1. Introduction
Over the last decade, launcher reusability has become the new paradigm for reducing the cost of access to space and enabling future manned missions, such as a return to the Moon or, even more ambitiously, the first steps on Mars. This technology was already developed in the Space Shuttle era; however, unanticipated costs and risks led to the cancellation of the programme in 2011. Nevertheless, some years ago, private companies, such as SpaceX and Blue Origin, completely disrupted the space sector and demonstrated the cost effectiveness and technical feasibility of reusable rockets. More specifically, SpaceX’s Falcon 9 became in 2017 the first Vertical Take-Off Vertical Landing (VTVL) vehicle, having its first stage recovered after launch and reused for another mission, and then became in 2020 the first private rocket to take astronauts to the International Space Station thanks to its spacecraft Dragon [
1]. Today, SpaceX has flown reusable boosters more than 100 times, with some single boosters reused more than 10 times, proving the feasibility and economic sustainability of such a technology. This leading company is now successfully testing its Super Heavy rocket equipped with the Starship spacecraft with the objective of carrying both crew and cargo on long-duration interplanetary flights, achieving humanity’s return to the Moon, and travelling to Mars and beyond. Meanwhile, Blue Origin is also developing advanced reusable launchers such as New Shepard, a suborbital launch vehicle designed for space tourism, and New Glenn, a heavy-lift reusable rocket that should be able to carry heavy payloads to Earth’s orbit and beyond [
2]. Consequently, national agencies and intergovernmental institutions are following the same path, increasing research and development related to launcher reusability.
The descent and precision soft-landing of Reusable Launch Vehicles (RLVs) on Earth are very challenging, mainly due to the presence of the atmosphere. Indeed, during this phase, the vehicle is subjected to fast system dynamics changes induced by external loads such as lift and drag, unpredictable wind gusts, and control-induced actuation commands to comply with the landing requirements, allowing so-called pinpoint landing while preserving the vehicle’s integrity. All of these factors involve uncertainties and nonlinearities, which lead to vehicle instability and therefore justify the implementation of a high-performance guidance, navigation, and control (GNC) system. A solution to this demanding problem became feasible in the past decade with the development of convex optimisation: a particular class of methods that allow one to compute, in real time and based on the current flight conditions, optimal trajectories to be followed satisfying the desired constraints (which must be convex). This technology was demonstrated by the Masten Space Systems’ VTVL demonstrator Xombie, which used a vision-based system and a fuel-optimal convex guidance algorithm for precision landing [
3].
Research on convex optimisation for the entry, descent, and soft pinpoint landing of VTVL reusable launchers has actively been carried out in recent years with the development of advanced techniques such as successive convex optimisation [
4] and pseudospectral convex optimisation [
5,
6]. In Ref. [
7], Liu extended this first method by combining aerodynamic forces and propulsion as control inputs to gain optimality with the consideration of vehicle aerodynamics, which had previously been ignored. Then, in Ref. [
8], Sagliano et al. combined both methods and proposed separating the aerodynamic descent and powered landing into two different optimal control problems, using aerodynamic forces as the control input for the first phase and a combination of aerodynamic and propulsive control for the second phase. Finally, in Ref. [
9], Simplício et al. solved a simplified optimal control problem in a first step and passed the solution to a second step involving successive convex optimisation to include aerodynamic effects.
The coupled flight mechanics involved in the reusable launcher descent and landing (D&L) phase are in fact usually not considered in the design of optimal guidance algorithms. The disturbances and uncertainties acting on the vehicle and arising from the nonlinear dynamics; external events (e.g., wind and aerodynamics); the actuation system; and the environment are counteracted by a properly designed robust control system. Classic techniques involve the use of linear control theory based on linearising the equations of motion and feedback of defined control parameters with gain scheduling [
10]. However, these techniques require an extensive verification and validation campaign with Monte Carlo analyses, which render the process very time-consuming and costly. Lately, advanced robust control methods have been studied in both academia and industry, such as the Linear Parameter-Varying (LPV) approach [
11] and the
family of methods, specifically the structured
technique [
12].
The steering of a VTVL reusable rocket during the D&L phase is generally achieved by a Thrust Vector Control (TVC) system, which actuates by deflecting the engine nozzle along the two body axes perpendicular to the vehicle’s longitudinal axis through specific gimbal angles computed using the guidance and control (G&C) algorithms. To increase the control authority of the RLV, especially at low thrust during aerodynamic descent, steerable fins are crucial. They are typically placed above the vehicle’s centre of pressure, with one pair usually applied for controlling the pitch motion and another pair for controlling the yaw motion. Finally, a Reaction Control System (RCS) based on cold gas thrusters is often added for use at a high altitude in low-dynamic-pressure conditions or to provide roll control capabilities.
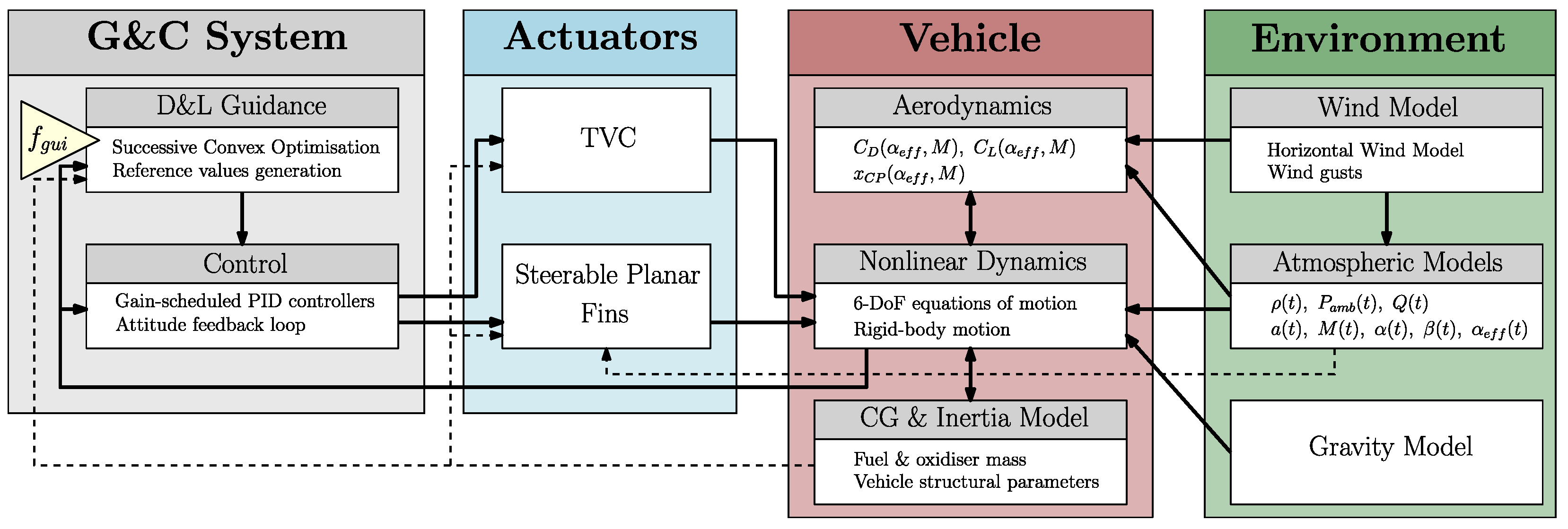
To understand the interactions between G&C and D&L flight mechanics, an RLV controlled dynamics simulator is proposed herein. This could serve as a baseline for the design and analysis of more advanced G&C methods for the D&L phase of reusable launchers. It covers the descent and soft pinpoint landing of a VTVL vehicle first-stage booster with closed-loop guidance and control integration. It includes the six-degrees-of-freedom (6-DoF) descent dynamics of a rigid-body model with a varying mass, evolving in the terrestrial atmosphere with varying environmental parameters, uncertainties, and disturbances (atmospheric density, ambient pressure, and wind) and subjected to external forces (gravity and aerodynamics). The steering of the spacecraft is carried out by a TVC system and planar fins, correcting the trajectory deviations with respect to the reference profile. The G&C system consists of a successive convex optimisation guidance algorithm updated several times during the flight and a control system composed of gain-scheduled Proportional–Integral–Derivative (PID) controllers. The main contributions of the proposed work can be summarised as follows:
The development of a 6-DoF RLV controlled dynamics simulator with closed-loop guidance and control integration for the descent and precise landing phase. This tool allows one to assess G&C methods for realistic scenarios, more specifically with respect to environmental models (aerodynamics, wind, and atmospheric parameters) and the actuation system (TVC and steerable planar fins). Moreover, it has a modular architecture and therefore can be easily modified to integrate more complex models (e.g., propulsion and aerodynamics). To the best of the authors’ knowledge, such a simulator is not publicly available and therefore provides the opportunity to understand the challenges involved in designing G&C algorithms for reusable launcher descent and precise landing and perform preliminary assessments of multiple recovery strategies.
The implementation and assessment of a successive convex optimisation guidance algorithm that solves the 6-DoF equations of motion for the powered descent and pinpoint landing problem.
The generation of corrections using classical linear feedback control through gain-scheduled PID controllers. Then, commands are allocated between the TVC system and the steerable planar fins according to the level of thrust. This feature also allows a certain modularity for studying different actuation configurations according to the mission requirements (e.g., propellant consumption) and the flight phase: TVC-only, planar fins-only, or both.
The paper is organised as follows.
Section 2 introduces the reusable launcher controlled dynamics simulator with a description of all the building blocks: from the reference frames, environmental and aerodynamic models, and vehicle dynamics to the definition of the different actuation systems. Then, the successive convex optimisation guidance algorithm is introduced in
Section 3. In addition,
Section 4 presents the preliminary control method using classic linear control theory with gain-scheduled PID controllers and explains how the command is then allocated to the TVC system and/or the steerable planar fins. Subsequently, several simulations are performed in
Section 5 with different actuation configurations. A sensitivity analysis is also carried out, adding wind and dispersion to several parameters in order to study their impact on the D&L performance and better address them for future developments in advanced G&C methods. Finally, conclusions are provided in
Section 6.
2. Reusable Launcher Controlled Dynamics Modelling
The RLV controlled dynamics simulator developed in this paper relies on the nonlinear 6-DoF dynamics of a VTVL vehicle first-stage booster modelled as a rigid body with a varying mass subjected to external forces induced by the terrestrial atmosphere and controlled through embedded closed-loop guidance and control strategies. Therefore, it is made up of several building blocks with interconnections. A description of the developed architecture is provided in
Figure 1. The elements were implemented through MATLAB/Simulink R2021b and will be briefly presented in the following subsections. A performance analysis of the simulator described below with a simplified aerodynamic model and TVC actuation only was carried out in Ref. [
13].
The reference frames and environmental models adopted for gravity, atmospheric parameters, and wind are explained in
Section 2.1. Then, the equations of motion and the centre of gravity (CG) and inertia estimations are described in
Section 2.2. The developed aerodynamic model is presented in
Section 2.3. The vehicle is steered via TVC and planar fins depending on their level of control authority. These actuators are introduced in
Section 2.4 and
Section 2.5, respectively.
Finally, the G&C algorithms are organised into two subsystems. First, “D&L Guidance” is responsible for the real-time generation of the reference control values, here in terms of thrust magnitude and attitude angles. Note that this feature is executed at frequency
, which differs from the simulator time step. A dedicated passage on the development of the guidance algorithm is provided in
Section 3. Then, the “Control” subsystem, responsible for the computation of the commands allocated among the aforementioned actuators, is defined in
Section 4.
2.1. Reference Frames and Environmental Models
This subsection describes the reference frames and environmental models that are adopted in the RLV controlled dynamics simulator. They are essential to simulating the re-entry of a reusable rocket into the terrestrial atmosphere.
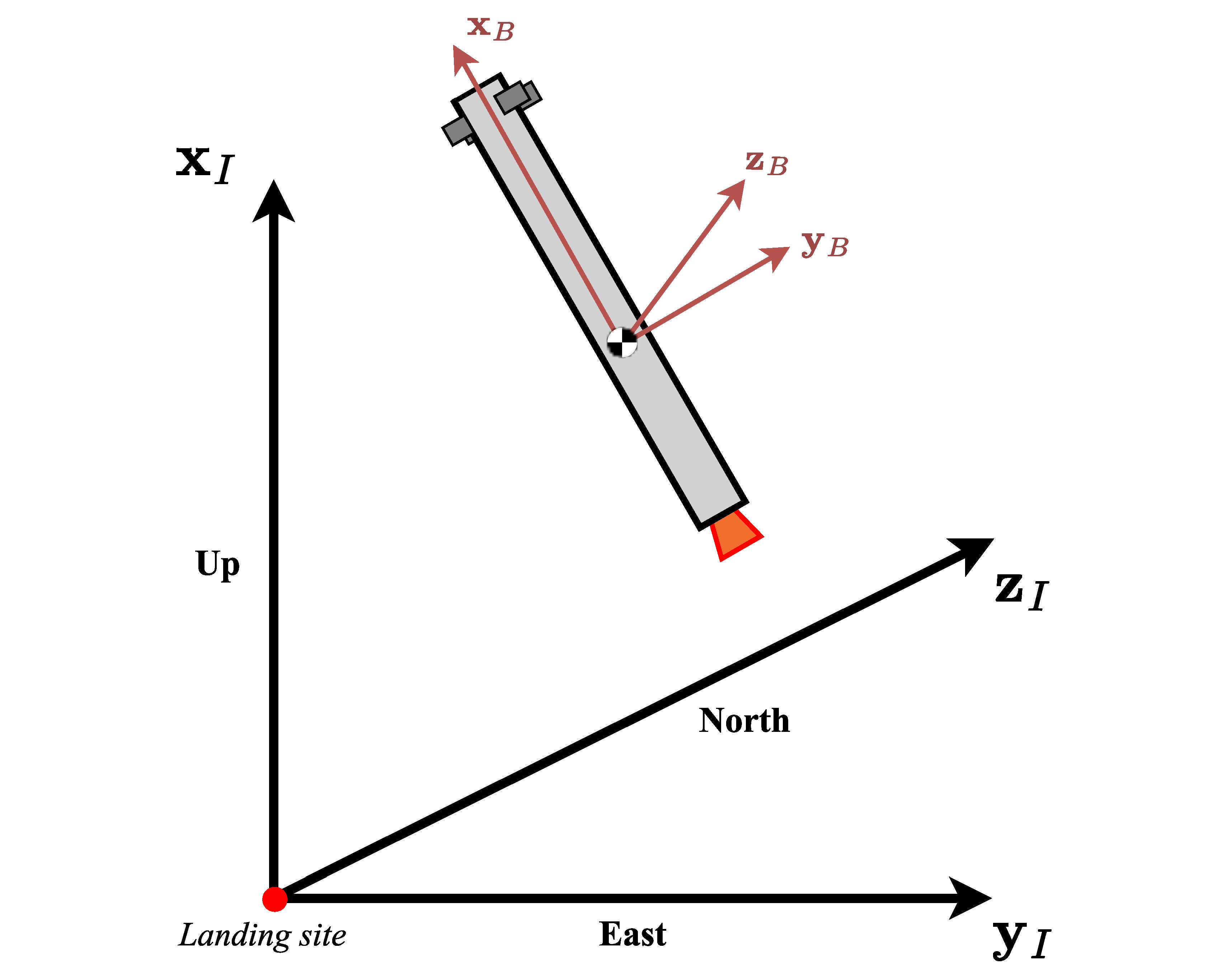
Two reference frames are considered and are shown in
Figure 2. The first is the landing-site-centred reference frame. Its origin is at the landing site and it is an up–east–north reference frame, such that the
-axis points up, the
-axis east, and the
-axis north. This reference frame is considered inertial, and the equations of motion refer to it. Simulations start from an initial position in this reference frame
, with an initial velocity
. The second reference frame is the vehicle’s body-fixed reference frame. This is fixed to the vehicle’s CG, and the basis vectors can be defined as follows: the
-axis lies along the vehicle’s longitudinal axis, the
-axis is defined so as to remain perpendicular to the pitch plane, and the
-axis completes the right-handed system (and thus remains perpendicular to the yaw plane). Following these definitions, the roll, pitch, and yaw angles (
,
, and
, respectively) represent the orientation of the body-fixed reference frame with respect to the landing-site-centred inertial reference frame. These angles are useful for controlling the vehicle trajectory. However, in the formulation of the equations of motion, the rotation quaternion
is used to translate the attitude of the vehicle. Therefore,
represents the rotation matrix from the inertial reference frame to the vehicle’s body-fixed reference frame. The angular velocity is defined in the body-fixed reference frame with an initial value
.
The atmosphere model adopted in this study, available in the MATLAB Aerospace Toolbox [
14], implements the mathematical representation of the 1976 Committee on Extension to the Standard Atmosphere (COESA) [
15], which provides, as a function of altitude
, the atmospheric density
, the speed of sound
, and the ambient atmospheric pressure
. Then, the gravitational field is defined in the inertial frame by
, where
is obtained as a function of the altitude and expressed by
Here, is the standard gravity of Earth, and is the radius of the Earth. For conciseness, these values will now be written as a function of time t.
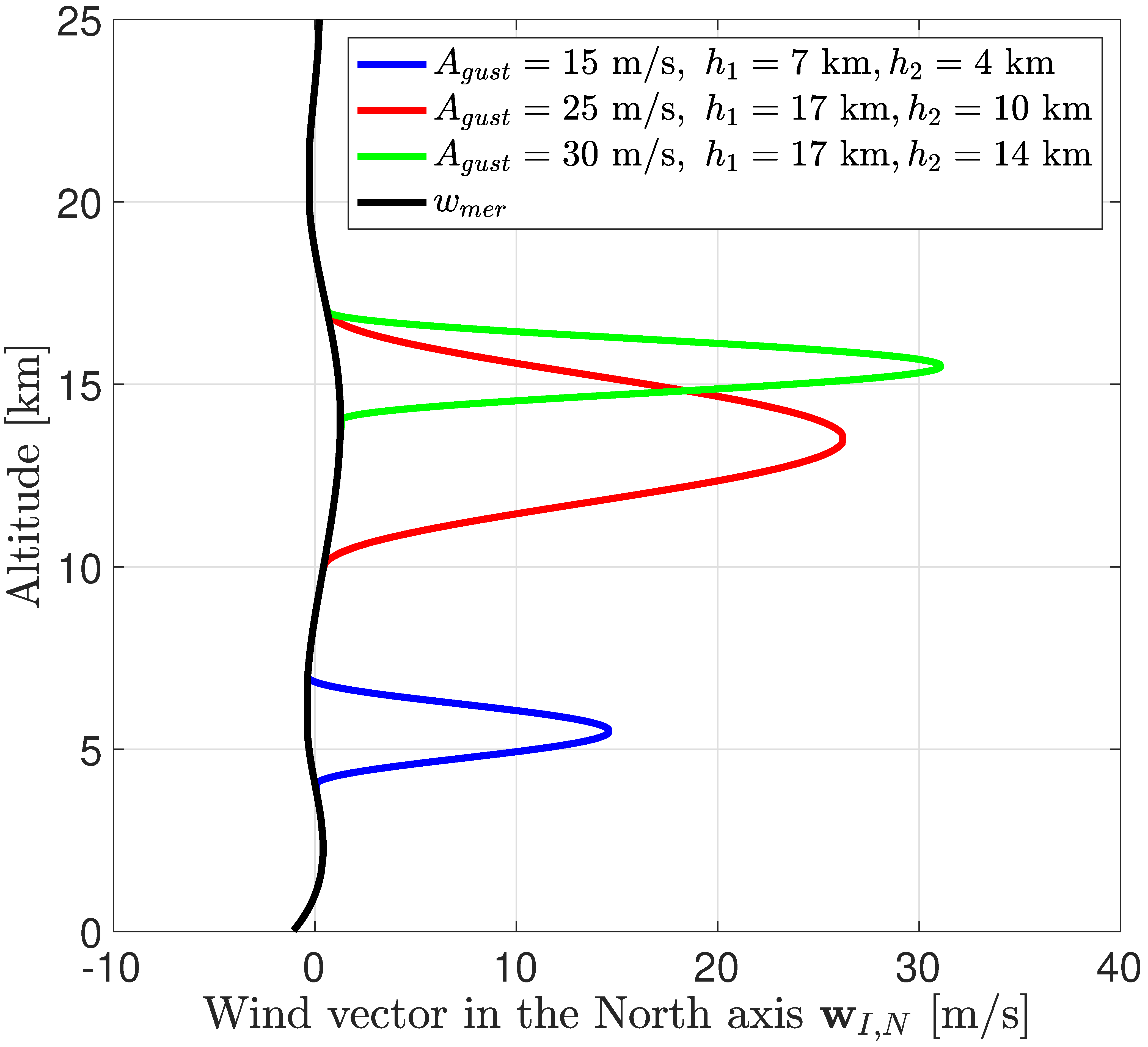
Finally, the constant wind is computed with the US Naval Research Laboratory model Horizontal Wind Model 14, also available in Ref. [
14], which generates the meridional
and zonal
components of the wind for a set of geophysical data. Wind gusts are modelled as a cosine-shaped function, so the user can define the amplitude of the gust and the altitude at which it occurs. The function is expressed as follows:
where
specifies the amplitude of the gust in three directions,
is the current altitude of the spacecraft,
specifies the altitude at which the gust starts, and
is the altitude range in which the gust is applied. Therefore, the maximum intensity of the gust is reached in the middle of the specified altitude region. Consequently, the wind vector is written in the inertial reference frame as follows:
Note that the wind model is not considered in the descent dynamics of the guidance algorithm described in
Section 3.
2.2. Equations of Motion and CG/Inertia Estimations
The equations of motion are written using the reference frames previously defined in
Section 2.1. They are based on
, the initial state vector, and the assumption that the vehicle is a rigid body with no effects induced by the varying mass (e.g., propellant sloshing) and structural flexibility.
The mass depletion dynamics are modelled by an affine function of the thrust magnitude as follows:
where
is the vacuum specific impulse of the engine, which is assumed to be constant for simplicity, and
is the nozzle exit area of the engine.
is the thrust vector coming from the TVC system, introduced in
Section 2.4. The second term is related to the reduction in the specific impulse due to the atmospheric back pressure [
4].
The translational states, position, and velocity of the vehicle in the inertial reference frame,
and
, are governed by the following dynamics:
where
describes the aerodynamic force acting on the vehicle in the inertial reference frame (
Section 2.3), and
represents the control force generated by the planar fins (
Section 2.5).
Then, the attitude states are governed by the following rotational dynamics, using the quaternion-based kinematics equation:
where
is the inertia matrix of the vehicle, introduced below.
,
, and
(
Section 2.3,
Section 2.4 and
Section 2.5) represent the aerodynamic and control torques acting on the vehicle. In Equation (
6), the coupling between angular velocity and inertia along the three axes and the effect of centroid movement on the inertia caused by mass consumption are ignored.
Finally, because of the propellant mass and the level variations throughout the flight, the total vehicle CG and the moments of inertia also vary. The CG is considered to lie along the vehicle body’s longitudinal axis, i.e.,
, while the inertia tensor is assumed to be diagonal, i.e.,
. Following the model and data available in Ref. [
16], the vehicle’s mass is broken down into structural mass and time-dependent propellant mass, which is updated via Equation (
4) during engine burn. Therefore, the reader is referred to Ref. [
16] for details of the parameters defining the inertial and CG properties and their numerical values.
2.3. Aerodynamic Model
The aerodynamic forces and moments generated by the vehicle depend on its structure, as well as the instantaneous dynamic pressure. This atmospheric parameter is usually given by
where
and
are the air-relative velocity vectors written in the inertial reference frame that account for the wind
.
For the computation of aerodynamic loads, it is common to define a velocity reference frame that is fixed to the vehicle’s CG but directed along the air-relative velocity written in the body-fixed reference frame
. This reference frame enables the definition of the two aerodynamic angles, the angle of attack
and the sideslip angle
, in order to illustrate the rotation from the body-fixed to the velocity reference frame
, as follows:
where the aerodynamic angles are given by
With these definitions and assuming that the vehicle has an axisymmetric shape, the aerodynamic forces and moments generated by the vehicle are expressed in the body-fixed reference frame as
where
is the vehicle reference area;
is the vehicle’s center of pressure (CP); and
are the drag and lift coefficients, respectively. These parameters are estimated as functions of the effective angle of attack
and the Mach number
, where
is the speed of sound, also obtained from COESA as a function of altitude.
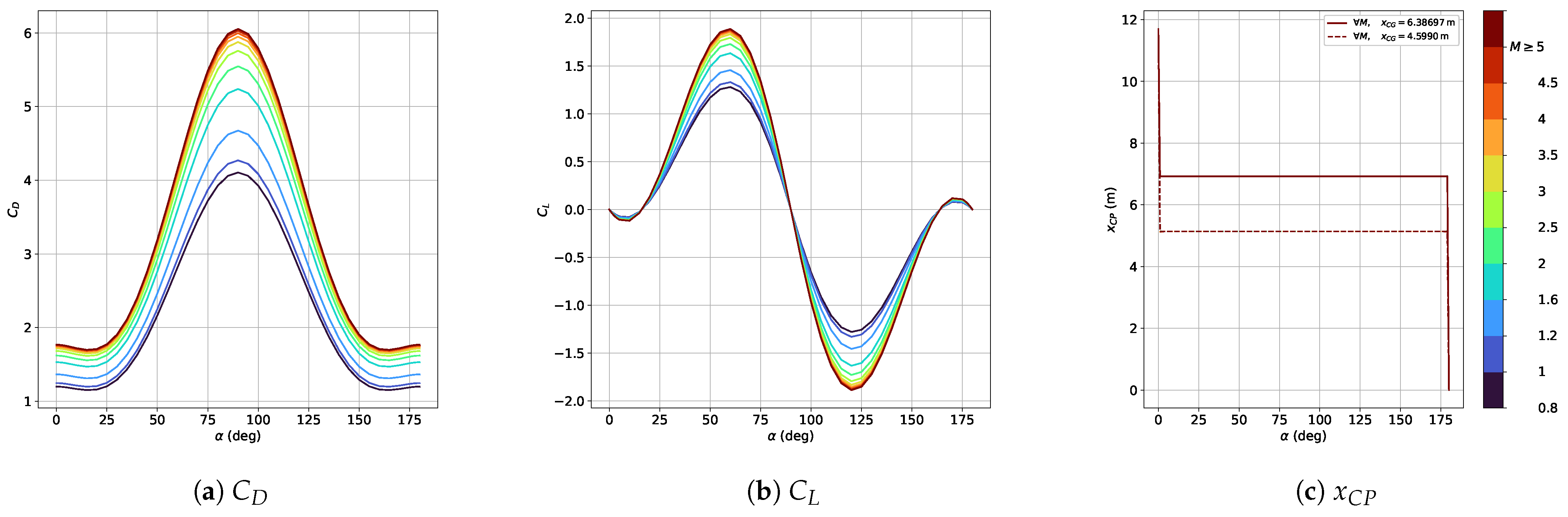
Aerodynamic parameters are obtained using the Supersonic/Hypersonic Arbitrary-Body Program (S/HABP) for a cylindrical-shape first-stage rocket, with an angle of attack from 0 to 180 deg and a Mach number from 0.8 to 5. This programme, which was developed in 1973 by the United States Air Force Flight Dynamics Laboratory [
17] and used by the National Aeronautics and Space Administration, has been adapted to obtain an aerodynamic database composed of the aerodynamic coefficients and the CP as function of the Mach number and the aerodynamic angles. More details on the development of the aerodynamic database and its validation are given in Ref. [
18]. These coefficients are then linearly interpolated in the simulator according to the current flight conditions. The variation of
,
and
with respect to
and
is illustrated in
Figure 3.
Note that this aerodynamic database has some limitations. In fact, S/HABP was designed to operate from about Mach 2 to the hypersonic range [
19]. However, for the RLV descent phase, and particularly for this study, the Mach number range starts around Mach 5 and then drops below Mach 1 until reaching zero velocity at landing. In addition, the aerodynamic coefficients are assumed to be independent of the thrust level. This approximation is very rough for retro-propulsive flight, where there are significant interactions between the exhaust plume of the engine and the oncoming flow that substantially impact the drag coefficient and the heat loads [
20]. Therefore, the approximations obtained for the aerodynamic coefficients might diverge from the true values [
18]. However, the goal of this simulator is not to gather high-fidelity models but to study the interactions and challenges that exist in the design of an RLV controlled dynamics simulator and assess the advanced and robust G&C methods that must be developed accordingly.
2.4. TVC System
The trajectory of the vehicle during descent is controlled by adjusting the magnitude and direction of the thrust vector generated by the main engine. This is achieved by the TVC actuator deflecting the engine nozzle by
and
, respectively, along the
-axis and
-axis. The required thrust magnitude
and deflection angles
are obtained from the guidance algorithm (
Section 3) and the control method (
Section 4), respectively. Decoupling between translational and rotational dynamics is common for TVC control due to the fact that the attitude of the vehicle can change faster than its trajectory [
16]. Thus, the TVC-generated force and moment can be expressed in the body-fixed frame by
where
is the TVC pivot position (
).
2.5. Steerable Planar Fins Model
The implementation of planar fins for a G&C strategy has already been studied in the literature. Usually, two pairs of fins are placed above the vehicle’s CG: one pair, with deflections
, controlls the motion in the pitch plane, while the other, with
, controlls the motion in the yaw plane. Therefore, it is considered that there is no roll perturbation, meaning that the two pairs always remain in the trajectory yaw and pitch planes, respectively. In Ref. [
8], Sagliano et al. used aerodynamic coefficient lookup tables that directly considered the state of the vehicle (angle of attack
, sideslip angle
, and Mach number
) and fin deflections
. In Ref. [
21], the authors developed a fin model with a corresponding lookup table for the axial coefficient and the derivative of the normal coefficient, depending on only the Mach number. Therefore, the lookup tables were the same for the four fins, and the generated force was determined by the fin’s local angle of attack, defined as a function of the fin deflection and the vehicle’s angle of attack or sideslip angle. Finally, in Ref. [
16], Simplício et al. also developed a fin model, but it only considered the normal force, which was calculated as a function of the fin’s local angle of attack. The same approach is used in this paper, and the obtained planar fins model was validated in Ref. [
22].
Table 1 defines the fin positions with the corresponding deflections.
Furthermore, due to the reduced fin area compared to the RLV body, only the normal force contribution is considered [
16]. Then, the value of the normal coefficient of the fin is estimated using lifting-line theory [
23]. In fact, for a symmetric airfoil, the lift coefficient can be approximated by
To obtain the lift coefficient
of the corresponding wing, it is necessary to define the aspect ratio, denoted by
and defined as
where
b is the wing span,
S is the wing reference area, and
c is the wing chord. Therefore, the following approximation is obtained [
24]:
This theory is then adapted for the fins of the RLV. Because flow separation is neglected and the angle of attack of the rocket is around
during descent, the normal fin coefficient has a sinusoidal dependence on the fin angle of attack
and can be approximated by
It remains to define the
ith fin’s angle of attack and its associated force
and moment
in the vehicle’s body-fixed reference frame.
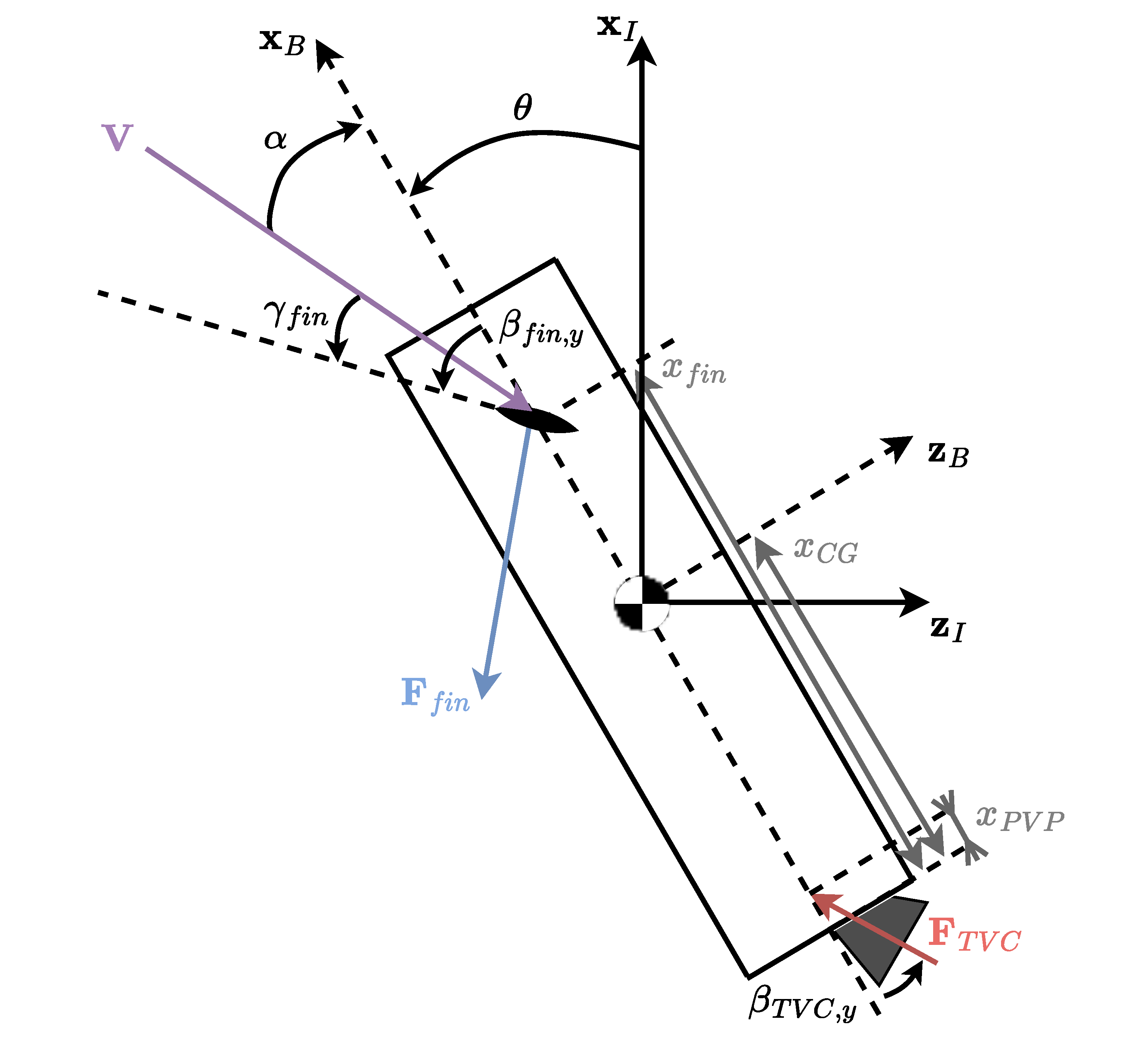
Figure 4 shows the motion of the vehicle in the pitch plane; from this figure and Ref. [
16], it is possible to state the following:
where
is the vehicle’s angle of attack, and
is the fin reference area. Similarly, the following formula is obtained in the yaw plane:
where
is the vehicle’s sideslip angle.
Finally, the total force generated by the fixed planar fins in the inertial reference frame and the total moment generated in the vehicle’s body-fixed reference frame are given by
Table 2 specifies the parameters of the planar fins that are implemented in the simulator.
3. Guidance Strategy
For the RLV D&L simulator introduced in the previous section, the guidance algorithm is responsible for the real-time generation of a reference trajectory to be followed by the vehicle with thrust and attitude commands. Here, a direct method is used within the convex optimisation framework. This consists in transforming the fuel-optimal trajectory problem into a convex one—more precisely, into a Second-Order Cone Programming (SOCP) problem, which can be solved with efficient solvers in polynomial time. These challenging tasks rely on converting nonconvex state and control constraints into the convex form, requiring high computational power. Recently, the so-called lossless convexification method [
25] and advances in computational development have enabled these issues to be overcome and therefore allow real-time trajectory generation in a closed-loop fashion.
Moreover, a particular class of convex optimisation, successive convex optimisation, can be applied to approximate the remaining nonlinearities in the optimal landing problem, such as the aerodynamic effects, which have previously been ignored. This consists in iteratively solving convex optimisation SOCP subproblems in which the nonconvex dynamics and constraints are repeatedly linearised using information originating from the previous iteration’s solution. This algorithm was first developed by Szmuk et al. in Ref. [
4] and then adapted in different ways in Refs. [
7,
9]. In this paper, the successive convex optimisation algorithm relies on the work achieved by Guadagnini et al. in Ref. [
26], where the strategy defined in Ref. [
4] was improved to be applicable in a closed-loop fashion for a 6-DoF controlled dynamics simulator.
In this study, the successive convex optimisation guidance algorithm is implemented in MATLAB using the CVX library [
27] to formulate the convex problem and the ECOS routine [
28] to solve it. At each simulation instance defined by the simulation rate
, the reference thrust profile
and the reference attitude angles
are calculated from the most recent guidance solution by linear interpolation. In fact, this solution is stored as an online lookup table, which is updated at each guidance step, with the guidance update frequency
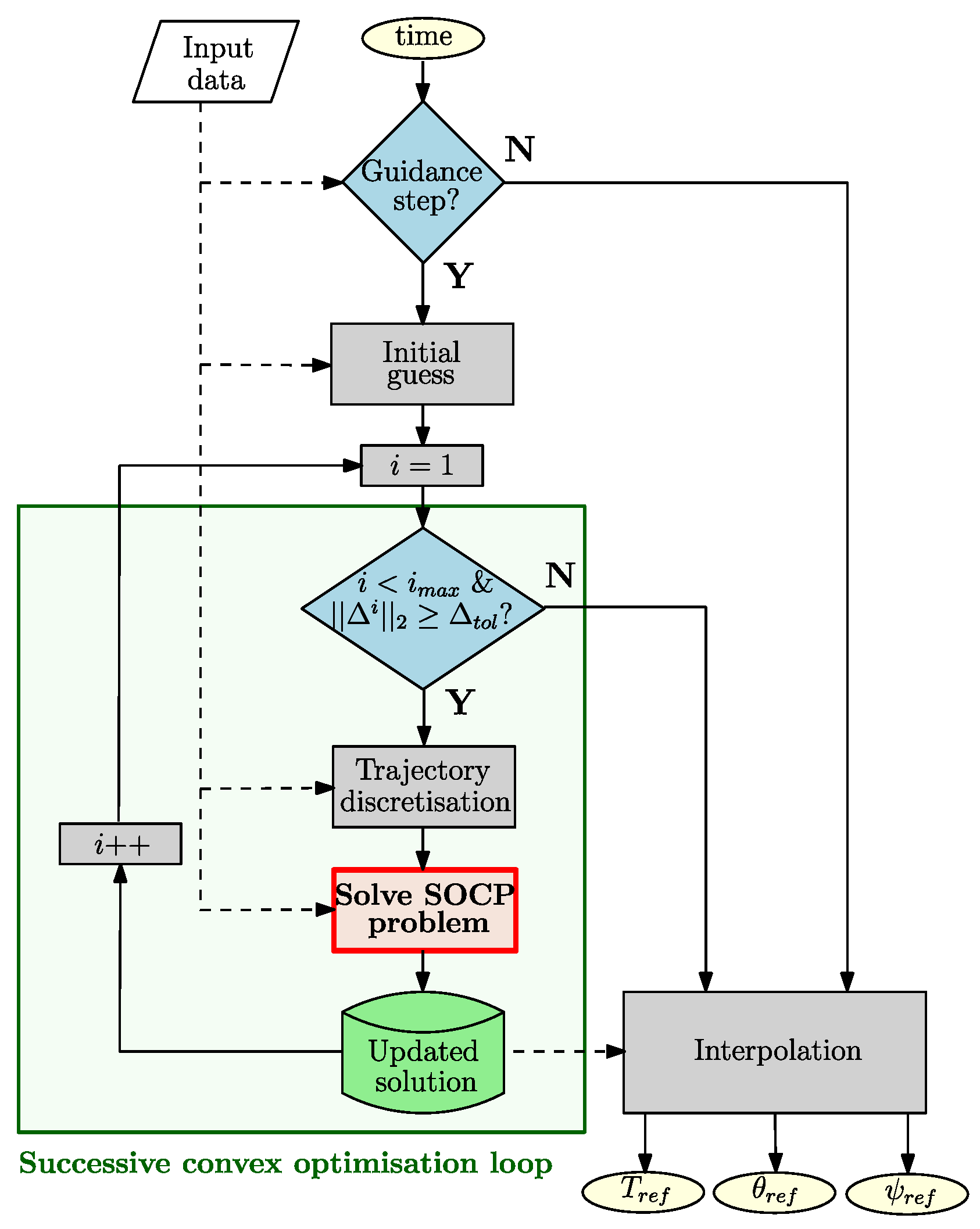
Hz, that is, every 10 s. The guidance algorithm inside the “D&L Guidance” building block of the simulator (recall
Figure 1) is schematised in
Figure 5.
Before describing the algorithm, a description of the adopted notation is provided. In the following paragraphs and subsections, the discrete time instant is specified with the parameter k. Consequently, a variable a at the time instant k is represented as . Then, since we are handling an iterative process, the considered iterative solution is specified with the superscript i. Therefore, the solution a obtained at iteration i is specified as . Thus, a variable a at a time instant k, relative to iteration i, is denoted .
First, it is necessary to initialise the process with a dynamically inconsistent guess solution. The simplest approach for the state vector is to create a linear interpolation of the discrete state variables under the initial and final conditions. Regarding the control vector, a good guess for the 6-DoF D&L problem is to match the gravitational force at each time step. In this study, the time of flight, which is the final time
, is also an optimisation variable and therefore must be initialised. The initial guess for the state and control vector solutions at each time instant, starting at time
and for the time of flight
, are defined by
The algorithm is not specifically sensitive to initial guesses, but poor guesses can lead to an increased convergence time [
4].
Once the initial guess is defined, we enter the successive convex optimisation loop, which consists of solving the SOCP problem several times until reaching the user-defined maximum iteration number or the tolerance relative to the trust region radius , defined in the next subsection. Note that several exit conditions can be defined, such as a tolerance with respect to the norm of the virtual controls or the norm of the difference in the cost function between two iterations. Those defined here lead to satisfactory results and enable the coupling of the guidance algorithm with the other building blocks of the 6-DoF RLV controlled dynamics simulator, which is the main focus of this paper.
Then, to enable the formulation of the SOCP subproblems, the optimal control problem must be converted into a finite-dimensional parameter optimisation problem. Therefore, the trajectory and optimisation variables are discretised into
K uniformly spaced points, ranging from the current instant of time
to the final time
. At each guidance step, the time vector is divided in the following way:
Additionally, because the estimated time of flight as , where is the actual time of flight achieved by the simulation, the accuracy of the discretisation becomes more precise towards the end. More specifically, the sampling time is given by . The linearisation and discretisation methods are explained in the next subsection, together with the definition of the SOCP problem.
When the optimisation algorithm converges to an optimal solution, this reference trajectory is saved to be used for the next iteration, or, if the exit criterion of the successive convex optimisation routine is met, it is transferred to the online look-up table from which the actual reference parameters corresponding to the simulation instance can be generated. In this study, this involves the reference thrust magnitude profile and the reference pitch and yaw angle profiles and , respectively.
3.1. Nonconvex Optimal Control Problem
The guidance law relies on solving an optimal control problem with dynamic constraints. These involve the descent dynamics, but it is also possible to add several state and control constraints. The following paragraphs describe the optimisation problem implemented in the successive convex optimisation loop. Note that the superscript
i that defines the current iteration loop is omitted from the following description for the sake of clarity.
Figure 6 shows the nonconvex optimisation problem defined for this study.
It can be observed that the 6-DoF nonlinear descent dynamics displayed in Equations (
4)–(
6) are re-adapted to the 6-DoF descent of a powered-only first-stage booster, meaning that only the thrust vector of the main engine, denoted hereafter as
, is considered as the control input
. In fact, the steerable planar fins are not included in the optimisation problem for the rocket D&L in order to avoid adding complexity due to the nonlinearities generated by the addition of these aerodynamic loads. This is common practice for launcher re-entry, since the thrust vector (magnitude and direction) is a good indicator for reference trajectory generation. The allocation between the actuators, TVC, and steerable planar fins is achieved afterwards by the control subsystem using the reference values obtained in terms of thrust magnitude and attitude angles.
In addition, the aerodynamics are modelled through a so-called spherical aerodynamic model. This model, introduced by Szmuk et al. in Ref. [
4], approximates the relationship between the aerodynamic force and the velocity vector and has the advantage of being easily implementable with the successive convex optimisation guidance method. More specifically, the aerodynamic force
is considered to be always anti-parallel with respect to the velocity
as if the vehicle were subjected to a pure drag force. Assuming that the rocket is axisymmetric, the aerodynamic forces and moments in the vehicle’s body-fixed reference frame are expressed by
Here,
is the aerodynamic coefficient matrix, where
is a positive scalar defined as follows
Here,
is the drag coefficient, which is estimated from the available lookup tables defined in
Section 2.3.
Regarding the state constraints, the first is a lower bound of the mass: for any time
, the mass cannot be lower than the dry mass of the vehicle. This constraint is expressed as follows:
The second constraint is the so-called glide-slop constraint: it restricts the inertial position to lie within a glide-slope cone with half-angle
and a vertex at the landing site. This constraint is enforced by
where
are the versors. The third constraint then concerns the tilt angle, that is, the angle between the
-axes of the two reference frames, which is limited to a maximum of
. It is defined by
Then, the fourth constraint limits the angular rate of the vehicle and is enforced by
Finally, an additional constraint preserves the unit norm of the quaternion as follows:
Moreover, a so-called State-Triggered Constraint (STC) [
4] is added. In the present case, it consists in imposing an angle of attack
constraint,
, when the dynamic pressure
is larger than a prescribed value
. This constraint is written in a continuous formulation with a trigger function
and a constraint function
as follows:
Two control constraints are considered to bound the direction and magnitude of the thrust force. The direction is bounded by limiting the TVC up to a maximum gimbal angle
. It is enforced by
Then, the thrust magnitude is bounded between minimum and maximum values, i.e.,
where
and
are the lower and upper bounds, respectively.
The objective of the optimal control problem defined herein is to find the optimal trajectory subject to the defined re-entry dynamics and state and control constraints while minimising the vehicle’s fuel consumption, which corresponds to maximising the vehicle’s final mass. Therefore, the cost function can be written as follows at each
ith SOCP iteration:
3.2. SOCP Problem
However, the optimisation problem subject to the described dynamics and state and control constraints is not convex and must therefore be convexified. In order to achieve this, the first step is to convert the free-final-time nonlinear continuous-time optimal control problem into an equivalent fixed-final-time nonlinear continuous-time problem. This is achieved by normalising the time of flight from
to
, where
is the normalised time of flight. The nonlinear dynamics are summarised as
with
as the state vector and
as the control vector, which can be rewritten as follows:
Therefore, with
, the normalised nonlinear dynamics are expressed by
where
, since
.
Then, the nonlinear descent dynamics equations, defined above, are linearised and discretised about the solution of the previous iteration through a first-order Taylor approximation and using a zero-order-hold interpolation scheme. First, the original continuous-time problem is transformed into a Linear Time-Varying (LTV) problem defined by
where the parameters are evaluated about a reference trajectory corresponding to the previous (
)th SOCP solution:
Second, the discretised LTV system is given for each
by
Once the descent dynamics are linearised and discretised, the next step is the convexification of the nonconvex constraints. This concerns two state constraints, the norm of the quaternion (Equation (
28)) and the STC (Equation (
29)), and one control constraint, the lower bound of the thrust magnitude (Equation (
31)). The convexification of Equation (
28) is obtained through a first-order Taylor expansion approximation evaluated about the previous
th SOCP iteration:
The same method is used for the STC (Equation (
29)). However, due to the
function, the constraint is approximated as follows:
where
are the reference trajectory parameters obtained from the
ith SOCP iteration. Lastly, it is applied to the lower bound of the thrust magnitude, obtaining the following expression for
:
The successive convex optimisation strategy involves the use of trust regions and virtual controls to prevent unboundedness and artificial infeasibility, respectively. In fact, these issues are due to the linearisation process. They could be avoided using the nonlinearity preservation and linearisation approach instead of the direct linearisation approach adopted in this guidance law to reduce complexity [
29,
30]. The implementation of trust regions allows one to limit the deviation between two consecutive iterations responsible for artificial unboundedness. They consist of quadratic inequality constraints. The aim is to define a region near the previous iteration so that the deviation is mitigated. As a consequence, this involves the radius being penalised in the cost function. In this optimisation problem, the trust regions are defined first for the state and control vectors and then for the time of flight as follows:
is then defined as the state and control trust region vector. To convert this trust region vector into the SOCP formulation, it is necessary to define a joint state and control vector at each time instant,
,
so that Equation (
41) can be rewritten as
Finally, the size of the trust regions must be bounded; therefore, the norms
and
must be inserted into the cost function. Regarding the state and control trust region vector, a slack variable
must be introduced in order to avoid a quadratic term in the cost function. This implies the addition of the following inequality constraint [
26]:
Virtual controls are additional control inputs
that allow one to reach each point of the solution domain through dynamics relaxation and therefore avoid artificial infeasibility. They are commonly met during the first iterations of the algorithm due to the dynamically inconsistent initial guess, but they also compensate for the high-order terms neglected by the discretisation process. Therefore, the linear discrete dynamics of Equation (
37) become
We can then define a concatenated vector
. Similarly to the trust regions, all these terms must be penalised in the cost function, and to avoid a quadratic term, a slack variable
must be again be defined in conjunction with the following inequality constraint:
Finally, the cost function of Equation (
32) is augmented with the previously defined features and becomes:
where
,
, and
are penalisation weights.
The obtained SOCP optimisation problem, which is solved iteratively in the successive convex optimisation algorithm, is summarised in
Figure 7.
Table 3 provides the SOCP problem parameters.
4. Control Approach
From the reference trajectory computed by the previously defined guidance algorithm and the current states of the vehicle, the control algorithm must be able to generate the necessary commands in terms of the thrust magnitude ; TVC deflection angles ; and fin deflections to be applied by the actuators in order to correct the trajectory of the vehicle. For this study, we assume and . The method adopted here considers the use of two gain-scheduled PID controllers to compute the respective deflection angles. In fact, the thrust magnitude command is taken directly from the guidance algorithm . This approximation is penalised by a low-pass filter, which simulates the intrinsic physics of the device, and the delay induced is compensated for by a PI controller. In fact, the descent control system is more complex than the ascent phase due to the throttleability of the thrust force generated by the rocket’s main engine. If this were considered as a control input, the pitch and yaw motion could not be decoupled, as is usually carried out for rocket preliminary attitude control design. We followed this approach herein since the objective was primarily to study the interactions between all the subsystems, rather than the development of a highly accurate, high-performance control system.
Usually, the 6-DoF problem is separated into two 3-DoF problems. One is characterised by the motion in the
plane with the controller on the pitch angle
through the deflection angles
and
. The second problem is characterised by the motion in the
plane with the controller on the yaw angle
through the deflection angles
and
. An assumption is made that the roll angle
is small so that no coupling effects can arise in the dynamics. Therefore, two linear systems are built using a reference trajectory precomputed offline. This reference trajectory corresponds to the solution of the successive convex optimisation algorithm in its first run, meaning that the initial conditions of the studied problem are used. These can be rewritten in terms of the perturbed variables
and
, where
and
are the reference state and control vectors, respectively, to finally obtain
where
and
are the Jacobian matrices of the nonlinear equations with respect to the state and control variables respectively, computed with the function
in MATLAB, and
enables the extraction of the pitch angle error
and the yaw angle error
. Therefore, the decoupling into two 3-DoF is achieved, and the following linear systems are obtained:
where
,
, and
are the
x,
y, and
z components of
, respectively, and
and
are the
y and
z components of
. The corresponding Jacobian matrices are computed similarly to the linear system defined in Equation (
47). This decoupling of the dynamics was validated in [
26].
With these definitions and because two control inputs are considered in each linear system (TVC and fin deflections), the latter is considered as a Multiple-Input Multiple-Output (MIMO) control system for which it is complex to apply classical linear control theory since every channel must be iteratively addressed in a single-loop fashion. The solution to overcome this drawback would be the use of advanced robust control methods such as the
family of methods or the LPV approach. A preliminary study of structured
control synthesis within this simulator is available in Ref. [
31]. In this study, to develop a baseline simulator and stay in line with the current state of the art in control design for launchers [
10,
32], the linear systems are adapted to Single-Input Single-Output (SISO) control systems, for which it is possible to use gain-scheduled PID controllers. Two configurations are chosen and are explained in the next subsections. The first is the TVC-only configuration, for which the fins are considered fixed and the only input is therefore the TVC deflection. The second configuration lies in the definition of a control moment, introduced in Ref. [
16], which gathers TVC and fin control authorities and then allocates the necessary command to each actuator according to the level of thrust.
4.1. TVC-Only SISO Configuration
In this case, the only control inputs are
for the pitch plane and
for the yaw plane. Therefore, the two linear systems consider the following parameters:
where
,
, and
are the
x,
y, and
z components of
, respectively, and
and
are the
y and
z components of
. The corresponding Jacobian matrices are computed similarly to the linear system defined in Equation (
47).
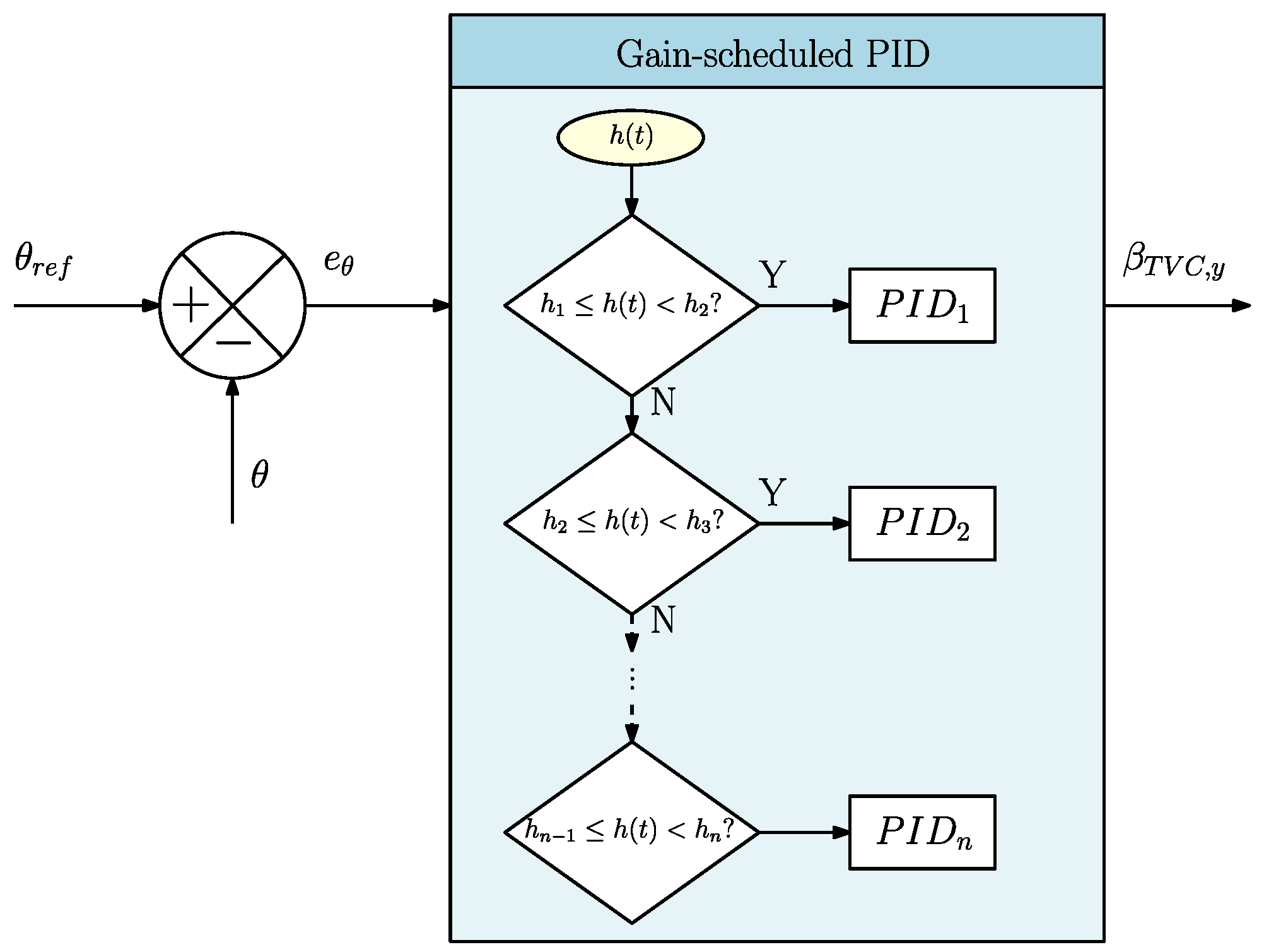
Due to the time-varying nature of the problem, a single PID controller might be unable to stabilise the system for the whole trajectory. Therefore, the reference altitude profile is discretised into 25 slots where linearisation is performed. This was chosen as the scheduling parameter since it evolves monotonically with respect to time and has been well validated in the literature [
33,
34]. Moreover, it allows one to capture the variations in terms of thrust magnitude. In this way, the problem is divided into regions wherein it is possible to analyse if the controller is able to stabilise the system. Thanks to this, the controllers can be considered gain-scheduled PID controllers, as the gains can be changed to achieve the desired levels of performance in all the regions. For each system, the gains are tuned with the following performance requirements: an overshoot inferior to 10%, a settling time strictly inferior to 1 s, a gain margin superior to 6 dB, and a phase margin superior to 60 deg. The tuning is performed with the MATLAB application
.
4.2. TVC and Fin SISO Configuration
Here, the MIMO formulation is translated into an SISO formulation by defining a surrogate variable that gathers gimbal and fin angle deflections and achieving control synthesis on it. More specifically, following Ref. [
16], the control moment
is defined as a parameter that specifies the necessary pitch or yaw moment to correct the trajectory of the vehicle. Knowing the control effectiveness level of each actuator, a control allocation algorithm is then used to determine the actual control inputs
,
and
,
.
The control effectiveness levels are expressed as follows. The effectiveness of TVC in generating control moments is quantified by
Regarding the fins, the control effectiveness is given by
where
is the normal fin force gradient with
computed from Equation (
37) for the pitch plane and Equation (
38) for the yaw plane. The relationship between the control moment and the control inputs is then expressed as
where
for the pitch plane and the yaw plane, respectively.
Therefore, these parameters are obtained from the reference trajectory, and similarly to Equation (
47), the following linear systems are built for the pitch and the yaw planes:
The Jacobian matrices and the corresponding PIDs for the given altitude slots are computed in the same manner as for the previous configuration. Note that the obtained controllers must be robust enough to cope with a range of trajectories since the guidance is recomputed several times during the descent, but not the tuning of the gains. However, it is observed that the updated guidance trajectories follow the same scheme, which is enforced by the boundary constraint on the quaternion (recall
Figure 7), and since the controllers are interpolated with respect to the altitude (and not the time of flight, which is unknown), the obtained gains provide satisfactory results all along the descent flight.
Finally, the commanded control moment
is allocated between the TVC system and the planar fins following the algorithm in Ref. [
16], repeated in Algorithm 1. More specifically, if the commanded thrust magnitude
is above the user-defined high thrust limit
, then the TVC system is used as the primary actuator, and the planar fins are used only if the maximum authority
of the TVC system is reached. In contrast, if the thrust magnitude command
is below the user-defined high thrust limit
, then the planar fins are used as the primary actuator, and the TVC system is used as the secondary actuator if the maximum authority
of the planar fins is reached. Here,
and
.
| Algorithm 1 Control allocation [16] |
- 1:
if
then - 2:
- 3:
- 4:
if then - 5:
- 6:
- 7:
end if - 8:
else - 9:
- 10:
- 11:
if then - 12:
- 13:
- 14:
end if - 15:
end if - 16:
OUTPUTS: ,
|
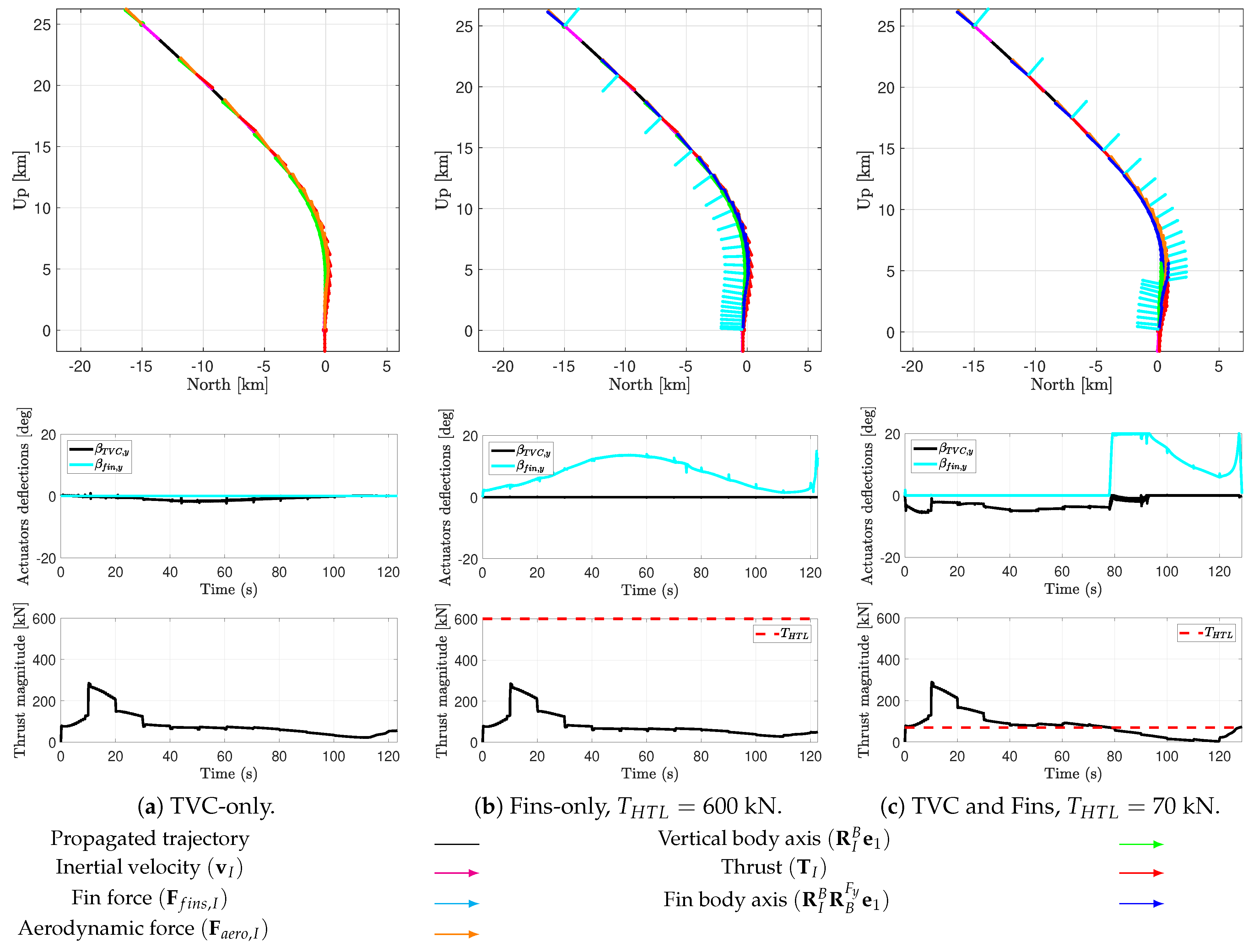
Note that this control configuration also enables a fin-only actuation configuration by setting a high thrust limit superior to the maximum thrust magnitude allowed by the guidance algorithm. Note also that this choice of criteria for changing the actuator allocation configuration was made after further analyses. Other criteria were tested, such as dynamic pressure or control effectiveness levels, that is, allocation primarily to the TVC system if and to the planar fins otherwise. However, the dynamic pressure profile was not accurate enough, since at the beginning of the trajectory the dynamic pressure is high, as well as the thrust magnitude; thus, the planar fins are efficient but in reality not as efficient as the TVC system. Furthermore, the control effectiveness level was not optimal, since some overlaps when both actuators had a similar control authority were observed that could lead to convergence issues, since it would involve rapid switches in the commands given to the actuators. Moreover, since the reference thrust magnitude is among the control inputs and completely decoupled from the TVC system by design, this parameter is less complex to implement, preventing coupling effects and therefore leading to the best results.
Once verified through linear analysis, the controllers were implemented in the nonlinear simulator according to the actual altitude following the scheme described in
Figure 8. Basically, no interpolation was achieved, and a controller was selected as soon as we entered the altitude region in which this controller had been defined. Note that the controllers’ gains could have been interpolated linearly with respect to the altitude using a finite-difference method as in Ref. [
33]. However, this solution was not adopted, since the values of two adjacent gain-scheduled controllers were considerably different, leading to inaccuracies when achieving the interpolation. Another strategy would be to use a so-called signal blending scheme to mitigate the previous issue [
34]. However, this could cause large transients in the switching regions and would be quite complex to implement. Therefore, this technique was not studied, since the objective was primarily the design of a closed-loop baseline simulator. The gain-scheduling method should be more thoroughly investigated in future work, since an improved scheduling strategy would be a substantial extension for enhanced robustness.
6. Conclusions
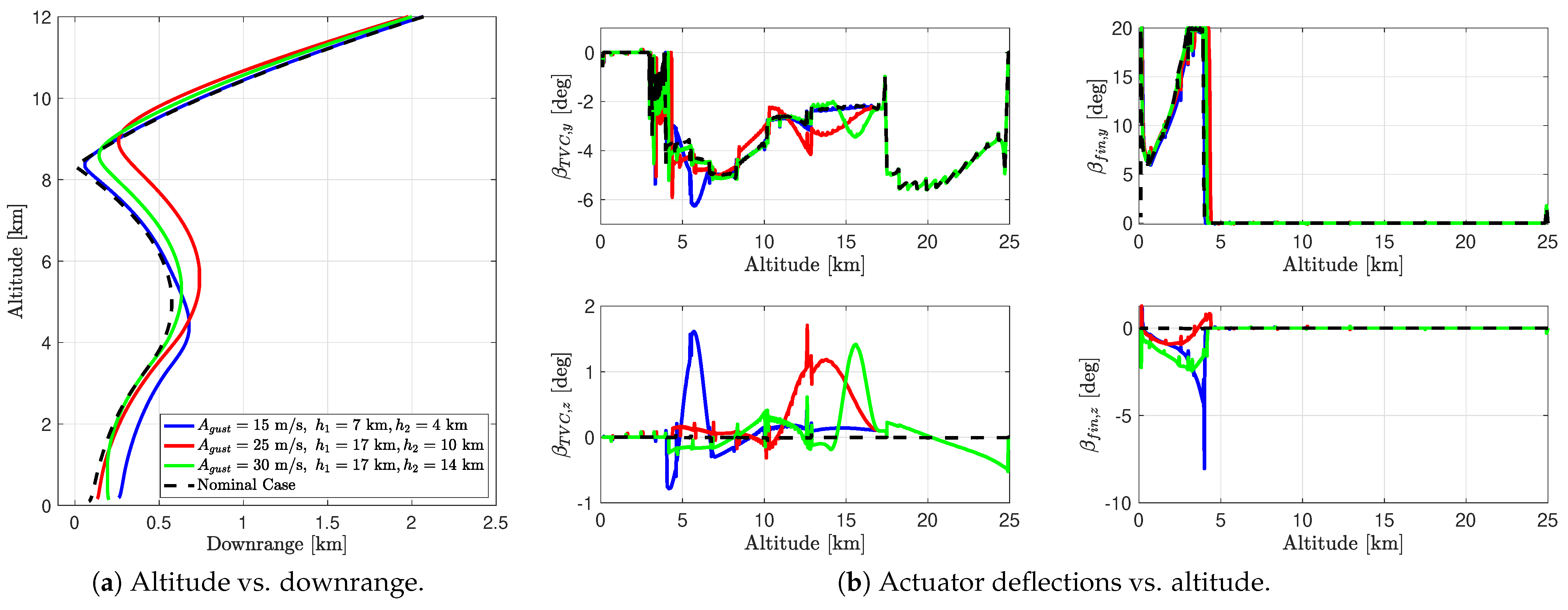
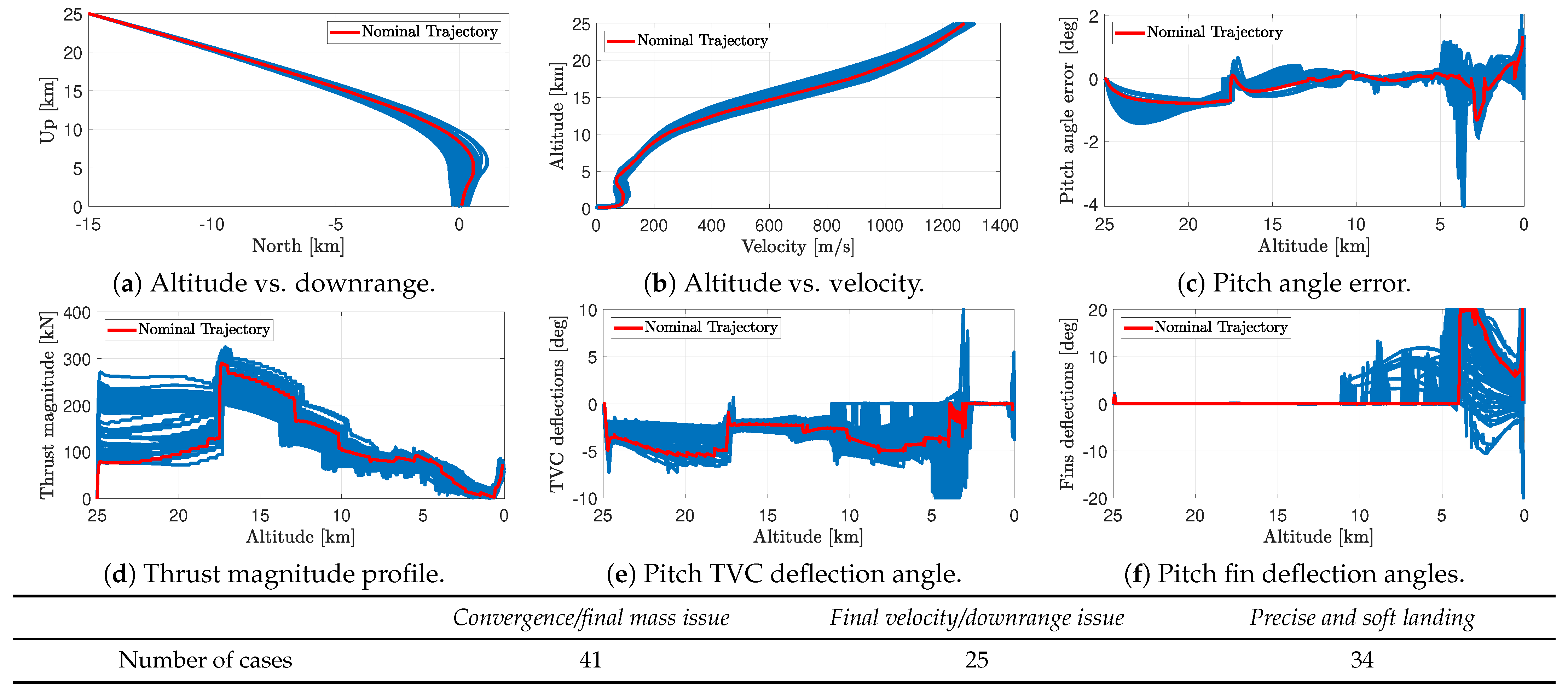
This paper described the development of a controlled dynamics simulator with closed-loop guidance and control integration for the D&L phase of reusable launchers. We considered a VTVL first-stage booster descent and soft pinpoint landing. The simulator included the 6-DoF descent dynamics of a rigid-body model with a varying mass, evolving in the terrestrial atmosphere with varying environmental parameters, uncertainties, and disturbances and subjected to external forces. To steer the spacecraft towards a controlled descent and a soft pinpoint landing, the vehicle is equipped with a TVC system and steerable planar fins controlled by gain-scheduled PID controllers, which correct the trajectory deviations with respect to the reference profile generated by a successive convex optimisation guidance algorithm. More specifically, the simulator involved a modular control architecture, allowing us to study different actuation configurations according to the mission requirements and the flight phase: TVC-only, planar fins-only, or both.
Several simulations were carried out that allowed us to provide preliminary assessments of the controllability challenges encountered by a rocket during the D&L phase while highlighting the necessary improvements for enhanced robustness to uncertainties. The combination of the TVC system and steerable planar fins was critical to provide a fuel-optimal trajectory and a precise landing for the reusable rocket while counteracting the possible disturbances and uncertainties existing in the terrestrial atmosphere. Despite the simplifying assumptions used in the simulator design and the low complexity of the control and allocation laws adopted, the tool obtained represents a powerful and versatile baseline for the development of more sophisticated G&C techniques. For example, as mentioned in the previous section, the guidance could be leveraged to generate the so-called bang-bang thrust magnitude profile, likely leading to less propellant consumption. Advanced approaches such as pseudospectral convex optimisation could be assessed and compared with the actual successive convex optimisation strategy. Concerning the control system synthesis, methods based on robust algorithms such as structured could also be assessed in the simulator and are expected to provide improved performance.



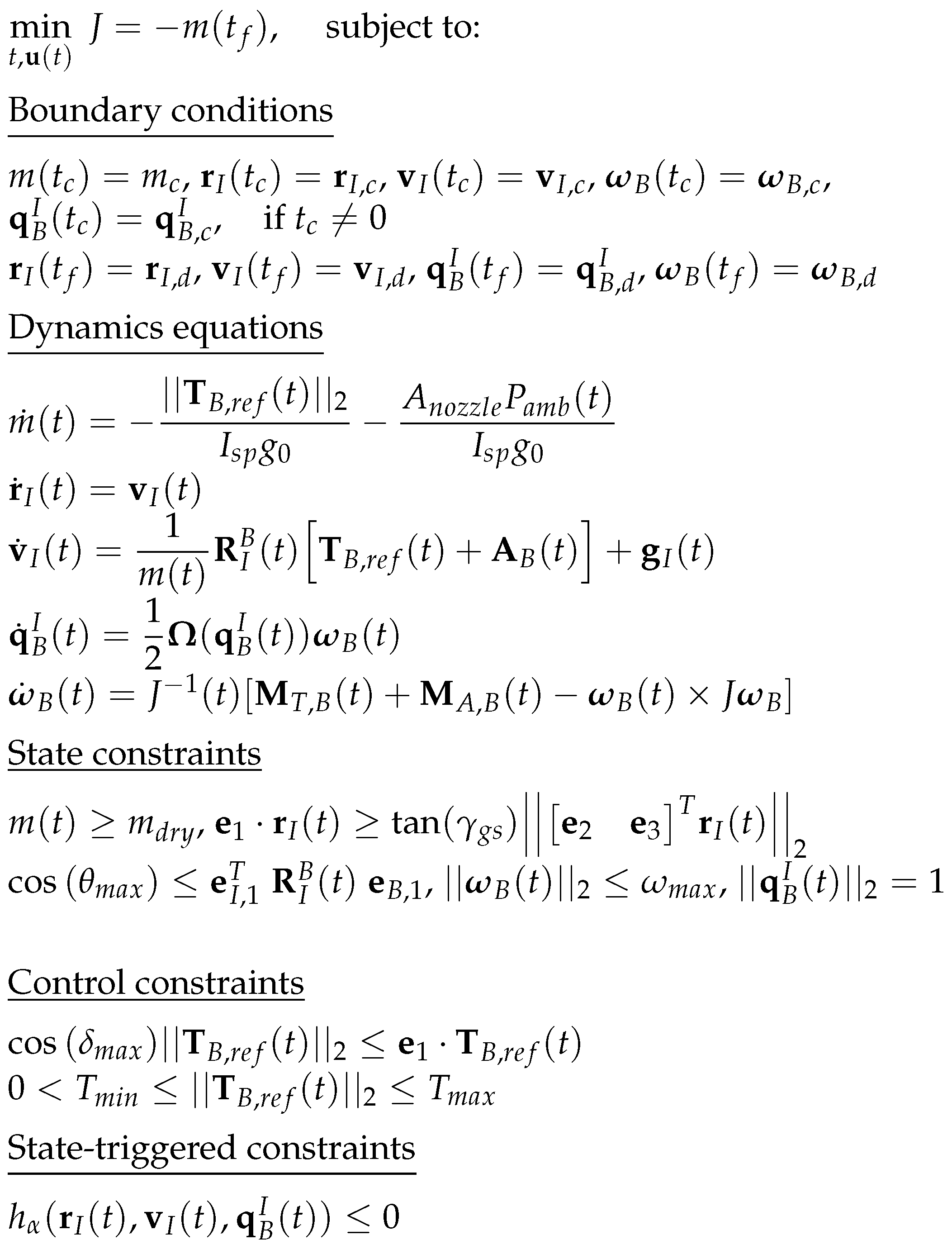


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}