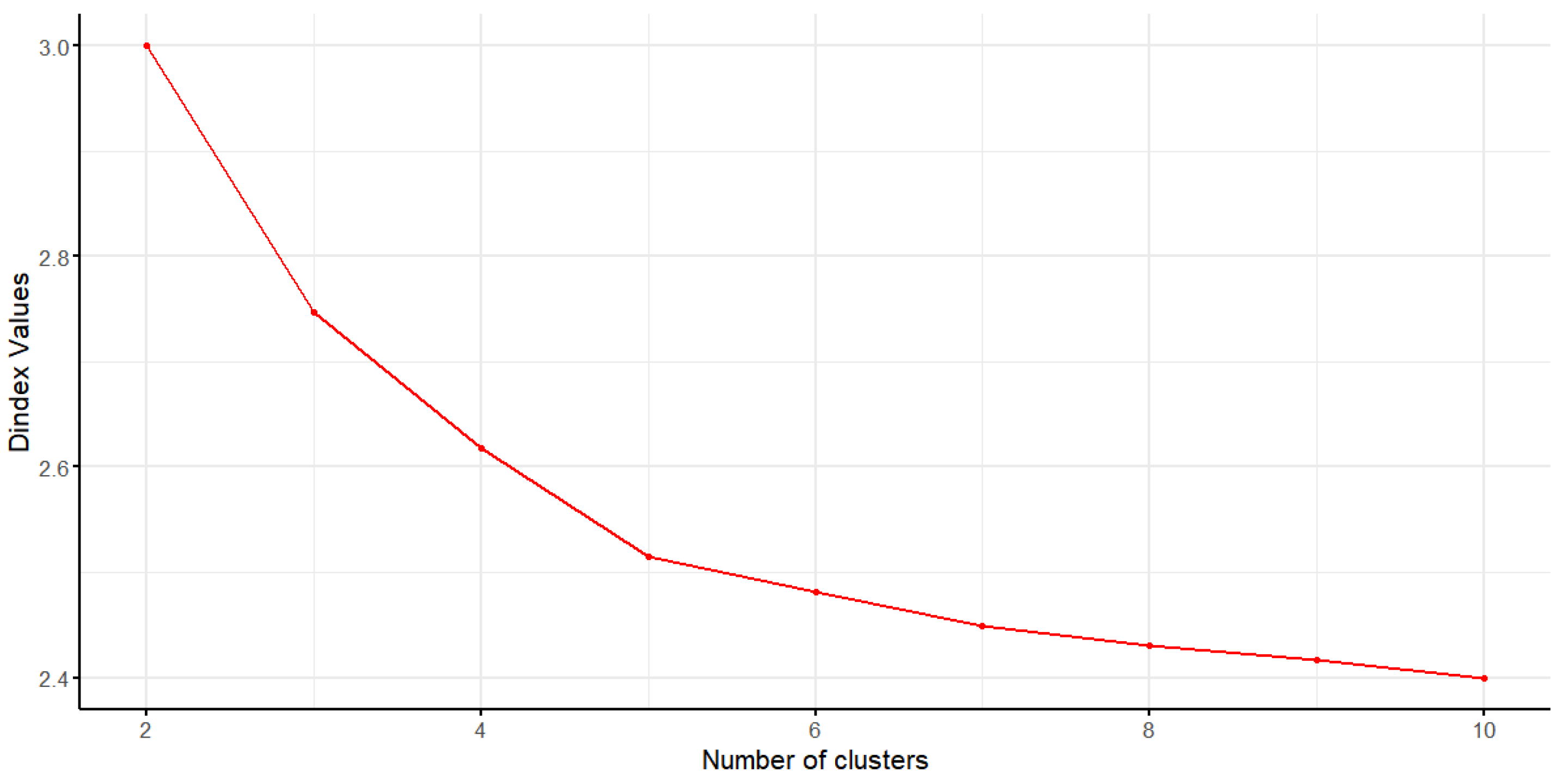
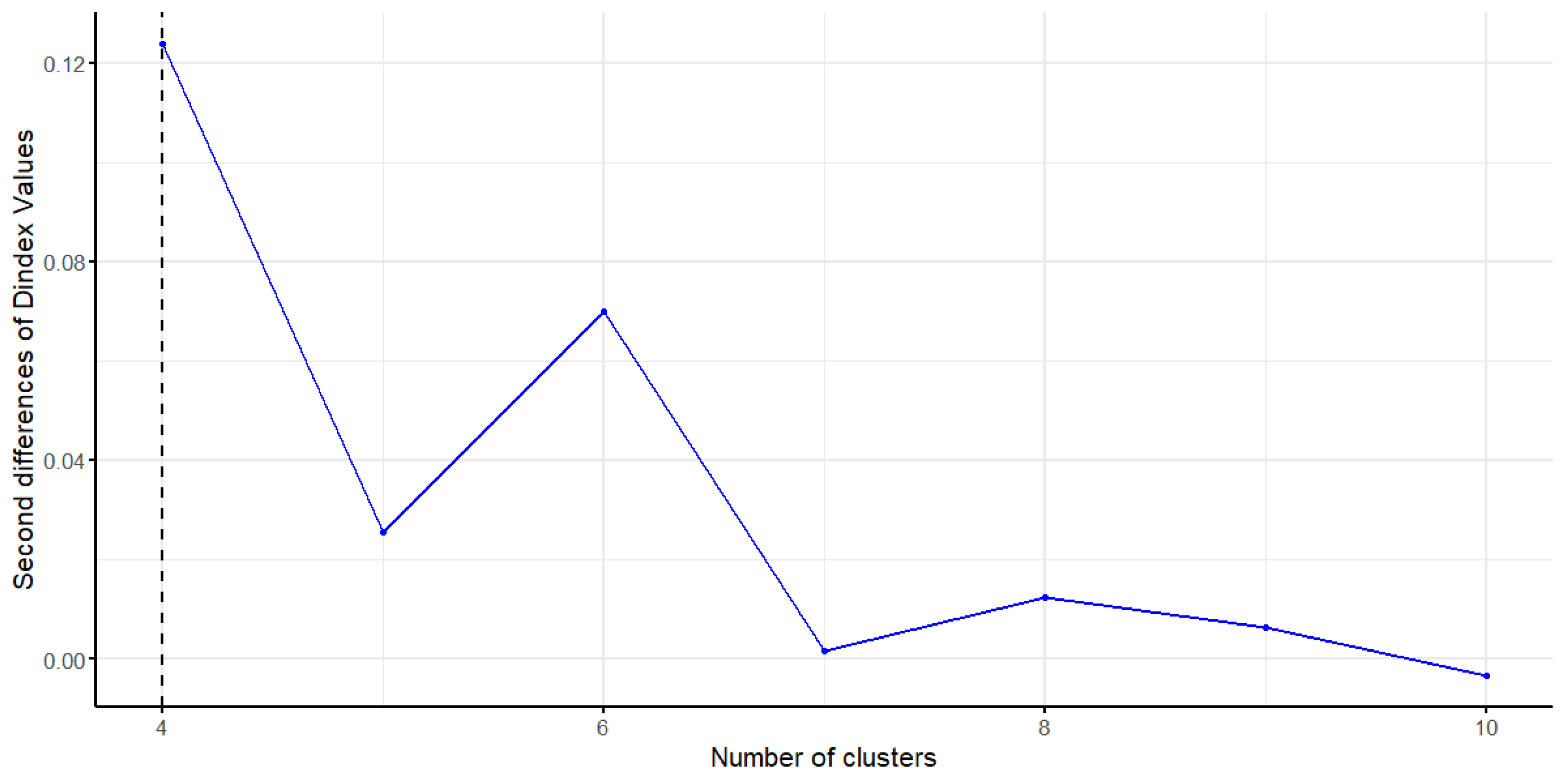
5.4.2. Markov Models with Covariates
This study incorporates GDP growth rate, population growth rate, and energy investment as determinants to examine their potential influences on transitions among carbon emission patterns. To investigate the practical effects of these covariates, GDP growth rate is first introduced into the model to analyze its impact on emission transitions from Pattern I to Pattern IV.
Table 7 reports transition probability matrices at three quantile levels of GDP growth (0.25, 0.50 and 0.75) to expose the modulatory effect of GDP growth as a covariate on carbon emission pattern transitions. Taking the 0.50 quantile as the baseline, state persistence probabilities attenuate at the 0.75 level. In particular, Pattern I persistence diminishes from 0.604 to 0.365, Pattern II from 0.732 to 0.619, Pattern III from 0.700 to 0.400, and Pattern IV from 0.756 to 0.725. Concurrently, interpattern transition probabilities escalate with GDP growth: the probability of transition from Pattern I to Pattern II rises from 0.215 to 0.401 and from Pattern II to Pattern III from 0.037 to 0.094.
Under conditions of elevated GDP growth, transitions from higher emission patterns to lower emission patterns become more pronounced. Specifically, the probability of transitioning from Pattern III to Pattern I rises from 0.089 at the 0.25 level to 0.324 at the 0.75 level; from Pattern IV to Pattern I, it increases from 0.016 to 0.067; from Pattern III to Pattern II, it increases from 0.013 to 0.209; and from Pattern IV to Pattern II, it increases from 0.060 to 0.093. These results suggest that provinces characterized by higher emission regimes exhibit an increased likelihood of downward transitions under high GDP growth.
By contrast, at the 0.25 quantile level of GDP growth emission pattern stability is strongest. Persistence probabilities reach 0.755 for Pattern I, 0.796 for Pattern II, 0.800 for Pattern III and 0.772 for Pattern IV. This suggests that emission states remain more persistent under conditions of sluggish economic growth.
Table 8 presents the corresponding transition intensity matrix supplementing the transition probability matrix by detailing instantaneous transition intensities. The matrix shows that at the 0.75 quantile of GDP growth transition intensities between emission states significantly increase consistent with trends in the transition probability matrix. This confirms that GDP growth accelerates dynamic transitions between patterns.
Overall, varying GDP growth levels significantly impact the stability of the emission pattern and dynamic transition characteristics. High GDP growth reduces emission pattern stability and accelerates interpattern transitions, while lower GDP growth tends to enhance emission pattern stability.
When using the population growth rate as a covariate, carbon emission transition pathways exhibit notable differences.
Table 9 presents the transition probability matrices under the 0.25, 0.50, and 0.75 quantile levels, indicating the probabilities of moving among the four carbon emission patterns.
At the 0.50 quantile level, Pattern II exhibits a persistence probability of 0.696 and Pattern IV has a 0.748 probability of persisting in that state, reflecting significant inertia in medium emission and high emission categories. At the same time, mobility between adjacent patterns remains substantial, as Pattern II transitions to Pattern I with a probability of 0.231 and Pattern IV transitions to Pattern III with a probability of 0.134. The moderate transition rate from Pattern III to Pattern I further demonstrates that Pattern III can still adjust downward under typical demographic conditions.
Under low population growth at the 0.25 quantile level, Pattern I’s persistence probability decreases to 0.426, reflecting diminished stability of the low-emission regime under slow demographic conditions. Pattern II’s persistence probability increases to 0.713, denoting reinforced stability of the medium emission pattern. The probability of transition from Pattern III to Pattern I rises to 0.195 and to Pattern II rises to 0.089, suggesting a marked tendency for Pattern III to shift downward when demographic pressures are subdued. Pattern IV transitions to Pattern I with a probability of 0.038. The elevated transition rate from Pattern III to Pattern I under low growth underscores the potential for downward adjustment when population pressures are minimal.
Under high population growth at the 0.75 quantile level, Pattern I’s persistence probability increases to 0.495, denoting enhanced stability in the low emission pattern relative to the median scenario. Pattern III transitions to Pattern I with probability 0.213, while Pattern IV transitions to Pattern I with probability 0.035. Upward transitions also intensify, as Pattern II moves to Pattern III with probability 0.075. Furthermore, simultaneous increases in the probabilities of Pattern I directly transitioning to Pattern III and Pattern II directly transitioning to Pattern IV indicate that accelerated demographic growth can induce divergence, enabling some provinces to bypass intermediate patterns.
A comparison across quantile levels reveals that transitions from Pattern II to Pattern III and from Pattern III to Pattern I display asymmetric responsiveness to population growth, implying nonlinear feedback mechanisms between demographic dynamics and emission pattern evolution that warrant further investigation.
Table 10 provides the transition intensity matrix, serving as supplementary analysis to the transition probability. At the 0.5 quantile level, negative diagonal elements reflect strong stability in states, particularly notable for Patterns I and II. Although off-diagonal transition intensities (e.g., Pattern II to Pattern III) remain low, they slightly increase at higher quantile levels, further confirming unfavorable transition trends under higher population growth conditions.
In summary, introducing population growth as a covariate highlights its minor but consistent effect on reinforcing existing emission states, particularly stabilizing both extreme low and high emission patterns. While it slightly elevates probabilities of transitions toward higher-emission patterns, it does not significantly alter the fundamental dynamics of carbon emission transitions.
Transitions of carbon emission patterns (Patterns I to IV) vary significantly across different levels of energy investment.
Table 11 presents the transition probability matrices at the 0.25, 0.50, and 0.75 quantile levels of energy investment, showing the probabilities of transitions among the emission patterns. At the 0.50 quantile level, Pattern II exhibits strong state persistence at 0.693, while Pattern IV also demonstrates significant persistence at 0.721. In contrast, Patterns I (0.496) and III (0.422) show lower persistence, indicating a higher likelihood of transitions to other patterns. At the 0.25 quantile level of energy investment, the transition probability from Pattern III to Pattern I is notably high at 0.533, and that from Pattern II to Pattern I is also relatively high at 0.411, highlighting increased probabilities of movement toward lower emission states. However, at the 0.75 quantile level of energy investment, the probability of transitioning from Pattern III to Pattern I sharply decreases to 0.103, while transitions from Pattern II to Pattern I significantly decline to 0.087, suggesting that high energy investment markedly suppresses downward transitions from high to low emission patterns. The probability of moving from Pattern III to Pattern IV increases from 0.035 to 0.082, indicating a greater tendency toward upward transitions to higher emission states under high energy investment.
Table 12 presents the transition intensity matrix with energy investment as a covariate, providing supplementary insight into the rates of state transitions between emission patterns. At the 0.5 quantile level, the relatively small magnitudes of the negative diagonal entries, particularly for Patterns I and III, imply longer average dwell times and thus greater state stability. Comparing the 0.75 to the 0.5 quantile levels, the intensities of upward transitions into higher-emission patterns (e.g., Pattern II→III, III→IV) increase, whereas the intensities of downward transitions into lower-emission patterns (e.g., Pattern II→I, III→I) decrease markedly. Notably, Pattern IV’s diagonal entry increases in magnitude, indicating a shorter dwell time and reduced stability under higher energy investment.
Collectively, the results presented in
Table 11 and
Table 12 indicate that energy investment exerts a nuanced bidirectional influence on emission pattern transitions. Higher investment levels inhibit transitions from high emission to low emission states and simultaneously foster transitions from low emission to high emission states and bolster aggregate state stability. These results suggest that increased energy investment may not yield effective reconfiguration of emission profiles and underscore the necessity for strategic optimization of investment allocation.
This study constructs an ACI, GDP growth rate, population growth rate, and energy investment to comprehensively evaluate their combined effects on carbon emission transitions.
Table 13 presents the transition probability matrix, employing aggregated indices of ACI, GDP growth rate, population growth rate, and energy investment as covariates to analyze transition probabilities between emission patterns. When the quantile level increases from 0.25 to 0.5, the transition probability from Pattern I to Pattern II rises from 0.312 to 0.357, indicating an increased likelihood of provinces shifting from low to medium emission categories, in contrast the probability from Pattern II to Pattern III slightly decreases from 0.055 to 0.044, yet the overall emission patterns remain oriented toward higher emissions. Further elevating the quantile level from 0.5 to 0.75 results in the transition probability from Pattern I to Pattern II increasing to 0.389 and notably from Pattern II to Pattern III rising to 0.070. At the 0.25 quantile level, Pattern II and Pattern III demonstrate moderate inertia with self transition probabilities of 0.612 and 0.518 respectively, whereas Pattern IV already exhibits strong stability at 0.715; this stability intensifies at the 0.50 quantile level to 0.749 and the 0.75 quantile level to 0.769, highlighting growing persistence in higher emission states under stronger covariate influences. Concurrently, the probabilities of downward shifts such as from Pattern II back to Pattern I or from Pattern III back to Pattern II steadily decline as the aggregated index increases, suggesting that provinces facing higher combined economic, demographic, and investment pressures become less likely to revert to lower emission categories, such asymmetric behavior underscores an increasing lock-in effect in high emission patterns at elevated quantile levels, implying that conventional mitigation measures may lose efficacy unless the underlying covariate pressures are directly addressed.
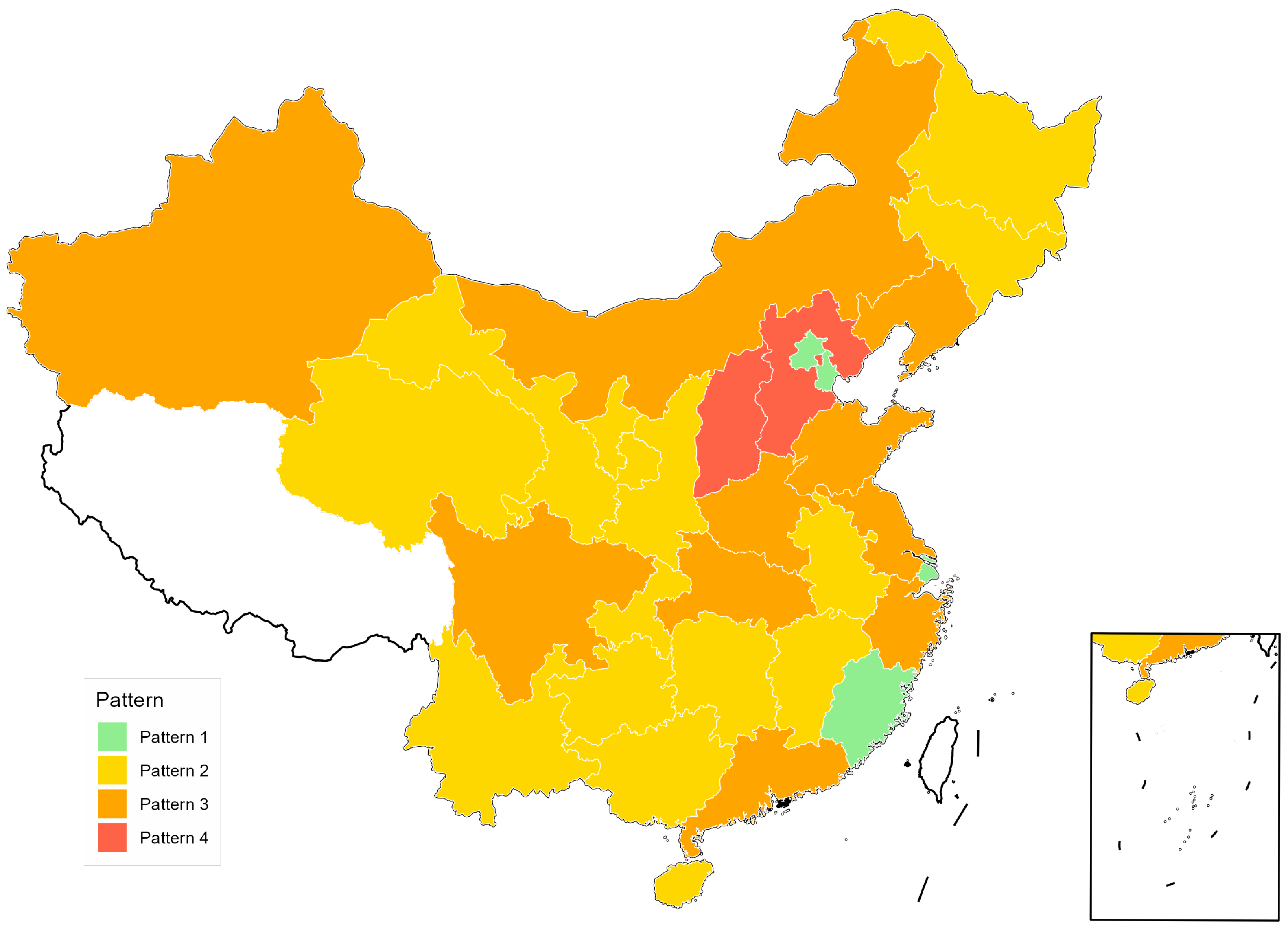
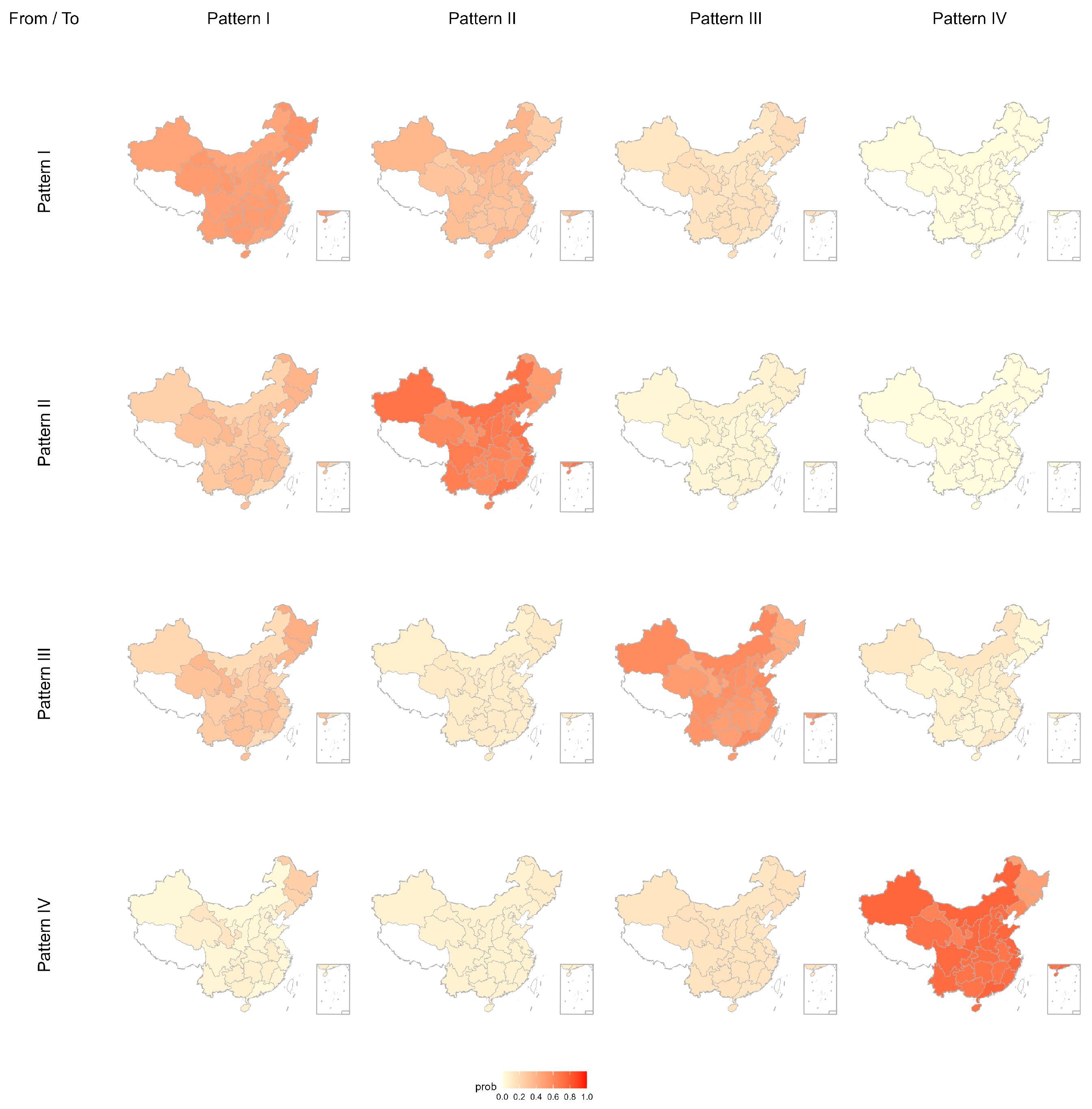
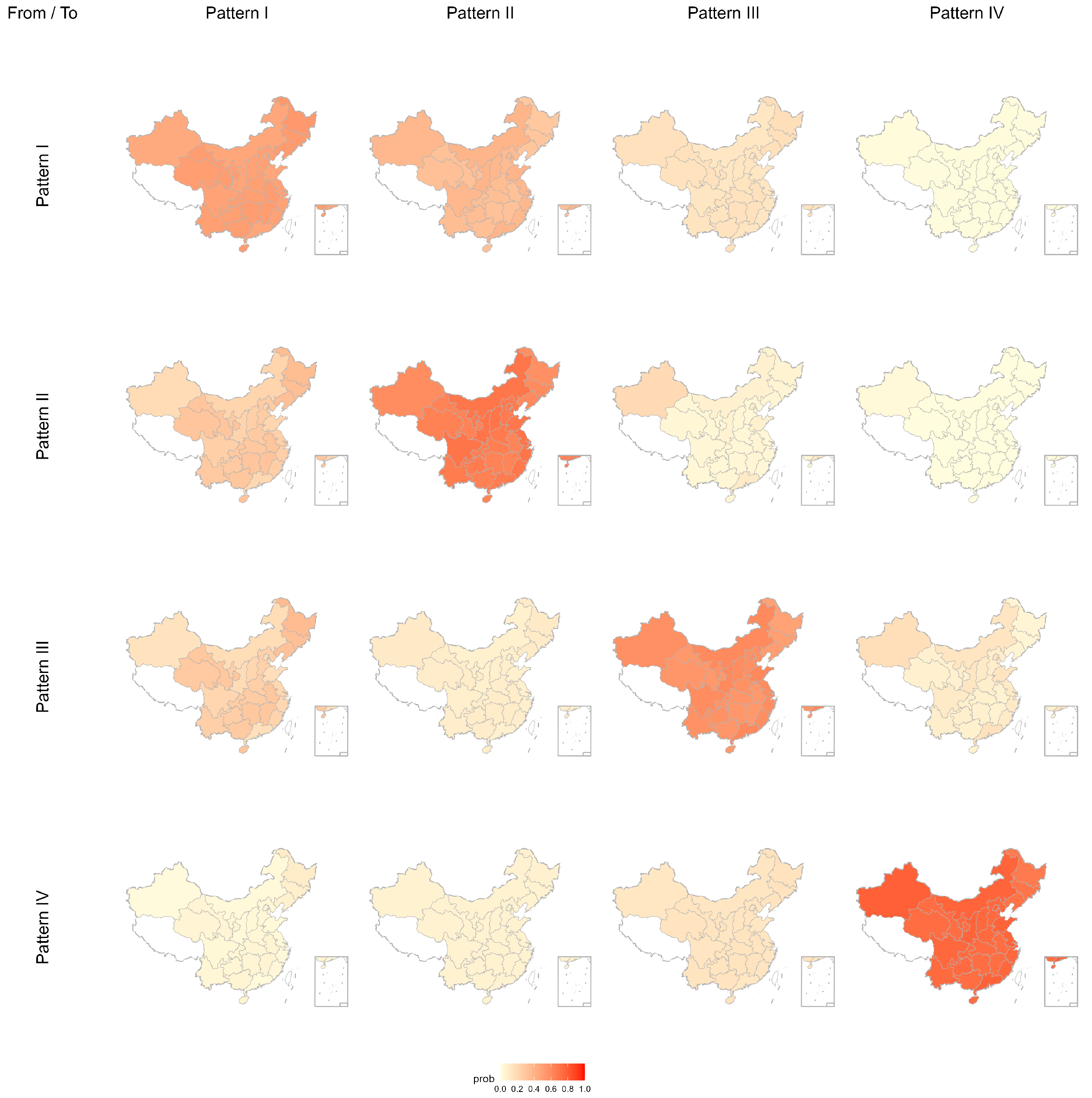
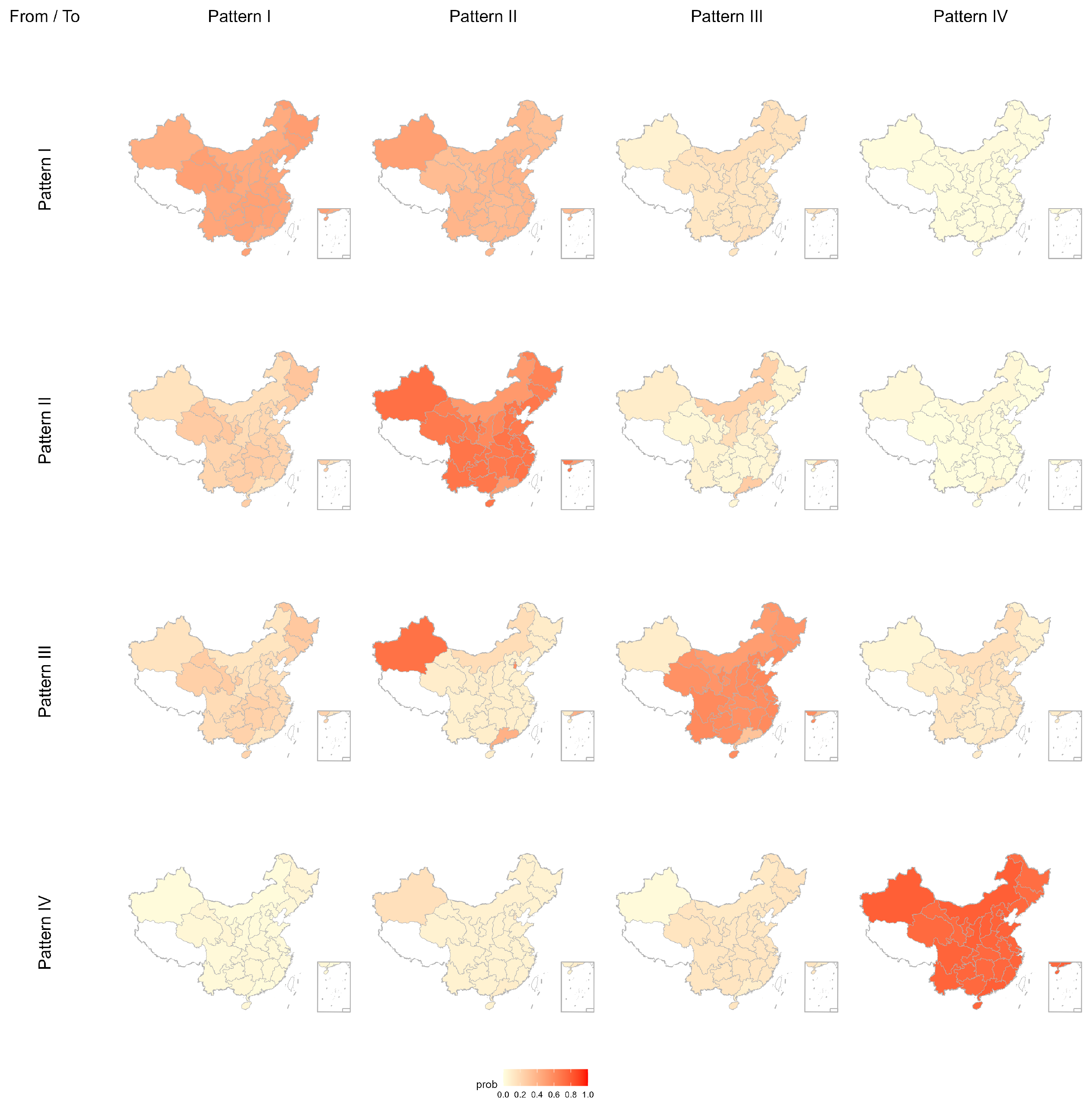
Moreover, to better illustrate the combined influence of GDP growth rate, population growth rate, and energy investment on carbon emission pattern transitions, we plotted spatial distribution maps of transition probabilities (
Figure 4,
Figure 5 and
Figure 6), where darker shading indicates higher probabilities and lighter shading indicates lower probabilities.
Combining the self-transition probabilities reported in
Table 13 with these maps at the 0.25, 0.50, and 0.75 quantile levels reveals a clear trend of increasing spatial stability for the medium and high emission patterns as the aggregated covariate index rises.
At the 0.25 quantile level (
Figure 4), Pattern I and Pattern III exhibit self-transition probabilities of 0.515 and 0.518, respectively, corresponding to moderate shading; Pattern II rises to 0.612 with darker shading; and Pattern IV attains 0.715, showing the darkest shading and widest coverage, indicating relatively strong persistence under low covariate pressure. At the 0.50 quantile level (
Figure 5), Pattern I declines to 0.490 with slightly lighter shading; Pattern II and Pattern III increase to 0.678 and 0.572 respectively, both showing marked deepening of shading; and Pattern IV reaches 0.749 with its darkest areas expanding substantially, reflecting enhanced spatial stability of the medium and high emission categories under moderate covariate pressure. At the 0.75 quantile level (
Figure 6), Pattern I further decreases to 0.466, maintaining lighter shading; Pattern II and Pattern III rise to 0.696 and 0.602; and Pattern IV peaks at 0.769, all three exhibiting the darkest shading, with Pattern III and Pattern IV covering the largest area.
This pattern demonstrates that under high covariate pressure the medium and high emission categories retain their states more robustly than under lower pressures. Overall, the spatial patterns align closely with the numerical values, highlighting how covariate intensity shapes the persistence of emission patterns.
Table 14 presents the transition intensity matrix using ACI as the covariate, illustrating how instantaneous transition intensities among emission patterns vary across quantile levels. As the quantile level increases from the lower quartile to the median, the instantaneous transition rate from Pattern II to Pattern III exhibits a moderate upward trend; further ascent to the upper quartile induces a marked acceleration in this rate, signifying an enhanced propensity for provinces to migrate into higher-emission regimes under elevated ACI.
Collectively, these findings indicate that in contexts of vigorous economic expansion, demographic growth, and intensified energy investment, provincial emission trajectories predominantly shift toward higher emission categories before stabilizing at elevated levels. Furthermore, once high-emission states become established, they demonstrate substantial persistence and a low likelihood of downward migration, underscoring their intrinsic stability and resistance to reversal.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}