
An Automatic Speaker Clustering Pipeline for the Air Traffic Communication Domain

 , , ,
, , ,
Abstract
:1. Introduction
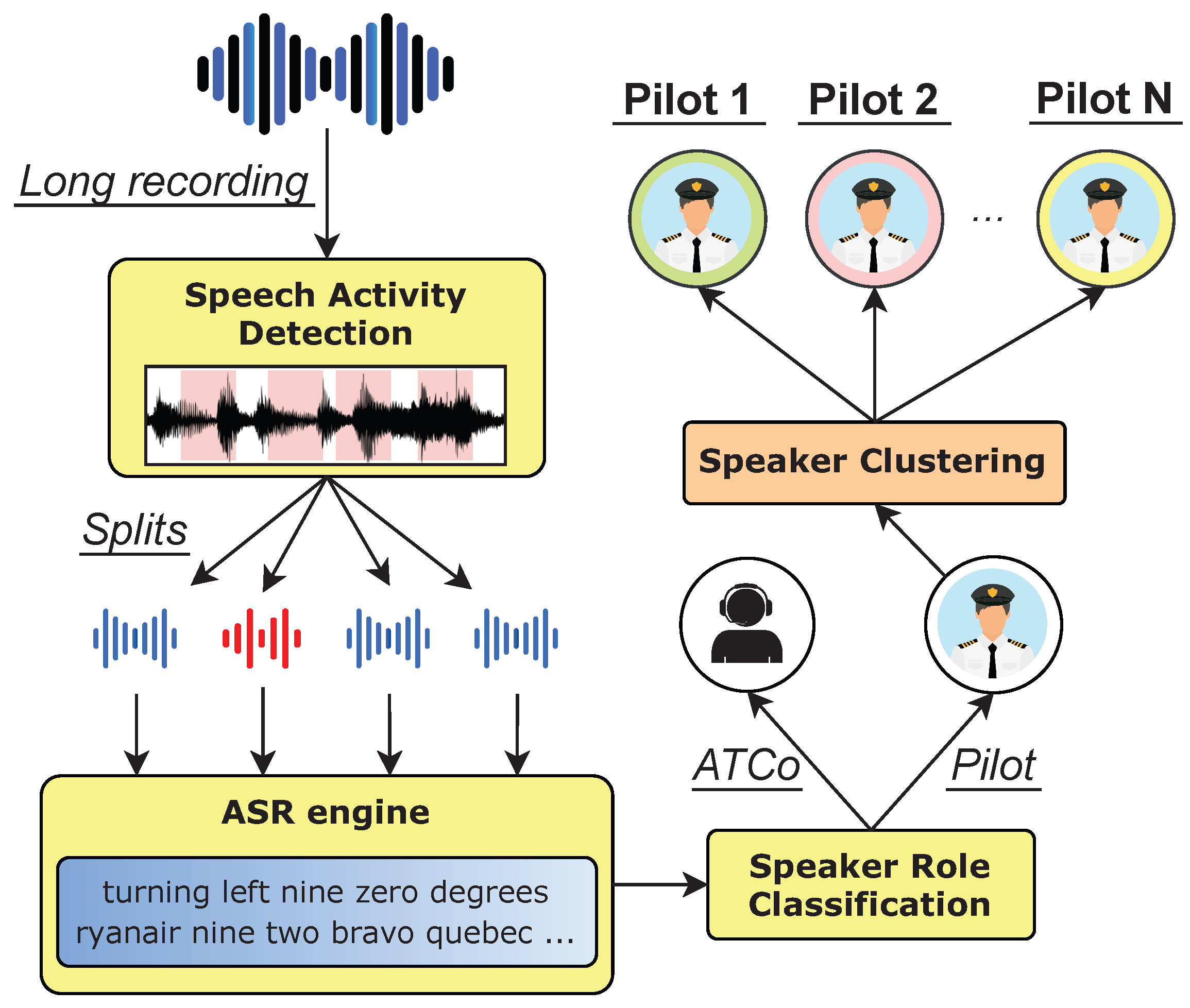
2. Automatic Speaker Clustering Pipeline
2.1. Speech Activity Detection
2.2. Automatic Speech Recognition (ASR)
2.3. Speaker Role Classification
- ATCo: “lufthansa seven eight two descend flight level seven zero” and,
- PILOT: “descend flight level seven zero lufthansa seven eight two”.
2.4. Speaker Clustering
- Calculate the distance matrix D:
- 2.
- Calculate the minimum distance pair in the distance matrix D:
- 3.
- Calculate the new cluster k by averaging the distances between and all objects in the cluster containing and :
- 4.
- Update the distance matrix D by removing rows and columns and and adding a new row and column for the newly formed cluster k:
- 5.
- Repeat steps 2–4 until all objects are in a single cluster or the process is stopped based on a fixed threshold.
3. Datasets
3.1. Training
3.1.1. Speaker Role Classification
3.1.2. Speaker Clustering
3.2. Evaluation
4. Experiments and Results
4.1. Automatic Speech Recognition
4.2. Speaker Role Classification
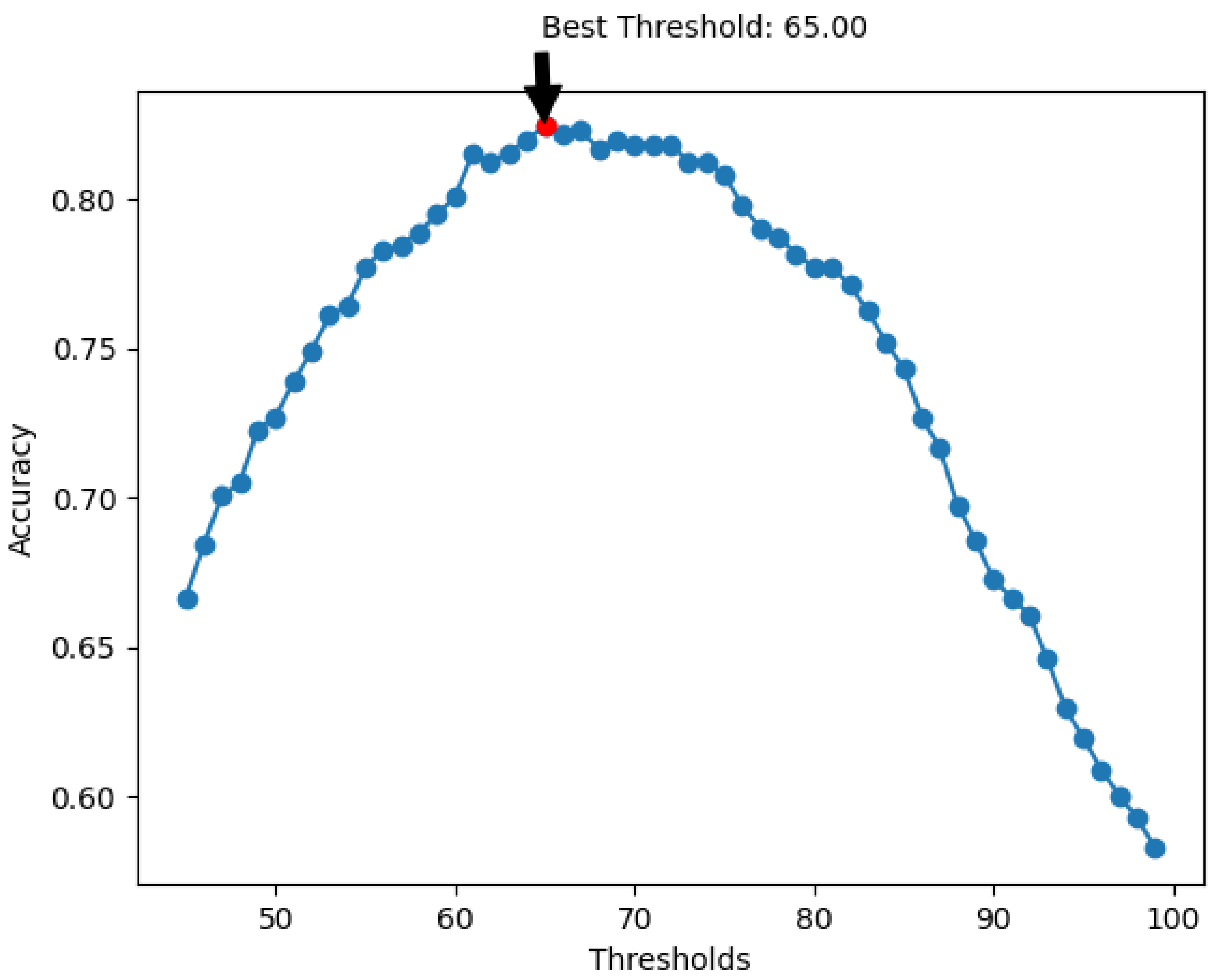
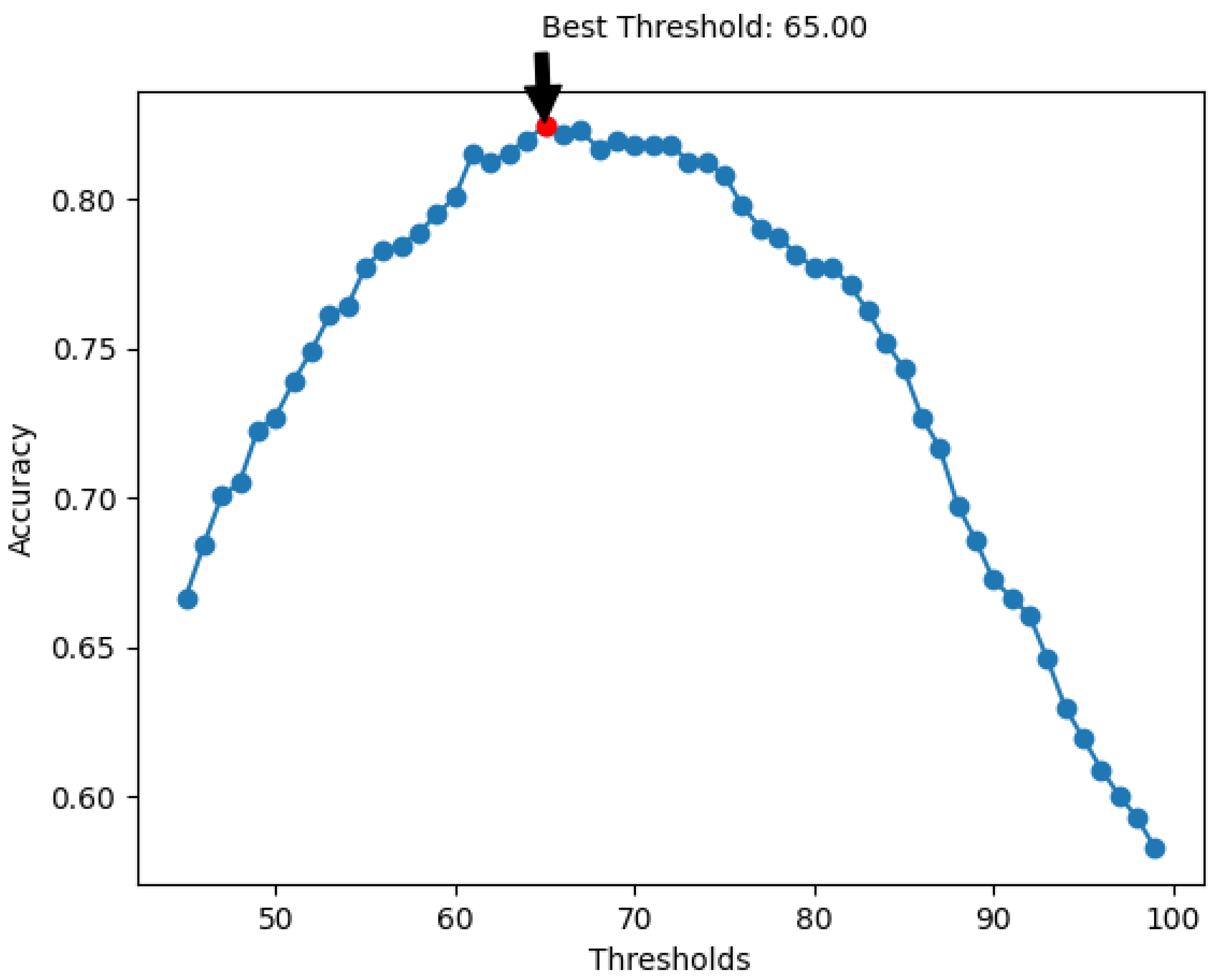
4.3. Speaker Clustering
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zuluaga-Gomez, J.; Motlicek, P.; Zhan, Q.; Veselý, K.; Braun, R. Automatic Speech Recognition Benchmark for Air-Traffic Communications. In Proceedings of the Interspeech; ISCA: Singapore, 2020; pp. 2297–2301. [Google Scholar] [CrossRef]
- Szöke, I.; Kesiraju, S.; Novotný, O.; Kocour, M.; Veselý, K.; Černocký, J. Detecting English Speech in the Air Traffic Control Voice Communication. In Proceedings of the Interspeech; ISCA: Singapore, 2021; pp. 3286–3290. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Veselỳ, K.; Blatt, A.; Motlicek, P.; Klakow, D.; Tart, A.; Szöke, I.; Prasad, A.; Sarfjoo, S.; Kolčárek, P.; et al. Automatic call sign detection: Matching air surveillance data with air traffic spoken communications. Proc. Multidiscip. Digit. Publ. Inst. 2020, 59, 14. [Google Scholar]
- Prasad, A.; Juan, Z.G.; Motlicek, P.; Sarfjoo, S.S.; Iuliia, N.; Ohneiser, O.; Helmke, H. Grammar Based Speaker Role Identification for Air Traffic Control Speech Recognition. arXiv 2022, arXiv:2108.12175. [Google Scholar]
- Lukic, Y.X.; Vogt, C.; Dürr, O.; Stadelmann, T. Learning embeddings for speaker clustering based on voice equality. In Proceedings of the 2017 IEEE 27th International Workshop on Machine Learning for Signal Processing (MLSP), Tokyo, Japan, 25–28 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Sarfjoo, S.S.; Madikeri, S.; Motlicek, P. Speech Activity Detection Based on Multilingual Speech Recognition System. arXiv 2020, arXiv:2010.12277. [Google Scholar]
- Kleinbaum, D.G.; Dietz, K.; Gail, M.; Klein, M.; Klein, M. Logistic Regression; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Mohri, M.; Pereira, F.; Riley, M. Weighted finite-state transducers in speech recognition. Comput. Speech Lang. 2002, 16, 69–88. [Google Scholar] [CrossRef]
- Mohri, M.; Pereira, F.; Riley, M. Speech recognition with weighted finite-state transducers. In Springer Handbook of Speech Processing; Springer: Berlin/Heidelberg, Germany, 2008; pp. 559–584. [Google Scholar]
- Riley, M.; Allauzen, C.; Jansche, M. OpenFst: An Open-Source, Weighted Finite-State Transducer Library and its Applications to Speech and Language. In Proceedings of the Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Companion Volume: Tutorial Abstracts, Boulder, Colorado, 31 May–5 June 2009; Association for Computational Linguistics: Boulder, CO, USA, 2009; pp. 9–10. [Google Scholar]
- Srinivasamurthy, A.; Motlicek, P.; Himawan, I.; Szaszak, G.; Oualil, Y.; Helmke, H. Semi-supervised learning with semantic knowledge extraction for improved speech recognition in air traffic control. In Proceedings of the 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Kleinert, M.; Helmke, H.; Siol, G.; Ehr, H.; Cerna, A.; Kern, C.; Klakow, D.; Motlicek, P.; Oualil, Y.; Singh, M.; et al. Semi-supervised adaptation of assistant based speech recognition models for different approach areas. In Proceedings of the 37th Digital Avionics Systems Conference (DASC), London, UK, 23–27 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–10. [Google Scholar]
- Khonglah, B.; Madikeri, S.; Dey, S.; Bourlard, H.; Motlicek, P.; Billa, J. Incremental semi-supervised learning for multi-genre speech recognition. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 7419–7423. [Google Scholar]
- Zuluaga-Gomez, J.; Nigmatulina, I.; Prasad, A.; Motlicek, P.; Veselỳ, K.; Kocour, M.; Szöke, I. Contextual Semi-Supervised Learning: An Approach to Leverage Air-Surveillance and Untranscribed ATC Data in ASR Systems. In Proceedings of the Interspeech; ISCA: Singapore, 2021; pp. 3296–3300. [Google Scholar] [CrossRef]
- Kocour, M.; Veselý, K.; Blatt, A.; Gomez, J.Z.; Szöke, I.; Cernocky, J.; Klakow, D.; Motlicek, P. Boosting of Contextual Information in ASR for Air-Traffic Call-Sign Recognition. In Proceedings of the Interspeech; ISCA: Singapore, 2021; pp. 3301–3305. [Google Scholar] [CrossRef]
- Nigmatulina, I.; Braun, R.; Zuluaga-Gomez, J.; Motlicek, P. Improving callsign recognition with air-surveillance data in air-traffic communication. arXiv 2021, arXiv:2108.12156. [Google Scholar]
- Nigmatulina, I.; Zuluaga-Gomez, J.; Prasad, A.; Sarfjoo, S.S.; Motlicek, P. A two-step approach to leverage contextual data: Speech recognition in air-traffic communications. In Proceedings of the ICASSP; ISCA: Singapore, 2022. [Google Scholar]
- Zuluaga-Gomez, J.; Prasad, A.; Nigmatulina, I.; Sarfjoo, S.; Motlicek, P.; Kleinert, M.; Helmke, H.; Ohneiser, O.; Zhan, Q. How Does Pre-trained Wav2Vec2.0 Perform on Domain Shifted ASR? An Extensive Benchmark on Air Traffic Control Communications. arXiv 2023, arXiv:2203.16822. [Google Scholar]
- Povey, D.; Peddinti, V.; Galvez, D.; Ghahremani, P.; Manohar, V.; Na, X.; Wang, Y.; Khudanpur, S. Purely sequence-trained neural networks for ASR based on lattice-free MMI. In Proceedings of the Interspeech; ISCA: Singapore, 2016; pp. 2751–2755. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised Pre-Training for Speech Recognition. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; ISCA: Singapore, 2019; pp. 3465–3469. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020. [Google Scholar]
- He, Z.; Wang, Z.; Wei, W.; Feng, S.; Mao, X.; Jiang, S. A Survey on Recent Advances in Sequence Labeling from Deep Learning Models. arXiv 2020, arXiv:2011.06727. [Google Scholar]
- Grishman, R.; Sundheim, B. Message Understanding Conference-6: A Brief History. In Proceedings of the COLING 1996 Volume 1: The 16th International Conference on Computational Linguistics, Copenhagen, Denmark, 5–9 August 1996. [Google Scholar]
- Yadav, V.; Bethard, S. A Survey on Recent Advances in Named Entity Recognition from Deep Learning models. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; Association for Computational Linguistics: Santa Fe, NM, USA, 2018; pp. 2145–2158. [Google Scholar]
- Zhou, C.; Cule, B.; Goethals, B. Pattern based sequence classification. IEEE Trans. Knowl. Data Eng. 2015, 28, 1285–1298. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zuluaga-Gomez, J.; Sarfjoo, S.S.; Prasad, A.; Nigmatulina, I.; Motlicek, P.; Ondre, K.; Ohneiser, O.; Helmke, H. BERTraffic: BERT-based Joint Speaker Role and Speaker Change Detection for Air Traffic Control Communications. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023. [Google Scholar]
- Prasad, A.; Zuluaga-Gomez, J.; Motlicek, P.; Sarfjoo, S.; Nigmatulina, I.; Veselý, K. Speech and Natural Language Processing Technologies for Pseudo-Pilot Simulator. arXiv 2022, arXiv:2212.07164. [Google Scholar]
- Zuluaga-Gomez, J.; Prasad, A.; Nigmatulina, I.; Motlicek, P.; Kleinert, M. A Virtual Simulation-Pilot Agent for Training of Air Traffic Controllers. Aerospace 2023, 10, 490. [Google Scholar] [CrossRef]
- Pellegrini, T.; Farinas, J.; Delpech, E.; Lancelot, F. The Airbus Air Traffic Control speech recognition 2018 challenge: Towards ATC automatic transcription and call sign detection. arXiv 2018, arXiv:1810.12614. [Google Scholar]
- Wang, J.; Xiao, X.; Wu, J.; Ramamurthy, R.; Rudzicz, F.; Brudno, M. Speaker diarization with session-level speaker embedding refinement using graph neural networks. arXiv 2020, arXiv:2005.11371. [Google Scholar]
- Garcia-Romero, D.; Snyder, D.; Sell, G.; Povey, D.; McCree, A. Speaker diarization using deep neural network embeddings. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4930–4934. [Google Scholar] [CrossRef]
- Zeinali, H.; Wang, S.; Silnova, A.; Matějka, P.; Plchot, O. BUT System Description to VoxCeleb Speaker Recognition Challenge. arXiv 2019, arXiv:1910.12592. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Zisserman, A. VoxCeleb: A Large-Scale Speaker Identification Dataset. arXiv 2017, arXiv:1706.08612. [Google Scholar]
- Chung, J.S.; Nagrani, A.; Zisserman, A. VoxCeleb2: Deep Speaker Recognition. arXiv 2018, arXiv:1806.05622. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 5206–5210. [Google Scholar]
- Zuluaga-Gomez, J.; Veselỳ, K.; Szöke, I.; Motlicek, P.; Kocour, M.; Rigault, M.; Choukri, K.; Prasad, A.; Sarfjoo, S.S.; Nigmatulina, I.; et al. ATCO2 corpus: A Large-Scale Dataset for Research on Automatic Speech Recognition and Natural Language Understanding of Air Traffic Control Communications. arXiv 2022, arXiv:2211.04054. [Google Scholar]
- Povey, D.; Cheng, G.; Wang, Y.; Li, K.; Xu, H.; Yarmohammadi, M.; Khudanpur, S. Semi-Orthogonal Low-Rank Matrix Factorization for Deep Neural Networks. In Proceedings of the Interspeech; ISCA: Singapore, 2018; pp. 3743–3747. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011; IEEE Signal Processing Society: Piscataway, NJ, USA, 2011. [Google Scholar]
- Conneau, A.; Baevski, A.; Collobert, R.; Mohamed, A.; Auli, M. Unsupervised cross-lingual representation learning for speech recognition. arXiv 2020, arXiv:2006.13979. [Google Scholar]
- Vyas, A.; Madikeri, S.; Bourlard, H. Lattice-Free Mmi Adaptation of Self-Supervised Pretrained Acoustic Models. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6219–6223. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Lhoest, Q.; del Moral, A.V.; Jernite, Y.; Thakur, A.; von Platen, P.; Patil, S.; Chaumond, J.; Drame, M.; Plu, J.; Tunstall, L.; et al. Datasets: A Community Library for Natural Language Processing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 7–11 November 2021; pp. 175–184. [Google Scholar]


{kind=link}
{kind=link}
| Model | ATCO2 | LDC-ATCC |
|---|---|---|
| Baseline | 36.6 | 13.5 |
| XLSR-KALDI | 25.7 | 18.7 |
| Model | ATCO2 | LDC-ATCC |
|---|---|---|
| Manual Transcripts | ||
| LDC-ATCC | 0.83 | 0.94 |
| UWB | 0.85 | 0.87 |
| LDC-ATCC + UWB | 0.87 | 0.93 |
| Automatic Transcripts | ||
| LDC-ATCC | 0.5 | 0.9 |
| UWB | 0.51 | 0.8 |
| LDC-ATCC + UWB | 0.53 | 0.9 |
| Experiment | Number of Segments | Number of Correct | Number of Incorrect |
|---|---|---|---|
| Classified as ATCo | Segments | Segments | |
| ATCO2 | |||
| SRC Ground Truth | - | 739 | 368 |
| Manual transcript | 118 | 663 | 470 |
| ASR transcript | 337 | 661 | 655 |
| LDC-ATCC | |||
| SRC Ground Truth | - | 908 | 257 |
| Manual transcript | 111 | 897 | 366 |
| ASR transcript | 128 | 896 | 379 |
| Dataset | SRC Ground Truth | Manual Transcript | ASR Transcript |
|---|---|---|---|
| ATCO2 | 66% | 58% | 50% |
| LDC-ATCC | 78% | 71% | 70% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khalil, D.; Prasad, A.; Motlicek, P.; Zuluaga-Gomez, J.; Nigmatulina, I.; Madikeri, S.; Schuepbach, C. An Automatic Speaker Clustering Pipeline for the Air Traffic Communication Domain. Aerospace 2023, 10, 876. https://doi.org/10.3390/aerospace10100876
Khalil D, Prasad A, Motlicek P, Zuluaga-Gomez J, Nigmatulina I, Madikeri S, Schuepbach C. An Automatic Speaker Clustering Pipeline for the Air Traffic Communication Domain. Aerospace. 2023; 10(10):876. https://doi.org/10.3390/aerospace10100876
Chicago/Turabian StyleKhalil, Driss, Amrutha Prasad, Petr Motlicek, Juan Zuluaga-Gomez, Iuliia Nigmatulina, Srikanth Madikeri, and Christof Schuepbach. 2023. "An Automatic Speaker Clustering Pipeline for the Air Traffic Communication Domain" Aerospace 10, no. 10: 876. https://doi.org/10.3390/aerospace10100876
APA StyleKhalil, D., Prasad, A., Motlicek, P., Zuluaga-Gomez, J., Nigmatulina, I., Madikeri, S., & Schuepbach, C. (2023). An Automatic Speaker Clustering Pipeline for the Air Traffic Communication Domain. Aerospace, 10(10), 876. https://doi.org/10.3390/aerospace10100876