
Lessons Learned in Transcribing 5000 h of Air Traffic Control Communications for Robust Automatic Speech Understanding

 , , ,
, , ,
Abstract
1. Introduction
2. Early Work on Automatic Speech Recognition and Understanding in ATC
3. ATCO2 Corpora
3.1. ATCO2 System and Generalities
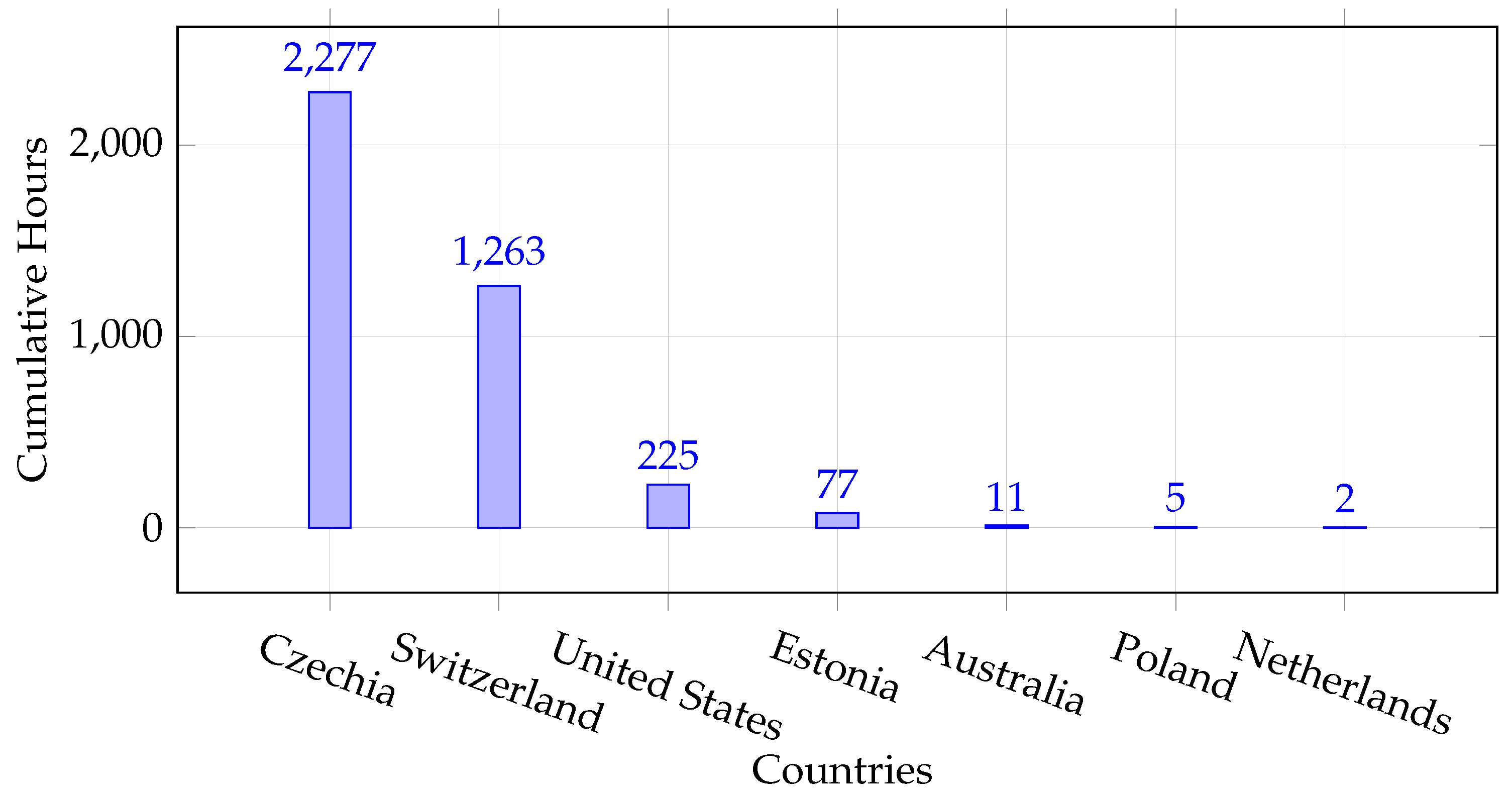
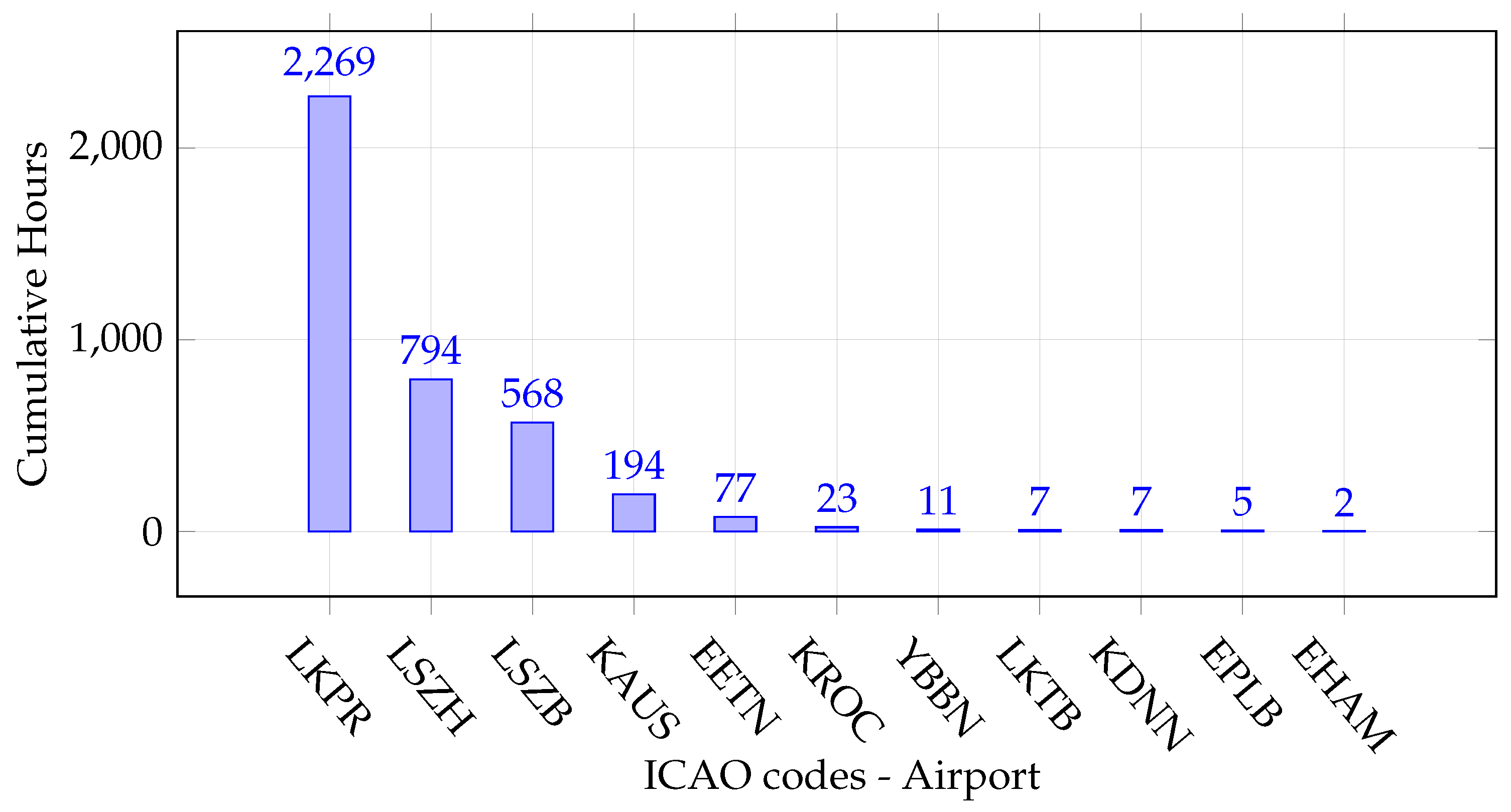
- First, the ATCO2-T set corpus is the first ever release of a large-scale dataset targeted to ATC communications. We recorded, preprocessed, and automatically transcribed ∼5281 h of ATC speech from ten different airports (see Table 2). To the best of the authors’ knowledge, this is the largest and richest dataset in the area of ATC ever created that is accessible for research and commercial use. Further information and details are available in [7].
- Second, ATCO2-test-set-4h corpus was built for the evaluation and development of automatic speech recognition and understanding systems for English ATC communications. This dataset was annotated by humans. There are two partitions of the dataset, as stated in Table 1. The ATCO2-test-set-1h corpus is a ∼1 h long open-sourced corpus, and it can be accessed for free at https://www.atco2.org/data (accessed on 10 October 2023). The ATCO2-test-set-4h corpus contains ATCO2-test-set-1h corpus and adds to it ∼3 more hours of manually annotated data. The full corpus is available for purchase through ELDA at http://catalog.elra.info/en-us/repository/browse/ELRA-S0484 (accessed on 10 October 2023).
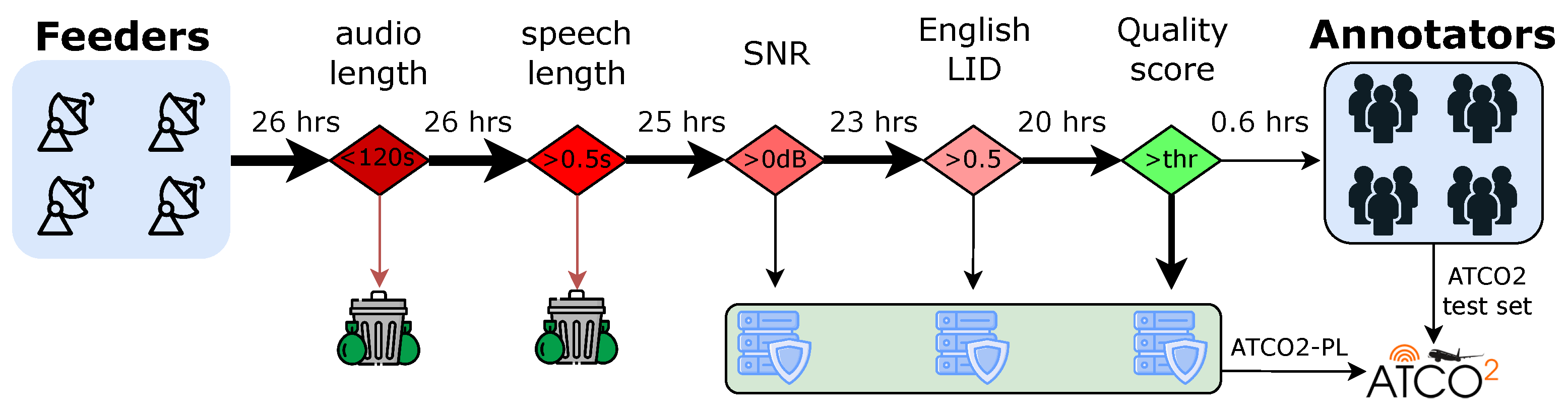
3.2. Data Collection Pipeline
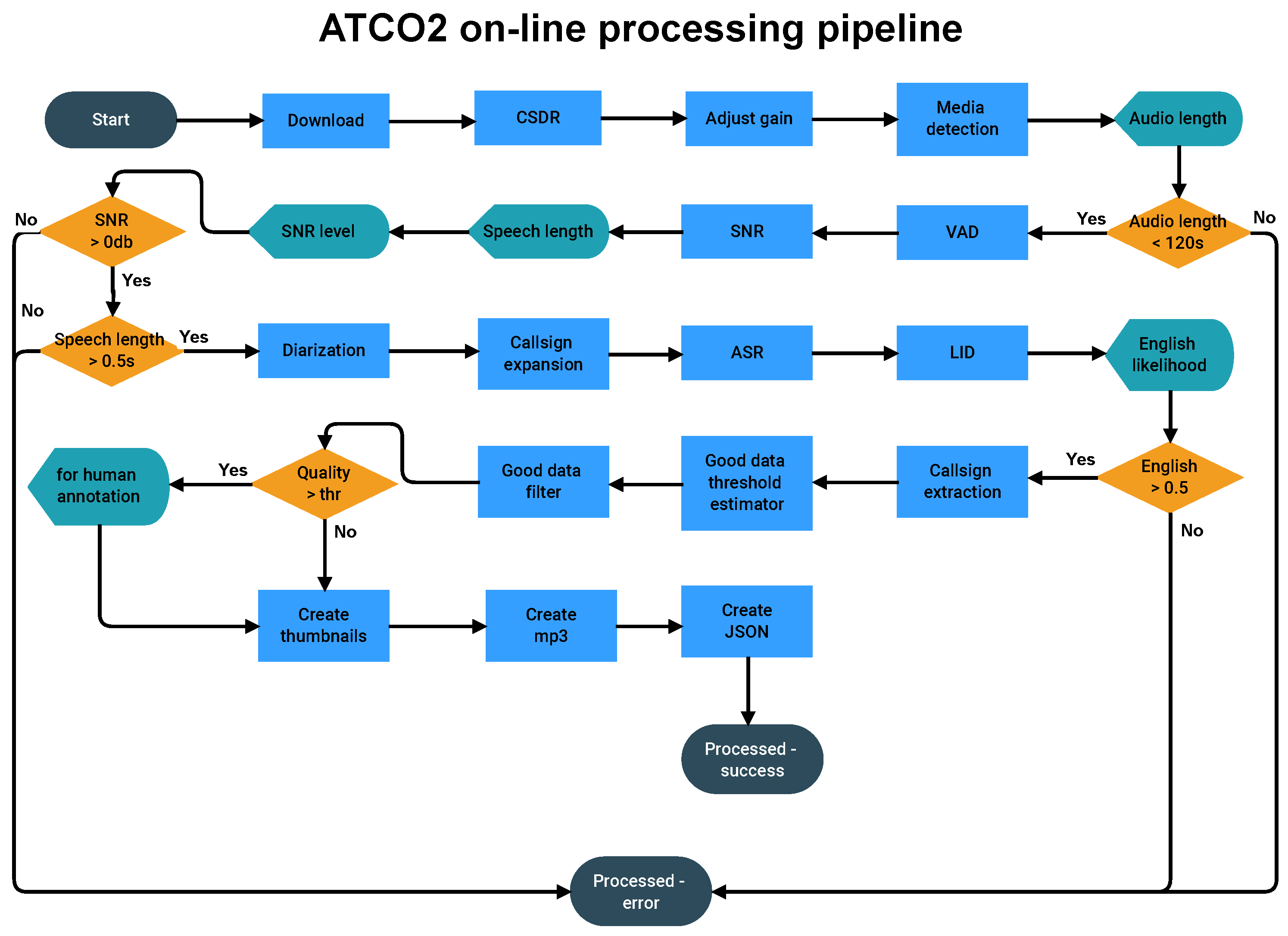
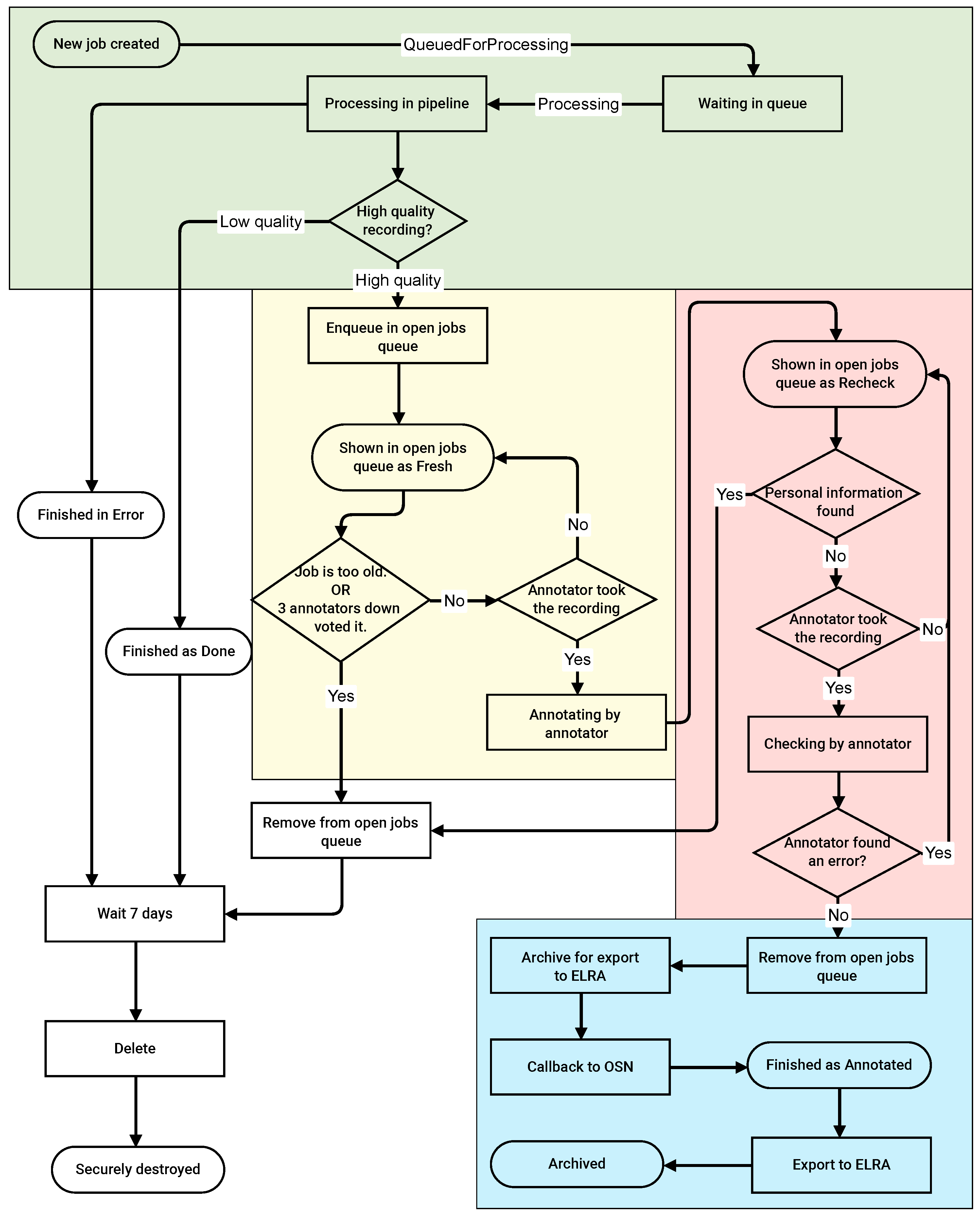
3.3. Quality Estimation for Data Transcription
- —provides average SNR of speech in range <0, 40>. SNR needs to be as high as possible;
- —provides the number of speakers in the audio in the range of <1, 10>. The more speakers detected in audio, the better;
- —provides the amount of speech in seconds;
- —provides the overall audio length. More speech detected in audio is better;
- provides “probability” of audio being English in the range <0.0, 1.0>. The higher the ELD score, the better;
- —provides average confidence of the speech recognizer <0.0, 1.0>. We want data where the recognizer is confident. Higher is better;
- —provides the number of words spoken in the range of <0, ∼150>. The more words, the better.
3.4. Runtime Characteristics
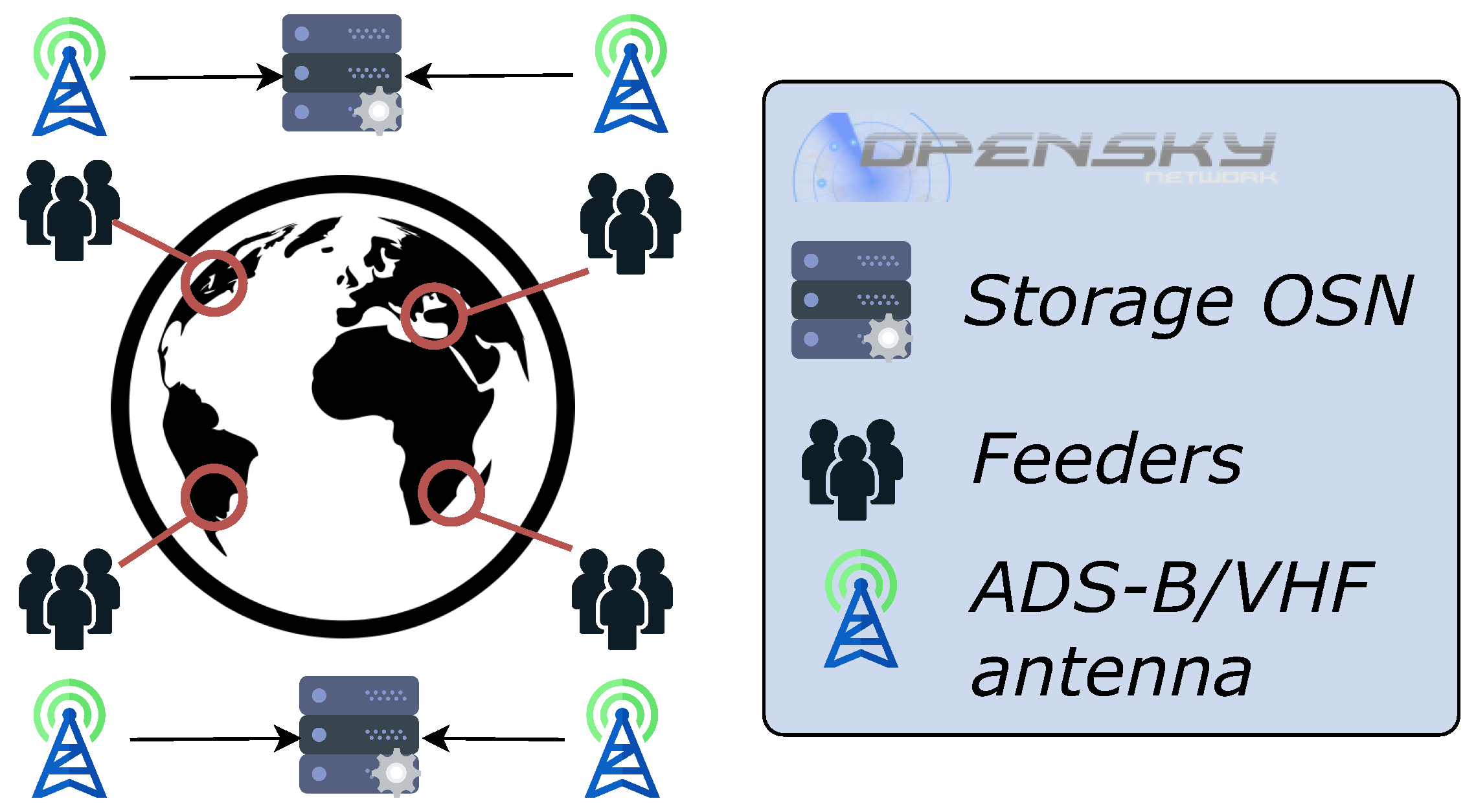
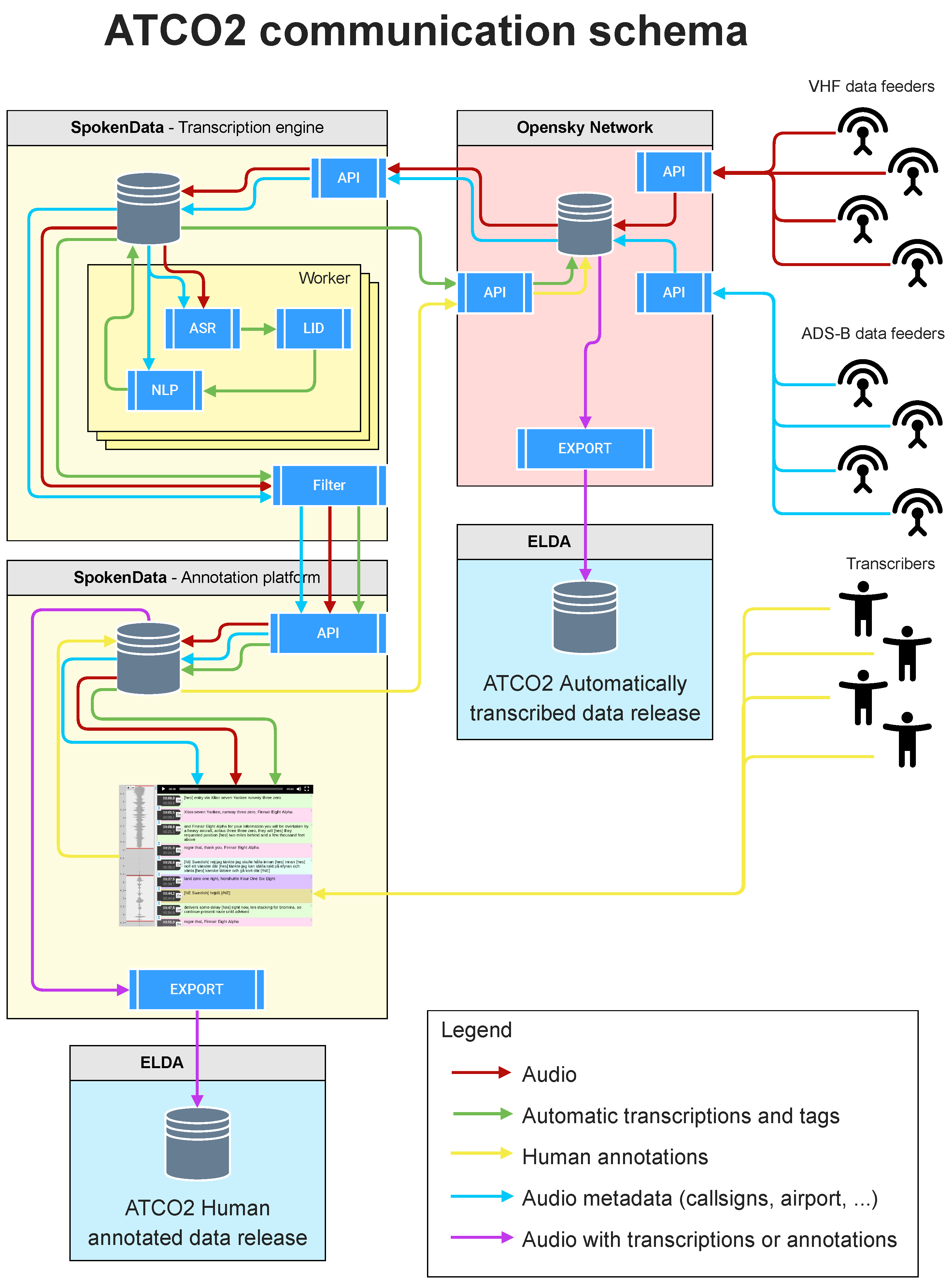
4. Collection Platform and Community of Volunteers
4.1. The Platform
- Support a similar number of users to the current OpenSky Automatic Dependent Surveillance–Broadcast system (ADS-B);
- Keep the feeder equipment simple and affordable;
- Provide data to different types of users in a simple and intuitive way;
- Interface external services (e.g., voice annotation) in a simple and intuitive way;
- Keep maintenance and error handling as simple as possible.
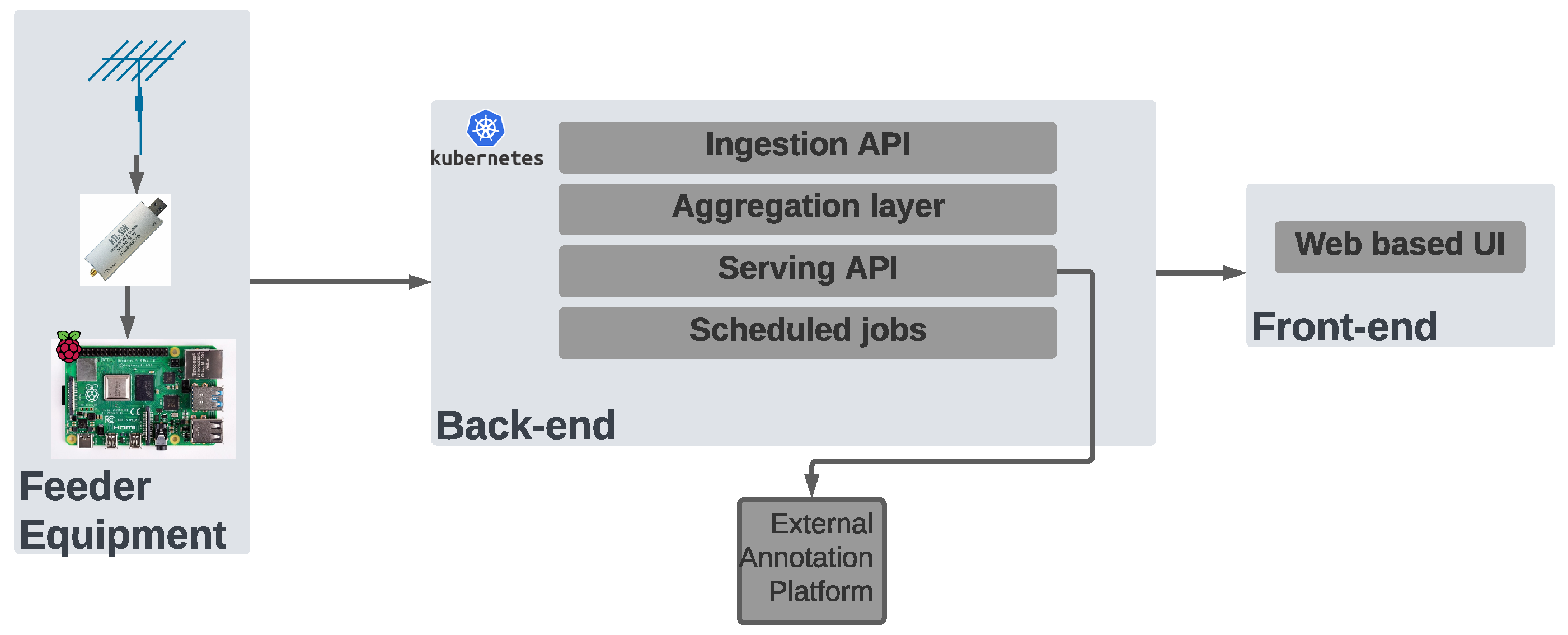
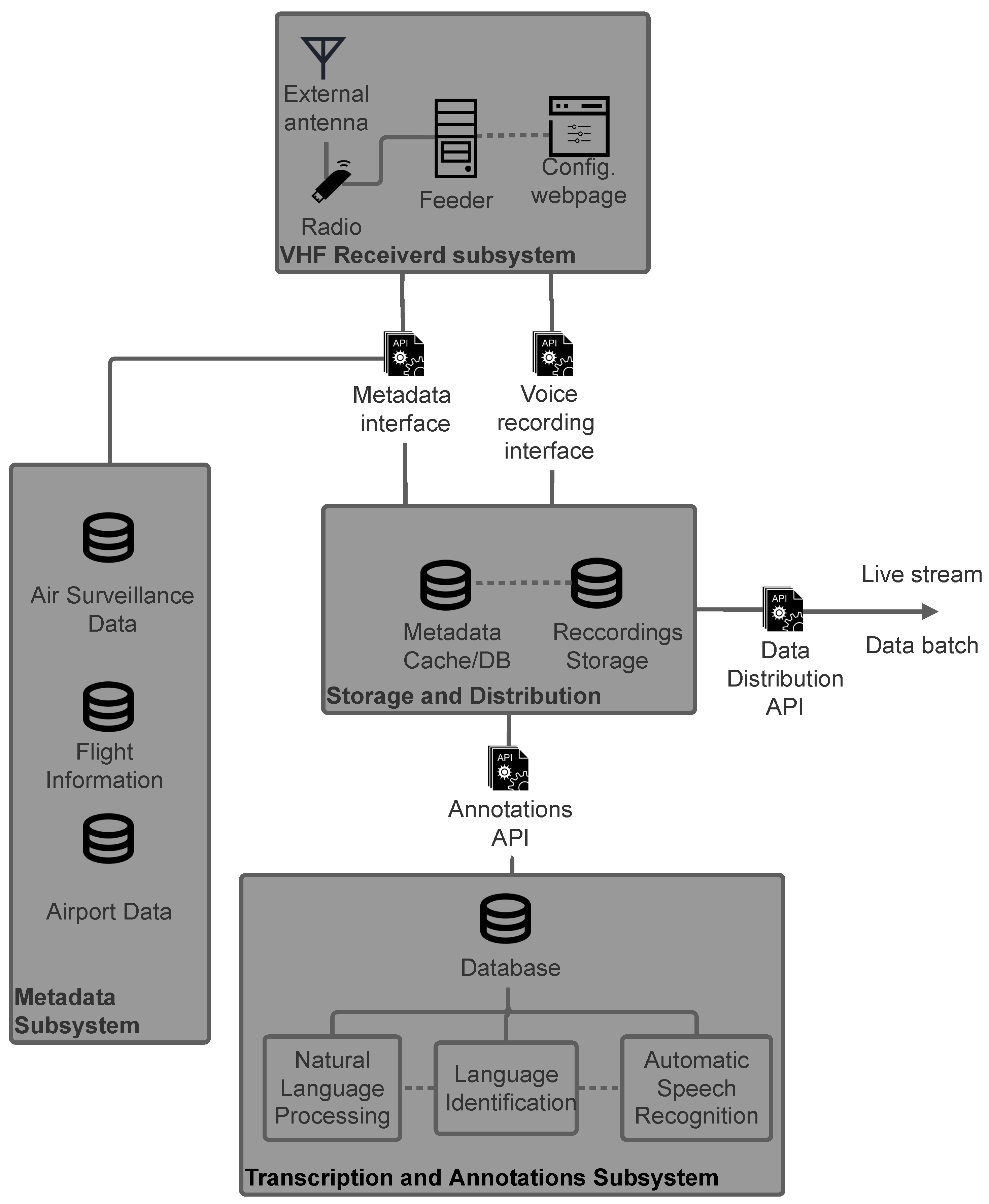
- Ingestion API: receives recording segments and metadata and queues them for processing in Kafka/S3 compatible object storage;
- Aggregation layer: converts raw data to flac audio, stores metadata, and triggers transcription using Kafka Streams, S3, and Serving API;
- Serving API: provides external interfaces to consume metadata, store, and consume transcript and statistics;
- Scheduled jobs: run processes that are not part of the streaming process like statistics aggregation and data housekeeping.
4.2. Data Annotators
5. Technologies
5.1. Automatic Speech Recognition
5.1.1. Training Data Configuration
- Scenario (a) only supervised data: we employ a mix of public and private supervised ATC databases (recordings with gold transcriptions). It comprises ∼190 h of audio data (or 573 h after speed perturbation);
- Scenario (b) only ATCO2-T 500 h dataset: we use only a subset of 500 h from the ATCO2-T corpus (see introductory paper [7]);
- Scenario (c) only ATCO2-T 2500 h dataset: same as scenario (b), but instead of only using 500 h subset, we use five times more, i.e., a 2500 h subset. This subset is only used to train a hybrid-based ASR model (CNN-TDNNF; convolutional neural network and time-delay neural network) to test the boosting experiments in Section 5.2.2.
5.1.2. Test Data Configuration
5.2. Conventional ASR
5.2.1. End-to-End ASR
5.2.2. Callsign Boosting
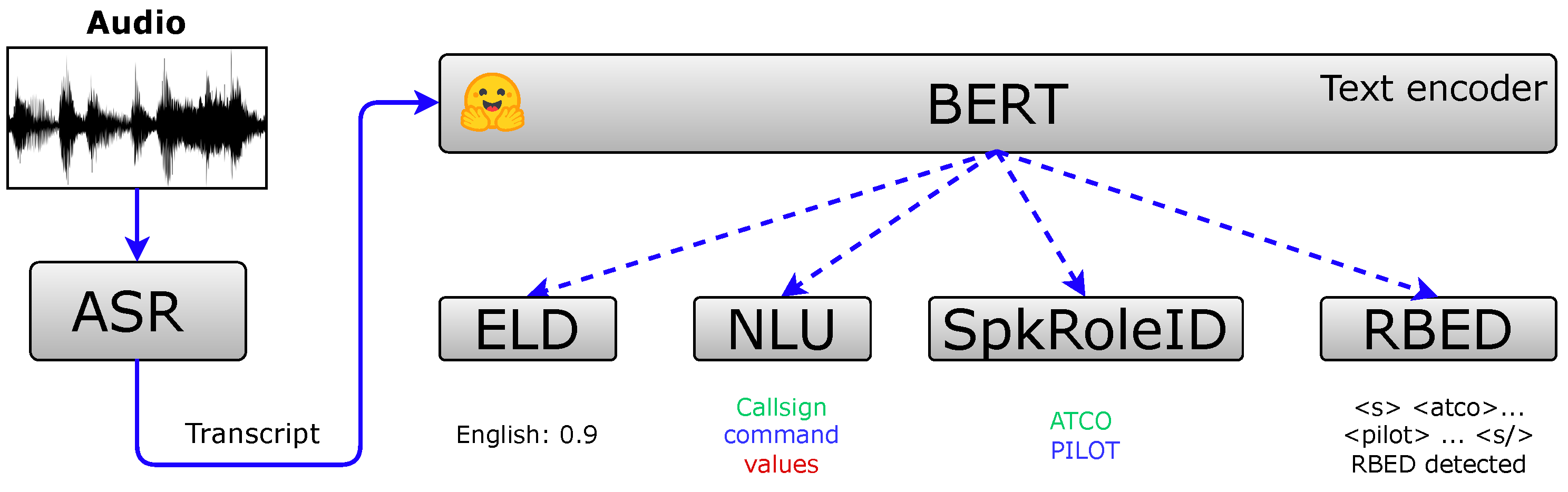
5.3. Natural Language Understanding of Air Traffic Control Communications
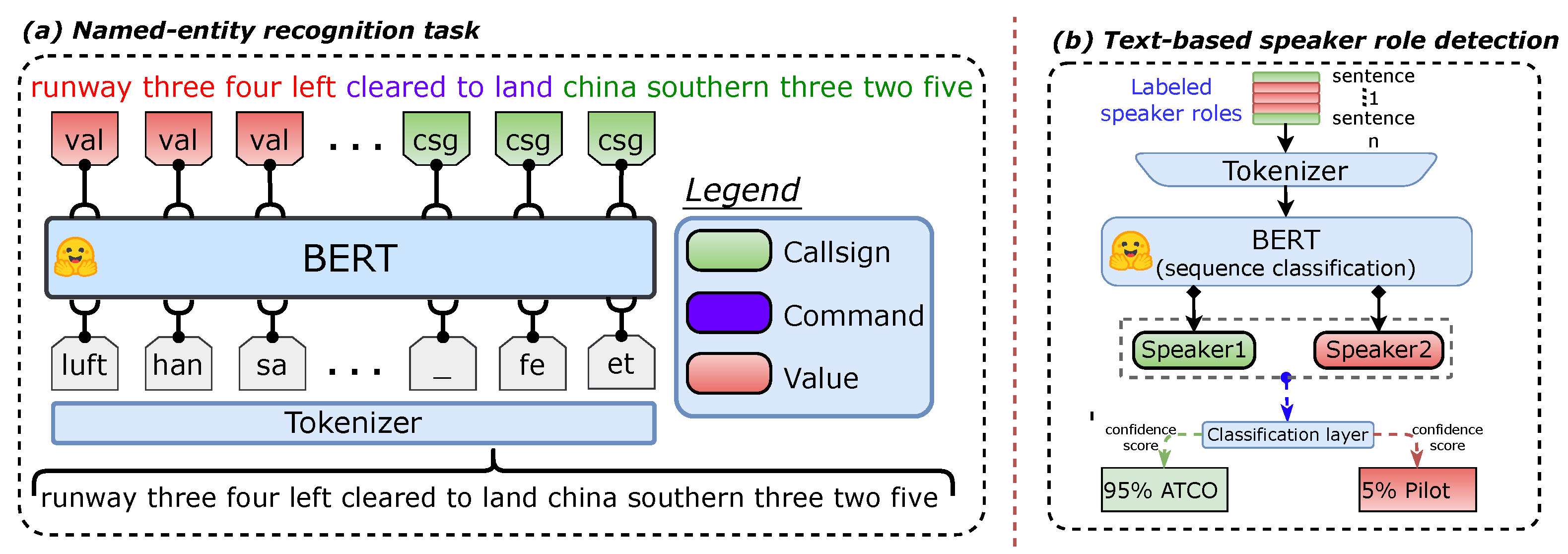
5.3.1. Named Entity Recognition for Air Traffic Control Communications
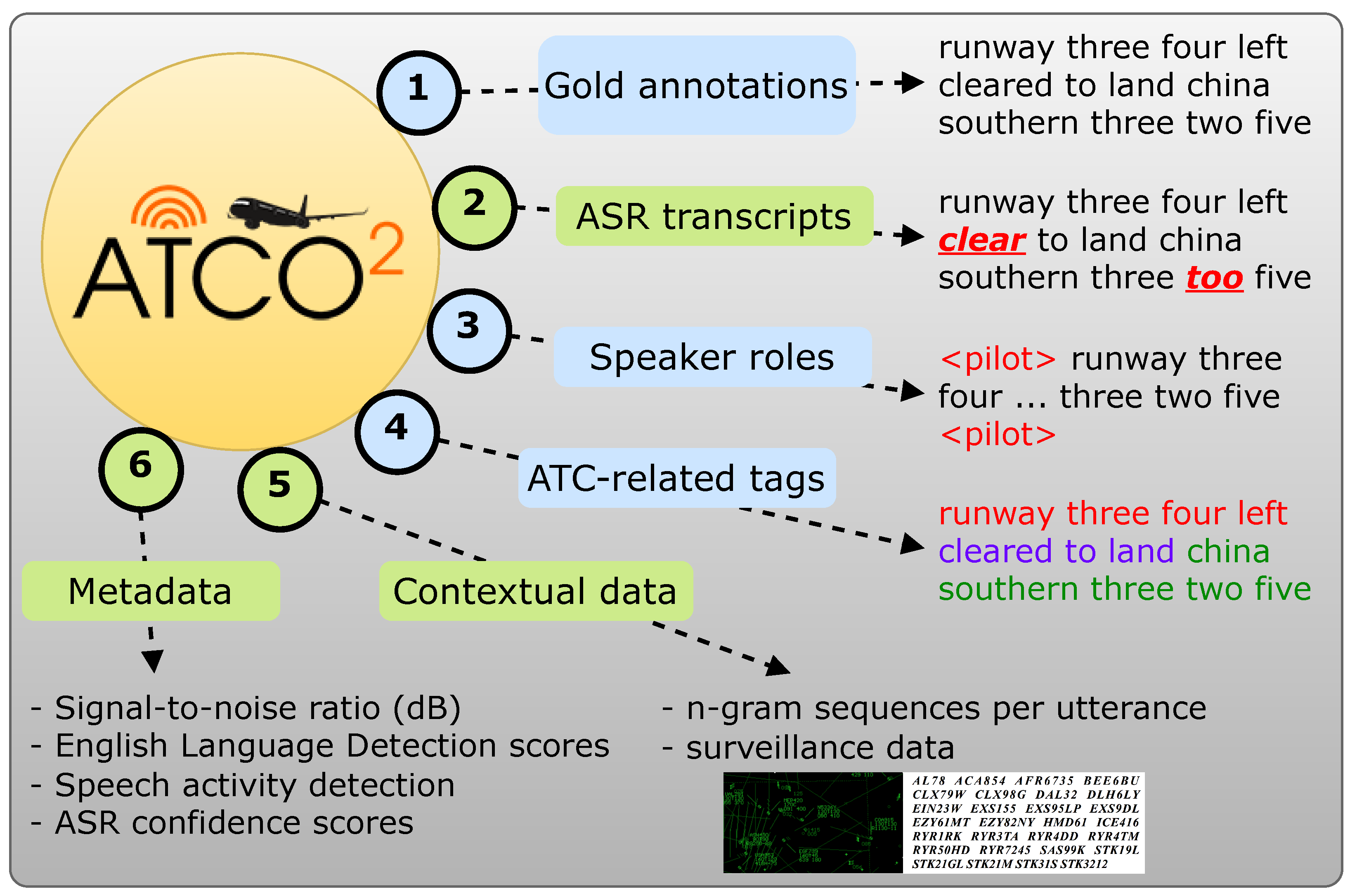
- ASR transcript: runway three four left cleared to land china southern three two five,
- would be converted to high-level entity format with the NER system to:
- Output: <value> runway three four left </value> <command> cleared to land </command> <callsign> china southern three two five </callsign>.

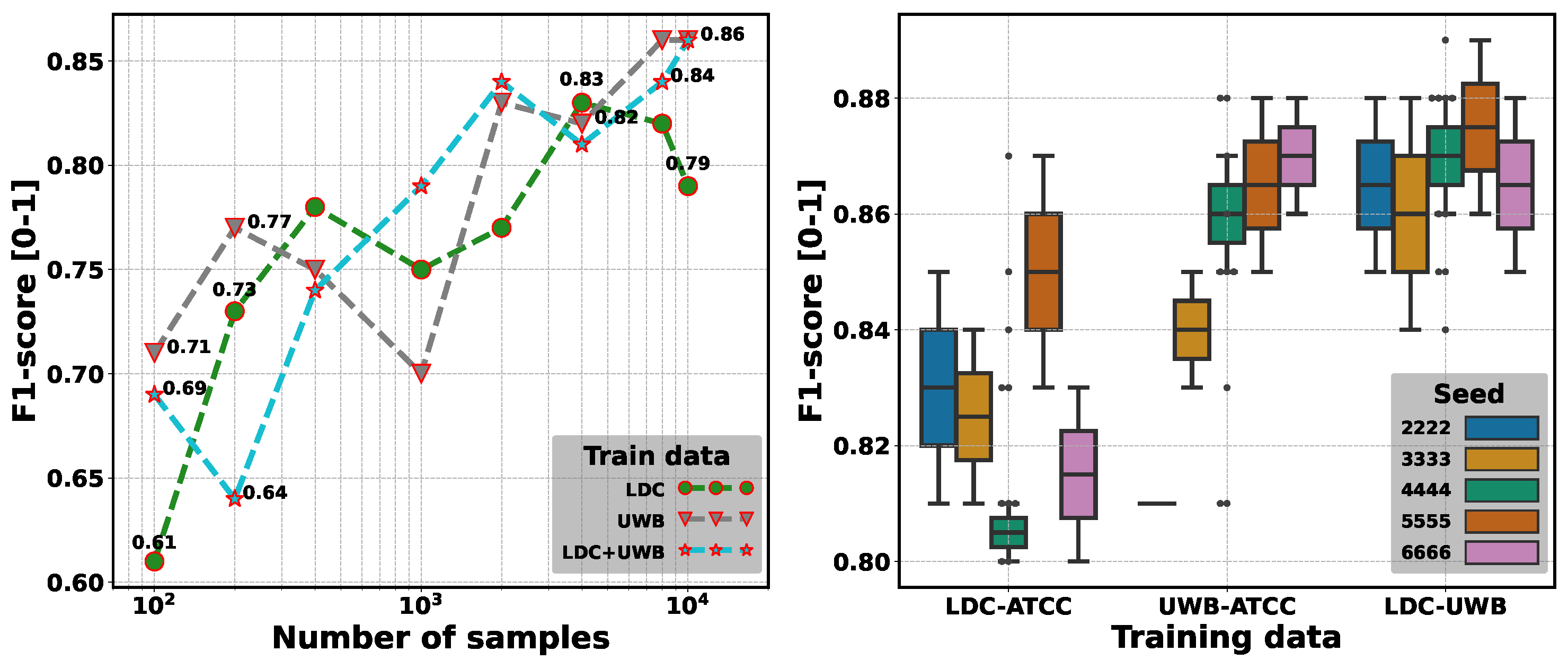
5.3.2. Text-Based Speaker Role Detection
5.3.3. Text-Based Diarization
5.4. Future Work Enabled by ATCO2
5.4.1. End of Communication Detection
5.4.2. Read-Back Error Detection
5.4.3. English Language Detection
- Various noise conditions. The majority of data are clean, but there are some very noisy segments;
- Strongly accented English. The speakers’ English accent varies widely. From native speakers (pilots) to international accents (French, German, Russian, etc.) (pilots and ATCos) and strong Czech accents (pilots and ATCos);
- Mixed words and phrases. For example, the vocabulary of Czech ATCos is a mix of Czech and English words. They use standard greetings in Czech which can be a significant portion of an “English” sentence if a command is short. On the other hand, they use many English words (alphabet, some commands) in “Czech” sentences. Moreover, they use a significant set of “Czenglish” words.
6. Conclusions
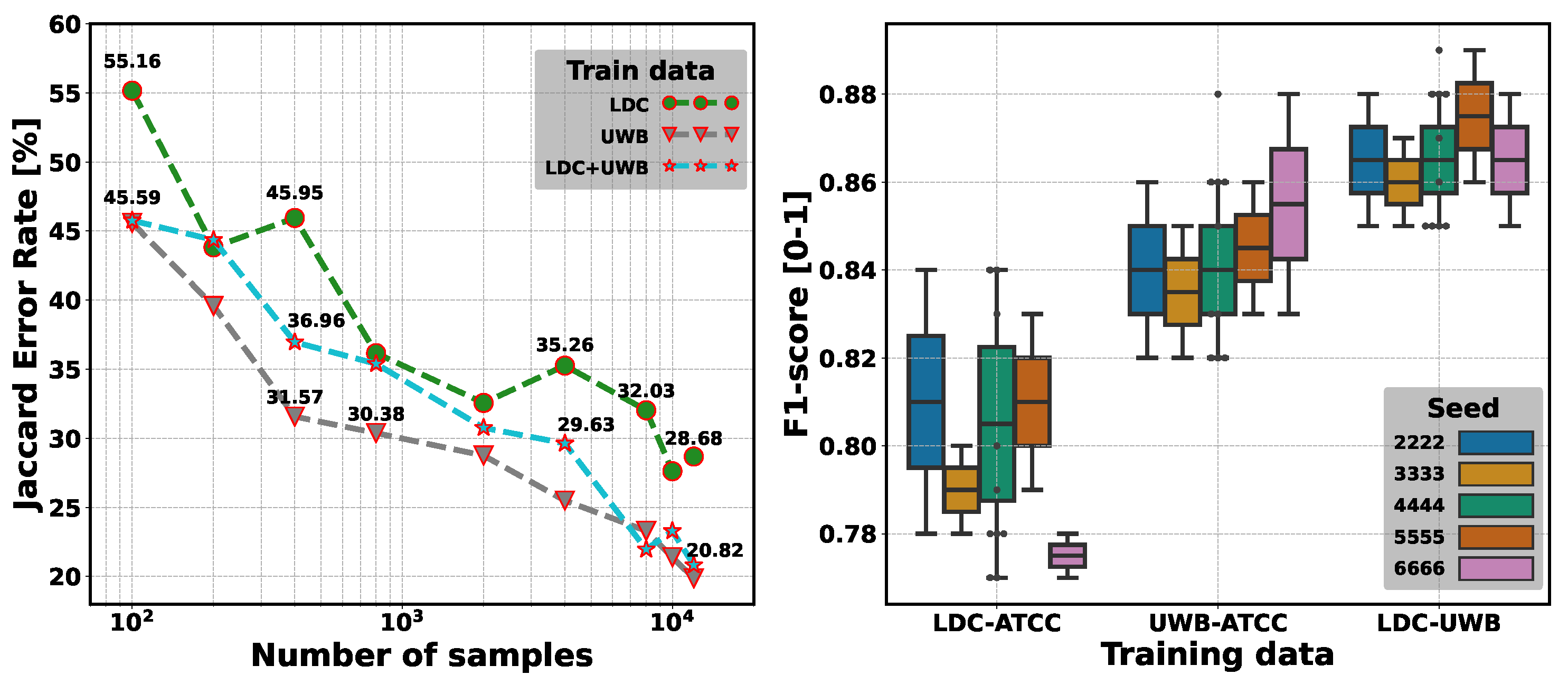
- Lesson 1: ATCO2’s automatic transcript engine (see Appendix B) and annotation platform (see Appendix C) have proven to be reliable (∼20% WER on ATCO2-test-set-4h) for collection of a large-scale audio dataset targeted to ATC communications;
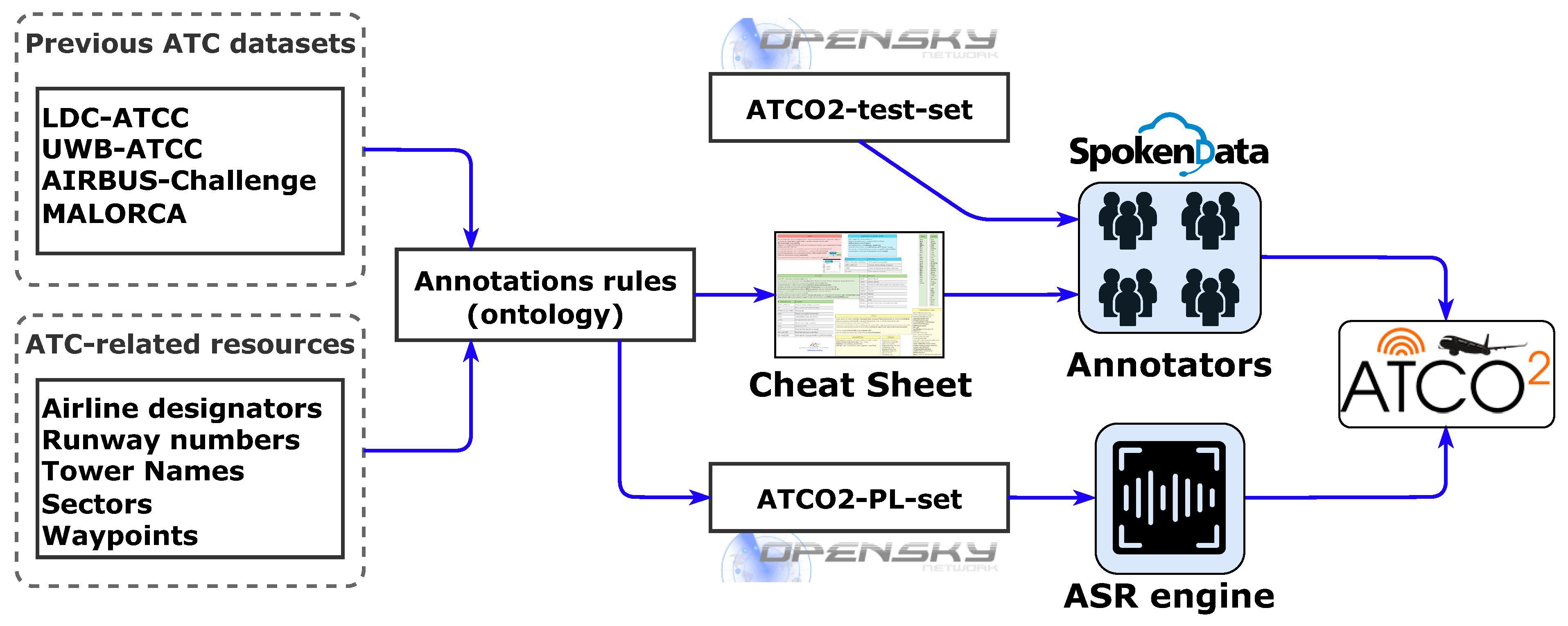
- Lesson 2: Good transcription practices for ATC communications have been developed based on ontologies published by previous projects [5]. A cheat sheet (see Appendix E) has been created to provide guidance for future ATC projects and reduce confusion while generating transcripts;
- Lesson 3: The most demanding modules of the ATCO2 collection platform are the speaker diarization and automatic speech recognition engines, each accounting for ∼32% of the overall system processing time. The complete statistics regarding runtime are covered in the Table 3. In ATCO2, we make these numbers public so they can be used as baselines in future work aligned to reducing the overall memory and runtime footprint of large-scale collection of ATC audio and radar data;
- Lesson 4: Training ASR systems purely on ATCO2 datasets (e.g., ATCO2-T 500h set corpus) can achieve competitive WERs on ATCO2 test sets (see Table 4). The ASR model can achieve up to 17.9%/24.9% WERs on ATCO2-test-set-1h/ATCO2-test-set-4h, respectively. More importantly, these test sets contain noisy accented speech, which is highly challenging in standard ASR systems;
- Lesson 5: ATC surveillance data are an optimal source of real-time information to improve ASR outputs. The integration of air surveillance data can lead to up to 11.8% absolute callsign WERs reduction, which represents an amelioration of 20% (62.6% no boosting → 82.9% GT boosted) absolute callsign accuracy in ATCO2-test-set-4h, as shown in Table 5;
- Lesson 6: ATCO2 corpora can be used for natural language understanding of ATC communications. BERT-based NER and speaker role detection modules have been developed based on ATCO2-test-set-4h. These systems can detect callsigns, commands, and values from the textual inputs. Additionally, speaker roles can also be detected based on textual inputs. For instance, as few as 100 samples are necessary to achieve 60% F1-score on speaker role detection. Furthermore, the NLU task is of special interest to the ATC community because this high-level information can be used to assist ATCos in their daily tasks, thus reducing their overall workload.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Nomenclature
| AI | Artificial Intelligence |
| AM | Acoustic Model |
| ATC | Air Traffic Control |
| ATM | Air Traffic Management |
| ASR | Automatic Speech Recognition |
| ATCo | Air Traffic Controller |
| ATCC | Air Traffic Control Corpus |
| ADS-B | Automatic Dependent Surveillance–Broadcast |
| CTC | Connectionist Temporal Classification |
| Conformer | Convolution-augmented Transformer |
| dB | Decibel |
| DNN | Deep Neural Networks |
| E2E | End-To-End |
| ELDA | European Language Resources Association |
| FST | Finite State Transducer |
| ICAO | International Civil Aviation Organization |
| GELU | Gaussian Error Linear Units |
| LF-MMI | Lattice-Free Maximum Mutual Information |
| LM | Language Model |
| ML | Machine Learning |
| NER | Named Entity Recognition |
| NLP | Natural Language Processing |
| NLU | Natural Language Understanding |
| PTT | Push-To-Talk |
| SNR | Signal-To-Noise |
| VAD | Voice Activity Detection |
| VHF | Very-High Frequency |
| WER | Word Error Rate |
| WFST | Weighted Finite State Transducer |
| RBE | Read-back Error |
| RBED | Read-back Error Detection |
Appendix A. ATCO2 Project
- The latest news and blog posts from ATCO2 project are located in the following website: https://www.atco2.org/; accessed on 10 October 2023.
- The ATCO2 corpus can be downloaded for a fee at https://catalog.elra.info/en-us/repository/browse/ELRA-S0484/; accessed on 10 October 2023.
- The ATCO2-test-set-1h can be downloaded for free at https://www.atco2.org/data; accessed on 10 October 2023.
- Stats and voice feeding of ATC data is listed at https://ui.atc.opensky-network.org/set-up; accessed on 10 October 2023.
- ATC training and transcription service is provided by SpokenData at: https://www.spokendata.com/atco2; accessed on 10 October 2023.
Appendix B. Automatic Transcription Engine
- Audio input format choices;
- Rejection threshold for too-long audio;
- Rejection threshold for too-short audio;
- Rejection threshold for too-noisy audio;
- Rejection threshold for non-English audios;
- Switching the language of automatic speech recognizer.

Appendix C. Transcription Platform: Data Flow

Appendix D. Communication Schema

Appendix E. Transcription Cheat Sheet

References
- Helmke, H.; Ohneiser, O.; Buxbaum, J.; Kern, C. Increasing ATM efficiency with assistant based speech recognition. In Proceedings of the 13th USA/Europe Air Traffic Management Research and Development Seminar, Seattle, WA, USA, 27–30 June 2017. [Google Scholar]
- Shetty, S.; Helmke, H.; Kleinert, M.; Ohneiser, O. Early Callsign Highlighting using Automatic Speech Recognition to Reduce Air Traffic Controller Workload. In Proceedings of the International Conference on Applied Human Factors and Ergonomics (AHFE2022), New York, NY, USA, 24–28 July 2022; Volume 60, pp. 584–592. [Google Scholar]
- Ohneiser, O.; Helmke, H.; Shetty, S.; Kleinert, M.; Ehr, H.; Murauskas, Š.; Pagirys, T.; Balogh, G.; Tønnesen, A.; Kis-Pál, G.; et al. Understanding Tower Controller Communication for Support in Air Traffic Control Displays. In Proceedings of the SESAR Innovation Days, Budapest, Hungary, 5–8 December 2022. [Google Scholar]
- Helmke, H.; Ohneiser, O.; Mühlhausen, T.; Wies, M. Reducing controller workload with automatic speech recognition. In Proceedings of the 2016 IEEE/AIAA 35th Digital Avionics Systems Conference (DASC), Sacramento, CA, USA, 25–29 September 2016; pp. 1–10. [Google Scholar]
- Helmke, H.; Slotty, M.; Poiger, M.; Herrer, D.F.; Ohneiser, O.; Vink, N.; Cerna, A.; Hartikainen, P.; Josefsson, B.; Langr, D.; et al. Ontology for transcription of ATC speech commands of SESAR 2020 solution PJ. 16-04. In Proceedings of the IEEE/AIAA 37th Digital Avionics Systems Conference (DASC), London, UK, 23–27 September 2018; pp. 1–10. [Google Scholar]
- Guo, D.; Zhang, Z.; Yang, B.; Zhang, J.; Lin, Y. Boosting Low-Resource Speech Recognition in Air Traffic Communication via Pretrained Feature Aggregation and Multi-Task Learning. IEEE Trans. Circuits Syst. II Express Briefs 2023, 70, 3714–3718. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Veselỳ, K.; Szöke, I.; Motlicek, P.; Kocour, M.; Rigault, M.; Choukri, K.; Prasad, A.; Sarfjoo, S.S.; Nigmatulina, I.; et al. ATCO2 corpus: A Large-Scale Dataset for Research on Automatic Speech Recognition and Natural Language Understanding of Air Traffic Control Communications. arXiv 2022, arXiv:2211.04054. [Google Scholar]
- Zuluaga-Gomez, J.; Sarfjoo, S.S.; Prasad, A.; Nigmatulina, I.; Motlicek, P.; Ondre, K.; Ohneiser, O.; Helmke, H. BERTraffic: BERT-based Joint Speaker Role and Speaker Change Detection for Air Traffic Control Communications. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023. [Google Scholar]
- Kocour, M.; Veselý, K.; Szöke, I.; Kesiraju, S.; Zuluaga-Gomez, J.; Blatt, A.; Prasad, A.; Nigmatulina, I.; Motlíček, P.; Klakow, D.; et al. Automatic processing pipeline for collecting and annotating air-traffic voice communication data. Eng. Proc. 2021, 13, 8. [Google Scholar]
- Ferreiros, J.; Pardo, J.; De Córdoba, R.; Macias-Guarasa, J.; Montero, J.; Fernández, F.; Sama, V.; González, G. A speech interface for air traffic control terminals. Aerosp. Sci. Technol. 2012, 21, 7–15. [Google Scholar] [CrossRef]
- Tarakan, R.; Baldwin, K.; Rozen, N. An automated simulation pilot capability to support advanced air traffic controller training. In Proceedings of the 26th Congress of ICAS and 8th AIAA ATIO, Anchorage, AK, USA, 14–19 September 2008. [Google Scholar]
- Cordero, J.M.; Dorado, M.; de Pablo, J.M. Automated speech recognition in ATC environment. In Proceedings of the 2nd International Conference on Application and Theory of Automation in Command and Control Systems, London, UK, 29–31 May 2012; pp. 46–53. [Google Scholar]
- Zuluaga-Gomez, J.; Motlicek, P.; Zhan, Q.; Veselỳ, K.; Braun, R. Automatic Speech Recognition Benchmark for Air-Traffic Communications. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 2297–2301. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Nigmatulina, I.; Prasad, A.; Motlicek, P.; Veselỳ, K.; Kocour, M.; Szöke, I. Contextual Semi-Supervised Learning: An Approach to Leverage Air-Surveillance and Untranscribed ATC Data in ASR Systems. In Proceedings of the Interspeech, Brno, Czech Republic, 30 August–3 September 2021; pp. 3296–3300. [Google Scholar] [CrossRef]
- Nigmatulina, I.; Zuluaga-Gomez, J.; Prasad, A.; Sarfjoo, S.S.; Motlicek, P. A two-step approach to leverage contextual data: Speech recognition in air-traffic communications. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 7–13 May 2022. [Google Scholar]
- Chen, S.; Kopald, H.; Avjian, B.; Fronzak, M. Automatic Pilot Report Extraction from Radio Communications. In Proceedings of the 2022 IEEE/AIAA 41st Digital Avionics Systems Conference (DASC), Portsmouth, VA, USA, 18–22 September 2022; pp. 1–8. [Google Scholar]
- Godfrey, J. The Air Traffic Control Corpus (ATC0)—LDC94S14A. 1994. Available online: https://catalog.ldc.upenn.edu/LDC94S14A (accessed on 4 September 2023).
- Šmídl, L.; Švec, J.; Tihelka, D.; Matoušek, J.; Romportl, J.; Ircing, P. Air traffic control communication (ATCC) speech corpora and their use for ASR and TTS development. Lang. Resour. Eval. 2019, 53, 449–464. [Google Scholar] [CrossRef]
- Segura, J.; Ehrette, T.; Potamianos, A.; Fohr, D.; Illina, I.; Breton, P.; Clot, V.; Gemello, R.; Matassoni, M.; Maragos, P. The HIWIRE Database, a Noisy and Non-Native English Speech Corpus for Cockpit Communication. 2007. Available online: http://www.hiwire.org (accessed on 10 October 2023).
- Delpech, E.; Laignelet, M.; Pimm, C.; Raynal, C.; Trzos, M.; Arnold, A.; Pronto, D. A Real-life, French-accented Corpus of Air Traffic Control Communications. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Pellegrini, T.; Farinas, J.; Delpech, E.; Lancelot, F. The Airbus Air Traffic Control speech recognition 2018 challenge: Towards ATC automatic transcription and call sign detection. arXiv 2018, arXiv:1810.12614. [Google Scholar]
- Graglia, L.; Favennec, B.; Arnoux, A. Vocalise: Assessing the impact of data link technology on the R/T channel. In Proceedings of the 24th IEEE Digital Avionics Systems Conference, Washington, DC, USA, 30 October–3 November 2005; Volume 1. [Google Scholar]
- Lopez, S.; Condamines, A.; Josselin-Leray, A.; O’Donoghue, M.; Salmon, R. Linguistic analysis of English phraseology and plain language in air-ground communication. J. Air Transp. Stud. 2013, 4, 44–60. [Google Scholar] [CrossRef][Green Version]
- Szöke, I.; Kesiraju, S.; Novotný, O.; Kocour, M.; Veselý, K.; Černocký, J. Detecting English Speech in the Air Traffic Control Voice Communication. In Proceedings of the Interspeech, Brno, Czech Republic, 30 August–3 September 2021; pp. 3286–3290. [Google Scholar] [CrossRef]
- International Civil Aviation Organization. ICAO Phraseology Reference Guide; International Civil Aviation Organization: Montreal, QC, Canada, 2020. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Ardila, R.; Branson, M.; Davis, K.; Henretty, M.; Kohler, M.; Meyer, J.; Morais, R.; Saunders, L.; Tyers, F.M.; Weber, G. Common voice: A massively-multilingual speech corpus. arXiv 2019, arXiv:1912.06670. [Google Scholar]
- Godfrey, J.J.; Holliman, E.C.; McDaniel, J. SWITCHBOARD: Telephone speech corpus for research and development. In Proceedings of the Acoustics, Speech, and Signal Processing, IEEE International Conference on IEEE Computer Society, San Francisco, CA, USA, 23–26 March 1992; Volume 1, pp. 517–520. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding IEEE Signal Processing Society, Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing, 2nd ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Wang, D.; Wang, X.; Lv, S. An Overview of End-to-End Automatic Speech Recognition. Symmetry 2019, 11, 1018. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Berlin, Germany, 2016; pp. 1715–1725. [Google Scholar] [CrossRef]
- Kingsbury, B. Lattice-based optimization of sequence classification criteria for neural-network acoustic modeling. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 3761–3764. [Google Scholar]
- Dehak, N.; Kenny, P.J.; Dehak, R.; Dumouchel, P.; Ouellet, P. Front-end factor analysis for speaker verification. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 788–798. [Google Scholar] [CrossRef]
- Snyder, D.; Garcia-Romero, D.; Povey, D. Time delay deep neural network-based universal background models for speaker recognition. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 92–97. [Google Scholar]
- Peddinti, V.; Povey, D.; Khudanpur, S. A time delay neural network architecture for efficient modeling of long temporal contexts. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015; pp. 3214–3218. [Google Scholar] [CrossRef]
- Povey, D.; Peddinti, V.; Galvez, D.; Ghahremani, P.; Manohar, V.; Na, X.; Wang, Y.; Khudanpur, S. Purely sequence-trained neural networks for ASR based on lattice-free MMI. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016; pp. 2751–2755. [Google Scholar]
- Povey, D.; Cheng, G.; Wang, Y.; Li, K.; Xu, H.; Yarmohammadi, M.; Khudanpur, S. Semi-orthogonal low-rank matrix factorization for deep neural networks. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 3743–3747. [Google Scholar]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech recognition using deep neural networks: A systematic review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Graves, A.; Jaitly, N. Towards End-to-End Speech Recognition with Recurrent Neural Networks. In Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21–26 June 2014; Volume 32, pp. 1764–1772. [Google Scholar]
- Karita, S.; Chen, N.; Hayashi, T.; Hori, T.; Inaguma, H.; Jiang, Z.; Someki, M.; Soplin, N.E.Y.; Yamamoto, R.; Wang, X.; et al. A comparative study on transformer vs rnn in speech applications. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 449–456. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, Pennsylvania, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-Based Models for Speech Recognition. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 577–585. [Google Scholar]
- Watanabe, S.; Hori, T.; Kim, S.; Hershey, J.R.; Hayashi, T. Hybrid CTC/attention architecture for end-to-end speech recognition. IEEE J. Sel. Top. Signal Process. 2017, 11, 1240–1253. [Google Scholar] [CrossRef]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020. [Google Scholar]
- Baevski, A.; Schneider, S.; Auli, M. vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; Wei, F.; et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. arXiv 2021, arXiv:2110.13900. [Google Scholar] [CrossRef]
- Babu, A.; Wang, C.; Tjandra, A.; Lakhotia, K.; Xu, Q.; Goyal, N.; Singh, K.; von Platen, P.; Saraf, Y.; Pino, J.; et al. XLS-R: Self-supervised cross-lingual speech representation learning at scale. arXiv 2021, arXiv:2111.09296. [Google Scholar]
- Zuluaga-Gomez, J.; Prasad, A.; Nigmatulina, I.; Sarfjoo, S.; Motlicek, P.; Kleinert, M.; Helmke, H.; Ohneiser, O.; Zhan, Q. How Does Pre-trained Wav2Vec2.0 Perform on Domain Shifted ASR? An Extensive Benchmark on Air Traffic Control Communications. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented Transformer for Speech Recognition. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 5036–5040. [Google Scholar] [CrossRef]
- Mai, F.; Zuluaga-Gomez, J.; Parcollet, T.; Motlicek, P. HyperConformer: Multi-head HyperMixer for Efficient Speech Recognition. In Proceedings of the Interspeech, Dublin, Ireland, 20–24 August 2023. [Google Scholar]
- Radfar, M.; Lyskawa, P.; Trujillo, B.; Xie, Y.; Zhen, K.; Heymann, J.; Filimonov, D.; Strimel, G.; Susanj, N.; Mouchtaris, A. Conmer: Streaming Conformer without self-attention for interactive voice assistants. In Proceedings of the Interspeech, Dublin, Ireland, 20–24 August 2023. [Google Scholar]
- Peng, Y.; Dalmia, S.; Lane, I.; Watanabe, S. Branchformer: Parallel mlp-attention architectures to capture local and global context for speech recognition and understanding. In Proceedings of the International Conference on Machine Learning, Guangzhou, China, 18–21 February 2022; pp. 17627–17643. [Google Scholar]
- Ravanelli, M.; Parcollet, T.; Plantinga, P.; Rouhe, A.; Cornell, S.; Lugosch, L.; Subakan, C.; Dawalatabad, N.; Heba, A.; Zhong, J.; et al. SpeechBrain: A general-purpose speech toolkit. arXiv 2021, arXiv:2106.04624. [Google Scholar]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Enrique Yalta Soplin, N.; Heymann, J.; Wiesner, M.; Chen, N.; et al. ESPnet: End-to-End Speech Processing Toolkit. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2207–2211. [Google Scholar] [CrossRef]
- Kuchaiev, O.; Li, J.; Nguyen, H.; Hrinchuk, O.; Leary, R.; Ginsburg, B.; Kriman, S.; Beliaev, S.; Lavrukhin, V.; Cook, J.; et al. Nemo: A toolkit for building ai applications using neural modules. arXiv 2019, arXiv:1909.09577. [Google Scholar]
- Zhang, B.; Wu, D.; Peng, Z.; Song, X.; Yao, Z.; Lv, H.; Xie, L.; Yang, C.; Pan, F.; Niu, J. Wenet 2.0: More productive end-to-end speech recognition toolkit. arXiv 2022, arXiv:2203.15455. [Google Scholar]
- Hall, K.; Cho, E.; Allauzen, C.; Beaufays, F.; Coccaro, N.; Nakajima, K.; Riley, M.; Roark, B.; Rybach, D.; Zhang, L. Composition-based on-the-fly rescoring for salient n-gram biasing. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015; pp. 1418–1422. [Google Scholar]
- Aleksic, P.; Ghodsi, M.; Michaely, A.; Allauzen, C.; Hall, K.; Roark, B.; Rybach, D.; Moreno, P. Bringing Contextual Information to Google Speech Recognition. 2015. Available online: https://research.google/pubs/pub43819/ (accessed on 4 September 2023).
- Serrino, J.; Velikovich, L.; Aleksic, P.S.; Allauzen, C. Contextual Recovery of Out-of-Lattice Named Entities in Automatic Speech Recognition. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 3830–3834. [Google Scholar]
- Chen, Z.; Jain, M.; Wang, Y.; Seltzer, M.L.; Fuegen, C. End-to-end contextual speech recognition using class language models and a token passing decoder. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6186–6190. [Google Scholar]
- Yadav, V.; Bethard, S. A Survey on Recent Advances in Named Entity Recognition from Deep Learning models. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 2145–2158. [Google Scholar]
- Sharma, A.; Chakraborty, S.; Kumar, S. Named Entity Recognition in Natural Language Processing: A Systematic Review. In Proceedings of the Second Doctoral Symposium on Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2022; pp. 817–828. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl.-Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Qiao, B.; Zou, Z.; Huang, Y.; Fang, K.; Zhu, X.; Chen, Y. A joint model for entity and relation extraction based on BERT. Neural Comput. Appl. 2022, 34, 3471–3481. [Google Scholar] [CrossRef]
- Zaib, M.; Zhang, W.E.; Sheng, Q.Z.; Mahmood, A.; Zhang, Y. Conversational question answering: A survey. Knowl. Inf. Syst. 2022, 64, 3151–3195. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations; Association for Computational Linguistics: Berlin, Germany, 2020; pp. 38–45. [Google Scholar]
- Lhoest, Q.; del Moral, A.V.; Jernite, Y.; Thakur, A.; von Platen, P.; Patil, S.; Chaumond, J.; Drame, M.; Plu, J.; Tunstall, L.; et al. Datasets: A Community Library for Natural Language Processing. arXiv 2021, arXiv:2109.02846. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- He, Z.; Wang, Z.; Wei, W.; Feng, S.; Mao, X.; Jiang, S. A Survey on Recent Advances in Sequence Labeling from Deep Learning Models. arXiv 2020, arXiv:2011.06727. [Google Scholar]
- Zhou, C.; Cule, B.; Goethals, B. Pattern based sequence classification. IEEE Trans. Knowl. Data Eng. 2015, 28, 1285–1298. [Google Scholar] [CrossRef]
- He, P.; Gao, J.; Chen, W. Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing. arXiv 2021, arXiv:2111.09543. [Google Scholar]
- Zuluaga-Gomez, J.; Prasad, A.; Nigmatulina, I.; Motlicek, P.; Kleinert, M. A Virtual Simulation-Pilot Agent for Training of Air Traffic Controllers. Aerospace 2023, 10, 490. [Google Scholar] [CrossRef]
- Madikeri, S.; Bourlard, H. Filterbank slope based features for speaker diarization. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 111–115. [Google Scholar]
- Sell, G.; Snyder, D.; McCree, A.; Garcia-Romero, D.; Villalba, J.; Maciejewski, M.; Manohar, V.; Dehak, N.; Povey, D.; Watanabe, S.; et al. Diarization is Hard: Some Experiences and Lessons Learned for the JHU Team in the Inaugural DIHARD Challenge. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2808–2812. [Google Scholar]
- Landini, F.; Profant, J.; Diez, M.; Burget, L. Bayesian HMM clustering of x-vector seq uences (VBx) in speaker diarization: Theory, implementation and analysis on standard tasks. Comput. Speech Lang. 2022, 71, 101254. [Google Scholar] [CrossRef]
- Fujita, Y.; Watanabe, S.; Horiguchi, S.; Xue, Y.; Nagamatsu, K. End-to-end neural diarization: Reformulating speaker diarization as simple multi-label classification. arXiv 2020, arXiv:2003.02966. [Google Scholar]
- Fujita, Y.; Kanda, N.; Horiguchi, S.; Xue, Y.; Nagamatsu, K.; Watanabe, S. End-to-end neural speaker diarization with self-attention. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 296–303. [Google Scholar]
- Fujita, Y.; Kanda, N.; Horiguchi, S.; Nagamatsu, K.; Watanabe, S. End-to-end neural speaker diarization with permutation-free objectives. arXiv 2019, arXiv:1909.05952. [Google Scholar]
- Ryant, N.; Church, K.; Cieri, C.; Cristia, A.; Du, J.; Ganapathy, S.; Liberman, M. The Second DIHARD Diarization Challenge: Dataset, Task, and Baselines. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 978–982. [Google Scholar]
- Ariav, I.; Cohen, I. An end-to-end multimodal voice activity detection using wavenet encoder and residual networks. IEEE J. Sel. Top. Signal Process. 2019, 13, 265–274. [Google Scholar] [CrossRef]
- Lin, Y. Spoken Instruction Understanding in Air Traffic Control: Challenge, Technique, and Application. Aerospace 2021, 8, 65. [Google Scholar] [CrossRef]
- Cardosi, K.M. An Analysis of en Route Controller-Pilot Voice Communications; NASA STI/Recon Technical Report N; Federal Aviation Administration: Washington, DC, USA, 1993; Volume 93, p. 30611. [Google Scholar]
- Prasad, A.; Zuluaga-Gomez, J.; Motlicek, P.; Sarfjoo, S.; Nigmatulina, I.; Ohneiser, O.; Helmke, H. Grammar Based Speaker Role Identification for Air Traffic Control Speech Recognition. arXiv 2021, arXiv:2108.12175. [Google Scholar]
- Helmke, H.; Ondřej, K.; Shetty, S.; Arilíusson, H.; Simiganoschi, T.; Kleinert, M.; Ohneiser, O.; Ehr, H.; Zuluaga-Gomez, J.; Smrz, P. Readback Error Detection by Automatic Speech Recognition and Understanding—Results of HAAWAII Project for Isavia’s Enroute Airspace. In Proceedings of the 12th SESAR Innovation Days. Sesar Joint Undertaking, Budapest, Hungary, 5–8 December 2022. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Details | Licensed | Accents | Hours | Ref. |
|---|---|---|---|---|---|
| Released corpora by ATCO2 project | |||||
| ATCO2 corpora | Data from different airports and countries: public corpora catalog.elra.info/en-us/repository/browse/ELRA-S0484/ (accessed on 10 October 2023) | Several | [7] | ||
| ATCO2-test-set | Real life data for ASR and NLP research. | ✔ | Several | 4 | [7] |
| ATCO2-T set | ASR-based transcribed dataset. Real data for research in ASR and NLU. | ✔ | Several | 5281 | [7,9] |
| Free access databases released by ATCO2 project | |||||
| ATCO2-test-set-1h | `ASR dataset’: public 1 h sample, a subset of ATCO2-test-set. https://www.atco2.org/data (accessed on 10 October 2023) | ✔ | Several | 1 | [9] |
| ATCO2-ELD set | `ELD dataset’: public dataset for English language detection. https://www.atco2.org/data (accessed on 10 October 2023) | ✔ | Several | 26.5 | [24] |
| ICAO (airport identifier)—City | ||||||||||
| EETN—Tallinn | EPLB—Lublin | LKPR—Prague | LKTB—Brno | LSGS—Sion | LSZB—Bern | LSZH—Zurich | LZIB—Bratislava | YBBN—Brisbane | YSSY—Sydney | others—others |
| English Data (language score ) | ||||||||||
| 131 | <1 | 1762 | 888 | 330 | 699 | 921 | 24 | 170 | 77 | <1 |
| Non-English Data (language score ) | ||||||||||
| 2 | <1 | 187 | 611 | 83 | 55 | 49 | 26 | 10 | 3 | <1 |
| Processing Step | Time [s] | Percentage [%] |
|---|---|---|
| Preprocessing | 2.5 | 11.6 |
| VAD segmentation | 2.4 | 11.1 |
| SNR estimation | 0.6 | 3.0 |
| Diarization | 7.1 | 32.6 |
| Callsign expansion | 0.5 | 2.1 |
| Speech-to-text (ASR) | 7.0 | 32.1 |
| English detection | 1.3 | 5.9 |
| Callsign extraction | 0.1 | 0.4 |
| Post-processing | 0.2 | 1.2 |
| Total time | 21.6 | 100.0 |
| Model | Test Sets | |
|---|---|---|
| CNN-TDNNF | ATCO2-1h | ATCO2-4h |
| Scenario (a) only supervised 573 h dataset | 24.5 | 32.5 |
| Scenario (b) only ATCO2-T 500 h dataset | 18.1 | 25.1 |
| Scenario (c) only ATCO2-T 2500 h dataset | 17.9 | 24.9 |
| Boosting | ATCO2-test-set-1h | ATCO2-test-set-4h | ||||
|---|---|---|---|---|---|---|
| WER | CallWER | ACC | WER | CallWER | ACC | |
| scenario (a) only supervised dataset | ||||||
| Baseline | 24.5 | 26.9 | 61.3 | 32.5 | 36.7 | 42.4 |
| Unigrams | 24.4 | 25.5 | 63.2 | 33.1 | 35.0 | 45.8 |
| N-grams | 23.8 | 23.8 | 66.4 | 31.3 | 33.7 | 47.9 |
| GT boosted | 22.9 | 19.1 | 75.2 | 29.7 | 29.1 | 58.5 |
| scenario (b) only ATCO2-T 500 h dataset | ||||||
| Baseline | 18.1 | 16.2 | 71.2 | 25.1 | 24.8 | 62.6 |
| Unigrams | 19.1 | 14.6 | 74.2 | 26.0 | 22.8 | 65.6 |
| N-grams | 17.5 | 13.5 | 75.3 | 24.3 | 21.4 | 66.6 |
| GT boosted | 16.3 | 6.9 | 88.9 | 22.5 | 13.0 | 82.9 |
| scenario (c) only ATCO2-T 2500 h dataset | ||||||
| Baseline | 17.9 | 16.7 | 70.5 | 24.9 | 24.2 | 62.0 |
| Unigrams | 18.3 | 14.4 | 73.8 | 25.6 | 22.0 | 65.9 |
| N-grams | 17.3 | 14.2 | 74.3 | 24.3 | 21.1 | 66.5 |
| GT boosted | 15.9 | 6.5 | 89.4 | 22.2 | 12.5 | 83.9 |
| Model | Callsign | Command | Values | ||||||
|---|---|---|---|---|---|---|---|---|---|
| @P | @R | @F1 | @P | @R | @F1 | @P | @R | @F1 | |
| Bert-base | 97.1 | 97.8 | 97.5 | 80.4 | 83.6 | 82.0 | 86.3 | 88.1 | 87.2 |
| RoBERTa-base | 97.1 | 97.7 | 97.5 | 80.2 | 83.7 | 81.9 | 85.6 | 88.6 | 87.1 |
| Training Corpora | BERT | DEBERTA | ROBERTA | |||
|---|---|---|---|---|---|---|
| ATCO | PILOT | ATCO | PILOT | ATCO | PILOT | |
| LDC-ATCC | 82.4 | 79.2 | 82.4 | 79.6 | 84.0 | 80.2 |
| UWB-ATCC | 86.2 | 83.2 | 86.8 | 84.0 | 87.0 | 82.8 |
| ↪ + LDC-ATCC | 87.6 | 85.2 | 88.8 | 85.8 | 88.0 | 84.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuluaga-Gomez, J.; Nigmatulina, I.; Prasad, A.; Motlicek, P.; Khalil, D.; Madikeri, S.; Tart, A.; Szoke, I.; Lenders, V.; Rigault, M.; et al. Lessons Learned in Transcribing 5000 h of Air Traffic Control Communications for Robust Automatic Speech Understanding. Aerospace 2023, 10, 898. https://doi.org/10.3390/aerospace10100898
Zuluaga-Gomez J, Nigmatulina I, Prasad A, Motlicek P, Khalil D, Madikeri S, Tart A, Szoke I, Lenders V, Rigault M, et al. Lessons Learned in Transcribing 5000 h of Air Traffic Control Communications for Robust Automatic Speech Understanding. Aerospace. 2023; 10(10):898. https://doi.org/10.3390/aerospace10100898
Chicago/Turabian StyleZuluaga-Gomez, Juan, Iuliia Nigmatulina, Amrutha Prasad, Petr Motlicek, Driss Khalil, Srikanth Madikeri, Allan Tart, Igor Szoke, Vincent Lenders, Mickael Rigault, and et al. 2023. "Lessons Learned in Transcribing 5000 h of Air Traffic Control Communications for Robust Automatic Speech Understanding" Aerospace 10, no. 10: 898. https://doi.org/10.3390/aerospace10100898
APA StyleZuluaga-Gomez, J., Nigmatulina, I., Prasad, A., Motlicek, P., Khalil, D., Madikeri, S., Tart, A., Szoke, I., Lenders, V., Rigault, M., & Choukri, K. (2023). Lessons Learned in Transcribing 5000 h of Air Traffic Control Communications for Robust Automatic Speech Understanding. Aerospace, 10(10), 898. https://doi.org/10.3390/aerospace10100898