. [
18] utilized the LSTM prediction method to predict the remaining service life of satellite reaction wheels. By utilizing a large amount of satellite data, Huang et al. [
19] established a degradation model to predict the remaining lifetime of in-orbit satellites. Song et al. [
20] proposed a hybrid method combining an IDN-AR model and PF algorithm to improve the accuracy of predicting the remaining life of lithium-ion batteries in satellites. Islam et al. [
21] used time-series forecasting methods to predict the faults of satellite reaction wheels. Suo et al. [
22] proposed a data-driven fault diagnosis strategy combining the fast iterative method and support vector machine, and verified its effectiveness using satellite power system data. Varvani Farahani et al. [
23] proposed an enhanced data-driven fault diagnosis method based on the support vector machine approach, which can achieve high-precision detection of the faults in satellite gyros. Chen et al. [
24] considered the performance degradation of actuators and used the transfer learning method for the fault detection of complex systems.
However, component lifetime is heavily influenced by random environments and is difficult to verify. The analysis of component fault probability requires a large sample of faults, which is often difficult to obtain [
25]. The health assessment of components through the degree of state deviation is a novel research perspective proposed in recent years. It does not rely on a priori knowledge, has low sample requirements, and is easy to validate. However, the study of in-orbit real-time health assessment for satellite components with complex periodic changes, precise structure, and challenging mechanism modeling is still in its early stages [
26].
In terms of the selection of characteristic parameters for health assessment research, most of the current research uses a single parameter for analysis. Although a single key characteristic parameter reflecting performance degradation selected through expert experience can show the trend of the component’s health status, it is difficult to fully describe the working characteristics of the component with a single parameter. A reasonable weighting must be assigned when considering multiple parameters. There are two main types of methods for assigning weights: subjective weighting methods [
27,
28] and objective weighting methods [
29,
30,
31]. Different weighting methods have their own advantages and disadvantages. The results of weight assignment directly affect the final results of the health assessment. Therefore, appropriate methods must be adopted for the weighting of multiple parameters. The Criteria Importance through Intercriteria Correlation (CRITIC) method determines weights based on the strength of comparison between different parametric data and the correlation between parameters, but does not reflect the degree of dispersion of the individual parametric data themselves [
32,
33]. The entropy weighting method is a multicriteria decision analysis method mainly used for determining the weights of parameters. Its basic idea is to determine the weights of each parameter in the parameter set by calculating the information entropy value of each parameter. However, it does not take into account the relationships between different parameters [
34]. Combining the CRITIC method with the entropy weight method can make the weight assignment results more objective, reasonable, and reliable.
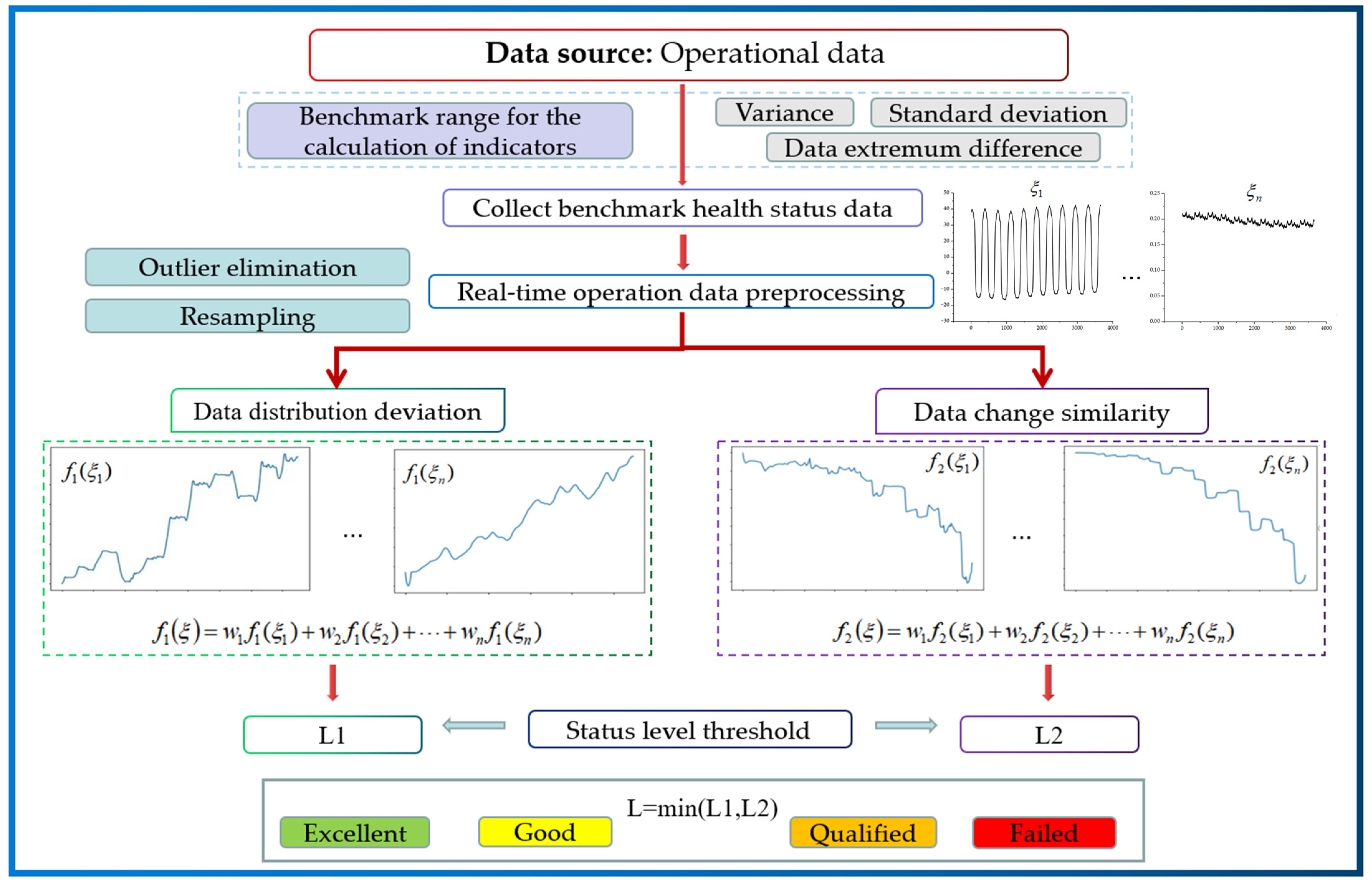
This study focused on the in-orbit health assessment of key satellite components. It presented a new universal health assessment method based on the multiparametric data distribution characteristics from the perspective of describing the deviation of component health status. The main innovations are as follows: (1) rearranging the operational data, and then characterizing the operational data from the perspective of data distribution deviations (DDD) and similarity of operational data changes (SOC). This addresses the difficulty of analyzing trends in state change with short-term data; (2) fusing the CRITIC weighting method and the entropy weighting method to assign weights to the health characteristic parameters selected using expert experience and mechanism analysis. This approach addresses the difficulty of fully describing the operating characteristics of a component with a single parameter and avoids excessive subjective influences. This leads to a component health assessment model; and (3) the empirical mode decomposition algorithm, which is used to extract the trends of DDD, differences in the similarity of operational data changes (DSOC), and original data after preprocessing. The validity and reliability of the method was verified by comparison and analysis.
3. A Single-Parameter Health Assessment Method Based on Data Distribution Characteristics
3.1. Selection and Benchmarking of Component Health Characteristic Parameters
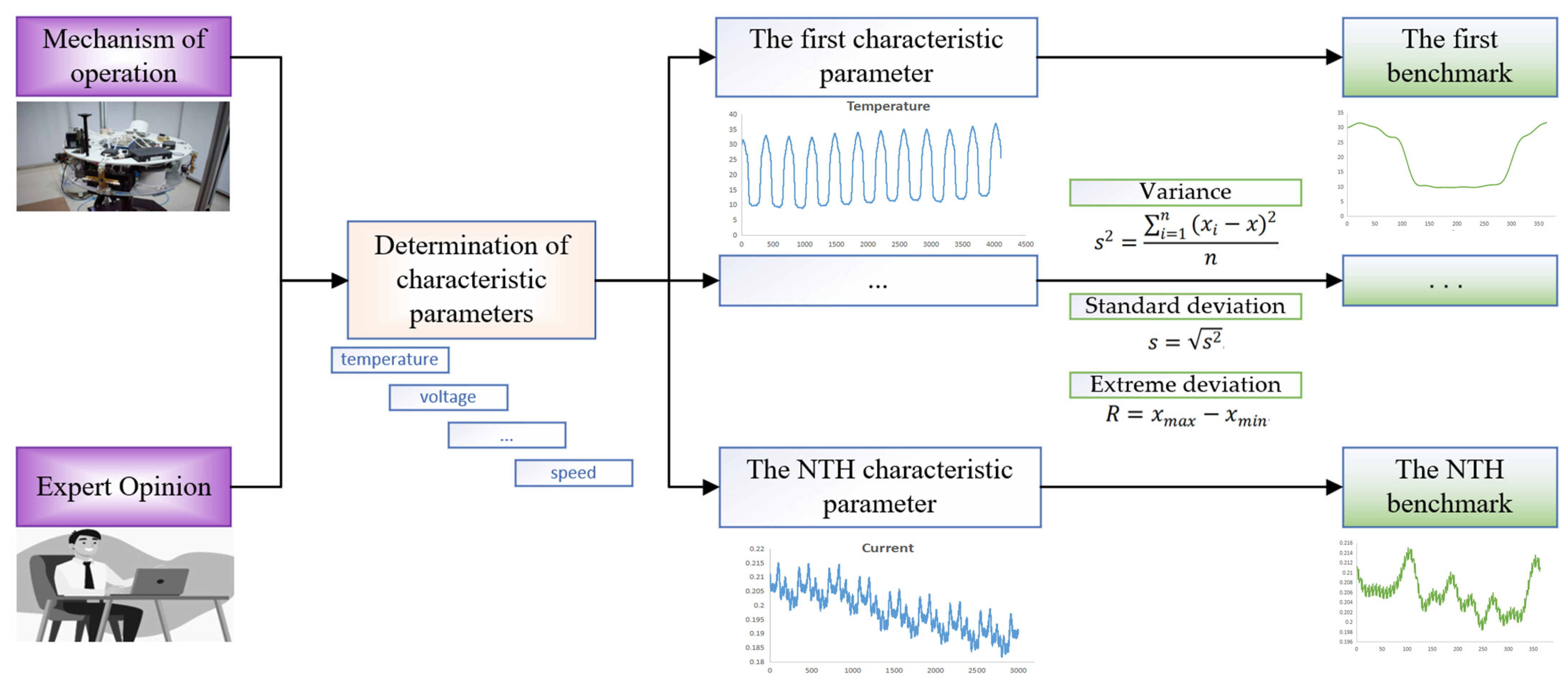
To carry out a component health assessment study, it is necessary to first select the main health characteristic parameters that reflect changes in the health status of the component. The selection of health state characteristic parameters is based on two main considerations: (1) the analysis of the working mechanism: by analyzing the working mechanism of the component, the main health characteristic parameters that reflect the changes in the health status are selected. (2) Referring to expert experience: experts in the field have studied the target component for a long time and are familiar with the parameters that characterize the health status of the component. Therefore, reference to expert opinion can considerably improve the validity and relevance of the parameters selected for assessment.
Describing the degree of deviation of a parameter must determine the health state benchmark for each parameter, which is a difficult task. Historical data from similar satellites can be analyzed to determine the benchmark range, which facilitates the subsequent real-time in-orbit health assessments of the satellites. For data where satellite components exhibit complex cyclical changes, no performance degradation or fault in the initial state of smooth operation of the component, the first full cycle or the first few full cycles can be selected as the health status benchmark. First, the first few cycles are preprocessed with outlier elimination, resampling, and data completion. Then, the variance, standard deviation, and extreme deviation of the operational data are used to quantify the most stable period of the component’s operation as a benchmark.
The aforementioned method is illustrated in
Figure 2.
From the abovementioned analysis, the first prerequisite for the application of this method is clear: health benchmark data need to be collected in advance and no health assessment is carried out at this stage. Any abnormalities in the operational data of the component in the first cycle are considered as initial configuration problems or initial faults of the component. Long-term health status monitoring and assessment are not carried out.
3.2. Single Parametric Deviation Calculation Based on Data Distribution
This study presented a method for describing the health status of parametric data based on the combination of DDD and SOC. The maximum mean discrepancy (MMD) algorithm was used to calculate the distribution discrepancy between real-time operational data and benchmark data. The Pearson correlation coefficient was used to calculate the similarity of change between operational data and benchmark data after rearrangement.
MMD enables the accurate calculation of the variation in data distribution deviation. However, there are two drawbacks: (1) its inability to measure the difference between same-value data changes, and (2) its insensitivity to local data changes. The Pearson correlation coefficient has interpretability, robustness, and a hypothesis-testing process. Meanwhile, the range of its results allows it to compare the correlation of different datasets without being affected by the size of the dataset. The advantages of the Pearson correlation coefficient calculations are as follows: (1) the accurate measurement of data-change similarity, and (2) sensitivity to local data changes and the ability to capture initial anomalous data in a timely manner. However, factors that do not affect change similarity, such as amplitude, cannot be measured. The two approaches measure the variation of component data from different perspectives. The combination of DDD and SOC provides an accurate, complete, and reasonable description of the variation of data distribution.
3.2.1. Data Distribution Deviations
The maximum mean discrepancy (MMD) is an algorithm that has been widely used in migration learning in recent years. It can characterize data distributions: the maximum of the difference between the expectations of two distributions is mapped by an arbitrary function
in a well-defined function F [
36,
37,
38]. It is primarily used to measure the distance between the distributions of two different, but related, random variables. The MMD measures distance by calculating arbitrary order moments for two variables. If the results are the same, the distribution is consistent, and the distance is 0. If they are different, the distance is measured by the maximum difference.
The basic definition formula is as follows:
The meaning of this equation is to find a mapping function that maps a variable to a higher dimensional space. The difference between the expectations of the two random variables of the distribution after mapping is called Mean Discrepancy. Then, the upper bound of this Mean Discrepancy is determined, the maximum value of which is the MMD.
The key to MMD is to find a suitable φ(x) as a mapping function, but the target mapping function varies with the task and is difficult to pick or define. Therefore, the kernel trick is used and the key to the kernel trick is to find the inner product of two vectors without explicitly representing the mapping function [
39]. The MMD is squared, simplified to obtain the inner product, and expressed as a kernel function. After a derivative calculation, the MMD algorithm can be reduced to matrix form, as follows [
40,
41]:
In Equation (6), the matrix K represents the kernel matrix computed by the Gaussian kernel function. In Equation (7), n represents the number of samples in the source domain, while m represents the number of samples in the target domain.
For the results of the MMD calculation, the health degree of the data distribution deviations (HDDD) can be defined as Equation (8):
3.2.2. Similarity of Operational Data Changes
Calculating data similarity is generally considered in terms of operational data variation. The difference in sample change is described by calculating the Pearson correlation coefficient. The Pearson correlation coefficient between two variables is defined as the quotient of the covariance and standard deviation between the two variables [
42,
43]:
In Equation (9), the numerator is the covariance of two variables. Covariance is the degree to which two variables vary together when they are randomly changing. The denominator in the equation is the product of the standard deviations of each variable. Standard deviation is used to measure the variability of a variable, which is the square root of the average of the squared deviations of each data point from the mean.
For Pearson calculations, the difference between the real-time operational data changes and the benchmark data changes of a component can be defined as Equation (10):
It should be noted that if the data changes are negatively correlated, that is, SOC < 0, it indicates a fault or anomaly. Therefore, when the DSOC result is greater than 1, it also indicates that the component’s health status is very poor.
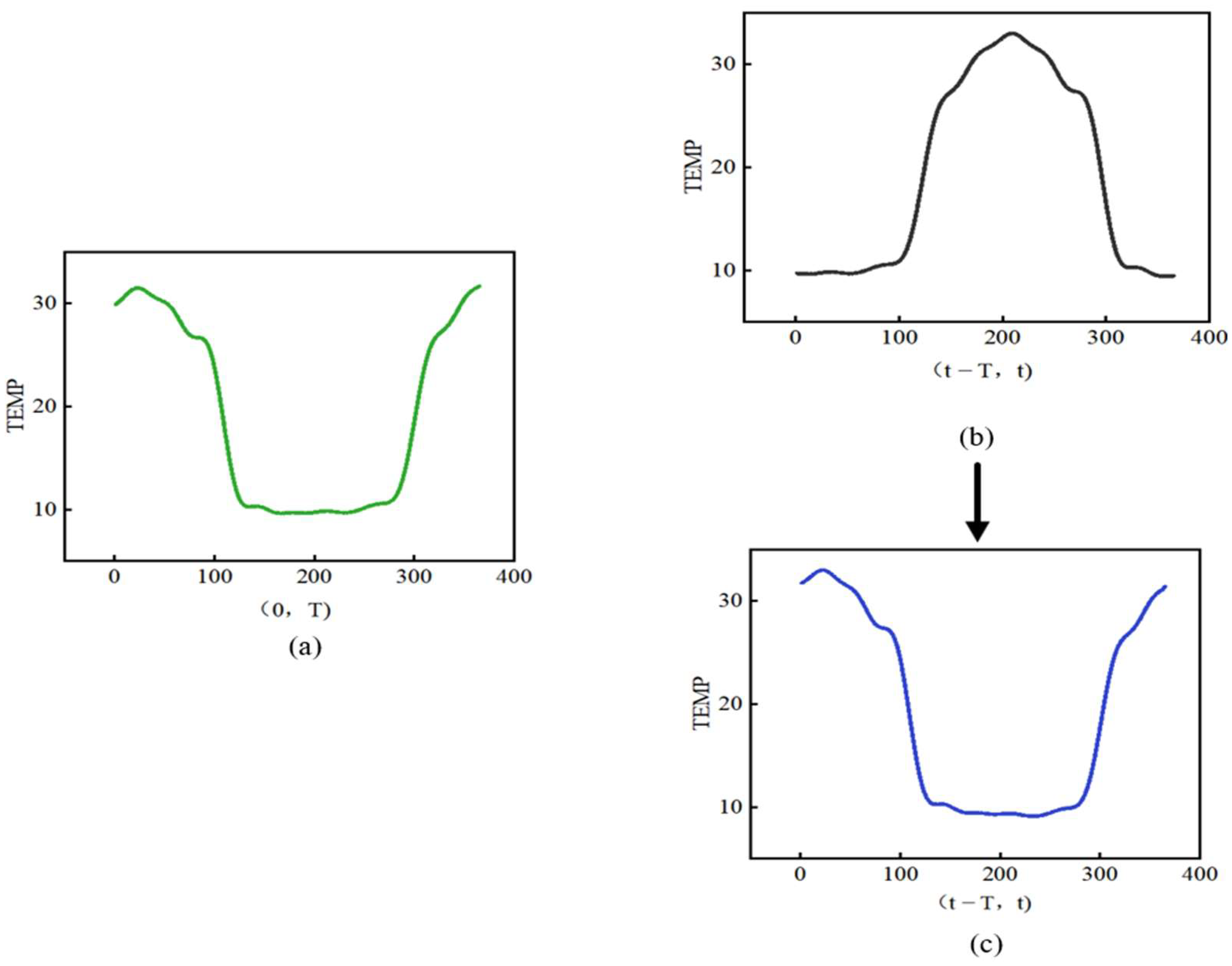
For smoothed data, it is straightforward to calculate the SOC between the health state benchmark data and the real-time operational data. However, for data with complex cyclical changes, the real-time operational data need to be rearranged. To maintain a consistent trend between the change in data for the most recent full cycle where the assessment point data are located and the change in health status benchmark data, the method of operation is to fill in the corresponding position state data of the last orbital cycle by replacing them with real-time in-orbit operational data. The Pearson coefficient is then calculated to analyze the similarity of change. The effect is shown in
Figure 3.
The DDD before and after rearrangement are the same as those calculated for the ideal health benchmark data. However, the variation in SOC is significant. This difference is not due to the poor operational status of the data, but mainly to the different points in time of the assessment. Such effects can be eliminated by rearranging and analyzing the differences between the operational and benchmark data changes.
3.3. Single Parametric Health Assessment Based on HDDD and SOC
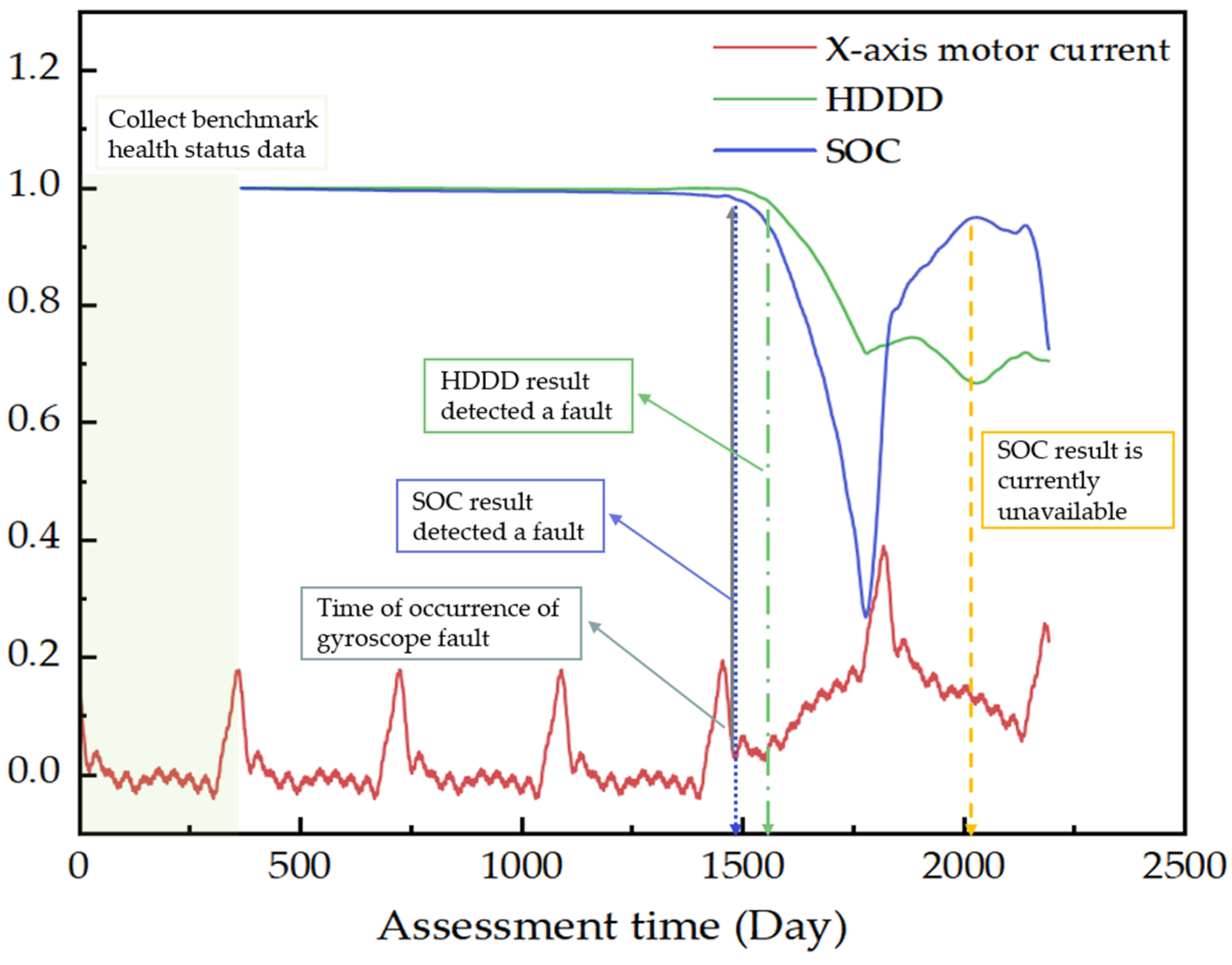
The motor current is an important health characteristic parameter of the gyroscope component. Taking the preprocessed X-axis motor current of a gyroscope component with a fault as an example, the single-parameter health state description method presented in this paper is shown in
Figure 4. During in-orbit health assessment, the benchmark data of the current health status should be collected first. Following data collection, the HDDD and SOC of the current data should be calculated separately. From the start of the assessment until day 1500, both HDDD and SOC exhibited only a slow and slight downward trend. From
Figure 4, it can be seen that a fault occurred around day 1500, when the current data became abnormal. Soon after, the SOC result decreased significantly, indicating an abnormal health status of the component, which reflects the advantage of SOC in detecting changes in component status in the early stage. After a period of time, the HDDD result also decreased to a certain extent, indicating a change in the component status. However, after day 1760, due to the increasing similarity between the real-time current operating data and the baseline data, the SOC result showed an upward trend, and temporarily became invalid on day 2000. At this point, the HDDD perfectly compensated for the deficiency of the SOC in assessing data changes when the data amplitude was different, but the similarity was high. In summary, the DDD and SOC analyze the health status of parameters from different perspectives, complementing each other. Combining DDD and SOC can accurately, reasonably, and comprehensively describe the health status changes of a single parameter.
4. Multi-Parameter Component Evaluation Model and Verification Method
4.1. Establishment of Multi-Parameter Component Evaluation Model
The objective of the weighting model is to accurately and scientifically reflect the importance of the different parameters. The main health characteristic parameters selected through work mechanism analysis and expert experience can exclude the influence of irrelevant parameters. Irrelevant parameters mainly include parameters that cannot significantly reflect the changes of component health status, flag bits, etc. In this case, the use of the subjective weighting method cannot avoid the influence of strong subjectivity. The objective weighting method relies solely on the data and can yield more reasonable results. The entropy method and the CRITIC method complement each other, and the combination of the two can yield more reasonable weight results.
4.1.1. CRITIC Method
The CRITIC (Criteria Importance through Intercriteria Correlation) method is an objective weighting method. The idea is to compare the intensity and conflicting indicators [
44]. The intensity of the comparison is expressed using the standard deviation, with a higher standard deviation of the data indicating greater fluctuations and a higher weighting. Conflict is expressed using the correlation coefficient. The higher the value of the correlation coefficient between parameters, the less conflicting it is. Therefore, the more information that is repeated in the evaluation content, the lower the weighting will be. For multi-parameter comprehensive evaluation problems, the CRITIC method can eliminate the influence of some highly correlated parameters, reducing the overlap of information on the parameters. This is more conducive to obtaining credible evaluation results [
45].
The steps to model the configuration of the parameter weights are as follows.
- (1)
Normalization of data for each parametric indicator.
- (2)
Calculation of indicator variability.
In Equation (13), denotes the standard deviation of the jth parametric indicator.
- (3)
Indicator conflict calculation.
In Equation (14), denotes the correlation coefficient between the ith parametric indicator and the jth parametric indicator.
- (4)
Calculation of information volume.
The greater the amount of information reflected by a parameter, the greater the role of that parameter in the overall picture and the greater the weight should be given.
- (5)
Determining weights.
Based on the above analysis, the objective weight for parametric indicator j is:
4.1.2. Entropy Method
Compared with subjective assignment methods such as Delphi and hierarchical analysis, the entropy method is more objective and better able to interpret the results [
46]. It uses the variability between information to assign weights and avoid bias caused by human factors.
The steps to build an entropy-weighted configuration model of the parametric capacity indicator system are as follows [
47,
48].
- (1)
Determining the objective function.
Construct an objective function for the objective weighting model of a performance indicator based on the criterion of great entropy of information entropy theory:
In Equation (17), denotes the jth performance indicator weight for the ith capability. There are a total of m performance indicators describing that capability.
- (2)
Determining constraints.
First, the weight sum is 0. Second, the weight value is greater than 0. Third, the ability of different covariate degradation amounts to reflect the overall degradation trend is calculated, and constitutes a parametric capacity variability constraint. It is also necessary to standardize and make dimensionless the parametric indicators here.
- (3)
Constructing an entropic configuration model of the capacity indicator system.
Based on the abovementioned objective function and constraints, the following objective planning is established to solve for the objective weights of the performance indicators for the ith capability.
Analyzing the objective function, the Hessian matrix of the objective function is as follows:
Since > 0, then |H| > 0. The objective function is convex and the constraints are linear, so it is a convex set. Therefore, the weight allocation model is a convex programming problem on a convex set, and then there must be a unique optimal solution. This leads to the optimal weight assignment of the covariates.
The weights
and
are calculated for each covariate under the CRITIC method and the entropy weight method, respectively. The formula for calculating the combined weight of the covariates is shown in Equation (20):
Based on this, a multi-parameter component health assessment model can be established, as shown in Equation (21):
When i = 1, it represents the component DDD model, and when i = 2, it represents the component SOC model. Additionally, the model can be utilized to calculate the component’s HDDD and DSOC. The model’s corresponding thresholds for different health states were determined through testing with historical data from similar satellites. Once the ideal health state benchmark data for the component are collected, real-time health assessment of the component can be carried out in orbit.
As can be seen from the above-shown analysis, the second prerequisite for the application of this method is that a relatively sufficient sample set of component data is available. This facilitates the testing of algorithms to determine reasonable thresholds for different health status levels.
4.2. Verification of Component Health State Variation Trends Based on Empirical Mode Decomposition
The accuracy and validity of the method can be verified by comparing and analyzing the variation trends extracted from the component DDD, the differences in the similarity of operational data changes (DSOC), and the original data after preprocessing. The current mainstream trend extraction algorithms such as low-pass filtering, least squares, and mean slope methods all require a pre-determined type of trend term for the parametric data [
49]. Yet there are so many satellite component parameters that it is impossible to determine the trend of the parameters in advance. The Empirical Mode Decomposition (EMD) algorithm is adaptive and does not require the type of change in the trend term to be determined in advance. This makes it very suitable for trend extraction and comparative analysis [
50,
51].
The key to the EMD is modal decomposition. The complex data series is decomposed into a finite number of intrinsic mode functions (IMF) and a residual r(t), which is the underlying trend term. The method can be smoothed to handle non-linear, non-smooth data. The EMD method is essentially a way of decomposing the data by the characteristic time scale of the data to ‘filter’ out the eigenmodal function components. The original data series can be expressed as a sum of n IMFs and a residual
, as shown in Equation (22):
The stopping condition for the EMD is that the residual is a monotonic function, so that it is the trend term of the original data series. Therefore, the residuals obtained from the EMD method can be used to efficiently and accurately extract the trends from the data without providing any a priori basis functions.
As the trend term extracted by the EMD algorithm reflects the trend of the overall data, DDD and DSOC can also reflect the degree of deviation from the overall data. Therefore, the EMD algorithm can be employed to extract the change trend of preprocessed raw data, DDD, and DSOC. The validity and accuracy of the method can be verified by calculating the similarity of the three trend lines and analyzing the correlation of changes.
5. Experiment and Verification
5.1. Benchmarking Based on Indicators
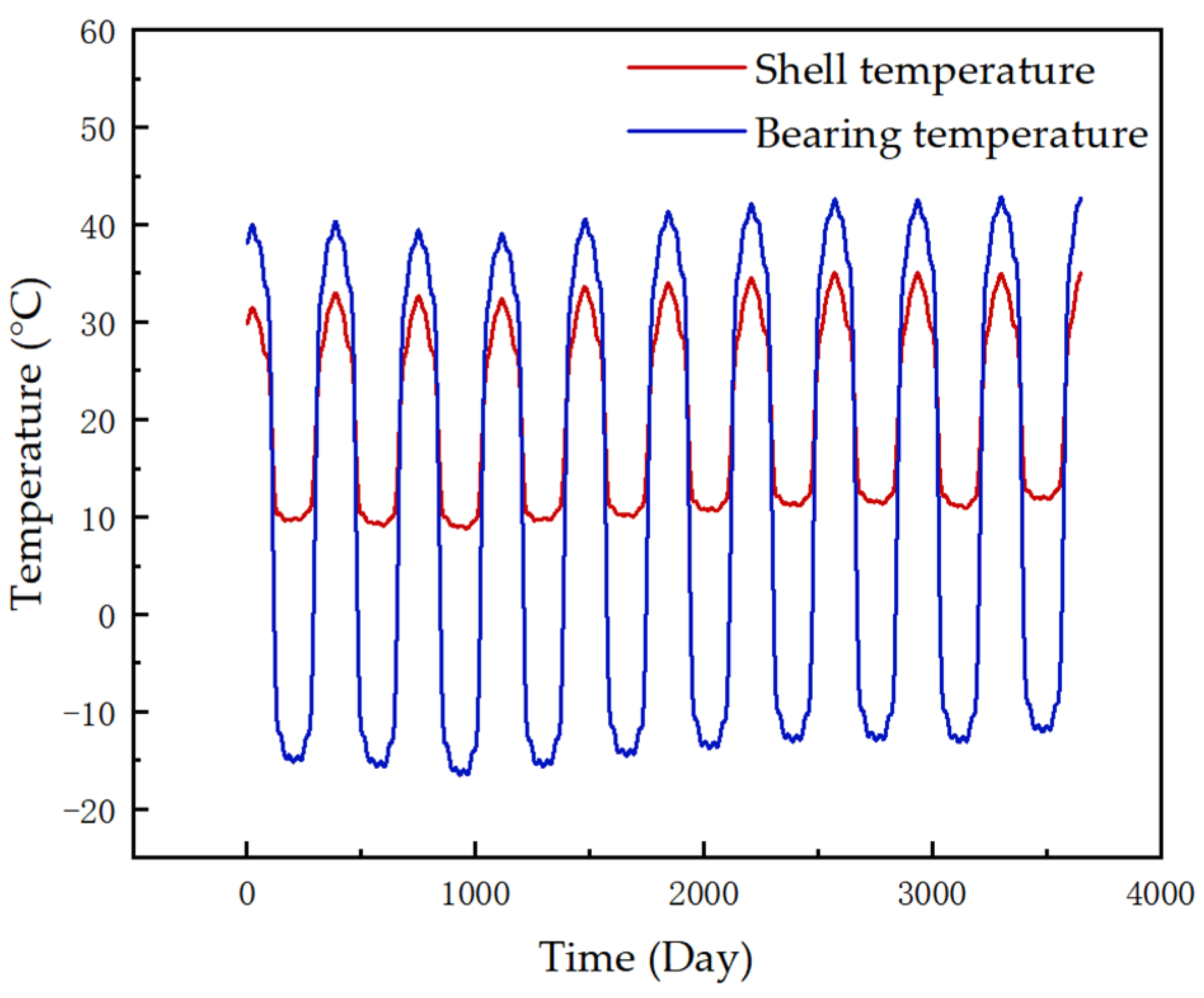
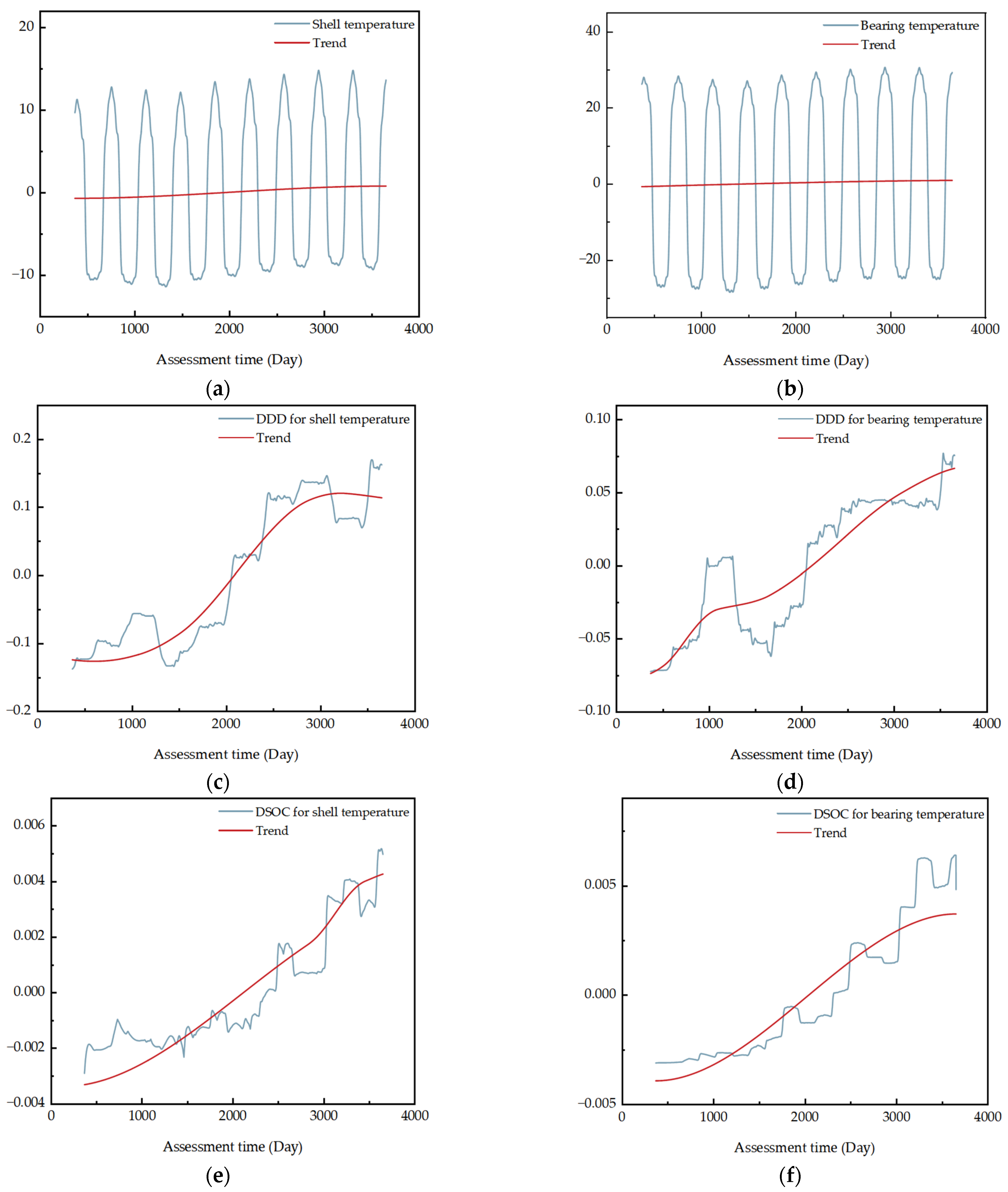
A solar sail component was used as an example to validate the health assessment method described in this paper. The solar sail is a key component of the satellite’s energy system and temperature data best reflect trends in the component’s health status. Two parameters, bearing temperature and shell temperature, were selected for the south solar sail. The sources of the data were telemetry data from a satellite. The two-parametric-decade-run data after preprocessing are shown in
Figure 5.
The initial phase of the component run data is more stable. The benchmark is quantified by the variance, standard deviation, and data extreme difference for different cycle quantities of data. The indicators are calculated as shown in
Table 1.
Based on the results of the indicator calculations, it can be found that when the benchmark data are taken as the first full cycle data, all three indicators are the smallest. This indicates the most stable operating data and the best operating condition of the components. Hence, the first-cycle operating data are the most suitable as the ideal health benchmark data.
It is important to note that in order to avoid calculation errors caused by the different magnitudes of parameters, it is necessary to standardize different parameter benchmarks to the same amplitude after collecting the benchmark data.
5.2. Establishment of a Solar Sail Health Assessment Model
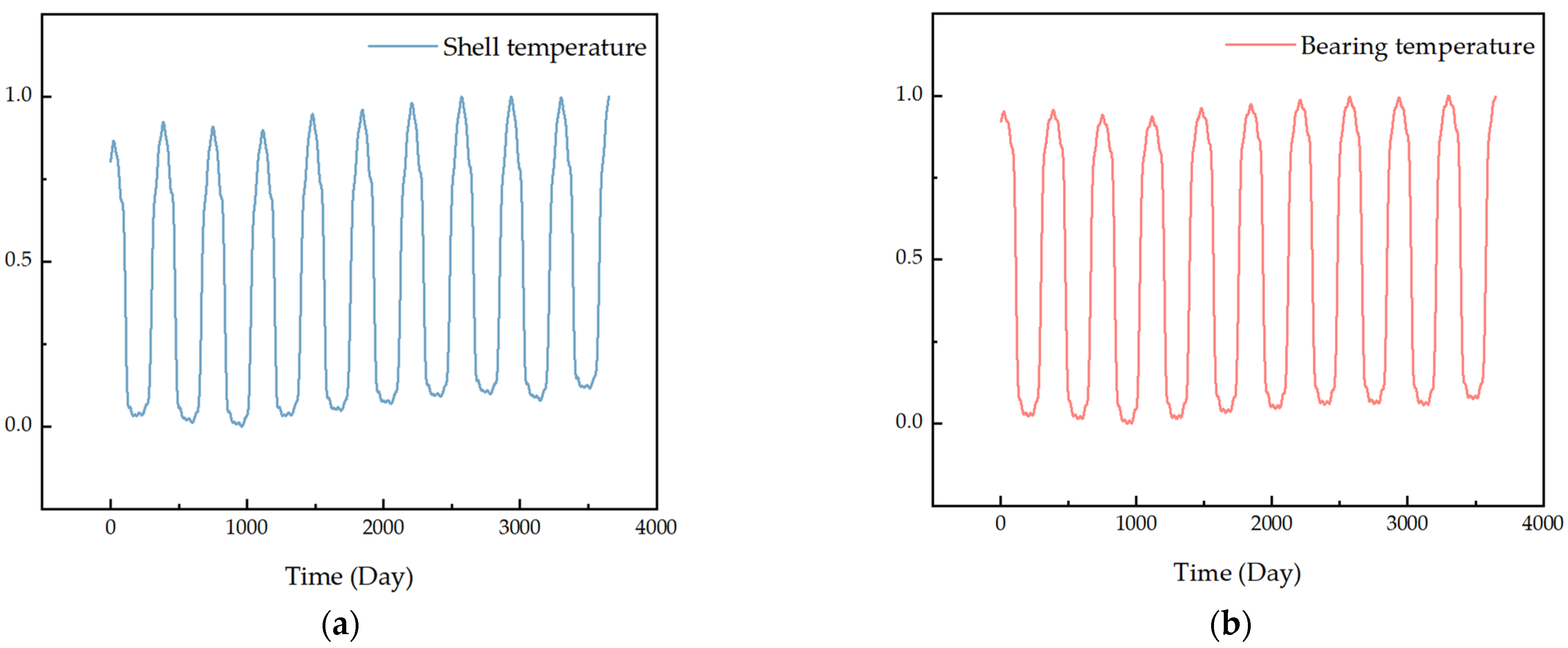
The full life cycle shell and bearing temperature data for a stable operating solar sail were normalized positively and the results are shown in
Figure 6. The parameter weights were calculated by the entropy weight method and CRITIC method, and the mean value was taken as the final weight. The results are shown in
Table 2.
With a combined shell temperature weight of 0.4821 and a combined bearing temperature weight of 0.5179, the evaluation model is shown in Equation (23):
5.3. Solar Sail Health Status Assessment
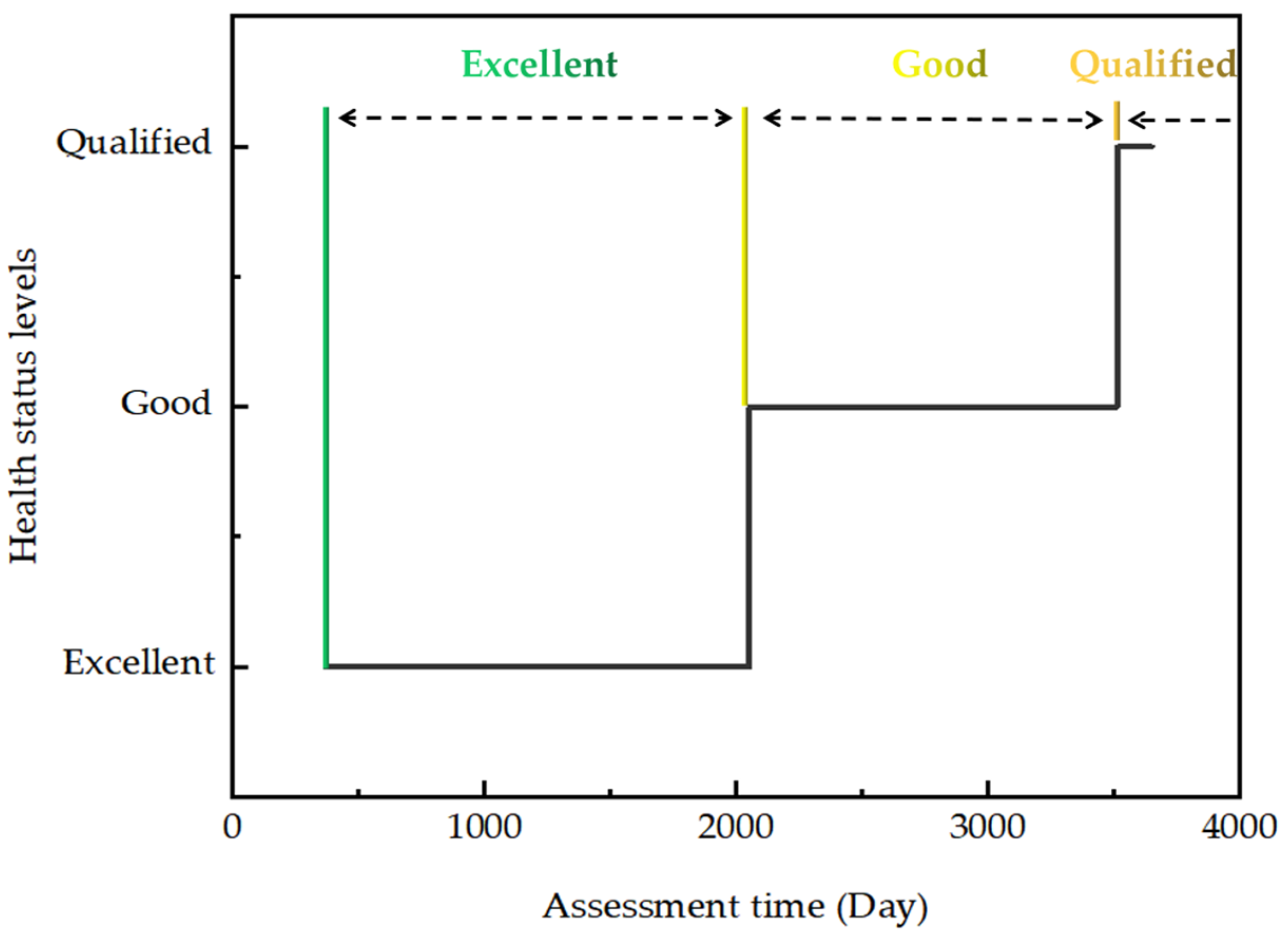
Solar sail temperature data have high stability requirements. After testing a large number of historical data, 0.95, 0.9, and 0.85 were used as the thresholds for the “Excellent”, “Good”, and “Qualified” status levels based on HDDD, respectively. The cycle variation data should ideally be perfectly positively linearly correlated, i.e., p = 1, and in this case, T = 365, so the sample size is richer. In addition, because of the high reliability requirements of the components, the conventional Pearson correlation coefficient thresholds cannot be used as a basis for the health status classification. Therefore, 0.99, 0.98, and 0.97 were chosen as the thresholds for the “Excellent”, “Good”, and “Qualified” status levels based on SOC, respectively. “Excellent” means that the component is in excellent operating condition and can perform all tasks stably. “Good” means that the component is in good operating condition and can perform most tasks. “Qualified” means that the component is in average operating condition and can only perform some tasks with low performance requirements. A result below the “Qualified” threshold is considered a component fault. It should be noted that there should be a difference in the selection of thresholds for components with high precision requirements and those with low performance requirements.
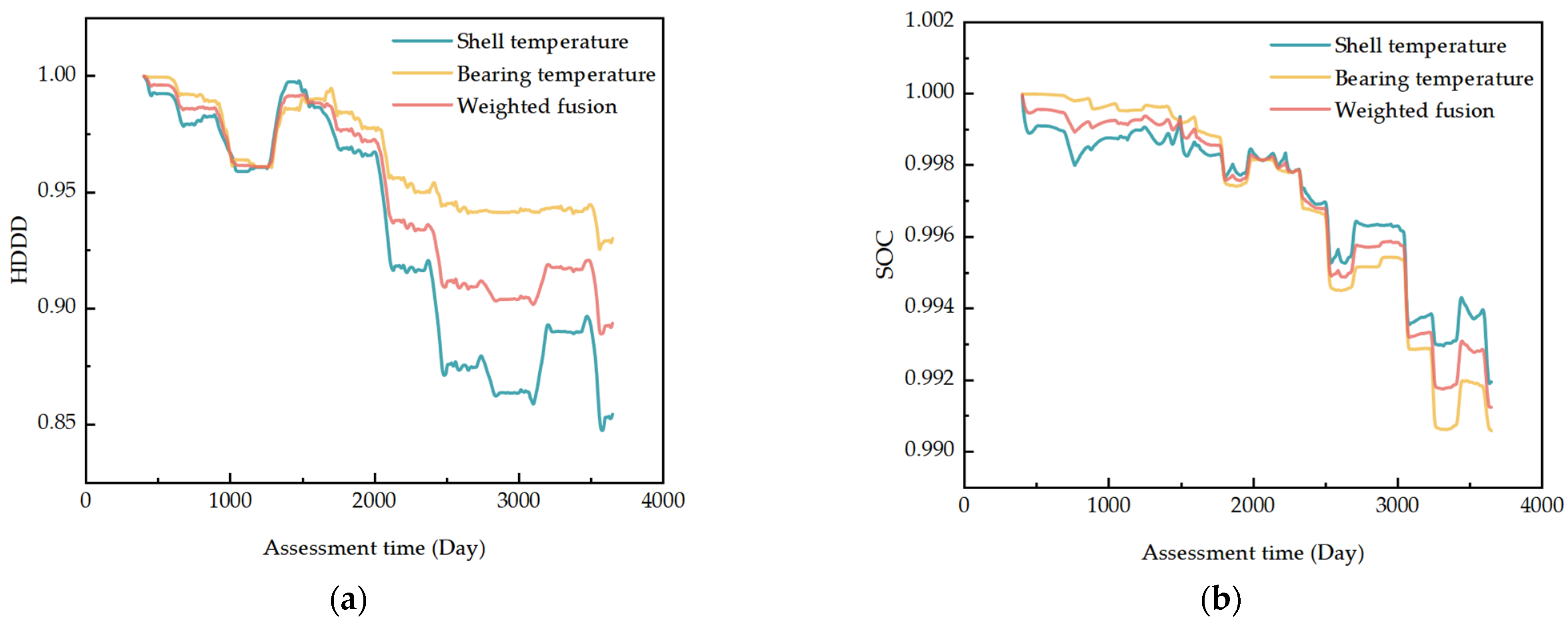
According to the benchmark determined by the index calculation, HDDD and SOC were calculated separately for shell temperature data and bearing temperature data. The results are shown in
Figure 7.
The original data showed a downward and then an upward trend, and the fourth-cycle data were most similar to the benchmark data distribution. Thus, the health of the data distribution showed a significant upward trend in the fourth cycle period. This indicates that the MMD algorithm is able to accurately sense changes in the data distribution, consistent with the actual situation. As the MMD is mainly influenced by the bottom region where the data are more predominant in the calculation of this example data, the health of the component data changes more when it is run to that stage. At the same time, the data selected are stable operational data without faults and abnormalities. Therefore, the similarity results are good and show an approximate monotonic downward trend. It can also be seen from the calculations that the weighted data distribution health indicator HDDD and the SOC trend more smoothly and more closely align with the actual component performance trends. The variation in component status levels in the example is mainly influenced by DDD. The variation in health status levels is shown in
Figure 8.
5.4. Verification of Component Health State Variation Trends
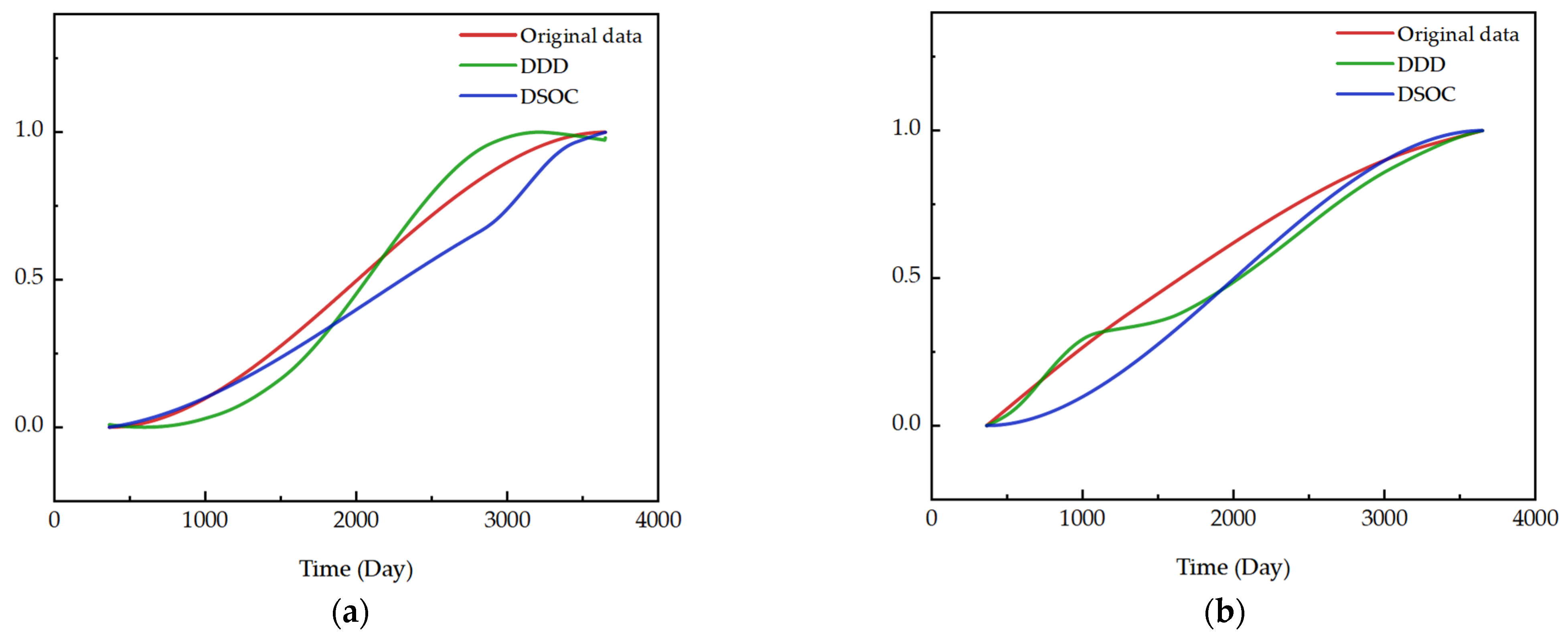
Based on the principle of the algorithm, the data were first zeroed to the mean value separately. The trends in the original data, the results of the DDD calculations, and the results of DSOC were then extracted. The results are shown in
Figure 9.
The normalized comparison plots of original data trends after preprocessing, DDD trends, and DSOC trends of the two parameters’ data are shown in
Figure 10. The reason for the differences in the details of trend changes is that different algorithms have different principles for describing data changes.
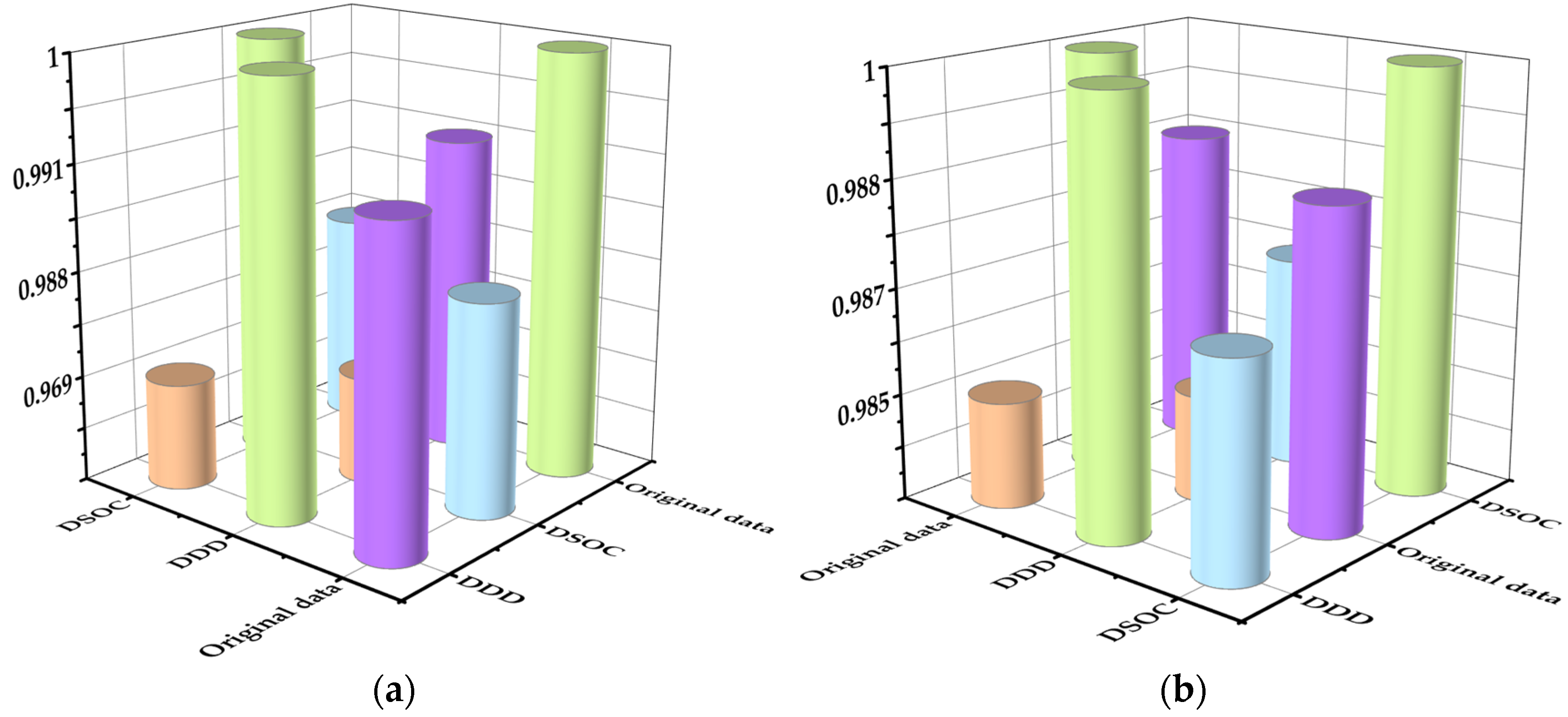
The Pearson correlation coefficient was used to calculate the trend change correlation and the results are shown in
Figure 11.
From the calculation results, it can be observed that the original data trend, the trend of DDD, and the trend of DSOC were highly correlated. This verifies the accuracy and validity of the health assessment method utilized in this paper.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}