
Intelligent Pursuit–Evasion Game Based on Deep Reinforcement Learning for Hypersonic Vehicles



Abstract
1. Introduction
- Unlike simulations in other papers, this paper chose the most unfavorable classic head-on situation for a hypersonic vehicle to design the evasion strategy in the scenario of a pursuit and evasion confrontation; this is because the speed advantage of a hypersonic vehicle in this scenario is greatly weakened, and the evasion process is more dependent on the strategy device.
- Most research on strategy design for hypersonic aircraft has been based on unilateral ballistic planning. However, this paper focuses on the process of game confrontation between the two parties and constructs the problem of a pursuer-and-evasion game.
- Based on the twin delayed deep deterministic (TD3) policy gradient, deep reinforcement learning was used to study the decision-making strategy of evasion control, improving the evasion strategy of a hypersonic vehicle from being a programmed maneuver evasion to an intelligent maneuver evasion.
2. PE problem Modeling
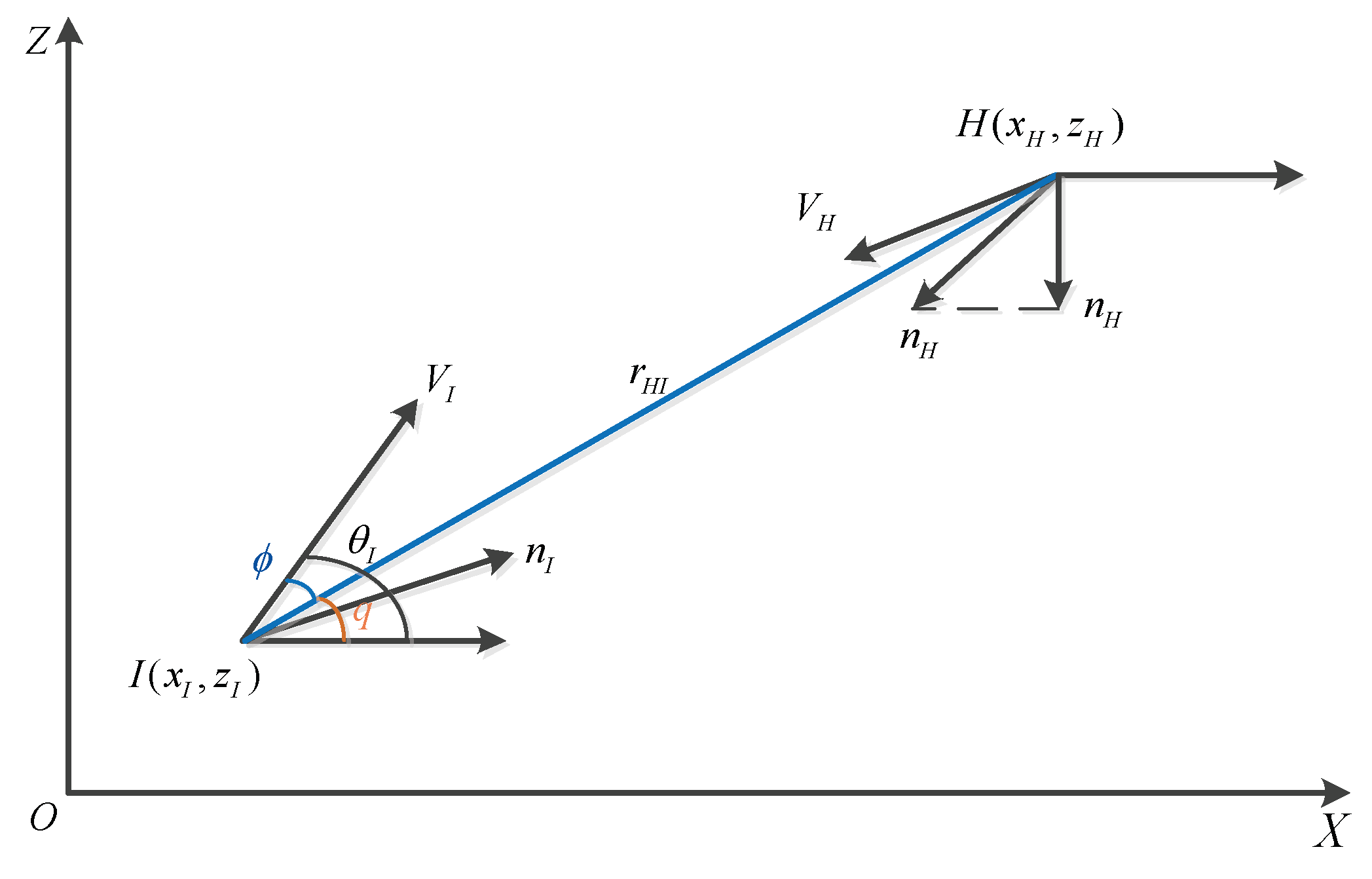
2.1. Modeling
2.2. The Scenario Description
2.3. The Designing Goal
3. Method
3.1. TD3 Method
- The updated value function is different from the DDPG algorithm, which uses the maximum estimation method to estimate value functions; it is, therefore, common for over-estimation problems to occur with the DDPG algorithm. For this reason, the TD3 algorithm was improved. Referring to the idea of two action value functions in twinned Q-learning, the minimum value of two Q-functions was adopted when updating the Q-function of the critic.
- Referring to the experience replay and target network technology in deep Q-learning, the TD3 algorithm stores the data obtained from the system exploration environment and then randomly takes a sample to update the parameters of the deep neural network to reduce the correlation between the data. Moreover, the sample can be reused to improve learning efficiency.
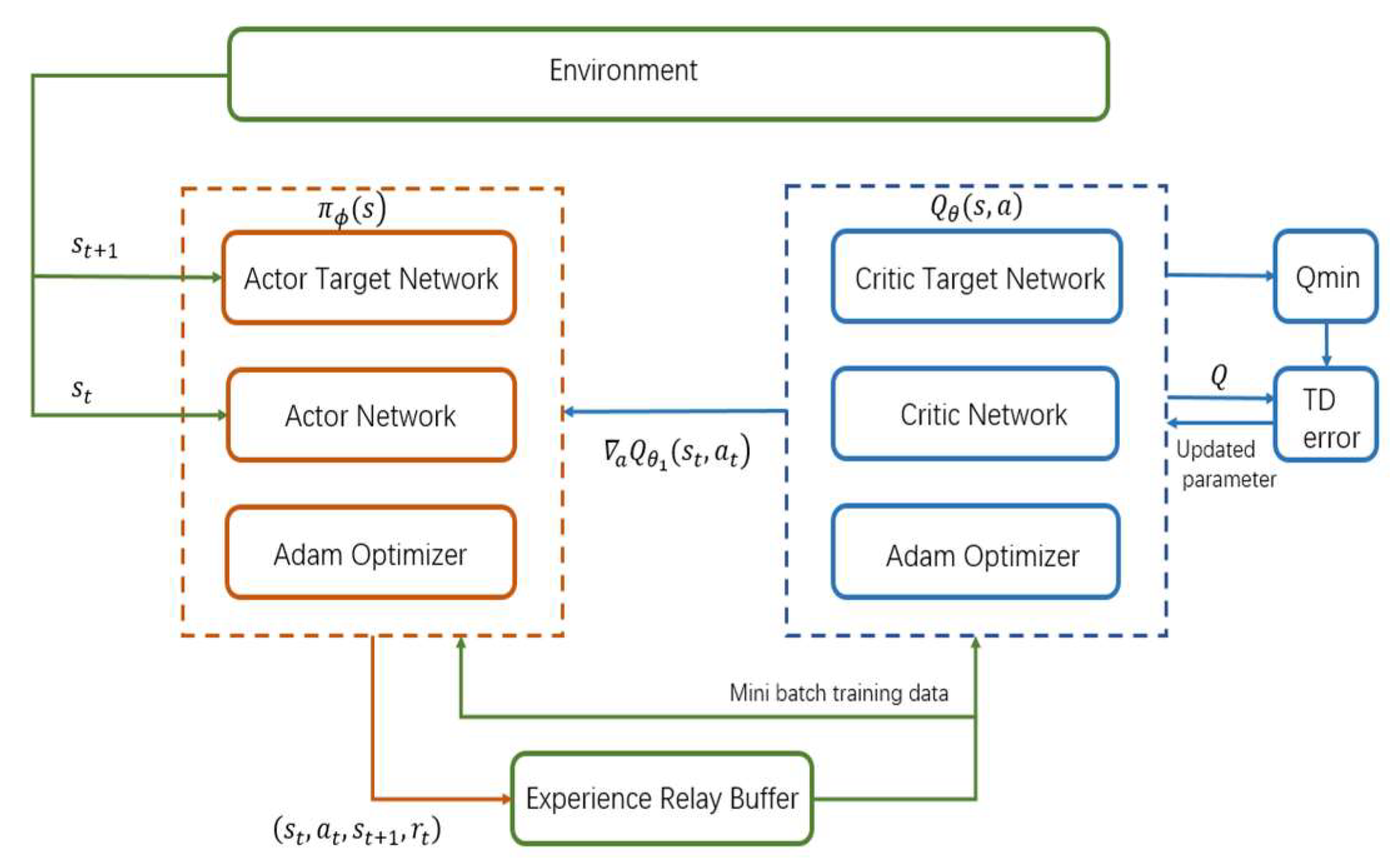
- To ensure its smoothness, regularization of the strategy was carried out, and disturbance was introduced when the TD3 network output the action. Thus, the Twin delayed deep deterministic policy gradient algorithm can be obtained. The algorithm framework is shown in the Figure 2 below:
3.1.1. Actor–Critic Structure
3.1.2. Twin Delayed Deep Deterministic (TD3) Policy Gradient
3.2. Method Design Based on Head-On Scenario
3.2.1. Design of the State Space and the Motion Space
3.2.2. Design of the Reward Function and the Termination Function
- Termination function
- Reward function
3.2.3. Design of the Network Structure
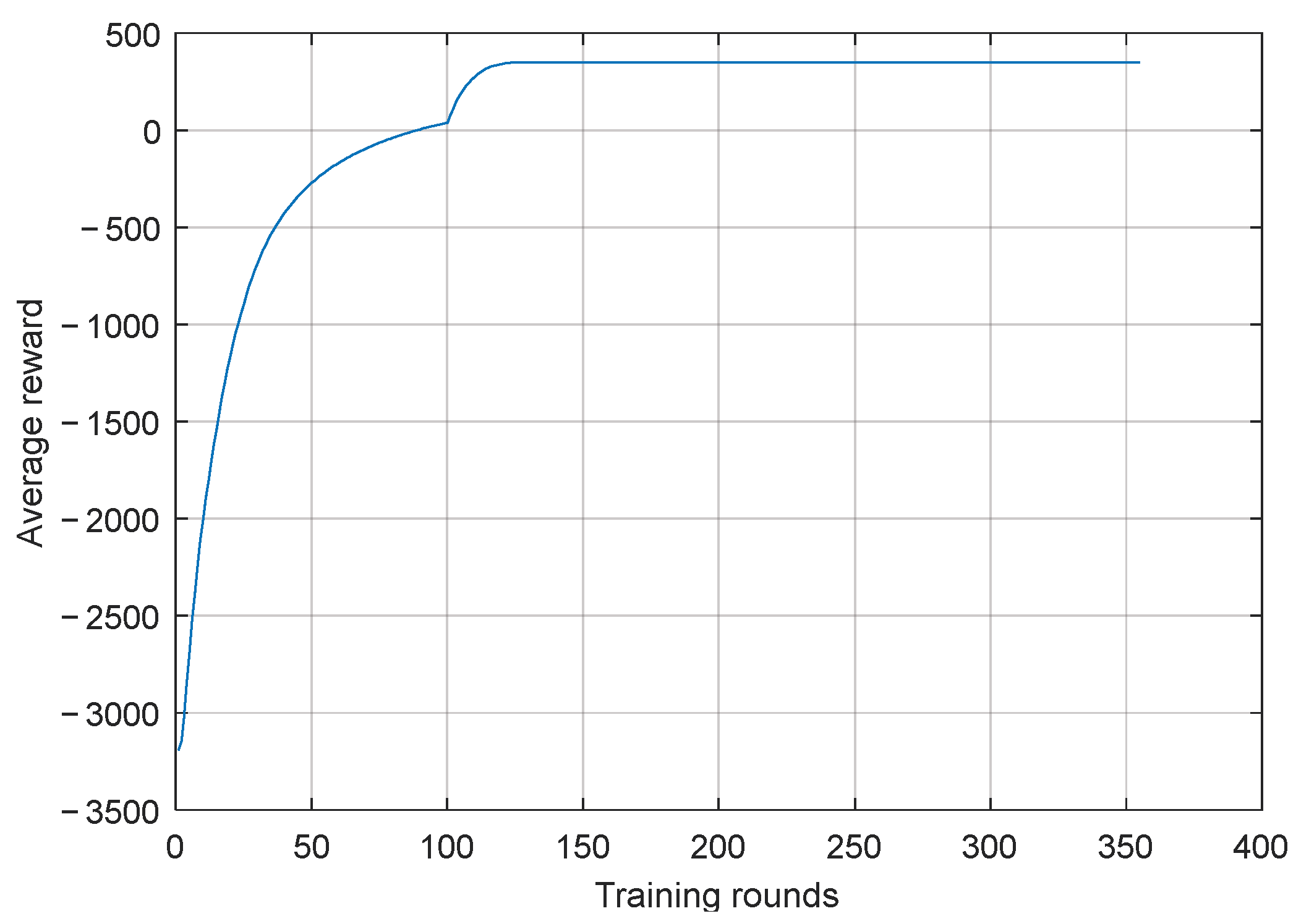
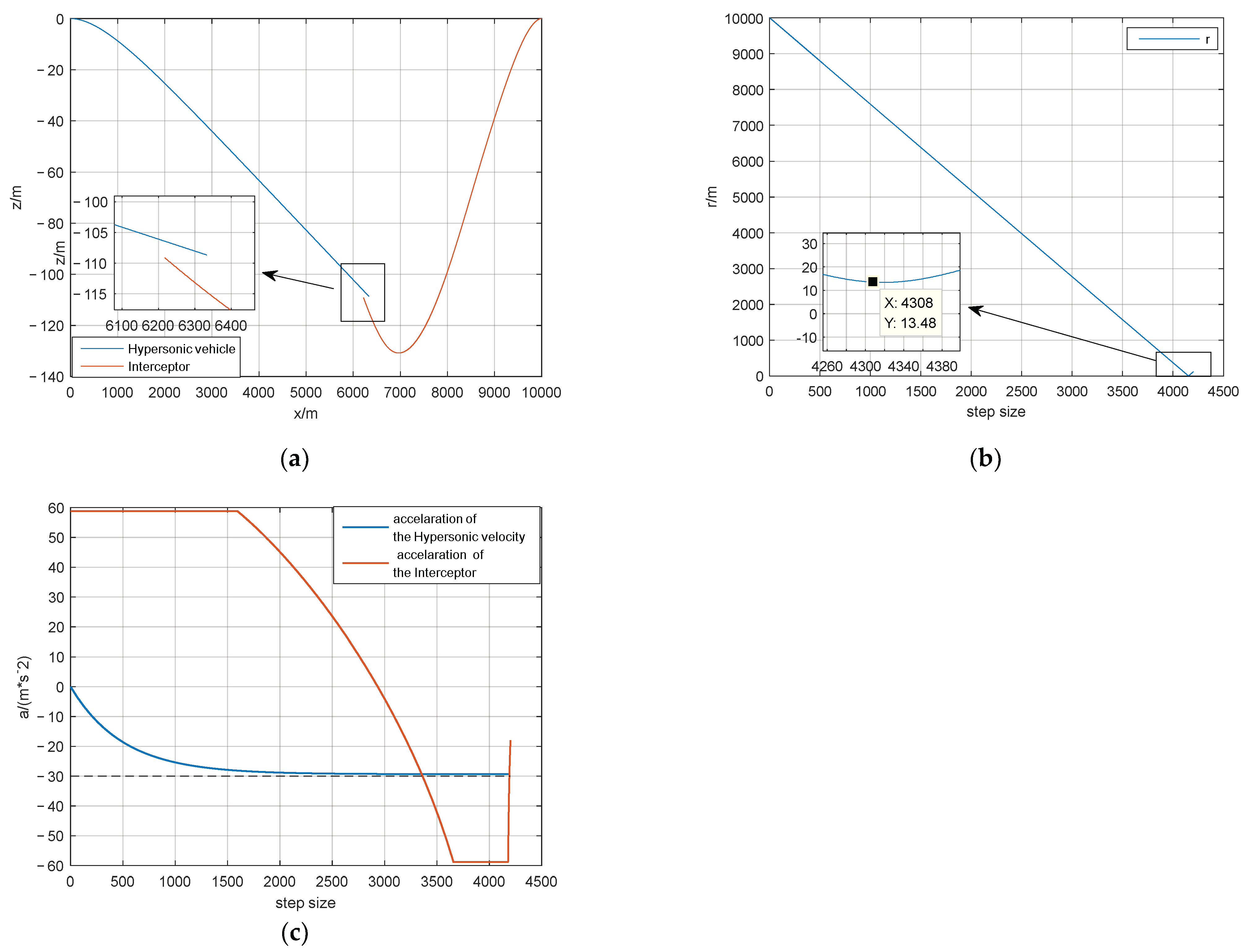
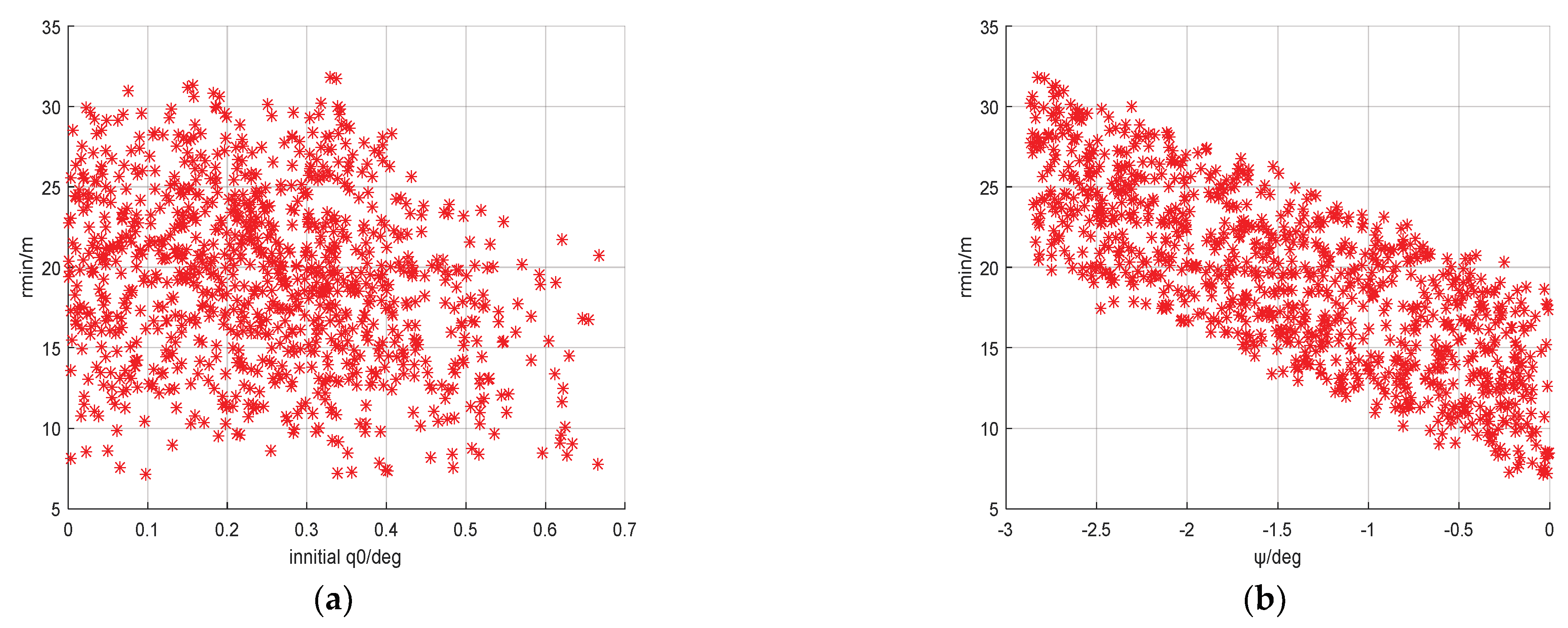
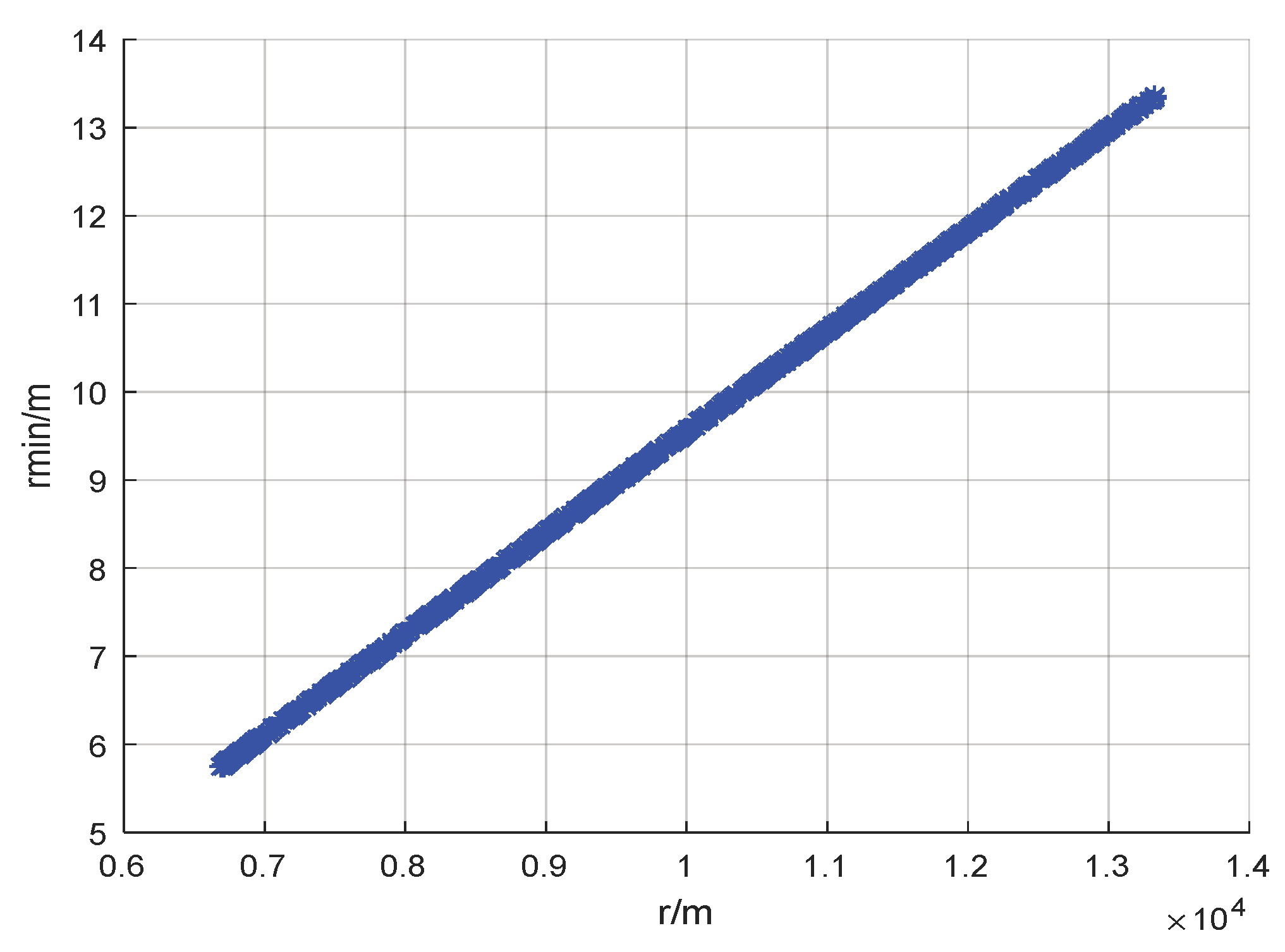
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, S.; Li, X.; Zuo, J.; Qin, J.; Cheng, K.; Feng, Y.; Bao, W. Research progress on active thermal protection for hypersonic vehicles. Prog. Aerosp. Sci. 2020, 119, 100646. [Google Scholar] [CrossRef]
- Chen, J.; Fan, X.; Xiong, B.; Meng, Z.; Wang, Y. Parameterization and optimization for the axisymmetric forebody of hypersonic vehicle. Acta Astronaut. 2020, 167, 239–244. [Google Scholar] [CrossRef]
- Chen, K.; Pei, S.; Zeng, C.; Ding, G. SINS/BDS tightly coupled integrated navigation algorithm for hypersonic vehicle. Sci. Rep. 2022, 12, 6144. [Google Scholar] [CrossRef]
- Wang, J.; Cheng, L.; Cai, Y.; Tang, G. A novel reduced-order guidance and control scheme for hypersonic gliding vehicles. Aerosp. Sci. Technol. 2020, 106, 106115. [Google Scholar] [CrossRef]
- Liu, J.; Hao, A.; Gao, Y.; Wang, C.; Wu, L. Adaptive control of hypersonicflight vehicles with limited angle-of-attack. IEEE/ASME Trans. Mechatron. 2018, 23, 883–894. [Google Scholar] [CrossRef]
- Zhu, J.; He, R.; Tang, G.; Bao, W. Pendulum maneuvering strategy for hypersonic glide vehicles. Aerosp. Sci. Technol. 2018, 78, 62–70. [Google Scholar] [CrossRef]
- Carr, W.R.; Cobb, R.G.; Pachter, M.; Pierce, S. Solution of a pursuit-evasion game using a near-optimal strategy. J. Guid. Control Dyn. 2018, 41, 841–850. [Google Scholar] [CrossRef]
- Liang, L.; Deng, F.; Peng, Z.; Li, X.; Zha, W. A differential game for cooperative target defense. Automatica 2019, 102, 58–71. [Google Scholar] [CrossRef]
- Shen, Z.; Yu, J.; Dong, X.; Hua, Y.; Ren, Z. Penetration trajectory optimization for the hypersonic gliding vehicle encountering two interceptors. Aerosp. Sci. Technol. 2022, 121, 107363. [Google Scholar] [CrossRef]
- Zhao, B.; Liu, T.; Dong, X.; Hua, Y.; Ren, Z. Integrated design of maneuvering penetration and guidance based on line deviation control. J. Astronaut. 2022, 43, 12. [Google Scholar]
- Zhao, K.; Cao, D.; Huang, W. Integrated design of maneuver, guidance and control for penetration missile. Syst. Eng. Electron. 2018, 40, 8. [Google Scholar]
- Zhou, H.; Li, X.; Bai, Y.; Wang, X. Optimal guidance for hypersonic vehicle using analytical solutions and an intelligent reversal strategy. Aerosp. Sci. Technol. 2022, 132, 108053. [Google Scholar] [CrossRef]
- Xian, Y.; Ren, L.; Xu, Y.; Li, S.; Wu, W.; Zhang, D. Impact point prediction guidance of ballistic missile in high maneuver penetration condition. Def. Technol. 2022. [Google Scholar] [CrossRef]
- Lee, J.Y.; Jo, B.U.; Moon, G.H.; Tahk, M.J.; Ahn, J. Intercept point prediction of ballistic missile defense using neural network learning. Int. J. Aeronaut. Space Sci. 2020, 21, 1092–1104. [Google Scholar] [CrossRef]
- Liang, H.; Li, Z.; Wu, J.; Zheng, Y.; Chu, H.; Wang, J. Optimal Guidance Laws for a Hypersonic Multiplayer Pursuit–Evasion Game Based on a Differential Game Strategy. Aerospace 2022, 9, 97. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, K.; Zhang, Y.; Shi, H.; Tang, L.; Li, M. Near-optimal interception strategy for orbital pursuit-evasion using deep reinforcement learning. Acta Astronaut. 2022, 198, 9–25. [Google Scholar] [CrossRef]
- Tang, X.; Ye, D.; Huang, L.; Sun, Z.; Sun, J. Pursuit-evasion game switching strategies for spacecraft with incomplete-information. Aerosp. Sci. Technol. 2021, 119, 107112. [Google Scholar] [CrossRef]
- Yan, T.; Cai, Y.; Xu, B. Evasion guidance algorithms for air-breathing hypersonic vehicles in three-player pursuit-evasion games. Chin. J. Aeronaut. 2020, 33, 3423–3436. [Google Scholar] [CrossRef]
- Dwivedi, P.N.; Bhattacharya, A.; Padhi, R. Suboptimal midcourse guidance of interceptors for high-speed targets with alignment angle constraint. J. Guid. Control Dyn. 2011, 34, 860–877. [Google Scholar] [CrossRef]
- Liu, K.; Meng, H.; Wang, C.; Li, J.; Chen, Y. Anti-Head-on interception penetration guidance law for slide vehicle. Mod. Def. Tech. 2018, 46, 7. [Google Scholar]
- Hwangbo, J.; Sa, I.; Siegwart, R.; Hutter, M. Control of a quadrotor with reinforcement learning. IEEE Robot. Autom. Lett. 2017, 2, 2096–2103. [Google Scholar] [CrossRef]
- Liu, C.; Dong, C.; Zhou, Z.; Wang, Z. Barrier Lyapunov function based reinforcement learning control for air-breathing hypersonic vehicle with variable geometry inlet. Aerosp. Sci. Technol. 2019, 96, 105537. [Google Scholar] [CrossRef]
- Yoo, J.; Jang, D.; Kim, H.J.; Johansson, K.H. Hybrid reinforcement learning control for a micro quadrotor flight. IEEE Control Syst. Lett. 2020, 5, 505–510. [Google Scholar] [CrossRef]
- Qiu, X.; Gao, C.; Jing, W. Maneuvering penetration strategies of ballistic missiles based on deep reinforcement learning. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2022, 236, 3494–3504. [Google Scholar] [CrossRef]
- Gao, A.; Dong, Z.; Ye, H.; Song, J.; Guo, Q. Loitering munition penetration control decision based on deep reinforcement learning. Acta Armamentarii 2021, 42, 1101–1110. [Google Scholar]
- Jiang, L.; Nan, Y.; Zhang, Y.; Li, Z. Anti-Interception guidance for hypersonic glide vehicle: A deep reinforcement learning approach. Aerospace 2022, 9, 424. [Google Scholar] [CrossRef]
- Li, W.; Zhu, Y.; Zhao, D. Missile guidance with assisted deep reinforcement learning for head-on interception of maneuvering target. Complex Intell. Syst. 2021, 8, 1205–1216. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of the Network | Actor | Critic |
|---|---|---|
| Network | Actor Network | Network Network |
| Target Network | Actor Target Network | Target Network Target Network |
| Type of the Network | Policy Network | Action Value Function Network | ||
|---|---|---|---|---|
| Number of Nodes | Activation Function | Number of Nodes | Activation Function | |
| The input layer | 3 | None | 4 | None |
| The hidden layer1 | 128 | ReLu | 64 | ReLu |
| The hidden layer2 | 128 | ReLu | 64 | ReLu |
| The hidden layer3 | 64 | ReLu | 64 | ReLu |
| The output layer | 1 | tanh | 1 | Fully Connection |
| Variable | Value | Variable | Value |
|---|---|---|---|
| 3 Ma | Experience pool capability | 4000 | |
| 6 Ma | Small batch sample size | 128 | |
| 6 | The updating frequency of the policy network | 300 | |
| 3 | The updating frequency of the target network | 300 | |
| Initial position of the pursuer/m | (100,000) | 4 | |
| Initial position of the Hypersonic vehicle | (0,0) | Discount factor | 0.99 |
| Navigation coefficient | 4 | Inertial factor | 0.99 |
| Type of the guidance law | PN | Soft updating rate | 0.001 |
| Initial line-of-sight angle | 0 | 0.1 s | |
| Deflection angle of the pursuer | 5 | ||
| Deflection angle of the hypersonic vehicle | 0 | 8 | |
| 1 | The time threshold of distance judgment | 4 s | |
| The target network smoothing noise variance | 0.2 | 0.4 | |
| Sampling time | 0.1 | 1 × 10−5 | |
| The mean of reward window length | 100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, M.; Yan, T.; Li, Q.; Fu, W.; Zhang, J. Intelligent Pursuit–Evasion Game Based on Deep Reinforcement Learning for Hypersonic Vehicles. Aerospace 2023, 10, 86. https://doi.org/10.3390/aerospace10010086
Gao M, Yan T, Li Q, Fu W, Zhang J. Intelligent Pursuit–Evasion Game Based on Deep Reinforcement Learning for Hypersonic Vehicles. Aerospace. 2023; 10(1):86. https://doi.org/10.3390/aerospace10010086
Chicago/Turabian StyleGao, Mengjing, Tian Yan, Quancheng Li, Wenxing Fu, and Jin Zhang. 2023. "Intelligent Pursuit–Evasion Game Based on Deep Reinforcement Learning for Hypersonic Vehicles" Aerospace 10, no. 1: 86. https://doi.org/10.3390/aerospace10010086
APA StyleGao, M., Yan, T., Li, Q., Fu, W., & Zhang, J. (2023). Intelligent Pursuit–Evasion Game Based on Deep Reinforcement Learning for Hypersonic Vehicles. Aerospace, 10(1), 86. https://doi.org/10.3390/aerospace10010086