
Asymptotic and Finite Sample Properties for Multivariate Rotated GARCH Models





Abstract
1. Introduction
2. RBEKK-GARCH Model
- (a)
- The distribution of is absolutely continuous with respect to the Lebesgue measure of and zero is an interior point of the support of the distribution.
- (b)
- The matrices and satisfy .
3. 2sQML Estimation
- (a)
- The process is strictly stationary and ergodic.
- (b)
- The true parameters and Θ are compact.
- (c)
- For , if , then almost surely, for all .
- (a)
- .
- (b)
- is in the interior of Θ.
4. Monte Carlo Experiments
4.1. Experimental Framework
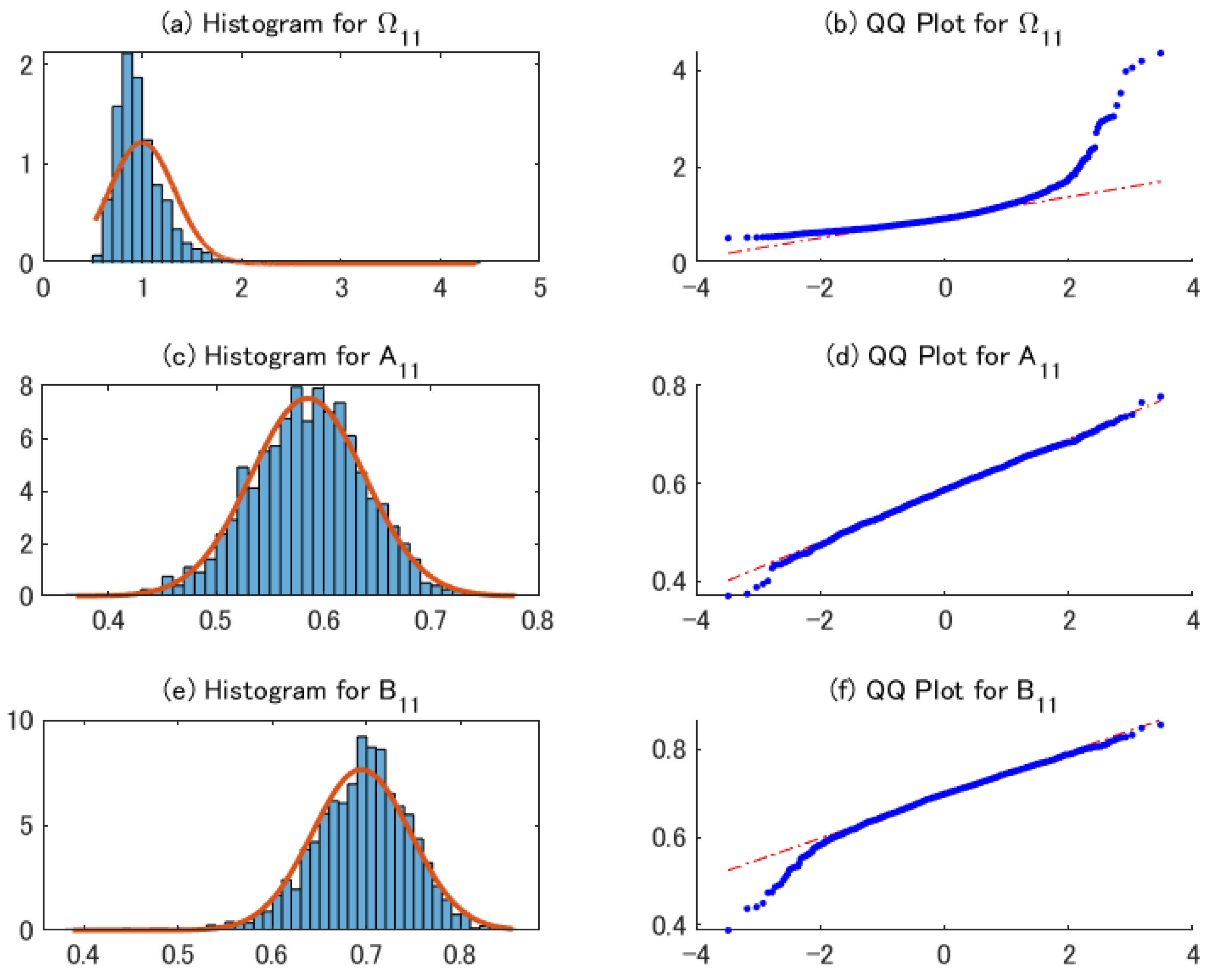
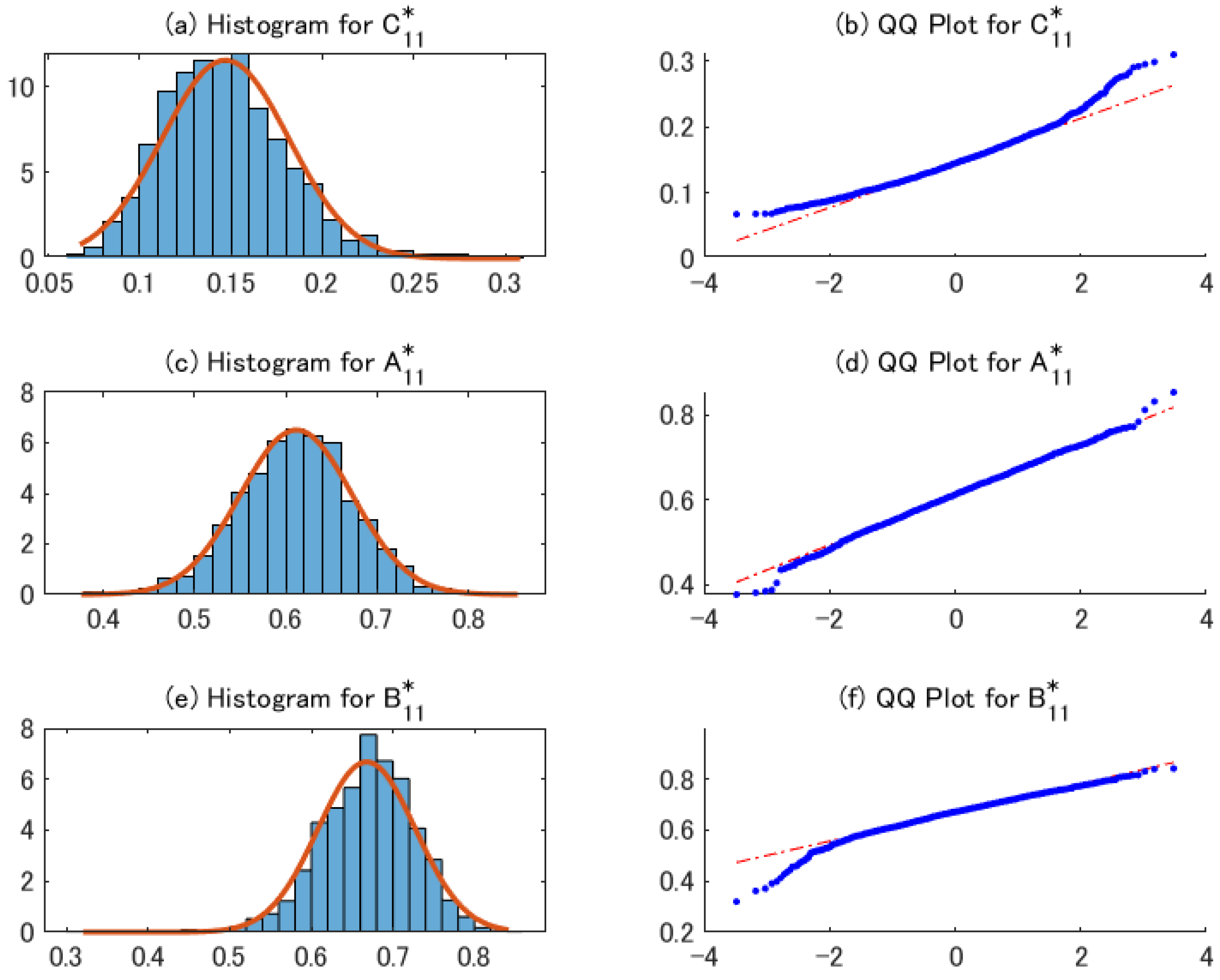
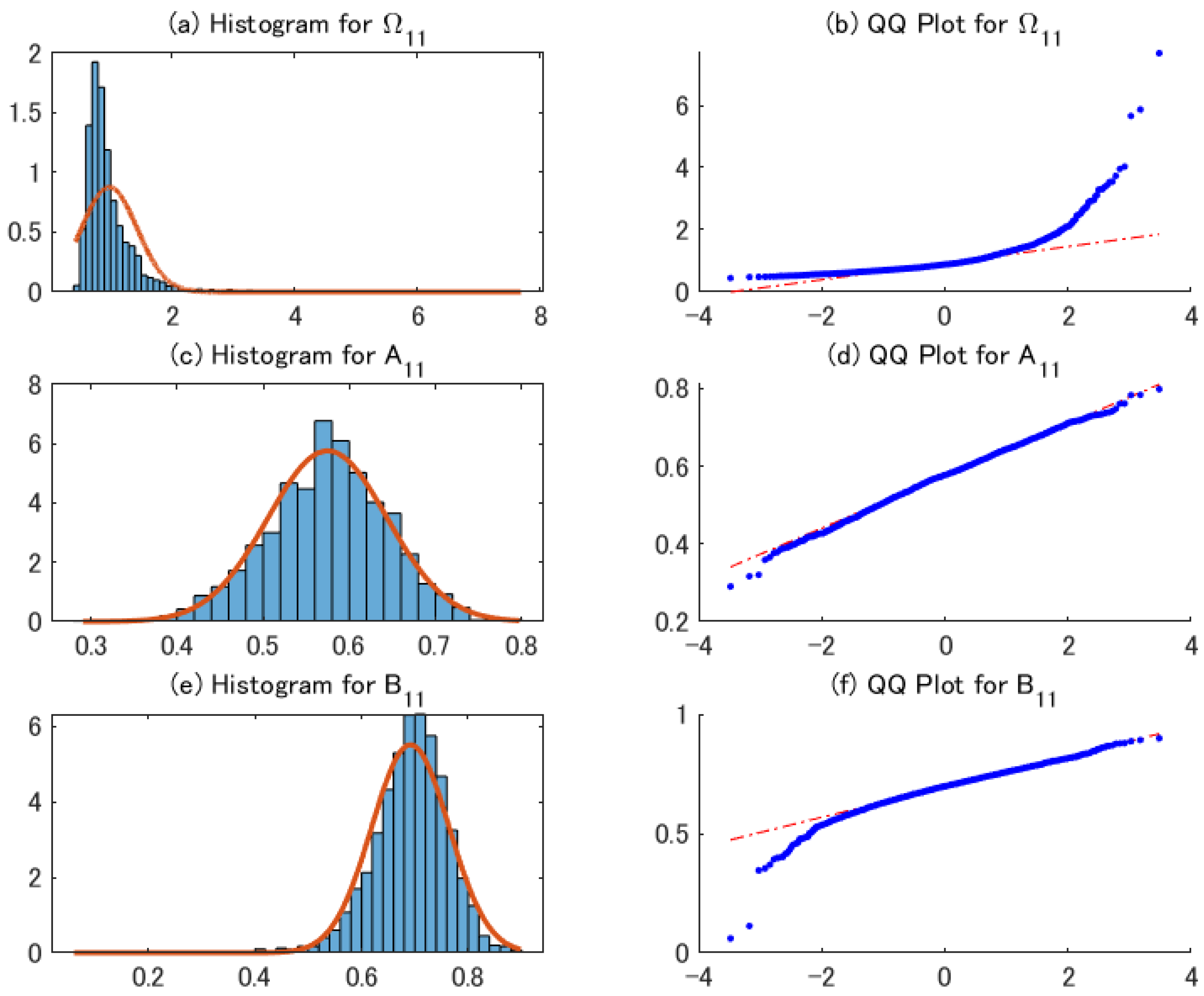
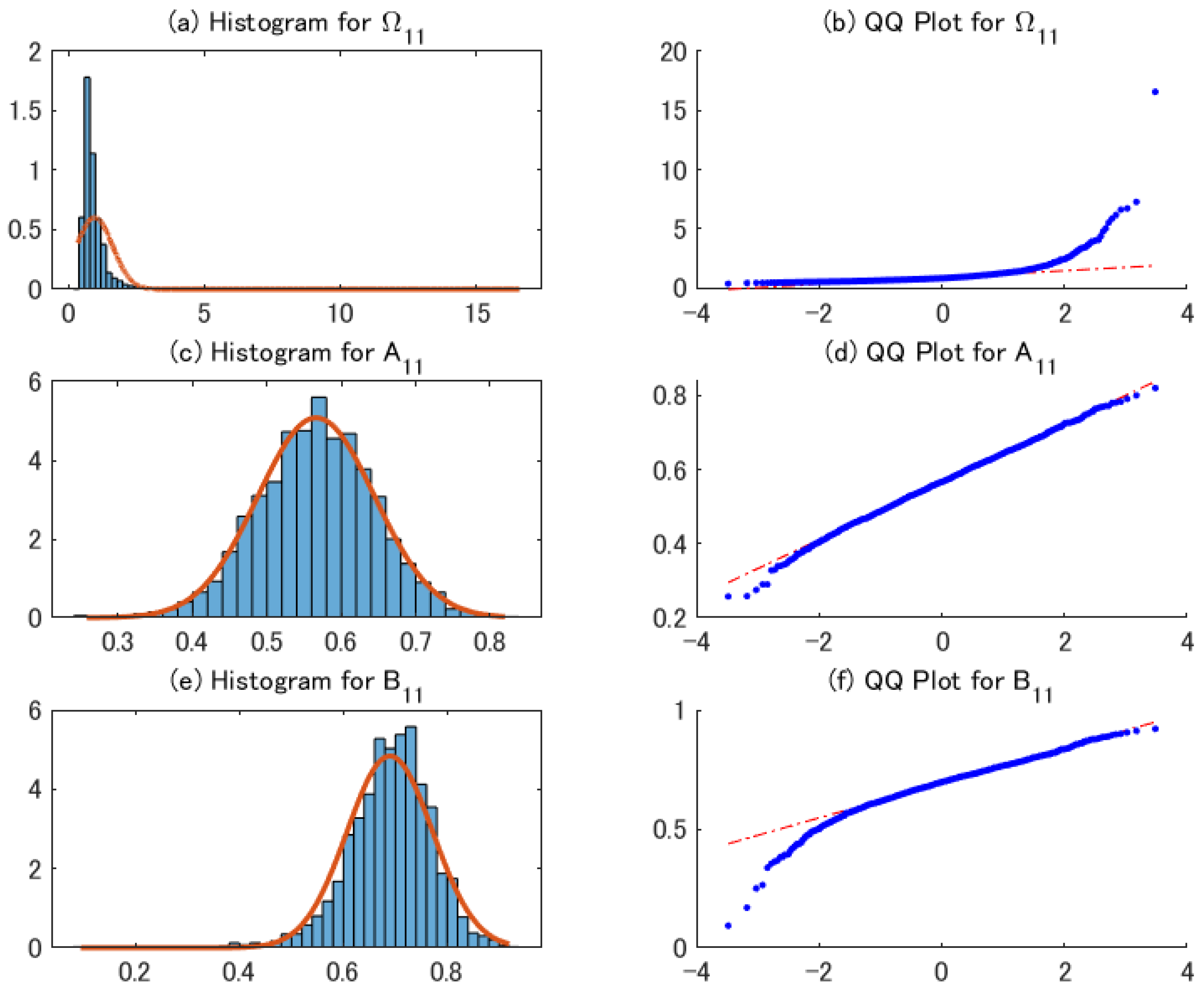
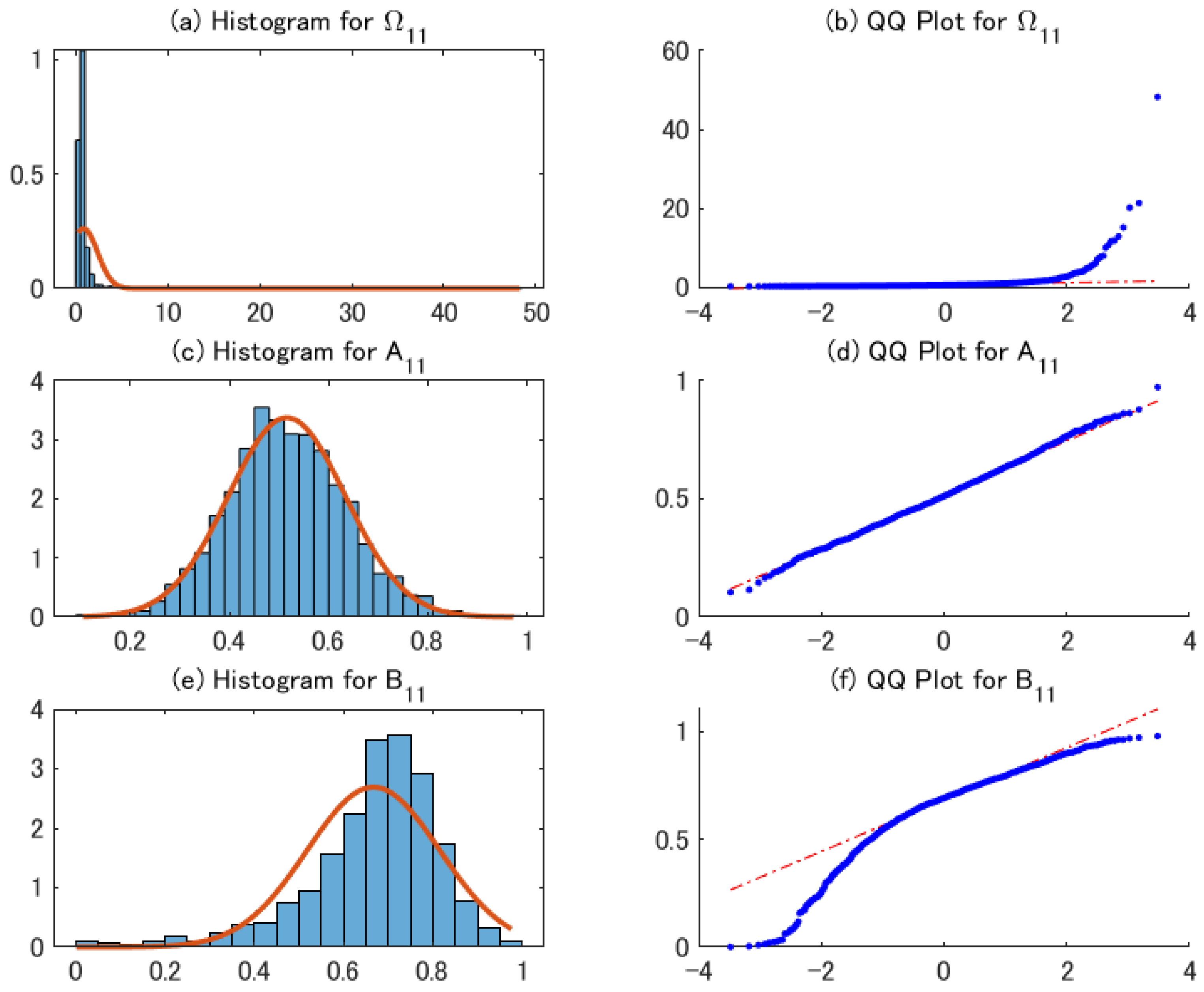
4.2. Performance of the 2sQML Estimator
4.3. Performance of Conditional Covariance Matrix Estimator
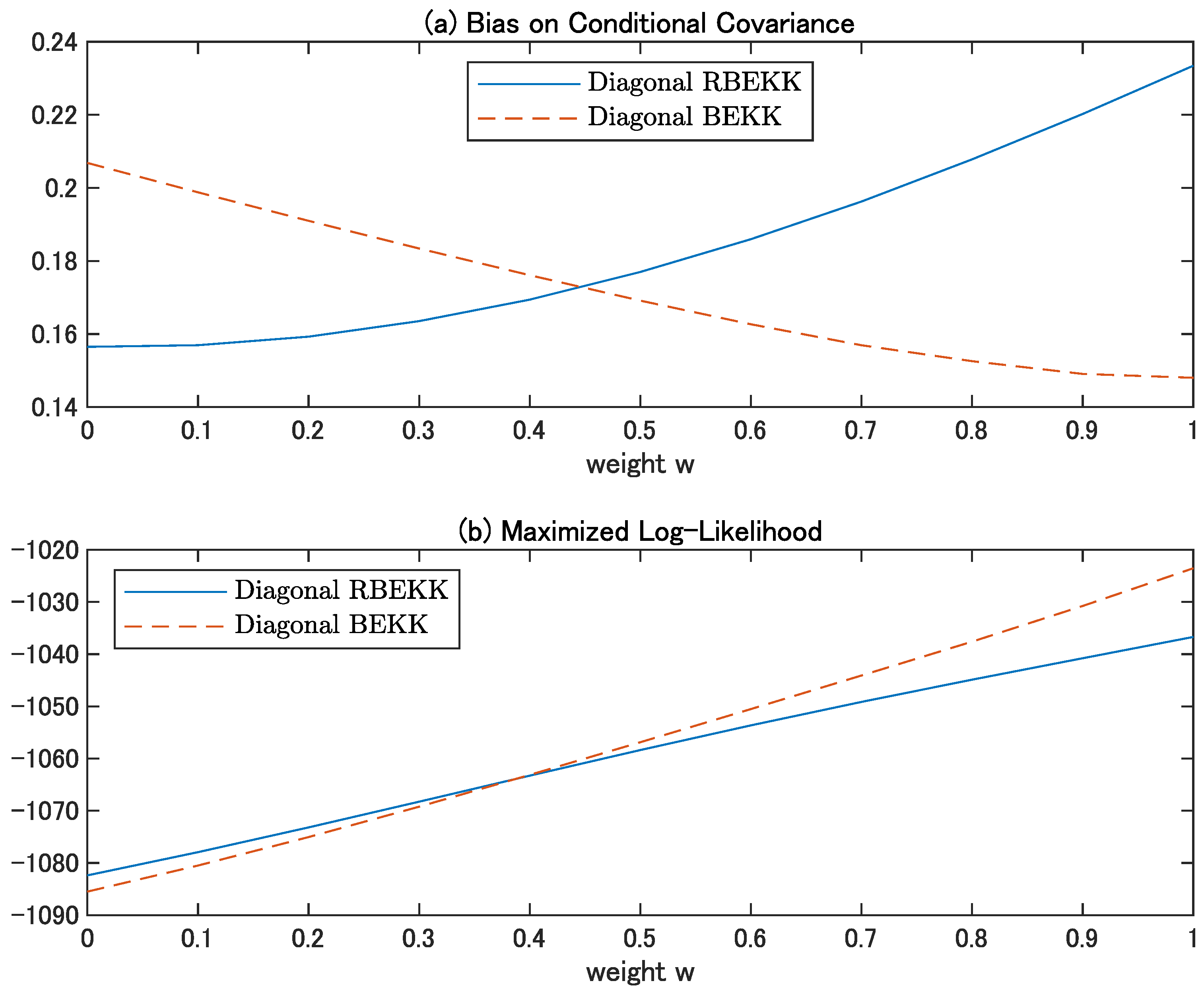
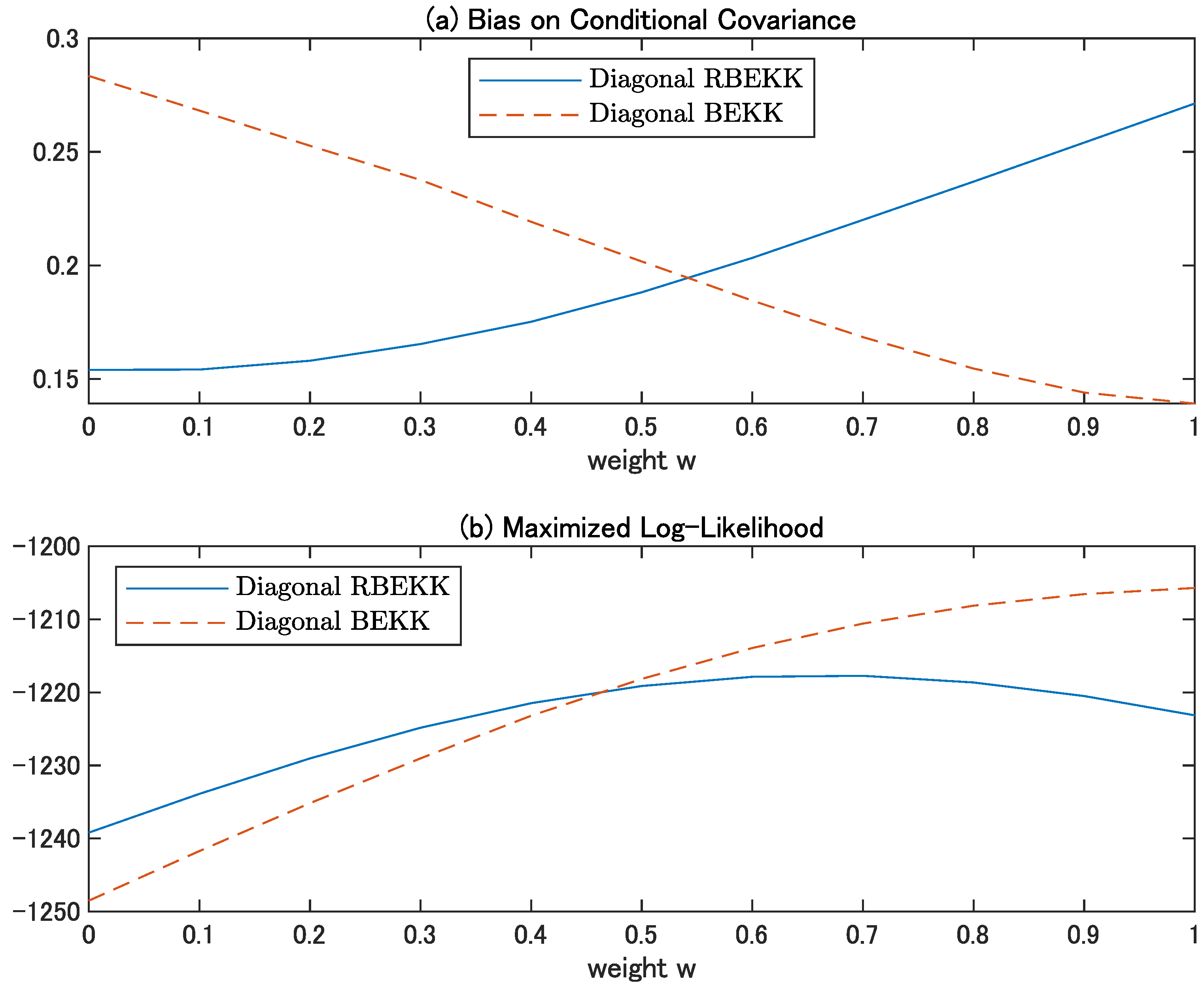
4.4. Effects of Diagonal Specification
4.5. Heavy Tails and Moment Conditions
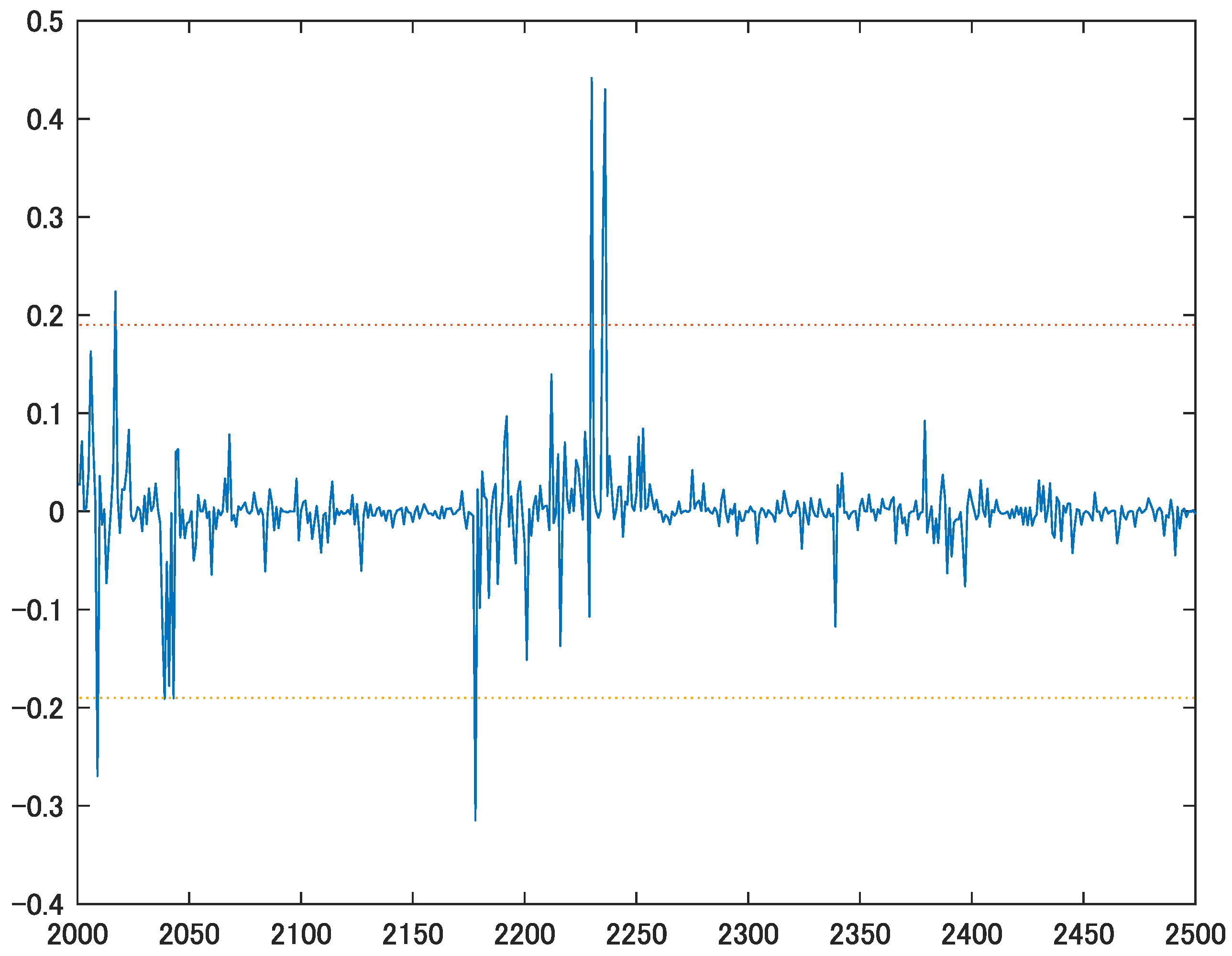
5. Empirical Analysis
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 2sQML | Two-step quasi-maximum likelihood |
| ARCH | Autoregressive conditional heteroskedasticity |
| BEKK | Baba, Engle, Kraft, and Kroner |
| DCC | Dynamic conditional correlation |
| GARCH | Generalized autoregressive conditional heteroskedasticity |
| QML | Quasi-maximum likelihood |
| RBEKK | Rotated BEKK |
| VT | Variance targeting |
Appendix A
Appendix A.1. Derivatives of the Log-Likelihood Function
Appendix A.2. Proofs of Propositions 1–3
References
- Alexander, Carol, ed. 2001. Orthogonal GARCH. In Mastering Risk. Hoboken: Financial Times-Prentice Hall, pp. 21–28. [Google Scholar]
- Asai, Manabu, and Michael McAleer. 2020. Multivariate Hyper-Rotated GARCH-BEKK: Asymptotic Theory and Practice. Tokyo: Soka University, Unpublished Paper. [Google Scholar]
- Baba, Yoshihisa, Robert. F. Engle, Dennis Kraft, and Kenneth F. Kroner. 1985. Multivariate Simultaneous Generalized ARCH. San Diego: University of California, Unpublished Paper. [Google Scholar]
- Bauwens, Luc, Sébastian Laurent, and Jeroen K. V. Rombouts. 2006. Multivariate GARCH models: A survey. Journal of Applied Econometrics 21: 79–109. [Google Scholar] [CrossRef]
- Bollerslev, Tim. 1986. Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef]
- Boussama, Farid, Florian Fuchs, and Robert Stelzer. 2011. Stationarity and geometric ergodicity of BEKK multivariate GARCH models. Stochastic Processes and Their Applications 121: 2331–60. [Google Scholar] [CrossRef]
- Chang, Chia-Lin, and Michael McAleer. 2019. The fiction of full BEKK: Pricing fossil fuels and carbon emissions. Finance Research Letters 28: 11–19. [Google Scholar] [CrossRef]
- Comte, Fabienne, and Offer Lieberman. 2003. Asymptotic theory for multivariate GARCH processes. Journal of Multivariate Analysis 84: 61–84. [Google Scholar] [CrossRef]
- Diebold, Francis X., and Roberto S. Mariano. 1995. Comparing predictive accuracy. Journal of Business & Economic Statistics 13: 253–63. [Google Scholar]
- Engle, Robert F. 1982. Autoregressive conditional heteroskedasticity with estimates of the variance of United Kingdom inflation. Econometrica 50: 987–1007. [Google Scholar] [CrossRef]
- Engle, Robert F. 2002. Dynamic conditional correlation: A simple class of multivariate generalized autoregressive conditional heteroskedasticity models. Journal of Business & Economic Statistics 20: 339–50. [Google Scholar]
- Engle, Robert F., and Kenneth F. Kroner. 1995. Multivariate simultaneous generalized ARCH. Econometric Theory 11: 122–50. [Google Scholar] [CrossRef]
- Engle, Robert F., and Riccardo Colacito. 2006. Testing and valuing dynamic correlations for asset allocation. Journal of Business & Economic Statistics 24: 238–53. [Google Scholar]
- Francq, Christian, Lajos Horváth, and Jean-Michel Zakoïan. 2011. Merits and drawbacks of variance targeting in GARCH models. Journal of Financial Econometrics 9: 619–56. [Google Scholar] [CrossRef]
- Hafner, Christian M. 2003. Fourth moment structure of multivariate GARCH models. Journal of Financial Econometrics 1: 26–54. [Google Scholar] [CrossRef]
- Hafner, Christian M., Helmut Herwartz, and Simone Maxand. 2020. Identification of structural multivariate GARCH models. Journal of Econometrics. [Google Scholar] [CrossRef]
- Hafner, Christian M., and Arie Preminger. 2009. On asymptotic theory for multivariate GARCH models. Journal of Multivariate Analysis 100: 2044–54. [Google Scholar] [CrossRef]
- Lanne, Markku, and Pentti Saikkonen. 2007. A multivariate generalized orthogonal factor GARCH model. Journal of Business & Economic Statistics 25: 61–75. [Google Scholar]
- Laurent, Sébastian, Jeroen V. K. Rombouts, and Francesco Violante. 2012. On the forecasting accuracy of multivariate GARCH models. Journal of Applied Econometrics 27: 934–55. [Google Scholar] [CrossRef]
- Lütkepohl, Helmut. 1996. Handbook of Matrices. New York: John Wiley & Sons. [Google Scholar]
- McAleer, Michael. 2005. Automated inference and learning in modeling financial volatility. Econometric Theory 21: 232–61. [Google Scholar] [CrossRef]
- McAleer, Michael. 2018. Stationarity and invertibility of a dynamic correlation matrix. Kybernetika 54: 363–74. [Google Scholar] [CrossRef]
- McAleer, Michael, Felix Chan, Suhejla Hoti, and Offer Lieberman. 2008. Generalized autoregressive conditional correlation. Econometric Theory 24: 1554–83. [Google Scholar] [CrossRef]
- Noureldin, Diaa, Neil Shephard, and Kevin Sheppard. 2014. Multivariate rotated ARCH models. Journal of Econometrics 179: 16–30. [Google Scholar] [CrossRef]
- Pedersen, Rasmus S., and Anders Rahbek. 2014. Multivariate variance targeting in the BEKK-GARCH model. Econometrics Journal 17: 24–55. [Google Scholar] [CrossRef]
- Silvennoinen, Annastiina, and Timo Teräsvirta. 2009. Multivariate GARCH models. In Handbook of Financial Time Series. Edited by Toben G. Andersen, Richard A. Davis, Jens-Peter Kreiss and Thomas Mikosch. New York: Springer, pp. 201–29. [Google Scholar]
- Tse, Y. K., and Albert K. C. Tsui. 2002. A multivariate generalized autoregressive conditional heteroscedasticity model with time-varying correlations. Journal of Business & Economic Statistics 20: 351–61. [Google Scholar]
- van der Weide, Roy. 2020. GO-GARCH: A multivariate generalized orthogonal GARCH model. Journal of Applied Econometrics 17: 549–64. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | DGP1 | DGP2 | ||||||
|---|---|---|---|---|---|---|---|---|
| True | Mean | Std. Dev. | RMSE | True | Mean | Std. Dev. | RMSE | |
| 1.00 | 1.0150 | 0.5831 | 0.5832 | 0.640 | 0.6375 | 0.2031 | 0.2031 | |
| 0.54 | 0.5492 | 0.3654 | 0.3654 | −0.264 | −0.2635 | 0.0552 | 0.0552 | |
| 0.81 | 0.8250 | 0.7143 | 0.7143 | 1.210 | 1.2067 | 0.1474 | 0.1474 | |
| 0.60 | 0.5853 | 0.0531 | 0.0551 | 0.600 | 0.5855 | 0.0567 | 0.0586 | |
| 0.40 | 0.3921 | 0.0424 | 0.0431 | −0.300 | −0.3032 | 0.0523 | 0.0524 | |
| 0.70 | 0.6939 | 0.0593 | 0.0596 | 0.700 | 0.6920 | 0.0710 | 0.0714 | |
| 0.90 | 0.8921 | 0.0463 | 0.0470 | −0.900 | −0.8666 | 0.1025 | 0.1078 | |
| Parameters | DGP1 | DGP2 | ||||||
|---|---|---|---|---|---|---|---|---|
| True | Mean | Std. Dev. | RMSE | True | Mean | Std. Dev. | RMSE | |
| 0.1392 | 0.1469 | 0.0346 | 0.0354 | 0.0950 | 0.1007 | 0.0262 | 0.0268 | |
| 0.0505 | 0.0559 | 0.0175 | 0.0183 | −0.0319 | −0.0396 | 0.0174 | 0.0190 | |
| 0.0351 | 0.0433 | 0.0165 | 0.0184 | 0.1220 | 0.1707 | 0.1185 | 0.1281 | |
| 0.6249 | 0.6113 | 0.0613 | 0.0628 | 0.6212 | 0.6072 | 0.0582 | 0.0599 | |
| 0.0706 | 0.0685 | 0.0260 | 0.0261 | −0.1644 | −0.1656 | 0.0281 | 0.0281 | |
| −0.0794 | −0.0817 | 0.0375 | 0.0375 | 0.1187 | 0.1181 | 0.0230 | 0.0230 | |
| 0.3751 | 0.3661 | 0.0487 | 0.0495 | −0.3212 | −0.3250 | 0.0542 | 0.0543 | |
| 0.6751 | 0.6678 | 0.0597 | 0.0601 | 0.7376 | 0.7313 | 0.0613 | 0.0616 | |
| −0.0706 | −0.0714 | 0.0266 | 0.0266 | −0.2922 | −0.2912 | 0.0521 | 0.0521 | |
| 0.0794 | 0.0824 | 0.0303 | 0.0304 | 0.2110 | 0.2067 | 0.0360 | 0.0363 | |
| 0.9249 | 0.9195 | 0.0311 | 0.0315 | −0.9376 | −0.9045 | 0.1073 | 0.1123 | |
| Sample Size | Diagonal RBEKK | Diagonal BEKK | ||||
|---|---|---|---|---|---|---|
| 1.1377 | 3.9358 | 41.047 | 1.5176 | 6.3447 | 64.909 | |
| 0.7883 | 2.7948 | 24.570 | 1.3800 | 5.9794 | 57.433 | |
| Parameter | Estimate | HAC S.E. | t-Value |
|---|---|---|---|
| 0.0010 | 0.0043 | 0.2192 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asai, M.; Chang, C.-L.; McAleer, M.; Pauwels, L. Asymptotic and Finite Sample Properties for Multivariate Rotated GARCH Models. Econometrics 2021, 9, 21. https://doi.org/10.3390/econometrics9020021
Asai M, Chang C-L, McAleer M, Pauwels L. Asymptotic and Finite Sample Properties for Multivariate Rotated GARCH Models. Econometrics. 2021; 9(2):21. https://doi.org/10.3390/econometrics9020021
Chicago/Turabian StyleAsai, Manabu, Chia-Lin Chang, Michael McAleer, and Laurent Pauwels. 2021. "Asymptotic and Finite Sample Properties for Multivariate Rotated GARCH Models" Econometrics 9, no. 2: 21. https://doi.org/10.3390/econometrics9020021
APA StyleAsai, M., Chang, C.-L., McAleer, M., & Pauwels, L. (2021). Asymptotic and Finite Sample Properties for Multivariate Rotated GARCH Models. Econometrics, 9(2), 21. https://doi.org/10.3390/econometrics9020021