
Ernie-Gram BiGRU Attention: An Improved Multi-Intention Recognition Model for Air Traffic Control

Abstract
:1. Introduction
2. Challenges
- (1)
- Model performance problem: Most of the intention recognition models currently studied are mainly used as a sub-module in the ATC monitoring system [17], so most scholars’ work is mainly focused on improving the overall performance of the system. This results in a lack of in-depth research on the intention recognition sub-module. It is necessary to apply the latest technology to the field of ATC and build a model with high performance and good compatibility.
- (2)
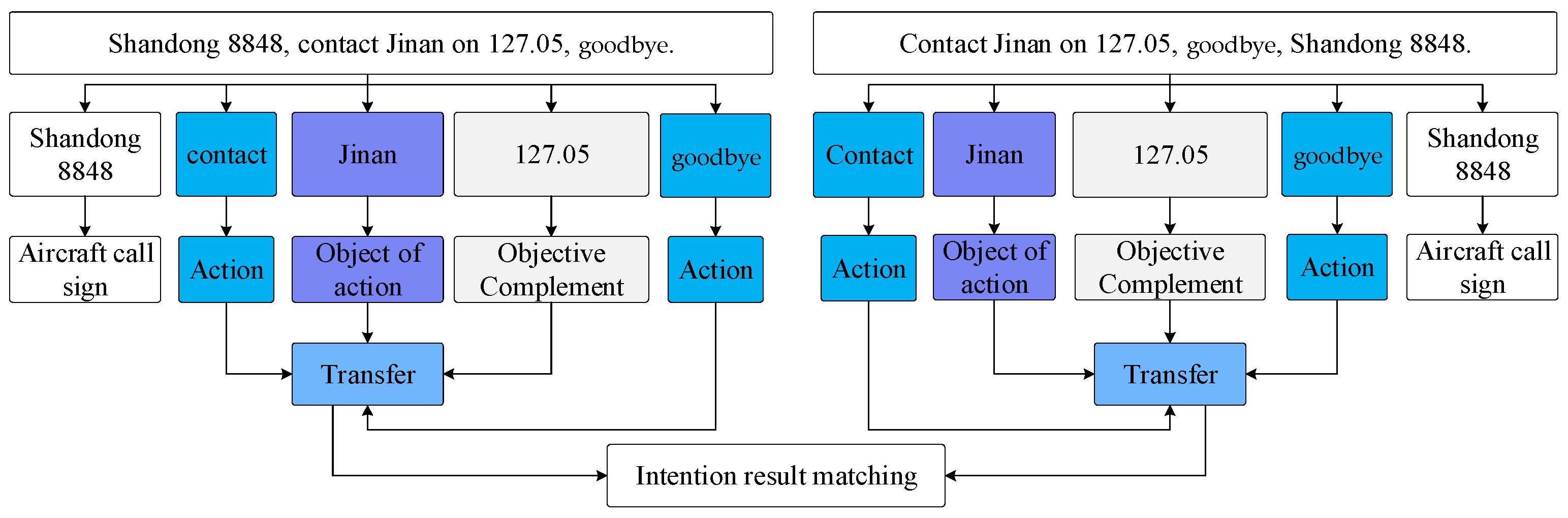
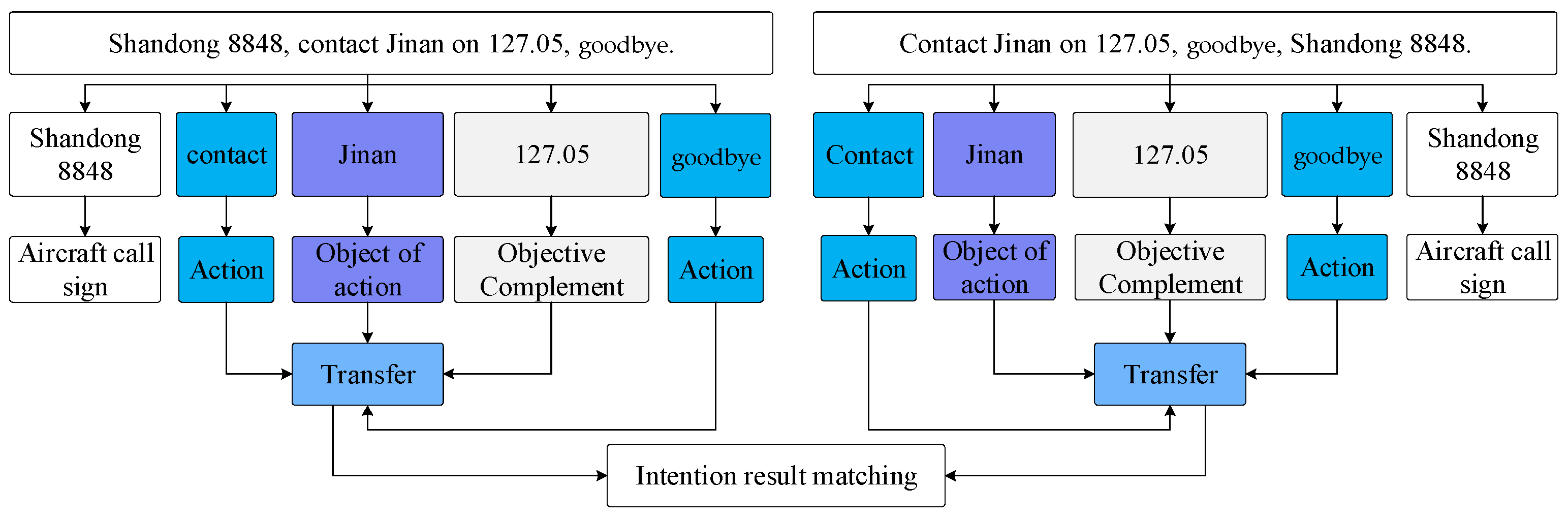
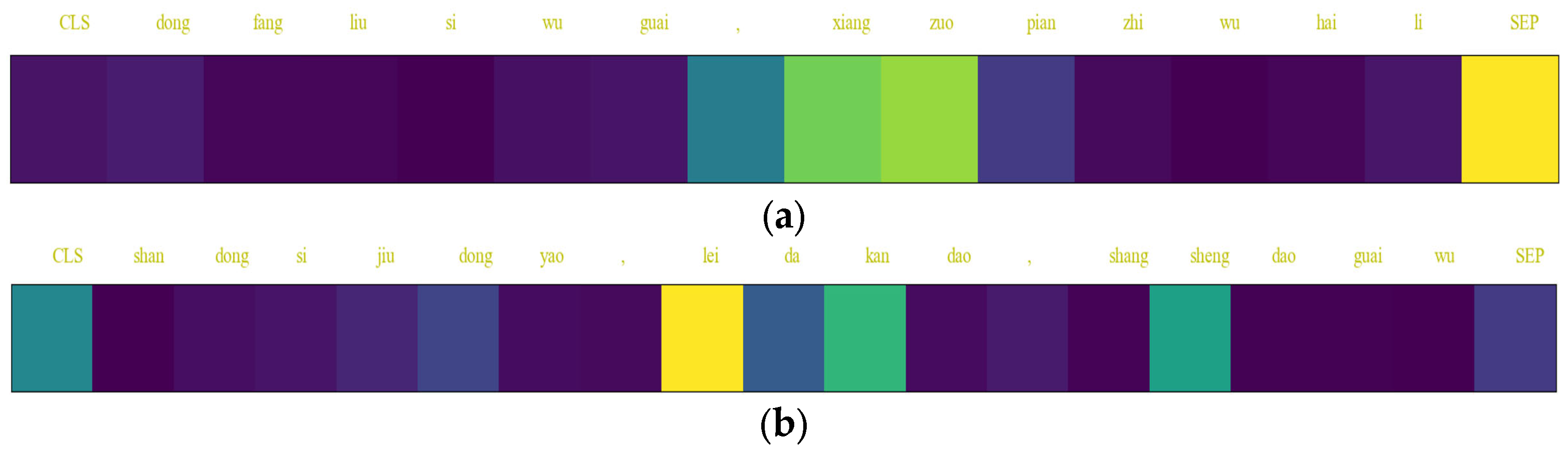
- Multiple intention recognition problem: At present, intention recognition based on deep learning technology is mainly aimed at single intention recognition. Since ATC instructions are characterized by short sentences, concise content, and no ambiguity, multi-intention recognition is a difficulty in this field. For example, the sentence shun feng/wu yao san guai/, lei da/kan dao/, shang sheng/dao/guai liang/bao chi only contains seven words and one word, but contains two intentions, which are aircraft identification and positioning and aircraft altitude adjustment. How to improve the accuracy of multi-intention recognition in short texts is a difficult problem that few people have studied.
- (3)
- Fewer data and higher labeling costs: With the increasing number of deep learning model parameters, for supervised learning, a multi-intention recognition model with superior performance needs to be trained with a large amount of data. In the field of ATC, data acquisition is difficult due to the confidentiality of data. In addition, the acquired original ATC speech data can only be used after being marked by professionals, which brings great challenges to the application and development of deep learning technology in this field [18].
3. Methodology
3.1. Response Strategies to Challenges
3.2. Model Introduction
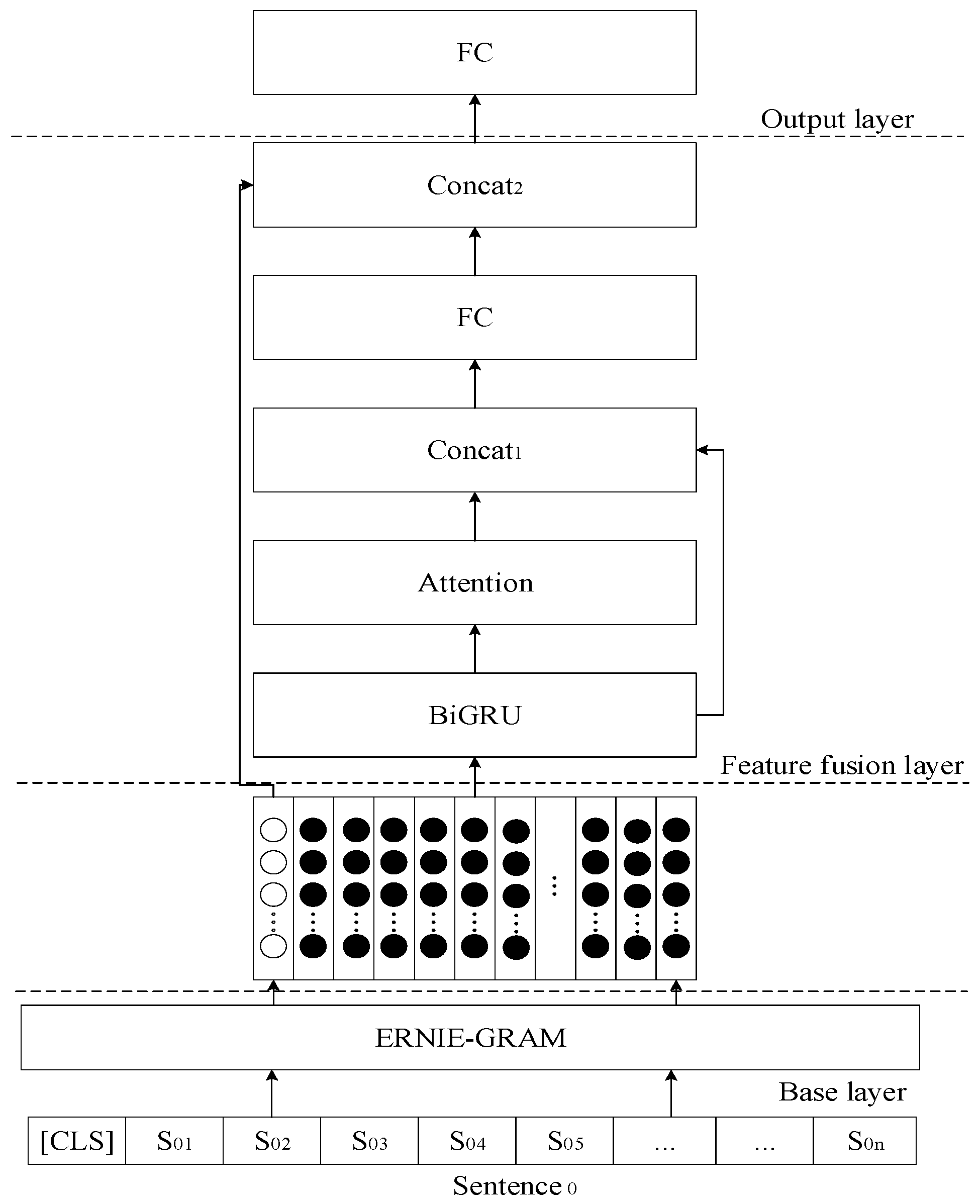
3.2.1. Model Structure
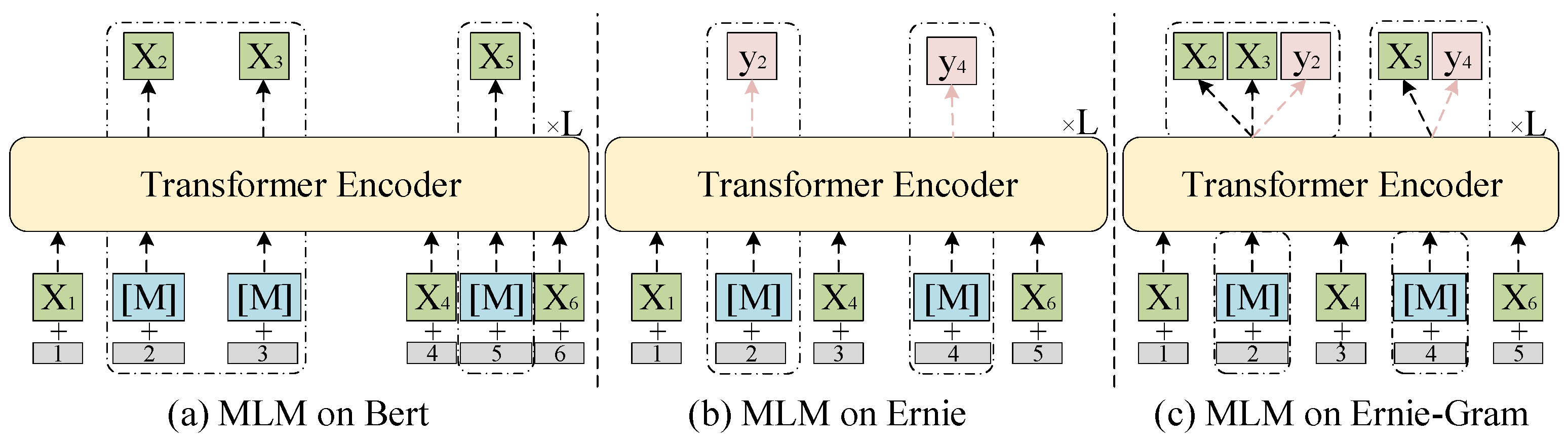
3.2.2. Ernie-Gram Module
3.2.3. The Difference between Ernie-Gram and BERT
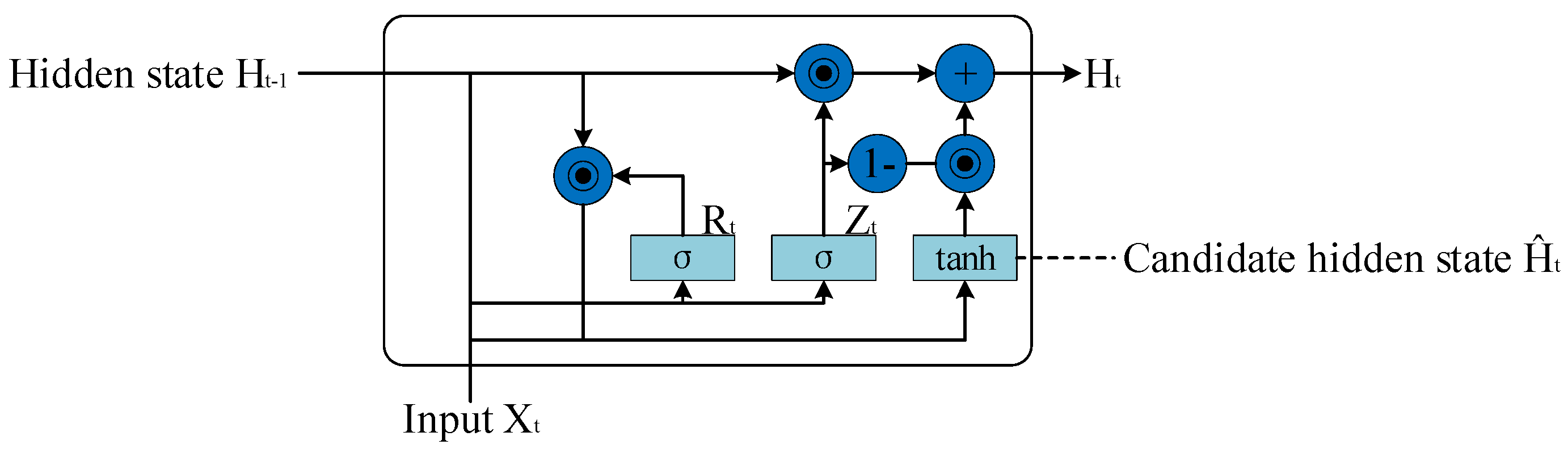
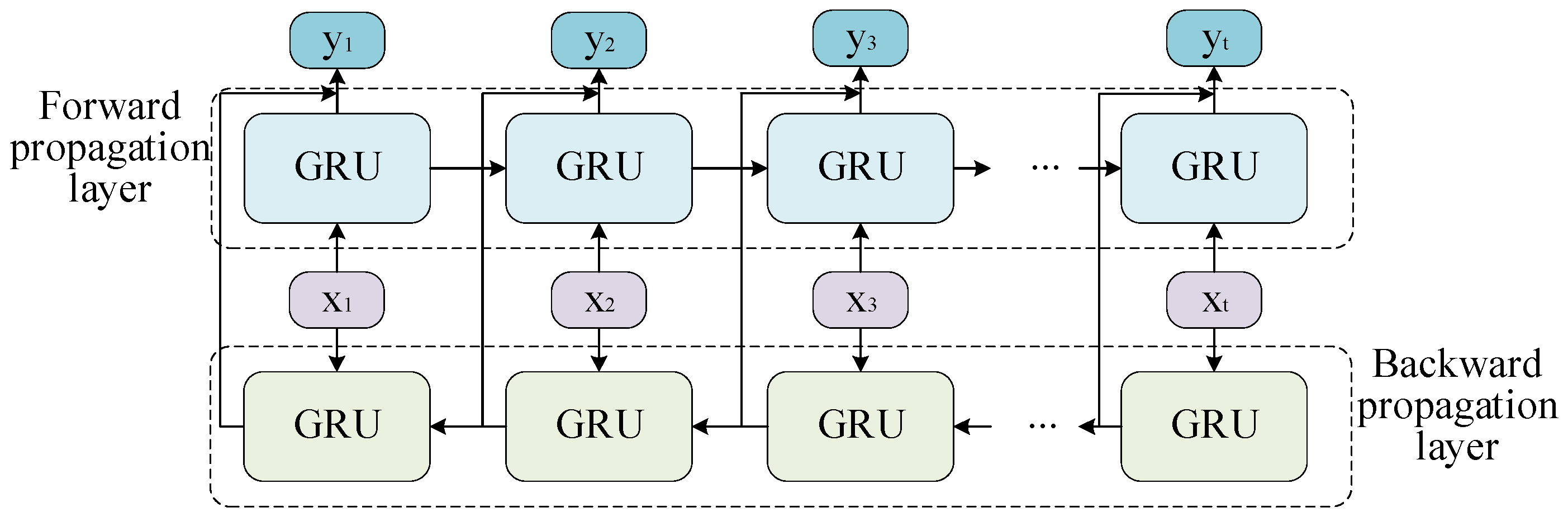
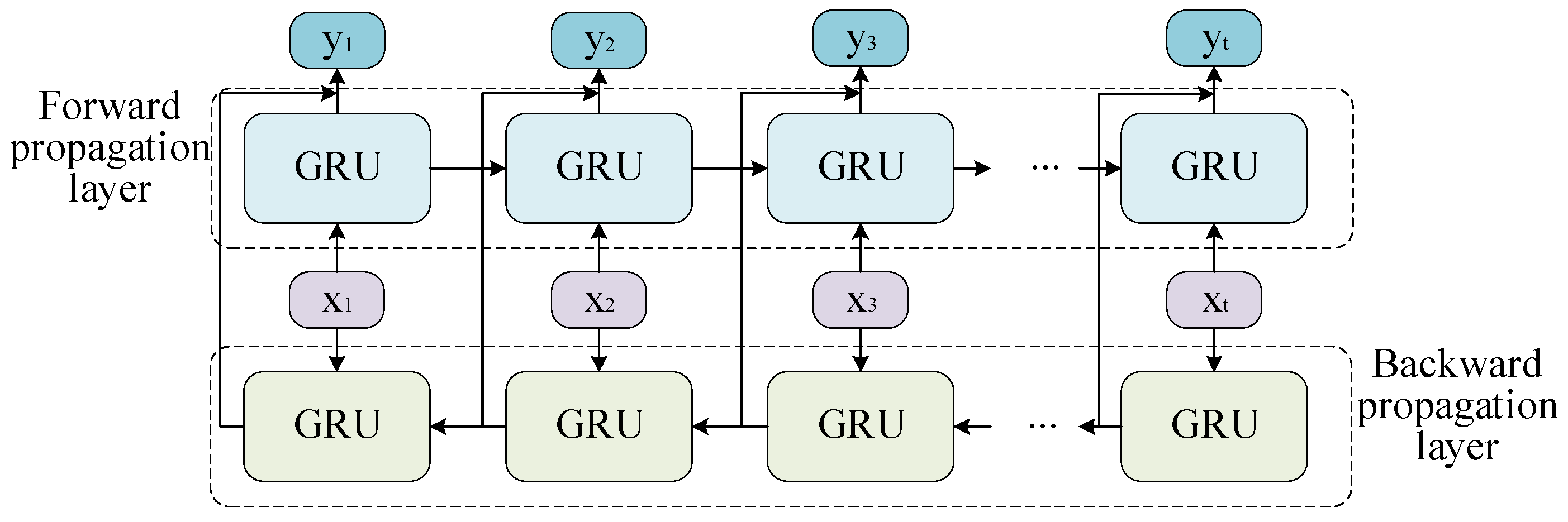
3.2.4. BiGRU Module
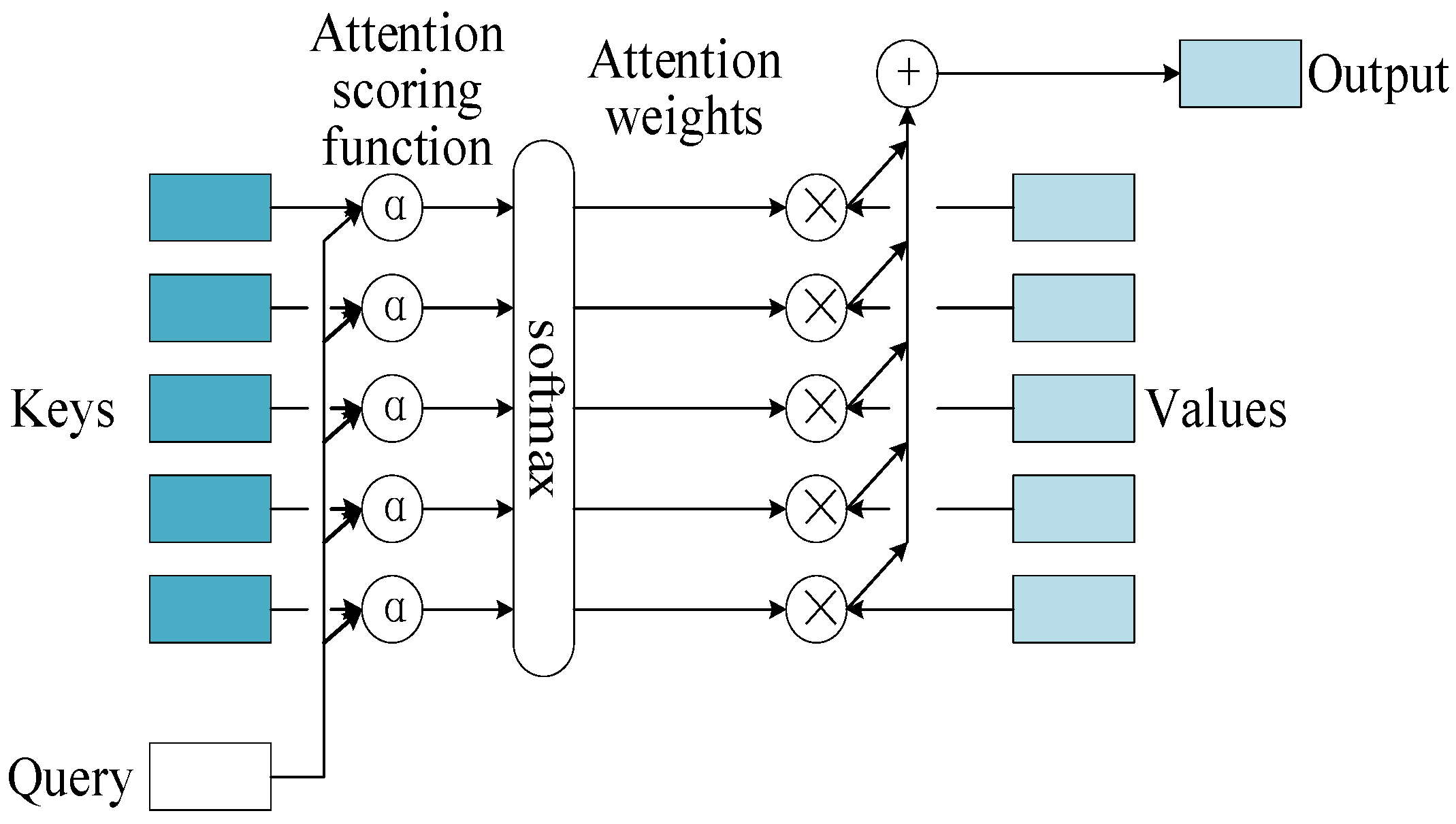
3.2.5. Attention Mechanism
3.3. Motivation and Details for Model Building
4. Experiments
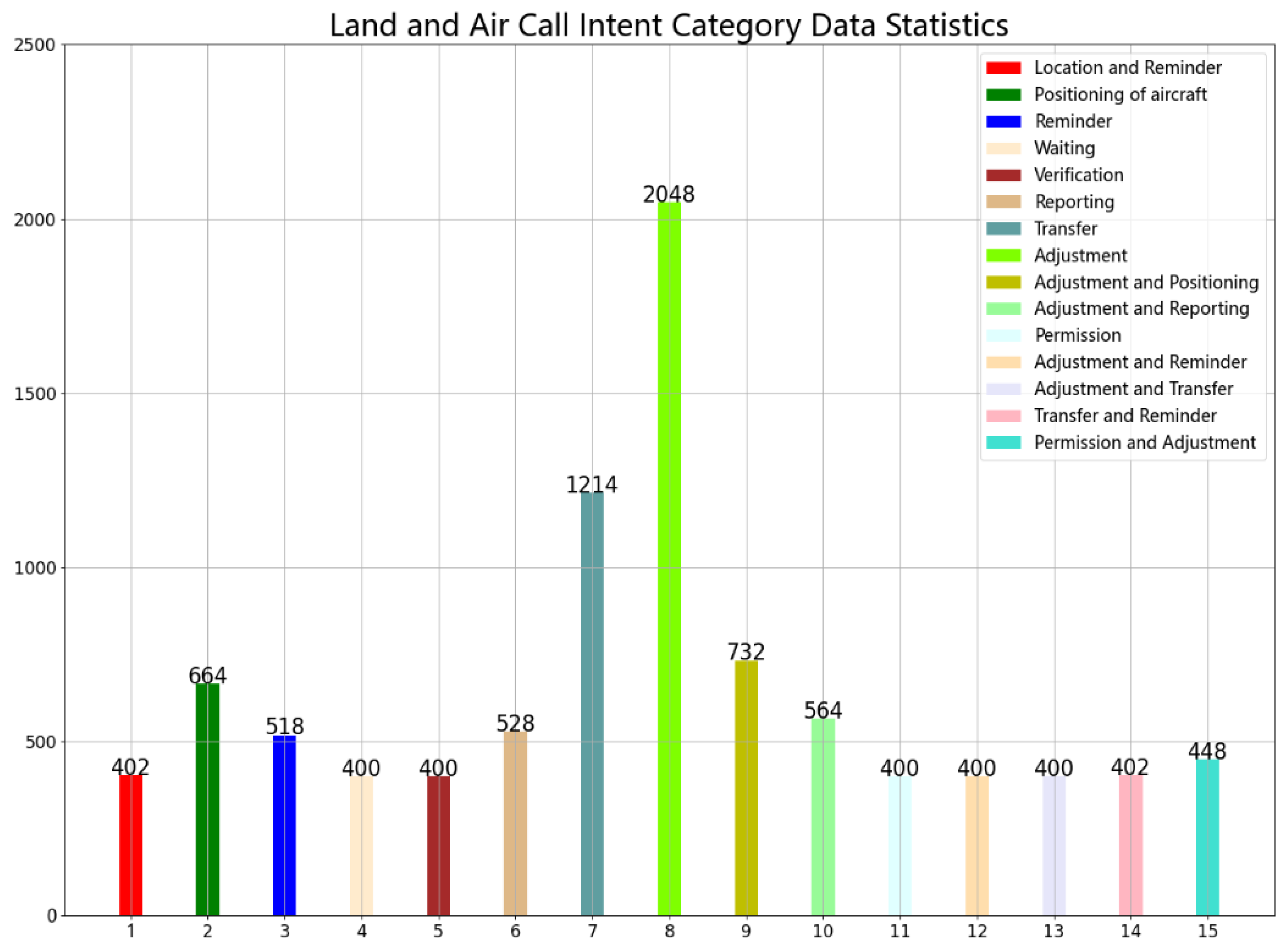
4.1. Experimental Data
4.2. Experimental Platform
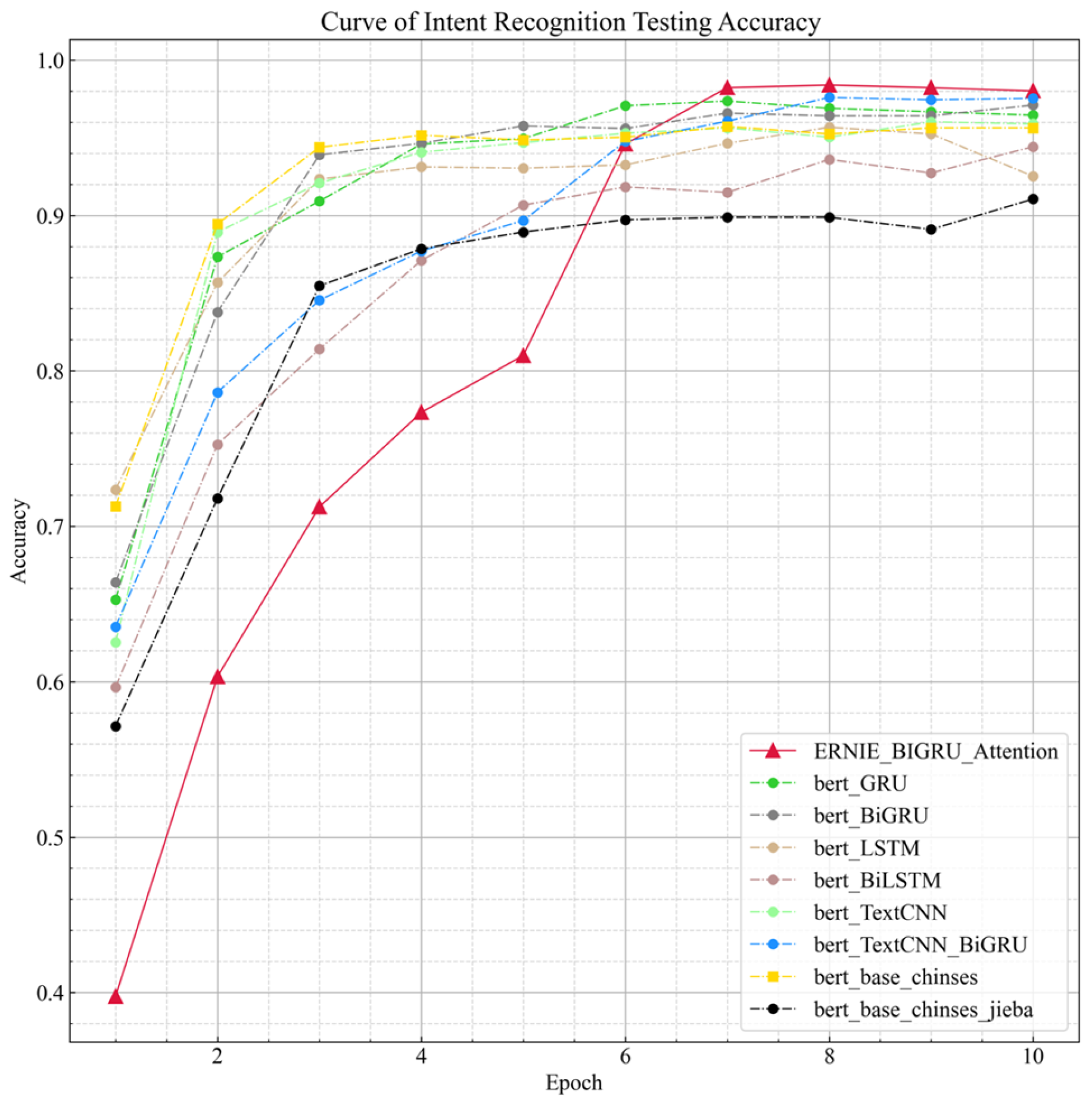
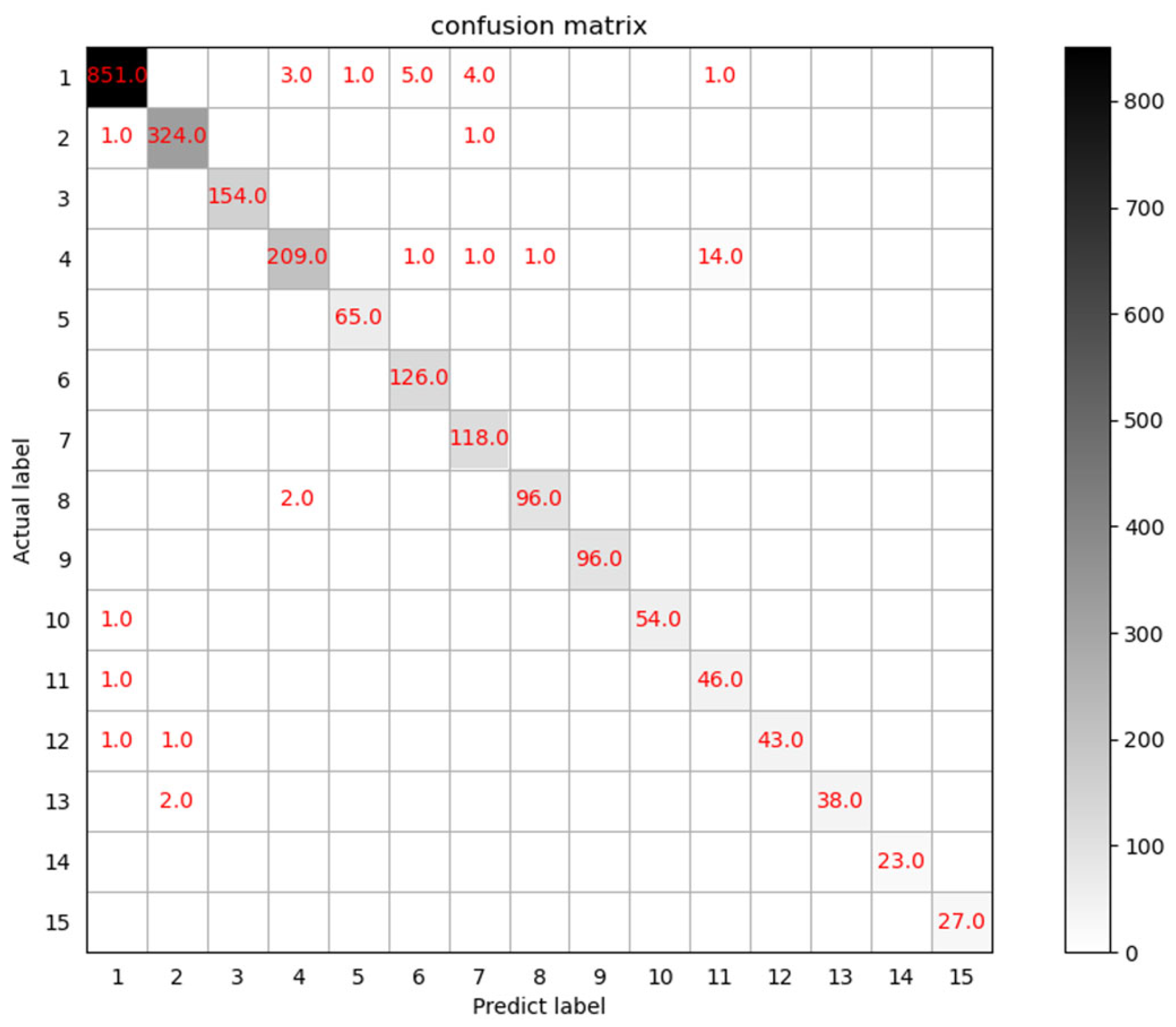
4.3. Ablation Experiment
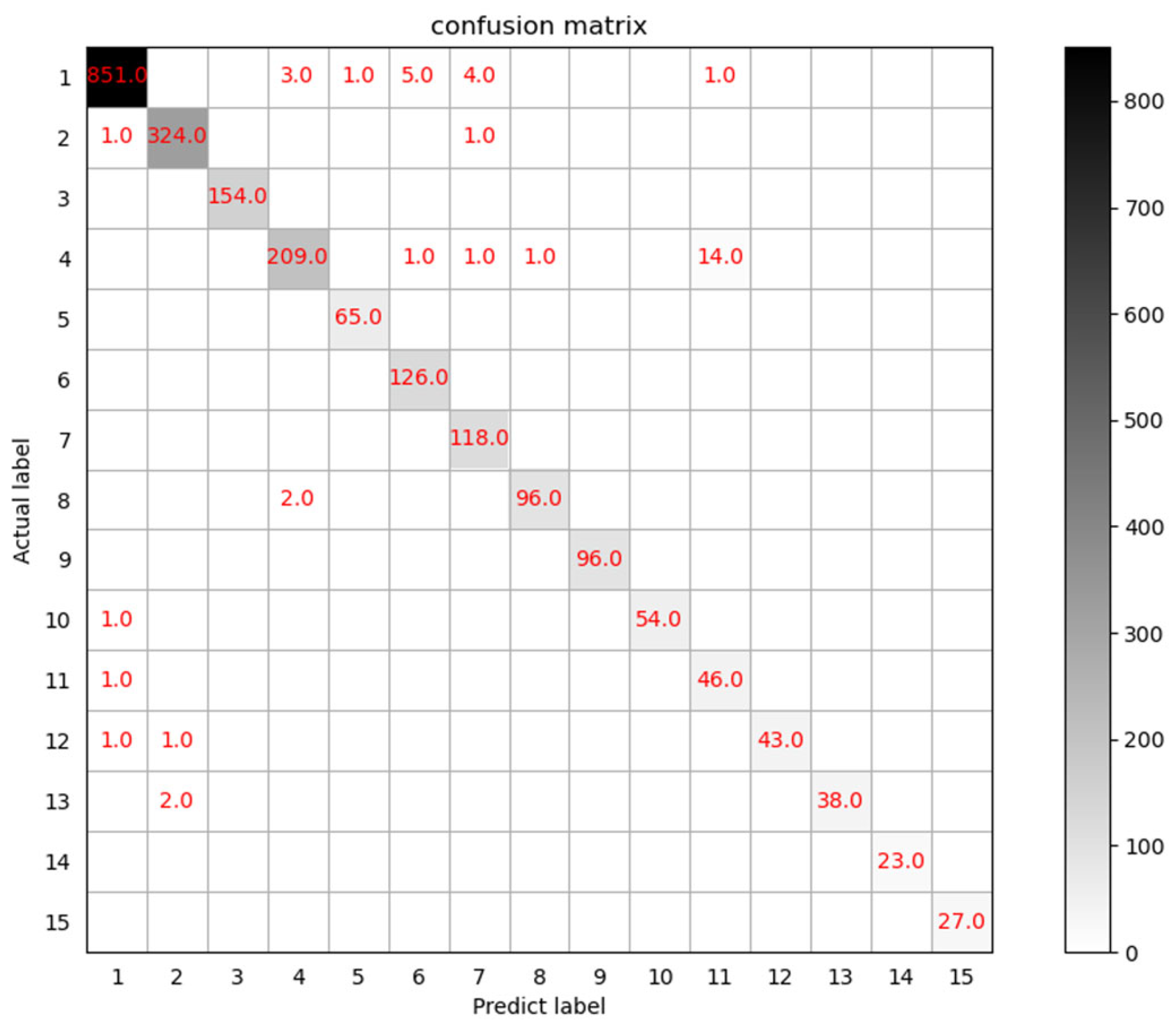
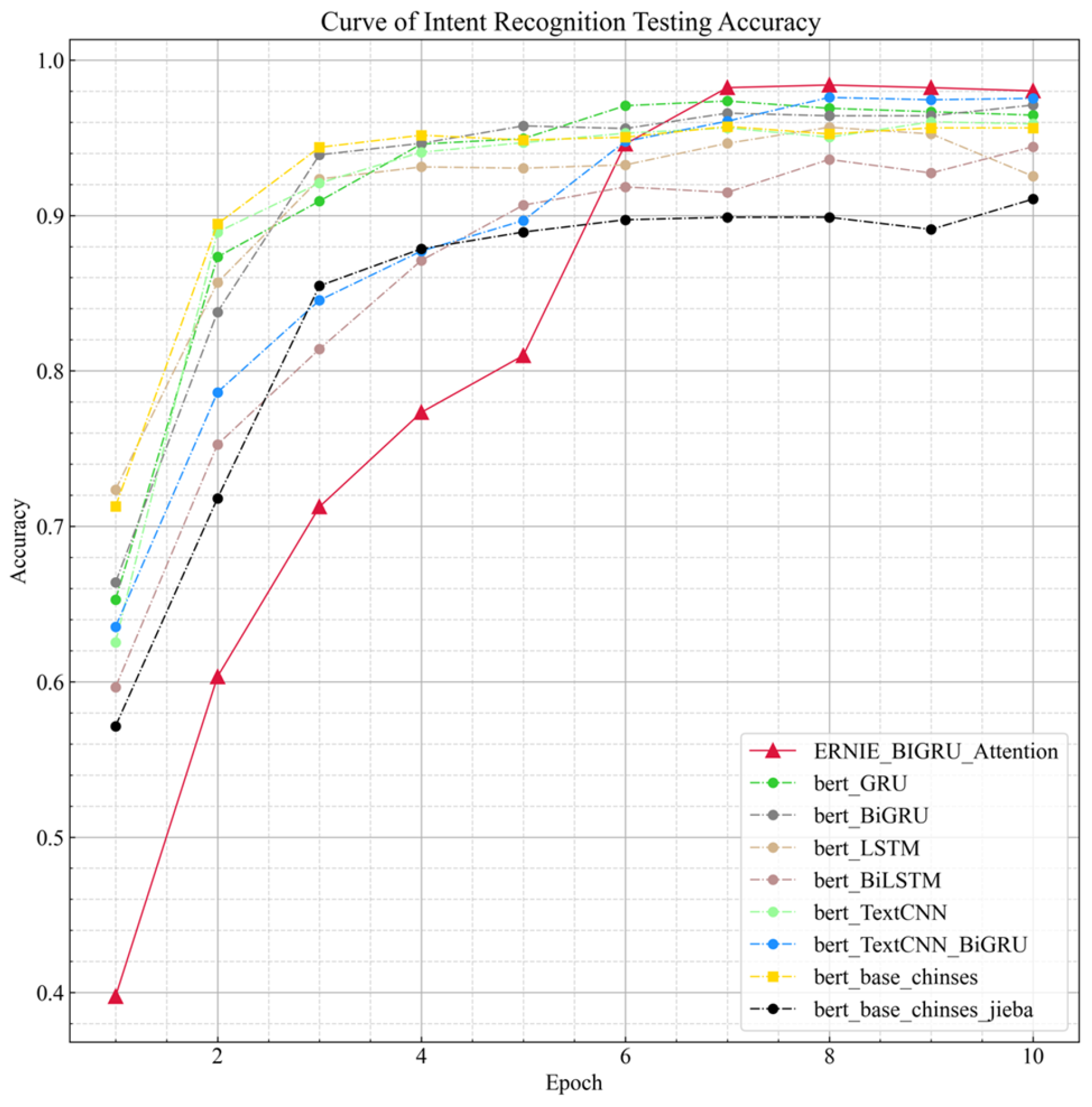
4.4. Experimental Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| RNN | Recurrent neural networks |
| EBA | Ernie-Gram_BiGRU_Attention |
| BiGRU | Bidirectional gate recurrent unit |
| FC | Fully connected layer |
| ICAO | International Civil Aviation Organization |
| ATC | Air traffic control |
| ATS | Air traffic services |
| CAAC | Civil Aviation Administration of China |
| ATCO | Air traffic controller |
| SVM | Support vector machine |
| CNN | Convolutional neural networks |
| TextCNN | Convolutional neural networks for sentence classification |
| RCNN | Recurrent convolutional neural networks |
| LSTM | Long short-term memory |
| BiLSTM | Bidirectional long short-term memory |
| NLP | Natural language processing |
| NLU | Natural language understanding |
| MLM | Masked language model |
| EG | Ernie-Gram |
| EGB | Ernie-Gram bidirectional gate recurrent unit |
References
- Lin, Y. Spoken Instruction Understanding in Air Traffic Control: Challenge, Technique, and Application. Aerospace 2021, 8, 65. [Google Scholar] [CrossRef]
- Guo, S.; Wang, Q. Application of Knowledge Distillation Based on Transfer Learning of ERNIE Model in Intelligent Dialogue In-tention Recognition. Sensors 2022, 22, 1270. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Xu, X. AMFF: A new attention-based multi-feature fusion method for intention recognition. Knowl. Based Syst. 2021, 233, 107525. [Google Scholar] [CrossRef]
- Dušek, O.; Jurčíček, F. A context-aware natural language generator for dialogue systems. arXiv 2016, arXiv:1608.07076. [Google Scholar]
- Haffner, P.; Tur, G.; Wright, J.H. Optimizing SVMs for complex call classification. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing(ICASSP), Hong Kong, China, 6–10 April 2003. [Google Scholar]
- Hakkani-Tur, D.; Tür, G.; Chotimongkol, A. Using semantic and syntactic graphs for call classification. In Proceedings of the ACL Workshop on Feature Engineering for Machine Learning in Natural Language Processing, Ann Arbor, MI, USA, 29 June 2005. [Google Scholar]
- Kim, J.-K.; Tur, G.; Celikyilmaz, A.; Cao, B.; Wang, Y.-Y. Intent detection using semantically enriched word embeddings. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Juan, WA, USA, 12–13 December 2016. [Google Scholar]
- Jeong, M.; Lee, G.G. Triangular-Chain Conditional Random Fields. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 1287–1302. [Google Scholar] [CrossRef]
- Sutton, C.; McCallum, A. An Introduction to Conditional Random Fields. Foundations and Trends® in Machine Learning; IEEE: Picataway, NJ, USA, 2012; Volume 4, pp. 267–373. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Wang, R.; Li, Z.; Cao, J.; Chen, T.; Wang, L. Convolutional Recurrent Neural Networks for Text Classification. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Zhou, C.; Sun, C.; Liu, Z.; Lau, F. A C-LSTM Neural Network for Text Classification. arXiv 2015, arXiv:1511.08630. [Google Scholar]
- Liu, B.; Lane, I. Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling. arXiv 2016, arXiv:1609.01454. [Google Scholar]
- Lin, Z.; Feng, M.; Santos, C.N.D.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A Structured Self-Attentive Sentence Embedding. arXiv 2016, arXiv:1703.03130. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? In Proceedings of the China National Conference on Chinese Com-putational Linguistics, Kunming, China, 18–20 October 2019. [Google Scholar]
- Yepes, J.L.; Hwang, I.; Rotea, M. New Algorithms for Aircraft Intent Inference and Trajectory Prediction. J. Guid. Control. Dyn. 2007, 30, 370–382. [Google Scholar] [CrossRef]
- Lin, Y.; Deng, L.; Chen, Z.; Wu, X.; Zhang, J.; Yang, B. A Real-Time ATC Safety Monitoring Framework Using a Deep Learning Approach. In Proceedings of the IEEE Transactions on Intelligent Transportation Systems, Auckland, New Zealand, 27–30 October 2019. [Google Scholar]
- Zhang, S.; Kong, J.; Chen, C.; Li, Y.; Liang, H. Speech GAU: A Single Head Attention for Mandarin Speech Recognition for Air Traffic Control. Aerospace 2022, 9, 395. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Xiao, D.; Li, Y.-K.; Zhang, H.; Sun, Y.; Tian, H.; Wu, H.; Wang, H. ERNIE-Gram: Pre-Training with Explicitly N-Gram Masked Language Modeling for Natural Language Understanding. arXiv 2020, arXiv:2010.12148. [Google Scholar]
- Lu, Q.; Zhu, Z.; Xu, F.; Zhang, D.; Wu, W.; Guo, Q. Bi-GRU Sentiment Classification for Chinese Based on Grammar Rules and BERT. Int. J. Comput. Intell. Syst. 2020, 13, 538–548. [Google Scholar] [CrossRef]
- ArunKumar, K.; Kalaga, D.V.; Kumar, C.M.S.; Kawaji, M.; Brenza, T.M. Comparative analysis of Gated Recurrent Units (GRU), long Short-Term memory (LSTM) cells, autoregressive Integrated moving average (ARIMA), seasonal autoregressive Integrated moving average (SARIMA) for forecasting COVID-19 trends. Alex. Eng. J. 2022, 61, 7585–7603. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Deng, J.; Cheng, L.; Wang, Z. Attention-based BiLSTM fused CNN with gating mechanism model for Chinese long text classification. Comput. Speech Lang. 2021, 68, 101182. [Google Scholar] [CrossRef]
- Church, K.W.; Chen, Z.; Ma, Y. Emerging trends: A gentle introduction to fine-tuning. Nat. Lang. Eng. 2021, 27, 763–778. [Google Scholar] [CrossRef]
- Cheng, X.; Zhang, C.; Li, Q. Improved Chinese Short Text Classification Method Based on ERNIE_BiGRU Model. In Proceedings of the 14th International Conference on Computer and Electrical Engineering (ICCEE), Beijing, China, 25–27 June 2021. [Google Scholar]
- Zuluaga-Gomez, J.; Veselý, K.; Blatt, A.; Motlicek, P.; Klakow, D.; Tart, A.; Szöke, I.; Prasad, A.; Sarfjoo, S.; Kolčárek, P.; et al. Automatic Call Sign Detection: Matching Air Surveillance Data with Air Traffic Spoken Communications. Multidiscip. Digit. Publ. Inst. Proc. 2020, 59, 14. [Google Scholar]
- Ding, X.; Mei, Y. Research on short text classification method based on semantic fusion and BiLSTM-CNN. In Proceedings of the 4th International Conference on Information Science, Electrical, and Automation Engineering (ISEAE 2022), Online, 25–27 May 2022. [Google Scholar]
- Zhang, J.; Zhang, P.; Guo, D.; Zhou, Y.; Wu, Y.; Yang, B.; Lin, Y. Automatic repetition instruction generation for air traffic control training using multi-task learning with an improved copy network. Knowl. Based Syst. 2022, 241, 108232. [Google Scholar] [CrossRef]
- Lin, Y.; Wu, Y.; Guo, D.; Zhang, P.; Yin, C.; Yang, B.; Zhang, J. A Deep Learning Framework of Autonomous Pilot Agent for Air Traffic Controller Training. IEEE Trans. Hum. Mach. Syst. 2021, 51, 442–450. [Google Scholar] [CrossRef]
- Kici, D.; Malik, G.; Cevik, M.; Parikh, D.; Başar, A. A BERT-based transfer learning approach to text classification on software requirements specifications. In Proceedings of the Canadian Conference on AI, Vancouver, BC, Canada, 25–28 May 2021. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structural Order | Input Size | Output Size | Parameter Setup |
|---|---|---|---|
| Ernie-Gram | (32, 50) | (32, 50, 768), (32, 768) | Batch_size = 32, Max_length = 50 |
| BiGRU | (32, 50, 768) | (32, 50, 768), (4, 32, 384) | Hidden_size = 384, Number_layers = 2 |
| Extraction | (4, 32, 384) | (32, 768) | |
| Attention layer | (32, 768) | (32, 768) | Extraction (32, 768) for q; BiGRU_output (32, 50, 768) for k and v; |
| Concat1 | (32, 768), (32, 768) | (32, 1536) | dimension = −1 |
| FC | (32, 1536) | (32, 768) | FC (Concat1) |
| Concat2 | (32, 768), (32, 768) | (32, 1536) | dimension = −1 |
| FC | (32, 1536) | (32, 15) | Num_class = 15 |
| Class of Intention | ATC Instructions | Instance Analysis |
|---|---|---|
| Adjustment | China Eastern 9916, veer right by five nautical miles; China Eastern 2453, climb to and maintain 5700; China Eastern 3401, reduce indicated airspeed to 255. | Aircraft transverse distance adjustment; aircraft altitude adjustment; aircraft speed adjustment. |
| Transfer | China Southern 0055, contact Zhengzhou on 130.0, good day. | Transfer of aircraft control. |
| Positioning of aircraft | Shunfeng 6954, Zhengzhou, radar contact. | The radar located the aircraft. |
| Reminder | China Eastern 2125, similar flight number Dongfang 2135, monitor closely. | Similar flight number conflict alert. |
| Adjustment and positioning | Lucky Air 9525, Zhengzhou, radar contact, climb to and maintain 7800. | The radar locates the aircraft and adjusts its altitude. |
| Waiting | Hainan 7188, maintain radio silence on this frequency, I’ll call you later. | Aircraft waiting at communications channel. |
| Permission | Lucky Air 9970, push back and start up approved, taxiway alpha, runway 36R. | The controller granted the pilot’s request for a slip-out. |
| Reporting | Okay Airways 6311, report at 25 nautical miles out, flying over Zhengzhou. | Fly over the Zhengzhou reporting point, report at 25 nautical miles from reporting point. |
| Adjustment and reporting | Yangtze River 5643, speed 260, report passing waypoint. | Aircraft speed adjustment and report past the reporting point. |
| Verification | China Southern 6960, affirm, adjust heading to 210. | Confirm course adjustment to 210. |
| Adjustment and reminder | Air China 1671, climb to 7200, there’s a convergence ahead. | Aircraft altitude adjustment and conflict alert. |
| Adjustment and transfer | Shunfeng 5137, set QNH 5300, contact ground on 125.3. | Aircraft altimeter adjustment and control transfer. |
| Transfer and reminder | Hainan 3211, contact Shanghai Control on 120.8, and be aware of the passing time of the waypoint. | Control transfer and past report point time reminder. |
| Location and reminder | China Express 3211, radar contact, you can contact your own dispatch for communication. | Radar locates aircraft and reminds them to communicate with the flight despatcher first. |
| Permission and adjustment | Chongqing 1205, descend to 900, cleared for ILS approach, runway 03. | Adjust altitude and agree to use instrument approach procedure for aircraft approach. |
| Hyperparameters | Number |
|---|---|
| Dropout | 0.2 |
| Max sequence length | 50 |
| Learning rate | 2 × 10−5 |
| Batch size | 32 |
| Number of epochs | 10 |
| Model | Dev_Acc | Recall | Precision | F1 |
|---|---|---|---|---|
| EG | 0.970 | 0.969 | 0.971 | 0.970 |
| EGB | 0.977 | 0.977 | 0.977 | 0.977 |
| EBA | 0.982 | 0.982 | 0.981 | 0.981 |
| Feature Fusion Method | Dimensionality of the Fused Features | Dev_Acc | Recall | Precision | F1 |
|---|---|---|---|---|---|
| Not fused (using only feature vectors from the base layer) | 768 | 0.970 | 0.971 | 0.969 | 0.970 |
| Not fused (using only feature vectors from the BiGRU Attention layer) | 768 | 0.065 | 0.070 | 0.065 | 0.068 |
| Dimensionality-changing feature fusion | 768 | 0.058 | 0.062 | 0.058 | 0.060 |
| 1536 | 0.077 | 0.080 | 0.077 | 0.079 | |
| Additive feature fusion | 768 | 0.972 | 0.972 | 0.972 | 0.972 |
| Concatenation feature fusion | 1536 | 0.982 | 0.982 | 0.981 | 0.981 |
| Model | Dev_Acc | Recall | Precision | F1 |
|---|---|---|---|---|
| BERT | 0.957 | 0.956 | 0.957 | 0.956 |
| BERT-Jieba tokenizer | 0.911 | 0.912 | 0.911 | 0.911 |
| BERT-LSTM | 0.956 | 0.92 | 0.956 | 0.937 |
| BERT-BiLSTM | 0.951 | 0.93 | 0.951 | 0.94 |
| BERT-TextCNN | 0.96 | 0.96 | 0.97 | 0.96 |
| BERT-GRU | 0.968 | 0.967 | 0.968 | 0.967 |
| BERT-BiGRU | 0.971 | 0.969 | 0.971 | 0.97 |
| BERT-TextCNN-BiGRU | 0.975 | 0.974 | 0.975 | 0.974 |
| EBA | 0.982 | 0.982 | 0.981 | 0.981 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, W.; Jiang, P.; Wang, Z.; Li, Y.; Liao, Z. Ernie-Gram BiGRU Attention: An Improved Multi-Intention Recognition Model for Air Traffic Control. Aerospace 2023, 10, 349. https://doi.org/10.3390/aerospace10040349
Pan W, Jiang P, Wang Z, Li Y, Liao Z. Ernie-Gram BiGRU Attention: An Improved Multi-Intention Recognition Model for Air Traffic Control. Aerospace. 2023; 10(4):349. https://doi.org/10.3390/aerospace10040349
Chicago/Turabian StylePan, Weijun, Peiyuan Jiang, Zhuang Wang, Yukun Li, and Zhenlong Liao. 2023. "Ernie-Gram BiGRU Attention: An Improved Multi-Intention Recognition Model for Air Traffic Control" Aerospace 10, no. 4: 349. https://doi.org/10.3390/aerospace10040349
APA StylePan, W., Jiang, P., Wang, Z., Li, Y., & Liao, Z. (2023). Ernie-Gram BiGRU Attention: An Improved Multi-Intention Recognition Model for Air Traffic Control. Aerospace, 10(4), 349. https://doi.org/10.3390/aerospace10040349